
Driver Clustering Based on Individual Curve Path Selection Preference


Abstract
1. Introduction
- C1
- We cluster drivers based on their curve path preferences, using the Linear Driver Model and its parameters, and in this way, behavioral differences are quantified. It is shown that the clusters are indeed different in their curve driving behavior. Two groups of dynamic and cautious drivers are created that are used as reference groups for the classification.
- C2
- An Extended Kalman Filter-based approach is proposed to learn the driver model parameters. It is proven that this solution is suitable for embedded applications as its computational needs are low, while its convergence to the real parameter values is fast. This way, a compact solution is introduced that can be directly used for the next generation of lane centering systems.
2. Methods and Materials
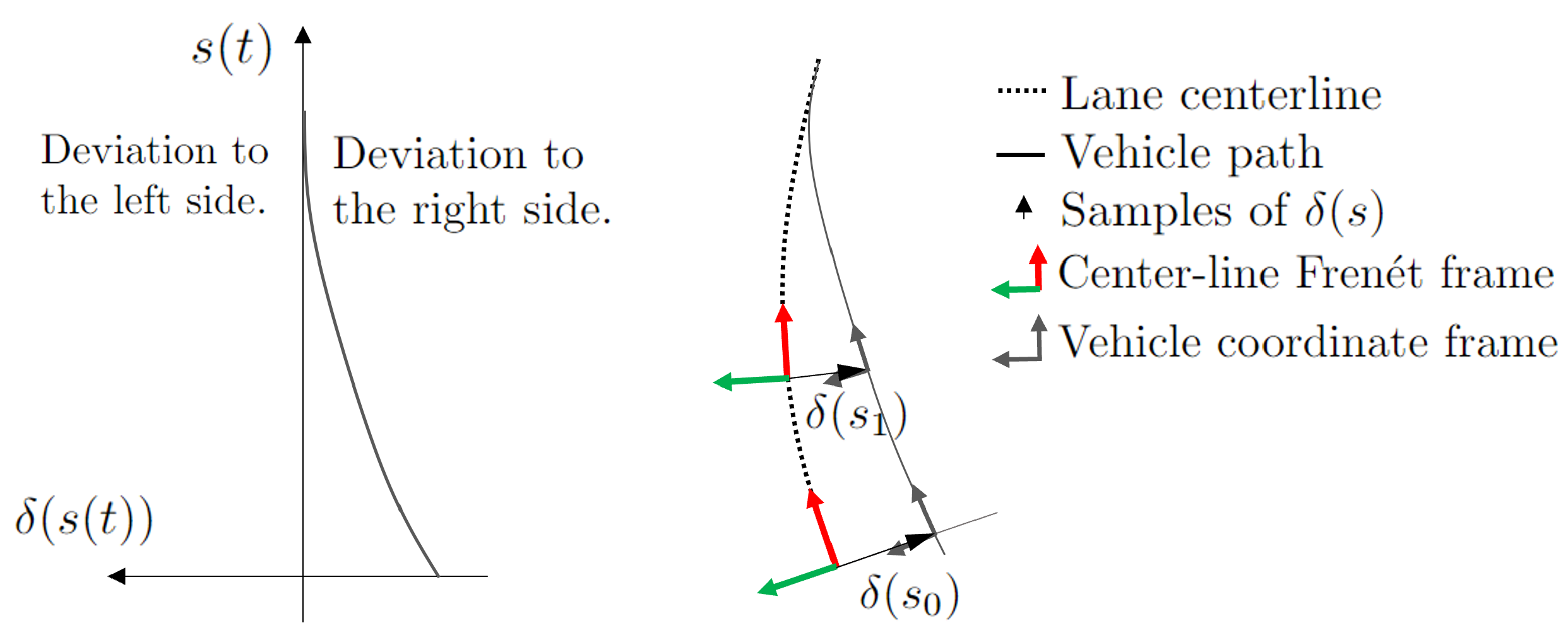
2.1. Lane Offset Modeling
2.2. Parameter Fitting
2.3. Parameter Clustering
2.4. Online Parameter Identification
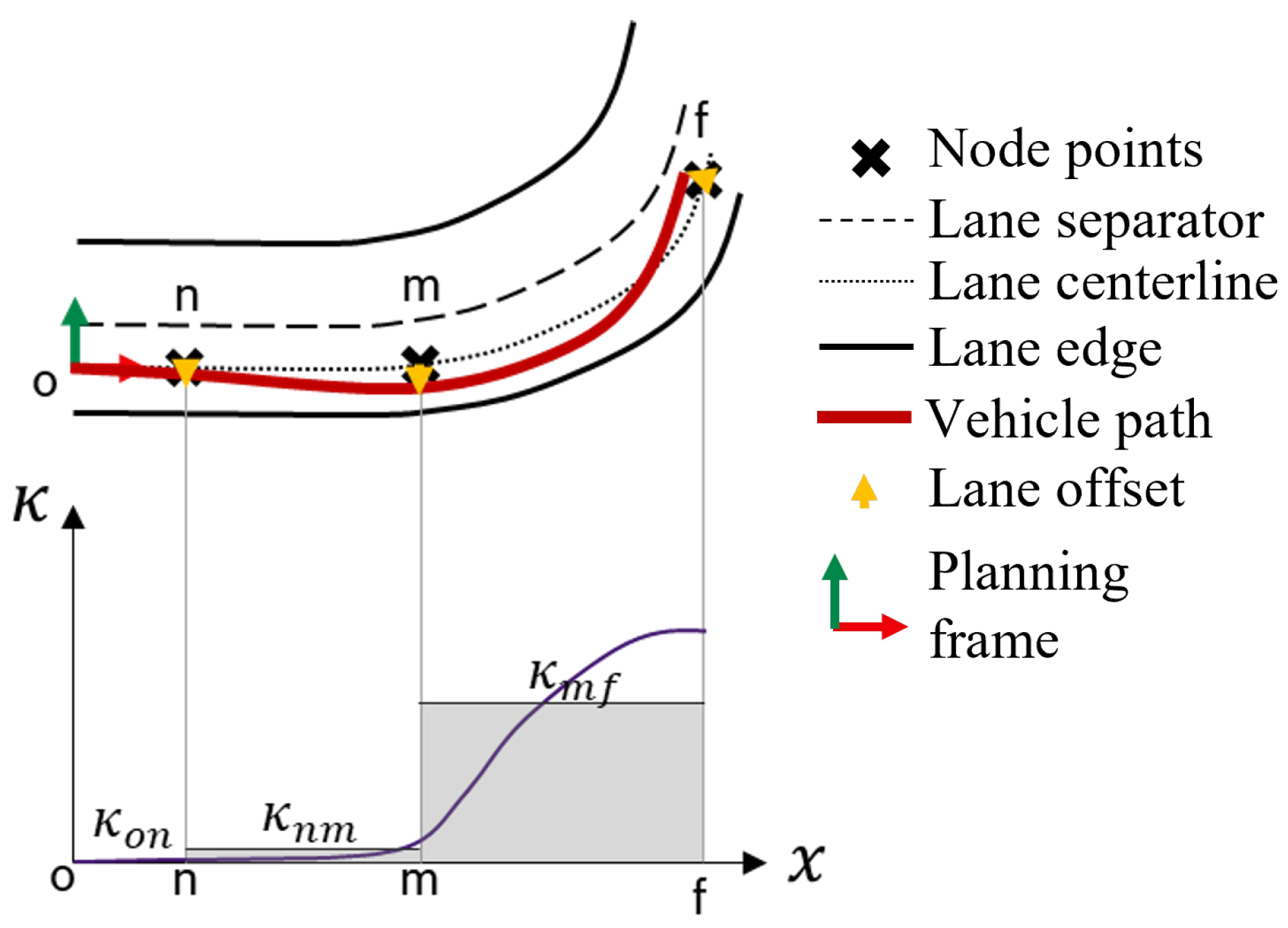
2.5. Path Planning
3. Results
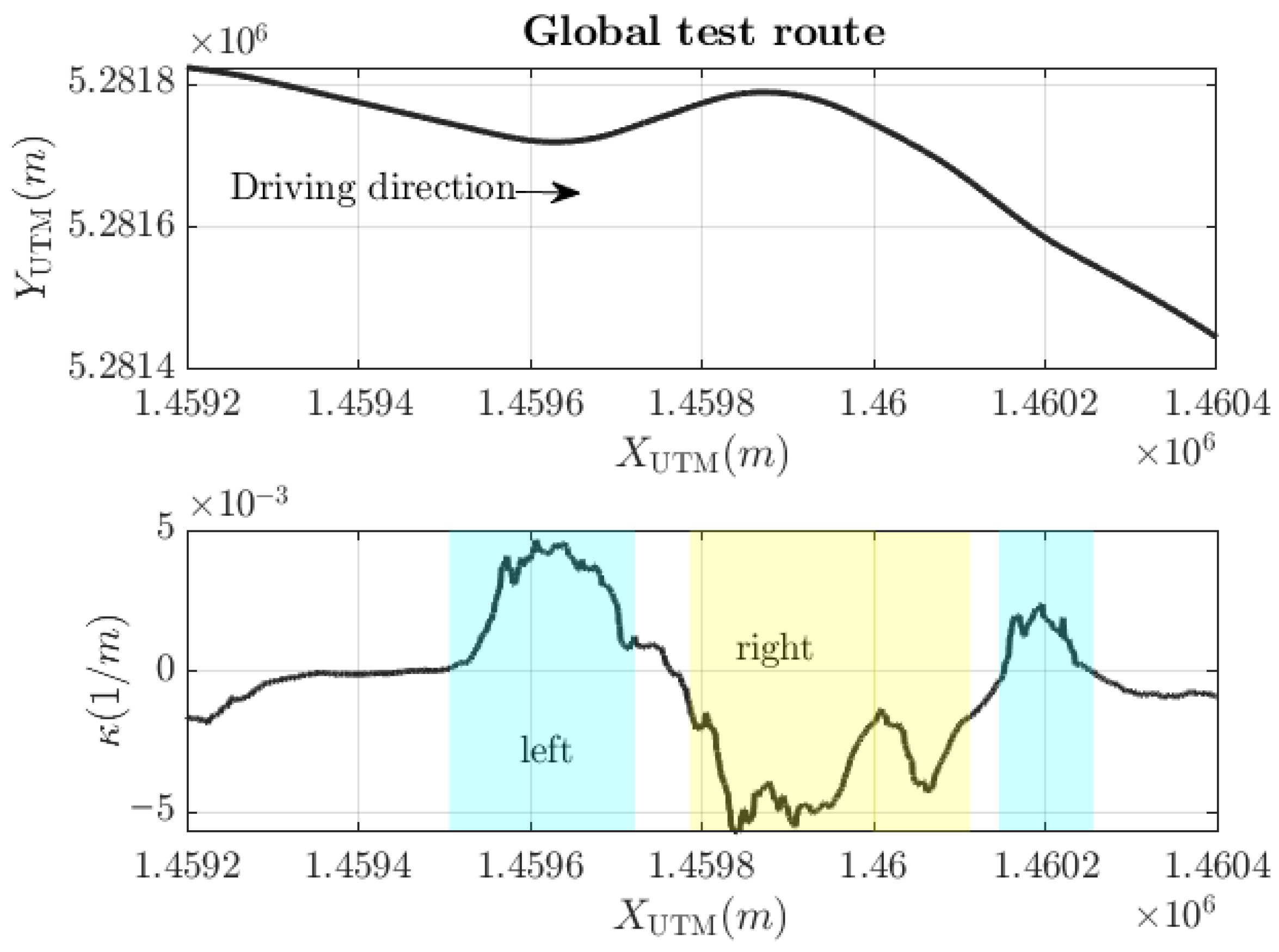
3.1. Dataset
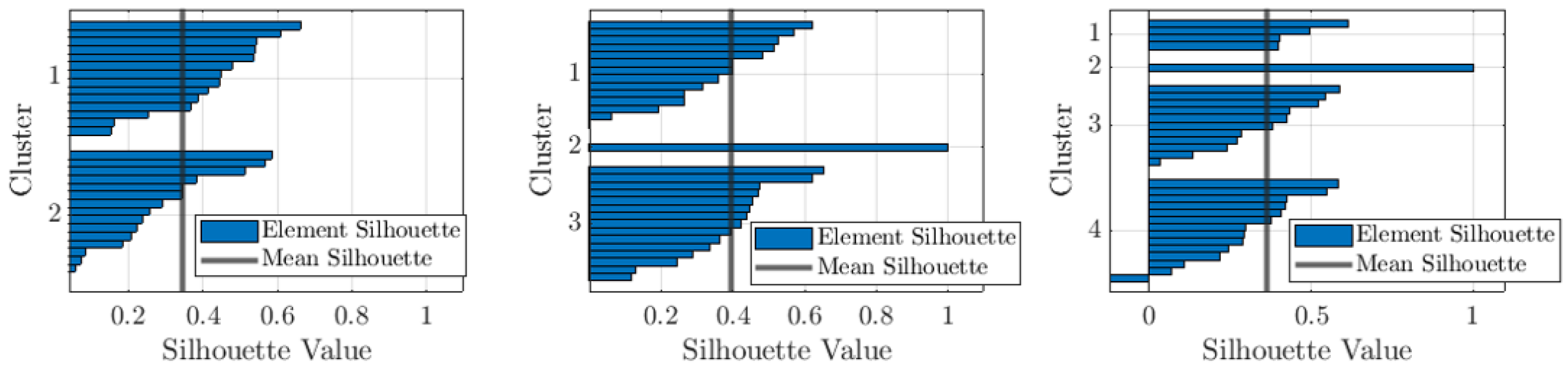
3.2. Driver Clustering
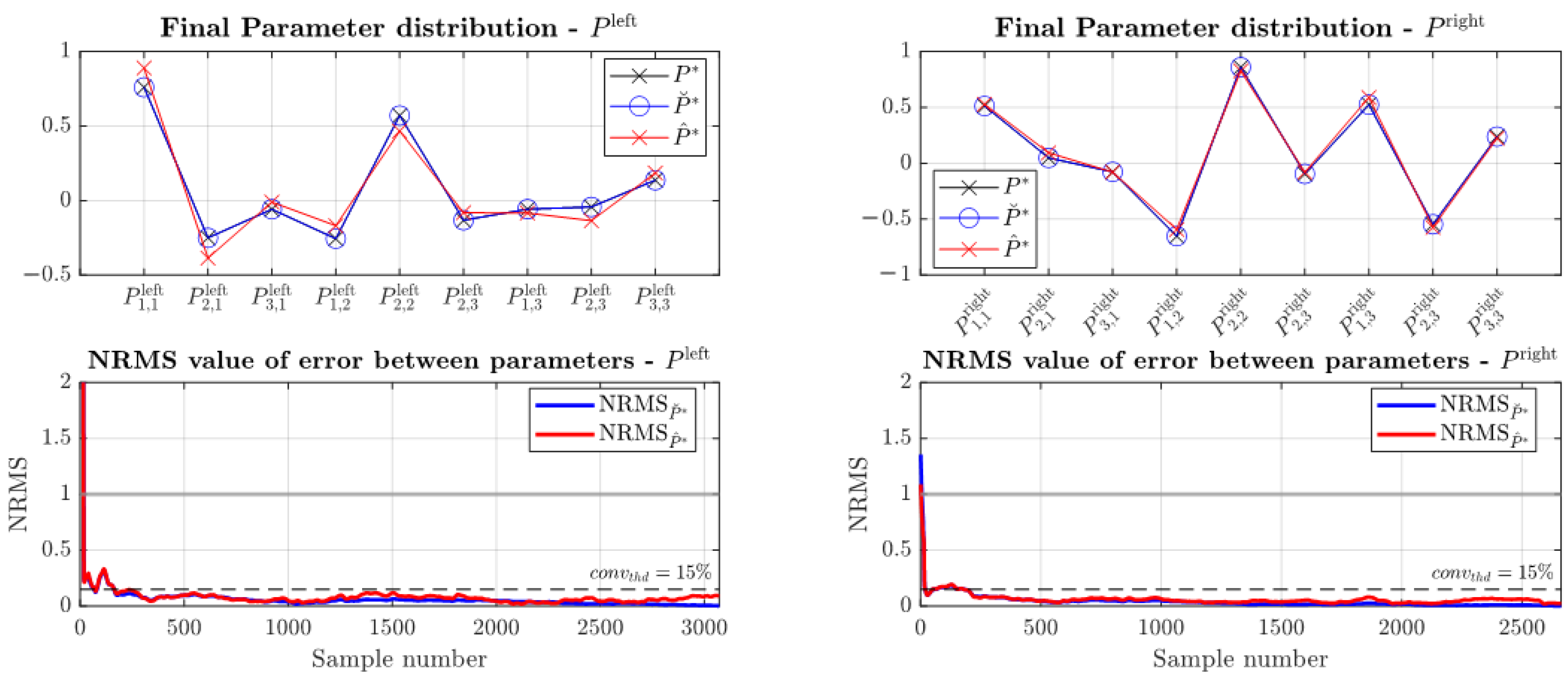
3.3. Online Parameter Learning
3.4. Driver Classification
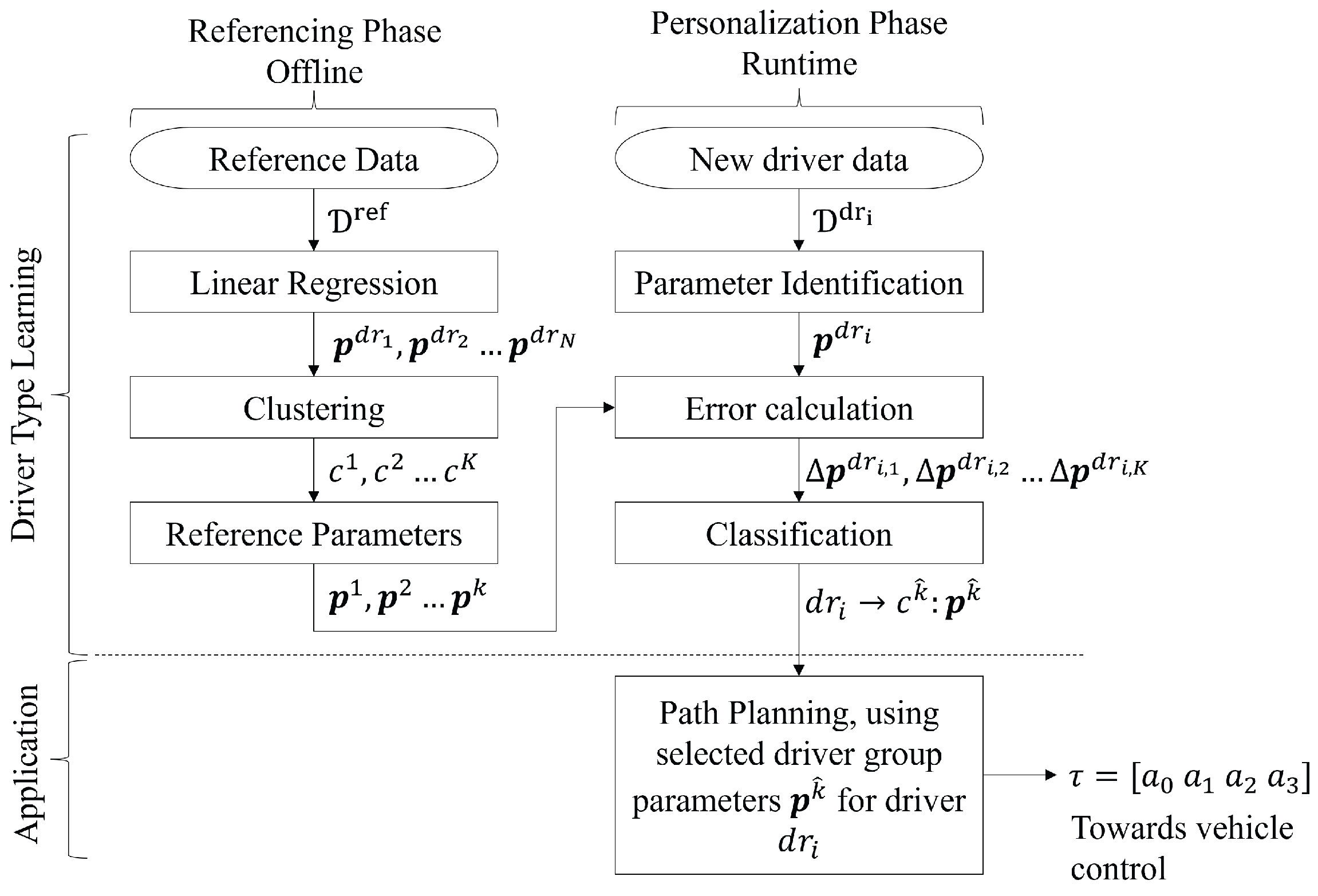
3.5. Proposed Workflow
- 1
- Data of reference drivers is collected, the LDM parameters of these drivers are calculated offline, using (20) to form the driver clusters . This is called the referencing phase.
- 2
- Then, new test drivers, who are not part of the reference group, are measured, and their parameter vector is calculated online using the EKF algorithm given in Section 2.4. Using the identified parameter vector, the new driver is classified into one of the driving clusters (27) and (28). This is called the personalization phase.
4. Conclusions
- Linear Driver Model (LDM), a simple, static, parametric model can be used to efficiently characterize drivers by their curve path preferences. The model parameters can be fitted on measured data and can be used to cluster drivers into a dynamic and a cautious driving style group.
- The curve driving groups identified by the LDM parameters are also separated by vehicle kinematics, therefore they are indeed dynamic and cautious drivers, not only from curve driving perspective but from motion perspective, too.
- Extended Kalman Filter can be used to learn the LDM parameters in an environment where memory consumption shall be low (e.g., in an embedded environment). With this, the real-time application of the proposed driver classification workflow is possible.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bongiorno, N.; Pellegrino, O.; Stuiver, A.; de Waard, D. Cumulative lateral position: A new measure for driver performance in curves. Traffic Saf. Res. 2022, 4, 20–34. [Google Scholar] [CrossRef]
- Qi, H.; Hu, X. Behavioral investigation of stochastic lateral wandering patterns in mixed traffic flow. Transp. Res. Part C 2023, 4, 104310. [Google Scholar] [CrossRef]
- Aoxue, L.; Haobin, J.; Li, Z.; Zhou, J.; Zhou, X. Human-Like Trajectory Planning on Curved Road: Learning From Human Drivers. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3388–3397. [Google Scholar]
- Li, A.; Jiang, H.; Zhou, J.; Zhou, X. Learning Human-Like Trajectory Planning on Urban Two-Lane Curved Roads From Experienced Drivers. IEEE Access 2016, 4, 65828–65838. [Google Scholar] [CrossRef]
- Zhao, J.; Song, D.; Zhu, B.; Sun, Z.; Han, J.; Sun, Y. A Human-Like Trajectory Planning Method on a Curve Based on the Driver Preview Mechanism. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11682–11698. [Google Scholar] [CrossRef]
- Chen, S.; Cheng, K.; Yang, J.; Zang, X.; Luo, Q.; Li, J. Driving Behavior Risk Measurement and Cluster Analysis Driven by Vehicle Trajectory Data. Appl. Sci. 2023, 13, 5675. [Google Scholar] [CrossRef]
- Conlter, R.C. Implementation of the Pure Pursuit Path Tracking Algorithm; Defense Technical Information Center: Fort Belvoir, VA, USA, 1992. [Google Scholar]
- McAdam, C.C. An Optimal Preview Control for Linear Systems. J. Dyn. Syst. Meas. Control. 1980, 102, 188–190. Available online: https://hdl.handle.net/2027.42/65011 (accessed on 5 May 2025). [CrossRef]
- Jiang, H.; Tian, H.; Hua, Y. Model predictive driver model considering the steering characteristics of the skilled drivers. Adv. Mech. Eng. 2019, 11, 1687814019829337. [Google Scholar] [CrossRef]
- Ungoren, A.Y.; Peng, H. An adaptive lateral preview driver model. Veh. Syst. Dyn. 2005, 43, 245–259. [Google Scholar] [CrossRef]
- Hess, R.; Modjtahedzadeh, A. A control theoretic model of driver steering behavior. IEEE Control. Syst. Mag. 1990, 10, 3–8. [Google Scholar] [CrossRef]
- Igneczi, G.; Horvath, E.; Toth, R.; Nyilas, K. Curve Trajectory Model for Human Preferred Path Planning of Automated Vehicles. Automot. Innov. 2023, 1, 50–60. [Google Scholar] [CrossRef]
- de Zepeda, M.V.N.; Meng, F.; Su, J.; Zeng, X.J.; Wang, Q. Dynamic clustering analysis for driving styles identification. Eng. Appl. Artif. Intell. 2021, 97, 104096–104105. [Google Scholar] [CrossRef]
- Lina, X.; Zejun, K. Driving Style Recognition Model Based on NEV High-Frequency Big Data and Joint Distribution Feature Parameters. World Electr. Veh. J. 2021, 12, 142. [Google Scholar] [CrossRef]
- Chu, D.; Deng, Z.; He, Y.; Wu, C.; Sun, C.; Lu, Z. Curve speed model for driver assistance based on driving style classification. IET Intell. Transp. Syst. 2017, 11, 501–510. [Google Scholar] [CrossRef]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. Trans. ASME—J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Zhao, Y.; Chevrel, P.; Claveau, F.; Mars, F. Continuous Identification of Driver Model Parameters via the Unscented Kalman Filter. IFAC-Pap. Online 2019, 52, 126–133. [Google Scholar] [CrossRef]
- Igneczi, G.F.; Horvath, E. Node Point Optimization for Local Trajectory Planners based on Human Preferences. In Proceedings of the IEEE 21st World Symposium on Applied Machine Intelligence and Informatics, Herl’any, Slovakia, 19–21 January 2023; pp. 1–6. [Google Scholar]
- Gergo, I.; Erno, H. Human-Like Behaviour for Automated Vehicles (HLB4AV) Naturalistic Driving Dataset. In Proceedings of the 2024 IEEE 22nd Jubilee International Symposium on Intelligent Systems and Informatics (SISY), Pula, Croatia, 19–21 September 2024. [Google Scholar]
- Hartigan, J.A. Clustering Algorithms, 99th ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1975. [Google Scholar]
- Cristian-David, R.L.; Carlos-Andres, G.M.; Carlos-Anibal, C.V. Classification of Driver Behavior in Horizontal Curves of Two-Lane Rural Roads. Rev. Fac. Ing. 2021, 30. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P. Finding Groups in Data: An Introduction To Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1990. [Google Scholar] [CrossRef]
- Li, X.; Lei, A.; Zhu, L.; Ban, M. Improving Kalman filter for cyber physical systems subject to replay attacks: An attack-detection-based compensation strategy. Appl. Math. Comput. 2023, 466, 128444. [Google Scholar] [CrossRef]
- Semino, D.; Moretta, M.; Scali, C. Parameter estimation in Extended Kalman Filters for quality control in polymerization reactors. Comput. Chem. Eng. 1996, 20, 913–918. [Google Scholar] [CrossRef]
- Sun, X.; Jin, L.; Xiong, M. Extended Kalman Filter for Estimation of Parameters in Nonlinear State-Space Models of Biochemical Networks. PLoS ONE 2023, 3, e3758. [Google Scholar] [CrossRef]
- Na, W.; Yoo, C. Real-Time Parameter Estimation of a Dual-Pol Radar Rain Rate Estimator Using the Extended Kalman Filter. Remote Sens. 2021, 13, 2365. [Google Scholar] [CrossRef]
- Gackstatter, C.; Heinemann, P.; Thomas, S.; Klinker, G. Stable Road Lane Model Based on Clothoids. In Advanced Microsystems for Automotive Applications 2010: Smart Systems for Green Cars and Safe Mobility; Springer: Berlin/Heidelberg, Germany, 2010; pp. 133–143. [Google Scholar] [CrossRef]
- Fatemi, M.; Hammarstrand, L.; Svensson, L.; García-Fernández, Á.F. Road geometry estimation using a precise clothoid road model and observations of moving vehicles. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 238–244. [Google Scholar] [CrossRef]
- Götte, C.; Keller, M.; Nattermann, T.; Haß, C.; Glander, K.H.; Bertram, T. Spline-Based Motion Planning for Automated Driving. IFAC-Pap. Online 2017, 50, 9114–9119. [Google Scholar] [CrossRef]
- Xu, W.; Wang, Q.; Dolan, J.M. Autonomous Vehicle Motion Planning via Recurrent Spline Optimization. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 7730–7736. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, D.; Teoh, K. Lane detection using spline model. Pattern Recognit. Lett. 2000, 21, 677–689. [Google Scholar] [CrossRef]
- Moritz, W.; Julius, Z.; Sören, K.; Sebastian, T. Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenét Frame. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 987–993. [Google Scholar]
- Papadimitriou, I.; Tomizuka, M. Fast lane changing computations using polynomials. In Proceedings of the 2003 American Control Conference, Denver, CO, USA, 4–6 June 2003; Volume 1, pp. 48–53. [Google Scholar] [CrossRef]
- Nelson, W. Continuous-Curvature Paths for Autonomous Vehicles; AT&T Bell Laboratories: Murray Hill, NJ, USA, 1984. [Google Scholar] [CrossRef]
- Advanced Vehicle Tecnhologies Consortium. Advanced Vehicle Technology Consortium Dataset. 2024. Available online: https://avt.mit.edu/ (accessed on 15 April 2024).
- Strategic Highway Research Program by Virginia Tech Transportation Institute. The SHRP 2 Naturalistic Driving Study. 2012. Available online: https://insight.shrp2nds.us/ (accessed on 15 April 2024).
- Administration, Federal Motor Carrier Safety Data Repository of Naturalistic Driving and Other Dataset. 2023. Available online: https://fmcsadatarepository.vtti.vt.edu/ (accessed on 15 April 2024).
- Alam, M.R.; Batabyal, D.; Yang, K.; Brijs, T.; Antoniou, C. Application of naturalistic driving data: A systematic review and bibliometric analysis. Accid. Anal. Prev. 2023, 190, 107155. [Google Scholar] [CrossRef]
- Zheng, Y.; Shyrokau, B.; Keviczky, T. Reconstructed Roundabout Driving Dataset. 2021. Available online: https://dx.doi.org/10.21227/7t54-mt12 (accessed on 9 June 2025).
- Aydin, M.M. A new evaluation method to quantify drivers’ lane keeping behaviors on urban roads. Transp. Lett. 2020, 12, 738–749. [Google Scholar] [CrossRef]
- Society of Automobile Engineers International. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles J3016_202104; SAE Mobilus: Amsterdam, The Netherlands, 2021. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step 0: Initialization |
| and |
| Step 1: Prediction (prior estimates) |
| Step 2: Kalman gain calculation |
| Step 3: Correction (posterior estimates) |
| Feature | Cluster 1 | Cluster 3 |
|---|---|---|
| Curve cutting extent—left curve | low | high |
| Curve cutting extent—right curve | moderate | high |
| Curve entry outer driving | moderate | moderate |
| Driving style | cautious | dynamic |
| Cluster 1 (cautious) | 23.62 | 30.35 | −4.09 | 3.29 | 0.29 | 0.32 |
| Cluster 3 (dynamic) | 23.50 | 33.06 | −6.28 | 5.92 | 0.75 | 0.35 |
| Classification Results | |
|---|---|
| Driver group match | 27 |
| Driver group mismatch | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Igneczi, G.; Dobay, T.; Horvath, E.; Nyilas, K. Driver Clustering Based on Individual Curve Path Selection Preference. Appl. Sci. 2025, 15, 7718. https://doi.org/10.3390/app15147718
Igneczi G, Dobay T, Horvath E, Nyilas K. Driver Clustering Based on Individual Curve Path Selection Preference. Applied Sciences. 2025; 15(14):7718. https://doi.org/10.3390/app15147718
Chicago/Turabian StyleIgneczi, Gergo, Tamas Dobay, Erno Horvath, and Krisztian Nyilas. 2025. "Driver Clustering Based on Individual Curve Path Selection Preference" Applied Sciences 15, no. 14: 7718. https://doi.org/10.3390/app15147718
APA StyleIgneczi, G., Dobay, T., Horvath, E., & Nyilas, K. (2025). Driver Clustering Based on Individual Curve Path Selection Preference. Applied Sciences, 15(14), 7718. https://doi.org/10.3390/app15147718