Featured Application
The proposed hybrid AI-driven translation system’s architecture integrates phrase-based machine translation (PBMT) and neural machine translation (NMT) within a recursive learning framework. It provides a blueprint for institutions that digitize, translate, or teach under-resourced languages. Due to its ability to adapt to multilingual inputs and preserve cultural expressions, it is highly suitable for applications in education, community media, cultural preservation, and government-supported language revitalization initiatives.
Abstract
This study presents a hybrid artificial intelligence model designed to enhance translation quality for low-resource languages, specifically targeting the Hakka language. The proposed model integrates phrase-based machine translation (PBMT) and neural machine translation (NMT) within a recursive learning framework. The methodology consists of three key stages: (1) initial translation using PBMT, where Hakka corpus data is structured into a parallel dataset; (2) NMT training with Transformers, leveraging the generated parallel corpus to train deep learning models; and (3) recursive translation refinement, where iterative translations further enhance model accuracy by expanding the training dataset. This study employs preprocessing techniques to clean and optimize the dataset, reducing noise and improving sentence segmentation. A BLEU score evaluation is conducted to compare the effectiveness of PBMT and NMT across various corpus sizes, demonstrating that while PBMT performs well with limited data, the Transformer-based NMT achieves superior results as training data increases. The findings highlight the advantages of a hybrid approach in overcoming data scarcity challenges for minority languages. This research contributes to machine translation methodologies by proposing a scalable framework for improving linguistic accessibility in under-resourced languages.
1. Introduction
Cultural diversity and participation fairness are critical for achieving a democratic society. Minorities and marginalized populations often experience ethnic assimilation, racism, discrimination, and bullying [1]. This course can be attributed to communication barriers, in that mainstream populations cannot understand the native languages of minorities. International and national crises often highlight labor market inequalities that disproportionately affect marginalized individuals [2]. These minority social participation failures are caused by acts of linguistic microaggression against linguistically marginalized populations [3]. Thus, the first critical issue for achieving cultural diversity and participation fairness in society is that the minority language needs to be understood. In this regard, effective AI-based MT can assist communication with ethnic groups who speak different languages.
Millions of people use mobile applications and online translation services to communicate across languages. With the development of artificial intelligence technology, machine translation plays an increasingly crucial role in global communication. Machine translations are becoming increasingly important for minority languages to enter mainstream society, and more and more research is focused on this subject [4,5,6,7]. Thus, an effective AI-based methodology is necessary to develop a high-quality translation system for minority languages with low resources to ensure a culturally and ethnically diverse society.
Hybrid methodologies that combine rule-based approaches with neural machine translation have demonstrated significant potential in improving translation quality for under-resourced language pairs [8]. This research underscores the critical role of integrating artificial intelligence with human intelligence to enhance translation efficiency, particularly for minority languages. Proactive learning frameworks have been identified as effective tools for constructing machine translation (MT) systems tailored to minority languages with limited resources, e.g., a lack of time and budget for developing MT to collect enough lexicons to cover the entire range of the target translations and their corresponding grammar rules [9]. Effective machine translation for minority languages is critical; for effective communication and eradicating language barriers on a global scale, all languages, including more than 200 minority languages, should be understood and not be left in the hands of ineffective translation [10]. Despite the advances in human-centered machine translation for low-resource languages—e.g., effective datasets and computational models for AI-based MT [10]—considerable challenges persist in safeguarding linguistic diversity and meeting the distinctive needs of minority language speakers [11,12]. Recent innovations, such as integrating neural translation engines with rule-based systems, have yielded encouraging results in enhancing translation accuracy for endangered languages, including those of Lemko [13]. These developments in MT technologies hold substantial promise for supporting language revitalization initiatives and empowering minority language communities [14]. This study introduces a hybrid AI-driven machine translation system that combines phrase-based and neural machine translation techniques to enhance the quality of Hakka-to-Chinese translation, where Hakka is a minority language and Chinese is the primary stream language spoken in Taiwan.
The proposed system addresses the limitations of purely statistical or neural methods by integrating phrase-based MT with neural approaches, particularly in low-resource settings. The key to improving translation quality is adopting a recursive translation approach, dynamically generating parallel corpora, and leveraging them for continuous, profound learning improvements. This methodology enhances immediate translation services for Hakka speakers and contributes to the broader goal of preserving and revitalizing this language through AI-driven solutions.
This hybrid machine translation system primarily aims to establish a robust and scalable platform for Hakka language translation, addressing the challenges posed by its low-resource nature. The system is designed to facilitate effective communication in Hakka while preserving its linguistic and cultural heritage. To achieve this, the translation model incorporates Hakka culture-specific items (CSIs), including idiomatic expressions, proverbs, master words, ancient dialects, and emerging linguistic trends.
There has been an increase in research addressing the challenge of producing applicable translation models in the absence of translated training data [15]. Machine translations of dialects mainly face the problem of scarce parallel data in language pairs. The other issue is that the existing data often has a lot of noise or is from a very specialized domain.
Previous research has implemented machine translation systems using CNNs with attention mechanisms to translate Mandarin into Sixian-accented Hakka [16]. These studies have addressed dialectal variations by separately training exclusive models for Northern and Southern Sixian accents and analyzing corpus differences. Given the limited availability of Hakka corpora, previous systems have faced challenges with unseen words frequently occurring during real-world translation. To mitigate this, past research has employed forced segmentation for Hakka idioms and common Mandarin word substitutions to improve translation intelligibility, leading to promising results even with small datasets. These systems have been proposed for applications in Hakka language education and as front-end processors for Mandarin–Hakka code-switching speech synthesis [16]. In contrast to previous research using CNNs with attention mechanisms, this study introduces a hybrid AI-driven machine translation system that combines phrase-based and neural machine translation techniques to enhance the quality of Hakka-to-Chinese translation.
Traditional Transformer neural machine translation does not employ recurrent neural networks (RNNs) for natural language processing tasks like machine translation. It mainly focuses on self-attention mechanisms, with the Transformer being very close to human-level learning effects; however, it does not consider the critical issue of the minority language translation via machine translation, when the language translated is a low-resource language with sparse parallel corpora, limited linguistic annotations, and a lack of robust language models for neural machine translation, such as natural language processing (NLP). Thus, this study proposes a hybrid machine translation approach integrating RNN to resolve these shortcomings, including a lack of parallel data in language pairs, significant noise from data or very specialized domains, unseen words frequently occurring during real-world translation, and the neglect of RNNs in enhancing translation quality.
The remainder of this paper is structured as follows. Section 2 is a literature review of low-resource languages, machine translation systems, and the Hakka corpus used for language translation. Section 3 introduces hybrid machine translation, including the objectives of the system, preprocessing, the system’s development process and architecture, neural machine translation (NMT), phrase-based machine translation (PBMT), and hybrid AI-driven translation system development. Section 4 is the system evaluation, reporting the performance of phrase-based machine translation and describing the hybrid artificial intelligence model. Section 5 is the conclusion, addressing theoretical implications, practical implications, research limitations, and directions for future research.
2. Literature Review
2.1. Low-Resource Languages
Low-resource languages are often characterized by limited digitized text data, posing significant challenges to the development of effective natural language processing (NLP) and machine translation (MT) systems. Unlike high-resource languages, which benefit from extensive corpora and well-established linguistic resources, low-resource languages face obstacles such as sparse parallel corpora, limited linguistic annotations, and a lack of robust language models. These limitations hinder the ability of traditional MT systems to achieve high-quality translations, particularly when it comes to preserving unique cultural nuances and idiomatic expressions. In a pluralistic society, it is increasingly difficult to inherit one’s mother tongue. Thus, to preserve and revitalize minority languages, such as Hakka, systems that can translate minority languages are deeply needed. However, the Hakka language is a low-resource language. As noted, low-resource languages are challenging for NLP applications [17]. They possess rich cultural and linguistic diversity, including dialectal variations and unique idiomatic expressions that are difficult for conventional translation models to capture accurately. Furthermore, many low-resource languages lack standardized orthography or consistent grammar rules, complicating the development of reliable and consistent translation models. Taken together, these factors make it challenging to create generalized translation systems that can effectively handle the nuances of low-resource languages.
2.2. Machine Translation System
A machine translation system is computer software that takes a text or voice in one natural language (the source language) and translates it into another (the target language) [18]. Currently, the best system for this purpose is neural machine translation (NMT), which utilizes tens of millions of parallel sentences from training data. Such a huge amount of training data is only available for a handful of language pairs and only in particular domains, such as news and official proceedings [19].
Neural networks are computational models inspired by biological neurons, used extensively in machine learning applications [20]. They consist of interconnected nodes organized into layers, processing input data to produce outputs [21]. Neural networks can be implemented in various architectures, including feedforward, convolutional, and recurrent networks, each suited for different tasks [22]. These structures enable neural networks to perform complex tasks such as image recognition, speech processing, and natural language understanding. NMT represents a significant advancement in machine translation, utilizing deep learning techniques and neural networks to improve translation quality. Unlike traditional statistical methods, NMT builds a single neural network that can be jointly optimized for translation performance [23].
RNNs are designed explicitly for sequential data processing, making them particularly effective for natural language processing tasks like machine translation [24]. Unlike other neural network types (such as feedforward neural networks), RNNs have cyclic connections that maintain internal memory and capture temporal dependencies [25]. This architecture makes RNNs well suited for language modeling, speech recognition, and time series prediction. Variants such as Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs) have shown improved performance in handling long-term dependencies [26]. Integrating RNN language and translation models into phrase-based decoding systems has demonstrated promising results in machine translation tasks [27].
Various architectures have been explored, including RNNs, Convolutional Neural Networks (CNNs), and the Transformer model, with the latter showing superior capabilities in handling long-range dependencies [28]. For machine translation, NMT models typically consist of an encoder–decoder structure, where the encoder extracts a fixed-length representation from the input sentence, and the decoder generates the translation [29]. Recent developments include attention mechanisms, which allow the model to focus on relevant parts of the source sentence during translation [23]. While NMT performs well on short sentences, its performance can degrade with longer sentences and unknown words [29].
Machine translation and language teaching chatbots are all uses of artificial intelligence to enhance language learning. Machine translation can be integrated into dialect learning with the help of neural machine translation. Several advances have been made in NMT. The RNN-based sequence-to-sequence model (Seq2Seq) was proposed in 2014 as a type of encoder–decoder.Seq2Seq models have been widely used for machine interaction and machine translation in end-to-end speech processing, for example, automatic speech recognition (ASR), speech translation (ST), and text-to-speech (TTS) [30]. In 2015, RNN with attention was developed to solve Seq2Seq problems. Furthermore, the Convolutional Encoder Model for neural machine translation was proposed in 2017. Finally, the proposed Transformer network architecture is based entirely on attention mechanisms and can achieve new, state-of-the-art results in neural machine translation [31].
2.3. Hakka Corpus
A corpus is a text database that scientifically organizes and stores electronic texts and is an important material for linguistic research [32], specifically collecting text or spoken corpora of a set scale for one or more application goals. Linguistically, this word refers to a large amount of text, usually organized with a given format and markup. A corpus has a set structure; is representative; can be retrieved by a computer program; and is generally used in the fields of lexicography, language teaching, and traditional language research. The corpus related to the Hakka language includes the national “Taiwan Hakka Corpus”, which was opened in 2021. This corpus was commissioned in 2017 by the Hakka Affairs Council, which asked the National ChengChi University research team to build the first native language corpus. The other Hakka corpus is the Taiwan Hakka Speech Corpus. Its most prominent feature is its Hakka speech recognition and speech synthesis corpus of various accents. In the future, it will be combined with artificial intelligence technology to develop Hakka digital applications.
Creating parallel corpora is a problem that many researchers have tried to deal with [33], and the nature of low-resource languages like Hakka makes this issue even more complicated. Currently, the world has around 7000 spoken languages, but most language pairs do not have enough resources to train machine translation models.
3. Hybrid Machine Translation
3.1. Objectives of the Hybrid Machine Translation System
This system supports multilingual translations, enabling seamless conversion between Hakka, Chinese, English, and other Asian languages commonly spoken by Hakka diaspora communities, such as Japanese, Thai, Indonesian, and Malay. A prototype system was developed to evaluate the proposed hybrid approach. This system primarily focuses on literal Chinese-to-Hakka translation, ensuring fidelity in linguistic representation. The system dynamically adapts to different contextual interpretations, allowing for nuanced translations that accurately reflect Hakka cultural elements.
To enhance cultural representation in translations, the system integrates phrase-based machine translation, which incorporates an expanded translation lexicon featuring Hakka culture-specific terms. This approach ensures that key cultural expressions are explicitly retained in translations rather than omitted or misrepresented by conventional deep learning models [34]. Unlike traditional “black-box” deep learning-based translation models, which often lack transparency in handling culture-specific vocabulary, this system adopts a “white-box” approach, enabling direct control over translation references. By doing so, the system preserves the authenticity of Hakka language expressions while improving overall translation quality.
This hybrid AI model provides a structured methodology for improving machine translation in low-resource languages, balancing linguistic accuracy, cultural relevance, and computational efficiency. Future iterations of this system will continue refining translation accuracy through recursive learning, ensuring that the platform evolves alongside the expansion of Hakka language digital resources.
3.2. Preprocessing
Preprocessing is crucial in optimizing training datasets for neural machine translation, particularly in handling low-resource languages like Hakka. Raw textual data often contains long sentences, extraneous noise, and inconsistent formatting, negatively impacting model performance. To enhance training efficiency and maintain translation accuracy, this study establishes a detailed preprocessing pipeline to standardize, clean, and refine the dataset before input into the machine translation system. The preprocessing process was implemented using Python 3.10.12 within a Jupyter Notebook 3.6.3 environment. Text segmentation was performed using the Jieba tokenizer, followed by manual adjustment to accommodate Hakka-specific linguistic features. Regular expressions from Python’s re library were used to remove punctuation, annotations, and extraneous symbols. A maximum sentence length of 40 Chinese characters was imposed to reduce sentence complexity and improve alignment accuracy. Sentences exceeding this threshold were excluded. Additional cleaning rules included the removal of parentheses and brackets containing synonym explanations; filtering of ambiguous separators such as slashes (“/” or “//”); and elimination of blank lines, non-Chinese characters, and excessive whitespace. All data was normalized using UTF-8 encoding to ensure script consistency and prevent character corruption during processing. This standardized preprocessing pipeline improves the quality and consistency of the dataset, thereby enhancing the overall performance and reliability of both the phrase-based and neural machine translation components. To improve data quality, the preprocessing phase consists of the following five key steps:
- Sentence Segmentation: Split training sentences based on punctuation marks to enhance structural clarity.
- Punctuation Removal: Eliminating unnecessary punctuation that may introduce inconsistencies in translation.
- Synonym Annotation Removal: Removing comments enclosed within “()” or “[]”, which often contain redundant synonym explanations.
- Ambiguous Symbol Cleanup: Discarding “/” or “//” symbols used as separators for alternative expressions, reducing lexical redundancy.
- Whitespace and Non-Chinese Character Filtering: Stripping blank lines, excessive spaces, and non-Chinese characters that do not contribute to model learning.
These preprocessing steps for raw textual data standardize sentence structures, eliminate noise, and enhance dataset consistency, thereby creating the parallel corpus and ultimately improving the accuracy and efficiency of the NMT model. Experimental results confirm that segmentation based on punctuation and the systematic removal of redundant symbols significantly enhance translation quality. The refined dataset ensures that both phrase-based and neural machine translation models can generate more accurate and culturally appropriate translations for Hakka.
Example of Preprocessing:
- Raw Sentence. This is a sample sentence containing [synonyms] and/different/expressions. After Preprocessing. This is a sentence containing synonyms and different expressions.
This example illustrates how synonyms, extraneous annotations (e.g., brackets, parentheses, and slashes), non-standard punctuation, and redundant symbols are removed in order to create a cleaner and more uniform dataset. Such standardization plays a crucial role in ensuring data quality and boosting the performance of the translation model during training.
3.3. System Development Process and Architecture
Figure 1 illustrates the proposed hybrid machine translation system’s architecture, highlighting the integration of PBMT, NMT, and recursive learning cycles for text translation. The following introduces the functionality of PBMT and NMT in the proposed system, thereby suggesting the hybrid AI-driven translation system framework.
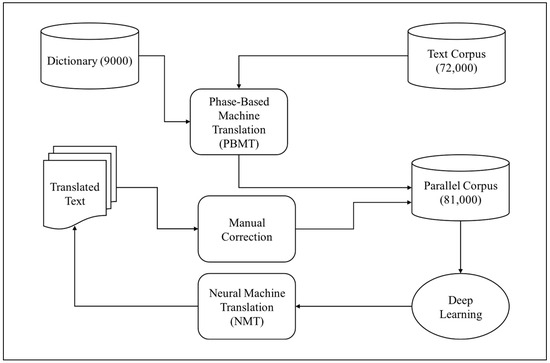
Figure 1.
System architecture of hybrid machine translation.
3.4. Phrase-Based Machine Translation (PBMT)
Phrase-based machine translation is a good alternative when designing a dialect machine translation system with limited parallel corpus resources. The Hakka language is one of the eight major dialects of Chinese, all of which are written in Chinese characters. To fully present the cultural characteristics of Hakka, cultural feature words are manually sorted and added to the phrase lexicon. The translated text at this stage can better reflect Hakka cultural characteristics and improve translation quality. Thus, phrase-based machine translation with Hakka culture-specific items can achieve good translation quality.
The accuracy rate of this translation design is quite high, but there are still many problems. The original Hakka text is first divided into single words or phrases, and then, statistics and a limited vocabulary and phrase comparison table are used to select the most common translation methods for these words or phrases, which are then recomposed into sentences according to Hakka grammar. This study adapted phrase-based machine translation to construct a parallel corpus of Hakka-Chinese.
The problem with phrase-based machine translation is that it generates the most likely translations based on statistical principles, which are not always accurate. For example, polysemic words can sometimes be problematic. Second, phrase-based machine translation mainly translates single-word phrases, and its ability to translate sentences is limited. When sentences are long, complex, ambiguous, or have grammatical exceptions, phrase-based machine translation is prone to mistranslation. When the number of parallel corpus thesauruses is small, compared with neural machine translation, the translation accuracy rate of phrase-based machine translation is acceptable. Thus, when parallel corpus resources are limited, phrase-based machine translation can be used. However, the translation quality is restricted and cannot produce high-quality results. Conversely, when a rich parallel corpus is available, neural machine translation can produce high-quality translation results. Thus, this study also integrates NMT into the proposed system to enhance translation quality.
3.5. Neural Machine Translation (NMT)
Neural machine translation usually relies on parallel corpora in two languages (the source language and target language) to train models. For example, the Chinese-to-English model uses millions of parallel corpora as training datasets. However, low-resource languages, such as minority languages and most dialects, do not have enough parallel corpora as training datasets. As open sources of parallel data have been exhausted, one avenue for improving low-resource NMT is to obtain more parallel data through web-crawling. However, even web-crawling may not yield enough text to train high-quality MT models. Nonetheless, monolingual texts will almost always be more plentiful than parallel texts, and leveraging monolingual data has been one of the most important and successful research areas in low-resource MT. A recent study showed how carefully targeted data gathering can lead to clear MT improvements in low-resource language pairs [35]. For successful translation models, data is the most important factor, and the curation and creation of datasets are key elements for future success [15].
3.6. Hybrid AI-Driven Translation System Development
By integrating PBMT and NMT, the proposed machine translation system can enhance translation accuracy for low-resource languages like Hakka. The system follows a structured three-stage development process, which is depicted in Figure 2 and outlined below.
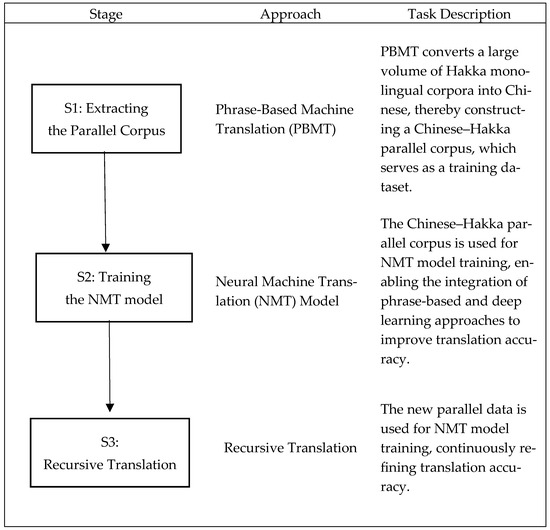
Figure 2.
Flowchart of the hybrid AI translation framework.
Stage 1: Extracting the Parallel Corpus. We designed the five preprocessing procedures for raw textual data, including (1) Sentence Segmentation, (2) Punctuation Removal, (3) Synonym Annotation Removal, (4) Ambiguous Symbol Cleanup, and (5) Whitespace and Non-Chinese Character Filtering, as mentioned above, to assist in creating the parallel corpus and optimize the training datasets. A phrase-based machine translation (PBMT) approach is implemented using a limited Chinese–Hakka dictionary. This dictionary-driven translation converts a large volume of Hakka monolingual corpora into Chinese, thereby constructing a parallel corpus, which serves as a training dataset. In this stage, the PBMT procedure utilizes a curated Hakka–Mandarin dictionary comprising 9000 culture-specific lexical items, including idiomatic expressions, proverbs, and traditional vocabulary, primarily derived from the Hakka Proficiency Test word list (Sixian dialect), the Ministry of Education’s Hakka–Chinese dictionary, and a manually annotated set of culture-specific terms. These lexical items translated 72,000 Hakka monolingual sentences into Mandarin through rule-based alignment, resulting in an initial parallel corpus. An additional 9000 sentence pairs were manually compiled and validated by native Hakka speakers with linguistic expertise, bringing the total corpus to 81,000 Hakka–Mandarin sentence pairs. Sentences exceeding 40 Chinese characters or containing ambiguous or redundant entries were excluded. The dataset was randomly split into 80% for training and 20% for evaluation. This process ensures the preservation of linguistic structures and culturally embedded expressions and establishes a reproducible foundation for model training and testing. Table 1 summarizes the extracted items for the establishment of the parallel corpus.

Table 1.
Hakka–Mandarin dictionary for the parallel corpus.
Stage 2: Training the NMT Model. In this stage, the parallel corpus gained from stage 1 is utilized to train a neural machine translation (NMT) model, integrating the phrase-based and deep learning approaches to improve translation accuracy. This allows the system to enhance contextual understanding and sentence-level coherence. By leveraging both methods, the proposed hybrid system overcomes the limitations of purely statistical or neural-based models, particularly in low-resource languages.
Stage 3: Recursive Translation. The final stage involves recursive translation. New parallel data is iteratively added to retrain the NMT model, continuously refining translation accuracy by expanding the dataset and improving its ability to process Hakka language patterns, idiomatic expressions, and syntactic structures.
The above hybrid approach effectively combines the rule-based advantages of PBMT with the deep learning capabilities of NMT. Its recursive learning mechanism, designed for the translation of low-resource languages, ensures the ongoing enhancement of translation quality. This methodology enhances immediate translation services for Hakka speakers while contributing to the broader goal of preserving and revitalizing their language through AI-driven solutions.
4. System Evaluation
4.1. Experimental Setup
The Hakka language in Taiwan has six different accents, namely, the Sixian (Nansixian and South Sixian), Hailu, Dapu, Raoping, and Zhao’an dialects. This study collects a parallel corpus of the Hakka language in the form of sentences. Vocabulary from the Certificate of Hakka Proficiency Test is taken only from the Sixian accent, with about 5000 entries; conversely, the Ministry of Education dictionary has about 20,000 entries, more thoroughly sorting the examples. There are about 32,000 entries in the parallel corpus in this experiment.
The external Chinese–Hakka language parallel corpus includes the Hakka dictionary, the Hakka entry on the website of the Ministry of Education, and the culture-specific items compiled in this study. These parallel corpora are used in our phrase-based machine translation system. It utilizes statistics and the collected vocabulary of the languages to determine the most common translations for these words and phrases. According to the appropriate grammar, they are then reorganized into sentences, with the Chinese words translated into Hakka words and sentences.
To measure the effectiveness of our machine translation, we adopted the BLEU (Bilingual Evaluation Understudy) metric as the primary evaluation standard. BLEU is one of the most widely accepted and reproducible automated metrics in machine translation research. It can assess the closeness of a machine-generated translation to a professional human translation by comparing overlapping n-grams, making it particularly suitable for large-scale, sentence-level translation quality assessment. Quality is measured by the correspondence between a machine’s output and that of a human: “the closer a machine translation is to a professional human translation, the better it is” [36]. This metric’s computational efficiency and objectivity also allow for consistent evaluation across experimental conditions, especially when applied to low-resource language scenarios where extensive human evaluations may be infeasible in early-stage system development. Given the exploratory nature of this study and its aim to benchmark translation quality across different system configurations (PBMT vs. hybrid models), BLEU provides a sufficient and reliable basis for performance comparison. In the experimental setup, 500 out-of-sample entries were extracted from the Ministry of Education’s Hakka dictionary as the evaluation corpus. These entries were deliberately excluded from the training data to ensure objective performance measurement and generalization.
The BLEU score is computed using various parameters, including the Brevity Penalty (BP), which penalizes translations shorter than the reference translations to prevent artificially high scores; in our experiments, BP = 1.000, indicating no significant penalty. The ratio represents the proportion of the hypothesis (machine-translated) text length to the reference (human-translated) text length, which is 1.062 in our case, meaning machine-generated translations were slightly longer. Hypothesis length (hyp_len) and reference length (ref_len) refer to the total number of words in the machine-translated and human-translated texts, which were 9174 and 8641, respectively. The slight difference in length suggests that the machine translation system tends to generate longer output sentences. The BLEU score for the phrase-based machine translation system was 47.52, demonstrating competitive translation quality despite the limited corpus. BP is 1.0 when the candidate translation length is the same as any reference translation length. The closest reference sentence length is the best match length [36].
While BLEU is a widely used evaluation metric, it has limitations, particularly in capturing nuances and contextual meaning in low-resource language translation. Therefore, alternative metrics such as METEOR (Metric for Evaluation of Translation with Explicit ORdering) and TER (Translation Edit Rate) were also considered. METEOR accounts for synonymy, stemming, and paraphrasing, making it a comprehensive evaluation method [37]. Conversely, TER evaluates the number of edits required to convert machine-generated translations into human translations, providing insight into translation fluency and coherence [38]. Future studies may integrate human evaluation methods alongside automated metrics to obtain a holistic translation quality assessment.
4.2. Experiment
Translating dialects and minority languages has always been a significant problem in machine translation. There are several approaches to mitigating the issue of low-resource machine translation, including transfer learning, semi-supervised learning, and unsupervised learning techniques [39]. The current study adopted the hybrid artificial intelligence model, combining phrase-based and neural machine translation to translate a Hakka language text into Chinese. Table 2 lists the parameters of the model specification.
Table 2.
Model specification.
The machine translation models were trained for 40,000 epochs with a batch size of 64, using the Adam optimizer and an initial learning rate of 0.002. Early stopping was applied if the BLEU score on the validation set did not improve for five consecutive epochs. A validation split of 10% was used to monitor model performance during training. The training was conducted using an NVIDIA RTX 4090 GPU (24 GB VRAM) with 128 GB of RAM (NVIDIA, Santa Clara, CA, USA) on an Ubuntu 20.04 LTS system. The models were implemented using TensorFlow 2.0 and trained via the OpenNMT-tf framework. This configuration was chosen to balance computational efficiency with effective convergence, ensuring stable optimization for low-resource Hakka translation tasks.
The hybrid translation model for experiments constructed in this study consists of three stages, as depicted and described in Figure 2, including: (1) phrase-based machine translation (Extracting the Parallel Corpus), (2) neural machine translation (Training the NMT model), and (3) recursive translation. As the Hakka text corpus is collected, the first stage of translation work is then carried out through phrase-based machine translation to generate an 81,000 parallel corpus. The generated parallel corpus is utilized as the training dataset in stage 2 to complete the Transformer machine translation training work. Further, recursive translation with increased parallel corpora can improve the translation quality in stage 3.
4.3. Discussion of Results
The changes observed in Figure 3 are primarily due to the impact of increasing training data size and refining the hybrid AI-driven translation system. Initially, PBMT demonstrated better performance when the dataset was small, effectively utilizing statistical alignments. However, as the dataset expanded and the NMT model was trained on a more comprehensive parallel corpus, its ability to generalize improved significantly. This resulted in higher BLEU scores in later stages. Additionally, improvements in encoder parameters, including deeper networks, increased hidden units, and additional attention heads, contributed to better contextual learning and enhanced translation accuracy. The recursive refinement of the hybrid model, where PBMT-generated translations were incorporated into NMT training, further reinforced learning, making translations progressively more accurate. The improvements in Figure 3 validate the effectiveness of the hybrid approach, demonstrating that while PBMT is advantageous for low-resource settings, the integration with deep learning models yields superior long-term translation performance.
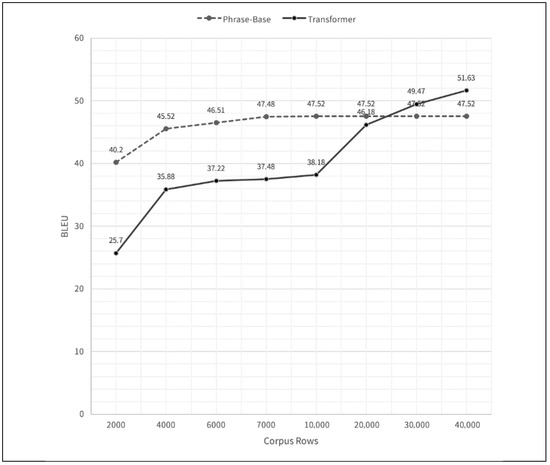
Figure 3.
BLEU scores with PBMT vs. hybrid model (Transformer).
As Table 2 notes, we implemented an encoder–decoder Transformer model consisting of six layers, with key hyperparameters set as follows: the model dimension (dmodel) was configured to 256, the feedforward network dimension (dff) was set to 1024, and the number of attention heads (num_heads) was fixed at 2. Additionally, the model employed learned positional embeddings to effectively capture word order dependencies and incorporated weight-sharing between the token embedding and output layers to improve efficiency and reduce the number of trainable parameters. The initial training results yielded the best BLEU score at 46.18.
To address the challenge posed by the limited availability of parallel corpora for Hakka, we utilized a monolingual Hakka text corpus comprising 751,960 words provided by the Hakka Affairs Council. We employed a PBMT system to perform reverse translation to expand the available training data, converting the monolingual Hakka corpus into Mandarin. This process resulted in a Chinese–Hakka parallel corpus, which served as the training dataset for the final NMT model. We conducted additional training cycles to refine the Transformer model using this expanded parallel corpus. The final model achieved an optimal BLEU score of 51.63, reflecting a substantial improvement in translation quality.
The evaluation metrics for this result were as follows: BP = 1.000, indicating that there was no significant length penalty applied; ratio = 1.015, signifying that the machine-translated output was approximately 1.5% longer than the human reference translations; hypothesis length (hyp_len) = 8774, representing the total number of words in the model-generated translations; and reference length (ref_len) = 8641, corresponding to the length of the human-translated reference corpus. The increase in BLEU score from 46.18 to 51.63 suggests that the quality of Hakka translation was significantly enhanced through reverse translation, data augmentation, and iterative training refinements. These results demonstrate the effectiveness of integrating PBMT with NMT, allowing for the creation of a robust hybrid translation system. This approach improves translation accuracy and provides a viable solution for data scarcity in low-resource languages like Hakka.
5. Conclusions
5.1. Theoretical Implications
This study contributes to the theoretical development of low-resource language processing by proposing a hybrid artificial intelligence translation framework that combines PBMT with NMT within a recursive learning mechanism. This model advances current translation theory by demonstrating that rule-based and neural approaches are not mutually exclusive but can be synergistically integrated to overcome the limitations of sparse parallel corpora and dialectal diversity. Moreover, the explicit incorporation of culture-specific items into the translation pipeline highlights the necessity of culturally grounded modeling in multilingual NLP systems, offering a novel perspective on how linguistic form and cultural meaning can be preserved through computational means. The recursive expansion of training data through iterative translation–refinement further reinforces that machine learning architecture can be adapted to low-resource environments by leveraging linguistically aware strategies.
5.2. Practical Implications
From a practical standpoint, the hybrid framework developed in this research offers a replicable and modular solution for minority language translation, particularly for Hakka, which suffers from fragmented digital resources and dialectal complexity. The system’s architecture, including preprocessing protocols and recursive learning loops, provides a blueprint for institutions aiming to digitize, translate, or teach under-resourced languages. Its adaptability to multilingual inputs and capacity to retain cultural expressions make it highly suitable for applications in education, community media, cultural preservation, and government-supported language revitalization initiatives. This study thus demonstrates how AI-driven translation systems can serve as technological tools and as instruments of sociolinguistic inclusion, language equity, and digital citizenship for marginalized language communities.
5.3. Research Limitations
While the proposed hybrid machine translation system demonstrates promising performance, several limitations must be acknowledged. The training corpus used in this study focuses exclusively on Hakka’s Sixian dialect. As a result, the model’s applicability to other major Hakka dialects—such as Hailu, Dapu, and Raoping—remains untested, limiting its generalizability across dialectal variations. Furthermore, the current system is designed to operate at the sentence level and does not incorporate mechanisms for modeling discourse-level coherence, contextual dependencies, or semantic flow across multiple sentences. In terms of evaluation, this study relies primarily on automated metrics such as BLEU. While BLEU provides a valuable benchmark for translation quality, it does not fully capture linguistic nuances such as idiomatic expression, syntactic fluidity, or cultural appropriateness. The absence of human evaluations also restricts the interpretability of the system’s performance in practical settings, particularly in language learning or real-world communication scenarios involving minority language users. These limitations highlight important areas for future development and refinement.
5.4. Directions for Future Research
To build on the present findings, future studies should pursue several directions. Expanding the corpus to include diverse dialectal variants would enhance the system’s linguistic coverage and robustness, while incorporating ASR and TTS technologies would enable the development of multimodal, voice-based Hakka translation tools. Furthermore, integrating the translation system into practical applications—such as AI-powered chatbots, virtual tour guides, or language-learning platforms—would allow for the empirical testing of user experience, effectiveness, and usability. Finally, human-centered evaluation methods should be implemented to assess translation quality regarding semantic fidelity, cultural relevance, and communicative function, including expert reviews and end-user feedback. Teaching the minority language to minority ethnic groups positively impacts their chances of long-term survival and fluency [40]. These research trajectories would not only extend the current model but also its relevance to other endangered or low-resource languages needing digital preservation and revitalization.
Author Contributions
C.-C.C. was responsible for the initial conceptualization of the research, the design of the study’s framework, and writing—original draft preparation; Y.-H.L. was responsible for writing—review and editing; Y.-H.H. was responsible for programming and system development; I.-H.F. took charge of data collection and analysis. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science and Technology Council (NSTC), Taiwan, grant number NSTC 112-2410-H-239-015-MY2. The APC was funded by Ming Chi University of Technology.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://github.com/yuripeyamashita/ha-zh-corpus (accessed on 13 August 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hansen, K.L.; Melhus, M.; Høgmo, A.; Lund, E. Ethnic discrimination and bullying in the Sami and non-Sami populations in Norway: The SAMINOR study. Int. J. Circumpolar Health 2008, 67, 99–115. [Google Scholar] [CrossRef]
- Kantamneni, N. The impact of the COVID-19 pandemic on marginalized populations in the United States: A research agenda. J. Vocat. Behav. 2020, 119, 103439. [Google Scholar] [CrossRef]
- Sah, P. Linguistic diversity and social justice: An introduction of applied sociolinguistics. Crit. Inq. Lang. Stud. 2018, 15, 228–230. [Google Scholar] [CrossRef]
- Forcada, M. Open source machine translation: An opportunity for minor languages. In Proceedings of the Workshop “Strategies for Developing Machine Translation for Minority Languages”, LREC, Genoa, Italy, 24–26 May 2006; pp. 1–6. [Google Scholar]
- Crossley, S.A. Technological disruption in foreign language teaching: The rise of simultaneous machine translation. Lang. Teach. 2018, 51, 541–552. [Google Scholar] [CrossRef]
- Somers, H. Machine translation and minority languages. In Proceedings of the Translating and the Computer 19, Manchester, UK, 13–14 November 1997. [Google Scholar]
- Kenny, D.; Moorkens, J.; Do Carmo, F. Fair MT: Towards ethical, sustainable machine translation. Transl. Spaces 2020, 9, 1–11. [Google Scholar] [CrossRef]
- Sánchez-Cartagena, V.M.; Forcada, M.L.; Sánchez-Martínez, F. A multi-source approach for Breton-French hybrid machine translation. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020. [Google Scholar]
- Ambati, V.; Carbonell, J.G. Proactive learning for building machine translation systems for minority languages. In Proceedings of the NAACL HLT 2009 Workshop on Active Learning for Natural Language Processing, Boulder, CO, USA, 5 June 2009. [Google Scholar]
- Costa-jussà, M.R.; Cross, J.; Çelebi, O.; Elbayad, M.; Heafield, K.; Heffernan, K.; Kalbassi, E.; Lam, J.; Licht, D.; Maillard, J. No language left behind: Scaling human-centered machine translation. arXiv 2022, arXiv:2207.04672. [Google Scholar] [CrossRef]
- Cronin, M. Altered states: Translation and minority languages. Trad. Terminol. Réd. 1995, 8, 85–103. [Google Scholar] [CrossRef]
- Kuusi, P.; Kolehmainen, L.; Riionheimo, H. Introduction: Multiple roles of translation in the context of minority languages and revitalisation. Trans-Kom Z. Für Transl. Fachkommun. 2017, 10, 138–163. [Google Scholar]
- Orynycz, P. BLEU Skies for Endangered Language Revitalization: Lemko Rusyn and Ukrainian Neural AI Translation Accuracy Soars. In International Conference on Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Herbig, N.; Pal, S.; van Genabith, J.; Krüger, A. Integrating Artificial and Human Intelligence for Efficient Translation. arXiv 2019, arXiv:1903.02978. [Google Scholar] [CrossRef]
- Haddow, B.; Bawden, R.; Barone, A.V.M.; Helcl, J.; Birch, A. Survey of Low-Resource Machine Translation. Comput. Linguist. 2022, 48, 673–732. [Google Scholar] [CrossRef]
- Hung, Y.-H.; Huang, Y.-C. A Preliminary Study on Mandarin-Hakka neural machine translation using small-sized data. In Proceedings of the 34th Conference on Computational Linguistics and Speech Processing (ROCLING 2022), Taipei, Taiwan, 21–22 November 2022. [Google Scholar]
- Karakanta, A.; Dehdari, J.; van Genabith, J. Neural machine translation for low-resource languages without parallel corpora. Mach. Transl. 2018, 32, 167–189. [Google Scholar] [CrossRef]
- Goyal, V.; Lehal, G.S. Advances in machine translation systems. Lang. India 2009, 9, 138–150. [Google Scholar]
- Awadalla, H.H. Bringing Low-Resource Languages and Spoken Dialects into Play with Semi-Supervised Universal Neural Machine Translation. Microsoft Research Blog. 2018. Available online: https://www.microsoft.com/en-us/research/blog/bringing-low-resource-languages-spoken-dialects-play-semi-supervised-universal-neural-machine-translation/ (accessed on 13 August 2025).
- Han, S.-H.; Kim, K.W.; Kim, S.; Youn, Y.C. Artificial neural network: Understanding the basic concepts without mathematics. Dement. Neurocogn. Disord. 2018, 17, 83–89. [Google Scholar] [CrossRef]
- Vanchurin, V. Toward a theory of machine learning. Mach. Learn. Sci. Technol. 2021, 2, 035012. [Google Scholar] [CrossRef]
- Lote, S.; Praveena, K.; Patrer, D. Neural networks for machine learning applications. World J. Adv. Res. Rev. 2020, 6, 270–282. [Google Scholar] [CrossRef]
- Bahdanau, D. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Bisong, E.; Bisong, E. Recurrent Neural Networks (RNNs). Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: Berkeley, CA, USA, 2019; pp. 443–473. [Google Scholar]
- Lipton, Z.C. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019. [Google Scholar] [CrossRef]
- Lee, H.; Song, J. Understanding recurrent neural network for texts using English-Korean corpora. Commun. Stat. Appl. Methods 2020, 27, 313–326. [Google Scholar] [CrossRef]
- Agrawal, R.; Sharma, D.M. Experiments on different recurrent neural networks for English-Hindi machine translation. In Proceedings of the Computer Science and Information Technology (CS & IT), Telangana, India, 2017; pp. 63–74. [Google Scholar]
- Hu, J. Neural Machine Translation (NMT): Deep learning approaches through Neural Network Models. Appl. Comput. Eng. 2024, 82, 93–99. [Google Scholar] [CrossRef]
- Cho, K. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar] [CrossRef]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Wang, X. A comparative study on transformer vs rnn in speech applications. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar]
- Raganato, A.; Tiedemann, J. An analysis of encoder representations in transformer-based machine translation. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, The Association for Computational Linguistics. Brussels, Belgium, 1 November 2018. [Google Scholar]
- Zhang, F. Application of data storage and information search in english translation corpus. Wirel. Netw. 2021, 2021, 1–11. [Google Scholar] [CrossRef]
- Harrat, S.; Meftouh, K.; Smaïli, K. Creating parallel Arabic dialect corpus: Pitfalls to avoid. In Proceedings of the 18th International Conference on Computational Linguistics and Intelligent Text Processing (CICLING), Budapest, Hungary, 17–23 April 2017. [Google Scholar]
- Horbačauskienė, J.; Kasperavičienė, R.; Petronienė, S. Issues of culture specific item translation in subtitling. Procedia-Soc. Behav. Sci. 2016, 231, 223–228. [Google Scholar] [CrossRef]
- Hasan, T.; Bhattacharjee, A.; Samin, K.; Hasan, M.; Basak, M.; Rahman, M.S.; Shahriyar, R. Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online: Association for Computational Linguistics. Brussels, Belgium, 16–20 November 2020; pp. 2621–2623. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lavie, A.; Denkowski, M.J. The METEOR metric for automatic evaluation of machine translation. Mach. Transl. 2009, 23, 105–115. [Google Scholar] [CrossRef]
- Snover, M.G.; Madnani, N.; Dorr, B.; Schwartz, R. Ter-plus: Paraphrase, semantic, and alignment enhancements to translation edit rate. Mach. Transl. 2009, 23, 117–127. [Google Scholar] [CrossRef]
- Gibadullin, I.; Valeev, A.; Khusainova, A.; Khan, A. A survey of methods to leverage monolingual data in low-resource neural machine translation. arXiv 2019, arXiv:1910.00373. [Google Scholar] [CrossRef]
- Civico, M. The dynamics of language minorities: Evidence from an agent-based model of language contact. J. Artif. Soc. Soc. Simul. 2019, 22, 27. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).