Abstract
The energy management strategy of Hybrid Electric Vehicles (HEVs) plays a key role in improving fuel economy and reducing battery energy consumption. This paper proposes a Deep Reinforcement Learning-based energy management strategy optimized by the experience pool (P-HER-DDPG), aimed at improving the fuel efficiency of HEVs while accelerating the training speed. The method integrates the mechanisms of Prioritized Experience Replay (PER) and Hindsight Experience Replay (HER) to address the reward sparsity and slow convergence issues faced by the traditional Deep Deterministic Policy Gradient (DDPG) algorithm when handling continuous action spaces. Under various standard driving cycles, the P-HER-DDPG strategy outperforms the traditional DDPG strategy, achieving an average fuel economy improvement of 5.85%, with a maximum increase of 8.69%. Compared to the DQN strategy, it achieves an average improvement of 12.84%. In terms of training convergence, the P-HER-DDPG strategy converges in 140 episodes, 17.65% faster than DDPG and 24.32% faster than DQN. Additionally, the strategy demonstrates more stable State of Charge (SOC) control, effectively mitigating the risks of battery overcharging and deep discharging. Simulation results show that P-HER-DDPG can enhance fuel economy and training efficiency, offering an extended solution in the field of energy management strategies.
1. Introduction
During recent years, the steady progress of new energy vehicle technology has brought Hybrid Electric Vehicles (HEVs) to the forefront, with their energy management challenges increasingly drawing significant research attention. An HEV is an advanced vehicle system that combines traditional powertrains with modern electric technology, aiming to improve fuel efficiency and reduce emissions. These vehicles are designed to leverage the advantages of both internal combustion engines (ICEs), which commonly use gasoline or diesel, and electric motors supplied with power from rechargeable batteries [1]. To enhance fuel efficiency and extend battery lifespan, the energy management strategy (EMS) in HEVs employs sophisticated control algorithms and software methods to optimize the coordinated operation of the internal combustion engine and energy storage systems like batteries [2]. The primary goal of energy management strategies is to enhance fuel economy while ensuring that the vehicle has good range. Currently, new energy vehicles mainly include Electric Vehicles (EVs), Hybrid Electric Vehicles (HEVs), and Plug-In Hybrid Electric Vehicles (PHEVs) [3]. Among these, HEVs stand out not only for their excellent performance in improving fuel economy but also for overcoming the limitations of battery range by combining multiple energy sources such as engines and batteries, making them a research hotspot in the field [4]. For effective coordination among multiple energy systems, energy management strategies often adopt mathematical optimization techniques to adjust the real-time output of each energy source, keeping the engine within its optimal efficiency range, thereby lowering fuel usage and enhancing overall fuel efficiency [5]. However, crafting an EMS for HEVs that is both timely and computationally efficient continues to pose a formidable hurdle.
Recent publications typically group Hybrid Electric Vehicle energy management strategies into three main categories: rule-oriented methods, optimization-based techniques, and reinforcement learning approaches [6,7]. Among these approaches, rule-based methods coordinate and switch the operating modes of the engine and battery system through a predefined control logic [8]. These approaches can be subdivided into precise deterministic rules and fuzzy rule sets. Wu et al. [9] introduced an EMS integrating energy usage patterns with power maintenance strategies. By introducing fuzzy control methods, the strategy optimizes the correction factor for the State of Charge, significantly enhancing the range of an autonomous electric tractor. However, the work was based on almost idealized conditions, without accounting for how differences in soil properties, changes in moisture, and terrain fluctuations could diminish the algorithm’s adaptability and robustness in real-world scenarios. Yamanaka et al. [10] introduced a hybrid approach that fuses instantaneous optimization with a rule-based mode selector, leveraging pre-computed Functional Analysis (FA) results to refine the equivalent parameters in real time. In the CS mode, this strategy significantly improved power distribution; in the CD mode, the driving range was extended to 55 km (based on the NEDC standard) and 42.66 km (based on the WLTP standard). Uralde et al. [11] presented a rule-oriented control method designed for a fuel cell Electric Vehicle EMS. The strategy was experimentally validated through multiple driving cycles and different SOC critical points, demonstrating its effectiveness in practical applications. Experimental results showed that this energy management system performed excellently in terms of performance optimization. However, relying on fixed deterministic rules limits the strategy’s ability to handle complex traffic situations and adapt to the dynamic characteristics of hybrid powertrains. Overall, while the implementation of rule-based control methods is relatively simple, they lack sufficient flexibility and are difficult to adapt to the complex and ever-changing real driving environment.
In contrast to rule-based strategies, global optimizers fuse heterogeneous inputs—road conditions, traffic patterns, and driver habits—into a single, cohesive assessment. By evaluating a wider range of environmental and system parameters, they can determine the optimal control solution with greater precision. As a result, global optimization methods have demonstrated significant advantages in improving fuel economy and enhancing the vehicle’s adaptability to various environmental conditions. Representative global optimization techniques encompass DP [12,13], which achieves a global optimal solution by solving the best control sequence; the Equivalent Consumption Minimization Strategy (ECMS) [14,15], which minimizes overall energy consumption by adjusting the equivalent consumption parameters in real time; the Genetic Algorithm (GA) [16,17], which optimizes decision variables by simulating the natural selection process; and Model Predictive Control (MPC) [18,19], which uses vehicle dynamics models to predict future states and optimize control strategies. Liu et al. [20] proposed an energy management strategy combined with the dynamic programming algorithm, which uses a hybrid drive model to model and predict a vehicle’s speed trajectory. This approach achieved up to 78% trajectory matching accuracy, demonstrating excellent energy optimization results. However, this approach faces some constraints in real-world use, as dynamic programming algorithms generally depend on having full information about the driving cycle in advance, requiring accurate prior knowledge of the vehicle’s future route. Moreover, DP is affected by the curse of dimensionality, where the computational load increases exponentially with the growth in state variables, reducing solution efficiency and making real-time application challenging. Conversely, ECMS markedly eases the computational load yet retains near-optimal performance, rendering it well-suited for on-board, real-time vehicle control. Wei et al. [21] developed an adaptive EMS that leverages driving behavior recognition to modify energy distribution logic in response to driving pattern variations, thereby improving the system’s operational efficiency. Compared to traditional control strategies, this method achieved a 6.41% fuel savings rate and significantly reduced the fluctuations in battery SOC, with a suppression magnitude of 11.61%. Z Zhu et al. [22] designed a speed prediction model based on LSTM that integrates heterogeneous multi-modal data and enhanced an ELM using the Whale Optimization Algorithm (WSO), thereby establishing an efficient Model Predictive Control (MPC) framework incorporating environmental governance costs. The strategy showed notable benefits in energy management, achieving a 73.4% reduction in driving costs compared with conventional rule-based control approaches. The aforementioned approaches have, to some degree, enhanced the real-time capability and fuel efficiency of EMSs. However, existing EMSs still face challenges such as large computational loads, poor adaptability to complex driving conditions, and suboptimal performance, rendering them ill-suited for the intricate, ever-changing conditions that real vehicles confront.
In recent years, learning-based methods have become a viable solution for the EMSs of HEVs, particularly with RL algorithms [23,24,25,26]. In HEV energy management, studies have shown that RL methods exhibit excellent adaptability when facing complex and variable driving conditions, while having relatively low computational resource dependency, thus ensuring higher application efficiency [27]. Liu T. et al. [28,29] introduced a Q-learning-based adaptive EMS tailored for optimizing the energy usage of hybrid tracked vehicles. The research showed that, compared to stochastic dynamic programming methods, this strategy demonstrated stronger environmental adaptability, superior policy optimization performance, and higher learning capability, while significantly reducing the time cost associated with computations. Lian R. et al. [30] proposed an EMS integrating specialist knowledge and embedded it into the DDPG algorithm to address the issues caused by a large number of control variables. This method not only improved the algorithm’s learning efficiency but also significantly enhanced fuel economy performance, thus demonstrating higher performance and feasibility in practical applications. However, during the application of reinforcement learning, the issue of sparse reward signals is commonly encountered. To overcome this problem, more complex reward mechanisms are often required to guide the agent’s learning. Du G. et al. [31] introduced an enhanced optimization method, AMSGrad, for updating network weights in series hybrid electric tracked vehicles, successfully addressing the learning challenges posed by sparse rewards. Shi X. et al. [32] introduced a reinforcement learning-based EMS combined with an experience enhancement mechanism, aimed at improving control performance under random driving conditions and alleviating the low learning efficiency typical of traditional reinforcement learning methods. Tan H. [33] conducted an in-depth study of the DDPG algorithm, particularly for its efficacy within continuous state–action domains and introduced a Prioritized Experience Replay mechanism to further optimize the learning process, thereby enhancing the learning efficiency of the EMS. Although the DDPG algorithm has shown widespread potential in HEV energy distribution optimization due to its ability to handle continuous action spaces, it still faces issues during practical training, such as low experience utilization efficiency, scarcity of learning samples, and poor policy stability. Although various EMSs for HEVs have been proposed, including rule-based, optimization-based, and reinforcement learning-based control strategies, challenges such as sparse rewards and slow convergence remain significant, particularly in the context of fuel economy optimization and battery stability management. Existing studies typically focus on addressing these issues separately, neglecting the integration of these challenges into a unified strategy that can adapt to complex practical on-road scenarios. Although various EMSs for Hybrid Electric Vehicles have been developed—including rule-based, optimization-based, and RL-based approaches—existing RL methods still generally suffer from sparse reward signals, low experience utilization efficiency, and slow convergence when optimizing fuel economy under complex and variable driving conditions. Previous studies typically proposed improvements targeting individual problems, lacking a unified solution that simultaneously enhances fuel economy, ensures stable battery SOC control, and maintains robustness across diverse driving cycles. In addition, research on integrating PER and HER into continuous action–space RL frameworks for HEV energy management remains limited, and a performance gap still exists compared with theoretical optimal benchmarks (such as DP) and advanced RL baseline algorithms.
This study aims to propose a novel EMS for HEVs, which is based on the combination of Prioritized Experience Replay (PER) and Hindsight Experience Replay (HER) to design the P-HER experience replay mechanism, integrated within the DDPG framework. This method aims to improve fuel economy while ensuring stable battery management, addressing the issues of sparse rewards and slow convergence in traditional reinforcement learning methods. Section 2 provides a detailed introduction to the modeling process of various modules of the HEV. Section 3 offers a comprehensive overview of the construction of the P-HER experience pool optimization module and the improvements made to the traditional DDPG algorithm. Section 4 presents a simulation validation and comparative analysis of the presented method, evaluating its performance in terms of fuel efficiency, stability, adaptability, and engine operating efficiency. Section 5 outlines the key research outcomes and suggests potential avenues for future optimization.
2. Hybrid Electric Vehicle Modeling
2.1. System Configuration
A Hybrid Electric Vehicle (HEV) refers to a vehicle that incorporates at least two different power sources, which can operate independently or together [34]. Depending on the actual power demand, the vehicle’s required torque can be delivered either by one energy source or through the combined output of multiple sources. Based on the classification of power sources, HEVs are mainly categorized into series, parallel, and hybrid configurations.
In this study, a series–parallel Hybrid Electric Vehicle (HEV) was selected as the research object, and a backward simulation model was established for the training and evaluation of the EMS. Figure 1 shows the configuration of the vehicle’s powertrain, consisting of an engine, electric motor, generator, battery, and a planetary gear set. Compared to series or parallel configurations, the series–parallel architecture achieves flexible coupling of multiple power sources through the planetary gear, allowing for electric drive or series mode operation under low-speed conditions, while enabling the engine to directly drive and transmit mechanical power at mid-to-high speeds. This structure combines the high energy regulation capability of the series configuration with the transmission efficiency advantages of the parallel configuration. It enhances overall fuel efficiency while also increasing the system’s ability to adapt to complex operating conditions. Furthermore, the series–parallel architecture is better suited for energy distribution optimization when integrated with intelligent control strategies, as it offers multi-path controllable energy distribution characteristics, facilitating the balance of energy consumption and performance under multiple objectives. Table 1 presents the parameters of the series–parallel HEV.
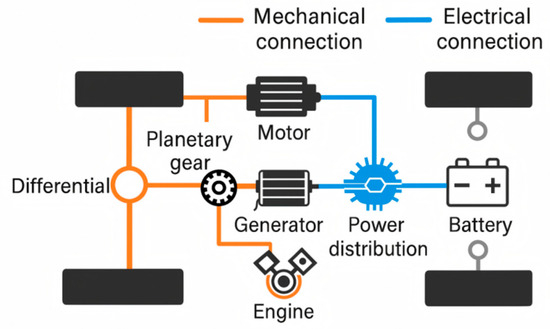
Figure 1.
Vehicle powertrain system architecture.

Table 1.
Vehicle specifications for Hybrid Electric Vehicle.
2.2. Vehicle Dynamics Model
Under the given driving conditions, the vehicle’s required power output can be derived using the longitudinal dynamic equilibrium equation, with the demand primarily influenced by the combined effects of rolling resistance, ; aerodynamic drag, ; gradient resistance, ; and acceleration resistance, ; among other factors.
The various terms are defined as follows:
Rolling Resistance: , where ;
Aerodynamic Drag: ;
Gradient Resistance: ;
Acceleration Resistance: .
In the equations, denotes the total vehicle mass, refers to gravitational acceleration, indicates the tire–road rolling resistance coefficient, represents the air density, represents the vehicle’s frontal cross-sectional area, represents its air-drag coefficient, represents the vehicle’s driving speed (ignoring wind speed effects), represents the road gradient angle (not considered in this study), and represents the vehicle’s acceleration. The above parameters all play a role in determining the vehicle’s total resistance and required traction force under the preset driving conditions, which provides the basis for the energy management strategy formulation and simulation calculations.
2.3. Planetary Gear Power Split Mechanism
By employing a three-shaft planetary gear configuration, the series–parallel powertrain integrates the engine, electric motor, and generator, allowing for mechanical coupling and electrical power distribution. The generator is connected through the sun gear, the traction motor through the ring gear, and the engine is rigidly mounted to the planet carrier, enabling power transmission and coordinated operation among the different power sources in this configuration.
The kinematic and mechanical constraints can be described by the following formulas:
Angular velocity relationship:
Torque balance condition:
where and represent the tooth counts of the sun gear and the ring gear, respectively. The variables , , and correspond to the rotational speeds of the sun gear, ring gear, and carrier, respectively, while , , and correspond to their associated torque values. Additionally, the electric motor is linked to the ring gear via a fixed gear ratio to the wheels, contributing to the vehicle’s overall propulsion.
2.4. Engine Modeling
The engine model is constructed based on the optimal power curve and brake-specific fuel consumption (BSFC) map [30], illustrated in Figure 2. After setting the desired power output, the corresponding engine speed is first obtained through interpolation. Then, based on this engine speed, the required output torque can be further calculated:
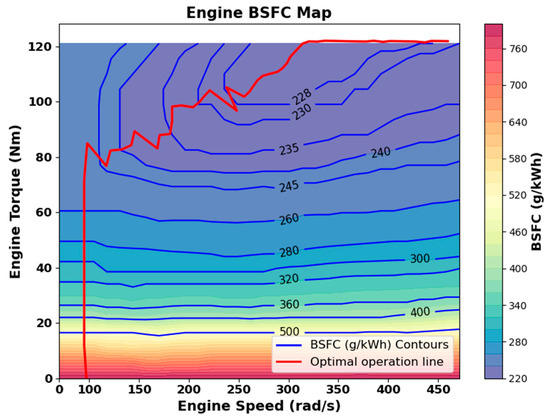
Figure 2.
Engine optimal brake-specific fuel consumption curve.
Subsequently, based on the given engine speed and output power, the corresponding BSFC value is extracted from the BSFC map, allowing the calculation of the fuel consumption rate of the engine under the following operating condition:
From this, the engine power output is derived as follows:
where LHV denotes the fuel’s lower heating value. The engine stops supplying torque and energy when the vehicle is in braking mode or when operating conditions drop below its minimum fuel power, thereby avoiding unnecessary fuel consumption.
2.5. Motor Model
In a series–parallel Hybrid Electric Vehicle, the motor serves as the primary actuator of the powertrain, delivering propulsion and enabling energy recuperation during braking. This research employs two motors—the generator (MG1) and the drive motor (MG2)—operating in coordination. Quasi-static models for both MG1 and MG2 are developed using their respective motor efficiency maps [35], illustrated in Figure 3. The output torque of the motor is subject to several constraints, including speed-related maximum and minimum torque limits, battery power capacity, and efficiency. These constraints together determine the motor’s performance and energy recovery efficiency.
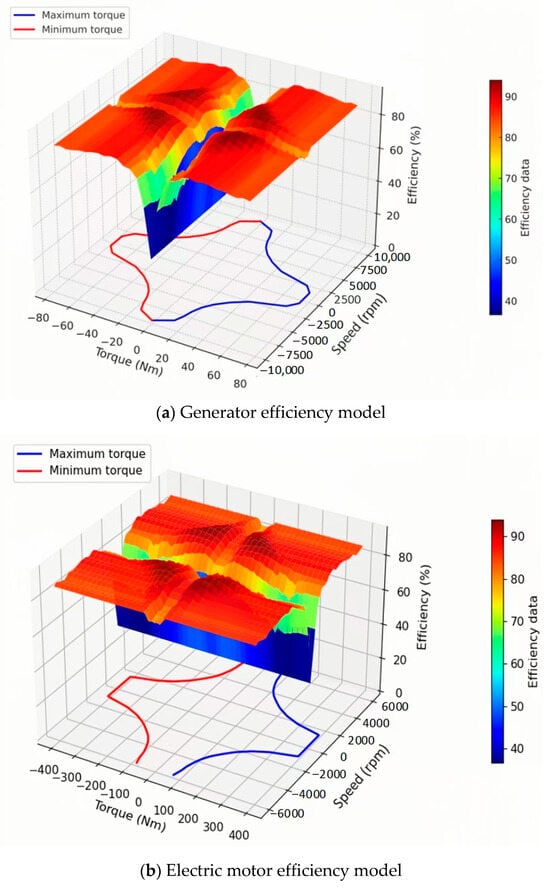
Figure 3.
HEV motor efficiency model.
The drive motor’s output torque is formulated as follows:
where represents the required torque for the vehicle motor; and indicate, respectively, the maximum and minimum torque that can be delivered at the present motor speed; and and are the maximum discharge and charge torque limits derived based on the current battery power and efficiency constraints.
The motor efficiency, , is represented through a two-dimensional interpolation map that relates torque and speed. This method allows for the accurate calculation of the motor’s efficiency value based on the actual operating conditions, including speed and torque, which can then be used to calculate the motor power:
The above model can simultaneously cover both driving and braking modes, ensuring that the motor’s output power always remains within its operating capability range and complies with the battery’s power constraints under various operating conditions. This design effectively balances the motor’s performance with the battery’s limitations, ensuring that the system operates efficiently under different conditions.
2.6. Battery Model
In this study, the energy storage system is a high-voltage battery pack, with its SOC indicating the proportion of the current remaining capacity to the battery’s rated capacity. For a precise characterization of the dynamic behavior of the battery under different power loads, an equivalent circuit model is adopted for battery modeling. This model mainly calculates key parameters, such as electromotive force, current, and resistance, to comprehensively reflect the battery’s electrical performance under various operating conditions.
The battery’s SOC can be expressed and updated through the following differential equation:
where denotes the battery current and represents the battery’s total capacity.
After further considering the effects of internal resistance and efficiency, the battery current per unit time can be derived from the power balance relationship and expressed as follows:
where signifies the battery’s open-circuit potential, represents the effective series resistance of the battery, and represents the battery’s current power output (positive for discharging and negative for charging). In this equation, temperature impacts on resistance and voltage are ignored, with emphasis placed on the influence of SOC on the battery’s no-load voltage and inherent resistance. The relevant parameters are derived using table interpolation, with the battery characteristic curve shown in Figure 4.
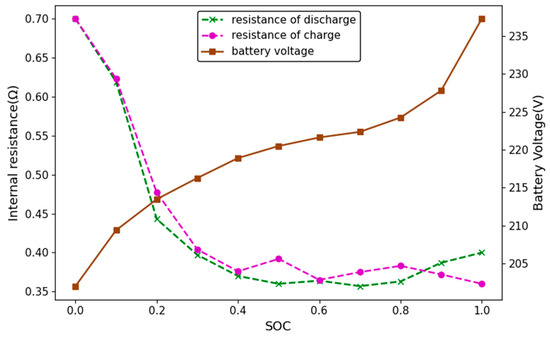
Figure 4.
Battery characteristic curve.
3. Energy Management Strategy Modeling
3.1. Reinforcement Learning-Based EMS
To maximize fuel efficiency, the engine must operate in the low BSFC region [30]. In this study, the engine’s optimal BSFC curve (Figure 2) together with the battery characteristic curve (Figure 4) are utilized as prior knowledge to steer the energy management strategy toward achieving a global optimum.
RL enables an agent to engage in continuous interaction with its environment, learning via trial-and-error to maximize cumulative rewards and ultimately determine the optimal strategy [36]. Reinforcement learning fundamentally comprises an environment and an agent that interact. At each time step t = 0, 1, 2, 3, …, n, the agent obtains the current state, (∈), from the environment and selects the current strategy, choosing the action, (∈), that it believes is optimal. This action is then applied to the environment, forcing the environment’s state to transition from the current state, , to the next state, . Meanwhile, the environment returns the reward, , corresponding to the current action to the agent. The agent uses this reward value to evaluate the effectiveness of its current strategy. If the returned reward is large, this indicates that the action chosen in that state performed well, so the probability of choosing that action in the future increases when the same state is encountered. Conversely, if the reward is small, the agent will adjust its strategy. Through continuous iterations and adjustments, the agent gradually optimizes its strategy, ultimately achieving the goal of learning the optimal control strategy.
In this study, the HEV model is treated as the environment, with its state space composed of parameters such as vehicle speed (), acceleration (), and State of Charge (SOC), and models the vehicle engine power as the action to be executed. The details are shown in the following equation.
One primary goal of the EMS is to reduce fuel consumption, thereby improving the vehicle’s overall fuel efficiency. Another goal is to prevent the battery from being overcharged or overdischarged in order to extend the battery’s lifespan and keep SOC within a safe range. This results in a multi-objective reward function, which is defined as follows:
In the equation, represents the instantaneous fuel consumption of the engine at each time step, indicates the reference value for maintaining a sustainable charging state of the battery, represents the battery’s current State of Charge at time t, represents the weight coefficient associated with fuel consumption, and represents the weighting factor for maintaining a sustainable charging state of the battery.
Adjusting these parameters enables the EMS to balance fuel efficiency with maintaining the battery’s SOC within a sustainable range. In particular, adjusting the constant coefficients and enables the strategy to balance fuel economy with SOC stability. We adopted the parameter tuning method proposed by Lian et al. [30] and determined . Figure 5 presents the overall structure of the EMS proposed in this study.
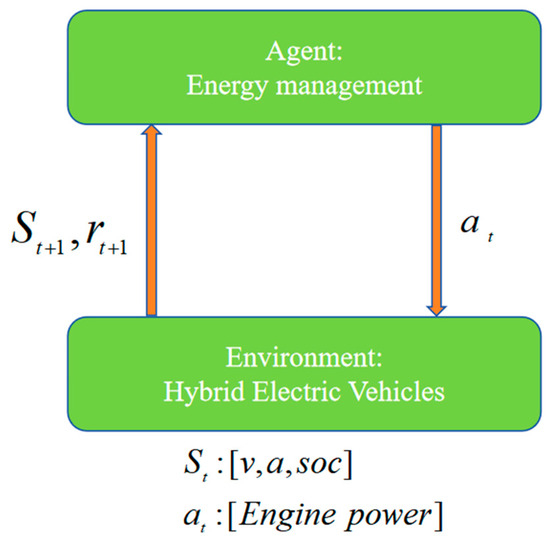
Figure 5.
General structure of the EMS in this study.
3.2. Experience Replay Pool Optimization Strategy by Integrating PER and HER
3.2.1. Prioritized Experience Replay (PER)
Prioritized Experience Replay (PER) is a strategy that assigns different priorities to each experience, allowing the agent to prioritize learning from more important experiences. Traditional Experience Replay (ER) typically uses uniform sampling, where each experience is processed with the same probability, which may lead to suboptimal sampling efficiency [37]. PER evaluates the importance of each experience by calculating its Temporal Difference (TD) error, allowing the agent to learn more efficiently from valuable experiences. This method combines uniform random sampling and greedy priority sampling, thus improving the efficiency of the sampling process [38]. The TD error is given by the following formula:
where denotes the immediate reward, is the discount factor, is the Q-value under the current policy at state , and is the maximum Q-value of the next state, .
By calculating the TD error, the sampling probability for each experience can be obtained as follows:
In the formula, is the sampling probability of experience , is the TD error of the experience, and is a small constant used to avoid the issue of zero sampling probability. In this way, the agent will more frequently select experiences that have a greater impact on improving the policy during the replay process, thereby accelerating the learning process.
3.2.2. Hindsight Experience Replay (HER)
HER is a method used to address the problem of sparse rewards in reinforcement learning. In complex tasks, the agent often encounters situations where the goals are difficult to achieve, and Traditional Experience Replay mechanisms may not effectively utilize these “failed” experiences. HER reconstructs these “failed” experiences by replacing the original goal state with a state that the agent has actually reached, making these experiences valuable and providing more learning signals to the agent [39].
The reward reconstruction formula for HER is as follows:
where is the reward after reconstruction and represents the operation where the goal state, , is replaced by the state that the agent actually reaches. Through this approach, even when the agent does not reach the original target, it can still receive reward signals by experiencing new goal states from past experiences.
3.2.3. Combination of PER and HER (P-HER)
To address the issue of sparse rewards and expand the experience pool, this paper proposes the combination of PER and HER, leveraging the advantages of both: PER increases the focus on important experiences by prioritizing their replay, while HER reconstructs failed experiences. Specifically, PER helps the agent more effectively select experiences with large TD errors for learning, while HER enhances the value of experiences even if the goal state has not been reached. Overall, effectively utilizing experiences in the experience replay buffer is key to improving training efficiency. The working process of P-HER is as follows, as shown in Figure 6:
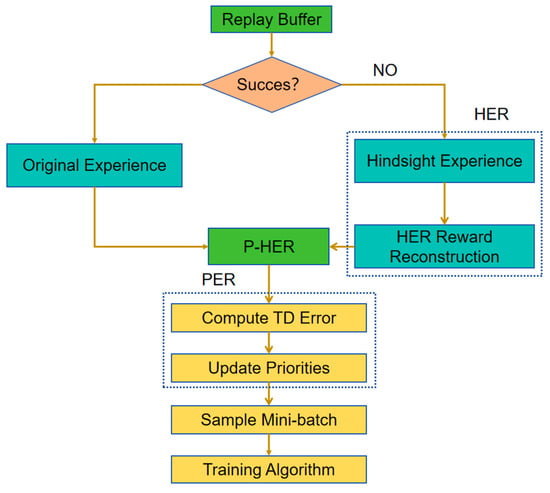
Figure 6.
P-HER working process diagram.
Experience Recording: During the interaction between the agent and the environment, each step’s state, action, reward, and next state are stored as a tuple in the experience buffer.
Positive/Negative Experience Determination: If the execution result achieves the original goal (SOC falls within the target range), the experience is marked as an original experience and retains its original reward value; if the goal is not achieved (SOC falls outside the target range), the experience is marked as a reconstructed experience.
Experience Reconstruction: For negative experiences, HER uses the actual state reached by the agent to calculate a new SOC target range, then computes an HER-reconstructed reward value. This transforms an originally “failed” experience into a “successful” one relative to the new target, thereby enhancing its learning value.
Prioritized Replay (with PER): Both original and reconstructed experiences calculate the TD error, and priorities are assigned based on the magnitude of the error, ensuring that samples contributing more to learning are more likely to be sampled.
The ultimate objective is to achieve the highest possible optimized reward, which can be expressed as follows:
where represents the expected return of the agent, represents the total count of experiences stored in the experience pool, is the sampling probability of the experience based on PER, and is the reward after reconstruction via HER.
First, we use HER to reconstruct the rewards of experiences that failed to reach their original goals, converting them into successful experiences based on a newly generated target range derived from the actual SOC dynamics, thereby enhancing their learning value. Next, PER is applied to both the original and reconstructed experiences by calculating the TD error, obtaining their sampling probabilities according to the PER formula, and updating their priorities accordingly. The workflow of P-HER is illustrated in Figure 6.
In summary, by introducing the P-HER experience replay mechanism to restructure the failure experience reward and expand the experience pool, the reinforcement learning algorithm can handle sparse reward problems more efficiently, greatly improving learning efficiency, stability, and convergence speed.
3.3. Improved DDPG Energy Management Strategy Based on Experience Pool Optimization
This paper proposes an improved EMS based on experience pool optimization, namely, the P-HER-DDPG algorithm. The strategy introduces HER to reconstruct “failed” experiences and combines PER to assign priorities to each experience, ensuring that important experiences are prioritized for replay, further improving learning efficiency and accelerating training speed. This approach is used to expand the experience pool, and at the same time, sparse rewards can be converted into dense rewards, greatly increasing the number of task-completing experiences in the experience pool. Figure 7 illustrates the technical framework used in this study.
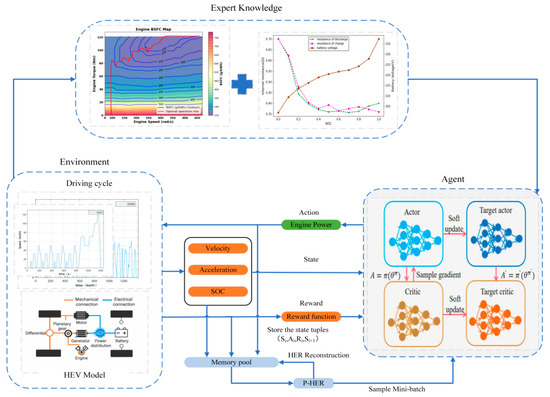
Figure 7.
DDPG energy management strategy framework based on P-HER optimization.
DDPG is an Actor–Critic-based reinforcement learning approach tailored for optimization tasks within continuous action spaces. In energy management strategies, DDPG is applied to continuously interact with the environment to maximize cumulative rewards. The algorithm establishes two core modules—an Actor and a Critic—realized by four distinct neural networks: the Actor network, , for policy evaluation; its target counterpart, ; the Critic network, , for estimating Q-values; and the Critic target network, [2]. In the training process, the Actor network determines actions according to the environment’s present state. To enhance the chances of finding the optimal solution, Laplace noise is incorporated into the actions, as shown in Equation (18). The configuration of the DDPG hyperparameters is presented in Table 2.
Table 2.
Hyperparameter settings of DDPG.
In the process of updating the network, samples (, , , ) are randomly drawn from the experience pool. The Critic network calculates the target value, , and loss, , using the following Equation (19).
In the equation, denotes the critical discount factor used to balance immediate and future rewards, where ∈ [0, 1]; represents the value of the current state, , which is calculated using Equation (20). The target Actor network and target Critic network are represented as and , respectively. The network parameters are updated according to Equation (21).
where denotes the learning rate, commonly assigned a value of 0.001. The target network is refreshed by taking a weighted average of its previous parameters and those from the newly generated network. Since this weight is set to a value far less than 1, the update occurs progressively through a soft update mechanism, thereby significantly improving the stability of the learning process [2].
In the Actor network, π, the principle of the deterministic policy gradient theorem is applied to enhance the performance of the network. By minimizing the policy gradient, the network parameters can be effectively updated to optimize the agent’s policy. In this process, the policy update is achieved through gradient descent to ensure that the agent’s behavior gradually approaches the optimal policy:
Based on the above DDPG algorithm, we introduce the P-HER experience replay mechanism for optimization. First, by using HER, the failed goals (i.e., those that did not achieve the expected SOC range) are transformed into successful goals to reconstruct experiences. For this purpose, we propose a dynamic target range model as follows:
According to the actual SOC value of the failed goal, the upper and lower bounds of the new SOC target range are calculated:
The newly generated target range and its midpoint are as follows:
And it satisfies the following constraint conditions:
In the above equation, is the initial target SOC value and is the currently measured SOC value. is the dynamic adjustment range, and are the penalty limits for the battery, with values set at 0.4 and 0.8, respectively.
The reward after reconstruction by HER is obtained as follows:
Next, through PER, the original experiences and the Hindsight Experience with HER reconstructed rewards are updated and prioritized according to Equation (15). Finally, P-HER emphasizes replaying experiences with higher priority, enabling the agent to more effectively learn from those that greatly influence policy improvement. Table 3 presents the pseudo-code of P-HER-DDPG.
Table 3.
Pseudo-code of P-HER-DDPG algorithm.
Regarding the computational requirements and feasibility of deploying the P-HER-DDPG strategy in real-time vehicle control systems, we evaluated its computational complexity and real-time deployment potential in our study. Leveraging the parallel update mechanism of the Actor–Critic architecture and the efficient experience management of PER and HER, the P-HER-DDPG strategy enables rapid convergence during the training phase under reasonable hardware conditions (such as high-end GPUs or automotive-grade embedded AI modules), while in the inference phase, only forward propagation is required, resulting in significantly lower computational overhead compared to training. When deployed, after offline training and network parameter compression, the strategy can achieve millisecond-level decision responses on automotive-grade embedded platforms (e.g., NVIDIA Jetson series or Huawei MDC), meeting real-time control requirements.
We compared our proposed P-HER-DDPG strategy with the more advanced reinforcement learning algorithm TD3. TD3 focuses on improving the accuracy of Q-value estimation by using two evaluation networks to avoid overestimation. However, P-HER-DDPG addresses the sparse reward problem by optimizing the utilization efficiency of the experience replay buffer. By combining PER and HER, P-HER-DDPG can effectively leverage “failure” experiences, which might otherwise be ignored in traditional replay mechanisms, thereby accelerating the learning process. In contrast, TD3 does not have a similar mechanism to enhance the value of failure experiences, and the inclusion of additional networks (such as the dual Q-value networks) makes its update process more complex, potentially leading to slower learning in environments with sparse reward feedback.
4. Simulation Results and Analysis
To verify the effectiveness of the proposed P-HER-DDPG energy management strategy based on experience pool optimization, this paper compares the control performance of three algorithms, traditional DQN, DDPG, and P-HER-DDPG, from multiple perspectives. The simulation analysis is based on the standard NEDC driving cycle (as shown in Figure 8), and the comparison includes analysis of strategy convergence efficiency and stability, fuel economy evaluation, adaptability comparison under different operating conditions, and engine operating point comparison.
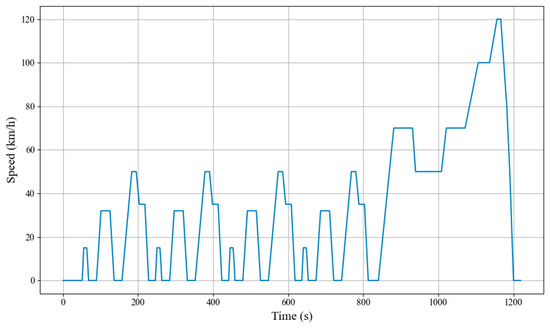
Figure 8.
NEDC driving cycle.
4.1. Strategy Convergence Efficiency and Stability Analysis
In Deep Reinforcement Learning training, the loss function cannot serve as a reliable indicator of convergence. Since policy updates cause continual changes in the data, it is common for the Q-loss to fluctuate rather than converge. Consequently, rewards are used instead to assess both the convergence speed and the stability of the learned policy [28].
Figure 9 plots the evolution of mean cumulative reward across training episodes for P-HER-DDPG, DDPG, and DQN. The figure shows that the reward curve of P-HER-DDPG converges at a faster rate. After approximately 140 episodes, the reward curve quickly stabilizes with minimal fluctuations, indicating that the algorithm quickly finds a stable policy during the learning process. The introduction of P-HER significantly improves the efficiency of experience utilization during learning, thereby enhancing the effectiveness of policy learning. In contrast, DDPG has a slower learning speed, and its reward curve takes about 170 episodes to stabilize. This shows that, without experience pool optimization, DDPG converges slowly and is less efficient. DQN performs the worst in this figure, with a reward curve that fluctuates significantly in the early stages of training and takes about 185 episodes to stabilize at a consistent reward level. The learning process of DQN is more unstable and slower to converge compared to DDPG and P-HER-DDPG, which is related to the fact that DQN is primarily designed for discrete action spaces and has limitations when applied to continuous action spaces.
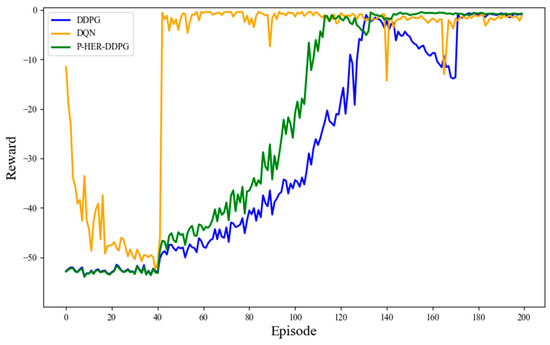
Figure 9.
Reward value of the three strategies under the NEDC driving cycle.
As shown in Table 4, P-HER-DDPG achieves a 17.65% and 24.32% improvement in convergence efficiency compared to traditional DDPG and DQN, respectively. This indicates that P-HER-DDPG has faster convergence efficiency and higher stability, highlighting the significant advantages of introducing the experience pool optimization mechanism in solving the sparse reward problem and accelerating convergence efficiency.
Table 4.
Comparison of convergence efficiency of the three algorithms.
4.2. Fuel Economy Evaluation and Comparison of Adaptability Under Different Operating Conditions
To assess the gains in fuel efficiency and adaptability to operating conditions after introducing the P-HER mechanism, simulation tests were conducted on several typical driving cycles. In addition to the proposed P-HER-DDPG, the RL algorithms used in the ablation experiment included DQN and DDPG. The simulation test results are presented in Table 5, and the fuel economy bar chart is presented in Figure 10.
Table 5.
Comparison of results under different driving cycles.
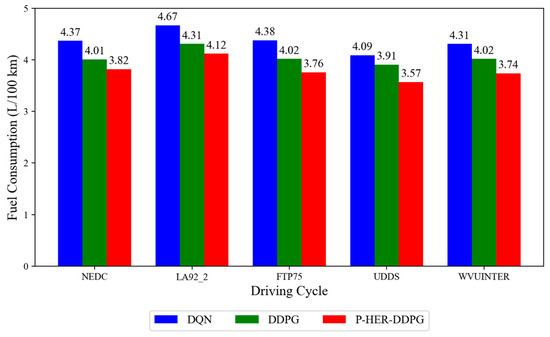
Figure 10.
Fuel economy under typical driving cycles.
As shown in Table 5, in the five driving cycles of NEDC, LA92_2, FTP75, UDDS, and WVUINTER, the fuel efficiency of the EMS based on P-HER-DDPG improved by 4.73%, 4.4%, 6.46%, 8.69%, and 6.96%, respectively, compared to the typical DDPG energy management strategy. Compared to the discrete control-based typical DQN energy management strategy, the improvements were 12.5%, 11.7%, 14.1%, 12.7%, and 13.2%, respectively. These results indicate that the P-HER-DDPG strategy exhibits superior fuel economy and strong adaptability to different complex operating conditions across multiple driving cycles.
Table 6 compares the fuel consumption, the fuel economy percentage relative to the optimal baseline DP (dynamic programming) algorithm [30], and the performance robustness (including the 95% confidence intervals) of the DQN, DDPG, and P-HER-DDPG algorithms under four typical driving cycles (NEDC, LA92_2, UDDS, and FTP75). Here, fuel economy (%) indicates the proportion of the DP optimal strategy’s fuel economy achieved by the algorithm, with values closer to 100% representing performance nearer to the optimum. The results show that P-HER-DDPG outperforms the comparison algorithms across all metrics, achieving the lowest fuel consumption in all four driving cycles; for instance, in the UDDS cycle, its consumption is 3.57 L/100 km, significantly lower than that of DQN (4.09 L/100 km) and DDPG (3.91 L/100 km). In terms of fuel economy, P-HER-DDPG achieves 90.8%, 87.6%, 93.3%, and 91.8% in the four cycles, consistently exceeding DQN (79.4%, 77.3%, 81.4%, and 78.8%) and DDPG (86.5%, 83.8%, 85.2%, and 85.8%), and reaching the highest value in the table (93.3%) in the UDDS cycle, indicating that its performance is closest to the optimum in high-speed variation scenarios. Regarding robustness, P-HER-DDPG achieves an average of 90.9%, higher than DQN (79.2%) and DDPG (85.3%), with a 95% confidence interval of [87.04%, 94.71%], substantially higher than DQN’s [76.52%, 81.93%] and only slightly overlapping with DDPG’s [83.50%, 87.15%]. This indicates that P-HER-DDPG has a statistically significant performance advantage, demonstrating that the algorithm offers higher average performance, fuel economy closer to the optimal solution, and better cross-cycle consistency in multi-cycle fuel optimization.
Table 6.
Comparison of fuel economy and robustness across multiple driving cycles for different algorithms.
We set the initial SOC value to 0.65. As shown in Figure 11, both DQN and DDPG exhibit a certain degree of SOC fluctuation during execution, particularly the DQN curve, which shows a noticeable dip in the middle and later stages, indicating a risk of overdischarge. On the other hand, the P-HER-DDPG strategy demonstrates a much smoother SOC evolution throughout the driving cycle, especially between 400 and 1100 s, where it maintains a stable level around 0.53 with no sharp fluctuations or abnormal drops. This indicates the potential of the P-HER-DDPG-based energy management strategy to maintain SOC within a certain range, prevent battery overcharging and overdischarging, extend battery life, and improve system stability.
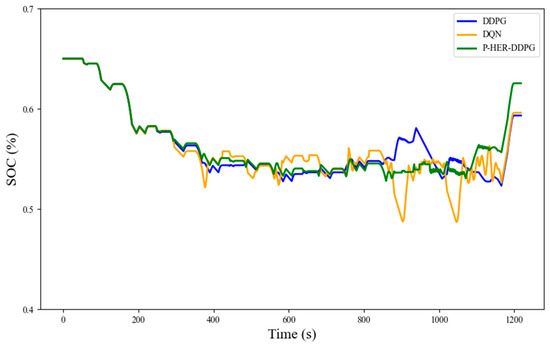
Figure 11.
SOC profiles for the three strategies on the NEDC cycle.
4.3. Engine Operating Point Comparison Analysis
By comparing the engine operating point distribution maps for (a) DDPG, (b) DQN, and (c) P-HER-DDPG in Figure 12, as well as the fuel consumption rate distribution maps in Figure 13, it can be clearly observed that within the engine speed range of 0–150 rad/s, the DDPG operating points are mostly concentrated in the higher BSFC region. Due to the lack of effective experience optimization, the operating points of DDPG deviate from the optimal low fuel consumption area in the low BSFC region. This indicates that the engine operating mode selected by DDPG in this speed range has not been optimized for fuel economy, resulting in higher energy consumption and lower fuel efficiency. The engine operating points of DQN perform relatively poorly compared to DDPG. However, in the P-HER-DDPG chart, the majority of engine operation locations are concentrated in the low BSFC region, especially when the vehicle requires high-speed and high-torque driving. This shows that by introducing experience pool optimization, P-HER-DDPG avoids the high BSFC operating points at low speeds, thereby improving fuel economy.
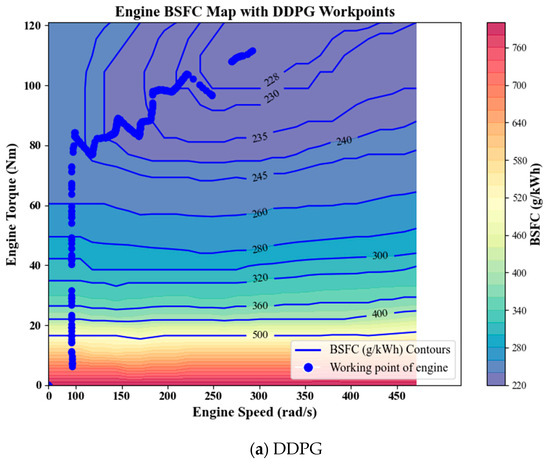
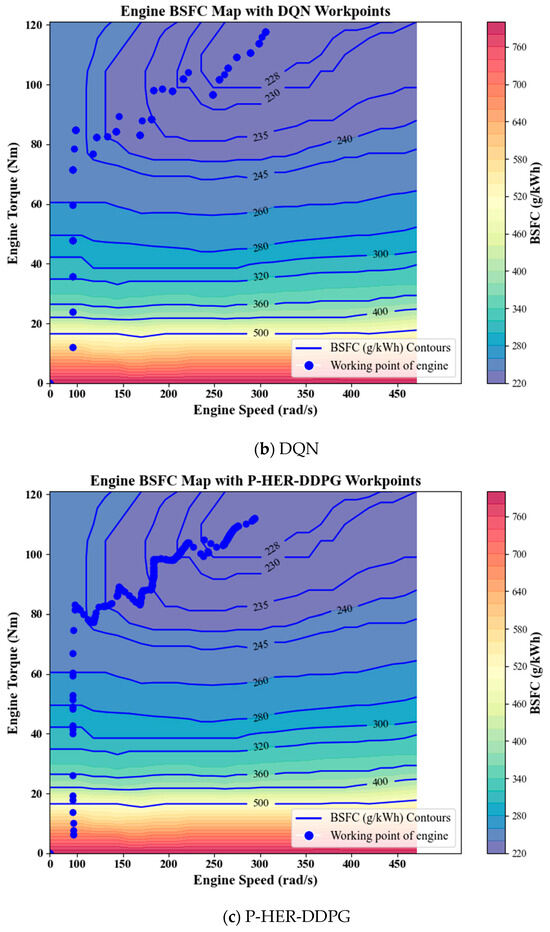
Figure 12.
Engine operating points: (a) DDPG; (b) DQN; (c) P-HER-DDPG.
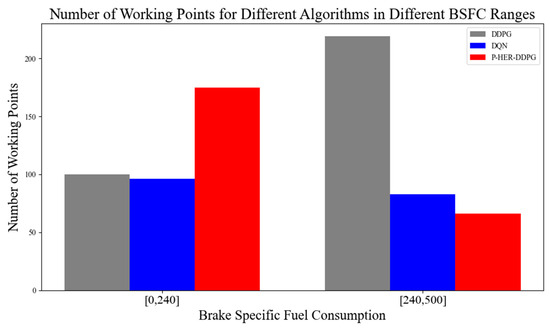
Figure 13.
Distributions of fuel consumption rate.
P-HER, by reconstructing failed experiences and prioritizing the replay of important experiences, allows the algorithm to better explore and leverage historical experiences in real-world operations, especially those where the expected goals were not achieved. With this mechanism, P-HER-DDPG not only avoids unnecessary high BSFC operating points but also operates more efficiently within the optimal fuel economy range, overcoming the inefficiencies seen in DDPG and DQN. The results show that the P-HER-DDPG strategy is more likely to control the engine output in high-efficiency regions, reducing unnecessary starts and frequent switches, effectively lowering energy losses, and demonstrating better global optimization capabilities.
4.4. Sensitivity Analysis
This section conducts a sensitivity analysis of key factors in the reward function, namely, and (beta). Since primarily affects the fuel consumption term and primarily affects the SOC deviation penalty term, the analysis is performed by varying while keeping fixed.
Figure 14 shows that as gradually increases, fuel consumption rises from approximately 3.59 L/100 km to 3.98 L/100 km. For larger values, fuel consumption increases in an approximately linear manner. This indicates that when SOC tracking requirements are more stringent (i.e., at higher β values), the flexibility of the control strategy in power distribution is reduced, thereby leading to a decline in fuel economy.
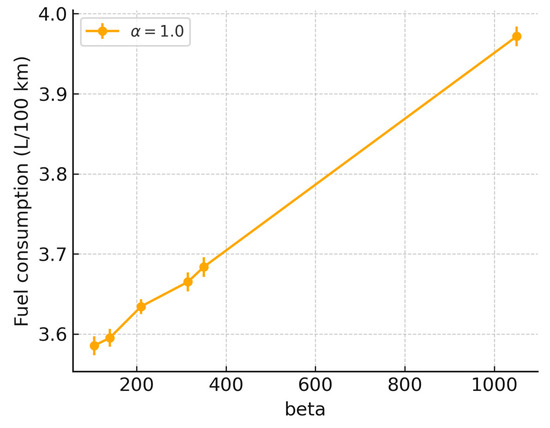
Figure 14.
Sensitivity of fuel consumption to .
Figure 15 presents the trend of the mean absolute SOC deviation with varying . It can be observed that as increases, the deviation decreases significantly from approximately 0.060 to tracking about 0.018, indicating that a higher SOC penalty weight markedly improves SOC performance.
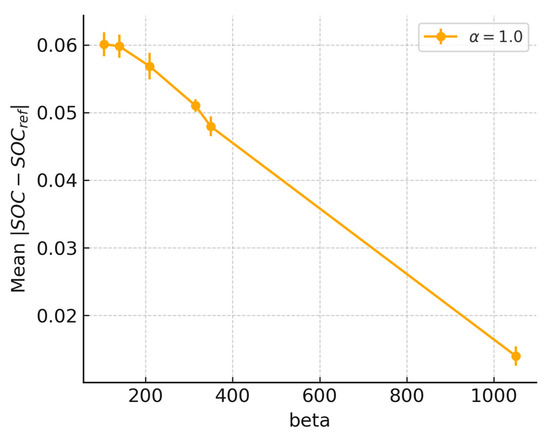
Figure 15.
Sensitivity of SOC deviation to .
Figure 16 illustrates a Pareto-like relationship between fuel consumption and SOC deviation. Lower values (e.g., 105, 140, and 210) achieve better fuel economy but result in larger SOC deviations, whereas higher values (e.g., 350 and 1050) significantly improve SOC stability at the expense of fuel economy. Moreover, the curve exhibits an inflection point around : further increasing can slightly reduce SOC deviation, but the fuel consumption cost per unit improvement rises substantially. Based on this observation, the weighting factors used in this study were selected to achieve a reasonable compromise between fuel economy and SOC management.
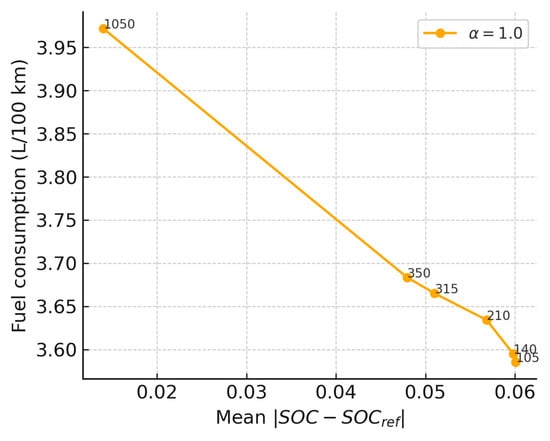
Figure 16.
Fuel–SOC trade-off.
5. Conclusions
To improve the fuel efficiency of HEVs while accelerating the training speed, this paper proposes a Deep Reinforcement Learning-based energy management strategy optimized by the experience pool (P-HER-DDPG). By introducing PER and HER mechanisms, PER enhances the focus on important experiences through prioritized replay, while HER reconstructs failed experiences, effectively improving experience utilization and accelerating the policy convergence process.
The results show that the proposed P-HER-DDPG energy management strategy significantly outperforms traditional methods in HEV control:
- (1)
- The proposed algorithm converges stably after only about 140 training episodes, improving convergence efficiency by 17.65% and 24.32% compared to DDPG and DQN, respectively.
- (2)
- In five typical driving cycles, the strategy reduces fuel consumption by an average of 5.85%, with a maximum reduction of 8.69%. The improvement compared to DQN reaches 12.84%, demonstrating its significant advantage in enhancing fuel economy.
- (3)
- Moreover, the P-HER-DDPG strategy exhibits more stable SOC control, avoiding the risk of overcharging and overdischarging due to SOC fluctuations, thereby effectively extending battery life.
At the same time, the method focuses engine operation control in low-fuel-consumption regions, improving the overall system efficiency.
6. Future Work Outlook
Future research will expand upon the current framework by incorporating more detailed models for battery aging and health status (SOH). While the present study focuses on fuel economy and SOC stability, we recognize the importance of battery lifespan evaluation for a more comprehensive EMS. The P-HER-DDPG strategy has already mitigated some aspects of battery aging by constraining SOC within safe limits, indirectly reducing the speed of battery degradation (avoiding overcharge and deep discharge).
Future work will involve the integration of more advanced battery aging models, such as those accounting for capacity decay and internal resistance growth. Additionally, we plan to introduce key battery metrics, such as capacity retention rate and impedance growth, to quantify the effects of our strategy on battery longevity. This will allow for a synergistic optimization of both fuel efficiency and battery lifespan, enhancing the practical application of the strategy in real-world vehicle operations.
Moreover, we acknowledge the necessity of testing the robustness of our approach under extreme or non-standard conditions, such as low initial SOC, fluctuating load demands, and steep gradients. While the current study demonstrates strong performance under standard conditions, future research will extend the validation to these more challenging scenarios. In addition, experimental tests under these conditions will further evaluate the adaptability and stability of the strategy, with plans to include the corresponding results in the extended work.
Author Contributions
Conceptualization, J.Z. and P.L.; methodology, J.Z.; software, P.L.; validation, J.Z. and H.M.; formal analysis, L.L. and X.C.; data curation, P.L.; writing—original draft preparation, J.Z. and P.L.; writing—review and editing, H.M., L.L., and X.C.; visualization, P.L., L.L., and X.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data are included in the article.
Acknowledgments
The authors want to thank the editor and anonymous reviewers for their valuable suggestions for improving this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Sadeq, A.M. Hybrid and Electric Vehicles: A Comprehensive Guide; Kindle Direct Publishing: Seattle, WA, USA, 2024. [Google Scholar]
- Qin, J.; Huang, H.; Lu, H.; Li, Z. Energy management strategy for hybrid electric vehicles based on deep reinforcement learning with consideration of electric drive system thermal characteristics. Energy Convers. Manag. 2025, 332, 119697. [Google Scholar] [CrossRef]
- Pan, M.; Cao, S.; Zhang, Z.; Ye, N.; Qin, H.; Li, L.; Guan, W. Recent progress on energy management strategies for hybrid electric vehicles. J. Energy Storage 2025, 116, 115936. [Google Scholar] [CrossRef]
- Zare, A.; Boroushaki, M. A knowledge-assisted deep reinforcement learning approach for energy management in hybrid electric vehicles. Energy 2024, 313, 134113. [Google Scholar] [CrossRef]
- Qi, C.; Song, C.; Xiao, F.; Song, S. Generalization ability of hybrid electric vehicle energy management strategy based on reinforcement learning method. Energy 2022, 250, 123826. [Google Scholar] [CrossRef]
- Yan, M.; Li, G.; Li, M.; He, H.; Xu, H.; Liu, H. Hierarchical predictive energy management of fuel cell buses with launch control integrating traffic information. Energy Convers. Manag. 2022, 256, 115397. [Google Scholar] [CrossRef]
- İnci, M.; Büyük, M.; Demir, M.H.; İlbey, G. A review and research on fuel cell electric vehicles: Topologies, power electronic converters, energy management methods, technical challenges, marketing and future aspects. Renew. Sustain. Energy Rev. 2021, 137, 110648. [Google Scholar] [CrossRef]
- Yuan, H.B.; Zou, W.J.; Jung, S.; Kim, Y.B. Optimized rule-based energy management for a polymer electrolyte membrane fuel cell/battery hybrid power system using a genetic algorithm. Int. J. Hydrogen Energy 2022, 47, 7932–7948. [Google Scholar]
- Wu, Z.; Wang, J.; Xing, Y.; Li, S.; Yi, J.; Zhao, C. Energy management of sowing unit for extended-range electric tractor based on improved CD-CS fuzzy rules. Agriculture 2023, 13, 1303. [Google Scholar]
- Yamanaka, G.; Kuroishi, M.; Matsumori, T. Optimization for the minimum fuel consumption problem of a hybrid electric vehicle using mixed-integer linear programming. Eng. Optim. 2023, 55, 1516–1534. [Google Scholar]
- Uralde, J.; Barambones, O.; del Rio, A.; Calvo, I.; Artetxe, E. Rule-based operation mode control strategy for the energy management of a fuel cell electric vehicle. Batteries 2024, 10, 214. [Google Scholar] [CrossRef]
- Lü, X.; He, S.; Xu, Y.; Zhai, X.; Qian, S.; Wu, T.; Wangpei, Y. Overview of improved dynamic programming algorithm for optimizing energy distribution of hybrid electric vehicles. Electr. Power Syst. Res. 2024, 232, 110372. [Google Scholar] [CrossRef]
- Xu, N.; Kong, Y.; Yan, J.; Zhang, Y.; Sui, Y.; Ju, H.; Xu, Z. Global optimization energy management for multi-energy source vehicles based on “Information layer-Physical layer-Energy layer-Dynamic programming” (IPE-DP). Appl. Energy 2022, 312, 118668. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, Y.; Zhang, Y.; Lei, Z.; Chen, Z.; Li, G. A neural network-based ECMS for optimized energy management of plug-in hybrid electric vehicles. Energy 2022, 243, 122727. [Google Scholar] [CrossRef]
- Feng, J.; Han, Z. Progress in research on equivalent consumption minimization strategy based on different information sources for hybrid vehicles. IEEE Trans. Transp. Electrif. 2023, 10, 135–149. [Google Scholar] [CrossRef]
- Shi, F. A genetic algorithm-based virtual machine scheduling algorithm for energy-efficient resource management in cloud computing. Concurr. Comput. Pract. Exp. 2024, 36, e8207. [Google Scholar] [CrossRef]
- dos Santos Junior, L.C.; Tabora, J.M.; Reis, J.; Andrade, V.; Carvalho, C.; Manito, A.; Bezerra, U. Demand-side management optimization using genetic algorithms: A case study. Energies 2024, 17, 1463. [Google Scholar] [CrossRef]
- Hao, J.; Ruan, S.; Wang, W. Model predictive control based energy management strategy of series hybrid electric vehicles considering driving pattern recognition. Electronics 2023, 12, 1418. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, Y.; Chen, Z.; Li, G.; Liu, Y. A novel learning-based model predictive control strategy for plug-in hybrid electric vehicle. IEEE Trans. Transp. Electrif. 2021, 8, 23–35. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y.; Li, W.; Shang, F.; Zhan, J. Hybrid-trip-model-based energy management of a PHEV with computation-optimized dynamic programming. IEEE Trans. Veh. Technol. 2017, 67, 338–353. [Google Scholar] [CrossRef]
- Wei, C.; Chen, Y.; Li, X.; Lin, X. Integrating intelligent driving pattern recognition with adaptive energy management strategy for extender range electric logistics vehicle. Energy 2022, 247, 123478. [Google Scholar] [CrossRef]
- Zhu, P.; Hu, J.; Zhu, Z.; Xiao, F.; Li, J.; Peng, H. An efficient energy management method for plug-in hybrid electric vehicles based on multi-source and multi-feature velocity prediction and improved extreme learning machine. Appl. Energy 2025, 380, 125096. [Google Scholar] [CrossRef]
- Hua, M.; Shuai, B.; Zhou, Q.; Wang, J.; He, Y.; Xu, H. Recent progress in energy management of connected hybrid electric vehicles using reinforcement learning. arXiv 2023, arXiv:2308.14602. [Google Scholar] [CrossRef]
- Jui, J.J.; Ahmad, M.A.; Molla, M.I.; Rashid, M.I.M. Optimal energy management strategies for hybrid electric vehicles: A recent survey of machine learning approaches. J. Eng. Res. 2024, 12, 454–467. [Google Scholar] [CrossRef]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.M.; Shah, A. Learning to drive in a day. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8248–8254. [Google Scholar]
- Wang, H.; Ye, Y.; Zhang, J.; Xu, B. A comparative study of 13 deep reinforcement learning based energy management methods for a hybrid electric vehicle. Energy 2023, 266, 126497. [Google Scholar] [CrossRef]
- Zhang, F.; Hu, X.; Langari, R.; Cao, D. Energy management strategies of connected HEVs and PHEVs: Recent progress and outlook. Prog. Energy Combust. Sci. 2019, 73, 235–256. [Google Scholar] [CrossRef]
- Liu, T.; Zou, Y.; Liu, D.; Sun, F. Reinforcement learning of adaptive energy management with transition probability for a hybrid electric tracked vehicle. IEEE Trans. Ind. Electron. 2015, 62, 7837–7846. [Google Scholar] [CrossRef]
- Zou, Y.; Liu, T.; Liu, D.; Sun, F. Reinforcement learning-based real-time energy management for a hybrid tracked vehicle. Appl. Energy 2016, 171, 372–382. [Google Scholar] [CrossRef]
- Lian, R.; Peng, J.; Wu, Y.; Tan, H.; Zhang, H. Rule-interposing deep reinforcement learning based energy management strategy for power-split hybrid electric vehicle. Energy 2020, 197, 117297. [Google Scholar] [CrossRef]
- Du, G.; Zou, Y.; Zhang, X.; Liu, T.; Wu, J.; He, D. Deep reinforcement learning based energy management for a hybrid electric vehicle. Energy 2020, 201, 117591. [Google Scholar] [CrossRef]
- Shi, X.; Jiang, D.; Liang, Y.; Liu, H.; Hu, X. Reinforcement learning with experience augmentation for energy management optimization in hybrid electric vehicles. Appl. Therm. Eng. 2025, 274, 126561. [Google Scholar] [CrossRef]
- Tan, H.; Zhang, H.; Peng, J.; Jiang, Z.; Wu, Y. Energy management of hybrid electric bus based on deep reinforcement learning in continuous state and action space. Energy Convers. Manag. 2019, 195, 548–560. [Google Scholar] [CrossRef]
- Qi, C.; Zhu, Y.; Song, C.; Yan, G.; Xiao, F.; Zhang, X.; Song, S. Hierarchical reinforcement learning based energy management strategy for hybrid electric vehicle. Energy 2022, 238, 121703. [Google Scholar] [CrossRef]
- Huang, R.; He, H.; Su, Q.; Härtl, M.; Jaensch, M. Enabling cross-type full-knowledge transferable energy management for hybrid electric vehicles via deep transfer reinforcement learning. Energy 2024, 305, 132394. [Google Scholar] [CrossRef]
- Qi, X.; Wu, G.; Boriboonsomsin, K.; Barth, M.J.; Gonder, J. Data-driven reinforcement learning–based real-time energy management system for plug-in hybrid electric vehicles. Transp. Res. Rec. 2016, 2572, 1–8. [Google Scholar] [CrossRef]
- Hou, Y.; Liu, L.; Wei, Q.; Xu, X.; Chen, C. A novel DDPG method with prioritized experience replay. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 316–321. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; Zaremba, W. Hindsight experience replay. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]

















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).