Abstract
Offensive language and hate speech have a detrimental effect on victims and have become a significant problem on social media platforms. Recent research has developed automated techniques for detecting Arabic offensive language and hate speech but remains limited, and further research is required compared to the research on high-resource languages such as English due to limited resources, annotated corpora, and morphological analysis. Most social media users who use profanities attempt to modify their text while maintaining the same meaning, thereby deceiving detection methods that forbid offending phrases. Therefore, this study proposes an adversarially robust multitask learning framework for detection of Arabic offensive and hate speech. For this purpose, this study used the OSACT2020 dataset, augmented with additional posts collected from the X social media platform. To improve contextual understanding, classification models based on various configurations were constructed using four pre-trained Arabic language models integrated with various sequential layers that were trained and evaluated in three different settings: single-task learning with the original dataset, single-task learning with the augmented dataset, and multitask learning with the augmented dataset. The multitask MARBERTv2+BiGRU model achieved the best results, with an 88% macro-F1 for hate speech and 93% for offensive language on clean data. To improve the model’s robustness, adversarial samples were generated using attacks on both the character and sentence levels. These attacks subtly change the text to mislead the model while maintaining the overall appearance and meaning. The clean model’s performance dropped significantly under attack, especially for hate speech, to a 74% macro-F1; however, adversarial training, which re-trains the model using both clean and adversarial data, improved the results to a 78% macro-F1 for hate speech. Further improvements were achieved with input transformation techniques, boosting the macro-F1 to 81%. Notably, the adversarially trained model maintained high performance on clean data, demonstrating both robustness and generalization.
1. Introduction
In recent years, the growth and spread of offensive language and hate speech on social media platforms have become a significant societal concern. These types of content contribute to online toxicity, fuel discrimination, and can even lead to real-world violence. Manually filtering offensive messages is difficult due to the vast number of social media users and the increasing proliferation of abusive content on social media platforms, as manual review processes are time-consuming, labor-intensive, unscalable, and unsustainable [1,2]. Consequently, automatic detection systems are becoming critical for detecting and mitigating offensive content on a large scale. Nevertheless, hate speech and offensive language detection is a challenging task due to the lack of common understanding and agreement on what constitutes offensive and hate speech [3].
Many studies still frequently confuse offensive language and hate speech since these concepts do not have a clear meaning. Therefore, distinguishing hate speech from other types of offensive language is a major obstacle to its automatic detection on social media platforms [4].
Hate speech is defined as the use of offensive, insulting, or abusive language toward a person or group of people to promote bigotry and hatred based on race, gender, religion, or disability, whereas offensive language refers to the use of inappropriate language, as well as any implicit or explicit assault or insult against another person [5,6]. Furthermore, [7] defined offensive language as insulting, discriminatory, threatening, or involving profanity. As a result, hate speech is classified as a subset of offensive language, whereas offensive language encompasses all forms of profanity or insult [8]. Offensive language can take numerous forms, including hate speech, cyberbullying, violent content, and toxic comments [9]. Due to the lack of a universally agreed-upon definition, current studies rely on machine learning models to determine what constitutes hate speech. Consequently, trained hate speech classifiers are unlikely to be generalized across new domains and datasets [10].
The research on detecting offensive content and hate speech on social media has largely concentrated on explicit forms, which are often recognized by identifying hateful words and phrases; in comparison, the topic of performing adversarial attacks on offensive content has been neglected [11]. Adversarial attacks involve the use of symbols, modified letters and words, and manipulative language within textual data; this significantly hinders the efficacy of automated offensive language detection systems, which rely on predefined linguistic patterns and algorithms. Although deep networks perform well on classification tasks, they are still vulnerable to adversarial attacks wherein a network is tricked by subtle input perturbations [12]. As a result, identifying and classifying harmful content becomes more challenging, requiring the creation of robust models that can successfully detect and counteract adversarial influences.
Adversarial machine learning is a subfield of machine learning that incorporates machine learning and computer security. It investigates how adversarial examples affect machine learning algorithms, as well as their strengths and limitations. It also seeks to design effective machine learning techniques to resist adversarial examples [13]. In adversarial attacks, the adversary inserts noise and minor perturbations into a clean text sequence to deceive a target model to make it produce incorrect outputs. As a result, an adversarial example is a modified text sequence that has been purposefully perturbed to defeat machine learning [13]. There are various ways to target text-based detection models by modifying the input text such that the human reader maintains the intended meaning even though the detection model misclassifies the text. Attack strategies are categorized into four types based on which components are altered in the text: character-level attacks, word-level attacks, sentence-level attacks, and multi-level attacks. In these adversarial attacks, text data are generally inserted, removed, swapped/replaced, or flipped [14]. Examples include word-change attacks (e.g., inserting misspellings or alternative spellings into words), word boundary changes (e.g., inserting or deleting characters such as white space), and word appending to alter the classification (e.g., inserting non-hateful content into hate speech) [15].
The authors of [12] also found that training models on multiple tasks simultaneously through MTL increases their resilience to adversarial attacks on individual tasks. Multi-task learning (MTL) is a subfield of machine learning in which a shared model learns multiple tasks simultaneously. Its goal is to leverage useful information contained in multiple related tasks to improve the generalization performance of all tasks. MTL can be used with other learning paradigms to boost learning task performance even further [16,17]. It can provide benefits such as increased data efficiency, reduced overfitting through shared representations, and faster learning through the use of auxiliary data [16,17].
Despite significant advancements in English and other high-resource languages, the creation of reliable models for low-resource languages such as Arabic is still largely limited and unexplored. This situation is attributable to the linguistic complexity, dialectal variety, and data scarcity of low-resource languages. Datasets for offensive Arabic content and Arabic hate speech detection are often limited in size and suffer from class imbalances. These challenges hinder the generalization and real-world applicability of traditional models.
Arabic is spoken by approximately 422 million people throughout 22 Arab countries [18]. The characteristics of the Arabic language make the task of identifying hate speech and offensive language complex. Arabic is a complicated, morphologically rich, and highly inflected language. The Arabic language encompasses three primary forms: Classical Arabic, the language of the Holy Quran; Modern Standard Arabic (MSA), used in media, publications, and academia; and Dialectical Arabic, which varies by region and is employed in daily communication [19]. Arabic’s several dialects vary not just between countries but even between regions within the same country. Further, Dialectal Arabic is difficult due to its departure from spelling rules and standard grammar. Many words are spelled and pronounced the same in different dialects, yet they have entirely distinct meanings. For example, the term “ناصح/Nasih” means “overweight” in Levantine, “advisor” in Gulf, and “smart” in Egyptian [19]. Furthermore, a term with the same spelling might have different meanings and pronunciations depending on the punctuation and diacritical markings employed. Moreover, certain Arabic words may be considered harmful in one region but normal in another [20]. Unlike other languages, the Arabic alphabet consists of 28 letters and is read and written from right to left. Each letter can be written differently depending on its position in a word, and vowels are represented by diacritics, which may or may not be used. Most available Arabic text lacks these markers, which leads to lexical ambiguity issues. The diversity of Arabic dialects and forms makes analyzing and processing Arabic text particularly challenging [19]. These complexities necessitate language-specific text analysis methods when addressing Arabic hate speech and offensive language detection.
In the Arabic language, certain groups of Arabic letters have high visual similarity, such as (ذ، د، ز ، ز سـ، شـ، جـ، حـ، خـ، صـ ضـ، ط، ظ ،عـ ،غـ ،فـ، قـ ، بـ، تـ، يـ، ثـ،), and there are also certain letters that are similar in pronunciation and different in shape such as (س-ص، ض-ظ، ت-د، ط-ت), which may be used to build adversarial attacks. It is worthwhile to illustrate examples of adversarial attacks in the Arabic language to highlight how minor alterations in word spelling can significantly affect the semantic and sentimental interpretation of a sentence. For instance, the sentence “أنت انسان حاسد” (translated as “You are envious”) conveys a negative sentiment. However, by substituting a single character, the sentence becomes “أنت انسان حاصد” (translated as “You are a reaper”), which carries a more positive and productive connotation that modifies the sentiment to positive. Similarly, the phrase “لديك الكثير من الحكم المفسدة” (translated as “You have a lot of corrupting judgments”) initially reflects a negative sentiment. When modified to “لديك الكثير من الحكم المفيدة” (translated as “You have a lot of useful wisdom”), the sentiment shifts to positive. These examples underscore the sensitivity of Arabic natural language processing models to subtle orthographic variations, which attackers can exploit in adversarial contexts to manipulate model predictions.
The novelty of this study resides in its development of an adversarial multitask learning framework that integrates multitask learning with adversarial learning to achieve our goal of enhancing the detection of Arabic offensive language and hate speech. Additionally, this study develops a robust model capable of generalizing across various forms of offensive content and resisting adversarial attacks. While previous studies have addressed detection of offensive or hate speech in Arabic as single-task problems, this study is among the first to explore multitask learning for the joint classification of both tasks using multiple Arabic pre-trained language models (PLMs)— MARBERTV2, AraBERTv2-Twitter, CAMeLBERT-DA, and QARiB —integrated with various recurrent neural networks (RRNs), including GRU, BiGRU, LSTM, and BiLSTM, to extract both contextual and sequential features simultaneously. In addition, we present a systematic evaluation of these various configurations trained under three different learning settings: single-task learning with the original dataset, single-task learning with the augmented dataset, and multitask learning with the augmented dataset. This evaluation enables us to determine the best configuration with the best performance. This comprehensive approach, along with the integration of real-world augmented data from the X social media platform, offers a new pathway for improving model robustness and performance in handling Arabic, which is a dialectally diverse and morphologically complex language. Furthermore, we propose novel adversarial attack scenarios to generate adversarial samples specifically designed for Arabic text. These samples subtly modify an input while preserving its meaning and readability, and effectively deceive standard detection models. To counter these threats, we implement and evaluate defensive strategies, including adversarial training and input transformation techniques, to enhance the resilience and robustness of the trained models against adversarial attacks, while maintaining their performance under adversarial conditions. In contrast to earlier work that often presents results on balanced or pre-processed datasets, we maintain imbalanced test conditions, thereby demonstrating the model’s reliability in practical deployments. The integration of multitask learning, adversarial learning, pre-trained language model benchmarking, and data augmentation strategies makes this work a significant advancement in detection of offensive Arabic speech and Arabic hate speech.
This study aims to answer the following research question (RQ) and its sub-questions:
- RQ1: How can we develop an adversarially robust multitask model that combines adversarial and multitask learning to improve the detection of Arabic hate speech and offensive language on social media platforms and resist adversarial attacks?
- How can we evaluate various configurations of Arabic pre-trained language models combined with various sequential layers across three settings to identify the most suitable model for detection of Arabic offensive language and hate speech?
- Can an augmented dataset effectively improve a model’s performance in detecting Arabic offensive language and hate speech compared to a non-augmented dataset?
- Can multitask learning effectively improve a model’s performance in detecting Arabic offensive language and hate speech compared to single-task models?
- How can we perform an effective adversarial attack strategy to generate adversarial examples that can defeat the detection model?
- How can we perform a defensive strategy against adversarial attacks to improve the robustness of the detection model?
The major contributions of this study consist of the following:
- We propose a novel adversarial multitask learning framework that combines multitask learning with adversarial learning to enhance the robustness and generalization of the detection of Arabic offensive language and hate speech detection models;
- We augment the training dataset with a substantial number of Arabic posts collected from the X social media platform to address the class imbalance problem and improve the model’s generalizability, while preserving the test set’s natural class distribution to reflect realistic conditions;
- We conduct a comprehensive comparison of learning models by evaluating multiple combinations of Arabic pre-trained language models with various recurrent architectures trained under diverse learning settings;
- We demonstrate the effectiveness of multitask learning compared to that of single-task models by showing improved performance and better generalization across both offensive and hate speech classification tasks;
- We propose novel adversarial attack scenarios that are specifically designed for Arabic text, which subtly modify the input while preserving their meaning and readability, and which effectively deceive standard detection models;
- We implement and evaluate targeted defensive strategies, including adversarial training and input transformation techniques, to maintain model performance under adversarial conditions;
- We evaluate the model’s performance under real-world imbalanced conditions by maintaining the original distribution of the test dataset, offering a more realistic assessment of its robustness in practical scenarios.
The remaining structure of this paper is organized as follows. Section 2 reviews the related work on Arabic offensive and hate speech detection, multitask learning, the use of adversarial attacks to generate adversarial text in natural language processing (NLP), and gaps in the current literature. Section 3 details the methodology of the proposed adversarial multitask learning framework, including a description of the dataset, data augmentation approach, data pre-processing, model architecture, adversarial attack used to generate adversarial samples, and defensive strategies. Section 4 reports and discusses the results, including model comparisons under the three settings, the effectiveness of the adversarial attack, and a robustness analysis before and after defensive techniques are applied. Section 5 concludes this paper and outlines potential directions for future research. Finally, Section 6 presents the study constraints regarding its scope, methodology, and data.
2. Related Work
2.1. Studies on Arabic Offensive/Hate Speech Detection
Several studies have been conducted using a range of machine and deep learning approaches to detect offensive and hate speech in Arabic, particularly on social media platforms such as Twitter and YouTube. Boulouard et al. [21] proposed a method for detecting offensive and hate speech on Arabic social media using transfer learning. Along with standard Arabic, their training set contained comments in four distinct Arabic dialects. The researchers evaluated the efficacy of various BERT-based models that had been trained to categorize comments as abusive or neutral on both original Arabic comments and their English translations. The results showed that the classical BERT model outperformed the other models with 98% accuracy when the comments were translated into English.
Husain and Uzuner [22] presented a transfer learning approach for detecting offensive language across Arabic dialects using the BERT model. The findings revealed that pre-training AraBERT with extra training sets from each dialectal dataset enhanced its performance with Arabic offensive language recognition as well as with various Arabic dialects, including Egyptian and Tunisian, with the model achieving an accuracy of 81% and 78%, respectively.
In further research, [23] suggested a novel method for identifying hate speech in Arabic based on enhancing AraBERT with personality trait features. Additionally, the researchers investigated different traditional machine learning and deep learning models, including RF, extra trees, DT, SVM, gradient boosting, XGBoost, LR, LSTM, BI-LSTM, GRU, CNN-GRU, CNN-LSTM, and CNN-BILSTM. The results showed that the proposed method outperformed the other models with a macro-F1 score of 82.3%.
Mohamed et al. [24] enhanced Arabic offensive language detection by addressing data imbalance difficulties with focal loss functions alongside traditional loss functions and oversampling techniques. The OSACT-2020 shared task’s Arabic offensive language dataset was utilized. Quasi-recurrent neural networks were used to fine-tune cutting-edge transformer-based models such as MARBERTv2, MARBERTv1, and ARBERT. The proposed ensemble model incorporates three MARBERTv2 variations: one trained with focal loss on the original dataset, another using data augmentation to train with binary cross-entropy on an oversampled dataset, and a third trained with binary cross-entropy on an oversampled dataset that was enhanced with external resources. The ensemble obtained a macro-F1 score of 91.6% by aggregating predictions through voting methods.
In an additional study, [25] applied the CAMeLBERT transformer-based model to identify Arabic offensive language in tweets. Four benchmark Arabic Twitter datasets, which are annotated for hate speech and offensive language identification, were used to evaluate the model. The findings indicate that transformer models can improve the detection of offensive Arabic language. The model correctly detected offensive speech with an F1 score of 83.6% and an accuracy of 87.15%.
Mazari et al. [26] developed a comprehensive dataset in the Algerian dialect for detecting toxic text, which included 14,150 comments that were collected from Facebook, Twitter, and YouTube and classified as hate speech, offensive language, or cyberbullying. Different ML models were applied, including NB, LR, RF, SGD, and linear SVC, as well as DL models such as LSTM, GRU, CNN, Bi-LSTM, and Bi-GRU. The machine learning models used TF-IDF text representations, whereas the deep learning models used word2vec and FastText embeddings. The results demonstrated that the Bi-GRU model outperformed deep learning classification, reaching 73.6% accuracy and a 75.8% F1 score. However, the SGD strategy performed best in deep learning classification, obtaining 71.6% accuracy using TF-IDF features. Moreover, deep learning models demonstrated their efficacy in text data analysis by outperforming traditional machine learning techniques.
Al-Ibrahim et al. [27] suggested new deep learning architectures that contain an improved BiLSTM model and a modified CNN, in addition to a traditional machine learning algorithm, to detect hate speech in Arabic tweets. The researchers used a dataset of 15,000 Arabic tweets containing 14 features collected from Twitter. The improved BiLSTM model achieved the highest performance with an accuracy of 92.20% and an overall F1 score of 92%, while the modified CNN model followed with an accuracy of 92.10% and an overall F1 score of 91%.
AlSukhni et al. [28] introduced a deep learning model that used three models to detect Arabic offensive language, with a focus on the Egyptian dialect: a deep neural network with LSTM, a deep neural network with BiLSTM, and an SVM. They used a dataset of 7000 tweets in the Egyptian dialect that were labeled for binary classification (OFF or NOT_OFF). The findings revealed that the RNN models outperformed the SVMs with 95.6% accuracy. This study demonstrates the efficacy of deep neural networks, especially RNN-based designs, in detecting offensive language in low-resource, dialect-specific circumstances.
In addition, [29] introduced a novel ensemble learning method for identifying Arabic offensive language. The proposed method includes three models: the BERT model, BERT with Global Average and Global Max pooling layers, and BERT with pooled stacking Bi-LSTM networks. The study used the OffensEval2020 (OSACT2020) Arabic dataset, which was created specifically to identify offensive language. The ensemble model achieved an F1 score of 90.97%, particularly when using weighted average predictions. Furthermore, on an augmented dataset, the model further improved to an F1 score of 94.56%, demonstrating its efficacy in improving the identification of offensive language in Arabic social media contexts.
Mousa et al. [30] proposed a cascaded deep learning model that includes BERT models (e.g., QARiB, GigaBERT, mBERT, XLMRoBERTa, ArabicBERT, and AraBERT), deep learning techniques (BiLSTM and 1D-CNN), and traditional machine learning classifiers (SVM, MLP, KNN, NB, and radial basis function) to classify Arabic offensive language into five categories: profane, bullying, racism, insulting, and non-offensive. The balanced dataset, which was gathered from Twitter, consists of binary, multiclass, and multilabel classification tasks. Furthermore, two additional datasets were used for validation. The cascade model, especially the combination of ArabicBERT with BiLSTM and RBF, achieved outstanding results, with 98.4% accuracy, 98.2% precision, 92.8% recall, and a 98.4% F1 score.
Khairy et al. [31] created a balanced dataset to improve the automated detection of abusive language and cyberbullying in Arabic texts. The study used three Arabic datasets—two publicly accessible offensive datasets and one newly constructed dataset—to evaluate the performance of different single and ensemble machine learning techniques. The datasets were gathered from YouTube, Twitter, and Facebook postings, and features were created using the TF-IDF method. Three single classifiers—K-neighbors (KNN), LR, and linear SVC—as well as three ensemble techniques—bagging (using random forest), voting, and boosting (using AdaBoost)—were used in the study. Across the three datasets, the ensemble methods with a voting classifier achieved the greatest accuracy scores of 71.1%, 76.7%, and 98.5%, which demonstrated that the ensemble approaches outperform the individual classifiers. Table 1 summarizes these studies, highlighting their data sources, modeling techniques, and performance metrics.

Table 1.
Studies using machine learning and deep learning to detect offensive language and hate speech in Arabic.
As indicated, researchers have utilized a range of machine and deep learning techniques. The most promising results come from pre-trained transformer-based models, particularly those that are fine-tuned using data from Twitter. BERT [21,29]), AraBERT ([22,23]), MARBERTv2 [24], and CAMeLBERT [25] have achieved strong performances, with domain-specific models—such as AraBERT and MARBERT—being significantly enhanced in this regard. For instance, the authors of [24] employed an ensemble of MARBERTv2 variants, achieving a macro-F1 score of 91.6%, which indicates a strong performance, with dialect-rich Twitter data. These models more effectively capture semantic and dialectal variation in Arabic text.
Other studies have focused on enhancing RNN architectures. For instance, the authors of [27] combined an enhanced BiLSTM with a modified CNN, achieving a 92% macro-F1, while the authors of [28] explored hybrid RNN+LSTM and RNN+BiLSTM configurations, reporting an accuracy of 95.6%. This demonstrates their effectiveness in short text classification and highlights the value of combining sequential modeling with deep contextual embeddings.
On the other hand, while classical machine learning approaches using TF-IDF and traditional classifiers (e.g., SVM, NB, RF, SVC, and KNN) have still appeared in recent studies ([26,31]), they often lag behind in terms of performance, with F1 scores in the 71–76% range. This reflects the limitations of sparse features and shallow models, particularly when handling both the complexity of Dialectal Arabic and the nuanced semantics of hate speech.
2.2. Multitask Learning in Offensive/Hate Speech Detection
The adoption of the multitask learning approach in the field of NLP offensive language detection remains a new approach [32]. This section presents the recent work employing multitask learning (MTL) for hate and offensive language detection in different languages. Farha and Magdy [33] evaluated various techniques for identifying Arabic hate speech and offensive language. The experiments covered CNN-BiLSTM-based multitask learning architecture, transfer learning (mBERT), and deep learning (BiLSTM and CNN-BiLSTM). In addition, they investigated the use of sentiment analysis to accomplish this task. The CNN-BiLSTM-based multitask learning architecture achieved the highest F1 score of 87.7% for hate speech and an F1 score of 76% for offensive language.
Mulki and Ghanem [34] presented the first benchmark dataset for Arabic misogyny: the Levantine Arabic dataset for misogynistic language (LeT-Mi). Several models were validated, including the NB classifier, an ensemble technique that combines predictions from three separate classifiers (SVM, NB, and LR), LSTM, and BERT. The impact of multitask learning on classification was also evaluated. The results showed that the usage of MTL enhanced the performance of classification tasks. BERT+MTL achieved the best outcome, with 90% accuracy and an F1 score.
Shapiro et al. [35] studied a variety of training paradigms, including contrastive learning, classification fine-tuning, multitask learning, and an ensemble of the best performers. For Arabic offensive language detection, the ensemble of MarBERT-based models achieved a macro F1-average of 0.841. For Arabic hate speech detection, the multitasking model based on MarBERT achieved a macro F1-average of 0.817.
Aldjanabi et al. [3] developed a multitask learning (MTL) model to classify offensive and hate speech using a pre-trained BERT language model for Arabic (AraBERT and MarBERT). Two distinct language models were employed to cover both Dialectal Arabic and Modern Standard Arabic. On three of the four datasets, the developed MTL+ MarBERT model beat existing approaches in identifying hate speech and offensive language in Arabic, with accuracy rates of 95.20%, 97.90%, and 87.46%, respectively.
Alrashidi et al. [36] investigated three main methods for detecting abusive content in Arabic: machine learning (ML), deep learning (DL), and pre-trained Arabic language models (LMs). They specifically targeted Dialectal Arabic (DA) using a multi-aspect annotation schema. To overcome low-resource issues and boost model performance, they employed data augmentation on a dataset of 3353 Arabic tweets annotated with this schema. Deep learning models such as CNN and LSTM used AraVec, whereas machine learning models such as SVM and NB employed TF-IDF. Different pre-trained LMs, including MARBERT, CAMeLBERT, ArabicBERT, QARiB, and AraBERTv0.2, were fine-tuned for text classification, with MARBERT consistently producing better results. Furthermore, MARBERT was used as a foundation for the development of multitask learning (MTL) models, alongside hybrid neural architectures (e.g., LSTM+CNN). The study discovered that MARBERT and CAMeLBERT outperformed the other models.
AlKhamissi and Diab [37] provided an ensemble of MARBERT models that used multitask learning and a self-consistency correction approach to identify whether or not a tweet contained Arabic abusive language and was labeled hate speech. If it did, the model would decide which of the six categories best matches the tweet’s fine-grained hate speech classification. The results showed that their approach produced an accuracy of 86.0% and an F1-macro of 84.5% on the offensive subtask, as well as an accuracy of 94.1% and an F1-macro of 82.7% on the hate speech subtask.
Djandji et al. [38] examined the application of multitask learning with the AraBERT model to identify offensive language on Arabic social media platforms. This method allows the model to effectively learn from a limited dataset, improving its ability to detect hate speech and offensive language. The findings indicate that the proposed Multitask AraBERT model outperformed both the single-task and Multilabel AraBERT models, achieving a macro-F1 score of 90% for the offensive language task and a macro-F1 score of 82.28% for the hate speech task, thereby demonstrating its efficacy in various tasks related to offensive language detection.
Mnassri et al. [32] introduced a multitask joint learning strategy designed to identify hate speech and offensive language in English, leveraging emotional features to improve the model’s classification performance. The findings reveal that multitask models outperform single-task models, with a 3% enhancement in hate speech detection and a reduction in false positive errors. Although the performance improvement in abusive language detection was not statistically significant due to a dataset imbalance, the emotional features contributed positively to the classification task, which demonstrated the effectiveness of the multitask learning approach.
Kapil et al. [39] presented a multitask learning (MTL) architecture for detecting hate speech in English, which incorporates user-based information. The researchers evaluated the MTL model on three datasets focused on hate speech classification, sexism detection, and abusive language detection. By sharing lower layers among tasks and employing task-specific layers, the model demonstrated a significantly enhanced performance. The integration of intra-user and inter-user features boosts detection accuracy, reducing false positives and improving macro-F1 and weighted-F1 scores across the datasets.
Dai et al. [40] examined the use of multitask learning for offensive language detection in English, leveraging BERT-based models to obtain an enhanced performance. By incorporating supervision signals from related tasks, the model effectively learns representations for noisy social media text. This approach not only improved offensive language detection but also achieved a competitive F1 score of 91.51%. This result demonstrates the effectiveness of multitask learning in addressing the challenges of detecting offensive content.
Kapil et al. [41] proposed a convolutional neural network (CNN)-based multitask learning model to enhance hate speech detection in English by leveraging information from multiple sources. This approach addresses the data sparsity problem and improves the model’s ability to generalize across different types and subtypes of hate speech. Empirical analysis of the model’s performance on three benchmark datasets demonstrated significant improvements in accuracy and the F-score, with the model achieving state-of-the-art performance compared to existing systems and thus effectively utilizing multitask learning for offensive language detection.
Halat et al. [42] investigated the use of multitask learning (MTL) for detecting hate speech and offensive language (HOF) in English by integrating sentiment analysis, emotion analysis, and target detection. The authors hypothesized that jointly modeling these concepts enhances HOF detection. The experimental results show that using a BERT-based multi-head MTL model, with relevant datasets, achieved an F1 score of 0.79, with the model outperforming plain BERT. The approach significantly improves the recall for HOF, indicating its effectiveness for use in early warning systems on social media platforms.
Plaza-Del-Arco et al. [43] proposed a multitask learning (MTL) approach for hate speech (HS) detection that incorporates polarity and emotion classification tasks. By leveraging shared affective knowledge, the MTL model improves the accuracy of HS detection in Spanish tweets. Previous studies have shown that incorporating polarity and emotional features can enhance offensive language identification. The authors demonstrate that their transformer-based MTL model outperforms traditional single-task models, highlighting the effectiveness of combining related tasks for better HS detection outcomes.
Zampieri et al. [44] proposed a novel multitask learning (MTL) architecture that can predict the following: first, offensiveness at both the post and token levels in English; second, offensiveness and related subjective tasks such as humor, engaging content, and gender bias identification in multilingual settings. The results show that the proposed multitask learning architecture outperformed current state-of-the-art methods trained to identify offensiveness at the post level. The results further demonstrate that MTL outperformed single-task learning (STL) across different tasks and language combinations.
These studies clearly demonstrate that multitask learning (MTL) enhances generalization by enabling shared representation learning across related tasks. In Arabic, there is a noticeable shift towards advanced models, such as MTL with AraBERT and MarBERT, reflecting an increasing emphasis on the use of context-aware embeddings to improve performance in dialect-rich datasets.
2.3. Adversarial Attacks Methods for Generating Adversarial Text
In 2017, Jia et al. [45] were the first to investigate the use of text-based deep neural networks to generate adversarial examples. In their research, a black-box attack was executed on a reading comprehension system by adding distracting but meaningless phrases to the end of paragraphs. The semantics of paragraphs and answers are unaffected by these distracting sentences, but they can mislead the neural network model. Since then, other researchers have started to pay attention to creating adversarial examples for text. In addition, [46] demonstrated how to create text adversarial samples in an efficient way. The important text items for classification are identified by computing the cost gradients of the input (white-box attack) or by producing a series of occluded test samples (black-box attack). The researchers devised three perturbation procedures to generate adversarial samples based on these items: insertion, modification, and removal. The results of the experiments showed that the method’s adversarial samples could successfully trick both state-of-the-art character-level and word-level DNN-based text classifiers. Furthermore, [47] developed Hot-Flip, an effective method to generate white-box adversarial examples to fool a character-level neural classifier. Based on the gradients of the one-hot input vectors, the approach used an atomic flip operation to swap one token for another. Insertion and deletion operations were also supported by Hot-Flip. The authors demonstrated that it can be used to perform adversarial training and adapted to attack a word-level classifier using a few semantics-preserving constraints.
In 2018, the authors in [48] developed an attack that adds perturbations to the input data of neural machine translation applications in two ways: synthesis, which changes the arrangement of characters, for example by swapping or randomly changing the order of characters except the first and last characters or randomly changing the order of all characters, and keyboard typing error types. In [49], DeepWordBug was designed, which is an approach for effectively generating minor text perturbations in a black-box setting by using novel scoring strategies to identify the critical tokens. If these tokens are altered, the classifier generates an incorrect prediction. Simple character-level changes are performed to the highest-ranked tokens, including swapping, substitution, deletion, and insertion. The study’s results demonstrated that DeepWordBug successfully reduced the prediction accuracy of today’s state-of-the-art deep learning models. In another study, [50] proposed TEXTBUGGER, a general attack framework for generating adversarial texts. Under a white-box context, the process of generating adversarial examples on text involves, first, finding important words and producing five different types of bugs and then, second, choosing the best bug. Two types of perturbations are considered: character-level perturbations (misspelling important words) and word-level perturbations (inserting a space into the word, deleting a random character, swapping two random adjacent letters in the word but not changing the first or last letter, replacing characters with visually similar characters or adjacent characters in the keyboard, or replacing a word with its nearest neighbors in a context-aware word vector space). Under a black box setting, the attack consists of three steps: identify the key sentences; use a scoring function to determine the importance of each word in relation to the classification result and then rank the words according to their scores; and, finally, change the selected words using the bug selection algorithm.
In 2019, ref. [51] presented a greedy algorithm for text adversarial attacks that utilized probability-weighted word saliency (PWWS). A new vocabulary replacement method was presented based on POS saliency and classification likelihood, which is based on the synonym replacement strategy. Further, the authors in [52] designed the first set of black-box adversarial attacks to perturb Arabic textual inputs. To create adversarial examples, they applied two steps: first, identify the most important token in the input sequence by considering its effect on the targeted classifier’s prediction; second, if the most important token is an adjective, attack it by changing the morphological form of the adjective (this is because adjectives carry sentiment, and the sentiment analysis task is the target of the suggested adversarial attacks). The results showed that the proposed attacks effectively undermined the sentiment classification task.
In 2020, ref. [53] developed TEXTFOOLER, a black-box attack method. The authors defined a novel approach to ranking the importance of words in which the words were replaced based on their importance score. This technique performed well in text categorization and text implication tasks. In another study, [54] presented a CNN model for text classification using a perturbation that was applied to the word embedding layer rather than the original input. According to the results, the classifier with adversarial training was more resistant to tiny perturbations and successfully controlled overfitting. In addition, [55] developed BAE, a black-box attack utilizing contextual perturbations from a BERT masked language model to generate adversarial samples. By masking a portion of the text and leveraging the BERT-MLM to generate alternatives for the masked tokens, BAE replaces and inserts tokens in the original text. They showed that BAE is more effective at attacking and generating adversarial cases, with better grammaticality and semantic coherence.
2.4. Gaps in the Literature
According to previous studies, there are still a number of gaps and open issues in hate speech and offensive language detection research. The major research gaps include the following: relatively few studies have addressed the detection of hate speech and offensive language in Arabic; no studies consider the vulnerability of machine learning models to adversarial attacks; and no previous researchers have applied any defensive techniques to resist adversarial attacks (e.g., adding or deleting some symbols, spelling errors, and adding positive words to negative phrases to confuse the workbook), thereby boosting the robustness of the detection systems. Furthermore, there is a lack of a comprehensive dataset. Most data are not publicly available and are often limited in size. The existing datasets also suffer from class imbalances, where harmful content constitutes a small fraction of the data. These challenges hinder the generalization and real-world applicability of traditional models. Therefore, it is important to have publicly available and standard review datasets that researchers can use to evaluate and compare hate speech and offensive language detection techniques.
To bridge the gaps in the literature, this research aims to develop a novel framework for improving Arabic hate speech and offensive language detection on social networks to resist adversarial attacks. Multitask learning improves models’ resilience against such attacks in completing individual tasks by training multiple related tasks concurrently and leveraging shared information [12]. This approach also strengthens the model’s ability to learn robust features and enhances its generalization, especially when dealing with limited datasets. Therefore, this framework integrates multitask and adversarial learning. Our research clarifies how to apply effective attack strategies to generate adversarial examples, as well as how to use these examples in adversarial training as a defensive strategy against possible adversarial attacks to improve machine learning classifier robustness. Furthermore, one objective of the proposed research is to enhance and augment an existing public dataset on Arabic hate speech and offensive language using real samples collected from the X social media platform. This can then serve as a ground truth for the proposed model, as well as aid in further testing and training. The integration of multitask learning, adversarial learning, and data augmentation strategies makes this work a significant advancement in Arabic offensive and hate speech detection.
3. Methodology
In this section, we present a proposed framework for building a robust multitask model for detecting Arabic offensive language and hate speech. It includes eight main components: problem formulation, dataset and augmentation, data pre-processing, model architecture, handling imbalanced datasets and evaluation metrics, adversarial sample generation, defense and robustness enhancement techniques, and hyperparameter settings.
3.1. Problem Definition
Considering the scarcity of Arabic-language resources and the presence of malicious users who often attempt to bypass filtering systems using textual noise, we propose an adversarial multitask learning framework that integrates multitask learning with adversarial learning. This framework aims to enhance the detection of Arabic offensive language and hate speech while developing a robust model that can generalize across various forms of offensive content and resist adversarial attacks.
This framework is designed to jointly detect two forms of harmful content in Arabic text: offensive language and hate speech. This task is designed as a multitask binary classification problem, where each input text is associated with two binary labels: one for offensive language (OFF) and the other for hate speech (HS). A shared encoder is used to extract semantic representations from each text, which is followed by the use of two task-specific classifiers to predict OFF and HS independently.
3.2. Dataset and Augmentation
The OSACT2020 dataset created by [56] was used as the primary source of Arabic tweets in which both offensive and hate speech content is labelled. The original dataset was divided into three subsets: a training set, a validation set, and a test set. Given the skewed class distribution, as shown in Table 2, particularly regarding hate speech, we augmented the training data with 374 and 1068 hate speech samples from two public Arabic datasets, L-HSAB and T-HSAB, respectively [57,58]. Additionally, we collected 4136 offensive Arabic posts from X, of which 3787 were classified as hate speech using carefully selected keyword filters to extract offensive and hateful content. These posts were manually filtered, labeled using the same annotation guidelines used in [56], and added to the training set. The annotation was conducted by three native Arabic-speaking annotators with experience in analyzing social media content. The annotation process consisted of two stages:
Table 2.
OSACT2020 label distribution for subtasks A and B.
- Offensive language detection: each post was first assessed as either “Clean” (i.e., free of any offensive, hateful, or profane content) or “Offensive” (i.e., containing unacceptable language such as insults, profanity, threats, swear words, or any form of untargeted profanity);
- Hate speech identification: posts labeled as “Offensive” were further categorized as follows:
- Hateful posts: posts that targeted individuals or groups based on protected characteristics such as race, religion, gender, ethnicity/nationality, ideology, social class, disability, or disease;
- Offensive but not hateful posts: posts that contained profanity or general offensive language but did not target individuals based on their identity or group characteristics.
Each post was labeled independently by at least two annotators. In cases of disagreement, a third annotator resolved the conflict. Inter-annotator agreement was monitored, and disagreements were resolved through discussion and consensus. This dual-stage annotation ensured good consistency and reliability across the newly added samples. For the offensive language (OFF) subtask, a label of OFF = 1 indicates offensive content and OFF = 0 indicates non-offensive content (NOT-OFF). Similarly, for the hate speech (HS) subtask, a label of HS = 1 denotes hate speech, while HS = 0 denotes non-hate speech (NOT-HS). Therefore, the distribution of task labels became 5590 non-offensive samples and 6988 offensive samples for the first task, and 5590 hate speech samples and 6988 non-hate speech samples for the second task, as shown in Table 3. We augmented the training dataset to enhance the model’s ability to learn from a wide range of examples, thereby enhancing its generalization capabilities. However, we kept the testing dataset non-augmented to maintain a realistic evaluation of the model’s performance. This approach enabled us to evaluate the model’s performance based on real, unseen data, ensuring that the results reflected the model’s efficacy in real-world scenarios.
Table 3.
New label distribution for subtasks A and B after augmentation.
3.3. Data Pre-Processing
To prepare the data for the model input, a comprehensive pre-processing pipeline was implemented. These steps were consistently applied to the training, validation, and test sets to ensure consistent input quality. Preprocessing was implemented using Python 3.12.11 with the nltk, pyarabic, and emoji libraries. The pre-processing pipeline included the following steps:
- Normalization of Arabic characters (e.g., unifying Alef variants, replacing “ة” with “ه”);
- Removal of diacritics, URLs, emojis, numbers, and non-Arabic characters;
- User mention stripping and hashtag splitting (e.g., حريةـالرأي#حرية الرأي → );
- Text cleaning was performed by eliminating punctuation, character elongation (e.g., “راااائع”), and repetitive letters;
- Tokenization using the corresponding tokenizer for each Arabic PLM (e.g., MARBERT tokenizer) with truncation and padding to a fixed maximum sequence length.
3.4. Model Architecture
Previous studies have demonstrated the effectiveness of using multitask learning and PLMs in similar contexts. Consequently, the proposed architecture is designed to leverage the strengths of both contextualized transformer embeddings and sequential modeling to extract sequential and important contextual features for the joint classification of Arabic offensive and hate speech. Specifically, Arabic PLMs integrated with sequential layers were used to form a shared encoder to capture the complex syntactic and semantic patterns of Arabic.
Figure 1 presents the general architecture of the proposed multitask learning model for Arabic offensive and hate speech detection. The pipeline begins with raw input text, which undergoes a preprocessing stage as described in Section 3.3. The preprocessed text is subsequently turned into a tokenized input (input_ids and attention_mask) that is compatible with pretrained Arabic language models. The shared encoding layer utilizes the transformer-based Arabic model, which generates contextualized word embeddings for the input sequence.
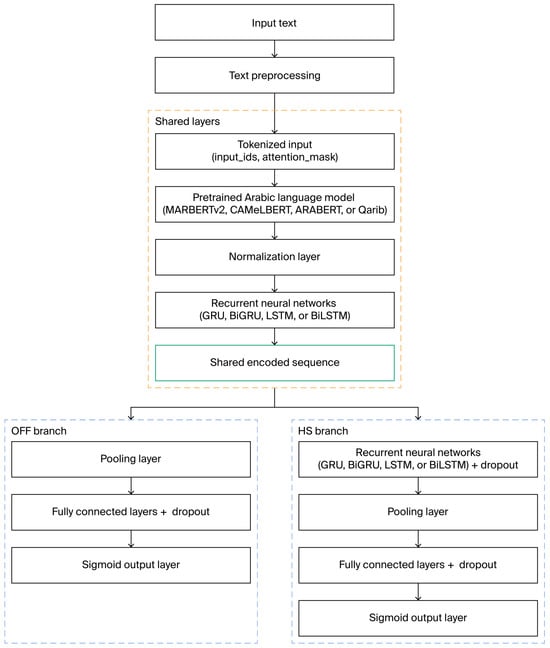
Figure 1.
General architecture of the proposed model.
A normalization layer is applied to stabilize the output distributions before passing the encoded sequence into a shared recurrent neural network (RNN) layer. This layer can consist of GRU, BiGRU, LSTM, or BiLSTM units, and is responsible for capturing temporal and sequential dependencies across the embedded text. The resulting representation (shared encoded sequence) is then passed to two separate task-specific branches:
- The offensive language detection (OFF) branch applies a pooling layer to compress the sequential output, followed by fully connected layers with ReLU activation and dropout regularization to reduce overfitting. The final output is generated through a sigmoid activation layer that produces a binary classification indicating whether the input text is offensive;
- The hate speech detection (HS) branch extends the sequence with an additional RNN layer to further refine task-specific temporal patterns. This is followed by pooling and fully connected layers with ReLU activation and dropout. Finally, a sigmoid output layer provides binary prediction for hate speech presence.
Both branches are trained simultaneously using a multitask learning setup with shared lower layers and separate task-specific heads.
We experimented with several configurations using four pre-trained Arabic language models, MARBERTV2, AraBERTv2-Twitter, CAMeLBERT-DA, and QARiB, integrated with sequential layers such as GRU, BiGRU, LSTM, and BiLSTM. Each language model was combined with each recurrent architecture and trained and evaluated in the following three settings:
- Setting 1: single-task learning using the original dataset
In this setting, we trained individual models independently for each task (i.e., one model for offensive language and another for hate speech) using only the original (non-augmented) dataset. This served as the baseline setting for all architectures;
- Setting 2: single-task learning using the augmented dataset
In this setting, the training data for both tasks were augmented using additional data, as described in section ‘b’. The same model configurations from Setting 1 were retrained using the expanded dataset to assess the impact of data augmentation on performance;
- Setting 3: multitask learning using the augmented dataset
In this setting, we trained a single multitask model to jointly predict offensive and hate speech labels using a shared Arabic PLM integrated with sequential layers to form a shared encoder. The same augmented training data used in Setting 2 were used in this setting to investigate whether multitask learning would further enhance the model’s effectiveness, given that hate speech is a subset of offensive language.
3.5. Handling Imbalanced Datasets and Evaluation Metrics
To address the class imbalance, weighted loss functions (weighted binary cross-entropy for each task) were applied. Class weights were dynamically calculated for each fold using Scikit-learn’s compute_class_weight function based on training label distribution. These weights were then applied at runtime by assigning a higher penalty to underrepresented classes, ensuring the model focused on minority labels. Stratified cross-validation was used to better manage imbalanced datasets, ensuring that each class was proportionally represented in each fold. This approach helped maintain the class balance during training and evaluation. For the final evaluation, each model’s performance was evaluated using an ensemble of the stratified 5-fold cross-validation models, by averaging their predictions, and validated on a clean test set. This custom implementation allowed our model to effectively balance the learning signal without overfitting to dominant classes. The primary evaluation metrics were the macro-F1 score, precision, recall, and robustness under clean input conditions. The optimal combination with the best performance in both tasks was selected for further robustness evaluation. Consequently, the MARBERTv2 + BiGRU combination achieved the highest macro-F1 in the multitask learning setting, consistently outperforming the other configurations on both tasks. This setup was chosen as the base model for additional robustness evaluation and adversarial attacks.
3.6. Adversarial Sample Generation
To assess the model’s vulnerabilities and enhance its robustness against prevalent adversarial attacks, we crafted multiple adversarial attack scenarios targeting Arabic text to generate adversarial samples for the model. We focused more on the character-level types of attacks that malicious users commonly use in Arabic text to deceive automated content detection systems. These attacks make subtle changes to the text that are difficult for readers to notice, while preserving the overall appearance and meaning; in this way, the attacker ensures that the text is read correctly and maintains its overall meaning. These modifications make it harder for models to detect misleading information, increasing the effectiveness of the attack.
To accomplish this, we identified the most influential word for each task by obtaining the prediction probabilities from the model and computing the importance of each word by measuring the drop in probability when the word was removed. A word is considered important if its removal significantly reduces the probability of the model’s predictions. The greater the reduction, the greater the word’s influence. The most influential words were selected for each task (OFF and HS). These words were then altered using one of the following perturbation techniques:
Sub-Char: Replace a character with the following: a visually similar Arabic character; a similar Arabic character with diacritics such as sukūn to replace dots on letters; an adjacent character on the keyboard; or its Arabic Leetspeak equivalent, which can involve substitutions such as the letter "ح" being replaced with the number 7, "و" with 9, "ع" with 3, "ط" with 6, "ث" with 4, "خ" with 5, "ق" with 8, and "ا" with 1. For example, حيوان →يوان 7 or خيوان;
- Insert-Space: Insert spaces between characters. For example, وقح → و ق ح;
- Delete-Char: Randomly remove characters from a word. For example, تافهه → تاهه;
- Swap-Letters: Swap adjacent characters. For example, خائن → اخئن;
- Moreover, we applied a sentence-level adversarial attack:
- Back-Translation: translate the text from Arabic to English and back to Arabic.
These perturbations were applied to all the samples in a cyclic sequence. For each original sample in the training, development, and testing datasets, one adversarial sample was generated. This technique preserves the text structure and label alignment while ensuring that adversarial perturbations target semantically important terms. These modifications are intended to simulate actual strategies that users can employ to trick detection systems by slightly changing surface forms while maintaining semantic meaning.
3.7. Defense and Robustness Enhancement Techniques
After generating the adversarial samples, we evaluated model performance on the adversarial test set. As a result, the model’s macro-f1 score decreased by 14% and 6% for hate speech and offensive language, respectively. This indicates that the model lacks robustness, is easily misled, has not been generalized substantively beyond its training data, and is extremely sensitive to certain patterns or noise provided by adversarial attacks. To mitigate the impact of adversarial attacks and improve model robustness, we applied a combination of the following adversarial training and input transformation techniques:
- Adversarial training
This process involves retraining the model input using the same weighted loss formulation on a combined dataset that incorporates both the original, clean, pre-processed data and adversarially modified samples without removing adversarial patterns (e.g., keeping diacritics, numbers, and typos). This approach enabled the model to learn from noisy patterns and strengthens the model’s ability to generalize and maintain performance under noisy or intentionally manipulated inputs.
- Input Transformation techniques
In addition to adversarial training, we implemented input transformation-based defensive techniques to automatically correct or normalize adversarial perturbations before classification. These techniques included the following:
- Letter concatenation: reunite sequential characters that have been separated by spaces;
- Leetspeak conversion: if a number appears within a word and is not separated by spaces, convert it to the corresponding similar character.
The adversarially trained model was then tested again on the adversarial test data to assess its improved robustness. These defensive strategies improved the model’s performance on the adversarial data by up to 6% for hate speech and 3% for offensive language, with a slight decrease (about 1%) on the clean data. This step quantifies the effectiveness of adversarial training and input transformation-based defensive techniques in mitigating the impact of input perturbations.
3.8. Hyperparameter Settings
To ensure optimal model performance and effective learning and generalization, the training process relied on a set of well-defined hyperparameters, which were tuned using automated optimization frameworks. Specifically, Optuna was used to efficiently search the hyperparameter space through a combination of Bayesian optimization and early pruning techniques. The objective function optimized the macro-F1 score obtained on the validation set within the first fold of the stratified 5-fold cross-validation. This approach allowed for an efficient and principled exploration of the search space, rather than relying on arbitrary manual selections. All tuning was conducted using validation folds only, which ensured that no information from the test set leaked into the training process. Table 4 presents the key hyperparameters used during training and evaluation of the best configuration (MARBERTv2+BiGRU).
Table 4.
Training hyperparameters.
4. Results and Discussion
This section presents the results of our experimental pipeline, which included multiple training settings and robustness evaluations for offensive language and hate speech detection in Arabic text. First, we present a comparative evaluation of multiple combinations of pre-trained Arabic language models and recurrent neural networks (RNNs) across multiple settings, including the original and augmented datasets and single-task and multitask learning models. Then, we present the evaluation results of the best-performing model based on the clean and adversarial test datasets, along with the results of evaluating the effectiveness of adversarial training and input transformation-based defensive techniques in enhancing robustness.
4.1. Comparison of Model Configurations
We first compared different combinations of pre-trained language models (MARBERTV2, AraBERTv2-Twitter, CAMeLBERT-DA, and QARiB) with recurrent architectures (GRU, BiGRU, LSTM, and BiLSTM) under the following three training settings:
- Setting 1: single-task models trained on the original dataset.
As shown in Table 5, we observe that MARBERTv2 combined with GRU-based sequential layers, specifically MARBERTv2+BiGRU and MARBERTv2+GRU, achieved the highest macro-F1 scores: 85 for hate speech (HS) detection and 93 for offensive content (OFF). These models also demonstrated high precision and recall across various tasks, which indicates that combining MARBERTv2 with GRU layers enhances the representation learning of offensive and hateful content. In contrast, the CAMeLBERT-DA-based models exhibited the lowest performance, particularly in hate speech detection, with macro-F1 scores ranging from 70 to 77. While AraBERTv2-Twitter and QARiB outperformed CAMeLBERT-DA, achieving macro-F1 scores in the low to mid-80s, these models still fell short of MARBERTv2’s results.
Table 5.
Results of single-task models trained on the original dataset.
The superior performance of MARBERTv2 compared to other Arabic PLMs such as AraBERTv2-Twitter, CAMeLBERT-DA, and QARiB can be attributed to differences in pretraining strategy, data volume, domain alignment, and dialectal diversity. Specifically, MARBERTv2 was pretrained on a massive dataset of 1 billion Arabic tweets. It was then further enhanced with MSA content (e.g., AraNews) that totaled 29 billion tokens over 40 epochs. Its architecture includes longer sequence lengths (512 tokens), making it more effective at collecting long-range dependencies in Arabic sentences, especially where contextual clues are needed for hate or offensive classification. Its architecture and data alignment make it particularly effective for classifying hate and offensive speech on social media platforms, which often appears in noisy, informal, and dialect-rich forms.
Interestingly, QARiB achieved the second-best performance across most evaluation metrics. This can be explained by its pretraining on a huge and diversified corpus (~14 billion tokens), including 420 million Arabic tweets and a combination of formal and dialectal text. While QARiB is not specifically designed for Twitter, its use of extensive social media data, its broad vocabulary (64K tokens), and its deep pretraining mean it is adaptable to a wide range of language styles, including offensive and hate-related content.
In contrast, despite being trained on 60 million tweets, AraBERTv2-Twitter used only one epoch and a maximum sentence length of 64 tokens, which may have limited its ability to generalize to more complex or context-dependent cases. Although it was designed for dialects, CAMeLBERT-DA was trained on a 5.8 billion token dataset that included annotated dialect sources. Although this makes it dialect-aware, the pretraining data are limited in terms of diversity, and the model is not Twitter-specific, which reduces its informal, noisy input robustness.
These differences explain why MARBERTv2 consistently outperforms the other models in our classification setup. Its large-scale, domain-specific, and dialect-rich pretraining, as well as its optimized architectural parameters, allows it to better understand and classify nuanced expressions of hate and offensive language in Arabic social media.
Furthermore, when comparing the GRU, LSTM, and BiGRU/BiLSTM architectures, GRU and its bidirectional variant, BiGRU, generally outperformed LSTM-based models. Notably, BiGRU either slightly outperformed or matched GRU, which highlights the advantages of bidirectional recurrence in capturing contextual information from both directions.
This performance disparity can be attributed to several architectural and task-specific factors. Firstly, GRU (gated recurrent unit) models are known to be computationally more efficient than LSTMs, with fewer parameters and a simpler gating mechanism. This makes GRUs particularly well suited for short text, such as tweets, where long-term dependencies are less critical. The simpler structure also reduces the risk of overfitting, which is beneficial given the imbalance and noisiness of offensive/hate speech data. Secondly, BiGRU slightly outperformed or matched GRU, which indicates that capturing bidirectional context in short sentences provides some advantage, especially in morphologically rich languages like Arabic. Arabic syntax often places important cues (e.g., negation, emphasis, or hate-indicative words) at the beginning or end of sentences, making bidirectional models more robust in interpreting the full context of Arabic text.
- Setting 2: single-task models trained with the augmented dataset.
After applying data augmentation, we observed significant improvements in the recall and macro-F1 scores across most models, particularly in the challenging hate speech (HS) task, which often suffers from class imbalance, as shown in Table 6. Specifically, MARBERTv2+BiGRU demonstrated a slight increase in its macro-F1, from 85 to 86, for HS and a minor decrease, from 93 to 92, for offensive (OFF) content, which indicates stabilization in its performance. The augmentation notably enhanced the recall and macro-F1 scores of the QARiB and CAMeLBERT-DA models, making these models more robust compared to their performance in Setting 1.
Table 6.
Results of single-task models trained with augmented data.
Data augmentation consistently led to performance gains, especially in hate speech detection, where data sparsity is a significant issue. MARBERTv2+BiGRU and MARBERTv2+GRU remained the top configurations, which confirms the benefits of pre-trained transformer embeddings combined with GRU-based encoders. Notably, CAMeLBERT-DA models experienced the most significant improvements as a result of augmentation, which suggests that weaker PLMs can disproportionately benefit from data expansion strategies. Moreover, for both HS and OFF tasks, GRU and BiGRU consistently outperformed LSTM and BiLSTM, which is likely attributable to their fewer parameters and superior generalization capabilities on limited or noisy data.
- Setting 3: multitask models trained with the augmented dataset.
In this setting, we evaluated multitask models that jointly learned hate speech (HS) and offensive language (OFF) tasks using a shared encoder and task-specific output layers, all of which were trained with augmented data. This approach aimed to leverage the relationship between tasks, as hate speech is a subset of offensive language.
Compared to the single-task models used in Setting 2, multitask learning either maintained or slightly improved the models’ performance, particularly in hate speech detection, where MARBERTv2+BiGRU improved from a macro-F1 of 86 to a macro-F1 of 88, as shown in Table 7. The shared learning approach facilitated better generalization on the smaller hate speech label, which confirms the benefit of leveraging inter-task relationships.
Table 7.
Results of multitask models trained with augmented data.
MARBERTv2 consistently outperformed the other PLMs in the multitask setup, which reinforces its strong representation capabilities. The QARiB and AraBERTv2-Twitter models demonstrated competitive performance, achieving macro-F1 scores around 85–86 for HS and 92–93 for OFF, with the multitask settings yielding slightly better results than the single-task settings.
BiGRU outperformed GRU, LSTM, and BiLSTM in most cases across all PLMs, which indicates that bidirectional recurrence effectively enhances multitask models’ ability to capture context. The distinction between multitask and single-task models was more evident in hate speech, where label scarcity made shared representation learning more beneficial.
The MARBERTv2+BiGRU model achieved the highest macro-F1 scores across both tasks, with a score of 88 for hate speech (HS) and 93 for offensive language (OFF). Our results demonstrate improved performance compared to previous studies on the same dataset. We outperformed the results reported in [59], which used an ensemble model and ranked first in the 4th Open Source Arabic Text Processing Tools Workshop (OSACT4), with a macro-F1 score of 90.5 in detecting offensive language and a score of 80.6 in detecting hate speech. Similarly, we outperformed the results reported in [38], which used multitask learning and ranked second in detecting hate speech with a macro-F1 score of 82.3 and a score of 90 in detecting offensive language.
Multitask learning with augmented data (Setting 3) produced the best results, particularly for hate speech. This result is attributable to the combined benefits of task-sharing and data augmentation. Hate speech detection often faces skewed class distributions, making it challenging to learn effectively from limited examples. By sharing information between the hate speech task and offensive language task, the model could generalize better by leveraging patterns learned from the more abundant offensive language data. Additionally, data augmentation increased the variety of training examples, helping the model become more robust in recognizing hate speech despite its skewed distribution. This synergy between multitask learning and data augmentation ultimately enhanced the models’ performance in the more challenging hate speech task.
The bar chart in Figure 2 summarizes the performance of the best-performing model (MARBERTv2 + BiGRU) across the three experimental settings: single-task on original data, single-task with augmented data, and multitask with augmented data.
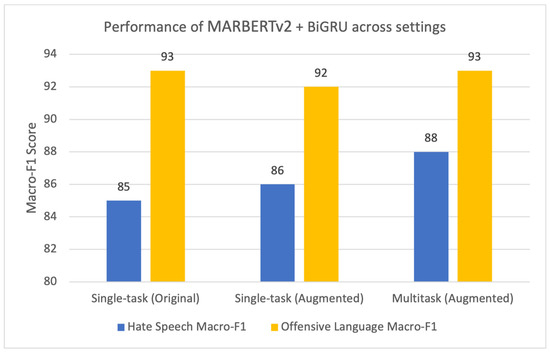
Figure 2.
Performance of MARBERTv2 + BiGRU across settings.
4.2. Final Evaluation on Clean vs Adversarial Data
To validate the robustness of the model under various adversarial conditions, we selected the multitask MARBERTv2 + BiGRU model from Setting 3 for final evaluation. The model demonstrated strong performance on the clean test data, achieving an OFF macro-F1 score of 93 and a HS macro-F1 score of 88.
However, when evaluated on adversarially perturbed test samples, the model performance dropped significantly. In particular, the OFF macro-F1 score decreased to 87 and the HS macro-F1 score decreased to 74. Consequently, the model’s macro-F1 decreased by 14% for hate speech and 6% for offensive language. This highlights the sensitivity of Arabic text classification models to subtle input perturbations, particularly in the more nuanced hate speech task.
Based on these decreases, we analyzed the misclassification rates across the different types of adversarial attacks. As shown in Figure 3 and Figure 4, in the HS task, back-translation was the most impactful attack, resulting in 43% of the total misclassifications, followed by insert space (24%). In the OFF task, insert space (26%) and delete character (23%) led to the most significant misclassification rates. This highlights the model’s vulnerability to both semantic-preserving transformations (e.g., back-translation) and minor surface perturbations (e.g., character-level edits).
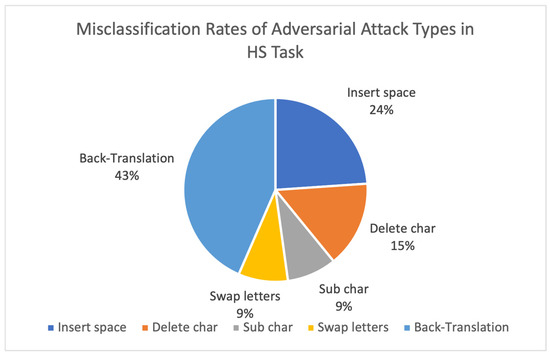
Figure 3.
Misclassification rates of adversarial attack types in HS task.
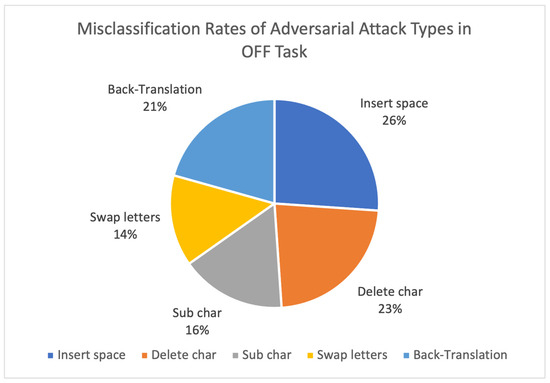
Figure 4.
Misclassification rates of adversarial attack types in OFF task.
The observed performance degradation, especially the 14% drop in macro-F1 for the HS task under adversarial attacks, can be attributed to both model limitations and inherent linguistic challenges in Arabic text processing. While MARBERTv2 and similar models are pre-trained on clean data and large-scale corpora, they are not naturally robust to minor perturbations, which leads to embeddings that differ significantly from the clean input. Moreover, RNN-based layers lack explicit semantic awareness. While BiGRU captures sequence dependencies, it lacks mechanisms to explicitly model higher-level semantics or handle paraphrases. Furthermore, the model lacks a built-in defense mechanism against noisy or perturbed inputs. In addition, the Arabic language exhibits rich morphology, dialectal diversity, and multiple orthographic forms, which increase models’ sensitivity to small perturbations. For instance, the insertion of spaces in Arabic can split a word into unintelligible units, disrupting the semantic flow. Similarly, dialectal variation and limited annotated data for non-MSA (Modern Standard Arabic) contribute to increased misclassification risk, especially in offensive and hateful contexts where informal and regional language is prevalent.
4.3. Effectiveness of Adversarial Training
To mitigate the adversarial vulnerability, we applied a combination of adversarial training and input transformation techniques. After re-training the selected multitask model using a combination of clean and adversarial training samples, the adversarially trained model showed a notable improvement in robustness, achieving an OFF macro-F1 score of 88 and a HS macro-F1 score of 78. Subsequently, after implementing input transformation techniques, these results improved further, with the OFF macro-F1 score reaching 90 and the HS macro-F1 score increasing to 81. Compared to the clean model tested on adversarial data, this represents an average macro-F1 improvement of approximately 7%, which validates the effectiveness of the used defense methods as a robust mechanism.
These defensive strategies have also proven effective in correcting adversarial misclassifications. As shown in Figure 5 and Figure 6, the insert space attacks were corrected at rates exceeding 80%, while the substitution attacks reached correction rates of 75–80%, which demonstrates the benefit of incorporating adversarial training and preprocessing normalization techniques. However, back-translation, swap letters, and delete character attacks remain harder to fully neutralize, which highlights the need for further semantic-level defenses and minor surface perturbations.
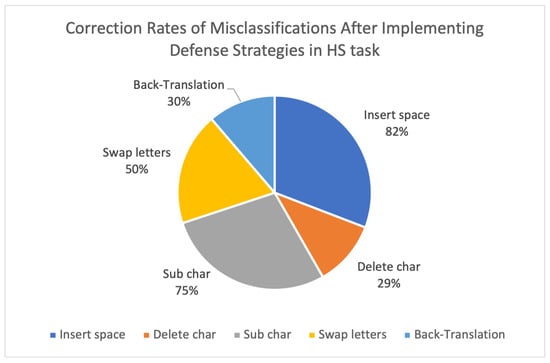
Figure 5.
Correction rates of misclassifications after implementing defense strategies in HS task.
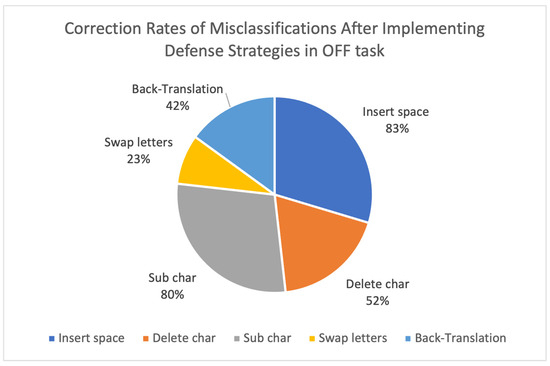
Figure 6.
Correction rates of misclassifications after implementing defense strategies in OFF task.
Additionally, when the adversarially trained model was tested on a clean dataset, it achieved a macro-F1 score of 86 for hate speech and a score of 92 for offensive language, which is commendable. In contrast, the clean model on the clean dataset achieved a macro-F1 score of 88 for hate speech and 93 for abusive language. This demonstrates a balance between robustness and performance: while adversarial training improved the model’s robustness to perturbations, it resulted in slightly lower scores on clean data.
The bar chart in Figure 7 shows the macro-F1 scores for both the hate speech and offensive language classifications of the best model (MARBERTv2 + BiGRU) across the five models’ robustness evaluation scenarios. The results highlight the model’s improvements in terms of robustness through adversarial training and input transformation techniques.
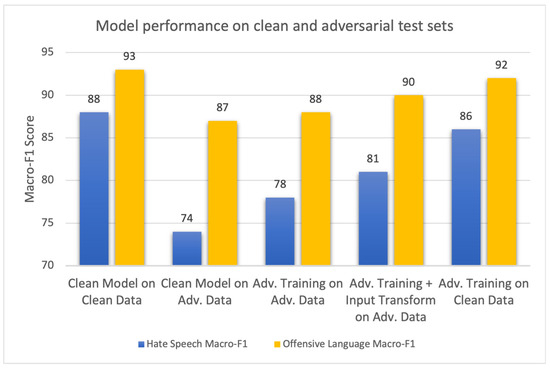
Figure 7.
Model performance on clean and adversarial test sets.
5. Conclusions and Future Work
In this study, we proposed an effective framework to build a robust multitask classification model based on different pre-trained Arabic language models and recurrent neural networks (RNNs) which jointly learns Arabic offensive language and hate speech detection and incorporates adversarial robustness through applying both adversarial training and input transformation techniques. Our work incorporated a range of strategies to enhance the model’s performance and generalization, as well as to address challenges related to data imbalance and adversarial vulnerability, including data augmentation, weighted loss functions, class weighting, stratified cross-validation, adversarial training, and input transformation techniques.
The experimental results demonstrate the effectiveness of our approach. The clean model achieved a strong baseline performance on the clean dataset, reaching macro-F1 scores of 88 for hate speech and 93 for offensive language. However, under adversarial attack, the performance of the clean model degraded significantly, especially for hate speech (dropping to 74). To address this, we applied adversarial training, which improved the model’s performance on adversarial data (macro-F1: 78 for hate speech, 88 for offensive language). Furthermore, the integration of input transformation techniques yielded additional improvements, with the model achieving macro-F1 scores of 81 for hate speech and 90 for offensive language. Notably, the adversarially trained model maintained high performance on clean data as well (macro-F1: 86 for hate speech and 92 for offensive language), demonstrating both robustness and generalization.
Despite these improvements, challenges remain in handling more subtle and implicit forms of hate speech and offensive content, particularly under adversarial perturbations.
Future work will explore the following:
- We will develop more sophisticated adversarial attack and defense mechanisms at multiple linguistic levels. At the word level, we will explore context-aware word substitution attacks using masked language models and synonym replacement strategies, as well as defense based on embedding consistency and lexical similarity. At the sentence level, we aim to implement paraphrase-based attacks, generating semantically equivalent but structurally varied sentences to challenge models’ generalization. These methods will allow for a more thorough evaluation of the model’s robustness under realistic and diverse adversarial scenarios;
- We intend to extend the framework to multi-label or multi-lingual classification tasks. We plan to adapt our multitask model to handle overlapping labels more effectively and evaluate it across multiple dialects or languages by incorporating multilingual pretrained language models such as XLM-R or mBERT. This will help generalize robustness strategies beyond Arabic;
- We will integrate character-level or sub-word-level neural components, such as CNNs or byte-pair encoding (BPE), before or within the encoder layers. These components will allow the model to better capture morphological variations and defend against character-level perturbations, which are particularly prevalent in noisy Arabic social media text. We plan to compare the performance of CNN-enhanced models against pure transformer-based approaches to assess their gains in robustness and generalization.
This work serves as a foundation for developing more resilient Arabic NLP models capable of handling real-world challenges in content moderation.
6. Limitations
Despite the strong performance and robustness of our model, several limitations persist:
- Dialect and domain generalization: the model, trained on Arabic posts from the X social media platform, may not generalize well to other domains (e.g., forums, news comments) or less-represented Arabic dialects, which limits its applicability across various text sources and societal contexts;
- Adversarial attack coverage: our evaluation focused on specific perturbation types (e.g., keyboard typos, diacritics, equivalent Leetspeak) but did not consider more advanced adversarial attacks such as word substitutions, which could degrade model performance;
- Limited linguistic context: despite using MARBERTv2 embeddings, the model may struggle with deep semantic nuances, sarcasm, or implicit hate speech, which require broader discourse or world knowledge for accurate detection.
Author Contributions
Conceptualization, E.S.A. and M.S.A.; methodology, E.S.A.; software, E.S.A.; validation, E.S.A., and M.S.A.; formal analysis, E.S.A.; investigation, E.S.A.; resources, E.S.A.; data curation, E.S.A.; writing—original draft preparation, E.S.A.; writing—review and editing, E.S.A. and M.S.A.; visualization, E.S.A.; supervision, M.S.A.; project administration, E.S.A. and M.S.A.; funding acquisition, E.S.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
The authors would like to thank Deanship of scientific research in King Saud University for funding and supporting this research through the initiative of DSR Graduate Students Research Support (GSR).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| OFF | Offensive Language |
| HS | Hate Speech |
| MTL | Multitask Learning |
| MSA | Modern Standard Arabic |
| PLMs | Pre-trained Language Models |
| RNN | Recurrent Neural Networks |
| GRU | Gated Recurrent Unit |
| BiGRU | Bidirectional Gated Recurrent Unit |
| LSTM | Long Short-Term Memory |
| BiLSTM | Bidirectional Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| ARABERT | Arabic BERT Language Model |
| Qarib | An Arabic Pre-Trained Language Model |
| NLP | Natural Language Processing |
References
- Chen, Y.; Zhou, Y.; Zhu, S.; Xu, H. Detecting offensive language in social media to protect adolescent online safety. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Confernece on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; pp. 71–80. [Google Scholar]
- Shende, S.B.; Deshpande, L. A computational framework for detecting offensive language with support vector machine in social communities. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; pp. 1–4. [Google Scholar]
- Aldjanabi, W.; Dahou, A.; Al-qaness, M.A.; Abd Elaziz, M.; Helmi, A.M.; Damaševičius, R. Arabic Offensive and Hate Speech Detection Using a Cross-Corpora Multi-Task Learning Model. In Informatics; Multidisciplinary Digital Publishing Institute: Basel, Switzerland, 2021; Volume 8, p. 69. [Google Scholar]
- Vogel, I.; Regev, R. FraunhoferSIT at GermEval 2019: Can Machines Distinguish Between Offensive Language and Hate Speech? Towards a Fine-Grained Classification. In Proceedings of the 15th Conference on Natural Language Processing (KONVENS 2019), KONVENS, Erlangen, Germany, 9–11 October 2019; pp. 315–319. Available online: https://www.researchgate.net/profile/Inna-Vogel-2/publication/336373536_FraunhoferSIT_at_GermEval_2019_Can_Machines_Distinguish_Between_Offensive_Language_and_Hate_Speech_Towards_a_Fine-Grained_Classification/links/5d9eb6c292851cce3c910f74/FraunhoferSIT-at-GermEval-2019-Can-Machines-Distinguish-Between-Offensive-Language-and-Hate-Speech-Towards-a-Fine-Grained-Classification.pdf. (accessed on 10 August 2025).
- Haddad, B.; Orabe, Z.; Al-Abood, A.; Ghneim, N. Arabic Offensive Language Detection with Attention-based Deep Neural Networks. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 11–16 May 2020; pp. 76–81. [Google Scholar]
- Alshalan, R.; Al-Khalifa, H. A Deep Learning Approach for Automatic Hate Speech Detection in the Saudi Twittersphere. Appl. Sci. 2020, 10, 8614. [Google Scholar] [CrossRef]
- Wiedemann, G.; Ruppert, E.; Jindal, R.; Biemann, C. Transfer learning from lda to bilstm-cnn for offensive language detection in twitter. arXiv 2018, arXiv:1811.02906. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Predicting the Type and Target of Offensive Posts in Social Media. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1. [Google Scholar]
- Schmidt, A.; Wiegand, M. A survey on hate speech detection using natural language processing. In Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 1–10. [Google Scholar]
- Yuan, L.; Rizoiu, M.-A. Generalizing hate speech detection using multi-task learning: A case study of political public figures. Comput. Speech Lang. 2025, 89, 101690. [Google Scholar] [CrossRef]
- ElSherief, M.; Ziems, C.; Muchlinski, D.; Anupindi, V.; Seybolt, J.; De Choudhury, M.; Yang, D. Latent hatred: A benchmark for understanding implicit hate speech. arXiv 2021, arXiv:2109.05322. [Google Scholar] [CrossRef]
- Mao, C.; Gupta, A.; Nitin, V.; Ray, B.; Song, S.; Yang, J.; Vondrick, C. Multitask learning strengthens adversarial robustness. In Proceedings of the European Conference on Computer Vision, Montreal, QC, Canada, 11 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 158–174. [Google Scholar]
- Alshemali, B.; Kalita, J. Improving the reliability of deep neural networks in NLP: A review. Knowl.Based Syst. 2020, 191, 105210. [Google Scholar] [CrossRef]
- Huq, A.; Pervin, M. Adversarial attacks and defense on texts: A survey. arXiv 2020, arXiv:2005.14108. [Google Scholar] [CrossRef]
- Gröndahl, T.; Pajola, L.; Juuti, M.; Conti, M.; Asokan, N. All You Need is” Love” Evading Hate Speech Detection. In Proceedings of the 11th ACM Workshop on Artificial Intelligence and Security, New York, NY, USA, 15–19 October 2018; pp. 2–12. [Google Scholar]
- Zhang, Y.; Yang, Q. A survey on multi-task learning. IEEE Trans. Knowl. Data Eng. 2021, 34, 5586–5609. [Google Scholar] [CrossRef]
- Crawshaw, M. Multi-task learning with deep neural networks: A survey. arXiv 2020, arXiv:2009.09796. [Google Scholar] [CrossRef]
- Duwairi, R.; Hayajneh, A.; Quwaider, M. A Deep Learning Framework for Automatic Detection of Hate Speech Embedded in Arabic Tweets. Arab. J. Sci. Eng. 2021, 46, 4001–4014. [Google Scholar] [CrossRef]
- Husain, F.; Uzuner, O. A survey of offensive language detection for the arabic language. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–44. [Google Scholar] [CrossRef]
- Al-Hassan, A.; Al-Dossari, H. Detection of hate speech in social networks: A survey on multilingual corpus. In Proceedings of the 6th International Conference on Computer Science and Information Technology, Zurich, Switzerland, 23–24 November 2019; Volume 10. [Google Scholar]
- Boulouard, Z.; Ouaissa, M.; Ouaissa, M.; Krichen, M.; Almutiq, M.; Gasmi, K. Detecting Hateful and Offensive Speech in Arabic Social Media Using Transfer Learning. Appl. Sci. 2022, 12, 12823. [Google Scholar] [CrossRef]
- Husain, F.; Uzuner, O. Transfer Learning Across Arabic Dialects for Offensive Language Detection. In Proceedings of the 2022 International Conference on Asian Language Processing (IALP), Singapore, 27–28 October 2022; pp. 196–205. [Google Scholar]
- Elzayady, H.; Mohamed, M.S.; Badran, K.M.; Salama, G.I. A hybrid approach based on personality traits for hate speech detection in Arabic social media. Int. J. Electr. Comput. Eng. 2023, 13, 1979. [Google Scholar]
- Mohamed, M.S.; Elzayady, H.; Badran, K.M.; Salama, G.I. An efficient approach for data-imbalanced hate speech detection in Arabic social media. J. Intell. Fuzzy Syst. 2023, 45, 6381–6390. [Google Scholar] [CrossRef]
- Al-Dabet, S.; ElMassry, A.; Alomar, B.; Alshamsi, A. Transformer-based arabic offensive speech detection. In Proceedings of the 2023 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 1–3 March 2023; pp. 1–6. [Google Scholar]
- Mazari, A.C.; Kheddar, H. Deep learning-based analysis of Algerian dialect dataset targeted hate speech, offensive language and cyberbullying. Int. J. Comput. Digit. Syst. 2023, 13, 965–972. [Google Scholar] [CrossRef]
- Al-Ibrahim, R.M.; Ali, M.Z.; Najadat, H.M. Detection of hateful social media content for Arabic language. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–26. [Google Scholar] [CrossRef]
- AlSukhni, E.; AlAzzam, I.; Hanandeh, S. Offensive Language Detection of Arabic Tweets Using Deep Learning Algorithm. In Proceedings of the 2024 15th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 13–15 August 2024; pp. 1–6. [Google Scholar]
- Mazari, A.C.; Benterkia, A.; Takdenti, Z. Advancing offensive language detection in Arabic social media: A BERT-based ensemble learning approach. Soc. Netw. Anal. Min. 2024, 14, 186. [Google Scholar] [CrossRef]
- Mousa, A.; Shahin, I.; Nassif, A.B.; Elnagar, A. Detection of Arabic offensive language in social media using machine learning models. Intell. Syst. Appl. 2024, 22, 200376. [Google Scholar] [CrossRef]
- Khairy, M.; Mahmoud, T.M.; Omar, A.; Abd El-Hafeez, T. Comparative performance of ensemble machine learning for Arabic cyberbullying and offensive language detection. Lang. Resour. Eval. 2024, 58, 695–712. [Google Scholar] [CrossRef]
- Mnassri, K.; Rajapaksha, P.; Farahbakhsh, R.; Crespi, N. Hate speech and offensive language detection using an emotion-aware shared encoder. In Proceedings of the ICC 2023-IEEE International Conference on Communications, Rome, Italy, 28 May–1 June 2023; pp. 2852–2857. [Google Scholar]
- Farha, I.A.; Magdy, W. Multitask learning for arabic offensive language and hate-speech detection. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 11–16 May 2020; pp. 86–90. [Google Scholar]
- Mulki, H.; Ghanem, B. Let-mi: An Arabic levantine twitter dataset for Misogynistic language. arXiv 2021, arXiv:2103.10195. [Google Scholar] [CrossRef]
- Shapiro, A.; Khalafallah, A.; Torki, M. AlexU-AIC at Arabic Hate Speech 2022: Contrast to Classify. arXiv 2022, arXiv:2207.08557. [Google Scholar]
- Alrashidi, B.; Jamal, A.; Alkhathlan, A. Abusive content detection in arabic tweets using multi-task learning and transformer-based models. Appl. Sci. 2023, 13, 5825. [Google Scholar] [CrossRef]
- AlKhamissi, B.; Diab, M. Meta ai at arabic hate speech 2022: Multitask learning with self-correction for hate speech classification. arXiv 2022, arXiv:2205.07960. [Google Scholar]
- Djandji, M.; Baly, F.; Antoun, W.; Hajj, H. Multi-task learning using AraBert for offensive language detection. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 11–16 May 2020; pp. 97–101. [Google Scholar]
- Kapil, P.; Ekbal, A. A Unified Multi-Task Learning Architecture for Hate Detection Leveraging User-Based Information. arXiv 2024, arXiv:2411.06855. [Google Scholar]
- Dai, W.; Yu, T.; Liu, Z.; Fung, P. Kungfupanda at semeval-2020 task 12: Bert-based multi-task learning for offensive language detection. arXiv 2020, arXiv:2004.13432. [Google Scholar]
- Kapil, P.; Ekbal, A. Leveraging multi-domain, heterogeneous data using deep multitask learning for hate speech detection. arXiv 2021, arXiv:2103.12412. [Google Scholar] [CrossRef]
- Halat, S.; Plaza-Del-Arco, F.M.; Padó, S.; Klinger, R. Multi-Task Learning with Sentiment, Emotion, and Target Detection to Recognize Hate Speech and Offensive Language. arXiv 2022, arXiv:2109.10255. [Google Scholar] [CrossRef]
- Plaza-Del-Arco, F.M.; Molina-González, M.D.; Ureña-López, L.A.; Martín-Valdivia, M.T. A multi-task learning approach to hate speech detection leveraging sentiment analysis. IEEE Access 2021, 9, 112478–112489. [Google Scholar] [CrossRef]
- Zampieri, M.; Ranasinghe, T.; Sarkar, D.; Ororbia, A. Offensive language identification with multi-task learning. J. Intell. Inf. Syst. 2023, 60, 613–630. [Google Scholar] [CrossRef]
- Jia, R.; Liang, P. Adversarial examples for evaluating reading comprehension systems. arXiv 2017, arXiv:1707.07328. [Google Scholar] [CrossRef]
- Liang, B.; Li, H.; Su, M.; Bian, P.; Li, X.; Shi, W. Deep text classification can be fooled. arXiv 2017, arXiv:1704.08006. [Google Scholar]
- Ebrahimi, J.; Rao, A.; Lowd, D.; Dou, D. Hotflip: White-box adversarial examples for text classification. arXiv 2017, arXiv:1712.06751. [Google Scholar]
- Belinkov, Y.; Bisk, Y. Synthetic and natural noise both break neural machine translation. arXiv 2017, arXiv:1711.02173. [Google Scholar]
- Gao, J.; Lanchantin, J.; Soffa, M.L.; Qi, Y. Black-box generation of adversarial text sequences to evade deep learning classifiers. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 50–56. [Google Scholar]
- Li, J.; Ji, S.; Du, T.; Li, B.; Wang, T. Textbugger: Generating adversarial text against real-world applications. arXiv 2018, arXiv:1812.05271. [Google Scholar]
- Ren, S.; Deng, Y.; He, K.; Che, W. Generating natural language adversarial examples through probability weighted word saliency. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1085–1097. [Google Scholar]
- Alshemali, B.; Kalita, J. Adversarial examples in arabic. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 371–376. [Google Scholar]
- Jin, D.; Jin, Z.; Zhou, J.T.; Szolovits, P. Is bert really robust? a strong baseline for natural language attack on text classification and entailment. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8018–8025. [Google Scholar]
- Li, L.; Zhu, Z.; Du, D.; Ren, S.; Zheng, Y.; Chang, G. Adversarial Convolutional Neural Network for Text Classification. In Proceedings of the 2020 4th International Conference on Electronic Information Technology and Computer Engineering, Xiamen, China, 18–20 October 2020; pp. 692–696. [Google Scholar]
- Garg, S.; Ramakrishnan, G. Bae: Bert-based adversarial examples for text classification. arXiv 2020, arXiv:2004.01970. [Google Scholar] [CrossRef]
- Mubarak, H.; Rashed, A.; Darwish, K.; Samih, Y.; Abdelali, A. Arabic offensive language on twitter: Analysis and experiments. arXiv 2020, arXiv:2004.02192. [Google Scholar]
- Mulki, H.; Haddad, H.; Ali, C.B.; Alshabani, H. L-hsab: A levantine twitter dataset for hate speech and abusive language. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1 August 2019; pp. 111–118. [Google Scholar]
- Haddad, H.; Mulki, H.; Oueslati, A. T-hsab: A tunisian hate speech and abusive dataset. In Proceedings of the International Conference on Arabic Language Processing, Nancy, France, 16–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 251–263. [Google Scholar]
- Hassan, S.; Samih, Y.; Mubarak, H.; Abdelali, A.; Rashed, A.; Chowdhury, S.A. ALT submission for OSACT shared task on offensive language detection. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 11–16 May 2020; pp. 61–65. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).