
Authenticity at Risk: Key Factors in the Generation and Detection of Audio Deepfakes †


Abstract

1. Introduction
2. Related Work
3. The WELIVE Dataset
4. Methodology
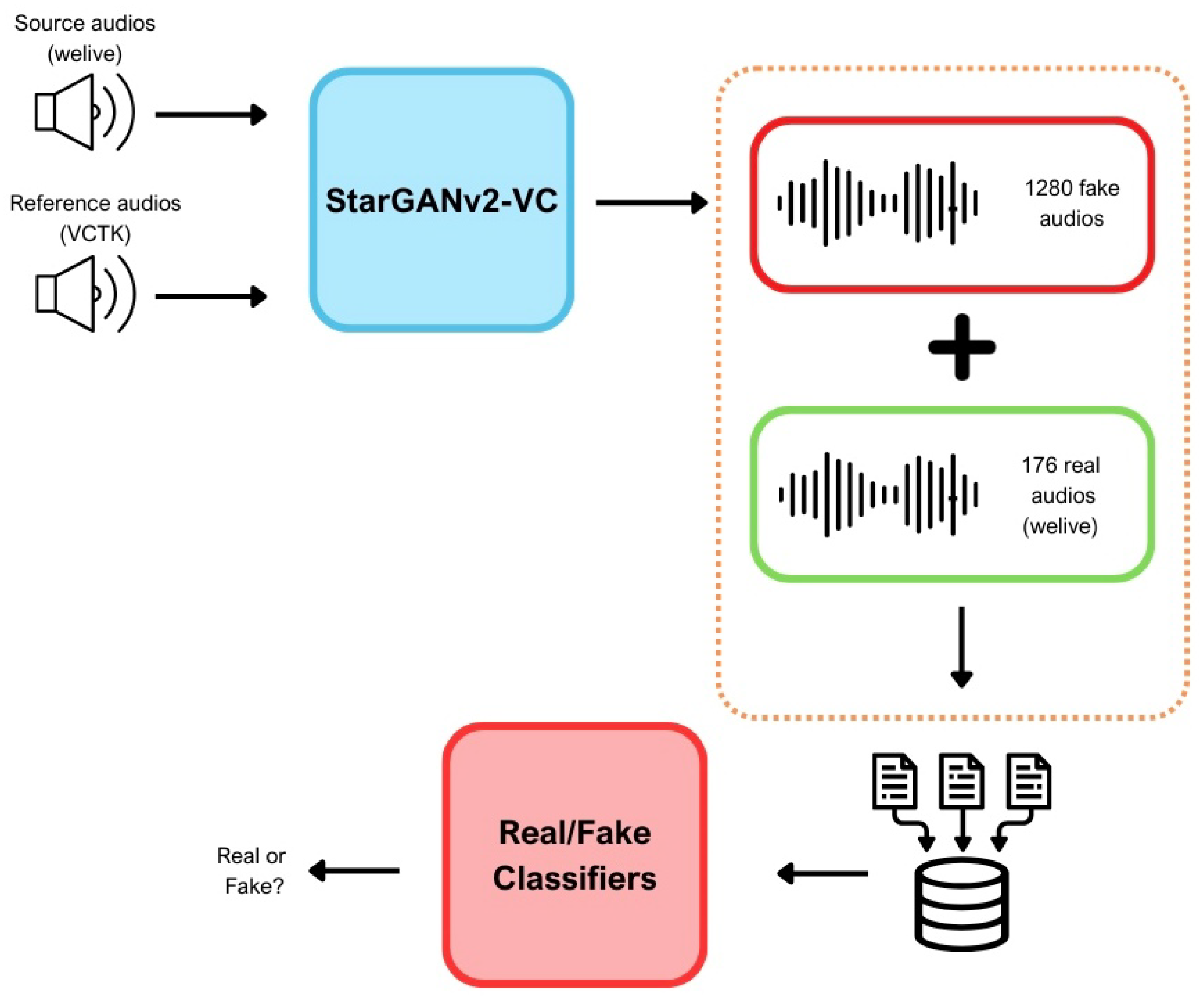
4.1. Generation of Deepfakes
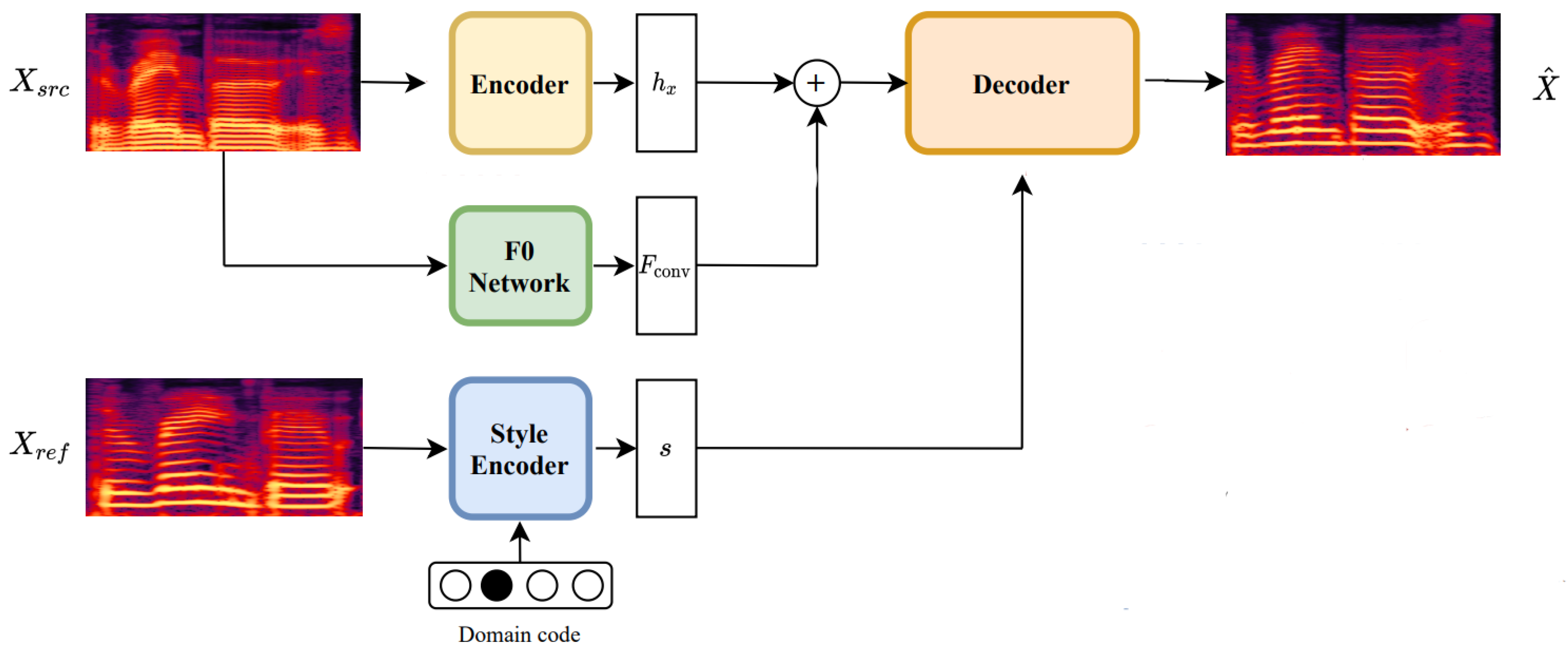
- Generator (G): an encoder–decoder architecture that receives a mel-spectrogram as input and transforms it into one that reflects the vocal style and fundamental frequency (F0) of the target speaker. The style is obtained through a style encoder, while the fundamental frequency (F0) is derived through a network specialized in its detection.
- Style encoder (S) and mapping network (M): The style encoder extracts the stylistic features from a reference spectrogram, allowing conversion between different vocal styles.
- F0 extraction network: In order to preserve tonal consistency in the converted voice, the model uses a pre-trained F0 detection (JDC) network [37], which extracts the fundamental frequency, important to avoid distortions in the generated voice and ensures the pitch remains true to the target speaker.
4.2. Detection of Deepfakes
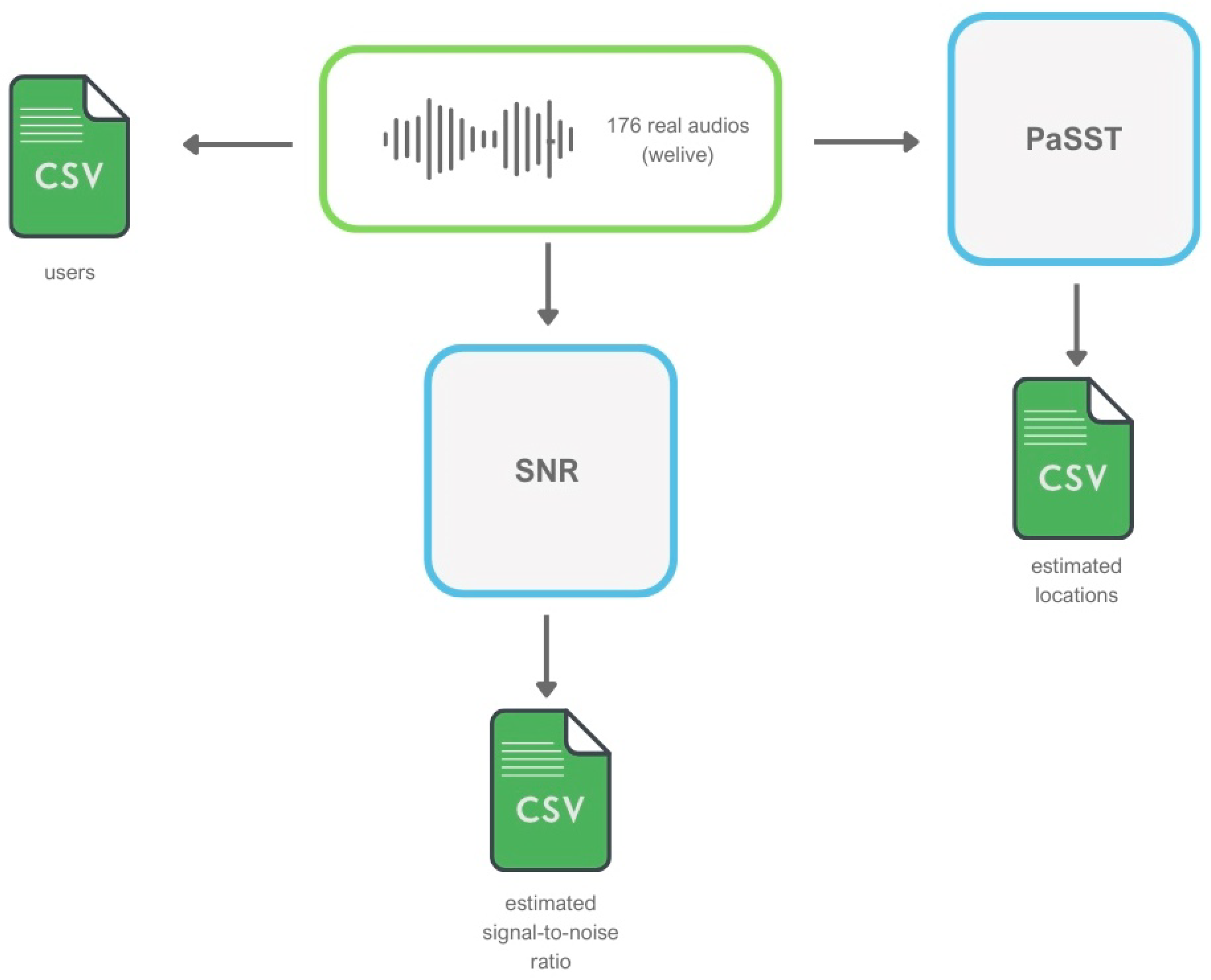
4.3. Automatic Determination of the Acoustic Context
4.4. Automatic Determination of the SNR
5. Experimental Settings
5.1. Data Preprocessing
5.2. Generation of Deepfakes
5.3. Detection of Deepfakes
6. Results and Discussion
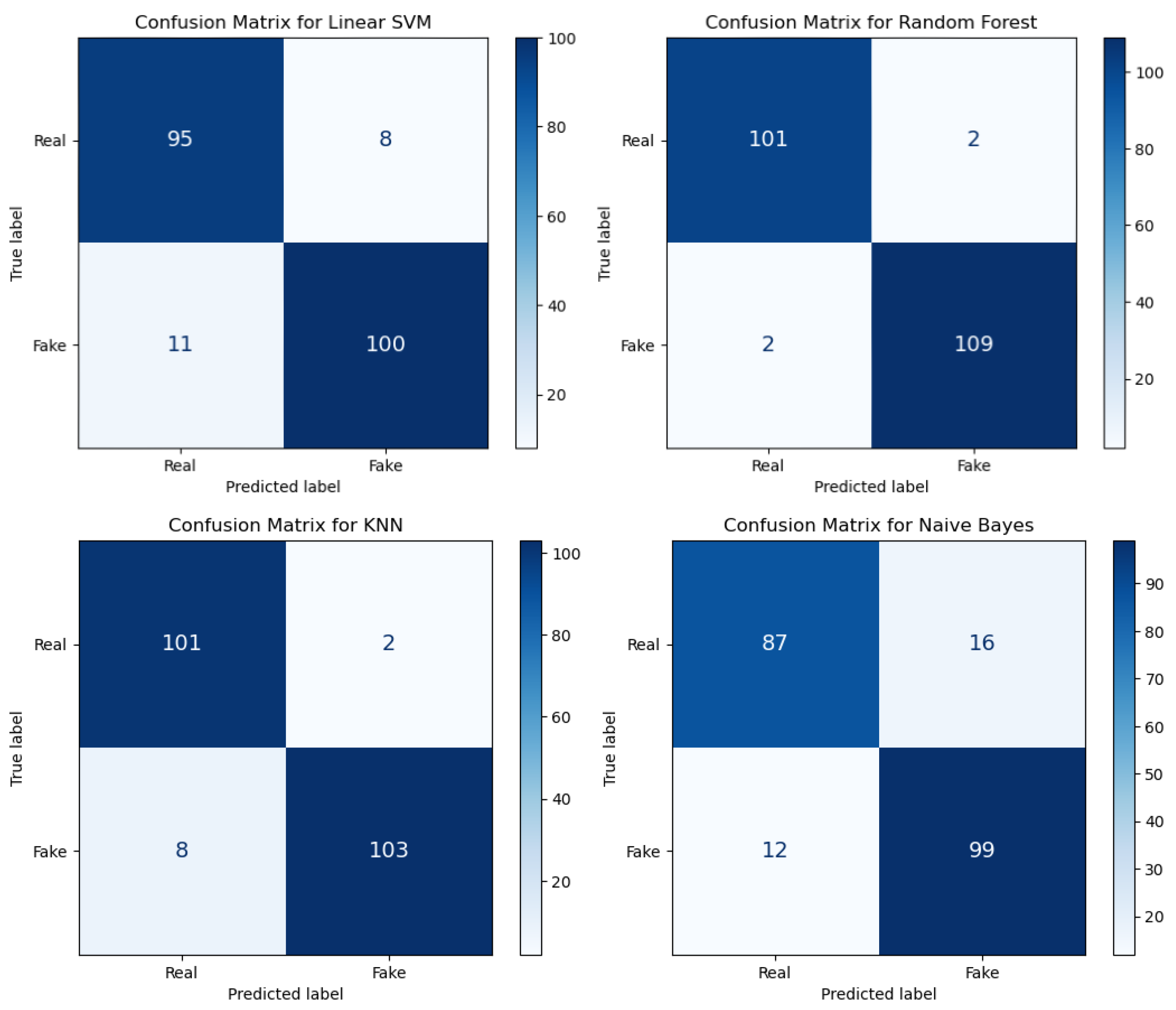
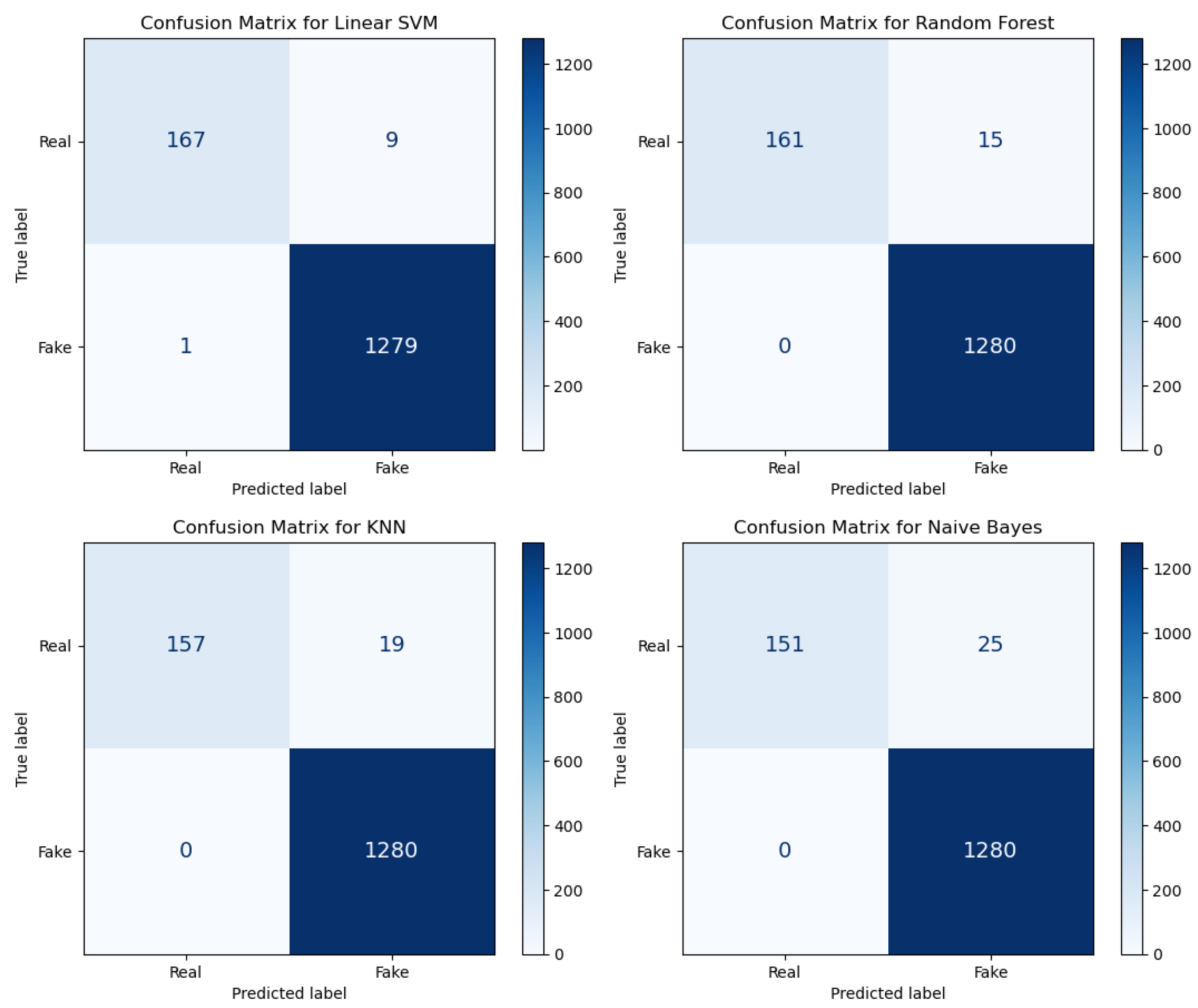
6.1. Results of the Classification of Deepfakes
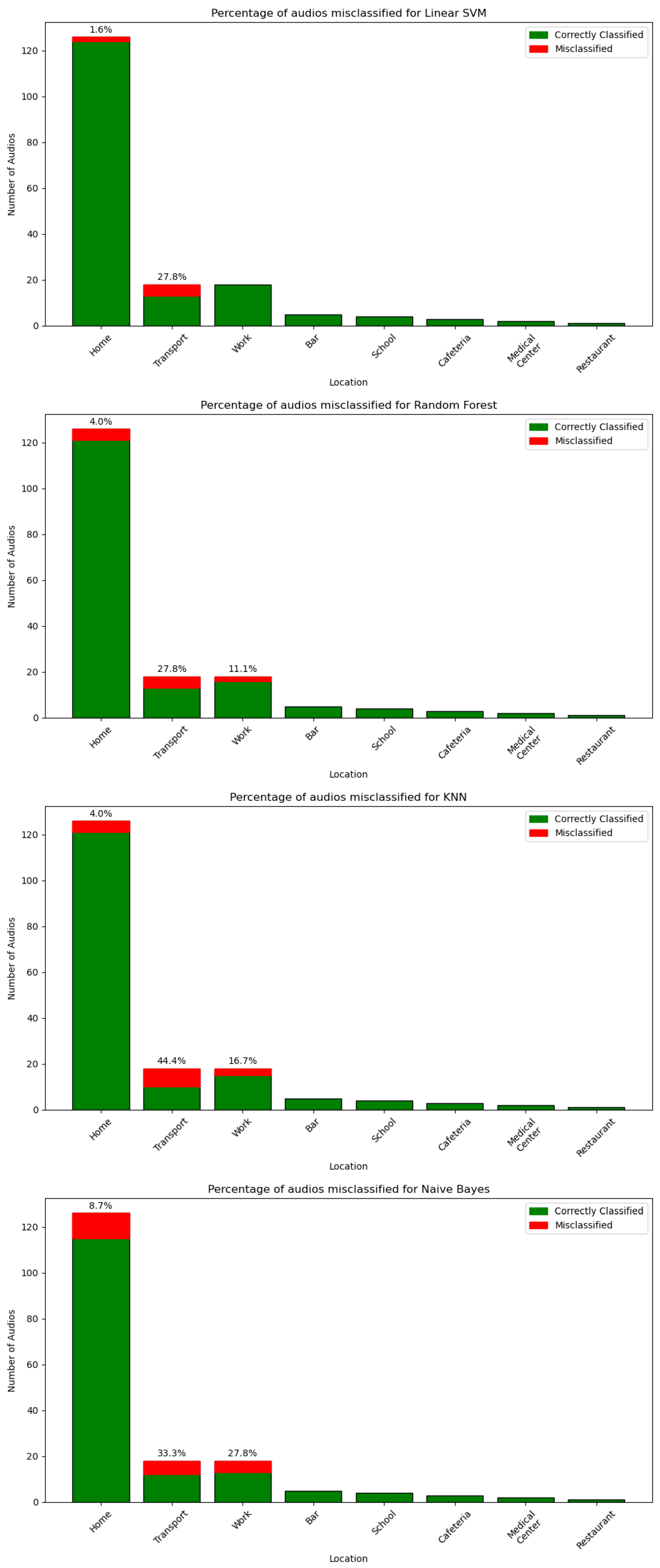
6.2. The Influence of the Acoustic Context
6.3. The Influence of the User
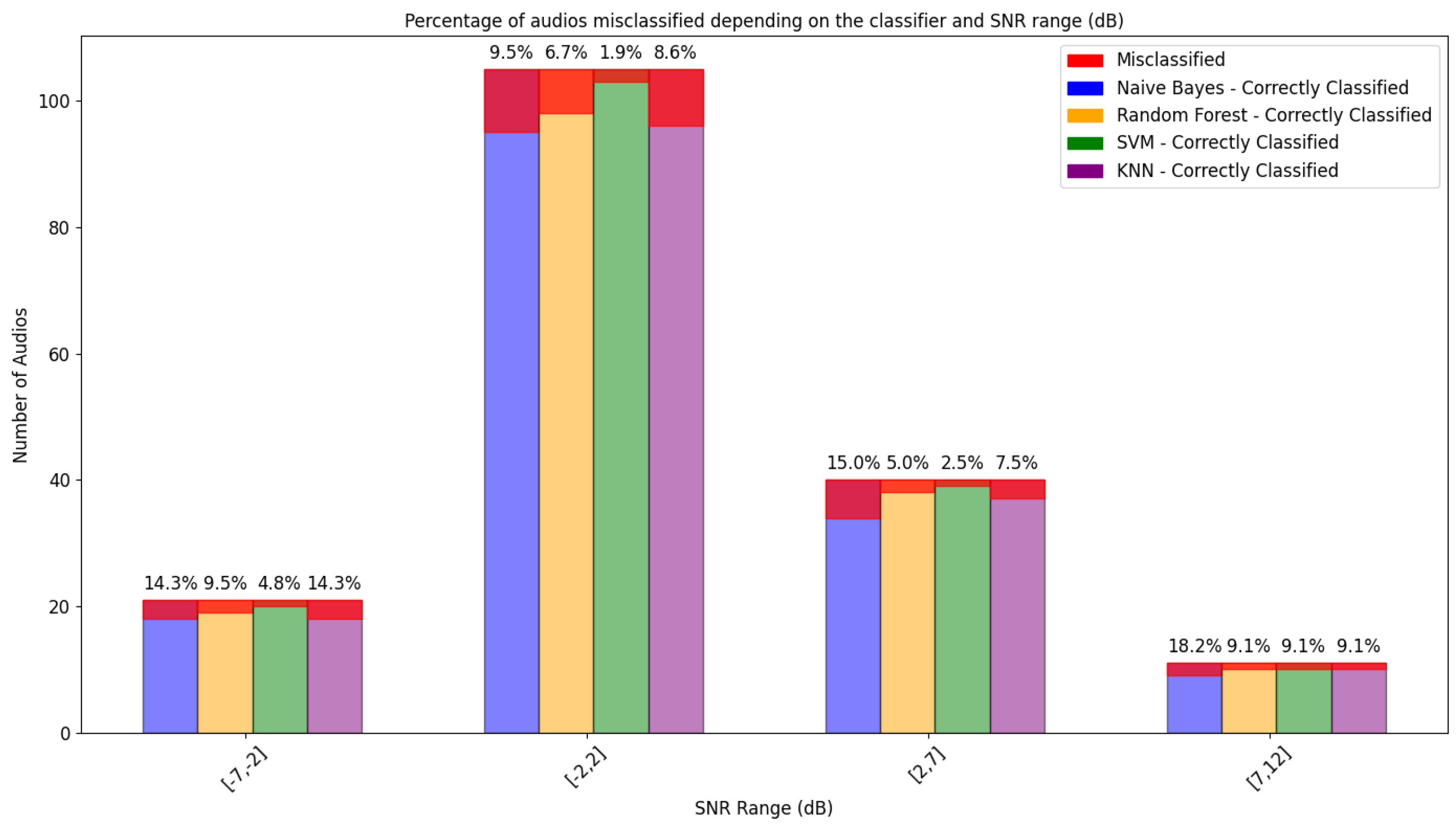
6.4. The Influence of the SNR
6.5. The Influence of Other Factors
7. Conclusions
8. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| AD | Audio Deepfakes |
| TTS | Text-To-Speech |
| GBV | Gender-Based Violence |
| GBVV | Gender-Based Violence Victims |
| GPS | Global Positioning System |
| SNR | Signal-to-Noise Ratio |
| VAD | Voice Activity Detection |
| MFCC | Mel Frequency Cepstral Coefficients |
| SVM | Support Vector Machines |
| KNN | K-Nearest Neighbours |
| GANs | Generative Adversarial Networks |
| CNN | Convolutional Neural Network |
References
- Martínez-Serrano, A.; Montero-Ramírez, C.; Peláez-Moreno, C. The Influence of Acoustic Context on the Generation and Detection of Audio Deepfakes. In Proceedings of the Iberspeech 2024, Aveiro, Portugal, 11–13 November 2024. [Google Scholar]
- Zhang, J.; Tao, D. Empowering Things with Intelligence: A Survey of the Progress, Challenges, and Opportunities in Artificial Intelligence of Things. IEEE Internet Things J. 2021, 8, 7789–7817. [Google Scholar] [CrossRef]
- Gambín, Á.F.; Yazidi, A.; Vasilakos, A.; Haugerud, H.; Djenouri, Y. Deepfakes: Current and future trends. Artif. Intell. Rev. 2024, 57, 64. [Google Scholar] [CrossRef]
- Hu, H.R.; Song, Y.; Liu, Y.; Dai, L.R.; McLoughlin, I.; Liu, L. Domain robust deep embedding learning for speaker recognition. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7182–7186. [Google Scholar]
- Mcuba, M.; Singh, A.; Ikuesan, R.A.; Venter, H. The effect of deep learning methods on deepfake audio detection for digital investigation. Procedia Comput. Sci. 2023, 219, 211–219. [Google Scholar] [CrossRef]
- Miranda Calero, J.A.; Rituerto-González, E.; Luis-Mingueza, C.; Canabal Benito, M.F.; Ramírez Bárcenas, A.; Lanza Gutiérrez, J.M.; Peláez-Moreno, C.; López-Ongil, C. Bindi: Affective Internet of Things to Combat Gender-Based Violence. IEEE Internet Things J. 2022, 9, 21174–21193. [Google Scholar] [CrossRef]
- Salvi, D.; Hosler, B.; Bestagini, P.; Stamm, M.C.; Tubaro, S. TIMIT-TTS: A text-to-speech dataset for multimodal synthetic media detection. IEEE Access 2023, 11, 50851–50866. [Google Scholar] [CrossRef]
- Sun, C.; Jia, S.; Hou, S.; Lyu, S. Ai-synthesized voice detection using neural vocoder artifacts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 904–912. [Google Scholar]
- Toda, T.; Chen, L.H.; Saito, D.; Villavicencio, F.; Wester, M.; Wu, Z.; Yamagishi, J. The Voice Conversion Challenge 2016. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; Volume 2016, pp. 1632–1636. [Google Scholar]
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.O.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep voice 3: Scaling text-to-speech with convolutional sequence learning. arXiv 2017, arXiv:1710.07654. [Google Scholar]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.Y. Fastspeech 2: Fast and high-quality end-to-end text to speech. arXiv 2020, arXiv:2006.04558. [Google Scholar]
- Kaneko, T.; Kameoka, H.; Tanaka, K.; Hojo, N. Cyclegan-vc2: Improved cyclegan-based non-parallel voice conversion. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6820–6824. [Google Scholar]
- Li, Y.A.; Zare, A.; Mesgarani, N. Starganv2-vc: A diverse, unsupervised, non-parallel framework for natural-sounding voice conversion. arXiv 2021, arXiv:2107.10394. [Google Scholar]
- Yamamoto, R.; Song, E.; Kim, J.M. Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram. arXiv 2020, arXiv:1910.11480. [Google Scholar]
- Ballesteros, D.M.; Rodriguez, Y.; Renza, D. A dataset of histograms of original and fake voice recordings (H-Voice). Data Brief 2020, 29, 105331. [Google Scholar] [CrossRef]
- Khalid, H.; Tariq, S.; Kim, M.; Woo, S.S. FakeAVCeleb: A novel audio-video multimodal deepfake dataset. arXiv 2021, arXiv:2108.05080. [Google Scholar]
- Yi, J.; Bai, Y.; Tao, J.; Ma, H.; Tian, Z.; Wang, C.; Wang, T.; Fu, R. Half-truth: A partially fake audio detection dataset. arXiv 2021, arXiv:2104.03617. [Google Scholar]
- Barni, M.; Campisi, P.; Delp, E.J.; Doërr, G.; Fridrich, J.; Memon, N.; Pérez-González, F.; Rocha, A.; Verdoliva, L.; Wu, M. Information Forensics and Security: A quarter-century-long journey. IEEE Signal Process. Mag. 2023, 40, 67–79. [Google Scholar] [CrossRef]
- Kalpokas, I.; Kalpokiene, J. Deepfakes: A Realistic Assessment of Potentials, Risks, and Policy Regulation; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Martín-Doñas, J.M.; Álvarez, A. The vicomtech audio deepfake detection system based on wav2vec2 for the 2022 add challenge. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 9241–9245. [Google Scholar]
- Yi, J.; Tao, J.; Fu, R.; Yan, X.; Wang, C.; Wang, T.; Zhang, C.Y.; Zhang, X.; Zhao, Y.; Ren, Y.; et al. Add 2023: The second audio deepfake detection challenge. arXiv 2023, arXiv:2305.13774. [Google Scholar]
- Rodríguez-Ortega, Y.; Ballesteros, D.M.; Renza, D. A machine learning model to detect fake voice. In International Conference on Applied Informatics; Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–13. [Google Scholar]
- Singh, A.K.; Singh, P. Detection of ai-synthesized speech using cepstral & bispectral statistics. In Proceedings of the 2021 IEEE 4th International Conference on Multimedia Information Processing and Retrieval (MIPR), Tokyo, Japan, 8–10 September 2021; pp. 412–417. [Google Scholar]
- Li, X.; Li, N.; Weng, C.; Liu, X.; Su, D.; Yu, D.; Meng, H. Replay and synthetic speech detection with res2net architecture. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6354–6358. [Google Scholar]
- Gomez-Alanis, A.; Peinado, A.M.; Gonzalez, J.A.; Gomez, A.M. A light convolutional GRU-RNN deep feature extractor for ASV spoofing detection. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; Volume 2019, pp. 1068–1072. [Google Scholar]
- Subramani, N.; Rao, D. Learning efficient representations for fake speech detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5859–5866. [Google Scholar]
- Ballesteros, D.M.; Rodriguez-Ortega, Y.; Renza, D.; Arce, G. Deep4SNet: Deep learning for fake speech classification. Expert Syst. Appl. 2021, 184, 115465. [Google Scholar] [CrossRef]
- Xie, Z.; Li, B.; Xu, X.; Liang, Z.; Yu, K.; Wu, M. FakeSound: Deepfake General Audio Detection. arXiv 2024, arXiv:2406.08052. [Google Scholar]
- Xu, X.; Ma, Z.; Wu, M.; Yu, K. Towards Weakly Supervised Text-to-Audio Grounding. arXiv 2024, arXiv:2401.02584. [Google Scholar] [CrossRef]
- Liu, H.; Chen, K.; Tian, Q.; Wang, W.; Plumbley, M.D. AudioSR: Versatile audio super-resolution at scale. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 1076–1080. [Google Scholar]
- Kim, C.D.; Kim, B.; Lee, H.; Kim, G. Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 119–132. [Google Scholar]
- Rituerto González, E. Multimodal Affective Computing in Wearable Devices with Applications in the Detection of Gender-Based Violence; Programa de Doctorado en Multimedia y Comunicaciones, Universidad Carlos III de Madrid: Madrid, Spain, 2023. [Google Scholar]
- Montero-Ramírez, C.; Rituerto-González, E.; Peláez-Moreno, C. Evaluation of Automatic Embeddings for Supervised Soundscape Classification in-the-wild. In Proceedings of the Iberspeech 2024, Aveiro, Portugal, 11–13 November 2024. [Google Scholar]
- Rituerto-González, E.; Miranda, J.A.; Canabal, M.F.; Lanza-Gutiérrez, J.M.; Peláez-Moreno, C.; López-Ongil, C. A Hybrid Data Fusion Architecture for BINDI: A Wearable Solution to Combat Gender-Based Violence. In Multimedia Communications, Services and Security; Dziech, A., Mees, W., Czyżewski, A., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2020; pp. 223–237. [Google Scholar]
- Montero-Ramírez, C.; Rituerto-González, E.; Peláez-Moreno, C. Building Artificial Situational Awareness: Soundscape Classification in Daily-life Scenarios of Gender based Violence Victims. Eng. Appl. Artif. Intell. 2024; submitted for publication. [Google Scholar]
- Kum, S.; Nam, J. Joint detection and classification of singing voice melody using convolutional recurrent neural networks. Appl. Sci. 2019, 9, 1324. [Google Scholar] [CrossRef]
- Veaux, C.; Yamagishi, J.; MacDonald, K. Superseded-CSTR VCTK Corpus: English Multi-Speaker Corpus for CSTR Voice Cloning Toolkit. 2016. Available online: http://datashare.is.ed.ac.uk/handle/10283/2651 (accessed on 13 May 2024).
- Rabiner, L.; Schafer, R. Theory and Applications of Digital Speech Processing, 1st ed.; Prentice Hall Press: Hoboken, NJ, USA, 2010. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian Network Classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef]
- Koutini, K.; Schlüter, J.; Eghbal-Zadeh, H.; Widmer, G. Efficient training of audio transformers with patchout. arXiv 2021, arXiv:2110.05069. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Gong, Y.; Chung, Y.A.; Glass, J. Ast: Audio spectrogram transformer. arXiv 2021, arXiv:2104.01778. [Google Scholar]
- Bredin, H.; Laurent, A. End-to-end speaker segmentation for overlap-aware resegmentation. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021. [Google Scholar]
- Tamayo Flórez, P.A.; Manrique, R.; Pereira Nunes, B. HABLA: A Dataset of Latin American Spanish Accents for Voice Anti-spoofing. In Proceedings of the Interspeech, Dublin, Ireland, 20–24 August 2023; pp. 1963–1967. [Google Scholar] [CrossRef]
- Park, K.; Mulc, T. CSS10: A Collection of Single Speaker Speech Datasets for 10 Languages. arXiv 2019, arXiv:1903.11269. [Google Scholar]
- Guevara-Rukoz, A.; Demirsahin, I.; He, F.; Chu, S.H.C.; Sarin, S.; Pipatsrisawat, K.; Gutkin, A.; Butryna, A.; Kjartansson, O. Crowdsourcing Latin American Spanish for Low-Resource Text-to-Speech. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., et al., Eds.; European Language Resources Association: Paris, France, 2020; pp. 6504–6513. [Google Scholar]
- Popov, V.; Vovk, I.; Gogoryan, V.; Sadekova, T.; Kudinov, M.; Wei, J. Diffusion-based voice conversion with fast maximum likelihood sampling scheme. arXiv 2021, arXiv:2109.13821. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mittag, G.; Naderi, B.; Chehadi, A.; Möller, S. NISQA: A deep CNN-self-attention model for multidimensional speech quality prediction with crowdsourced datasets. arXiv 2021, arXiv:2104.09494. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User | Number of Audios | Length |
|---|---|---|
| P007 | 10 | 2 min 13 s |
| P008 | 4 | 29 s |
| P041 | 12 | 2 min 40 s |
| P059 | 4 | 40 s |
| T01 | 16 | 5 min 33 s |
| T02 | 28 | 10 min 29 s |
| T03 | 17 | 3 min 30 s |
| T05 | 8 | 3 min 6 s |
| V042 | 4 | 46 s |
| V104 | 5 | 38 s |
| V110 | 51 | 6 min 48 s |
| V124 | 5 | 2 min 22 s |
| V134 | 13 | 1 min 33 s |
| Dataset | Classifier | F1-Score | Standard Deviation |
|---|---|---|---|
| WELIVE | Linear SVM | 98.34% | 0.36% |
| Random Forest | 97.41% | 0.84% | |
| KNN | 96.71% | 0.82% | |
| Naive Bayes | 95.53% | 1.24% | |
| HABLA | Linear SVM | 93.67% | 1.20% |
| Random Forest | 94.60% | 1.63% | |
| KNN | 94.01% | 0.68% | |
| Naive Bayes | 85.33% | 1.29% |
| Linear SVM | Random Forest | KNN | Naive Bayes | |
|---|---|---|---|---|
| Home | 28.57% | 41.66% | 31.25% | 50% |
| Transport | 71.42% | 41.66% | 50% | 27.27% |
| Work | 0% | 16.66% | 18.75% | 27.27% |
| Bar | 0% | 0% | 0% | 0% |
| School | 0% | 0% | 0% | 0% |
| Cafeteria | 0% | 0% | 0% | 0% |
| Medical Center | 0% | 0% | 0% | 0% |
| Restaurant | 0% | 0% | 0% | 0% |
| Linear SVM | Random Forest | KNN | Naive Bayes | |
|---|---|---|---|---|
| V11O | 28.57% | 50% | 37.50% | 68.18% |
| T02 | 14.28% | 0% | 6.25% | 4.54% |
| T03 | 0% | 0% | 0% | 0% |
| T01 | 28.57% | 16.66% | 12.50% | 4.54% |
| V134 | 0% | 0% | 0% | 4.54% |
| P041 | 0% | 0% | 0% | 0% |
| P007 | 28.57% | 25% | 18.75% | 4.54% |
| T05 | 0% | 0% | 12.50% | 4.54% |
| V104 | 0% | 0% | 0% | 4.54% |
| V124 | 0% | 0% | 0% | 0% |
| P008 | 0% | 0% | 0% | 0% |
| V042 | 0% | 8.33% | 12.50% | 4.54% |
| P059 | 0% | 0% | 0% | 0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez-Serrano, A.; Montero-Ramírez, C.; Peláez-Moreno, C. Authenticity at Risk: Key Factors in the Generation and Detection of Audio Deepfakes. Appl. Sci. 2025, 15, 558. https://doi.org/10.3390/app15020558
Martínez-Serrano A, Montero-Ramírez C, Peláez-Moreno C. Authenticity at Risk: Key Factors in the Generation and Detection of Audio Deepfakes. Applied Sciences. 2025; 15(2):558. https://doi.org/10.3390/app15020558
Chicago/Turabian StyleMartínez-Serrano, Alba, Claudia Montero-Ramírez, and Carmen Peláez-Moreno. 2025. "Authenticity at Risk: Key Factors in the Generation and Detection of Audio Deepfakes" Applied Sciences 15, no. 2: 558. https://doi.org/10.3390/app15020558
APA StyleMartínez-Serrano, A., Montero-Ramírez, C., & Peláez-Moreno, C. (2025). Authenticity at Risk: Key Factors in the Generation and Detection of Audio Deepfakes. Applied Sciences, 15(2), 558. https://doi.org/10.3390/app15020558