
Grid Anchor Lane Detection Based on Attribute Correlation

 , ,
, ,
Abstract
1. Introduction
- (1)
- Grid Anchor Design: A novel representation for lane lines, termed “grid anchor”, was proposed. This design has the same resolution as the feature map and can be directly computed through convolution. Furthermore, it can accurately capture and describe the interrelations between lane lines by incorporating attribute information.
- (2)
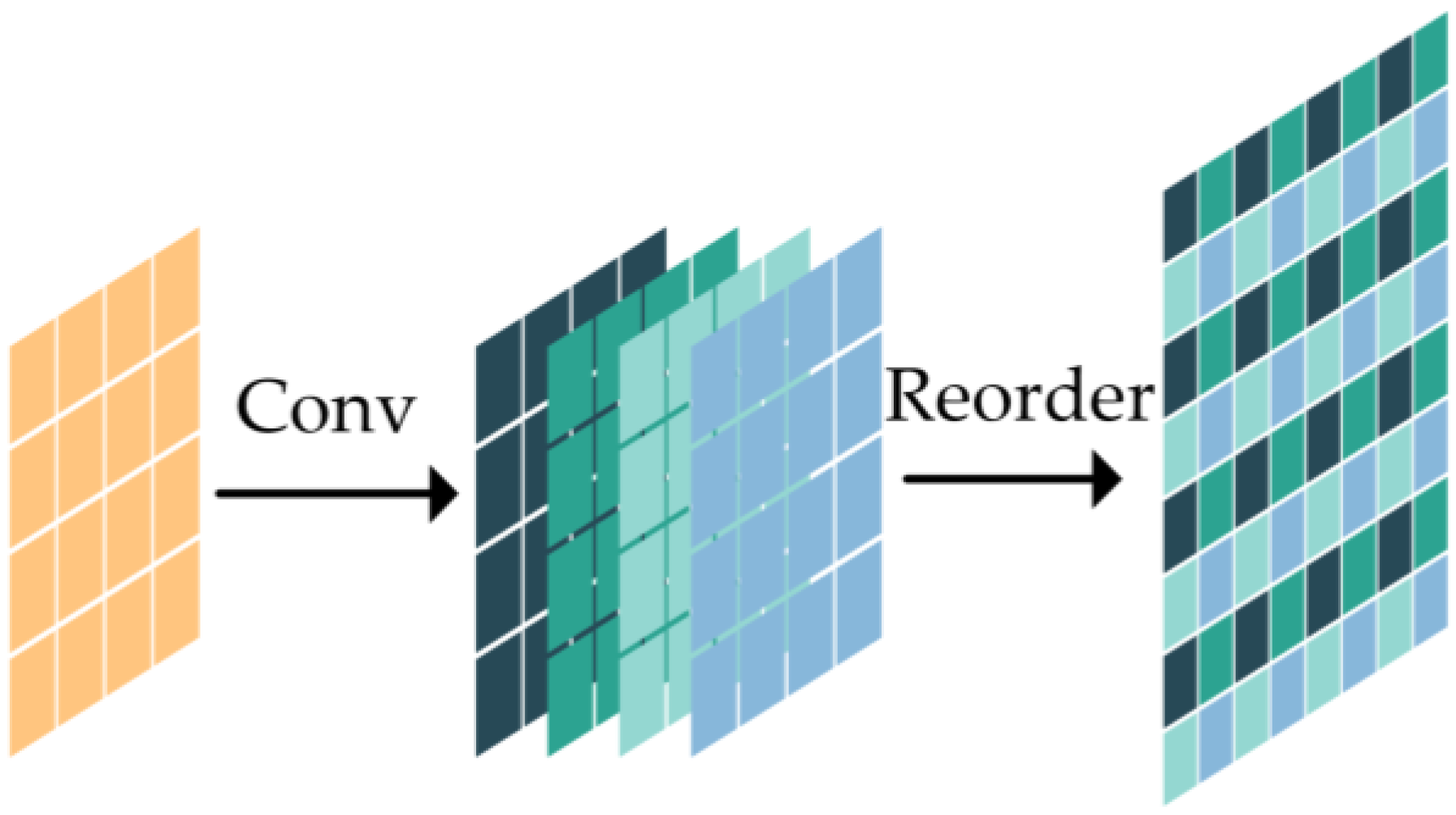
- FPN Improvements: The FPN was optimized by integrating an MLP to construct a long-range feature association and proposing a convolutional reordering upsampling method. The improved FPN enhances the interaction between global and local features.
- (3)
- Attribute Correlation Loss: An attribute correlation loss function was designed to establish feature associations between anchors. This ensures that the loss value is not only dependent on the predictions of individual anchors but also influenced by the predictions of neighboring anchors.
2. Related Work
3. Methods
3.1. Grid Anchor Representation Method for Lane Lines
3.2. Calculation of the Grid Anchor Labels
| Algorithm 1: The transformation process of label data from lane line coordinates to anchor attribute values. | ||||
| 1 | Initialization: , | |||
| 2 | for all do | |||
| 3 | for all do | |||
| 4 | Compute the intersection points between the lane line segment formed by and and the anchor boundaries. | |||
| 5 | if intersection points exist then | |||
| 6 | Record the intersection coordinates, and . | |||
| 7 | end if | |||
| 8 | end for | |||
| 9 | end for | |||
| 10 | if the number of intersection points is 2 then | |||
| 11 | if then | |||
| 12 | The anchor is classified as background, all attribute values are set to 0, and the program ends. | |||
| 13 | end if | |||
| 14 | The anchor is classified as lane lines, and the attribute values are calculated based on the two intersections. | |||
| 15 | end if | |||
| 16 | if the number of intersection points is 1 then | |||
| 17 | if then | |||
| 18 | The anchor is classified as background, all attribute values are set to 0, and the program ends. | |||
| 19 | end if | |||
| 20 | The anchor is classified as lane lines, and the attribute values are calculated based on the single intersection. | |||
| 21 | end if | |||
3.2.1. Two Intersections
3.2.2. Single Intersection
3.2.3. No Intersection
3.3. Network Design
3.4. Attribute Correlation Loss Function
3.5. Model Inference
- (1)
- The anchor must contain lane line features, with the existence attribute ;
- (2)
- The lane line within the anchor must be a part of a single lane line, with the sum of the instance attribute channel values equaling 1, ;
- (3)
- The anchor classified as a lane line must contain directional features, with the sum of the direction attribute values greater than or equal to 1, .
4. Experimental Results
4.1. Experimental Setting
4.1.1. Datasets and Evaluation Metrics
4.1.2. Implementation Details
4.2. Results
4.2.1. Results on CULane
4.2.2. Results on Tusimple
4.2.3. Qualitative Results
4.3. Ablation Study
4.3.1. Impact of Different Attributes
4.3.2. Model Comparison
4.3.3. Impact of Loss Function on Model Performance
4.4. Experimental Summary
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nidamanuri, J.; Nibhanupudi, C.; Assfalg, R.; Venkataraman, H. A progressive review: Emerging technologies for ADAS driven solutions. IEEE Trans. Intell. Veh. 2021, 7, 326–341. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Li, S.; Liu, P. A review of lane detection methods based on deep learning. Pattern Recognit. 2021, 111, 107623. [Google Scholar] [CrossRef]
- Zakaria, N.J.; Shapiai, M.I.; Abd Ghani, R.; Yassin, M.N.M.; Ibrahim, M.Z.; Wahid, N. Lane detection in autonomous vehicles: A systematic review. IEEE Access 2023, 11, 3729–3765. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Hu, X.; Yang, J. Line-cnn: End-to-end traffic line detection with line proposal unit. IEEE Trans. Intell. Transp. Syst. 2019, 21, 248–258. [Google Scholar] [CrossRef]
- Qin, Z.; Zhang, P.; Li, X. Ultra fast deep lane detection with hybrid anchor driven ordinal classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 2555–2568. [Google Scholar] [CrossRef] [PubMed]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Keep your eyes on the lane: Real-time attention-guided lane detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 294–302. [Google Scholar]
- Xu, H.; Wang, S.; Cai, X.; Zhang, W.; Liang, X.; Li, Z. Curvelane-nas: Unifying lane-sensitive architecture search and adaptive point blending. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 689–704. [Google Scholar]
- Zheng, T.; Huang, Y.; Liu, Y.; Tang, W.; Yang, Z.; Cai, D.; He, X. Clrnet: Cross layer refinement network for lane detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 898–907. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 286–291. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zheng, T.; Fang, H.; Zhang, Y.; Tang, W.; Yang, Z.; Liu, H.; Cai, D. Resa: Recurrent feature-shift aggregator for lane detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 3547–3554. [Google Scholar]
- Zou, Q.; Jiang, H.; Dai, Q.; Yue, Y.; Chen, L.; Wang, Q. Robust lane detection from continuous driving scenes using deep neural networks. IEEE Trans. Veh. Technol. 2019, 69, 41–54. [Google Scholar] [CrossRef]
- Feng, Z.; Guo, S.; Tan, X.; Xu, K.; Wang, M.; Ma, L. Rethinking efficient lane detection via curve modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17062–17070. [Google Scholar]
- Liu, R.; Yuan, Z.; Liu, T.; Xiong, Z. End-to-end lane shape prediction with transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3694–3702. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Polylanenet: Lane estimation via deep polynomial regression. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6150–6156. [Google Scholar]
- Van Gansbeke, W.; De Brabandere, B.; Neven, D.; Proesmans, M.; Van Gool, L. End-to-end lane detection through differentiable least-squares fitting. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 905–913. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Tusimple. Tusimple Benchmark. Available online: https://github.com/TuSimple/tusimple-benchmark (accessed on 2 September 2020).
- Wang, W.; Lin, H.; Wang, J. CNN based lane detection with instance segmentation in edge-cloud computing. J. Cloud Comput. 2020, 9, 27. [Google Scholar] [CrossRef]
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the 2008 IEEE intelligent vehicles symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 7–12. [Google Scholar]
- Bar Hillel, A.; Lerner, R.; Levi, D.; Raz, G. Recent progress in road and lane detection: A survey. Mach. Vis. Appl. 2014, 25, 727–745. [Google Scholar] [CrossRef]
- Maček, K.; Williams, B.; Kolski, S.; Siegwart, R. A Lane Detection Vision Module for Driver Assistance; Sascha Eysoldt Verlag: Aachen, Germany, 2004. [Google Scholar]
- Wu, C.-F.; Lin, C.-J.; Lee, C.-Y. Applying a functional neurofuzzy network to real-time lane detection and front-vehicle distance measurement. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2011, 42, 577–589. [Google Scholar]
- Beyeler, M.; Mirus, F.; Verl, A. Vision-based robust road lane detection in urban environments. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 4920–4925. [Google Scholar]
- Kang, S.-N.; Lee, S.; Hur, J.; Seo, S.-W. Multi-lane detection based on accurate geometric lane estimation in highway scenarios. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Ypsilanti, MI, USA, 8–11 June 2014; pp. 221–226. [Google Scholar]
- Ko, Y.; Lee, Y.; Azam, S.; Munir, F.; Jeon, M.; Pedrycz, W. Key points estimation and point instance segmentation approach for lane detection. IEEE Trans. Intell. Transp. Syst. 2021, 23, 8949–8958. [Google Scholar] [CrossRef]
- Qu, Z.; Jin, H.; Zhou, Y.; Yang, Z.; Zhang, W. Focus on local: Detecting lane marker from bottom up via key point. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14122–14130. [Google Scholar]
- Wang, J.; Ma, Y.; Huang, S.; Hui, T.; Wang, F.; Qian, C.; Zhang, T. A keypoint-based global association network for lane detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1392–1401. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A. Attention is all you need. In Advances in Neural Information Processing Systems. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Washington, DC, USA, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Burrus, C.S.; Parks, T. Convolution Algorithms; Citeseer: New York, NY, USA, 1985; Volume 6, p. 15. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31, 8792–8802. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Yoo, S.; Lee, H.S.; Myeong, H.; Yun, S.; Park, H.; Cho, J.; Kim, D.H. End-to-end lane marker detection via row-wise classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1006–1007. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 276–291. [Google Scholar]
- Zoljodi, A.; Abadijou, S.; Alibeigi, M.; Daneshtalab, M. Contrastive Learning for Lane Detection via cross-similarity. Pattern Recognit. Lett. 2024, 185, 175–183. [Google Scholar] [CrossRef]
- Kao, Y.; Che, S.; Zhou, S.; Guo, S.; Zhang, X.; Wang, W. LHFFNet: A hybrid feature fusion method for lane detection. Sci. Rep. 2024, 14, 16353. [Google Scholar] [CrossRef] [PubMed]
- Nie, S.; Zhang, G.; Yun, L.; Liu, S. A Faster and Lightweight Lane Detection Method in Complex Scenarios. Electronics 2024, 13, 2486. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, Q.; Lian, C. Pointlanenet: Efficient end-to-end cnns for accurate real-time lane detection. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2563–2568. [Google Scholar]
- Philion, J. Fastdraw: Addressing the long tail of lane detection by adapting a sequential prediction network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11582–11591. [Google Scholar]
- Zhang, J.; Deng, T.; Yan, F.; Liu, W. Lane detection model based on spatio-temporal network with double convolutional gated recurrent units. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6666–6678. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Segmentation | Keypoint | Parameter | Anchor |
|---|---|---|---|---|
| Representative methods | LaneNet SCNN ENet-SAD | PINet FOLOLane GANet | PolyLaneNet BezierLaneNet E2ET | Line-CNN LaneATT Ufldv2 |
| Relative advantages of the proposed method | Reduced computational complexity; high speed; indicating internal relationships. | Indicating internal relationships; flexible representation. | Flexible representation; indicating internal relationships. | Simple computation method; flexible representation; correspondence between features and data at the same position; indicating internal relationships. |
| Direction | ||||
|---|---|---|---|---|
| - | - | No lane | 0 | 0 |
| Left | 1 | 0 | ||
| Down | 1 | 1 | ||
| Right | 0 | 1 |
| Dataset | Train | Test | Image Size | Lanes |
|---|---|---|---|---|
| CULane | 88,880 | 34,680 | 1640 × 590 | 4 |
| Tusimple | 3626 | 2782 | 1280 × 720 | 5 |
| Method | Backbone | F1 | GFlops | Normal | Crowd | Dazzle | Shadow | No Line | Arrow | Curve | Cross | Night |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SCNN [13] | VGG16 | 71.60 | 328.4 | 90.60 | 69.70 | 58.50 | 66.90 | 43.40 | 84.10 | 64.40 | 1990 | 66.10 |
| RESA [14] | ResNet34 | 74.50 | 41.0 | 91.90 | 72.40 | 66.50 | 72.00 | 46.30 | 88.10 | 68.60 | 1896 | 69.80 |
| ENet-SAD [11] | ENet | 70.80 | 3.9 | 90.10 | 68.80 | 60.20 | 65.90 | 41.60 | 84.00 | 65.70 | 1998 | 66.00 |
| PINet [29] | Hourglass | 74.40 | - | 90.30 | 72.30 | 66.30 | 68.40 | 49.80 | 83.70 | 65.60 | 1427 | 67.70 |
| FOLOLane [30] | ERFNet | 78.80 | - | 92.70 | 77.80 | 75.20 | 79.30 | 52.10 | 89.00 | 69.40 | 1569 | 74.50 |
| BezierLaneNet [16] | ResNet34 | 75.57 | - | 91.59 | 73.20 | 69.20 | 76.74 | 48.05 | 87.16 | 62.45 | 888 | 69.90 |
| ERF-E2E [38] | ERFNet | 74.00 | - | 91.00 | 73.10 | 64.50 | 74.10 | 46.60 | 85.80 | 71.90 | 2022 | 67.90 |
| LaneATT [8] | ResNet34 | 76.68 | 18.0 | 92.14 | 75.03 | 66.47 | 78.15 | 49.39 | 88.38 | 67.72 | 1330 | 70.72 |
| CurveLanes-L [9] | Searched | 74.80 | 86.5 | 90.70 | 72.30 | 67.70 | 70.10 | 49.40 | 85.80 | 68.40 | 1746 | 68.90 |
| UFLD [39] | ResNet34 | 72.30 | 16.9 | 90.70 | 70.20 | 59.50 | 69.30 | 44.40 | 85.70 | 69.50 | 2037 | 66.70 |
| UFLDv2 [7] | ResNet34 | 75.90 | 20.6 | 92.50 | 74.90 | 65.70 | 75.30 | 49.00 | 88.50 | 70.20 | 1864 | 70.60 |
| CLLD [40] | U-Net | 70.43 | - | 89.80 | 68.39 | 58.93 | 68.86 | 40.68 | 84.50 | 66.20 | 2656 | 71.21 |
| LHFFNet [41] | Hourglass | 75.90 | - | 92.00 | 73.40 | 67.30 | 71.90 | 51.30 | 87.80 | 69.60 | 1401 | 70.60 |
| CBGA [42] | ResNet-34 | 71.00 | - | 90.80 | 70.80 | 61.60 | 71.40 | 44.50 | 86.30 | 65.10 | 2028 | 66.10 |
| GAAC (ours) | ResNet18 | 76.22 | 23.4 | 92.97 | 74.35 | 68.46 | 74.51 | 48.85 | 88.20 | 72.30 | 1785 | 71.63 |
| GAAC (ours) | ResNet34 | 76.41 | 28.6 | 93.05 | 75.26 | 65.65 | 69.75 | 49.41 | 89.01 | 73.27 | 2035 | 72.29 |
| Method | Backbone | F1 | Acc | FP | FN |
|---|---|---|---|---|---|
| LaneNet [12] | H-NET | 94.80 | 96.38 | 7.80 | 2.44 |
| SCNN [13] | VGG16 | 95.97 | 96.53 | 6.17 | 1.80 |
| PointLaneNet [43] | GoogLeNet | 95.07 | 96.34 | 4.67 | 5.18 |
| ENet-SAD [11] | ENet | 95.92 | 96.64 | 6.02 | 2.05 |
| FastDraw [44] | ResNet50 | 93.92 | 95.20 | 7.60 | 4.50 |
| PolyLaneNet [18] | EfficientNet | 90.62 | 93.36 | 9.42 | 9.33 |
| ERF-E2E [38] | ERFNet | 96.25 | 96.02 | 3.21 | 4.28 |
| PINet [29] | Hourglass | 87.10 | 97.62 | 15.30 | 10.50 |
| ConvGRUs [45] | ConvGRU | 90.97 | 97.98 | 13.26 | 4.38 |
| UFLD [39] | ResNet34 | 88.02 | 95.86 | 18.91 | 3.75 |
| UFLDv2 [7] | ResNet34 | 96.22 | 95.56 | 3.18 | 4.37 |
| CLLD [40] | RESA | 94.99 | 96.17 | 5.50 | 4.50 |
| CBGA [42] | ResNet34 | 95.93 | 96.10 | 18.80 | 3.61 |
| GAAC (ours) | ResNet18 | 96.43 | 96.18 | 3.86 | 3.27 |
| GAAC (ours) | ResNet34 | 96.47 | 96.27 | 4.13. | 2.91 |
| Existence | Instance | Direction | Offset | Slope | F1 |
|---|---|---|---|---|---|
| ✓ | ✓ | 74.31 | |||
| ✓ | ✓ | ✓ | 74.52 | ||
| ✓ | ✓ | ✓ | 74.93 | ||
| ✓ | ✓ | ✓ | 74.61 | ||
| ✓ | ✓ | ✓ | ✓ | ✓ | 75.17 |
| FPN | Upsampling | MLP | F1 |
|---|---|---|---|
| ✓ | 75.09 | ||
| ✓ | ✓ | 75.68 | |
| ✓ | ✓ | 75.27 | |
| ✓ | ✓ | ✓ | 75.83 |
| F1 | |||
|---|---|---|---|
| ✓ | 75.80 | ||
| ✓ | ✓ | 76.07 | |
| ✓ | ✓ | 76.31 | |
| ✓ | ✓ | ✓ | 76.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Q.; Chi, C.; Chen, F.; Shen, J.; Xu, G.; Wen, H. Grid Anchor Lane Detection Based on Attribute Correlation. Appl. Sci. 2025, 15, 699. https://doi.org/10.3390/app15020699
Feng Q, Chi C, Chen F, Shen J, Xu G, Wen H. Grid Anchor Lane Detection Based on Attribute Correlation. Applied Sciences. 2025; 15(2):699. https://doi.org/10.3390/app15020699
Chicago/Turabian StyleFeng, Qiaohui, Cheng Chi, Fei Chen, Jianhao Shen, Gang Xu, and Huajie Wen. 2025. "Grid Anchor Lane Detection Based on Attribute Correlation" Applied Sciences 15, no. 2: 699. https://doi.org/10.3390/app15020699
APA StyleFeng, Q., Chi, C., Chen, F., Shen, J., Xu, G., & Wen, H. (2025). Grid Anchor Lane Detection Based on Attribute Correlation. Applied Sciences, 15(2), 699. https://doi.org/10.3390/app15020699