

Cooperative Formation Control of a Multi-Agent Khepera IV Mobile Robots System Using Deep Reinforcement Learning




Abstract
1. Introduction
- Design and implementation: The design and implementation of a control law for the formation position control of a group of robots based on DRL. This control law helps robots maintain precise formations and adapt to their surroundings, improving on the results presented in [18], where classical controllers were used.
- Simulation environment: The implementation of the proposed algorithm in a simulation environment, including obstacle avoidance. This enables thorough testing and validation of the effectiveness of the algorithm in maintaining formation and avoiding obstacles. The obstacle avoidance logic presented in [19] was expanded to all robots in the formation.
- Comparison with traditional position control approaches: Comparison of the results of the new approach against existing control laws under similar conditions. This comparison highlights the advantages and improvements offered by the RL-based method. This work expands on [20] by experimenting with a more explicit reward function for faster target tracking.
- Performance evaluation: The evaluation of the performance of the proposed control law using their control surfaces. This provides a quantitative assessment of the algorithm’s efficiency, robustness, and adaptability. Similar metrics as used in [19] were selected for a more accurate comparison.
2. Background
2.1. Simulation Environment—CoppeliaSim Simulator
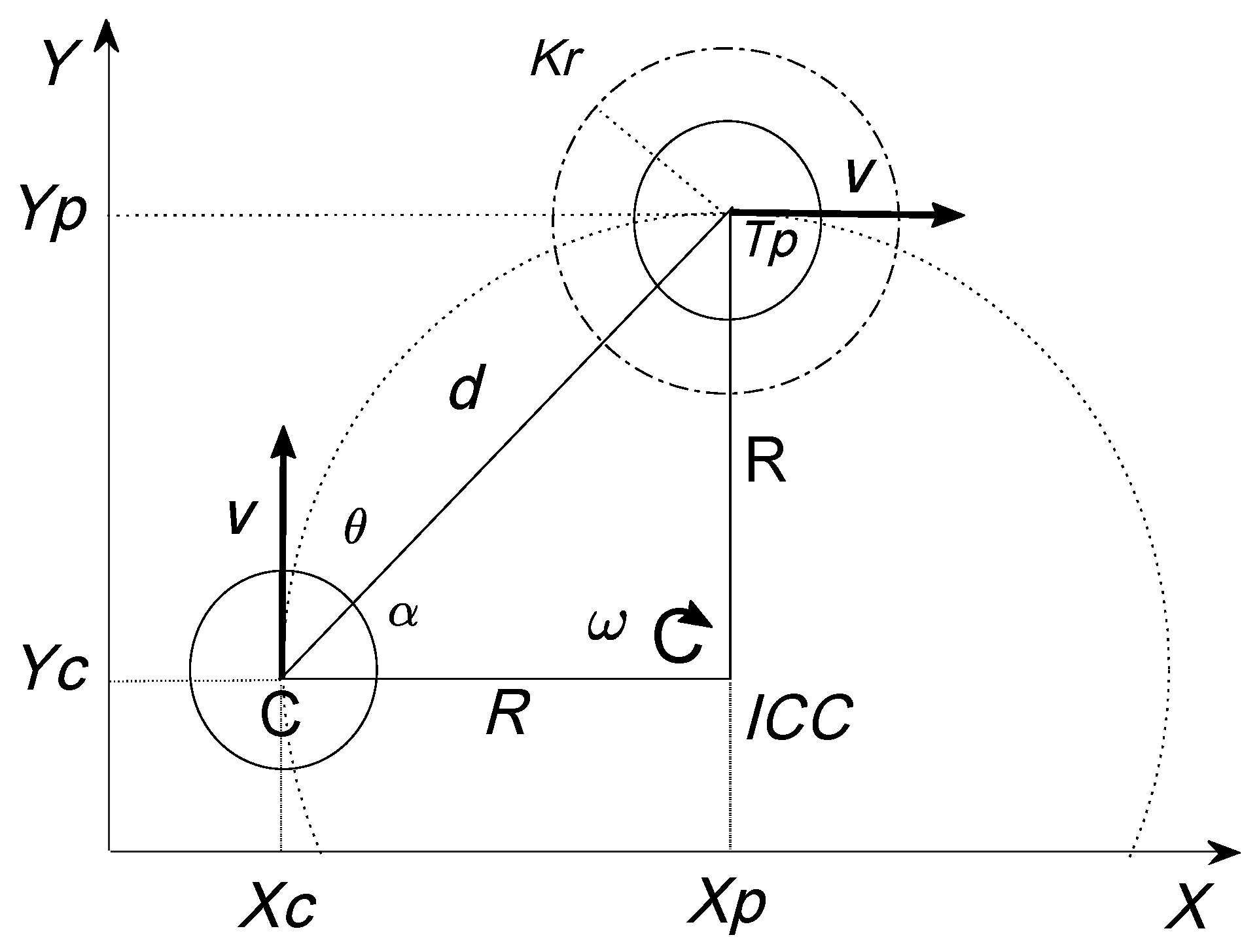
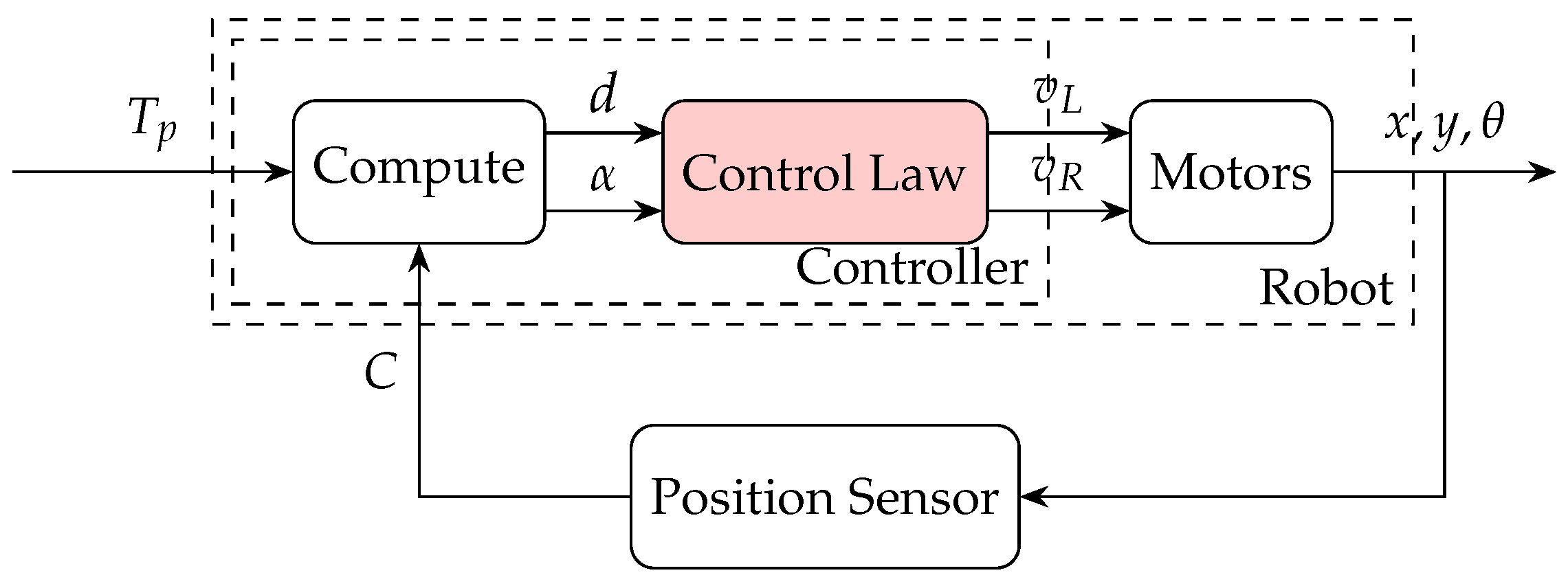
2.2. Robot Position Control
2.2.1. Kinematic Model for the Robot
2.2.2. Position Control Problem
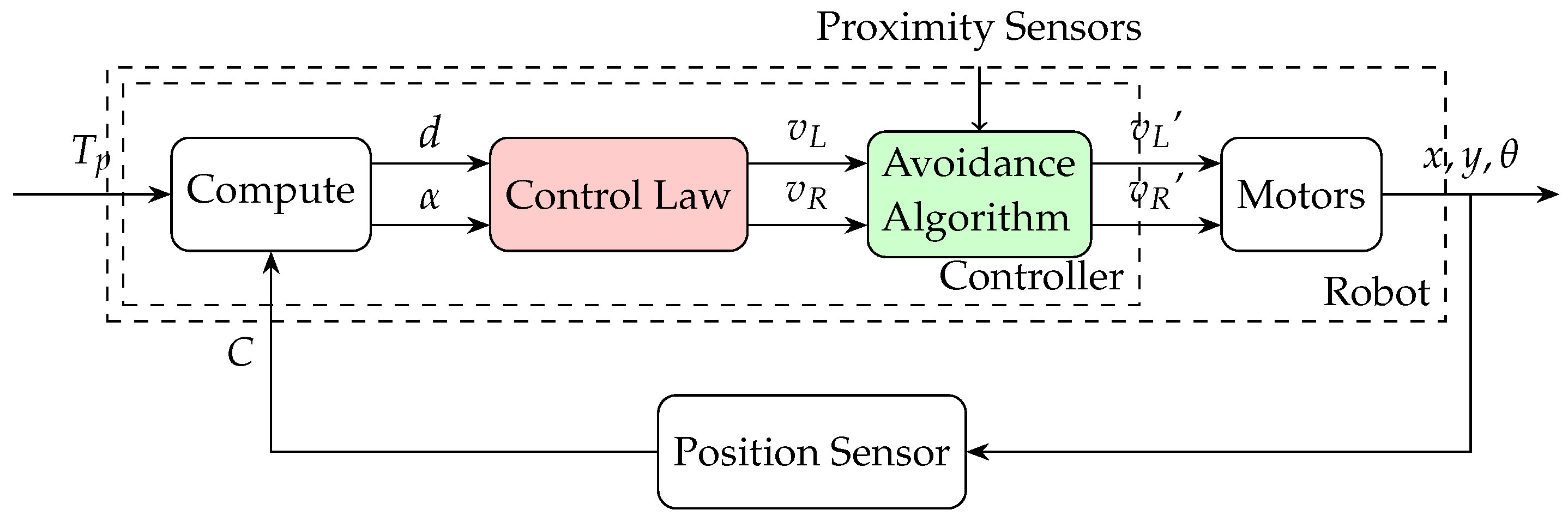
2.3. Obstacles Avoidance (Braitenberg Algorithm)
2.4. Multi-Agent Systems
Deep Reinforcement Learning and Multi-Agent Systems
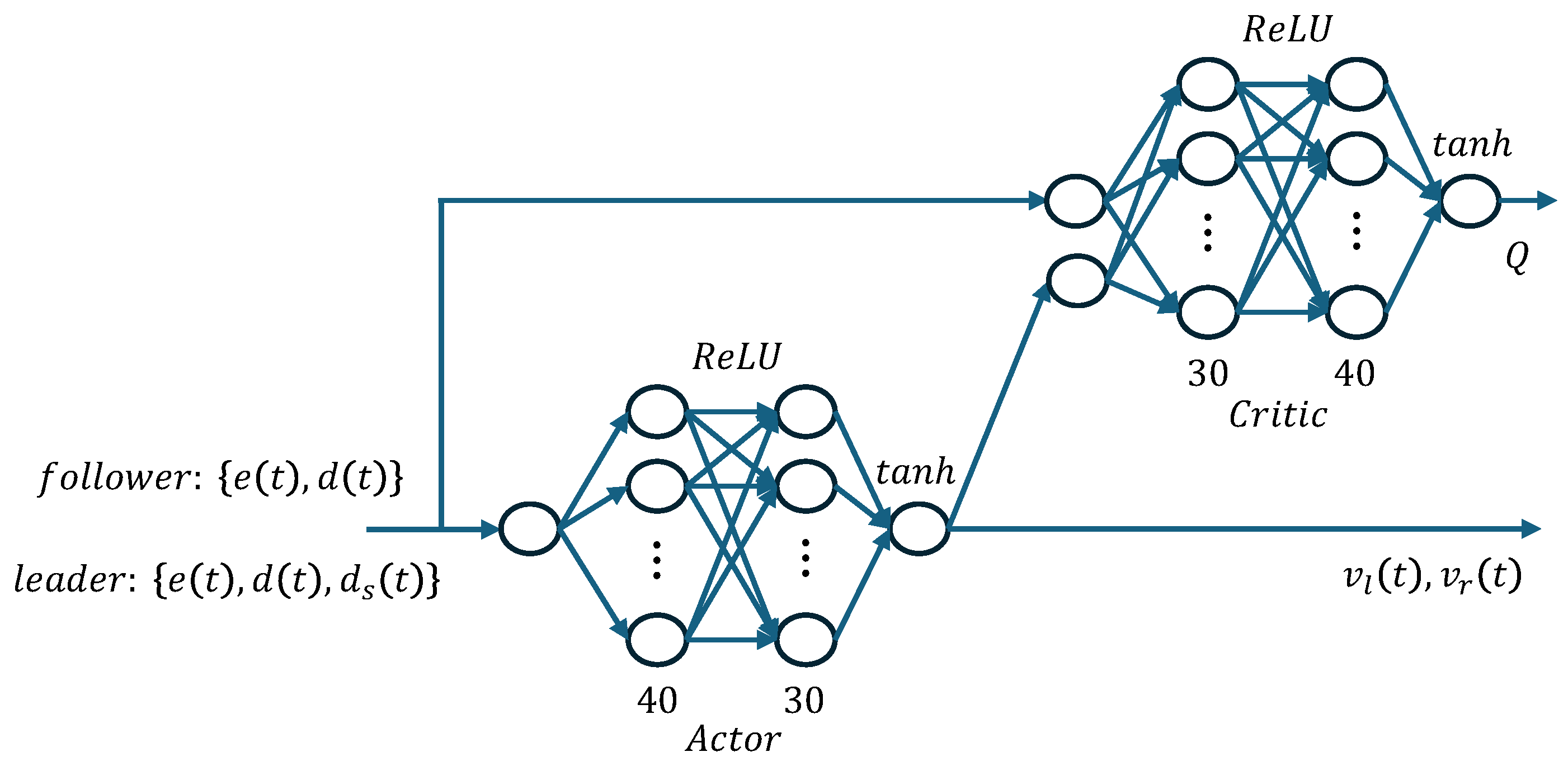
3. Proposed Approach
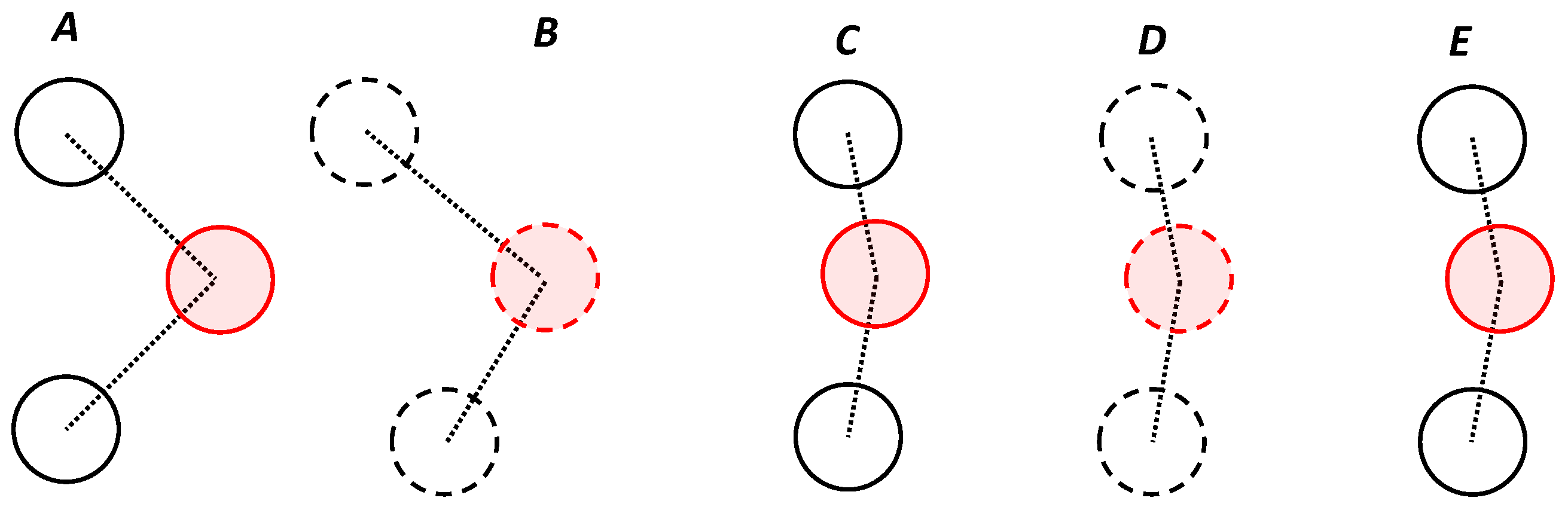
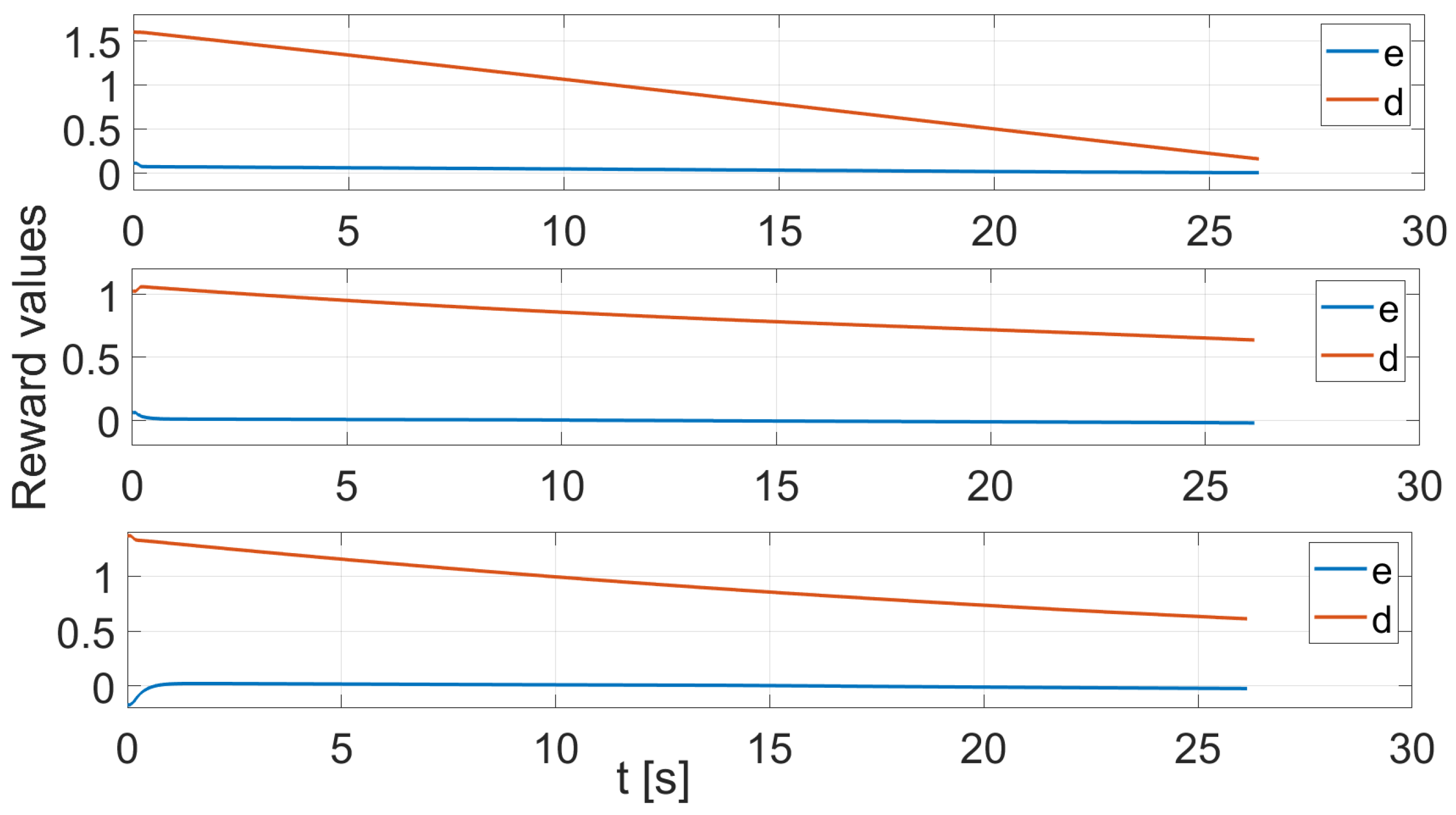
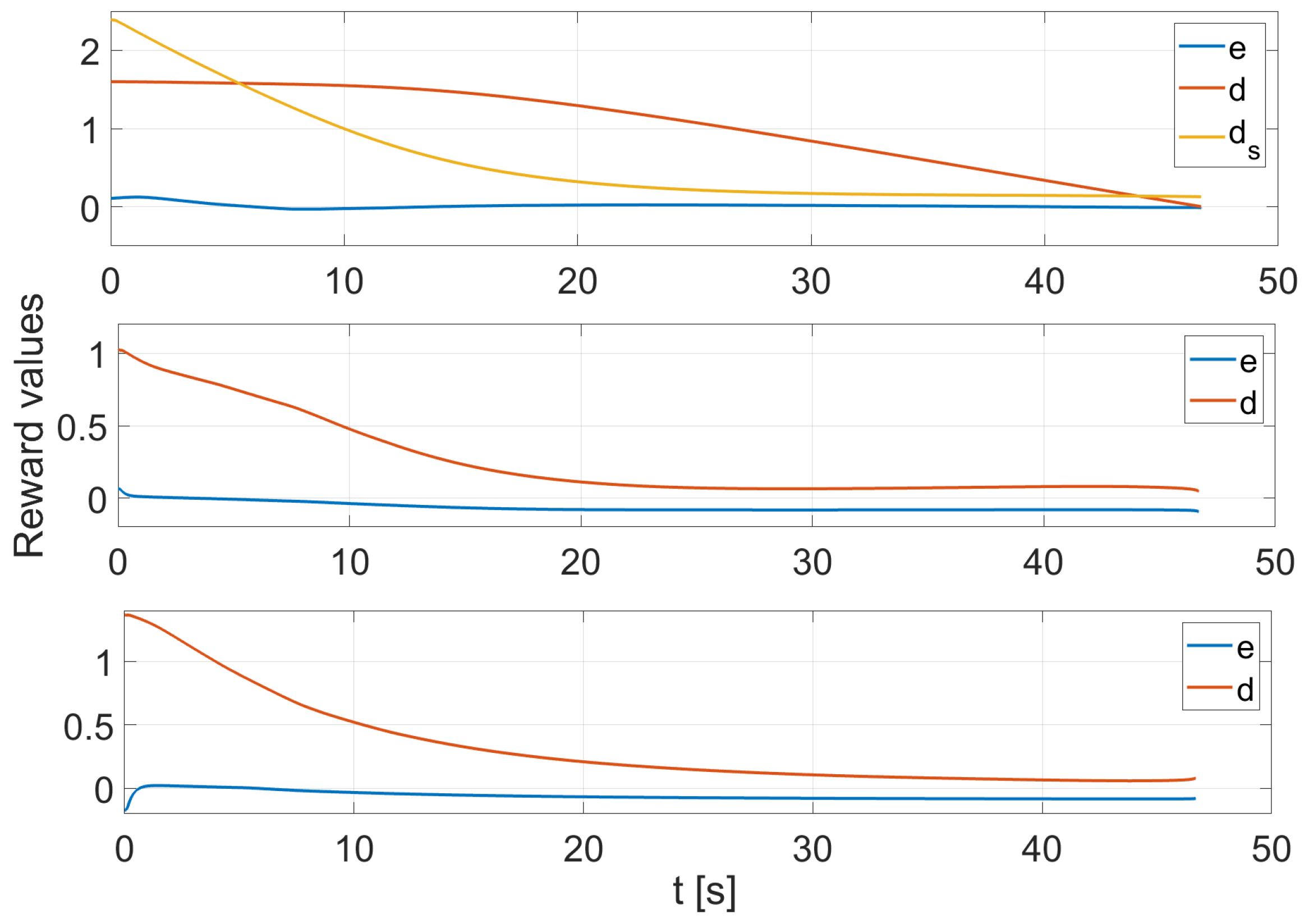
3.1. Reward Function for the Followers
3.2. Reward Function for the Leader
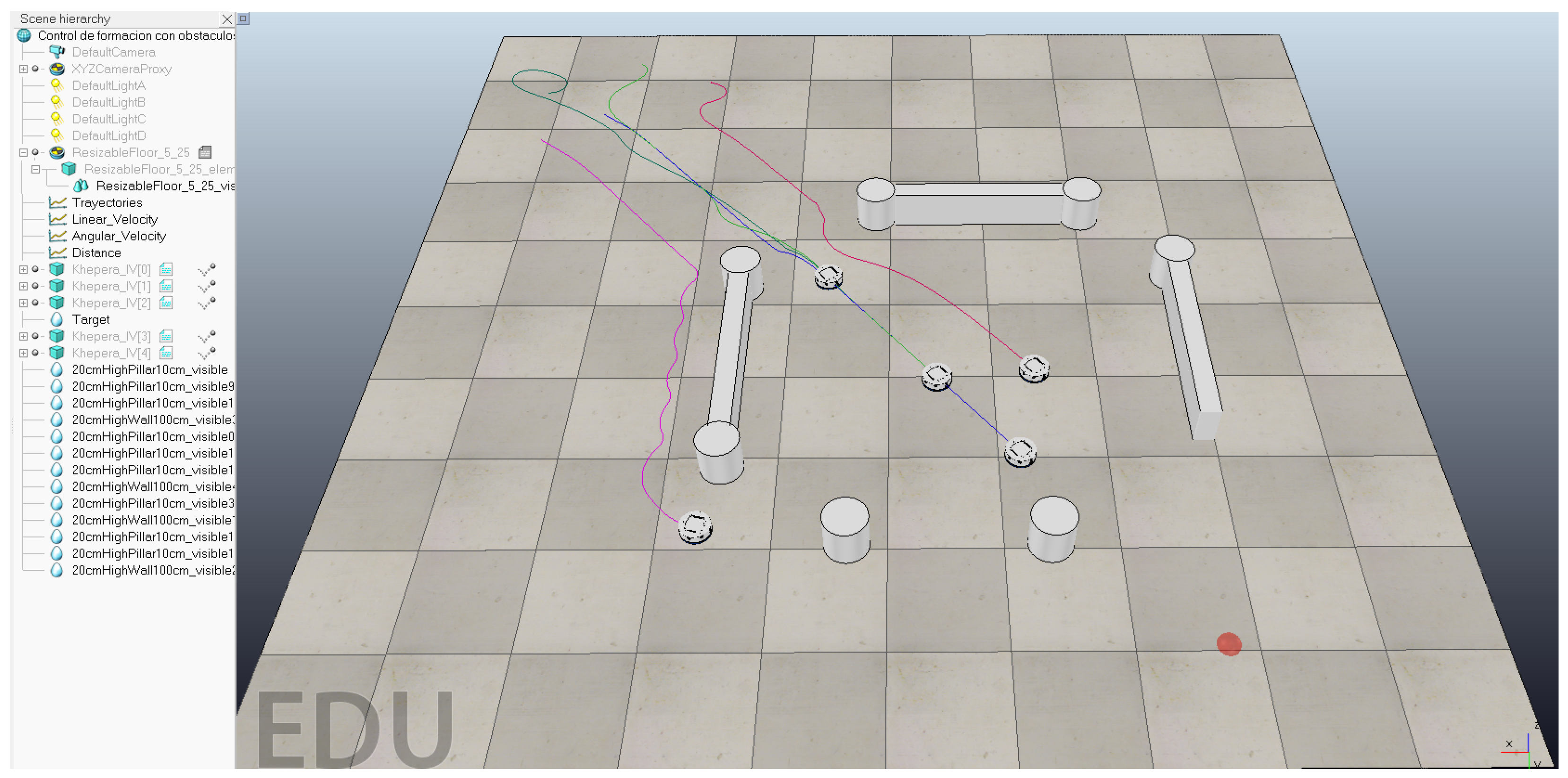
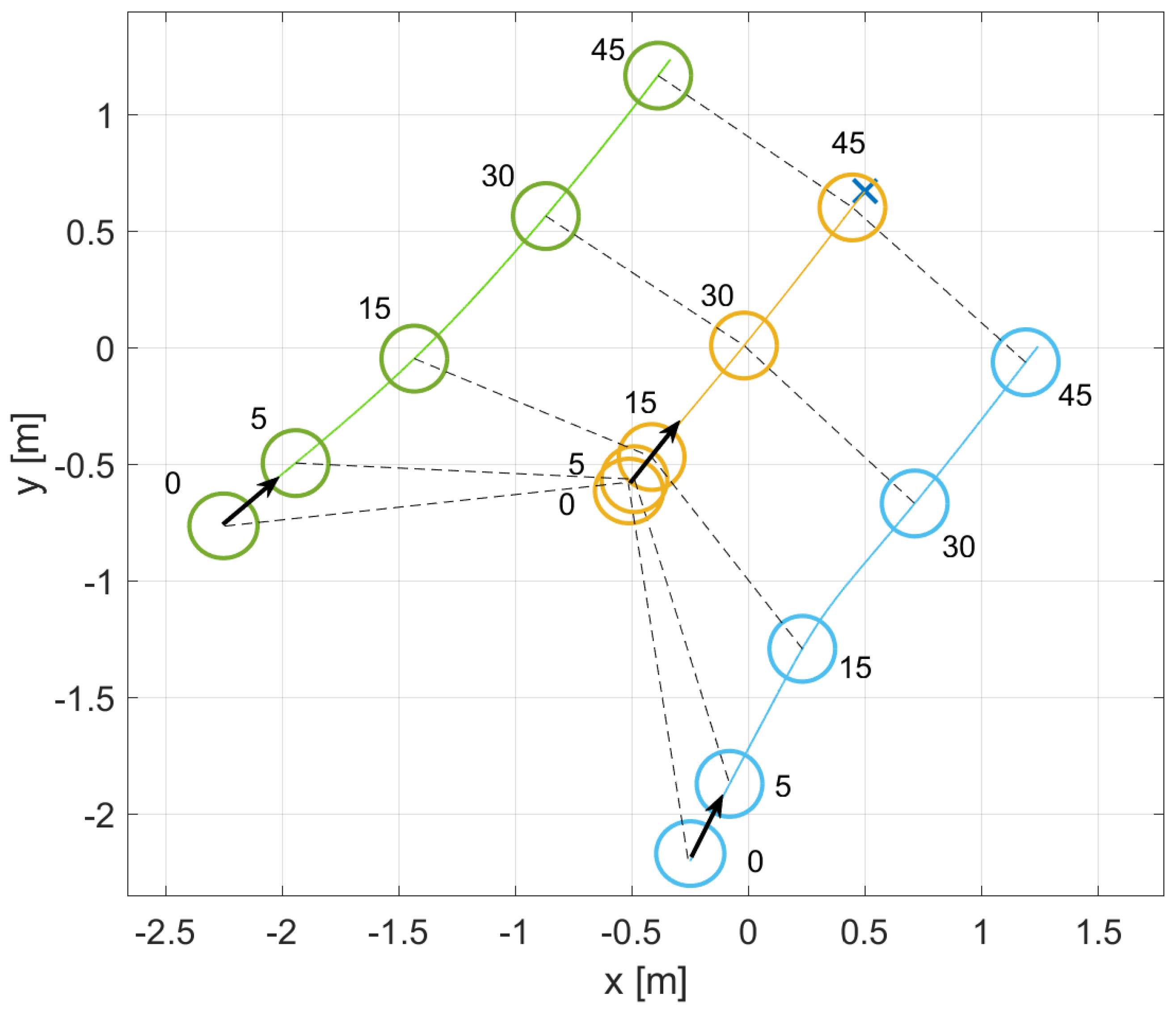
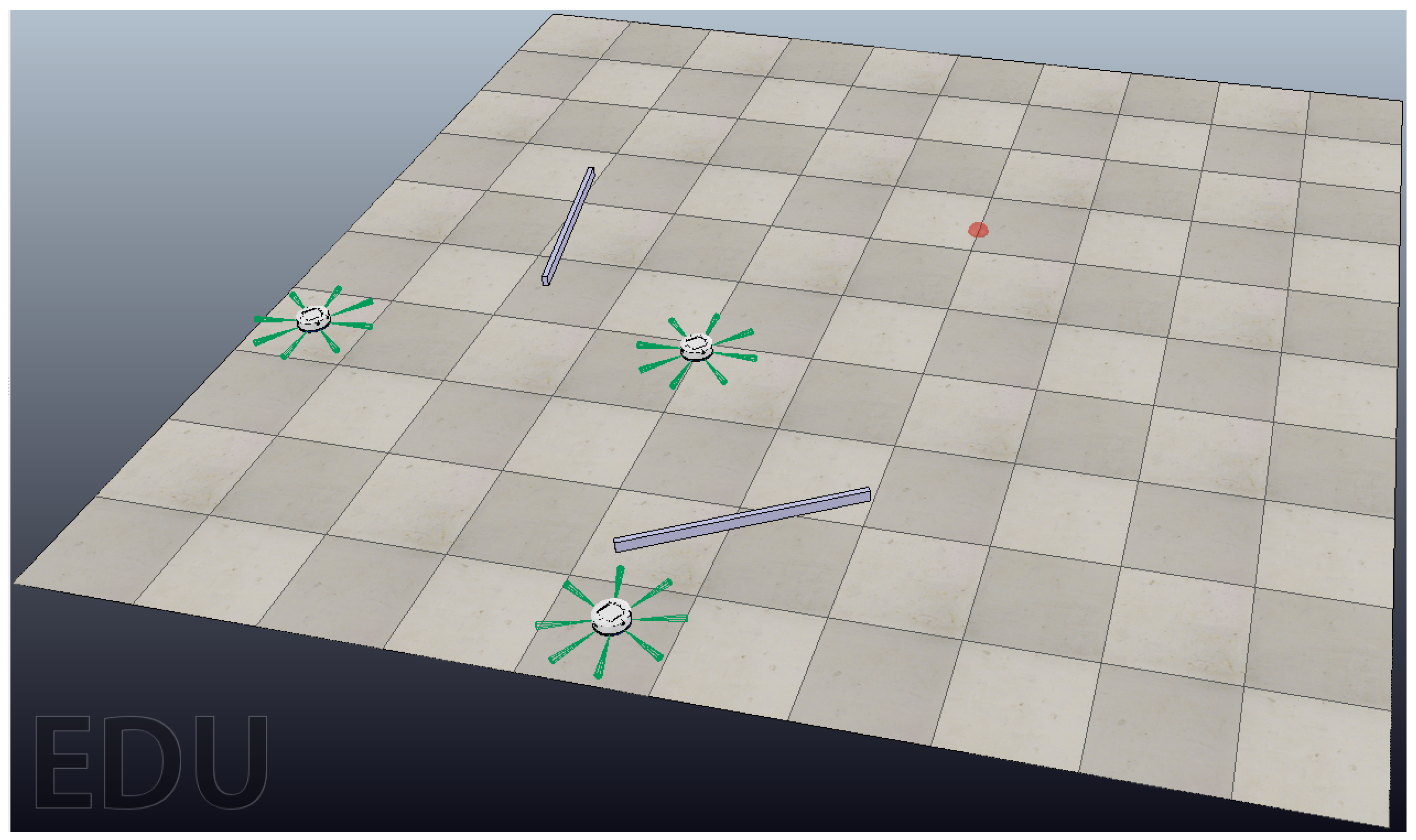
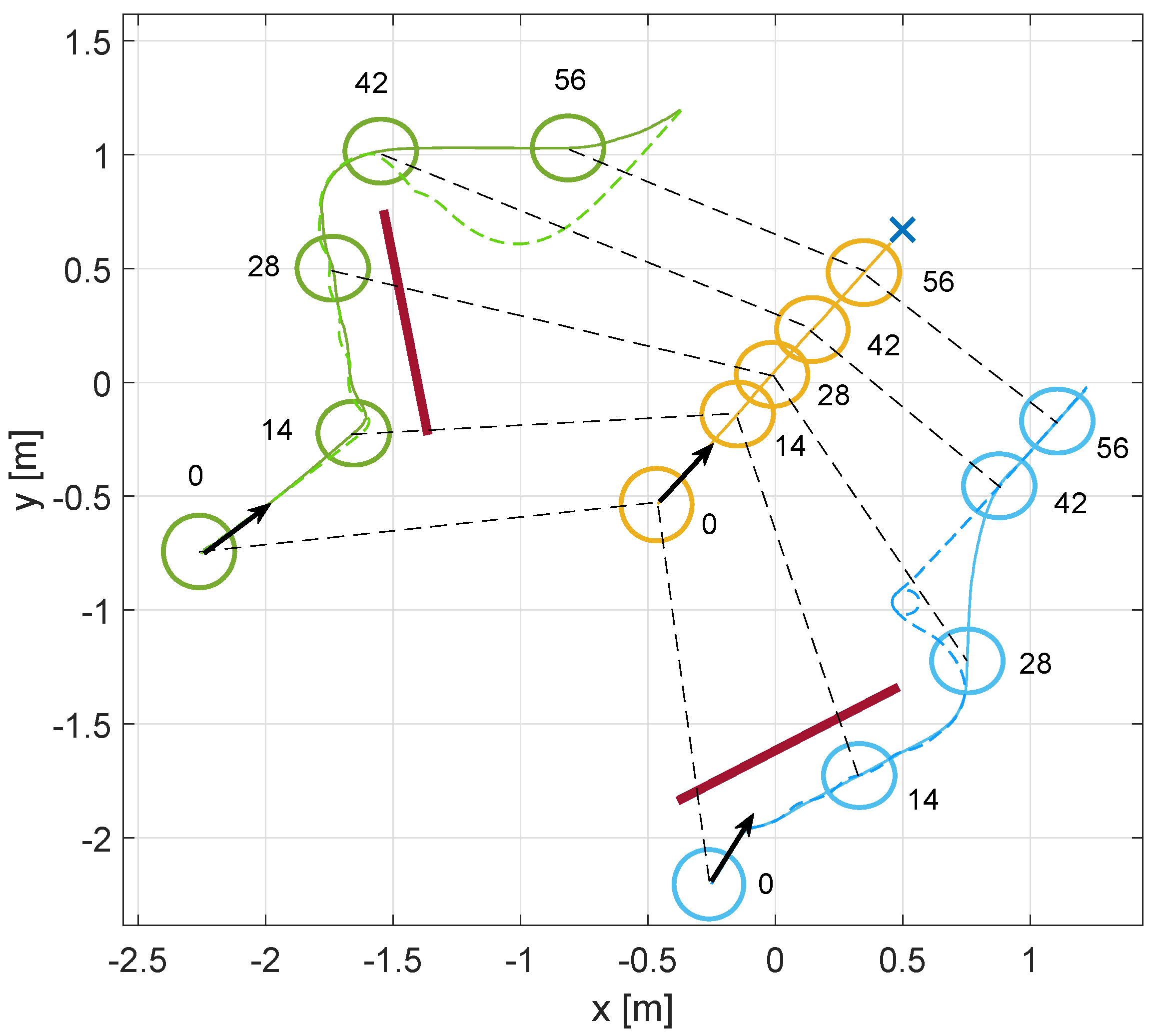
4. Results
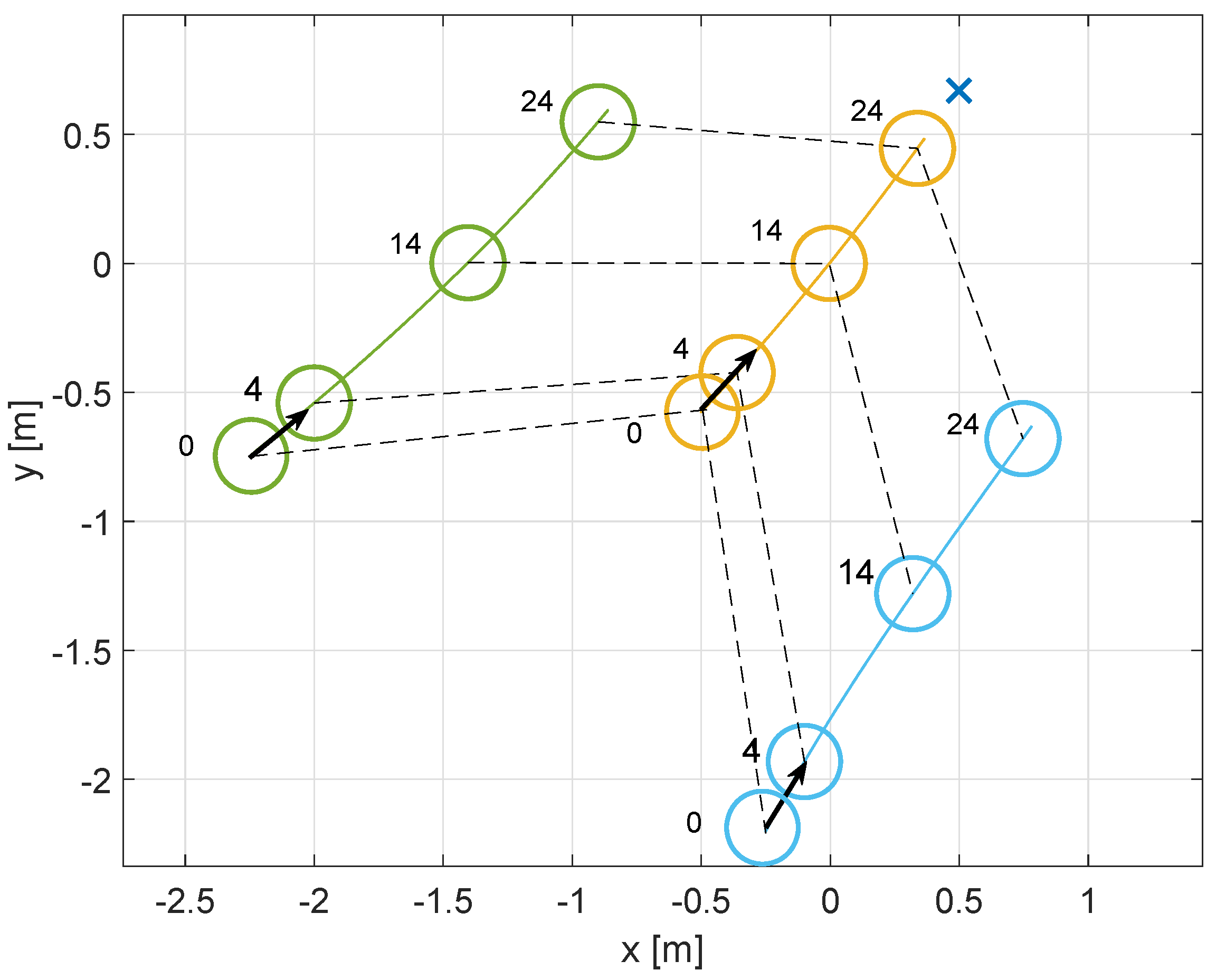
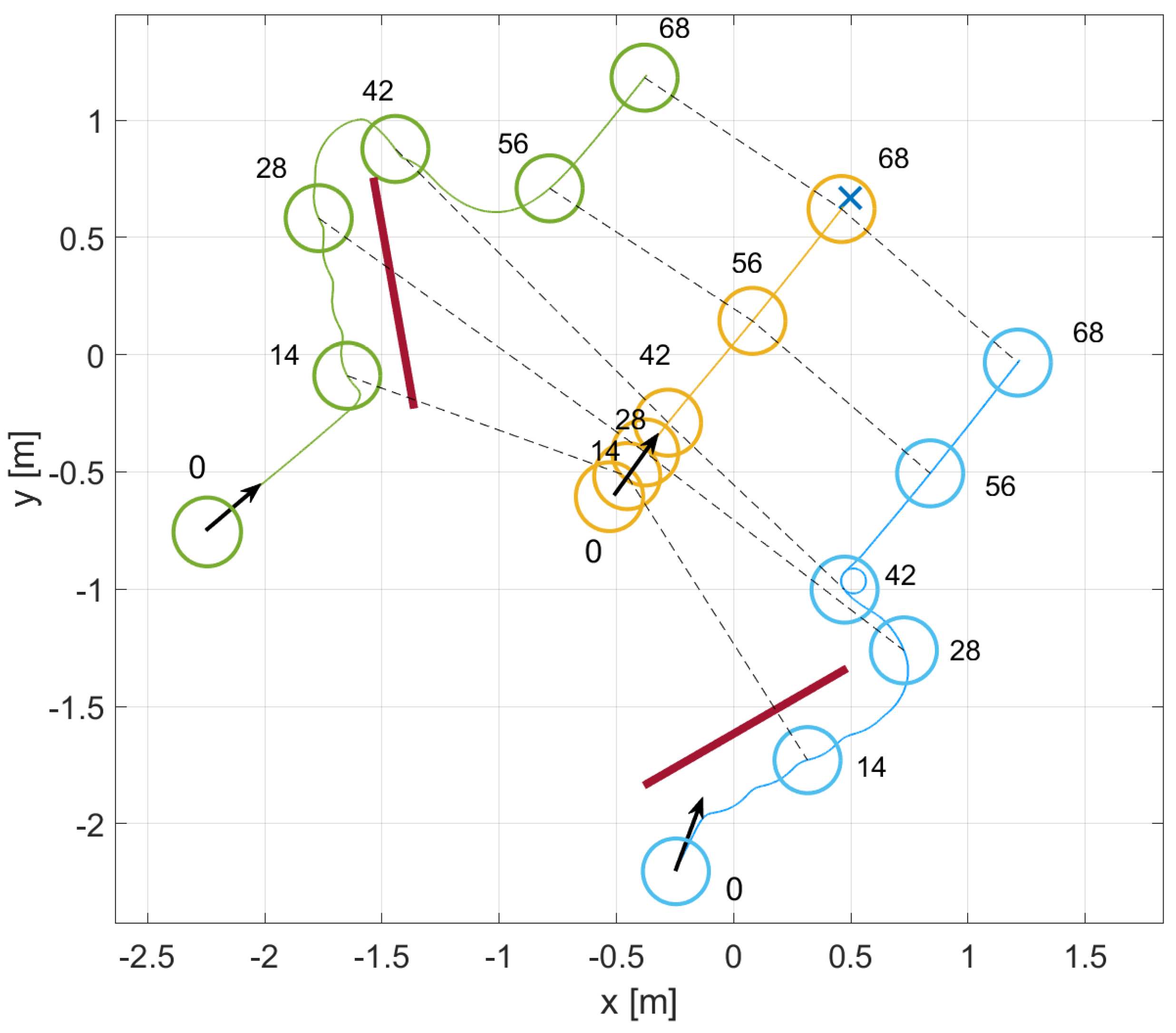
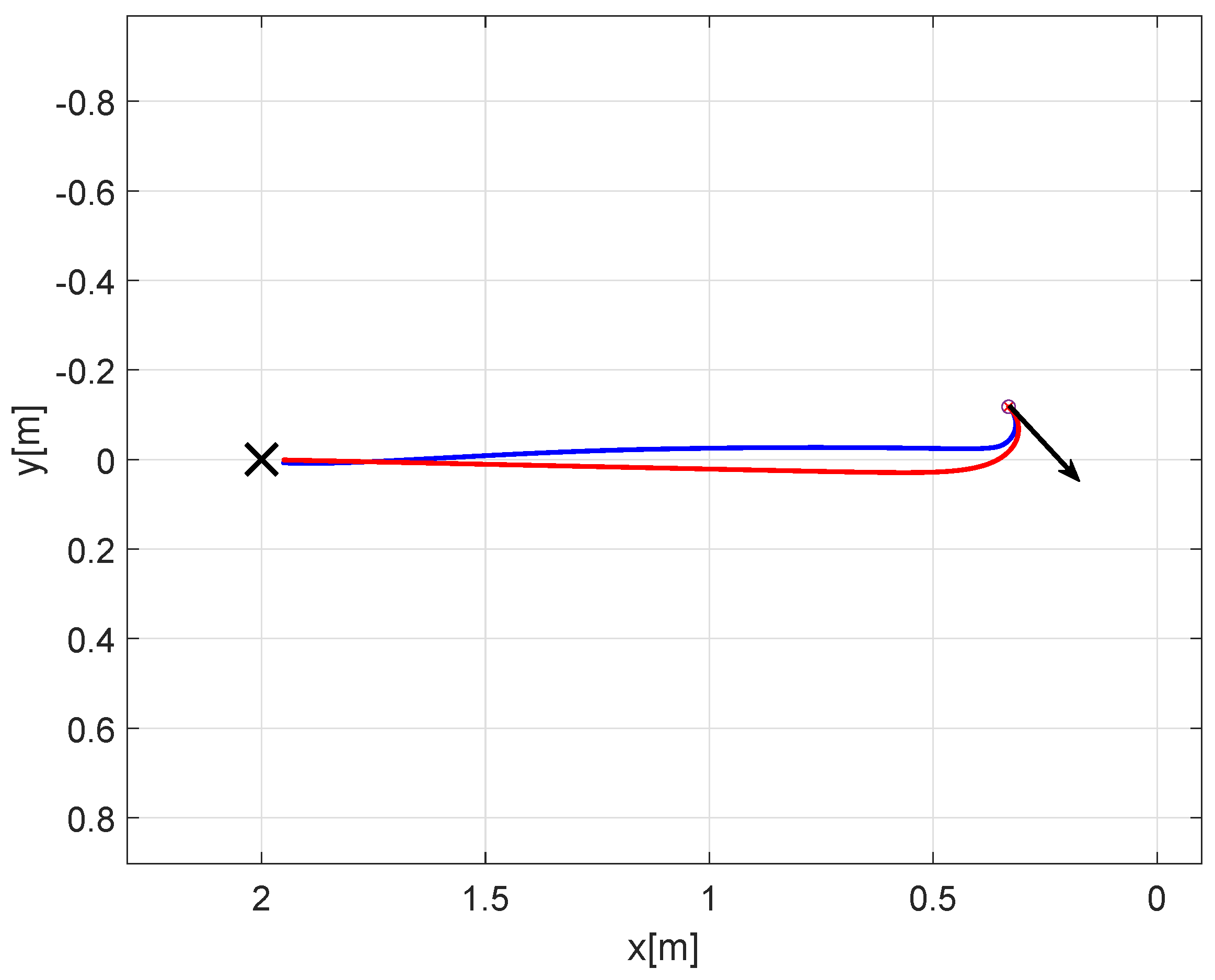
4.1. First Scenario: Cooperative vs. Non-Cooperative Formation
4.2. Second Scenario: Obstacle Avoidance
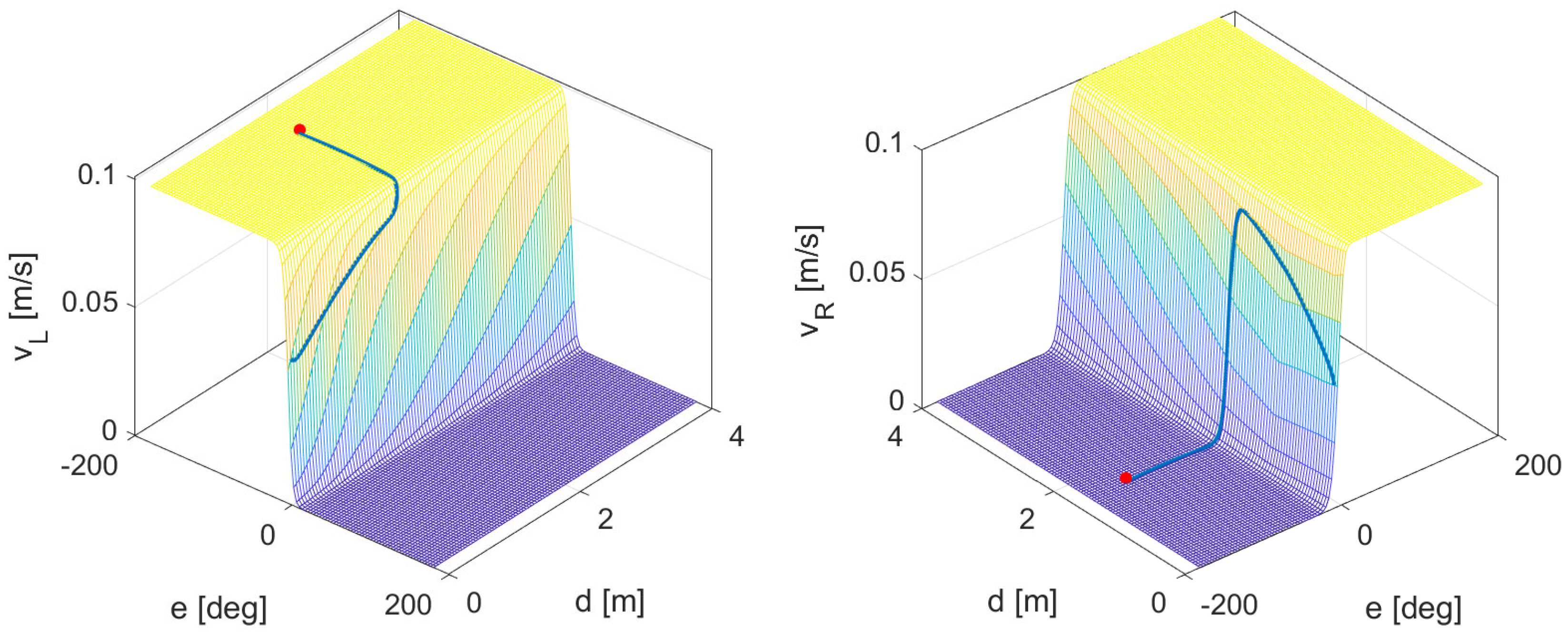
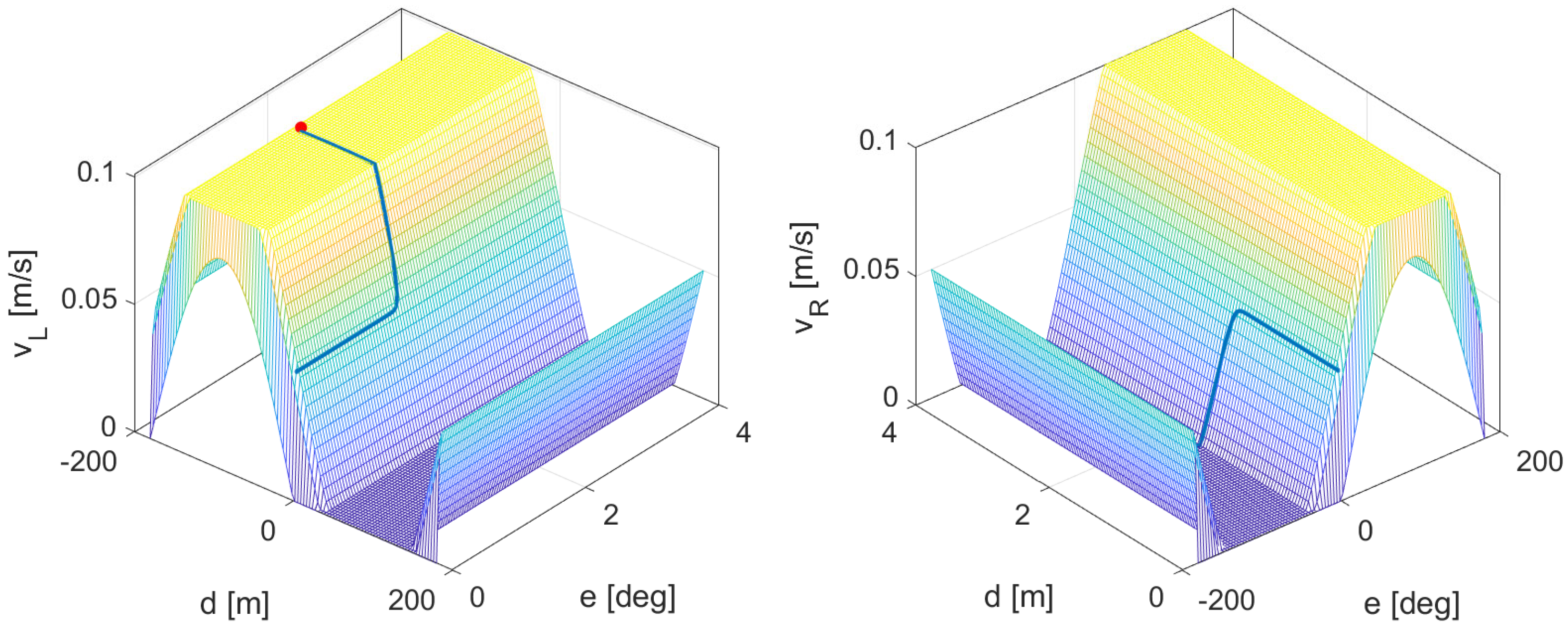
4.3. Control Laws Performance Comparison
4.3.1. Non-Cooperative Control Case
4.3.2. Cooperative Formation Control Case
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson: London, UK, 2016. [Google Scholar]
- McCarthy, J. What Is Artificial Intelligence? 2007. Available online: http://jmc.stanford.edu/articles/whatisai/whatisai.pdf (accessed on 1 December 2024).
- Domingos, P. The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World; Basic Books: New York, NY, USA, 2015. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Wang, X.; Zhao, Y.; Pourpanah, F. Recent Advances in Deep Learning. Int. J. Mach. Learn. Cybern. 2020, 11, 385–400. [Google Scholar] [CrossRef]
- Talaei Khoei, T.; Ould Slimane, H.; Kaabouch, N. Deep Learning: Systematic Review, Models, Challenges, and Research Directions. Neural Comput. Appl. 2023, 35, 23103–23124. [Google Scholar] [CrossRef]
- Mienye, I.D.; Swart, T.G. A Comprehensive Review of Deep Learning: Architectures, Recent Advances, and Applications. Information 2024, 15, 755. [Google Scholar] [CrossRef]
- Ghasemi, M.; Mousavi, A.H.; Ebrahimi, D. Comprehensive Survey of Reinforcement Learning: From Algorithms to Practical Challenges. arXiv 2024, arXiv:2411.18892. [Google Scholar] [CrossRef]
- Wong, A.; Bäck, T.; Kononova, A.V.; Plaat, A. Deep multiagent reinforcement learning: Challenges and directions. Artif. Intell. Rev. 2023, 56, 5023–5056. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, Y.; Chen, X. Recent advances in deep learning models: A systematic review. Multimed. Tools Appl. 2023, 82, 15295–15320. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multi-Agent Systems: A Review of Challenges, Solutions and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef]
- Gronauer, S.; Diepold, K. Multi-agent deep reinforcement learning: A survey. Artif. Intell. Rev. 2022, 55, 895–943. [Google Scholar] [CrossRef]
- Dutta, A.; Orr, J. Kernel-based Multiagent Reinforcement Learning for Near-Optimal Formation Control of Mobile Robots. Appl. Intell. 2022, 52, 12345–12360. [Google Scholar] [CrossRef]
- Dawood, M.; Pan, S.; Dengler, N.; Zhou, S.; Schoellig, A.P.; Bennewitz, M. Safe Multi-Agent Reinforcement Learning for Formation Control without Individual Reference Targets. arXiv 2023, arXiv:2312.12861. [Google Scholar] [CrossRef]
- Mukherjee, S. Formation Control of Multi-Agent Systems. Master’s Thesis, University of North Texas, Denton, TX, USA, 2017. [Google Scholar]
- Nagahara, M.; Azuma, S.I.; Ahn, H.S. Formation Control. In Control of Multi-Agent Systems; Springer: Berlin/Heidelberg, Germany, 2024; pp. 113–158. [Google Scholar] [CrossRef]
- Farias, G.; Fabregas, E.; Peralta, E.; Vargas, H.; Dormido-Canto, S.; Dormido, S. Development of an Easy-to-Use Multi-Agent Platform for Teaching Mobile Robotics. IEEE Access 2019, 7, 55885–55897. [Google Scholar] [CrossRef]
- Farias, G.; Garcia, G.; Montenegro, G.; Fabregas, E.; Dormido-Canto, S.; Dormido, S. Reinforcement Learning for Position Control Problem of a Mobile Robot. IEEE Access 2020, 8, 152941–152951. [Google Scholar] [CrossRef]
- Quiroga, F.; Hermosilla, G.; Farias, G.; Fabregas, E.; Montenegro, G. Position Control of a Mobile Robot through Deep Reinforcement Learning. Appl. Sci. 2022, 12, 7194. [Google Scholar] [CrossRef]
- Gonzalez-Villela, V.; Parkin, R.; Lopez, M.; Dorador, J.; Guadarrama, M. A wheeled mobile robot with obstacle avoidance capability. Ing. Mecánica. Tecnol. Y Desarro. 2004, 1, 150–159. [Google Scholar]
- Baillieul, J. The geometry of sensor information utilization in nonlinear feedback control of vehicle formations. In Proceedings of the Cooperative Control: A Post-Workshop Volume 2003 Block Island Workshop on Cooperative Control; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–24. [Google Scholar] [CrossRef]
- Siegwart, R.; Nourbakhsh, I.R.; Scaramuzza, D. Introduction to Autonomous Mobile Robots; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Fabregas, E.; Farias, G.; Aranda-Escolástico, E.; Garcia, G.; Chaos, D.; Dormido-Canto, S.; Bencomo, S.D. Simulation and Experimental Results of a New Control Strategy For Point Stabilization of Nonholonomic Mobile Robots. IEEE Trans. Ind. Electron. 2020, 67, 6679–6687. [Google Scholar] [CrossRef]
- Rohmer, E.; Singh, S.P.N.; Freese, M. V-REP: A Versatile and Scalable Robot Simulation Framework. In Proceedings of the Proc. of The International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013. [Google Scholar] [CrossRef]
- Farias, G.; Fabregas, E.; Peralta, E.; Torres, E.; Dormido, S. A Khepera IV library for robotic control education using V-REP. IFAC-PapersOnLine 2017, 50, 9150–9155. [Google Scholar] [CrossRef]
- Ma, Y.; Cocquempot, V.; El Najjar, M.E.B.; Jiang, B. Actuator failure compensation for two linked 2WD mobile robots based on multiple-model control. Int. J. Appl. Math. Comput. Sci. 2017, 27, 763–776. [Google Scholar] [CrossRef]
- Morales, G.; Alexandrov, V.; Arias, J. Dynamic model of a mobile robot with two active wheels and the design an optimal control for stabilization. In Proceedings of the 2012 IEEE Ninth Electronics, Robotics and Automotive Mechanics Conference, Cuernavaca, Mexico, 19–23 November 2012; pp. 219–224. [Google Scholar] [CrossRef]
- Fabregas, E.; Farias, G.; Dormido-Canto, S.; Guinaldo, M.; Sánchez, J.; Dormido Bencomo, S. Platform for teaching mobile robotics. J. Intell. Robot. Syst. 2016, 81, 131–143. [Google Scholar] [CrossRef]
- Shayestegan, M.; Marhaban, M.H. A Braitenberg Approach to Mobile Robot Navigation in Unknown Environments. In Proceedings of the Trends in Intelligent Robotics, Automation, and Manufacturing, Kuala Lumpur, Malaysia, 28–30 November 2012; pp. 75–93. [Google Scholar] [CrossRef]
- Gogoi, B.J.; Mohanty, P.K. Path Planning of E-puck Mobile Robots Using Braitenberg Algorithm. In Proceedings of the International Conference on Artificial Intelligence and Sustainable Engineering; Springer: Berlin/Heidelberg, Germany, 2022; pp. 139–150. [Google Scholar] [CrossRef]
- Dorri, A.; Kanhere, S.S.; Jurdak, R. Multi-agent systems: A survey. IEEE Internet Things J. 2018, 6, 285–298. [Google Scholar] [CrossRef]
- Brambilla, M.; Ferrante, E.; Birattari, M.; Dorigo, M. Swarm robotics: A review from the swarm engineering perspective. Swarm Intell. 2013, 7, 1–41. [Google Scholar] [CrossRef]
- Osooli, H.; Robinette, P.; Jerath, K.; Ahmadzadeh, S.R. A Multi-Robot Task Assignment Framework for Search and Rescue with Heterogeneous Teams. arXiv 2023, arXiv:2309.12589v1. [Google Scholar] [CrossRef]
- Lawton, J.; Beard, R.; Young, B. A decentralized approach to formation maneuvers. IEEE Trans. Robot. Autom. 2003, 19, 933–941. [Google Scholar] [CrossRef]
- Oh, K.K.; Park, M.C.; Ahn, H.S. A survey of multi-agent formation control. Automatica 2015, 53, 424–440. [Google Scholar] [CrossRef]
- Oroojlooy, J.; Snyder, L.V. A Review of Cooperative Multi-Agent Deep Reinforcement Learning. arXiv 2021, arXiv:2106.15691. [Google Scholar] [CrossRef]
- Morales, M. Grokking Deep Reinforcement Learning; Co., Manning Publications: Shelter Island, NY, USA, 2020. [Google Scholar]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. Found. Trends Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef]

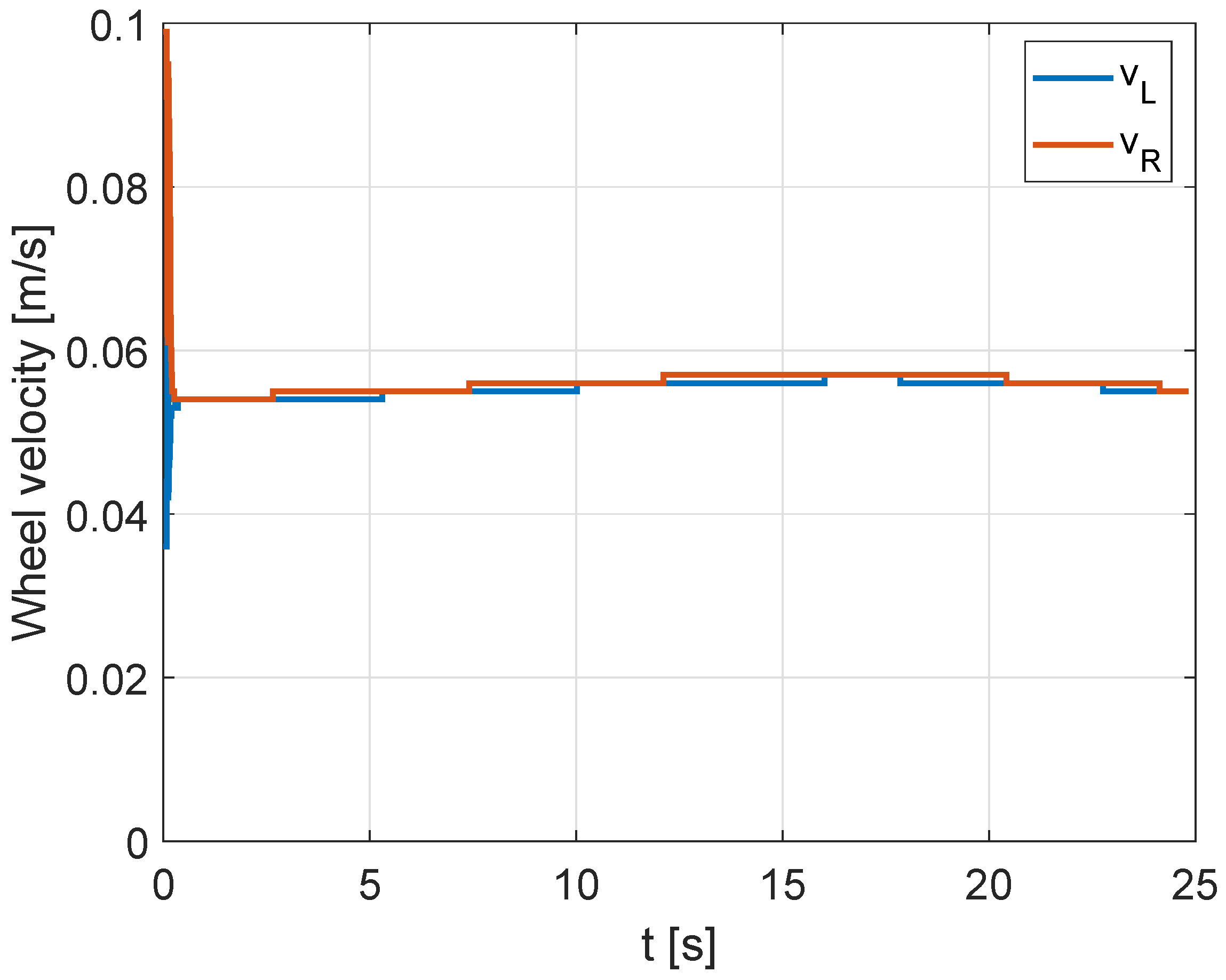




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indexes | Villela | DRL |
|---|---|---|
| IAE | ||
| ISE |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garcia, G.; Eskandarian, A.; Fabregas, E.; Vargas, H.; Farias, G. Cooperative Formation Control of a Multi-Agent Khepera IV Mobile Robots System Using Deep Reinforcement Learning. Appl. Sci. 2025, 15, 1777. https://doi.org/10.3390/app15041777
Garcia G, Eskandarian A, Fabregas E, Vargas H, Farias G. Cooperative Formation Control of a Multi-Agent Khepera IV Mobile Robots System Using Deep Reinforcement Learning. Applied Sciences. 2025; 15(4):1777. https://doi.org/10.3390/app15041777
Chicago/Turabian StyleGarcia, Gonzalo, Azim Eskandarian, Ernesto Fabregas, Hector Vargas, and Gonzalo Farias. 2025. "Cooperative Formation Control of a Multi-Agent Khepera IV Mobile Robots System Using Deep Reinforcement Learning" Applied Sciences 15, no. 4: 1777. https://doi.org/10.3390/app15041777
APA StyleGarcia, G., Eskandarian, A., Fabregas, E., Vargas, H., & Farias, G. (2025). Cooperative Formation Control of a Multi-Agent Khepera IV Mobile Robots System Using Deep Reinforcement Learning. Applied Sciences, 15(4), 1777. https://doi.org/10.3390/app15041777