Abstract
Multi-agent reinforcement learning (MARL) has proven to be effective and promising in team collaboration tasks. Knowledge transfer in MARL has also received increasing attention. Compared to knowledge transfer in single-agent tasks, knowledge transfer in multi-agent tasks is more complex due to the need to account for coordination among agents. However, existing knowledge transfer-based methods only focus on strategies or agent-level knowledge in a single task, and the transfer of knowledge in such a specific task to new and different types of tasks is likely to fail. In this paper, we propose a multitask-based training framework termed MTT in cooperative MARL, which aims to learn shared collaborative knowledge across multiple tasks simultaneously and then apply it to solve other related tasks. However, models obtained from multitask learning may fail on other tasks because the gradients from different tasks may conflict with each other. To obtain a model with shared knowledge, we provide conflict-free updates by ensuring a positive dot product between the final update and the gradient of each specific task. It also maintains a consistent optimization rate for all tasks. Experiments conducted in two popular environments, StarCraft II Multi-Agent Challenge and Google Research Football, demonstrate that our method outperforms the baselines, significantly improving the efficiency of team collaboration.
1. Introduction
With the booming development of the deep learning field, significant progress has been made in deep reinforcement learning, especially in multi-agent reinforcement learning. In real-life scenarios, multi-agent reinforcement learning techniques have been widely applied to numerous fields, such as autonomous driving [1,2], cluster collaborative operations [3], and robot manipulation [4,5]. Particularly in the field of games, reinforcement learning has demonstrated robust capabilities, enabling agents to complete various tasks with high efficiency. Examples include symmetric game [6], AlphaStar [7], StarCraft II Multi-Agent Challenge (SMAC) [8], Google Research Football (GRF) [9], OpenAI Five [10], and JUEWU [11].
Although existing MARL has achieved significant success in various fields, limited knowledge acquisition by agents—such as restricted observation range or insufficient information—can result in inaccurate decisions, hindering the convergence of training algorithms. Previous studies have explored various dimensions, particularly focusing on leveraging knowledge from other tasks to facilitate learning for new tasks, a strategy commonly referred to as transfer learning.
Take StarCraft II game as an example, there are many symmetric tasks, such as , , , and . In the and , the number of agents differs, but the types of agents remain the same. When facing the same type of opponent, these two tasks are likely to share cooperative patterns or knowledge. In the above case, it is very suitable to transfer the knowledge of the learned tasks to new similar tasks to improve learning efficiency and team collaboration. For example, Schroeder et al. [12] proposed a multi-agent common knowledge reinforcement learning method for collaborative tasks in StarCraft II. However, this approach assumes that the agents share common observations as common knowledge, whereas in practice, the agents may not have access to the same observations. Wang et al. [13] utilized decision-making knowledge to enhance team collaboration performance, yet this method only supports value-based algorithms. Hu et al. [14] introduced a knowledge transfer method with an intermediate task for confrontation decision-making. In the field of MARL, the majority of transfer learning research focuses on agent-centered knowledge, with only a few studies involving transfer at the policy level. For instance, Chen et al. [15] proposed a transfer learning method based on an attention mechanism. Nonetheless, this approach is grounded in the transfer of knowledge from a single task and necessitates a high degree of similarity between the source and target tasks for effective transfer. Furthermore, existing works on transfer learning in MARL ignore cross-task knowledge.
In this paper, we propose a multitask-based transfer framework aiming to improve team collaboration performance in multi-agent reinforcement learning. Different from other approaches that reuse the policy of a trained task or the coordination knowledge of multiple agents, our method consists of two stages. First, we extract the shared cooperation knowledge in multiple tasks through multitask training and then transfer it to the new task. In our framework, each task is equipped with an observation embedding network and a decision network, and a shared knowledge extraction network is set between them. It is expected that after multitask training, this shared knowledge extraction network can extract the shared collaborative knowledge across multiple tasks. Sometimes, learning multiple tasks simultaneously results in lower accuracy than learning only the target task, which is known as negative transfer. This problem is often attributed to the gradient conflicts among tasks. To alleviate the problem of model performance degradation caused by gradient conflicts between tasks during multitask training, MTT achieves conflict-free updates by ensuring a positive dot product between the final update and the gradient of each specific task, while maintaining a consistent optimization rate for all loss terms and dynamically adjusting the gradient magnitude according to the conflict level. Moreover, since each task in the framework has an independent observation embedding network and decision network, the framework shows strong adaptability to various reinforcement learning algorithms. The framework is capable of selectively integrating value-based reinforcement learning algorithms, including DQN [16] or policy-based approaches, like PPO [17], contingent upon the specific application context, thereby conferring the architecture with pronounced versatility.
We evaluate the proposed method in two commonly used multi-agent environments, StarCraft II and Google Research Football. The experimental results show that our method outperforms the baseline methods in all tasks, and the model trained in StarCraft II can be effectively transferred to the Google Research Football environment, which fully verifies that our method can achieve efficient cross-domain transfer.
The main contributions of this paper are as follows:
- (1)
- We propose a two-stage multitask-based transfer framework, which is compatible with multiple reinforcement learning algorithms, covering value-based methods and policy-based methods.
- (2)
- During the training process, we extract the collaborative knowledge shared among multiple tasks based on a multitask training approach and then transfer it to new unseen tasks to promote their learning efficiency and teamwork effects.
- (3)
- To solve the conflict problem in the multitask learning process, we introduce a gradient processing method to ensure conflict-free updates during training.
- (4)
- We evaluate our framework in the two complex environments of StarCraft II and Google Research Football. The experimental results show that our method outperforms the baseline methods in all tasks and can achieve effective cross-domain transfer.
2. Related Work
2.1. Cooperative Multi-Agent Reinforcement Learning
In this section, we will review research approaches and the current state of the art in CMARL, highlighting existing methods and frameworks based on different environments. CMARL explores algorithms and strategies that facilitate collaborative learning, adaptation, and decision-making in shared environments by multiple agents. In a technologically driven world where multi-agent systems are becoming increasingly prevalent, ensuring effective and seamless cooperation between agents is of paramount importance. To address this, various research environments have been developed, each designed to test and refine the strategies and algorithms in CMARL. These environments provide distinct challenges, facilitating the exploration of collaborative behaviors, task allocation, and adaptation in dynamic settings. The authors in [18,19,20] build upon the cooperative video game environment Overcooked [21], where agents collaboratively prepare and serve onion soup by dividing tasks and adapting to varying teammates, focusing on scenarios in which agents must cooperate with new individuals they have not encountered during prior training, thereby exploring approaches for effective human–AI coordination in future applications. In [22,23,24], multi-agent cooperation is investigated in the MuJoCo Soccer environment [25], a simplified 2v2 team-based game where agents navigate a 3D space with the objective of coordinating to kick a ball into the opposing team’s goal. Their work focuses on enhancing coordination, communication, and tactical behavior to improve performance and facilitate real-world applications in dynamic, team-based tasks.
The StarCraft II Multi-Agent Challenge (SMAC) [8] and Google Research Football (GRF) [9] provide environments for the study of multi-agent cooperation. In the context of SMAC, agents collaborate in a real-time strategy environment where partial observability applies, while in GRF, they engage in dynamic collaborative play in a football game with the objective of controlling the ball and scoring goals. To narrow the gap between multi-agent systems and real-world applications, Deng et al. [26] and Ellis et al. [27] increase environmental complexity and introduce challenges that promote deeper cooperation. Specifically, Ellis et al. [27] incorporates randomized elements such as varying unit types and spawn locations, whereas Deng et al. [26] introduces hybrid opponent strategy scripts. In addition, Liu et al. [28] improves training efficiency by adaptively selecting the most informative learning segments and explores ways to optimize information sharing and decision coordination. Lan et al. [29] leverages contrastive learning and temporal attention mechanisms to mitigate negative transfer, accelerating agent adaptation to new environments. Meanwhile, Chen et al. [30] presents a general training framework that tackles the curse of dimensionality by training on alternating subsets of agents, using existing deep MARL algorithms as base trainers. Yang et al. [31] proposes the Dynamic Subtask Assignment framework, which dynamically allocates agents to subtasks based on their abilities using a subtask encoder and ability-based selection strategy, alongside regularizers to stabilize training and boost performance in both SMAC and GRF. Li et al. [32] introduce the dynamic skill learning framework, enabling agents to acquire diverse abilities through intrinsic rewards, which enhances performance in cooperative MARL tasks like SMAC and GRF. Wang et al. [33] proposes a metric for evaluating cooperation between an ego-agent and unfamiliar partners in dynamic team compositions, emphasizing adaptability and generalization in collaborative scenarios.
However, the aforementioned studies predominantly focus on multi-agent cooperation tasks within single environments and generally lack cross-domain experimental analysis, limiting the broader applicability of their findings. This emphasis on isolated environments overlooks the potential for transferability of learned cooperation strategies across domains, which is crucial for advancing generalizable multi-agent systems. In contrast, one of the key contributions of our work is the investigation of task transfer across different environments. Through a series of rigorous experiments, we show that despite inherent differences in task specificities, cooperative scenarios across domains share underlying commonalities. These commonalities provide a basis for the transfer of learned cooperation strategies, thereby enhancing the adaptability and scalability of multi-agent systems in real-world applications.
In addition to the study of cooperative multi-agent systems, this paper also covers the domain knowledge of multitasking and transfer learning, which we will introduce in the following subsections.
2.2. Multitask Learning
Here, we will provide a review of existing solutions for multitask learning (MTL) [34,35,36], particularly in the context of reinforcement learning (RL). MTL, a method that follows a “learning-to-learn” approach to utilize a system’s shared representations to train, in parallel, the domain-relevant information accumulated from individually relevant tasks, has become a state-of-the-art learning method for many benchmark tasks and even certain real-world problems. This ability to leverage shared representations has been particularly effective in domains such as natural language processing (NLP) [37] and computer vision (CV) [38], where a wide range of tasks often share underlying structures or features. Just as “Jade can be polished with stones from other mountains”. Researchers [39,40,41] have also demonstrated the effectiveness of MTL in reinforcement learning, a task known as multitask reinforcement learning (MTRL).
Moreover, attention-based mechanisms [29] have been incorporated into MTRL to selectively focus on task-relevant features, improving knowledge transfer and task performance. The authors in [42,43] focus on solving gradient challenges in multitask learning, especially in optimizing task-specific gradients and dealing with conflicting gradients between tasks. The works [44,45] can be classified as routing-based methods, where different strategies are employed to allocate resources (e.g., encoders, modules, or parameters) across tasks based on their specific requirements or difficulty levels.
However, the MTRL studies mentioned above are all based on a single-agent environment, which we refer to as multitask single-agent reinforcement learning (MT-SARL). Although MT-SARL research has made significant progress, it still faces significant challenges when applied to real-world problems, which often involve complex and dynamic tasks. Furthermore, the limitations of the single-agent framework in MT-SARL hinder its ability to effectively manage the interactions and diverse tasks present in more realistic multi-agent settings. These challenges highlight the growing need for multitask multi-agent reinforcement learning (MT-MARL), where multiple agents must simultaneously collaborate, compete, and adapt to various tasks, reflecting the complexity of real-world scenarios.
Recent research in MT-MARL has made significant progress in overcoming key challenges, focusing on enhancing knowledge sharing, coordination, and efficient resource allocation among agents. Zhu et al. [46] address these challenges by employing pre-trained language models for task encoding, utilizing a task entity transformer to handle varying agent numbers and task complexity, and optimizing training efficiency through task learning weight adjustments based on task regret. Li et al. [47] introduce a novel MT-MARL algorithm that improves performance by modeling agent interactions via interactive value decomposition and learning task representations from local trajectories, facilitating knowledge transfer across related tasks in both multitask and zero-shot scenarios. Mai et al. [48] proposes a new multitask approach for cooperative MARL, leveraging knowledge transfer from task-specific teachers to enable a single team of agents to achieve expert-level performance across multiple tasks. This method uses a knowledge distillation algorithm tailored for multi-agent architectures and incorporates teacher annealing, which gradually shifts learning from distillation to environmental rewards, enabling the multitask model to surpass its singletask counterparts. In contrast to the approach in [48], which requires a two-step process of pre-training a teacher model for each task before learning, our method simplifies the process by starting multitask training directly from scratch without the need for a teacher model.
2.3. Transfer Learning
Existing works on transfer in reinforcement learning mainly focus on two directions: multi-agent [44,49] and multitask [47,48]. In multi-agent transfer learning, there are two branches: one is intra-agent transfer, and the other is inter-agent transfer. In this paper, we focus on cross-task collaborative knowledge transfer, and most of the work in this area is concentrated on designing adaptive network architectures. In the studies by Tian (2024) and Wang (2024), an attention mechanism is incorporated to process observational features and compute the value or the probability of action selection by Tian et al. [50] and Wang et al. [51]. Tian et al. [50] proposed a novel framework called decompose a task into generalizable subtasks (DT2GSs), which achieved efficient generalization and transfer of knowledge across tasks by decomposing tasks into task-independent subtasks and dynamically adapting their semantics through attention mechanisms. Tian et al. [50] and Yang et al. [52] model knowledge transfer among multiple agents as an option learning problem, in which Yang et al. [52] use an option module to dynamically select appropriate policies for each agent while leveraging termination probabilities to determine when to stop using a policy to avoid negative transfer. Guo et al. [53] proposed a structure named explainable action advising (EAA), which is based on the teacher–student paradigm, where the teacher agent not only provides action advice (state–action pairs) but also offers explanations to clarify why the action is taken. These explanations are presented in the form of decision paths, helping the student understand the reasoning behind the advice to enhance the interpretability and transferability of knowledge.
In the studies by Liu et al. [54] and Zhou et al. [55], a network architecture was developed that is independent of the number of agents, facilitating coordinated migration across various-sized multi-agent scenarios. Among these, Zhou et al. [55] introduced a policy network termed “population invariant agent with Transformer (PIT)”, which incorporates an adaptive action module to enhance its functionality. The module adaptively constructs the action space of the agent according to different situations and interactions between agents. Yang et al. [56] used graph neural networks to create a structured policy network. The network learns the policies for each source task by capturing the intrinsic properties of the state–action space.
3. Preliminaries
3.1. Decentralized Partially Observable Markov Decision Process
The decentralized partially observable Markov decision process (Dec-POMDP) [57] can be used to model partially observable cooperative multi-agent tasks. A Dec-POMDP consists of a tuple . S is the state space, where represents the global environment state. Every agent picks an action from the action space U at each timestep and forms the joint-action to interact with the environment. Then, a state transition will occur according to a state transition function . Agents will receive a reward signal from the reward function with a discount factor . In the execution stage, every agent draws a local observation by an observation function . Every agent stores an observation–action history , based on which agent a derives a policy . Joint-action value is the expectation of the discounted reward sum under joint-policy . In this article, we use to represent a state pair (state transition) consisting of two consecutive states: . We consider Dec-POMDPs, where agents cooperate to fulfill a common purpose, and each agent has a finite discrete action set.
3.2. Multitask Learning
Definition 1 (Multitask Learning).
Given N learning tasks , where all the tasks or a subset of them are related, multitask learning aims to learn the n tasks together to improve the learning of a model for each task by using the knowledge contained in all or some of the other tasks.
Based on the definition of MTL, we take supervised learning tasks as an example; then, a task is usually accompanied by a training dataset consisting of training samples, i.e., , where is the jth training instance in and is its label. We denote by the training data matrix for , i.e., .
According to the definition of MTL, there are three problems to be addressed: when to share, what to share, and how to share. The when to share issue is to make choices between singletask and multitask models for a multitask problem. Currently, such a decision is made by human experts, and there are few works to study it. What to share needs to determine the form through which knowledge sharing among all the tasks could occur. Existing MTL studies mainly focus on feature-based and parameter-based methods, and only a few works belong to the instance-based method. After establishing what to share, the how to share aspect delineates the specific strategies for knowledge sharing among tasks. In feature-based MTL, the primary method is the feature learning approach, which focuses on learning a common feature representation for multiple tasks using shallow or deep models.
4. Methodology
In contrast to knowledge transfer methodologies rooted in singletask learning, the multitask learning-based approach enables the extraction and transfer of knowledge across a spectrum of related tasks, thereby enhancing learning efficiency and the model’s capacity for generalization. In this section, we introduce the proposed multitask-based transfer framework, which utilizes multitask training to facilitate knowledge transfer in the domain of multi-agent reinforcement learning. Our framework leverages multitask training to extract shared cooperative knowledge from multiple tasks and then transfers this knowledge to novel multi-agent collaborative tasks, with the objective of augmenting the collaborative efficacy of multi-agent teams. Specifically, we commence by delineating the overall architecture of the method, proceeding with an in-depth explication of the individual components within the framework.
4.1. Overview of Our Framework
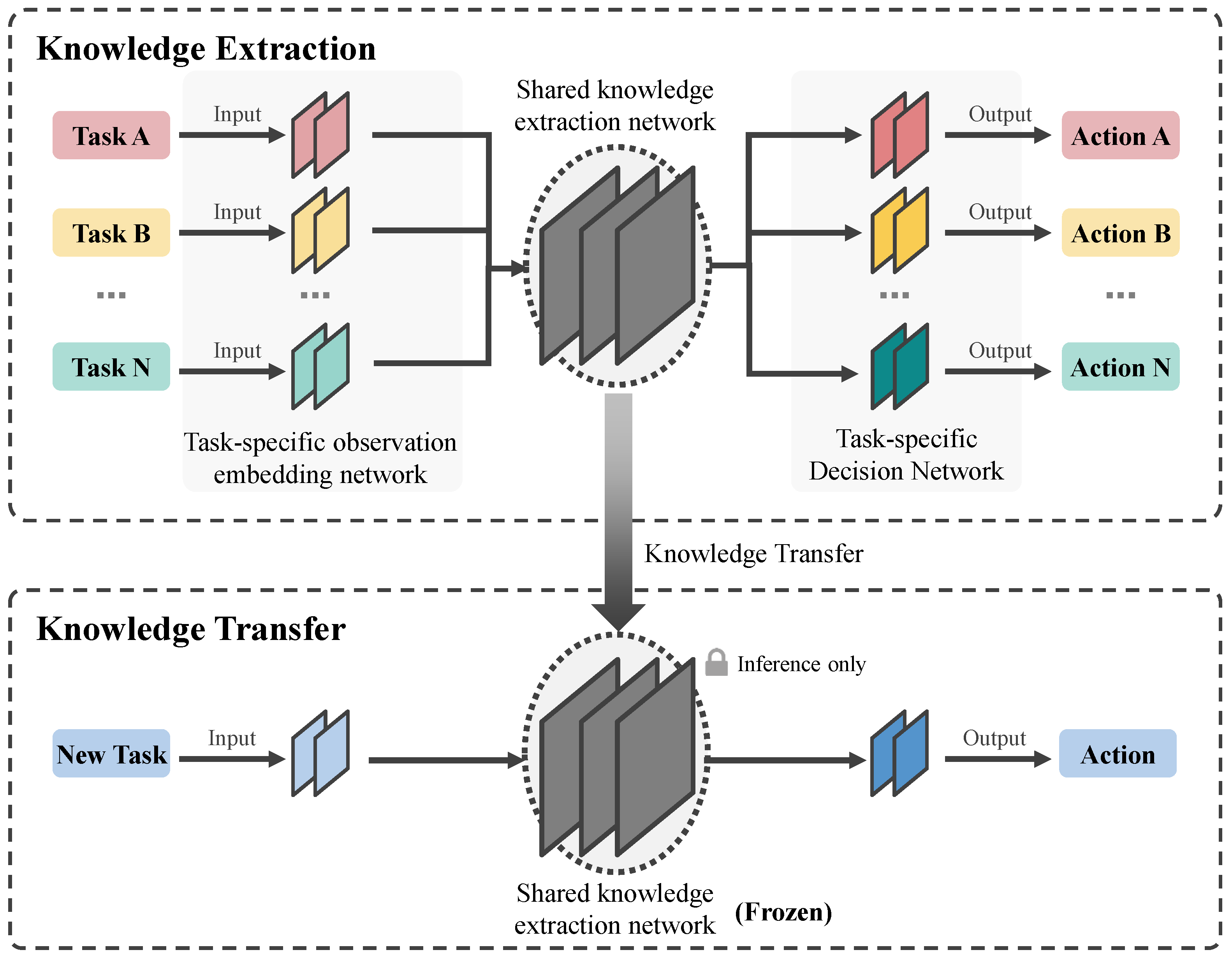
We begin by presenting the overarching framework of our methodology, as depicted in Figure 1. During multitask training, each task is equipped with dedicated perception and decision layers, while a shared knowledge layer resides between these two layers, being optimized by the gradients of every task. Our approach leverages the independent proximal policy optimization (IPPO) [58] policy-based algorithm to construct our framework. Given that each task within our framework possesses independent perception and decision layers, our framework exhibits flexibility and universality, accommodating both value-based algorithms such as QMIX and VDN, as well as policy-based algorithms like PPO and soft actor–critic (SAC) [59].
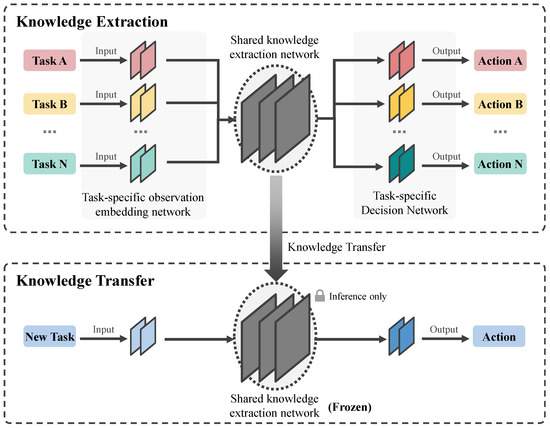
Figure 1.
Overview of the architecture of our proposed framework.
The framework is comprised of two integral components: knowledge transfer via multitask training and conflict resolution in multitask training. The knowledge transfer component, situated within the multitask training paradigm, extracts collaborative knowledge across various tasks. This shared knowledge layer, acquired upon the conclusion of training, is elaborated in Section IV-B. The conflict resolution module in multitask training addresses the individual orientations of each task, mitigating conflicts that may arise during the optimization of the shared knowledge extraction layer. A detailed discussion of this module is provided in Section IV-C.
4.2. Knowledge Transfer Based on Multitask Training
As illustrated in Figure 1, our framework encompasses two phases: the knowledge extraction phase and the knowledge transfer phase.
Knowledge Extraction: The knowledge extraction component adheres to a conventional multitask training architecture, comprising task-specific observation embedding networks and decision networks, as well as a shared knowledge extraction network for all tasks. Suppose we have N tasks . Consequently, we will have N observation embedding networks, N action mapping networks, and one knowledge extraction network. The architecture for each task-specific observation embedding network is uniform, consisting of a two-layer neural network with an initial fully connected layer followed by an LSTM layer. The input dimensions of each task’s observation embedding network vary due to the distinct state space dimensions across different tasks. The observation embedding network takes the task’s state s as input and outputs a fixed 256-dimensional embedding. Subsequently, a shared knowledge extraction network, which is a two-layer fully connected neural network, processes the output of the observation embedding networks to produce a fixed-dimensional embedding. Similar to the observation embedding networks, the decision networks for all tasks share an identical architecture, consisting of a two-layer fully connected neural network that takes the output of the shared knowledge extraction network as input and produces the final output. The final layer of the decision network is adjusted according to the action space dimensions of the respective task, as each task’s action space dimensionality may differ. For each task, we employ the IPPO algorithm for training.
IPPO is a multi-agent reinforcement learning algorithm that extends the widely used proximal policy optimization (PPO) algorithm to multi-agent settings. Unlike centralized approaches that rely on global observations or joint action spaces, IPPO adopts a decentralized training paradigm, where each agent independently optimizes its own policy while interacting with the environment and other agents. This independence simplifies training and scales efficiently to scenarios with a large number of agents. IPPO assumes a partially observable Markov game, where each agent i has its own observation space , action space , and policy parameterized by . The goal of each agent is to maximize its cumulative discounted reward:
where denotes the trajectory, is the discount factor, and is the reward received by agent i at time step t. Similar to PPO, IPPO uses a clipped surrogate objective to update each agent’s policy. The objective function for agent i is given by:
where is the probability ratio between the new and old policies, is the advantage estimate for agent i, is a hyperparameter controlling the clipping range.
Within each episode, tasks are trained in a round-robin fashion until all tasks have converged or the predefined maximum number of training steps is reached. The shared knowledge extraction network obtained upon completion of training is regarded as the common knowledge extracted during multitask training. This network is then transferred to new tasks to enhance the collaborative performance of multi-agent teams.
Knowledge Transfer: In the knowledge transfer phase, we employ a singletask training architecture where the shared knowledge network, acquired from the knowledge extraction phase in the previous stage, is directly applied to the training process of the new task, as depicted in the lower half of Figure 1. It is important to note that the shared knowledge network is transferred to the new task in a frozen state. This implies that only the parameters of the observation embedding network and the decision network undergo continuous updates during the training of the new task.
4.3. Handling Gradient Conflict in Multitask Training
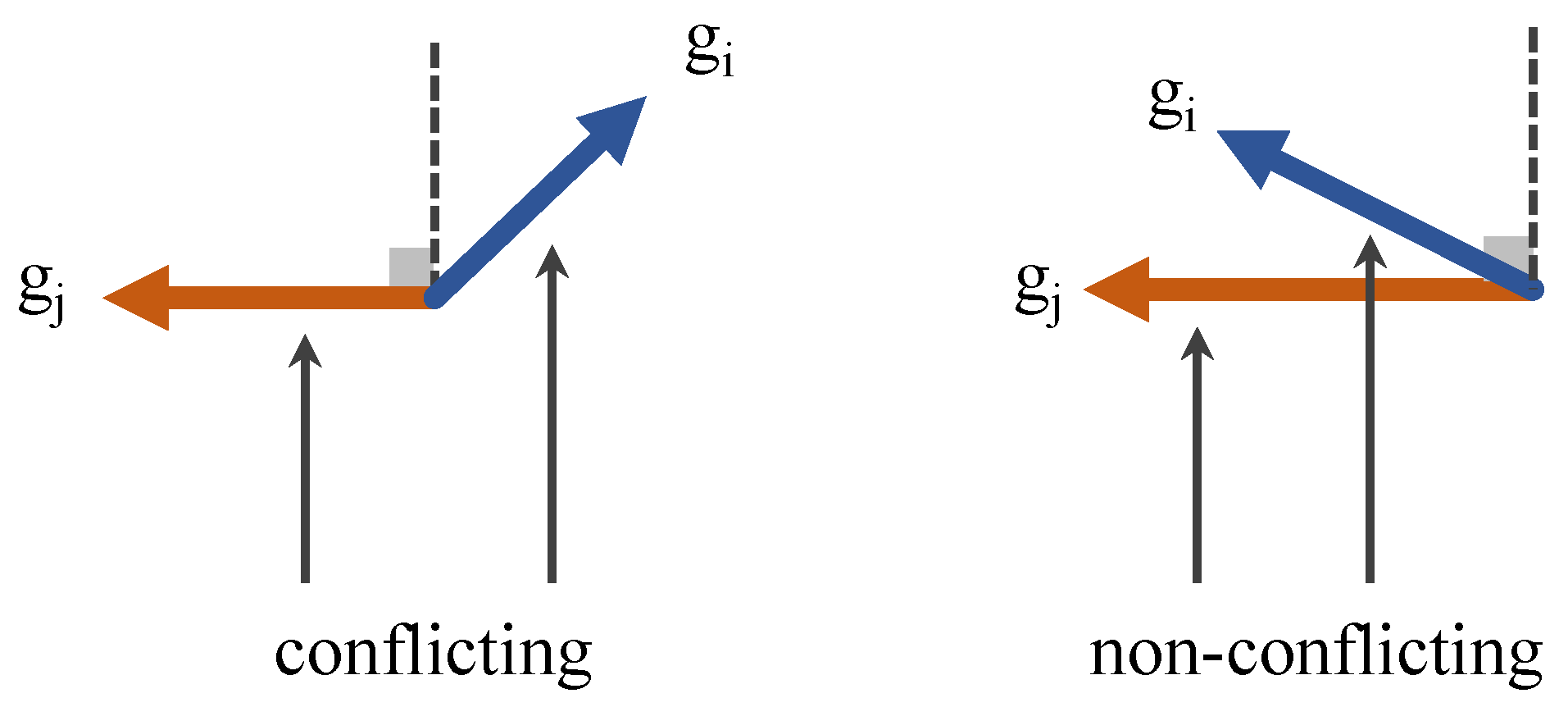
We focus on the optimization conflict problem in multitask learning as shown in Figure 2. The gradient size and direction of different tasks may be different, which may lead to gradient conflict and hinder model learning [42,60]. The degree of gradient conflict is usually measured by gradient cosine similarity [61]. We aim to reduce the conflict in the optimization process by processing the gradient in multitask training.
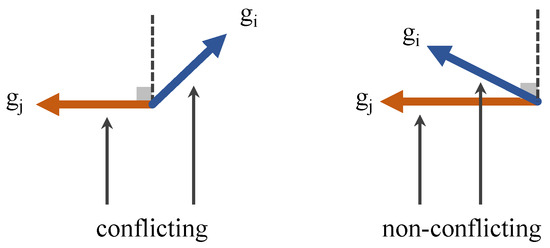
Figure 2.
Visualization of toy example showing the conflict between different losses during optimization.
Specifically, we consider a multitask training optimization process with N tasks, i.e., . The gradients of the loss functions corresponding to each task are represented by . There is a gradient , and we assume the gradient of task . These two gradients are conflicting if is negative [62]. Therefore, in order to update the gradient without conflict, it is necessary to ensure that are positive. The above conditions for conflict-free gradient updates can be transformed into , where is a vector with n positive components. Here, represents the pseudoinverse of the transposed matrix .
A positive vector guarantees a conflict-free update direction for all losses, it is also necessary to determine the specific direction of . Since the value of influences the precise orientation of , it is essential to regulate the specific value of accordingly. We reformulate as , where is a normalization operator and . Now, k controls the length of and the ratio of ’s components corresponds to the ratio of ’s projections onto each task-specific . can be called the direction weight. The projection length of on each task-specific gradient serves as an effective “learning rate” for each task.
However, setting a fixed k value is not always optimal during the optimization process, as the length of the gradient vector g should be adaptively adjusted according to different optimization scenarios. Specifically, when all gradients related to the task nearly point in the same direction, it indicates the presence of a favorable optimization direction, and the length of should be increased to enhance optimization in this direction. Conversely, if the gradients for specific tasks are close to each other, the length of should be decreased to avoid over-optimization. Addressing this issue, we propose an adaptive strategy where the length of is adjusted to the sum of the projected lengths of each task-specific gradient, thereby dynamically controlling the length of . The above process is summarized as follows:
where is a unit vector with n components. In addition, to ensure conflict-free gradient updates, the pseudo-inverse matrix needs to be calculated each time the gradient optimization is performed, which may bring some additional computational cost, but it is insignificant compared to the back-propagation calculation of the loss term.
5. Experiments
5.1. Experimental Setup
In this section, we demonstrate that our framework can improve learning efficiency and enhance the collaborative performance of multi-agent teams. We verify our findings through comprehensive experiments on SMAC and GRF, two widely used experimental environments in MARL. First, we provide an overview of the experimental scenarios, baselines, and settings, followed by a detailed presentation of the results, highlighting the superiority of our framework. In addition, we conduct ablation studies to confirm the contribution of each module to the enhancement of the framework.
5.1.1. SMAC
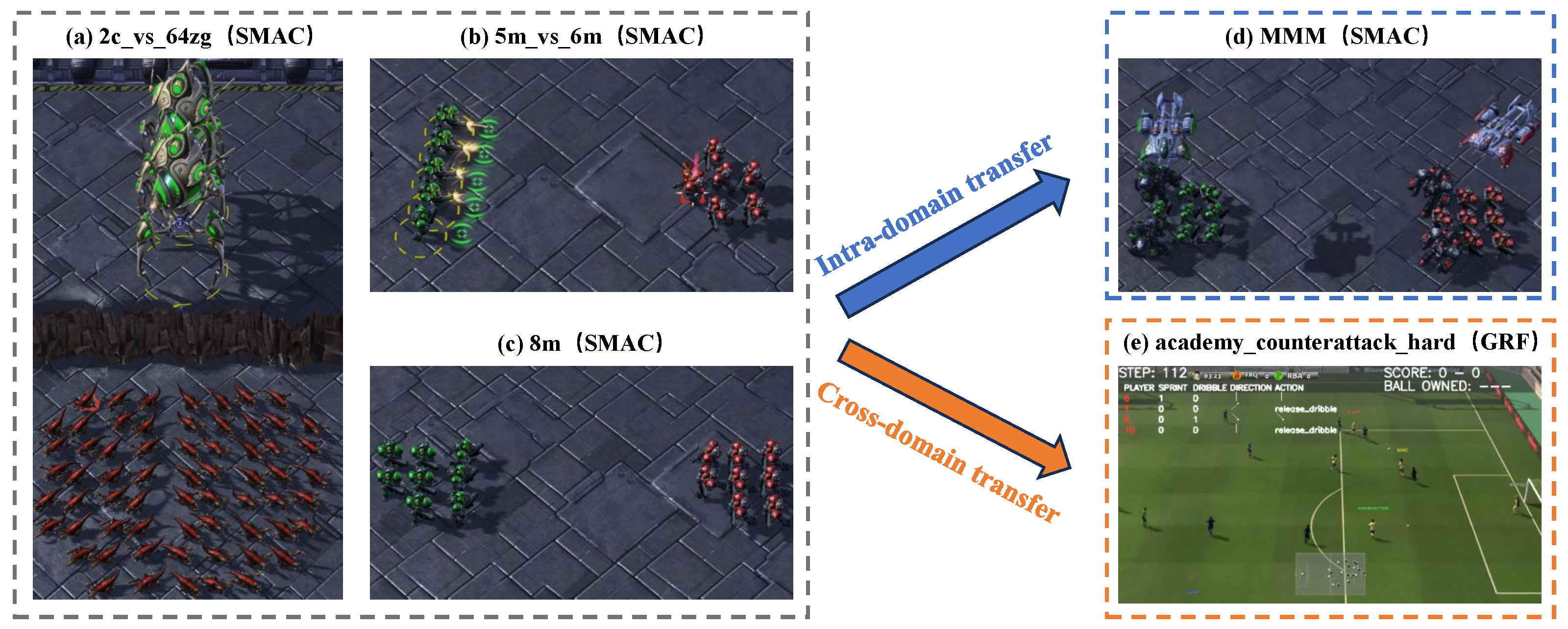
SMAC comprises a collection of cooperative multi-agent tasks derived from the real-time strategy game StarCraft II, such as symmetric and asymmetric tasks, as well as homogeneous and heterogeneous tasks, as shown in Figure 3a–d. In each map, each unit can only observe the ally and enemy agents within a limited range. In our experimental setting, our proposed MTT methods try to control the left group agents to fight against enemy units controlled by the StarCraft II built-in game AI. We keep the default settings of SMAC, such as the reward function and unit health points. An episode terminates when either the enemy or ally team is eliminated or a predefined time limit is reached. The goal is to maximize the win rate, which is a function of environment steps over 2000 k total training steps. The performance is evaluated by periodically running a fixed number of test episodes with no exploration behavior. After all test episodes terminate, the average win rate is recorded as the performance metric. The maps and unit types of each map in our SMAC experiments are given in Table 1.
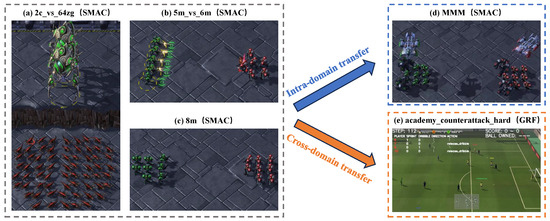
Figure 3.
Transfer demonstration in intra-domain and cross-domain scenarios.

Table 1.
Basic information of ten tasks in SMAC.
5.1.2. Google Research Football
Google Research Football Environment (GRF) is a simulation environment for validating reinforcement learning algorithms, where RL agents are trained to play football, which is shown in Figure 3e. The environment simulates the whole process of a real football match. There are two teams called the left team and the right team. In this paper, one player closest to the ball in the left team is regarded as an agent who is called an active player, while other players act according to the built-in rules. Based on the state representations, there are 19 actions to be chosen by the active player, including move actions in eight directions and different ways to kick the ball. The left team will obtain a +1 reward after scoring a goal and a -1 reward after the right team scores a goal. The maps and unit types of each map in our GRF experiments are given in Table 2.
Table 2.
Basic information of four tasks in GRF.
5.1.3. Baseline Method
We compare our proposed method with SATF [15], a scalable attention transfer framework that aims to address the efficiency issues of multi-agent reinforcement learning when training large-scale agents. SATF integrates a dynamic observation representation network that effectively compresses high-dimensional observations using a multihead attention mechanism and integrates the observation and action dimensions of different types of agents through an entity-action aggregation mechanism, thereby enabling the effective transfer of policy knowledge between different tasks. Similar to our proposed MTT method, we train the SATF framework using the IPPO algorithm. Moreover, we use the IPPO algorithm to train from scratch in each task as the second baseline.
5.1.4. Training and Evaluation Setup
For the completeness and credibility of the experiment, we carefully selected two groups of tasks in SMAC for multitask training in the knowledge extraction stage, namely MTT (three tasks): , , and MTT (six tasks): , , , , , . During the multitask training phase, each task is trained for at least 10 million steps, at which point all tasks can reach convergence. Then, we transferred the extracted knowledge to new tasks, including intra-domain task transfer in SMAC and cross-domain task transfer in GRF. For each experiment, we use five random seeds for experiments in each map. Performance is quantified using mean standard deviation. In the experimental results graphs, the solid line denotes the mean, while the shaded area indicates the standard deviation. The servers utilized for training comprise two Intel® Xeon® Gold 6148 processors, each equipped with 20 CPU cores (actors), and 8 NVIDIA GeForce RTX 4090 GPUs. Specifically, the training time is proportional to the number of tasks and the complexity of each task, including the number of agents and iterations. For MTT (three tasks), training required 10 GB of CPU memory and 65 GB of GPU memory, while for MTT (six tasks), it required 30 GB of CPU memory and 170 GB of GPU memory. The complexity of SMAC tasks also contributes to higher resource demands. We can adjust the model’s performance and resource usage by modifying network layers and their dimensions.
5.2. Experimental Result
5.2.1. Intra-Domain Transfer Experiment
In this section, we evaluate the transfer performance of the MTT method and training from scratch using the IPPO algorithm. Before knowledge transfer, we first obtain the shared knowledge obtained through multitask training based on MTT (three tasks) and MTT (six tasks). Then, we transfer the shared knowledge to other new tasks in SMAC to evaluate the transfer performance.
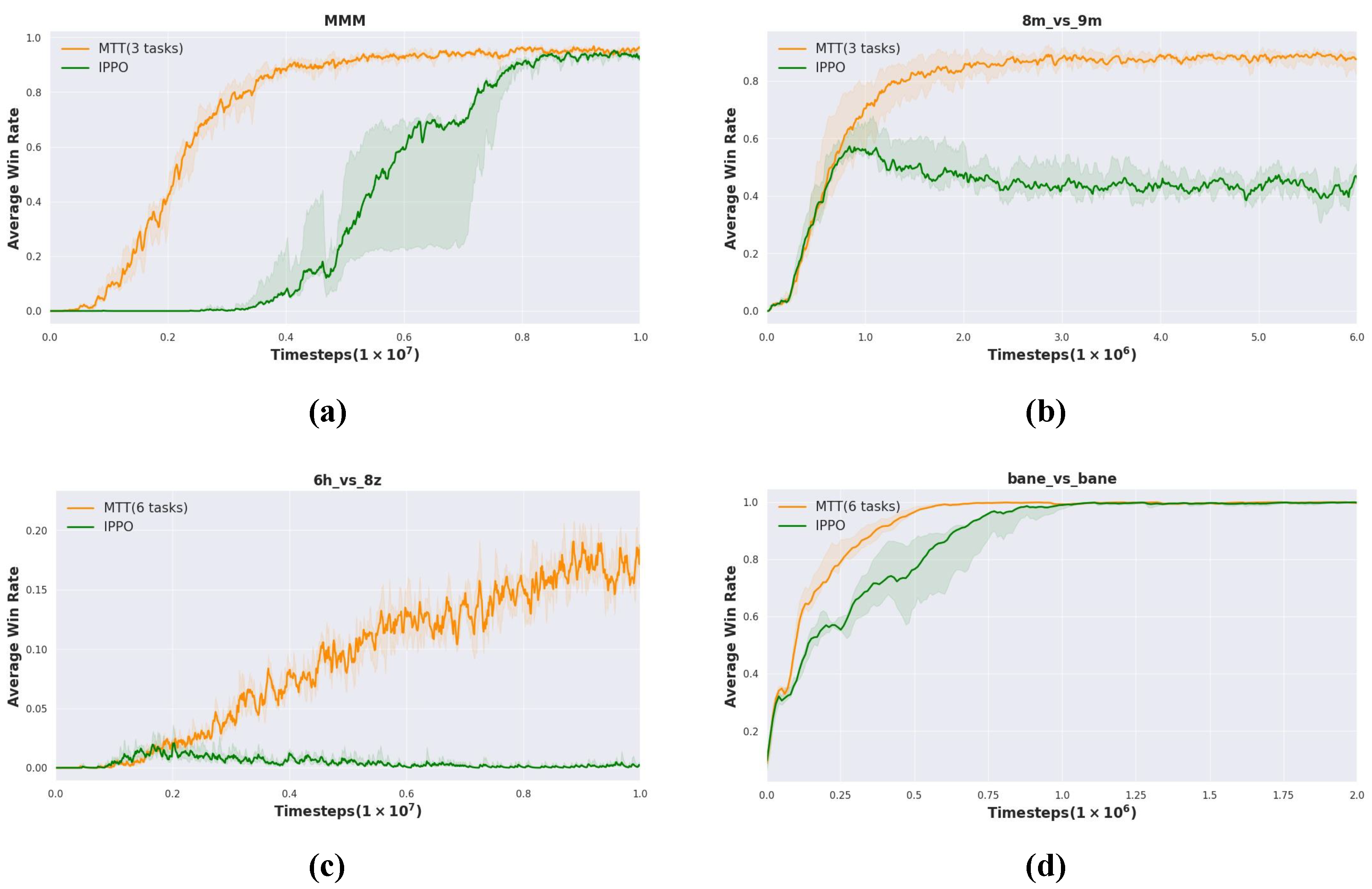
As shown in Figure 4a, in the task, the average win rate of the MTT increases rapidly and reaches a stable high level. In contrast, the average win rate of the IPPO increases slowly and is always lower than that of the MTT. For the task, Figure 4b shows that both curves show an upward trend, and MTT shows a better learning ability and higher win rate. Figure 4c depicts that although the average win rates of both methods have increased, the advantage of MTT is more significant. Especially in the later stages, the win rate of MTT far exceeds that of IPPO, proving its superiority in complex asymmetric and heterogeneous environments. Figure 4d demonstrates that MTT achieves faster convergence compared to IPPO in the symmetric task .
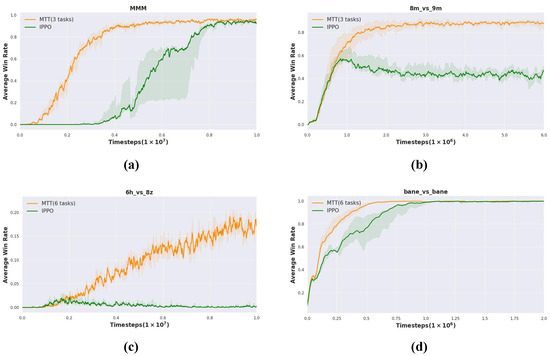
Figure 4.
Performance of intra-domain transfer experiments in SMAC, including symmetric and heterogeneous tasks, such as and , as well as asymmetric and homogeneous tasks, like and . (a) (from MTT (3 tasks)). (b) (from MTT (3 tasks)). (c) (from MTT (6 tasks)). (d) (from MTT (6 tasks)).
According to the above experimental results under four different tasks, we can clearly see that the MTT method has achieved better results than the IPPO baseline in most cases. MTT achieves a higher winning rate, where IPPO fails in task .
5.2.2. Cross-Domain Transfer Experiment
In this section, we evaluate the performance of the cross-domain transfer of the MTT and IPPO algorithms. We also train the two sets of tasks in SMAC to obtain shared knowledge and then transfer it to the new tasks in GRF to evaluate the cross-domain transfer performance.
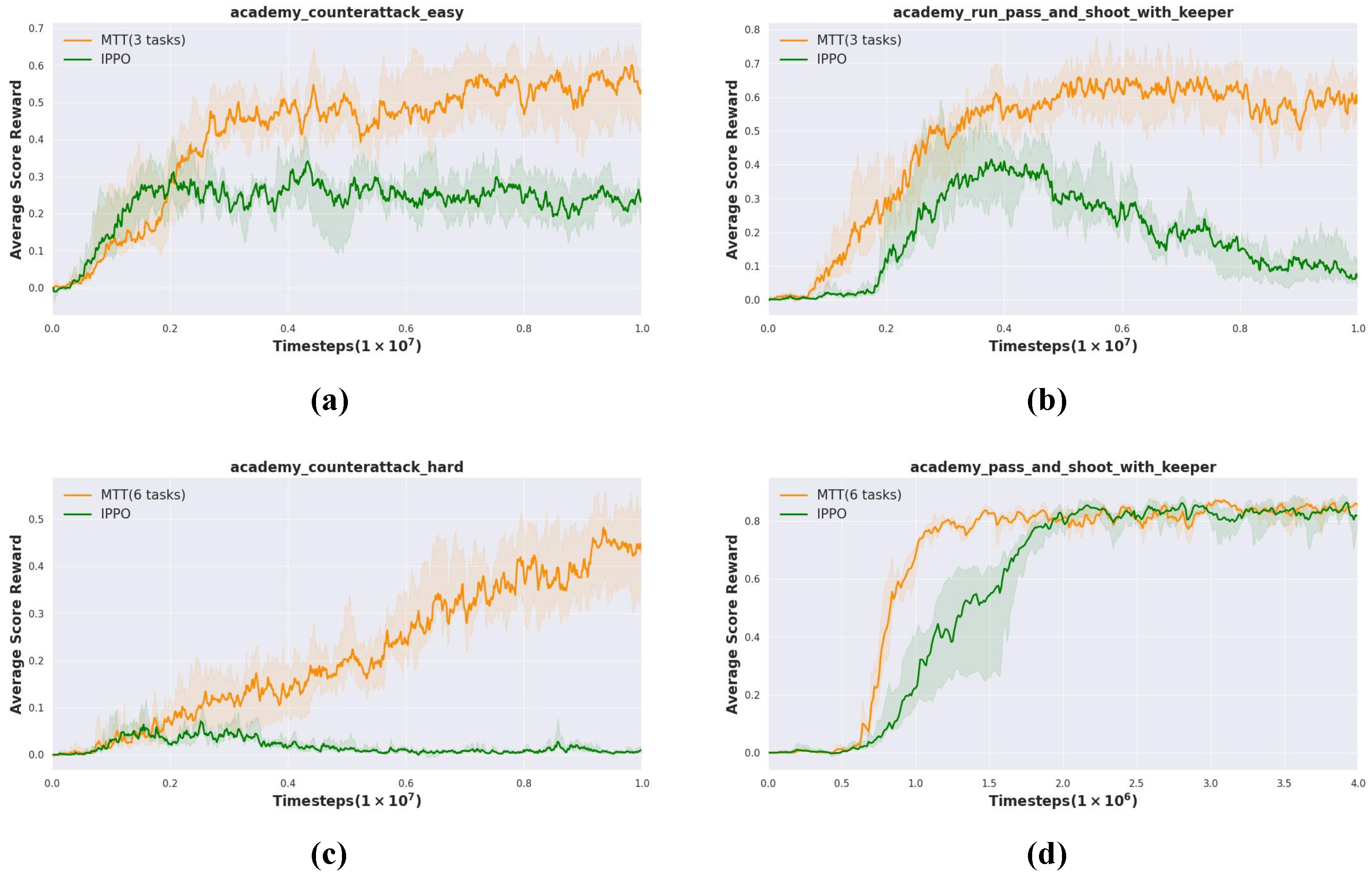
Experimental results show that MTT outperforms the baseline on all four unseen GRF tasks. MTT shows excellent average score reward in most tasks, as shown in Figure 5a,b,d. Especially in the difficult task , the advantage of MTT is more obvious in Figure 5c. We notice that IPPO fails in both and . These results show that MTT is not only effective on simple tasks, but also performs well in more challenging environments, demonstrating its strong adaptability and generalization capabilities.
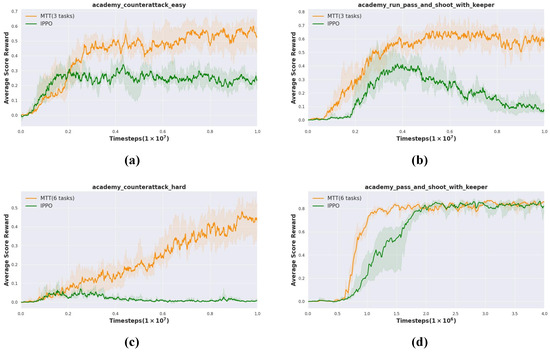
Figure 5.
Performance of cross-domain transfer experiments from SMAC to GRF. We evaluate the effect of knowledge transfer from MTT (3 tasks) and MTT (6 tasks) to 4 tasks of various difficulty levels in GRF. (a) (from MTT (3 tasks)). (b) (from MTT (3 tasks)). (c) (from MTT (6 tasks)). (d) (from MTT (6 tasks)).
5.2.3. Baseline Performance
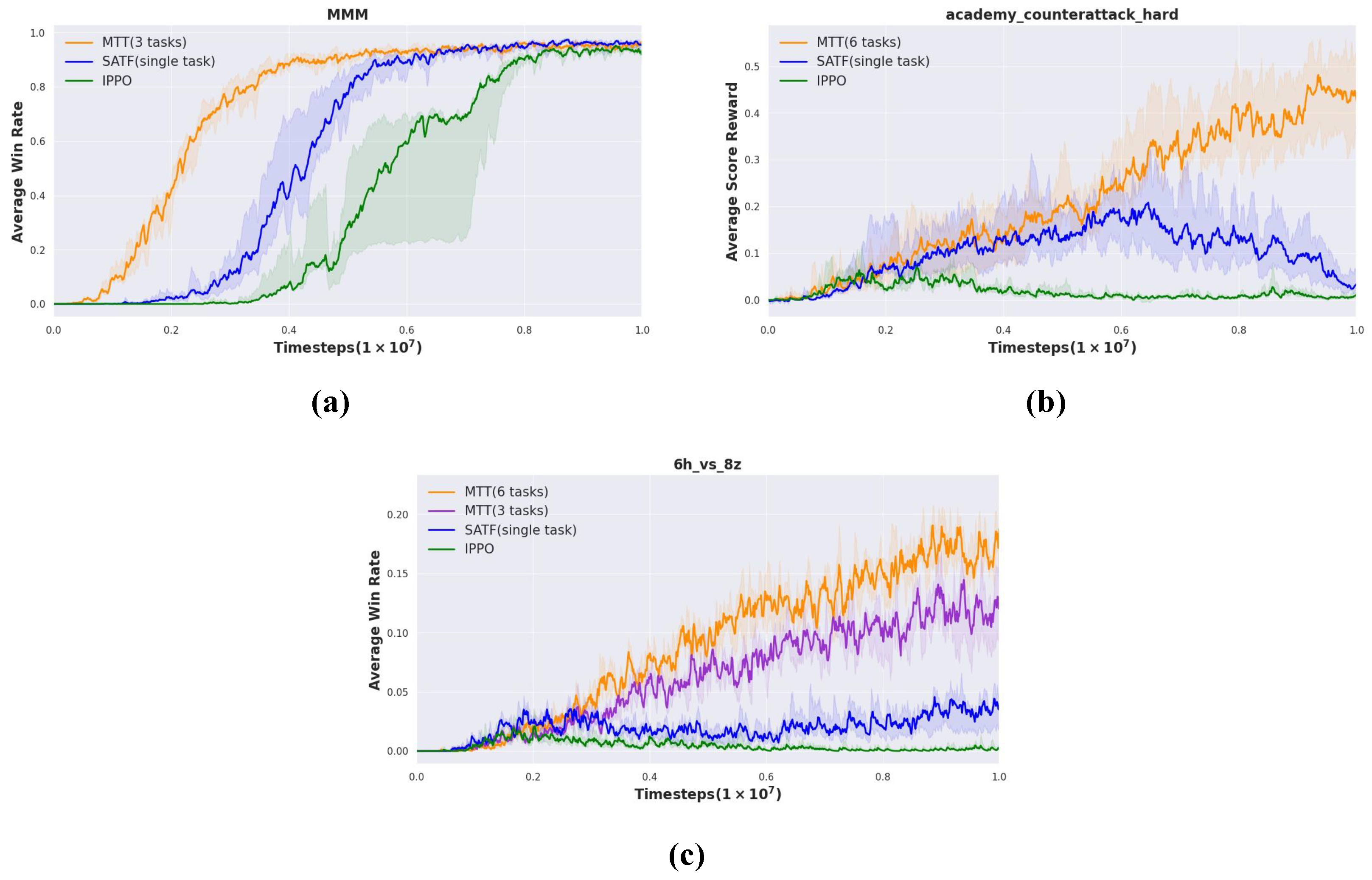
As depicted in Figure 6, we compare MTT with other baseline methods using the MMM and in SMAC and in GRF.
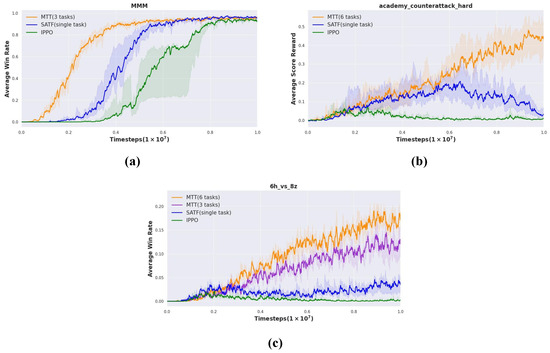
Figure 6.
Experimental results of MTT, SATF, and IPPO. We compare our method with baselines on three representative symmetric and heterogeneous tasks. SATF is trained based on singletask , , and in (a), (b), and (c), respectively.
Figure 6a indicates that MTT not only outperforms these baselines but also achieves faster convergence. As shown in Figure 6b, our MTT achieves a high average score reward on a difficult task of GRF where both SAFT and IPPO fail. In addition, we evaluate our method on the difficult task in SMAC, including MTT (6 tasks) and MTT (3 tasks). As depicted in Figure 6c, the performance of MTT (6 tasks) and MTT (3 tasks) are better than other baselines, and the effect of MTT (6 tasks) is better than MTT (3 tasks). This means that the shared knowledge gained from training based on six tasks is more than that based on three tasks, and it has a greater effect in promoting team collaboration.
5.3. Analysis and Visualization
Action Statistics
In this experiment, we analyze the model obtained from transfer learning with the model trained from scratch, focusing on the learning of shared collaborative knowledge under the same task in them, and we experimentally validate and analyze the shared knowledge learned by the model in the following aspects.
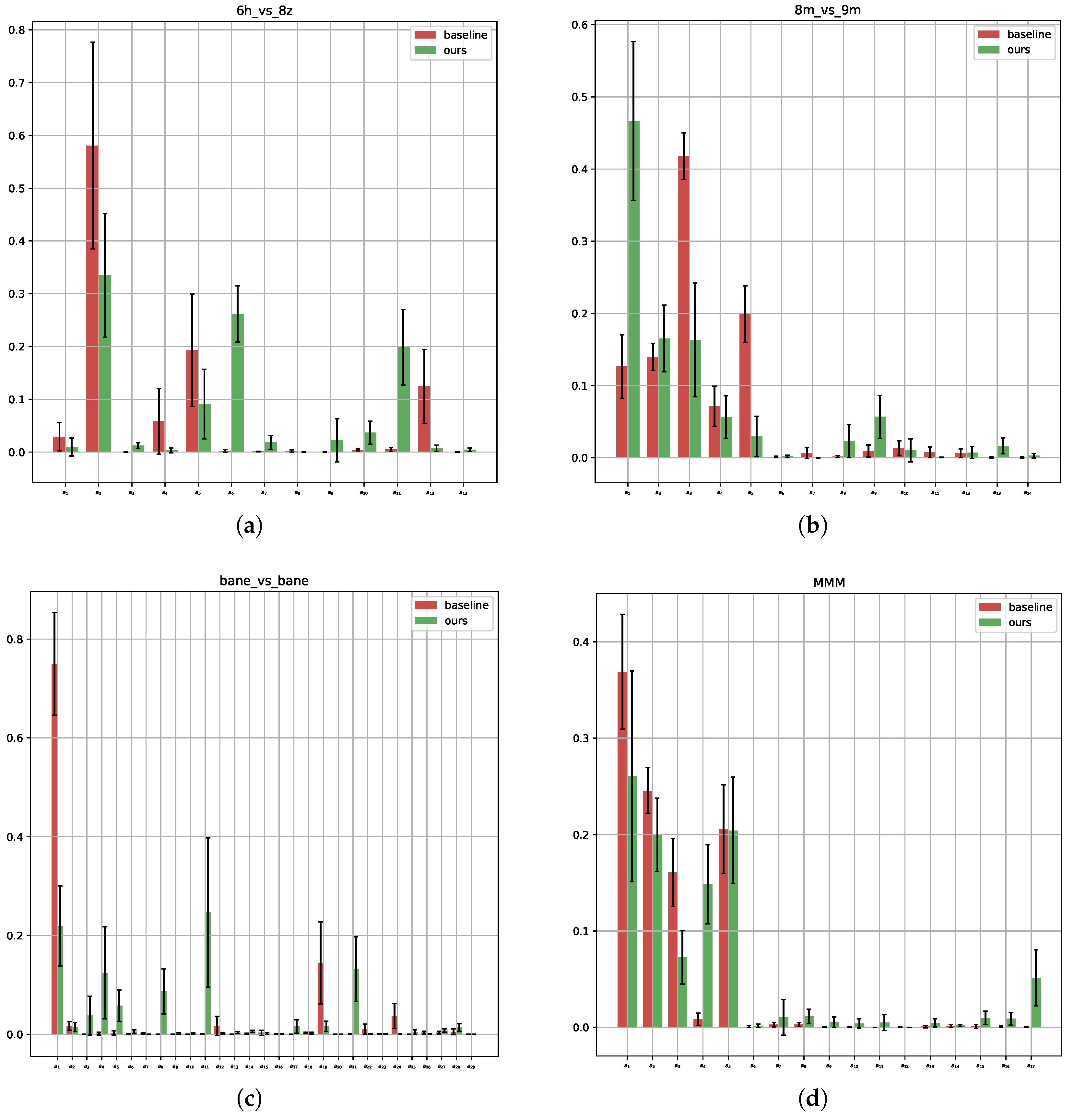
What are the behavioral characteristics of agents in our framework? To explore this question, we performed experimental analyses on multiple maps in SMAC, as before, to assess the behavioral diversity and strategy learning of agents in the framework. Figure 7 shows the action statistics of our agents on four maps in SMAC. Specifically, Figure 7a,b present the statistics for and , respectively.
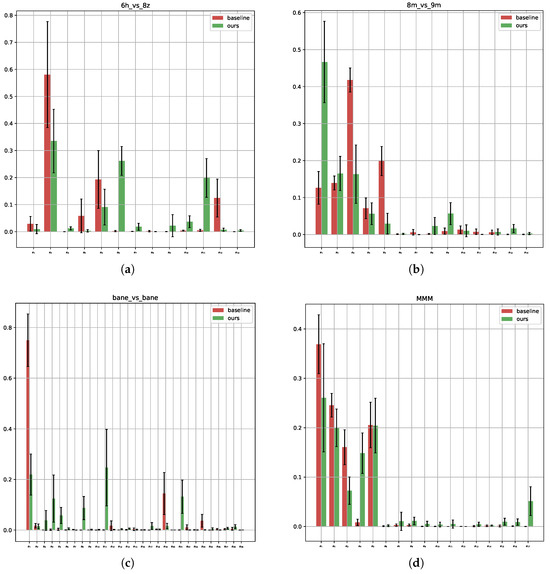
Figure 7.
In this analysis, we examine the distribution of the agent’s actions across 32 game instances on different maps in the SMAC environment. The first action was excluded from the analysis because it is only available after the death of a unit and therefore lacks statistical significance. (a–c) correspond to the matches , and , respectively. Meanwhile, (d) is associated with and does not include the healing unit.
These results indicate that both the baseline and our agents have learned some useful knowledge, but our agents show a stronger tendency to select enemy targets for attacks and significantly reduce meaningless movement actions. This suggests that the agents trained under our framework are able to acquire more useful knowledge. On the other hand, Figure 7c,d present the action statistics for and . It is evident that when the number of agents increases, the baseline agents fail to learn better strategies, with many of their actions simply being the meaningless stop action. In contrast, our agents exhibit more diverse action choices and demonstrate a better understanding of how to perform pulling tactics and select appropriate enemy targets.
5.4. Ablation Study
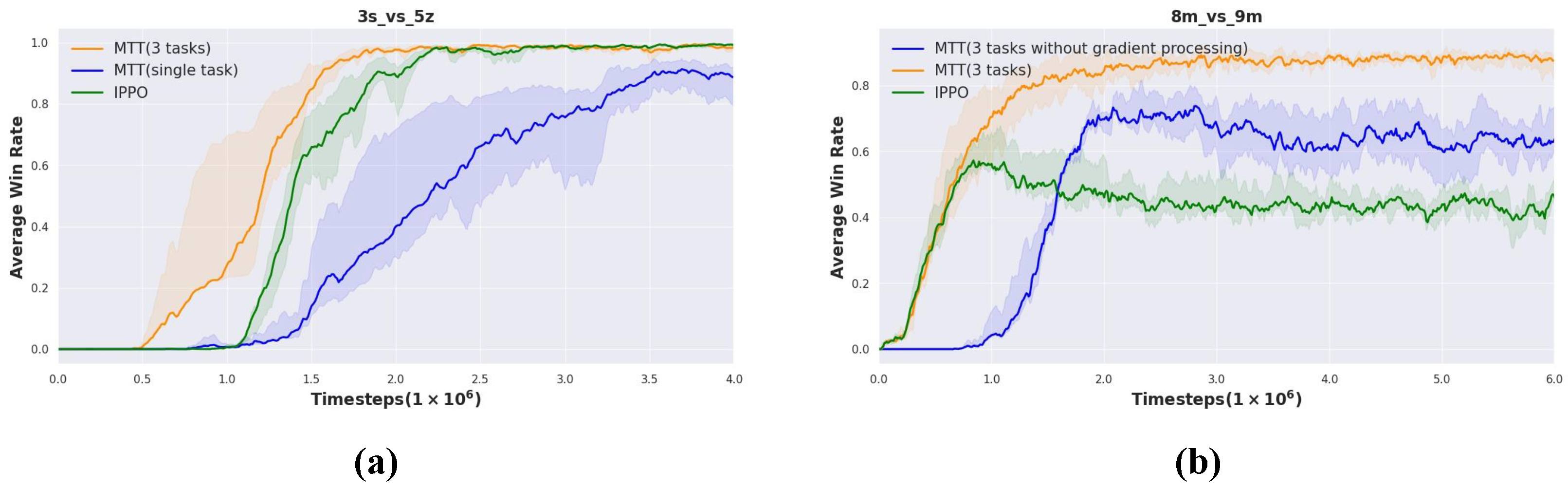
In the section on the ablation study, we evaluated the utility of each module in MTT. We use the shared knowledge gained from MTT (three tasks) training to transfer to new tasks in this section. Compared to MTT (three tasks), which trains on three tasks, we transfer the knowledge gained from training on a single task to . As shown in Figure 8a, the final performance of MTT (three tasks) is better than that of the singletask transfer and converges faster. It can be found that the knowledge extracted from multitask training is more than that extracted from singletask training, which has a greater role in promoting multi-agent team collaboration.
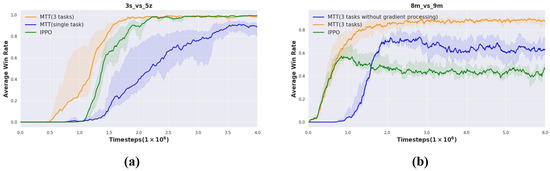
Figure 8.
Ablation study in and . (a) Transfer based on singletask (from to ) versus transfer based on multitask. (b) Transfer based on multitask training with or without a gradient conflict handling module.
Figure 8b shows that the average win rate will decrease when there is no gradient conflict handling module. It can be seen that the gradient conflict handling module leads to performance improvement, and it is necessary to deal with gradient conflicts in multitask training to improve learning efficiency. The performance of MTT (three tasks) without a gradient conflict handling module is still better than IPPO that trains from scratch without knowledge transfer.
6. Conclusions
This paper introduces a multitask-based training framework designed to address the challenges in some complex and difficult tasks. MTT is able to leverage shared cooperative knowledge learned across multiple tasks to improve learning efficiency and performance on symmetric, heterogeneous tasks, and even tasks in other domains. Our framework consists of a two-stage process. The first stage is to use multitask training to train on multiple selected tasks, with the aim of extracting some cooperative knowledge that coexists in multiple tasks. The second stage consists of a transfer of the shared knowledge extracted in the first stage to new unseen cooperative tasks for training. This can promote the learning of tasks that would fail if trained from scratch, speed up convergence, and improve the performance of the team collaboration. Then, during the first phase of multitask training in the framework, different tasks may interfere with each other, causing the model to perform worse on all tasks than when trained individually. This is because the loss functions of different tasks may produce gradients in different directions, which makes optimization difficult. Therefore, we propose a gradient conflict processing module to process the gradient length and direction of each task during multitask learning to enable conflict-free learning. We evaluated the proposed method in two commonly used multi-agent environments, StarCraft II and Google Research Football. The experimental results show that our method outperforms the baseline methods in all tasks. The knowledge extracted from training on the tasks in StarCraft II was transferred to the Google Research Football environment, which can effectively improve the learning efficiency and collaborative performance of the tasks in GRF, which fully verifies that our method can achieve efficient cross-domain transfer.
Multitask training improves knowledge transfer by learning cooperative policies across tasks simultaneously. In the MTT framework, a shared decision layer helps develop generalized representations that are beneficial for multiple tasks, allowing real-time knowledge sharing and synergy from the outset. This comprehensive training process contrasts with approaches that train tasks separately and combine knowledge afterward, such as through knowledge distillation or ensemble methods. These ex post methods fail to promote cross-task knowledge sharing during training and risk negative transfer and overfitting to task-specific nuances. In contrast, MTT promotes better generalization by optimizing across tasks simultaneously, enabling agents to cooperate and share knowledge in a structured manner.
Our experiments are mainly conducted on SMAC and GRF environments because they are complex and relevant in multi-agent reinforcement learning (MARL), but our MTT framework is designed to handle multiple tasks by using a shared decision layer for cooperative learning and a task-specific layer for specialized behavior. This structure allows flexible adaptation to different environments, such as robotics, autonomous vehicles, and multi-agent resource management, because the shared decision layer can learn generalized cooperative policies, while the task-specific layer can capture the unique dynamics of each task.
The MTT framework contains a shared decision layer and task-specific observation embedding layers and decision layers. The number of task-specific feature extraction layers and decision layers increases with the number of tasks and the number of optimization objectives, which makes conflict-free updates more complicated. The number of tasks can be controlled to balance performance and training overhead and stability. As the number of tasks increases, the model can learn more collaborative knowledge shared across tasks, leading to improved performance and generalization. However, this also results in longer training times, slower convergence, and higher computational costs. Conversely, when the number of tasks is too small, such as in the extreme case of a single task, the model may overfit and fail to generalize to other tasks. Therefore, the number of tasks impacts both model performance and training efficiency, and careful consideration of task selection and training cost is necessary.
Future work will focus on testing the MTT method on more diverse tasks in other domains, especially when there is a large gap between the source and target tasks of the knowledge transfer. It can effectively promote the collaborative effect of agents in complex tasks such as symmetric and heterogeneous tasks. This is crucial to improving the learning efficiency of multi-agent reinforcement learning algorithms and saving computing resources. In addition, combining various value-based and policy-based reinforcement learning algorithms can further enhance the versatility of the framework, enabling it to be used flexibly in various complex tasks.
Author Contributions
Conceptualization, C.H. and L.X.; methodology, C.H.; software, C.H. and W.L.; validation, C.H., L.X. and C.Y.; formal analysis, C.H.; investigation, C.H., C.Y. and W.L.; resources, C.H.; data curation, C.Y and W.L.; writing—original draft preparation, C.H.; writing—review and editing, C.H., L.X. and C.W.; visualization, C.H. and W.L.; supervision, C.W.; project administration, Z.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhao, R.; Li, Y.; Fan, Y.; Gao, F.; Tsukada, M.; Gao, Z. A Survey on Recent Advancements in Autonomous Driving Using Deep Reinforcement Learning: Applications, Challenges, and Solutions. IEEE Trans. Intell. Transp. Syst. 2024, 25, 19365–19398. [Google Scholar] [CrossRef]
- Huang, Z.; Wu, J.; Lv, C. Efficient deep reinforcement learning with imitative expert priors for autonomous driving. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7391–7403. [Google Scholar] [CrossRef] [PubMed]
- Hou, Y.; Zhao, J.; Zhang, R.; Cheng, X.; Yang, L. UAV swarm cooperative target search: A multi-agent reinforcement learning approach. IEEE Trans. Intell. Veh. 2023, 9, 568–578. [Google Scholar] [CrossRef]
- Singh, B.; Kumar, R.; Singh, V.P. Reinforcement learning in robotic applications: A comprehensive survey. Artif. Intell. Rev. 2022, 55, 945–990. [Google Scholar] [CrossRef]
- Gu, S.; Kuba, J.G.; Chen, Y.; Du, Y.; Yang, L.; Knoll, A.; Yang, Y. Safe multi-agent reinforcement learning for multi-robot control. Artif. Intell. 2023, 319, 103905. [Google Scholar] [CrossRef]
- Hu, S.; Leung, C.W.; Leung, H.F. Modelling the dynamics of multiagent q-learning in repeated symmetric games: A mean field theoretic approach. Adv. Neural Inf. Process. Syst. 2019, 32, 12134–12144. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. Starcraft ii: A new challenge for reinforcement learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Kurach, K.; Raichuk, A.; Stańczyk, P.; Zając, M.; Bachem, O.; Espeholt, L.; Riquelme, C.; Vincent, D.; Michalski, M.; Bousquet, O.; et al. Google research football: A novel reinforcement learning environment. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4501–4510. [Google Scholar]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Ye, D.; Chen, G.; Zhang, W.; Chen, S.; Yuan, B.; Liu, B.; Chen, J.; Liu, Z.; Qiu, F.; Yu, H.; et al. Towards playing full moba games with deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 621–632. [Google Scholar]
- Schroeder de Witt, C.; Foerster, J.; Farquhar, G.; Torr, P.; Boehmer, W.; Whiteson, S. Multi-agent common knowledge reinforcement learning. Adv. Neural Inf. Process. Syst. 2019, 32, 9927–9939. [Google Scholar]
- Wang, J.; Zhao, J.; Cao, Z.; Feng, R.; Qin, R.; Yu, Y. Multi-Task Multi-Agent Shared Layers are Universal Cognition of Multi-Agent Coordination. arXiv 2023, arXiv:2312.15674. [Google Scholar]
- Hu, C. A confrontation decision-making method with deep reinforcement learning and knowledge transfer for multi-agent system. Symmetry 2020, 12, 631. [Google Scholar] [CrossRef]
- Chen, B.; Cao, Z.; Bai, Q. SATF: A Scalable Attentive Transfer Framework for Efficient Multiagent Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2024. [Google Scholar] [CrossRef] [PubMed]
- Hester, T.; Vecerik, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Horgan, D.; Quan, J.; Sendonaris, A.; Osband, I.; et al. Deep q-learning from demonstrations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lou, X.; Guo, J.; Zhang, J.; Wang, J.; Huang, K.; Du, Y. Pecan: Leveraging policy ensemble for context-aware zero-shot human-ai coordination. arXiv 2023, arXiv:2301.06387. [Google Scholar]
- Li, Y.; Zhang, S.; Sun, J.; Zhang, W.; Du, Y.; Wen, Y.; Wang, X.; Pan, W. Tackling cooperative incompatibility for zero-shot human-ai coordination. J. Artif. Intell. Res. 2024, 80, 1139–1185. [Google Scholar] [CrossRef]
- Liang, Y.; Chen, D.; Gupta, A.; Du, S.S.; Jaques, N. Learning to Cooperate with Humans using Generative Agents. arXiv 2024, arXiv:2411.13934. [Google Scholar]
- Carroll, M.; Shah, R.; Ho, M.K.; Griffiths, T.; Seshia, S.; Abbeel, P.; Dragan, A. On the utility of learning about humans for human-ai coordination. Adv. Neural Inf. Process. Syst. 2019, 32, 5174–5185. [Google Scholar]
- Haarnoja, T.; Moran, B.; Lever, G.; Huang, S.H.; Tirumala, D.; Humplik, J.; Wulfmeier, M.; Tunyasuvunakool, S.; Siegel, N.Y.; Hafner, R.; et al. Learning agile soccer skills for a bipedal robot with deep reinforcement learning. Sci. Robot. 2024, 9, eadi8022. [Google Scholar] [CrossRef]
- Tirumala, D.; Wulfmeier, M.; Moran, B.; Huang, S.; Humplik, J.; Lever, G.; Haarnoja, T.; Hasenclever, L.; Byravan, A.; Batchelor, N.; et al. Learning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning. arXiv 2024, arXiv:2405.02425. [Google Scholar]
- Abreu, M.; Reis, L.P.; Lau, N. Learning to run faster in a humanoid robot soccer environment through reinforcement learning. In Robot World Cup; Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–15. [Google Scholar]
- Liu, S.; Lever, G.; Merel, J.; Tunyasuvunakool, S.; Heess, N.; Graepel, T. Emergent coordination through competition. arXiv 2019, arXiv:1902.07151. [Google Scholar]
- Deng, Y.; Yu, Y.; Ma, W.; Wang, Z.; Zhu, W.; Zhao, J.; Zhang, Y. SMAC-Hard: Enabling Mixed Opponent Strategy Script and Self-play on SMAC. arXiv 2024, arXiv:2412.17707. [Google Scholar]
- Ellis, B.; Cook, J.; Moalla, S.; Samvelyan, M.; Sun, M.; Mahajan, A.; Foerster, J.; Whiteson, S. Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2023, 36, 37567–37593. [Google Scholar]
- Liu, L.; Jiang, W.; Wang, Y. Tacit Learning with Adaptive Information Selection for Cooperative Multi-Agent Reinforcement Learning. arXiv 2024, arXiv:2412.15639. [Google Scholar]
- Lan, S.; Zhang, R.; Yi, Q.; Guo, J.; Peng, S.; Gao, Y.; Wu, F.; Chen, R.; Du, Z.; Hu, X.; et al. Contrastive modules with temporal attention for multi-task reinforcement learning. Adv. Neural Inf. Process. Syst. 2023, 36, 36507–36523. [Google Scholar]
- Chen, W.; Koenig, S.; Dilkina, B. MARL-LNS: Cooperative Multi-agent Reinforcement Learning via Large Neighborhoods Search. arXiv 2024, arXiv:2404.03101. [Google Scholar]
- Yang, M.; Zhao, J.; Hu, X.; Zhou, W.; Zhu, J.; Li, H. Ldsa: Learning dynamic subtask assignment in cooperative multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2022, 35, 1698–1710. [Google Scholar]
- Li, T.; Bai, C.; Xu, K.; Chu, C.; Zhu, P.; Wang, Z. Skill matters: Dynamic skill learning for multi-agent cooperative reinforcement learning. Neural Netw. 2025, 181, 106852. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, S.; Zhang, W.; Dong, W.; Chen, J.; Wen, Y.; Zhang, W. Zsc-eval: An evaluation toolkit and benchmark for multi-agent zero-shot coordination. In Proceedings of the Thirty-Eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; Hadsell, R. Progressive neural networks. arXiv 2016, arXiv:1606.04671. [Google Scholar]
- Chen, S.; Zhang, Y.; Yang, Q. Multi-task learning in natural language processing: An overview. ACM Comput. Surv. 2024, 56, 1–32. [Google Scholar] [CrossRef]
- Fontana, M.; Spratling, M.; Shi, M. When Multitask Learning Meets Partial Supervision: A Computer Vision Review. Proc. IEEE 2024, 112, 516–543. [Google Scholar] [CrossRef]
- Teh, Y.; Bapst, V.; Czarnecki, W.M.; Quan, J.; Kirkpatrick, J.; Hadsell, R.; Heess, N.; Pascanu, R. Distral: Robust multitask reinforcement learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4499–4509. [Google Scholar]
- Xu, Z.; Wu, K.; Che, Z.; Tang, J.; Ye, J. Knowledge transfer in multi-task deep reinforcement learning for continuous control. Adv. Neural Inf. Process. Syst. 2020, 33, 15146–15155. [Google Scholar]
- Deng, J.; Wang, J.; Wang, X.; Cai, Y.; Liu, P. Multi-Task Multi-Objective Evolutionary Search Based on Deep Reinforcement Learning for Multi-Objective Vehicle Routing Problems with Time Windows. Symmetry 2024, 16, 1030. [Google Scholar] [CrossRef]
- Liu, B.; Liu, X.; Jin, X.; Stone, P.; Liu, Q. Conflict-averse gradient descent for multi-task learning. Adv. Neural Inf. Process. Syst. 2021, 34, 18878–18890. [Google Scholar]
- Fernando, H.; Shen, H.; Liu, M.; Chaudhury, S.; Murugesan, K.; Chen, T. Mitigating gradient bias in multi-objective learning: A provably convergent approach. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Sodhani, S.; Zhang, A.; Pineau, J. Multi-task reinforcement learning with context-based representations. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 9767–9779. [Google Scholar]
- Sun, L.; Zhang, H.; Xu, W.; Tomizuka, M. Paco: Parameter-compositional multi-task reinforcement learning. Adv. Neural Inf. Process. Syst. 2022, 35, 21495–21507. [Google Scholar]
- Zhu, Y.; Huang, S.; Zuo, B.; Zhao, D.; Sun, C. Multi-Task Multi-Agent Reinforcement Learning With Task-Entity Transformers and Value Decomposition Training. IEEE Trans. Autom. Sci. Eng. 2024. [Google Scholar] [CrossRef]
- Li, C.; Dong, S.; Yang, S.; Hu, Y.; Ding, T.; Li, W.; Gao, Y. Multi-Task Multi-Agent Reinforcement Learning With Interaction and Task Representations. IEEE Trans. Neural Netw. Learn. Syst. 2024. [Google Scholar] [CrossRef]
- Mai, Y.; Zang, Y.; Yin, Q.; Ni, W.; Huang, K. Deep Multitask Multiagent Reinforcement Learning With Knowledge Transfer. IEEE Trans. Games 2024, 16, 566–576. [Google Scholar] [CrossRef]
- Bose, A.; Du, S.S.; Fazel, M. Offline multi-task transfer rl with representational penalization. arXiv 2024, arXiv:2402.12570. [Google Scholar]
- Tian, Z.; Chen, R.; Hu, X.; Li, L.; Zhang, R.; Wu, F.; Peng, S.; Guo, J.; Du, Z.; Guo, Q.; et al. Decompose a task into generalizable subtasks in multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2023, 36, 78514–78532. [Google Scholar]
- Wang, C.; Zhu, X. ATA-MAOPT: Multi-Agent Online Policy Transfer using Attention Mechanism with Time Abstraction. IEEE Access 2024, 12, 158282–158291. [Google Scholar] [CrossRef]
- Yang, T.; Wang, W.; Tang, H.; Hao, J.; Meng, Z.; Mao, H.; Li, D.; Liu, W.; Chen, Y.; Hu, Y.; et al. An efficient transfer learning framework for multiagent reinforcement learning. Adv. Neural Inf. Process. Syst. 2021, 34, 17037–17048. [Google Scholar]
- Guo, Y.; Campbell, J.; Stepputtis, S.; Li, R.; Hughes, D.; Fang, F.; Sycara, K. Explainable action advising for multi-agent reinforcement learning. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 19–23 May 2023; pp. 5515–5521. [Google Scholar]
- Liu, W.; Dong, L.; Liu, J.; Sun, C. Knowledge transfer in multi-agent reinforcement learning with incremental number of agents. J. Syst. Eng. Electron. 2022, 33, 447–460. [Google Scholar] [CrossRef]
- Zhou, T.; Zhang, F.; Shao, K.; Dai, Z.; Li, K.; Huang, W.; Wang, W.; Wang, B.; Li, D.; Liu, W.; et al. Cooperative multi-agent transfer learning with coalition pattern decomposition. IEEE Trans. Games 2023, 16, 352–364. [Google Scholar] [CrossRef]
- Yang, T.; You, H.; Hao, J.; Zheng, Y.; Taylor, M.E. A Transfer Approach Using Graph Neural Networks in Deep Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 16352–16360. [Google Scholar]
- Oliehoek, F.A.; Amato, C. A Concise Introduction to Decentralized POMDPs; Springer: Berlin/Heidelberg, Germany, 2016; Volume 1. [Google Scholar]
- De Witt, C.S.; Gupta, T.; Makoviichuk, D.; Makoviychuk, V.; Torr, P.H.; Sun, M.; Whiteson, S. Is independent learning all you need in the starcraft multi-agent challenge? arXiv 2020, arXiv:2011.09533. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Zhang, Y.; Yang, Q. A survey on multi-task learning. IEEE Trans. Knowl. Data Eng. 2021, 34, 5586–5609. [Google Scholar] [CrossRef]
- Yu, T.; Kumar, S.; Gupta, A.; Levine, S.; Hausman, K.; Finn, C. Gradient surgery for multi-task learning. Adv. Neural Inf. Process. Syst. 2020, 33, 5824–5836. [Google Scholar]
- Du, Y.; Czarnecki, W.M.; Jayakumar, S.M.; Farajtabar, M.; Pascanu, R.; Lakshminarayanan, B. Adapting auxiliary losses using gradient similarity. arXiv 2018, arXiv:1812.02224. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).