
A Multi-Task Dynamic Weight Optimization Framework Based on Deep Reinforcement Learning


Abstract
1. Introduction
- Heterogeneous data distributions and loss landscapes;
- Varying gradient magnitudes and optimization difficulties;
- Time-varying task correlations in dynamic environments.
- A strategic decision-making framework: Formulating weight adaptation as a Markov Decision Process enables long-term optimization planning through value function estimation, addressing the myopia of existing methods.
- Automated relationship discovery: Unlike methods requiring pre-defined task similarity metrics, our DRL agent autonomously learns inter-task relationships through environment interactions, eliminating manual bias in weight initialization.
- Adaptive credit assignment: The framework introduces a novel reward mechanism that jointly optimizes immediate task balancing and long-term representation quality, overcoming the local optimum trap in greedy gradient-based methods.
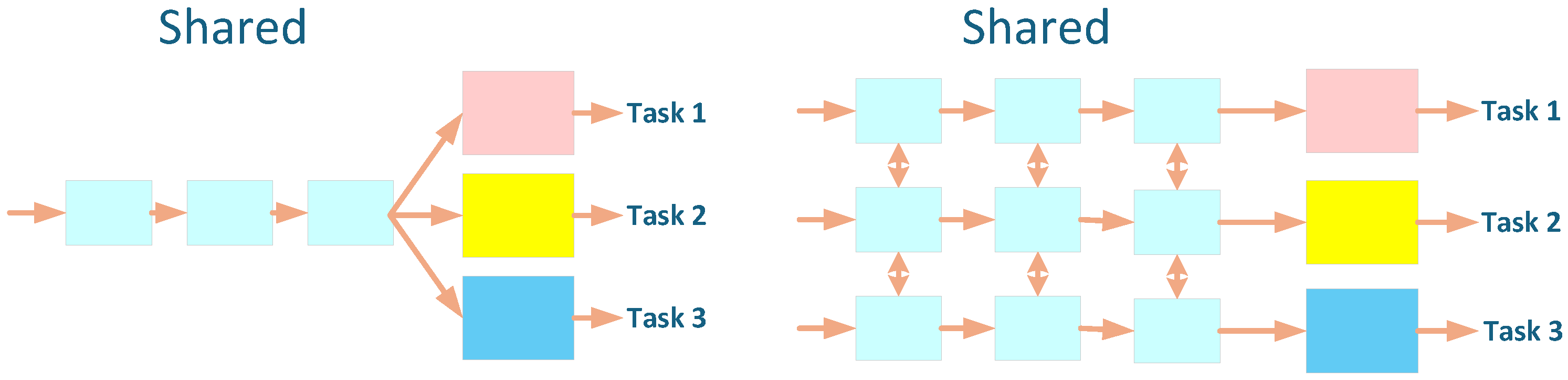
2. Relate Work
3. Methodology
| Algorithm 1 Training Process |
|
4. Experiments
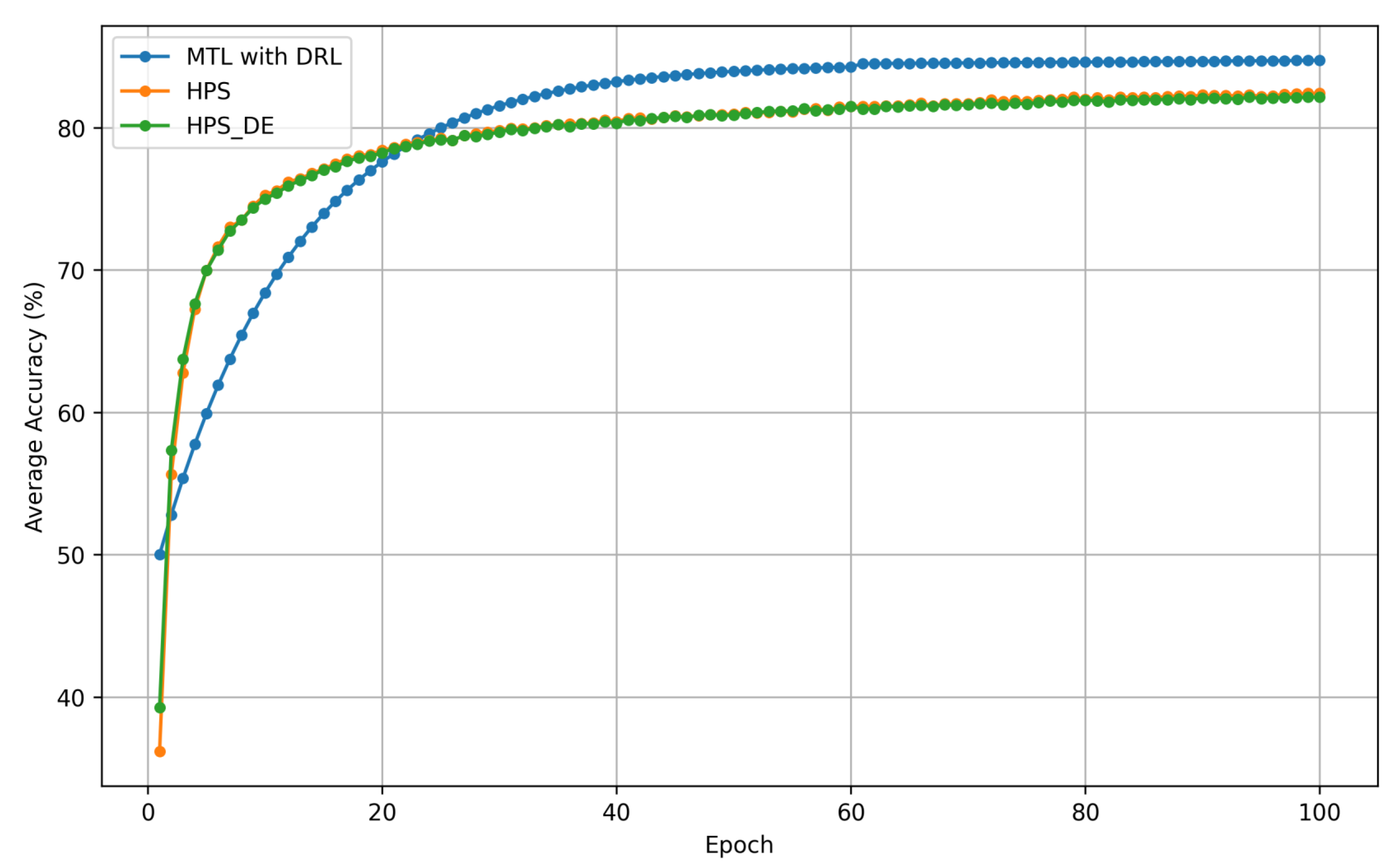
4.1. Comparison Experiments
- Key Observations:
4.2. Ablation Studies
4.3. Implementation Details
4.4. Summary and Robustness Analysis
5. Conclusions
- Main Contributions
- We propose a DRL-driven adaptive weight adjustment mechanism for MTL, achieving up to 84.73% mean accuracy and effectively balancing heterogeneous task optimization.
- Our novel reward design utilizes the geometric mean as a balancing signal, incentivizing performance improvements in underperforming tasks and promoting uniform performance distribution across tasks.
- The framework reduces training time by up to 35% compared to state-of-the-art methods, demonstrating enhanced scalability and computational efficiency.
- Comprehensive experiments and ablation studies validate that our method not only boosts overall performance but also generates a diverse set of non-dominated solutions approaching the Pareto front, providing insights for multi-objective MTL optimization.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Miettinen, K. Nonlinear Multiobjective Optimization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999; pp. 1–300. [Google Scholar]
- Weinan, E. A proposal on machine learning via dynamical systems. Commun. Math. Stat. 2017, 1, 1–11. [Google Scholar]
- Marino, R.; Buffoni, L.; Chicchi, L.; Giambagli, L.; Fanelli, D. Stable attractors for neural networks classification via ordinary differential equations (SA-nODE). Mach. Learn. Sci. Technol. 2024, 5, 035087. [Google Scholar] [CrossRef]
- Geshkovski, B.; Letrouit, C.; Polyanskiy, Y.; Rigollet, P. A mathematical perspective on transformers. arXiv 2023, arXiv:2312.10794. [Google Scholar]
- Fliege, J.; Svaiter, B.F. Steepest descent methods for multicriteria optimization. Math. Methods Oper. Res. 2000, 51, 479–494. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Aguirre, A.H.; Zitzler, E. Evolutionary Multi-Criterion Optimization; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–350. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3994–4003. [Google Scholar]
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; Hadsell, R. Progressive neural networks. arXiv 2016, arXiv:1606.04671. [Google Scholar]
- Ruder, S.; Bingel, J.; Augenstein, I.; Søgaard, A. Latent multi-task architecture learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 4822–4829. [Google Scholar]
- Gao, Y.; Ma, J.; Zhao, M.; Liu, W.; Yuille, A.L. NDDR-CNN: Layerwise feature fusing in multi-task CNNs by neural discriminative dimensionality reduction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3205–3214. [Google Scholar]
- Hai, Z.; Zhao, P.; Cheng, P.; Yang, P.; Li, X.-L.; Li, G. Deceptive review spam detection via exploiting task relatedness and unlabeled data. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1817–1826. [Google Scholar]
- Guo, H.; Pasunuru, R.; Bansal, M. Soft layer-specific multi-task summarization with entailment and question generation. arXiv 2018, arXiv:1805.11004. [Google Scholar]
- Lan, M.; Wang, J.; Wu, Y.; Niu, Z.-Y.; Wang, H. Multi-task attention-based neural networks for implicit discourse relationship representation and identification. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1299–1308. [Google Scholar]
- Dankers, V.; Rei, M.; Lewis, M.; Shutova, E. Modelling the interplay of metaphor and emotion through multitask learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 2218–2229. [Google Scholar]
- Huang, J.; Feris, R.S.; Chen, Q.; Yan, S. Cross-domain image retrieval with a dual attribute-aware ranking network. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1062–1070. [Google Scholar]
- Ranjan, R.; Patel, V.M.; Chellappa, R. Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 121–135. [Google Scholar] [CrossRef] [PubMed]
- Jou, B.; Chang, S.-F. Deep cross residual learning for multitask visual recognition. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 998–1007. [Google Scholar]
- Bilen, H.; Vedaldi, A. Integrated perception with recurrent multi-task neural networks. In Advances in Neural Information Processing Systems, Proceedings of the Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Kokkinos, I. Ubernet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6129–6138. [Google Scholar]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. Blitznet: A real-time deep network for scene understanding. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4154–4162. [Google Scholar]
- Guo, P.; Lee, C.-Y.; Ulbricht, D. Learning to branch for multi-task learning. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 3854–3863. [Google Scholar]
- Zhang, Y.; Yeung, D.-Y. A convex formulation for learning task relationships in multi-task learning. arXiv 2012, arXiv:1203.3536. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7482–7491. [Google Scholar]
- Guo, M.; Haque, A.; Huang, D.-A.; Yeung, S.; Li, F.-F. Dynamic task prioritization for multitask learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 270–287. [Google Scholar]
- Li, C.; Georgiopoulos, M.; Anagnostopoulos, G.C. Pareto-path multitask multiple kernel learning. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 51–61. [Google Scholar] [CrossRef] [PubMed]
- Sener, O.; Koltun, V. Multi-task learning as multi-objective optimization. In Advances in Neural Information Processing Systems, Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Chen, Z.; Badrinarayanan, V.; Lee, C.-Y.; Rabinovich, A. GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 794–803. [Google Scholar]
- Hotegni, S.S.; Berkemeier, M.; Peitz, S. Multi-objective optimization for sparse deep multi-task learning. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–9. [Google Scholar]
- Asadi, S.; Gharibzadeh, S.; Zangeneh, S.; Reihanifar, M.; Rahimi, M.; Abdullah, L. Comparative analysis of gradient-based optimization techniques using multidimensional surface 3D visualizations and initial point sensitivity. arXiv 2024, arXiv:2409.04470. [Google Scholar]
- Vithayathil Varghese, N.; Mahmoud, Q.H. A survey of multi-task deep reinforcement learning. Electronics 2020, 9, 1363. [Google Scholar] [CrossRef]
- Tomov, M.S.; Schulz, E.; Gershman, S.J. Multi-task reinforcement learning in humans. Nat. Hum. Behav. 2021, 5, 764–773. [Google Scholar] [CrossRef] [PubMed]
- Borsa, D.; Graepel, T.; Shawe-Taylor, J. Learning shared representations in multi-task reinforcement learning. arXiv 2016, arXiv:1603.02041. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Fernando, C.; Banarse, D.; Blundell, C.; Zwols, Y.; Ha, D.; Rusu, A.A.; Pritzel, A.; Wierstra, D. PathNet: Evolution channels gradient descent in super neural networks. arXiv 2017, arXiv:1701.08734. [Google Scholar]
- Rosenbaum, C.; Klinger, T.; Riemer, M. Routing networks: Adaptive selection of non-linear functions for multi-task learning. arXiv 2017, arXiv:1711.01239. [Google Scholar]
- Sun, L.; Zhang, H.; Xu, W.; Tomizuka, M. PACO: Parameter-compositional multi-task reinforcement learning. In Advances in Neural Information Processing Systems, Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Curran Associates Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 21495–21507. [Google Scholar]
- Vuong, T.-L.; Nguyen, D.-V.; Nguyen, T.-L.; Bui, C.-M.; Kieu, H.-D.; Ta, V.-C.; Tran, Q.-L.; Le, T.-H. Sharing experience in multitask reinforcement learning. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3642–3648. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Advances in Neural Information Processing Systems, Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–7 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Liu, S.; Johns, E.; Davison, A.J. End-to-end multi-task learning with attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1871–1880. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | Task 1 Accuracy | Task 2 Accuracy | Task 3 Accuracy | Mean Accuracy | Training Time (Minutes) |
|---|---|---|---|---|---|---|
| MultiMNIST | STL | 98.62% | 95.08% | - | 96.85% | 34 |
| MTAN | 97.85% | 96.73% | - | 97.29% | 37 | |
| HPS | 97.14% | 95.35% | - | 96.25% | 17 | |
| HPS_DE | 99.14% | - | 27 | |||
| MGDA | 97.26% | 95.90% | - | 96.58% | 52 | |
| MDMTN | 99.08% | 98.67% | - | 98.88% | 25 | |
| MTL with DRL | 98.94% | - | 99.06% | |||
| CIFAR10MNIST | STL | 54.32% | - | 76.62% | 18 | |
| MTAN | 59.14% | 97.25% | - | 78.20% | 29 | |
| HPS | 56.86% | 96.15% | - | 76.50% | ||
| HPS_DE | 60.90% | 97.02% | - | 78.96% | 47 | |
| MGDA | 46.28% | 96.80% | - | 71.54% | 67 | |
| MDMTN | 59.28% | 94.45% | - | 76.86% | 41 | |
| MTL with DRL | 95.67% | - | 17 | |||
| CIFAR10MultiMNIST | STL | 48.75% | 96.86% | 96.92% | 81.34% | 51 |
| MTAN | 53.16% | 96.95% | 96.87% | 82.33% | 57 | |
| HPS | 51.31% | 82.15% | ||||
| HPS_DE | 53.20% | 97.00% | 97.07% | 82.42% | 60 | |
| MGDA | 43.83% | 96.18% | 95.12% | 78.38% | 76 | |
| MDMTN | 57.18% | 96.15% | 96.25% | 83.19% | 49 | |
| MTL with DRL | 96.80% | 96.99% |
| Parameter Category | Configuration |
|---|---|
| Optimizer | Adam |
| Initial Learning Rate | 1 × (with cosine decay) |
| Batch Size | 64 |
| DRL Agent Architecture | Actor: 2-layer MLP; Critic: 1-layer MLP |
| Experience Replay Buffer Size | 10,000 |
| Discount Factor | 0.99 |
| Minimum Task Weight | 0.2 |
| Reward Function Parameter | 0.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, L.; Ma, Z.; Li, X. A Multi-Task Dynamic Weight Optimization Framework Based on Deep Reinforcement Learning. Appl. Sci. 2025, 15, 2473. https://doi.org/10.3390/app15052473
Mao L, Ma Z, Li X. A Multi-Task Dynamic Weight Optimization Framework Based on Deep Reinforcement Learning. Applied Sciences. 2025; 15(5):2473. https://doi.org/10.3390/app15052473
Chicago/Turabian StyleMao, Lingpei, Zheng Ma, and Xiang Li. 2025. "A Multi-Task Dynamic Weight Optimization Framework Based on Deep Reinforcement Learning" Applied Sciences 15, no. 5: 2473. https://doi.org/10.3390/app15052473
APA StyleMao, L., Ma, Z., & Li, X. (2025). A Multi-Task Dynamic Weight Optimization Framework Based on Deep Reinforcement Learning. Applied Sciences, 15(5), 2473. https://doi.org/10.3390/app15052473