Abstract
Three-dimensional object recognition is crucial in modern applications, including robotics in manufacturing, household items, augmented and virtual reality, and autonomous driving. Extensive research and numerous surveys have been conducted in this field. This study aims to create a model selection guide by addressing key questions we need to answer when we want to select a 6D pose estimation model: inputs, modalities, real-time capabilities, hardware requirements, evaluation datasets, performance metrics, strengths, limitations, and special attributes such as symmetry or occlusion handling. By analyzing 84 models, including 62 new ones beyond previous surveys, and identifying 25 datasets 14 newly introduced, we organized the results into comparison tables and standardized summarization templates. This structured approach facilitates easy model comparison and selection based on practical application needs. The focus of this study is on the practical aspects of utilizing 6D pose estimation models, providing a valuable resource for researchers and practitioners.
1. Introduction
Six Degrees of Freedom (6D) pose estimation is a pivotal task in the realm of computer vision, aimed at accurately determining the position and orientation of objects within a three-dimensional space. This capability is essential for a multitude of applications, including robotics, augmented reality (AR), virtual reality (VR), autonomous driving, industrial automation, and satellite navigation. In robotics, precise 6D pose estimation enables manipulators to interact seamlessly with objects, facilitating tasks such as assembly, sorting, and handling. With the evolution of technology, robotic items now exist even inside our homes like robotic vacuum cleaners and the importance of fast, accurate, and reliable object position detection will be even more crucial. In AR and VR, understanding the spatial orientation of objects enhances the realism and interactivity of virtual environments, and the user experience is achieved by the ability of the object detection models to place virtual objects in a real environment. Autonomous vehicles rely on 6D pose estimation for obstacle detection, navigation, and environment mapping, ensuring safe and efficient operation. Moreover, in industrial settings, 6D pose estimation supports automated quality control, inventory management, and complex manufacturing processes by providing reliable object localization and tracking.
Despite significant advancements, 6D pose estimation remains a challenging problem due to factors such as occlusions, varying lighting conditions, object symmetries, and the necessity for real-time performance on small devices. The diversity of input modalities—ranging from RGB images to RGB-D, 3D models, LiDAR, and depth maps—further complicates the development of robust and versatile pose estimation models. As the demand for accurate and efficient 6D pose estimation grows, along with new publications, there is a need for comprehensive reviews that present the new findings and provide detailed comparisons based on performance metrics, input types, and application-specific requirements.
The main research question of this study is to create a detailed selection guide for 6D pose estimation object models, addressing the primary characteristics that are critical when selecting a model for a specific application. These characteristics include input modalities, real-time capabilities, hardware requirements, datasets used for evaluation, performance metrics, objects tested on, strengths, limitations, and special attributes such as symmetry and occlusion handling. To answer this question, we systematically analyzed 83 computer vision models, generating template summaries for each model, categorizing the models and developing comparison tables to facilitate informed decision-making.
This study offers several novel contributions to the field of 6D pose estimation:
- Comprehensive Model Analysis: We systematically analyzed 83 computer vision models for 6D pose estimation (61 new from the latest review), addressing key characteristics such as input types, real-time capabilities, hardware requirements, datasets used, performance metrics, strengths, limitations, and the ability to handle complex scenarios like symmetrical objects and occlusions.
- Expanded Dataset Coverage: In addition to identifying and describing 25 distinct datasets (14 new from the latest review) providing detailed summaries and statistical insights into their adoption within the research community.
- Analytical Specification Tables: We introduced detailed analytical tables that summarize each model’s characteristics, performance metrics, and capabilities. These tables serve as a novel resource for quick comparisons and informed selection, offering a structured overview that was previously unavailable.
- Categorization of Models: To enhance organization and usability, models are categorized into Real-Time Models and Non-Real-Time Models. This division allows researchers to efficiently navigate models based on their real-time processing needs and computational constraints. Also, we created template-based summaries to make it easier to understand and compare models.
- Structured Framework for Model Selection: By addressing nine key questions for each model and presenting the findings in a standardized format, this study provides a structured framework that assists researchers and practitioners in selecting the most appropriate 6D pose estimation models for their specific needs and applications.
The remainder of this paper is organized as follows: In Section 2, we present the related work. In Section 3, we outline the systematic approach. In Section 4, we categorize the 83 models into real-time and non-real-time groups, and we provide model summaries providing answers to all research questions for each article. In Section 5, we provide an overview of 29 datasets, offering detailed descriptions. In Section 6, we present analytical tables that summarize the research findings. In Section 7, there is a discussion of this study. In Section 8, a guide on how to use this proposed framework to find the nearest model to your needs, in Section 9 we present the limitations of the current study and finally in Section 10 we present the Conclusions.
2. Related Work
The field of 6D object pose estimation has seen significant advancements in recent years, driven by the proliferation of deep learning techniques and the increasing demand for accurate and efficient pose estimation in various application domains. Several comprehensive surveys have been conducted to synthesize the existing methodologies, datasets, and evaluation metrics. This section reviews three latest survey articles—Hoque et al. (2021) [1], Gorschlüter et al. [2]. (2022), and Guan et al. (2024) [3]—highlighting their contributions and delineating how the present study extends beyond their scopes to offer novel insights and resources.
Hoque et al. (2021) [1] present an extensive review of deep learning-based methods for 3D object detection and 6D pose estimation, with a particular emphasis on applications in autonomous vehicles. The survey meticulously categorizes existing techniques, discusses popular datasets and evaluation metrics, and identifies key challenges in the field. The authors highlight the limitations of current methods, such as the inability to handle multi-object scenarios and the challenges posed by textureless objects. Additionally, the paper underscores the necessity for real-time operation in practical applications, advocating for the development of faster and more reliable detection and pose estimation systems.
Gorschlüter et al. (2022) [2] focus their survey on 6D object detection algorithms tailored for industrial applications. The study categorizes algorithms based on their training methodologies—specifically, model-based training—and their support for RGB-D inputs. The authors provide a comprehensive analysis of both qualitative and quantitative data, evaluating various object detectors and identifying promising candidates for specific industrial challenges. A notable contribution of this survey is its emphasis on the practical applicability of algorithms in controlled industrial environments, addressing issues such as occlusion, rotational symmetry, and the handling of textureless and reflective objects. Furthermore, the paper highlights the scarcity of empirical data for many methods, advocating for standardized benchmarking to better assess algorithm suitability for industrial use cases.
Guan et al. (2024) [3] offer a thorough survey of 6D pose estimation methods, categorizing them into instance-level and category-level approaches based on the necessity of computer-aided design (CAD) models during training. This categorization facilitates a clearer understanding of applicable scenarios and underlying assumptions for each method. The survey provides detailed descriptions of widely used datasets, along with primary evaluation metrics. Guan et al. also discuss ongoing challenges like occlusion handling, illumination variations, and real-time performance, proposing future research directions such as zero-shot learning and multi-view information integration.
Building upon the foundational work of the three previous surveys, the present study extends the landscape of 6D pose estimation research as described in the introduction.
3. Methodology
This research originated from the foundational review conducted by Jian Guan et al. in 2024 [3], and more particularly from models in Table 1 [3], focused on 6D pose estimation models using RGB data, serving as a starting point for our study. Building upon their initial list of 25 RGB-based models, we aimed to extend the scope and provide a comprehensive resource—a kind of reference manual—to guide researchers and practitioners in selecting models best suited to their particular needs.
Scopus Analysis
During the data collection process, we recognized that the existing literature encompassed a wide array of input modalities beyond simple RGB, such as RGB-D, 3D models, LiDAR, depth maps, and other sensor data. Although our original goal centered on RGB models, the wealth of information encountered led us to broaden our investigation to include these additional input types. This strategic expansion allows our review to present a more holistic overview of the field, ensuring that readers have access to insights that cover a broad spectrum of approaches, thus stepping slightly beyond the original RGB-focused scope.
To collect relevant literature, we performed comprehensive keyword-based searches in the Scopus database. We began with the 25 RGB models identified in the baseline survey and then searched using their model names in the title, abstract, and keywords of articles. This search yielded 155 articles. The keywords used were: the name of each 25 RGB model, “Pose Estimation”, “6D pose” and “object”. After examining the content, 124 articles appeared closely related to 6D pose estimation in computer vision contexts. Further scrutiny led to the removal of studies that did not introduce or evaluate a 6D pose estimation model, and researches published more that once ultimately leaving a corpus of 84 articles—models, Figure 1.
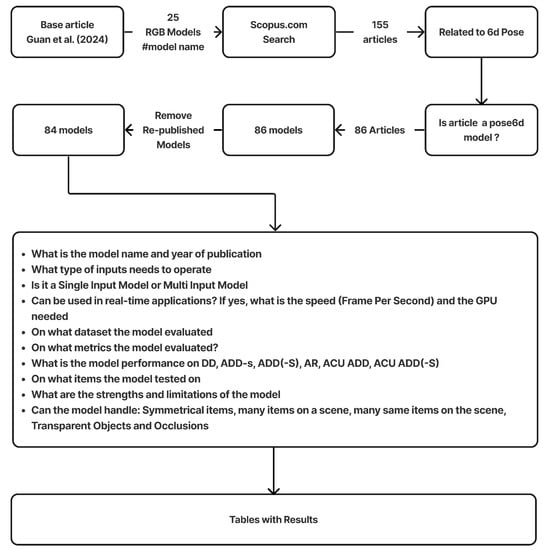
Figure 1.
Research Workflow. Base article [3].
To facilitate a meaningful analysis, we established a structured set of questions for each model:
- Model name and publication year.
- Input type(s) required by the model.
- Single-image or multi-image input capability.
- Real-time applicability, including reported speed (in FPS) and the GPU hardware needed.
- Datasets used for model evaluation.
- Metrics employed to measure model performance, focusing on Average Distance of Model Points (ADD), Average Distance of Model Points-Symmetric Object (ADD-S), Average Distance of Model Points for Symmetric and Non-Symmetric Objects (ADD(-S)), average recall (AR), Area Under Curve for (ADD AUC ADD), and Area Under Curve for ADD(-S) (AUC ADD(-S)).
- Performance values reported for the above metrics.
- Specific items or objects on which the model was tested.
- Strengths and limitations of the model.
- The ability of the model to handle symmetrical objects, multiple objects, multiple identical objects, transparent objects, objects of different shapes, and occlusions.
We systematically recorded the available information for each model, creating a standardized template that allows for clear, comparable summaries of model capabilities. The final aim was to distill our findings into a set of comprehensive tables, thereby offering a high-level reference that researchers and developers can consult when selecting 6D pose estimation models that best align with their particular requirements—ranging from computational constraints and input modality to robustness against environmental challenges and object characteristics.
4. Models
In this section, we provide a structured summary of each of the 83 analyzed 6D pose estimation models presenting a very short description of the inputs, the real-time information, the datasets, and the evaluation metrics. Later in the analysis chapter, analytical tables present more detailed and organized information. The models are categorized into two distinct sections: Real-Time Models with 52 models and Non-Real-Time Models with 30 models. This division allows researchers to efficiently navigate through models based on their real-time processing needs and computational constraints.
4.1. Real-Time Models
The model proposed by Tristan et al. [4], published in 2015, presents a pose estimation method for rendezvous and docking with passive objects, relevant to space debris removal, by fusing data from a 3D time-of-flight camera and a high-resolution grayscale camera, achieving an average distance error of 3 cm and up to 60 FPS in real-time tests using the European Proximity Operations Simulator (EPOS), making it applicable to space operations.
The model BB8 [5], published in 2017, presents a method for 3D object detection and pose estimation using only color images by leveraging segmentation and a CNN-based holistic approach to predict 3D poses, addressing challenges posed by rotationally symmetric objects through restricted training ranges and classification
The model SSD6D [6], published in 2017, introduces an SSD-based approach for 3D instance detection and 6D pose estimation from RGB images, trained exclusively on synthetic model data, achieving high-speed performance (10Hz) while demonstrating that color-based methods can effectively replace depth-dependent techniques, with future improvements focusing on robustness to color variations and loss term optimization.
The model PoseCNN [7], published in 2017, presents PoseCNN, a convolutional neural network for 6D object pose estimation that separately predicts 3D translation and rotation, introduces loss functions to handle occlusions and object symmetries, and operates using only color images, making it applicable for robotic vision tasks while also contributing the YCB-Video dataset for further research.
The model CDPN [8], published in 2019, presents the Coordinates-based Disentangled Pose Network (CDPN), a 6-DoF object pose estimation method that separately predicts rotation and translation using specialized techniques to enhance accuracy and robustness, making it effective for handling texture-less and occluded objects in real-world applications such as robotics and augmented reality.
The model CullNet [9], published in 2019, proposes CullNet, a confidence calibration network for single-view object pose estimation that enhances the reliability of pose proposal selection by refining confidence scores using pose masks rendered from 3D models and cropped image regions, with experimental validation on LINEMOD and Occlusion LINEMOD datasets demonstrating its effectiveness.
The model Pix2Pose [10], published in 2019, proposes Pix2Pose, a 6D object pose estimation method that predicts per-pixel 3D coordinates from RGB images without requiring textured 3D models, using an auto-encoder architecture to estimate 3D coordinates and errors per pixel, generative adversarial training for occlusion recovery, and a transformer loss to handle object symmetries, with validation on multiple benchmark datasets.
The model PoseRBPF [11], published in 2019, proposes PoseRBPF, a Rao–Blackwellized particle filter for 6D object pose tracking that decouples 3D translation and 3D rotation by discretizing the rotation space and using an autoencoder-based codebook of feature embeddings, enabling robust tracking of symmetric and textureless objects, with validation on two benchmark datasets for robotic applications such as manipulation and navigation.
The DPOD (Dense Pose Object Detector) model [12], published in 2019, presents DPOD, a deep learning-based method for 3D object detection and 6D pose estimation from RGB images, which computes dense multi-class 2D-3D correspondences to estimate object poses via PnP and RANSAC, followed by a deep learning-based refinement step, demonstrating effectiveness on both synthetic and real training data while being real-time capable.
The model AAE [13], published in 2018, presents a real-time RGB-based pipeline for object detection and 6D pose estimation, utilizing an Augmented Autoencoder trained on synthetic 3D model views with domain randomization to enable robust self-supervised 3D orientation estimation across various RGB sensors, without requiring pose-annotated training data, while inherently handling object symmetries and perspective errors.
The model CosyPose [14], published in 2020, presents CosyPose, a multi-view 6D object pose estimation method that integrates single-view predictions, robust hypothesis matching, and object-level bundle adjustment for global scene refinement, using a render-and-compare approach to handle unknown camera viewpoints, explicitly managing object symmetries, and operating without depth measurements, with applications in visually driven robotic manipulation.
The model G2L-Net [15], published in 2020, presents G2L-Net, a real-time 6D object pose estimation framework that processes point clouds from RGB-D detection using a divide-and-conquer approach, incorporating 3D sphere-based localization to constrain the search space, embedding vector features (EVF) for viewpoint-aware rotation estimation, and a rotation residual estimator for refinement.
The model HybridPose [16], published in 2020, presents HybridPose, a real-time 6D object pose estimation method that integrates keypoints, edge vectors, and symmetry correspondences as a hybrid intermediate representation, enhancing robustness to occlusions and extreme poses while filtering outliers through a robust regression module, with future extensions planned for incorporating additional geometric features.
The model YOLO-6D+ [17], published in 2020, presents YOLO-6D+, an end-to-end deep learning framework for real-time 6D object pose estimation from a single RGB image, incorporating a silhouette prediction branch to enhance feature learning and an edge restrain loss to improve 3D shape constraints, predicting 2D keypoints for PnP-based pose estimation, demonstrating efficiency for augmented reality and robotic grasping applications.
The model ASPP-DF-PVNet [18], presents ASPP-DF-PVNet, an occlusion-resistant 6D pose estimation framework that enhances PVNet with an Atrous Spatial Pyramid Pooling (ASPP) module for improved segmentation and a distance-filtered voting scheme for better keypoint localization, demonstrating effectiveness on LINEMOD and Occlusion LINEMOD datasets.
The model BundleTrack [19], published in 2021, presents BundleTrack, a real-time 6D pose tracking framework that operates without relying on instance- or category-level 3D models, combining deep learning-based segmentation, robust feature extraction, and pose graph optimization for long-term, low-drift tracking under challenging conditions, with applications in robotic manipulation, pick-and-place, and in-hand dexterous tasks.
The model CloudAAE [20], published in 2021, presents a point cloud-based 6D pose estimation system that leverages an augmented autoencoder (AAE) for pose regression and a lightweight synthetic data generation pipeline, significantly reducing training costs while enabling agile deployment for robotic applications, demonstrating effectiveness among synthetic-trained methods on public benchmarks.
The model FS-Net [21], published in 2021, presents FS-Net, a real-time category-level 6D pose estimation framework that utilizes a 3D graph convolutional autoencoder for feature extraction, a decoupled rotation mechanism for improved orientation decoding, and a residual-based translation and size estimation strategy, demonstrating strong generalization and efficiency for fast and accurate object pose tracking.
The model RePOSE [22], published in 2021,a real-time 6D object pose refinement method that replaces CNN-based refinement with efficient deep texture rendering and differentiable Levenberg-Marquardt optimization, enabling fast and accurate pose tracking, with potential applications in real-time object manipulation and robotics.
The SO-Pose model [23], published on 2021, presents SO-Pose, an end-to-end 6D pose estimation framework that introduces a two-layer model combining 2D-3D correspondences and self-occlusion reasoning, enhancing spatial reasoning and robustness in cluttered environments, with potential applications in object tracking, manipulation, and self-supervised pose estimation.
The model developed by Jingrui Song et al. [24], published in 2021, presents a satellite pose estimation framework that leverages a degraded image rendering pipeline to simulate atmospheric turbulence and a deep learning-based method inspired by YOLO-6D, incorporating a relative depth prediction branch to enhance pose estimation accuracy, with applications in ground-based optical telescope tracking of non-cooperative space targets.
The model GDR-NET [25], published in 2021, presents GDR-Net, a geometry-guided direct regression network for end-to-end 6D object pose estimation, integrating dense geometric feature representations with a Patch-PnP module to enable real-time, differentiable, and accurate pose estimation, with applications in robotics, augmented reality, and computer vision tasks requiring differentiable poses.
This paper [26], published in 2021 introduces FFB6D, a Full Flow Bidirectional fusion network for 6D pose estimation that integrates RGB and depth features throughout the encoding and decoding process and incorporates a SIFT-FPS keypoint selection algorithm, demonstrating strong performance on benchmark datasets with potential applications in 3D perception tasks.
The model DPOPV2 [27], published in 2022 presents DPODv2, a three-stage 6D object pose estimation framework that integrates YOLOv3-based detection, CENet for dense 2D-3D correspondences, and multi-view optimization, supporting both RGB and depth modalities. It also introduces a differentiable rendering-based refinement stage to improve pose consistency across multiple views, demonstrating scalability and strong performance across multiple datasets.
The model FS6D-DPM [28], published in 2022, introduces FS6D-DPM, a few-shot 6D object pose estimation framework that predicts the pose of unseen objects using only a few support views, leveraging dense RGBD prototype matching with transformers, ShapeNet6D for large-scale pre-training, and online texture blending for enhanced generalization, addressing challenges in open-set pose estimation with potential applications in robotics and augmented reality.
The model GPV-Pose [29], published in 2022,presents GPV-Pose, a category-level 6D pose estimation framework that introduces a confidence-driven rotation representation and a geometry-guided point-wise voting mechanism to improve robustness across intra-class variations, achieving real-time inference speed and state-of-the-art performance on public datasets, with applications in robotics, augmented reality, and 3D scene understanding.
The model MV6D [30], published in 2022, presents MV6D, an end-to-end multi-view 6D pose estimation framework that fuses RGB-D data from multiple perspectives using DenseFusion and joint point cloud processing, achieving robust pose estimation in cluttered and occluded scenes, with applications in robotics, augmented reality, and autonomous systems.
The model OVE6D [31], published in 2022, presents OVE6D, a model-based 6D pose estimation framework that decomposes pose into viewpoint, in-plane rotation, and translation, using lightweight cascaded modules trained purely on synthetic data, enabling strong generalization to real-world objects without fine-tuning, with applications in robotics, industrial automation, and large-scale object recognition.
The model PVNet (Pixel-wise Voting Network) [32], published in 2022, presents PVNet, a 6D object pose estimation framework that uses a pixel-wise voting mechanism for keypoint localization and an uncertainty-driven PnP solver for final pose estimation, improving robustness against occlusion and truncation, with applications in robotics, augmented reality, and automated inspection.
The model SC6D [33], published in 2022, presents SC6D, a symmetry-agnostic, correspondence-free 6D object pose estimation framework that utilizes an SO(3) encoder for rotation learning, object-centric coordinate transformations for localization, and classification-based depth estimation, eliminating the need for CAD models on the T-LESS dataset.
The model SSP-Pose [34], published in 2022, presents SSP-Pose, an end-to-end category-level 6D pose estimation framework that integrates shape priors into direct pose regression, leveraging symmetry-aware constraints and multiple learning branches to improve accuracy while maintaining real-time inference speed, with applications in robotics, autonomous driving, and augmented reality.
The model proposed by Yan Ren et al. [35], published in 2022, presents a multi-scale convolutional feature fusion framework for 6D object pose estimation, enhancing correspondence-based keypoint extraction through residual learning and improved feature representation, achieving higher accuracy and robustness in challenging conditions, with applications in robotic grasping and real-time object tracking.
The model proposed by Yi-Hsiang Kao et al. [36], published in 2022, presents a PVNet-based 6D object pose estimation framework for robotic arm applications in smart manufacturing, leveraging multi-angle image transformations and point cloud registration to improve pose estimation, feature extraction, and object grasping accuracy, addressing limitations of traditional 2D vision-based systems.
The model ZebraPose [37], published in 2022, presents a coarse-to-fine surface encoding technique for 6D object pose estimation, introducing a hierarchical binary grouping strategy for efficient 2D-3D correspondence prediction, leveraging a PnP solver for final pose estimation, achieving state-of-the-art accuracy on benchmark datasets, with applications in robotics, augmented reality, and industrial automation.
The model article [38], published in 2022, introduces Gen6D, a generalizable model-free 6D pose estimator that predicts object poses using only posed images, integrating a novel viewpoint selector and volume-based pose refiner to achieve accurate results for unseen objects in arbitrary environments.
The model proposed by Antoine Legrand et al. [39], published in 2023, presents a two-stage deep learning framework for spacecraft 6D pose estimation, where a convolutional network predicts keypoint locations, and a Pose Inference Network estimates the final pose, achieving efficient processing for space-grade hardware while maintaining competitive accuracy on the SPEED dataset.
The model Compressed YOLO-6D [40], published in 2023, presents a mobile-optimized real-time 6D pose estimation framework for augmented reality (AR), enhancing YOLO-6D with model compression techniques such as channel pruning and knowledge distillation to improve inference speed and efficiency, enabling low-latency AR interactions on mobile devices.
The CRT-6D model [41], published in 2022, presents CRT-6D (Cascaded Pose Refinement Transformers), a real-time 6D object pose estimation framework that replaces dense intermediate representations with Object Surface Keypoint Features (OSKFs) and employs deformable transformers for iterative pose refinement, achieving state-of-the-art performance on benchmark datasets while being significantly faster than existing methods, with applications in robotics, augmented reality, and industrial automation.
The model DFTr network [42], published in 2023, presents DR-Pose, a two-stage 6D pose and 3D size estimation framework that integrates point cloud completion for unseen part recovery and scaled registration for pose-sensitive feature extraction, with applications in robotics, augmented reality, and automated object recognition.
The model PoET [43], published in 2022, presents PoET, a transformer-based 6D multi-object pose estimation framework that predicts object poses using only a single RGB image, integrating object detection with a transformer decoder to process multiple objects simultaneously, with applications in robotic grasping, localization, and real-time perception in resource-constrained environments.
The model HS-Pose [44], published in 2023, presents HS-Pose, a category-level 6D object pose estimation framework that introduces the HS-layer, an improved 3D graph convolutional module designed to enhance local-global feature extraction, robustness to noise, and encoding of size and translation information, running in real-time, with applications in robotics, augmented reality, and industrial automation.
The Improved PVNet model [45], published in 2023, presents an enhanced PVNet-based 6D pose estimation framework for amphibious robots, introducing confidence score prediction and keypoint filtering to improve accuracy in occluded target scenarios, with applications in robotic tracking, docking, and grasping, and plans for further optimization to reduce computational costs and improve real-time performance.
The 6D object pose estimation model proposed by Lichun Wang et al. [46], published in 2023, presents an enhanced voting-based 6D object pose estimation method that improves PVNet by introducing a distance-aware vector-field prediction loss and a vector screening strategy, reducing angular deviations in keypoint predictions and preventing parallel vector hypotheses, achieving higher accuracy on benchmark datasets, with future work aimed at applying these improvements to robotic grasping tasks.
The model PLuM [47], published in 2023, presents PLuM (Pose Lookup Method), a probabilistic reward-based 6D pose estimation framework that replaces complex geometric operations with precomputed lookup tables, enabling accurate and efficient pose estimation from point clouds, with applications in field robotics, including real-time haul truck tracking in excavation scenarios.
The model proposed by by Zih-Yun Chiu et al. [48], published in 2023, presents a real-time 6D pose estimation framework for in-hand suture needle localization, incorporating a novel state space and feasible grasping constraints into Bayesian filters, ensuring consistent and accurate needle tracking relative to the end-effector, with applications in autonomous suturing and surgical robotics.
The model SE-UF-PVNet [49], published in 2023, is a 6DoF object pose estimation framework that enhances keypoint localization from a single RGB image by integrating structural information via a keypoint graph and Graph Convolution Network, utilizing novel vector field predictions and multi-scale feature extraction to improve robustness, particularly in occlusion scenarios, while maintaining real-time inference.
The model BSAM-PVNet [50], published in 2024, introduces BSAM-PVNet, a two-stage pose estimation method combining ResNet18 with blueprint separable convolutions and a convolutional attention mechanism for feature extraction, validated on a self-built insulator dataset, highlighting improvements in accuracy and efficiency while addressing generalization challenges in future research. The model CoS-PVNet [51], published in 2024, is a robust 6D pose estimation framework designed for complex environments in augmented reality, virtual reality, robotics, and autonomous driving, enhancing PVNet with pixel-weighting, dilated convolutions, and a global attention mechanism to improve keypoint localization and feature extraction, demonstrating strong performance in occlusion-heavy conditions and potential for broader industry applications.
The model EPro-PnP [52], published in 2025, is a probabilistic PnP layer that transforms traditional non-differentiable pose estimation into an end-to-end learnable framework by modeling pose as a probability distribution on the SE(3) manifold, enhancing 2D-3D correspondence learning with KL divergence minimization and derivative regularization, demonstrating strong applicability in robotics and autonomous driving.
The model “Focal Segmentation” proposed in [53], published in 2024, presents an improved 6D pose estimation method for augmented reality, enhancing PVNet with a focal segmentation mechanism to improve object pixel segmentation under severe occlusion, enabling robust keypoint localization and pose estimation via a PnP algorithm while maintaining real-time performance, with future work exploring backbone network modifications and hyperparameter tuning.
The model proposed by Fupan Wang et al. [54], introduces a lightweight 6DoF pose estimation method that enhances PVNet with depth-wise separable convolutions, coordinate attention, and an improved ASPP module for better multi-scale feature fusion, achieving robustness to scale variations while reducing computational complexity, making it suitable for deployment on low-performance devices such as mobile platforms.
The model Lite-HRPE [55], published in 2024, is a lightweight 6DoF pose estimation network designed for intelligent robotics, incorporating a multi-branch parallel structure, Ghost modules, and an optimized feature extraction network to reduce computational complexity while maintaining accuracy, making it well-suited for real-time deployment in resource-constrained environments.
The model YOLOX-6D-Pose [56], published in 2024, is an end-to-end multi-object 6D pose estimation framework that enhances the YOLOX detector to directly predict object poses from a single RGB image, eliminating the need for correspondences, CAD models, or post-processing, making it a highly efficient and accurate solution for real-time applications.
The model IFFNeRF [57], published in 2024, is a real-time 6DoF camera pose estimation method that utilizes NeRF-based Metropolis-Hastings sampling and an attention-driven ray matching mechanism to estimate poses without an initial guess, demonstrating improved robustness and efficiency across synthetic and real-world datasets.
4.2. Non-Real-Time Models
The model “Chen et al.” [58], published in 2019, introduces a 3D object detection and pose estimation framework for robotic applications, combining SSD-based object detection, modified LineMOD template matching, and ICP refinement to improve accuracy and reduce false positives, demonstrating its effectiveness in real-world robotic grasping and polishing tasks.
The model DeepVCP [59], published in 2019, presents an end-to-end 3D hand pose estimation framework that eliminates the need for prior hand information by introducing a keypoint-based detection method and integrating biological hand constraints, improving accuracy and robustness for real-world applications in unconstrained environments.
The “Autonomous Mooring” model [60], published in 2020, proposes an algorithm for autonomous mooring that refines bollard detection by converting Mask R-CNN segmentation into a single reference point, improving localization accuracy and reducing error for precise maritime navigation and offshore operations.
The model DeepIM [61], published in 2018, is a deep learning-based 6D pose estimation framework for robot manipulation and virtual reality, using an iterative pose refinement approach that predicts relative transformations from color images, enabling accurate pose estimation without depth data or prior object models.
The model EPOS [62], published in 2020, introduces a 6D object pose estimation method that models objects using compact surface fragments, predicts per-pixel 3D correspondences, and refines poses with a robust PnP-RANSAC algorithm, enabling accurate pose estimation for diverse objects, including those with global or partial symmetries.
The model LatentFusion [63], published in 2020, presents a keypoint-based 6D pose estimation framework for spacecraft applications, using a two-stage neural network to predict keypoints and infer pose, achieving real-time processing while balancing accuracy and computational efficiency for deployment on space-grade hardware.
The model Self6D [64], published in 2020, introduces Self6D, a self-supervised 6D pose estimation framework that refines models trained on synthetic data using neural rendering and geometric constraints, enabling improved accuracy on real-world data without requiring 6D pose annotations.
The model “Category Level Metric Scale Object Shape and Pose Estimation” [65], published in 2021, introduces a framework for estimating metric scale shape and 6D pose from a single RGB image, utilizing the MSOS and NOCS branches along with the NOCE module to predict object mesh, coordinate space, and geometrically aligned object centers, demonstrating strong performance in robotics and augmented reality applications.
The model ConvPoseCNN2 [66], published in 2021, is a fully convolutional 6D object pose estimation framework for robotics, utilizing dense pixel-wise predictions to improve spatial resolution and inference speed while integrating an iterative refinement module to enhance accuracy, making it well-suited for cluttered environments.
The model DCL-Net [67], published in 2022, is a deep learning-based 6D object pose estimation framework that enhances correspondence learning between partial object observations and complete CAD models using dual Feature Disengagement and Alignment modules, integrating confidence-weighted pose regression and iterative refinement for improved accuracy across multiple benchmark datasets.
The “Hayashi et al.” model [68] using Augmented Auto Encoder and Faster R-CNN, published in 2021, introduces a joint learning framework that integrates object detection and pose estimation, using shared feature maps to enhance pose accuracy by reducing errors from mislocalized bounding boxes, with potential applications in real-world object recognition tasks.
The model proposed by Ivan Shugurov et al. [69], published in 2021, introduces a multi-view 6DoF object pose refinement method that enhances DPOD-based 2D-3D correspondences using a differentiable renderer and geometric constraints, demonstrating robust performance across multiple datasets and enabling automatic annotation of real-world training data for practical applications.
The model proposed by Haotong Lin et al. [70], published in 2022, presents a self-supervised learning framework for 6DoF object pose estimation, utilizing depth-based pose refinement to supervise an RGB-based estimator, achieving competitive accuracy without real image annotations and offering a scalable solution for applications with limited labeled data.
The model “Primitive Pose” [71], published in 2022,is a 3D pose and size estimation framework for robotic applications, using stereo depth-based geometric cues to predict oriented 3D bounding boxes for unseen objects without CAD models or semantic information, enabling open-ended object recognition in dynamic environments.
The model “RANSAC Voting” [72], published in 2022, introduces a 6D pose estimation method for robotic grasping, leveraging EfficientNet for feature extraction and per-pixel keypoint prediction using RANSAC voting, demonstrating high accuracy under occlusions and enabling stable object grasping in real-world environments.
The model 3DNEL [73], published in 2023, is a probabilistic inverse graphics framework for robotics and 3D scene understanding, integrating neural embeddings from RGB with depth information to improve robustness in sim-to-real 6D pose estimation, enabling uncertainty quantification, multi-object tracking, and principled scene modeling.
The model Multistream ValidNet [74], introduces a validation framework for robotic manipulation that enhances 6D pose estimation by distinguishing between True and False Positive results using depth images and point clouds, improving pose accuracy and robustness in real-world applications.
The model C2FNET [75], published in 2023, is a two-stage 6D pose estimation framework that refines keypoint localization using deformable convolutional networks (DCN), improving accuracy in occlusion-heavy conditions, as demonstrated on LINEMOD and Occlusion LINEMOD datasets.
The model DR-Pose [76], published in 2023, is a 6D object pose estimation method that enhances RGBD feature integration using a Deep Fusion Transformer (DFTr) block and improves 3D keypoint localization with a weighted vector-wise voting algorithm.
The model Improved CDPN [77], published in 2023, presents an enhanced pose estimation method for robotics by employing separate networks for translation and rotation prediction, integrating Convolutional Block Attention Module (CBAM) and Pyramid Pooling Module (PPM) to mitigate feature degradation, and validating its effectiveness in object pose estimation and robotic grasping tasks using the Linemod dataset and real-world experiments.
The Improved PVNet 2 model [78], published in 2023, presents an improved PVNet-based pose estimation method with an enhanced ResNet18 backbone and ELU activation function to support real-time pose tracking in virtual-real fusion maintainability test scenarios, validated on a custom Linemod-format air filter dataset for improved accuracy in component detection and virtual reconstruction.
The model MSDA [79], published in 2023, introduces a self-supervised domain adaptation approach for 6D object pose estimation that fine-tunes a synthetic pre-trained model using real RGB(-D) images with pose-aware consistency and depth-guided pseudo-labeling, reducing reliance on real pose labels and differentiable rendering while improving real-world applicability.
The Scale Adaptive Skip-ASP Pixel Voting Network (SASA-PVNet) model [80], published in 2023, presents SASA-PVNet, a scale-adaptive 6D object pose estimation method that enhances keypoint-based approaches by dynamically resizing small objects and incorporating a Skip-ASP module for multi-scale information fusion.
The model proposed by Sijin Luo et al. [81], published in 2022, presents a vision system for UAV-based logistics that integrates 2D image and 3D point cloud data to detect, segment, and estimate 6D object poses, demonstrating its effectiveness through experiments on the YCB-Video and SIAT datasets and highlighting future improvements for real-time deployment.
The model StereoPose [82], published in 2023, presents StereoPose, a stereo image-based framework for category-level 6D pose estimation of transparent objects, integrating a back-view NOCS map, a parallax attention module for feature fusion, and an epipolar loss to enhance stereo consistency, with validation on the TOD dataset and potential applications in robotics.
The model SwinDePose [83], published in 2023, proposes SwinDePose, a fusion network that extracts geometric features from depth images, combines them with point cloud representations, and predicts poses through semantic segmentation and keypoint localization, validated on the LineMod, Occlusion LineMod, and YCB-Video datasets.
The model Yolo 7 [84], published in 2023, presents an improved YOLOv7-based 6D pose estimation method that extends prediction networks, modifies the loss function, and incorporates keypoint interpolation to enhance pose accuracy while reducing reliance on precise 3D models, validated on public and custom datasets.
The model developed by Junhao Cai et al. [85], published in 2024, introduces an open-vocabulary 6D object pose and size estimation framework that utilizes pre-trained DinoV2 and text-to-image diffusion models to infer NOCS maps, enabling generalization to novel object categories described in human text, supported by the large-scale OO3D-9D dataset.
The model RNNPose [86], published in 2024, presents RNNPose, a recurrent neural network-based framework for 6D object pose refinement that iteratively optimizes poses using a differentiable Levenberg-Marquardt algorithm, leveraging descriptor-based consistency checks for robustness against occlusions and erroneous initial poses, validated on multiple public datasets.
The model developed by Yiwei Song et al. [87], published in 2024, presents a cross-modal fusion network for 6D pose estimation that extracts and integrates RGB and depth features using transformer-based fusion, demonstrating improved accuracy in occluded and truncated environments through evaluations on Occlusion Linemod and Truncation Linemod datasets.
5. Datasets
In this section, we present a comprehensive analysis of the datasets identified through our examination of 84 research papers on 6D pose estimation. A total of 25 datasets were discovered, each offering unique attributes and challenges pertinent to the field. We provide a succinct description of each dataset, highlighting their specific characteristics and applications. Additionally, we focus on the eight most frequently utilized datasets within the reviewed literature, namely Linemod, OCCLUSION Linemod, YCB-VIDEO, T-LESS KITTI, CAMERA25, REAL25, and TEJANI. These datasets are summarized in detailed tables, accompanied by a statistical chart in Figure 2 that illustrates the distribution of dataset usage for the evaluation of the 6D Pose estimation models.

Figure 2.
Distribution of Dataset Usage Across 6D Pose Estimation Models.
5.1. Datasets Summaries
Through our extensive analysis, we identified a total of 25 datasets, which are detailed in Table 1, Table 2 and Table 3 presented below. Notably, 14 of these datasets have not been included in previous surveys, highlighting significant additions to the existing body of resources. This expanded collection provides researchers with a broader spectrum of data sources, facilitating more robust and diverse evaluations in the field of 6D pose estimation.

Table 1.
Summary of Datasets for 6D Pose Estimation (Part I).
Table 2.
Summary of Datasets for 6D Pose Estimation (Part II).
Table 3.
Summary of Datasets for 6D Pose Estimation (Part III).
5.2. Datasets Analytics
Table 4, Table 5 and Table 6 and outline the 84 6D pose estimation model analyzed in this study, listing each model alongside its corresponding reference. Presented the 8 most common datasets found to be used in this study. Each model may be evaluated in more than one dataset. Each dataset represented by a specific column: Linemod (LN), OCCLUSION Linemod (OLN), YCB-VIDEO (YCBV), T-LESS (T-L), KITTI (KIT), CAMERA25 (CAM), REAL (RE), and TEJANI (TEJ). An ’X’ in the table indicates that a particular model has been validated on the corresponding dataset. Additionally, there are 17 other datasets referenced across the studies that are not included in this table for conciseness but exist in the dataset section. Analytical information about what dataset was used on each model is available in the above section of the model presentation.
Table 4.
Datasets per model (Part I).
Table 5.
Datasets per model (Part II).
Table 6.
Datasets per model (Part III).
The statistical analysis presented in Figure 2 reveals that the majority of the models have been validated on the OCCLUSION Linemod and Linemod datasets, with 24.88% and 23.96% of the models respectively utilizing these benchmarks. The YCB-VIDEO dataset is also prominently used, with 13.36% of the models validating their performance on it. These three datasets serve as the primary benchmarks for evaluating a 6D pose estimation model, underscoring their significance in the field. Other datasets such as T-LESS, KITTI, CAMERA25, REAL, and TEJANI have been employed less frequently, with usage rates ranging from 0.46% to 5.99% and a 24% used also other datasets.
6. Analysis
6.1. Metric Evaluation
In our comprehensive analysis of 84 6D pose estimation models, a multitude of evaluation metrics were utilized, reflecting the diverse methodologies and objectives within the field. To ensure a coherent and standardized benchmark comparison, this section focuses exclusively on models assessed using the common metrics: ADD, ADD-S, ADD(-S), average recall (AR), AUC ADD, and AUC ADD(-S). While numerous additional metrics are employed across various studies, detailed information about these supplementary evaluations is provided in the models section. We begin by presenting the performance of the models on the Linemod dataset, followed by evaluations on the Occlusion Linemod and YCB-Video datasets. For each metric, we report the maximum performance values identified in the respective research papers, thereby highlighting the most effective models within each dataset.
The primary metrics employed in our analysis include the following:
- ADD: Measures the average distance between the estimated and ground truth object poses.
- ADD-S: Accounts for symmetric objects by considering the closest point distances.
- ADD(-S): Similar to ADD but excludes symmetry considerations.
- Average recall (AR): Evaluates the proportion of correctly estimated poses.
- AUC ADD: Calculates the area under the ADD curve, providing a comprehensive performance measure across different thresholds.
- AUC ADD(-S): Measures the area under the ADD(-S) curve.
6.1.1. Linemod Dataset
Table 7 and Table 8 present the evaluation metrics for various 6D pose estimation models on the Linemod dataset. Analysis of these tables reveals that certain models consistently achieve the highest values across different metrics. Notably, the DFTr network [42] attains the highest scores in both the ADD and AUC ADD metrics with values of 99.80%. For the ADD-S metric, which accounts for symmetric objects, GPV-Pose [29] leads with a score of 98.20%, while DCL-Net [67] achieves the highest value of 99.50% in the ADD(-S) metric. Regarding the Average Recall (AR) metric, FS-Net [21] records the top performance with a score of 97.60%. In the AUC ADD(-S) metric, FS-Net [21] also achieves the highest value of 95.92%.
Table 7.
Model Evaluation (in %) on Linemod Dataset (Part I).
Table 8.
Model Evaluation (in %) on Linemod Dataset (Part II).
6.1.2. Occlusion Linemod Dataset
Table 9 and Table 10 detail the evaluation metrics for various models on the Occlusion Linemod dataset. The DFTr network [42] achieves the highest ADD score of 77.7%. For the ADD-S metric, HybridPose [16] leads with 79.2%, and OVE6D [31] records the highest ADD(-S) value of 74.80%. In terms of Average Recall (AR), both DeepIM [61] and Pix2Pose [10] achieve the highest scores of 93%. Additionally, Pix2Pose [10] stands out with an AUC ADD score of 93%, while DeepIM [61] leads the AUC ADD(-S) metric with 95.92%.
Table 9.
Occlusion Linemod Evaluation (in %) (Part I).
Table 10.
Occlusion Linemod Evaluation (in %) (Part II).
6.1.3. YCB-Video Dataset
Table 11 presents the evaluation metrics for various models on the YCB-Video dataset. The PoseRBPF [11] achieves the highest ADD value of 92.4%, and CloudAAE [20] leads the ADD-S metric with a score of 93.6%. DCL-Net [67] records the highest ADD(-S) value of 99%. For the Average Recall (AR) metric, Ivan Shugurov et al. [69] achieves the highest score of 86%. In the AUC ADD metric, the DFTr network [42] stands out with a score of 96.7%, while Sijin Luo et al. [81] achieves the highest AUC ADD(-S) value of 94.8%.
Table 11.
YCB-Video Dataset Evaluation (in %).
6.2. Real-Time Capabilities
In this section, we categorize the models based on their ability to operate in real-time environments. This distinction is essential for researchers who aim to implement pose estimation in applications where processing speed and hardware constraints are critical. The results are presented in two separate tables, Part I (Table 12) and Part II (Table 13). Each includes their processing speed measured frames per second (FPS), along with the GPU hardware required for their execution, and a column that shows the one marked as real-time by the authors. In order for a more accurate classification we sort the models per speed so it can be more effective to select a model based on its speed.
Table 12.
Model Speeds and GPU Usage.
Table 13.
Model Speeds and GPU Usage (Part II).
Figure 3 represents the distribution of Pose6D models based on their speed, measured in frames per second (FPS). The number of models is plotted against various FPS categories (up to 10 FPS, 10 to 20 FPS, 30 to 30 FPS, 30 to 40 FPS, 40 to 50 FPS, greater than 50 FPS), showcasing how many models achieve specific speed thresholds. The largest group is in the 40 FPS category, containing 16 models, indicating that this speed is a common benchmark for real-time Pose6D performance. Following closely is the 10 FPS group with 15 models, suggesting that a significant number of models operate at lower speeds not able to perform real-time tasks. The 20 FPS have 10 models and 30 FPS have 9 models, indicating moderate performance clusters. As the speed increases, the number of models decreases, with 6 models achieving 50 FPS and only 4 models exceeding 50 FPS, signifying that higher-speed models are less common and potentially more optimized for real-time performance.
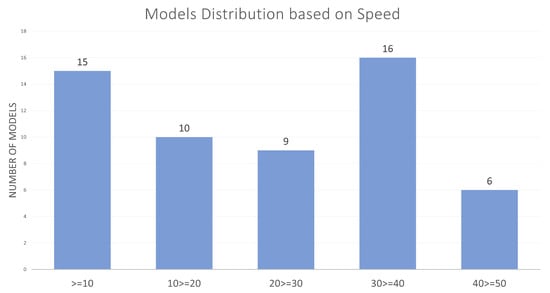
Figure 3.
Model Distribution Based on Model Speed.
6.3. Models by Input Type
In this section, we categorize the 84 analyzed 6D pose estimation models based on their input types, distinguishing between single image and non-single image models. Table 14, Table 15, Table 16 and Table 17 present the detailed specifications of these models, including their processing speeds measured in frames per second (FPS) and the types of input data they utilize.
Table 14.
Single Image Models and Input Types (Part I).
Table 15.
Single Image Models and Input Types (Part II).
Table 16.
Single Image Models and Input Types (Part III).
Table 17.
Non-Single Image Models and Input Types.
Out of the total models (84), 71 are single image models, while the remaining 13 are non-single image models. Among the single image models, 14 operate below 13 FPS, 11 up 25 FPS and 48 achieve speeds exceeding 25 FPS. However, speed information is unavailable for 13 of these models. In contrast, within the non-single image category (13 models), 3 models run below 10 FPS, 4 models are able to run between 20 adn 50 FPs and 6 models lack speed information.
Analyzing the input types, a majority of the models accept RGB images, with 56 models supporting this input modality 52 of which are single image models and 4 are multi-image models. From the 52 Single image models 38 accept only one RGB image while 14 accept more than one modality. RGB-D inputs are supported by 21 models, comprising 17 single image and 4 multi-image models. Of the 21 single image models 17 accept only RGB-D images and 4 accept also other modalities. Additionally, 7 models utilize 3D data inputs (6 single and 1 multi), while 10 models incorporate Lidar and Point Cloud data (5 single and 5 multi). Depth Maps are accepted by 8 models (6 single and 2 multi), and specialized inputs such as Pose Masks and Gray Scale images are supported by 2 single image models each.
This distribution indicates a strong preference for RGB-based inputs in both single and multi-image models, reflecting their versatility and widespread applicability in various pose estimation tasks. The presence of models utilizing RGB-D, 3D, Lidar, Point Cloud, Depth Map, Pose Mask, and Gray Scale inputs underscores the diversity of approaches in the field, catering to different application requirements and environmental conditions. Moreover, the higher prevalence of single image models with RGB inputs suggests that these models strike a balance between performance and computational efficiency, making them suitable for real-time applications where speed is paramount.
6.4. Model Capabilities
In this section, we analyze the capabilities of the 84 evaluated 6D pose estimation models as presented in Table 18 and Table 19. These tables indicate whether each model can handle symmetrical objects, multiple objects within the same scene, multiple instances of the same object, transparent objects, objects with varying shapes, and occlusions. A check mark (✓) signifies that the authors have declared the model’s ability to manage the respective capability, an X indicates the inability to handle it, and a dash (−) denotes the absence of related information in the article.
Table 18.
Model Capabilities (Part I).
Table 19.
Model Capabilities (Part II).
The statistical analysis of these capabilities reveals that a majority of the models (66%) can effectively handle symmetrical objects, highlighting the importance of symmetry in pose estimation tasks. Furthermore, 47% of the models are capable of managing multiple objects within a single scene, which is crucial for complex environments. However, only 5% of the models can handle multiple instances of the same object in one scene, indicating a significant area for improvement. Transparent objects present an even greater challenge, with merely 2% of the models addressing this capability. Conversely, 37% of the models are designed to handle objects with different shapes, and a substantial 53% can manage occlusions, underscoring the necessity of robustness in real-world applications where objects may be partially obscured.
These findings suggest that while there has been considerable progress in developing models that can manage symmetrical objects and occlusions, there remains a considerable gap in handling multiple instances of the same object and transparent objects. The ability to process objects with varying shapes is moderately addressed, reflecting ongoing efforts to enhance model versatility. The relatively low percentage of models capable of handling transparent objects underscores a critical challenge in the field, likely due to the inherent difficulty in accurately perceiving and estimating the poses of such objects.
6.5. Model Strengths and Limitations
To provide a comprehensive understanding of the various 6D pose estimation models analyzed in this study, we have systematically categorized their strengths and limitations into five distinct categories. This classification facilitates a clearer comparison of the models by highlighting recurring themes and common challenges across different approaches.
Table 20.
Model strengths classification (Part I).
Table 21.
Model strengths classification (Part II).
- Accuracy and Performance (A&P): This category includes strengths that emphasize high precision, superior performance metrics, and advancements over existing state-of-the-art methods. Examples include “high accuracy”, “validated performance”, and “superior performance compared to state-of-the-art methods.”
- Robustness and Generalization (R&G): This encompasses strengths related to the method’s ability to handle challenging scenarios such as occlusions, symmetries, and varying environmental conditions. It also includes the capacity to generalize well across different datasets and real-world applications. Examples are “robustness to occlusions”, “handling symmetries”, and “generalization to real-world scenarios”.
- Efficiency and Real-Time Capability (E&R): Strengths under this category focus on computational efficiency, speed of inference, and suitability for real-time applications. This is crucial for deployment in time-sensitive environments like robotics and augmented reality. Examples include “real-time performance”, “fast inference”, and “computational efficiency.”
- Scalability and Flexibility (S&F): This category covers strengths that allow the method to scale to multiple objects, adapt to different sensors or environments, and maintain flexibility in various applications without extensive retraining. Examples include “scalability to multi-object scenarios”, “flexibility with detectors”, and “scalability to multiple objects without retraining”.
- Methodological and Architectural Innovation (M&AI): This includes novel technical approaches, innovative architectures, and unique methodological contributions that advance the field. These strengths highlight the cutting-edge nature of the methods, such as “dense correspondence estimation“, “end-to-end trainability”, and “hybrid intermediate representation”.
These categories encapsulate the key areas where models excel, such as achieving high accuracy on benchmark datasets, demonstrating resilience to challenging conditions, operating efficiently in real-time applications, scaling effectively to handle multiple objects or diverse input modalities, and introducing novel methodological advancements.
Table 22.
Model limitations classification (Part I).
Table 23.
Model limitations classification (Part II).
- Data and Model Dependencies (D&MD): This category includes limitations stemming from reliance on specific data types, sensors, or precomputed models that may not be universally available or may introduce constraints in diverse applications. For example, “PMD sensor accuracy issues due to non-linearities and multi-path effects”, “dependence on accurate 3D object models”, and “reliance on synthetic training data” illustrate how dependency on particular data sources or models can hinder the method’s applicability and accuracy in real-world scenarios where such dependencies may not hold.
- Limited Generalization and Robustness (LG&R): This category captures challenges related to a method’s ability to maintain performance across varied and unforeseen conditions. Examples include “color deviations between synthetic and real data”, “struggles with heavy occlusions”, “domain gap due to synthetic training data”, and “reduced performance on objects with little variation in color and geometry”. These limitations highlight the difficulties methods face in adapting to new environments, object types, lighting conditions, and occlusions, thereby affecting their reliability and versatility.
- Computational Complexity and Efficiency Constraints (CC&EC): This category addresses limitations arising from high computational demands, inefficiencies, or lack of real-time capabilities that impede practical deployment. Examples such as “increased computational cost”, “computational overhead during training”, “runtime being 3–4 times slower than some RGB methods”, and “high computational complexity” demonstrate how these constraints can limit the usability of pose estimation methods in time-sensitive or resource-constrained applications.
- Narrow Evaluation Scope and Limited Benchmarking (NES&LB): This category includes limitations related to insufficient or limited evaluation, such as testing on a narrow range of datasets, object types, or lacking comprehensive performance metrics. Examples like “limited evaluation on a single object and synthetic dataset”, “lack of information on computational complexity and real-time performance beyond FPS”, and ”limited evaluation on occluded objects” indicate that methods may not have been thoroughly tested across diverse scenarios, making it difficult to assess their true effectiveness and generalizability.
- Architectural and Methodological Restrictions (A&MR): This category encompasses inherent design and methodological constraints that limit a method’s flexibility, adaptability, or performance. Examples include ”dependence on accurate initial segmentation“, “reliance on a robust 2D detector”, “susceptibility to local minima with specific loss functions”, and “absence of a refinement stage”. These restrictions often stem from specific architectural choices or methodological dependencies, which can hinder the method’s ability to adapt to varying conditions or improve upon its limitations.
These categories address the common obstacles faced by models, including reliance on specific types of data or external modules, difficulties in generalizing to unseen scenarios, high computational demands, insufficient evaluation across diverse datasets, and inherent design limitations that restrict adaptability.
This structured classification not only highlights the current state of 6D pose estimation models but also identifies critical areas for future research and development. By systematically evaluating both strengths and limitations, researchers can better understand the trade-offs involved in different approaches and make informed decisions when selecting or designing models for specific applications.
7. Discussion
This study provides a comprehensive analysis of 84 computer vision models developed for 6D pose estimation, examining a diverse range of attributes and performance aspects. By systematically addressing nine key questions for each model—spanning from publication year and input modality to real-time capabilities, dataset usage, evaluation metrics, tested objects, strengths and limitations, and the capacity to handle various challenging conditions—we have established a multifaceted guide in order to help select the appropriate model by execution task and needs.
Our findings reveal a rich ecosystem of datasets employed in the literature, with a total of 29 distinct datasets identified. Among these, eight stand out as the most frequently utilized—Linemod, Occlusion Linemod, YCB-Video, T-LESS, KITTI, CAMERA25, REAL25, and Tejani—serving as common ground for benchmarking and comparison. This reliance on a limited set of widely accepted datasets ensures a degree of standardization but may inadvertently limit broader exploration. Expanding the diversity of benchmark datasets could help models generalize more effectively to heterogeneous real-world conditions.
The assessment of performance metrics focused on six core measures (ADD, ADD-S, ADD(-S), AR, AUC ADD, and AUC ADD(-S)) underscores the need for common evaluation standards. Models demonstrating top performance on these metrics often excel in handling symmetrical objects and occlusions, key challenges inherent in many real-world scenarios. However, while performance on established benchmarks is strong, additional metrics and more varied evaluations are necessary to fully capture a model’s robustness and versatility, particularly for less-studied challenges. In many models, these metrics were available but not in an an amount such that we could generalize results.
In terms of real-time capabilities, we noted a wide range of speeds and GPU dependencies. Some models achieve impressive frame rates suitable for demanding applications like robotics or augmented reality, and we show that low-cost mid-level GPUs could handle these models’ executions. On the other hand, many models are found to need the latest state-of-the-art cloud-based GPUs for training. Striking a balance between accuracy and efficiency remains an ongoing challenge, as reducing computational overhead without sacrificing performance is critical for broader adoption, especially in resource-constrained environments.
An examination of the input modalities confirms the predominance of RGB-based methods, likely due to their general availability and ease of integration. Nevertheless, the presence of models leveraging RGB-D, 3D, LiDAR, point cloud, and depth map inputs indicates a growing interest in leveraging richer data modalities for improved accuracy and robustness. Single-image approaches tend to offer higher speeds, while multi-image or multi-modal methods, although generally slower, may yield more robust estimates under complex conditions.
Classifying model capabilities with respect to symmetries, multiple objects, identical object instances, transparency, shape variability, and occlusions reveals both strengths and gaps. From all models 10 (11.9%) provided no info about each capability. 65.48% (55 models) can handle symmetrical objects, 44.5% (37 models) can handle many objects on the same scene, 57.14% (48 models) can address occlusions, 10.71% (9 models) can manage multiple instances of the same object, and a mere 2.38% (2 models) can cope with transparency. These shortcomings highlight the complexities that remain unaddressed, signaling important avenues for future research. Handling transparent objects, in particular, poses a significant hurdle, likely owing to their physical properties, which obscure traditional visual cues.
Finally, categorizing the strengths and limitations of each model into five broad groups—Accuracy and Performance, Robustness and Generalization, Efficiency and Real-Time Capability, Scalability and Flexibility, and Methodological and Architectural Innovation—provides a structured framework to understand trade-offs. While many models excel in achieving state-of-the-art accuracy, resilience to occlusions, or efficient real-time performance, others struggle with data dependencies, limited generalization to new domains, or high computational demands. Also, most of the models have been trained in 8 of the 30 datasets; this provides a very good comparison base but new datasets able to handle more real-scale and focused situations would be helpful to further understand the limits and strengths of the models in real-life scenarios.
8. Using the Tables to Select the Most Suitable Model
Depending on the problem you want to solve, you may either have specific requirements or be in an exploratory phase where you need to map the available models. This guide provides a structured way to use the tables, allowing you to iteratively filter out models that do not meet your criteria.
If you have a specific problem, such as a robotic arm with a monocular camera that must operate in real time and grasp a specific item in a production line, you should define key parameters and their importance. Then, you can progressively filter models by examining different tables and eliminating those that do not meet your needs.
The selection process follows an iterative approach where you can combine tables in any order that best suits your problem:
- Identify Relevant Datasets: If dataset selection is critical, start with Table 1, Table 2 and Table 3 to find datasets similar to your problem. If your dataset appears in Table 4, Table 5 and Table 6, which present the eight most common datasets, you can filter models accordingly. If not, external research may be required.
- Apply Key Model Constraints: Depending on your requirements, filter models using criteria such as:
The order of these steps is not fixed—you can adjust it based on your priorities. Each selection step filters out models that do not meet your requirements, ensuring an efficient and targeted search.
Finally, for a deeper understanding of the underlying model technologies and architectures, you can refer to Section 4. This information may be useful if specific architectures are better suited to your problem.
By iteratively combining tables and filtering models at each step, you can efficiently identify the best model for your specific use case.
9. Limitations
While this study provides a comprehensive overview of 6D pose estimation models, several limitations must be acknowledged to contextualize the findings and guide future research efforts:
- Database Restriction: The literature review was exclusively conducted using the Scopus database. Although Scopus is a robust and extensive repository of scientific publications, relying solely on a single database may result in the exclusion of relevant studies published in journals or conferences not indexed by Scopus. Consequently, some pertinent models and advancements in the field might have been overlooked, potentially limiting the comprehensiveness of the review.
- Initial Focus on RGB Models: The research initially concentrated on RGB-based 6D pose estimation models, as outlined in the foundational survey by Jian Guan et al. [3]. This primary focus was later expanded to include additional input modalities such as RGB-D, 3D models, LiDAR, and depth maps based on the information gathered during the analysis of the selected articles. However, this approach may have inadvertently neglected other emerging modalities or articles presenting models that primarily utilize different types of input data. As a result, there may exist relevant models employing alternative modalities that were not captured within the scope of this study.
- Standardization of Evaluation Metrics: The evaluation metrics reported across different models varied significantly in their presentation and emphasis. To facilitate meaningful comparisons, this study standardized the focus to six common metrics: ADD, ADD-S, ADD(-S), average recall (AR), AUC ADD, and AUC ADD(-S). While this approach ensures a consistent benchmark for comparison, it inherently excludes other valuable metrics that different studies might have employed to assess model performance. This standardization may therefore limit the ability to fully capture the multifaceted performance characteristics of each model.
- Focus on Evaluation Characteristics Over Internal Mechanisms: The primary objective of this review was to catalog and compare models based on their evaluation metrics, input types, real-time capabilities, and other selection characteristics. Consequently, the internal workings, architectural designs, and algorithmic innovations of the models were not extensively analyzed. This focus means that nuanced insights into the methodological advancements and unique approaches that differentiate each model are not comprehensively covered, potentially overlooking key factors that contribute to their performance and applicability.
- Exclusion of Application Articles and Reviews: This study included only articles that present a 6D pose estimation model, thereby excluding application-focused studies and review articles. As a result, insights derived from practical implementations and meta-analyses of existing models were not considered, potentially limiting the breadth of perspectives on the application and comparative effectiveness of different pose estimation approaches.
These limitations highlight areas where future research could expand to provide a more exhaustive and nuanced understanding of 6D pose estimation models. Expanding the literature search to include multiple databases, incorporating a broader range of input modalities, standardizing a wider array of evaluation metrics, delving deeper into the internal mechanisms of models, and including application-focused studies and reviews would enhance the robustness and comprehensiveness of subsequent reviews in this domain.
10. Conclusions
In summary, although 6D pose estimation has matured considerably, producing a variety of robust, accurate, and in some cases real-time solutions, critical challenges persist. Future efforts should emphasize overcoming obstacles such as the recognition of multiple identical objects and transparent materials, reducing hardware requirements, the ability to run on the device, expanding benchmark datasets, and incorporating new metrics that better reflect the complexities of real-world scenarios. By addressing these challenges, the field can move closer to developing universally applicable, efficient, and reliable 6D pose estimation models poised for deployment across a wide range of applications and environments.
Author Contributions
Conceptualization, K.O. and G.A.P.; methodology, K.O.; software, K.O.; validation, K.O. and G.A.P.; formal analysis, K.O.; investigation, K.O.; resources, K.O.; data curation, K.O.; writing—original draft preparation, K.O.; writing—review and editing, G.A.P.; visualization, K.O.; supervision, G.A.P.; project administration, G.A.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
This work was supported by the “MPhil program Advanced Technologies in Informatics and Computers”, which was hosted by the Department of Informatics, Democritus University of Thrace, Kavala, Greece. For this research LLM tools are used for syntax but always under the supervision of the authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hoque, S.; Arafat, M.Y.; Xu, S.; Maiti, A.; Wei, Y. A Comprehensive Review on 3D Object Detection and 6D Pose Estimation With Deep Learning. IEEE Access 2021, 9, 123456–123789. [Google Scholar] [CrossRef]
- Gorschlüter, F.; Rojtberg, P.; Pöllabauer, T. A Survey of 6D Object Detection Based on 3D Models for Industrial Applications. J. Imaging 2022, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Guan, J.; Hao, Y.; Wu, Q.; Li, S.; Fang, Y. A Survey of 6D object pose estimation Methods for Different Application Scenarios. Sensors 2024, 24, 1076. [Google Scholar] [CrossRef]
- Tzschichholz, T.; Boge, T.; Schilling, K. Relative pose estimation of satellites using PMD-/CCD-sensor data fusion. Acta Astronaut. 2015, 109, 25–33. [Google Scholar] [CrossRef]
- Rad, M.; Lepetit, V. BB8: A scalable, accurate, robust to partial occlusion method for predicting the 3D poses of challenging objects without using depth. Proc. IEEE Int. Conf. Comput. Vis. 2017, 2017, 3848–3856. [Google Scholar] [CrossRef]
- Kehl, W.; Manhardt, F.; Tombari, F. SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1530–1538. [Google Scholar] [CrossRef]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. In Proceedings of the Robotics: Science and Systems 2018, 14th Robotics: Science and Systems, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Li, Z.; Wang, G.; Ji, X. CDPN: Coordinates-based disentangled pose network for real-time RGB-based 6-DoF object pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7677–7686. [Google Scholar] [CrossRef]
- Gupta, K.; Petersson, L.; Hartley, R. CullNet: Calibrated and pose aware confidence scores for object pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops 2019, Seoul, Republic of Korea, 27–28 October 2019; pp. 2758–2766. [Google Scholar]
- Park, K.; Patten, T.; Vincze, M. Pix2pose: Pixel-wise coordinate regression of objects for 6D pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7667–7676. [Google Scholar]
- Deng, X.; Mousavian, A.; Xiang, Y.; Xia, F.; Bretl, T.; Fox, D. PoseRBPF: A Rao-Blackwellized Particle Filter for 6D Object Pose Tracking. Robot. Sci. Syst. 2019, 37, 1328–1342. [Google Scholar] [CrossRef]
- Zakharov, S.; Shugurov, I.; Ilic, S. DPOD: 6D Pose Object Detector and Refiner. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Sundermeyer, M.; Marton, Z.C.; Durner, M.; Triebel, R. Augmented Autoencoders: Implicit 3D Orientation Learning for 6D Object Detection. Int. J. Comput. Vis. 2020, 128, 714–729. [Google Scholar] [CrossRef]
- Labbe, Y.; Carpentier, J.; Aubry, M. CosyPose: Consistent Multi-view Multi-object 6D Pose Estimation. Lect. Notes Comput. Sci. 2020, 12362, 574–591. [Google Scholar]
- Chen, W.; Jia, X.; Chang, H.J. G2L-Net: Global to local network for real-time 6D pose estimation with embedding vector features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4232–4241. [Google Scholar] [CrossRef]
- Song, C.; Song, J.; Huang, Q. HybridPose: 6D Object Pose Estimation under Hybrid Representations. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 428–437. [Google Scholar] [CrossRef]
- Kang, J.; Liu, W.; Tu, W.; Yang, L. YOLO-6D+: Single Shot 6D Pose Estimation Using Privileged Silhouette Information. In Proceedings of the International Conference on Image Processing and Robotics, ICIPRoB 2020, Colombo, Sri Lanka, 6–8 March 2020. [Google Scholar]
- Zhu, Y.; Wan, L.; Xu, W.; Wang, S. ASPP-DF-PVNet: Atrous Spatial Pyramid Pooling and Distance-Filtered PVNet for Occlusion Resistant 6D Object Pose Estimation. Signal Process. Image Commun. 2021, 95, 116268. [Google Scholar] [CrossRef]
- Wen, B.; Bekris, K. BundleTrack: 6D Pose Tracking for Novel Objects without Instance or Category-Level 3D Models. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 8067–8074. [Google Scholar] [CrossRef]
- Gao, G.; Lauri, M.; Hu, X.; Zhang, J.; Frintrop, S. CloudAAE: Learning 6D Object Pose Regression with On-line Data Synthesis on Point Clouds. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11081–11087. [Google Scholar] [CrossRef]
- Chen, W.; Jia, X.; Chang, H.J. FS-Net: Fast Shape-based Network for Category-Level 6D Object Pose Estimation with Decoupled Rotation Mechanism. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2021, 2021, 1581–1590. [Google Scholar]
- Iwase, S.; Liu, X.; Khirodkhar, R.; Yokota, R.; Kitani, K.M. RePOSE: Fast 6D Object Pose Refinement via Deep Texture Rendering. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV 2021), Online, 11–17 October 2021; pp. 3283–3292. [Google Scholar]
- Di, Y.; Manhardt, F.; Wang, G.; Ji, X.; Navab, N.; Tombari, F. SO-Pose: Exploiting Self-Occlusion for Direct 6D Pose Estimation. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12376–12385. [Google Scholar]
- Song, J.; Hao, S.; Xu, K. Uncooperative Satellite 6D Pose Estimation with Relative Depth Information. Lect. Notes Comput. Sci. 2021, 13018, 166–177. [Google Scholar]
- Feng, W.; Zhang, J.; Zhou, Y. GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- He, Y.; Huang, H.; Fan, H.; Chen, Q.; Sun, J. FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3002–3012. [Google Scholar] [CrossRef]
- Shugurov, I.; Ilic, S. DPODv2: Dense Correspondence-Based 6 DoF Pose Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7417–7435. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Wang, Y.; Fan, H. FS6D: Few-Shot 6D Pose Estimation of Novel Objects. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6804–6814. [Google Scholar]
- Di, Y.; Zhang, R.; Lou, Z.; Manhardt, F.; Ji, X.; Navab, N.; Tombari, F. GPV-Pose: Category-level Object Pose Estimation via Geometry-guided Point-wise Voting. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6771–6781. [Google Scholar] [CrossRef]
- Duffhauss, F.; Demmler, T.; Neumann, G. MV6D: Multi-View 6D Pose Estimation on RGB-D Frames Using a Deep Point-wise Voting Network. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 3568–3575. [Google Scholar] [CrossRef]
- Cai, D.; Heikkia, J.; Rahtu, E. OVE6D: Object Viewpoint Encoding for Depth-based 6D Object Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6793–6803. [Google Scholar] [CrossRef]
- Peng, S.; Zhou, X.; Liu, Y.; Lin, H.; Huang, Q.; Bao, H. PVNet: Pixel-Wise Voting Network for 6D object pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3212–3223. [Google Scholar] [CrossRef] [PubMed]
- Cai, D.; Heikkila, J.; Rahtu, E. SC6D: Symmetry-agnostic and Correspondence-free 6D Object Pose Estimation. In Proceedings of the 2022 International Conference on 3D Vision, 3DV 2022, Prague, Czech Republic, 12–15 September 2022; pp. 536–546. [Google Scholar] [CrossRef]
- Zhang, R.; Di, Y.; Manhardt, F.; Tombari, F.; Ji, X. SSP-Pose: Symmetry-Aware Shape Prior Deformation for Direct Category-Level Object Pose Estimation. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 7452–7459. [Google Scholar]
- Ren, Y.; Liu, J. Multi-scale Convolutional Feature Fusion for 6D Pose Estimation. In Proceedings of the 2022 6th International Conference on Video and Image Processing (ICVIP ’22), Shanghai, China, 23–26 December 2023; pp. 84–90. [Google Scholar] [CrossRef]
- Kao, Y.-H.; Chen, C.-K.; Chen, C.-C.; Lan, C.-Y. Object Pose Estimation and Feature Extraction Based on PVNet. IEEE Access 2022, 10, 122387–122398. [Google Scholar] [CrossRef]
- Su, Y.; Saleh, M.; Fetzer, T. ZebraPose: Coarse to Fine Surface Encoding for 6D object pose estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6728–6738. [Google Scholar] [CrossRef]
- Liu, Y.; Avidan, S.; Brostow, G.; Cissé, M.; Farinella, G.M.; Hassner, T. Gen6D: Generalizable Model-Free 6-DoF Object Pose Estimation from RGB Images. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13692. [Google Scholar] [CrossRef]
- Legr, A.; Detry, R.; De Vleeschouwer, C. End to end neural estimation of spacecraft pose with intermediate detection of keypoints. Lect. Notes Comput. Science. LNCS 2023, 13801, 154–169. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, S.; Zhao, W.; Wei, Y.; Peng, J. Augmented Reality System Based on Real-Time Object 6D Pose Estimation. In Proceedings of the 2023 2nd International Conference on Image Processing and Media Computing, ICIPMC 2023, Xi’an, China, 26–28 May 2023; pp. 27–34. [Google Scholar] [CrossRef]
- Castro, P.; Kim, T.-K. CRT-6D: Fast 6D Object Pose Estimation with Cascaded Refinement Transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; Volume 5735, pp. 5735–5744. [Google Scholar] [CrossRef]
- Zhou, L.; Liu, Z.; Gan, R.; Wang, H.; Ang, M.H. DR-Pose: A Two-Stage Deformation-and-Registration Pipeline for Category-Level 6D Object Pose Estimation. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Detroit, MI, USA, 1–5 October 2023; pp. 1192–1199. [Google Scholar] [CrossRef]
- Jantos, T.G.; Hamdad, M.A.; Granig, W.; Weiss, S.; Steinbrener, J. PoET: Pose Estimation Transformer for Single-View, Multi-Object 6D Pose Estimation. Proc. Mach. Learn. Res. 2023, 205, 1060–1070. [Google Scholar]
- Zheng, L.; Wang, C.; Sun, Y. HS-Pose: Hybrid Scope Feature Extraction for Category-level Object Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17163–17173. [Google Scholar] [CrossRef]
- Du, C.; Guo, J.; Guo, S.; Fu, Q. Study on 6D Pose Estimation System of Occlusion Targets for the Spherical Amphibious Robot Based on Neural Network. In Proceedings of the 20th IEEE International Conference on Mechatronics and Automation (ICMA 2023), Harbin, China, 6–9 August 2023; pp. 2058–2063. [Google Scholar]
- Wang, L.; Yang, C.; Xin, J.; Yin, B. Distance-Aware Vector-Field and Vector Screening Strategy for 6D Object Pose Estimation. Lect. Notes Comput. Sci. 2023, 14356, 373–388. [Google Scholar]
- Bhandari, V.; Phillips, T.G.; McAree, P.R. Real-Time 6-DOF Pose Estimation of Known Geometries in Point Cloud Data. Sensors 2023, 23, 3085. [Google Scholar] [CrossRef]
- Chiu, Z.Y.; Richter, F.; Yip, M.C. Real-Time Constrained 6D Object-Pose Tracking of An In-Hand Suture Needle for Minimally Invasive Robotic Surgery. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 4761–4767. [Google Scholar] [CrossRef]
- Huang, Y.; Wu, K.; Sun, F.; Cai, C. SE-UF-PVNet: A Structure Enhanced Pixel-wise Union Vector Fields Voting Network for 6DoF Pose Estimation. In Proceedings of the ACM International Conference Proceeding Series 2023, 4th International Conference on Computing, Networks and Internet of Things, CNIOT 2023, Xiamen, China, 26–28 May 2023; pp. 426–439. [Google Scholar]
- Chen, S.; Tian, Y.; Bai, J.; Han, W.; Wang, K.; Liu, L. Research on Insulator Pose Estimation Algorithm for High-Voltage Live Working Robot. In Proceedings of the 36th Chinese Control and Decision Conference, CCDC 2024, Xi’an, China, 25–27 May 2024; Volume 1136, pp. 1136–1140. [Google Scholar] [CrossRef]
- Yong, J.; Lei, X.; Dang, J.; Wang, Y. A Robust CoS-PVNet Pose Estimation Network in Complex Scenarios. Electronics 2024, 13, 2089. [Google Scholar] [CrossRef]
- Chen, H.; Wang, P.; Wang, F.; Tian, W.; Xiong, L.; Li, H. EPro-PnP: Generalized End-to-End Probabilistic Perspective-N-Points for Monocular Object Pose Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 1, 2781–2790. [Google Scholar] [CrossRef]
- Ye, Y.; Park, H. Focal segmentation for robust 6D object pose estimation. Multimed. Tools Appl. 2024, 83, 47563–47585. [Google Scholar] [CrossRef]
- Liao, J. A Lightweight 6D Pose Estimation Network Based on Improved Atrous Spatial Pyramid Pooling. Electronics 2024, 13, 1321. [Google Scholar] [CrossRef]
- Liu, X.; Guan, Q.; Xue, S. Lite-HRPE: A 6D object pose estimation Method for Resource-Limited Platforms. In Proceedings of the IEEE International Conference on Control and Automation, Reykjavik, Iceland, 18–21 June 2024; pp. 1006–1011. [Google Scholar] [CrossRef]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. YOLO-6D-Pose: Enhancing YOLO for Single-Stage Monocular Multi-Object 6D Pose Estimation. In Proceedings of the 2024 International Conference on 3D Vision, 3DV 2024, Davos, Switzerland, 18–21 March 2024; pp. 1616–1625. [Google Scholar]
- Bortolon, M.; Tsesmelis, T.; James, S.; Poiesi, F.; Del Bue, A. IFFNeRF: Initialisation Free and Fast 6DoF Pose Estimation from a Single Image and a NeRF Model. In Proceedings of the IEEE International Conference on Robotics and Automation, Nancy, France, 22–24 November 2024; pp. 3002–3012. [Google Scholar] [CrossRef]
- Chen, S.; Hong, J.; Liu, X.; Li, J.; Zhang, T.; Wang, D.; Guan, Y. A Framework for 3D Object Detection and Pose Estimation in Unstructured Environment Using Single Shot Detector and Refined Linemod Template Matching. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 499–504. [Google Scholar] [CrossRef]
- Lu, W.; Wan, G.; Zhou, Y.; Fu, X.; Yuan, P.; Song, S. DeepVCP: An End-to-End Deep Neural Network for Point Cloud Registration. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 12–21. [Google Scholar]
- Jha, A.; Subedi, D.; Lovsland, P.-O. Autonomous Mooring towards Autonomous Maritime Navigation and Offshore Operations. In Proceedings of the 15th IEEE Conference on Industrial Electronics and Applications, Kristiansand, Norway, 9–13 November 2020; pp. 1171–1175. [Google Scholar] [CrossRef]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. DeepIM: Deep Iterative Matching for 6D Pose Estimation. Int. J. Comput. Vis. 2020, 128, 657–678. [Google Scholar] [CrossRef]
- Hodaň, T.; Baráth, D.; Matas, J. EPOS: Estimating 6D Pose of Objects with Symmetries. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 14–19 June 2020; pp. 11700–11709. [Google Scholar] [CrossRef]
- Park, K.; Mousavian, A.; Xiang, Y.; Fox, D. LatentFusion: End-to-end differentiable reconstruction and rendering for unseen object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Wang, G.; Manhardt, F.; Shao, J.; Ji, X.; Navab, N.; Tombari, F. Self6D: Self-supervised Monocular 6D Object Pose Estimation. Lect. Notes Comput. Sci. 2020, 12346, 108–125. [Google Scholar]
- Lee, T.; Lee, B.-U.; Kim, M.; Kweon, I.S. Category-Level Metric Scale Object Shape and Pose Estimation. IEEE Robot. Autom. Lett. 2021, 6, 8575–8582. [Google Scholar] [CrossRef]
- Periyasamy, A.S.; Capellen, C.; Schwarz, M.; Behnke, S. ConvPoseCNN2: Prediction and Refinement of Dense 6D Object Pose. In Proceedings of the Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2020), Virtual Event, 6–8 February 2022; pp. 353–371. [Google Scholar]
- Liu, E.; Zheng, Y.; Pan, B.; Xu, X.; Shi, Z. DCL-Net: Augmenting the Capability of Classification and Localization for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7933–7944. [Google Scholar] [CrossRef]
- Hayashi, R.; Shimokura, A.; Matsumoto, T.; Ukita, N. Joint learning of object detection and pose estimation using augmented autoencoder. In Proceedings of the MVA 2021—17th International Conference on Machine Vision Applications, Online, 25–27 July 2021; Volume 17, p. 9511343. [Google Scholar]
- Shugurov, I.; Pavlov, I.; Zakharov, S.; Ilic, S. Multi-View Object Pose Refinement with Differentiable Renderer. IEEE Robot. Autom. Lett. 2021, 6, 2579–2586. [Google Scholar] [CrossRef]
- Lin, H.; Peng, S.; Zhou, Z.; Zhou, X. Learning to Estimate Object Poses without Real Image Annotations. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 1159–1165. [Google Scholar]
- Zhang, Y.; Li, X.; Wang, Z. A novel approach to enhance the performance of machine learning algorithms. Int. J. Comput. Intell. Appl. 2023, 22, 2350001. [Google Scholar]
- She, R.; Shi, J.; Gu, J.; Yuan, Y.; Zhang, J.; Zhang, W. Estimating 6D Pose Using RANSAC Voting. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022. [Google Scholar]
- Zhou, G.; Gothoskar, N.; Wang, L.; Tenenbaum, J.B.; Gutfreund, D.; Lázaro-Gredilla, M.; George, D.; Mansinghka, V.K. 3D Neural Embedding Likelihood: Probabilistic Inverse Graphics for Robust 6D Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 21568–21579. [Google Scholar] [CrossRef]
- Mazumder, J.; Zand, M.; Greenspan, M. Multistream validnet: Improving 6d object pose estimation by automatic multistream validation. In Proceedings of the International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 3143–3147. [Google Scholar] [CrossRef]
- Sun, J.; Ma, X.; Li, Y. C2FNet: Coarse-to-fine Keypoint Localization Network for Monocular 6D Object Pose Estimation. In Proceedings of the 2023 China Automation Congress, CAC 2023, Nanjing, China, 2–5 October 2023; pp. 5306–5311. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, K.; Xu, L. Deep Fusion Transformer Network with Weighted Vector-Wise Keypoints Voting for Robust 6D Object Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Bellevue, WA, USA, 17–22 September 2023; pp. 13921–13931. [Google Scholar] [CrossRef]
- Wang, S.; Liu, J.; Lu, Q.; Liu, Z.; Zeng, Y.; Zhang, D.; Chen, B.O. 6D Pose Estimation for Vision-guided Robot Grasping Based on Monocular Camera. In Proceedings of the 6th International Conference on Robotics, Control and Automation Engineering, RCAE 2023, Suzhou, China, 3–5 November 2023; pp. 13–17. [Google Scholar] [CrossRef]
- Wang, F.; Ge, Z.; Qi, C.; Yang, Y.; Luo, X. Pose Estimation Method of Maintainability Test Components Based on PVNet. In Proceedings of the 2023 3rd International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology, CEI 2023, Wuhan, China, 15–17 December 2023; pp. 660–664. [Google Scholar]
- Cai, D.; Heikkilä, J.; Rahtu, E. MSDA: Monocular Self-supervised Domain Adaptation for 6D Object Pose Estimation. Lect. Notes Comput. Sci. 2023, 13886, 467–481. [Google Scholar]
- Wu, L.; Ma, X. Scale Adaptive Skip ASP Pixel Voting Network for Monocular 6D Object Pose Estimation. In Proceedings of the 42nd Chinese Control Conference, Tianjin, China, 24–26 July 2023. [Google Scholar]
- Luo, S.; Liang, Y.; Luo, Z.; Liang, G.; Wang, C.; Wu, X. Vision-Vision Guided Object Recognition and 6D Pose Estimation System Based on Deep Neural Network for Unmanned Aerial Vehicles towards Intelligent Logistics. Appl. Sci. 2023, 13, 115. [Google Scholar] [CrossRef]
- Chen, K.; James, S.; Sui, C.; Liu, Y.H.; Abbeel, P.; Dou, Q. StereoPose Category-Level 6D Transparent Object Pose Estimation from Stereo Images via Back-View NOCS. In Proceedings of the IEEE International Conference on Robotics and Automation, London, UK, 29 May–2 June 2023; pp. 2855–2861. [Google Scholar] [CrossRef]
- Li, Z.; Stamos, I. Depth-Based 6D object pose estimation Using Swin Transformer. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Detroit, MI, USA, 1–5 October 2023; pp. 1185–1191. [Google Scholar] [CrossRef]
- Hu, M.; Meng, X.; Li, Y. 6d Pose Estimation Method Based on Improved Yolov7. In Proceedings of the 2023 International Conference on Frontiers of Robotics and Software Engineering, Changsha, China, 16–18 June 2023; pp. 311–316. [Google Scholar] [CrossRef]
- Cai, J.; He, Y.; Yuan, W.; Zhu, S.; Dong, Z.; Bo, L.; Chen, Q. Open-Vocabulary Category-Level Object Pose and Size Estimation. IEEE Robot. Autom. Lett. 2024, 9, 7661–7668. [Google Scholar] [CrossRef]
- Xu, Y.; Lin, K.Y.; Zhang, G.; Wang, X.; Li, H. RNNPose: 6-DoF Object Pose Estimation via Recurrent Correspondence Field Estimation and Pose Optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 4669–4683. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Tang, C.; Signal, I. A rgb d feature fusion network for occluded object 6d pose estimation. Signal Image Video Process. 2024, 18, 6309–6319. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Kaskman, R.; Zakharov, S.; Shugurov, I.; Ilic, S. Home Brewed DB: RGB-D Dataset for 6D Pose Estimation of 3D Objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Seoul, Republic of korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Kleeberger, K.; Landgraf, C.; Huber, M.F. Large-scale 6D Object Pose Estimation Dataset for Industrial Bin-Picking. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 2573–2578. [Google Scholar] [CrossRef]
- MVTec ITODD. MVTec Industrial 3D Object Detection Dataset (MVTec ITODD). MVTec Res. 2020. Available online: https://www.mvtec.com/company/research/datasets/mvtec-itodd (accessed on 3 March 2025).
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes. In Lecture Notes in Computer Science; Springer: Cham, Switerland, 2013; Volume 7724, pp. 548–562. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Chen, L.; Yang, H.; Wu, C.; Wu, S. MP6D: An RGB-D Dataset for Metal Parts’ 6D Pose Estimation. IEEE Robot. Autom. Lett. 2020, 7, 3425–3432. [Google Scholar] [CrossRef]
- Wang, H.; Sridhar, S.; Huang, J.; Valentin, J.; Song, S.; Guibas, L.J. Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Yu, F. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Kisantal, M.; Sharma, S.; Park, T.H.; Izzo, D.; Märtens, M.; D’Amico, S. Satellite Pose Estimation Challenge: Dataset, Competition Design, and Results. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 4083–4098. [Google Scholar] [CrossRef]
- Hodan, T.; Haluza, P.; Obdržálek, Š; Matas, J.; Lourakis, M.; Zabulis, X. T-LESS: An RGB-D Dataset for 6D Pose Estimation of Texture-Less Objects. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 27–29 March 2017; 2017; pp. 880–888. [Google Scholar] [CrossRef]
- Kehl, W.; Millettari, F.; Tombari, F.; Ilic, S.; Navab, N. Deep Learning of Local RGB-D Patches for 3D Object Detection and 6D Pose Estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14 2016. Springer: Cham, Switzerland, 2016; pp. 205–220. [Google Scholar] [CrossRef]
- Hodan, T.; Sundermayer, M.; Drost, B.; Labbé, Y.; Brachmann, E.; Michel, F.; Rother, C.; Matas, J. BOP Challenge 2020 on 6D Object Localization. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16 2020. Springer: Cham, Switzerland, 2020; Volume 16, pp. 577–594. [Google Scholar] [CrossRef]
- Wen, B.; Mitash, C.; Ren, B.; Bekris, K.E. SE(3)-TrackNet: Data-driven 6D Pose Tracking by Calibrating Image Residuals in Synthetic Domains. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
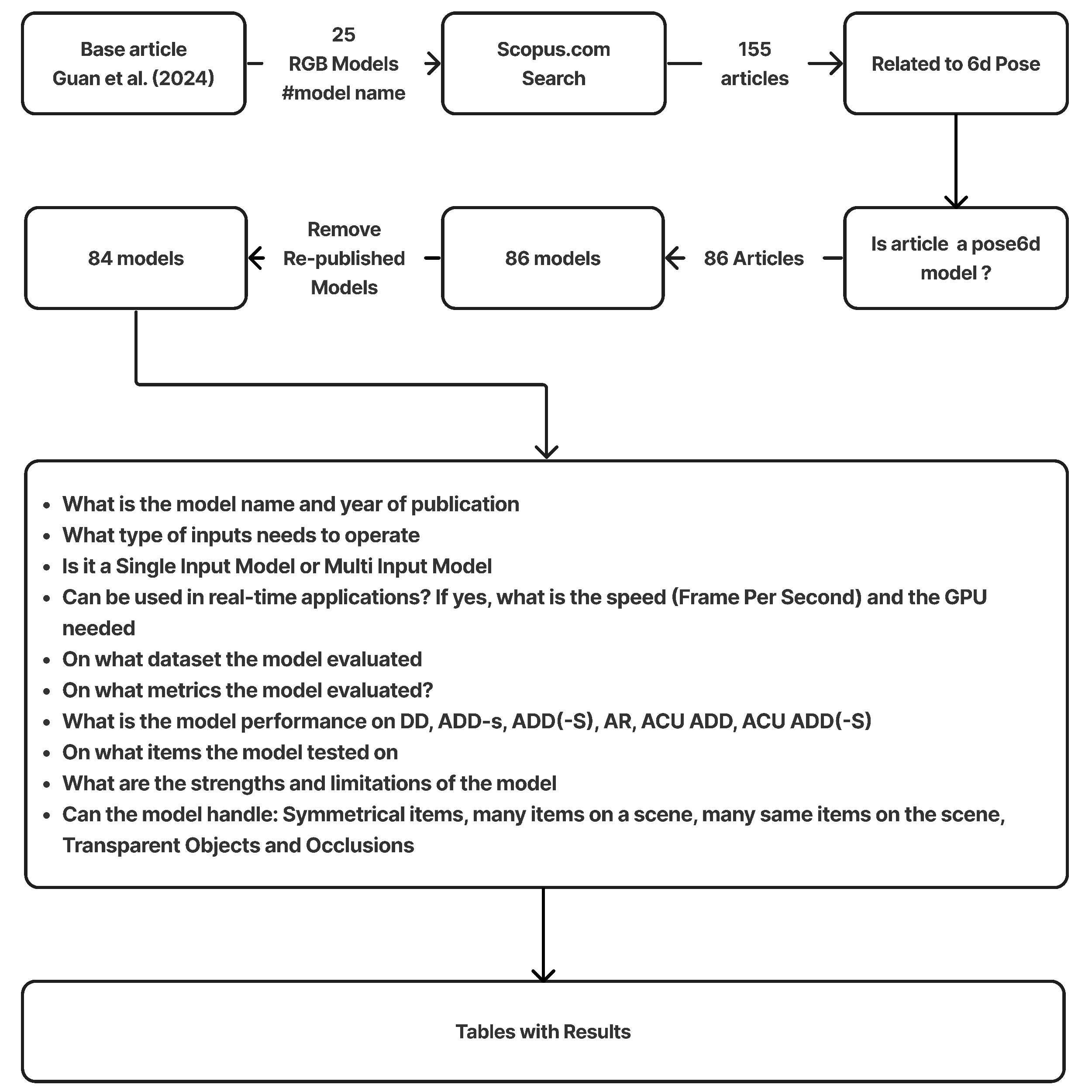
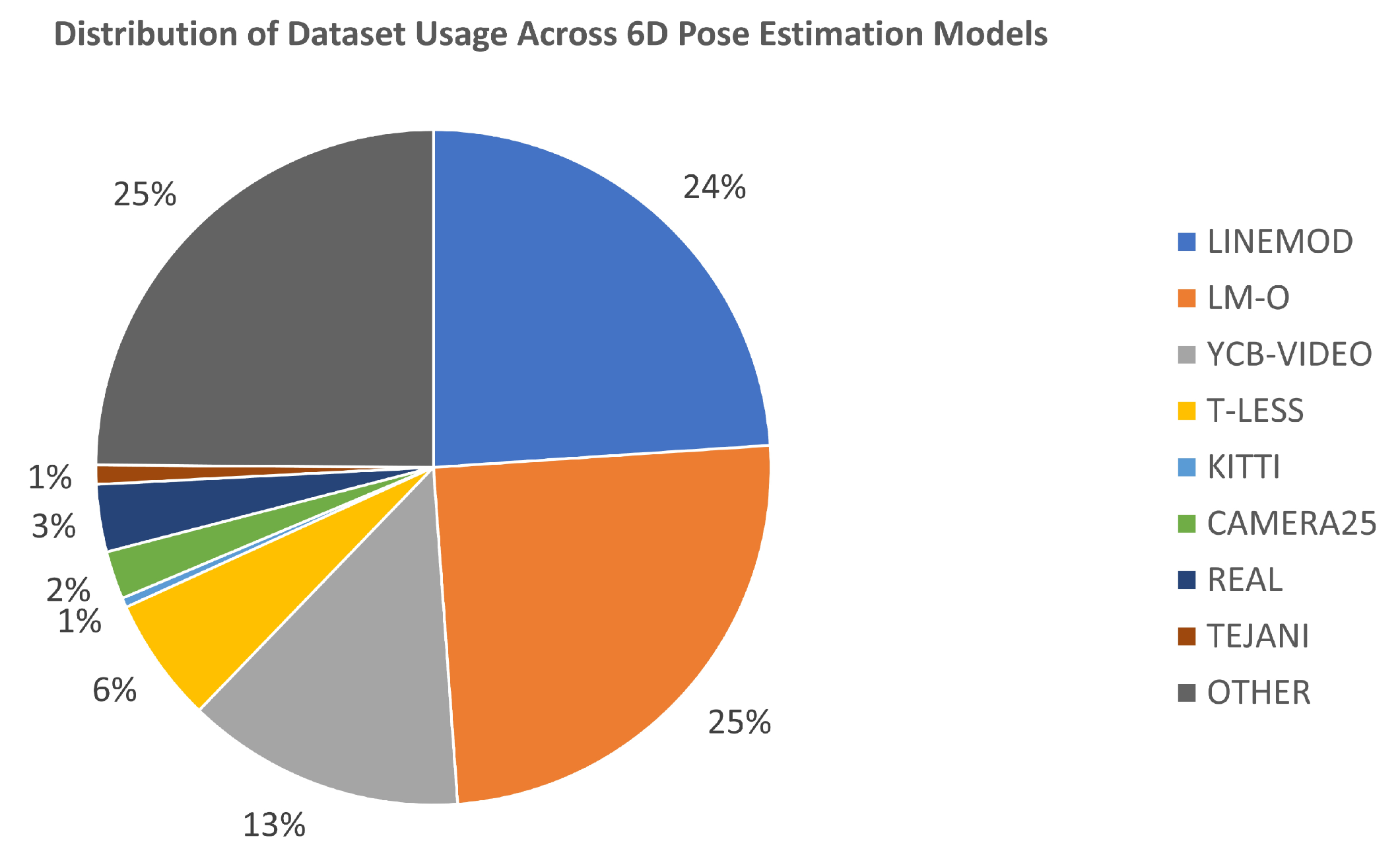
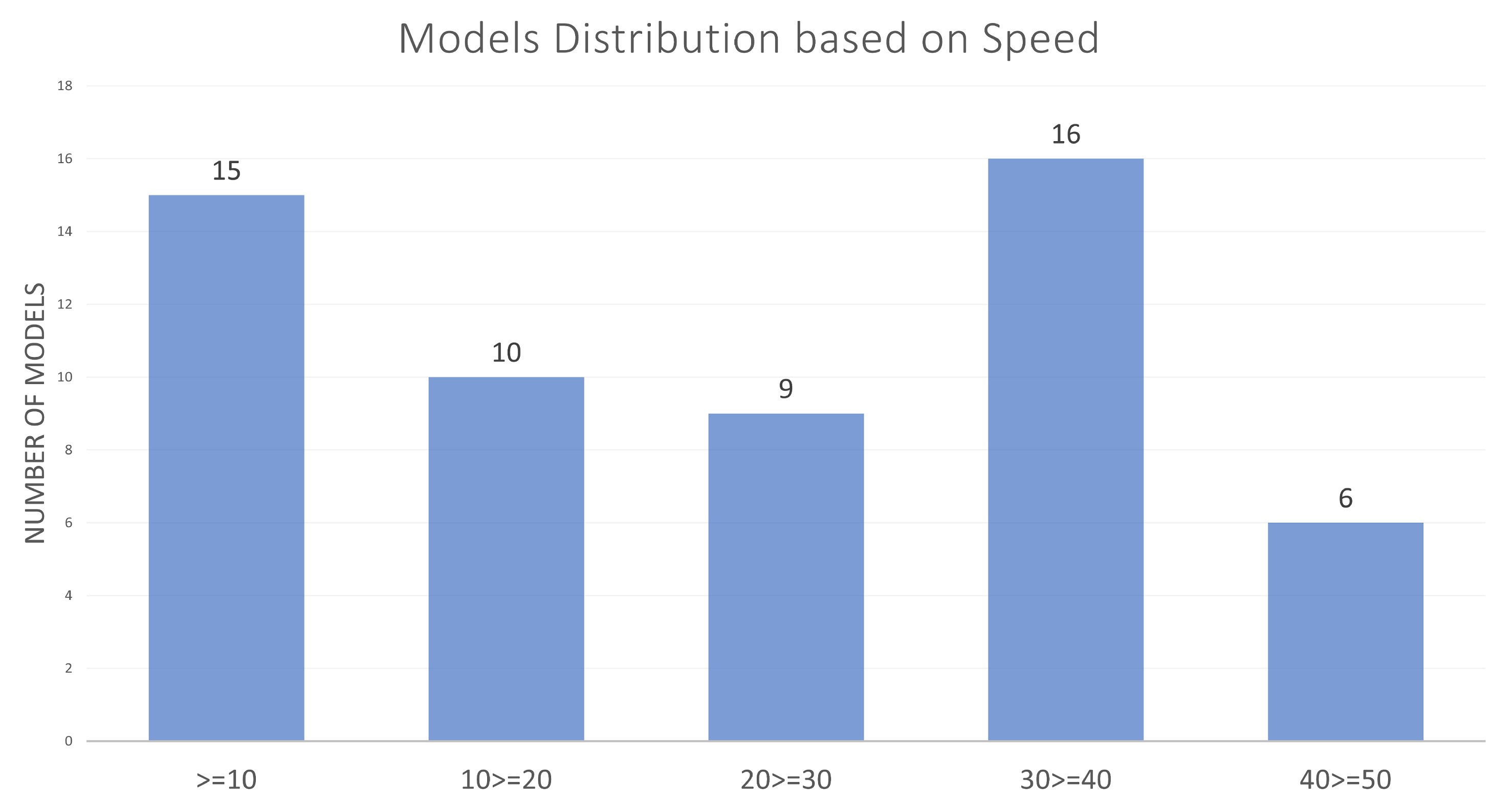
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).