
In-Depth Analysis of Phishing Email Detection: Evaluating the Performance of Machine Learning and Deep Learning Models Across Multiple Datasets



Abstract
1. Introduction
- Most prior studies rely on a single or a limited number of datasets, which restricts the generalizability of their findings to diverse phishing scenarios.
- Despite the success of DL in other domains, its potential in phishing detection—especially using advanced architectures such as transformer-based models—has not been fully investigated.
- Existing studies often lack a standardized framework for consistently implementing and evaluating ML and DL models across multiple datasets.
- RQ1: What are the most effective ML and DL models for phishing email detection?
- RQ2: How does the performance of ML and DL models vary when applied to multiple individual datasets versus a merged dataset?
- RQ3: What are the key performance differences between ML and DL models in terms of accuracy, robustness, and generalizability for phishing email detection?
- RQ4: Which DL models demonstrate superiority over ML models in phishing detection, and why?
- We develop a novel framework for implementing and evaluating 14 ML and DL models for phishing email detection, ensuring a standardized and comprehensive assessment of their effectiveness.
- The study utilizes nine publicly available datasets and a merged dataset, addressing the limitations of previous research that relied on single or limited datasets, thereby enhancing the robustness and generalizability of the findings.
- Through an extensive comparison using various evaluation metrics (e.g., accuracy, precision, recall, F1-score), we demonstrate that deep learning models, particularly transformer-based architectures like BERT [21] and RoBERTa [30], consistently outperform traditional ML models, reinforcing the potential of AI-driven phishing detection.
2. Related Work
3. Research Methodology
3.1. Data Collection
- Ling: Derived from the Linguist List online email communication in the early 2000s [36], it consists of 458 spam and 2401 legitimate emails. This dataset is useful for linguistics-related studies but is limited in scope and size.
- Enron: The dataset was extracted from the Enron email corpus around the year 2005 [37]. It consists of spam and ham emails. It includes extensive corporate communications but with limited diversity.
- SpamAssassin: Developed by the Apache Software Foundation from 2002 to 2006 [38], it consists of 1670 spam and 3928 ham emails. It provides diverse public spam emails but might contain outdated tactics.
- TREC: It includes TREC-05 (2005), TREC-06 (2006), and TREC-07 (2007), focusing on diverse email communications [39,40]. TREC-05 consists of spam and ham emails. Its diverse sources enhance utility but may include specific period biases. TREC-06 consists of 3642 spam and ham emails. It is useful for text classification but may not mirror real-world interactions. Dataset TREC-07 consists of spam and ham emails. It is a large and diverse dataset, but its periodic nature may affect consistency.
- CEAS: This dataset is from the CEAS 2008 Challenge Lab Evaluation Corpus [41]. It contains spam and ham emails. It captures a broad range of communications but may reflect dated spam characteristics.
- Nazario: It is a balanced dataset of different sources [42]: 1469 phishing and 1482 legitimate emails. It is useful for model testing; however, it lacks broad phishing tactic coverage.
- Nigerian: This is a publicly available dataset featuring advance-fee scams from 1998 to 2007 [43]. It contains 1586 scam emails and 2967 legitimate emails.
- Our merged dataset: We integrated all nine datasets, covering various features and fields. This merged dataset contains emails, of which 94,376 (45.81%) are phishing emails, and 111,681 (54.19%) are safe emails. The spam/scam emails from all datasets were labeled as phishing emails. We have used the Pandas library in Python to combine the data into a single DataFrame. To balance this dataset, we used the down-sampling technique to reduce the number of safe emails to match the number of phishing emails.
3.2. Data Preprocessing
3.3. Models Selection
3.3.1. Selected Machine Learning Models
3.3.2. Selected Deep Learning Models
4. Results and Discussion
4.1. Experimental Setup
4.2. Evaluation Metrics
- Accuracy: Calculated as the ratio of correct phishing and safe email predictions to the total number of emails.
- Precision: The ratio of true identifications of phishing emails that were phishing.
- Recall or Sensitivity: The ratio of actual positive phishing emails that were correctly identified as phishing.
- F1 Score: A metric that emphasizes the balance between precision and recall.or
4.3. Results
4.4. Practical Strategies for Implementing AI-Driven Techniques in Phishing Email Detection
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Experiments Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 97.85% | 97.86% | 97.58% | 97.72% | 0.4045 S |
| Logistic Regression | 98.29% | 97.11% | 99.32% | 98.21% | 6.0422 S |
| SGD Classifier | 98.35% | 97.11% | 99.11% | 98.27% | 4.7780 S |
| XGBoost | 97.23% | 95.46% | 98.83% | 97.12% | 32.8451 S |
| Decision Tree | 95.38% | 94.93% | 95.30% | 95.12% | 186.7102 S |
| Random Forest | 98.09% | 97.37% | 98.61% | 97.99% | 92.4306 S |
| Extra Tree | 98.37% | 97.98% | 98.58% | 98.28% | 251.8828 S |
| CNN | 98.34% | 98.21% | 98.25% | 98.23% | 1394.9935 S |
| RNN | 96.56% | 98.11% | 94.49% | 96.26% | 1198.6864 S |
| LSTM | 98.14% | 98.27% | 97.75% | 98.01% | 1616.3018 S |
| BERT | 99.31% | 99.21% | 99.31% | 99.26% | 705.5716 S |
| DistilBERT | 99.16% | 99.03% | 99.17% | 99.10% | 420.9068 S |
| RoBERTa | 99.19% | 99.24% | 99.02% | 99.13% | 713.6597 S |
| GCN | 72.49% | 72.45% | 72.49% | 72.43% | 1456.7544 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 96.70% | 95.58% | 93.64% | 94.60% | 0.0774 S |
| Logistic Regression | 96.25% | 97.80% | 89.88% | 93.67% | 4.3615 S |
| SGD Classifier | 97.68% | 97.80% | 96.24% | 96.24% | 0.8779 S |
| XGBoost | 96.79% | 96.13% | 93.35% | 94.72% | 16.4625 S |
| Decision Tree | 90.98% | 83.56% | 88.15% | 85.79% | 22.4780 S |
| Random Forest | 96.88% | 95.07% | 94.80% | 94.93% | 11.3588 S |
| Extra Tree | 97.23% | 96.19% | 94.80% | 95.49% | 33.3333 S |
| CNN | 98.11% | 95.74% | 97.97% | 96.84% | 250.6515 S |
| RNN | 97.07% | 94.80% | 95.35% | 95.07% | 200.5724 S |
| LSTM | 97.42% | 95.38% | 95.93% | 95.65% | 415.1188 S |
| BERT | 98.88% | 98.23% | 97.94% | 98.09% | 283.1131 S |
| DistilBERT | 98.88% | 99.40% | 96.76% | 98.06% | 164.1796 S |
| RoBERTa | 98.80% | 97.94% | 97.94% | 97.94% | 298.7486 S |
| GCN | 79.78% | 80.13% | 79.78% | 77.24% | 315.2311 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 98.43% | 100.00% | 90.22% | 94.86% | 0.4096 S |
| Logistic Regression | 97.20% | 100.00% | 82.61% | 90.48% | 0.4096 S |
| SGD Classifier | 99.48% | 100.00% | 97.83% | 98.36% | 0.4595 S |
| XGBoost | 98.43% | 98.82% | 91.30% | 94.92% | 24.9872 S |
| Decision Tree | 94.76% | 81.00% | 88.04% | 84.38% | 4.4804 S |
| Random Forest | 98.60% | 98.84% | 92.39% | 95.51% | 4.0028 S |
| Extra Tree | 97.73% | 100.00% | 85.87% | 92.40% | 11.6939 S |
| CNN | 98.25% | 92.71% | 96.74% | 94.68% | 53.4167 S |
| RNN | 95.45% | 83.00% | 90.22% | 86.46% | 97.6607 S |
| LSTM | 98.43% | 93.68% | 96.74% | 95.19% | 109.0630 S |
| BERT | 100.00% | 100.00% | 100.00% | 100.00% | 156.4819 S |
| DistilBERT | 99.83% | 100.00% | 98.68% | 99.34% | 85.1270 S |
| RoBERTa | 99.83% | 98.70% | 100.00% | 99.35% | 164.4693 S |
| GCN | 86.71% | 75.19% | 86.71% | 80.54% | 101.6573 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 92.27% | 95.14% | 84.53% | 89.52% | 0.7002 S |
| Logistic Regression | 97.46% | 95.40% | 98.22% | 96.79% | 14.0869 S |
| SGD Classifier | 97.00% | 95.40% | 98.24% | 96.24% | 9.3601 S |
| XGBoost | 95.77% | 92.21% | 97.39% | 94.73% | 42.6082 S |
| Decision Tree | 94.22% | 92.52% | 92.68% | 92.60% | 684.2861 S |
| Random Forest | 96.99% | 96.65% | 95.61% | 96.12% | 293.0442 S |
| Extra Tree | 97.14% | 97.31% | 95.31% | 96.30% | 683.8933 S |
| CNN | 96.57% | 97.68% | 96.89% | 97.84% | 2873.5432 S |
| RNN | 94.64% | 96.59% | 90.34% | 93.36% | 2051.2652 S |
| LSTM | 97.15% | 97.84% | 95.27% | 96.54% | 2594.2131 S |
| BERT | 98.94% | 98.73% | 98.71% | 98.72% | 1290.6487 S |
| DistilBERT | 98.85% | 98.75% | 98.47% | 98.61% | 721.0618 S |
| RoBERTa | 98.88% | 99.01% | 98.28% | 98.64% | 1336.9023 S |
| GCN | 72.44% | 72.26% | 72.44% | 72.31% | 2437.8352 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 93.16% | 96.27% | 72.57% | 82.76% | 0.2044 S |
| Logistic Regression | 97.30% | 96.58% | 91.28% | 93.85% | 5.8902 S |
| SGD Classifier | 97.74% | 96.58% | 95.22% | 95.02% | 3.0694 S |
| XGBoost | 96.92% | 93.00% | 93.39% | 93.19% | 19.8026 S |
| Decision Tree | 94.82% | 87.74% | 89.59% | 88.66% | 30.6576 S |
| Random Forest | 96.63% | 96.04% | 88.75% | 92.25% | 33.9499 S |
| Extra Tree | 96.95% | 97.09% | 89.17% | 92.96% | 108.0892 S |
| CNN | 97.80% | 96.83% | 95.80% | 97.81% | 332.5567 S |
| RNN | 95.67% | 91.43% | 90.51% | 90.97% | 412.7603 S |
| LSTM | 96.77% | 96.80% | 96.77% | 96.78% | 1802.2137 S |
| BERT | 98.54% | 96.82% | 96.82% | 96.82% | 388.8494 S |
| DistilBERT | 98.57% | 96.57% | 97.21% | 96.89% | 218.7989 S |
| RoBERTa | 98.63% | 96.95% | 97.08% | 97.02% | 396.7849 S |
| GCN | 76.17% | 78.18% | 76.17% | 66.25% | 566.2911 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 96.61% | 98.89% | 94.76% | 96.78% | 0.6891 S |
| Logistic Regression | 99.04% | 98.71% | 99.51% | 99.11% | 4.6597 S |
| SGD Classifier | 99.25% | 98.71% | 99.60% | 99.31% | 6.7983 S |
| XGBoost | 98.80% | 98.48% | 99.30% | 98.89% | 38.7431 S |
| Decision Tree | 97.48% | 97.60% | 97.72% | 97.66% | 407.0792 S |
| Random Forest | 98.96% | 99.01% | 99.06% | 99.03% | 249.9548 S |
| Extra Tree | 98.93% | 99.32% | 98.69% | 99.01% | 527.6884 S |
| CNN | 99.45% | 99.24% | 99.76% | 99.50% | 3395.9233 S |
| RNN | 98.04% | 98.78% | 97.62% | 98.20% | 3983.1043 S |
| LSTM | 99.27% | 99.42% | 99.25% | 99.34% | 4897.9552 S |
| BERT | 99.24% | 99.38% | 99.23% | 99.30% | 1106.4427 S |
| DistilBERT | 99.09% | 99.11% | 99.23% | 99.17% | 615.7078 S |
| RoBERTa | 98.91% | 99.09% | 98.92% | 99.00% | 1168.1359 S |
| GCN | 72.41% | 72.35% | 72.41% | 72.37% | 4258.3391 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 97.47% | 99.57% | 95.92% | 97.71% | 0.5992 S |
| Logistic Regression | 99.04% | 98.66% | 99.66% | 99.16% | 4.5619 S |
| SGD Classifier | 99.10% | 98.66% | 99.66% | 99.20% | 5.3173 S |
| XGBoost | 98.75% | 98.28% | 99.52% | 98.90% | 29.1080 S |
| Decision Tree | 98.23% | 97.91% | 98.97% | 98.44% | 250.7007 S |
| Random Forest | 99.15% | 99.00% | 99.50% | 99.25% | 170.5102 S |
| Extra Tree | 99.28% | 99.25% | 99.47% | 99.36% | 421.4103 S |
| CNN | 99.39% | 99.59% | 99.31% | 99.45% | 999.6245 S |
| RNN | 99.27% | 99.18% | 99.52% | 99.35% | 1148.2347 S |
| LSTM | 99.12% | 98.75% | 99.68% | 99.21% | 1454.6466 S |
| BERT | 99.66% | 99.72% | 99.65% | 99.69% | 877.7004 S |
| DistilBERT | 99.68% | 99.68% | 99.75% | 99.71% | 493.6949 S |
| RoBERTa | 98.99% | 99.21% | 98.96% | 99.09% | 937.3521 S |
| GCN | 73.25% | 73.15% | 73.25% | 73.13% | 1345.6267 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 98.82% | 97.53% | 100.00% | 98.75% | 0.0414 S |
| Logistic Regression | 97.97% | 99.25% | 96.38% | 97.79% | 2.2404 S |
| SGD Classifier | 98.82% | 99.25% | 97.83% | 98.72% | 0.5486 S |
| XGBoost | 97.80% | 98.88% | 96.38% | 97.61% | 7.3258 S |
| Decision Tree | 94.42% | 92.63% | 95.65% | 94.12% | 3.9194 S |
| Random Forest | 97.63% | 95.17% | 100.00% | 97.53% | 3.2221 S |
| Extra Tree | 97.97% | 95.83% | 100.00% | 97.87% | 7.7123 S |
| CNN | 98.37% | 98.10% | 98.72% | 98.41% | 73.8962 S |
| RNN | 96.90% | 96.82% | 97.12% | 96.97% | 105.0173 S |
| LSTM | 97.55% | 96.27% | 99.04% | 97.64% | 201.7589 |
| BERT | 99.51% | 99.34% | 99.67% | 99.50% | 96.2193 S |
| DistilBERT | 99.35% | 99.01% | 99.67% | 99.34% | 60.7465 S |
| RoBERTa | 99.51% | 99.67% | 99.33% | 99.50% | 82.6740 S |
| GCN | 69.98% | 70.06% | 69.98% | 69.91% | 122.2786 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 99.23% | 100.00% | 97.73% | 98.85% | 0.0639 S |
| Logistic Regression | 98.79% | 100.00% | 96.43% | 98.18% | 2.6391 S |
| SGD Classifier | 99.34% | 100.00% | 98.05% | 99.02% | 0.6771 S |
| XGBoost | 98.68% | 99.33% | 96.75% | 98.03% | 22.6479 S |
| Decision Tree | 95.06% | 89.25% | 97.08% | 93.00% | 7.9171 S |
| Random Forest | 99.34% | 99.67% | 98.38% | 99.02% | 7.2300 S |
| Extra Tree | 98.79% | 97.75% | 98.70% | 98.22% | 19.4767 S |
| CNN | 99.45% | 99.55% | 99.40% | 99.47% | 60.3413 S |
| RNN | 98.18% | 97.35% | 99.25% | 98.29% | 62.5940 S |
| LSTM | 98.82% | 99.39% | 98.35% | 98.87% | 363.3502 S |
| BERT | 99.61% | 99.53% | 99.69% | 99.61% | 150.1970 S |
| DistilBERT | 99.37% | 99.37% | 99.37% | 99.37% | 84.3074 S |
| RoBERTa | 99.45% | 99.69% | 99.22% | 99.45% | 152.0265 S |
| GCN | 72.06% | 72.16% | 72.06% | 72.04% | 200. 3135 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 92.93% | 95.84% | 88.49% | 92.02% | 2.7606 S |
| Logistic Regression | 97.19% | 96.77% | 97.15% | 96.96% | 14.9105 S |
| SGD Classifier | 96.66% | 96.77% | 97.01% | 96.40% | 25.6718 S |
| XGBoost | 95.65% | 93.57% | 97.25% | 95.37% | 86.8558 S |
| Decision Tree | 94.17% | 93.72% | 93.63% | 93.67% | 8523.5984 S |
| Random Forest | 97.20% | 97.95% | 95.94% | 96.93% | 1994.3688 S |
| Extra Tree | 97.31% | 98.58% | 95.55% | 97.04% | 4287.0341 S |
| CNN | 98.07% | 97.33% | 98.65% | 97.99% | 33,641.1476 S |
| RNN | 95.14% | 96.20% | 93.50% | 94.83% | 39,072.5457 S |
| LSTM | 97.43% | 98.04% | 96.53% | 97.28% | 35,495.7471 S |
| BERT | 98.65% | 98.61% | 98.57% | 98.59% | 5137.9657 S |
| DistilBERT | 98.74% | 98.89% | 98.46% | 98.67% | 2839.2592 S |
| RoBERTa | 99.03% | 99.17% | 98.80% | 98.98% | 5062.8701 S |
| GCN | 70.99% | 70.88% | 70.99% | 70.88% | 34,604.4459 S |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (S) |
|---|---|---|---|---|---|
| Naive Bayes | 92.93% | 95.92% | 89.74% | 92.73% | 2.4230 S |
| Logistic Regression | 97.00% | 96.50% | 97.56% | 97.03% | 20.9376 S |
| SGD Classifier | 96.51% | 96.50% | 97.45% | 96.56% | 23.2197 S |
| XGBoost | 95.56% | 93.74% | 97.68% | 95.67% | 88.0840 S |
| Decision Tree | 94.13% | 93.86% | 94.50% | 94.18% | 7494.3420 S |
| Random Forest | 97.23% | 98.06% | 96.39% | 97.22% | 2057.4461 S |
| Extra Tree | 97.38% | 98.55% | 96.21% | 97.36% | 4209.5902 S |
| CNN | 98.09% | 97.91% | 98.33% | 98.12% | 37,260.0418 S |
| RNN | 96.36% | 96.05% | 96.83% | 96.44% | 32,016.6140 S |
| LSTM | 97.67% | 97.65% | 97.76% | 97.71% | 25,345.1311 S |
| BERT | 98.99% | 99.29% | 98.69% | 98.99% | 4626.4871 S |
| DistilBERT | 98.83% | 99.03% | 98.64% | 98.83% | 2751.6064 S |
| RoBERTa | 99.08% | 99.20% | 98.96% | 99.08% | 5013.7805 S |
| GCN | 71.11% | 72.21% | 72.59% | 72.87% | 24,417.8203 S |
Appendix B. Graphical Representation of Experiments Results
Appendix B.1. Machine Learning Models









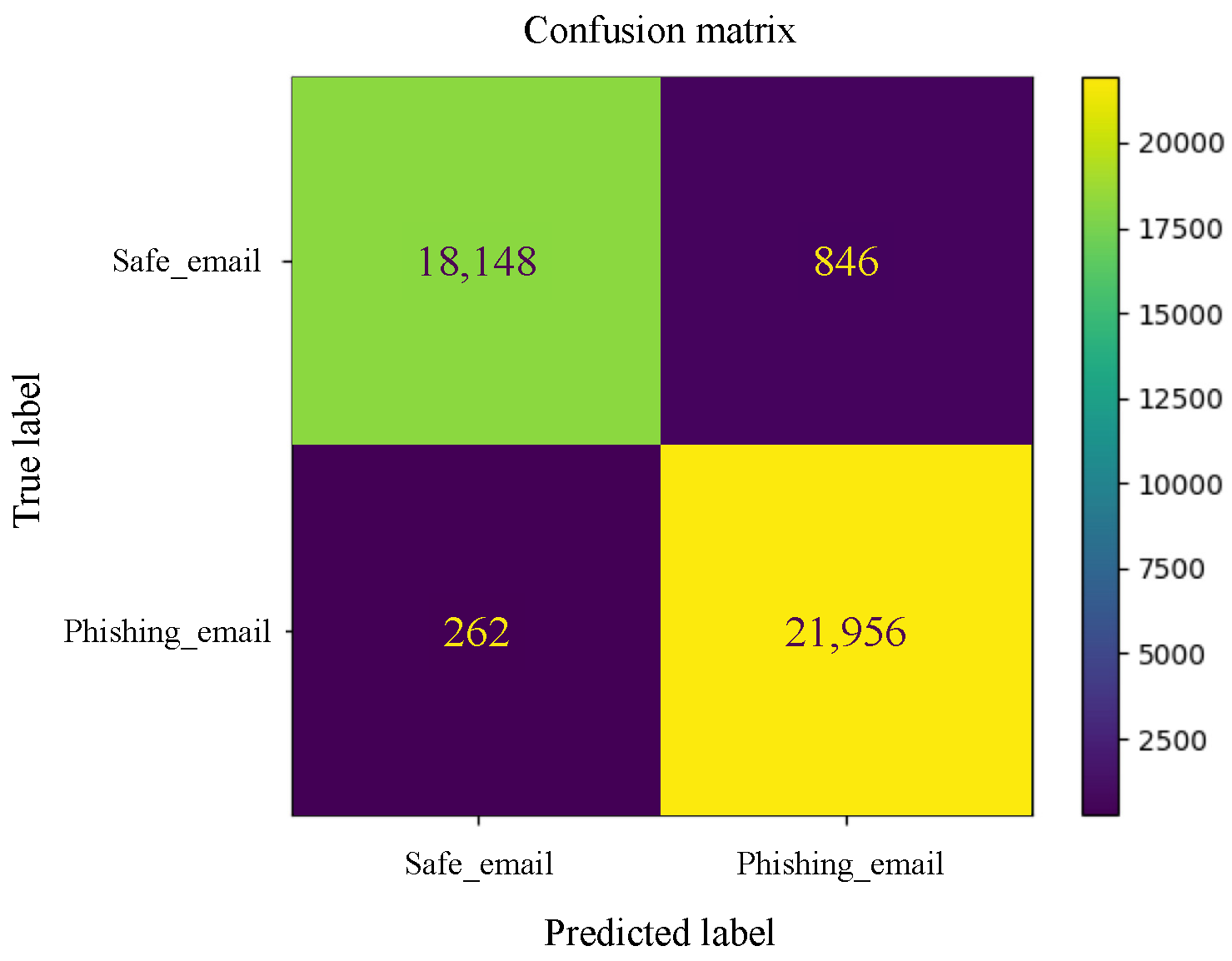
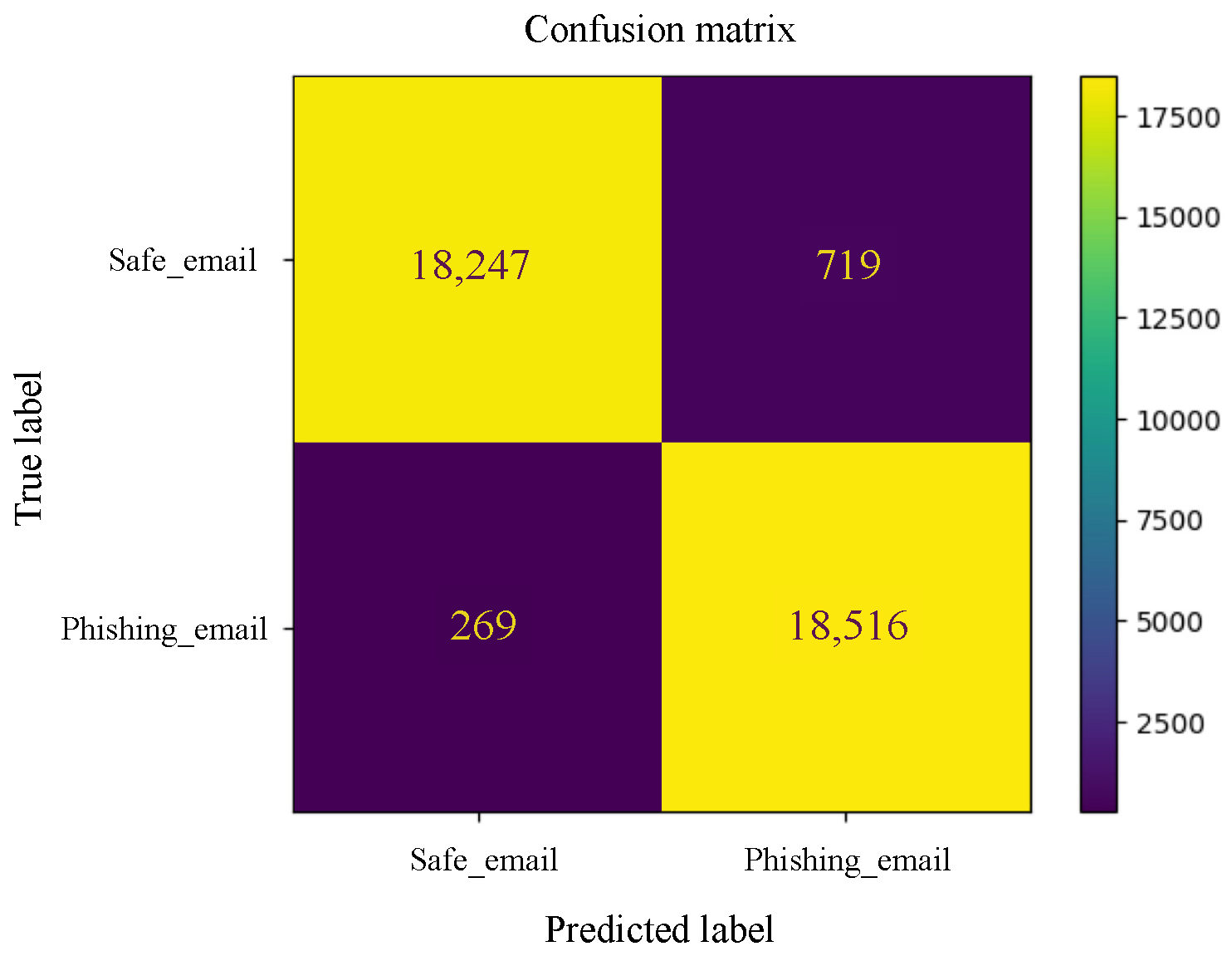


Appendix B.2. Deep Learning Models



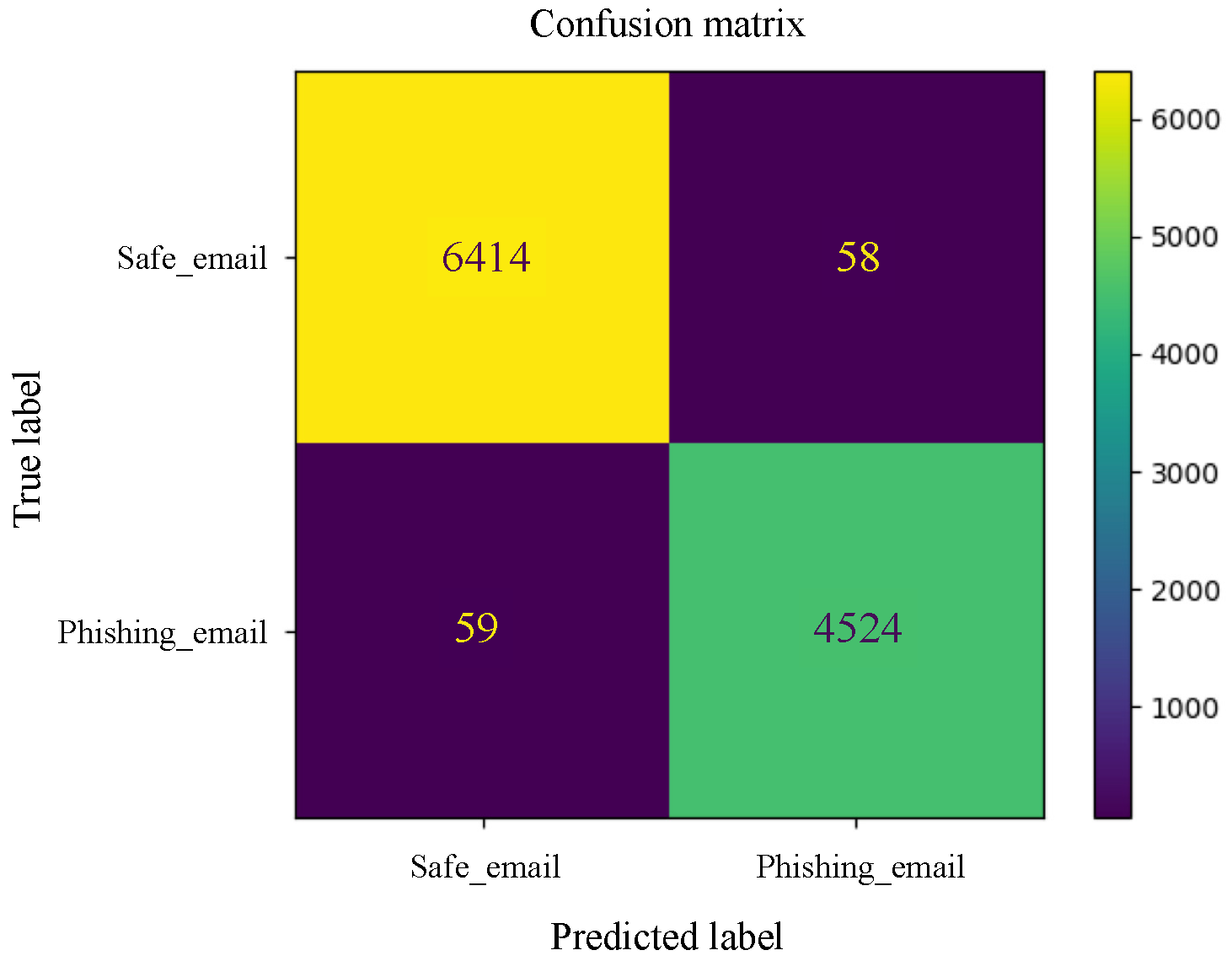
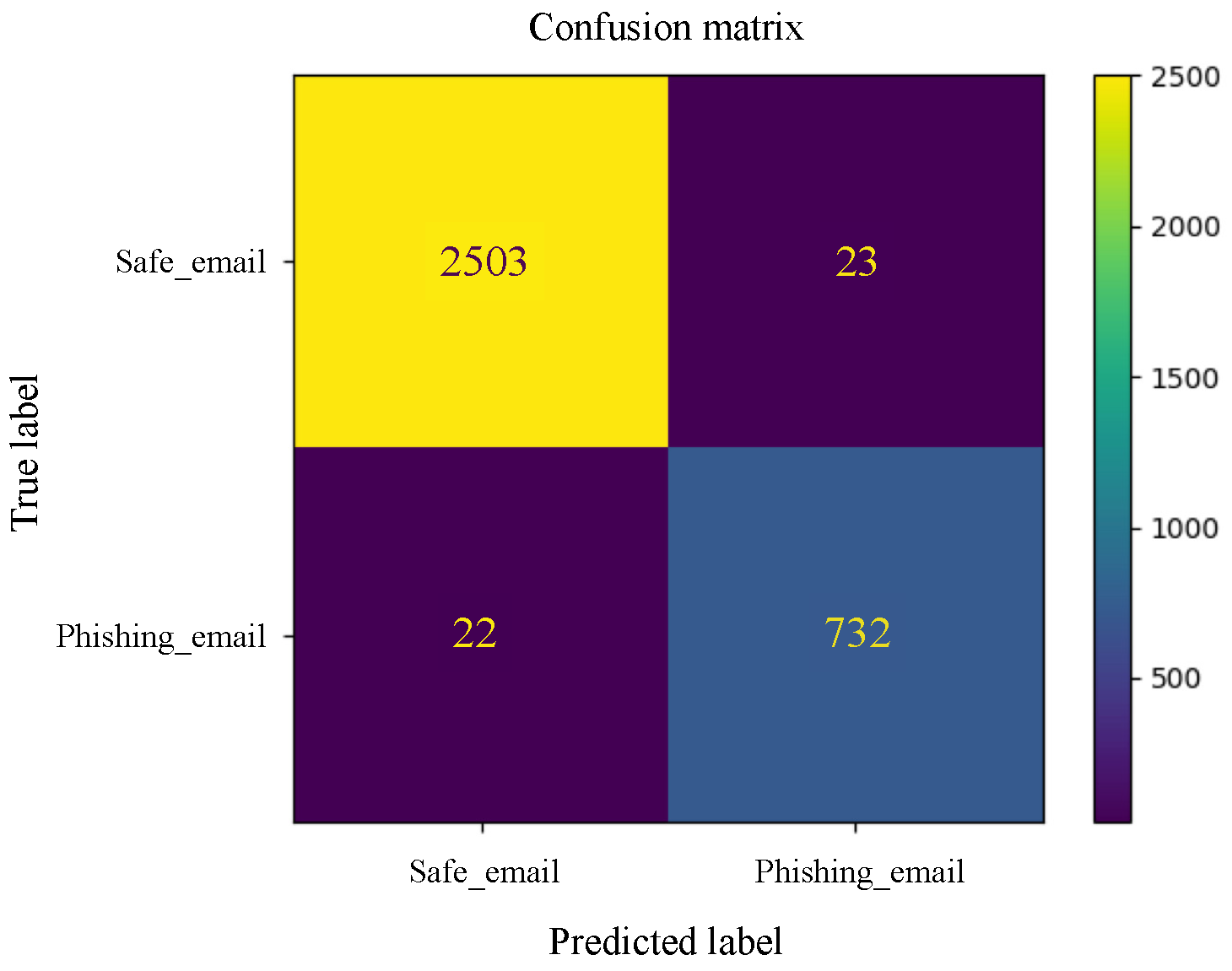
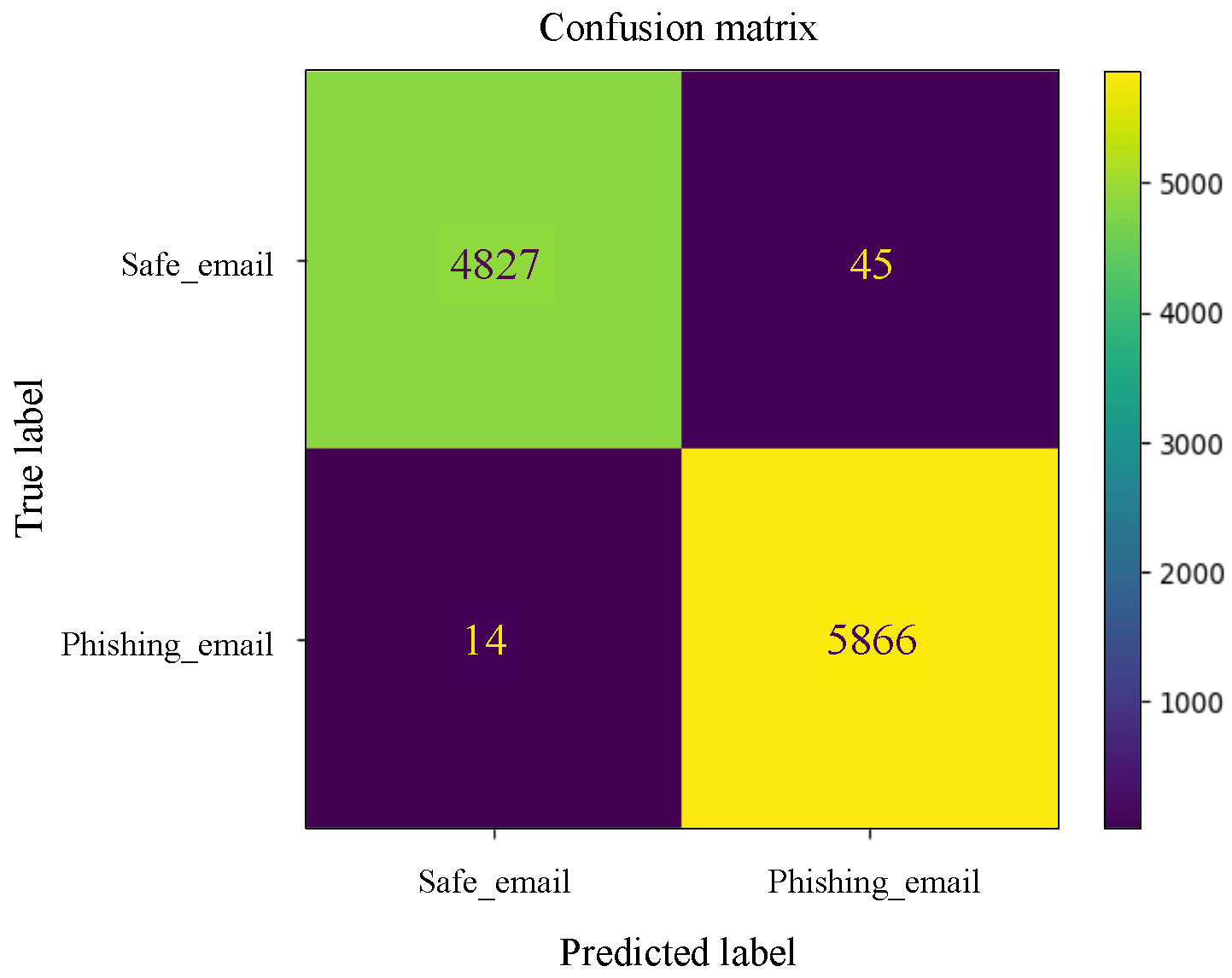



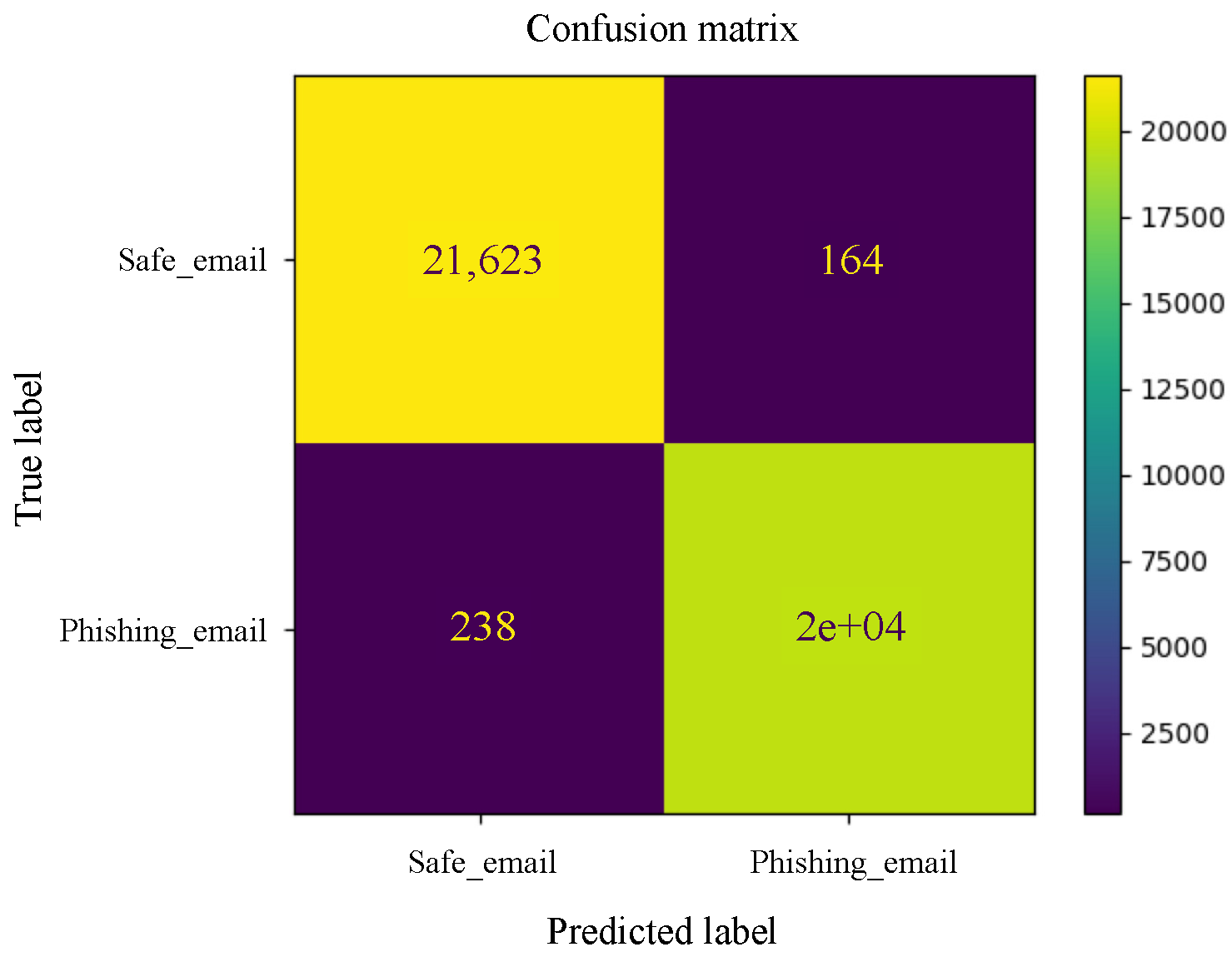



References
- Federal Bureau of Investigation (FBI). Business Email Compromise. 2023. Available online: https://www.fbi.gov/how-we-can-help-you/scams-and-safety/common-frauds-and-scams/business-email-compromise (accessed on 6 March 2025).
- ZDNet. Hackers Are Targeting Billions of Gmail Users with a Realistic AI Scam: How You Can Stay Safe. 2023. Available online: https://www.zdnet.com/article/hackers-are-targeting-billions-of-gmail-users-with-a-realistic-ai-scam-how-you-can-stay-safe/ (accessed on 6 March 2025).
- AAG IT. The Latest Phishing Statistics. 2023. Available online: https://aag-it.com/the-latest-phishing-statistics/ (accessed on 6 March 2025).
- Verizon. Data Breach Investigations Report. 2023. Available online: https://www.verizon.com/business/resources/reports/dbir/ (accessed on 6 March 2025).
- VIPRE. Email Threats: Latest Trends Q2 2024. 2024. Available online: https://vipre.com/resources/email-threats-latest-trends-q2-2024 (accessed on 6 March 2025).
- Bergholz, A.; De Beer, J.; Glahn, S.; Moens, M.F.; Paaß, G.; Strobel, S. New filtering approaches for phishing email. J. Comput. Secur. 2010, 18, 7–35. [Google Scholar]
- Fette, I.; Sadeh, N.; Tomasic, A. Learning to detect phishing emails. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 649–656. [Google Scholar]
- Eze, C.S.; Shamir, L. Analysis and prevention of AI-based phishing email attacks. Electronics 2024, 13, 1839. [Google Scholar] [CrossRef]
- Agarwal, K.; Kumar, T. Email spam detection using integrated approach of Naïve Bayes and particle swarm optimization. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; pp. 685–690. [Google Scholar]
- Gokul, S.; PK, N.B. Analysis of phishing detection using logistic regression and random forest. J. Appl. Inf. Sci. 2020, 8, 7–13. [Google Scholar]
- Akinyelu, A.A.; Adewumi, A.O. Classification of phishing email using random forest machine learning technique. J. Appl. Math. 2014, 2014, 425731. [Google Scholar]
- Al-Subaiey, A.; Al-Thani, M.; Alam, N.A.; Antora, K.F.; Khandakar, A.; Zaman, S.A.U. Novel interpretable and robust web-based AI platform for phishing email detection. Comput. Electr. Eng. 2024, 120, 109625. [Google Scholar]
- Rafat, K.F.; Xin, Q.; Javed, A.R.; Jalil, Z.; Ahmad, R.Z. Evading obscure communication from spam emails. Math. Biosci. Eng 2022, 19, 1926–1943. [Google Scholar] [PubMed]
- Bagui, S.; Nandi, D.; Bagui, S.; White, R.J. Machine learning and deep learning for phishing email classification using one-hot encoding. J. Comput. Sci 2021, 17, 610–623. [Google Scholar]
- Verma, P.; Goyal, A.; Gigras, Y. Email phishing: Text classification using natural language processing. Comput. Sci. Inf. Technol. 2020, 1, 1–12. [Google Scholar]
- Noah, N.; Tayachew, A.; Ryan, S.; Das, S. Poster: PhisherCop-An Automated Tool Using ML Classifiers for Phishing Detection. In Proceedings of the 43rd IEEE Symposium on Security and Privacy (IEEE S&P 2022), San Francisco, CA, USA, 23–26 May 2022. [Google Scholar]
- Kim, S.; Park, J.; Ahn, H.; Lee, Y. Detection of Korean Phishing Messages Using Biased Discriminant Analysis under Extreme Class Imbalance Problem. Information 2024, 15, 265. [Google Scholar] [CrossRef]
- Alotaibi, R.; Al-Turaiki, I.; Alakeel, F. Mitigating email phishing attacks using convolutional neural networks. In Proceedings of the 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 19–21 March 2020; pp. 1–6. [Google Scholar]
- Halgaš, L.; Agrafiotis, I.; Nurse, J.R. Catching the Phish: Detecting phishing attacks using recurrent neural networks (RNNs). In Proceedings of the Information Security Applications: 20th International Conference, WISA 2019, Jeju Island, Republic of Korea, 21–24 August 2019; Revised Selected Papers 20. Springer: Berlin/Heidelberg, Germany, 2020; pp. 219–233. [Google Scholar]
- Li, Q.; Cheng, M.; Wang, J.; Sun, B. LSTM based phishing detection for big email data. IEEE Trans. Big Data 2020, 8, 278–288. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Uddin, M.A.; Sarker, I.H. An Explainable Transformer-based Model for Phishing Email Detection: A Large Language Model Approach. arXiv 2024, arXiv:2402.13871. [Google Scholar]
- Gogoi, B.; Ahmed, T. Phishing and Fraudulent Email Detection thrgh Transfer Learning using pretrained transformer models. In Proceedings of the 2022 IEEE 19th India Council International Conference (INDICON), IEEE, Kochi, India, 24–26 November 2022; pp. 1–6. [Google Scholar]
- ou Sarker, I.H. Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef]
- Islam, M.R.; Ahmed, M.U.; Barua, S.; Begum, S. A systematic review of explainable artificial intelligence in terms of different application domains and tasks. Appl. Sci. 2022, 12, 1353. [Google Scholar] [CrossRef]
- Doshi, J.; Parmar, K.; Sanghavi, R.; Shekokar, N. A comprehensive dual-layer architecture for phishing and spam email detection. Comput. Secur. 2023, 133, 103378. [Google Scholar] [CrossRef]
- Hoheisel, R.; van Capelleveen, G.; Sarmah, D.K.; Junger, M. The development of phishing during the COVID-19 pandemic: An analysis of over 1100 targeted domains. Comput. Secur. 2023, 128, 103158. [Google Scholar] [CrossRef] [PubMed]
- Alkhalil, Z.; Hewage, C.; Nawaf, L.; Khan, I. Phishing attacks: A recent comprehensive study and a new anatomy. Front. Comput. Sci. 2021, 3, 563060. [Google Scholar] [CrossRef]
- Thakur, K.; Ali, M.L.; Obaidat, M.A.; Kamruzzaman, A. A systematic review on deep-learning-based phishing email detection. Electronics 2023, 12, 4545. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 1907, arXiv:1907.11692. [Google Scholar]
- Chinta, P.C.R.; Moore, C.S.; Karaka, L.M.; Sakuru, M.; Bodepudi, V.; Maka, S.R. Building an Intelligent Phishing Email Detection System Using Machine Learning and Feature Engineering. Eur. J. Appl. Sci. Eng. Technol. 2025, 3, 41–54. [Google Scholar] [CrossRef]
- Meléndez, R.; Ptaszynski, M.; Masui, F. Comparative Investigation of Traditional Machine-Learning Models and Transformer Models for Phishing Email Detection. Electronics 2024, 13, 4877. [Google Scholar] [CrossRef]
- Atawneh, S.; Aljehani, H. Phishing email detection model using deep learning. Electronics 2023, 12, 4261. [Google Scholar] [CrossRef]
- Alhogail, A.; Alsabih, A. Applying machine learning and natural language processing to detect phishing email. Comput. Secur. 2021, 110, 102414. [Google Scholar]
- Fang, Y.; Zhang, C.; Huang, C.; Liu, L.; Yang, Y. Phishing email detection using improved RCNN model with multilevel vectors and attention mechanism. IEEE Access 2019, 7, 56329–56340. [Google Scholar]
- Sakkis, G.; Androutsopoulos, I.; Paliouras, G.; Karkaletsis, V.; Spyropoulos, C.D.; Stamatopoulos, P. A memory-based approach to anti-spam filtering for mailing lists. Inf. Retr. 2003, 6, 49–73. [Google Scholar]
- Klimt, B.; Yang, Y. The enron corpus: A new dataset for email classification research. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2004; pp. 217–226. [Google Scholar]
- Apache SpamAssassin. Available online: https://zenodo.org/records/8339691 (accessed on 20 September 2024).
- Craswell, N.; De Vries, A.P.; Soboroff, I. Overview of the TREC 2005 Enterprise Track. In Proceedings of the Fourteenth Text REtrieval Conference, TREC 2005, Gaithersburg, MD, USA, 15–18 November 2005; Volume 5, pp. 1–7. [Google Scholar]
- Bratko, A.; Filipic, B.; Zupan, B. Towards Practical PPM Spam Filtering: Experiments for the TREC 2006 Spam Track. In Proceedings of the Fifteenth Text REtrieval Conference, TREC 2006, Gaithersburg, MD, USA, 14–17 November 2006. [Google Scholar]
- DeBarr, D.; Wechsler, H. Spam detection using random boost. Pattern Recognit. Lett. 2012, 33, 1237–1244. [Google Scholar]
- Nazario, J. The Online Phishing Corpus. 2023. Available online: http://monkey.org/~jose/wiki/doku.php (accessed on 20 September 2024).
- Radev, D. CLAIR Collection of Fraud Email. 2008. Available online: https://aclweb.org/aclwiki (accessed on 12 December 2024).
- Harter, S.P. A probabilistic approach to automatic keyword indexing. Part I. On the distribution of specialty words in a technical literature. J. Am. Soc. Inf. Sci. 1975, 26, 197–206. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 267–288. [Google Scholar]
- Shahrivari, V.; Darabi, M.M.; Izadi, M. Phishing detection using machine learning techniques. arXiv 2020, arXiv:2009.11116. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Volume 1143, pp. 785–794. [Google Scholar]
- Odeh, A.; Al-Haija, Q.A.; Aref, A.; Taleb, A.A. Comparative study of catboost, xgboost, and lightgbm for enhanced URL phishing detection: A performance assessment. J. Internet Serv. Inf. Secur. 2023, 13, 1–11. [Google Scholar]
- Salloum, S.; Gaber, T.; Vadera, S.; Shaalan, K. A systematic literature review on phishing email detection using natural language processing techniques. IEEE Access 2022, 10, 65703–65727. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Salloum, S.; Gaber, T.; Vadera, S.; Shaalan, K. Phishing email detection using natural language processing techniques: A literature survey. Procedia Comput. Sci. 2021, 189, 19–28. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar]
- Champa, A.I.; Rabbi, M.F.; Zibran, M.F. Curated datasets and feature analysis for phishing email detection with machine learning. In Proceedings of the 2024 IEEE 3rd International Conference on Computing and Machine Intelligence (ICMI), Mt Pleasant, MI, USA, 13–14 April 2024; pp. 1–7. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Wang, P.; Xu, J.; Xu, B.; Liu, C.; Zhang, H.; Wang, F.; Hao, H. Semantic clustering and convolutional neural network for short text categorization. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; pp. 352–357. [Google Scholar]
- Zhou, Y.; Li, J.; Chi, J.; Tang, W.; Zheng, Y. Set-CNN: A text convolutional neural network based on semantic extension for short text classification. Knowl. Based Syst. 2022, 257, 109948. [Google Scholar] [CrossRef]
- Moriya, S.; Shibata, C. Transfer learning method for very deep CNN for text classification and methods for its evaluation. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), IEEE, Tokyo, Japan, 23–27 July 2018; Volume 2, pp. 153–158. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Jacovi, A.; Shalom, O.S.; Goldberg, Y. Understanding convolutional neural networks for text classification. arXiv 2018, arXiv:1809.08037. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef]
- Hochreiter, S. Long Short-Term Memory; Neural Computation MIT-Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Khataei Maragheh, H.; Gharehchopogh, F.S.; Majidzadeh, K.; Sangar, A.B. A new hybrid based on long short-term memory network with spotted hyena optimization algorithm for multi-label text classification. Mathematics 2022, 10, 488. [Google Scholar] [CrossRef]
- Eang, C.; Lee, S. Improving the Accuracy and Effectiveness of Text Classification Based on the Integration of the Bert Model and a Recurrent Neural Network (RNN_Bert_Based). Appl. Sci. 2024, 14, 8388. [Google Scholar] [CrossRef]
- Hajer, M.A.; Alasadi, M.K.; Obied, A. Transfer Learning Models for E-mail Classification. J. Cybersecur. Inf. Manag. 2025, 15, 342. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Farhangian, F.; Cruz, R.M.; Cavalcanti, G.D. Fake news detection: Taxonomy and comparative study. Inf. Fusion 2024, 103, 102140. [Google Scholar]
- Jamal, S.; Wimmer, H.; Sarker, I.H. An improved transformer-based model for detecting phishing, spam and ham emails: A large language model approach. Secur. Priv. 2024, 7, e402. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. Proc. Aaai Conf. Artif. Intell. 2019, 33, 7370–7377. [Google Scholar]
- Prasad, R. Phishing Email Detection Using Machine Learning: A Critical Review. In Proceedings of the 2024 IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT), IEEE, Greater Noida, India 9–10 February 2024; Volume 5, pp. 1176–1180. [Google Scholar]
- Miltchev, R.; Dimitar, R.; Evgeni, G. Phishing Validation Emails Dataset. Zenodo. 2024. Available online: https://zenodo.org/records/13474746 (accessed on 20 January 2025).
- Microsoft Defender. 2025. Available online: https://www.microsoft.com/en-us/security/business/microsoft-defender (accessed on 5 March 2025).

| Ref. | Year | Dataset | Model (s) | Result (Accuracy) |
|---|---|---|---|---|
| [31] | 2025 | Public datasets (UCI, SpamAssassin) | CNN, XGBoost, RNN, SVM, BERT-LSTM | 99.55% |
| [32] | 2024 | Enron and multiple phishing repositories | Logistic Regression, Random Forest, SVM, Naive Bayes, distilBERT, BERT, XLNet, RoBERTa, ALBERT | 99.43% |
| [12] | 2024 | Merged (6 datasets) | SVM, Naive Bayes, Random Forest | 99.19% |
| [22] | 2024 | Kaggle phishing dataset | DistilBERT | 98.48% |
| [33] | 2023 | Public datasets (UCI, Kaggle) | CNN, RNN, LSTM, BERT | 99.61% |
| [26] | 2023 | Nazario phishing corpus | ANN, RNN, CNN | 99.51% |
| [13] | 2022 | SpamAssassin | LSTM, Gaussian Naive Bayes | 97.18% |
| [23] | 2022 | N/A | BERT, DistilBERT | 99% |
| [14] | 2021 | Custom dataset | CNN, LSTM | 96.34% |
| [34] | 2021 | Fraud dataset | GCN | 98% |
| [15] | 2020 | SMS Spam Collection v.1 | SVM, Decision Tree, Random Forest | 98.77% |
| [35] | 2019 | IWSPA-AP 2018 | RCNN | 99.848% |
| Model | Optimizer | Loss Function | Batch Size | Number of Epochs | Learning Rate |
|---|---|---|---|---|---|
| CNN | Adam | Binary Crossentropy | 32 | 5 | 0.01 |
| RNN | Adam | Binary Crossentropy | 32 | 5 | 0.01 |
| LSTM | Adam | Binary Crossentropy | 32 | 5 | 0.01 |
| GCN | Adam | Crossentropy Loss | Entire graph is processed in a single batch | 10 | 0.01 |
| BERT | Adam | Binary Crossentropy | 8 | 5 | 5 × 10−5 |
| DistilBERT | Adam | Cross Entropy Loss with class weights | 8 | 5 | Automatically tuned by DistilBERT model |
| RoBERTa | Adam | Crossentropy Loss with class weights | 8 | 5 | Automatically tuned by RoBERTa model |
| Model | Enron | SpamAssassin | Ling | TREC_05 | TREC_06 | TREC_07 | CEAS_08 | Nazario_5 | Nigerian_5 | Merged | Merged (Balanced) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Naive Bayes | 97.85% | 96.70% | 98.43% | 92.27% | 93.16% | 96.61% | 97.47% | 98.82% | 99.23% | 92.93% | 92.93% |
| Logistic Regression | 98.29% | 96.25% | 97.20% | 97.46% | 97.30% | 99.04% | 99.04% | 97.97% | 98.79% | 97.19% | 97.00% |
| SGD Classifier | 98.35% | 97.68% | 99.48% | 97.00% | 97.74% | 99.25% | 99.10% | 98.82% | 99.34% | 96.66% | 96.51% |
| XGBoost | 97.23% | 96.79% | 98.43% | 95.77% | 96.92% | 98.80% | 98.75% | 97.80% | 98.68% | 95.65% | 95.56% |
| Decision Tree | 95.38% | 90.98% | 94.76% | 94.22% | 94.82% | 97.48% | 98.23% | 94.42% | 95.06% | 94.17% | 94.13% |
| Random Forest | 98.09% | 96.88% | 98.60% | 96.99% | 96.63% | 98.96% | 99.15% | 97.63% | 99.34% | 97.20% | 97.23% |
| Extra Tree | 98.37% | 97.23% | 97.73% | 97.14% | 96.95% | 98.93% | 99.28% | 97.97% | 98.79% | 97.31% | 97.38% |
| CNN | 98.34% | 98.11% | 98.25% | 96.57% | 97.80% | 99.45% | 99.38% | 98.37% | 99.45% | 98.07% | 98.09% |
| RNN | 96.56% | 97.07% | 95.45% | 94.64% | 95.67% | 98.04% | 99.27% | 96.90% | 98.18% | 95.14% | 96.63% |
| LSTM | 98.14% | 97.42% | 98.43% | 97.15% | 96.77% | 99.27% | 99.12% | 97.55% | 98.82% | 97.43% | 97.67% |
| BERT | 99.31% | 98.88% | 100.00% | 98.94% | 98.54% | 99.24% | 99.66% | 99.51% | 99.61% | 98.65% | 98.99% |
| DistilBERT | 99.16% | 98.88% | 99.83% | 98.85% | 98.57% | 99.09% | 99.68% | 99.35% | 99.37% | 98.74% | 98.83% |
| RoBERTa | 99.19% | 98.80% | 99.83% | 98.88% | 98.63% | 98.91% | 98.99% | 99.51% | 99.45% | 99.03% | 99.08% |
| GCN | 72.49% | 79.78% | 86.71% | 72.44% | 76.17% | 72.41% | 73.25% | 69.98% | 72.06% | 70.99% | 71.11% |
| Dataset | Best Model (s) | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Enron | BERT | 99.31% | 99.21% | 99.31% | 99.26% |
| SpamAssassin | BERT | 98.88% | 98.23% | 97.94% | 98.09% |
| Ling | BERT | 100.00% | 100.00% | 100.00% | 100.00% |
| TREC_05 | BERT | 98.94% | 98.73% | 98.71% | 98.72% |
| TREC_06 | RoBERTa | 98.63% | 96.95% | 97.08% | 97.02% |
| TREC_07 | CNN | 99.45% | 99.24% | 99.76% | 99.50% |
| CEAS_08 | DistilBERT | 99.68% | 99.68% | 99.75% | 99.71% |
| Nazario | RoBERTa | 99.51% | 99.67% | 99.33% | 99.50% |
| Nigerian | BERT | 99.61% | 99.53% | 99.69% | 99.61% |
| Merged | RoBERTa | 99.03% | 99.17% | 98.80% | 98.98% |
| Merged (Balanced) | RoBERTa | 99.08% | 99.20% | 98.96% | 99.08% |
| Model | Enron | SpamAssassin | Ling | TREC_05 | TREC_06 | TREC_07 | CEAS_08 | Nazario_5 | Nigerian_5 | Merged | Balanced Merged |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Naive Bayes | 0.4045 | 0.0774 | 0.4096 | 0.7002 | 0.2044 | 0.6891 | 0.5992 | 0.0414 | 0.0639 | 2.7606 | 2.4230 |
| Logistic Regression | 6.0422 | 4.3615 | 0.4096 | 14.0869 | 5.8902 | 4.6597 | 4.5619 | 2.2404 | 2.6391 | 14.9105 | 20.9376 |
| SGD Classifier | 4.7780 | 0.8779 | 0.4595 | 9.3601 | 3.0694 | 6.7983 | 5.3173 | 0.5486 | 0.6771 | 25.6718 | 23.2197 |
| XGBoost | 32.8451 | 16.4625 | 24.9872 | 42.6082 | 19.8026 | 38.7431 | 29.1080 | 7.3258 | 22.6479 | 86.8558 | 88.0840 |
| Decision Tree | 186.7102 | 22.4780 | 4.4804 | 684.2861 | 30.6576 | 407.0792 | 250.7007 | 3.9194 | 7.9171 | 8523.5984 | 7494.3420 |
| Random Forest | 92.4306 | 11.3588 | 4.0028 | 293.0442 | 33.9499 | 249.9548 | 170.5102 | 3.2221 | 7.2300 | 1994.3688 | 2057.4461 |
| Extra Tree | 251.8828 | 33.3333 | 11.6939 | 683.8933 | 108.0892 | 527.6884 | 421.4103 | 7.7123 | 19.4767 | 4287.0341 | 4209.5902 |
| CNN | 1394.9935 | 250.6515 | 53.4167 | 2873.5432 | 332.5567 | 3395.9233 | 999.6245 | 73.8962 | 60.3413 | 33,641.1476 | 37,260.0418 |
| RNN | 1198.6864 | 200.5724 | 97.6607 | 2051.2652 | 412.7603 | 3983.1043 | 1148.2347 | 105.0173 | 62.5940 | 39,072.5457 | 32,016.6140 |
| LSTM | 1616.3018 | 415.1188 | 109.0630 | 2594.2131 | 1802.2137 | 4897.9552 | 1454.6466 | 201.7589 | 363.3502 | 35,495.7471 | 25,345.1311 |
| BERT | 705.5716 | 283.1131 | 156.4819 | 1290.6487 | 388.8494 | 1106.4427 | 877.7004 | 96.2193 | 150.1970 | 5137.9657 | 4626.4871 |
| DistilBERT | 420.9068 | 164.1796 | 85.1270 | 721.0618 | 218.7989 | 615.7078 | 493.6949 | 60.7465 | 84.3074 | 2839.2592 | 2751.6064 |
| RoBERTa | 713.6597 | 298.7486 | 164.4693 | 1336.9023 | 396.7849 | 1168.1359 | 937.3521 | 82.6740 | 152.0265 | 5062.8701 | 5013.7805 |
| GCN | 1456.7544 | 315.2311 | 101.6573 | 2437.8352 | 566.2911 | 4258.3391 | 1345.6267 | 122.2786 | 200. 3135 | 34,604.4459 | 24,417.8203 |
| Model | Merged | Balanced Merged |
|---|---|---|
| BERT | 0.0364 | 0.0329 |
| DistilBERT | 0.0291 | 0.0258 |
| RoBERTa | 0.0379 | 0.0340 |
| Model | Enron | SpamAssassin | Ling | TREC_05 | TREC_06 | TREC_07 | CEAS_08 | Nazario_5 | Nigerian_5 | Merged | Merged (Balanced) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SGD Classifier | 69.60% | 55.85% | 64.90% | 73.50% | 77.75% | 50.80% | 69.55% | 85.80% | 50.00% | 77.35% | 77.15% |
| BERT | 82.45% | 55.30% | 71.90% | 69.65% | 90.65% | 62.50% | 75.90% | 79.70% | 61.60% | 88.80% | 81.30% |
| DistilBERT | 75.60% | 60.90% | 71.05% | 70.90% | 91.95% | 51.90% | 73.60% | 75.70% | 61.80% | 85.75% | 80.40% |
| RoBERTa | 88.80% | 50.85% | 74.85% | 70.25% | 92.10% | 60.05% | 75.15% | 80.35% | 65.00% | 96.00% | 95.00% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alhuzali, A.; Alloqmani, A.; Aljabri, M.; Alharbi, F. In-Depth Analysis of Phishing Email Detection: Evaluating the Performance of Machine Learning and Deep Learning Models Across Multiple Datasets. Appl. Sci. 2025, 15, 3396. https://doi.org/10.3390/app15063396
Alhuzali A, Alloqmani A, Aljabri M, Alharbi F. In-Depth Analysis of Phishing Email Detection: Evaluating the Performance of Machine Learning and Deep Learning Models Across Multiple Datasets. Applied Sciences. 2025; 15(6):3396. https://doi.org/10.3390/app15063396
Chicago/Turabian StyleAlhuzali, Abeer, Ahad Alloqmani, Manar Aljabri, and Fatemah Alharbi. 2025. "In-Depth Analysis of Phishing Email Detection: Evaluating the Performance of Machine Learning and Deep Learning Models Across Multiple Datasets" Applied Sciences 15, no. 6: 3396. https://doi.org/10.3390/app15063396
APA StyleAlhuzali, A., Alloqmani, A., Aljabri, M., & Alharbi, F. (2025). In-Depth Analysis of Phishing Email Detection: Evaluating the Performance of Machine Learning and Deep Learning Models Across Multiple Datasets. Applied Sciences, 15(6), 3396. https://doi.org/10.3390/app15063396