

The Impact of Linguistic Variations on Emotion Detection: A Study of Regionally Specific Synthetic Datasets


Abstract
1. Introduction
- Demonstrate the feasibility of generating region-specific synthetic datasets for emotion detection using advanced language models.
- Provide a comprehensive analysis of the linguistic diversity and regional differences in the generated datasets.
- Show that region-specific synthetic datasets can significantly improve the performance of emotion detection models.
- The findings highlight the importance of incorporating regional language variations in synthetic dataset generation, offering valuable insights for future research and applications in NLP.
2. Related Work
2.1. Synthetic Dataset Generation for NLP
2.2. Emotion Detection: Advancements and Challenges
2.3. Regional Language Variations in NLP
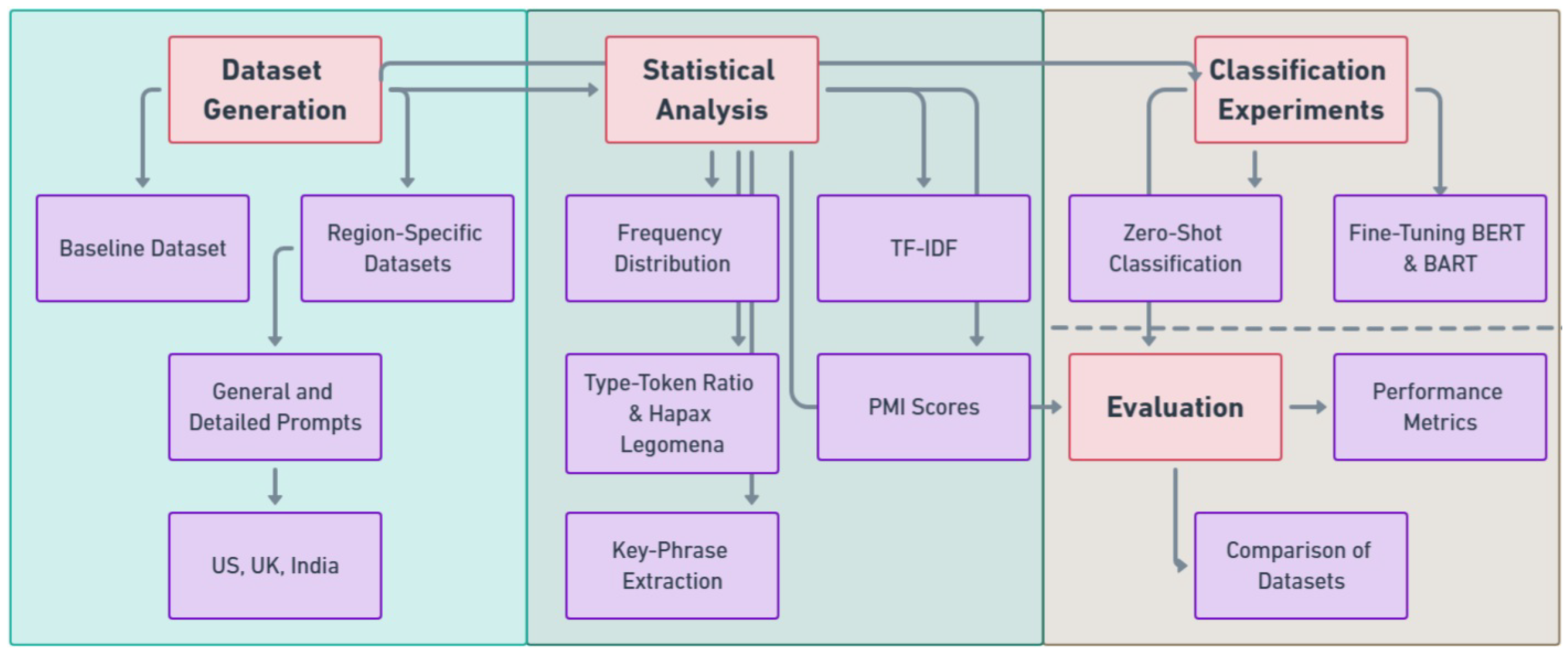
3. Methodology
3.1. Objectives
- RQ1: How do region-specific prompts influence the linguistic diversity of synthetic datasets?
- RQ2: What are the regional differences in language use for expressing emotions in synthetic datasets?
- RQ3: How do region-specific synthetic datasets affect the performance of emotion detection models compared to baseline datasets?
- H1: Prior research has shown that prompt engineering can guide language models to generate domain-specific content [19]. By incorporating region-specific cues, prompts are expected to elicit greater linguistic diversity, reflecting local idioms, word choices, and syntactic structures.
- H3: Empirical findings indicate that training NLP models on more diverse and contextually relevant data improves performance [15]. Since region-specific datasets are expected to better capture local linguistic nuances, models trained on them should outperform those trained on baseline datasets.
3.2. Overview
- Dataset Generation: Synthetic datasets are generated using the GPT-3.5 language model, incorporating English variations from the United States, United Kingdom, and India, alongside a general baseline dataset. Two levels of prompt specificity are employed to assess the influence of regional linguistic nuances on the generated data.
- Statistical Analysis: A range of statistical analyses are conducted to evaluate the linguistic diversity and regional differences in the generated datasets. These analyses include frequency distribution, TF-IDF, type–token ratio, hapax legomena, PMI scores, and key-phrase extraction.
- Classification Experiments: BERT and BART models are employed to conduct classification experiments, starting with zero-shot classification on the CARER dataset, followed by fine-tuning with both baseline and region-specific datasets. This stage evaluates the impact of region-specific synthetic datasets on emotion detection performance.
- Evaluation: The performance of the models is evaluated using standard metrics, and comparisons are made between the baseline and region-specific datasets to assess the impact of regional language variations on model performance.
3.3. Dataset Generation
3.4. Statistical Analysis
3.4.1. Frequency Distribution
3.4.2. TF-IDF
3.4.3. Type–Token Ratio and Hapax Legomena
3.4.4. PMI Scores
3.4.5. Key-Phrase Extraction
3.5. Classification Experiments
3.5.1. Zero-Shot Classification
3.5.2. Fine-Tuning
- Baseline synthetic dataset (general English)
- Region-specific synthetic datasets with general prompts
- Region-specific synthetic datasets with detailed prompts
3.6. Evaluation
4. Results
4.1. Zero-Shot Classification
4.2. Fine-Tuning with Synthetic Datasets
4.3. Statistical Analysis of Datasets
5. Discussion
5.1. Linguistic Diversity and Regional Differences
5.2. Impact on Emotion Detection Performance
5.3. Implications for Future Research and Applications
5.4. Ethical Considerations
5.4.1. Bias and Fairness
5.4.2. Privacy and Consent
5.4.3. Misuse and Misinterpretation
5.4.4. Transparency and Accountability
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alswaidan, N.; Menai, M.E.B. A survey of state-of-the-art approaches for emotion recognition in text. Knowl. Inf. Syst. 2020, 62, 2937–2987. [Google Scholar] [CrossRef]
- Plaza-del-Arco, F.M.; Curry, A.; Curry, A.C.; Hovy, D. Emotion Analysis in NLP: Trends, Gaps and Roadmap for Future Directions. arXiv 2024, arXiv:2403.01222. [Google Scholar]
- Safari, F.; Chalechale, A. Emotion and personality analysis and detection using natural language processing, advances, challenges and future scope. Artif. Intell. Rev. 2023, 56, 3273–3297. [Google Scholar]
- Prajapati, Y.; Khande, R.; Parasar, A. Sentiment Analysis of Emotion Detection Using Natural Language Processing; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Systematic Review of Emotion Detection with Computer Vision and Deep Learning. Sensors 2024, 24, 3484. [CrossRef] [PubMed]
- Gamage, G.; Silva, D.D.; Mills, N.; Alahakoon, D.; Manic, M. Emotion AWARE: An artificial intelligence framework for adaptable, robust, explainable, and multi-granular emotion analysis. J. Big Data 2024, 11, 93. [Google Scholar] [CrossRef]
- Mozes, M.; Tutelman, D.; Winter, Y.; Globerson, A. Synthetic Data for Natural Language Processing: A Survey. CoRR 2023. abs/2304.03751. [Google Scholar]
- Bowman, S.R.; Vilnis, L.; Vinyals, O.; Dai, A.M.; Jozefowicz, R.; Bengio, S. Generating sentences from a continuous space. arXiv 2015, arXiv:1511.06349. [Google Scholar]
- Saharia, C.; Tamkin, A.; Allmendinger, F.; Lowe, R.; Pang, R.; Tabrizian, M.; Liang, P.; Joshi, N.; Wei, J.; Chowdhery, A.; et al. Language Models Can Teach Themselves to Program Better. CoRR 2023. abs/2305.12413. [Google Scholar]
- Chen, X.; Sun, T.; Qiu, X.; Huang, X. A Survey on Multilingual Pre-trained Language Models. CoRR 2022. abs/2210.10271. [Google Scholar]
- Zhao, J.; Lin, Z.; Lin, J.; Tan, M.; Yu, J. Generative Pre-trained Models for Text Generation: A Survey. CoRR 2022. abs/2204.08582. [Google Scholar]
- Li, D.; Bu, K.; Wu, J.; Chang, B. Data Augmentation for Cross-lingual Transfer Learning of BERT-based Dependency Parsers. Trans. Assoc. Comput. Linguist. 2021, 9, 942–957. [Google Scholar]
- Sánchez-Junquera, J.; Fernández-González, D.; Rodríguez-Fórtiz, M.J.; Montero, J.M.; Ordóñez, L. Generating Synthetic Data for Emotion Recognition in Conversation. CoRR 2021. abs/2104.08773. [Google Scholar]
- Schuff, H.; Barnes, J.; Crossley, S.; McNamara, D.S.; Cai, Z. Culture and Emotion in Text: A Computational Analysis of Emotion Expression in English and Chinese. CoRR 2020. abs/2010.06435.. [Google Scholar]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. arXiv 2020, arXiv:2011.04071. [Google Scholar]
- Blodgett, S.L.; Green, L.; O’Connor, B. Demographic Dialectal Variation in Social Media: A Case Study of African-American English. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), Berlin, Germany, 7–12 August 2016; pp. 1119–1130. [Google Scholar]
- Jurgens, D.; Lu, T.C. Incorporating geolocation into supervised learning models of user demographics. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 2359–2368. [Google Scholar]
- Han, X.; Su, J.; Wan, X. Unsupervised Multi-Target Domain Adaptation: An Information-Theoretic Approach. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 3006–3016. [Google Scholar]
- Wang, A.; Cho, K.; Lewis, M. Towards understanding the impact of artificial data on sequential language tasks. arXiv 2021, arXiv:2109.09193. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; So, P.; Srinivasan, M.; Shinn, J.; Stoyanov, V. Synthetic data generation for natural language processing. arXiv 2022, arXiv:2204.08582. [Google Scholar]
- Hovy, D.; Purschke, C. Social and regional variation in language processing and its implications for NLP. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 632–637. [Google Scholar]
- Bamman, D.; Dyer, C.; Smith, N.A. Distributed representations of geographically situated language. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MA, USA, 22–27 June 2014; pp. 828–834. [Google Scholar]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic keyword extraction from individual documents. In Text Mining; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2010; pp. 1–20. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Li, J.; Zettlemoyer, L.; Schuster, M. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics 2020, Virtually, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Saravia, E.; Liu, H.; Huang, Y.; Wu, J.; Chen, Y. CARER: Contextualized affect representations for emotion recognition. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing 2018, Brussels, Belgium, 31 October–4 November 2018; pp. 3687–3697. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Wang, X.; Zhao, J.; Li, Y. Prompt-Based Learning for Text-Based Emotion Detection: A Survey. CoRR 2022. abs/2210.10271. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Records by Emotion | Total | |||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | Anger | Fear | Joy | Love | Sadness | Surprise | ||
| Baseline | 471 | 514 | 504 | 517 | 505 | 489 | 3000 | |
| Regional General | US | 155 | 178 | 169 | 163 | 159 | 176 | 1000 |
| UK | 173 | 148 | 157 | 169 | 176 | 177 | 1000 | |
| IN | 162 | 155 | 158 | 184 | 169 | 172 | 1000 | |
| Regional Detailed | US_2 | 150 | 174 | 169 | 162 | 171 | 174 | 1000 |
| UK_2 | 177 | 150 | 168 | 163 | 187 | 155 | 1000 | |
| IN_2 | 160 | 160 | 168 | 169 | 160 | 183 | 1000 | |
| Baseline | Regional General | Regional Detailed | ||||
|---|---|---|---|---|---|---|
| US | UK | IN | US_2 | UK_2 | IN_2 | |
| feeling | feeling | feeling | feeling | like | proper | feeling |
| love | love | absolutely | love | just | feeling | just |
| today | today | love | india | feeling | just | like |
| life | grateful | today | today | today | chuffed | yaar |
| absolutely | life | uk | absolutely | right | mate | today |
| grateful | believe | life | let | life | like | chai |
| believe | absolutely | grateful | sending | got | absolutely | time |
| spread | right | believe | believe | believe | believe | life |
| fear | joyful | just | grateful | vibes | right | believe |
| sadness | time | right | time | shook | today | bollywood |
| right | let | sending | life | good | gutted | totally |
| time | spread | fuming | stay | blessed | cuppa | movie |
| remember | world | bit | knows | feelin | time | hai |
| joyful | scared | people | staystrong | bummed | bits | world |
| just | stay | okay | times | deal | mates | kya |
| wow | just | chuffed | boundaries | living | innit | vibe |
| let | times | spooked | spread | best | ve | boss |
| okay | support | remember | support | ride | fuming | desi |
| spreadlove | staystrong | blimey | fear | time | life | shake |
| unexpected | way | throws | just | love | blimey | nailed |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calderón Alvarado, F.H. The Impact of Linguistic Variations on Emotion Detection: A Study of Regionally Specific Synthetic Datasets. Appl. Sci. 2025, 15, 3490. https://doi.org/10.3390/app15073490
Calderón Alvarado FH. The Impact of Linguistic Variations on Emotion Detection: A Study of Regionally Specific Synthetic Datasets. Applied Sciences. 2025; 15(7):3490. https://doi.org/10.3390/app15073490
Chicago/Turabian StyleCalderón Alvarado, Fernando Henrique. 2025. "The Impact of Linguistic Variations on Emotion Detection: A Study of Regionally Specific Synthetic Datasets" Applied Sciences 15, no. 7: 3490. https://doi.org/10.3390/app15073490
APA StyleCalderón Alvarado, F. H. (2025). The Impact of Linguistic Variations on Emotion Detection: A Study of Regionally Specific Synthetic Datasets. Applied Sciences, 15(7), 3490. https://doi.org/10.3390/app15073490