
Adaptive BBU Migration Based on Deep Q-Learning for Cloud Radio Access Network


Abstract
1. Introduction
- Problem: In a standard RAN or distributed BS architecture, the number of BS increases and the matching cell size reduces as the number of cellular users rises. This results in higher CAPEX and OPEX as well as increased power consumption [17,18].Solution: The baseband processing is performed at a centralized site, whereas the RF unit is kept at a distributed position under the architecture that China Mobile introduced. Therefore, centralization lowers power consumption and associated costs even as the number of cells grows.
- 2.
- Problem: The conventional RAN relies on a costly radio frequency (RF) component and a specialized signal processing unit, which results in a large unit that requires additional room to operate [19].Solution: Because the RF unit is small and light, it may be placed in any commonplace, such as a light pool, tree trunk, or rooftop. Once more, C-BBU’s usage of load balancing and virtualization technology results in a smaller BS architecture by reducing the size of the BBU pool.
- 3.
- Problem: The main switching center (MSC) is the only component responsible for network connectivity in the conventional RAN architecture, which lengthens network latency.Solution: C-RAN integrates certain MSC control plane functions into the C-BBUs. The overall end-to-end time delay and backhaul congestion are further minimized, as control and processing tasks are handled at the C-BBU, which is positioned closer to the user equipment (UE).
- Create a BBU pool and virtualize it using the iCanCloud platform, a tool designed for modeling cloud environments.
- Implement a two-threshold migration mechanism dynamically. Start with an adaptive migration trigger scheme with a deep reinforcement learning (DQN) algorithm that can detect when migration will best occur, skipping unnecessary migration in case of transient spikes in server resource consumption, high or low. Next, make a smart decision about selecting a virtual machine for migration through consideration of both migration count and duration.
- The iCanCloud platform runs a simulation in an attempt to assess the proposed migration scheme, and it can enable efficiency in terms of energy and considerable migration count and migration time savings. Unlike a conventional manual scheme, such a scheme utilizes artificial intelligence for accuracy, evasion of invalid migration, and achievement of load balancing and adaptive dynamic migration.
2. Literature Review
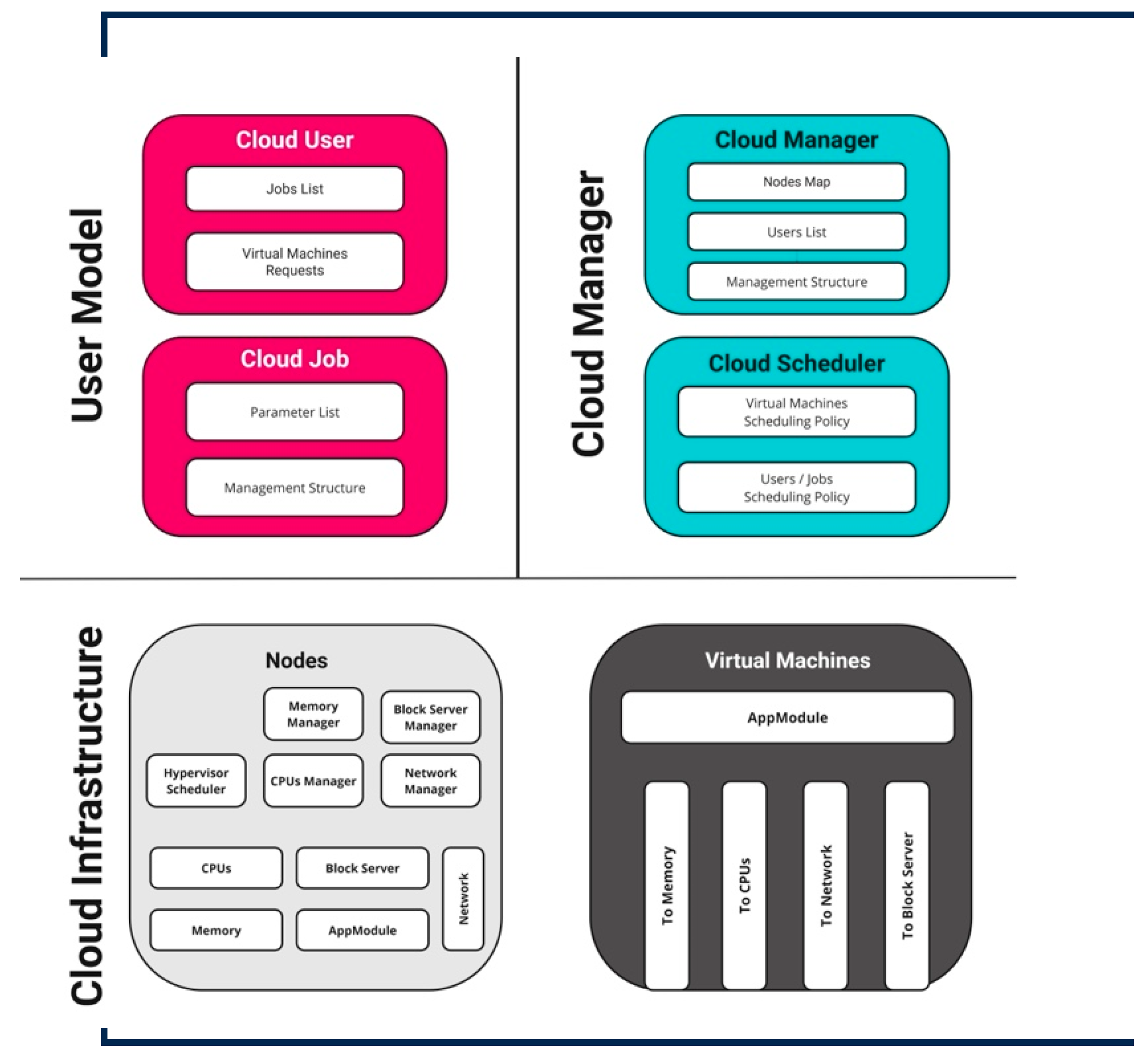
3. Proposed System Model
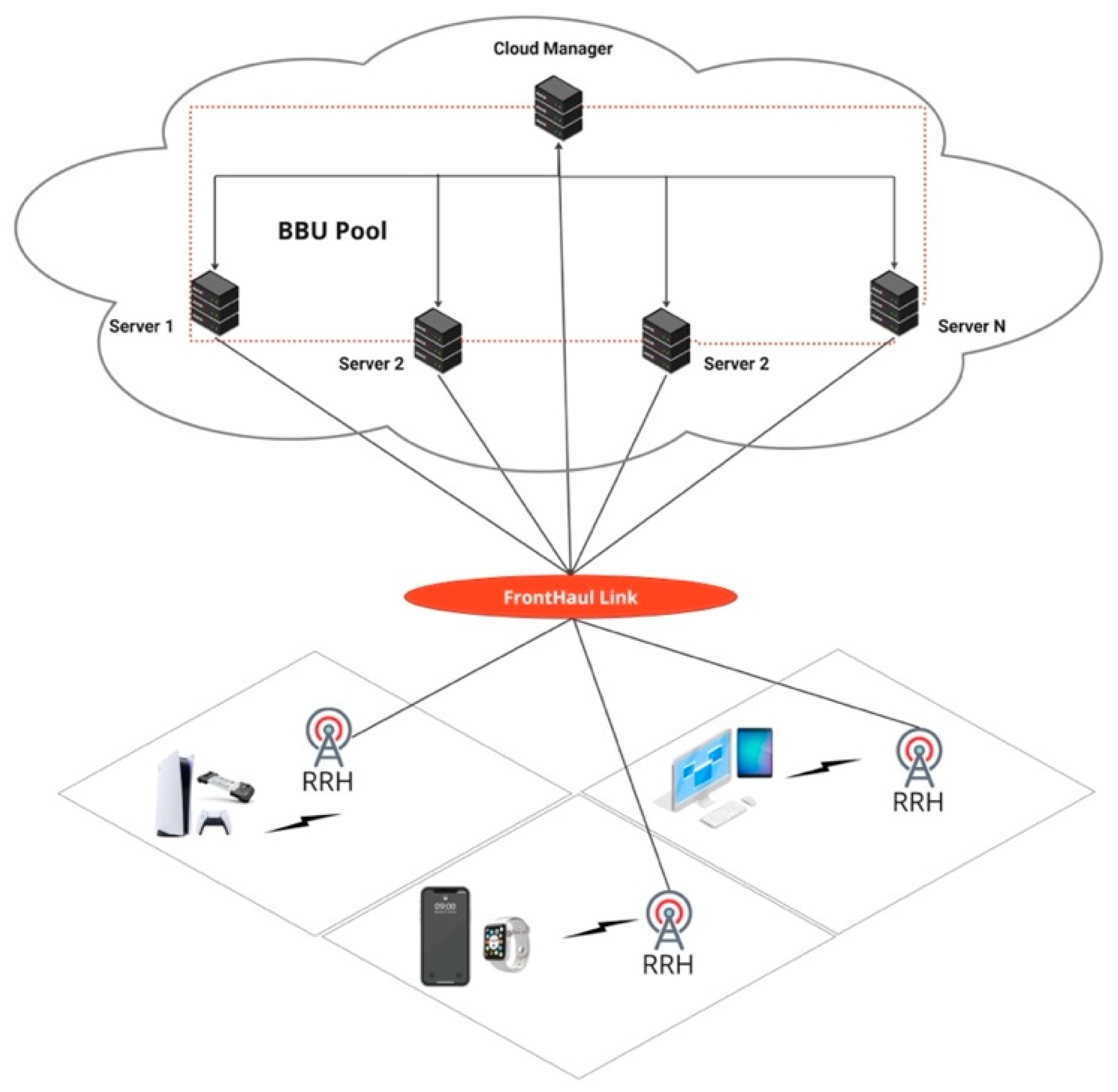
3.1. System Scenario
3.2. Power Consumption Model
3.3. Resource Utilization
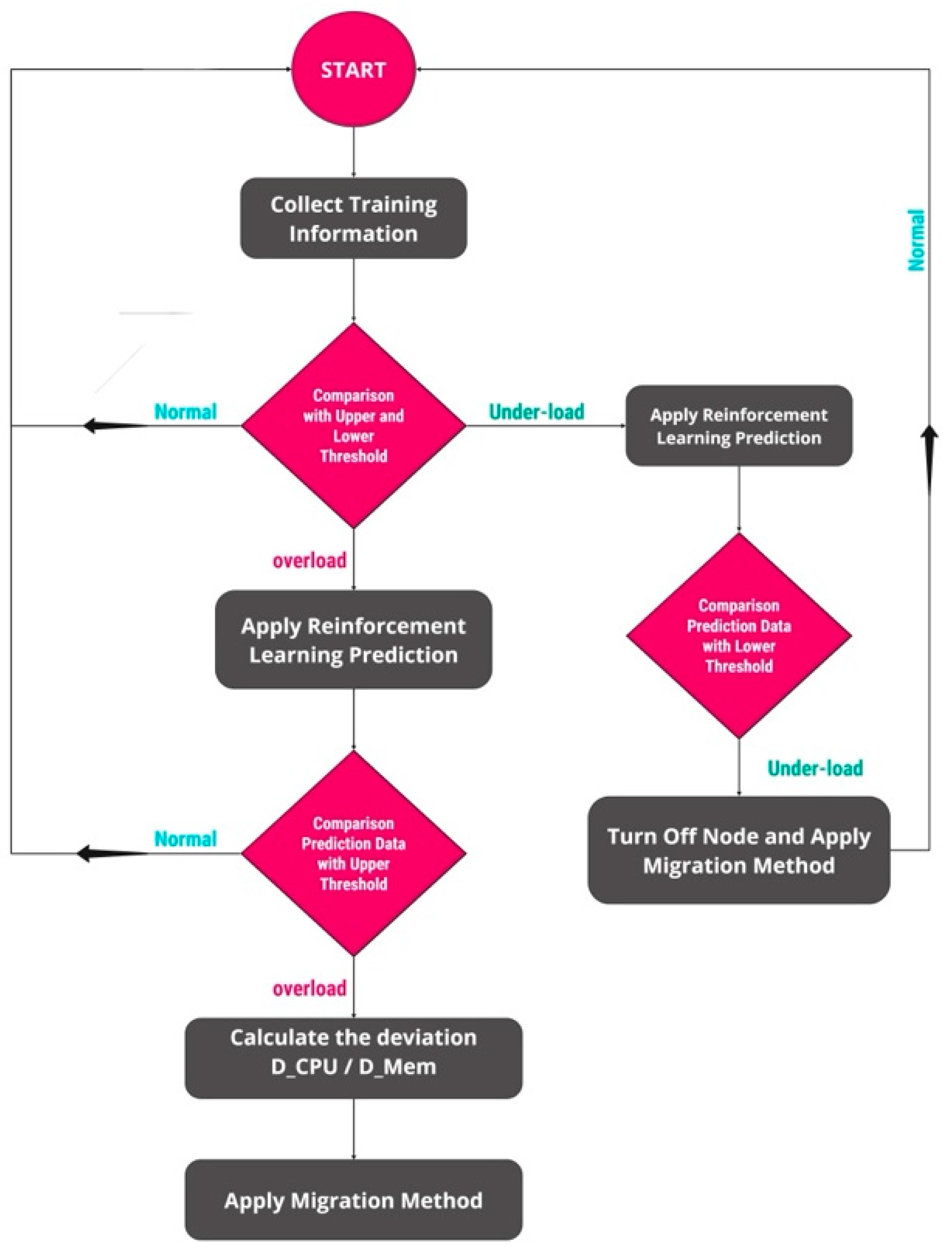
4. Proposed Dynamic Migration System
- Non-linear decision making: DQN can handle complex, dynamic resource utilization patterns.
- Policy optimization: Through training, DQN learns optimal migration strategies based on past experience and rewards.
- Continuous improvement: Unlike static methods like the Kalman filter, DQN improves as it receives feedback.
- State variables: CPU and memory utilization, current load on BBUs, and system energy consumption.
- Action space: Decisions on whether to migrate VMs or not, and the selection of target physical machines for migration.
- Reward function: The reward was based on optimizing resource utilization and min. imizing energy consumption, and the number of migrations. The reward is positive for resource behaviors that reduce energy consumption.
- ○
- CPU usage: 50% (below threshold)
- ○
- Migration cost: 0
- ○
- Energy consumption: 0
- ○
- CPU usage: 90% (above threshold)
- ○
- Migration cost: 0.1
- ○
- Energy consumption: 0.05
- Input layer: takes the current state of CPU and memory utilization, energy consumption, and migration metrics.
- Hidden layers: fully connected layers with ReLU activation functions to handle the non-linearity in the data.
- Output layer: produces the Q-values corresponding to the possible migration actions, where higher Q-values indicate better decisions.
| Algorithm 1: DQN migration method with dual threshold pseudo-code |
| Initialize DQN_Model with trained weights Set threshold (upper and lower) for resource utilization (e.g., CPU_threshold, Memory_threshold) While the simulation is running: # Step 1: Collect environment state For each host in the iCanCloud environment: current_CPU_utilization = host.getCPUUtilization() current_Memory_utilization = host.getMemoryUtilization() current_Energy_consumption = host.getEnergyConsumption() # Step 2: Define the state (combine CPU, Memory, and Energy into a state vector) state = [current_CPU_utilization, current_Memory_utilization, current_Energy_consumption] # Step 3: Feed state to DQN model to obtain action = DQN_Model.predict(state) # Step 4: Action decision If action == ‘MIGRATE_VM’: # Perform migration target_host = selectBestHostForMigration() vm_to_migrate = selectVMToMigrate(host) migrate(vm_to_migrate, target_host) log("Migration performed from", host, "to", target_host) Else if action == ‘DO_NOTHING’: # No migration needed, continue monitoring log("No migration required for", host) # Step 5: Monitor environment and obtain feedback for reward post_migration_CPU_utilization = host.getCPUUtilization() post_migration_Memory_utilization = host.getMemoryUtilization() post_migration_Energy_consumption = host.getEnergyConsumption() reward = computeReward(post_migration_CPU_utilization, post_migration_Memory_utilization, post_migration_Energy_consumption) # Step 6: Train DQN with the reward (optional for continued training) DQN_Model.update(state, action, reward) # Continue to the next host or iteration |
| Algorithm 2: VM Migration selection strategy pseudo-code |
| Input: Over_load_Host, DCPU and DMem Output: VM_to_migrate Step1 # Calculate the utilization load for eachVM in Over_load_Host do case0: VMk-DCPU = VMk_CPU-DCPU,VMk-DMem = VMk_Mem-DMem case1: VMk-DCPU = VMk_CPU-DCPU case2: VMk-DMem = VMk_Mem-DMem Step2# Check the VMk-DCPU and VMk-DMem for each VMs to be migrated if (case 0:VM k-DCPU >= 0 and VM k-DMem >= 0; case 1:VM k-DCPU >= 0; case 2:VM k-DMem >= 0) Step3# If the difference is greater than or equal to zero sort the VMlist_count according to minimum memory usage and then select the smallest one to be migrated VM_list ←VMk sort VM_list by memory VM_to_migrate = VM_list[0] Step4# Or else, calculate the utilization weight of the three cases as follows: case0 e case1: e1 = 1, e2 = 0 case2: e1 = 0, e2 = 1 fk = w1⋅VMk-DCPU + w2⋅VMk-DMem VMlist_f ←VMk, fk Step5# Sort the list of VMs according to f sort VMlist_f by f k VM_to_migrate = VMlist_f [0] return VM_to_migrate |
5. Simulation Results
5.1. The Proposed Simulation Environment
5.2. The Proposed Evaluation Results and Analysis
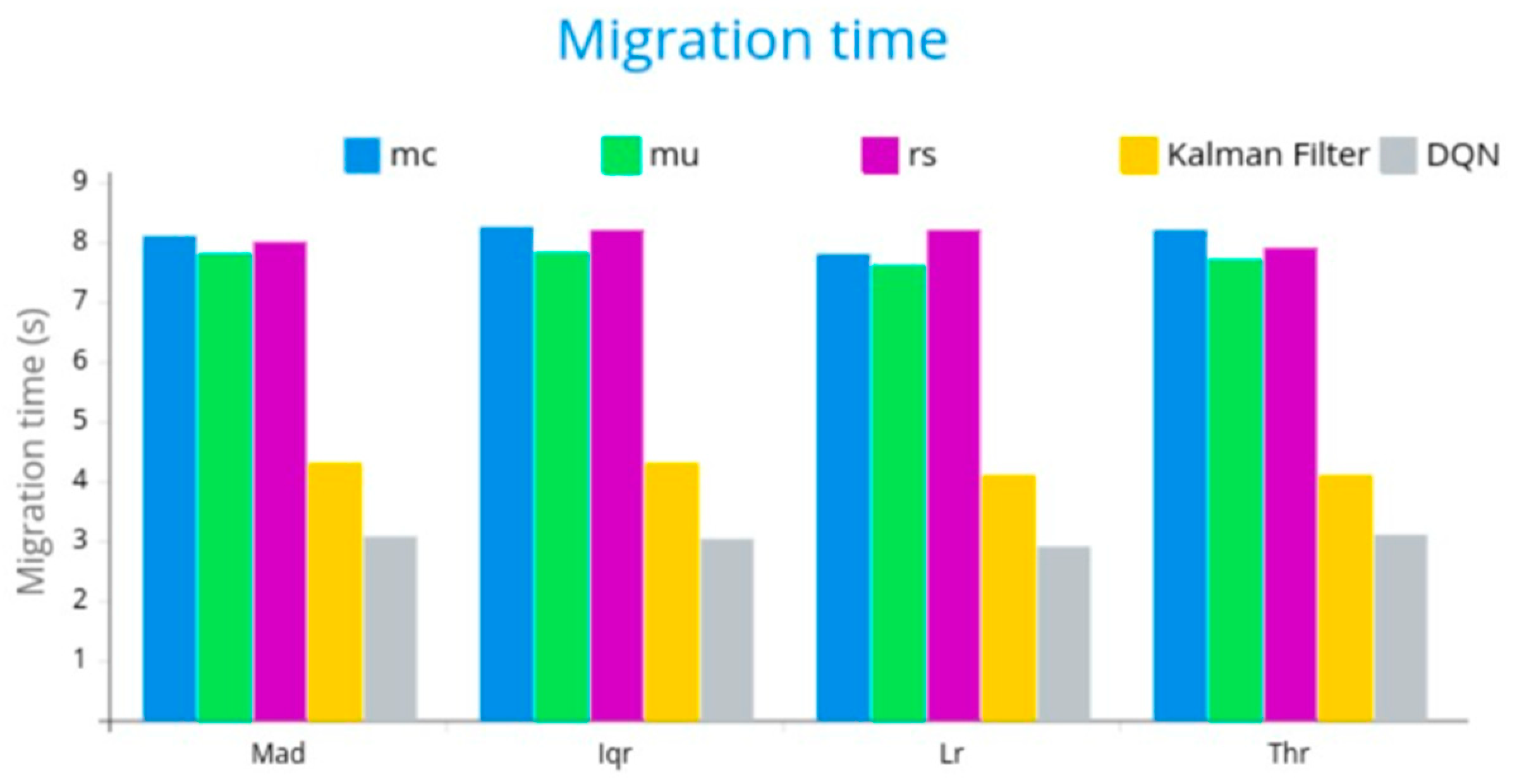
- MAD (median absolute deviation). It could be used to identify nodes with unusually high or low resource usage compared to the median usage across the pool.
- IQR (interquartile range). IQR can be used to understand the range within which the central 50% of resource usage data lies. It helps in understanding the spread of the middle portion of the data and can be useful for setting thresholds.
- LR (load ratio). LR can help determine how heavily a particular resource (such as CPU, memory, or network bandwidth) is being utilized relative to its total capacity. It is a key metric for deciding when to trigger migrations to balance the load.
- Thr (threshold). A threshold is a predefined value used to trigger certain actions. In the context of resource management, thresholds are typically set for metrics like CPU usage, memory usage, etc.
- Resource utilization: The DQN model improved by 6.2% and memory utilization improved by 6.4% compared to the Kalman filter. This was because DQN was better at identifying and reacting to resource usage patterns over time.
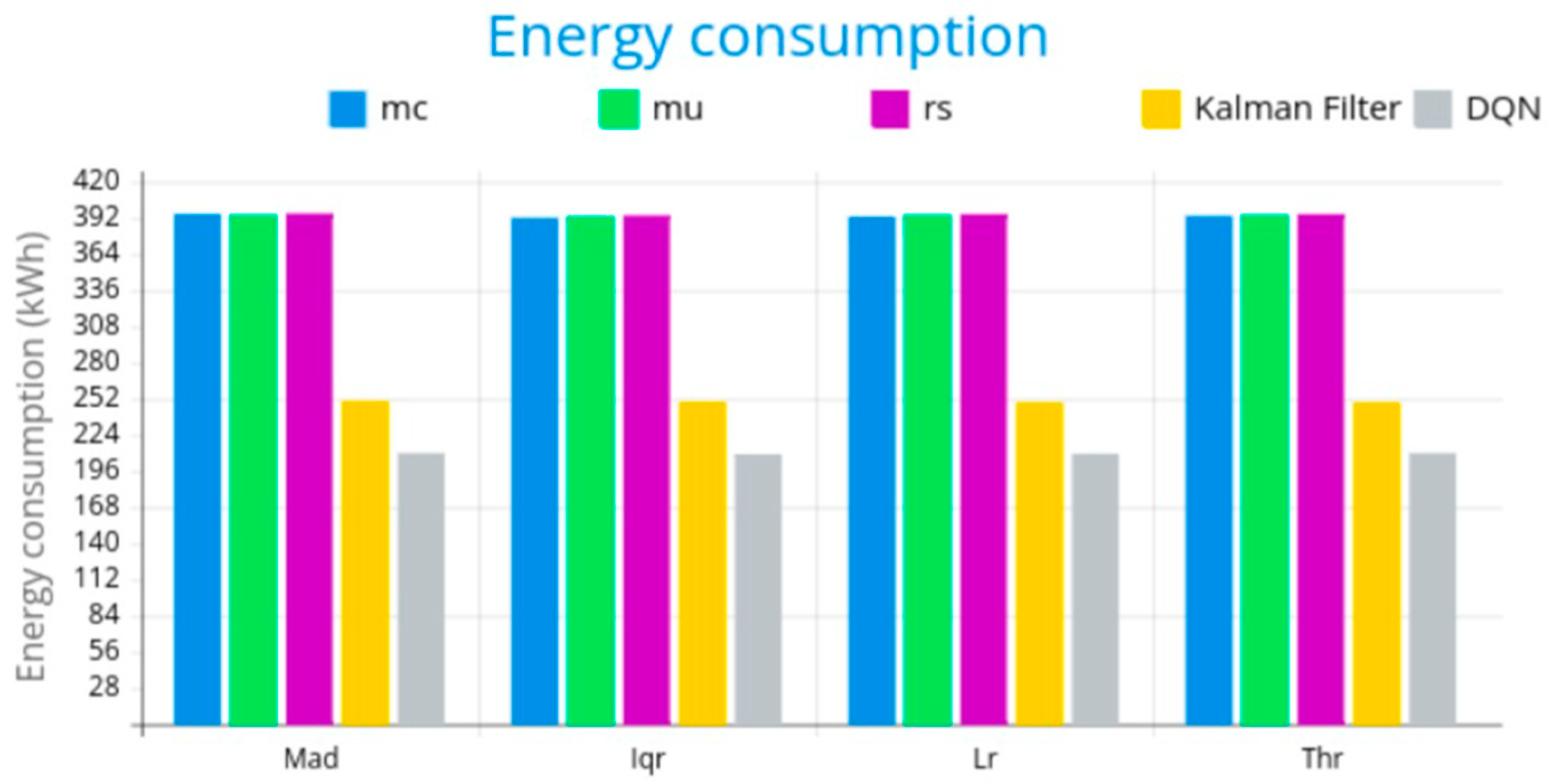
- Energy consumption: DQN also resulted in a 16% reduction in energy consumption, as it optimized the system’s load balancing by triggering migrations only when necessary and consolidating resources more effectively.
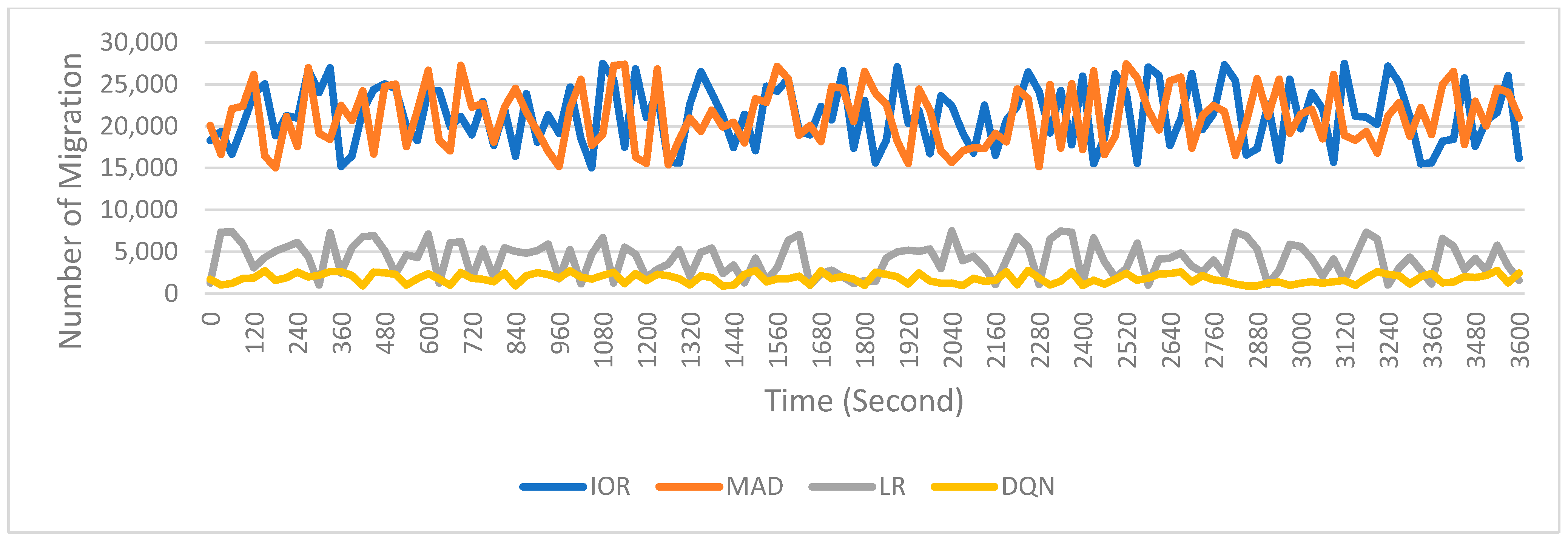
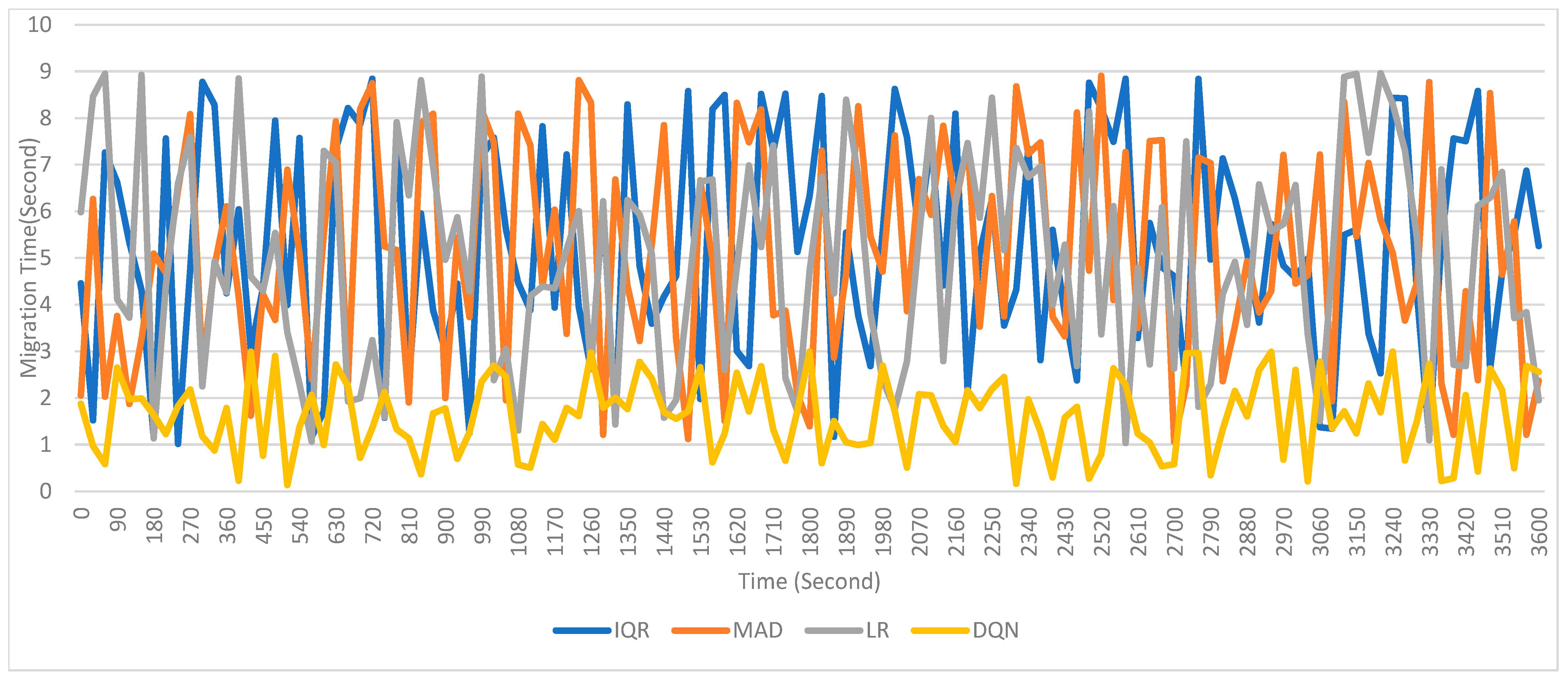
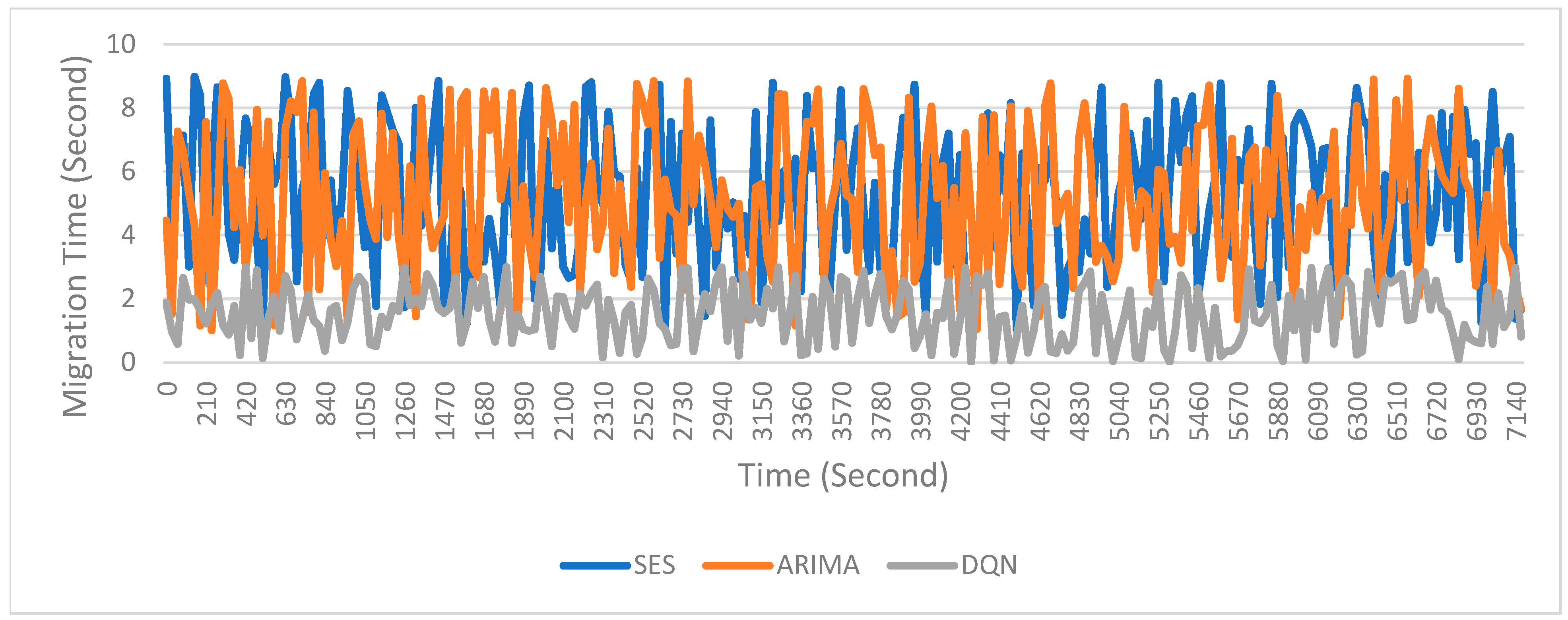
- Migration time and number of migrations: The DQN model reduced migration time by 31% and the number of migrations by 28%, compared to the Kalman filter. By learning from previous migration events, DQN minimized unnecessary migrations and improved the selection of target machines, resulting in fewer, but more efficient, migration events.
5.3. Comparative Study of the Proposed System with Some Statistical Methods
- Median Absolute Deviation (MAD)
- Data collection: Gather the number of linked VMs from eligible nodes.
- Median calculation: Sort the data and compute the median number of linked VMs.
- Deviation computation: Calculate the absolute deviations for each node from the median.
- Candidate selection: Choose the node with the smallest deviation, indicating a balanced or typical resource usage. If no node has linked VMs, the algorithm defaults to a first-come-first-serve (FCFS) approach.
- B.
- Interquartile Range (IQR)
- Data collection: Obtain the count of linked VMs across candidate nodes.
- Quartile calculation: Sort the data, compute Q1 and Q3, and then derive the IQR.
- Threshold determination: Establish a lower threshold Q1 − 1.5 × IQR and an upper threshold Q3 + 1.5 × IQR.
- Candidate filtering: Nodes with VM counts below the lower threshold are classified as underutilized, while those within the threshold are deemed acceptable. Nodes exceeding the upper threshold are considered overutilized and are excluded from selection.
- Selection logic: Preferentially select the underutilized node with the fewest VMs; if none exist, choose the node with an acceptable load.
- C.
- Load Ratio (LR)
- Data collection:Gather the forecasted load values (e.g., predicted number of linked VMs) and the capacity or baseline load for each candidate node.
- Ratio calculation:Compute the Load Ratio for each node by dividing its forecasted load by its capacity:
- Threshold determination:Define thresholds or criteria to classify nodes based on their Load Ratios. For example, nodes may be categorized as:
- ○
- Underutilized: Nodes with a low load ratio, indicating significant available capacity.
- ○
- Balanced: Nodes with a load ratio within an acceptable range.
- ○
- Overutilized: Nodes with a high load ratio, suggesting that they are approaching or exceeding their resource limits.
- Candidate filtering:Filter out nodes based on their classification:
- ○
- Underutilized nodes: These are preferred since they have the greatest capacity headroom.
- ○
- Acceptable nodes: Considered if no underutilized nodes are available.
- ○
- Overutilized nodes: Excluded from selection to prevent potential overloads.
- Selection logic:Preferentially select the node with the lowest load ratio to ensure efficient and balanced resource utilization. If multiple nodes exhibit similar ratios, additional criteria (such as current load or historical performance) can be used as tie-breakers.
- Dynamic adaptation:Unlike static statistical thresholds derived from historical data, the DQN continually learns and adapts to current system dynamics, making it more resilient to changes in workload patterns.
- Multivariate optimization:DQN considers multiple performance indicators simultaneously (e.g., CPU, memory, energy, and VM count) rather than relying on a single metric. This holistic approach can optimize trade-offs between competing objectives.
- Proactive decision making:The DQN’s ability to predict future states allows for proactive adjustments in node selection, potentially preventing overload before it occurs.
- Scalability:As the system grows in complexity, the DQN model can scale to incorporate additional features and parameters, whereas the statistical methods might require significant re-tuning.
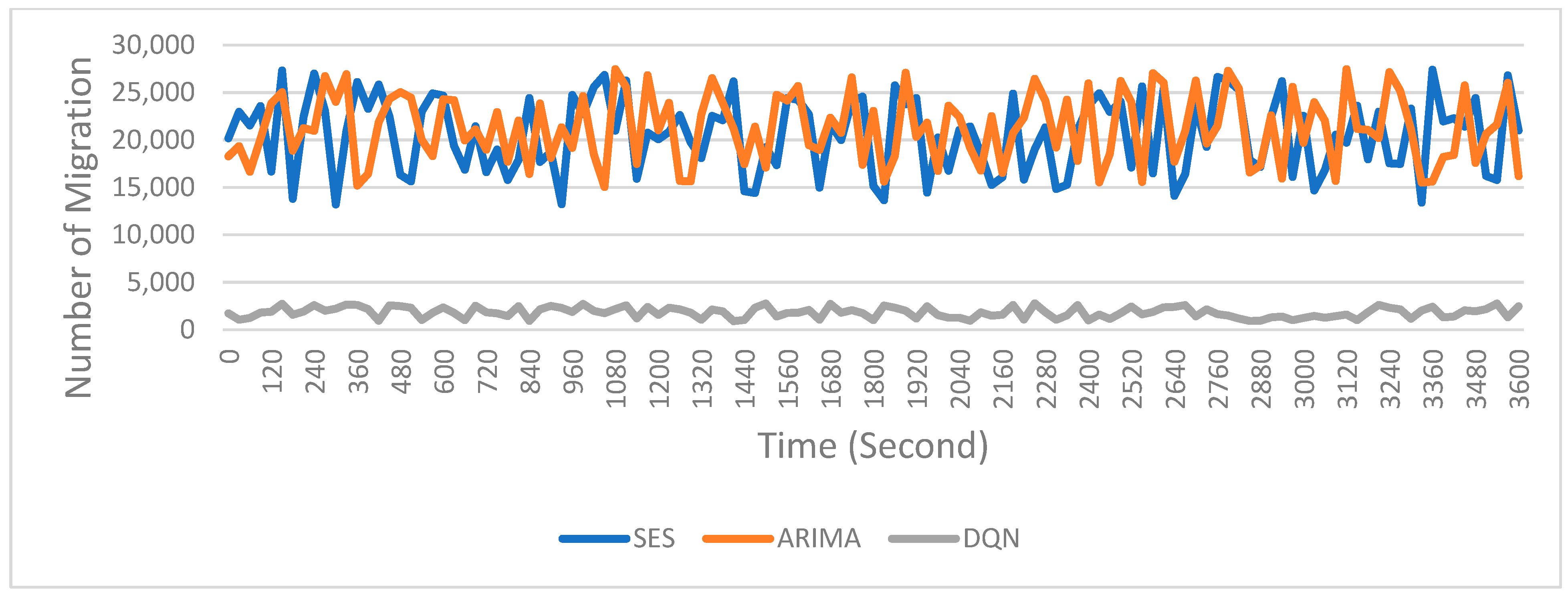
5.4. A Comparative Analysis with Some Time Series Methods
- Simple exponential smoothing (SES) To predict the near-term load (calculated as the number of linked virtual machines) for potential nodes in a BBU cloud environment, use simple exponential smoothing (SES). The objective is to proactively choose a node that, given its anticipated resource demand, is anticipated to be underutilized [48].The key steps for the implementation of the method:
- Candidate collection:The algorithm iterates through a set of eligible nodes and collects each node along with its current number of linked VMs. Each node’s current value serves as an initial forecast since historical data or a previous forecast may not be available.
- Forecast update:For each candidate node, the forecast is updated using the SES formula:forecast = α × current Value + (1 − α) × previous ForecastIn this simplified implementation, the forecast is initialized with the current observation.
- Thresholding:A threshold is defined (e.g., 10 linked VMs) to distinguish underutilized nodes from acceptable ones. Nodes with a forecast below this threshold are considered underutilized.
- Node selection:
- ○
- If there are underutilized nodes, the algorithm selects the node with the smallest forecasted value.
- ○
- If no underutilized node exists, it selects from the acceptable nodes based on the minimum forecasted load.
- ○
- If no candidate nodes exist or if no node has any linked VMs, a fallback selection strategy (e.g., FCFS) is used.
- B.
- Auto-regressive integrated moving average: Converts the IQR-based node selection method into one that leverages a time series forecasting model (ARIMA) to predict future resource usage (number of linked VMs) for each candidate node. The idea is to use historical data for each node to forecast its next time-step value, then apply a similar thresholding approach (using forecasted values) to identify underutilized or acceptable nodes [49].The key Steps for the implementation of this method:
- ○
- Data collection and forecasting: For each candidate node, the algorithm retrieves its historical time series of linked VMs. An ARIMA model is applied to predict the next value for the number of linked VMs. If sufficient historical data are unavailable, it falls back to using the current observed value.
- ○
- Threshold computation: The forecasted values for all candidate nodes are sorted, and the first quartile (Q1) and third quartile (Q3) are computed. The interquartile range (IQR) is used to derive a lower threshold and an upper threshold (using the conventional 1.5 X QR rule).
- ○
- Candidate filtering: Nodes with forecasted values below the lower threshold are classified as underutilized. Nodes with forecasted values within the threshold are acceptable. Nodes with forecasted values above the upper threshold are considered overutilized and are not selected.
- ○
- Selection: Preference is given to underutilized nodes (lowest forecasted load), and if none are available, then acceptable nodes are considered. If no node meets the criteria, a fallback strategy (such as FCFS) is used.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qadir, Z.; Le, K.N.; Saeed, N.; Munawar, H.S. Towards 6G Internet of Things: Recent advances, use cases, and open challenges. ICT Express 2022, 1, 1–17. [Google Scholar]
- Guo, F.; Yu, F.R.; Zhang, H.; Li, X.; Ji, H.; Leung, V.C. Enabling massive IoT toward 6G: A comprehensive survey. IEEE Internet Things J. 2021, 8, 11891–11915. [Google Scholar] [CrossRef]
- Faizan, Q. Enhancing QOS Performance of the 5G Network by Characterizing Mm-Wave Channel and Optimizing Interference Cancellation Scheme/Faizan Qamar; University of Malaya: Kuala Lumpur, Malaysia, 2019. [Google Scholar]
- Bani-Bakr, A.; Dimyati, K.; Hindia, M.N.; Wong, W.R.; Izam, T.F.T.M.N. Joint successful transmission probability, delay, and energy efficiency caching optimization in fog radio access network. Electronics 2021, 10, 1847. [Google Scholar] [CrossRef]
- Abdulsaheb, J.A.; Kadhim, D.J. Robot Path Planning in Unknown Environments with Multi-Objectives Using an Improved COOT Optimization Algorithm. Int. J. Intell. Eng. Syst. 2022, 15, 548–565. [Google Scholar]
- Chen, S.; Liang, Y.-C.; Sun, S.; Kang, S.; Cheng, W.; Peng, M. Vision, requirements, and technology trend of 6G: How to tackle the challenges of system coverage, capacity, user data-rate and movement speed. IEEE Wirel. Commun. 2020, 27, 218–228. [Google Scholar]
- Jabbar, S.Q.; Kadhim, D.J.; Li, Y. Developing a Video Buffer Framework for Video Streaming in Cellular Networks. Wirel. Commun. Mob. Comput. 2018, 2018, 6584845. [Google Scholar]
- Jaber, Z.H.; Kadhim, D.J.; Al-Araji, A.S. Medium access control protocol design for wireless communications and networks review. Int. J. Electr. Comput. Eng. (IJECE) 2022, 12, 1711–1723. [Google Scholar]
- Hindia, M.; Qamar, F.; Majed, M.B.; Abd Rahman, T.; Amiri, I.S. Enabling remote-control for the power sub stations over LTE-A networks. Telecommun. Syst. 2019, 70, 37–53. [Google Scholar]
- Hasan, M.Y.; Kadhim, D.J. A new smart approach of an efficient energy consumption management by using a machine-learning technique. Indones. J. Electr. Eng. Comput. Sci. 2022, 25, 68–78. [Google Scholar]
- Chih-Lin, I.; Rowell, C.; Han, S.H.; Xu, Z.; Li, G.; Pan, Z. Toward green and soft: A 5G perspective. IEEE Commun. Mag. 2014, 52, 66–73. [Google Scholar]
- Lin, Y.; Shao, L.; Zhu, Z.; Wang, Q.; Sabhikhi, R.K. Wireless network cloud: Architecture and system requirements. IBM J. Res. Dev. 2010, 54, 4:1–4:12. [Google Scholar] [CrossRef]
- Gao, Z.; Zhang, J.; Yan, S.; Xiao, Y.; Simeonidou, D.; Ji, Y. Deep Reinforcement Learning for BBU Placement and Routing in C-RAN. In Proceedings of the 2019 Optical Fiber Communications Conference and Exhibition (OFC), San Diego, CA, USA, 3–7 March 2019; p. 18618440. [Google Scholar]
- Li, Y.; Bhopalwala, M.; Das, S.; Yu, J.; Mo, W.; Ruffini, M.; Kilper, D.C. Joint Optimization of BBU Pool Allocation and Selection for C-RAN Networks. In Proceedings of the 2018 Optical Fiber Communications Conference and Exposition (OFC), San Diego, CA, USA, 11–15 March 2018; p. 17855949. [Google Scholar]
- Pizzinat, A.; Chanclou, P.; Saliou, F.; Diallo, T. Things You Should Know About Fronthaul. J. Light. Technol. 2015, 33, 1077–1083. [Google Scholar] [CrossRef]
- Ismail, S.F.; Kadhim, D.J. Towards 6G Technology: Insights into Resource Management for Cloud RAN Deployment. IoT 2024, 5, 409–448. [Google Scholar] [CrossRef]
- Zhang, Y.; Budzisz, L.; Meo, M.; Conte, A.; Haratcherev, I.; Koutitas, G.; Tassiulas, L.; Marsan, M.A.; Lambert, S. An overview of energy-efficient base station management techniques. In Proceedings of the 2013 24th Tyrrhenian International Workshop on Digital Communications-Green ICT (TIWDC), Genoa, Italy, 23–25 September 2013; pp. 1–6. [Google Scholar]
- Ran, C.; Wang, S.H.; Wang, C. Optimal load balancing in cloud radio access networks. In Proceedings of the Wireless Communications and Networking Conference, WCNC, New Orleans, LA, USA, 9–12 March 2015; pp. 1006–1011. [Google Scholar]
- Debaillie, B.; Desset, C.; Louagie, F. A flexible and future-proof power model for cellular base stations. In Proceedings of the 2015 IEEE 81st Vehicular Technology Conference, VTC Spring, Scotland, UK, 11–14 May 2015; pp. 1–7. [Google Scholar]
- Checko, A.; Christiansen, H.L.; Yan, Y.; Scolari, L.; Kardaras, G.; Berger, M.S.; Dittmann, L. Cloud ran for mobile networks—A technology overview. IEEE Commun. Surv. Tutor. 2015, 17, 405–426. [Google Scholar] [CrossRef]
- Vaezi, M.; Zhang, Y. Cloud Mobile Networks; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Mahapatra, B.; Kumar, R.; Kumar, S.; Turuk, A.K. A Heterogeneous Load Balancing Approach in Centralized BBU-Pool of C-RAN Architecture. In Proceedings of the 2018 3rd International Conference for Convergence in Technology (I2CT), Pune, India, 6–8 April 2018; pp. 1–5. [Google Scholar]
- Yıldız, O.; Sokullu, R.I. Deep Q-Learning based resource allocation and load balancing in a mobile edge system serving different types of user requests. J. Electr. Eng. 2023, 74, 48–56. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Qian, M.; Wang, Y.; Zhou, Y.; Tian, L.; Shi, J. A super base station based centralized network architecture for 5g mobile communication systems. Digit. Commun. Netw. 2015, 1, 152–159. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Y.; Gong, C.; Wan, Y.; Cai, L.; Luo, Q. A study on virtual bs live migration—A seamless and lossless mechanism for virtual bs migration. In Proceedings of the Annual International Symposium on Personal, Indoor, and Mobile Radio Communications, PIMRC, London, UK, 8–11 September 2013; pp. 2803–2807. [Google Scholar]
- Beloglazov, A.; Buyya, R. Adaptive threshold-based approach for energy-efficient consolidation of virtual machines in cloud data centers. In Proceedings of the 8th International Workshop on Middleware for Grids, Clouds and e-Science, MCG 2010, Bangalore, India, 29 November–3 December 2010; pp. 4–10. [Google Scholar]
- Ferdouse, L.; Ejaz, W.; Anpalagan, A.; Khattak, A.M. Joint workload scheduling and bbu allocation in cloud-ran for 5g networks. In Proceedings of the Symposium on Applied Computing, Marrakech, Morocco, 3–7 April 2017; pp. 621–627. [Google Scholar]
- Schiller, E.; Ajayi, J.; Weber, S.; Braun, T.; Stiller, B. Toward a Live BBU Container Migration in Wireless Networks. IEEE Open J. Commun. Soc. 2021, 3, 301–321. [Google Scholar] [CrossRef]
- Satpathy, A.; Addya, S.K.; Turuk, A.K.; Majhi, B.; Sahoo, G. Crow search based virtual machine placement strategy in cloud data centers with live migration. Comput. Electr. Eng. 2018, 69, 334–350. [Google Scholar] [CrossRef]
- Sabella, D.; Rost, P.; Sheng, Y.; Pateromichelakis, E.; Salim, U.; Guitton-Ouhamou, P.; Girolamo, D.; Giuliani, G. Ran as a service challenges of designing a flexible ran architecture in a cloud-based heterogeneous mobile network. In Proceedings of the 2013 Future Network & Mobile Summit, Lisbon, Portugal, 3–5 July 2013; pp. 1–8. [Google Scholar]
- Sharma, N.K.; Sharma, P.; Guddeti, R.M. Energy efficient quality of service aware virtual machine migration in cloud computing. In Proceedings of the International Conference on Recent Advances in Information Technology, RAIT, Dhanbad, India, 15–17 March 2018; pp. 1–6. [Google Scholar]
- Melhem, S.B.; Agarwal, A.; Goel, N.; Zaman, M. Minimizing Biased VM Selection in Live VM Migration. In Proceedings of the 2017 3rd International Conference of Cloud Computing Technologies and Applications (CloudTech), Rabat, Morocco, 24–26 October 2017. [Google Scholar] [CrossRef]
- Beloglazov, A. Energy-Efficient Management of Virtual Machines in Data Centers for Cloud Computing. Ph.D. Theis, University of Melbourne, Melbourne, Australia, February 2013. [Google Scholar]
- He, K.; Li, Z.; Deng, D.; Chen, Y. Energy-efficient framework for virtual machine consolidation in cloud data centers. Chin. Commun. 2017, 14, 192–201. [Google Scholar] [CrossRef]
- Li, Z.; Wu, G. Optimizing VM Live Migration Strategy Based on Migration Time Cost Modeling. In Proceedings of the 2016 Symposium on Architectures for Networking and Communications Systems, Santa Clara, CA, USA, 17–18 March 2016; pp. 99–109. [Google Scholar]
- Razali, R.A.M.; Ab Rahman, R.; Zaini, N.; Samad, M. Virtual machine migration implementation in load balancing for Cloud computing. In Proceedings of the 2014 5th International Conference on Intelligent and Advanced Systems (ICIAS), Kuala Lumpur, Malaysia, 3–5 June 2014; pp. 1–4. [Google Scholar]
- Raghunath, B.R.; Annappa, B. Dynamic Resource Allocation Using Fuzzy Prediction System. In Proceedings of the 2018 3rd International Conference for Convergence in Technology (I2CT), Pune, India, 6–8 April 2018; pp. 1–6. [Google Scholar]
- Yang, G.; Zhang, W.J. Research of optimized resource allocation strategy based on Openstack. In Proceedings of the 2015 12th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 18–20 December 2015. [Google Scholar]
- Wang, C.; Cao, Y.; Zhang, Z.; Wang, W. Dual threshold adaptive dynamic migration strategy of virtual resources based on bbu pool. Electronics 2020, 9, 314. [Google Scholar] [CrossRef]
- Castane, G.G.; Nunez, A.; Carretero, J. iCanCloud: A brief architecture overview. In Proceedings of the 2012 10th IEEE International Symposium on Parallel and Distributed Processing with Applications, Madrid, Spain, 10–13 July 2012. [Google Scholar]
- Beloglazov, A.; Abawajy, J.; Buyya, R. Energy-aware resource allocation heuristics for efficient management of data centers for Cloud computing. Future Gener. Comput. Syst. 2012, 28, 755–768. [Google Scholar]
- Fu, X.; Zhou, C. Virtual machine selection and placement for dynamic consolidation in Cloud computing environment. Front. Comput. Sci. 2015, 9, 322–330. [Google Scholar]
- Song, Y.; Wang, H.; Li, Y.; Feng, B.; Sun, Y. Multi-Tiered On-Demand Resource Scheduling for VM-Based Data Center. In Proceedings of the 2009 9th IEEE/ACM International Symposium on Cluster Computing and the Grid, Shanghai, China, 18–21 May 2009; pp. 148–155. [Google Scholar] [CrossRef]
- Li, Y.; Hu, X.; Wang, F. A robust statistical framework for anomaly detection in sensor networks using median absolute deviation. Sensors 2020, 20, 1739. [Google Scholar]
- Feng, W.; Qiao, M.; Li, X. An IoT-based anomaly detection method using interquartile range and K-means clustering for smart manufacturing. Sensors 2020, 20, 4356. [Google Scholar]
- Wang, X.; Zhang, Y.; Li, Q. A Load Ratio-Based Dynamic Scheduling Algorithm for Cloud Computing Environments. IEEE Access 2021, 9, 15012–15025. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning Forecasting Methods: Concerns and Ways Forward. PLoS ONE 2018, 13, e0194889. [Google Scholar]
- Benvenuto, D.; Giovanetti, M.; Vassallo, L.; Angeletti, S.; Ciccozzi, M. Application of the ARIMA Model on the COVID-2019 Epidemic Dataset. Data Brief 2020, 29, 105340. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terminology and Parameters | Meaning |
|---|---|
| Over_load_Host | Overload compute node |
| C_N_i[CPU/Mem] util | The utilization of the resources; CPU or memory for a compute node |
| DCPU/DMem | The distinction between the upper threshold and overflow resource utilization |
| C_N_i_pre[CPU/Mem]util | The prediction of resource utilization; CPU or memory for a compute node |
| VM k_[CPU/Mem] | CPU or memory utilization of the VMk |
| VM k-[DCPU/DMem] | Difference between VMk_[CPU/Mem] and DCPU/DMem |
| VM_to_migrate | Selected VM to be migrated from overload host |
| Parameter | Value | Unit |
|---|---|---|
| Number of BBU nodes in each compute node | 150 | - |
| Number of compute node | 2 | - |
| CPU capacity of the host | 2000 and 4000 | MIPS |
| Memory size of the host | 4096 and 6144 | MB |
| Number of VMs in each compute node | 450 | - |
| CPU capacity of the virtual machine | 1000, 2000 and 3000 | MIPS |
| Memory size of the virtual machine | 256, 512 and 1024 | MB |
| Number of users | 1500 | - |
| Metric | Kalman Filter Model | DQN Model |
|---|---|---|
| CPU Utilization (%) | 82.5 | 88.7 |
| Memory Utilization (%) | 79.2 | 85.6 |
| Energy Consumption (kWh) | 250 | 210 |
| Number of Migrations | 180 | 130 |
| Aspect | Statistical Methods (MAD, LR, and IQR) | DQN |
| Data Basis | Historical snapshot data | Real-time and historical combined data |
| Adaptability | Static thresholds; require periodic updates | Continuously adapts through learning |
| Multivariate Analysis | Typically univariate (e.g., VM count) | Incorporates multiple performance metrics |
| Decision Proactivity | Reactive; based on past distributions | Proactive; forecasts future trends |
| Complexity | Low computational complexity | Higher complexity; requires training time |
| Scalability | May need reconfiguration with new parameters | Naturally scales with high-dimensional data |
| Aspect | DQN | Time Series Methods (ARIMA and SES) |
|---|---|---|
| Energy Consumption | Learns optimal policies to reduce energy usage and balance loads. | ARIMA works well in stable settings; SES adapts to short-term changes but struggles with sudden spikes. |
| Migration Time | Optimizes timing for faster and more efficient migrations. | Forecast-based migration can help, but errors may delay migrations. |
| Load Variance | Dynamically balances workload, reducing resource hotspots. | Predicts future loads but lacks real-time adaptation. |
| Number of Migrations | Minimizes unnecessary migrations, improving system stability. | Forecasting helps, but inaccurate predictions may cause excessive migrations. |
| Computational Overhead and Implementation Complexity | Requires more processing power for training but offers long-term benefits. | Less resource-intensive but lacks adaptability. |
| Decision Stability and Robustness | Learns from experience and adapts, ensuring long-term stability. | Works well in stable environments but struggles with sudden demand changes. |
| Security | Can be enhanced with reinforcement learning-based anomaly detection for secure migrations. | Lacks built-in security features; relies on predefined patterns, making it vulnerable to unpredictable threats. |
| Scalability | Adapts to high-dimensional data and large cloud infrastructures efficiently. | Requires re-tuning when scaling to larger environments. |
| Adaptability to Dynamic Environments | Continuously learns and updates migration strategies in real-time. | Static thresholds or pre-defined patterns may not adjust well to sudden demand shifts. |
| Implementation Complexity | More complex due to deep learning models but highly effective. | Easier to implement but may require frequent adjustments. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ismail, S.F.; Kadhim, D.J. Adaptive BBU Migration Based on Deep Q-Learning for Cloud Radio Access Network. Appl. Sci. 2025, 15, 3494. https://doi.org/10.3390/app15073494
Ismail SF, Kadhim DJ. Adaptive BBU Migration Based on Deep Q-Learning for Cloud Radio Access Network. Applied Sciences. 2025; 15(7):3494. https://doi.org/10.3390/app15073494
Chicago/Turabian StyleIsmail, Sura F., and Dheyaa Jasim Kadhim. 2025. "Adaptive BBU Migration Based on Deep Q-Learning for Cloud Radio Access Network" Applied Sciences 15, no. 7: 3494. https://doi.org/10.3390/app15073494
APA StyleIsmail, S. F., & Kadhim, D. J. (2025). Adaptive BBU Migration Based on Deep Q-Learning for Cloud Radio Access Network. Applied Sciences, 15(7), 3494. https://doi.org/10.3390/app15073494