Abstract
This paper presents the development of a robotic workstation that integrates a collaborative robot as an assistant, leveraging advanced computer vision techniques to enhance human–robot interaction. The system employs state-of-the-art computer vision models, YOLOv7 and YOLOv8, for precise tool detection and gesture recognition, enabling the robot to seamlessly interpret operator commands and hand over tools based on gestural cues. The primary objective is to facilitate intuitive, non-verbal control of the robot, improving collaboration between human operators and robots in dynamic work environments. The results show that this approach enhances the efficiency and reliability of human–robot cooperation, particularly in manufacturing settings, by streamlining tasks and boosting productivity. By integrating real-time computer vision into the robot’s decision-making process, the system demonstrates heightened adaptability and responsiveness, creating the way for more natural and effective human–robot collaboration in industrial contexts.
1. Introduction
Since the beginning of the first industrial revolution, the industry has experienced continuous waves of innovation [1]. In the current era of Industry 4.0, digitization and the application of Information and Communication Technologies (ICT) are driving the development of intelligent manufacturing systems and smart factories, significantly enhancing operational efficiency [2,3]. A key component of this transformation is the deployment of collaborative robots (also known as cobots), which are designed to facilitate safe and effective human–robot interaction [4]. These robots can be programmed using a variety of methods, including manual guidance, to enable smooth and seamless collaboration. Meanwhile, computer vision technology has empowered machines to process and interpret visual information, revolutionizing fields such as healthcare and automotive manufacturing. The integration of machine vision with collaborative robots further enhances efficiency and adaptability in production environments [5].
While industrial robots have significantly contributed to automation and productivity, they can pose potential risks to operators if safety measures are not adequately implemented. These safety concerns have been partially addressed through the development of cobots. Cobots are designed to enable safe interaction and communication between human operators and other robots within shared work environments where close human–robot proximity is common [6]. The safety features of collaborative robots include the use of lightweight construction materials, rounded edges, and inherent limitations on speed and force, which are enforced through sensors or specialized software to ensure safe operation [7]. However, it is important to note that these inherent limitations in speed and force may restrict their effectiveness in applications that require high-speed or high-capacity processing.
Industrial robots can be programmed using several methods, with the most common approaches including offline programming, teach pendant programming, and manual robot guidance [8]. Offline programming involves configuring the robot’s workspace and developing its control program on a computer, allowing for detailed planning and simulation before deployment. Teach pendant programming utilizes a handheld device to remotely control and program the robot, providing a user-friendly interface for direct input. Manual robot guidance, on the other hand, involves the programmer physically guiding the robot through the desired motions, during which the robot records the path, tasks, and end positions. This method is particularly well-suited for collaborative robots, where seamless cooperation between the operator and the robot is essential for effective task execution.
Alternatively, computer vision represents a cutting-edge area of modern technology, fundamentally transforming human interaction with the world by enabling machines to interpret and comprehend visual information [9,10]. As an interdisciplinary field, it merges artificial intelligence with advanced image processing techniques to replicate—and in some cases, exceed—human visual perception. Through computer vision, machines are capable of recognizing patterns, identifying objects, and extracting meaningful insights from images and videos, driving innovation across diverse sectors such as healthcare, automotive, entertainment, and security [11,12].
The integration of machine vision with cobots offers significant opportunities for various industries. By combining these technologies, companies can enhance production efficiency and flexibility, optimizing processes and improving overall operational capabilities [13]. This study focuses on developing a robotic workstation equipped with a collaborative robot capable of supplying tools to a human operator by detecting them through a camera and interpreting operator gestures.
The main contributions of the work can be summarized as follows:
- Design and development of a robotic workplace utilizing a two-armed collaborative robot, which distinguishes it from other similar robotic systems.
- Integration of custom-made work tools designed to the specific needs of the robotic application, ensuring safe and efficient collaboration between the robot and human operator.
- End-to-end approach from workplace design to the selection of appropriate work tools, followed by production and testing, providing a comprehensive solution not commonly seen in other studies.
- Use of state-of-the-art algorithms for object detection, enhancing the system’s accuracy and performance.
- Contribution to the field by creating synthetic datasets for object detection, addressing the challenges of limited tools available.
While many aspects of this study align with existing robotic workplace implementations, the key distinctions lie in the use of a two-armed collaborative robot, the integration of custom-designed work tools, and the overall complexity of the proposed solution. While our approach integrates existing technologies such as YOLOv7 and YOLOv8, the novelty lies in the specific way these components are combined and optimized for real-time robot control. Unlike previous studies that focus on either object detection or gesture recognition independently, our method seamlessly integrates these technologies into a unified framework, enabling intuitive and efficient robot interaction. The system is designed to be robust to variations in lighting, occlusion, and hand positioning—challenges that existing solutions often struggle with.
2. Related Work
In the field of industrial automation, cobots represent a significant innovation, transforming traditional robotic workplaces by enabling close cooperation between humans and machines. Unlike conventional industrial robots, which are typically confined to cages or isolated work cells, cobots are specifically designed to operate in shared spaces with human operators, allowing for seamless interaction and collaboration. To ensure safety in these environments, organizations such as the International Organization for Standardization (ISO) have established specific rules and guidelines. The ISO/TS 15066 technical specification provides a framework for maintaining safety standards for collaborative industrial robots [14].
To protect human operators, cobots are equipped with specialized safety features, such as sensors that monitor speed and force to prevent accidents. Additionally, they are constructed with lightweight materials and have rounded edges to minimize the risk of injury in the event of unintended contact with obstacles [15].
The maximum payload capacity and operational speed of cobots vary significantly depending on the specific model and manufacturer. Typically, cobots are designed to manage payloads ranging from a few kilograms up to several tens of kilograms. Similarly, other parameters, such as maximum reach and physical dimensions, are also dependent on the manufacturer, the specific robot model, and the type of end effector employed [15,16,17,18].
In recent years, collaborative robots have gained significant popularity, primarily due to their ability to work alongside human operators without the need for safety enclosures. Human–Robot Collaboration (HRC) can be classified into three distinct levels: coexistence, cooperation, and collaboration [19], as illustrated in Figure 1. These levels are directly related to the nature of interaction between the human worker and the robot within their respective workspaces.
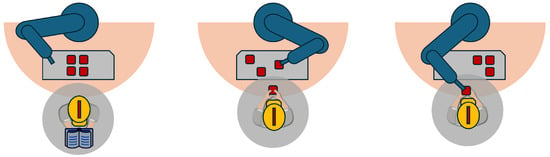
Figure 1.
Types of HRC: (left) coexistence, (middle) cooperation, and (right) collaboration.
Coexistence involves a human and a robot working in a partially or completely shared space without pursuing common goals; they operate independently within the same environment. In cooperation, the human and robot share a common goal while working in a partially or completely shared space, coordinating their efforts to achieve the desired outcome. The highest level, collaboration, occurs when both the human and robot work simultaneously on a shared object within a shared space, requiring close synchronization and direct interaction to complete the task effectively.
In Table 1, the various types of HRC are categorized based on different shared attributes.

Table 1.
Classification of different types of HRC based on various shared attributes.
HRC has generated considerable interest in research. Effective collaboration between humans and robots can alleviate workers from strenuous tasks if efficient communication channels are established between them. These channels rely on communication methods that are intuitive, unambiguous, and quickly executable for human operators. Multimodal intuitive programming enables robots to be programmed without the need for knowledge of programming languages or expertise in programming. Types of multimodal robot control include gesture-based control, voice command control, and control using haptic gloves [20,21].
Collaborative robotics has advanced considerably in recent years, with significant emphasis on enhancing human safety, increasing payload capacity, and improving mobility and flexibility. Leading companies in this sector, such as Universal Robots, Rethink Robotics, ABB Inc. Robotics, KUKA Robotics, and Omron, among others, continue to drive innovation in this rapidly evolving field. Ongoing developments in safety systems, programming interfaces, and application areas are making collaborative robots more accessible and versatile, thereby expanding their potential use in various industries where close human–robot interaction is essential [22].
Lastly, several challenges remain unaddressed. This work specifically targets three key gaps in the literature. First, real-time visual perception is not yet fully leveraged for intuitive and efficient robot control in dynamic environments. To address this, a vision-based control method is proposed, allowing seamless human–robot interaction. Second, precise object handling in collaborative settings remains a challenge, particularly in determining accurate pickup positions. This issue is addressed by introducing a method that utilizes a tool detection algorithm to improve the robot’s grasping accuracy. Third, while gesture-based control has been explored, its integration into collaborative robotic systems for enhanced adaptability and usability is still underdeveloped. This work presents a robust hand gesture recognition approach that improves natural and intuitive human–robot interaction. By filling these gaps, the proposed methods contribute to advancing the field of collaborative robotics, improving efficiency, precision, and user experience in human–robot collaboration.
2.1. Devices for Capturing Visual Inputs
Technical devices used for data collection can be classified into two main categories. The first category encompasses non-contact devices, such as RGBD (depth D and color RGB) cameras and Light Detection and Ranging (LIDAR) systems. The second category includes contact devices, such as sensor gloves [23].
Popular video cameras, such as webcams and camera modules for platforms like Arduino, are well-suited for various applications. Research discussed in [24,25,26] explores the use of these cameras for hand gesture recognition. A notable variant of the conventional camera is the RGBD camera, which differs by including a depth sensor, thereby capturing both color and depth information.
Another popular choice is depth sensor. It can capture depth information in addition to color or 2D image data. It measures the distance between the sensor and objects within the scene, enabling the generation of a three-dimensional representation of the environment. There are several types of depth sensors [27,28,29]:
- Structured light depth sensors project a light pattern onto the scene and analyze the distortion of the pattern to compute depth information.
- Stereo depth vision sensors utilize two or more cameras with fixed distances between them. These sensors calculate depth by comparing discrepancies between corresponding points in the images.
- Ultrasonic depth sensors can measure distance using sound waves and are particularly useful in applications where other methods may be impractical, such as in measuring liquid levels.
- Time-of-Flight (ToF) depth sensors emit light or laser pulses and measure the time it takes for the light to return to the sensor, thereby determining the distance to the objects in the scene.
In paper [30], the authors employed devices from Microsoft and Leap Motion to capture gestures. The Microsoft Kinect RGBD camera facilitated the recognition of body gestures, while hand gestures were processed using the Leap Motion sensor. The Leap Motion sensor provided precise 3D tracking of hands and fingers through the use of cameras and infrared sensors, making it suitable for applications in virtual reality, gaming, and 3D modeling due to its ability to enable intuitive and natural interactions. The paper proposed a method to streamline the programming of industrial robots by utilizing visual sensors to detect human movements. The authors created a dictionary of body and hand gestures that allows the robot to execute various directional movements. An application was developed on the robot to translate these gestures into corresponding movements. This method was integrated within an open communication architecture based on ROS. Additionally, the Kinect RGBD camera was also utilized by the authors in papers [31,32] for gesture recording.
Another applicable technology is LiDAR, a remote sensing technique that employs lasers to measure distances and produce high-resolution three-dimensional maps of the environment. LiDAR systems function by emitting laser pulses and measuring the time it takes for these pulses to return after reflecting off objects, thus enabling the generation of detailed and precise topographic data. LiDAR technology is utilized across various fields, including geography, geology, archaeology, autonomous vehicles, forestry, and urban planning [33,34]. In paper [35], the authors investigated two control methods, i.e., voice commands and visual pointing, to navigate a robot to a desired position. The use of pointing gestures is noted to be a more intuitive and natural approach compared to voice commands, as it requires only the user to indicate the target location without issuing a verbal command. However, practical application of pointing gestures presents two significant limitations. First, gesture recognition often involves complex image processing, leading to substantial computational demands. Second, the accuracy of pointing gestures can be insufficient, potentially causing the robot to navigate to an incorrect location. To address these issues, the authors proposed a hybrid control method, combining voice commands with pointing gestures, which they termed Voice-Guided Pointing Robot Navigation (VGPN). This method was successfully implemented and tested on the TurtleBot 2 robot platform, (Clearpath Robotics, by Rockwell Automation, Cambridge, ON, Canada) which was equipped with a 2D LiDAR and an RGBD camera. While the use of LiDAR for gesture recognition is relatively uncommon, the authors in article [36] proposed a system that leverages this technology. Their gesture recognition system comprises two primary components: body position estimation and gesture classification. The body position estimation module predicts the user’s body position based on LiDAR scans, while the gesture classification module utilizes these estimated positions to identify the user’s gestures. The position estimation system itself includes three key modules: 3D segmentation, 2D projection, and position estimation.
In contrast, contact devices such as the sensor glove are specialized input devices designed to enable users to control robots or robotic systems through hand gestures and movements. These gloves are equipped with various sensors and technologies that detect and interpret the user’s hand movements. Typically, glove-based systems require a wired connection and involve complex calibration and setup procedures [23,25,37,38]. In the study presented in [39], the authors utilized sensor gloves to control the ABB Yumi assistance robot mounted on a mobile wheelchair. The gloves are equipped with finger bend sensors as well as other sensors—3-axis gyroscope, 3-axis accelerometer, and a digital motion processor. The control unit responsible for processing signals from the gloves is an Arduino Mega microcontroller (Arduino, Monza, Italy).
The next device is the sensor band, which is designed to capture surface electromyography (EMG) signals from the muscles on the wearer’s arm. This device is typically fitted to the forearm or upper arm and is used to recognize hand gestures by analyzing EMG data [23,40].
Paper [41] proposed the use of the CSEM SwissRanger depth camera for visual input recognition and integrated voice commands, delivered through a Bluetooth headset, to enhance the control system. This combined approach was applied to the iRobot PackBot mobile robotic platform, enabling the robot to follow the operator, navigate through doors, and interact with the operator using an audiovisual control method.
Additionally, gestures can be detected using contact sensing methods, which involve sensors attached to devices such as sensor gloves or sensor strips. Inertial sensors, including gyroscopes and accelerometers, are integral components of MEMS (Micro-Electro-Mechanical Systems) technology. This technology is widely implemented in various consumer electronics, such as smartphones, tablets, gaming systems, TV remote controls, and toys.
In the study reported in [42], the authors employed a device that facilitates robot control through hand gestures. This sleeve monitors arm activity using both an EMG sensor and an inertial measurement unit (IMU). The sleeve interface is capable of recognizing 16 distinct gestures and determining the orientation of the forearm. Using this technology, the authors controlled the QinetiQ-NA Dragon Runner 20 tracked robot (QinetiQ North America, Waltham, MA USA), which is equipped with a four-degree-of-freedom manipulator.
2.2. Methods for Controlling Robots Using Visual Inputs
In the following chapter, methods utilizing video cameras or RGBD cameras will be explored, as these techniques are among the most widely adopted.
The VGPN method, which integrates voice commands and pointing gestures to guide a robot to a specified location, was proposed in [35]. This method was tested on the TurtleBot 2, a wheeled robot. Voice commands offer the advantage of being well-suited for simple and specific target locations, allowing the operator to maintain focus on other tasks without being constrained. However, voice commands can be less effective for complex navigational instructions. Pointing gestures, on the other hand, provide intuitive and natural control for the operator. Despite this, they can suffer from issues related to the accuracy of the operator’s pointing and the complexity of the computational processes involved. The VGPN prototype was implemented using ROS. To determine the operator’s pointing direction, two key points on the human body are utilized. These points are used to generate a vector that defines the direction of the point. In their work, the authors specifically employ a vector extending from the operator’s eye to their wrist to represent the pointing direction.
Static and dynamic gestures, including body poses and hand movements, are utilized to control the robot in paper [30]. Body gestures are recognized using an RGBD camera, while hand gestures are detected with a Leap Motion device. The recognized gestures are transmitted as messages within the ROS middleware. The defined gestures enable the operator to direct the robot’s movement in six directions: ±x, ±y, and ±z relative to a selected frame. For instance, an “up” gesture corresponds to movement in the +x direction, a “down” gesture for -x movement, and similar gestures are used for the other directions. Additionally, two specific static gestures are employed to stop the robot during operation. These gestures deactivate the robot’s motor controls, halting its movement.
The Kinect v2 RGBD camera (Microsoft Corporation, Redmond, WA, USA) was utilized in [31] to facilitate gesture recognition. Their application identified gestures based on the positioning of the operator’s arms and hands, focusing on static gestures. For voice control, the Kinect v2 was configured as the default microphone on the computer, with voice commands being converted into text and matched against a predefined dictionary. These recognized commands were then mapped to signals that control the ABB IRB 120 robot (ABB Inc. Robotics & Discrete Automation, Auburn Hills, MI, USA). The control program for the robot was developed using the RAPID language within the RobotStudio environment.
Additionally, the authors designed a user interface (GUI) to enhance the control of the industrial robot through hand movements in 3D space and voice commands. The GUI features a range of functions, including a help button, program information, a list of control methods, details on the current controlled axis, the robot’s position in x, y, and z axes, a list of available robots, a robot accuracy window, a speed selection window, and a start button. The interface also includes an “operator skeleton” field, which visually represents the operator’s movements and gestures, providing an intuitive control experience.
A novel control system for a mobile robot is presented in [32], which leverages dynamic gestures captured by the Microsoft Kinect 2 RGBD camera. The control system is divided into two main subsystems: turning and acceleration/braking. The turning subsystem enables the user to control the robot’s direction by holding and manipulating a virtual steering wheel. This interaction translates the rotation gestures into commands that adjust the robot’s wheel direction.
The acceleration and braking subsystem allows users to simulate vehicle controls such as shifting gears and adjusting speed. Gestures for shifting are used to command gear changes, while gestures for acceleration and braking modify the robot’s speed accordingly. This approach integrates intuitive, vehicle-like controls into the robot’s operation, providing a more natural and user-friendly interface for navigation.
In both robotic arm and wheeled robot control systems, RGBD cameras were employed, with their outputs subjected to further processing. The output from these RGBD cameras is typically handled using either proprietary software provided by the camera manufacturer or modified versions available from various programming communities. The coordinates of the operator’s joints are commonly utilized for controlling the robot, with specific gestures being inferred from these coordinates. Several software tools are available for tracking body and joint positions with RGBD cameras, including well-known platforms such as OpenPose, Kinect SDK, and RealSense SDK.
Controlling a robot via a camera necessitates advanced image processing techniques through computer vision algorithms. Image classification models, such as Convolutional Neural Networks (CNNs), enable the differentiation and categorization of objects within the visual field. For more precise tasks, object detection algorithms like YOLO (You Only Look Once) and YOLACT You Only Look At CoefficienTs not only identify objects but also accurately pinpoint their locations within the camera’s field of view. These technologies are fundamental for enhancing robotic control systems through visual inputs, and such algorithms are used in the system.
Lastly, recent advancements in deep learning have significantly improved gesture recognition accuracy through techniques such as hierarchical recurrent fusion [43], transformer-based architectures [44], and graph-based multimodal embeddings [45]. Studies on sign language translation have demonstrated the effectiveness of sequential learning and adaptive summarization in recognizing complex gestures [46]. These approaches highlight the potential of integrating such modeling techniques to enhance gesture-based control in robotic applications. By drawing from advancements in sign language recognition and applying them to robotic tool handling and gesture-based control, future research in that direction might explore more robust models capable of interpreting dynamic gestures in real time.
In the following chapter, the custom system that integrates these advanced image processing techniques for improved robot control and interaction is proposed.
3. Materials and Methods
The core of the work focuses on controlling a robot based on visual inputs from the operator, which led us to select cameras as the primary devices for capturing gestures. In the realm of non-contact gesture sensing, cameras offer an excellent solution for accurately and dynamically capturing the operator’s movements, eliminating the need for physical contact with sensors and allowing unrestricted movement within the workspace. Additionally, cameras are employed to detect objects on the work surface.
In the analysis of the current state of the problem (Section 2), it was identified that RGBD cameras are most frequently used for both gesture and object detection. These cameras, which combine color and depth imaging, provide comprehensive information that is particularly beneficial for tasks involving object recognition and localization in three-dimensional space. The objective of the design is to simplify the work environment and enhance the efficiency of managing the cobot. However, in the current approach, depth information acquired by the RGBD camera was not utilized for tool segmentation. The system exclusively relied on visual data from the RGB camera for detecting and recognizing tools. While depth data could potentially enhance segmentation accuracy, particularly in more complex or occluded scenarios, it was not incorporated into the present framework. Future work might explore the integration of depth information to improve segmentation and object recognition, particularly in environments where depth cues can aid in distinguishing objects in cluttered or dynamic scenes.
In the workplace, static gestures are employed to control the robot. The set of static gestures includes commands for initiating and halting processes (start/stop), confirming selections (OK), and representing quantities or numbers (ranging from 1 to 7). Compared to dynamic gestures or complex hand movements, static gestures are generally simpler and easier to learn, making them more accessible to a broader range of users, including those without extensive training in robotics or technology [47,48]. Moreover, static gestures offer clear and precise instructions, minimizing the risk of misinterpretation.
While the current approach focuses on static gestures, dynamic movements, such as continuous tool-handing trajectories, could provide additional contextual information and significantly enhance the model’s ability to interpret and predict human intentions more accurately. In real-world robotic applications, tool exchanges and other interactions often involve smooth, sequential motions rather than isolated static postures. Capturing these temporal dependencies could enable the system to better recognize patterns in human movement, anticipate actions, and facilitate more natural and responsive robotic assistance. Acknowledging these potential benefits, future work might explore methods to incorporate temporal information, enabling the model to generalize beyond static postures and improve its adaptability in complex, real-world environments where seamless human–robot collaboration is required.
As determining the distance between the hands and the camera is unnecessary for gesture recognition, a standard webcam will suffice for capturing hand gestures. To extract these gestures from the webcam feed, computer vision algorithms are required. The algorithm’s role will be to detect gestures from both hands, and for this purpose, a single-step YOLO detection algorithm has been chosen.
Object detection involves determining the precise position and orientation of objects relative to the robot, enabling the collaborative robot to manipulate these detected objects effectively. Implementing object detection in a workspace with a collaborative robot presents several challenges, including selecting the objects the robot will handle and positioning the camera correctly above the workspace to ensure comprehensive coverage of all objects. Algorithms like YOLACT and the latest versions of YOLO enable image segmentation, which can be utilized to calculate the orientation and size of detected objects on the work surface. Furthermore, the algorithm’s output can be used to determine the robot’s pick-up positions.
The workplace setup consists of a desk and two cameras: one focused on the desk for object detection and the other dedicated to capturing the operator’s gestures. A comparable setup was developed by the authors in [49], who utilized two collaborative robotic arms in their design. The layout of the robotic workspace, as modeled in the ABB RobotStudio simulation software (ver. 2021), is depicted in Figure 2 [50].
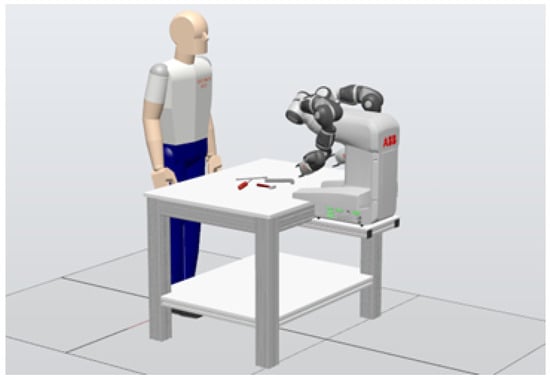
Figure 2.
Design of a robotic workplace in ABB RobotStudtio.
In the proposed configuration, the collaborative robot chosen is the dual-arm ABB Yumi (IRB 14000, ABB Inc. Robotics & Discrete Automation, Auburn Hills, MI, USA). The dimensions of the desk and the overall workspace are designed for easy relocation and to optimize space usage in the laboratory, as the tool-feeding application does not require extensive space.
Designing a robotic assistant for tool dispensing involves a complex solution that must be deconstructed into manageable components, which can be addressed individually before being integrated into a cohesive system. The design of the robotic workplace encompasses the following key elements:
- Detection of work tools on the worktable.
- Recognition of hand gestures.
- Integration of a collaborative robot and cameras within the robotic workplace.
After evaluating various factors, it was determined that selecting different types of hand tools for the workbench would be the most practical solution. The primary reason for this choice is the practicality and usability of a robotic hand tool-feeding application in real-world scenarios, particularly in production environments. Robotic feeding of hand tools to human operators can be especially useful on assembly lines, where it can help improve productivity by minimizing the time operators spend reaching or bending for tools.
Since a preexisting dataset of hand tools that met specific requirements could not be found, a custom dataset was created using the myGym tool [51]. The Generate Dataset tool within myGym allows for the creation of a synthetic dataset tailored for the custom training of vision models. A range of commonly used hand tools was selected, including combination pliers, a hammer, a flat screwdriver, a Phillips screwdriver, and various sizes of open-end wrenches (Figure 3). Each type of tool presents unique characteristics, shapes, purposes, and quantities, which increases the complexity of the robotic tool-feeding application. During the creation of the dataset, several key factors were varied, including the textures and colors of the objects, lighting conditions, and tool models. The dataset was generated multiple times with different color schemes for the tools and varying the number of images, significantly increasing the diversity and variability of the training data. This approach allowed for the simulation of a wide range of real-world visual scenarios, improving the model’s robustness and ability to recognize tools under diverse conditions. The variability in lighting and tool appearance was specifically aimed at enhancing the model’s performance in environments with fluctuating lighting, varying tool positions, and different background settings. Although the synthetic dataset provides a controlled environment for training, further testing in real-world conditions is necessary to fully assess the model’s applicability and robustness.

Figure 3.
Three-dimensional models of selected hand tools.
Finally, the ABB Yumi robot was utilized, mounted on a custom-made aluminum base. The initial setup of the workplace required several modifications. The first iteration involved mounting a camera directly on the robot, as depicted in Figure 4 left. However, this arrangement proved unstable. In the second version, both cameras were mounted on a stand positioned between the robot’s arms, as shown in Figure 4 middle. Although this setup was the most robust, it occasionally caused the robot to collide with the stand in certain positions.

Figure 4.
Various camera placements: (left camera attached directly to the robot, middle camera stand in front of the robot, and right camera stand behind the robot).
The third and final iteration involved mounting the cameras on a stand positioned behind the robot. As illustrated in Figure 4 right, the webcam for gesture detection is mounted similarly to the second version, while the RGBD camera is attached to an extendable profile. This profile is secured to the main frame using a custom-machined plastic spacer, which allows for the extension and retraction of the camera. The workspace is equipped with a workbench in front of the robot, where tool models are placed.
3.1. Hand Gesture Recognition
For the detection of static hand gestures, the Hand Gesture Recognition Image Dataset (HaGRID) is utilized [52]. This dataset is a comprehensive collection of images specifically designed for hand gesture recognition tasks, suitable for both image classification and detection purposes. The HaGRID dataset has a total size of 723 GB and includes 553,991 FullHD RGB images categorized into 18 different gesture classes. The dataset features 37,563 unique individuals, with participants ranging in age from 18 to 65 years.
The images in the dataset were primarily collected indoors under a variety of lighting conditions, including both artificial and natural light. Moreover, the dataset also comprises images captured in challenging scenarios, such as those facing directly toward or away from a window. To ensure diversity and robustness in gesture recognition, subjects were required to perform gestures at distances ranging from 0.5 to 4 m from the camera [52]. No additional modifications or techniques were employed beyond the original dataset. The only difference in the proposed approach is that for training, we specifically selected 13 static hand gestures from the original dataset.
Communication between the PC and the robot is facilitated through Ethernet/IP. Many collaborative robots come with Ethernet ports, enabling direct connection to a local network. This setup allows communication with computers or other devices using standard network protocols such as Ethernet/IP or TCP/IP, thereby supporting data exchange, control commands, and real-time monitoring. In this configuration, the router must be set up to assign static IP addresses to both the control PC and the robot, ensuring a stable and consistent connection. The arrangement of the connected devices is illustrated in Figure 5. A server is implemented on each robot arm, developed using the RAPID programming language and configured within ABB RobotStudio. Each robot arm is programmed with its own movement control program. On the client side, the control software is developed in Python 3.
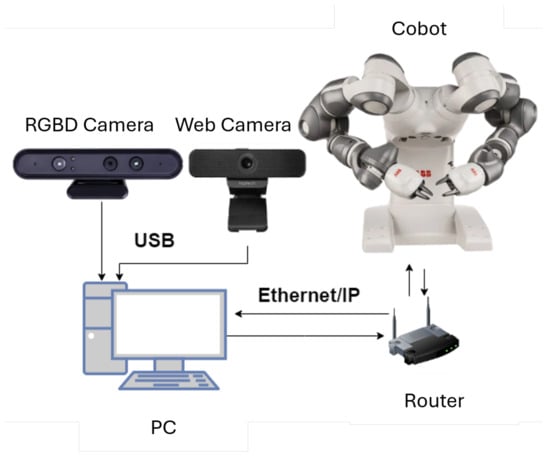
Figure 5.
Connection of cameras and the ABB Yumi robot with the PC for controlling and monitoring the workspace.
The RAPID programs in RobotStudio are responsible for managing command stack settings, specifying the robot’s IP address, and defining parameters for connection and command execution. The Python-based client software includes functions for calculating joint angles, managing robot parameters, and handling TCP/IP connections.
3.2. Determination of Object Position
The mathematical apparatus for determining the position of an object includes geometric transformations such as translation, rotation, and others. Geometric transformations in 3D space can be effectively represented using transformation matrices. These matrices allow the execution of linear geometric transformations of points in space, projecting them from the original position (P) to the new one (P′). The main advantage of transformation matrices is their compact representation in a homogeneous form. Homogeneous coordinates enable the expression of different types of transformations (translation, rotation, scaling, etc.) using a single matrix A
Translation matrices allow for the shifting of a point in 3D space by a translation vector , where , , and are the translation components along the X, Y, and Z axes, respectively.
A rotation matrix is used to rotate a point around an axis in 3D space.
The base transformation is a critical operation that allows the position and orientation of a point to be converted from one coordinate system to another. The key tool for performing a base transformation is the transformation matrix H10, also known as the coordinate transformation matrix. This matrix represents the relationship between two coordinate systems: the original coordinate system (0) from which the point is being transformed and the target coordinate system (1) to which the point is being transformed.
The matrix R10 is a rotation matrix that represents the rotation between coordinate systems. Similarly, the matrix T10 is a translation matrix that represents the displacement between coordinate systems [53,54]. The calculation of the position and orientation of point is, thus:
4. Experimental Results
In the design of the robotic workplace, two distinct computer vision models with varying training parameters were employed. Both models yielded suboptimal results, each exhibiting specific advantages and limitations. YOLOv8 demonstrated superior tool detection and greater robustness to varying tool rotation angles but was characterized by inaccurate segmentation of the detected tools. In contrast, YOLACT provided more precise segmentation of the tools but exhibited poor performance with respect to tool rotation angles. The issues encountered in calculating the take-off position of the tool and evaluating its rotation were likely due to an inadequate dataset size and suboptimal selection of the computer vision model. To provide a more comprehensive evaluation of the proposed approach, additional experimental results are presented in Appendix A and Appendix B.
To accurately assess the performance of various models, YOLACT and YOLOv8 were compared using a consistent dataset and identical initial conditions. YOLOv8 model was trained for 50 epochs. Due to constraints with YOLACT, training was conducted for 55 epochs. Initially, a qualitative evaluation of the trained models was performed. Each tool was rotated five times by approximately 45 degrees on the workbench, while the camera, providing input to the models, remained stationary. The ability of each model to detect tools in different orientations and the accuracy of the generated masks were qualitatively assessed. The process of tool rotation is illustrated in Figure 6.
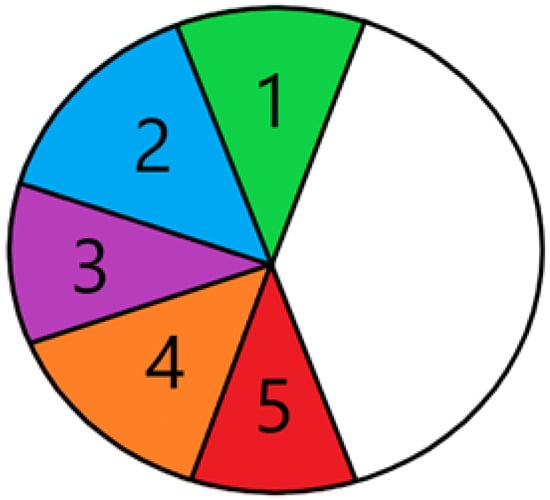
Figure 6.
Graphical representation of tool rotation angles during testing.
The qualitative assessment indicates that YOLOv8 outperforms other models for the specific application. YOLACT, in contrast, demonstrated significant limitations, particularly in its sensitivity to tool rotation on the workbench, leading to unreliable detection. Although YOLOv5 was initially trained, it exhibited notable issues with detecting a flat screwdriver, often misidentifying it as a Phillips screwdriver, and also performed poorly in image segmentation. The results suggest that with an adequately large and high-quality dataset, YOLOv8 could be trained to achieve reliable tool rotation calculations on the workbench. This improvement would enable the robot to consistently and accurately pick up and deliver the correctly oriented tool to the operator. A comparison of the segmentation results for the trained models is presented in Figure 7. Confusion matrix for the YOLOv8 model is shown in Figure 8 and hyperparameters used during training are shown in Table 2. The final decision to implement YOLOv8 was based on its superior performance compared to YOLOv5, YOLOv7, and YOLACT, as demonstrated in our evaluation. Among the tested models, YOLOv8 achieved the best results for object segmentation, as illustrated in Figure 7.
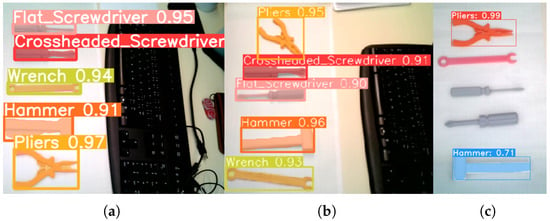
Figure 7.
Comparison of models for tool detection and segmentation: (a) YOLOv7, (b) YOLOv8, and (c) YOLACT.
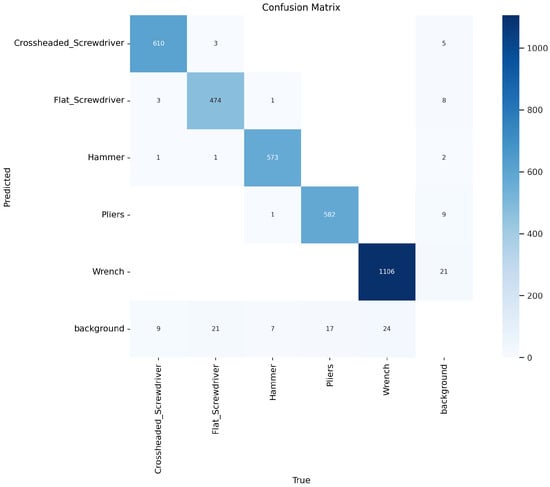
Figure 8.
Experimental results of working tool segmentation using the YOLOv8 model.
Table 2.
A summary of the YOLOv8 hyperparameters.
4.1. Gesture-Based Control Systems for Robotics
When designing gestures and gesture-based control for the system, several key criteria were considered:
- Gestures must be clear and easily distinguishable to ensure accurate interpretation without introducing confusion or ambiguity. This ensures that the system can reliably recognize and respond to the intended commands.
- Gestures should be straightforward and intuitive, even for users with minimal experience. Complex gestures might lead to errors or user frustration, so simplicity was a priority to enhance usability and reduce the likelihood of mistakes.
- The gestures should be comfortable and natural to perform, minimizing physical strain and fatigue. This consideration helps ensure that users can execute gestures repeatedly without discomfort, thereby supporting prolonged and effective interaction with the system. Furthermore, we acknowledge that our gesture selection could be improved by incorporating established gesture elicitation approaches or other existing datasets [49,55].
For the intended application, a total of 13 distinct gestures and their combinations are deemed sufficient. Given that there are 7 tools on the workbench, the gesture system must facilitate the selection of tools numbered 1 through 7. Predefined hand gestures have been established for the numbers 1 through 4. By combining these gestures, numbers 5 through 7 can be represented. For instance, raising one hand to signify the number 4 while simultaneously raising the other hand to signify the number 1 allows for the representation of the number 5. A comprehensive list of all gestures and their corresponding meanings is provided in Table 3.
Table 3.
Hand gestures and their use in robot control.
To train the gesture detection model, the annotations of the HaGRID dataset were first converted from the COCO format to the YOLO format. Following this conversion, the model training was carried out. The network exhibited excellent performance right from the initial training phase. The training process spanned approximately 6 days with 2 GTX 1080 Ti cards. The results of gesture detection using the trained YOLOv7 model can be observed in Figure 9 and Figure 10 with hyperparameters shown in Table 4. The decision to use YOLOv7 for gesture control instead of YOLOv8 was driven by availability constraints at the time of implementation. Specifically, when the gesture control system was developed, YOLOv7 was the most recent version accessible, preventing the use of YOLOv8 for this task. Although YOLOv8 was later trained as it became available, its performance was suboptimal due to the initial limitation of dataset size at that time. Only 20,000 images from the HaGRID dataset (approximately one-seventh of its full size) could be included, leading to significantly inferior outcomes compared to YOLOv7.

Figure 9.
Gesture detection results: selecting tool 2 (left) and stopping the process (right).
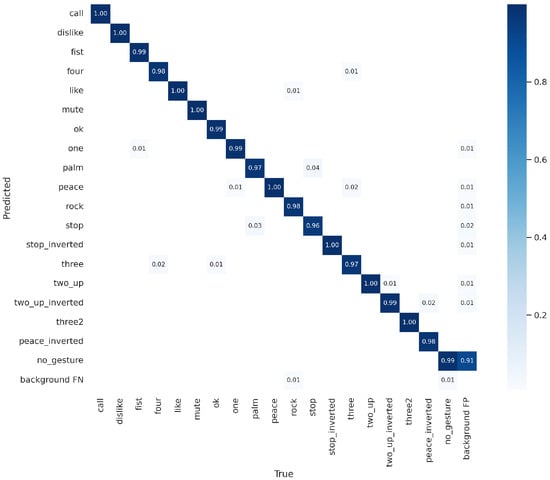
Figure 10.
Experimental results of hand gesture detection using the YOLOv7 model and HaGRID dataset.
Table 4.
A summary of the YOLOv7 hyperparameters.
4.2. Experimental Verification of the System
The initial practical tests at the robotic workplace were conducted using the YOLACT model for object detection. These tests began with simulations in the CoppeliaSim software (4.2), employing the Franka Emika Panda collaborative robot, which had been already preconfigured. To simulate a real-world scenario, the simulation environment was modified by integrating 3D tool models in DAE format, positioning a camera parallel to the work table, and adding a shelf model where the robot would place the tools during the simulation. The results of tool detection can be observed in Figure 11, and the complete simulated robotic workplace is depicted in Figure 12.
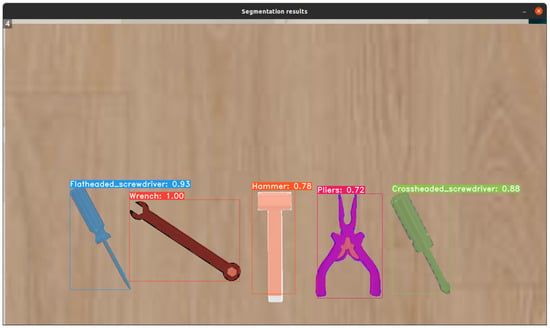
Figure 11.
Successful tool detection in CoppeliaSim.
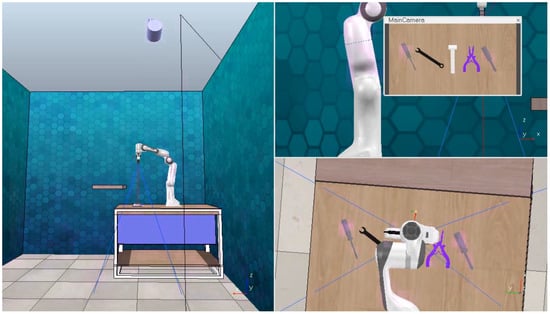
Figure 12.
Simulated workplace in CoppeliaSim.
Despite these preparations, the YOLACT model did not consistently achieve reliable tool detection, necessitating careful rotation of tools to improve accuracy. The objective of this simulation was to evaluate the feasibility of creating an accurate sampling position for the robot using the object detection algorithm. At this stage, operator gesture detection was not yet operational, so tools were selected manually by inputting corresponding numbers. The simulation was successful, leading us to proceed with testing in a real robotic workplace.
The tool feeding test at the physical workplace with the Franka Emika Panda collaborative robot was conducted in several phases. Unlike the simulation, where the camera was positioned parallel to the work table, in the physical setup, the camera was mounted directly on the robot. In the end, these experiments revealed the need for a more effective tool detection model, leading us to adopt the previously trained YOLOv8 model. Following these initial tests, the process advanced to the test phase using the ABB Yumi collaborative robot. Experimental testing with ABB Yumi is shown in Figure 13.

Figure 13.
Successful tool feeding test by ABB Yumi robot.
Next, after training the YOLOv7 model for gesture detection and integrating it into ROS 2, practical tests at the workplace were conducted. Figure 14 shows experimental results of object detection and tool recognition. Additionally, a GUI was created to visualize the list of detected tools, detect gestures, and recalculate the take-off position for the robot. In Figure 15, the individual elements of the graphical interface can be seen.
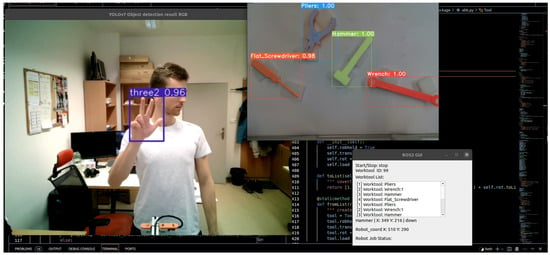
Figure 14.
PC screen displaying the graphical user interface with tool detection and gesture recognition.
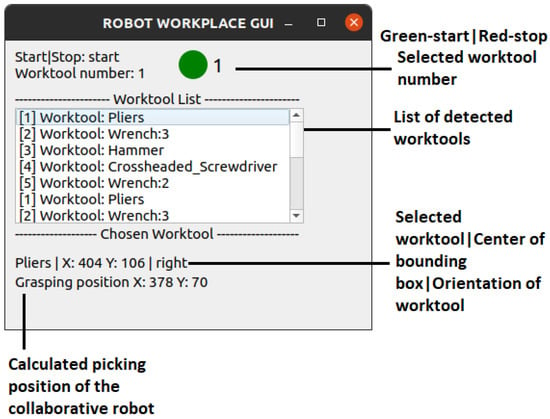
Figure 15.
Robotic workplace GUI.
Following the selection of a work tool through hand gestures, the robot calculates the tool’s orientation and grasping position. The orientation is determined from the segmentation mask of the detected tool, identifying the handle or gripping side. To enhance workflow efficiency, the robot presents the selected tool to the operator with the handle facing outward.
The final procedure for work tool feeding was as follows:
- Initially, the presence of work tools on the worktable is detected, and these work tools are arranged into a numbered list.
- Work tools are then selected from the list using gestures.
- The feeding process is started by a specific gesture.
- The selected work tool is then picked from the worktable by the robot.
- The work tool is oriented with its handle facing towards the operator.
- Handover of the work tool to the operator.
This scenario repeats until the feeding process is stopped by a stop gesture or until at least one work tool model remains on the table.
5. Discussion
This work successfully integrated tool detection, gesture recognition, and robotic control to create an efficient robotic workplace for feeding tools. The development began with generating a synthetic dataset of 150,000 images featuring various hand tools, which was crucial for training a robust computer vision algorithm. Initial challenges included adapting models such as YOLACT and YOLOv8 to detect tools accurately under diverse conditions. The switch to YOLOv8 proved effective in addressing issues with tool segmentation and rotation detection. Gesture recognition was seamlessly incorporated to allow the operator to control the robotic assistant intuitively. The final phase involved setting up the ABB Yumi robot in a workspace where the system could dynamically respond to operator inputs and handle tools with precision. Despite overcoming significant challenges, such as dataset creation and model training, the integrated system demonstrates significant potential for improving productivity and ergonomics in tool handling, showcasing the effectiveness of combining synthetic data, advanced vision models, and collaborative robotics in a real-world application.
The result of the first phase was multiple synthetic image datasets, a trained computer vision algorithm for tool detection, and a Python program integrated within ROS 2. The software solution consisted of approximately three nodes that communicated based on topics and a publisher/subscriber model. This program facilitated image segmentation and tool detection from RGBD images captured by the Intel RealSense camera. From the detection and segmentation results, the removal position for the robot was determined by locating the center of the bounding box of the selected tool, while tool rotation on the table was assessed using the tool’s mask. The custom-trained YOLOv8 model was employed for detection and segmentation, providing a comprehensive solution for tool handling in the robotic workspace.
The designed robotic workplace and control method reveal several limitations that need to be addressed for improved functionality and effectiveness:
- The ABB Yumi robot, with a maximum payload of 0.5 kg, imposes constraints on the type of tools it can handle. This limitation restricted the choice of tools used in the system to lighter models and impacted the use of real tools, as heavier or bulkier tools could not be accommodated by the robot’s grippers.
- The robotic workspace currently lacks a variety of gripping effectors, which limits the robot’s ability to handle different tool types and sizes effectively. The absence of adaptable or interchangeable end effectors could restrict the robot’s functionality in diverse operational scenarios.
- Due to the robot’s limited payload capacity, the system utilized synthetic models of tools rather than actual tools. This substitution may not fully capture the complexities and challenges associated with handling real-world tools, potentially affecting the accuracy and reliability of the tool detection and manipulation process.
- The current gesture-based control system requires the use of both hands to denote tool numbers 5 through 7. This requirement could complicate the gesture recognition process and may not be as intuitive or user-friendly as single-hand gestures, which could impact the efficiency and ease of use for operators.
- The method of mounting cameras in the current setup showed limited robustness and flexibility. The camera positioning needs to be improved to ensure stable and consistent image capture, which is crucial for accurate tool detection and gesture recognition.
- The articulated movement of the robot and the method for tool delivery to the operator require further optimization. Enhancements are needed to ensure smooth and precise tool handover, which is essential for effective operation in a real-world setting.
The use of a dual-armed collaborative robot introduced significant constraints in the implementation of the robotic workplace. These limitations, particularly related to the robot’s payload capacity and the fixed nature of the gripping effectors, impacted the overall design and functionality. Addressing these issues by exploring alternative robot models, enhancing the versatility of gripping tools, and improving the camera and gesture control systems could lead to more effective and practical solutions in future iterations of the robotic workplace.
The possibilities for improving the designed robotic workplace include several features that could enhance its functionality and user experience. Firstly, upgrading or customizing the grasping effectors of the ABB Yumi robot could significantly enhance its versatility and capability to handle a wider range of tools. Implementing adaptive or interchangeable end effectors could enable the robot to manage various tool types and sizes more effectively, addressing the current limitation related to the payload capacity and tool handling. By integrating QR codes onto tool models, the accuracy and reliability of tool detection could be improved. QR codes can provide unique identifiers for each tool, enabling the system to distinguish between different tools more effectively and reduce errors in tool identification and selection. This approach could complement existing image recognition algorithms and enhance overall tool handling efficiency. With the help of voice command functionality, the robot control system could offer a more intuitive and hands-free method of interacting with the robot. By integrating voice recognition technology, operators could issue commands to the robot without the need for physical gestures, potentially improving ease of use and operational efficiency. Finally, by implementing a sensor glove to detect hand gestures, a more precise and versatile method of controlling the robot could be provided. A sensor glove can capture a wide range of gestures with greater accuracy, allowing for more complex and nuanced control of the robot. This enhancement could address the current limitations related to gesture recognition and improve the overall interaction between the operator and the robotic system.
These improvements have the potential to address the existing limitations and enhance the functionality and usability of the robotic workplace. By exploring these options, future iterations of the robotic system could achieve greater flexibility, accuracy, and user satisfaction.
5.1. Comparison of Solutions
In this paper, a robotic tool feeding assistant is proposed using an ABB Yumi two-arm collaborative robot, an RGBD camera, and a web camera. The workplace was programmed in ROS 2, while the robot receives commands from the operator using static hand gestures captured via a web camera. The tools on the table were captured using an RGBD camera.
A similar solution was used in [56] with the help of a robotic workplace with a single-arm collaborative robot KUKA iiwa. The purpose of the robotic workplace was to feed tools and parts and also to hold the workpiece during assembly. The robot is controlled using static and dynamic gestures, while these gestures are recorded using five IMU sensors (Tech-MCS V3) mounted on the hands and torso of the operator’s body. The operator is also equipped with a UWB (ultra wideband) broadband tag. It ensures the sensing of the operator’s distance from the robot. The proposed solutions vary in the choice of collaborative robot, gesture sensing method, and tool detection capabilities. Results indicate that proposed implementation of gesture control, particularly in well-lit environments, offers a more intuitive and efficient interaction with the robot.
A similar solution was proposed in [57]. The authors proposed a robot control method using the same IMU sensors (Tech-MCS V3) mounted on the operator’s arms and torso as the authors in [56]. To capture finger and wrist movements, the operator wore a Myo armband sensor strip equipped with eight EMG sensors. The control scheme employed ten static and one dynamic gesture. The workspace served as both a platform for tool and part placement and a holding area for workpieces. Similarly, the findings suggest that the proposed robot control implementation is more efficient and intuitive in well-lit work environments.
Finally, a CyberGlove 2 and a Polhemus Liberty magnetic tracker to control a robot in a workspace similar to [56] was employed in [58]. The UC2017 dataset, presented in [58], contains static and dynamic hand gestures captured using the sensor glove. While glove-based control offers a wider range of gestures, suitable for complex tasks like food preparation, it limits the operator to one free hand, potentially hindering manual work.
5.2. Integration of QR Codes
Incorporating QR codes on work tools can significantly enhance the efficiency and accuracy of a robotic system in industrial applications. Computer vision algorithms are essential for performing key tasks such as detecting tool types, determining their orientation, and pinpointing their coordinates on the workbench. By integrating QR code detection into these algorithms, the ability to more quickly and reliably estimate the position, rotation, and identification of tools might be achieved, even in challenging environments with poor lighting conditions. QR codes offer a major advantage by encoding specific information that allows for immediate object recognition, reducing the dependence on visual features alone. This is particularly beneficial for distinguishing between tools that may appear similar to traditional object detection models. Each tool can be assigned a unique QR code, simplifying the recognition process. Moreover, QR code scanning is computationally less intensive than using deep learning models for object detection, which eases the load on the robot’s control system. Python’s extensive libraries, such as OpenCV, Pyzbar, and ZBar, are available to facilitate the efficient scanning of QR codes from RGB images. In theory, QR codes could serve as a secondary input channel, cross-validating the results of the object detection algorithm and thereby enhancing the overall system’s reliability and precision. However, one limitation is that QR codes are susceptible to damage from physical wear, oils, dirt, or frequent handling, which could hinder their functionality in industrial environments. This makes it crucial to balance the benefits of QR code integration with the practical challenges of ensuring their durability in demanding conditions.
5.3. Generalization
The ability of a deep learning model to generalize beyond its training data are crucial for real-world applications. In this study, the YOLOv8 model was trained on a specific set of work tools, including a combination spanner. While it performed well within this scope, its ability to distinguish similar but unseen tools, such as an adjustable pipe wrench, is limited. Without transfer learning or an expanded dataset, the model cannot reliably classify tools outside its training set. To improve generalization, incorporating a more diverse dataset with additional tool types, applying synthetic data generation, and leveraging data augmentation techniques can enhance robustness. Additionally, transfer learning from a larger dataset of industrial tools can improve adaptability with minimal additional training. Lastly, few-shot learning techniques could enable the model to recognize new tools with only a few annotated examples, reducing the need for extensive dataset expansion.
5.4. Future Work
The selection of YOLOv8 for the robotic system was primarily driven by its ability to balance accuracy, speed, and computational efficiency, which are critical factors for real-time robotic applications. In environments where rapid decision making is essential, YOLO-based models offer the advantage of high accuracy in object detection while maintaining the low processing latency required for real-time performance. In the proposed system, the gesture recognition latency is approximately 500 ms, ensuring timely and responsive interaction for the robotic application. This is particularly important in robotics, where systems must react quickly to dynamic environmental changes. Additionally, YOLO-based models are well-established in the field of computer vision and have proven effective in embedded systems, which makes them highly suitable for deployment in robotic workplaces.
Despite the advantages offered by YOLOv8, we also recognize the growing potential of transformer-based detectors, such as DETR [59], which have shown promise in recent research for handling complex object relationships and improving generalization across various tasks. Transformer models, due to their self-attention mechanism, can provide a more nuanced understanding of the spatial and contextual relationships between objects, which is particularly useful in scenarios where interactions between multiple objects or a deeper understanding of the scene is required. These models have been shown to outperform traditional CNN-based detectors in certain contexts, particularly in tasks that require more complex reasoning about object relationships and scene dynamics. Thus, while YOLOv8 is currently optimal for our application, the exploration of transformer-based detectors or newer YOLO models represents a promising approach for future research, where these models could be assessed for their applicability and potential performance benefits.
6. Conclusions
The primary goal of this research was to develop a robotic assistant, specifically the ABB Yumi collaborative robot, capable of autonomously managing the feeding of hand tools—an innovative application in collaborative robotics. To achieve this, state-of-the-art computer vision techniques were implemented, leveraging YOLOv7 and YOLOv8 algorithms for precise object detection and segmentation on the worktable. Initial experiments confirmed the system’s effectiveness in accurately identifying tools and determining their locations for robotic manipulation, leading to further refinements that improved both ergonomics and modularity.
Fully integrated within the ROS 2 framework, the system ensures seamless interaction and control. Its novelty lies in the fusion of advanced computer vision with collaborative robotics to perform complex tasks in dynamic environments. Through rigorous testing, the system has demonstrated reliable tool-feeding capabilities and operator gesture recognition, marking a significant advancement in intelligent robotic systems and paving the way for future innovations in human–robot collaboration.
Author Contributions
Conceptualization, B.M.; methodology, B.M.; software, B.M.; validation, P.K., J.K. (Júlia Kafková) and M.H.; writing—original draft preparation, J.K. (Júlia Kafková), P.K. and R.P.; writing—review and editing, J.K. (Jakub Krško) and M.M.; visualization, P.K.; supervision, M.H.; Funding acquisition, R.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research has been supported by the project APVV SK-IL-RD-23-0002: Advanced Localization Sensors and Techniques for Autonomous vehicles and Robots.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author(s).
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
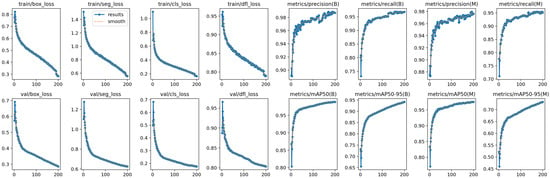
Figure A1.
Experimental results of YOLOv8 training.
Figure A1.
Experimental results of YOLOv8 training.
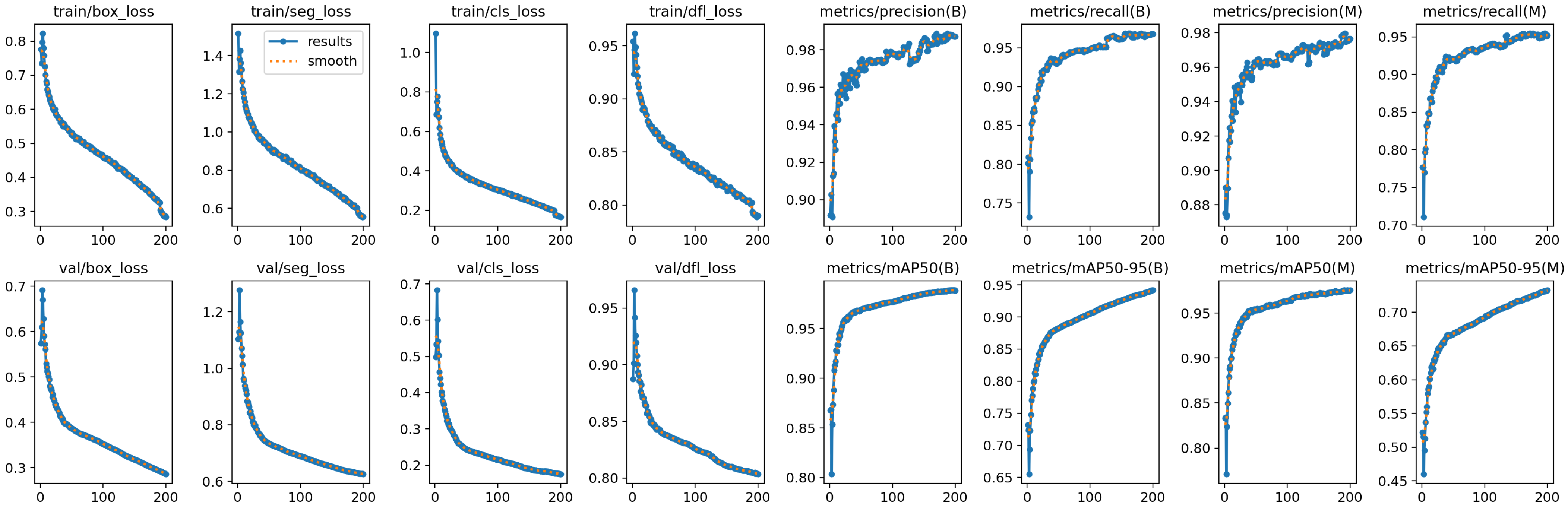
Table A1.
Evaluation of YOLOv8 metrics.
Table A1.
Evaluation of YOLOv8 metrics.
| Metrics | Value |
|---|---|
| Precision | 0.987 |
| Recall | 0.968 |
| mAP50 | 0.989 |
| mAP50-95 | 0.912 |
Appendix B
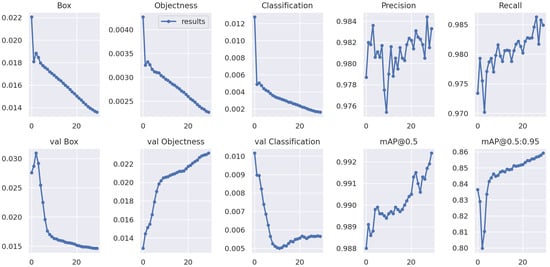
Figure A2.
Experimental results of YOLOv7 training.
Figure A2.
Experimental results of YOLOv7 training.
Table A2.
Evaluation of YOLOv7 metrics.
Table A2.
Evaluation of YOLOv7 metrics.
| Metrics | Value |
|---|---|
| Precision | 0.983 |
| Recall | 0.985 |
| mAP50 | 0.992 |
| mAP50-95 | 0.859 |
References
- Caruso, L. Digital innovation and the fourth industrial revolution: Epochal social changes? Ai Soc. 2018, 33, 379–392. [Google Scholar] [CrossRef]
- Castillo, J.F.; Ortiz, J.H.; Velásquez, M.F.D.; Saavedra, D.F. COBOTS in industry 4.0: Safe and efficient interaction. In Collaborative and Humanoid Robots; IntechOpen: London, UK, 2021; Volume 3. [Google Scholar]
- Liang, S.; Rajora, M.; Liu, X.; Yue, C.; Zou, P.; Wang, L. Intelligent manufacturing systems: A review. Int. J. Mech. Eng. Robot. Res. 2018, 7, 324–330. [Google Scholar] [CrossRef]
- Liu, L.; Guo, F.; Zou, Z.; Duffy, V.G. Application, development and future opportunities of collaborative robots (cobots) in manufacturing: A literature review. Int. J. Hum.—Comput. Interact. 2024, 40, 915–932. [Google Scholar] [CrossRef]
- Nuzzi, C.; Pasinetti, S.; Lancini, M.; Docchio, F.; Sansoni, G. Deep learning based machine vision: First steps towards a hand gesture recognition set up for collaborative robots. In Proceedings of the 2018 Workshop on Metrology for Industry 4.0 and IoT, Brescia, Italy, 16–18 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 28–33. [Google Scholar]
- Michaelis, J.E.; Siebert-Evenstone, A.; Shaffer, D.W.; Mutlu, B. Collaborative or simply uncaged? Understanding human-cobot interactions in automation. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–12. [Google Scholar]
- Bogue, R. Robots that interact with humans: A review of safety technologies and standards. Ind. Robot. Int. J. 2017, 44, 395–400. [Google Scholar] [CrossRef]
- Pan, Z.; Polden, J.; Larkin, N.; Van Duin, S.; Norrish, J. Recent progress on programming methods for industrial robots. Robot. Comput.-Integr. Manuf. 2012, 28, 87–94. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Bubeníková, E.; Halgaš, J. Application of image processing in intelligent transport systems. IFAC Proc. Vol. 2012, 45, 53–56. [Google Scholar] [CrossRef]
- Gao, J.; Yang, Y.; Lin, P.; Park, D.S. Computer vision in healthcare applications. J. Healthc. Eng. 2018, 2018, 5157020. [Google Scholar] [CrossRef] [PubMed]
- Bubeníková, E.; Franeková, M.; Holečko, P. Security increasing trends in intelligent transportation systems utilising modern image processing methods. In Proceedings of the Activities of Transport Telematics: 13th International Conference on Transport Systems Telematics, TST 2013, Katowice-Ustroń, Poland, 23–26 October 2013; Selected Papers 13. Springer: Berlin/Heidelberg, Germany, 2013; pp. 353–360. [Google Scholar]
- Tirmizi, A.; De Cat, B.; Janssen, K.; Pane, Y.; Leconte, P.; Witters, M. User-friendly programming of flexible assembly applications with collaborative robots. In Proceedings of the 2019 20th International Conference on Research and Education in Mechatronics (REM), Wels, Austria, 23–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- ISO/TS 15066; Robots and Robotic Devices—Collaborative Robots. ISO: Geneva, Switzerland, 2016.
- Rao, R. Cobots vs. Robots: Understanding the Key Differences and Applications, [Online] 5. 7 2023. Available online: https://www.wevolver.com/article/cobots-vs-robots-understanding-the-key-differences-and-applications (accessed on 29 February 2024).
- Arents, J.; Abolins, V.; Judvaitis, J.; Vismanis, O.; Oraby, A.; Ozols, K. Human–robot collaboration trends and safety aspects: A systematic review. J. Sens. Actuator Netw. 2021, 10, 48. [Google Scholar] [CrossRef]
- Bi, Z.M.; Luo, C.; Miao, Z.; Zhang, B.; Zhang, W.J.; Wang, L. Safety assurance mechanisms of collaborative robotic systems in manufacturing. Robot. Comput.-Integr. Manuf. 2021, 67, 102022. [Google Scholar] [CrossRef]
- Wang, L.; Liu, S.; Liu, H.; Wang, X.V. Overview of human–robot collaboration in manufacturing. In Proceedings of the 5th International Conference on the Industry 4.0 Model for Advanced Manufacturing: AMP 2020, Belgrade, Serbia, 1–4 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 15–58. [Google Scholar]
- Aaltonen, I.; Salmi, T.; Marstio, I. Refining levels of collaboration to support the design and evaluation of human–robot interaction in the manufacturing industry. Procedia CIRP 2018, 72, 93–98. [Google Scholar] [CrossRef]
- Liu, H.; Fang, T.; Zhou, T.; Wang, Y.; Wang, L. Deep learning-based multimodal control interface for human–robot collaboration. Procedia CIRP 2018, 72, 3–8. [Google Scholar] [CrossRef]
- Bright, T.; Adali, S.; Bright, G. Low-cost sensory glove for human–robot collaboration in advanced manufacturing systems. Robotics 2022, 11, 56. [Google Scholar] [CrossRef]
- Sherwani, F.; Asad, M.M.; Ibrahim, B.S.K.K. Collaborative robots and industrial revolution 4.0 (ir 4.0). In Proceedings of the 2020 International Conference on Emerging Trends in Smart Technologies (ICETST), Karachi, Pakistan, 26–27 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Liu, H.; Wang, L. Gesture recognition for human–robot collaboration: A review. Int. J. Ind. Ergon. 2018, 68, 355–367. [Google Scholar] [CrossRef]
- Dardas, N.H.; Georganas, N.D. Real-time hand gesture detection and recognition using bag-of-features and support vector machine techniques. IEEE Trans. Instrum. Meas. 2011, 60, 3592–3607. [Google Scholar] [CrossRef]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand gesture recognition based on computer vision: A review of techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef]
- Du, W.; Li, H. Vision based gesture recognition system with single camera. In Proceedings of the WCC 2000-ICSP 2000. 2000 5th International Conference on Signal Processing Proceedings. 16th World Computer Congress 2000, Beijing, China, 21–25 August 2000; IEEE: Piscataway, NJ, USA, 2000; Volume 2, pp. 1351–1357. [Google Scholar]
- Pinto, A.M.; Costa, P.; Moreira, A.P.; Rocha, L.F.; Veiga, G.; Moreira, E. Evaluation of depth sensors for robotic applications. In Proceedings of the 2015 IEEE International Conference on Autonomous Robot Systems and Competitions, Tomar, Portugal, 26–27 April 2023; IEEE: Piscataway, NJ, USA, 2015; pp. 139–143. [Google Scholar]
- Yim, H.; Kang, H.; Nguyen, T.D.; Choi, H.R. Electromagnetic Field & ToF Sensor Fusion for Advanced Perceptual Capability of Robots. IEEE Robot. Autom. Lett. 2024, 9, 4846–4853. [Google Scholar]
- Saleem, Z.; Gustafsson, F.; Furey, E.; McAfee, M.; Huq, S. A review of external sensors for human detection in a human robot collaborative environment. J. Intell. Manuf. 2024, 1–25. [Google Scholar] [CrossRef]
- Tsarouchi, P.; Athanasatos, A.; Makris, S.; Chatzigeorgiou, X.; Chryssolouris, G. High level robot programming using body and hand gestures. Procedia CIRP 2016, 55, 1–5. [Google Scholar] [CrossRef]
- Kaczmarek, W.; Panasiuk, J.; Borys, S.; Banach, P. Industrial robot control by means of gestures and voice commands in off-line and on-line mode. Sensors 2020, 20, 6358. [Google Scholar] [CrossRef]
- Zhou, D.; Shi, M.; Chao, F.; Lin, C.M.; Yang, L.; Shang, C.; Zhou, C. Use of human gestures for controlling a mobile robot via adaptive cmac network and fuzzy logic controller. Neurocomputing 2018, 282, 218–231. [Google Scholar] [CrossRef]
- Raj, T.; Hanim Hashim, F.; Baseri Huddin, A.; Ibrahim, M.F.; Hussain, A. A survey on LiDAR scanning mechanisms. Electronics 2020, 9, 741. [Google Scholar] [CrossRef]
- Chemweno, P.; Torn, R.J. Innovative safety zoning for collaborative robots utilizing Kinect and LiDAR sensory approaches. Procedia CIRP 2022, 106, 209–214. [Google Scholar] [CrossRef]
- Hu, J.; Jiang, Z.; Ding, X.; Mu, T.; Hall, P. Vgpn: Voice-guided pointing robot navigation for humans. In Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1107–1112. [Google Scholar]
- Chamorro, S.; Collier, J.; Grondin, F. Neural network based lidar gesture recognition for realtime robot teleoperation. In Proceedings of the 2021 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), New York, NY, USA, 25–27 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 98–103. [Google Scholar]
- Chang, H.T.; Chang, J.Y. Sensor glove based on novel inertial sensor fusion control algorithm for 3-D real-time hand gestures measurements. IEEE Trans. Ind. Electron. 2019, 67, 658–666. [Google Scholar] [CrossRef]
- Weber, P.; Rueckert, E.; Calandra, R.; Peters, J.; Beckerle, P. A low-cost sensor glove with vibrotactile feedback and multiple finger joint and hand motion sensing for human–robot interaction. In Proceedings of the 2016 25th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), New York, NY, USA, 26–31 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 99–104. [Google Scholar]
- Pan, S.; Lv, H.; Duan, H.; Pang, G.; Yi, K.; Yang, G. A sensor glove for the interaction with a nursing-care assistive robot. In Proceedings of the 2019 IEEE International Conference on Industrial Cyber Physical Systems (ICPS), Taipei, Taiwan, 6–9 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 405–410. [Google Scholar]
- Côté-Allard, U.; Gagnon-Turcotte, G.; Laviolette, F.; Gosselin, B. A low-cost, wireless, 3-D-printed custom armband for sEMG hand gesture recognition. Sensors 2019, 19, 2811. [Google Scholar] [CrossRef] [PubMed]
- Loper, M.M.; Koenig, N.P.; Chernova, S.H.; Jones, C.V.; Jenkins, O.C. Mobile human–robot teaming with environmental tolerance. In Proceedings of the 4th ACM/IEEE International Conference on Human Robot Interaction, La Jolla, CA, USA, 9–13 March 2009; pp. 157–164. [Google Scholar]
- Wolf, M.T.; Assad, C.; Vernacchia, M.T.; Fromm, J.; Jethani, H.L. Gesture-based robot control with variable autonomy from the JPL BioSleeve. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1160–1165. [Google Scholar]
- Guo, D.; Zhou, W.; Li, A.; Li, H.; Wang, M. Hierarchical recurrent deep fusion using adaptive clip summarization for sign language translation. IEEE Trans. Image Process. 2019, 29, 1575–1590. [Google Scholar] [CrossRef] [PubMed]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Sign language transformers: Joint end-to-end sign language recognition and translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10023–10033. [Google Scholar]
- Tang, S.; Guo, D.; Hong, R.; Wang, M. Graph-based multimodal sequential embedding for sign language translation. IEEE Trans. Multimed. 2021, 24, 4433–4445. [Google Scholar] [CrossRef]
- Kumar, S.S.; Wangyal, T.; Saboo, V.; Srinath, R. Time series neural networks for real time sign language translation. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 243–248. [Google Scholar]
- Herbert, O.M.; Pérez-Granados, D.; Ruiz, M.A.O.; Cadena Martínez, R.; Gutiérrez, C.A.G.; Antuñano, M.A.Z. Static and Dynamic Hand Gestures: A Review of Techniques of Virtual Reality Manipulation. Sensors 2024, 24, 3760. [Google Scholar] [CrossRef] [PubMed]
- Yaseen; Kwon, O.J.; Kim, J.; Lee, J.; Ullah, F. Vision-Based Gesture-Driven Drone Control in a Metaverse-Inspired 3D Simulation Environment. Drones 2025, 9, 92. [Google Scholar] [CrossRef]
- Cheng, Y.; Wu, Z.; Xiao, R. Exploring Methods to Optimize Gesture Elicitation Studies: A Systematic Literature Review. IEEE Access 2024, 12, 64958–64979. [Google Scholar] [CrossRef]
- Nákačka, J. Teoretický Prehľad v Oblasti Kolaboratívnej Robotiky. Bachelor’s Thesis, Žilinská Univerzita, Žiline, Slovakia, 2023. [Google Scholar]
- Vavrecka, M.; Sokovnin, N.; Mejdrechova, M.; Sejnova, G. mygym: Modular toolkit for visuomotor robotic tasks. In Proceedings of the 2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI), Virtual, 1–3 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 279–283. [Google Scholar]
- Kapitanov, A.; Kvanchiani, K.; Nagaev, A.; Kraynov, R.; Makhliarchuk, A. HaGRID–HFurthermore, Gesture Recognition Image Dataset. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 4572–4581. [Google Scholar]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Nature: Berlin, Germany, 2022. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Villarreal-Narvaez, S.; Sluÿters, A.; Vanderdonckt, J.; Vatavu, R.D. Brave new GES world: A systematic literature review of gestures and referents in gesture elicitation studies. ACM Comput. Surv. 2024, 56, 1–55. [Google Scholar] [CrossRef]
- Neto, P.; Simão, M.; Mendes, N.; Safeea, M. Gesture-based human–robot interaction for human assistance in manufacturing. Int. J. Adv. Manuf. Technol. 2019, 101, 119–135. [Google Scholar] [CrossRef]
- Mendes, N.; Safeea, M.; Neto, P. Flexible programming and orchestration of collaborative robotic manufacturing systems. In Proceedings of the 2018 IEEE 16th International Conference on Industrial Informatics (INDIN), Porto, Portugal, 18–20 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 913–918. [Google Scholar]
- Simao, M.A.; Gibaru, O.; Neto, P. Online recognition of incomplete gesture data to interface collaborative robots. IEEE Trans. Ind. Electron. 2019, 66, 9372–9382. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
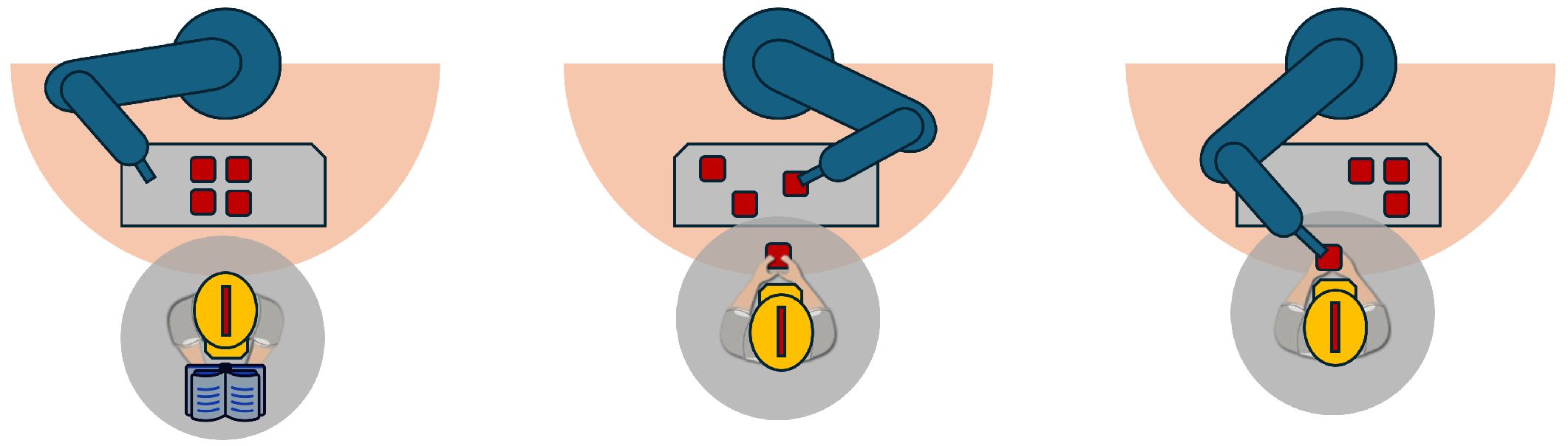
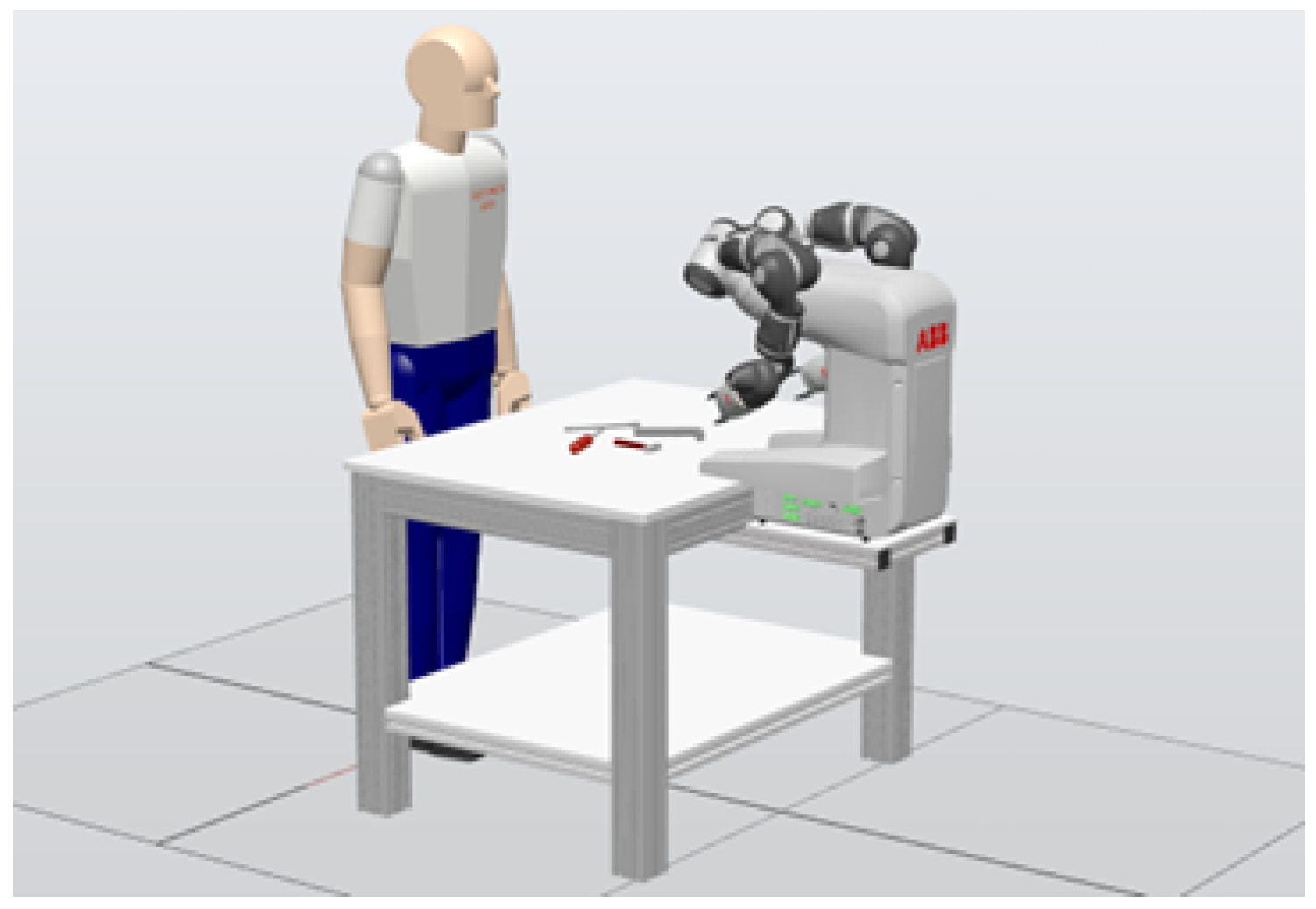


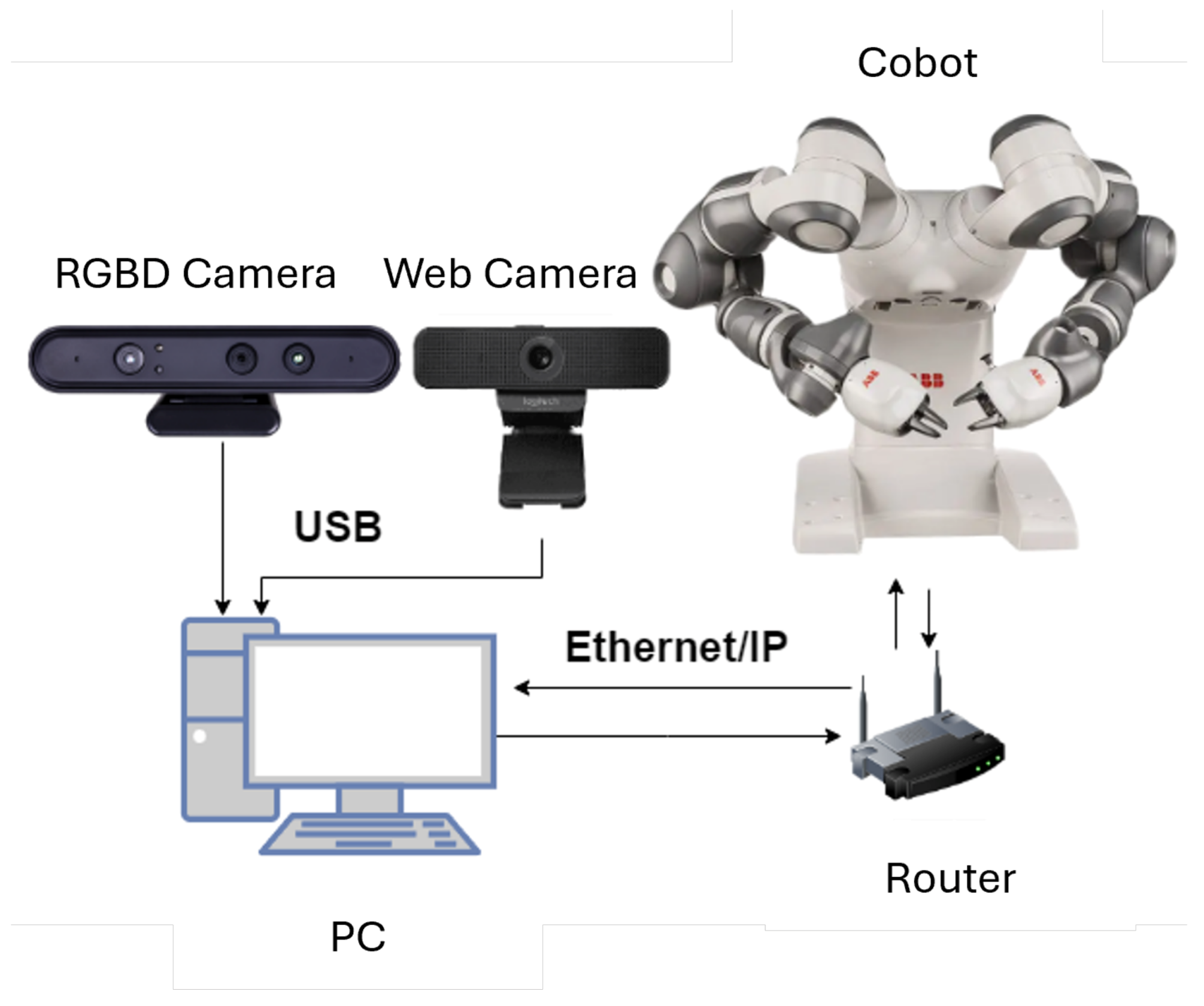
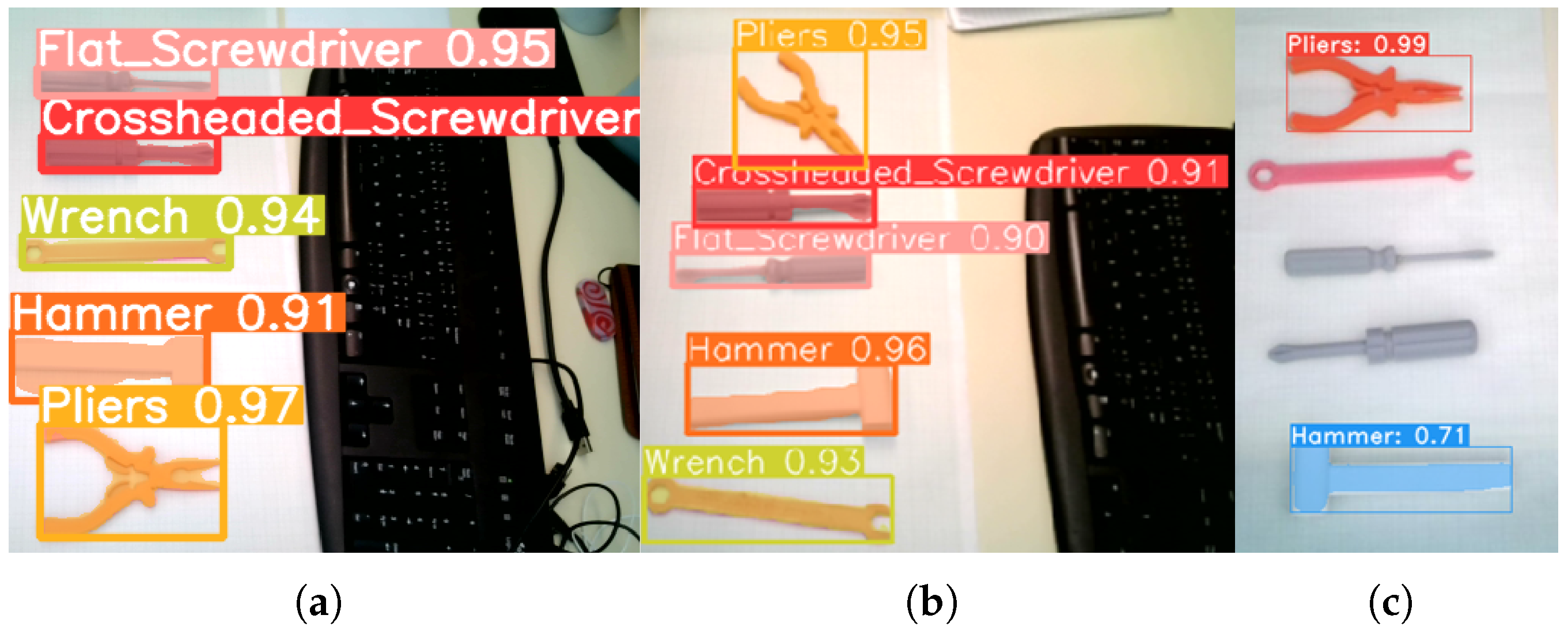
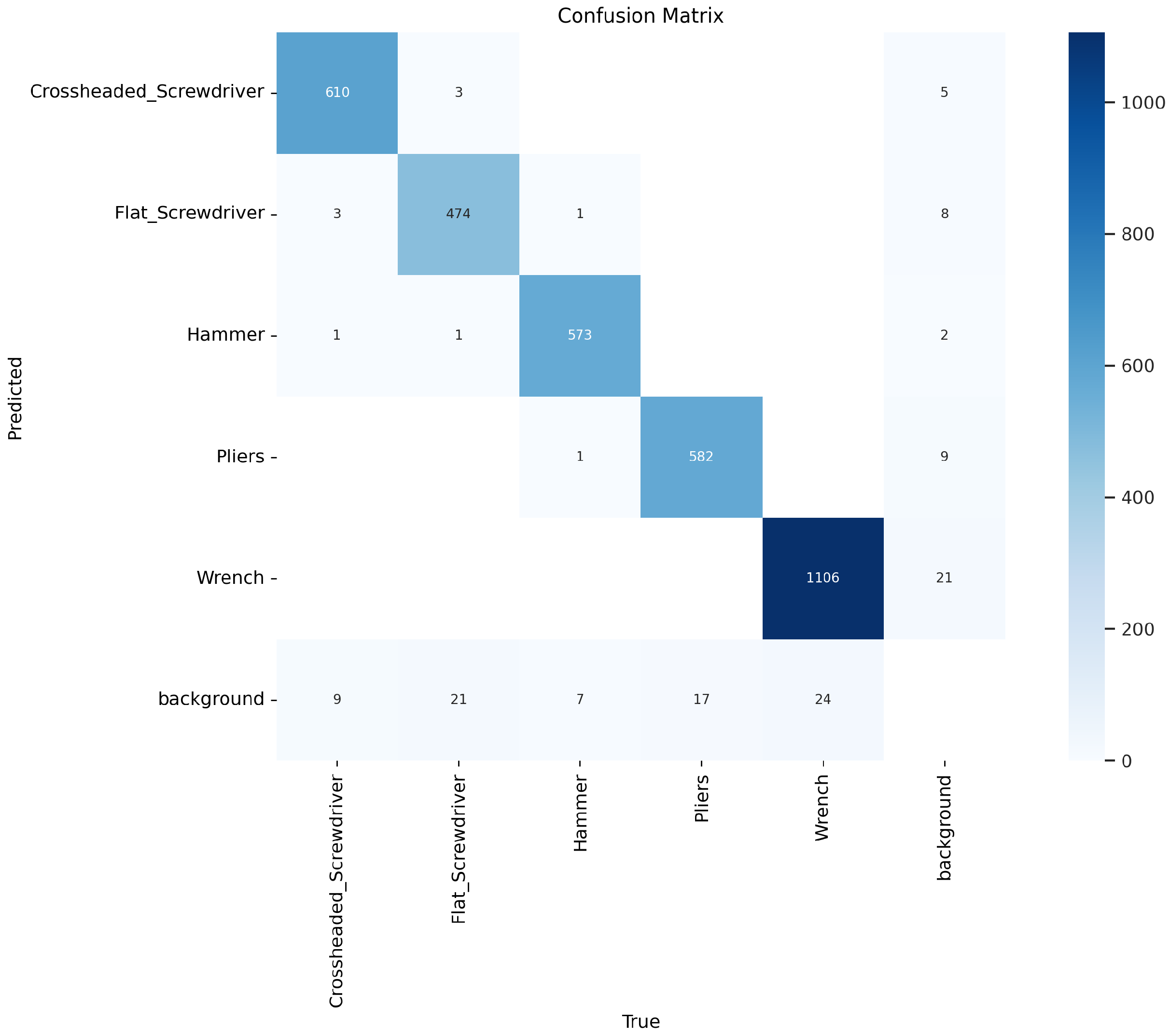

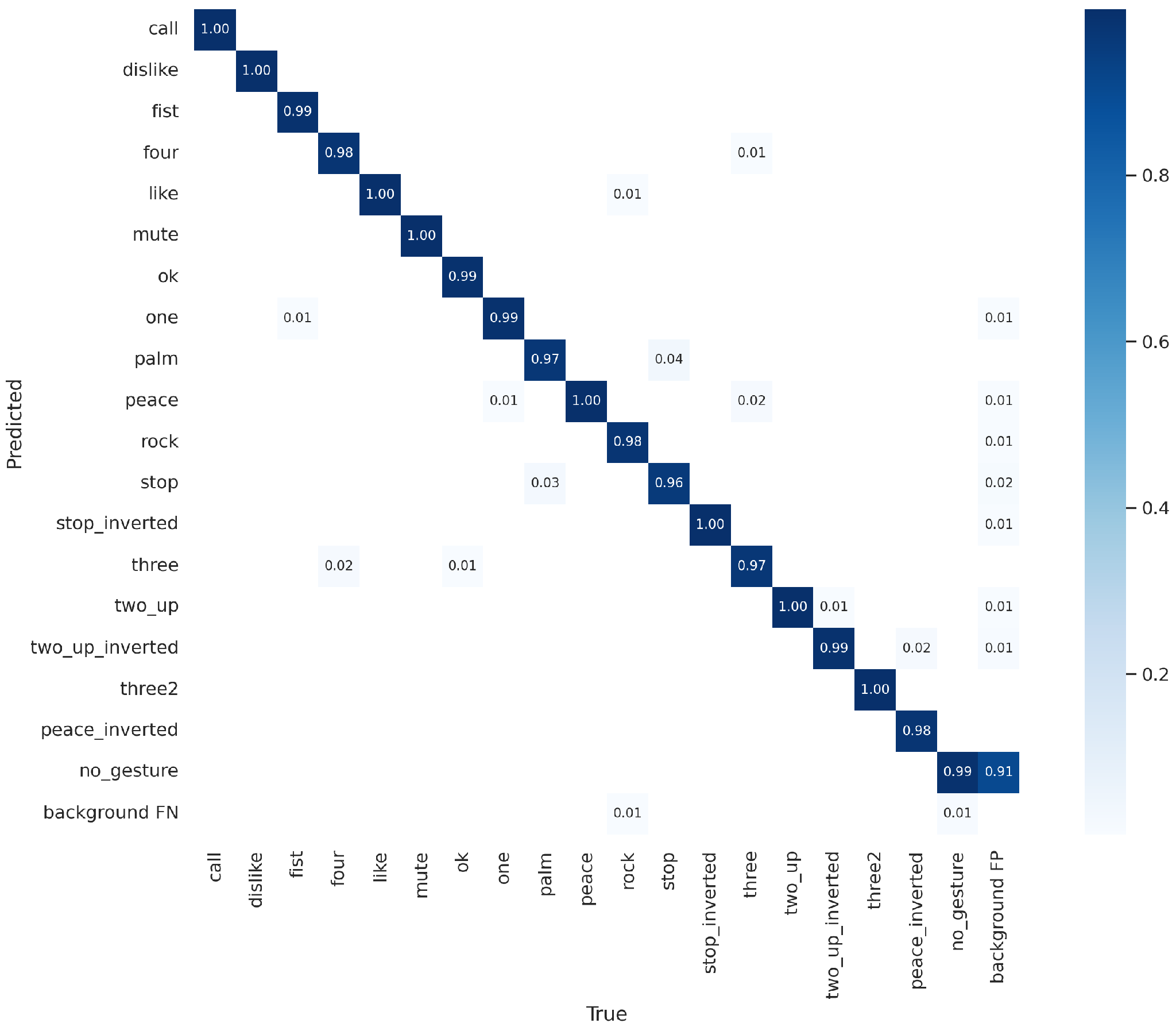
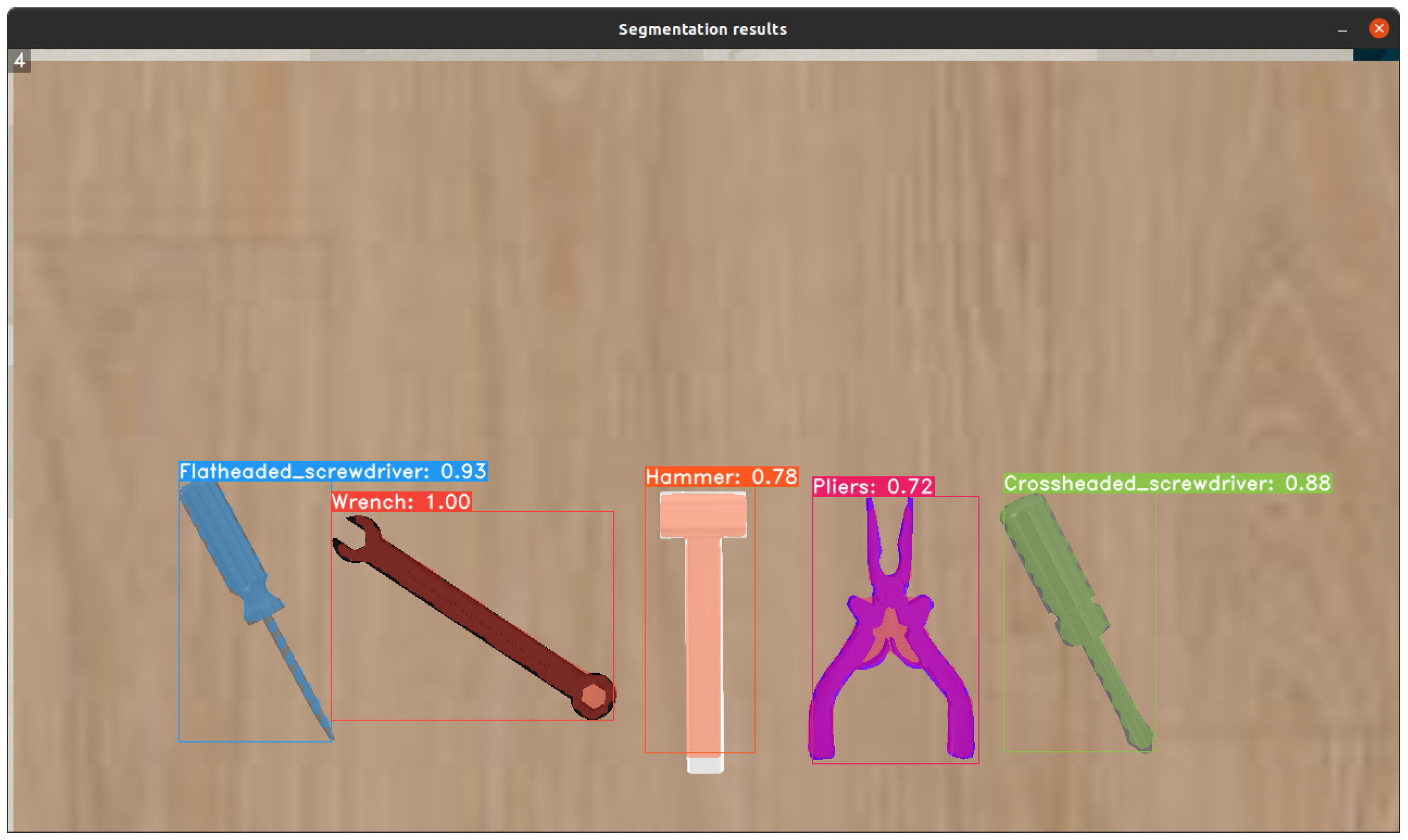
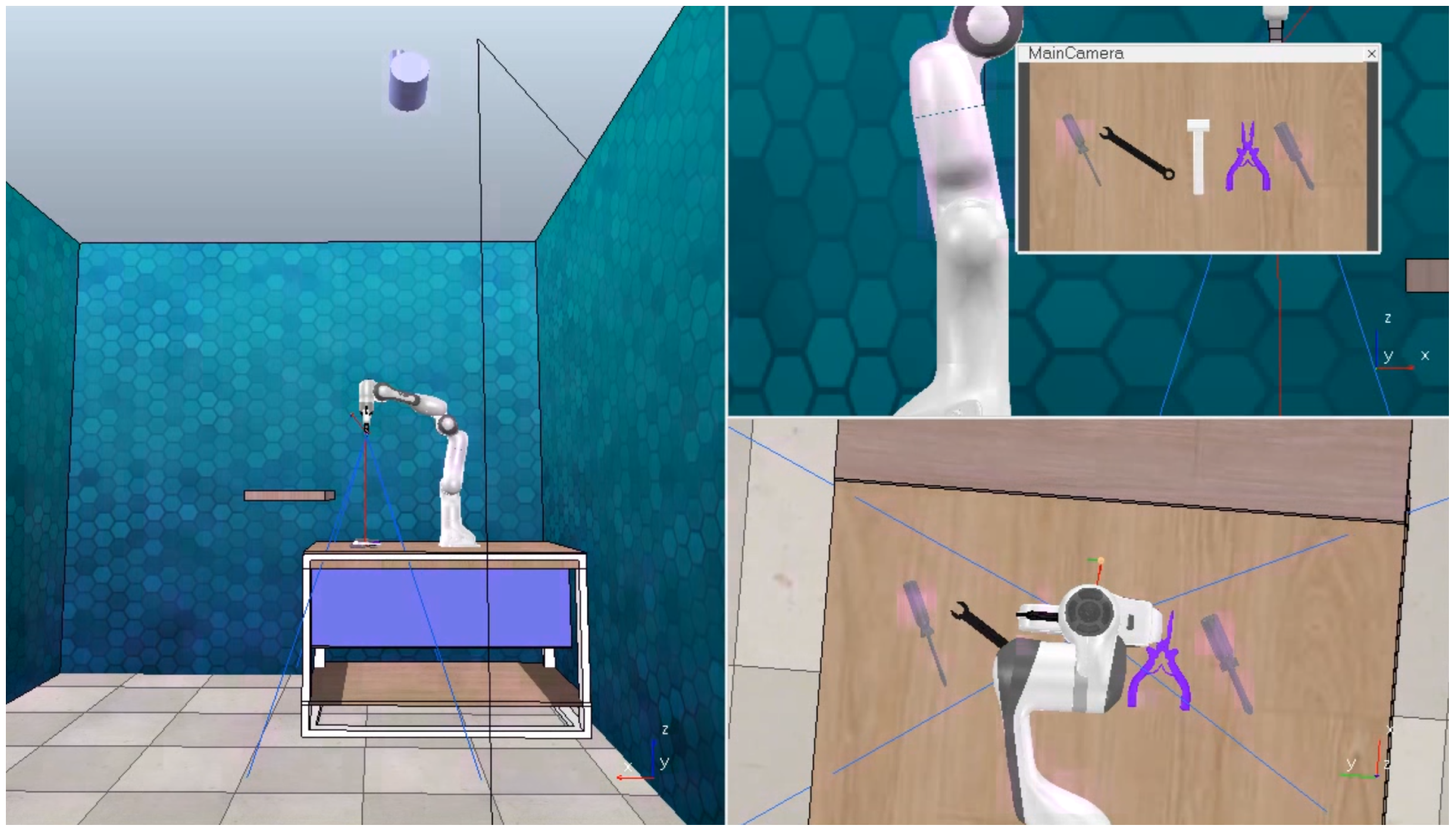

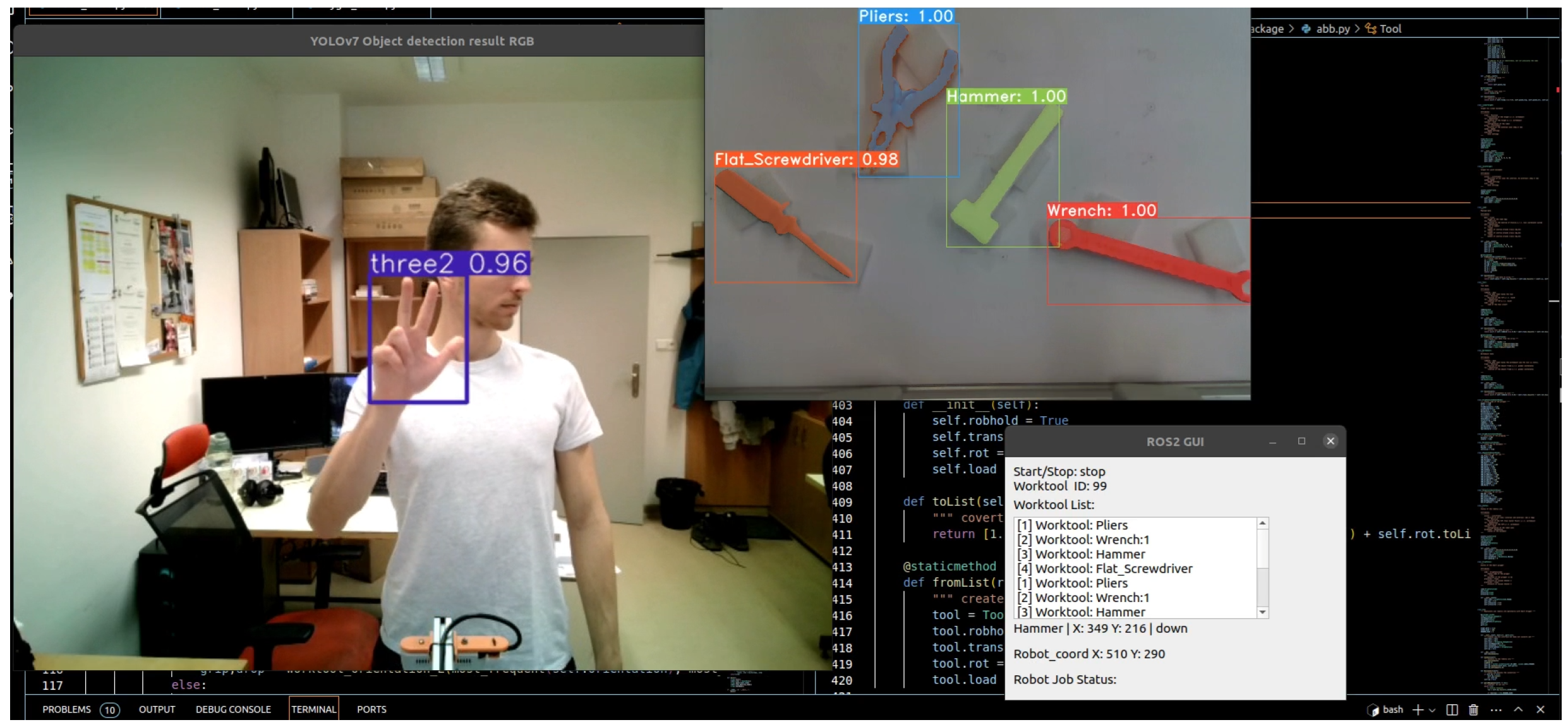
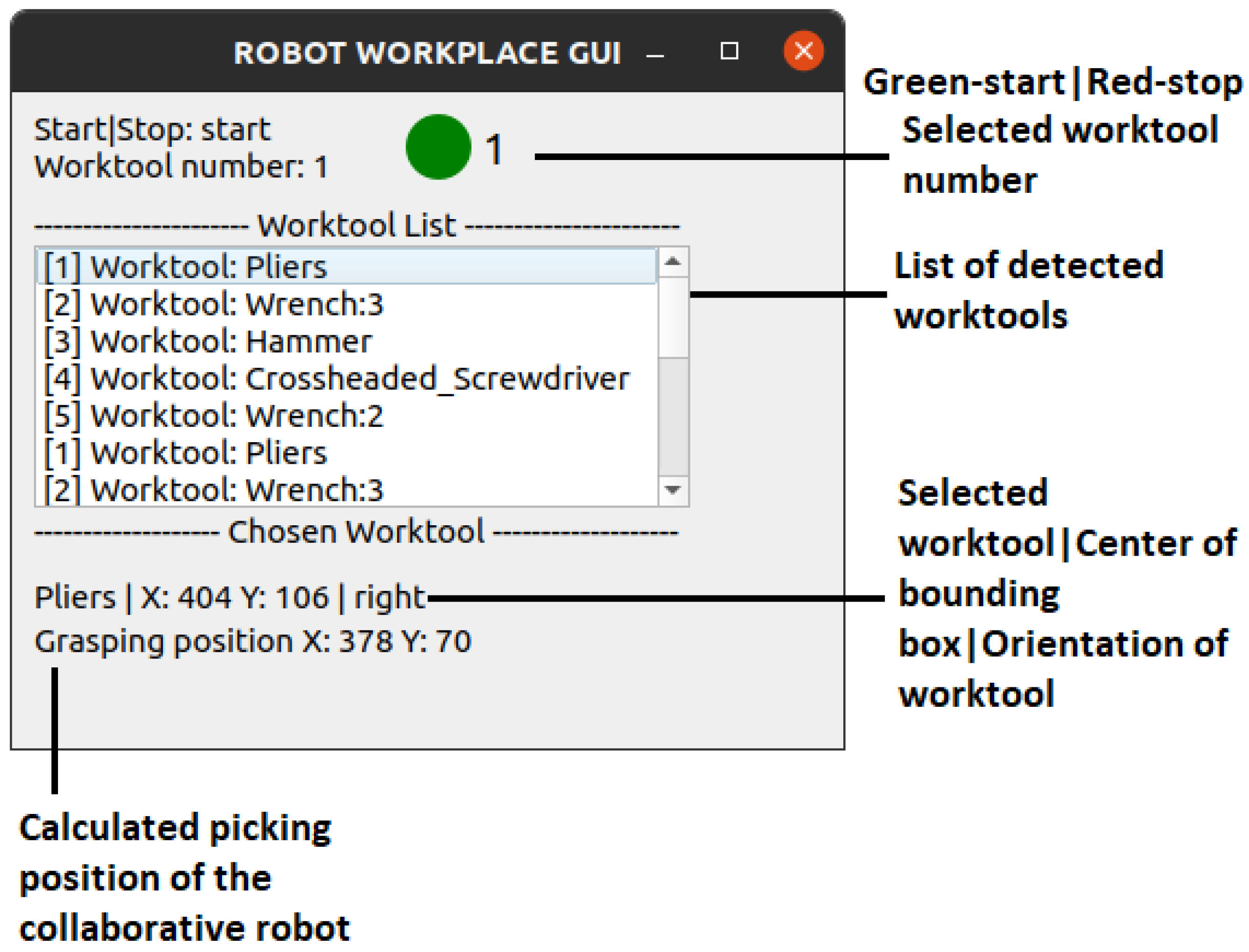
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).