Abstract
Low-resource natural language understanding is one of the challenges in the field of language understanding. As natural language processing and natural language understanding take center stage in machine learning, these challenges need solutions more than ever. This paper introduces the technique of Uncertainty-Aware Active Meta-Learning (UA-AML), a methodology designed to enhance the efficiency of models in low-resource natural language understanding tasks. This methodology is particularly significant in the context of limited data availability, a common challenge in the field of natural language processing. Uncertainty-Aware Active Meta-Learning enables the selection of high-quality tasks from a diverse range of task data available during the learning process. By quantifying the prediction uncertainty of the model for the input data, we provide a loss function and learning strategy that can adjust the influence of the input data on the model’s learning. This approach ensures that the most relevant and informative data are utilized during the learning process, optimizing learning efficiency and model performance. We have applied this meta-learning technique to tasks in low-resource natural language understanding, such as few-shot relation classification and few-shot sentiment classification. Our experimental results, which are carried out on the Amazon Review Sentiment Classification (ARSC) and the FewRel dataset, demonstrate that this technique can construct low-resource natural language understanding models with improved performance, providing a robust solution for tasks with limited data availability. This research contributes to the expansion of meta-learning techniques beyond their traditional application in computer vision, demonstrating their potential in natural language processing. Our findings suggest that this methodology can be effectively utilized in a wider range of application areas, opening new avenues for future research in low-resource natural language understanding.
1. Introduction
The field of natural language understanding (NLU), a key component of artificial intelligence, has seen substantial progress in recent years. Low-resource natural language understanding (NLU) involves developing models and systems that can process and understand human language in scenarios where available data are limited. This area is particularly crucial for languages and tasks that do not have large annotated datasets like English. However, developing learning techniques for low-resource NLU models remains a challenging task [1,2,3].
Low-resource NLU and few-shot text classification are closely related to enabling models to handle linguistic tasks in data-scarce environments. In low-resource NLU, models must be able to understand and process language with limited data across various languages or specific domains. Key tasks in NLU include intent classification, named entity recognition (NER), sentiment analysis, machine translation, and question answering, all demanding the ability to comprehend different linguistic expressions and analyze contexts. Few-shot text classification trains models to perform classification tasks with only a few examples, maximizing the ability of models to quickly adapt to data-scarce languages or tasks.
Although large language models (LLMs) have demonstrated excellent performance through instruct tuning, the use of smaller-scale models remains critical in few-shot text classification due to resource efficiency and practicality. Large models come with high computational costs and significant memory and power consumption, making them im-practical in real-world applications. Particularly in applications with limited hardware resources or where real-time processing is required, resource-efficient models are more suitable. Moreover, few-shot learning techniques that enable efficient performance with small data quantities are essential. Therefore, the few-shot text classification task remains a significant issue in the low-resource NLU area, and the development of resource-efficient models is crucial from both practical and economic perspectives.
This research focuses on the concept of meta-learning, a process of learning how to learn, which becomes particularly crucial when the amount of data available for a task is limited. Traditional machine learning models typically require substantial data to train effectively, but many real-world scenarios only provide small data quantities. Meta-learning techniques are designed to learn from small data quantities and generalize tasks efficiently [4,5], addressing the increasingly common issue of few-shot learning problems in machine learning. In few-shot learning problems, models must make accurate predictions based on limited data, a task at which traditional models often struggle.
However, this research also recognizes the limitations of existing meta-learning methodologies. Many such methodologies focus primarily on computer vision, leaving a gap in natural language processing. Computer vision and natural language processing are fundamentally different domains, each with distinct data types and challenges. There is a relative scarcity of research considering the domain-specific characteristics of natural language processing, and this research aims to bridge this gap.
Moreover, the problem of meta-overfitting in the meta-learning process is identified as a major cause of performance degradation in few-shot learning models [6,7,8]. Overfitting occurs when a model learns the training data too well, degrading its performance on unseen new data. This is a common issue in machine learning, particularly challenging within the context of meta-learning. Meta-learning models need to generalize well from small data quantities but are susceptible to high risks of overfitting.
In response to these challenges, this research proposes new meta-learning techniques for building efficient generalization models for natural language understanding tasks using limited resource learning data. The proposed technique, Uncertainty-Aware Meta-Learning, focuses on selecting high-quality tasks from the available data during the learning process. Additionally, a new loss function is designed to re-weight the importance of each task based on the model’s uncertainty about the input data, supporting model training in low-resource natural language understanding environments. This method represents a significant advancement in meta-learning, offering a potential solution to some of the most pressing issues in the field.
Several studies have explored uncertainty quantification in NLP, particularly leveraging Bayesian inference, probabilistic modeling, and ensemble methods [9,10,11,12], discussing the use of Bayesian inference, probabilistic modeling, and ensemble methods. However, most do not address the challenges of low-resource NLP scenarios. The primary contribution of this study is the extension of meta-learning techniques, previously focused mainly on computer vision, to the field of natural language processing to address this issue. This paper is expected to contribute to the following subject:
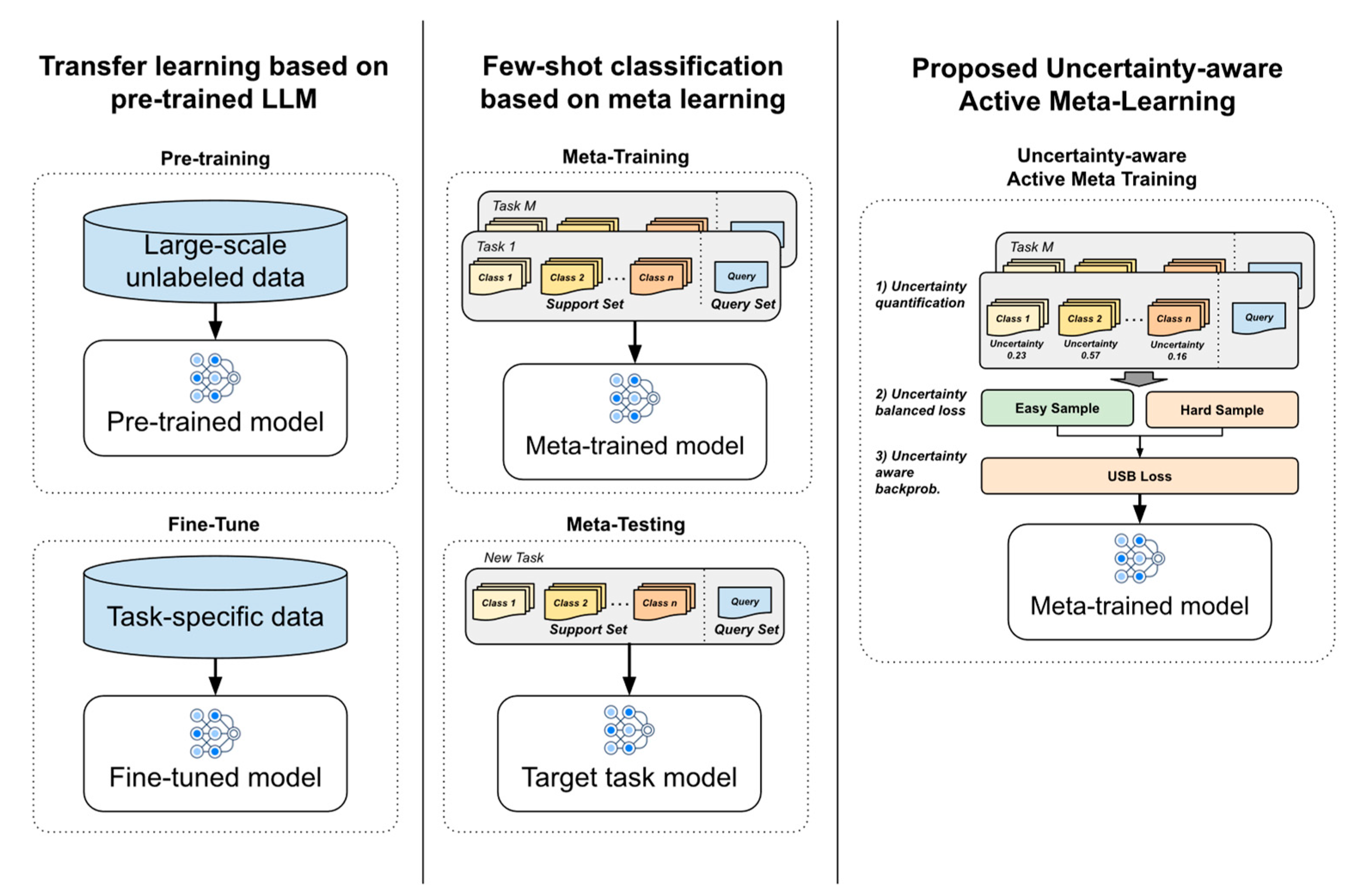
- We propose a novel active meta-learning approach that prioritizes high-uncertainty tasks and introduces a new Uncertainty-Based Sample-Balanced (USB) loss for better task generalization, summarized in Figure 1.
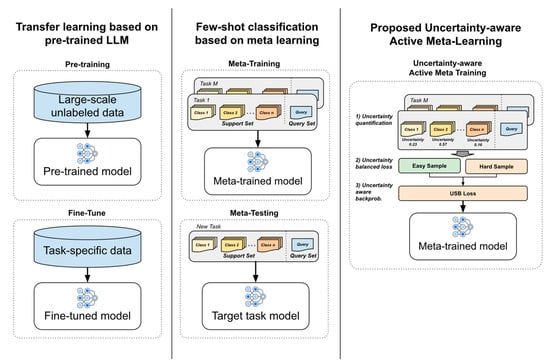 Figure 1. Comparison between different few-shot text classification methodologies.
Figure 1. Comparison between different few-shot text classification methodologies. - We extend meta-learning to NLP, demonstrating improved performance in few-shot sentiment (ARSC) and relation classification (FewRel) tasks.
- We introduce uncertainty quantification for task selection and validate UA-AML’s effectiveness with improved performance in few-shot NLP scenarios.
2. Background Literature
Low-resource natural language understanding (NLU) aims to develop models and systems that can process and understand human language in situations with limited available data. This field is particularly important for languages and tasks that lack large-scale annotated datasets like English. The scarcity of data poses significant challenges in training large neural network models, which typically require substantial amounts of labeled data to function effectively. Tasks such as machine translation, sentiment analysis, and Named Entity Recognition (NER) are especially challenging in low-resource settings due to a lack of parallel data or annotated examples. To address these issues, transfer learning utilizing pre-trained models like BERT, GPT, and XLM-R has emerged as an effective strategy. These models are initially trained on large-scale multilingual or cross-lingual data and then fine-tuned on small datasets of low-resource languages or tasks. Furthermore, cross-lingual transfer allows the transfer of knowledge from high-resource languages to low-resource tasks, facilitated by joint training or fine-tuning on small datasets.
Beyond transfer learning, data augmentation, and meta-learning techniques also provide important solutions in low-resource NLU. Synthetic data generation through back-translation or other representational techniques helps mitigate the data scarcity problem and expand the available datasets. Additionally, active learning techniques support effective model training by selectively annotating the most informative examples from unlabeled data. Meta-learning techniques like few-shot and zero-shot learning endow models with the ability to generalize to new tasks or languages with only a minimal number of labeled examples. These techniques simulate low-resource conditions to train models to learn from limited data. The ultimate goal of low-resource NLU is to build robust models that perform well in data-scarce environments through innovative technologies such as transfer learning, data augmentation, meta-learning, and multilingual models.
2.1. LLMs for Few-Shot Text Classification
In recent times, the field of natural language processing has seen the rise of language models trained through self-supervised learning, which is based on linguistic patterns and applied to vast amounts of text data [13,14]. Self-supervised learning involves creating a task that allows the learning model to discern patterns in a dataset that lacks answer labels. This method enables the model to learn patterns in the data without constructing supervised learning data on large amounts of text data.
The advent of such large language models can be traced back to the transformer model [15]. The transformer was introduced to enhance the computational speed of the Seq2Seq model, which is an existing translation model that applies attention based on Recurrent Neural Networks (RNNs) [16]. The transformer model is composed of a combination of encoder and decoder modules. Since the RNN model that processes the input data sequence has been removed, the transformer uses a positional encoding method that artificially provides order information of input data. As a result, the sum of the token vector arbitrarily assigned to each token and positional encodings, which is a vector expressing the relative positions of words in a sentence, is input to the encoder. The corresponding input value extracts various features through a self-attention layer, which encodes the meaning of each token considering context information in the currently input sentence [17]. There are various methods of self-attention depending on the method of calculating the weight between the query and the key-value pair, but in the transformer, the multi-head attention that performs the scaled dot-product attention was used.
Thereafter, the same linear transformation is performed for each token in a feed-forward layer and output representations. The output value goes into the input of the next encoder, and after repeating this process N times, it is input to the decoder. In performing each output, the decoder applies the attention mechanism using the information summarized in the encoder to perform the output for each sequence.
The effectiveness of the transformer has been demonstrated in both natural language understanding and generation, and various large language models have been proposed based on it. BERT is a language model built using only the encoder part of a transformer. It has been established as one of the transfer learning in the field of natural language processing by updating the best performance in the task of NLU [14]. The process of creating a model that performs a target task using BERT is divided into two steps. The first step is pre-training, a self-supervised learning process for a large amount of text data, and the second step is fine-tuning, a supervised learning process for the downstream task.
Despite the accomplishments NLU has so far, one of the biggest limitations, like other types of machine learning paradigms, is that they need large amounts of data. The performance in the different areas of NLP of such high-resource languages improved over time, but languages that lack these resources, i.e., low-resource languages, suffer performance loss [18]. Low-resource NLU is a task that requires an adequate understanding of a given natural language based on a small number of label examples. Meta-learning, discussed in the next section, gives an alternative solution to the problem of having a limited number of resources when training language models. It allows NLU models to understand low-resource languages better; hence, we utilize this method in combination with others to solve the problem of low-resource languages.
2.2. Meta-Learning for Few-Shot Text Classification
Deep learning models that require large-scale labeled data have significant limitations in their training and application process. First, in terms of model training, it takes a lot of time and money to build a large-scale labeled dataset, and it is also practically challenging to build a new training dataset suitable for a given domain for each specific task. Based on this awareness of the problem, diverse learning methodologies such as transfer learning were proposed, and a methodology to learn the neural network connection weight in advance and use it to train the neural network for a new task was introduced to train the model more efficiently [19,20,21,22]. In contrast, humans can quickly learn new tasks by using what they have learned in the past. For example, humans can learn the rules of multiplication based on their knowledge of addition or solve problems such as finding the person in a picture of multiple people based on a single facial picture. Bridging this gap in learning methods between AI and humans is very important.
Meta-learning is a useful methodology that can effectively perform model learning and generalize in an area using only these low resources. In the meta-learning process, “learning to learn” does not mean learning a model suitable for a specific task but a method of learning to effectively perform various tasks, as shown in research [23]. To this end, meta-learning performs learning on various tasks through the meta-train phase, enabling rapid generalization to low-resource data.
Three common meta-learning approaches are metric-based meta-learning, model-based meta-learning, and optimization-based meta-learning. Metric-based meta-learning uses a notion of distance in a certain space to compare tasks and transfer information between similar tasks. The core idea is to learn a function that captures the similarity (or difference) between different data points and use this function to make predictions for new tasks. In this method, instead of learning a mapping from input to output, the model learns an appropriate metric space where classification can be performed by computing distances to examples from the training set [24,25,26,27,28].
In model-based meta-learning, the objective is to learn a model of the learning process itself. This model can then be used to predict the outcomes of different learning strategies for new tasks. The acquired knowledge from previous tasks is used to build the new model, which in turn is used to make predictions for new tasks. One popular method in this category is Model-Agnostic Meta-Learning (MAML) [23], which aims to find a model initialization that can be fine-tuned quickly for new tasks. The last approach, optimization-based meta-learning, as the name suggests, is focused on optimizing the learning process. The idea is to adjust the learning algorithm to better suit the task at hand. The learning process is framed as an optimization problem, and techniques from the field of optimization are used to find the best solution [29]. Our proposed model, Uncertainty-Aware Active Meta-Learning (UA-AML), also implements a similar methodology where a model trains on different tasks, and the knowledge obtained from the training process is used for future tasks. It is unique because each task is selected by measuring uncertainty, allowing a high-quality selection.
3. Preliminaries
This section defines key concepts and notations used throughout the paper, including few-shot text classification, meta-learning, and active meta-learning.
3.1. Few-Shot Text Classification Framework
Few-shot text classification aims to train a model to classify text instances with a limited number of labeled examples per class. This problem follows the -way -shot formulation, where represents the number of unique classes in each task and denotes the number of labeled examples per class in the support set. Each classification task consists of a support set , which contains classes with labeled examples per class, and a query set , which includes unlabeled examples from the same classes for evaluation. A base classifier is trained on and evaluated on , with the objective of optimizing so that it can generalize effectively to , even when the classes in were not seen during training.
3.2. Meta-Learning
Meta-learning, or “learning to learn”, aims to train a meta-learner that generalizes across tasks by leveraging prior knowledge from multiple related tasks. Given a task distribution , meta-learning consists of two phases: meta-training and meta-testing. In the meta-training phase, a batch of tasks is sampled, where each task consists of a support set for training and a query set for evaluation. A base-learner is trained on and the meta-learner is optimized by minimizing the expected query loss:
The objective is to find an optimal initialization that allows rapid adaptation to new tasks. In the meta-testing phase, a new task is sampled, where the model is fine-tuned on and evaluated on . The accuracy on measures the model’s ability to generalize to unseen tasks. However, a key limitation of standard meta-learning is task selection, as most methods sample tasks randomly, leading to inefficient learning by treating all tasks as equally informative.
3.3. Notation Summary
To ensure clarity, Table 1 summarizes the notations used in this paper.

Table 1.
Summary of notations used in research.
4. Methodology
4.1. Problem Definition
Traditional meta-learning methods randomly select tasks from , often leading to inefficient training due to redundant and uninformative tasks. This work introduces Uncertainty-Aware Active Meta-Learning (UA-AML), a framework that actively selects high-uncertainty tasks to improve generalization. The problem is defined in this sub-section.
Given a dataset , where is a text instance is its class label, the few-shot learning objective is to train a classifier that generalizes to new tasks using only a small number of labeled examples. Each task consists of a support set which is used for training, and a query set used for evaluation. The goal of meta-learning is to learn a function that maps a set of training tasks to an optimal initialization for a base-learner , enabling fast adaptation to new tasks. Given a distribution of tasks and a classification loss , we define:
Standard meta-learning samples tasks randomly, which can be suboptimal as many tasks contribute little to improving generalization. We aim to address this problem in this work.
4.2. Active Meta-Learning
Training a model of a complex phenomenon from scratch using a model with general inductive bias usually requires large datasets. Meta-learning solves problems in the target domain by leveraging the learning experience in the source domain to efficiently learn new tasks. The meta-model captures the global properties of a domain and uses it as a learned inductive bias for subsequent tasks. The standard for these algorithms is to select the training task randomly. However, exhaustively exploring the realm of the entire task is impractical in many practical applications.
Probabilistic Active Meta-Learning (PAML) is a learning strategy that seeks to perform meta-learning by selecting only higher-quality tasks according to this awareness of the problem [30]. PAML adopts the view that the goal of a meta-learning algorithm is not only to learn a meta-model that rapidly generalizes to new tasks but also to use that experience to tell what tasks to learn next. This approach is similar to Automatic Curriculum Learning (ACL) [31]. Compared to ACL, PAML efficiently explores the space of a task from the start and samples more tasks that are closer to the learning goal to learn more. PAML learns the representation of a task space and performs direct comparisons in that space.
In this research, unlike the existing PAML, we propose a methodology for performing meta-learning by measuring uncertainty for each task used in meta-learning and selecting higher-quality tasks.
4.3. UA-AML: Uncertainty Aware Active Meta-Learning
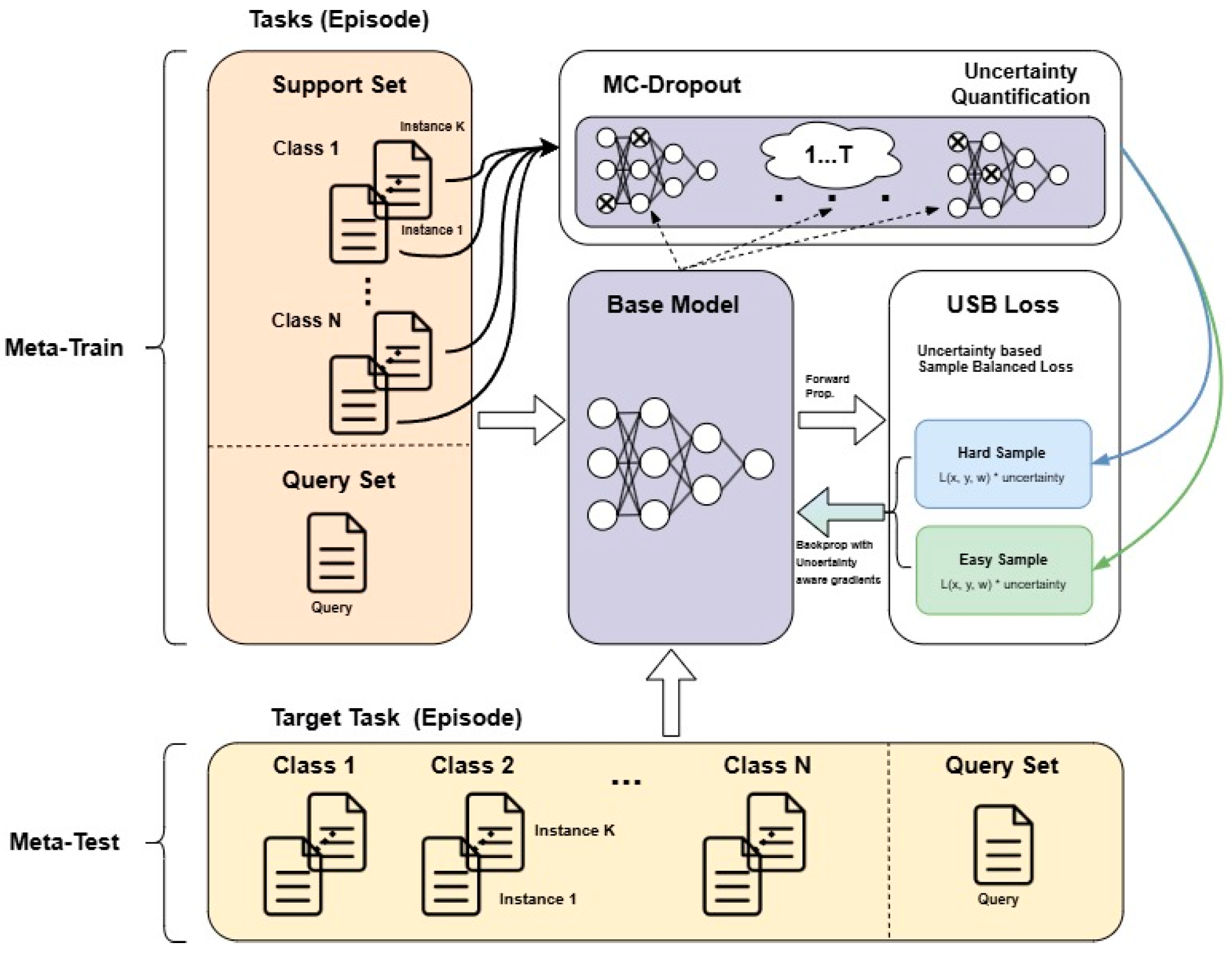
As depicted in Figure 2, the overall workflow of the proposed methodology is presented. The process begins with a support set and query set, where the model receives few-shot learning tasks. The base model processes the input data with the use of Monte Carlo Dropout (MC-Dropout) to estimate uncertainty by generating stochastic forward passes. The uncertainty quantification module then calculates uncertainty values using entropy-based methods for classification tasks and variance-based methods for regression tasks. These uncertainty values are then normalized and used to define sample importance, ensuring that the model focuses more on hard samples (high uncertainty) while still incorporating easier samples (low uncertainty, high confidence) for stable learning. The Uncertainty-Based Sample-Balanced (USB) loss further integrates these uncertainty values into the training process, re-weighting the contribution of each sample dynamically. The model is then updated using gradients derived from the USB loss, reinforcing generalization across diverse few-shot tasks. This approach differs from traditional active learning by not requiring explicit sample selection but instead adjusting sample importance weights during training. By using the data of the task possessed in the meta-learning process, the output value is stored by repeatedly inputting it times to the same base model in which the dropout layer is activated.
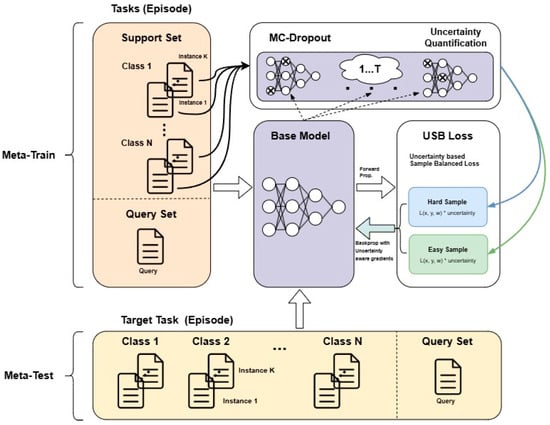
Figure 2.
Uncertainty Aware Active Meta-Learning (UA-AML) framework.
For the output values, in the case of a classification model using cross entropy, uncertainty is quantified using the entropy of the output distribution, and variance is quantified as uncertainty when MSE, which calculates the distance, is used as a loss function. Each uncertainty is mapped to a value in the range through min-max normalization. At this time, uncertainty is used as a value applied to samples that are difficult for the model to learn, and confidence value is defined as for easy samples to support stable learning of the model.
In this research, based on the approach of existing studies, the uncertainty of the model is quantified with respect to the input data, and the loss function is designed so that the influence of the more informative sample is reflected more when the model is trained. Through this, the model performs training mainly on difficult samples with high uncertainty for various tasks it has so that a more generalized meta-learning model can be built.
Unlike previous studies, our proposed method quantifies the prediction uncertainty of the model for the given data so that the uncertainty is reflected in the learning process or, in our case, the meta-learning process. Summarizing the entire framework of the meta-learning process, the uncertainty of the input data is quantified to quantitatively distinguish the data that the model judges to be uncertain from the data that the model judges to be certain. This allows the model to learn mainly from samples that are difficult to classify and supports the generalization of the model by providing a more severe environment as a constraint. However, the model may be underfitted if only difficult samples are continuously provided as input. Therefore, it is essential to include a certain percentage of easy samples in the training data to ensure stable learning of the model [30,32]. Existing active learning is a method to label useful data, but in this research, learning is performed by giving weight to valuable data, and if no weight is given, learning is not affected at all.
Next, this paper presents a method of applying uncertainty and confidence to the loss function. The loss function is regarded as a sample-balanced loss that re-weights the influence of given samples based on uncertainty and Uncertainty-Based Sample-Balanced (USB) loss. The gradients are obtained from the USB loss, and the base model is trained as a final step.
To compute loss based on uncertainty, we need tools to obtain the uncertainty of the model. From the various methods used in different research areas, this paper employs the Monte Carlo Dropout proposed in [33]. Dropout is a well-used regularization tool in deep learning to prevent overfitting. Dropout consists of randomly sampled network nodes and performs training by randomly zeroing neurons according to the Bernoulli distribution. At this time, the key idea is to apply dropout only during training and apply random dropout at test time, unlike the general methodology of using all nodes in the test phase to make multiple outputs for the same input. Monte Carlo Dropout (MC-Dropout) is a Bayesian approximation technique that uses dropout layers during training and inference. One can obtain a distribution of predictions by performing dropout at inference time and running the network multiple times. Model uncertainty can be obtained from MC-dropout and, in turn, used as an input to USB loss, as shown in Figure 2.
4.4. Uncertainty Quantification via Bayesian Neural Networks
Due to its excellent performance, deep learning has received much attention as a major machine learning methodology that can be applied in various fields. However, for typical deep learning models, these tools for regression and classification cannot measure model uncertainty. In other words, deep learning works well, but it is difficult to explain why. There are various approaches to quantifying the uncertainty of these deep learning models.
A Bayesian neural network is a type of deep learning algorithm that enables probabilistic analysis by assuming the probability distribution for the model’s weights. The Bayesian neural network converges to a Gaussian process as the number of weight parameters increases, which means that the limitations of the Gaussian process can be overcome and the uncertainty of model prediction can be expressed simultaneously. With these advantages, Bayesian neural networks are recently attracting attention in various fields, including computational science [34,35,36].
In general, the uncertainty of deep learning models is divided into aleatoric and epistemic uncertainty [36]. Aleatoric uncertainty refers to the uncertainty naturally occurring in the observed data, and an example is the problem of mapping the same observation to different data due to power supply noise in the sensor. In the case of aleatoric uncertainty, uncertainty cannot be reduced. Since the measurement error is constant for all samples, it is also called dynamic variance uncertainty. On the other hand, epistemic uncertainty occurs because the training data does not represent the entire dataset of the population and can explain what the model does not know when performing prediction and classification. Epistemic uncertainty is reduced when sufficient training data are given.
A representative way to quantify the uncertainty of such a deep learning model is to use a Bayesian neural network [37]. The Bayesian neural network enables probabilistic interpretation of neural network models by assuming a prior distribution for the model weights as in Equation (3) and calculating the posterior distribution for the weights through the Bayesian inference process. When the set of the input data and the set of the target data are given, the output of the Bayesian neural network is expressed as a posterior predictive distribution as shown in Equation (4), and this process is called inference.
The goal of this research is to find a way to quantify and measure the uncertainty of deep learning models and to find the estimated distribution most similar to the posterior. The Kullback–Leibler Divergence (KLD), which calculates the similarity between two different probability distributions, is used to determine the posterior distribution and the estimated distribution as in Equation (5). Calculating the similarity between the problem of minimizing the KLD between the posterior distribution and the estimated distribution is the same as the problem of maximizing the Evidence Lower Bound (ELBO), as shown in Equation (6). The process of training a neural network to solve such an optimization problem is called Bayes by backprop.
4.5. USB Loss: Uncertainty-Based Sample-Balanced Loss
As stated above, Bayesian neural networks provide a way to quantify the uncertainty of deep learning models. The objective function for weight learning of the Bayesian neural network is expressed in Equations (7)–(9) below, where is the number of training data, is the size of a mini-batch, and is the index of the mini-batch.
In order to perform Bayesian backpropagation, the gradient of the with respect to , which is a parameter of the estimated distribution, is obtained, and the existing is updated according to the slope. However, since backpropagation is impossible when sampling is performed, re-parameterization of for and is the same as Equation (8). Since the calculation process of also includes integration, it is still difficult to calculate when the neural network has more than two layers. Therefore, techniques such as Equation (9) that approximate through Monte Carlo sampling are used [33].
While a class-balanced loss is designed based on class distribution, USB loss has a different design based on model uncertainty for data [38]. In the case of a loss function commonly used in deep learning, the size of the loss value greatly affects the size of the initial gradient. For example, Equations (10)–(12) show the process when differentiation is performed with logits for cross-entropy, which is mainly used for training classification models. Equation (10) is a softmax function that outputs a discrete probability distribution when the logits obtained from the output layer of a general neural network are input. At this time, when cross-entropy is used as a loss function, as in Equation (11), the result of differentiating cross-entropy by logits is the same as subtracting the actual label y from the result of softmax, as in Equation (12). Therefore, if an operation of multiplying cross-entropy loss by a specific value as a coefficient is performed, the operation plays a role in adjusting the value of gradients.
Our hypothesis shows that more efficient learning is possible by focusing on the characteristics between the loss function and the gradients and applying a penalty to increase the loss on data with high uncertainty. This improvement is achieved by reflecting the uncertainty obtained from the data and the model.
Algorithm 1 describes the process of calculating USB loss. In order to calculate the USB loss, forward propagation is performed times, as in line 3, using the MC dropout technique, and the uncertainty of the model can be quantified by calculating variance based on this trial. First, in line 5, the average value is calculated for the MC dropout trial, and the variance for each sample and class is calculated using the average value in line 6. Then, the sample-wise uncertainty is calculated using the average of the variance of each class in line 7.
| Algorithm 1 Uncertainty-Based Sample-Balanced Loss (Hard Sample) |
| Input: data , label base model , dropout probability , |
| number of iterations |
| Output: |
| 1: % uncertainty quantification |
| 2: for to do |
| 3: ← Dropout |
| 4: end for |
| 5: ← where = trial, = class, = batch |
| 6: ← # class-wise variance per sample |
| 7: ← # sample-wise uncertainty |
| 8: % calculate USB loss |
| 9: ← Dropout |
| 10: ← |
| 11: return |
Learning is performed by applying this quantified uncertainty to the existing loss function, such as cross-entropy, and varying the weight of the loss for each sample. Therefore, the proposed loss function is called Uncertainty-Based Sample Balanced Loss. When the hard sample mode is selected as the learning strategy, uncertainty is applied, like in line 10, and when the easy sample mode is selected, confidence that is inversely proportional to uncertainty is applied.
5. Experiments
5.1. Experimental Setting
In this section, we describe the experimental setup used to evaluate the proposed Uncertainty-Aware Active Meta-Learning (UA-AML) methodology. The experiments were designed to assess the effectiveness of UA-AML in handling few-shot learning tasks, including relation classification, text classification, and out-of-scope intent detection. We conducted experiments using multiple benchmark datasets that are commonly used for evaluating meta-learning-based natural language understanding (NLU) models:
- FewRel [39]: A few-shot relation classification dataset containing 100 relation classes, where 64 classes are used for meta-training, 16 classes for meta-validation, and 20 classes for meta-testing.
- Amazon Review Sentiment Classification (ARSC) [40]: A sentiment classification dataset containing 13 domains. For evaluation, four domains (Books, DVDs, Electronics, and Kitchen) were used for meta-testing, while the remaining were used for meta-training.
- CLINC150 [37]: The CLINC150 dataset is a large-scale benchmark for intent classification in natural language understanding (NLU). It contains 22,500 utterances across 150 intent classes spanning 10 diverse domains, along with out-of-scope (OOS) examples for open-world evaluation. This dataset is widely used for benchmarking deep learning models, zero-shot and few-shot learning, and out-of-domain detection in conversational AI systems.
For all experiments, a pre-trained BERT base model was employed as the text encoder. The model was fine-tuned using a meta-learning framework, with task augmentation and Uncertainty-Aware Active Meta-Learning strategies applied to improve generalization.
To evaluate the effectiveness of UA-AML, we compared its performance against existing few-shot learning models, including BERT-PAIR, a BERT-based model used as a baseline for few-shot relation classification, and meta-learning baseline models such as Matching Networks, Prototypical Networks, Graph Networks, Relation Networks, and SNAIL for few-shot text classification tasks.
5.2. Few-Shot Relation Classification
One of the experiments carried out in this section is based on the FewRel dataset proposed in [41] by T. Gao et al. to evaluate the performance of the proposed method in low-resource NLU, which considers the class as a task type in the setting of meta-learning. The FewRel dataset is a dataset for few-shot relationship classification and consists of a total of 100 relations into classes. Among the 100 classes, meta-learning is performed with 64 classes for meta-learning, and meta-testing is performed using 16 classes for verification to measure the generalization performance of the proposed meta-learning methodology.
In the experiment, a pre-trained BERT base model was used as a text encoder, and the batch size was set to 1 in the meta-learning stage. Adam was used as the optimization method, and meta-learning was performed 10,000 times for each methodology to compare the performance of the model with the best performance in the learning process. After meta-learning, the final performance evaluation measured the N-way K-shot classification accuracy by randomly sampling 10,000 queries.
As a comparison target for performance evaluation, relational classification is performed by matching the support and query set with respect to the information that is matched at various levels and the existing publicly available BERT text encoder. The BERT-PAIR model [39] was selected and compared with the proposed methodology. Table 2 compares the performance evaluation when none of the above classes, NOTA, is added to the existing few-shot relation classification problem and the proposed methodology, UA-AML, is applied to the problem. Due to the characteristics of binary classification, there is generally no significant change in performance, even when the ratio of the data of the NOTA class increases to 50%. In this case, performance improvement could be confirmed. This can be interpreted as a more efficient classification by mitigating the overfitting of the model and creating an overconfident output by the proposed methodology.
Table 2.
Few-shot relation classification accuracy for FewRel development dataset in None-of-the-Above Detection (NOTA) problem.
5.3. Few-Shot Text Classification
The Amazon Review Sentiment Classification (ARSC) dataset was used to evaluate the performance of the method proposed in the field of low-resource NLU, which considers the domain as a task type in the setting of meta-learning. ARSC has text reviews of 13 domains for sentiment analysis. For each data, three tasks are composed based on the star score, and there are a total of 69 tasks. Among them, four domains—Books, DVDs, Electronics, and Kitchen—are considered test domains; meta training is performed in other domains, and few-shot text classification is performed based on how well learning is performed in the test domain. In other words, performing ARSC positive and negative binary classification is the same, but the ability to quickly adapt to domains with different domains is important. Of the total 23 domains of ARSC, 19 domains are used for meta-training tasks, and the other four domains are used for meta-testing tasks.
The training batch consists of 5 positive and 5 negative support samples, along with 27 positive and 27 negative query samples, totaling 64 instances per batch. The task is a binary classification that distinguishes between positive and negative, and it is a 2-way 5-shot problem because it utilizes five support data samples for each class. In the development and test phases, 54 queries are sampled, along with five support data samples for each class, and a total of 183 batches are utilized. Induction networks were used to train the model, and the model was generalized by performing 10,000 iterations for meta-training.
Table 3 compares and evaluates the average accuracy of episodes for a total of 10,000 test tasks. As a result of the experiment, compared to the induction networks implemented directly in this research, the proposed UA-AML induction networks model with USB loss showed that the performance could be improved more. As the existing induction networks show excellent performance, a model that replaces the encoder part among the three modules of the existing networks with a BERT model can be considered.
Table 3.
Few-shot sentiment classification accuracy results on Amazon Review Sentiment Classification dataset.
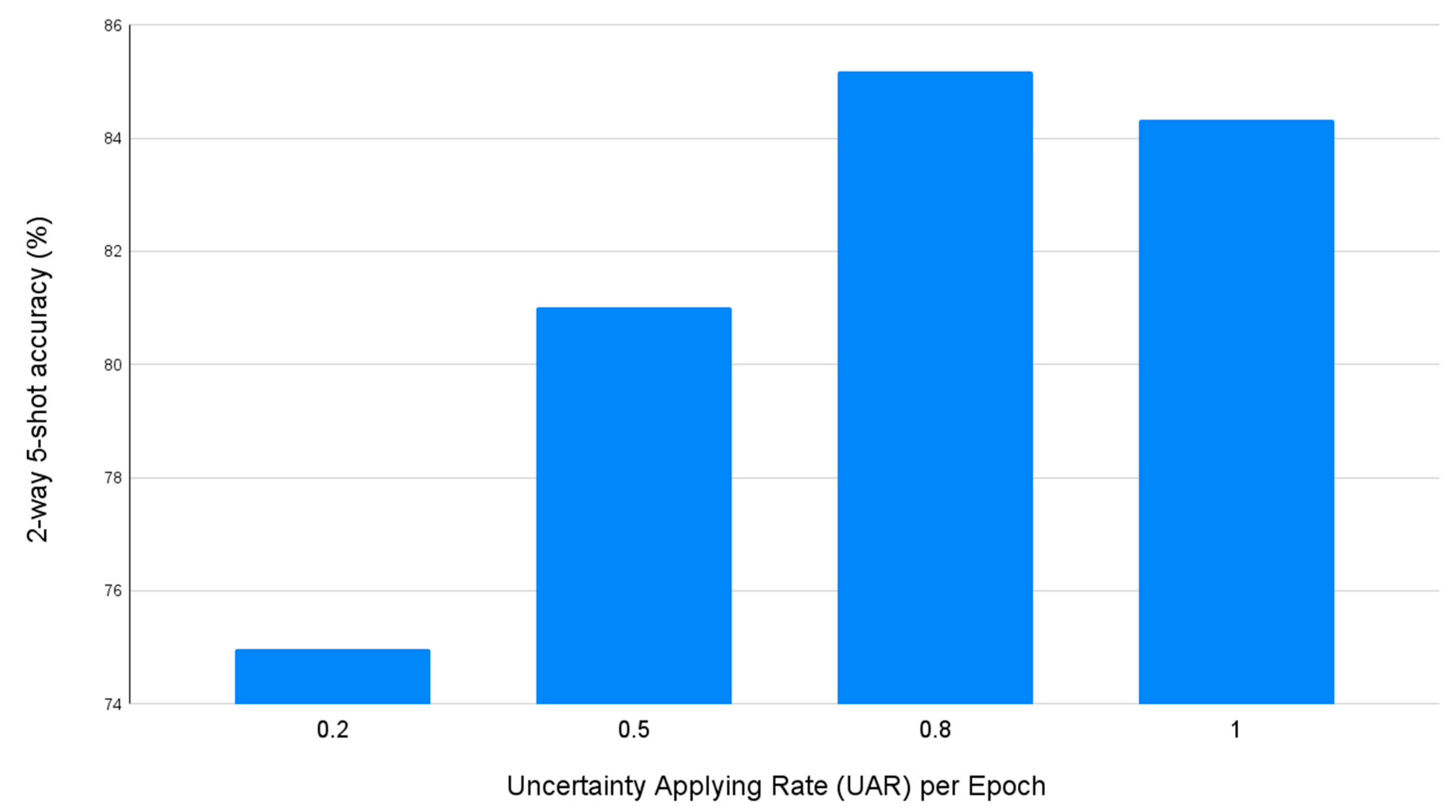
Next, in the learning process of the proposed UA-AML method, one can adjust the ratio of whether uncertainty is applied to the loss function or confidence in adjusting the gradients of the data using uncertainty. This ratio adjustment is made by replacing the uncertainty coefficient with confidence in the existing USB loss. Therefore, in this experiment, performance evaluation was performed by sequentially increasing the ratio of samples to which uncertainty is applied to 20%, 50%, 80%, and 100%. As shown in Figure 3, when the ratio selected as the hard sample was 20%, it showed the lowest performance. In contrast, when the ratio selected as the hard sample was 80%, it recorded 85.71% accuracy and showed the best performance. As a result of this experiment, it can be confirmed that the hard sample with high uncertainty has a positive effect on model learning, but the most positive learning effect appears only when the easy sample in an appropriate ratio is mixed. In addition, since these ratios may vary depending on the characteristics of each data or model, research on a methodology that can adaptively adjust the ratio is needed.
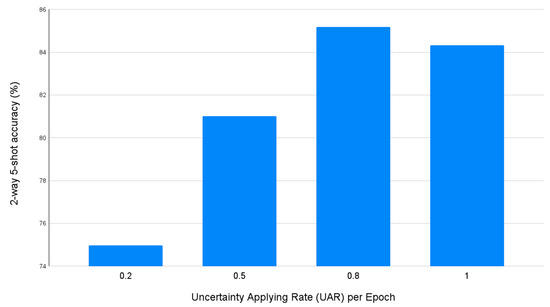
Figure 3.
Few-shot sentiment classification accuracy by Uncertainty Applying Rate (UAR).
5.4. Out of Scope Intent Detection
The CLINC150 dataset is a comprehensive benchmark designed to evaluate the performance of intent classification systems, particularly in the presence of out-of-scope (OOS) queries—queries that do not belong to any system-supported intent class. Unlike traditional datasets that only contain in-scope data, CLINC150 includes both 22,500 in-scope queries across 150 intent classes grouped into 10 domains and 1200 out-of-scope queries. Additionally, three variations in the dataset are available: Small, which limits in-scope training queries to 50 per intent instead of 100; Imbalanced, with a varying number of training queries (25, 50, 75, or 100 per intent); and a version where out-of-scope training data is expanded to 250 examples instead of 100. These variations simulate practical production scenarios where training data are often imbalanced or limited, making CLINC150 an essential benchmark for low-resource natural language understanding (NLU) tasks.
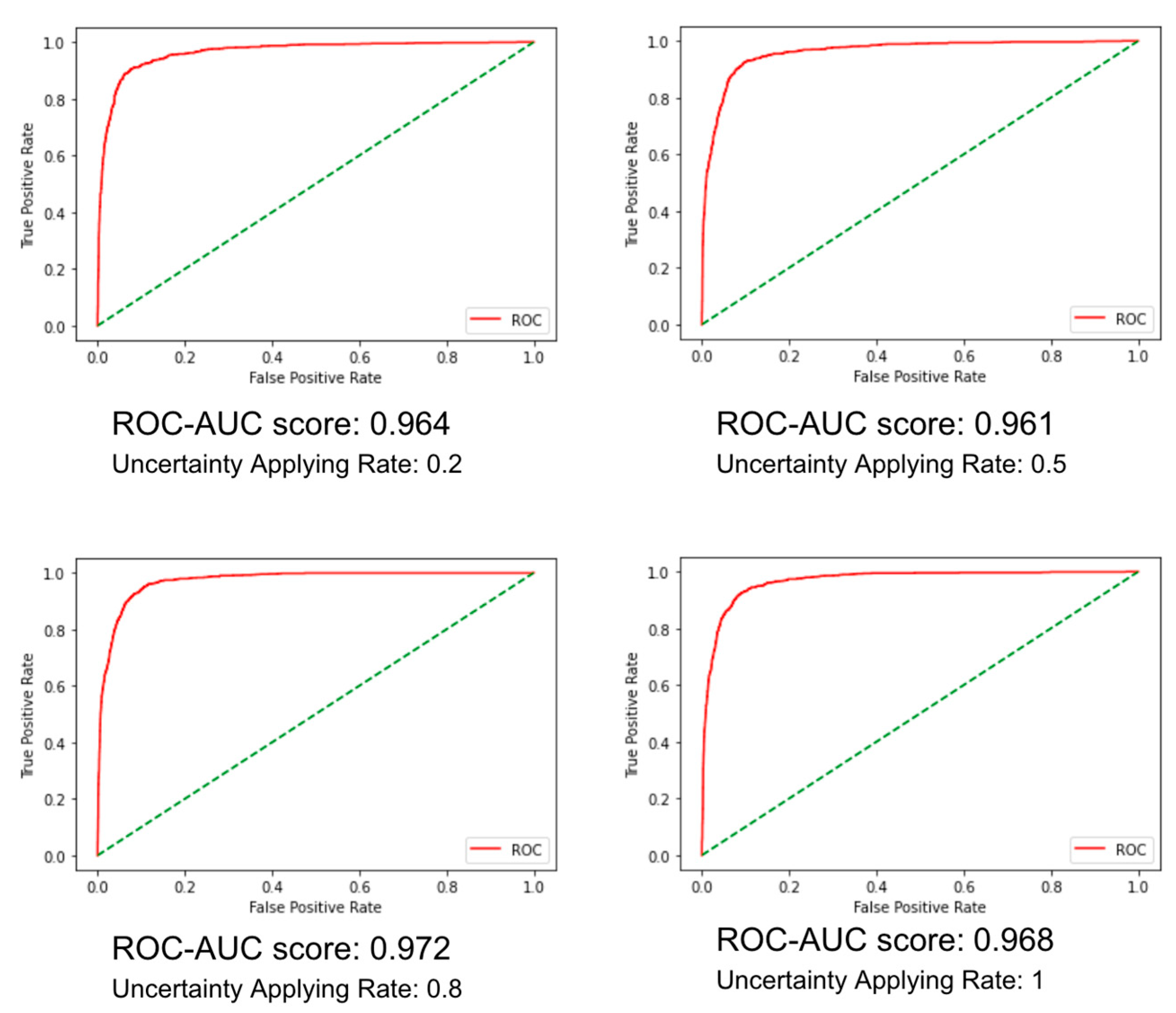
In the experiments, a BERT-based model with the SNGP methodology was used for out-of-scope classification, trained exclusively on in-scope data while uncertainty estimation techniques were applied. Comparative models included MC Dropout, Deep Ensemble, MCD-GP, DUQ, and other uncertainty-aware methods. Table 4 highlights that while most methods performed similarly on in-domain accuracy, Deep Ensemble achieved the highest performance but incurred high computational costs due to multi-model training and inference requirements. For out-of-scope detection, the proposed UA-AML SNGP model, enhanced with USB loss, outperformed other approaches with an AUROC of 0.972 and an AUPR of 0.884. Given the dataset imbalance of 4500 in-domain to 1000 OOS queries, AUPR was used to ensure balanced evaluation.
Table 4.
Out-of-scope detection results on CLINC150 dataset.
As shown in Figure 4, the Uncertainty Applying Rate (UAR) significantly impacted out-of-scope prediction. The best performance, with an ROC-AUC of 0.972, was recorded at an 80% UAR, reflecting an optimal balance between uncertainty estimation and prediction robustness. These results indicate that UA-AML SNGP effectively enhances out-of-scope intent detection while maintaining computational efficiency and robust uncertainty estimation. This makes it a compelling approach for practical applications where imbalanced and limited training data are common.
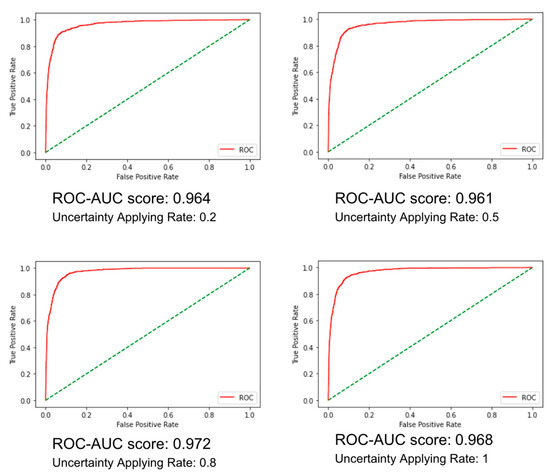
Figure 4.
ROC curve (in red) and ROC-AUC score by Uncertainty Applying Rate (UAR). The green dashed line represents the random guess baseline.
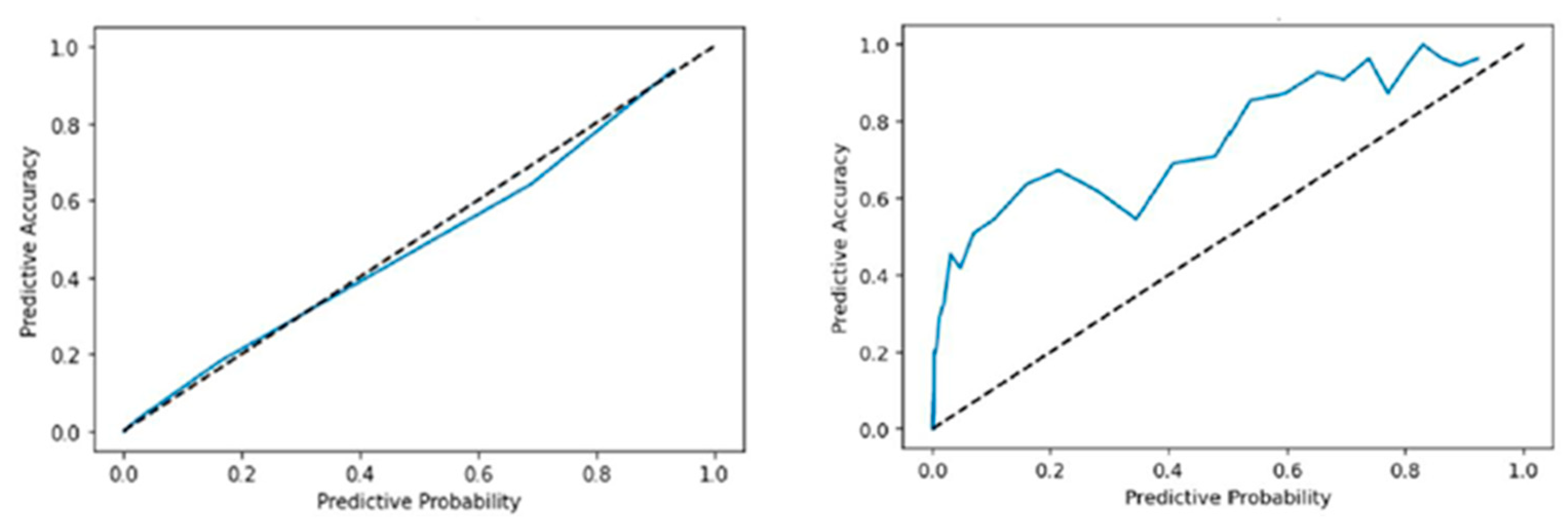
On the other hand, Figure 5 shows how calibrated the output confidence of the proposed model is. In the case of the existing SNGP, it shows very high calibration performance as a model for estimating uncertainty properly. In contrast, the method applying the proposed UA-AML SNGP model with USB loss has a higher ratio of actual accuracy, and the model underestimates the results. This can be inferred that the model has been trained to underestimate the overall model by training mainly on samples with high uncertainty and can indirectly explain the principle of the operation of the proposed methodology. As a result, the proposed UA-AML learning method can prevent overfitting by restricting the over-confidence output of the model and making low-confidence output for data not seen during training to more efficiently detect out-of-distribution.
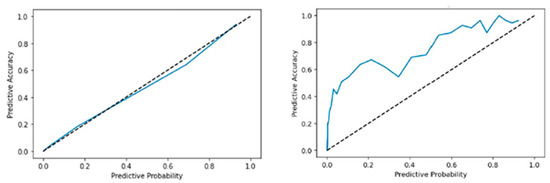
Figure 5.
Uncertainty Calibration Plots by Uncertainty (UAR) Applying Rate per Epoch comparing SNGP (left) and UA-AML + SNGP with Uncertainty Applying Rate: 0.8 (right). The blue line represents the model’s actual predictive accuracy at each predicted probability level, while the dashed black line indicates perfect calibration.
6. Conclusions
The issue of low-resource natural language understanding (NLU) presents a significant obstacle in the field of artificial intelligence, where the vast majority of models require large volumes of annotated data to perform well. However, such datasets are scarce or non-existent for many languages and specialized domains. This scarcity poses a challenge for developing robust NLU systems that can interpret and act upon human language with the same level of comprehension across diverse contexts.
Based on this awareness, this research proposes Uncertainty Aware Active Meta-Learning (UA-AML), a methodology that enables learning from informative data using uncertainty. It is shown through the experiments that the proposed methodology was applied to few-shot relation classification and few-shot sentiment classification, which are representative problems set as class-as-task and domain-as-task. As a result of such research, this study shows that the proposed meta-learning methodology can be effectively utilized in more diverse application fields by extending meta-learning research, mainly computer vision, to the field of natural language processing. In the future, it is necessary to research meta-learning methodologies suitable for diverse domain characteristics in natural language processing.
The findings suggest that UA-AML is a valuable addition to the toolkit of meta-learning strategies, extending its use beyond the realm of computer vision into natural language processing. This approach shows promise for a range of NLU applications, particularly where data are scarce. The research opens up new possibilities for future exploration in meta-learning for natural language understanding, indicating that UA-AML could be effectively adapted to various other NLU tasks with limited data resources.
While UA-AML introduces an efficient uncertainty-aware task selection framework, its deployment in real-world applications requires careful attention to ethical considerations, particularly regarding bias, fairness, and data sensitivity in low-resource settings. Since the model prioritizes high-uncertainty tasks, there is a potential risk that it may unintentionally amplify biases present in the dataset, as underrepresented or systematically mislabeled data may receive disproportionate weight during training. This could lead to biased model predictions, particularly in critical domains such as healthcare, finance, and legal AI applications. There needs to be further research exploring bias-aware uncertainty estimation techniques and fair task selection strategies to ensure that active learning prioritizes diverse and representative data without reinforcing existing biases. Furthermore, integrating explainability mechanisms to provide transparency into how uncertainty affects task selection can help mitigate ethical concerns and enhance trust in model predictions.
Future work could also explore alternative uncertainty quantification methods, such as Deep Ensembles, to assess whether they provide similar improvements as Monte Carlo Dropout while balancing computational efficiency and performance gains. Additionally, optimizing the computational efficiency of uncertainty estimation and active learning remains an important challenge, as the current approach introduces a computational overhead. Future research could focus on developing lightweight uncertainty estimation techniques or adaptive task selection strategies to improve efficiency while maintaining the benefits of uncertainty-aware learning. Furthermore, the principles of UA-AML could be extended beyond NLP to domains such as computer vision, speech recognition, and medical diagnosis, where Uncertainty-Aware Meta-Learning can enhance sample efficiency and generalization. Exploring these cross-domain applications will be an important direction for future work.
Author Contributions
Conceptualization, S.S.; Methodology, S.S.; Software, S.S.; Validation, S.S.; Investigation, H.D.; Resources, H.D.; Data curation, S.S.; Writing—original draft, H.D.; Writing—review and editing, S.S., H.D. and J.K.; Visualization, H.D.; Supervision, S.S. and J.K.; Project administration, J.K.; Funding acquisition, J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the MSIT (Ministry of Science and ICT), Korea, under the ITRC (Information Technology Research Center) support program (IITP-2025-2020-0-01789), the Artificial Intelligence Convergence Innovation Human Resources Development (IITP-2025-RS-2023-00254592) supervised by the IITP (Institute for Information and Communications Technology Planning and Evaluation), and the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (2021R1A2C2008414).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
We utilized publicly available datasets to train our models. The FewRel dataset, a large-scale few-shot relation extraction dataset, is accessible at https://github.com/thunlp/FewRel (last accessed on 10 February 2025). The ARSC (Amazon Review Sentiment Classification) dataset, containing sentiment-labeled reviews from various domains, can be found at https://github.com/asrcdataset/asrc (last accessed on 10 February 2025). The CLINC150 dataset, designed for intent classification and out-of-scope intent detection, is available at https://github.com/clinc/oos-eval (last accessed on 10 February 2025).
Acknowledgments
The writing process involved the use of AI language models. We declare that the authors reviewed and edited the content generated by these models to ensure accuracy and relevance.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, Z. Effective Transfer Learning for Low-Resource Natural Language Understanding. arXiv 2022, arXiv:2208.09180. [Google Scholar]
- Munaf, M.; Afzal, H.; Iltaf, N.; Mahmood, K. Low Resource Summarization Using Pre-Trained Language Models. ACM Trans. Asian Low Resource Lang. Inf. Process. 2024, 23, 1–19. [Google Scholar] [CrossRef]
- Dou, Z.-Y.; Yu, K.; Anastasopoulos, A. Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks. arXiv 2019, arXiv:1908.10423. [Google Scholar]
- Vettoruzzo, A.; Bouguelia, M.-R.; Vanschoren, J.; Rögnvaldsson, T.; Santosh, K.C. Advances and Challenges in Meta-Learning: A Technical Review. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 4763–4779. [Google Scholar]
- Conklin, H.; Wang, B.; Smith, K.; Titov, I. Meta-Learning to Compositionally Generalize. arXiv 2021, arXiv:2106.04252. [Google Scholar]
- Tian, H.; Liu, B.; Yuan, X.-T.; Liu, Q. Meta-Learning with Network Pruning. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Hui, S.; Zhou, S.; Deng, Y.; Wang, J. Understanding the Overfitting of the Episodic Meta-Training. arXiv 2023, arXiv:2306.16873. [Google Scholar]
- Rajendran, J.; Irpan, A.; Jang, E. Meta-Learning Requires Meta-Augmentation. arXiv 2020, arXiv:2007.05549. [Google Scholar]
- Xiao, Y.; Wang, W.Y. Quantifying Uncertainties in Natural Language Processing Tasks. Proc. AAAI Conf. Artif. Intell. 2019, 33, 7322–7329. [Google Scholar] [CrossRef]
- Ulmer, D. On Uncertainty In Natural Language Processing. arXiv 2024, arXiv:2410.03446. [Google Scholar]
- Hu, M.; Zhang, Z.; Zhao, S.; Huang, M.; Wu, B. Uncertainty in Natural Language Processing: Sources, Quantification, and Applications. arXiv 2023, arXiv:2306.04459. [Google Scholar]
- Hou, B.; Liu, Y.; Qian, K.; Andreas, J.; Chang, S.; Zhang, Y. Decomposing Uncertainty for Large Language Models through Input Clarification Ensembling. arXiv 2024, arXiv:2311.08718. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–17 June 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.-W. Unified Language Model Pre-Training for Natural Language Understanding and Generation. arXiv 2019, arXiv:1905.03197. [Google Scholar]
- Feng, S.Y.; Gangal, V.; Wei, J.; Chandar, S.; Vosoughi, S.; Mitamura, T.; Hovy, E. A Survey of Data Augmentation Approaches for NLP. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP, Bangkok, Thailand, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 968–988. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A Survey of Transfer Learning. J. Big Data 2016, 3, 1345–1459. [Google Scholar] [CrossRef]
- Bengio, Y. Deep Learning of Representations for Unsupervised and Transfer Learning. Workshop Conf. Proc. 2012, 27, 17–37. Available online: https://dl.acm.org/doi/10.5555/3045796.3045800 (accessed on 4 July 2023).
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. arXiv 2018, arXiv:1808.01974. [Google Scholar]
- Seo, S.; Na, S.; Kim, J. HMTL: Heterogeneous Modality Transfer Learning for Audio-Visual Sentiment Analysis. IEEE Access 2020, 8, 140426–140437. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. arXiv 2017, arXiv:1703.03400. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-Shot Learning. arXiv 2017. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. arXiv 2017, arXiv:1606.04080. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-Shot Image Recognition. CML Deep. Learn. Workshop 2015, 2, 1–8. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Geng, R.; Li, B.; Li, Y.; Zhu, X.; Jian, P.; Sun, J. Induction Networks for Few-Shot Text Classification. arXiv 2019, arXiv:1902.10482. [Google Scholar]
- Andrychowicz, M.; Denil, M.; Gomez, S.; Hoffman, M.W.; Pfau, D.; Schaul, T.; Shillingford, B.; de Freitas, N. Learning to Learn by Gradient Descent by Gradient Descent. arXiv 2016, arXiv:1606.04474. [Google Scholar]
- Kaddour, J.; Sæmundsson, S.; Deisenroth, M.P. Probabilistic Active Meta-Learning. arXiv 2020, arXiv:2007.08949. [Google Scholar]
- Graves, A.; Bellemare, M.G.; Menick, J.; Munos, R.; Kavukcuoglu, K. Automated Curriculum Learning for Neural Networks. In Proceedings of the 34th International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1311–1320. [Google Scholar]
- Yoo, D.; Kweon, I.S. Learning Loss for Active Learning. arXiv 2019, arXiv:1905.03677. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. arXiv 2016, arXiv:1506.02142. [Google Scholar]
- Farahani, A.; Pourshojae, B.; Rasheed, K.; Arabnia, H.R. A Concise Review of Transfer Learning. arXiv 2021, arXiv:2104.02144. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. arXiv 2020, arXiv:1911.02685. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Graves, A. Practical Variational Inference for Neural Networks. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Vancouver, CA, Canada, 6–9 December 2010; Curran Associates Inc.: Red Hook, NY, USA, 2011; pp. 2348–2356. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.-Y.; Song, Y.; Belongie, S. Class-Balanced Loss Based on Effective Number of Samples. arXiv 2019, arXiv:1901.05555. [Google Scholar]
- Gao, T.; Han, X.; Zhu, H.; Liu, Z.; Li, P.; Sun, M.; Zhou, J. FewRel 2.0: Towards More Challenging Few-Shot Relation Classification. arXiv 2019, arXiv:1910.07124. [Google Scholar]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, Bollywood, Boom-Boxes and Blenders: Domain Adaptation for Sentiment Classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; Zaenen, A., van den Bosch, A., Eds.; Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 440–447. [Google Scholar]
- Gao, T.; Han, X.; Xie, R.; Liu, Z.; Lin, F.; Lin, L.; Sun, M. Neural Snowball for Few-Shot Relation Learning. arXiv 2019, arXiv:1908.11007. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).