
Explainable Ensemble Learning Model for Residual Strength Forecasting of Defective Pipelines



Abstract
1. Introduction
2. Individual Methods
2.1. Machine Learning Algorithms
2.1.1. RF
2.1.2. LGB
2.1.3. SVM
2.1.4. GBRT
2.1.5. MLP
2.1.6. XGBoost
2.1.7. Hyper-Parameter Optimization of the Model
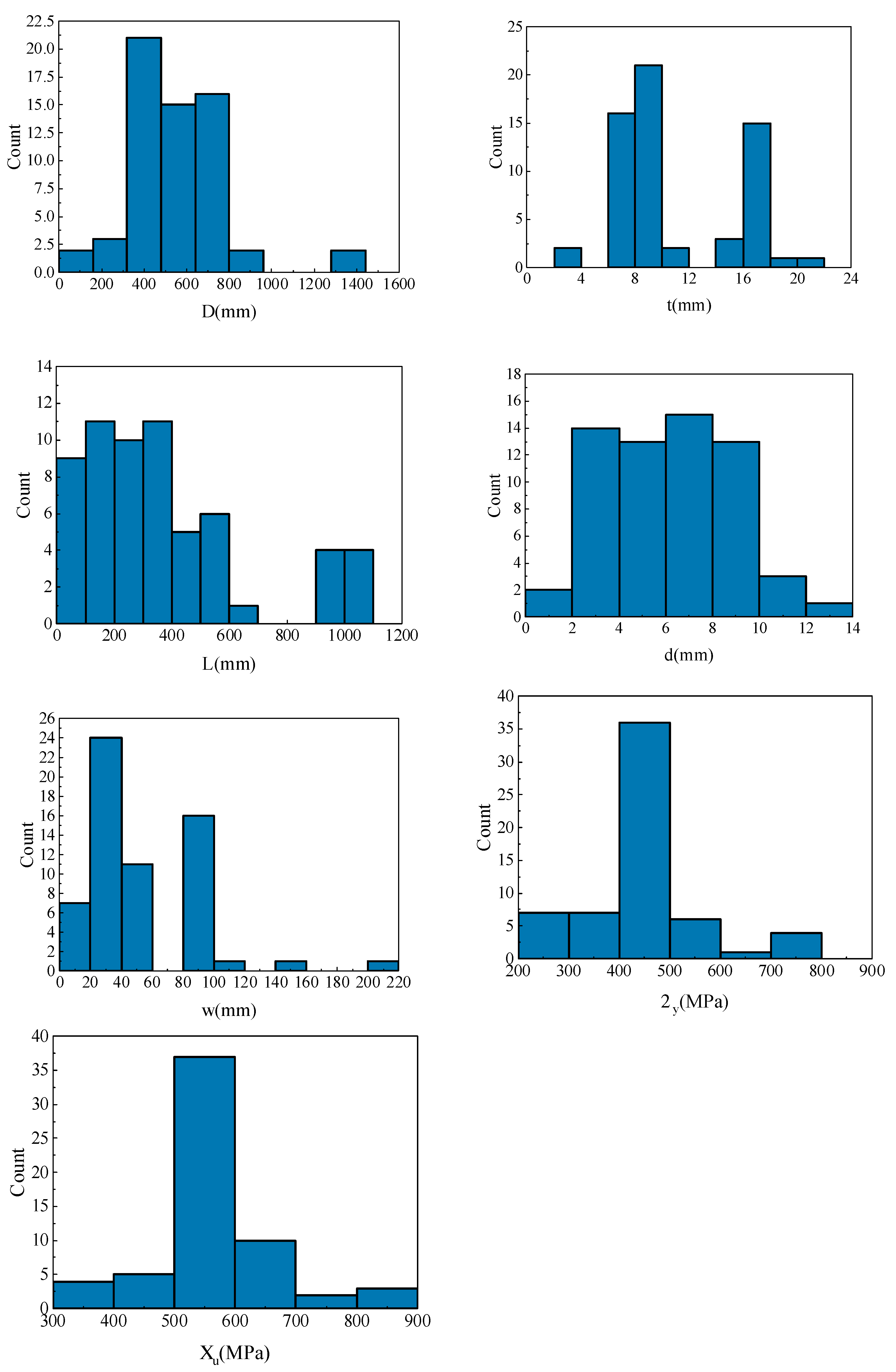
2.2. Data Collection
2.3. Data Processing
2.4. Evaluation Indexes of Models
2.5. Construction of Residual Strength Prediction Model
3. Case Study
3.1. Evaluation of Predictive Performance
3.2. Robustness Analysis of the BO-XGBoost Model
3.3. Overfitting Analysis of the BO-XGBoost Model
3.4. Grey Relational Analysis
3.5. SHAP Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, L.; Wang, Y.F.; Mo, L.; Tang, Y.F.; Wang, F.; Li, C.J. The research progress and prospect of data mining methods on corrosion prediction of oil and gas pipelines. Eng. Fail. Anal. 2023, 144, 106951. [Google Scholar]
- Li, X.H.; Liu, Y.Z.; Abbassi, R.; Khan, F.; Zhang, R.R. A Copula-Bayesian approach for risk assessment of decommissioning operation of aging subsea pipelines. Process Saf. Environ. Prot. 2022, 167, 412–422. [Google Scholar]
- Savanna, C.M.D.; Renato, D.S.M.; Silvana, M.B.A. An investigation on the collapse response of subsea pipelines with interacting corrosion defects. Eng. Struct. 2024, 321, 118911. [Google Scholar]
- Wen, J.; Zhang, C.; Xia, Y.Y.; Wang, C.X.; Sang, X.X.; Fang, H.Y.; Wang, N.N. UV/thermal dual-cured MWCNTs composites for pipeline rehabilitation: Mechanical properties and damage analysis. Constr. Build. Mater. 2024, 450, 138602. [Google Scholar]
- Velázquez, J.C.; González-Arévalo, N.E.; Dĺaz-Cruz, M.; Cervantes-Tonbón, A.; Herrera-Hernández, H.; Hernández-Sánchez, E. Failure pressure estimation for an aged and corroded oil and gas pipeline: A finite element study. J. Nat. Gas Sci. Eng. 2022, 101, 104532. [Google Scholar]
- Soomro, A.A.; Mokhtar, A.A.; Hussin, H.B.; Lashari, N.; Oladosu, T.L.; Jameel, S.M.; Inayat, M. Analysis of machine learning models and data sources to forecast burst pressure of petroleum corroded pipelines: A comprehensive review. Eng. Fail. Anal. 2024, 155, 107747. [Google Scholar]
- Xu, L.; Yu, P.F.; Wen, S.M.; Tang, Y.F.; Wang, Y.F.; Tian, Y.; Mao, T.; Li, C.J. Visualization and Analysis of Oil and Gas Pipeline Corrosion Research: A Bibliometric Data-Mining Approach. J. Pipeline Syst. Eng. Pract. 2024, 15, 04024017. [Google Scholar] [CrossRef]
- Kin, C.; Chen, L.; Wang, H.; Castandea, H. Global and local parameters for characterizing and modeling external corrosion in underground coated steel pipelines: A review of critical factors. J. Pipeline Sci. Eng. 2021, 1, 17–35. [Google Scholar]
- Zhou, R.; Gu, X.T.; Luo, X. Residual strength prediction of X80 steel pipelines containing group corrosion defects. Ocean Eng. 2023, 274, 114077. [Google Scholar]
- Sharples, J.; Hadley, I. Treatment of residual stress in fracture assessment: Background to the advice given in BS 7910, 2013. Int. J. Press. Vessel. Pip. 2018, 168, 323–334. [Google Scholar] [CrossRef]
- Miao, X.Y.; Zhao, H. Novel method for residual strength prediction of defective pipelines based on HTLBO-DELM model. Reliab. Eng. Syst. Saf. 2023, 237, 109369. [Google Scholar]
- Timashev, S.A.; Bushinskaya, A.V. Markov approach to early diagnostics, reliability assessment, residual life and optimal maintenance of pipeline systems. Struct. Saf. 2015, 56, 68–79. [Google Scholar]
- Garcĺa, D.; Burgos, J.B.; Chaparro, J.; Eicker, U.; Cárdenas, D.R.; Saldana-Robles, A. Analyzing joint efficiency in storage tanks: A comparative study of API 650 standard and API 579 using finite element analysis for enhanced reliability. Int. J. Press. Vessel. Pip. 2024, 207, 105113. [Google Scholar]
- Wei, W.L.; Zhang, R.; Zhang, Y.W.; Cheng, J.R.; Cao, Y.P.; Fang, F.Y. Study on the Residual Strength of Nonlinear Fatigue-Damaged Pipeline Structures. Appl. Sci. 2024, 14, 754. [Google Scholar] [CrossRef]
- Li, X.L.; Chen, G.T.; Liu, X.Y.; Ji, J.; Han, L.F. Analysis and Evaluation on Residual Strength of Pipelines with Internal Corrosion Defects in Seasonal Frozen Soil Region. Appl. Sci. 2021, 11, 12141. [Google Scholar] [CrossRef]
- Muda, M.F.; Hashim, M.H.M.; Kamarudin, M.K.; Mohd, M.H.; Tafsirojjaman, T.; Rahman, M.A.; Paik, J.K. Burst pressure strength of corroded subsea pipelines repaired with composite fiber-reinforced polymer patches. Eng. Fail. Anal. 2022, 136, 106204. [Google Scholar]
- Abyani, M.; Bahaari, M.R.; Zarrin, M.; Nasseri, M. Predicting failure pressure of the corroded offshore pipelines using an efficient finite element based algorithm and machine learning techniques. Ocean. Eng. 2022, 254, 111382. [Google Scholar]
- Chen, Z.F.; Li, X.Y.; Wang, W.; Li, Y.; Shi, L.; Li, Y.X. Residual strength prediction of corroded pipelines using multilayer perceptron and modified feedforward neural network. Reliab. Eng. Syst. Saf. 2023, 231, 108980. [Google Scholar]
- Li, X.H.; Jia, R.C.; Zhang, R.R. A data-driven methodology for predicting residual strength of subsea pipeline with double corrosion defects. Ocean Eng. 2023, 279, 114530. [Google Scholar] [CrossRef]
- Kumar, S.D.V.; Kai, M.L.Y.; Arumugam, T.; Karuppanan, S. A Review of Finite Element Analysis and Artificial Neural Networks as Failure Pressure Prediction Tools for Corroded Pipelines. Materials 2021, 14, 6135. [Google Scholar] [CrossRef]
- Sun, B.C.; Zhu, C.W.; Ling, X. Research on residual strength of pipeline with defects based on SVR. J. Saf. Sci. Technol. 2022, 18, 172–176. [Google Scholar]
- Peng, Y.D.; Fu, G.M.; Sun, B.J.; Chen, J.Y.; Zhang, W.G.; Ren, M.P.; Zhang, H. Data-driven collapse strength modelling for the screen pipes with internal corrosion defect based on finite element analysis and tree-based machine learning. Ocean Eng. 2023, 279, 114400. [Google Scholar] [CrossRef]
- Su, Y.; Li, J.F.; Yu, B.; Zhao, Y.L.; Yao, J. Fast and accurate prediction of failure pressure of oil and gas defective pipelines using the deep learning model. Reliab. Eng. Syst. Saf. 2021, 216, 108016. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Hyperopt: A Python Library for Optimizing the Hyperparameters of Machine Learning Algorithms. In Proceedings of the Python in Science Conference, Austin, TX, USA, 24–29 June 2013; pp. 13–19. [Google Scholar] [CrossRef]
- Nahiduzzaman, M.; Abdulrazak, L.F.; Ayari, M.A.; Khandakar, A.; Islam, S.M.R. A novel framework for lung cancer classification using lightweight convolutional neural networks and ridge extreme learning machine model with SHapley Additive exPlanations (SHAP). Expert Syst. Appl. 2024, 248, 123392. [Google Scholar]
- Jaramillo, J.P.; Munoz, C.; Arango, R.M.; Calderon, C.G.; Lange, A. Integrating multiple data sources for improved flight delay prediction using explainable machine learning. Res. Transp. Bus. Manag. 2024, 56, 101161. [Google Scholar]
- Sun, B.C.; Cui, W.J.; Liu, G.Y.; Zhou, B.; Zhao, W.J. A hybrid strategy of AutoML and SHAP for automated and explainable concrete strength prediction. Case Stud. Constr. Mater. 2023, 19, e02405. [Google Scholar] [CrossRef]
- Sheyyab, M.; Lynch, P.; Mayhew, P.; Brezinsky, K. Optimized synthetic data and semi-supervised learning for Derived Cetane Number prediction. Combust. Flame 2024, 259, 113184. [Google Scholar]
- Cheng, Y.; Huang, X.F.; Peng, Y.; Yang, S.Y.; Chen, G.M. A KPCA-BRANN based data-driven approach to model corrosion degradation of subsea oil pipelines. Environ. Pollut. 2023, 316, 120685. [Google Scholar] [PubMed]
- Wang, X.L.; Chen, A.R.; Liu, Y.Q. Explainable ensemble learning model for predicting steel section-concrete bond strength. Constr. Build. Mater. 2022, 356, 129239. [Google Scholar] [CrossRef]
- Bialek, J.; Bujalski, W.; Wojdan, K.; Guzek, M.; Kurek, T. Dataset level explanation of heat demand forecasting ANN with SHAP. Energy 2022, 261, 125075. [Google Scholar]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ke, G. Light GBM: A hightly efficient grasient boosting decision tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2021, 1189–1232. [Google Scholar] [CrossRef]
- Moshe, L.; Vladimir, Y.; Allan, P.; Schocken, S. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw. 1993, 6, 861–867. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the KDD’16: The 22nd ACM SIGKDD International Conferenceon Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Li, Y.R.; Zhang, Y.L.; Wang, J.C. Survey on Bayesian Optimization Methods for Hyper-Parameter Tuning. Comput. Sci. 2022, 49, 86–92. [Google Scholar] [CrossRef]
- Gao, J.; Yang, P.; Li, X.; Zhou, J.; Liu, J. K Analytical prediction of failure pressure for pipeline with long corrosion defect. Ocean Eng. 2019, 191, 106497. [Google Scholar] [CrossRef]
- Hens, A.B.; Tiwari, M.K. Computational time reduction for credit scoring: An integrated approach based on support vector machine and stratified sampling method. Expert Syst. Appl. 2012, 39, 6774–6781. [Google Scholar] [CrossRef]
- Xu, L.; Yu, J.; Zhu, Z.Y.; Man, J.F.; Yu, P.F.; Li, C.J.; Wang, X.T.; Zhao, Y.Q. Research and Application for Corrosion Rate Prediction of Natural Gas Pipelines Based on a Novel Hybrid Machine Learning Approach. Coatings 2023, 13, 856. [Google Scholar] [CrossRef]
- Lu, H.F.; Peng, H.Y.; Xu, Z.; Qin, G.J.; Azimi, M.; Matthews, J.; Cao, L. Theory and Machine Learning Modeling for Burst Pressure Estimation of Pipeline with Multipoint Corrosion. J. Pipeline Syst. Eng. Pract. 2023, 14, 1481. [Google Scholar] [CrossRef]
- Du, J.; Zheng, J.Q.; Liang, Y.T.; Xu, N.; Liao, Q.; Wang, B.H.; Zhang, H.R. Deeppipe: Theory-guided prediction method based automatic machine learning for maximum pitting corrosion depth of oil and gas pipeline. Chem. Eng. Sci. 2023, 278, 118927. [Google Scholar] [CrossRef]
- Davoodi, S.; Thanh, H.V.; Wood, D.; Mehrad, M.; Al-Shargabid, M.; Rukavishnikov, V. Committee machine learning: A breakthrough in the precise prediction of CO2 storage mass and oil production volumes in unconventional reservoirs. Geoenergy Sci. Eng. 2025, 245, 213533. [Google Scholar] [CrossRef]
- Xue, N.; Xu, S.H.; Shi, B. Study on statistical rule of surface corrosion depth of Q235 steel. Sichuan Build. Mater. 2013, 39, 117–118. [Google Scholar]
- Liu, C.L.; Yang, J.; Zhu, M.; Zhang, C.; Guan, J.; Xiao, N.J. Residual life prediction method of corroded pipelines based on normal distribution. Corros. Prot. 2023, 44, 100–106. [Google Scholar]
- Davoodi, S.; Thanh, H.V.; Wood, D.A.; Mehrad, M.; Muravyov, S.; Rukavishnikov, V. Carbon dioxide storage and cumulative oil production predictions in unconventional reservoirs applying optimized machine-learning models. Pet. Sci. 2025, 22, 296–323. [Google Scholar] [CrossRef]
- Wu, H.Y.; Lei, H.G.; Chen, Y. Grey relational analysis of static tensile properties of structural steel subjected to urban industrial atmospheric corrosion and accelerated corrosion. Constr. Build. Mater. 2022, 315, 125706. [Google Scholar]
- Wen, Z.P.; Liu, H.T.; Zhou, M.Q.; Liu, C.; Zhou, C.C. Explainable machine learning rapid approach to evaluate coal ash content based on X-ray fluorescence. Fuel 2023, 332, 125991. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Research Themes | Methods | Main Finding |
|---|---|---|---|
| Nahiduzzaman et al. (2024) [25] | Medical diagnosis | CNN-ELM | The proposed method exhibits high recognition accuracy. The SHAP can enhance the model’s interpretability, thus boosting confidence in lung cancer diagnosis. |
| Jaramillo et al. (2024) [26] | Flight delay prediction | SMOTE-ENN | The interpretable artificial intelligence method based on SHAP can accurately predict flight delays and offer actionable insights into the determinants of flight delays. |
| Sun et al. (2023) [27] | Concrete strength prediction | AutoML | The SHAP can provide a global interpretation of the impact of hybrid parameters on compressive strength, rendering the prediction process transparent and reliable. |
| Sheyyab et al. (2024) [28] | Combustion performance prediction | ANN | The SHAP can clarify the influence of different parameters on the prediction results of the combustion model. |
| Cheng et al. (2023) [29] | Environmental Pollution | XGBoost | This method demonstrates excellent prediction performance and can identify the impact of different emission sources on ozone formation. |
| Wang et al. (2022) [30] | Steel strength prediction | LightGBM | The constructed hybrid model is reliable. Combined with SHAP, it explains the contribution of basic features to LightGBM’s individual predictions. |
| Bialek et al. (2022) [31] | Energy demand forecasting | ANN | It accurately predicts energy demand based on SHAP and provides practical insights into the model’s internal principles. |
| Classification | Overall | Random | Stratified | Rand Error % | Strat Error % |
|---|---|---|---|---|---|
| 1 | 0.376 | 0.320 | 0.384 | 14.89 | −2.13 |
| 2 | 0.369 | 0.447 | 0.335 | −21.14 | 9.21 |
| 3 | 0.255 | 0.233 | 0.281 | 8.63 | −10.19 |
| Metric | Formulas | Best Performance Value |
|---|---|---|
| RE | Closest value to 0 | |
| R2 | Closest value to 1 | |
| MAPE | Minimum | |
| RMSE | Minimum |
| Target Parameter | SVM | MLP | LightGBM | RF | GBRT | BO-XGBoost |
|---|---|---|---|---|---|---|
| Residual strength forecasting | 0.042 | 0.037 | 0.025 | 0.021 | 0.016 | 0.011 |
| Testing Model | Data A |
|---|---|
| MLP | 0.824 |
| SVM | 0.835 |
| LightGBM | 0.860 |
| GBRT | 0.874 |
| RT | 0.896 |
| BO-XGBoost | 0.919 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Meng, X. Explainable Ensemble Learning Model for Residual Strength Forecasting of Defective Pipelines. Appl. Sci. 2025, 15, 4031. https://doi.org/10.3390/app15074031
Liu H, Meng X. Explainable Ensemble Learning Model for Residual Strength Forecasting of Defective Pipelines. Applied Sciences. 2025; 15(7):4031. https://doi.org/10.3390/app15074031
Chicago/Turabian StyleLiu, Hongbo, and Xiangzhao Meng. 2025. "Explainable Ensemble Learning Model for Residual Strength Forecasting of Defective Pipelines" Applied Sciences 15, no. 7: 4031. https://doi.org/10.3390/app15074031
APA StyleLiu, H., & Meng, X. (2025). Explainable Ensemble Learning Model for Residual Strength Forecasting of Defective Pipelines. Applied Sciences, 15(7), 4031. https://doi.org/10.3390/app15074031