
Enhancing Far-Field Speech Recognition with Mixer: A Novel Data Augmentation Approach


Abstract
:1. Introduction
2. Related Work
2.1. Far-Field ASR
2.2. Mixing Methods
3. Methods
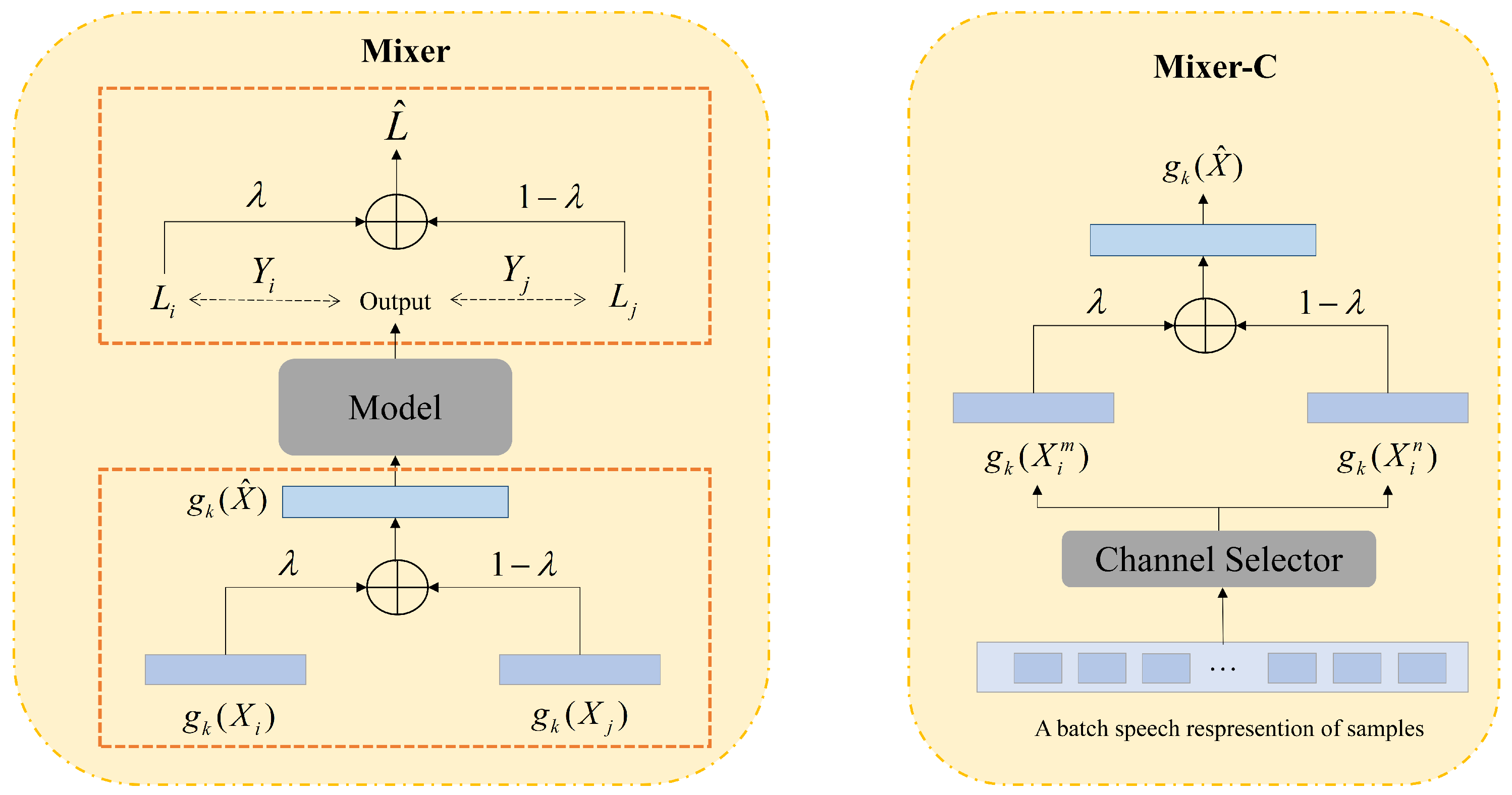
3.1. Model Structure
3.2. Mixing Methods
3.3. Mixer of FSR
3.4. Mixer-C of FSR
4. Experimental Setup
4.1. Datasets
4.2. Experimental Details
5. Results
5.1. Main Results
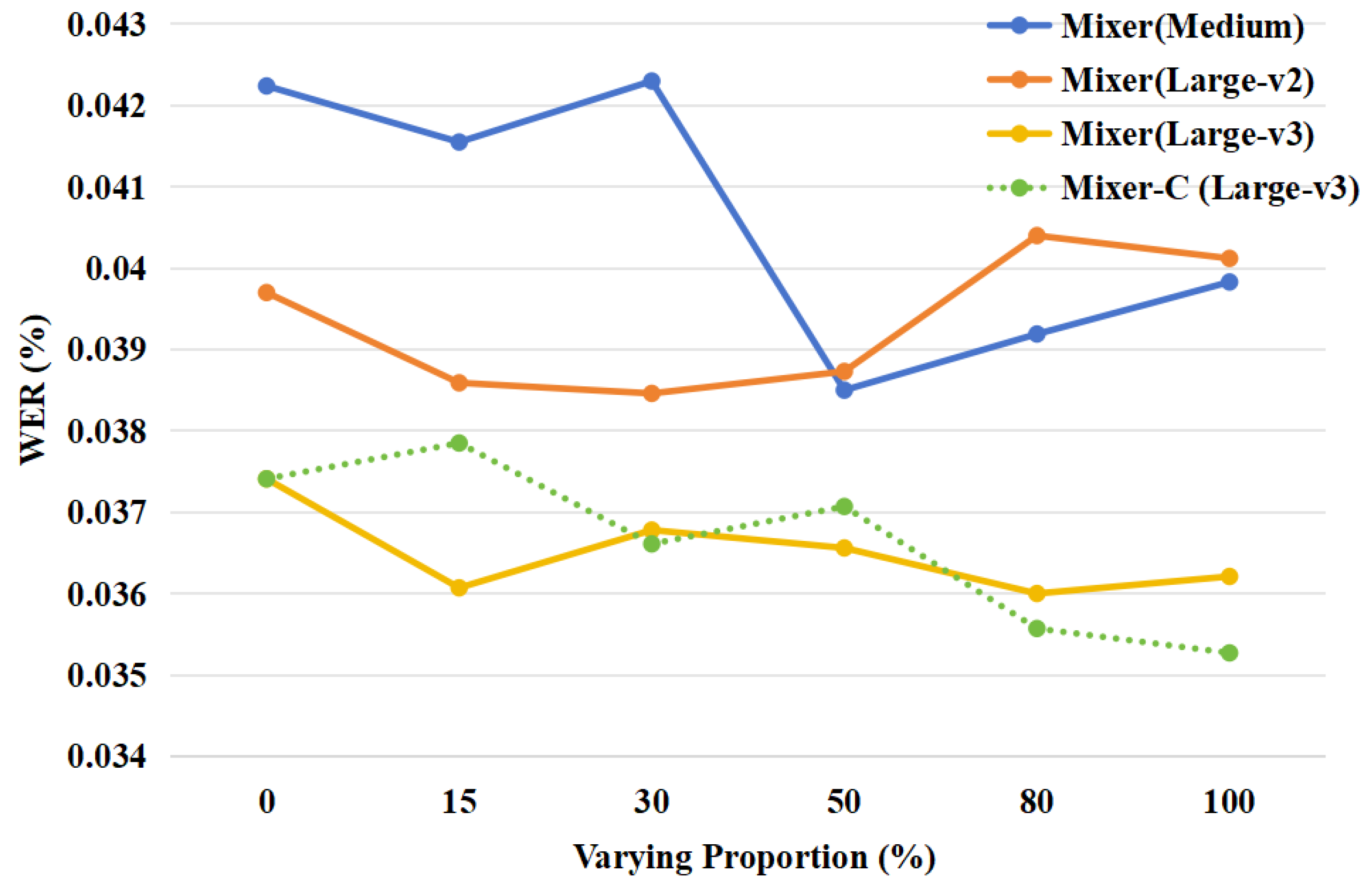
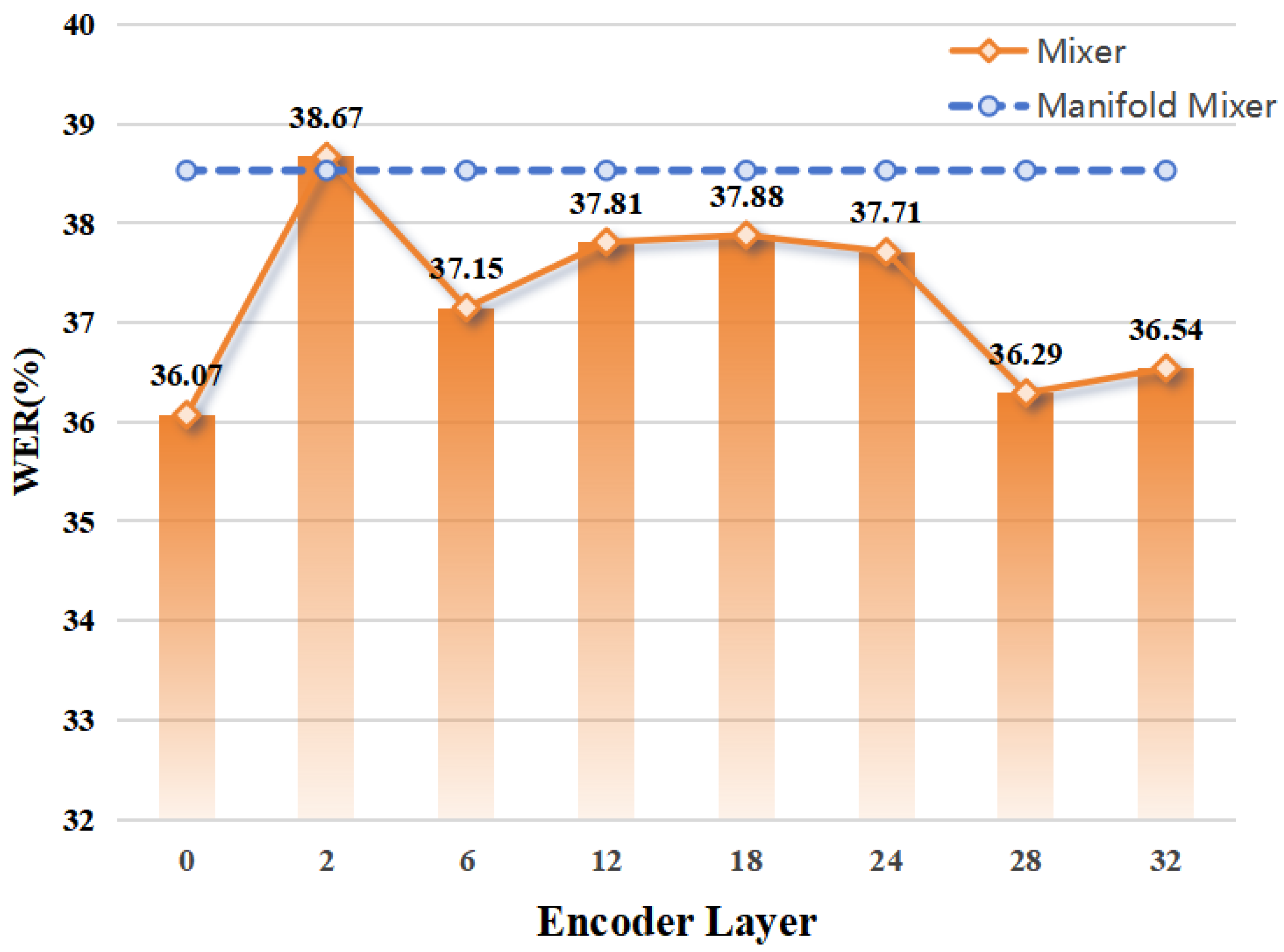
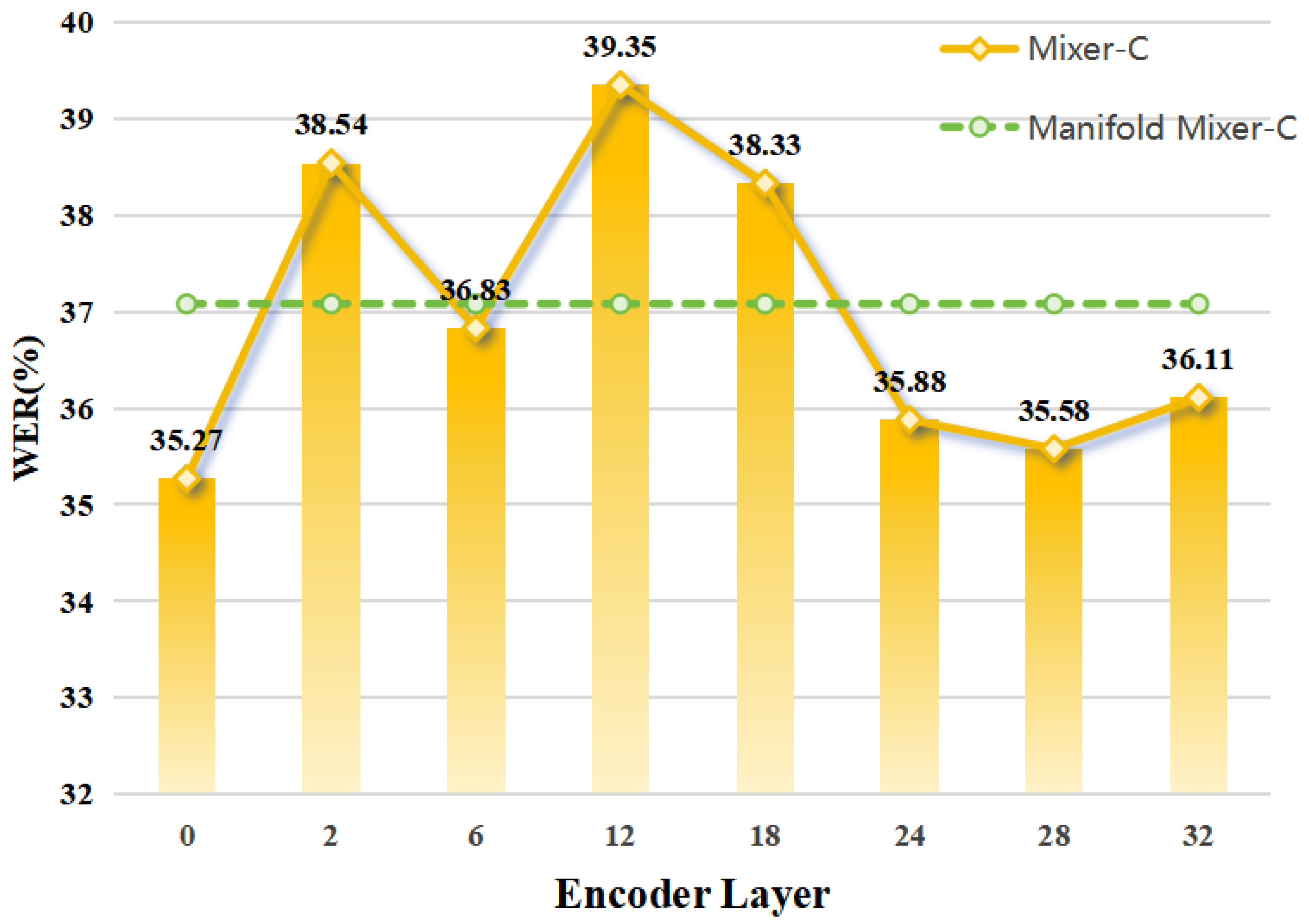
5.2. Method Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. In Proceedings of the International Conference on Machine Learning, ICML 2023, Honolulu, HI, USA, 23–29 July 2023; Proceedings of Machine Learning Research. Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J., Eds.; PMLR: New York, NY, USA, 2023; Volume 202, pp. 28492–28518. [Google Scholar]
- Pratap, V.; Tjandra, A.; Shi, B.; Tomasello, P.; Babu, A.; Kundu, S.; Elkahky, A.M.; Ni, Z.; Vyas, A.; Fazel-Zarandi, M.; et al. Scaling Speech Technology to 1000+ Languages. arXiv 2023, arXiv:2305.13516. [Google Scholar]
- Saon, G.; Tüske, Z.; Audhkhasi, K.; Kingsbury, B. Sequence Noise Injected Training for End-to-end Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6261–6265. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. In Proceedings of the 20th Annual Conference of the International Speech Communication Association, Interspeech 2019, Graz, Austria, 15–19 September 2019; Kubin, G., Kacic, Z., Eds.; ISCA: Grenoble, France, 2019; pp. 2613–2617. [Google Scholar] [CrossRef]
- Schrank, T.; Pfeifenberger, L.; Zöhrer, M.; Stahl, J.; Mowlaee, P.; Pernkopf, F. Deep beamforming and data augmentation for robust speech recognition: Results of the 4th CHiME challenge. Proc. CHiME 2016, 18–20. [Google Scholar] [CrossRef]
- Yalta, N.; Watanabe, S.; Hori, T.; Nakadai, K.; Ogata, T. CNN-based multichannel end-to-end speech recognition for everyday home environments. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Gaudesi, M.; Weninger, F.; Sharma, D.; Zhan, P. ChannelAugment: Improving Generalization of Multi-Channel ASR by Training with Input Channel Randomization. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2021, Cartagena, Colombia, 13–17 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 824–829. [Google Scholar] [CrossRef]
- Meng, L.; Xu, J.; Tan, X.; Wang, J.; Qin, T.; Xu, B. MixSpeech: Data augmentation for low-resource automatic speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, 25–29 April 2022. [Google Scholar]
- Karafiát, M.; Veselỳ, K.; Szöke, I.; Mošner, L.; Beneš, K.; Witkowski, M.; Barchi, G.; Pepino, L. BUT CHiME-7 system description. arXiv 2023, arXiv:2310.11921. [Google Scholar]
- Kovács, G.; Tóth, L.; Compernolle, D.V.; Liwicki, M. Examining the Combination of Multi-Band Processing and Channel Dropout for Robust Speech Recognition. In Proceedings of the 20th Annual Conference of the International Speech Communication Association, Interspeech 2019, Graz, Austria, 15–19 September 2019; Kubin, G., Kacic, Z., Eds.; ISCA: Grenoble, France, 2019; pp. 421–425. [Google Scholar] [CrossRef]
- Shimada, K.; Takahashi, N.; Takahashi, S.; Mitsufuji, Y. Sound event localization and detection using activity-coupled cartesian DOA vector and RD3Net. arXiv 2020, arXiv:2006.12014. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? Adv. Neural Inf. Process. Syst. 2017, 5580–5590. [Google Scholar]
- Zhang, H.; Cissé, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization, 2018. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Verma, V.; Lamb, A.; Beckham, C.; Najafi, A.; Mitliagkas, I.; Lopez-Paz, D.; Bengio, Y. Manifold mixup: Better representations by interpolating hidden states. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: New York, NY, USA, 2019; pp. 6438–6447. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Faramarzi, M.; Amini, M.; Badrinaaraayanan, A.; Verma, V.; Chandar, S. PatchUp: A Feature-Space Block-Level Regularization Technique for Convolutional Neural Networks. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022, Virtual Event, 22 February–1 March 2022; AAAI Press: Washington, DC, USA, 2022; pp. 589–597. [Google Scholar] [CrossRef]
- Guo, H.; Mao, Y.; Zhang, R. Augmenting Data with Mixup for Sentence Classification: An Empirical Study. arXiv 2019, arXiv:1905.08941. [Google Scholar]
- Yoon, S.; Kim, G.; Park, K. SSMix: Saliency-Based Span Mixup for Text Classification. In Proceedings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, 1–6 August 2021. [Google Scholar]
- Chen, J.; Yang, Z.; Yang, D. MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020. [Google Scholar]
- Chen, Y.; Jiao, X.; Zhang, H.; Yang, X.; Qu, D. MixLoss: A Data Augmentation Method for Sequence Generation Tasks. In Proceedings of the 2023 7th Asian Conference on Artificial Intelligence Technology (ACAIT), Jiaxing, China, 10–12 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 811–816. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; de Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-Efficient Transfer Learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Proceedings of Machine Learning Research. Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: New York, NY, USA, 2019; Volume 97, pp. 2790–2799. [Google Scholar]
- Thomas, B.; Kessler, S.; Karout, S. Efficient Adapter Transfer of Self-Supervised Speech Models for Automatic Speech Recognition. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7102–7106. [Google Scholar]
- Yang, C.H.; Li, B.; Zhang, Y.; Chen, N.; Prabhavalkar, R.; Sainath, T.N.; Strohman, T. From English to More Languages: Parameter-Efficient Model Reprogramming for Cross-Lingual Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2023, Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Gao, H.; Ni, J.; Qian, K.; Zhang, Y.; Chang, S.; Hasegawa-Johnson, M. WavPrompt: Towards Few-Shot Spoken Language Understanding with Frozen Language Models. In Proceedings of the 23rd Annual Conference of the International Speech Communication Association, Interspeech 2022, Incheon, Republic of Korea, 18–22 September 2022; Ko, H., Hansen, J.H.L., Eds.; ISCA: Grenoble, France, 2022; pp. 2738–2742. [Google Scholar] [CrossRef]
- Yang, C.H.; Tsai, Y.; Chen, P. Voice2Series: Reprogramming Acoustic Models for Time Series Classification. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Proceedings of Machine Learning Research. Meila, M., Zhang, T., Eds.; PMLR: New York, NY, USA, 2021; Volume 139, pp. 11808–11819. [Google Scholar]
- Carratino, L.; Cissé, M.; Jenatton, R.; Vert, J. On Mixup Regularization. arXiv 2020, arXiv:2006.06049. [Google Scholar]
- Zhang, L.; Deng, Z.; Kawaguchi, K.; Ghorbani, A.; Zou, J. How Does Mixup Help with Robustness and Generalization? In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021.
- Van Segbroeck, M.; Zaid, A.; Kutsenko, K.; Huerta, C.; Nguyen, T.; Luo, X.; Hoffmeister, B.; Trmal, J.; Omologo, M.; Maas, R. DiPCo–Dinner Party Corpus. arXiv 2019, arXiv:1909.13447. [Google Scholar]
- Mu, B.; Guo, P.; Guo, D.; Zhou, P.; Chen, W.; Xie, L. Automatic channel selection and spatial feature integration for multi-channel speech recognition across various array topologies. arXiv 2023, arXiv:2312.09746. [Google Scholar]
- Drude, L.; Heymann, J.; Boeddeker, C.; Haeb-Umbach, R. NARA-WPE: A Python package for weighted prediction error dereverberation in Numpy and Tensorflow for online and offline processing. In Proceedings of the Speech Communication; 13th ITG-Symposium, Oldenburg, Germany, 10–12 October 2018; VDE: Offenbach, Germany, 2018; pp. 1–5. [Google Scholar]
- Anguera, X.; Wooters, C.; Hernando, J. Acoustic beamforming for speaker diarization of meetings. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 2011–2022. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Whisper- | Whisper- | Whisper- | Whisper- | ||
|---|---|---|---|---|---|
| Small | Medium | Large-v2 | Large-v3 | Avg. | |
| Params | 0.4977 M | 1.1327 M | 2.2118 M | 2.2118 M | / |
| Testing | 46.98 | 42.76 | 46.11 | 42.04 | 44.47 |
| Finetune | 59.07 | 49.36 | / | / | / |
| LoRA | 52.65 | 39.70 | 42.24 | 37.41 | 43.00 |
| +SpecAugment [5] | 62.94 | 39.14 | 40.56 | 41.84 | 46.12 |
| +Mixer | 49.15 | 38.46 | 38.50 | 36.07 | 40.55 |
| +Mixer-C | 51.29 | 39.82 | 40.29 | 35.27 | 41.66 |
| 0.2 | 0.5 | 1 | 2 | 5 | 8 | |
| Mixer | 39.50 | 37.45 | 37.93 | 36.07 | 37.61 | 38.94 |
| Mixer-C | 35.72 | 36.77 | 36.20 | 35.27 | 37.43 | 36.82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, T.; Chen, Y.; Qu, D.; Hu, H. Enhancing Far-Field Speech Recognition with Mixer: A Novel Data Augmentation Approach. Appl. Sci. 2025, 15, 4073. https://doi.org/10.3390/app15074073
Niu T, Chen Y, Qu D, Hu H. Enhancing Far-Field Speech Recognition with Mixer: A Novel Data Augmentation Approach. Applied Sciences. 2025; 15(7):4073. https://doi.org/10.3390/app15074073
Chicago/Turabian StyleNiu, Tong, Yaqi Chen, Dan Qu, and Hengbo Hu. 2025. "Enhancing Far-Field Speech Recognition with Mixer: A Novel Data Augmentation Approach" Applied Sciences 15, no. 7: 4073. https://doi.org/10.3390/app15074073
APA StyleNiu, T., Chen, Y., Qu, D., & Hu, H. (2025). Enhancing Far-Field Speech Recognition with Mixer: A Novel Data Augmentation Approach. Applied Sciences, 15(7), 4073. https://doi.org/10.3390/app15074073