
Spatiotemporal Feature Enhancement for Lip-Reading: A Survey


Abstract
1. Introduction
2. Classification of Lip-Reading Methods
2.1. Lip-Reading Methods Based on Machine Learning
2.2. Lip-Reading Methods Based on Visual Features
2.3. Lip-Reading Methods Based on Spatiotemporal Features
2.4. Lip-Reading Methods Based on Spiking Neural Networks
3. Spatiotemporal Feature Enhancement Methods
3.1. Spatiotemporal Feature Enhancement Based on Spatial Features
3.1.1. Spatial Feature Enhancement Based on ResNet

3.1.2. Spatial Feature Enhancement Based on DenseNet

3.1.3. Spatial Feature Enhancement Based on Lightweight Networks
3.1.4. Other Spatial Feature Enhancement Methods
3.2. Spatiotemporal Feature Enhancement Based on Spatiotemporal Convolution
3.2.1. Three-Dimensional Spatiotemporal Convolution Enhancement
3.2.2. Two-Dimensional Spatiotemporal Convolution Enhancement
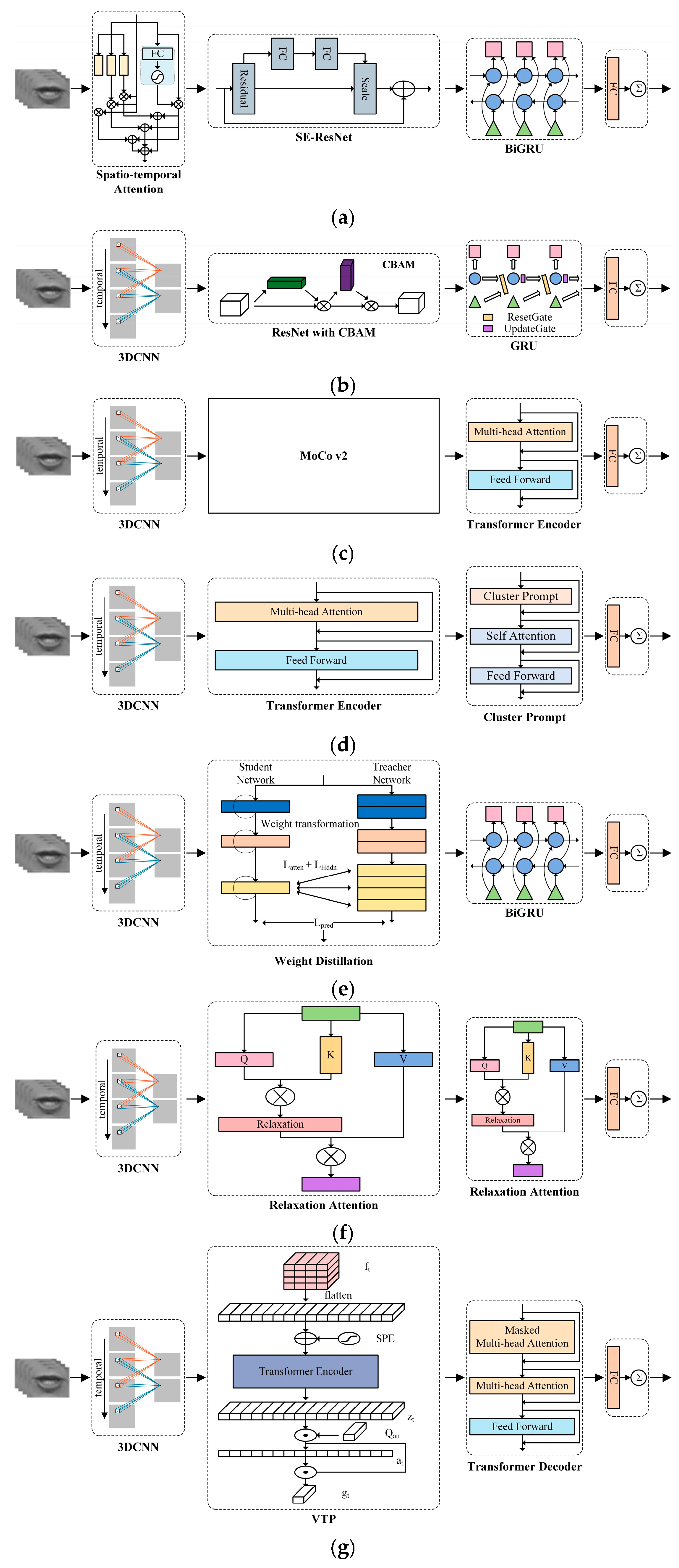
3.3. Spatiotemporal Feature Enhancement Based on Attention
3.3.1. Spatiotemporal Feature Enhancement Based on Channel Attention
3.3.2. Spatiotemporal Feature Enhancement Based on Hybrid Attention
3.3.3. Spatiotemporal Feature Enhancement Based on Self-Attention
3.4. Spatiotemporal Feature Enhancement Based on Pulse Features
3.4.1. Spatiotemporal Feature Enhancement Based on Event Cameras
3.4.2. Spatiotemporal Feature Enhancement Based on Spiking Neural Networks

3.5. Spatiotemporal Feature Enhancement Based on Audio-Visual Assisting
3.5.1. Audio Features Assisting Visual Recognition
3.5.2. Visual Features Assisting Audio Recognition
3.6. Other Spatiotemporal Feature Enhancement Methods


4. Difficulties and Challenges
4.1. Feature Alignment
4.2. Visual Ambiguity
4.3. Semantic Integrity
4.4. Feature Redundancy
5. Research Trends
5.1. Development of Time Convolution
5.2. Integration of Event Cameras and SNN
5.3. Multimodal Approaches
5.4. Large Models
5.5. Lightweight Models
5.6. Multi-Language Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Chen, H.; Li, W.; Cheng, Z.; Liang, X.; Zhang, Q. TCS-LipNet: Temporal & Channel & Spatial Attention-Based Lip Reading Network. In Proceedings of the International Conference on Artificial Neural Networks, Heraklion, Crete, Greece, 26–29 September 2023; pp. 413–424. [Google Scholar]
- Ma, P.; Wang, Y.; Petridis, S.; Shen, J.; Pantic, M. Training Strategies for Improved Lip-Reading. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 8472–8476. [Google Scholar]
- Preethi, S.J. Analyzing lower half facial gestures for lip reading applications: Survey on vision techniques. Comput. Vis. Image Underst. 2023, 233, 103738. [Google Scholar]
- Fenghour, S.; Chen, D.; Guo, K.; Li, B.; Xiao, A.P. Deep Learning-Based Automated Lip-Reading: A Survey. IEEE Access 2021, 9, 3107946. [Google Scholar]
- Pu, G.; Wang, H. Review on research progress of machine lip reading. Vis. Comput. 2023, 39, 3041–3057. [Google Scholar]
- Lu, Y.; Yan, J.; Gu, K. Review on Automatic Lip Reading Techniques. Int. J. Pattern Recognit. Artifcial Intell. 2018, 32, 1856007. [Google Scholar]
- Sheng, C.; Kuang, G.; Bai, L.; Hou, C.; Guo, Y.; Xu, X.; Pietikäinen, M.; Liu, L. Deep Learning for Visual Speech Analysis: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 6001–6022. [Google Scholar]
- Prabhavalkar, R.; Hori, T.; Sainath, T.N.; Schlüter, R.; Watanabe, S. End-to-End Speech Recognition: A Survey. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 325–351. [Google Scholar]
- Santos, C.; Cunha, A.; Coelho, P. A Review on Deep Learning-Based Automatic Lipreading. In Proceedings of the International Conference on Wireless Mobile Communication and Healthcare, Vila Real, Portugal, 29–30 November 2023; pp. 180–195. [Google Scholar]
- Oghbaie, M.; Sabaghi, A.; Hashemifard, K.; Akbari, M. Advances and Challenges in Deep Lip Reading. arXiv 2021, arXiv:2110.07879. [Google Scholar]
- Wang, C. Multi-grained spatio-temporal modeling for lip-reading. arXiv 2019, arXiv:1908.11618. [Google Scholar]
- Zhang, X.; Cheng, F.; Shilin, W. Spatio-Temporal Fusion Based Convolutional Sequence Learning for Lip Reading. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 713–722. [Google Scholar]
- Liu, Q.; Ge, M.; Li, H. Intelligent event-based lip reading word classification with spiking neural networks using spatio-temporal attention features and triplet loss. Inf. Sci. 2024, 675, 120660. [Google Scholar]
- Dampfhoffer, M.; Mesquida, T. Neuromorphic Lip-reading with signed spiking gated recurrent units. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 2141–2151. [Google Scholar]
- Morade, S.S.; Patnaik, S. Visual Lip Reading using 3D-DCT and 3D-DWT and LSDA. Int. J. Comput. Appl. 2016, 136, 7–15. [Google Scholar]
- Morade, S.S.; Patnaik, S. Lip reading using DWT and LSDA. In Proceedings of the 2014 IEEE International Advance Computing Conference (IACC), Gurgaon, India, 21–22 February 2014; pp. 1013–1018. [Google Scholar]
- Potamianos, G.; Graf, H.P.; Cosatto, E. An image transform approach for HMM based automatic lipreading. In Proceedings of the 1998 International Conference on Image Processing, Chicago, IL, USA, 7 October 1998; pp. 173–177. [Google Scholar]
- Yu, K.; Jiang, X.; Bunke, H. Lipreading using Fourier transform over time. In Proceedings of the Computer Analysis of Images and Patterns, Kiel, Germany, 10–12 September 1997; pp. 472–479. [Google Scholar]
- Lan, Y.; Harvey, R.; Theobald, B.-J. Insights into machine lip reading. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4825–4828. [Google Scholar]
- Deypir, M.; Alizadeh, S.; Zoughi, T.; Boostani, R. Boosting a multi-linear classifier with application to visual lip reading. Expert Syst. Appl. 2011, 38, 941–948. [Google Scholar] [CrossRef]
- Lin, B.-S.; Yao, Y.-H.; Liu, C.-F.; Lien, C.-F.; Lin, B.-S. Development of Novel Lip-Reading Recognition Algorithm. IEEE Access 2017, 5, 794–801. [Google Scholar] [CrossRef]
- Mase, K.; Pentland, A. Automatic Lip reading by optical flow analysis. Syst. Comput. Jpn. 1991, 22, 67–76. [Google Scholar] [CrossRef]
- Tamura, S.; Iwano, K.; Furui, S. Multi-Modal Speech Recognition Using Optical-Flow Analysis for Lip Images. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 36, 117–124. [Google Scholar] [CrossRef]
- Ma, X.; Yan, L.; Zhong, Q. Lip Feature Extraction Based on Improved Jumping-Snake Model. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; pp. 6928–6933. [Google Scholar]
- Wu, W.; Kuruoglu, E.E.; Wang, S.; Li, S.; Li, J. Automatic Lip Contour Extraction Using Both Pixel-Based and Parametric Models. Chin. J. Electron. 2013, 22, 76–82. [Google Scholar]
- Chen, J.; Tiddeman, B.; Zhao, G. Real-Time Lip Contour Extraction and Tracking Using an Improved Active Contour Model. In Proceedings of the 4th International Symposium (ISVC), Las Vegas, NV, USA, 1–3 December 2008; pp. 236–245. [Google Scholar]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active Appearance Models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef]
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active Shape Models-Their Training and Application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef]
- Haque, S.; Togneri, R.; Bennamoun, M.; Sui, C. A lip extraction algorithm using region-based ACM with automatic contour initialization. In Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision (WACV), Clearwater Beach, FL, USA, 15–17 January 2013; pp. 275–280. [Google Scholar]
- Petajan, E.D. Automatic Lipreading to Enhance Speech Recognition (Speech Reading). Ph.D. Thesis, Electrical Engineering, University of Illinois at Urbana, Champaign, IL, USA, 1984; p. 261. [Google Scholar]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Matthews, I.; Cootes, T.F.; Bangham, J.A.; SCox, R.H. Extraction of visual features for lipreading. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 198–213. [Google Scholar] [CrossRef]
- Ibrahim, M.Z.; Mulvaney, D.J. Geometrical-based lip-reading using template probabilistic multi-dimension dynamic time warping. J. Vis. Commun. Image Represent. 2015, 30, 219–233. [Google Scholar] [CrossRef]
- Bregler, C.; Hild, H.; Manke, S.; Waibe, A. Improving connected letter recognition by lipreading. In Proceedings of the 1993 IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, MN, USA, 27–30 April 1993; pp. 557–560. [Google Scholar]
- Morade, S.S.; Patnaik, S. Comparison of classifiers for lip reading with CUAVE and TULIPS database. Optik 2015, 126, 5753–5761. [Google Scholar]
- Pei, Y.; Kim, T.-K.; Zha, H. Unsupervised Random Forest Manifold Alignment for Lipreading. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 129–136. [Google Scholar]
- Rathod, S.B.; Mahajan, R.A.; Agrawal, P.; Patil, R.R.; Verma, D.A. Enhancing Lip Reading: A Deep Learning Approach with CNN and RNN Integration. J. Electr. Syst. 2024, 20, 463–471. [Google Scholar]
- Wang, H.; Pu, G.; Chen, T. A lip reading method based on 3D convolutional vision transformer. IEEE Access 2022, 10, 77205–77212. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten LV, D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 1–11. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Schmidt, R.M. Recurrent Neural Networks (RNNs): A gentle Introduction and Overview. arXiv 2019, arXiv:1912.05911. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd International Conference on Machine Learning (ICML), Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Ni, R.; Jiang, H.; Zhou, L.; Lu, Y. Lip Recognition Based on Bi-GRU with Multi-Head Self-Attention. In Proceedings of the International Conference on Artificial Intelligence Applications and Innovations, Corfu, Greece, 27–30 June 2024; pp. 99–110. [Google Scholar]
- Miled, M.; Messaoud, M.a.B.; Bouzid, A. Lip reading of words with lip segmentation and deep learning. Multimed. Tools Appl. 2022, 82, 551–571. [Google Scholar]
- Atila, Ü.; Sabaz, F. Turkish lip-reading using Bi-LSTM and deep learning models. Eng. Sci. Technol. Int. J. 2022, 35, 101206. [Google Scholar]
- Ma, P.; Wang, Y.; Shen, J.; Petridis, S.; Pantic, M. Lip-reading with Densely Connected Temporal Convolutional Networks. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2856–2865. [Google Scholar]
- Jeon, S.; Kim, M.S. End-to-End Sentence-Level Multi-View Lipreading Architecture with Spatial Attention Module Integrated Multiple CNNs and Cascaded Local Self-Attention-CTC. Sensors 2022, 9, 3597. [Google Scholar]
- Liu, Q.; Xing, D.; Tang, H.; Ma, D.; Pan, G. Event-based action recognition using motion information and spiking neural networks. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal-themed Virtual Reality, Montreal, QC, Canada, 19–26 August 2021; pp. 1743–1749. [Google Scholar]
- Kasabov, N.; Capecci, E. Spiking neural network methodology for modelling, classification and understanding of EEG spatio-temporal data measuring cognitive processes. Inf. Sci. 2015, 294, 565–575. [Google Scholar] [CrossRef]
- Luo, M.; Yang, S.; Chen, X.; Liu, Z.; Shan, S. Synchronous bidirectional learning for multilingual lip reading. arXiv 2020, arXiv:2005.03846. [Google Scholar]
- Zhang, X.; Zhang, C.; Sui, J.; Sheng, C.; Deng, W.; Liu, L. Boosting lip reading with a multi-view fusion network. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Xiao, Y.; Teng, L.; Liu, X.; Zhu, A. Exploring complementarity of global and local information for effective lip reading. J. Electron. Imaging 2023, 32, 023001. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Q.; Du, J.; Wan, G.-S.; Xiong, S.-F.; Yin, B.-C.; Pan, J.; Lee, C.-H. Collaborative Viseme Subword and End-to-end Modeling for Word-level Lip Reading. IEEE Trans. Multimed. 2024, 26, 9358–9371. [Google Scholar] [CrossRef]
- Chen, H.; Du, J.; Hu, Y.; Dai, L.-R.; Lee, C.-H.; Yin, B.-C. Lip-reading with hierarchical pyramidal convolution and self-attention. arXiv 2020, arXiv:2012.14360. [Google Scholar]
- Stafylakis, T.; Tzimiropoulos, G. Combining residual networks with LSTMs for lipreading. arXiv 2017, arXiv:1703.04105. [Google Scholar]
- Mudaliar, N.K.; Hegde, K.; Ramesh, A.; Patil, V. Visual speech recognition: A deep learning approach. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 1218–1221. [Google Scholar]
- Fenghour, S.; Chen, D.; Guo, K.; Xiao, P. Lip reading sentences using deep learning with only visual cues. IEEE Access 2020, 8, 215516–215530. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, W.; Xu, J.; Wang, Y. Lip Reading Based on 3D Face Modeling and Spatial Transformation Learning. In Proceedings of the 2021 7th International Conference on Computer and Communications (ICCC), Chengdu, China, 10–13 December 2021; pp. 965–969. [Google Scholar]
- Jiang, J.; Zhao, Z.; Yang, Y.; Tian, W. GSLip: A Global Lip-Reading Framework with Solid Dilated Convolutions. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Arakane, T.; Saitoh, T. Efficient DNN Model for Word Lip-Reading. Algorithms 2023, 16, 269. [Google Scholar] [CrossRef]
- Xiao, J.; Yang, S.; Zhang, Y.; Shan, S.; Chen, X. Deformation flow based two-stream network for lip reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 364–370. [Google Scholar]
- El-Bialy, R.; Chen, D.; Fenghour, S.; Hussein, W.; Xiao, P.; Karam, O.H.; Li, B. Developing phoneme-based lip-reading sentences system for silent speech recognition. CAAI Trans. Intell. Technol. 2023, 8, 129–138. [Google Scholar] [CrossRef]
- Zeng, Q.; Du, J.; Wang, Z. HMM-based Lip Reading with Stingy Residual 3D Convolution. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 1438–1443. [Google Scholar]
- Sun, B.; Xie, D.; Luo, D.; Yin, X. A Lipreading Model Based on Fine-Grained Global Synergy of Lip Movement. In Proceedings of the 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI), Macao, China, 31 October–2 November 2022; pp. 848–854. [Google Scholar]
- Huang, A.; Zhang, X. Dual-flow Spatio-temporal Separation Network for Lip Reading. J. Phys. Conf. Ser. 2022, 2400, 012028. [Google Scholar] [CrossRef]
- Xu, K.; Li, D.; Cassimatis, N.; Wang, X. LCANet: End-to-end lipreading with cascaded attention-CTC. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 548–555. [Google Scholar]
- He, L.; Ding, B.; Wang, H.; Zhang, T. An optimal 3D convolutional neural network based lipreading method. IET Image Process. 2022, 16, 113–122. [Google Scholar] [CrossRef]
- Bi, C.; Zhang, D.; Yang, L.; Chen, P. An lipreading Modle with DenseNet and E3D-LSTM. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 511–515. [Google Scholar]
- Jeon, S.; Kim, M.S. End-to-end lip-reading open cloud-based speech architecture. Sensors 2022, 22, 2938. [Google Scholar] [CrossRef] [PubMed]
- Wen, J.; Lu, Y. Automatic lip reading system based on a fusion lightweight neural network with Raspberry Pi. Appl. Sci. 2019, 9, 5432. [Google Scholar] [CrossRef]
- Jeevakumari, S.A.; Dey, K. LipSyncNet: A Novel Deep Learning Approach for Visual Speech Recognition in Audio-Challenged Situations. IEEE Access 2024, 12, 110891–110904. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, Y. Research on a Lip Reading Algorithm Based on Efficient-GhostNet. Electronics 2023, 12, 1151. [Google Scholar] [CrossRef]
- Fu, Y.; Lu, Y.; Ni, R. Chinese lip-reading research based on ShuffleNet and CBAM. Appl. Sci. 2023, 13, 1106. [Google Scholar] [CrossRef]
- Li, Y.; Hashim, A.S.; Lin, Y.; Nohuddin, P.N.; Venkatachalam, K.; Ahmadian, A. AI-based visual speech recognition towards realistic avatars and lip-reading applications in the metaverse. Appl. Soft Comput. 2024, 164, 111906. [Google Scholar] [CrossRef]
- Sumanth, S.; Jyosthana, K.; Reddy, J.K.; Geetha, G. Computer Vision Lip Reading(CV). In Proceedings of the 2022 International Conference on Advancements in Smart, Secure and Intelligent Computing (ASSIC), Bhubaneswar, India, 19–20 November 2022; pp. 1–6. [Google Scholar]
- Koumparoulis, A.; Potamianos, G. Accurate and resource-efficient lipreading with efficientnetv2 and transformers. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 8467–8471. [Google Scholar]
- Sarhan, A.M.; Elshennawy, N.M.; Ibrahim, D.M. HLR-net: A hybrid lip-reading model based on deep convolutional neural networks. Comput. Mater. Contin. 2021, 68, 1531–1549. [Google Scholar] [CrossRef]
- Tian, W.; Zhang, H.; Peng, C.; Zhao, Z.-Q. Lipreading model based on whole-part collaborative learning. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2425–2429. [Google Scholar]
- Tung, H.; Tekin, R. New Feature Extraction Approaches Based on Spatial Points for Visual-Only Lip-Reading. Trait. Signal 2022, 39, 659–668. [Google Scholar] [CrossRef]
- Peng, C.; Li, J.; Chai, J.; Zhao, Z.; Zhang, H.; Tian, W. Lip Reading Using Deformable 3D Convolution and Channel-Temporal Attention. In Proceedings of the International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2022; pp. 707–718. [Google Scholar]
- Tsourounis, D.; Kastaniotis, D.; Fotopoulos, S. Lip reading by alternating between spatiotemporal and spatial convolutions. J. Imaging 2021, 7, 91. [Google Scholar] [CrossRef] [PubMed]
- Jeon, S.; Elsharkawy, A.; Kim, M.S. Lipreading Architecture Based on Multiple Convolutional Neural Networks for Sentence-Level Visual Speech Recognition. Sensors 2022, 22, 72. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Teng, L.; Xiao, Y.; Zhu, A.; Liu, X. Lip Reading Using Temporal Adaptive Module. In Proceedings of the International Conference on Neural Information Processing, Changsha, China, 20–23 November 2023; pp. 347–356. [Google Scholar]
- Sun, B.; Xie, D.; Shi, H. MALip: Modal Amplification Lipreading based on reconstructed audio features. Signal Process. Image Commun. 2023, 117, 117002. [Google Scholar] [CrossRef]
- Hao, M.; Mamut, M.; Yadikar, N.; Aysa, A.; Ubul, K. How to use time information effectively? Combining with time shift module for lipreading. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7988–7992. [Google Scholar]
- Li, H.; Mamut, M.; Yadikar, N.; Zhu, Y.; Ubul, K. Channel Enhanced Temporal-Shift Module for Efficient Lipreading. In Proceedings of the Chinese Conference on Biometric Recognition, Shanghai, China, 10–12 September 2021; pp. 474–482. [Google Scholar]
- Wiriyathammabhum, P. SpotFast Networks with Memory Augmented Lateral Transformers for Lipreading. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 23–27 November 2020; pp. 554–561. [Google Scholar]
- Assael, Y.M.; Shillingford, B.; Whiteson, S.; Freitas, N.D. Lipnet: End-to-end sentence-level lipreading. arXiv 2016, arXiv:1611.01599. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Haq, M.A.; Ruan, S.-J.; Cai, W.-J.; Li, L.P.-H. Using lip reading recognition to predict daily Mandarin conversation. IEEE Access 2022, 10, 53481–53489. [Google Scholar] [CrossRef]
- Lu, Y.; Xiao, Q.; Jiang, H. A Chinese Lip-Reading System Based on Convolutional Block Attention Module. Math. Probl. Eng. 2021, 2021, 6250879. [Google Scholar] [CrossRef]
- Pan, X.; Chen, P.; Gong, Y.; Zhou, H.; Wang, X.; Lin, Z. Leveraging unimodal self-supervised learning for multimodal audio-visual speech recognition. arXiv 2022, arXiv:2203.07996. [Google Scholar]
- Cheng, X.; Jin, T.; Li, L.; Lin, W.; Duan, X.; Zhao, Z. Opensr: Open-modality speech recognition via maintaining multi-modality alignment. arXiv 2023, arXiv:2306.06410. [Google Scholar]
- Wang, H.; Cui, B.; Yuan, Q.; Pu, G.; Liu, X.; Zhu, J. Mini-3DCvT: A lightweight lip-reading method based on 3D convolution visual transformer. Vis. Comput. 2025, 41, 1957–1969. [Google Scholar] [CrossRef]
- Li, Z.; Lohrenz, T.; Dunkelberg, M.; Fingscheidt, T. Transformer-Based Lip-Reading with Regularized Dropout and Relaxed Attention. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023; pp. 723–730. [Google Scholar]
- Prajwal, K.R.; Afouras, T.; Zisserman, A. Sub-word level lip reading with visual attention. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5162–5172. [Google Scholar]
- Elashmawy, S.; Ramsis, M.; Eraqi, H.M.; Eldeshnawy, F.; Mabrouk, H.; Abugabal, O.; Sakr, N. Spatio-temporal attention mechanism and knowledge distillation for lip reading. arXiv 2021, arXiv:2108.03543. [Google Scholar]
- Yu, W.; Zeiler, S.; Kolossa, D. Reliability-based large-vocabulary audio-visual speech recognition. Sensors 2022, 22, 5501. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Gao, Y.; Zhu, C.; Wang, Q.; Wang, R. Improving speech recognition performance in noisy environments by enhancing lip reading accuracy. Sensors 2023, 23, 2053. [Google Scholar] [CrossRef]
- Varshney, M.; Yadav, R.; Namboodiri, V.P.; Hegde, R.M. Learning speaker-specific lip-to-speech generation. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 491–498. [Google Scholar]
- Yang, W.; Li, P.; Yang, W.; Liu, Y.; He, Y.; Petrosian, O.; Davydenko, A. Research on robust audio-visual speech recognition algorithms. Mathematics 2023, 11, 1733. [Google Scholar] [CrossRef]
- Lohrenz, T.; Möller, B.; Li, Z.; Fingscheidt, T. Relaxed attention for transformer models. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, QLD, Australia, 18–23 June 2023; pp. 1–10. [Google Scholar]
- Ma, P.; Petridis, S.; Pantic, M. Visual speech recognition for multiple languages in the wild. Nat. Mach. Intell. 2022, 4, 930–939. [Google Scholar]
- Tan, G.; Wang, Y.; Han, H.; Cao, Y.; Wu, F.; Zha, Z.-J. Multi-grained spatio-temporal features perceived network for event-based lip-reading. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20094–20103. [Google Scholar]
- Kanamaru, T.; Arakane, T.; Saitoh, T. Isolated single sound lip-reading using a frame-based camera and event-based camera. Front. Artif. Intell. 2023, 5, 1070964. [Google Scholar] [CrossRef]
- Tan, G.; Wan, Z.; Wang, Y.; Cao, Y.; Zha, Z.-J. Tackling Event-Based Lip-Reading by Exploring Multigrained Spatiotemporal Clues. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–13. [Google Scholar]
- Zhang, W.; Wang, J.; Luo, Y.; Yu, L.; Yu, W.; He, Z. MTGA: Multi-view Temporal Granularity aligned Aggregation for Event-based Lip-reading. arXiv 2024, arXiv:2404.11979. [Google Scholar]
- Li, X.; Neil, D.; Delbruck, T.; Liu, S.-C. Lip reading deep network exploiting multi-modal spiking visual and auditory sensors. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Ning, L.; Dong, J.; Xiao, R.; Tan, K.C.; Tang, H. Event-driven spiking neural networks with spike-based learning. Memetic Comput. 2023, 15, 205–217. [Google Scholar]
- Bulzomi, H.; Schweiker, M.; Gruel, A.E.; Martinet, J. End-to-end Neuromorphic Lip Reading. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Yu, X.; Wang, L.; Chen, C.; Tie, J.; Guo, S. Multimodal Learning of Audio-Visual Speech Recognition with Liquid State Machine. In Proceedings of the International Conference on Neural Information Processing, Changsha, China, 20–23 November 2023; pp. 552–563. [Google Scholar]
- Chung, J.S.; Zisserman, A. Learning to lip read words by watching videos. Comput. Vis. Image Underst. 2018, 173, 76–85. [Google Scholar]
- Handa, A.; Agarwal, R.; Kohli, N. A multimodel keyword spotting system based on lip movement and speech features. Multimed. Tools Appl. 2020, 79, 20461–20481. [Google Scholar]
- Kim, M.; Hong, J.; Park, S.J.; Ro, Y.M. CroMM-VSR: Cross-modal memory augmented visual speech recognition. IEEE Trans. Multimed. 2021, 24, 4342–4355. [Google Scholar]
- Adeel, A.; Gogate, M.; Hussain, A.; Whitmer, W.M. Lip-reading driven deep learning approach for speech enhancement. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 5, 481–490. [Google Scholar]
- Afouras, T.; Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Deep Audio-Visual Speech Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8717–8727. [Google Scholar]
- Kim, M.; Yeo, J.H.; Ro, Y.M. Distinguishing Homophenes Using Multi-Head Visual-Audio Memory for Lip Reading. In Proceedings of the The Thirty-Sixth AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022. [Google Scholar]
- Petridis, S.; Wang, Y.; Li, Z.; Pantic, M. End-to-End Multi-View Lipreading. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017; p. 161. [Google Scholar]
- Mesbah, A.; Berrahou, A.; Hammouchi, H.; Berbia, H.; Qjidaa, H.; Daoudi, M. Lip reading with Hahn convolutional neural networks. Image Vis. Comput. 2019, 88, 76–83. [Google Scholar]
- Sheng, C.; Liu, L.; Deng, W.; Bai, L.; Liu, Z.; Lao, S.; Kuang, G.; Pietikäinen, M. Importance-aware information bottleneck learning paradigm for lip reading. IEEE Trans. Multimed. 2022, 25, 6563–6574. [Google Scholar]
- Weng, X.; Kitani, K. Learning Spatio-Temporal Features with Two-Stream Deep 3D CNNs for Lipreading. In Proceedings of the British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019; pp. 1–13. [Google Scholar]
- Sheng, C.; Zhu, X.; Xu, H.; Pietikäinen, M.; Liu, L. Adaptive semantic-spatio-temporal graph convolutional network for lip reading. IEEE Trans. Multimed. 2021, 24, 3545–3557. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, H. Lip Reading using Local-Adjacent Feature Extractor and Multi-Level Feature Fusion. In Proceedings of the 2021 2nd International Conference on Computer Information and Big Data Applications, Wuhan, China, 26–28 March 2021; p. 012083. [Google Scholar]
- Liu, H.; Chen, Z.; Yang, B. Lip Graph Assisted Audio-Visual Speech Recognition Using Bidirectional Synchronous Fusion. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 3520–3524. [Google Scholar]
- Ma, P.; Martinez, B.; Petridis, S.; Pantic, M. Towards Practical Lipreading with Distilled and Efficient Models. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7608–7612. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Type of Features | Characteristic |
|---|---|---|
| pixel feature | multistage linear transformation, local pixel feature | The method uses lip-centered scanning lines as feature vectors, but it is sensitive to lighting variations and underperforms in high-complexity computations. |
| image transformation feature | Discrete Cosine Transform (DCT), Wavelet Transform (WT), Principal Component Analysis (PCA), Fourier Transform (FT), and LDA | The method uses the transformation results of all pixels as feature vectors and extracts high-frequency components for detailed information. |
| optical flow feature | optical flow field | The method extracts lip motion parameters and analyzes motion patterns but relies on precise positioning during preprocessing. |
| color feature | color space | The method focuses on color images. |
| model-based feature | active appearance model (AAM), active shape model (ASM), active contour model (ACM) | The method adjusts model parameters to approach the target but is prone to local minima and sensitive to the initial position. |
| Lip-Reading Methods | Characteristic Form | Front End/Encoder | Back End/Decoder | |
|---|---|---|---|---|
| Feature Extraction | Feature Enhancement | |||
| Lip-reading Methods Based on Machine Learning | Handcrafted features (shape, color, texture, optical flow, models, etc.) | DCT, DWT, PCA, FT, AAM, ACM | SVM, KNN, NB, RFM, HMM | |
| Lip-reading Methods Based on Visual Features | Spatial features (such as shape, color, texture, etc.) and temporal features | 2D/3D CNN + ResNet | RNN, LSTM, GRU | |
| Lip-reading Methods Based on Spatiotemporal Features | Spatial features (e.g., shape, color, texture), temporal features, and semantic features | 3D CNN 2D CNN | CNNs, TSM, Transformer, Lightweight Network, CBAM, GCN, | GRU, Bi-GRU, LSTM, Bi-LSTM, Transformer, MS-TCN, DC-TCN |
| Lip-reading Methods Based on Spiking Neural Networks (SNNs) | Spatial features (e.g., shape), temporal features (e.g., pulses, sequences), and motion features. | 3D CNN | ResNet, SNN | MS-TCN, Bi-GRU, Bi-LSTM, Transformer |
| Methods | Typical Networks | Elements | Enhancement Ability | Recognition Rate | Structure Complexity | Parameter | |
|---|---|---|---|---|---|---|---|
| Spatial Feature | Temporal Feature | ||||||
| spatial features [63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,133] | ResNet, DenseNet, ShuffleNet | Convolution block, residual block | Weak | Weak | Low | Low | Small |
| temporal convolution [88,89,90,91,92,93,94,95,96,97] | ACNet, TSM, GSF, TBC | Temporal convolution block | Weak | Strong | High | High | Small |
| attention [98,99,100,101,102,103,104,105,106,107,108,109,110,111] | CBAM, BAM, Transformer | Attention block | Strong | Strong | High | High | Large |
| event cameras [112,113,114,115] | Event streams | High-speed event stream, Low-speed event stream | Strong | Relatively Strong | High | High | Large |
| spiking neural network [13,14,55,116,117,118,119] | Spiking Neural Networks (SNNs) | Event streams, Pulse signal | Relatively Strong | Strong | High | Low | Fewer |
| audio-visual assisting [82,120,121,122,123,124,125] | Audio-visual complementation | Visual processing unit, audio processing unit | Strong | Strong | High | High | Huge |
| others [126,127,128,129,130,131,132] | graph, moment, filter, variational time masking | Graph convolution, moment feature, filter, variational encoder | Relatively Strong | Relatively Strong | High | - | Large |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Sun, X. Spatiotemporal Feature Enhancement for Lip-Reading: A Survey. Appl. Sci. 2025, 15, 4142. https://doi.org/10.3390/app15084142
Ma Y, Sun X. Spatiotemporal Feature Enhancement for Lip-Reading: A Survey. Applied Sciences. 2025; 15(8):4142. https://doi.org/10.3390/app15084142
Chicago/Turabian StyleMa, Yinuo, and Xiao Sun. 2025. "Spatiotemporal Feature Enhancement for Lip-Reading: A Survey" Applied Sciences 15, no. 8: 4142. https://doi.org/10.3390/app15084142
APA StyleMa, Y., & Sun, X. (2025). Spatiotemporal Feature Enhancement for Lip-Reading: A Survey. Applied Sciences, 15(8), 4142. https://doi.org/10.3390/app15084142