

Retrieval-Augmented Generation (RAG) Chatbots for Education: A Survey of Applications



Abstract
1. Introduction
- RQ1:
- How many and what kinds of works have been published on the topic so far?
- RQ2:
- What are the purposes served by the RAG-based chatbots in the educational domain?
- RQ3:
- What are the themes covered by the RAG-based chatbots in the educational domain?
- RQ4:
- Which of the available large language models are used by the RAG-based chatbots in the educational domain?
- RQ5:
- What are the criteria according to which the RAG-based educational chatbots were evaluated?
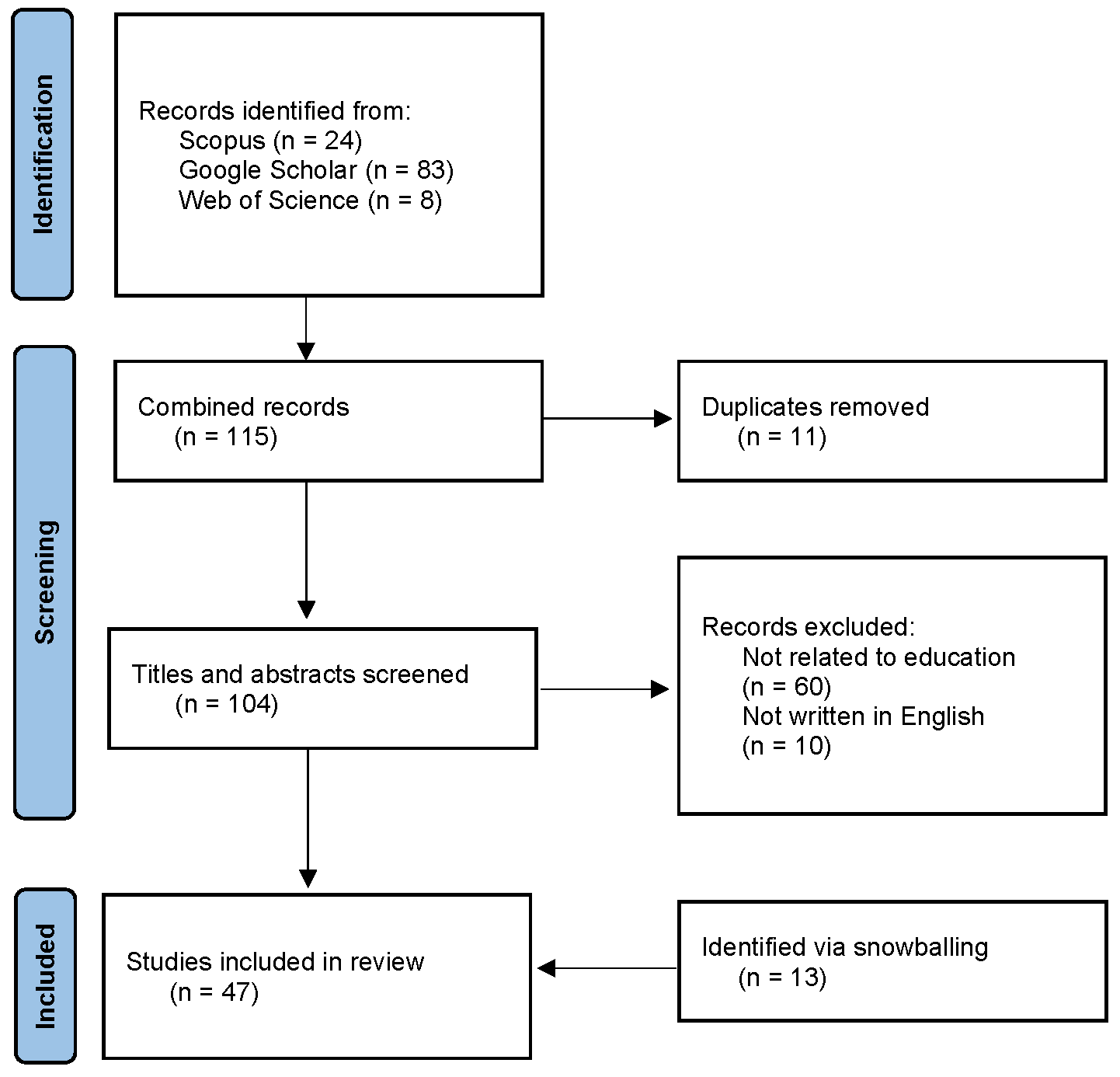
2. Materials and Methods
- TITLE-ABS-KEY ( "education*" ) AND TITLE-ABS-KEY ( "chatbot" )
- AND ( TITLE-ABS-KEY ( "RAG" ) OR
- TITLE-ABS-KEY ( "Retrieval Augmented Generation" ) )
- AND ( LIMIT-TO ( DOCTYPE , "ar" ) OR LIMIT-TO ( DOCTYPE , "cp" ) )
- AND PUBYEAR > 2021 AND ( LIMIT-TO ( LANGUAGE , "English" ) )
- (((((TI=(education*)) OR AK=(education*))) OR (AB=(education*)))
- AND ((((TI=(chatbot)) OR AK=(chatbot))) OR (AB=(chatbot))))
- AND (((((TI=("Retrieval Augmented Generation"))
- OR AK=("Retrieval Augmented Generation")))
- OR (AB=("Retrieval Augmented Generation"))) OR ((((TI=(RAG)) OR (AK=(RAG)))
- OR (AB=RAG)))) AND (PY>2021)
3. Results
3.1. Overview of Identified Studies
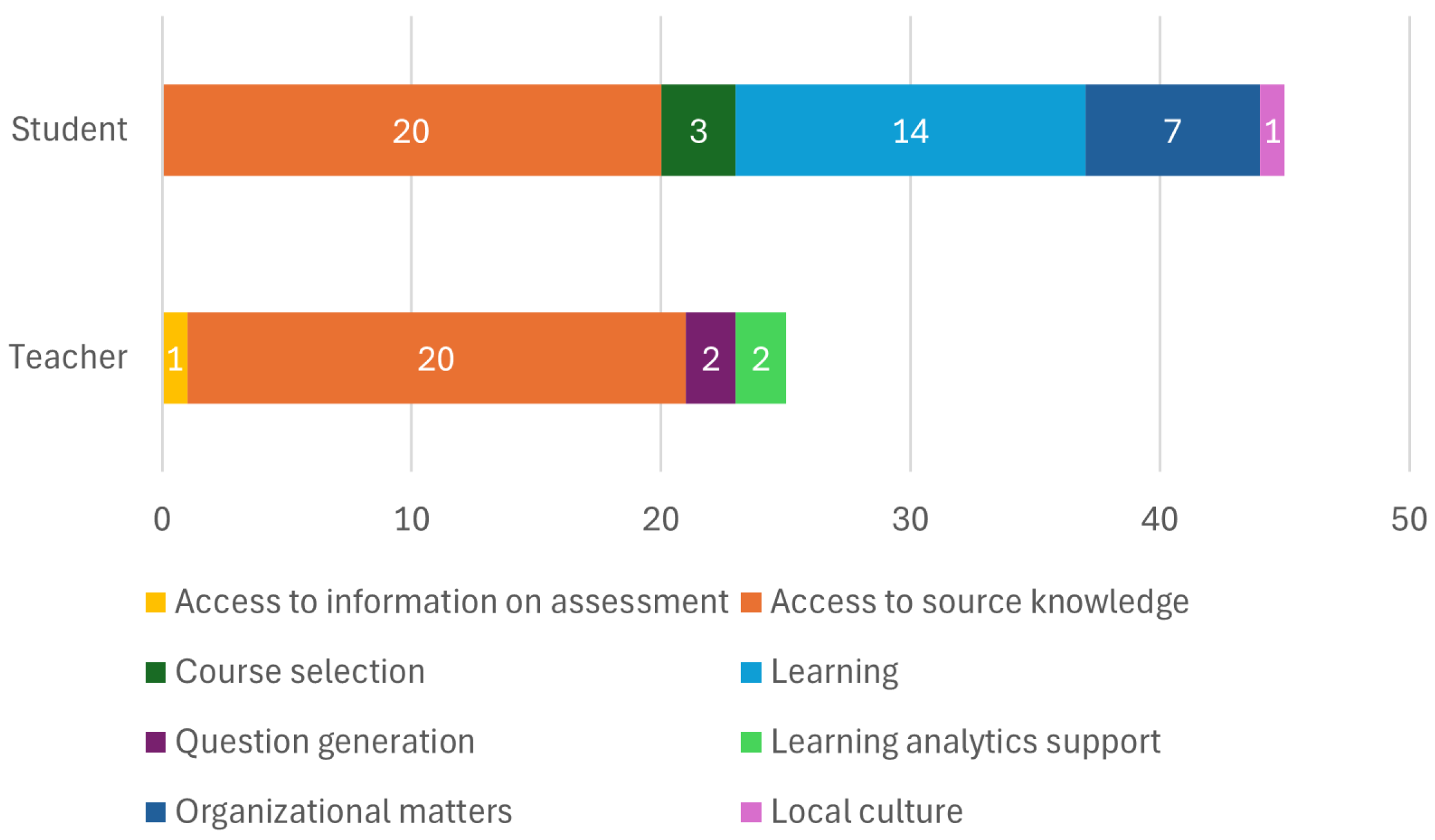
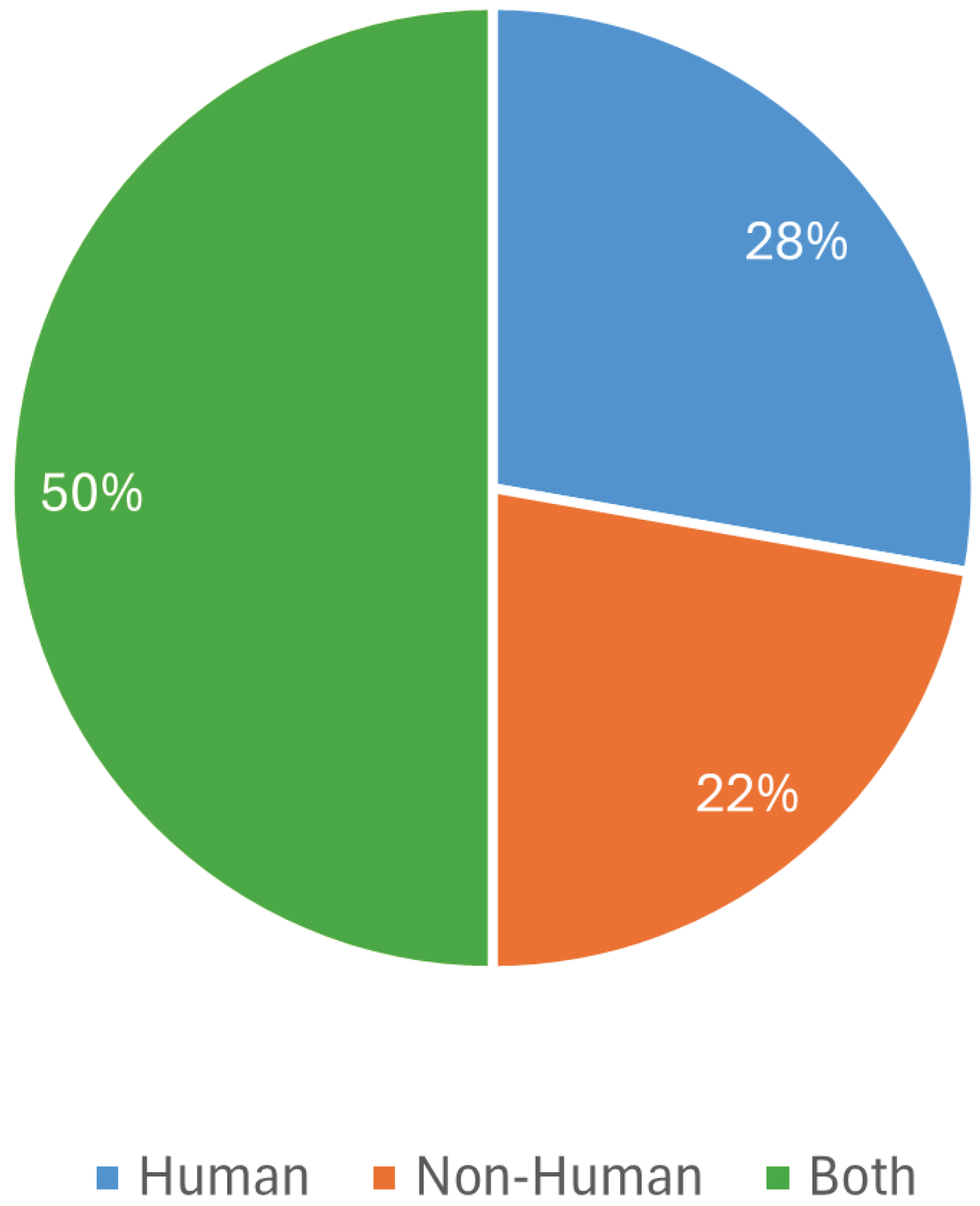
3.2. Target of Support
- Learning— chatbots whose sole purpose is to support the learning process, combining the access to knowledge on the studied subject with various learner support techniques, such as tailoring the responses to individual learning styles and pacing or arousing the learner’s engagement;
- Access to source knowledge—chatbots which provide convenient access to some body of source knowledge (the purpose of which is not necessarily learning);
- Access to information on assessment—this category has been distinguished as, in contrast to access to source knowledge, it is not the learning content that is accessed here but the information on how to assess the learned content;
- Organizational matters—chatbots which help students to learn the rules and customs at their alma mater;
- Local culture—applicable when the chatbot helps (international) students to become acquainted with the rules and customs of the specific nation or community rather than the educational institution;
- Course selection—chatbots helping candidates and/or students in choosing their educational path;
- Question generation—chatbots whose sole purpose is to support the teachers in developing questions about which they will ask the students;
- Learning analytics support—chatbots helping the teachers in analyzing the recorded effort of their students.
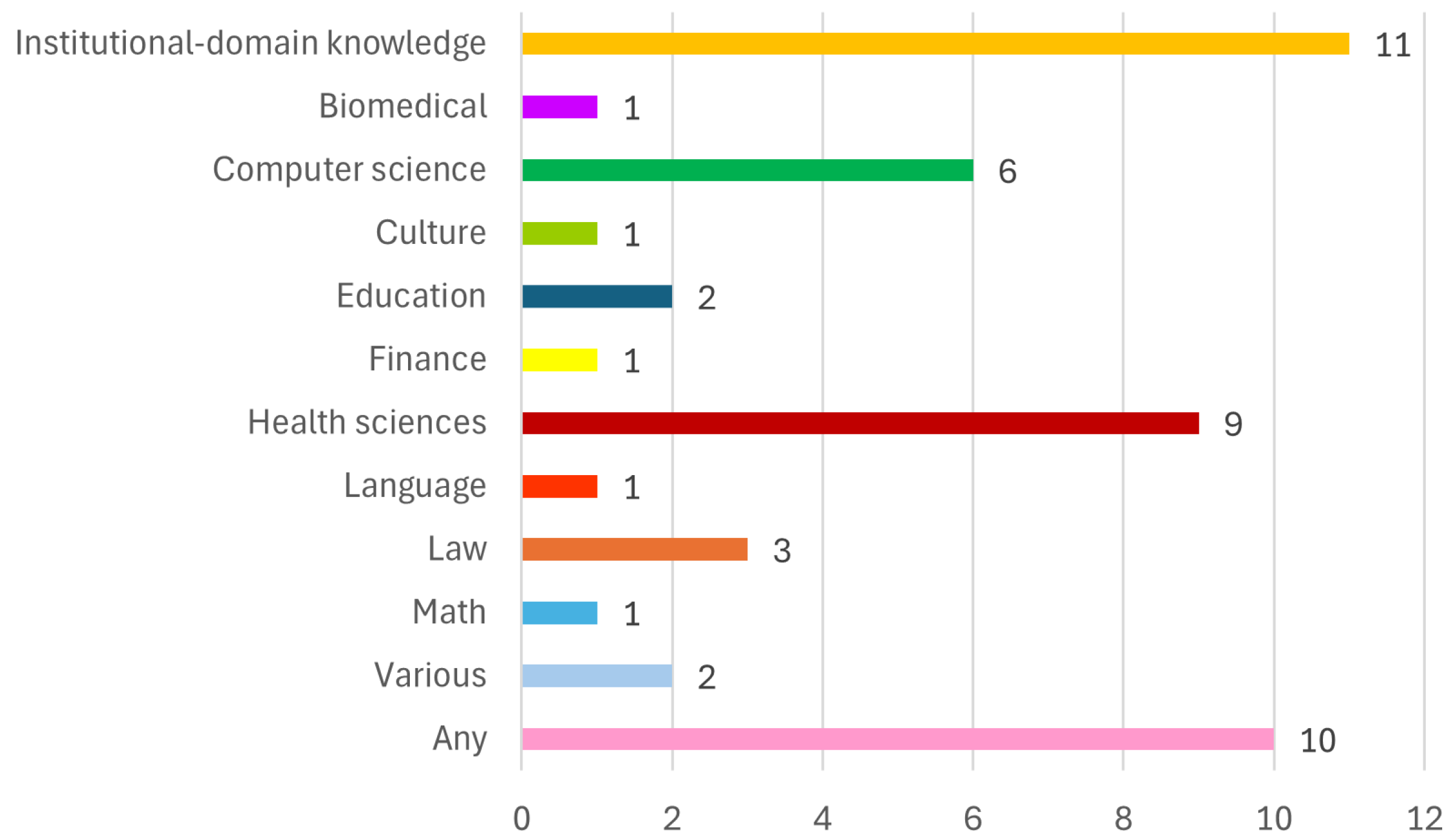
3.3. Thematic Scope
- Institutional-domain knowledge—chatbots focused on the knowledge about a given institution, including its policies and procedures, regardless of its field(s) of education.
- Area-specific—chatbots designed to support education in a particular area of education, including the following:
- (a)
- Biomedical;
- (b)
- Computer science;
- (c)
- Culture;
- (d)
- Education;
- (e)
- Finance;
- (f)
- Health sciences;
- (g)
- Language;
- (h)
- Law;
- (i)
- Math.
- Various—chatbots designed to support education in more than one field.
- Any—chatbots that may be used in any field of education.
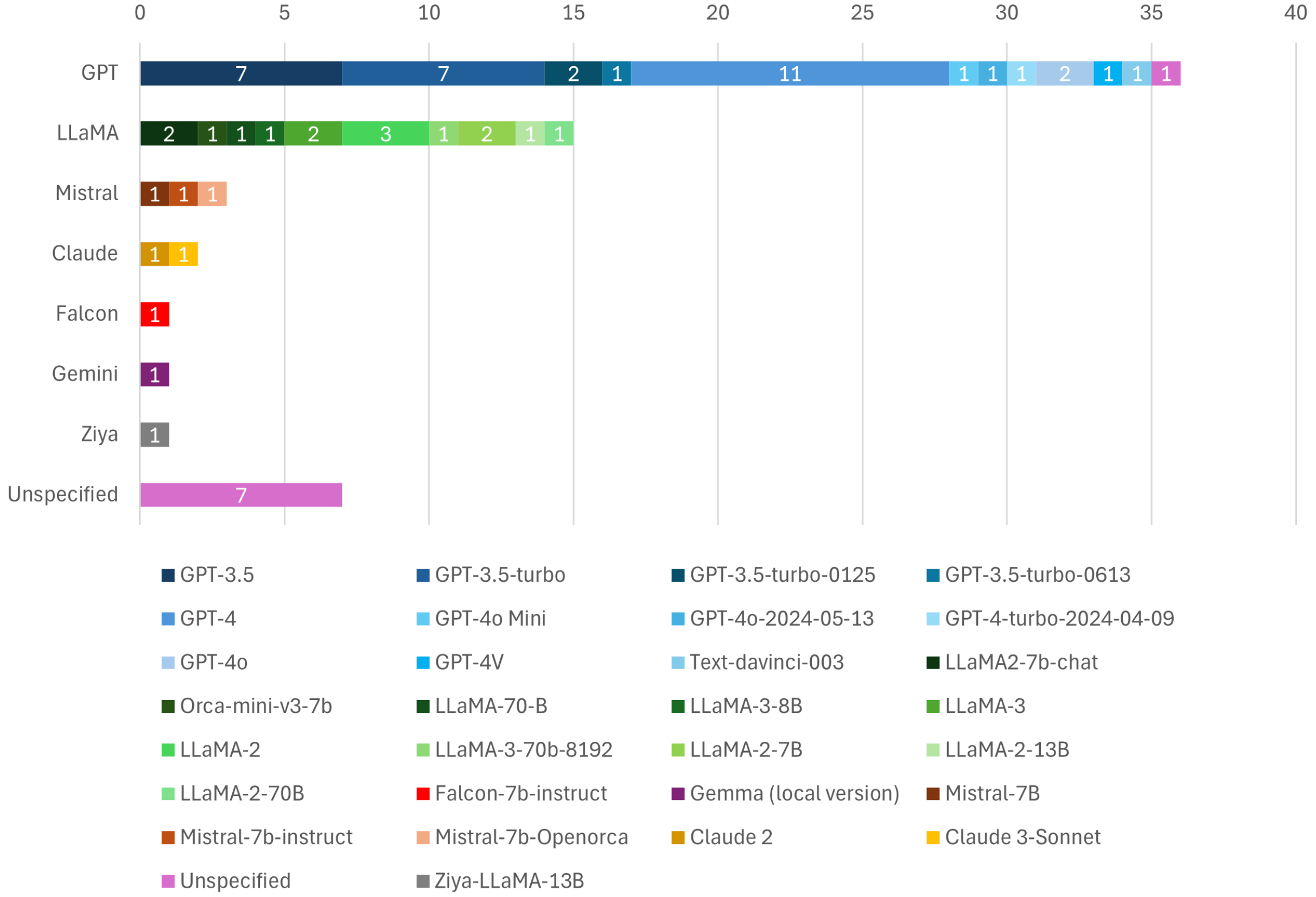
3.4. Used Large Language Models
3.5. Performed Evaluation
- Because of the retrieval component, we have examples of evaluation based on classic information retrieval measures [62], such as Precision, Recall, F1 Score, Accuracy, Sensitivity, and Specificity; these are instrumental in comparing the performance of different approaches that can be used to generate vector representations of the queries and responses—for instance, F1 Score reported in [25] (p. 5697) ranges from 0.35 for GloVe [63] to 0.67 for TF-IDF [64];
- Because of the LLM component, we have examples of evaluation based on LLM benchmarks, such as AGIEval [65], measuring the ability to pass human-centric standardized exams; this is instrumental in comparing the performance of different LLMs that can be used as the base of the RAG chatbots—for instance, AGIEval measurements reported in [55] range from 21.8 for Falcon-7B [66] to 54.2 for LLaMa2-70B [67];
- Because chatbots are made for conversation, we have examples of evaluation based on conversational quality measures, in particular based on Grice’s Maxims of Conversation [68], such as Correctness (assessing whether the chatbot’s answer is factually correct), Completeness (assessing whether the answer includes all relevant facts and information), and Communication (assessing whether the answer is clear and concise) [32], or (in Wölfel et al.’s interpretation) Information Quantity (assessing whether the provided amount of information is neither too much nor too little), Relevance (assessing whether the answer is pertinent to the ongoing topic or the context of the conversation), Clarity (assessing whether the answer is clear, concise, and in order), and Credibility (assessing whether the recipient trusts the chatbot) [53]; these could be used for, e.g., comparing the users’ trust in the answers generated with the help of different LLMs that can power the RAG chatbots (e.g., Wölfel et al. compared the trust level between two versions of GPT: 3.5 and 4.0 [69], and reported 5.50 for answers generated by GPT 3.5 and of 5.59 for answers generated by GPT 4.0 [53]), but also the change in the users’ trust due to incorporating RAG—interestingly and unexpectedly, the same source reports a decrease in the average trust level for answers generated by both GPT 3.5 (from 5.98 to 5.50) and GPT 4.0 (from 6.34 to 5.59) after combining them with the content extracted from lecture slides and their transcripts [53];
- Because chatbots are instances of generative Natural Language Processing, we have examples of computer-generated text quality measures such as the similarity to human-written text (measured with metrics such as K-F1++ [70], BERTscore [71], BLEURT [72], or ROUGE [73]) [28,46], text readability (measured with, e.g., Coleman–Liau [74] and Flesch–Kincaid [75] metrics) [44], and human-assessed text quality aspects such as Fluency, Coherence, Relevance, Context Understanding, and Overall Quality [17]; these, again, can be instrumental in comparing the performance of different LLMs that can be used as the base of the RAG chatbots—for instance, Šarčević et al. compared five models (LLaMa-2-7b [67], Mistral-7b-instruct [76], Mistral-7b-openorca [77], Zephyr-7b-alpha [78], and Zephyr-7b-beta [79]) in terms of human-assessed text quality to detect sometimes notable differences: the measured Fluency ranged from 4.81 for Zephyr-7b-alpha to 4.92 for Mistral-7b-openorca; Coherence from 4.58 for Mistral-7b-instruct to 4.88 for Mistral-7b-openorca; Relevance from 4.15 for Llama-2-7b to 4.43 for Zephyr-7b-alpha; Context Understanding from 3.73 for Mistral-7b-instruct to 4.44 for Mistral-7b-openorca; and Overall Quality from 3.67 for Zephyr-7b-alpha to 4.48 for Mistral-7b-openorca [17];
- Because chatbots are a kind of computer software, we have examples of evaluation based on software usability, including technical measures of Operational Efficiency (such as the average handling time [25] or response time [48]) and survey-based measures of general User Acceptance (the extent to which the user accepts to work with the software, assessed using, e.g., the Technology-Acceptance model constructs [80]) [21] and User Satisfaction (the extent to which the user is happy with a system, assessed using, e.g., System Usability Scale [81]) [29], as well as specific usability aspects, in particular, Safety—ensuring that the answer is appropriate and compliant with protocols, which is especially relevant for domains where wrong guidance could cause a serious material loss or increase the risk of health loss, e.g., in medical education [15,50]; the reported usability measurements can be used for comparisons not only with other chatbots but also with any kind of software evaluated using the same measurement tool, for instance, the average SUS score of 67.75 reported by Neupane et al. [29] for their chatbot providing campus-related information, such as academic departments, programs, campus facilities, and student resources, is little above the average score of 66.25 measured for 77 Internet-based educational platforms (LMS, MOOC, wiki, etc.) by Vlachogianni and Tselios [82] but is far below the score of 79.1 reported for the FGPE interactive online learning platform [83]; and
- Because chatbots’ development and maintenance incur costs, we have examples of economic evaluation based on measures such as cost per query or cost per student [21]; for instance, Neumann et al. compared the average cost per student of their RAG chatbot (USD 1.65 [21]) to that reported by Liu et al., who developed a set of AI-based educational tools featuring a GPT4-based chatbot without the RAG component (USD 1.90) [84].
4. Discussion and Recommendations
- For chatbots supporting learning, we recommend comparing learning outcomes attained by students using a chatbot and the control group. Competency tests specific to the learned subject should be performed before the chatbot is presented to the students and after a reasonable time of learning with its support. The higher test results in the experimental group indicate the positive effect of the chatbot;
- For chatbots providing access to source knowledge, we recommend comparing the project or exam grades received by students using a chatbot and the control group. The higher grades in the experimental group indicate the positive effect of the chatbot;
- For chatbots providing access to information on assessment, we recommend comparing the number of questions regarding assessment asked by students using a chatbot and the control group. The lower number of questions asked by members of the experimental group indicate the positive effect of the chatbot;
- For chatbots supporting students with organizational matters, we recommend comparing the number of help requests from students using a chatbot and the control group. The lower number of help requests by members of the experimental group indicate the positive effect of the chatbot;
- For chatbots educating students on local culture, we recommend comparing the number of questions related to local customs asked by international students using a chatbot and the control group. The lower number of questions asked by members of the experimental group indicate the positive effect of the chatbot;
- For chatbots supporting students in their course selection, we recommend comparing the students’ drop-out ratio from courses selected after chatbot recommendation and the control group. The lower drop-out ratio in the experimental group indicates the positive effect of the chatbot;
- For chatbots supporting teachers in question generation, we recommend comparing both the time of question development and the quality of the questions generated by a chatbot versus manually developed questions. This should consist in selecting a number of learning topics, then asking a small group of teachers to develop a partial set of questions relevant to these topics, one half without (and the other half with) the use of the chatbot, measuring their development time. Next, this should expose students to tests consisting of all questions, eventually either asking the involved students to directly assess the individual test questions (in terms of question comprehensibility, relevance, difficulty, and fairness) or, provided that a sufficiently large group of respondents is available, performing a statistical analysis of test results, e.g., using one of the models based on Item Response Theory [89] (pp. 3–4). The shorter development time and/or the higher quality of questions developed with the help of the chatbot indicates its positive effect;
- For chatbots supporting teachers in learning analytics, we recommend comparing the teacher-assessed ease and speed of obtaining specific insights regarding the effort of their students with the help of a chatbot and with the baseline learning analytics tool. This could be carried out by preparing task scenarios, then letting a small group of teachers perform them, measuring their time and success ratio. Task scenarios should have some context provided to make them engaging for the users, realistic, actionable, and free of clues or suggested solution steps [90]. The shorter execution time and/or the higher success ratio of tasks performed with the help of the chatbot indicate its positive effect.
- The three key elements that affect the output of RAG chatbots are the underlying LLM, the source of content to augment the responses, and the approach chosen to generate vector representations of the queries and responses. A number of papers provide insights regarding the choice of the first [17,28,32,33,43,55], but only a few help with choosing the second [53] and the third [25,39,41];
- As RAG chatbots are based on LLMs, they share their vulnerabilities with regard to data privacy and potential plagiarism [33]. The design and development of RAG chatbots should always strive to address any possible ethical and legal concerns;
- While the availability of ready-to-use components makes the development of new RAG chatbots relatively easy, it is still a project burdened with many risks. A number of papers provide more-or-less detailed step-by-step descriptions of the development process, which can be followed by future implementers [25,27,29,40,51,54,56];
- There are many aspects in which RAG chatbots can be evaluated, but the most important one is the extent to which they achieve their goal. Despite being unpopular in existing publications, this can be measured with some effort, as described in the recommendations listed above. Nonetheless, real-world RAG chatbot implementations are also constrained by technical and financial limitations, so pursuing the best available solution is not always a viable option.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Uyen Tran, L. Dialogue in education. J. Sci. Commun. 2008, 7, C04. [Google Scholar] [CrossRef]
- Roumeliotis, K.I.; Tselikas, N.D. ChatGPT and Open-AI Models: A Preliminary Review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Han, J.; Yoo, H.; Myung, J.; Kim, M.; Lee, T.Y.; Ahn, S.Y.; Oh, A.; Answer, A.N. Exploring Student-ChatGPT Dialogue in EFL Writing Education. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems. Neural Information Processing Systems Foundation, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Yu, H.; Gan, A.; Zhang, K.; Tong, S.; Liu, Q.; Liu, Z. Evaluation of Retrieval-Augmented Generation: A Survey. In Proceedings of the Big Data; Zhu, W., Xiong, H., Cheng, X., Cui, L., Dou, Z., Dong, J., Pang, S., Wang, L., Kong, L., Chen, Z., Eds.; Springer: Singapore, 2025; pp. 102–120. [Google Scholar]
- Gupta, S.; Ranjan, R.; Singh, S.N. A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, Current Landscape and Future Directions. arXiv 2024, arXiv:2410.12837. [Google Scholar]
- Zhao, P.; Zhang, H.; Yu, Q.; Wang, Z.; Geng, Y.; Fu, F.; Yang, L.; Zhang, W.; Jiang, J.; Cui, B. Retrieval-Augmented Generation for AI-Generated Content: A Survey. arXiv 2024, arXiv:2402.19473. [Google Scholar]
- Bora, A.; Cuayáhuitl, H. Systematic Analysis of Retrieval-Augmented Generation-Based LLMs for Medical Chatbot Applications. Mach. Learn. Knowl. Extr. 2024, 6, 2355–2374. [Google Scholar] [CrossRef]
- Pérez, J.Q.; Daradoumis, T.; Puig, J.M.M. Rediscovering the use of chatbots in education: A systematic literature review. Comput. Appl. Eng. Educ. 2020, 28, 1549–1565. [Google Scholar] [CrossRef]
- Wollny, S.; Schneider, J.; Di Mitri, D.; Weidlich, J.; Rittberger, M.; Drachsler, H. Are We There Yet?—A Systematic Literature Review on Chatbots in Education. Front. Artif. Intell. 2021, 4, 654924. [Google Scholar] [CrossRef]
- Okonkwo, C.W.; Ade-Ibijola, A. Chatbots applications in education: A systematic review. Comput. Educ. Artif. Intell. 2021, 2, 100033. [Google Scholar] [CrossRef]
- Nouzri, S.; EL Fatimi, M.; Guerin, T.; Othmane, M.; Najjar, A. Beyond Chatbots: Enhancing Luxembourgish Language Learning Through Multi-Agent Systems and Large Language Model. In Proceedings of the PRIMA 2024: Principles and Practice of Multi-Agent Systems 25th International Conference, Kyoto, Japan, 18–24 November 2024; Arisaka, R., Ito, T., Sanchez-Anguix, V., Stein, S., Aydoğan, R., van der Torre, L., Eds.; Lecture Notes in Artificial Intelligence (LNAI). Springer: Cham, Switzerland, 2025; Volume 15395, pp. 385–401. [Google Scholar] [CrossRef]
- Arun, G.; Perumal, V.; Urias, F.; Ler, Y.; Tan, B.; Vallabhajosyula, R.; Tan, E.; Ng, O.; Ng, K.; Mogali, S. ChatGPT versus a customized AI chatbot (Anatbuddy) for anatomy education: A comparative pilot study. Anat. Sci. Educ. 2024, 17, 1396–1405. [Google Scholar] [CrossRef] [PubMed]
- Kelly, A.; Noctor, E.; Van De Ven, P. Design, architecture and safety evaluation of an AI chatbot for an educational approach to health promotion in chronic medical conditions. In Proceedings of the 12th Scientific Meeting on International Society for Research on Internet Interventions, ISRII-12 2024, Limerick, Ireland, 9–14 October 2023; Anderson, P.P., Teles, A., Esfandiari, N., Badawy, S.M., Eds.; Procedia Computer Science. Elsevier B.V.: Amsterdam, The Netherlands, 2024; Volume 248, pp. 52–59. [Google Scholar] [CrossRef]
- Zhao, Z.; Yin, Z.; Sun, J.; Hui, P. Embodied AI-Guided Interactive Digital Teachers for Education. In Proceedings of the SIGGRAPH Asia 2024 Educator’s Forum, SA 2024, Tokyo, Japan, 3–6 December 2024; Spencer, S.N., Ed.; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Šarčević, A.; Tomičić, I.; Merlin, A.; Horvat, M. Enhancing Programming Education with Open-Source Generative AI Chatbots. In Proceedings of the 47th ICT and Electronics Convention, MIPRO 2024, Opatija, Croatia, 20–24 May 2024; Babic, S., Car, Z., Cicin-Sain, M., Cisic, D., Ergovic, P., Grbac, T.G., Gradisnik, V., Gros, S., Jokic, A., Jovic, A., et al., Eds.; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2024; pp. 2051–2056. [Google Scholar] [CrossRef]
- Thway, M.; Recatala-Gomez, J.; Lim, F.S.; Hippalgaonkar, K.; Ng, L.W. Harnessing GenAI for Higher Education: A Study of a Retrieval Augmented Generation Chatbot’s Impact on Human Learning. arXiv 2024, arXiv:2406.07796. [Google Scholar]
- Abraham, S.; Ewards, V.; Terence, S. Interactive Video Virtual Assistant Framework with Retrieval Augmented Generation for E-Learning. In Proceedings of the 3rd International Conference on Applied Artificial Intelligence and Computing, ICAAIC 2024, Salem, India, 5–7 June 2024; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2024; pp. 1192–1199. [Google Scholar] [CrossRef]
- Jiang, Y.; Shao, Y.; Ma, D.; Semnani, S.J.; Lam, M.S. Into the unknown unknowns: Engaged human learning through participation in language model agent conversations. arXiv 2024, arXiv:2408.15232. [Google Scholar]
- Neumann, A.; Yin, Y.; Sowe, S.; Decker, S.; Jarke, M. An LLM-Driven Chatbot in Higher Education for Databases and Information Systems. IEEE Trans. Educ. 2025, 68, 103–116. [Google Scholar] [CrossRef]
- Levonian, Z.; Li, C.; Zhu, W.; Gade, A.; Henkel, O.; Postle, M.E.; Xing, W. Retrieval-augmented Generation to Improve Math Question-Answering: Trade-offs Between Groundedness and Human Preference. In Proceedings of the NeurIPS’23 Workshop: Generative AI for Education (GAIED), New Orleans, LA, USA, 15 December 2023. [Google Scholar]
- Soliman, H.; Kravcik, M.; Neumann, A.; Yin, Y.; Pengel, N.; Haag, M. Scalable Mentoring Support with a Large Language Model Chatbot. In Proceedings of the 19th European Conference on Technology Enhanced Learning, EC-TEL 2024, Krems, Austria, 16–20 September 2024; Ferreira Mello, R., Rummel, N., Jivet, I., Pishtari, G., Ruipérez Valiente, J.A., Eds.; Lecture Notes in Computer Science (LNCS). Springer Science and Business Media: Berlin/Heidelberg, Germany, 2024; Volume 15160, pp. 260–266. [Google Scholar] [CrossRef]
- Al Ghadban, Y.; Lu, H.Y.; Adavi, U.; Sharma, A.; Gara, S.; Das, N.; Kumar, B.; John, R.; Devarsetty, P.; Hirst, J.E. Transforming Healthcare Education: Harnessing Large Language Models for Frontline Health Worker Capacity Building using Retrieval-Augmented Generation. In Proceedings of the NeurIPS’23 Workshop: Generative AI for Education (GAIED), New Orleans, LA, USA, 15 December 2023. [Google Scholar]
- Islam, M.; Warsito, B.; Nurhayati, O. AI-driven chatbot implementation for enhancing customer service in higher education: A case study from Universitas Negeri Semarang. J. Theor. Appl. Inf. Technol. 2024, 102, 5690–5701. [Google Scholar]
- Saad, M.; Qawaqneh, Z. Closed Domain Question-Answering Techniques in an Institutional Chatbot. In Proceedings of the International Conference on Electrical, Computer, Communications and Mechatronics Engineering, ICECCME 2024, Male, Maldives, 4–6 November 2024; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Olawore, K.; McTear, M.; Bi, Y. Development and Evaluation of a University Chatbot Using Deep Learning: A RAG-Based Approach. In Proceedings of the CONVERSATIONS 2024—The 8th International Workshop on Chatbots and Human-Centred AI, Thessaloniki, Greece, 4–5 December 2024. [Google Scholar]
- Chen, Z.; Zou, D.; Xie, H.; Lou, H.; Pang, Z. Facilitating university admission using a chatbot based on large language models with retrieval-augmented generation. Educ. Technol. Soc. 2024, 27, 454–470. [Google Scholar] [CrossRef]
- Neupane, S.; Hossain, E.; Keith, J.; Tripathi, H.; Ghiasi, F.; Golilarz, N.A.; Amirlatifi, A.; Mittal, S.; Rahimi, S. From Questions to Insightful Answers: Building an Informed Chatbot for University Resources. arXiv 2024, arXiv:2405.08120. [Google Scholar]
- Bimberg, R.; Quibeldey-Cirkel, K. AI assistants in teaching and learning: Compliant with data protection regulations and free from hallucinations! In Proceedings of the EDULEARN24, IATED, 2024, Palma, Spain, 1–3 July 2024. [Google Scholar]
- Hicke, Y.; Agarwal, A.; Ma, Q.; Denny, P. AI-TA: Towards an Intelligent Question-Answer Teaching Assistant Using Open-Source LLMs. arXiv 2023, arXiv:2311.02775. [Google Scholar]
- Zhang, T.; Patterson, L.; Beiting-Parrish, M.; Webb, B.; Abeysinghe, B.; Bailey, P.; Sikali, E. Ask NAEP: A Generative AI Assistant for Querying Assessment Information. J. Meas. Eval. Educ. Psychol. 2024, 15, 378–394. [Google Scholar] [CrossRef]
- Oldensand, V. Developing a RAG System for Automatic Question Generation: A Case Study in the Tanzanian Education Sector. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2024. [Google Scholar]
- Klymkowsky, M.; Cooper, M.M. The end of multiple choice tests: Using AI to enhance assessment. arXiv 2024, arXiv:2406.07481. [Google Scholar]
- Saha, B.; Saha, U. Enhancing International Graduate Student Experience through AI-Driven Support Systems: A LLM and RAG-Based Approach. In Proceedings of the 2024 International Conference on Data Science and Its Applications, ICoDSA 2024, Kuta, Bali, Indonesia, 10–11 July 2024; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2024; pp. 300–304. [Google Scholar] [CrossRef]
- Wong, L. Gaita: A RAG System for Personalized Computer Science Education. Master’s Thesis, Johns Hopkins University, Baltimore, MD, USA, 2024. [Google Scholar]
- Amarnath, N.; Nagarajan, R. An Intelligent Retrieval Augmented Generation Chatbot for Contextually-Aware Conversations to Guide High School Students. In Proceedings of the 4th International Conference on Sustainable Expert Systems, ICSES 2024, Lekhnath, Nepal, 15–17 October 2024; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2024; pp. 1393–1398. [Google Scholar] [CrossRef]
- Rao, J.; Lin, J. RAMO: Retrieval-Augmented Generation for Enhancing MOOCs Recommendations. In Proceedings of the Educational Datamining ’24 Human-Centric eXplainable AI in Education and Leveraging Large Language Models for Next-Generation Educational Technologies Workshop Joint Proceedings, Atlanta, GA, USA, 13 July 2024; CEUR-WS. Volume 3840. [Google Scholar]
- Yan, L.; Zhao, L.; Echeverria, V.; Jin, Y.; Alfredo, R.; Li, X.; Gašević, D.; Martinez-Maldonado, R. VizChat: Enhancing Learning Analytics Dashboards with Contextualised Explanations Using Multimodal Generative AI Chatbots. In Proceedings of the 25th International Conference on Artificial Intelligence in Education, AIED 2024, Recife, Brazil, 8–12 July 2024; Olney, A.M., Chounta, I.-A., Liu, Z., Santos, O.C., Bittencourt, I.I., Eds.; Lecture Notes in Artificial Intelligence (LNAI). Springer Science and Business Media: Berlin/Heidelberg, Germany, 2024; Volume 14830, pp. 180–193. [Google Scholar] [CrossRef]
- Forootani, A.; Aliabadi, D.; Thraen, D. Bio-Eng-LMM AI Assist chatbot: A Comprehensive Tool for Research and Education. arXiv 2024, arXiv:2409.07110. [Google Scholar]
- Wiratunga, N.; Abeyratne, R.; Jayawardena, L.; Martin, K.; Massie, S.; Nkisi-Orji, I.; Weerasinghe, R.; Liret, A.; Fleisch, B. CBR-RAG: Case-Based Reasoning for Retrieval Augmented Generation in LLMs for Legal Question Answering. In Proceedings of the Case-Based Reasoning Research and Development, Merida, Mexico, 1–4 July 2024; Recio-Garcia, J.A., Orozco-del Castillo, M.G., Bridge, D., Eds.; Springer: Cham, Switzerland, 2024; pp. 445–460. [Google Scholar]
- Li, Y.; Li, Z.; Zhang, K.; Dan, R.; Jiang, S.; Zhang, Y. ChatDoctor: A Medical Chat Model Fine-Tuned on a Large Language Model Meta-AI (LLaMA) Using Medical Domain Knowledge. Cureus 2023, 15, e40895. [Google Scholar] [CrossRef] [PubMed]
- Cui, J.; Ning, M.; Li, Z.; Chen, B.; Yan, Y.; Li, H.; Ling, B.; Tian, Y.; Yuan, L. Chatlaw: A Multi-Agent Collaborative Legal Assistant with Knowledge Graph Enhanced Mixture-of-Experts Large Language Model. arXiv 2024, arXiv:2306.16092. [Google Scholar]
- Dean, M.; Bond, R.; McTear, M.; Mulvenna, M. ChatPapers: An AI Chatbot for Interacting with Academic Research. In Proceedings of the 2023 31st Irish Conference on Artificial Intelligence and Cognitive Science, AICS 2023, Letterkenny, Ireland, 7–8 December 2023; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2023. [Google Scholar] [CrossRef]
- Bhavani Peri, S.; Santhanalakshmi, S.; Radha, R. Chatbot to chat with medical books using Retrieval-Augmented Generation Model. In Proceedings of the NKCon 2024—3rd Edition of IEEE NKSS’s Flagship International Conference: Digital Transformation: Unleashing the Power of Information, Bagalkot, India, 21–22 September 2024; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Maryamah, M.; Irfani, M.; Tri Raharjo, E.; Rahmi, N.; Ghani, M.; Raharjana, I. Chatbots in Academia: A Retrieval-Augmented Generation Approach for Improved Efficient Information Access. In Proceedings of the KST 2024—16th International Conference on Knowledge and Smart Technology, Krabi, Thailand, 28 February–2 March 2024; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2024; pp. 259–264. [Google Scholar] [CrossRef]
- Richard, R.; Veemaraj, E.; Thomas, J.; Mathew, J.; Stephen, C.; Koshy, R. A Client-Server Based Educational Chatbot for Academic Institutions. In Proceedings of the 2024 4th International Conference on Intelligent Technologies, CONIT 2024, Bangalore, India, 21–23 June 2024; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Dayarathne, R.; Ranaweera, U.; Ganegoda, U. Comparing the Performance of LLMs in RAG-Based Question-Answering: A Case Study in Computer Science Literature. In Proceedings of the Artificial Intelligence in Education Technologies: New Development and Innovative Practices, Barcelona, Spain, 29–31 July 2024; Schlippe, T., Cheng, E.C.K., Wang, T., Eds.; Springer: Singapore, 2025; pp. 387–403. [Google Scholar]
- Burgan, C.; Kowalski, J.; Liao, W. Developing a Retrieval Augmented Generation (RAG) Chatbot App Using Adaptive Large Language Models (LLM) and LangChain Framework. Proc. West Va. Acad. Sci. 2024, 96. [Google Scholar] [CrossRef]
- Ge, J.; Sun, S.; Owens, J.; Galvez, V.; Gologorskaya, O.; Lai, J.C.; Pletcher, M.J.; Lai, K. Development of a liver disease-specific large language model chat interface using retrieval-augmented generation. Hepatology 2024, 80, 1158–1168. [Google Scholar] [CrossRef]
- Alawwad, H.A.; Alhothali, A.; Naseem, U.; Alkhathlan, A.; Jamal, A. Enhancing textual textbook question answering with large language models and retrieval augmented generation. Pattern Recognit. 2025, 162, 111332. [Google Scholar] [CrossRef]
- Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Garcia Valencia, O.A.; Cheungpasitporn, W. Integrating Retrieval-Augmented Generation with Large Language Models in Nephrology: Advancing Practical Applications. Medicina 2024, 60, 445. [Google Scholar] [CrossRef]
- Wölfel, M.; Shirzad, M.; Reich, A.; Anderer, K. Knowledge-Based and Generative-AI-Driven Pedagogical Conversational Agents: A Comparative Study of Grice’s Cooperative Principles and Trust. Big Data Cogn. Comput. 2024, 8, 2. [Google Scholar] [CrossRef]
- Cooper, M.; Klymkowsky, M. Let us not squander the affordances of LLMS for the sake of expedience: Using retrieval augmented generative AI chatbots to support and evaluate student reasoning. J. Chem. Educ. 2024, 101, 4847–4856. [Google Scholar] [CrossRef]
- Amri, S.; Bani, S.; Bani, R. Moroccan legal assistant Enhanced by Retrieval-Augmented Generation Technology. In Proceedings of the 7th International Conference on Networking, Intelligent Systems and Security, NISS 2024, Meknes, Morocco, 18–19 April 2024; ACM International Conference Proceeding Series. Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Lála, J.; O’Donoghue, O.; Shtedritski, A.; Cox, S.; Rodriques, S.G.; White, A.D. PaperQA: Retrieval-Augmented Generative Agent for Scientific Research. arXiv 2023, arXiv:2312.07559. [Google Scholar]
- Wang, C.; Ong, J.; Wang, C.; Ong, H.; Cheng, R.; Ong, D. Potential for GPT Technology to Optimize Future Clinical Decision-Making Using Retrieval-Augmented Generation. Ann. Biomed. Eng. 2024, 52, 1115–1118. [Google Scholar] [CrossRef] [PubMed]
- Sree, Y.; Sathvik, A.; Hema Akshit, D.; Kumar, O.; Pranav Rao, B. Retrieval-Augmented Generation Based Large Language Model Chatbot for Improving Diagnosis for Physical and Mental Health. In Proceedings of the 6th International Conference on Electrical, Control and Instrumentation Engineering, ICECIE 2024, Pattaya, Thailand, 23 November 2024; Institute of Electrical and Electronics Engineers: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Habib, M.; Amin, S.; Oqba, M.; Jaipal, S.; Khan, M.; Samad, A. TaxTajweez: A Large Language Model-based Chatbot for Income Tax Information In Pakistan Using Retrieval Augmented Generation (RAG). In Proceedings of the 37th International Florida Artificial Intelligence Research Society Conference, FLAIRS 2024, Miramar Beach, FL, USA, 19–21 May 2024; Volume 37. [Google Scholar]
- Chen, J.; Lin, H.; Han, X.; Sun, L. Benchmarking Large Language Models in Retrieval-Augmented Generation. Proc. AAAI Conf. Artif. Intell. 2024, 38, 17754–17762. [Google Scholar] [CrossRef]
- ES, S.; James, J.; Anke, L.E.; Schockaert, S. RAGAs: Automated Evaluation of Retrieval Augmented Generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024—System Demonstrations, St. Julians, Malta, 17–22 March 2024; Aletras, N., Clercq, O.D., Eds.; Association for Computational Linguistics: St. Stroudsburg, PA, USA, 2024; pp. 150–158. [Google Scholar]
- Giner, F. An Intrinsic Framework of Information Retrieval Evaluation Measures. In Proceedings of the Intelligent Systems and Applications; Arai, K., Ed.; Springer: Cham, Switzerland, 2024; pp. 692–713. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Lan, F. Research on Text Similarity Measurement Hybrid Algorithm with Term Semantic Information and TF-IDF Method. Adv. Multimed. 2022, 2022, 1–11. [Google Scholar] [CrossRef]
- Zhong, W.; Cui, R.; Guo, Y.; Liang, Y.; Lu, S.; Wang, Y.; Saied, A.; Chen, W.; Duan, N. AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, 16–21 June 2024; pp. 2299–2314. [Google Scholar] [CrossRef]
- Aridoss, M.; Bisht, K.S.; Natarajan, A.K. Comprehensive Analysis of Falcon 7B: A State-of-the-Art Generative Large Language Model. In Generative AI: Current Trends and Applications; Springer: Berlin/Heidelberg, Germany, 2024; pp. 147–164. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Grice, H.P. Studies in the Way of Words; Harvard University Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Koubaa, A. GPT-4 vs. GPT-3.5: A Concise Showdown. Preprints 2023. [Google Scholar] [CrossRef]
- Chiesurin, S.; Dimakopoulos, D.; Sobrevilla Cabezudo, M.A.; Eshghi, A.; Papaioannou, I.; Rieser, V.; Konstas, I. The Dangers of trusting Stochastic Parrots: Faithfulness and Trust in Open-domain Conversational Question Answering. arXiv 2023, arXiv:2305.16519. [Google Scholar] [CrossRef]
- Hanna, M.; Bojar, O. A Fine-Grained Analysis of BERTScore. In Proceedings of the Sixth Conference on Machine Translation, Online, 10–11 November 2021; Barrault, L., Bojar, O., Bougares, F., Chatterjee, R., Costa-jussa, M.R., Federmann, C., Fishel, M., Fraser, A., Freitag, M., Graham, Y., et al., Eds.; pp. 507–517. [Google Scholar]
- Sellam, T.; Das, D.; Parikh, A. BLEURT: Learning Robust Metrics for Text Generation. arXiv 2020, arXiv:2004.04696. [Google Scholar] [CrossRef]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Liau, T.L.; Bassin, C.B.; Martin, C.J.; Coleman, E.B. Modification of the Coleman readability formulas. J. Read. Behav. 1976, 8, 381–386. [Google Scholar] [CrossRef]
- Solnyshkina, M.; Zamaletdinov, R.; Gorodetskaya, L.; Gabitov, A. Evaluating text complexity and Flesch-Kincaid grade level. J. Soc. Stud. Educ. Res. 2017, 8, 238–248. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar]
- Lian, W.; Goodson, B.; Wang, G.; Pentland, E.; Cook, A.; Vong, C. “Teknium”. MistralOrca: Mistral-7B Model Instruct-Tuned on Filtered OpenOrcaV1 GPT-4 Dataset. 2023. Available online: https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca (accessed on 4 April 2025).
- Tunstall, L.; Beeching, E.; Lambert, N.; Rajani, N.; Rasul, K.; Belkada, Y.; Huang, S.; von Werra, L.; Fourrier, C.; Habib, N.; et al. Zephyr: Direct Distillation of LM Alignment. arXiv 2023, arXiv:2310.16944. [Google Scholar]
- Tunstall, L.; Beeching, E.; Lambert, N.; Rajani, N.; Rasul, K.; Belkada, Y.; Huang, S.; von Werra, L.; Fourrier, C.; Habib, N.; et al. Zephyr 7B Beta. 2024. Available online: https://huggingface.co/HuggingFaceH4/zephyr-7b-beta (accessed on 4 April 2025).
- Lin, C.C. Exploring the relationship between technology acceptance model and usability test. Inf. Technol. Manag. 2013, 14, 243–255. [Google Scholar] [CrossRef]
- Lewis, J.R. The system usability scale: Past, present, and future. Int. J. Human Comput. Interact. 2018, 34, 577–590. [Google Scholar] [CrossRef]
- Vlachogianni, P.; Tselios, N. Perceived usability evaluation of educational technology using the System Usability Scale (SUS): A systematic review. J. Res. Technol. Educ. 2022, 54, 392–409. [Google Scholar] [CrossRef]
- Montella, R.; De Vita, C.G.; Mellone, G.; Di Luccio, D.; Maskeliūnas, R.; Damaševičius, R.; Blažauskas, T.; Queirós, R.; Kosta, S.; Swacha, J. Re-Assessing the Usability of FGPE Programming Learning Environment with SUS and UMUX. In Proceedings of the Information Systems Education Conference, Virtual, 19 October 2024; Foundation for IT Education: Chicago, IL, USA, 2024; pp. 128–135. [Google Scholar]
- Liu, R.; Zenke, C.; Liu, C.; Holmes, A.; Thornton, P.; Malan, D.J. Teaching CS50 with AI: Leveraging Generative Artificial Intelligence in Computer Science Education. In Proceedings of the 55th ACM Technical Symposium on Computer Science Education, Portland, OR, USA, 20–23 March 2024; Volume 1, pp. 750–756. [Google Scholar] [CrossRef]
- Wang, Y.; Hernandez, A.G.; Kyslyi, R.; Kersting, N. Evaluating Quality of Answers for Retrieval-Augmented Generation: A Strong LLM Is All You Need. arXiv 2024, arXiv:2406.18064. [Google Scholar]
- Hobert, S. How Are You, Chatbot? Evaluating Chatbots in Educational Settings—Results of a Literature Review. In DELFI 2019; Gesellschaft für Informatik e.V.: Bonn, Germany, 2019; pp. 259–270. [Google Scholar] [CrossRef]
- Amugongo, L.M.; Mascheroni, P.; Brooks, S.G.; Doering, S.; Seidel, J. Retrieval Augmented Generation for Large Language Models in Healthcare: A Systematic Review. 2024. Available online: https://www.preprints.org/manuscript/202407.0876/v1 (accessed on 4 April 2025).
- Raihan, N.; Siddiq, M.L.; Santos, J.C.; Zampieri, M. Large Language Models in Computer Science Education: A Systematic Literature Review. In Proceedings of the 56th ACM Technical Symposium on Computer Science Education, Pittsburgh, PA, USA, 26 February–1 March 2025; Volume 1, pp. 938–944. [Google Scholar] [CrossRef]
- Brown, G.T.L.; Abdulnabi, H.H.A. Evaluating the Quality of Higher Education Instructor-Constructed Multiple-Choice Tests: Impact on Student Grades. Front. Educ. 2017, 2, 24. [Google Scholar] [CrossRef]
- McCloskey, M. Turn User Goals into Task Scenarios for Usability Testing. 2014. Available online: https://www.nngroup.com/articles/task-scenarios-usability-testing/ (accessed on 4 April 2025).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Title | Thematic Scope | LLM |
|---|---|---|---|
| [13] | Beyond Chatbots: Enhancing Luxembourgish Language Learning Through Multi-agent Systems and Large Language Model | Language | GPT-4o |
| [14] | ChatGPT versus a customized AI chatbot (Anatbuddy) for anatomy education: A comparative pilot study | Health sciences | GPT-3.5 |
| [15] | Design, architecture and safety evaluation of an AI chatbot for an educational approach to health promotion in chronic medical conditions | Health sciences | GPT-3.5-turbo-0125 |
| [16] | Embodied AI-Guided Interactive Digital Teachers for Education | Any | LLaMA-3-8B |
| [17] | Enhancing Programming Education with Open-Source Generative AI Chatbots | Computer science | Mistral-7B-Openorca |
| [18] | Harnessing GenAI for Higher Education: A Study of a Retrieval Augmented Generation Chatbot’s Impact on Human Learning | Computer science | GPT4 changed to Claude 3-Sonnet |
| [19] | Interactive Video Virtual Assistant Framework with Retrieval Augmented Generation for E-Learning | Any | LLaMA-2-7B |
| [20] | Into the unknown unknowns: Engaged human learning through participation in language model agent conversations | Any | GPT-4o-2024-05-13 |
| [21] | An LLM-Driven Chatbot in Higher Education for Databases and Information Systems | Computer science | GPT-4 |
| [22] | Retrieval-augmented Generation to Improve Math Question-Answering: Trade-offs Between Groundedness and Human Preference | Math | GPT-3.5-turbo-0613 |
| [23] | Scalable Mentoring Support with a Large Language Model Chatbot | Any | GPT-3.5-turbo |
| [24] | Transforming Healthcare Education: Harnessing Large Language Models for Frontline Health Worker Capacity Building using Retrieval-Augmented Generation | Health sciences | GPT-3.5, GPT-4 |
| Paper | Title | LLM |
|---|---|---|
| [25] | AI-driven Chatbot Implementation for Enhancing Customer Service in Higher Education: A Case Study from Universitas Negeri Semarang | LLaMA-3 |
| [26] | Closed Domain Question-Answering Techniques in an Institutional Chatbot | LLaMA-2 |
| [27] | Development and Evaluation of a University Chatbot Using Deep Learning: A RAG-Based Approach | Unspecified |
| [28] | Facilitating university admission using a chatbot based on large language models with retrieval-augmented generation | GPT-3.5-turbo, Text-davinci-003 |
| [29] | From Questions to Insightful Answers: Building an Informed Chatbot for University Resources | GPT-3.5-turbo |
| Paper | Title | Target of Support | Thematic Scope | LLM |
|---|---|---|---|---|
| [30] | AI Assistants in Teaching and Learning: Compliant with Data Protection Regulations and Free from Hallucinations! | Learning + Question generation | Any | GPT-4 |
| [31] | AI-TA: Towards an Intelligent Question-Answer Teaching Assistant using Open-Source LLMs | Learning + Organizational matters | Computer science | GPT-4, LLaMA-2-7B, LLaMA-2-13B, LLaMA-2-70B |
| [32] | Ask NAEP: A Generative AI Assistant for Querying Assessment Information | Access to information on assessment | Education | GPT-3.5 changed to GPT-4o |
| [33] | Developing a RAG system for automatic question generation: A case study in the Tanzanian education sector | Question generation | Any | GPT-3.5-turbo-0125, GPT-4-turbo-2024-04-09, LLaMA-3-70b-8192 |
| [34] | The end of multiple choice tests: using AI to enhance assessment | Learning analytics support | Any | GPT (Unspecified) |
| [35] | Enhancing International Graduate Student Experience through AI-Driven Support Systems: A LLM and RAG-Based Approach | Organizational matters, Local culture | Local-culture and institutional-domain knowledge | GPT-3.5 |
| [36] | Gaita: A RAG System for Personalized Computer Science Education | Course selection | Institutional-domain knowledge | GPT-4o Mini |
| [37] | An Intelligent Retrieval Augmented Generation Chatbot for Contextually-Aware Conversations to Guide High School Students | Course selection | Institutional-domain knowledge | Unspecified |
| [38] | RAMO: Retrieval-Augmented Generation for Enhancing MOOCs Recommendations | Course selection | Institutional-domain knowledge | GPT-3.5-turbo, GPT-4, LLaMA-2, LLaMA-3 |
| [39] | VizChat: Enhancing Learning Analytics Dashboards with Contextualised Explanations Using Multimodal Generative AI Chatbots | Learning analytics support | Education | GPT-4V |
| Paper | Title | Thematic Scope | LLM |
|---|---|---|---|
| [40] | Bio-Eng-LMM AI Assist chatbot: A Comprehensive Tool for Research and Education | Various | GPT-4 |
| [41] | CBR-RAG: Case-Based Reasoning for Retrieval Augmented Generation in LLMs for Legal Question Answering | Law | Mistral-7B |
| [42] | ChatDoctor: A Medical Chat Model Fine-Tuned on a Large Language Model Meta-AI (LLaMA) Using Medical Domain Knowledge | Health sciences | LLaMA-7B |
| [43] | ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases | Law | Ziya-LLaMA-13B |
| [44] | ChatPapers: An AI Chatbot for Interacting with Academic Research | Computer science | Unspecified |
| [45] | Chatbot to chat with medical books using Retrieval-Augmented Generation Model | Health sciences | GPT-4 |
| [46] | Chatbots in Academia: A Retrieval-Augmented Generation Approach for Improved Efficient Information Access | Institutional-domain knowledge | GPT-3.5-turbo |
| [47] | A Client-Server Based Educational Chatbot for Academic Institutions | Any | Unspecified |
| [48] | Comparing the Performance of LLMs in RAG-Based Question-Answering: A Case Study in Computer Science Literature | Computer science | Mistral-7b-instruct, LLaMa2-7b-chat, Falcon-7b-instruct and Orca-mini-v3-7b, GPT-3.5 |
| [49] | Developing a Retrieval-Augmented Generation (RAG) Chatbot App Using Adaptive Large Language Models (LLM) and LangChain Framework | Institutional-domain knowledge | Gemma (local version) |
| [50] | Development of a liver disease–specific large language model chat interface using retrieval-augmented generation | Health sciences | GPT-3.5-turbo |
| [51] | Enhancing textual textbook question answering with large language models and retrieval augmented generation | Various | LLaMA-2 |
| [52] | Integrating Retrieval-Augmented Generation with Large Language Models in Nephrology: Advancing Practical Applications | Health sciences | GPT-4 |
| [53] | Knowledge-Based and Generative-AI-Driven Pedagogical Conversational Agents: A Comparative Study of Grice’s Cooperative Principles and Trust | Any | GPT-3.5, GPT-4 |
| [54] | Let us not squander the affordances of LLMS for the sake of expedience: using retrieval-augmented generative AI chatbots to support and evaluate student reasoning | Any | Unspecified |
| [55] | Moroccan legal assistant Enhanced by Retrieval-Augmented Generation Technology | Law | LLama 70-B |
| [56] | PaperQA: Retrieval-Augmented Generative Agent for Scientific Research | Biomedical | Claude-2, GPT-3.5, GPT-4 |
| [57] | Potential for GPT Technology to Optimize Future Clinical Decision-Making Using Retrieval-Augmented Generation | Health sciences | Unspecified |
| [58] | Retrieval-Augmented Generation Based Large Language Model Chatbot for Improving Diagnosis for Physical and Mental Health | Health sciences | Unspecified |
| [59] | TaxTajweez: A Large Language Model-based Chatbot for Income Tax Information In Pakistan Using Retrieval Augmented Generation (RAG) | Finance | GPT-3.5-turbo |
| Approaches (Measures)\Purposes | Response Content | Response Form | User Guidance | Value Added | User Experience | Specific Issues |
|---|---|---|---|---|---|---|
| Information retrieval (e.g., Precision, Recall, F1 Score) | R | - | - | - | - | - |
| LLM benchmarks (e.g., AGIEval) | r | r | R | - | - | - |
| Conversational quality (e.g., Correctness, Completeness, Communication) | r | R | - | - | - | - |
| Generated text quality (e.g., K-F1++, BLEURT, ROUGE) | r | R | - | - | - | - |
| Human-assessed text quality (e.g., Fluency, Coherence, Relevance) | r | R | - | - | r | - |
| Technical performance (e.g., operational efficiency, response time) | - | - | - | R | - | - |
| Economic performance (e.g., cost per query, cost per user) | - | - | - | R | - | - |
| User acceptance and satisfaction (e.g., SUS, Perceived Usability) | r | r | r | - | R | - |
| Overall RAG chatbot quality (e.g., RAGAS) | r | r | r | - | r | r |
| Qualitative evaluation (e.g., user interviews) | - | - | - | - | - | R |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Swacha, J.; Gracel, M. Retrieval-Augmented Generation (RAG) Chatbots for Education: A Survey of Applications. Appl. Sci. 2025, 15, 4234. https://doi.org/10.3390/app15084234
Swacha J, Gracel M. Retrieval-Augmented Generation (RAG) Chatbots for Education: A Survey of Applications. Applied Sciences. 2025; 15(8):4234. https://doi.org/10.3390/app15084234
Chicago/Turabian StyleSwacha, Jakub, and Michał Gracel. 2025. "Retrieval-Augmented Generation (RAG) Chatbots for Education: A Survey of Applications" Applied Sciences 15, no. 8: 4234. https://doi.org/10.3390/app15084234
APA StyleSwacha, J., & Gracel, M. (2025). Retrieval-Augmented Generation (RAG) Chatbots for Education: A Survey of Applications. Applied Sciences, 15(8), 4234. https://doi.org/10.3390/app15084234