
Advancing Spanish Speech Emotion Recognition: A Comprehensive Benchmark of Pre-Trained Models

 , ,
, ,  , , and
, , and
Abstract
:1. Introduction
- We present the first comprehensive benchmarking of PTMs for Spanish SER, covering six diverse databases and addressing the lack of evaluations in underrepresented languages.
- We devise a robust experimental framework combining LOSO validation with layer-wise feature extraction, enabling accurate and interpretable comparisons across models.
- Our proposed approach achieves superior results on multiple Spanish datasets, outperforming existing state-of-the-art baselines while highlighting the benefits of Spanish-focused fine-tuning.
- We reveal how architectural depth and pretraining strategies influence emotional representations, guiding model selection in Spanish SER tasks through a detailed layer-wise and LOSO analysis.
- We establish a reproducible benchmarking pipeline that advances research on feature extraction, generalization, and fine-tuning in Spanish SER, offering consistent metrics across diverse scenarios.
2. Related Works
2.1. State of the Art in Spanish SER
2.2. PTMs for SER
3. Materials and Methods
3.1. Databases
- EmoMatchSpanishDBThe EmoMatchSpanishDB (EM-SpDB) [64] database is part of EmoSpanishDB, which was created from recordings of 50 non-actor participants (30 men and 20 women) with Ekman’s seven basic emotions being simulated: surprise, disgust, fear, anger, happiness, sadness, and neutral. EmoSpanishDB initially contains 3550 audio files, free of intrinsic emotional load. Through a crowdsourcing process, perceived emotions were validated, and inconsistent samples were removed, leading to the development of EM-SpDB, with the set being reduced to 2020 audios with more reliable emotional labels.
- Mexican Emotional Speech Database.The Mexican Emotional Speech Database (MESD) [72] was created in 2021 and consists of 864 recordings in Mexican Spanish. Six emotions—anger, disgust, fear, happiness, sadness, and neutral—were simulated by sixteen individuals (4 men, 4 women, and 8 children). The recordings were conducted in a professional studio, and the audio was sampled at 48,000 Hz with 16-bit resolution. Each adult participant recorded 48 words per emotion, while children recorded 24 words per emotion. The database was validated in [72] using an SVM model, and an accuracy of 93.9% for men, 89.4% for women, and 83.3% for children was achieved
- Spanish MEACorpus.The Spanish MEACorpus [68] is a multimodal database created in 2022, containing 5129 audio segments extracted from 13.16 h of Spanish speech. The emotional distribution is based on Ekman’s basic emotions. The segments are derived from YouTube videos, with natural settings such as political speeches, sports events, and entertainment shows being captured and recorded spontaneously. The database includes 46% female voices and 54% male voices, though specific details on speaker ages are not provided. The audios are in WAV format at a sampling rate of 44,100 Hz, with an average length of 9.24 s, segmented using a noise and silence threshold-based algorithm. Manual annotation was performed by three annotators, with Ekman’s taxonomy being used.
- EmoWisconsin.EmoWisconsin [66] was created in 2011 in Mexican Spanish and contains 3098 segments of children’s speech, including 28 participants (17 boys and 11 girls) aged 7 to 13. The labeled emotions include six categories: Annoyed, Motivated, Nervous, Neutral, Doubtful, and Confident, along with the three continuous primitives of valence, arousal, and dominance. The recordings were made at 44,100 Hz in 16-bit PCM WAV format, totaling 11 h and 39 min of recordings across 56 sessions. Emotions were elicited using a modified version of the Wisconsin Card Sorting Test (WCST), with sessions divided into positive and negative interactions.
- INTERFACE (INTER1SP).The INTERFACE [73] database was created in 2002 and contains 5520 samples in Spanish (INTER1SP), along with recordings in English, Slovenian, and French. Six emotions are included: anger, sadness, joy, fear, disgust, and surprise. Additionally, neutral speech styles were recorded in Spanish, including variations like soft, loud, slow, and fast. Recordings were made by one professional actor and one actress in each language. For validation, 18 non-professional listeners evaluated 56 statements through subjective tests. Recognition accuracy in the first choice exceeded 80%, rising to 90% when a second option was included. This database is available in the ELRA repository [79].
- EmoFilm.EmoFilm [74] is a multilingual database created in 2018, designed to enrich underrepresented languages such as Spanish, Italian, and others. It consists of 1115 clips with an average length of 3.5 s, distributed as 360 clips in English, 413 in Italian, and 342 in Spanish. This dataset includes five emotions: anger, sadness, happiness, fear, and contempt. For this study, only the Spanish portion of EmoFilm was used (). Movie and TV series clips have been extracted, capturing emotional expressions in acted contexts. Emotion annotation was performed through evaluations by multiple annotators, achieving high perceptual reliability.
3.2. Pre-Trained Models
- Wav2Vec 2.0.Wav2Vec 2.0 [44] is a self-supervised framework that learns representations from raw audio by solving a contrastive task on latent masked speech samples. The architecture is based on a convolutional feature encoder that processes waveform inputs into latent speech representations, followed by a transformer context network that captures contextual information. A quantization module discretizes the latent representations for contrastive learning. The training objective maximizes the agreement between the real latent representations and the quantized versions for the masked time steps, effectively capturing local and global acoustic features without the need for transcribed data.We used several variants of Wav2Vec 2.0 in our experiments:
- facebook/wav2vec2-large-robust-ft-libri-960h (W2V2-L-R-Libri960h): Pre-trained on 60,000 h of audio, including noise and telephony data, and fine-tuned on 960 h of the LibriSpeech corpus. This model consists of 24 layers and contains 317 million parameters.
- jonatasgrosman/wav2vec2-xls-r-1b-spanish (W2V2-XLSR-ES): Based on the XLS-R architecture, this model was pre-trained on 436,000 h of multilingual data and fine-tuned on Spanish ASR tasks. It has 1 billion parameters and 48 transformer layers.
- facebook/wav2vec2-large-xlsr-53-spanish (W2V2-L-XLSR53-ES): Pre-trained with 56,000 h of speech data from 53 languages including Spanish, and fine-tuned with Spanish ASR data. This model has 317 million parameters and 24 hidden layers.
- Whisper.Whisper [47] is an encoder–decoder transformer model designed for ASR and speech translation tasks. Its training approach, using supervised data, allows the model to effectively generalize across languages and tasks, capturing both linguistic and paralinguistic features that can be essential for emotion recognition.
- openai/whisper-large-v3 (Whisper-L-v3): This model contains 1.55 billion parameters, 32 encoder and decoder layers, and is trained on 680,000 h of multilingual data.
- zuazo/whisper-large-v3-es (Whisper-L-v3-ES): This is an optimized version specifically tailored for Spanish ASR tasks, featuring 32 hidden layers.
- HuBERT.HuBERT [45] is a PTM developed by Facebook, with a fully transformer-based architecture. This model has been trained on 1,160,000 h of unlabeled audio data using a self-supervised learning paradigm similar to Wav2Vec 2.0, but optimized for mask prediction tasks within audio signals. In this study, a 24-layer, 316 million-parameter version has been employed facebook/hubert-large-ll60k (HuBERT-L-1160k).
- WavLM.WavLM [46] incorporates a controlled relative position bias to model long-range dependencies in the speech signal, which improves the model’s ability to capture global contextual information. Pre-training uses a masked speech prediction task with continuous inputs, similar to the HuBERT and Wav2Vec 2.0 methodologies. For our work, we use the microsoft/wavlm-large (WavLM-L) model, which consists of 24 transformer layers and 300 million parameters.
- TRILLsson.TRILLsson [75] is a compact and efficient model derived through the distillation of CAP12, a high-performance Conformer model trained on 900 million hours of audio from the YT-U dataset using self-supervised objectives. Tailored for non-semantic tasks, TRILLsson captures paralinguistic features critical for emotion recognition, such as tone, pitch, and rhythm. Although its size has been reduced from 6x to 100x compared to CAP12, it retains 90–96% of its performance. Its efficient architecture leverages local matching strategies to align smaller inputs with robust embeddings, enabling deployment on resource-constrained devices. From this model, it is only possible to obtain the final embeddings, so, unlike the others, it is not layer-wise analyzed.
- CLAP.CLAP [76] makes use of a dual-encoder architecture for audio and text modalities, trained through a contrastive loss that aligns audio and text embeddings in a shared latent space. The audio encoder processes audio inputs using the HTSAT architecture, while the text encoder processes textual descriptions. In our work, we use the laion/clap-htsat-unfused (L-CLAP-G) model, which, like TRILLsson, only yields final embeddings and not intermediate ones, so its analysis will not be layer-based either.
3.3. Layer-Wise Evaluation of PTMs
3.4. Embedding Extraction and Mean Pooling
3.5. Data Partitioning
3.6. LOSO Validation
3.7. Classifier Training
- K-Nearest Neighbors.The KNN algorithm is a non-parametric and lazy learning method used for classification and regression. KNN classification is performed by identifying the K nearest neighbors to a query point using a distance metric, such as the Euclidean distance. The optimal value of K and the nearest neighbors are determined through a search process that can involve techniques like Ktree and K*tree, where neighbor calculations are optimized using tree-like structures. Advanced methods, such as the one-step KNN, reduce neighbor calculation to a single matrix operation that integrates both K adjustment and neighbor search, using least squares loss functions and sparse regularization (like group lasso) to generate a relationship matrix containing the optimal neighbors and their corresponding weights [83].
- Support Vector Machine.SVMs are supervised learning algorithms used for classification and regression designed to identify the optimal separating hyperplane in a high-dimensional space that maximizes the margin between points from different classes. For non-linear problems, SVM employs kernel functions to project data into higher-dimensional spaces where linear separation becomes feasible. The maximum margin is expressed as , where w is the weight vector. The optimization problem is formulated as minimizing under correct classification constraints, and in cases where the margin cannot be strictly maintained, slack variables are introduced to allow some classification flexibility [84,85].
- Multi-Layer Perceptron.MLPs are artificial neural networks consisting of interconnected layers of nodes, where each node in intermediate and output layers applies a non-linear activation function (such as sigmoid or hyperbolic tangent). MLP training is typically performed using backpropagation, which adjusts the weights via gradient descent to minimize the mean squared error (MSE) between predicted and expected outputs. The mathematical model of an MLP can be expressed as:where and are weight matrices, and are bias vectors, and f is the non-linear activation function [86].
3.8. Calculation of Performance Metrics
4. Results
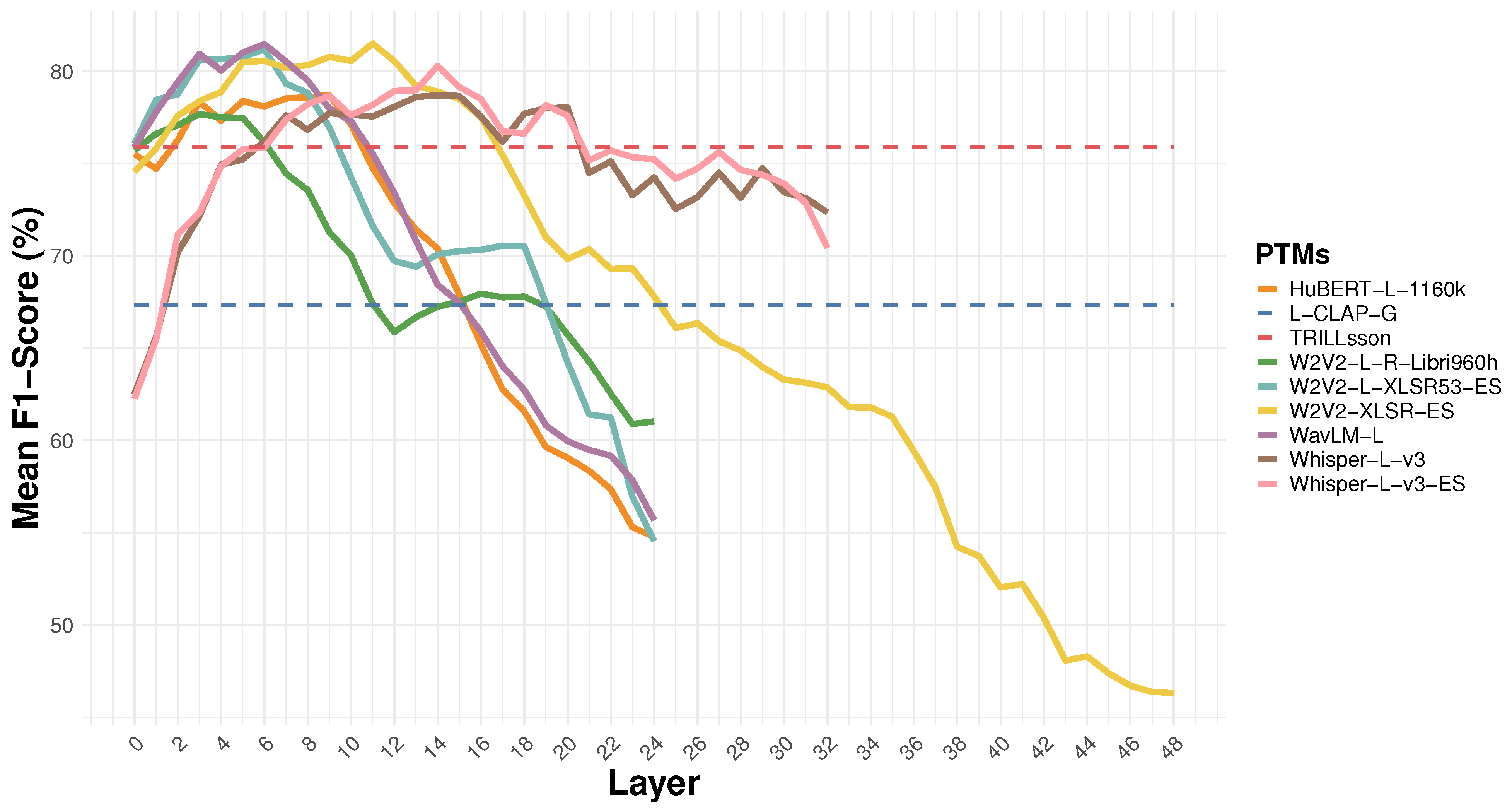
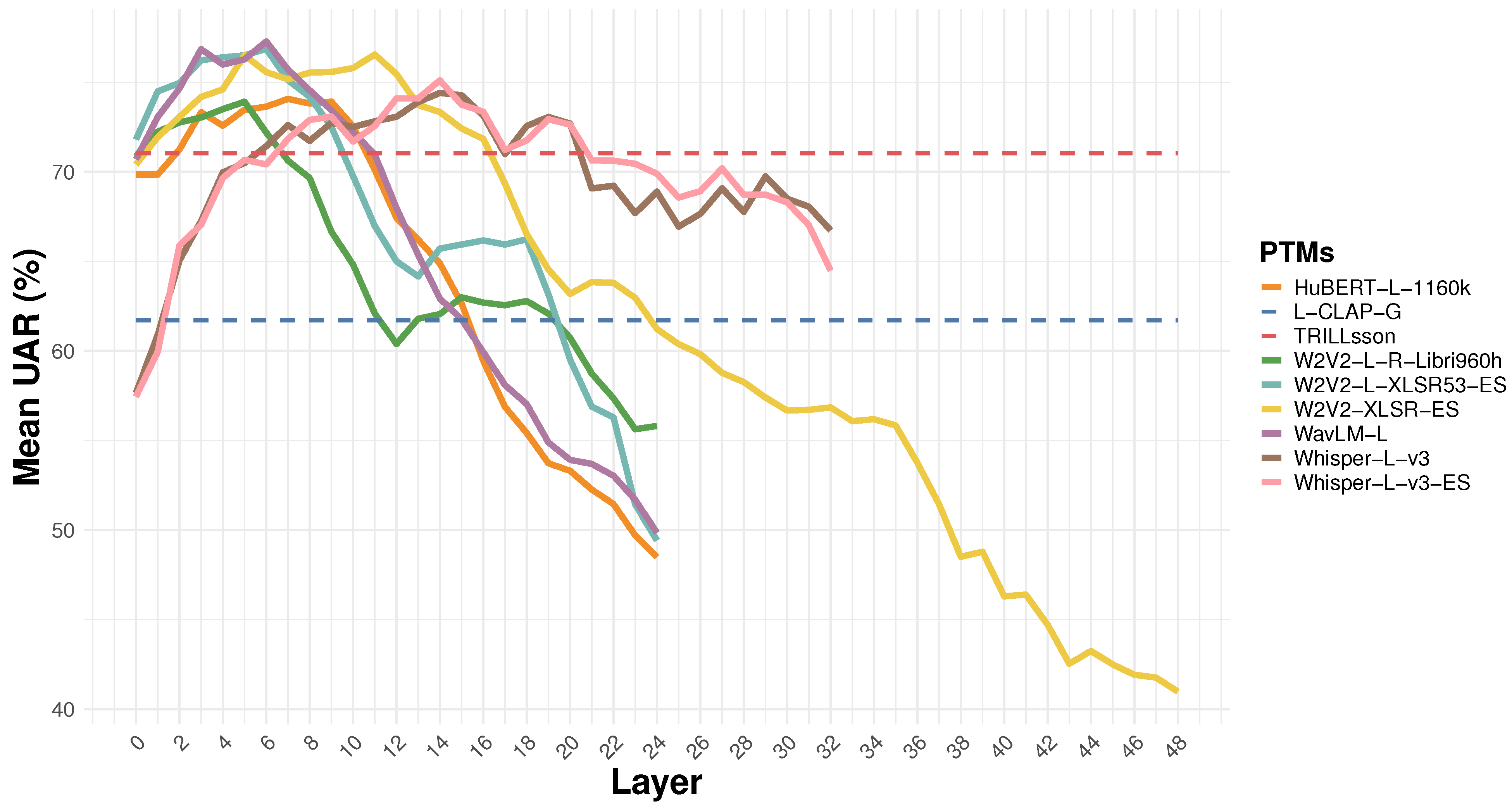
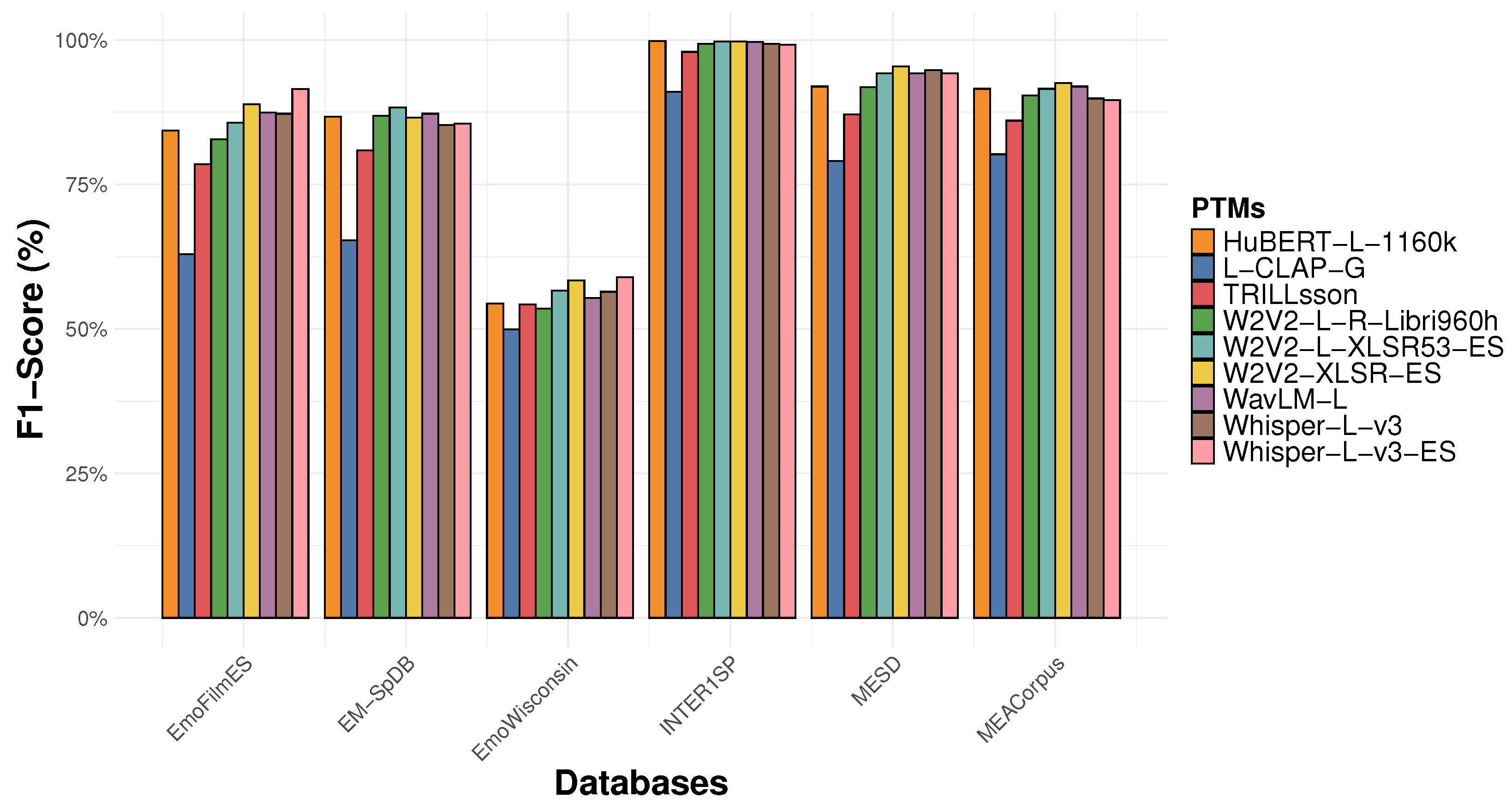
4.1. Layer-Wise Evaluation Results
4.1.1. Average Metric Values by Layer per Database and PTM
4.1.2. Database Performance Comparison
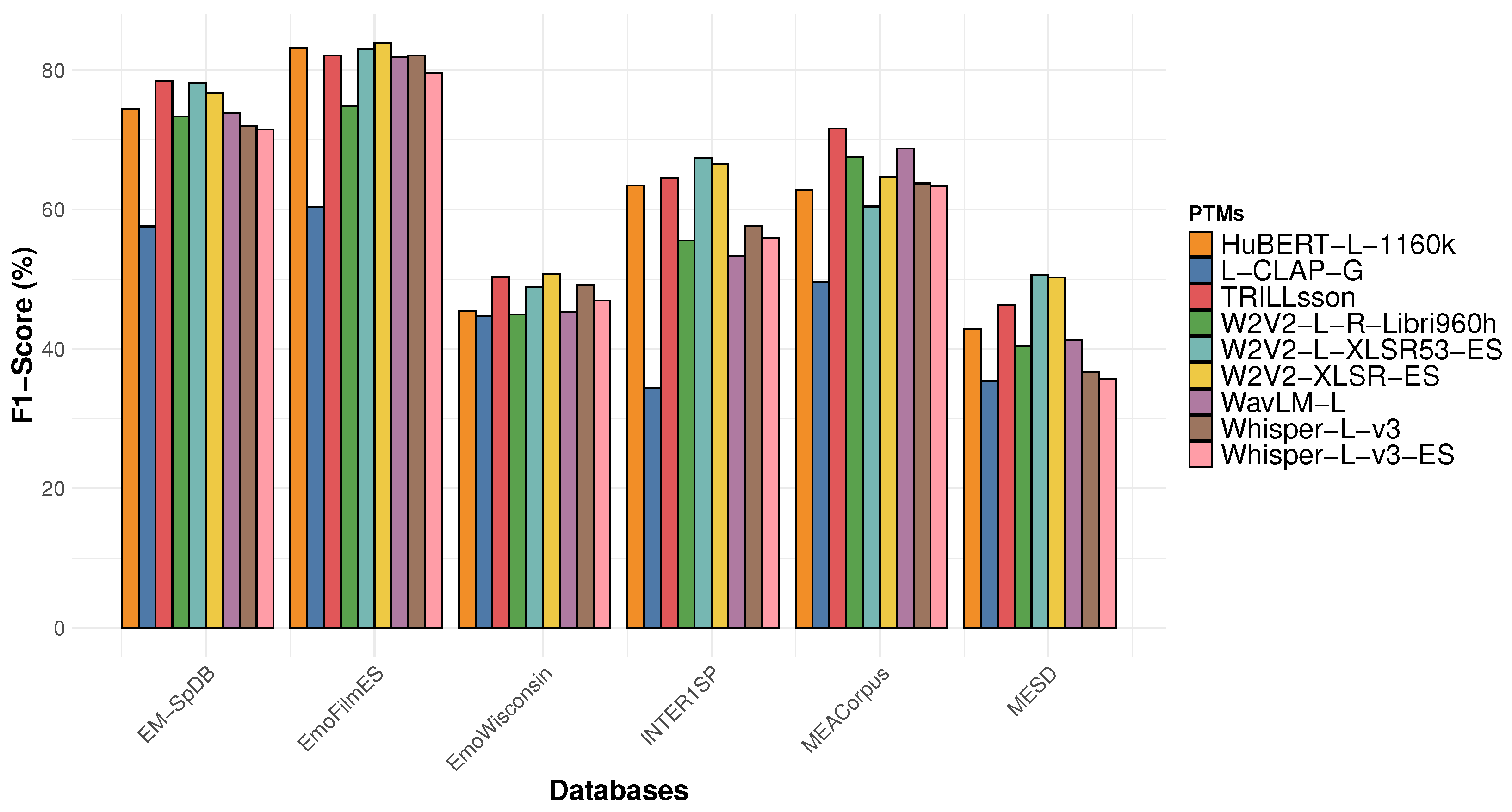
4.2. LOSO Validation Results
4.2.1. Performance Insights in LOSO Validation
4.2.2. Average Performance Metrics
5. Discussion and Comparative Analysis
5.1. PTMs Against SOTA for SER in Spanish
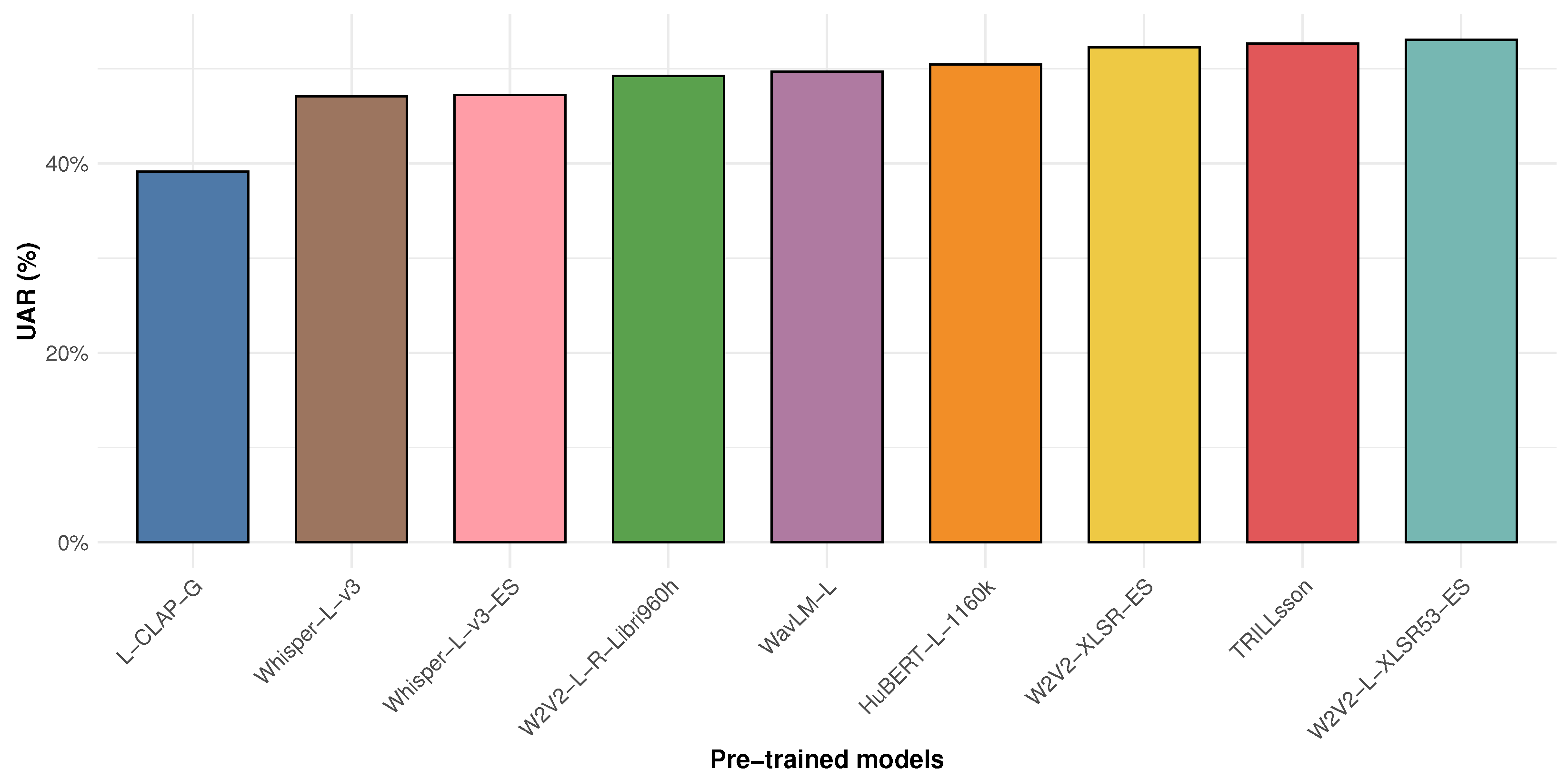
5.2. Performance Comparison Between PTMs
5.3. Impact of Database Nature on Emotion Recognition Performance
5.4. Fine-Tuning and Practical Applications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNNs | Convolutional Neural Networks |
| DS-AM | DeepSpectrum model with Attention Mechanism |
| EM-SpDB | EmoMatchSpanishDB |
| GMMs | Gaussian Mixture Models |
| GRUs | Gated Recurrent Units |
| HMMs | Hidden Markov Models |
| KNN | K-Nearest Neighbor |
| LOSO | Leave-One-Speaker-Out |
| LSTM | Long Short-Term Memory |
| MESD | Mexican Emotional Speech Database |
| MFCCs | Mel-Frequency Cepstral Coefficients |
| MLP | Multi-Layer Perceptron |
| P-TAPT | Pseudo-label Task Adaptive Pretraining |
| PTMs | Pre-Trained Models |
| RNNs | Recurrent Neural Networks |
| SER | Speech Emotion Recognition |
| SSL | Self-Supervised Learning |
| SOTA | State-Of-The-Art |
| SVM | Support Vector Machine |
| UAR | Unwieghted Average Recall |
| WCST | Wisconsin Card Sorting Test |
References
- Geethu, V.; Vrindha, M.K.; Anurenjan, P.R.; Deepak, S.; Sreeni, K.G. Speech Emotion Recognition, Datasets, Features and Models: A Review. In Proceedings of the 2023 International Conference on Control, Communication and Computing (ICCC), Thiruvananthapuram, India, 19–21 May 2023; pp. 1–6. [Google Scholar]
- Lee, C.M.; Narayanan, S. Toward detecting emotions in spoken dialogs. IEEE Trans. Speech Audio Process. 2005, 13, 293–303. [Google Scholar] [CrossRef]
- Shah Fahad, M.; Ranjan, A.; Yadav, J.; Deepak, A. A survey of speech emotion recognition in natural environment. Digit. Signal Process. 2021, 110, 102951. [Google Scholar] [CrossRef]
- Jahangir, R.; Teh, Y.W.; Hanif, F.; Mujtaba, G. Deep learning approaches for speech emotion recognition: State of the art and research challenges. Multimed. Tools Appl. 2021, 80, 23745–23812. [Google Scholar] [CrossRef]
- Khare, S.K.; Blanes-Vidal, V.; Nadimi, E.S.; Acharya, U.R. Emotion recognition and artificial intelligence: A systematic review (2014–2023) and research recommendations. Inf. Fusion 2024, 102, 102019. [Google Scholar] [CrossRef]
- Luo, B.; Lau, R.Y.K.; Li, C.; Si, Y.W. A critical review of state-of-the-art chatbot designs and applications. WIREs Data Min. Knowl. Discov. 2022, 12, e1434. [Google Scholar] [CrossRef]
- Chen, L.; Su, W.; Feng, Y.; Wu, M.; She, J.; Hirota, K. Two-layer fuzzy multiple random forest for speech emotion recognition in human-robot interaction. Inf. Sci. 2020, 509, 150–163. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, B.; Li, X.; Liu, F.; Wang, G.; Yang, J. Detecting Depression in Speech Under Different Speaking Styles and Emotional Valences. In Proceedings of the Brain Informatics, Beijing, China, 16–18 November 2017. [Google Scholar]
- France, D.; Shiavi, R.; Silverman, S.; Silverman, M.; Wilkes, M. Acoustical properties of speech as indicators of depression and suicidal risk. IEEE Trans. Biomed. Eng. 2000, 47, 829–837. [Google Scholar] [CrossRef]
- Li, H.C.; Pan, T.; Lee, M.H.; Chiu, H.W. Make Patient Consultation Warmer: A Clinical Application for Speech Emotion Recognition. Appl. Sci. 2021, 11, 4782. [Google Scholar] [CrossRef]
- Schuller, B.W. Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends. Commun. ACM 2018, 61, 90–99. [Google Scholar] [CrossRef]
- Hansen, J.H.; Cairns, D.A. ICARUS: Source generator based real-time recognition of speech in noisy stressful and Lombard effect environments. Speech Commun. 1995, 16, 391–422. [Google Scholar] [CrossRef]
- Cai, Y.; Li, X.; Li, J. Emotion Recognition Using Different Sensors, Emotion Models, Methods and Datasets: A Comprehensive Review. Sensors 2023, 23, 2455. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Zhang, C.; Song, Y.; Cai, W. ICE-GAN: Identity-aware and Capsule-Enhanced GAN with Graph-based Reasoning for Micro-Expression Recognition and Synthesis. arXiv 2021, arXiv:2005.04370. [Google Scholar]
- Wang, Y.; Song, W.; Tao, W.; Liotta, A.; Yang, D.; Li, X.; Gao, S.; Sun, Y.; Ge, W.; Zhang, W.; et al. A systematic review on affective computing: Emotion models, databases, and recent advances. Inf. Fusion 2022, 83–84, 19–52. [Google Scholar] [CrossRef]
- Ekman, P.; Sorenson, E.R.; Friesen, W.V. Pan-Cultural Elements in Facial Displays of Emotion. Science 1969, 164, 86–88. [Google Scholar] [CrossRef]
- Darwin, C. The Expression Of The Emotions In Man And Animals; Oxford University Press: Oxford, UK, 1998. [Google Scholar] [CrossRef]
- Bălan, O.; Moise, G.; Petrescu, L.; Moldoveanu, A.; Leordeanu, M.; Moldoveanu, F. Emotion Classification Based on Biophysical Signals and Machine Learning Techniques. Symmetry 2020, 12, 21. [Google Scholar] [CrossRef]
- Zhou, E.; Zhang, Y.; Duan, Z. Learning Arousal-Valence Representation from Categorical Emotion Labels of Speech. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 12126–12130. [Google Scholar]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Doğdu, C.; Kessler, T.; Schneider, D.; Shadaydeh, M.; Schweinberger, S.R. A Comparison of Machine Learning Algorithms and Feature Sets for Automatic Vocal Emotion Recognition in Speech. Sensors 2022, 22, 7561. [Google Scholar] [CrossRef]
- Stuhlsatz, A.; Meyer, C.; Eyben, F.; Zielke, T.; Meier, H.G.; Schuller, B. Deep neural networks for acoustic emotion recognition: Raising the benchmarks. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5688–5691. [Google Scholar]
- Ke, X.; Zhu, Y.; Wen, L.; Zhang, W. Speech Emotion Recognition Based on SVM and ANN. Int. J. Mach. Learn. Comput. 2018, 8, 198–202. [Google Scholar] [CrossRef]
- Bhavan, A.; Chauhan, P.; Hitkul; Shah, R.R. Bagged support vector machines for emotion recognition from speech. Knowl.-Based Syst. 2019, 184, 104886. [Google Scholar] [CrossRef]
- Jain, M.; Narayan, S.; Balaji, P.; P, B.K.; Bhowmick, A.; R, K.; Muthu, R.K. Speech Emotion Recognition using Support Vector Machine. arXiv 2020, arXiv:2002.07590. [Google Scholar]
- Nwe, T.L.; Foo, S.W.; De Silva, L.C. Speech emotion recognition using hidden Markov models. Speech Commun. 2003, 41, 603–623. [Google Scholar] [CrossRef]
- Nwe, T.L.; Foo, S.W.; Silva, L.C.D. Detection of stress and emotion in speech using traditional and FFT based log energy features. In Proceedings of the Fourth International Conference on Information, Communications and Signal Processing, 2003 and the Fourth Pacific Rim Conference on Multimedia. Proceedings of the 2003 Joint, Singapore, 15–18 December 2003; Volume 3, pp. 1619–1623. [Google Scholar]
- Mao, S.; Tao, D.; Zhang, G.; Ching, P.C.; Lee, T. Revisiting Hidden Markov Models for Speech Emotion Recognition. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6715–6719. [Google Scholar] [CrossRef]
- Neiberg, D.; Elenius, K.; Laskowski, K. Emotion recognition in spontaneous speech using GMMs. In Proceedings of the Interspeech, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Koolagudi, S.G.; Devliyal, S.; Chawla, B.; Barthwal, A.; Rao, K.S. Recognition of Emotions from Speech using Excitation Source Features. Procedia Eng. 2012, 38, 3409–3417. [Google Scholar] [CrossRef]
- Bhakre, S.K.; Bang, A. Emotion recognition on the basis of audio signal using Naive Bayes classifier. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 2363–2367. [Google Scholar] [CrossRef]
- Khan, A.; Roy, U.K. Emotion recognition using prosodie and spectral features of speech and Naïve Bayes Classifier. In Proceedings of the 2017 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 22–24 March 2017; pp. 1017–1021. [Google Scholar] [CrossRef]
- Younis, E.M.G.; Mohsen, S.; Houssein, E.H.; Ibrahim, O.A.S. Machine learning for human emotion recognition: A comprehensive review. Neural Comput. Appl. 2024, 36, 8901–8947. [Google Scholar] [CrossRef]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech Emotion Recognition from Spectrograms with Deep Convolutional Neural Network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Republic of Korea, 13–15 February 2017; pp. 1–5. [Google Scholar]
- Mustaqeem; Kwon, S. A CNN-Assisted Enhanced Audio Signal Processing for Speech Emotion Recognition. Sensors 2020, 20, 183. [Google Scholar]
- Latif, S.; Rana, R.; Khalifa, S.; Jurdak, R.; Epps, J. Direct Modelling of Speech Emotion from Raw Speech. arXiv 2020, arXiv:1904.03833. [Google Scholar]
- Xie, Y.; Liang, R.; Liang, Z.; Huang, C.; Zou, C.; Schuller, B. Speech Emotion Classification Using Attention-Based LSTM. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1675–1685. [Google Scholar] [CrossRef]
- Mustaqeem; Sajjad, M.; Kwon, S. Clustering-Based Speech Emotion Recognition by Incorporating Learned Features and Deep BiLSTM. IEEE Access 2020, 8, 79861–79875. [Google Scholar] [CrossRef]
- Lee, J.; Tashev, I.J. High-level feature representation using recurrent neural network for speech emotion recognition. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Mao, Q.; Dong, M.; Huang, Z.; Zhan, Y. Learning Salient Features for Speech Emotion Recognition Using Convolutional Neural Networks. IEEE Trans. Multimed. 2014, 16, 2203–2213. [Google Scholar] [CrossRef]
- Lim, W.; Jang, D.; Lee, T. Speech emotion recognition using convolutional and Recurrent Neural Networks. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Republic of Korea, 13–15 December 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, Y.; Zhang, Z.; Wang, H.; Zhao, Y.; Li, C. Exploring Spatio-Temporal Representations by Integrating Attention-based Bidirectional-LSTM-RNNs and FCNs for Speech Emotion Recognition. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Qin, C.; Schlemper, J.; Caballero, J.; Price, A.; Hajnal, J.V.; Rueckert, D. Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction. arXiv 2018, arXiv:1712.01751. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv 2020, arXiv:2006.11477. [Google Scholar]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. arXiv 2021, arXiv:2106.07447. [Google Scholar] [CrossRef]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing. IEEE J. Sel. Top. Signal Process. 2022, 16, 1505–1518. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar]
- Amiriparian, S.; Packań, F.; Gerczuk, M.; Schuller, B.W. ExHuBERT: Enhancing HuBERT Through Block Extension and Fine-Tuning on 37 Emotion Datasets. arXiv 2024, arXiv:2406.10275. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised Pre-training for Speech Recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]
- Wagner, J.; Triantafyllopoulos, A.; Wierstorf, H.; Schmitt, M.; Burkhardt, F.; Eyben, F.; Schuller, B.W. Dawn of the Transformer Era in Speech Emotion Recognition: Closing the Valence Gap. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10745–10759. [Google Scholar] [CrossRef]
- Osman, M.; Kaplan, D.Z.; Nadeem, T. SER Evals: In-domain and Out-of-domain Benchmarking for Speech Emotion Recognition. arXiv 2024, arXiv:2408.07851. [Google Scholar]
- Phukan, O.C.; Kashyap, G.S.; Buduru, A.B.; Sharma, R. Are Paralinguistic Representations all that is needed for Speech Emotion Recognition? In Proceedings of the Interspeech, Kos, Greece, 1–5 September 2024; pp. 4698–4702. [Google Scholar] [CrossRef]
- Triantafyllopoulos, A.; Batliner, A.; Rampp, S.; Milling, M.; Schuller, B. INTERSPEECH 2009 Emotion Challenge Revisited: Benchmarking 15 Years of Progress in Speech Emotion Recognition. In Proceedings of the Interspeech, Kos, Greece, 1–5 September 2024; pp. 1585–1589. [Google Scholar] [CrossRef]
- Pepino, L.; Riera, P.; Ferrer, L. Emotion Recognition from Speech Using Wav2vec 2.0 Embeddings. arXiv 2021, arXiv:2104.03502. [Google Scholar]
- Chen, L.W.; Rudnicky, A. Exploring Wav2vec 2.0 Fine Tuning for Improved Speech Emotion Recognition. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Gao, Y.; Chu, C.; Kawahara, T. Two-stage Finetuning of Wav2vec 2.0 for Speech Emotion Recognition with ASR and Gender Pretraining. In Proceedings of the Interspeech, Dublin, Ireland, 20–24 August 2023; pp. 3637–3641. [Google Scholar] [CrossRef]
- Jaiswal, M.; Provost, E.M. Best Practices for Noise-Based Augmentation to Improve the Performance of Deployable Speech-Based Emotion Recognition Systems. arXiv 2023, arXiv:2104.08806. [Google Scholar]
- Schrüfer, O.; Milling, M.; Burkhardt, F.; Eyben, F.; Schuller, B. Are you sure? Analysing Uncertainty Quantification Approaches for Real-world Speech Emotion Recognition. arXiv 2024, arXiv:2407.01143. [Google Scholar]
- Ülgen Sönmez, Y.; Varol, A. In-depth investigation of speech emotion recognition studies from past to present—The importance of emotion recognition from speech signal for AI–. Intell. Syst. Appl. 2024, 22, 200351. [Google Scholar] [CrossRef]
- Sahu, G. Multimodal Speech Emotion Recognition and Ambiguity Resolution. arXiv 2019, arXiv:1904.06022. [Google Scholar]
- Kamble, K.; Sengupta, J. A comprehensive survey on emotion recognition based on electroencephalograph (EEG) signals. Multimed. Tools Appl. 2023, 82, 27269–27304. [Google Scholar] [CrossRef]
- Kerkeni, L.; Serrestou, Y.; Mbarki, M.; Raoof, K.; Mahjoub, M.A. Speech Emotion Recognition: Methods and Cases Study. In Proceedings of the 10th International Conference on Agents and Artificial Intelligence, ICAART 2018, Madeira, Portugal, 16–18January 2018; Volume 1, pp. 175–182. [Google Scholar] [CrossRef]
- Ortega-Beltrán, E.; Cabacas-Maso, J.; Benito-Altamirano, I.; Ventura, C. Better Spanish Emotion Recognition In-the-wild: Bringing Attention to Deep Spectrum Voice Analysis. arXiv 2024, arXiv:2409.05148. [Google Scholar]
- Garcia-Cuesta, E.; Salvador, A.B.; Pãez, D.G. EmoMatchSpanishDB: Study of speech emotion recognition machine learning models in a new Spanish elicited database. Multimed. Tools Appl. 2023, 83, 13093–13112. [Google Scholar] [CrossRef]
- Begazo, R.; Aguilera, A.; Dongo, I.; Cardinale, Y. A Combined CNN Architecture for Speech Emotion Recognition. Sensors 2024, 24, 5797. [Google Scholar] [CrossRef]
- Pérez-Espinosa, H.; Reyes-García, C.A.; Villaseñor-Pineda, L. EmoWisconsin: An Emotional Children Speech Database in Mexican Spanish. In Affective Computing and Intelligent Interaction, Proceedings of the Fourth International Conference, ACII 2011, Memphis, TN, USA, 9–12 October 2011; D’Mello, S., Graesser, A., Schuller, B., Martin, J.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 62–71. [Google Scholar]
- Casals-Salvador, M.; Costa, F.; India, M.; Hernando, J. BSC-UPC at EmoSPeech-IberLEF2024: Attention Pooling for Emotion Recognition. arXiv 2024, arXiv:2407.12467. [Google Scholar]
- Pan, R.; García-Díaz, J.A.; Ángel Rodríguez-García, M.; Valencia-García, R. Spanish MEACorpus 2023: A multimodal speech–text corpus for emotion analysis in Spanish from natural environments. Comput. Stand. Interfaces 2024, 90, 103856. [Google Scholar] [CrossRef]
- Paredes-Valverde, M.A.; del Pilar Salas-Zárate, M. Team ITST at EmoSPeech-IberLEF2024: Multimodal Speech-text Emotion Recognition in Spanish Forum. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2024) at SEPLN 2024, Salamanca, Spain, 24 September 2024. [Google Scholar]
- Esteban-Romero, S.; Bellver-Soler, J.; Martín-Fernández, I.; Gil-Martín, M.; D’Haro, L.F.; Fernández-Martínez, F. THAU-UPMatEmoSPeech-IberLEF2024: Efficient Adaptation of Mono-modal and Multi-modal Large Language Models for Automatic Speech Emotion Recognition. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2024) at SEPLN 2024, Salamanca, Spain, 24 September 2024. [Google Scholar]
- Cedeño-Moreno, D.; Vargas-Lombardo, M.; Delgado-Herrera, A.; Caparrós-Láiz, C.; Bernal-Beltrán, T. UTPat EmoSPeech–IberLEF2024: Using Random Forest with FastText and Wav2Vec 2.0 for Emotion Detection. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2024) at SEPLN 2024, Salamanca, Spain, 24 September 2024. [Google Scholar]
- Duville, M.M.; Alonso-Valerdi, L.M.; Ibarra-Zárate, D.I. The Mexican Emotional Speech Database (MESD): Elaboration and assessment based on machine learning. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Mexico City, Mexico, 1–5 November 2021; pp. 1644–1647. [Google Scholar]
- Hozjan, V.; Kacic, Z.; Moreno, A.; Bonafonte, A.; Nogueiras, A. Interface Databases: Design and Collection of a Multilingual Emotional Speech Database. In Proceedings of the International Conference on Language Resources and Evaluation, Las Palmas, Spain, 29–31 May 2002. [Google Scholar]
- Parada-Cabaleiro, E.; Costantini, G.; Batliner, A.; Baird, A.; Schuller, B. Categorical vs Dimensional Perception of Italian Emotional Speech. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Shor, J.; Venugopalan, S. TRILLsson: Distilled Universal Paralinguistic Speech Representations. arXiv 2022, arXiv:2203.00236. [Google Scholar]
- Wu, Y.; Chen, K.; Zhang, T.; Hui, Y.; Nezhurina, M.; Berg-Kirkpatrick, T.; Dubnov, S. Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation. arXiv 2024, arXiv:2211.06687. [Google Scholar]
- Atmaja, B.T.; Sasou, A. Evaluating Self-Supervised Speech Representations for Speech Emotion Recognition. IEEE Access 2022, 10, 124396–124407. [Google Scholar] [CrossRef]
- Macary, M.; Tahon, M.; Estève, Y.; Rousseau, A. On the use of Self-supervised Pre-trained Acoustic and Linguistic Features for Continuous Speech Emotion Recognition. arXiv 2020, arXiv:2011.09212. [Google Scholar]
- Hozjan, V.; Kacic, Z.; Moreno, A.; Bonafonte, A.; Nogueiras, A. Emotional Speech Synthesis Database, ELRA catalogue. Available online: https://catalog.elra.info/en-us/repository/browse/ELRA-S0329/ (accessed on 12 December 2024).
- Chetia Phukan, O.; Balaji Buduru, A.; Sharma, R. Transforming the Embeddings: A Lightweight Technique for Speech Emotion Recognition Tasks. In Proceedings of the Interspeech, Dublin, Ireland, 20–24 August 2023; pp. 1903–1907. [Google Scholar] [CrossRef]
- Szeghalmy, S.; Fazekas, A. A Comparative Study of the Use of Stratified Cross-Validation and Distribution-Balanced Stratified Cross-Validation in Imbalanced Learning. Sensors 2023, 23, 2333. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zhang, S.; Li, J. KNN Classification With One-Step Computation. IEEE Trans. Knowl. Data Eng. 2023, 35, 2711–2723. [Google Scholar] [CrossRef]
- Somvanshi, M.; Chavan, P.; Tambade, S.; Shinde, S.V. A review of machine learning techniques using decision tree and support vector machine. In Proceedings of the 2016 International Conference on Computing Communication Control and automation (ICCUBEA), Pune, India, 12–13 August 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Gholami, R.; Fakhari, N. Chapter 27—Support Vector Machine: Principles, Parameters, and Applications. In Handbook of Neural Computation; Samui, P., Sekhar, S., Balas, V.E., Eds.; Academic Press: Cambridge, MA, USA, 2017; pp. 515–535. [Google Scholar] [CrossRef]
- Du, K.L.; Leung, C.S.; Mow, W.H.; Swamy, M.N.S. Perceptron: Learning, Generalization, Model Selection, Fault Tolerance, and Role in the Deep Learning Era. Mathematics 2022, 10, 4730. [Google Scholar] [CrossRef]
- Pasad, A.; Chou, J.C.; Livescu, K. Layer-Wise Analysis of a Self-Supervised Speech Representation Model. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; pp. 914–921. [Google Scholar] [CrossRef]
- Galal, O.; Abdel-Gawad, A.H.; Farouk, M. Rethinking of BERT sentence embedding for text classification. Neural Comput. Appl. 2024, 36, 20245–20258. [Google Scholar] [CrossRef]
- Botelho, C.; Gimeno-Gómez, D.; Teixeira, F.; Mendonça, J.; Pereira, P.; Nunes, D.A.P.; Rolland, T.; Pompili, A.; Solera-Ureña, R.; Ponte, M.; et al. Tackling Cognitive Impairment Detection from Speech: A submission to the PROCESS Challenge. arXiv 2024, arXiv:2501.00145. [Google Scholar]
- Ng, S.I.; Xu, L.; Siegert, I.; Cummins, N.; Benway, N.R.; Liss, J.; Berisha, V. A Tutorial on Clinical Speech AI Development: From Data Collection to Model Validation. arXiv 2024, arXiv:2410.21640. [Google Scholar]
- Gonçalves, T.; Reis, J.; Gonçalves, G.; Calejo, M.; Seco, M. Predictive Models in the Diagnosis of Parkinson’s Disease Through Voice Analysis. In Proceedings of the Intelligent Systems and Applications, 2024; Arai, K., Ed.; Springer: Cham, Switzerland, 2024; pp. 591–610. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Dataset(s) | Techniques/Models | Best Result |
|---|---|---|---|
| Kerkeni et al. [62] | ELRA-S0329 | MFCC, MS + RNN, SVC, MLR | 90.05% Acc. |
| Ortega-Beltrán et al. [63] | ELRA-S0329, EmoMatchSpanishDB | DeepSpectrum with attention (DS-AM) | 98.4% (ELRA) Acc., 68.3% (EmoMatch) Acc. |
| García-Cuesta et al. [64] | EmoMatchSpanishDB | ComParE, eGeMAPS + SVC/XGBoost | 64.2% Precision |
| Pan & García-Díaz [68] | MEACorpus | Late Fusion + Feature Concatenation | 90.06% F1-Score |
| Begazo et al. [65] | MESD | CNN-1D, CNN-2D, MLP + Spectral features | 96% F1-Score |
| Pérez-Espinosa et al. [66] | EmoWisconsin | SVM + handcrafted features | 40.7% F1-score |
| Casals-Salvador et al. [67] | MEACorpus | RoBERTa + XLSR-Wav2Vec 2.0 + Attention Pooling | 86.69% F1-Score |
| Database | Samples | Emotions | Type |
|---|---|---|---|
| EM-SpDB | 2020 | Surprise, Disgust, Fear, Anger, Happiness, Sadness, Neutrality | Acted |
| MESD | 864 | Anger, Disgust, Fear, Happiness, Sadness, Neutrality | Acted |
| MEACorpus | 5129 | Disgust, Anger, Joy, Sadness, Fear, Neutrality | Natural |
| EmoWisconsin | 3098 | Annoyed, Motivated, Nervous, Neutral, Doubtful, Confident | Induced |
| INTER1SP | 5520 | Anger, Sadness, Joy, Fear, Disgust, Surprise | Acted |
| 342 | Anger, Sadness, Happiness, Fear, Contempt | Acted |
| PTMs (Acronym) | Training Data/h | Parameters | Languages |
|---|---|---|---|
| W2V2-L-R-Libri960h | 60 K h + fine-tuning (960 h) | 317 M | English |
| W2V2-XLSR-ES | 436 K h + fine-tuning (Spanish) | 1 B | Multilingual (Spanish-focused) |
| W2V2-L-XLSR53-ES | 56 K h + fine-tuning (Spanish) | 317 M | 53 languages (Spanish-focused) |
| Whisper-L-v3 | 680 K h | 1.55 B | 96 languages |
| Whisper-L-v3-ES | Fine-tuned from Whisper-L-v3 | 1.55 B | Spanish |
| HuBERT-L-1160k | 1160 K h | 316 M | English |
| WavLM-L | 94 K h | 300 M | English |
| TRILLsson | Distilled from 900 M+ h (YT-U dataset) | N/A | Multilingual |
| L-CLAP-G | Multimodal audio-text pairs | N/A | Multilingual |
| PTM | Database | KNN | MLP | SVM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | F1 | UAR | Accuracy | F1 | UAR | Accuracy | F1 | UAR | ||
| HuBERT-L-1160k | 69.448 | 67.768 | 65.648 | 79.175 | 78.439 | 76.535 | 84.729 | 84.339 | 82.279 | |
| EM-SpDB | 66.337 | 64.877 | 60.913 | 86.785 | 86.755 | 85.26 | 86.035 | 85.935 | 84.33 | |
| EmoWisconsin | 54.912 | 48.8312 | 27.1715 | 56.1310 | 54.3710 | 38.1910 | 57.8413 | 54.078 | 32.97 | |
| INTER1SP | 97.63 | 97.593 | 98.073 | 99.755 | 99.755 | 99.815 | 99.836 | 99.836 | 99.886 | |
| MESD | 86.713 | 86.653 | 86.763 | 91.337 | 91.347 | 91.367 | 91.913 | 91.967 | 91.953 | |
| MEACorpus | 90.264 | 90.244 | 87.277 | 89.093 | 89.063 | 86.012 | 91.636 | 91.566 | 88.796 | |
| W2V2-L-XLSR53-ES | 76.396 | 75.266 | 75.286 | 86.114 | 85.688 | 84.974 | 86.116 | 85.676 | 84.396 | |
| EM-SpDB | 65.843 | 64.923 | 60.513 | 88.286 | 88.326 | 88.026 | 86.036 | 86.086 | 85.786 | |
| EmoWisconsin | 58.5812 | 52.7712 | 33.0112 | 57.356 | 55.916 | 35.6915 | 60.547 | 56.617 | 34.2316 | |
| INTER1SP | 96.864 | 96.844 | 97.54 | 99.54 | 99.56 | 99.634 | 99.755 | 99.755 | 99.815 | |
| MESD | 87.284 | 86.634 | 87.344 | 93.644 | 93.514 | 93.684 | 94.223 | 94.254 | 94.253 | |
| MEACorpus | 90.354 | 90.234 | 89.085 | 89.963 | 89.933 | 87.436 | 91.723 | 91.563 | 90.83 | |
| W2V2-L-R-Libri960h | 70.833 | 69.974 | 69.184 | 81.948 | 81.3520 | 81.888 | 83.3319 | 82.7919 | 81.7219 | |
| EM-SpDB | 62.090 | 60.770 | 56.690 | 86.785 | 86.95 | 85.935 | 85.796 | 85.816 | 84.956 | |
| EmoWisconsin | 55.648 | 49.938 | 29.934 | 56.376 | 53.546 | 36.082 | 57.611 | 52.8811 | 32.665 | |
| INTER1SP | 95.783 | 95.763 | 96.573 | 99.343 | 99.343 | 99.321 | 99.342 | 99.344 | 99.54 | |
| MESD | 85.553 | 85.43 | 85.573 | 91.332 | 91.334 | 91.384 | 91.913 | 91.833 | 91.953 | |
| MEACorpus | 76.242 | 77.312 | 80.186 | 87.152 | 87.072 | 86.855 | 90.463 | 90.383 | 86.223 | |
| WavLM-L | 80.563 | 79.963 | 81.333 | 86.116 | 85.856 | 85.27 | 87.59 | 87.4711 | 86.969 | |
| EM-SpDB | 68.332 | 67.192 | 62.972 | 86.784 | 86.614 | 85.344 | 87.283 | 87.243 | 86.043 | |
| EmoWisconsin | 54.4111 | 48.2911 | 26.5411 | 56.1310 | 53.7910 | 35.573 | 59.5610 | 55.3310 | 33.986 | |
| INTER1SP | 97.683 | 97.673 | 98.263 | 99.425 | 99.425 | 99.576 | 99.675 | 99.675 | 99.755 | |
| MESD | 89.023 | 88.833 | 89.083 | 93.064 | 93.044 | 93.084 | 94.226 | 94.256 | 94.256 | |
| MEACorpus | 90.756 | 90.656 | 89.926 | 90.174 | 90.14 | 89.954 | 92.023 | 91.963 | 89.833 | |
| Whisper-L-v3 | 75.012 | 74.1912 | 73.4419 | 87.515 | 87.1719 | 86.5315 | 87.516 | 87.2516 | 86.0716 | |
| EM-SpDB | 61.67 | 59.67 | 54.767 | 85.2920 | 85.2920 | 83.8714 | 83.7920 | 83.7220 | 82.1615 | |
| EmoWisconsin | 55.3918 | 50.3618 | 28.3818 | 58.3318 | 56.4418 | 35.597 | 60.0518 | 55.520 | 31.55 | |
| INTER1SP | 91.1514 | 91.1414 | 92.2714 | 99.1713 | 99.1716 | 99.3816 | 99.3414 | 99.3414 | 99.514 | |
| MESD | 83.2411 | 83.1211 | 83.3111 | 94.87 | 94.797 | 94.837 | 93.0613 | 93.0513 | 93.113 | |
| MEACorpus | 86.3512 | 86.1512 | 83.2714 | 88.799 | 88.739 | 87.511 | 90.0612 | 89.8912 | 88.8312 | |
| W2V2-XLSR-ES | 80.565 | 79.885 | 80.585 | 87.56 | 86.916 | 86.316 | 88.8911 | 88.8811 | 88.2711 | |
| EM-SpDB | 66.085 | 64.715 | 59.793 | 86.7815 | 86.5915 | 84.6615 | 85.0411 | 84.8811 | 83.535 | |
| EmoWisconsin | 58.0915 | 51.8116 | 28.561 | 60.7814 | 58.4114 | 40.014 | 62.515 | 54.7525 | 31.155 | |
| INTER1SP | 96.0311 | 96.011 | 97.0211 | 99.678 | 99.678 | 99.758 | 99.7512 | 99.7512 | 99.8112 | |
| MESD | 87.287 | 86.917 | 87.347 | 95.386 | 95.46 | 95.386 | 93.648 | 93.638 | 93.688 | |
| MEACorpus | 90.8411 | 90.7411 | 89.475 | 90.646 | 90.596 | 90.446 | 92.695 | 92.535 | 90.823 | |
| Whisper-L-v3-ES | 80.5620 | 80.020 | 78.5520 | 91.6722 | 91.5222 | 91.8322 | 87.516 | 87.323 | 86.0716 | |
| EM-SpDB | 61.16 | 59.397 | 55.057 | 85.5424 | 85.5426 | 83.7426 | 84.2926 | 84.2226 | 82.9630 | |
| EmoWisconsin | 55.8817 | 50.5317 | 28.6317 | 60.7831 | 58.9231 | 36.978 | 60.7819 | 56.027 | 31.9216 | |
| INTER1SP | 92.3914 | 92.3814 | 92.9414 | 99.099 | 99.0915 | 99.329 | 99.1714 | 99.1717 | 99.3816 | |
| MESD | 83.829 | 83.7714 | 83.8914 | 94.229 | 94.219 | 94.259 | 94.229 | 94.2210 | 94.259 | |
| MEACorpus | 85.8812 | 85.7512 | 85.1212 | 88.714 | 88.6114 | 87.8714 | 89.6814 | 89.5914 | 85.0219 | |
| TRILLsson | 63.89 | 63.01 | 61.31 | 79.17 | 78.5 | 77.88 | 73.61 | 72.3 | 69.88 | |
| EM-SpDB | 57.11 | 54.86 | 50.14 | 80.8 | 80.75 | 79.11 | 81.05 | 80.9 | 78.12 | |
| EmoWisconsin | 56.13 | 48.98 | 23.41 | 56.37 | 54.27 | 35.31 | 60.29 | 52.96 | 26.09 | |
| INTER1SP | 88.34 | 88.31 | 88.27 | 97.77 | 97.77 | 98.19 | 97.93 | 97.93 | 98.31 | |
| MESD | 70.52 | 70.3 | 70.65 | 87.28 | 87.11 | 87.34 | 84.39 | 84.42 | 84.48 | |
| L-CLAP-G | 61.11 | 58.59 | 56.87 | 62.5 | 59.44 | 57.21 | 63.89 | 62.93 | 60.35 | |
| EM-SpDB | 53.37 | 49.77 | 44.76 | 63.59 | 62.89 | 58.73 | 66.08 | 65.31 | 60.72 | |
| EmoWisconsin | 50.49 | 42.43 | 19.68 | 53.19 | 49.94 | 25.26 | 50.25 | 41.02 | 18.96 | |
| INTER1SP | 80.4 | 80.29 | 82.58 | 91.07 | 91.06 | 91.4 | 89.66 | 89.65 | 90.75 | |
| MESD | 68.79 | 68.29 | 68.88 | 78.03 | 77.76 | 78.08 | 79.19 | 79.08 | 79.21 | |
| MEACorpus | 75.34 | 75.08 | 72.67 | 78.17 | 78.13 | 69.33 | 80.21 | 80.21 | 75.29 | |
| Database | Metric | PTM | Classifier | Score (Layer) |
|---|---|---|---|---|
| INTER1SP | Accuracy | HuBERT-L-1160k | SVM | 99.83% (6) |
| F1-Score | HuBERT-L-1160k | SVM | 99.83% (6) | |
| UAR | HuBERT-L-1160k | SVM | 99.88% (6) | |
| Accuracy | Whisper-L-v3-ES | MLP | 91.67% (22) | |
| F1-Score | Whisper-L-v3-ES | MLP | 91.52% (22) | |
| UAR | Whisper-L-v3-ES | MLP | 91.83% (22) | |
| EM-SpDB | Accuracy | W2V2-L-XLSR53-ES | MLP | 88.28% (6) |
| F1-Score | W2V2-L-XLSR53-ES | MLP | 88.32% (6) | |
| UAR | W2V2-L-XLSR53-ES | MLP | 88.02% (6) | |
| EmoWisconsin | Accuracy | W2V2-XLSR-ES | MLP | 62.50% (15) |
| F1-Score | Whisper-L-v3-ES | MLP | 58.92% (31) | |
| UAR | W2V2-XLSR-ES | SVM | 40.0% (14) | |
| MESD | Accuracy | W2V2-XLSR-ES | MLP | 95.38% (6) |
| F1-Score | W2V2-XLSR-ES | MLP | 95.40% (6) | |
| UAR | W2V2-XLSR-ES | MLP | 95.38% (6) | |
| MEACorpus | Accuracy | W2V2-XLSR-ES | MLP | 92.69% (5) |
| F1-Score | W2V2-XLSR-ES | MLP | 92.53% (5) | |
| UAR | W2V2-XLSR-ES | SVM | 90.82% (3) |
| Database | PTM (Layer) | KNN | MLP | SVM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| UAR (%) | Accuracy (%) | F1 (%) | UAR (%) | Accuracy (%) | F1 (%) | UAR (%) | Accuracy (%) | F1 (%) | ||
| EM-SpDB | HuBERT-L-1160k (9) | 51.42 | 61.45 | 58.11 | 67.88 | 75.92 | 74.38 | 68.46 | 75.80 | 74.34 |
| L-CLAP-G | 41.32 | 51.79 | 48.07 | 50.59 | 58.94 | 56.99 | 49.87 | 59.58 | 57.59 | |
| TRILLsson | 49.76 | 60.03 | 56.26 | 70.82 | 78.17 | 76.99 | 71.42 | 79.66 | 78.48 | |
| W2V2-L-R-Libri960h (3) | 48.99 | 57.72 | 54.16 | 68.02 | 74.98 | 73.36 | 64.33 | 71.38 | 69.62 | |
| W2V2-L-XLSR53-ES (6) | 52.25 | 62.96 | 59.87 | 73.24 | 79.56 | 78.15 | 70.63 | 77.66 | 76.35 | |
| W2V2-XLSR-ES (11) | 51.68 | 60.66 | 56.96 | 70.94 | 78.21 | 76.68 | 70.37 | 77.40 | 75.89 | |
| WavLM-L (6) | 49.08 | 59.20 | 55.35 | 66.64 | 73.84 | 72.06 | 69.05 | 75.30 | 73.82 | |
| Whisper-L-v3 (14) | 41.57 | 50.71 | 46.47 | 65.23 | 73.41 | 71.96 | 65.53 | 72.34 | 70.81 | |
| Whisper-L-v3-ES (14) | 44.28 | 54.28 | 50.08 | 64.68 | 72.91 | 71.48 | 63.98 | 70.33 | 68.84 | |
| HuBERT-L-1160k (9) | 50.94 | 61.72 | 63.39 | 69.87 | 79.93 | 81.60 | 63.79 | 82.95 | 83.24 | |
| L-CLAP-G | 48.77 | 57.69 | 60.37 | 51.44 | 54.44 | 56.14 | 42.16 | 50.06 | 53.21 | |
| TRILLsson | 51.19 | 64.58 | 69.32 | 67.68 | 80.09 | 82.08 | 66.76 | 70.69 | 73.27 | |
| W2V2-L-R-Libri960h (3) | 56.34 | 73.74 | 74.71 | 65.56 | 74.54 | 74.80 | 57.36 | 68.88 | 70.45 | |
| W2V2-L-XLSR53-ES (6) | 62.45 | 76.05 | 76.96 | 69.09 | 83.68 | 83.01 | 65.13 | 79.13 | 80.66 | |
| W2V2-XLSR-ES (11) | 53.47 | 71.22 | 72.21 | 72.68 | 81.93 | 83.86 | 67.15 | 82.27 | 83.78 | |
| WavLM-L (6) | 57.29 | 70.85 | 72.33 | 66.78 | 81.15 | 81.86 | 62.01 | 74.41 | 76.13 | |
| Whisper-L-v3 (14) | 53.12 | 64.16 | 66.99 | 58.56 | 75.40 | 78.82 | 63.34 | 79.48 | 82.08 | |
| Whisper-L-v3-ES (14) | 59.35 | 68.96 | 71.15 | 57.67 | 73.37 | 77.24 | 71.72 | 77.60 | 79.61 | |
| EmoWisconsin | HuBERT-L-1160k (9) | 25.22 | 43.07 | 40.53 | 30.19 | 47.46 | 45.47 | 29.35 | 43.97 | 43.21 |
| L-CLAP-G | 22.89 | 41.38 | 38.93 | 28.37 | 48.23 | 44.66 | 25.68 | 43.39 | 42.54 | |
| TRILLsson | 28.40 | 47.60 | 43.81 | 34.48 | 52.65 | 50.33 | 32.66 | 54.03 | 49.72 | |
| W2V2-L-R-Libri960h (3) | 25.21 | 46.13 | 40.23 | 30.55 | 46.97 | 44.94 | 28.11 | 49.38 | 42.23 | |
| W2V2-L-XLSR53-ES (6) | 25.61 | 47.37 | 43.10 | 32.72 | 50.74 | 48.37 | 32.14 | 54.85 | 48.89 | |
| W2V2-XLSR-ES (11) | 25.19 | 44.61 | 42.36 | 34.71 | 53.08 | 50.75 | 30.47 | 43.67 | 43.66 | |
| WavLM-L (6) | 22.98 | 40.92 | 38.76 | 29.81 | 47.80 | 45.35 | 28.21 | 41.10 | 41.56 | |
| Whisper-L-v3 (14) | 25.60 | 43.76 | 41.09 | 30.22 | 50.92 | 49.15 | 29.01 | 43.51 | 43.70 | |
| Whisper-L-v3-ES (14) | 25.51 | 43.36 | 40.04 | 28.79 | 48.92 | 46.95 | 28.41 | 42.65 | 42.22 | |
| INTER1SP | HuBERT-L-1160k (9) | 50.20 | 52.96 | 50.32 | 61.08 | 63.83 | 63.47 | 55.84 | 64.73 | 62.04 |
| L-CLAP-G | 33.68 | 33.80 | 30.40 | 39.99 | 37.95 | 34.41 | 36.40 | 38.78 | 34.43 | |
| TRILLsson | 53.40 | 57.92 | 56.99 | 52.46 | 57.07 | 55.32 | 60.50 | 65.61 | 64.52 | |
| W2V2-L-R-Libri960h (3) | 49.66 | 49.38 | 45.54 | 55.32 | 55.45 | 51.88 | 52.25 | 59.67 | 55.57 | |
| W2V2-L-XLSR53-ES (6) | 58.55 | 59.89 | 57.45 | 65.99 | 67.34 | 65.45 | 60.98 | 70.04 | 67.44 | |
| W2V2-XLSR-ES (11) | 54.94 | 57.15 | 55.32 | 61.25 | 66.37 | 64.30 | 60.45 | 68.63 | 66.52 | |
| WavLM-L (6) | 51.61 | 53.83 | 50.41 | 50.94 | 54.43 | 49.97 | 50.56 | 57.83 | 53.35 | |
| Whisper-L-v3 (14) | 42.10 | 43.98 | 41.08 | 49.75 | 51.79 | 49.53 | 54.91 | 61.01 | 57.68 | |
| Whisper-L-v3-ES (14) | 46.46 | 48.18 | 43.97 | 42.43 | 44.67 | 41.23 | 52.69 | 59.75 | 55.97 | |
| MEACorpus | HuBERT-L-1160k (9) | 16.33 | 41.25 | 47.63 | 44.82 | 68.37 | 59.36 | 53.22 | 70.13 | 62.83 |
| L-CLAP-G | 13.80 | 31.36 | 37.54 | 24.37 | 49.59 | 46.35 | 18.83 | 46.17 | 49.64 | |
| TRILLsson | 33.28 | 59.67 | 58.38 | 54.92 | 75.85 | 71.64 | 50.19 | 66.62 | 59.82 | |
| W2V2-L-R-Libri960h (3) | 38.69 | 61.79 | 67.55 | 51.70 | 68.37 | 61.34 | 55.87 | 71.88 | 65.26 | |
| W2V2-L-XLSR53-ES (6) | 27.95 | 61.33 | 60.43 | 36.74 | 63.47 | 56.17 | 49.05 | 66.62 | 57.87 | |
| W2V2-XLSR-ES (11) | 21.56 | 51.80 | 54.20 | 50.38 | 70.49 | 64.61 | 36.77 | 66.62 | 61.62 | |
| WavLM-L (6) | 27.70 | 53.00 | 56.85 | 57.95 | 73.64 | 67.07 | 59.47 | 75.39 | 68.77 | |
| Whisper-L-v3 (14) | 23.54 | 57.85 | 63.76 | 53.79 | 70.13 | 63.36 | 42.55 | 63.11 | 57.06 | |
| Whisper-L-v3-ES (14) | 28.03 | 57.38 | 62.62 | 46.59 | 70.13 | 63.41 | 50.76 | 66.72 | 62.03 | |
| MESD | HuBERT-L-1160k (9) | 33.73 | 33.75 | 32.13 | 45.20 | 45.24 | 41.60 | 47.17 | 47.21 | 42.86 |
| L-CLAP-G | 33.59 | 33.65 | 28.67 | 37.75 | 37.82 | 33.29 | 39.60 | 39.68 | 35.38 | |
| TRILLsson | 35.70 | 35.72 | 32.73 | 47.30 | 47.31 | 44.71 | 48.20 | 48.23 | 46.30 | |
| W2V2-L-R-Libri960h (3) | 33.13 | 33.17 | 30.18 | 41.80 | 41.87 | 38.10 | 44.59 | 44.65 | 40.42 | |
| W2V2-L-XLSR53-ES (6) | 40.45 | 40.49 | 38.22 | 49.83 | 49.88 | 48.19 | 52.48 | 52.54 | 50.59 | |
| W2V2-XLSR-ES (11) | 36.86 | 36.88 | 34.18 | 48.21 | 48.26 | 44.59 | 53.09 | 53.12 | 50.25 | |
| WavLM-L (6) | 36.02 | 36.08 | 32.35 | 43.11 | 43.15 | 41.31 | 41.60 | 41.64 | 38.33 | |
| Whisper-L-v3 (14) | 30.24 | 30.28 | 26.49 | 39.51 | 39.56 | 36.63 | 37.42 | 37.47 | 35.64 | |
| Whisper-L-v3-ES (14) | 30.11 | 30.16 | 25.23 | 39.48 | 39.55 | 35.71 | 36.83 | 36.89 | 34.67 | |
| Database | Metric | Our Result | Our PTM (Layer) | SOTA Result | SOTA Reference |
|---|---|---|---|---|---|
| INTER1SP | Accuracy | 99.83% | HuBERT-L-1160k (6) | 98.40% | [63] |
| F1-Score | 99.83% | HuBERT-L-1160k (6) | - | - | |
| UAR | 99.88% | HuBERT-L-1160k (6) | - | - | |
| Accuracy | 91.67% | Whisper-L-v3-ES (6) | - | - | |
| F1-Score | 91.52% | Whisper-L-v3-ES (6) | - | - | |
| UAR | 91.83% | Whisper-L-v3-ES (6) | - | - | |
| EM-SpDB | Accuracy | 88.28% | W2V2-L-XLSR53-ES (6) | 68.30% | [63] |
| F1-Score | 88.32% | W2V2-L-XLSR53-ES (6) | - | - | |
| UAR | 88.02% | W2V2-L-XLSR53-ES (6) | - | - | |
| EmoWisconsin | Accuracy | 62.50% | W2V2-XLSR-ES (15) | - | - |
| F1-Score | 58.92% | Whisper-L-v3-ES (31) | 40.70% | [66] | |
| UAR | 40.0% | W2V2-XLSR-ES (14) | - | - | |
| MESD | Accuracy | 95.38% | W2V2-XLSR-ES (6) | 96.00% | [65] |
| F1-Score | 95.40% | W2V2-XLSR-ES (6) | 96.00% | ||
| UAR | 95.38% | W2V2-XLSR-ES (6) | - | - | |
| MEACorpus | Accuracy | 92.69% | W2V2-XLSR-ES (5) | - | - |
| F1-Score | 92.53% | W2V2-XLSR-ES (5) | 90.06% | [68] | |
| UAR | 90.82% | W2V2-XLSR-ES (3) | - | - |
| Database | Metric | Result | PTM (Layer) |
|---|---|---|---|
| EM-SpDB | Accuracy | 79.66% | TRILLsson |
| F1-Score | 78.48% | TRILLsson | |
| UAR | 73.24% | W2V2-L-XLSR53-ES (6) | |
| Accuracy | 83.68% | W2V2-L-XLSR53-ES (6) | |
| F1-Score | 83.86% | W2V2-XLSR-ES (11) | |
| UAR | 72.68% | W2V2-XLSR-ES (11) | |
| INTER1SP | Accuracy | 70.04% | W2V2-L-XLSR53-ES (6) |
| F1-Score | 67.44% | W2V2-L-XLSR53-ES (6) | |
| UAR | 65.99% | W2V2-L-XLSR53-ES (6) | |
| EmoWisconsin | Accuracy | 54.85% | W2V2-L-XLSR53-ES (6) |
| F1-Score | 50.75% | W2V2-XLSR-ES (11) | |
| UAR | 34.71% | W2V2-XLSR-ES (11) | |
| MEACorpus | Accuracy | 75.85% | TRILLsson |
| F1-Score | 71.64% | TRILLsson | |
| UAR | 59.47% | WavLM-L (6) | |
| MESD | Accuracy | 53.12% | W2V2-XLSR-ES (11) |
| F1-Score | 50.59% | W2V2-L-XLSR53-ES (6) | |
| UAR | 53.09% | W2V2-XLSR-ES (11) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mares, A.; Diaz-Arango, G.; Perez-Jacome-Friscione, J.; Vazquez-Leal, H.; Hernandez-Martinez, L.; Huerta-Chua, J.; Jaramillo-Alvarado, A.F.; Dominguez-Chavez, A. Advancing Spanish Speech Emotion Recognition: A Comprehensive Benchmark of Pre-Trained Models. Appl. Sci. 2025, 15, 4340. https://doi.org/10.3390/app15084340
Mares A, Diaz-Arango G, Perez-Jacome-Friscione J, Vazquez-Leal H, Hernandez-Martinez L, Huerta-Chua J, Jaramillo-Alvarado AF, Dominguez-Chavez A. Advancing Spanish Speech Emotion Recognition: A Comprehensive Benchmark of Pre-Trained Models. Applied Sciences. 2025; 15(8):4340. https://doi.org/10.3390/app15084340
Chicago/Turabian StyleMares, Alex, Gerardo Diaz-Arango, Jorge Perez-Jacome-Friscione, Hector Vazquez-Leal, Luis Hernandez-Martinez, Jesus Huerta-Chua, Andres Felipe Jaramillo-Alvarado, and Alfonso Dominguez-Chavez. 2025. "Advancing Spanish Speech Emotion Recognition: A Comprehensive Benchmark of Pre-Trained Models" Applied Sciences 15, no. 8: 4340. https://doi.org/10.3390/app15084340
APA StyleMares, A., Diaz-Arango, G., Perez-Jacome-Friscione, J., Vazquez-Leal, H., Hernandez-Martinez, L., Huerta-Chua, J., Jaramillo-Alvarado, A. F., & Dominguez-Chavez, A. (2025). Advancing Spanish Speech Emotion Recognition: A Comprehensive Benchmark of Pre-Trained Models. Applied Sciences, 15(8), 4340. https://doi.org/10.3390/app15084340