
Massive-MIMO Sparse Uplink Channel Estimation Using Implicit Training and Compressed Sensing


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
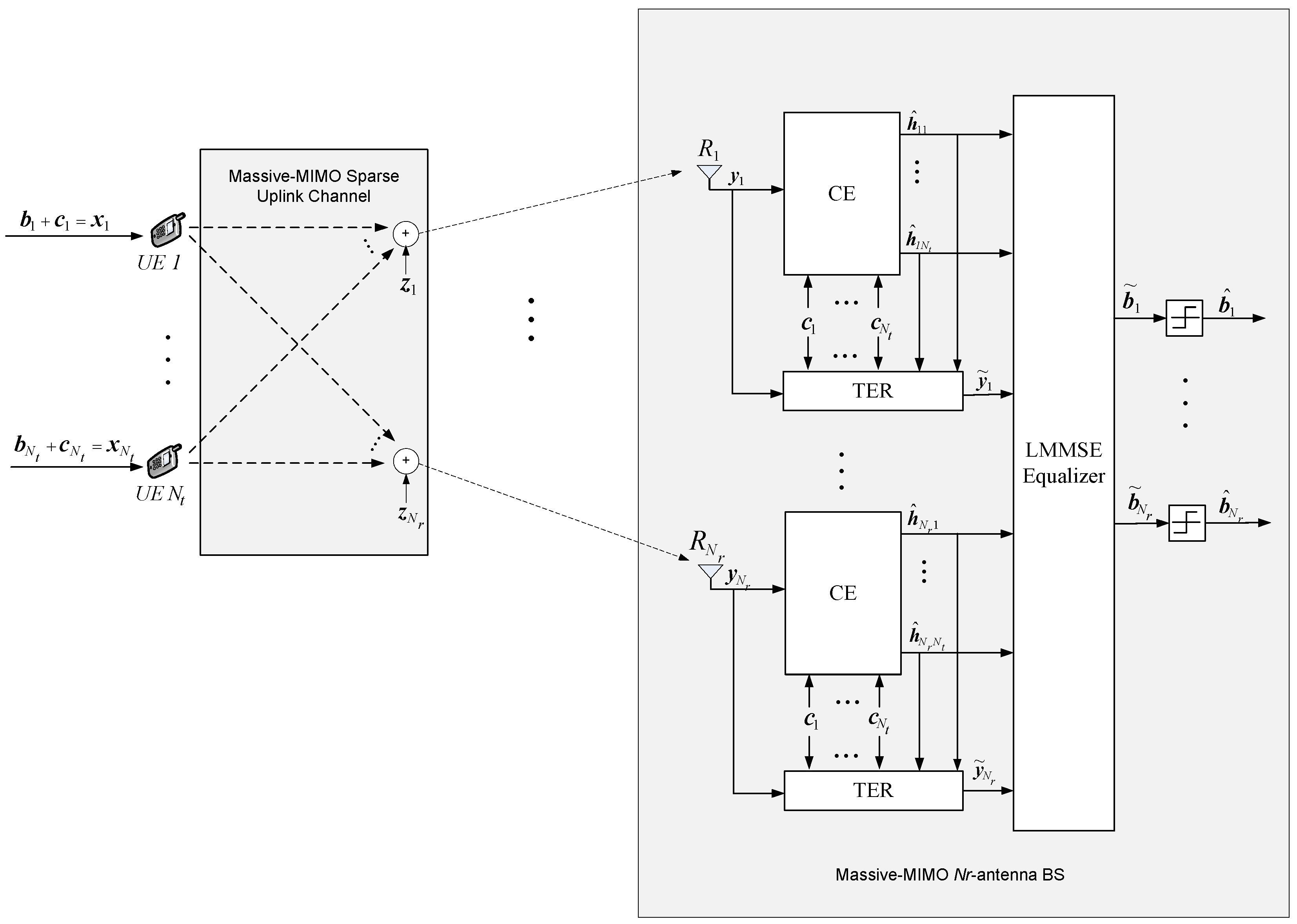
2. Massive-MIMO System Model for Uplink Communications
3. Massive-MIMO Sparse Uplink Channel Estimation Using a First-Order Statistics Based Approach
3.1. SiT Based Least Squares (SiT-LS) Channel Estimation Approach
3.2. Proposed SiT Based Massive-MIMO Sparse Uplink Channel Estimation Techniques
3.2.1. SiT Based Stage-Wise Orthogonal Matching Pursuit (SiT-StOMP)
- Input: Matrix , vector , and threshold .
- Output: Channel estimate vector .
- Initialize residual , index set , and iteration counter .
- Create a set consisting of the indices of all elements in the vector, , which are above the threshold
- Update the index set by and residual by
- Check stopping criteria; if it is not met then update index , and go to step 2; if stopping criteria is met, set the final output vector as .
3.2.2. SiT Based Gradient Pursuit (SiT-GP)
- Initialize the residual vector , the estimate of the channel coefficients vector , and ;
- for until stopping criteria is met, do
- (a)
- ;
- (b)
- ;
- (c)
- ;
- (d)
- Compute the update direction ;
- (e)
- ;
- (f)
- ;
- (g)
- ;
- (h)
- ;
- Output
4. Minimum Mean Square Error (MMSE) Based Equalizer
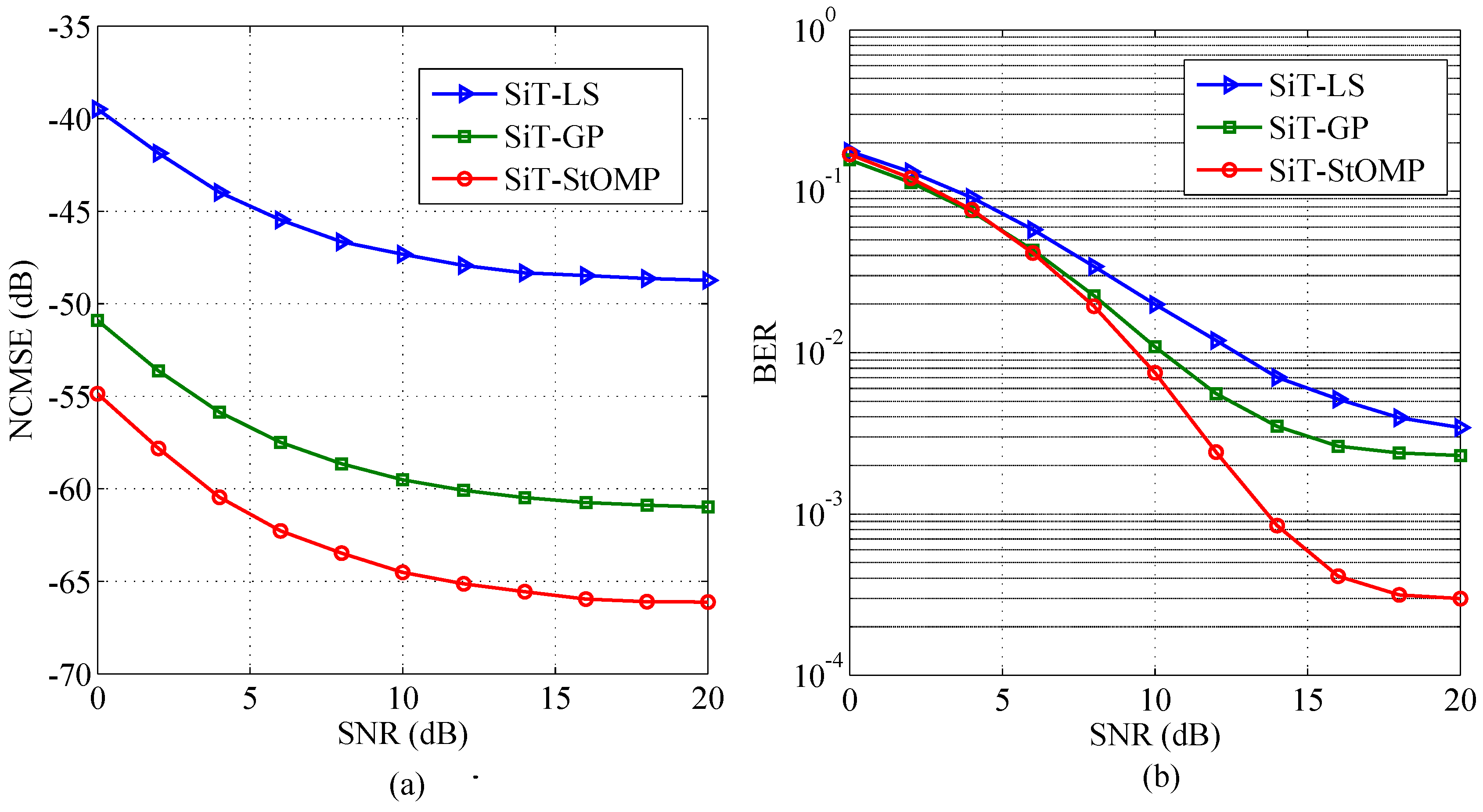
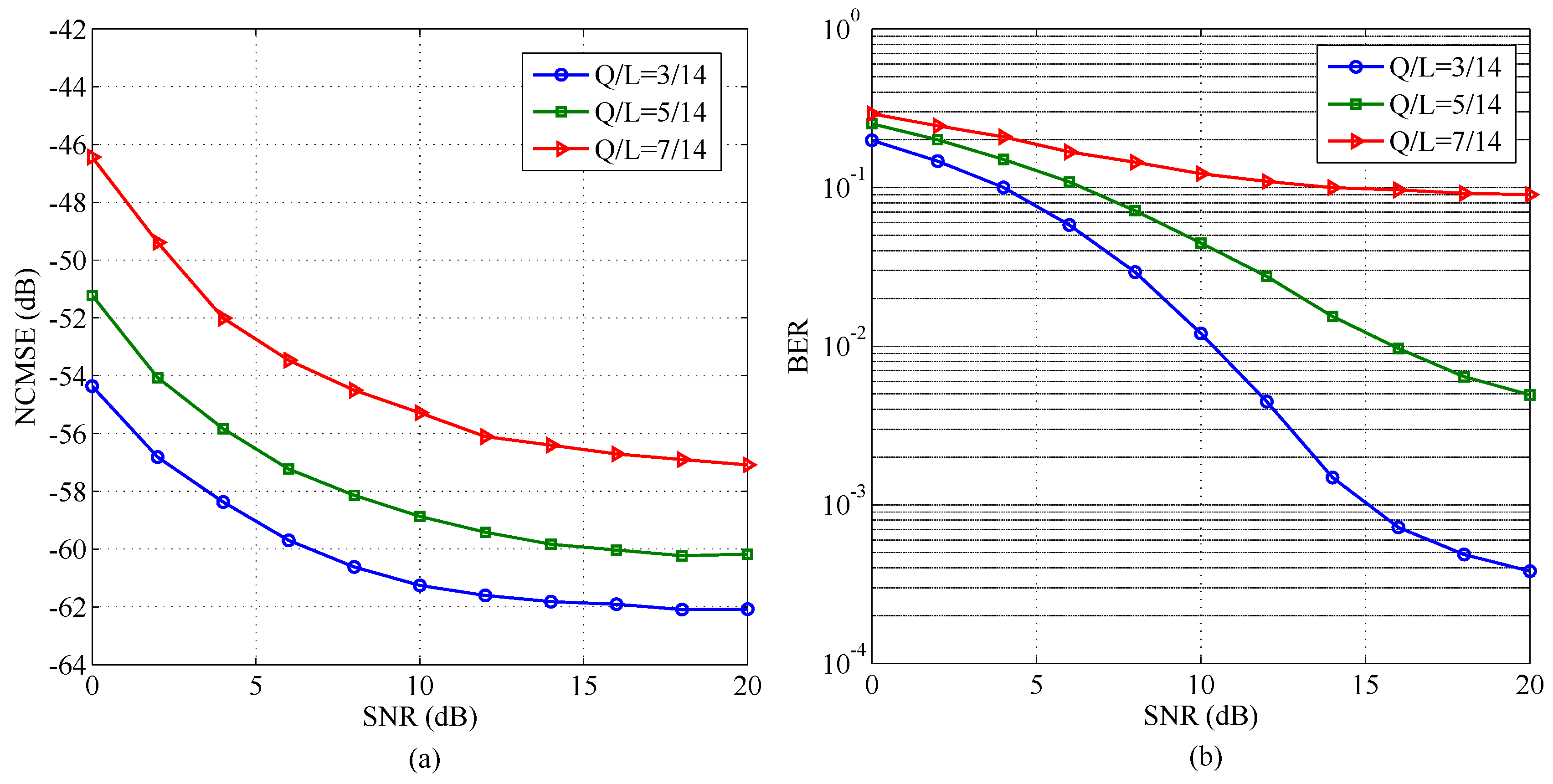
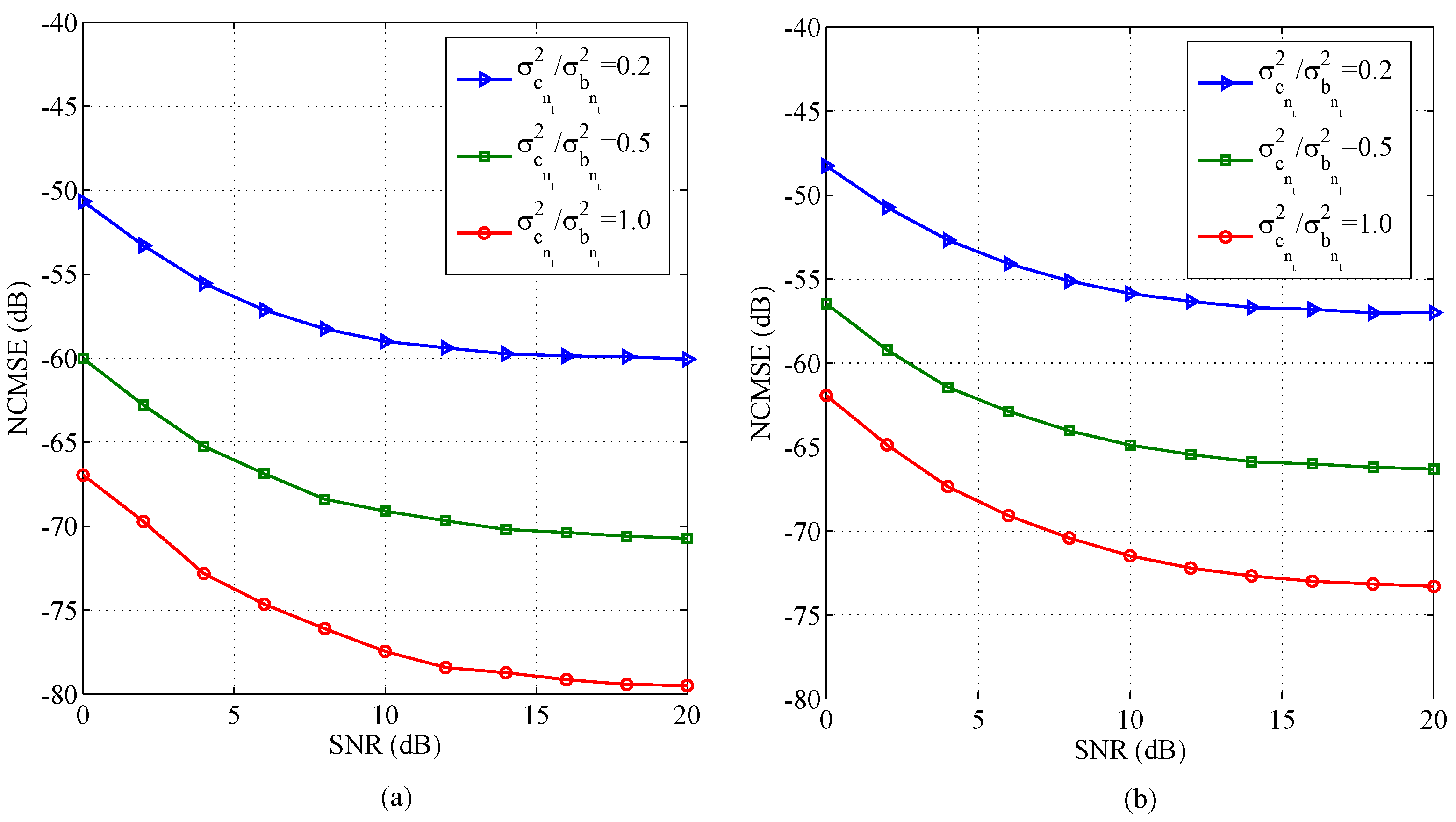
5. Results and Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Foschini, G.J.; Gans, M.J. On limits of wireless communications in a fading environment when using multiple antennas. Wirel. Pers. Commun. 1998, 6, 311–335. [Google Scholar] [CrossRef]
- Telatar, E. Capacity of Multi-antenna Gaussian Channels. Eur. Trans. Telecommun. 1999, 10, 585–595. [Google Scholar] [CrossRef]
- Caire, G.; Shamai, S. On the achievable throughput of a multiantenna Gaussian broadcast channel. IEEE Trans. Inf. Theory 2003, 49, 1691–1706. [Google Scholar] [CrossRef]
- Gesbert, D.; Kountouris, M.; Heath, R.W., Jr.; Chae, C.B.; Salzer, T. Shifting the MIMO Paradigm. IEEE Signal Process. Mag. 2007, 24, 36–46. [Google Scholar] [CrossRef]
- Gao, Z.; Dai, L.; Mi, D.; Wang, Z.; Imran, M.A.; Shakir, M.Z. mmWave massive-MIMO-based wireless backhaul for the 5G ultra-dense network. IEEE Wirel. Commun. 2015, 22, 13–21. [Google Scholar] [CrossRef]
- Marzetta, T.L. Massive MIMO: An Introduction. Bell Labs Tech. J. 2015, 20, 11–22. [Google Scholar] [CrossRef]
- Larsson, E.; Edfors, O.; Tufvesson, F.; Marzetta, T. Massive MIMO for next generation wireless systems. IEEE Commun. Mag. 2014, 52, 186–195. [Google Scholar] [CrossRef]
- Ngo, H.Q.; Larsson, E.G.; Marzetta, T.L. Energy and Spectral Efficiency of Very Large Multiuser MIMO Systems. IEEE Trans. Commun. 2013, 61, 1436–1449. [Google Scholar]
- Cotter, S.F.; Rao, B.D. Sparse channel estimation via matching pursuit with application to equalization. IEEE Trans. Commun. 2002, 50, 374–377. [Google Scholar] [CrossRef]
- Raghavan, V.; Hariharan, G.; Sayeed, A.M. Capacity of Sparse Multipath Channels in the Ultra-Wideband Regime. IEEE J. Sel. Top. Signal Process. 2007, 1, 357–371. [Google Scholar] [CrossRef]
- Kocic, M.; Brady, D.; Stojanovic, M. Sparse equalization for real-time digital underwater acoustic communications. In Proceedings of the MTS/IEEE Challenges of Our Changing Global Environment (OCEANS’95), San Diego, CA, USA, 9–12 October 1995.
- Ying, J.; Zhong, J.; Zhao, M.; Cai, Y. Turbo equalization based on compressive sensing channel estimation in wideband HF systems. In Proceedings of the International Conference on Wireless Communications & Signal Processing, Hangzhou, China, 24–26 October 2013; pp. 1–5.
- Schreiber, W. Advanced television systems for terrestrial broadcasting: Some problems and some proposed solutions. Proc. IEEE 1995, 83, 958–981. [Google Scholar] [CrossRef]
- Nawaz, S.J.; Ahmed, K.I.; Patwary, M.N.; Khan, N.M. Superimposed training-based compressed sensing of sparse multipath channels. IET Commun. 2012, 6, 3150–3156. [Google Scholar] [CrossRef]
- Matthaiou, M.; Sayeed, A.M.; Nossek, J.A. Sparse multipath MIMO channels: Performance implications based on measurement data. In Proceedings of the IEEE 10th Workshop on Signal Processing Advances in Wireless Communications, Perugia, Italy, 21–24 June 2009; pp. 364–368.
- Barbotin, Y.; Hormati, A.; Rangan, S.; Vetterli, M. Estimation of Sparse MIMO Channels with Common Support. IEEE Trans. Commun. 2012, 60, 3705–3716. [Google Scholar] [CrossRef]
- Gui, G.; Wan, Q.; Peng, W.; Adachi, F. Sparse multipath channel estimation using compressive sampling matching pursuit algorithm. In Proceedings of the IEEE APWCS, Kaohsiung, Taiwan, 20–21 May 2010; pp. 1–5.
- Hoydis, J.; Hoek, C.; Wild, T.; ten Brink, S. Channel measurements for large antenna arrays. In Proceedings of the International Symposium on Wireless Communication Systems, Paris, France, 28–31 August 2012; pp. 811–815.
- Yu, Y.; Wang, P.; Chen, H.; Li, Y.; Vucetic, B. A Low-Complexity Transceiver Design in Sparse Multipath Massive MIMO Channels. IEEE Signal Process. Lett. 2016, 23, 1301–1305. [Google Scholar] [CrossRef]
- Tugnait, J.K. Blind estimation and equalization of MIMO channels via multidelay whitening. IEEE J. Sel. Areas Commun. 2001, 19, 1507–1519. [Google Scholar] [CrossRef]
- Shin, C.; Heath, R.W.; Powers, E.J. Blind Channel Estimation for MIMO-OFDM Systems. IEEE Trans. Veh. Tech. 2007, 56, 670–685. [Google Scholar] [CrossRef]
- Shahbazpanahi, S.; Gershman, A.B.; Giannakis, G.B. Semiblind multiuser MIMO channel estimation using capon and MUSIC techniques. IEEE Trans. Signal Process. 2006, 54, 3581–3591. [Google Scholar] [CrossRef]
- Wan, F.; Zhu, W.P.; Swamy, M.N.S. Semiblind Sparse Channel Estimation for MIMO-OFDM Systems. IEEE Trans. Veh. Tech. 2011, 60, 2569–2582. [Google Scholar] [CrossRef]
- Lee, S.J. On the training of MIMO-OFDM channels with least square channel estimation and linear interpolation. IEEE Commun. Lett. 2008, 12, 100–102. [Google Scholar]
- Ma, J.; Orlik, P.; Zhang, J.; Li, G.Y. Pilot Matrix Design for Estimating Cascaded Channels in Two-Hop MIMO Amplify-and-Forward Relay Systems. IEEE Trans. Wirel. Commun. 2011, 10, 1956–1965. [Google Scholar] [CrossRef]
- He, S.; Tugnait, J.K.; Meng, X. On superimposed training for MIMO channel estimation and symbol detection. IEEE Trans. Signal Process. 2007, 55, 3007–3021. [Google Scholar] [CrossRef]
- Candes, E.J.; Tao, T. Decoding by linear programming. IEEE Trans. Inf. Theory 2005, 51, 4203–4215. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Taubock, G.; Hlawatsch, F.; Eiwen, D.; Rauhut, H. Compressive Estimation of Doubly Selective Channels in Multicarrier Systems: Leakage Effects and Sparsity-Enhancing Processing. IEEE J. Sel. Top. Signal Process. 2010, 4, 255–271. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic Decomposition by Basis Pursuit. SIAM J. Sci. Comput. 1998, 20, 33–61. [Google Scholar] [CrossRef]
- Mallat, S.G.; Zhang, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef]
- Davis, G.; Mallat, S.; Avellaneda, M. Adaptive greedy approximations. J. Constr. Approx. 1997, 13, 57–98. [Google Scholar] [CrossRef]
- Needell, D.; Vershynin, R. Signal Recovery From Incomplete and Inaccurate Measurements Via Regularized Orthogonal Matching Pursuit. IEEE J. Sel. Top. Signal Process. 2010, 4, 310–316. [Google Scholar] [CrossRef]
- Donoho, D.L.; Tsaig, Y.; Drori, I.; Starck, J.L. Sparse Solution of Underdetermined Systems of Linear Equations by Stagewise Orthogonal Matching Pursuit. IEEE Trans. Inf. Theory 2012, 58, 1094–1121. [Google Scholar] [CrossRef]
- Rath, G.; Guillemot, C. Sparse approximation with an orthogonal complementary matching pursuit algorithm. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 3325–3328.
- Needell, D.; Tropp, J. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. J. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef]
- Blumensath, T.; Davies, M.E. Gradient Pursuits. IEEE Trans. Signal Process. 2008, 56, 2370–2382. [Google Scholar] [CrossRef]
- Ngo, H.Q.; Larsson, E.G. EVD-based channel estimation in multicell multiuser MIMO systems with very large antenna arrays. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012; pp. 3249–3252.
- Nguyen, S.L.H.; Ghrayeb, A. Compressive sensing-based channel estimation for massive multiuser MIMO systems. In Proceedings of the IEEE Wireless Communication and Networking Conference, Shanghai, China, 7–10 April 2013; pp. 2890–2895.
- Rao, X.; Lau, V.K.N. Compressive Sensing With Prior Support Quality Information and Application to Massive MIMO Channel Estimation With Temporal Correlation. IEEE Trans. Signal Process. 2015, 63, 4914–4924. [Google Scholar] [CrossRef]
- Shariati, N.; Björnson, E.; Bengtsson, M.; Debbah, M. Low-complexity channel estimation in large-scale MIMO using polynomial expansion. In Proceedings of the IEEE 24th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), London, UK, 8–9 September 2013; pp. 1157–1162.
- Qi, C.; Wu, L. Uplink channel estimation for massive MIMO systems exploring joint channel sparsity. Electron. Lett. 2014, 50, 1770–1772. [Google Scholar] [CrossRef]
- Wen, C.K.; Jin, S.; Wong, K.K.; Chen, J.C.; Ting, P. Channel Estimation for Massive MIMO Using Gaussian-Mixture Bayesian Learning. IEEE Trans. Wirel. Commun. 2015, 14, 1356–1368. [Google Scholar] [CrossRef]
- Masood, M.; Afify, L.H.; Al-Naffouri, T.Y. Efficient collaborative sparse channel estimation in massive MIMO. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, Australia, 19–24 April 2015; pp. 2924–2928.
- Lalos, A.S.; Antonopoulos, A.; Kartsakli, E.; Renzo, M.D.; Tennina, S.; Alonso, L.; Verikoukis, C. RLNC-Aided Cooperative Compressed Sensing for Energy Efficient Vital Signal Telemonitoring. IEEE Trans. Wirel. Commun. 2015, 14, 3685–3699. [Google Scholar] [CrossRef]
- Nawaz, S.J.; Tiwana, M.I.; Patwary, M.N.; Khan, N.M.; Tiwana, M.I.; Haseeb, A. GA Based Sensing of Sparse Multipath Channels with Superimposed Training Sequence. Elektronika Elektrotechnika 2016, 22, 87–91. [Google Scholar] [CrossRef]
- Amin, B.; Mansoor, B.; Nawaz, S.J.; Sharma, S.K.; Patwary, M.N. Compressed Sensing of Sparse Multipath MIMO Channels with Superimposed Training Sequence. Wirel. Pers. Commun. 2016. [Google Scholar] [CrossRef]
- Mansoor, B.; Nawaz, S.J.; Amin, B.; Sharma, S.K.; Patwary, M.N. Superimposed training based estimation of sparse mimo channels for emerging wireless networks. In Proceedings of the IEEE International Conference on Telecommunications, Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6.
- Zhao, J.; Meng, W.; Jia, S. Sparse underwater acoustic OFDM channel estimation based on superimposed training. J. Mar. Sci. Appl. 2009, 8, 65–70. [Google Scholar] [CrossRef]
- Tugnait, J.K.; Luo, W. On channel estimation using superimposed training and first-order statistics. IEEE Commun. Lett. 2003, 7, 413–415. [Google Scholar] [CrossRef]
- Stoica, P.; Moses, R. Introduction to Spectral Analysis; Prentice Hall: Upper Saddle River, NJ, USA, 1997. [Google Scholar]
- Chen, S.; Livingstone, A.; Hanzo, L. Minimum bit-error rate design for space-time equalization-based multiuser detection. IEEE Trans. Commun. 2006, 54, 824–832. [Google Scholar] [CrossRef]






© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mansoor, B.; Nawaz, S.J.; Gulfam, S.M. Massive-MIMO Sparse Uplink Channel Estimation Using Implicit Training and Compressed Sensing. Appl. Sci. 2017, 7, 63. https://doi.org/10.3390/app7010063
Mansoor B, Nawaz SJ, Gulfam SM. Massive-MIMO Sparse Uplink Channel Estimation Using Implicit Training and Compressed Sensing. Applied Sciences. 2017; 7(1):63. https://doi.org/10.3390/app7010063
Chicago/Turabian StyleMansoor, Babar, Syed Junaid Nawaz, and Sardar Muhammad Gulfam. 2017. "Massive-MIMO Sparse Uplink Channel Estimation Using Implicit Training and Compressed Sensing" Applied Sciences 7, no. 1: 63. https://doi.org/10.3390/app7010063
APA StyleMansoor, B., Nawaz, S. J., & Gulfam, S. M. (2017). Massive-MIMO Sparse Uplink Channel Estimation Using Implicit Training and Compressed Sensing. Applied Sciences, 7(1), 63. https://doi.org/10.3390/app7010063