
A Geometric Dictionary Learning Based Approach for Fluorescence Spectroscopy Image Fusion



Abstract
:1. Introduction
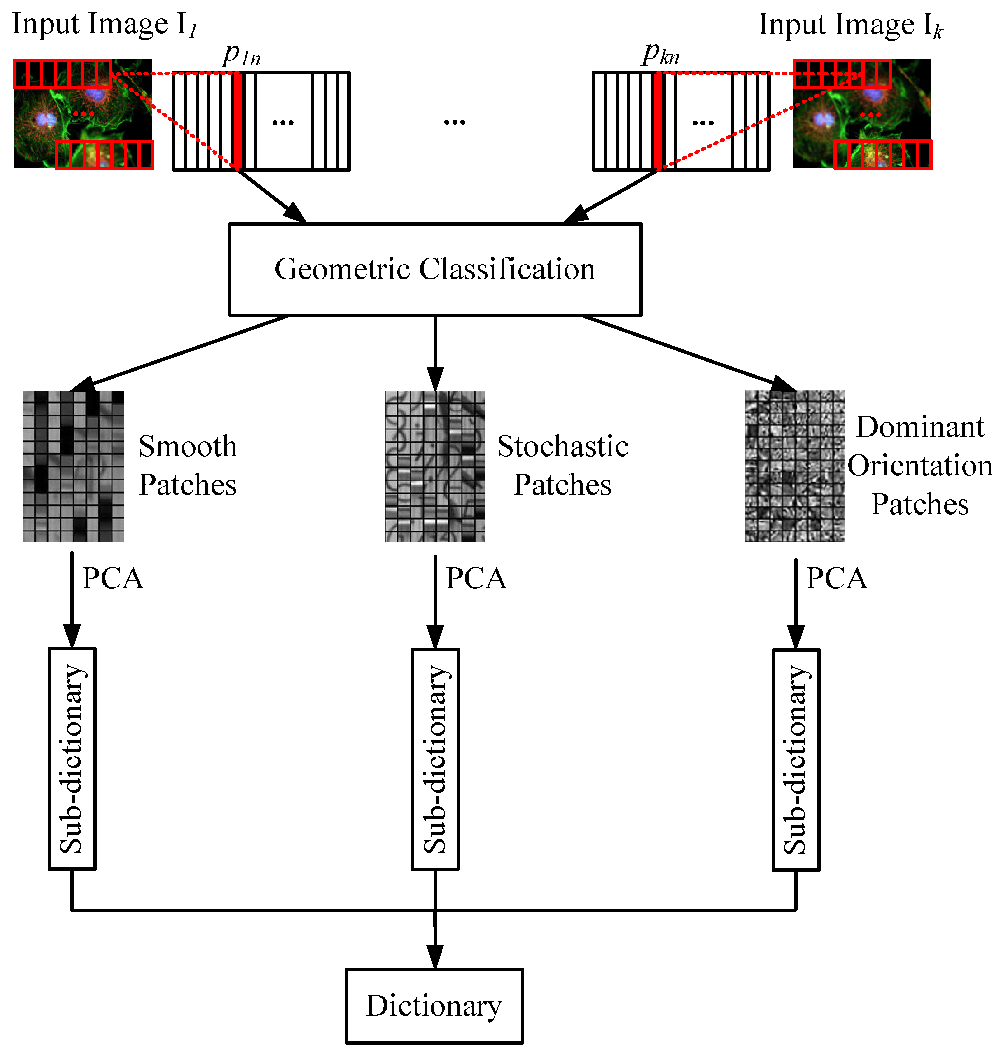
- In the first step, input source images are split into small blocks. According to the similarity of geometric patterns, these blocks are classified into smooth patches, stochastic patches, and dominant orientation patches.
- In the second step, it does principal component analysis (PCA) on each type of patches to extract crucial bases. The extracted PCA bases are used to construct the sub-dictionary of each image patch group.
- In the last step, the obtained sub-dictionaries are merged into a complete dictionary for sparse-representation-based fusion approach and the integrated sparse coefficients are inverted to fused image.
- A geometric image patches classification method is proposed for dictionary learning. The proposed geometry classification method can accurately split source image patches into different image patch groups for dictionary learning. Dictionary bases extracted from each image patch group have good performance, when they are used to describe the geometric features of source images.
- A PCA-based geometry dictionary construction method is proposed. The trained dictionary with PCA bases is informative and compact for sparse representation. The informative feature of trained dictionary ensures that different geometric features of source images can be accurately described. The compact feature of trained dictionary can speed up the sparse coding process.
2. Geometry Dictionary Construction and Fusion Scheme
2.1. Dictionary Learning Analysis
2.2. Geometry Dictionary Construction
- Smooth patches describe the structure information of source images, such as the background.
- Dominant orientation patches describe the edge information to provide the direction information in source images.
- Stochastic patches show the texture information to make up the missing detailed information that is not represented in dominant orientation patches.
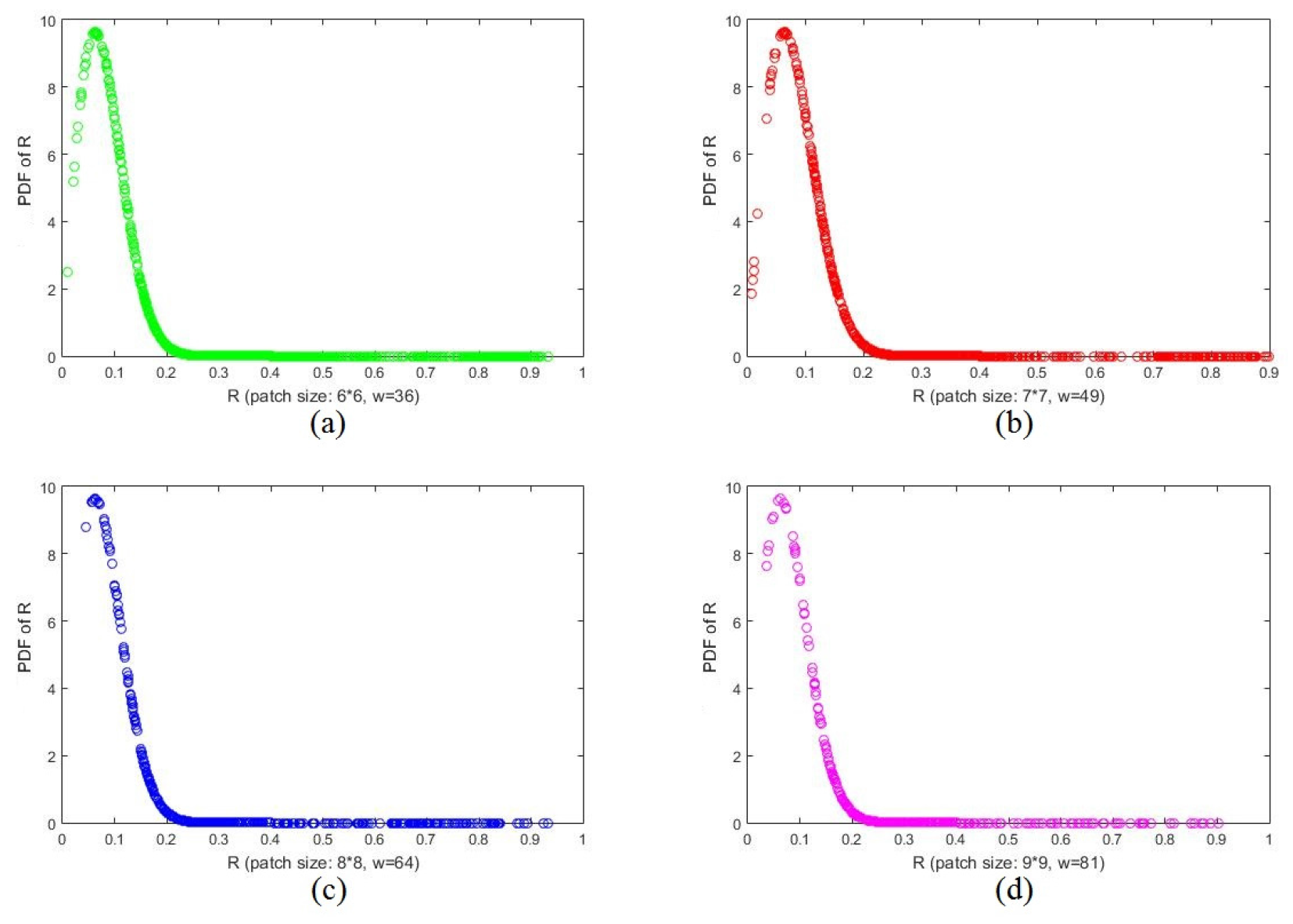
2.3. Geometric-Structure-Based Patches Classification
2.4. PCA-Based Dictionary Construction
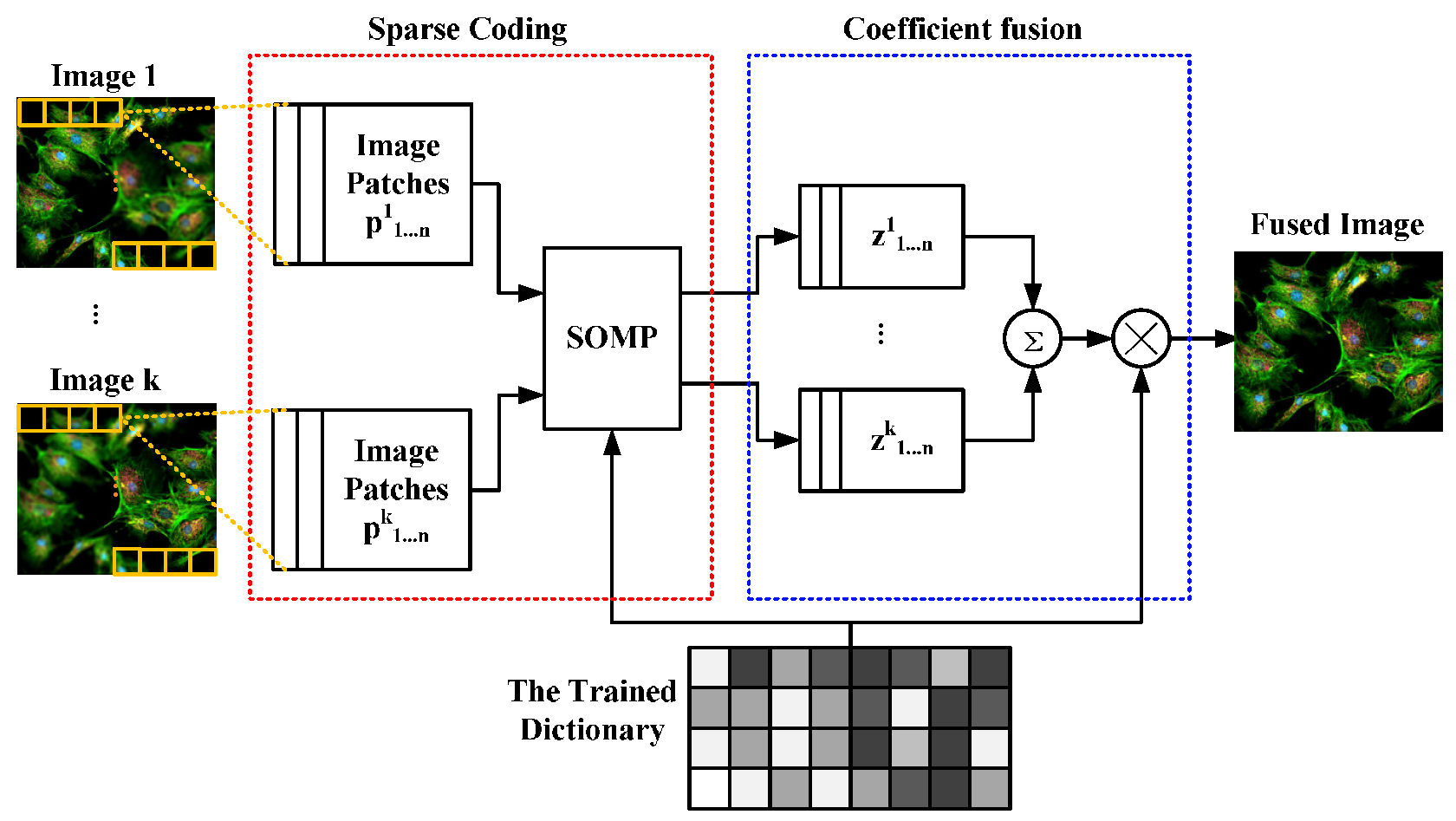
2.5. Fusion Scheme
3. Experiments and Analyses
3.1. Objective Evaluation Methods
3.1.1. Mutual Information
3.1.2.
3.1.3. Visual Information Fidelity
3.1.4.
3.1.5.
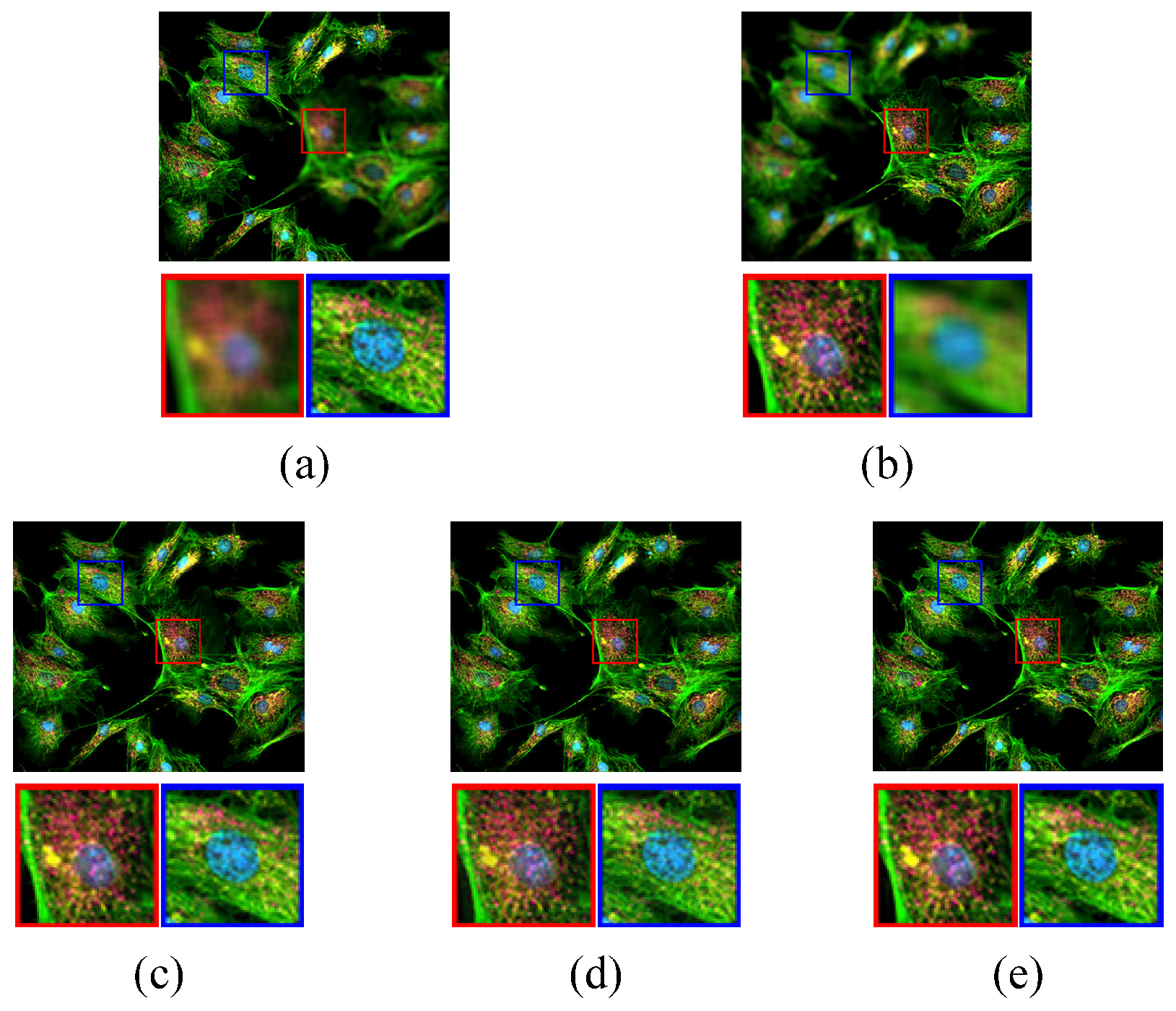
3.2. Image Quality Comparison
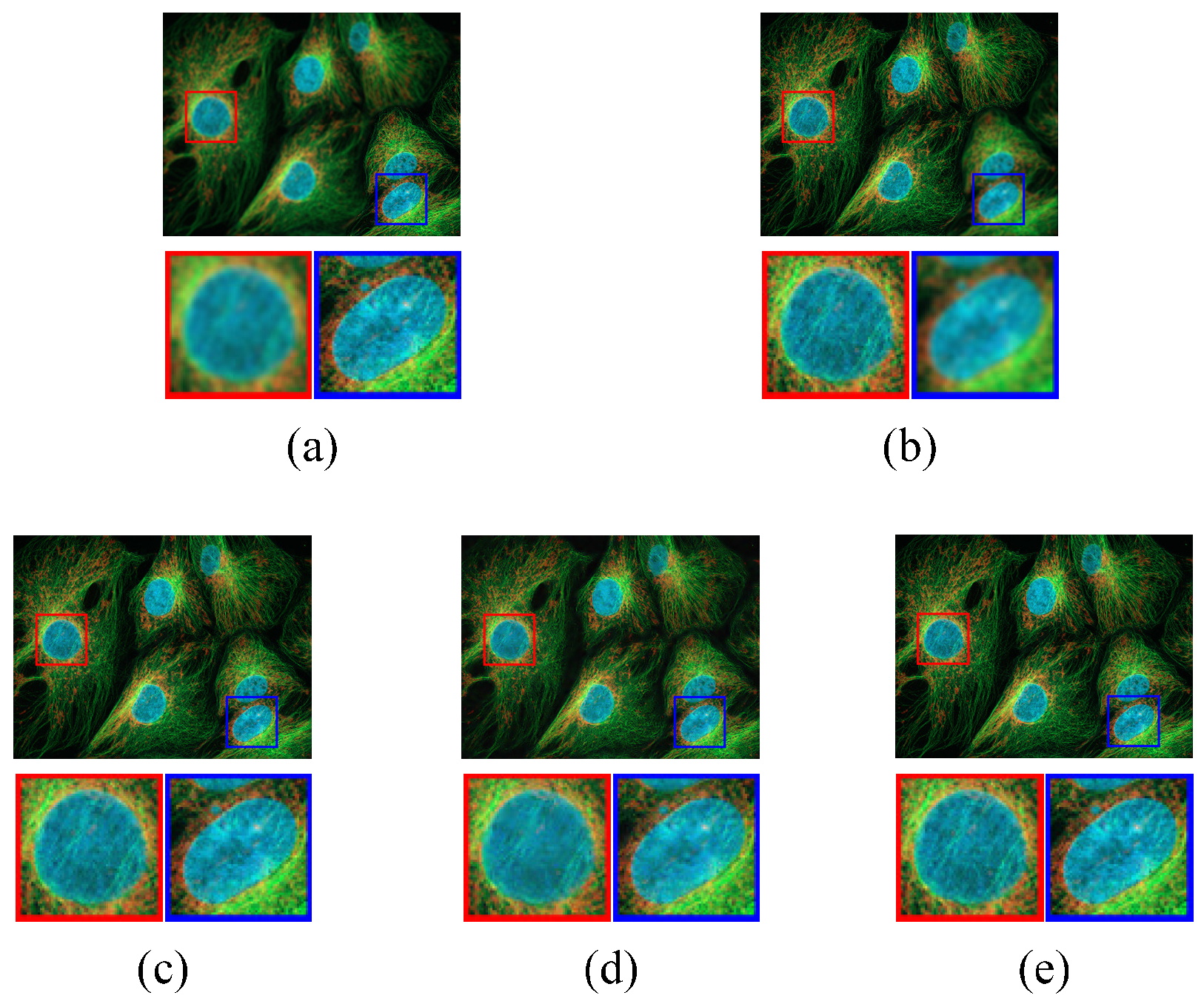
3.2.1. Comparison Experiment 1
3.2.2. Comparison Experiment 2 and 3
3.3. Processing Time Comparison
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tsai, W.; Qi, G. DICB: Dynamic Intelligent Customizable Benign Pricing Strategy for Cloud Computing. In Proceedings of the 5th IEEE International Conference on Cloud Computing, Honolulu, HI, USA, 24–29 June 2012; pp. 654–661.
- Wu, W.; Tsai, W.; Jin, C.; Qi, G.; Luo, J. Test-Algebra Execution in a Cloud Environment. In Proceedings of the 8th IEEE International Symposium on Service Oriented System Engineering, SOSE 2014, Oxford, UK, 7–11 April 2014; pp. 59–69.
- Tsai, W.; Qi, G.; Chen, Y. Choosing cost-effective configuration in cloud storage. In Proceedings of the 11th IEEE International Symposium on Autonomous Decentralized Systems, ISADS 2013, Mexico City, Mexico, 6–8 March 2013; pp. 1–8.
- Li, X.; Li, H.; Yu, Z.; Kong, Y. Multifocus image fusion scheme based on the multiscale curvature in nonsubsampled contourlet transform domain. Opt. Eng. 2015, 54, 073115-1–073115-15. [Google Scholar] [CrossRef]
- Rodger, J.A. Toward reducing failure risk in an integrated vehicle health maintenance system: A fuzzy multi-sensor data fusion Kalman filter approach for {IVHMS}. Expert Syst. Appl. 2012, 39, 9821–9836. [Google Scholar] [CrossRef]
- Li, H.; Li, X.; Yu, Z.; Mao, C. Multifocus image fusion by combining with mixed-order structure tensors and multiscale neighborhood. Inf. Sci. 2016, 349–350, 25–49. [Google Scholar] [CrossRef]
- Sun, J.; Zheng, H.; Chai, Y.; Hu, Y.; Zhang, K.; Zhu, Z. A direct method for power system corrective control to relieve current violation in transient with UPFCs by barrier functions. Int. J. Electr. Power & Energy Syst. 2016, 78, 626–636. [Google Scholar]
- Li, S.; Kang, X.; Hu, J.; Yang, B. Image matting for fusion of multi-focus images in dynamic scenes. Inf. Fusion 2013, 14, 147–162. [Google Scholar] [CrossRef]
- Li, H.; Liu, X.; Yu, Z.; Zhang, Y. Performance improvement scheme of multifocus image fusion derived by difference images. Signal Process. 2016, 128, 474–493. [Google Scholar] [CrossRef]
- Nejati, M.; Samavi, S.; Shirani, S. Multi-focus image fusion using dictionary-based sparse representation. Inf. Fusion 2015, 25, 72–84. [Google Scholar] [CrossRef]
- Li, S.; Yang, B. Multifocus image fusion using region segmentation and spatial frequency. Image Vis. Comput. 2008, 26, 971–979. [Google Scholar] [CrossRef]
- Li, H.; Yu, Z.; Mao, C. Fractional differential and variational method for image fusion and super-resolution. Neurocomputing 2016, 171, 138–148. [Google Scholar] [CrossRef]
- Li, H.; Qiu, H.; Yu, Z.; Zhang, Y. Infrared and visible image fusion scheme based on NSCT and low-level visual features. Infrared Phys. Technol. 2016, 76, 174–184. [Google Scholar] [CrossRef]
- Li, S.; Yang, B.; Hu, J. Performance comparison of different multi-resolution transforms for image fusion. Inf. Fusion 2011, 12, 74–84. [Google Scholar] [CrossRef]
- Vijayarajan, R.; Muttan, S. Discrete wavelet transform based principal component averaging fusion for medical images. Int. J. Electron. Commun. 2015, 69, 896–902. [Google Scholar] [CrossRef]
- Pajares, G.; de la Cruz, J.M. A wavelet-based image fusion tutorial. Pattern Recognit. 2004, 37, 1855–1872. [Google Scholar] [CrossRef]
- Makbol, N.M.; Khoo, B.E. Robust blind image watermarking scheme based on Redundant Discrete Wavelet Transform and Singular Value Decomposition. Int. J. Electron. Commun. 2013, 67, 102–112. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, Z.; Wu, X. A novel algorithm of remote sensing image fusion based on shift-invariant Shearlet transform and regional selection. Int. J. Electron. Commun. 2016, 70, 186–197. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Y.; Wang, J. Image fusion based on shearlet transform and regional features. Int. J. Electron. Commun. 2014, 68, 471–477. [Google Scholar] [CrossRef]
- Sulochana, S.; Vidhya, R.; Manonmani, R. Optical image fusion using support value transform (SVT) and curvelets. Optik-Int. J. Light Electron Opt. 2015, 126, 1672–1675. [Google Scholar] [CrossRef]
- Zhu, Z.; Chai, Y.; Yin, H.; Li, Y.; Liu, Z. A novel dictionary learning approach for multi-modality medical image fusion. Neurocomputing 2016, 214, 471–482. [Google Scholar] [CrossRef]
- Seal, A.; Bhattacharjee, D.; Nasipuri, M. Human face recognition using random forest based fusion of à-trous wavelet transform coefficients from thermal and visible images. Int. J. Electron. Commun. 2016, 70, 1041–1049. [Google Scholar] [CrossRef]
- Qu, X.B.; Yan, J.W.; Xiao, H.Z.; Zhu, Z.Q. Image Fusion Algorithm Based on Spatial Frequency-Motivated Pulse Coupled Neural Networks in Nonsubsampled Contourlet Transform Domain. Acta Autom. Sin. 2008, 34, 1508–1514. [Google Scholar] [CrossRef]
- Tsai, W.; Qi, G. A Cloud-Based Platform for Crowdsourcing and Self-Organizing Learning. In Proceedings of the 8th IEEE International Symposium on Service Oriented System Engineering, SOSE 2014, Oxford, UK, 7–11 April 2014; pp. 454–458.
- Elad, M.; Aharon, M. Image Denoising Via Learned Dictionaries and Sparse representation. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2006), New York, NY, USA, 17–22 June 2006; pp. 895–900.
- Tsai, W.T.; Qi, G. Integrated fault detection and test algebra for combinatorial testing in TaaS (Testing-as-a-Service). Simul. Model. Pract. Theory 2016, 68, 108–124. [Google Scholar] [CrossRef]
- Zhu, Z.; Qi, G.; Chai, Y.; Yin, H.; Sun, J. A Novel Visible-infrared Image Fusion Framework for Smart City. Int. J. Simul. Process Model. 2016, in press. [Google Scholar]
- Han, J.; Yue, J.; Zhang, Y.; Bai, L. Local Sparse Structure Denoising for Low-Light-Level Image. IEEE Trans. Image Process. 2015, 24, 5177–5192. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhang, S. Diffusion scheme using mean filter and wavelet coefficient magnitude for image denoising. Int. J. Electron. Commun. 2016, 70, 944–952. [Google Scholar] [CrossRef]
- Sun, J.; Chai, Y.; Su, C.; Zhu, Z.; Luo, X. BLDC motor speed control system fault diagnosis based on LRGF neural network and adaptive lifting scheme. Appl. Soft Comput. 2014, 14, 609–622. [Google Scholar] [CrossRef]
- Xu, J.; Feng, A.; Hao, Y.; Zhang, X.; Han, Y. Image deblurring and denoising by an improved variational model. Int. J. Electron. Commun. 2016, 70, 1128–1133. [Google Scholar] [CrossRef]
- Shi, J.; Qi, C. Sparse modeling based image inpainting with local similarity constraint. In Proceedings of the IEEE International Conference on Image Processing, ICIP 2013, Melbourne, Australia, 15–18 September 2013; pp. 1371–1375.
- Aslantas, V.; Bendes, E. A new image quality metric for image fusion: The sum of the correlations of differences. Int. J. Electron. Commun. 2015, 69, 1890–1896. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image Super-Resolution Via Sparse Representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Li, S. Multifocus Image Fusion and Restoration With Sparse Representation. IEEE Trans. Instrum. Meas. 2010, 59, 884–892. [Google Scholar] [CrossRef]
- Li, H.; Li, L.; Zhang, J. Multi-focus image fusion based on sparse feature matrix decomposition and morphological filtering. Opt. Commun. 2015, 342, 1–11. [Google Scholar] [CrossRef]
- Wang, J.; Liu, H.; He, N. Exposure fusion based on sparse representation using approximate K-SVD. Neurocomputing 2014, 135, 145–154. [Google Scholar] [CrossRef]
- Kim, M.; Han, D.K.; Ko, H. Joint patch clustering-based dictionary learning for multimodal image fusion. Inf. Fusion 2016, 27, 198–214. [Google Scholar] [CrossRef]
- Yang, S.; Wang, M.; Chen, Y.; Sun, Y. Single-Image Super-Resolution Reconstruction via Learned Geometric Dictionaries and Clustered Sparse Coding. IEEE Trans. Image Process. 2012, 21, 4016–4028. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Zheng, H.; Demarco, C.; Chai, Y. Energy Function Based Model Predictive Control with UPFCs for Relieving Power System Dynamic Current Violation. IEEE Trans. Smart Grid 2016, 7, 2933–2942. [Google Scholar] [CrossRef]
- Keerqinhu; Qi, G.; Tsai, W.; Hong, Y.; Wang, W.; Hou, G.; Zhu, Z. Fault-Diagnosis for Reciprocating Compressors Using Big Data. In Proceedings of the Second IEEE International Conference on Big Data Computing Service and Applications, BigDataService 2016, Oxford, UK, 29 March–1 April 2016; pp. 72–81.
- Bigün, J.; Granlund, G.H.; Wiklund, J. Multidimensional Orientation Estimation with Applications to Texture Analysis and Optical Flow. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 775–790. [Google Scholar] [CrossRef]
- Elad, M.; Yavneh, I. A Plurality of Sparse Representations is Better Than the Sparsest One Alone. IEEE Trans. Inf. Theor. 2009, 55, 4701–4714. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, L.; Lukac, R.; Shi, G. Sparse Representation Based Image Interpolation With Nonlocal Autoregressive Modeling. IEEE Trans. Image Process. 2013, 22, 1382–1394. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Zhang, L.; Shi, G.; Li, X. Nonlocally Centralized Sparse Representation for Image Restoration. IEEE Trans. Image Process. 2013, 22, 1620–1630. [Google Scholar] [CrossRef] [PubMed]
- Aharon, M.; Elad, M.; Bruckstein, A. rmK-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Takeda, H.; Farsiu, S.; Milanfar, P. Kernel Regression for Image Processing and Reconstruction. IEEE Trans. Image Process. 2007, 16, 349–366. [Google Scholar] [CrossRef] [PubMed]
- Ratnarajah, T.; Vaillancourt, R.; Alvo, M. Eigenvalues and Condition Numbers of Complex Random Matrices. SIAM J. Matrix Anal. Appl. 2004, 26, 441–456. [Google Scholar] [CrossRef]
- Chatterjee, P.; Milanfar, P. Clustering-Based Denoising With Locally Learned Dictionaries. IEEE Trans. Image Process. 2009, 18, 1438–1451. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Li, S. Pixel-level image fusion with simultaneous orthogonal matching pursuit. Inf. Fusion 2012, 13, 10–19. [Google Scholar] [CrossRef]
- Zhu, Z.; Qi, G.; Chai, Y.; Chen, Y. A Novel Multi-Focus Image Fusion Method Based on Stochastic Coordinate Coding and Local Density Peaks Clustering. Future Internet 2016, 8, 53. [Google Scholar] [CrossRef]
- Yin, H.; Li, S.; Fang, L. Simultaneous image fusion and super-resolution using sparse representation. Inf. Fusion 2013, 14, 229–240. [Google Scholar] [CrossRef]
- Petrovic, V.S. Subjective tests for image fusion evaluation and objective metric validation. Inf. Fusion 2007, 8, 208–216. [Google Scholar] [CrossRef]
- Tsai, W.; Colbourn, C.J.; Luo, J.; Qi, G.; Li, Q.; Bai, X. Test algebra for combinatorial testing. In Proceedings of the 8th IEEE International Workshop on Automation of Software Test, AST 2013, San Francisco, CA, USA, 18–19 May 2013; pp. 19–25.
- Wang, Q.; Shen, Y.; Zhang, Y.; Zhang, J.Q. Fast quantitative correlation analysis and information deviation analysis for evaluating the performances of image fusion techniques. IEEE Trans. Instrum. Meas. 2004, 53, 1441–1447. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Zhang, J.Q.; Wang, X.R.; Liu, X. A novel similarity based quality metric for image fusion. Inf. Fusion 2008, 9, 156–160. [Google Scholar] [CrossRef]
- Liu, Z.; Blasch, E.; Xue, Z.; Zhao, J.; Laganiere, R.; Wu, W. Objective Assessment of Multiresolution Image Fusion Algorithms for Context Enhancement in Night Vision: A Comparative Study. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 94–109. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Blum, R.S. A new automated quality assessment algorithm for image fusion. Image Vis. Comput. 2009, 27, 1421–1432. [Google Scholar] [CrossRef]
- Tsai, W.T.; Qi, G.; Zhu, Z. Scalable SaaS Indexing Algorithms with Automated Redundancy and Recovery Management. Int. J. Softw. Inform. 2013, 7, 63–84. [Google Scholar]
- Fluorescence Image Example - 1. Available online: https://www.thermofisher.com/cn/zh/home/references /newsletters- and-journals/probesonline/probesonline-issues-2014/probesonline-jan-2014.html/ (accessed on 21 December 2016).
- Fluorescence Image Example - 2. Available online: http://www2.warwick.ac.uk/services/ris/ impactinnovation/impact/analyticalguide/fluorescence/ (accessed on 21 December 2016).
- Fluorescence Image Example - 3. Available online: http://www.lichtstadt-jena.de/erfolgsgeschichten/ themen-detailseite/ (accessed on 21 December 2016).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MI | VIF | ||||
|---|---|---|---|---|---|
| KSVD | 0.4966 | 2.4247 | 0.5778 | 0.5960 | 0.5287 |
| JPDL | 0.5815 | 2.9258 | 0.6972 | 0.6944 | 0.7243 |
| Proposed Solution | 0.6226 | 3.4773 | 0.7428 | 0.7386 | 0.7974 |
| MI | VIF | ||||
|---|---|---|---|---|---|
| KSVD | 0.5600 | 2.4747 | 0.6099 | 0.6161 | 0.5477 |
| JPDL | 0.6952 | 3.1357 | 0.7013 | 0.7355 | 0.7423 |
| Proposed Solution | 0.7692 | 3.8982 | 0.7488 | 0.8058 | 0.8206 |
| MI | VIF | ||||
|---|---|---|---|---|---|
| KSVD | 0.6837 | 2.4624 | 0.8171 | 0.7855 | 0.6454 |
| JPDL | 0.8557 | 2.9358 | 0.8943 | 0.9325 | 0.7665 |
| Proposed Solution | 0.8979 | 3.9154 | 0.9129 | 0.9790 | 0.8237 |
| Experiment - 1 | Experiment - 2 | Experiment - 3 | |
|---|---|---|---|
| KSVD | 164.02 s | 215.09 s | 108.65 s |
| JPDL | 123.68 s | 171.93 s | 73.58 s |
| Proposed Solution | 76.23 s | 103.96 s | 25.47 s |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Z.; Qi, G.; Chai, Y.; Li, P. A Geometric Dictionary Learning Based Approach for Fluorescence Spectroscopy Image Fusion. Appl. Sci. 2017, 7, 161. https://doi.org/10.3390/app7020161
Zhu Z, Qi G, Chai Y, Li P. A Geometric Dictionary Learning Based Approach for Fluorescence Spectroscopy Image Fusion. Applied Sciences. 2017; 7(2):161. https://doi.org/10.3390/app7020161
Chicago/Turabian StyleZhu, Zhiqin, Guanqiu Qi, Yi Chai, and Penghua Li. 2017. "A Geometric Dictionary Learning Based Approach for Fluorescence Spectroscopy Image Fusion" Applied Sciences 7, no. 2: 161. https://doi.org/10.3390/app7020161
APA StyleZhu, Z., Qi, G., Chai, Y., & Li, P. (2017). A Geometric Dictionary Learning Based Approach for Fluorescence Spectroscopy Image Fusion. Applied Sciences, 7(2), 161. https://doi.org/10.3390/app7020161