1. Introduction
Audience research conducted by the British Broadcasting Corporation (BBC) has shown that approximately 60% of viewers in the UK experience some difficulties understanding speech content in programmes. This is due to a combination of factors such as background sound effects, intrinsically unintelligible speech, unfamiliar accents and loud ambient noise in the listening environment [
1]. This paper focusses on masking caused by inappropriate levels of background sound.
In films, TV and radio programmes, speech content is usually accompanied by background sounds and effects. These sounds (e.g., music) may be added by a programme producer for narrative purposes or to create a certain atmosphere. The sounds and effects may also exist in the original speech recordings, for example the recording might contain reverberation in a large conference room and clapping by an audience. While these background sounds and effects may improve an audience’s experiences by providing ‘realistic’ or ‘being there’ feelings, they can also lead to poorer speech intelligibility. In some situations, even listeners with normal hearing struggle to understand what is being said in programmes. It is even more difficult for listeners with hearing impairments or whose native language is different from that of the programme [
2].
A sound designer or producer usually decides on the mixing level of the speech and background based on his/her intentions and experiences. The speech-to-background ratio (SBR) may be chosen according to certain rules of thumb. Here are some examples for broadcasting from sound producers and audio professionals [
3]:
In the presence of background music, while the music is usually set to dB, the dialogue is about to dB. This makes sure that the background music does not interfere with the dialogue. Alternatively, speech level is empirically expected to be at between 4 and 6 (0 dB and +8 dB) on a peak programme meter. Music and effects are balanced to satisfy the artistic intentions.
The mixing level may greatly vary across different programmes based on the producer’s experiences and taste. As such, the relative level between dialogue and other tracks may be determined solely based on the producer’s preference.
The studio often represents optimal listening conditions. A responsible mixer/producer also checks mixes on other reproduction systems other than those in the studio, because there is always a compromise after the point when the mix sounds as good as it should in the studio. For example, the producer listens to the programme on TV speakers at the post-production stage in order to know how it would sound on the audiences’ TVs.
An approach to check the balance between the dialogue and music or sound effects is to trigger the variation of frequency sensitivity with volume (represented well by the Fletcher-Munson equal-loudness curves) by listening to the mix at low volume. If the dialogue is sufficiently intelligible at low volume, it will work on most speaker setups.
It is clear that in most cases, the decision on the final mixing level of broadcasting programmes relies to a great extent on sound producers’ own perception to the mix, and is based on their personal preference. Furthermore, all the checking work has to be done manually by the sound producer or someone during the postproduction stage, in order to make sure that the mixing level does not compromise both speech intelligibility and artistic intentions. Despite precautions, the audience still often needs the assistance of on-screen captions: 10% of the BBC audience uses subtitles [
4]. It is possible that the producer is so familiar with the script, and thus with the speech content, that the chosen SBR is set too low. While mumbled speech may not be a problem for the producer who has repeatedly heard the dialog during editing, audiences may struggle.
Sound designers or producers seem to lack a psychoacoustic guide that allows them to estimate the likelihood of the audience being able to understand the speech at their preferred mixing levels, or gives them minimum mixing levels for a desired intelligibility. Consequently, the mixing level decided by conventional empirical approaches may fail in maintaining intelligibility in two aspects. First, the mixing level may not work for all reproduction output configurations. While high-end spatial audio systems (e.g., 22.2 and 9.1) can preserve sufficient spatial cues (e.g., source azimuth) which listeners can use to enhance speech intelligibility, other systems with reduced spatial capabilities and often use down-mixed versions of the programme material (e.g., stereo) and so may not be able to provide the same level of intelligibility. Many studies (e.g., [
5,
6,
7,
8,
9]) have suggested that spatial cues can significantly improve speech intelligibility even when the SBR remains constant. Loss of these spatial cues may lead to poor intelligibility in low-end systems. Unfortunately, stereo loudspeakers in TVs are often of poor quality and mono audition is common for radios and mobile devices. Second, background sounds vary in their masking effect. It is well documented that the type of background sound affects listener speech perception differently [
10,
11,
12,
13,
14,
15,
16,
17]. Compared to fluctuating background sounds (e.g., temporally-modulated sounds), stationary background sounds (e.g., pink noise) usually introduce stronger masking effects to speech even at the same SBR level. This implies that an optimal SBR, which maintains speech intelligibility while providing a reasonable atmosphere to the audio scene, should vary over time.
Some research has focused on solving this problem by enabling the audience to gain control of the foreground-background mixing level. Shirley and Oldfield [
18] introduced an approach for ‘clean’ audio in TV broadcast, which is compatible to ISO/IEC 23008 High Efficiency Coding and Media Delivery in Heterogeneous Environments. This object-based method allows the stream carrying the speech content to be separately transmitted; end users therefore can alter the SBR level to achieve better intelligibility for the speech content. Paulus et al. [
19] proposed an object-based coding system to enhance dialogues for TV and radio broadcasts. This system enables renderer-listener interaction and permits listeners to control the mixing level for personalised intelligibility. Similar to [
18], this approach essentially adjusts the gain of speech as a single object against the gain of other objects in the background. Further subjective rating experiments suggested that this system improved listeners’ experience when auditioning speech content in background sounds. However, in order to make adaptations the system expects input from the listener, but the desired SBR varies as the broadcast material changes. Thus, this begs the question: is it possible to automatically adjust the mixing level? In this way, a preset intelligibility goal (set by either the sound producer or listener) can be ensured over time.
Objective intelligibility models (OIMs) have been improving in accuracy for almost a century. State-of-the-art OIMs (e.g., [
20,
21,
22,
23,
24]) are capable of making accurate intelligibility predictions in various masking conditions, with their binaural counterparts able to deal with more realistic situations [
25,
26,
27,
28]. Compared to conventional subjective evaluations which are usually time-consuming and expensive, OIMs are computationally fast and thus easy to incorporate into a closed-loop optimisation framework for intelligibility. OIMs have been used for interim speech intelligibility evaluations for optimising speech modification algorithms developed to boost speech intelligibility in noise (e.g., [
29,
30,
31]), prior to final subjective evaluation. Having demonstrated its applications, it may be possible to adopt an OIM in an audio system as an intelligibility meter and further as a guide to select appropriate mixing levels for the speech content. There are several reasons that OIMs may be useful for these purposes: (1) OIMs are physically and physiologically plausible—they are built based on valid auditory models, (2) their prediction is evaluated against human listeners’ perceptual performance in various conditions, (3) they can be treated as an independent input-output component, and hence can be plugged into existing systems without substantial alteration to other components in the entire system, and (4) from word to sentence, they can make predictions over time and thus enable dynamic online operation. Müsch attempted to adopt the Speech intelligibility Index (SII) [
20] to control the background level in a 5.1 system, in order to increases overall comprehension and to reduce listening effort for elderly people [
32]. However, the intelligibility criterion used to alter the background level was not detailed and the proposed system was not systematically evaluated. Thus, its performance is unknown.
In this article, we propose an approach to automate mixing levels based on intelligibility predictions from an OIM for an object-based audio system. In
Section 2, the framework of the proposed system is described. The first attempt to predict an appropriate SBR mixing level uses the OIM Binaural Distortion-Weighted Glimpse Proportion (BiDWGP) [
9]. This is detailed in
Section 3, where the predictive accuracy is also compared to four other OIMs including two standard intelligibility measures—SII and Speech Transmission Index (STI) [
21]—the Normalised-Covariance Measure (NCM) [
33], and the Short-Time Objective Intelligibility (STOI) [
23].
Section 4 details a psychoacoustic experiment where listeners give their preferred SBR. It is found that the SBR is not the same as that expected from the OIM work. A gain adjustment to the SBR is required and this depends on the type of background sound.
Section 5 details a subjective experiment to access the performance of the OIM system with the suggested gain adjustment from the previous experiment. Finally, conclusions are drawn in
Section 6.
2. Proposed System
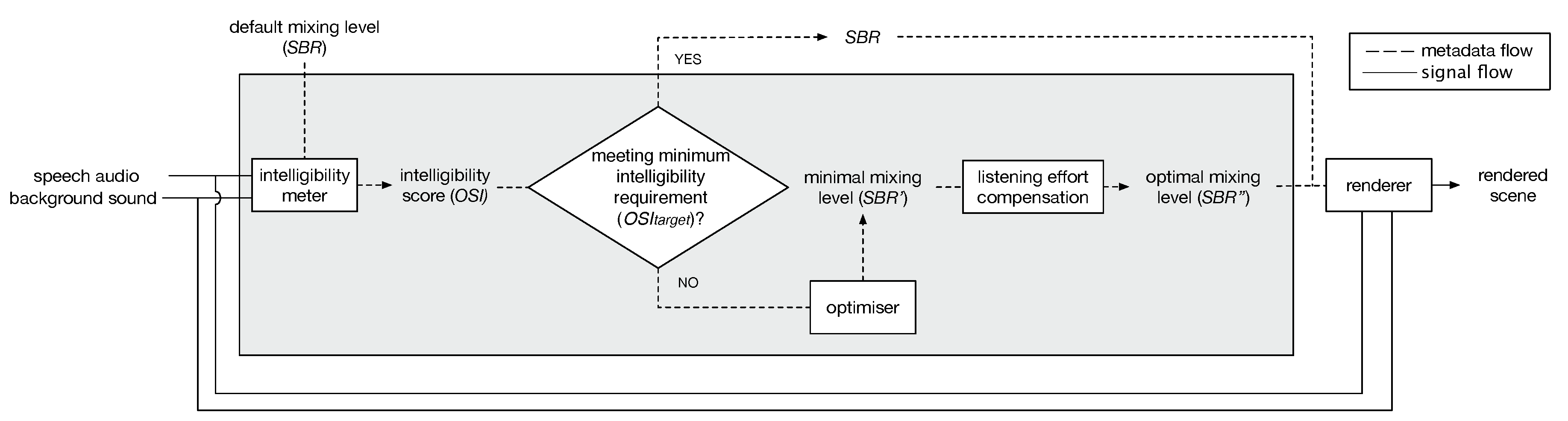
A schematic overview of the proposed system is shown in
Figure 1. In an object-based audio system, the intelligibility module using an OIM may sit prior to the renderer in the pipeline, acting on the metadata. In this case, no changes to the existing rendering algorithms are required. This intelligibility module essentially consists of two main components—the speech intelligibility meter and the mixing level optimiser that sets the SBR. The speech intelligibility meter takes speech and background sound objects and the default mixing level,
, as inputs, and it calculates an objective intelligibility score
. The objective score is then fed into a decision component, which makes a judgement on whether the intelligibility meets the minimum required (
Section 3). If the current default SBR leads to satisfactory intelligibility then nothing is altered. If the speech intelligibility falls below the minimum, then the optimiser will look for a new mixing level
that should push the intelligibility above the minimum required. To further take listener listening effort into account,
may need further adjustment to achieve an optimal mixing level
(See
Section 4).
2.1. Selection of OIM
In principle, any OIM may serve as the intelligibility meter in
Figure 1. However, previous studies (e.g., [
24,
34]) have shown that some OIMs do not work well across the broad range of maskers found in broadcast audio. The background may vary over time from music to crowd babble sound, from general soundscapes to competing talkers. Building a large database of statistics of various background sounds to rectify each model output is therefore impractical. To solve this problem, Tang proposed a metric—distortion-weighted glimpse proportion (DWGP, [
24])—based on a notion that both masked audibility and disturbance on speech modulation resulting from the masking effect of the noise masker, should account for the reduction of speech intelligibility in noise. The former aspect is quantified in each analytical frequency band as the percentage of the time-frequency regions on the speech signal with a speech-to-noise ratio above a pre-defined threshold (e.g., 3 dB); the latter effect is calculated as the distortion factor for each frequency, using cross-correlation between the envelopes of the clean and the noise-corrupted speech signals. The distortion factor is then used to weight the masked audibility in each band. The final predictive score is the sum of the masked audibilities across all the frequencies after further being weighted by the band importance function [
20], which determines the contribution of each frequency to the overall intelligibility. In assessment, the DWGP metric has demonstrated a good match to subjective data when treating each noise separately and across a wide range of background noise, with squared Pearson correlation coefficients
[
24].
In 2015, Tang et al. further extended the DWGP metric to binaural DWGP (BiDWGP), thus affording a more ecologically valid application of the metric [
9]. See [
28] for implementation details of BiDWGP. Two prominent aspects of binaural listening are modelled in this extension: the better-ear effect due to the head-shadowing and binaural unmasking. BiDWGP can predict intelligibility either directly from the binaural recordings or from monophonic recordings of each sound source along with their locations. Predictions made using the two input forms are almost identical in anechoic conditions [
28]. As an extension to DWGP, when BiDWGP is used for monaural situations it operates the same to DWGP. Therefore, BiDWGP is able to replace its monaural counterpart in any cases.
The evaluations in both anechoic [
28] and reverberant [
34] conditions have suggested that the BiDWGP outperformed the standard metrics such as the SII (
) and the STI (
) in many conditions, and was able to provide reliable intelligibility estimations (
).
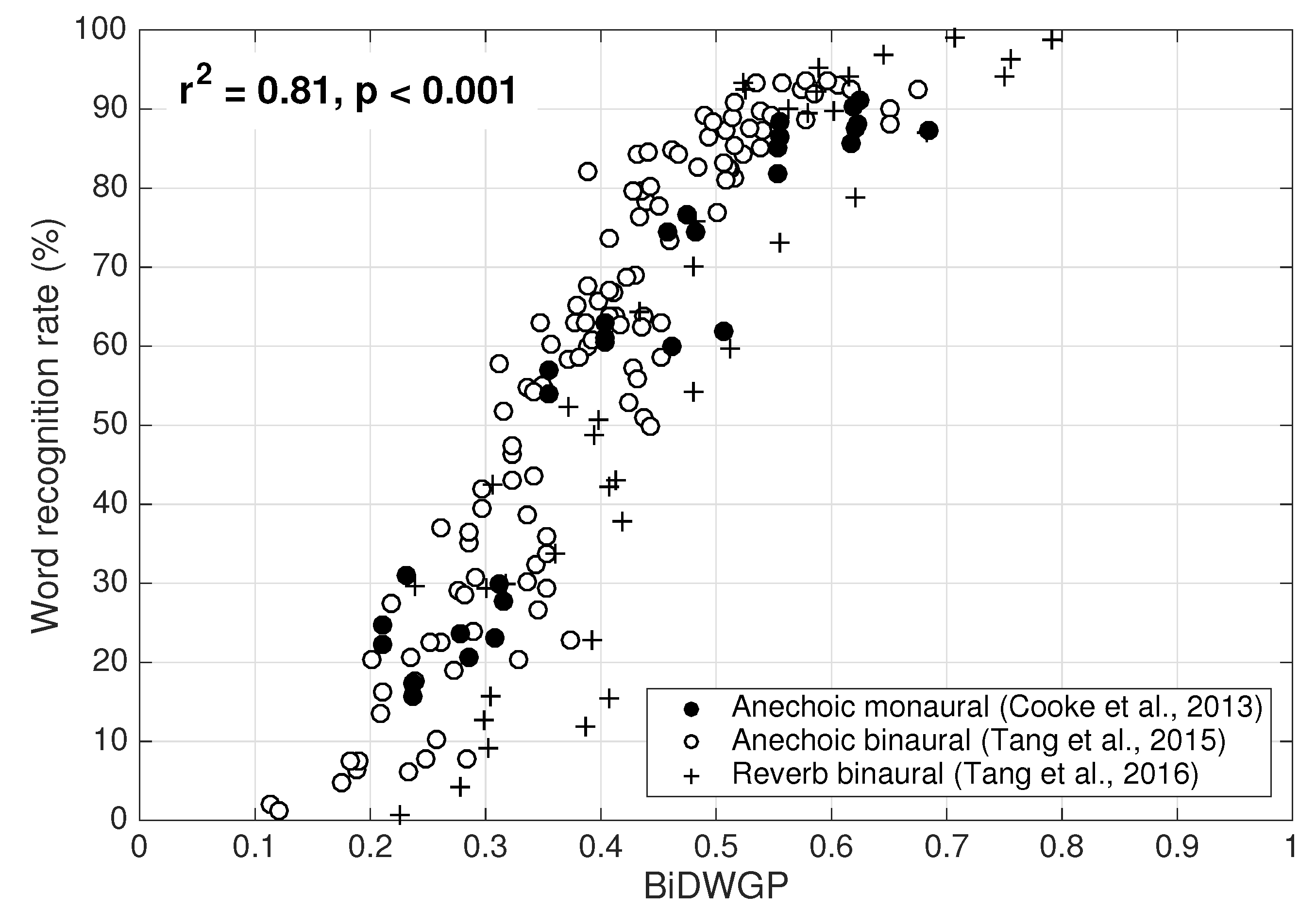
Figure 2 furthers compares the listeners’ word recognition rates at sentence level from three previous studies [
9,
34,
35] against BiDWGP predictions in both anechoic and reverberant conditions, in which stimuli were presented monaurally or binaurally. A strong linear relationship between the subjective data and BiDWGP prediction is evident with
across all 190 data points/conditions. Providing its robust predictive power, the BiDWGP metric was hence chosen as the OIM for intelligibility metering in the work presented here.
2.2. Intelligibility Criteria
Sound reproduction setup in end users’ living rooms can vary in their specifications. It may be unfeasible to build a system which is capable of making accurate speech intelligibility predictions for all different audio systems from high end down to low end, and in particular making adaptions to accommodate each system automatically. However, as aforementioned, down-mixing, from 22.2 to a stereo system for example, effectively leads to the gradual loss of spatial cues such as relative source separation and distance between objects. As such, given a dialogue scene with a default mixing level, intelligibility may decrease monotonically from a 22.2 to a mono system, with the worst intelligibility in the latter case. In turn, if the intelligibility of the mono system is guaranteed, with the same mixing level there should not be any further intelligibility issue for high-end systems in which spatial cues may be preserved.
The BiDWGP metric is in the form of a numeric index like other OIMs (e.g., SII and STI), which falls into the range of 0–1 with larger numbers indicating better intelligibility. The output does not directly provide any information about the SBR, however, and so a transformation from index to SBR is needed. What SBR is optimal for speech? To answer this key question, an assumption is made that the optimal SBR should guarantee that all the information conveyed by the speech will be well understood by listeners. The next section details an experiment to measure the minimum SBR leading to 100% intelligibility for normal hearing listeners in a range of background sounds when listening monaurally.
3. Experiment I: Minimal SBR for Full Sentence-Level Intelligibility
This experiment was designed to measure the possible lowest SBR for full intelligibility at sentence level for different background sounds. A further aim of this experiment was to quantify the relationship between the BiDWGP predictions and the measured .
3.1. Stimuli
Speech materials were drawn from the SCRIBE corpus [
36]. This corpus consists of speech sentences (e.g., ‘the EARTH USED to BE FLAT but NOW IT’S a SPHERE’, with the keywords capitalised) uttered by eight (four male and four female) native British English talkers. As many studies (e.g., [
37,
38]) have shown great variation in speech intelligibility between different talkers, having speech from many talkers makes the experiment more ecologically valid. In order to control the size of the experiment, speech produced by two male (M5 and M8) and two female (F6 and F7) talkers were used based on a pilot test, in which keyword recognition rate of listeners was measured as the intelligibility in speech-shaped noise (SSN) at −6 and 0 dB SBR. The results suggested that the chosen talkers are representative of the most and the least intelligible cases of each gender in the corpus under the tested background conditions.
The background sounds covered a wide range of types—both stationary and fluctuating— including: SSN, which has the long-term average spectrum of the speech corpus; cafeteria babble noise (BAB); competing speech (CS) drawn from news broadcasting; a rock song (SNG, ‘Song for Someone’ by U2), and the same song with vocal track being removed (MSC, i.e., instrumental sounds only). Note that in order to reduce the effect of informational masking caused by the same gender [
16], CS from a person of the opposite gender to the target talker was used. For each speech-background stimulus pair, the background signal was randomly cropped from a 5-min long signal, and preceded and followed the speech by 300 ms. In total, this setup led to 20 conditions (5 background sounds × 4 talkers).
3.2. Procedure and Listeners
The determination of
was a 1-up/1-down adaptive process in progression by following the procedure described in [
39]. The experiment was conducted using a MATLAB (v9.1 by MathWorks, Natick, MA, USA, 2016) graphical user interface (GUI). Each background condition consisted of 10 non-repetitive stimuli which were presented in a random order. Starting from a very low SBR (−21 dB), the listener was instructed to manually increase the background level until they could only just understand everything in the first sentence. Within the first trial, the listener could hear the sentence as many times as s/he needed to find the appropriate SBR. Once the initial SBR was set, the listener was required to type what was heard using a physical computer keyboard. Upon finishing the transcription of the sentence, the original correct answer was displayed with all the keywords capitalised. The listener self-checked the correctness of all the keywords; s/he was instructed to ignore any errors due to typos, homophones, contractions, punctuation or differences in tense and plurality. The programme then decreased or increased the SBR by 2 dB for the next sentence according to whether or not the listener obtained a score of 100% correct in the current sentence.
In the subsequent nine trials, the SBR could no longer be adjusted by the listener; instead it was adaptively controlled by the programme using the same 1-up/1-down criteria. Each sentence was played only once prior to the listener’s response. The final for this condition was the average SBR across the final eight trials. The same procedure was repeated for all the 20 conditions, the order of which was also randomised. Through all the conditions, the listener did not hear any utterance twice.
The experiment took place in an semi-anechoic room with a background noise level of 3.8 dB(A). The stimuli were presented to listeners monaurally over a pair of Sennheiser (Wedemark, Germany) HD650 headphones after being pre-amplified by a Focusrite (High Wycombe, UK) Scarlett 2i4 USB audio interface. The SBR for each speech-masker pair was calculated across the entire signals. The presentation level of speech only over the headphones was calibrated using Brüel & Kjær (B&K, Nærum, Denmark) 4153 artificial ear with a B&K 2610 measuring amplifier, and fixed at 69 dB(A). Thus, in the experiment the SBR was altered only by varying the level of the background sound.
A total of 14 native British English speakers (ages: 18–30 year, mean age: 24 year) participated in this experiment. All participants reported normal hearing, and were paid for their participation. The Research Ethics Panel at the College of Science and Technology, University of Salford, granted ethical approval for all the experiments conducted in this work.
3.3. Results
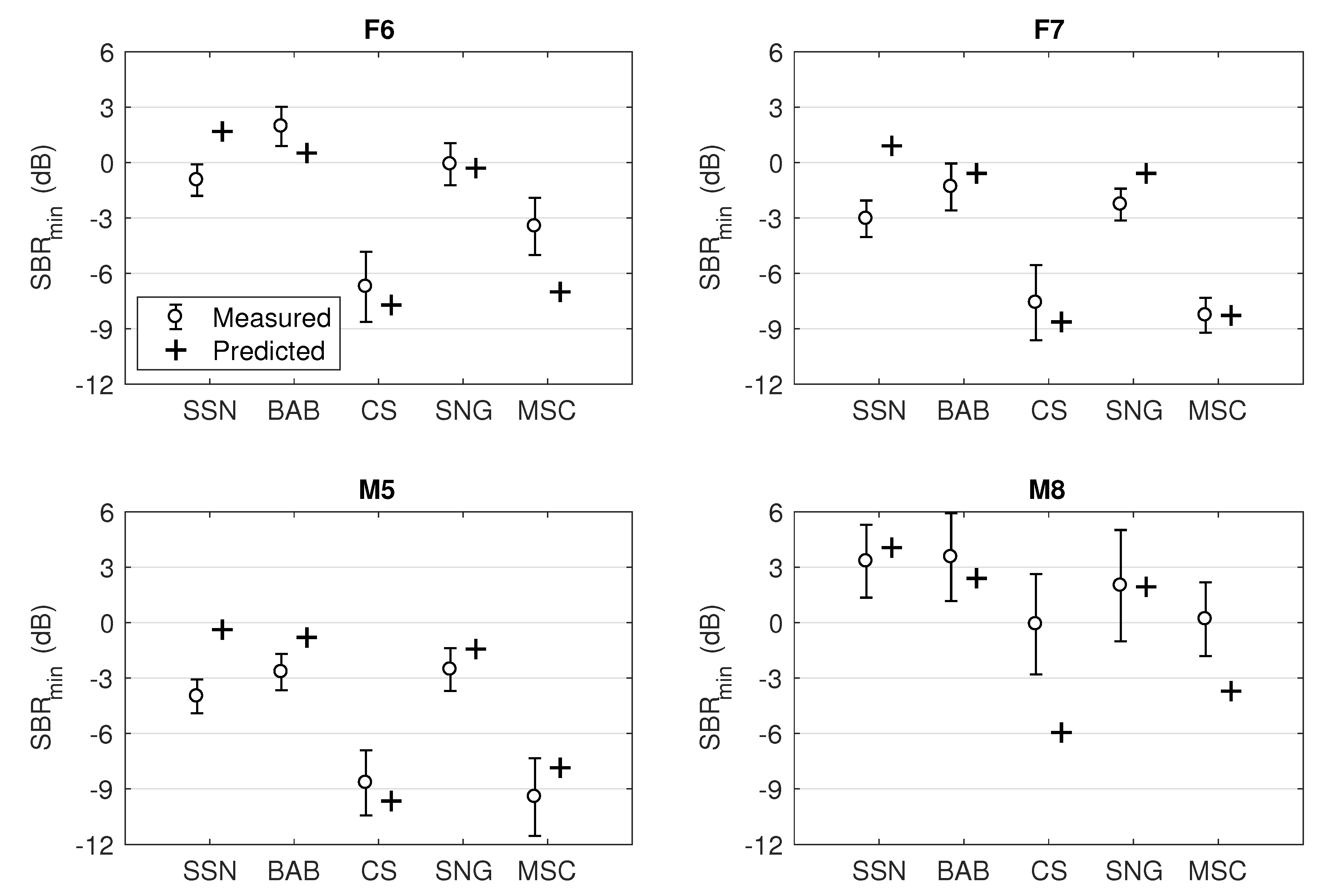
Of the 14 participants, two did not complete all the conditions due to slow progress; hence their data is excluded from the results presented below. Data of another participant was also discarded after an outlier analysis. Therefore, the mean
levels shown in
Figure 3 as open circles are based on the remaining 11 participants. The measured
levels fall into the range of
to 3.5 dB across all backgrounds and talkers. A two-way repeated measures ANOVA with within subject factors (5 background sounds × 4 talkers) revealed a significant effect of both background type [
] and talker [
], as well as a significant two-way interaction between background type and talker [
]. This suggests that the minimum SBR which listeners require varies significantly across various background sounds and speech content produced by different talkers.
Post-hoc pairwise comparisons with Bonferroni correction further confirmed the visual impression that stationary backgrounds (SSN and BAB) lead to higher
than fluctuating background (CS) for speech produced by all talkers [all
], except for M8. This is consistent with the findings reported in the literature (e.g., [
11,
13]). Furthermore, by removing the vocal track from SNG, which to some extent functions as competing speech and potentially introduces both energetic and informational masking to intelligibility,
for all talkers in MSC substantially decreased compared to that in SNG [all
] with M8 being an exception.
for the speech of M8 did not vary as dramatically as for other talkers across different backgrounds presumably because of its low intrinsic intelligibility that had been observed in the pilot test, leading to the relatively high
at which the intelligibility to listeners usually converges. Comparing across the four talkers, it is evident that speech produced by M8 had a higher
than other talkers in SSN, CS and MSC backgrounds [all
].
3.4. Model Predictions of
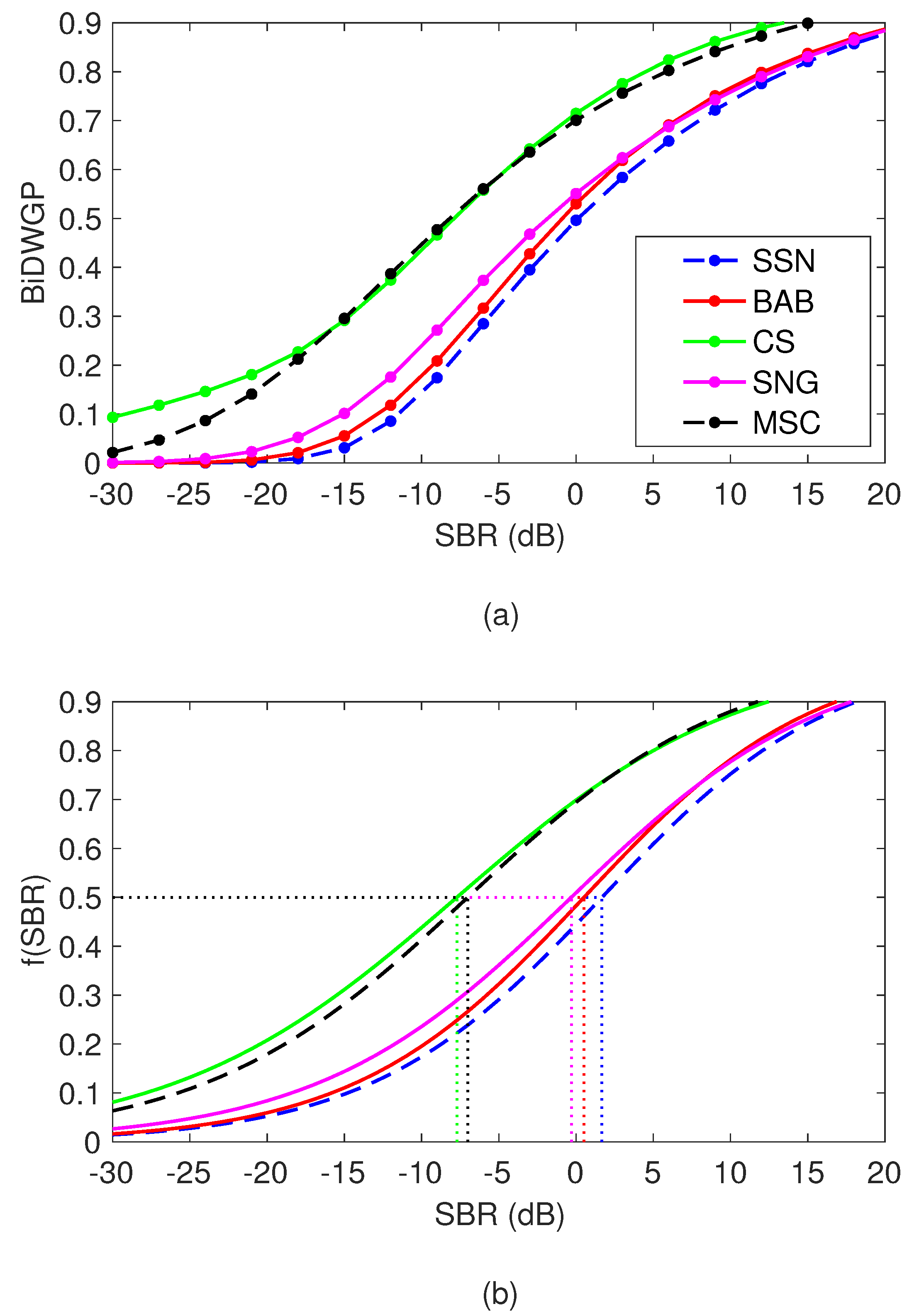
A function that allows conversion from a desired BiDWGP to the mixing level SBR is required. The upper panel of
Figure 4 illustrates the BiDWGP scores as a function of SBR in various background sounds for talker F6. Each data point on the plotted lines (in steps of 3-dB SBR) was calculated as the mean of the BiDWGP scores for all samples used in the
psychoacoustic experiment. In order to formulate a function relating BiDWGP and SBR, a two-parameter sigmoid function in the form of
with variables
a and
b was constructed using the MATLAB
glmfit function with a normal distribution and
logic link function. The fitted functions are shown in the lower panel of
Figure 4. Subsequently, given a desired BiDWGP score, the required SBR in the presence of each background sound can be calculated using the inverse of the function
f. Due to the masking effect varying between background sounds, different SBR values for a given BiDWGP score are found. In the lower panel of
Figure 4 the SBRs required in order to achieve a BiDWGP score of 0.5 in different background sounds is shown (The reason for choosing a BiDWGP score of 0.5 is explained below). This procedure was also applied to the other talkers.
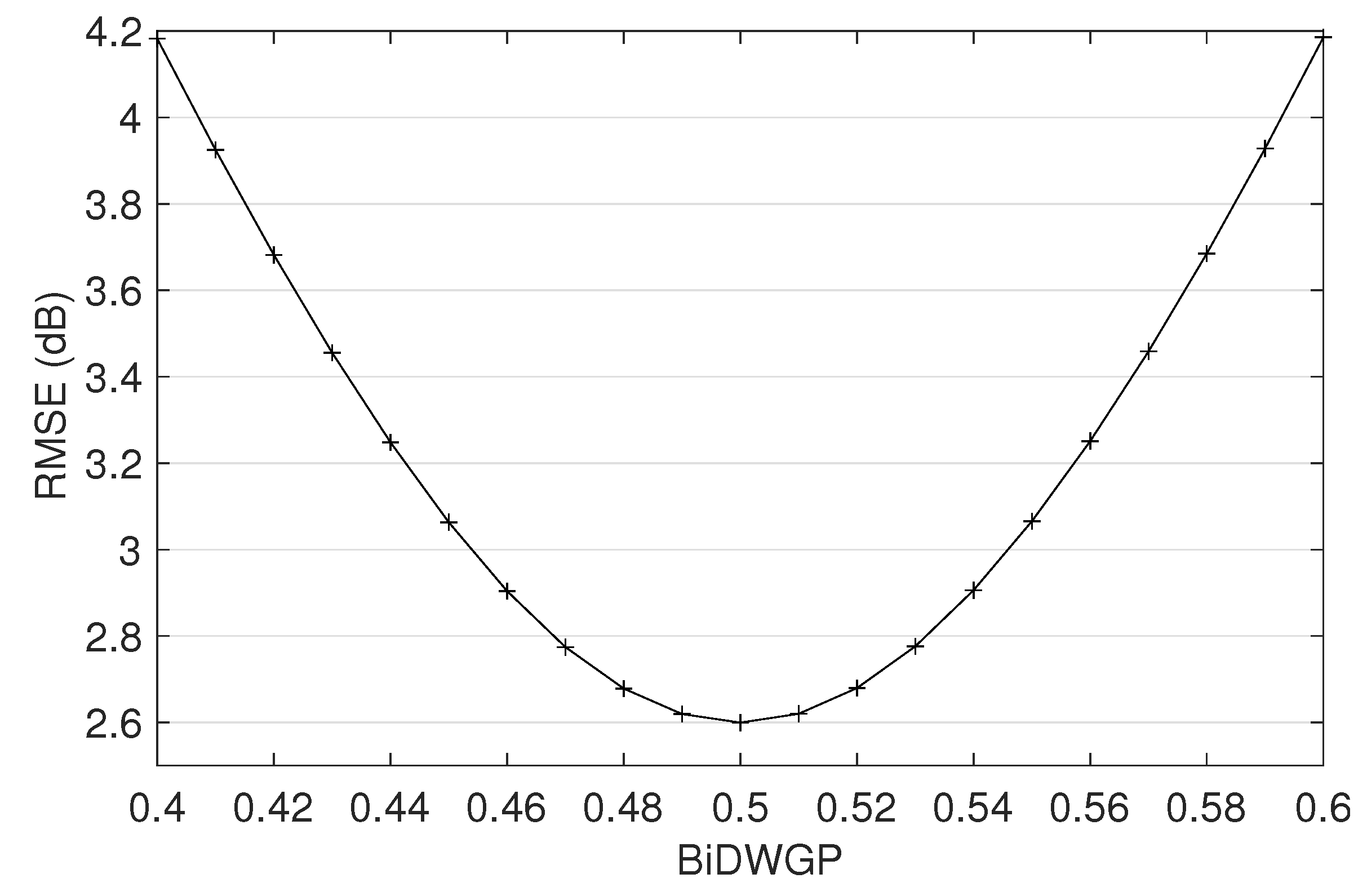
Drawing on the perceptual experiment that determined listeners’ , it is possible to derive the BiDWGP score which corresponds to the predicted in all tested conditions. This was performed by minimising the root-mean-square error (RMSE) between the measured and the predicted over 12 conditions (3 background sounds × 4 talkers) from SSN, BAB and CS. In order to investigate the robustness of this process for unseen conditions, 8 conditions from SNG and MSC were excluded from the RMSE minimisation and were reserved for testing only.
Figure 5 shows RMSE as a function of BiDWGP scores. It suggests that SBRs leading to a BiDWGP of 0.5 provides the closest match to the measured
, with a RMSE of 2.6 dB across SSN, BAB and CS. When predicting the
for the previously unseen SNG and MSC cases using 0.5 BiDWGP, the RMSEs are 1.0 and 2.8 dB across all the talkers, respectively. The BiDWGP scores corresponding to
were also individually learnt for SNG and MSC. They are 0.48 (RMSE: 0.8 dB) and 0.52 (RMSE: 2.4 dB) for SNG and MSC, respectively—the RMSEs of the predictions using 0.5 BiDWGP are merely 0.2 and 0.4 dB higher for the two maskers. Consequently, the value of 0.5 was used for all background sounds to derive the
. The predicted
levels in all conditions are displayed against the measured values for all speakers and markers in
Figure 3. With a strong linear relationship [
] and the least RMSE (2.4 dB) between the measured and the predicted values, the BiDWGP metric was considered capable of making reasonable
predictions in tested background sounds, especially as this was performed across both factors of background sound and talker.
Any OIM could be used in the place of BiDWGP here as the intelligibility predictor. However, the predictive power of the chosen OIM may affect the robustness of the system. As an illustration, the performance of another four OIMs was also investigated, including the SII and the STI—two standard intelligibility measures—and two more recent measures: NCM and STOI. The SII makes intelligibility predictions from the normalised frequency-dependent speech-to-noise ratios, which reflect the masked-audibility of each frequency in noise. The STI quantifies intelligibility by accounting for the reduction in the modulation depth of speech envelope using the modulation transfer function. Similar to the STI, NCM computes the distortions caused by the noise masker or reverberation by comparing the similarity between the envelopes of the noise-corrupted signal and the clean reference speech signal. Rather than long-term speech envelope, STOI operates on short-term envelope to quantify the distortions affecting intelligibility. It was originally proposed for estimating intelligibility of speech signals processed by enhancement algorithms.
Table 1 summarises the objective scores which led to the minimal RMSE of the predictions across SSN, BAB and CS. The RMSEs and
between the measured and predicted
in the second and the third rows were calculated from the predicted
values, using the objective score of each OIM across all 20 conditions (5 background sounds × 4 talkers).
3.5. Interim Discussion
A listening experiment was conducted to measure listeners’ for speech produced by four talkers in a set of background sounds. The results suggest that may vary considerably from one background sound to other. The talker effect is also evident, resulting in different levels even in the presence of the same background sound. All the evidence from this experiment supports the view that a constant SBR for speech-background mixing does not guarantee that target speech information can be understood over all background sounds and talkers. One possibility would be to make the SBR for the target speech very high. However, the potential problem of adopting a high SBR would be that a sound editor’s intentions (e.g., creating an atmosphere for an audio scene by adding background sounds) could no longer be fulfilled.
levels measured in this study were for monaural listening, simulating intelligibility reproduced by mono audio systems or stereo systems with the target speech played diotically. For multi-channel systems in which sound objects can be perceived spatially separated, the
may be expected to be lower than in monaural situations because human listeners are able to use different spatial cues such as interaural level and time differences to achieve better intelligibility [
5,
6,
7,
8,
28].
The predicted SBR level which led to a BiDWGP score of 0.5 was the closest to the measured
in each background sound. The performance of the BiDWGP metric in predicting
(
) is not as good as in predicting word recognition rates (
) reported in the previous studies [
9,
34,
35]. Although several types of background sounds were also used in those tests for measuring word recognition rate, speech sentences were usually uttered by a single talker. By introducing both the background and talker effects in the current experiment, the BiDWGP metric seems to lose some predictive accuracy after the function fitting for BiDWGP-SBR mapping. Nevertheless, compared to predictions by other OIMs (
Table 1), BiDWGP led to the lowest RMSE and the highest
. Thus, a RMSE of 2.4 dB over all tested conditions is considered acceptable as a first approximation for SBR adjustment.
For cases in which the proposed system is only used to examine whether an intended mixing level (
in
Figure 1) can meet the minimal intelligibility requirement, the proposed method is able to automatically fulfil this purpose. This method could also determine the optimal mixing level for a given foreground-background pair. However, the optimal SBR is not just about speech intelligibility, it should also provide a comfortable balance between the foreground and background sounds. In the next section, an experiment to determine the preferred SBR is outlined.
4. Experiment II: Listener-Preferred SBR for Speech-Background Mixing
Expt. I found the minimum SBR to correctly understand sentences. This is not necessarily the SBR that listeners prefer for everyday audio such as news broadcasting, radio drama and sport commentary. Therefore, Expt. II aimed to elicit listeners’ personal preference on the mixing level of diverse audio scenes, and to further compare it to the predicted SBR when a BiDWGP score of 0.5 is achieved.
4.1. Stimuli
Five audio scenes were created including football commentary, news broadcasting, public speech, radio drama, and radio poetry, all of which are quotidian audio content.
Table 2 details the foreground speech and background sound of the chosen audio scenes. As stimuli for each scene, four excerpts were created, leading to a total of 20 excerpts in the experiment. Each excerpt lasted 15–24 s. In all excerpts, the intensity of the foreground speech was normalised to the same root-mean-square value; the background sound preceded and followed the foreground speech by one second.
4.2. Procedure and Listeners
The playback and adjustment of foreground-background mixing level were controlled by a MATLAB GUI. The listener auditioned the scenes in the same room and using the same equipment as per Expt. I. While the foreground speech was presented diotically to the listener, the background sound was played stereophonically. The task for listeners was to choose an appropriate mixing level for the speech content and the background sound; the chosen mixing level for each scenario should result in the speech content being intelligible enough and the background sound providing good atmosphere to the scene. No reference scene was provided as a guide for either ‘well’ or ‘badly’ mixed content. The listener was allowed to adjust the master volume to a comfortable level at the beginning of the experiment. The mixing level was adjusted by only altering the background sound level using a vertical fader. Any changes to the mixing level took effect straight after the fader was adjusted while the audio was playing. The listener could listen to each excerpt as many times as necessary. A ‘Play’ and a ‘Stop’ button were provided for the listener in the programme to start and cease playing at anytime. The programme also informed the listener which sounds were the foreground and which were background sounds in the current scene. This ensured that the listener attended to the correct channel, especially in the ‘News broadcasting’ scene in which the background sound was also speech. Once a mixing level was chosen, pressing the ‘Next’ button started the next excerpt. The presentation order of the 20 excerpts was randomised for each listener.
Thirty native British English speakers (ages: 18–35 year, mean age: 25 year) with normal hearing participated in this experiment. Nine participants were undergraduates or graduates studying acoustics at the University of Salford, or sound professionals.
4.3. Results
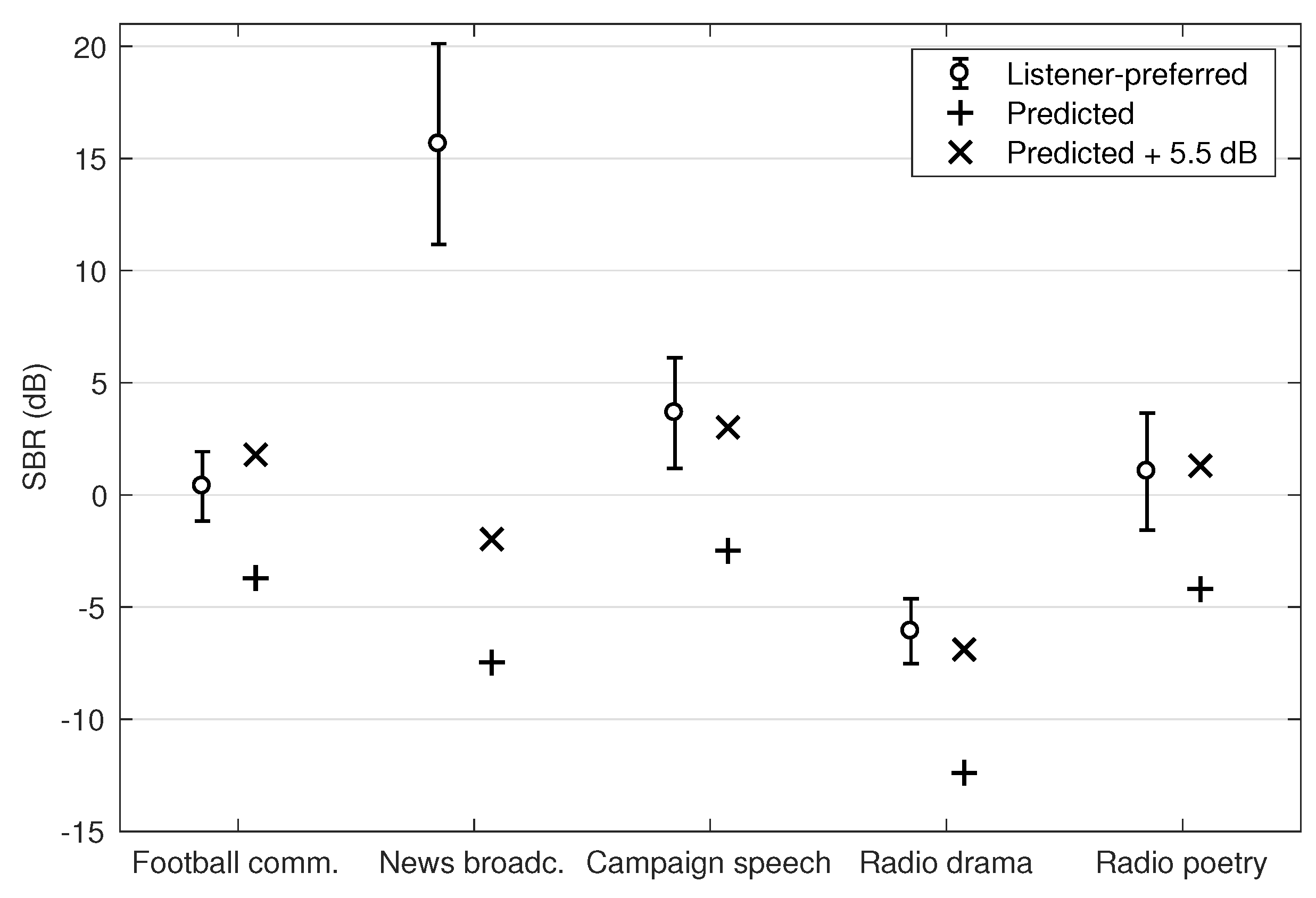
For each listener, the SBR for each audio scene was averaged over the four excerpts. The mean SBR level chosen by listeners for each type of audio content is displayed in
Figure 6 as open circles with error bars indicating 95% confidence intervals of the means. Across the five audio scenes, the listener-preferred SBRs for mixing are between −6.1 to 15.6 dB, with that for the ‘News Broadcasting’ and ‘Radio drama’ scenes being the highest and lowest, respectively. One-way within-subject ANOVA confirmed that the listener-preferred SBR significantly varied between audio scenes [
]. Post-hoc pairwise comparisons with Bonferroni correction further suggested that while listeners chose the same SBRs for the ‘Football commentary’, ‘Public speech’ and ‘Radio poetry’ scenes [all
], the SBRs for ‘News broadcasting’ [
] and ‘Radio drama’ [
] scenes were higher and lower respectively than those in the other scenes.
In
Figure 6, the model-predicted SBRs which led to a BiDWGP score of 0.5 are shown as ‘+’. A discrepancy between the listener-preferred and predicted
is evident: SBRs predicted as the minimum requirement for 100% speech intelligibility by the BiDWGP metric is clearly lower than those chosen by listeners, especially for ‘News broadcasting’, which differed from the model prediction by 23.1 dB. Interestingly, except for ‘News broadcasting’, the differences between the listener-preferred and predicted SBRs appear to be the same across background sounds. By minimising RMSE across the four scenes (i.e., ‘News broadcasting’ was excluded), it was found that applying a constant gain of 5.5 dB to the predicted
achieves a SBR level close to level preferred by listeners (RMSE of 0.9 dB). This is illustrated with ‘x’ markers in
Figure 6.
4.4. Interim Discussion
A group of listeners with normal hearing were instructed to choose their preferred SBR for mixing in five different audio scenes. Listeners’ preferred SBR depends on the accompanying background sounds. Compared to model-predicted , which is the minimum SBR for listeners to be able to understand all speech information, the listener-preferred SBRs are consistently higher. This suggests that when making a judgement on the optimal SBR level at which to listen, listeners go beyond intelligibility to consider other factors such as listening effort and comfort. Current OIMs are not able to account for this because they focus on intelligibility. When the background sound is noise, music, other sound effect or their combinations, an extra gain of 5.5 dB added to the model-predicted gets close to the preferred listening level.
For the ‘News broadcasting’ scene, in which speech by a male taker was artificially added as the background, a larger gain of 23 dB is required. Several participants tended to adjust the level of the background competing speech in the scene to as low as possible. According to the model prediction for this scene, intelligibility is no longer an issue when the SBR is above −7.5 dB (see
Figure 6). One possibility is that listeners did not expect a news broadcast to contain prominent competing speech. Or maybe they considered the competing speech to offer little enhancement to a news broadcast.
Informational masking introduced by competing speech could also be important. Unlike energetic masking to intelligibility, which is the consequence of interactions of physical signals acting to the peripheral auditory system, informational masking obstructs auditory identification and discrimination at the late stage of auditory pathway, when a sound is perceived in the presence of other similar sound(s) [
16,
17,
40,
41,
42,
43,
44]. As the competing speech in the ‘News broadcasting’ scene is uttered in the same language as the foreground speech, a considerable amount of informational masking is induced. Consequently, this requires more effort from the listener to overcome informational masking than when listening in other backgrounds, which introduce little informational masking [
45]. In the meantime, the listener’s attention is also more likely to be distracted by the background competing speech. Frequent attention switching between different channels may increase the cognitive load of the listener [
46], potentially leading to escalated annoyance arising from the background sound.
For implementation, the optimal SBR suggested by this system for a given scene can be calculated as the summation of the model-predicted
in this background and the additional gain
, which aims to compensate for other factors such as listening effort and comfort. Based on the scenes tested in this experiment,
dB can be applied to background sounds which are free of competing speech. However, when the background is competing speech, a larger gain is needed—it is found 23 dB for the competing speech by a male talker here. To automate the decision making, one solution could be to perform automatic sound classification (e.g., [
47,
48,
49]) to identify whether the background sound is speech. For cases where this information is known or can be predefined, the knowledge could be stored in the metadata. The system is then able to retrieve this information from the data flow to make a decision. However, if the background contains both speech and non-speech sounds, the intelligibility of the speech content belonging to the background may need to be estimated, in order to quantify its impact to the foreground speech. The more intelligible the background speech is, the greater the potential for informational masking [
50]. Further study is needed to quantify the relationship between the additional gain and the degree these factors affecting a listener’s preference at the cognitive level.
6. Conclusions
By using an objective intelligibility metric (BiDWGP) as a perceptual guide, an approach is proposed to automate the selection of speech-to-background ratio in broadcast audio scenes. When a desired mixing level is predefined for a scene, this method is able to automatically validate whether a minimal intelligibility requirement is satisfied. It can also estimate the lowest mixing level () needed to meet the intelligibility requirement. In addition, an optimal SBR can be estimated by applying an extra gain to the estimated , to get a mix that not only maintains speech intelligibility but also considers other aspects of listener preference such as auditory comfort.
Three perceptual listening experiments were conducted. In Expt. I, we investigated the target objective intelligibility score, which resulted from the minimum SBR level that listeners require to fully understand the speech content in a given background masker. When using each model prediction to estimate , the chosen BiDWGP metric yields the smallest errors compared to four state-of-the-art OIMs.
In Expt. II, listener-preferred SBR levels for mixing in five different audio scenes were measured. This showed that a gain needs to be applied to the model-predicted to get the preferred SBR. In the presence of noise, music, other sound effects or their combinations a gain of 5.5 dB is needed. When the background introduces informational masking (e.g., competing speech) a significantly larger gain of 23 dB may be required to alleviate the listening effort and the frequency of attention switching. However, further study is required to quantify the relationship between the additional gain and the degree of those factors affecting a listener’s preference for competing speech.
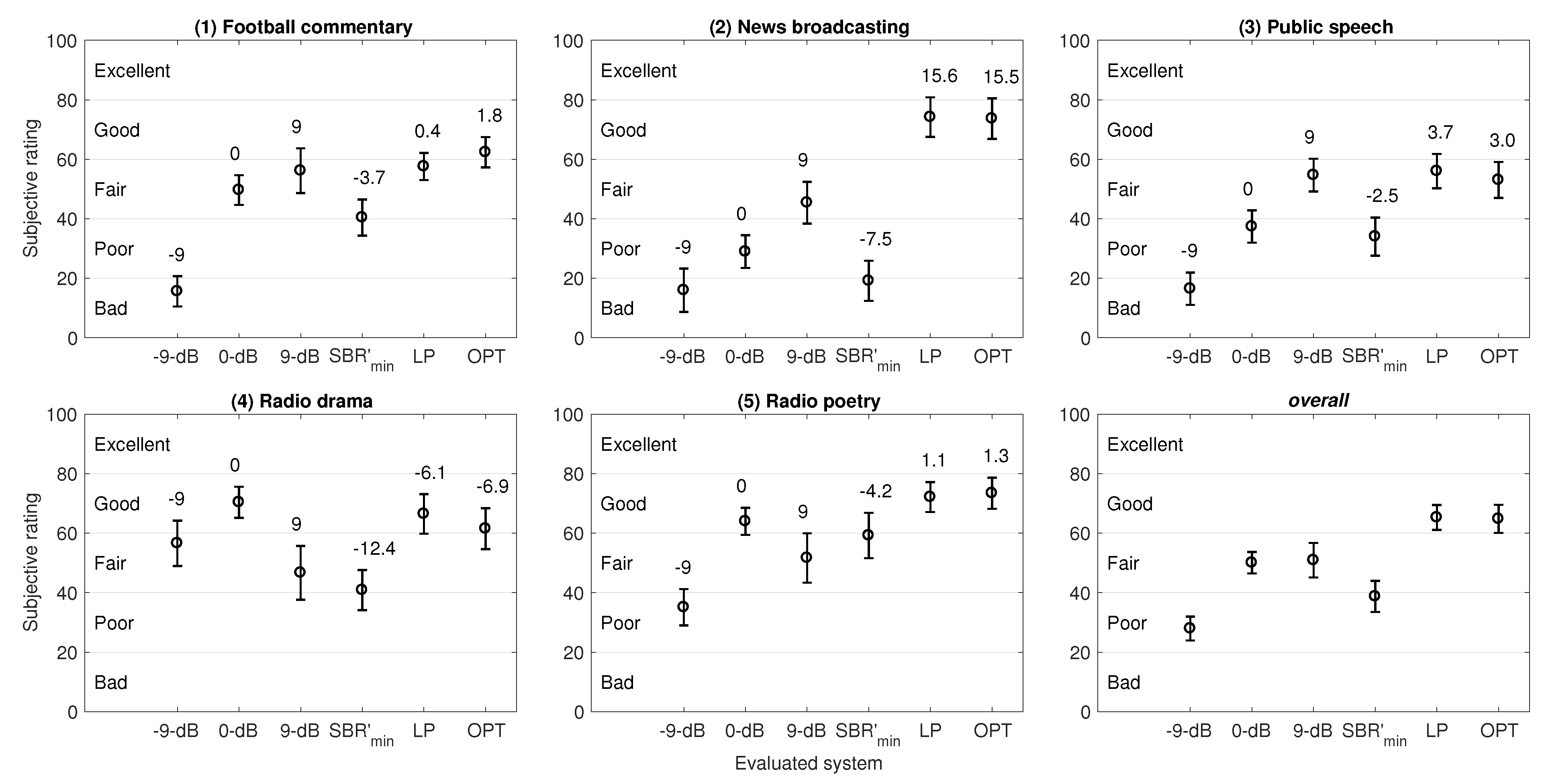
Expt. III was conducted to finally evaluate listening experiences in the audio scenes created using different mixing levels, including three constant and three scene-specific SBRs. The subjects ratings suggest that the SBR based on BiDWGP prediction with an additional gain derived from the measured listener-preferred SBRs in Expt. II, can provide the same good balance between speech intelligibility and background sound effects as the measured do, for the audio scenes tested in this study. Despite the optimal SBRs being acquired from fitting to the measured values, the ratings from different listeners—who were not involved in the measurement of the listener-preferred SBRs—confirmed the validity of the system-suggested SBRs.
For automatic decision making, automatic sound tagging could be a solution to identify the background sound. The system can then apply appropriate additional gains to the scene. In critical situations, such as live broadcasts, voice-over-IP, and adaptive systems for the hearing-impaired listeners, such a system could maintain high levels of speech intelligibility and listening comfort, improving the listening experience. Further study may extend the proposed system by suggesting the optimal SBRs with respect to other factors, such as room acoustics and ambient noise in the listening environment, which may also degrade speech intelligibility.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}