1. Introduction
As one of the most significant parts of rotating machines, rolling bearing has a great influence on operating status of mechanical equipment. According to the statistics of mechanical faults, more than 40% of the faults are caused by rolling bearings [
1,
2]. Therefore, it is important and meaningful for researchers to do research on fault diagnosis of rolling bearings. In bearing fault diagnosis, an essential role to improve the diagnosis accuracy of bearings is played by feature selection, which aims at selecting a subset from the original set of features according to discrimination capability [
3].
Traditional feature selection methods can be divided into three types: filters, wrappers and embedded methods [
4]. Filter methods evaluate the quality of features through some feature evaluation criteria and select the top high-ranked features. Based on the advantages of high generality and low computational cost, filter-based feature selection methods are suitable for high-dimensional datasets [
5,
6]. Although filter-based methods are computationally fast, they usually do not take feature relevance into considerations. Wrapper methods utilize the performance of machine learning model to judge the quality of the feature subset. They usually repeat the two steps, including searching for an optimal feature subset and evaluating the selected features, until a stopping measure is met [
5,
6]. The computational speed of wrapper-based methods is slow and the computational complexity is high, because of search strategies which involve sequential selection algorithms like sequential forward selection (SFS), sequential backward selection (SBS) and heuristic search algorithms like genetic algorithms (GAs), particle swarm optimization (PSO), gravitational search algorithm (GSA), and ant colony optimization (ACO). The complementary strengths of both filter and wrapper are exploited by embedded methods. Embedded methods define the feature that has the best ability to differentiate among classes in each stage and take feature selection as part of the training process. Thus, embedded methods are more effective than filter approaches since they involve interaction with the learning algorithm, and they are superior to wrapper methods as they do not need to evaluate the feature subsets iteratively [
5]. However, embedded methods have the shortcomings of low computational speed and high computational complexity as well.
As mentioned above, feature selection in bearing fault diagnosis is helpful to improve the accuracy of diagnosis and reduce the dimensions of features. Fu [
7] combined filter and wrapper methods to select features in bearing fault diagnosis. Ou [
8,
9] proposed a supervised Laplacian score (SLS)-based feature selection method. Hui [
10] applied an improved wrapper-based feature selection method for bearing fault diagnosis. Liu [
11] selected features through an evolutionary Monte Carlo method, which is a wrapper-based method. Islam [
12] proposed a hybrid feature selection method which employed a genetic algorithm (GA)-based filter analysis to select optimal features. Luo [
13] used the real-valued gravitational search algorithm (RGSA) to optimize the input weights and bias of extreme learning machine (ELM), and the binary GSA (BGSA) was used to select important features from a compound feature set. Yu [
14] combined the K-means method with standard deviation to select the most sensitive characteristics. Liu [
15] and Yang [
16] utilized distance evaluation technique (DET) to select sensitive features. Vepa [
17] presented a feature selection method involved in feature weight, monotonicity, correlation, and robustness. However, the above methods have some problems that lack considerations for relevance; for example, the computational speed is slow, and the computational complexity is high.
Some researchers recently took signal relevance into consideration. Cui [
18] selected intrinsic mode functions (IMFs) as features through correlation. A correlation coefficient of two simplified neutrosophic sets (SNSs) was proposed to diagnose the bearing fault types by Shi [
19]. In [
20], Laplacian Score (LS) for feature selection was utilized to refine the feature vector by sorting the features according to their importance and correlations. Besides, Zhang [
21] employed the Decision Tree algorithm to select the important features of the time-domain signal, and the low correlation features was selected. Jiang [
22] computed the mutual information (MI) of decomposed components and the original signal, and extracted the noiseless component, in order to obtain the reconstructed signal. However, in terms of relevance, researchers did not take relevance between features and fault categories into account in feature selection, only considering the correlation between features.
The purpose of feature selection is not just simply reducing dimensions for the data. It is more about eliminating redundant and irrelevant features. Redundant features can be eliminated by the measurement of relevance among features. The stronger the relevance between two features, the stronger the redundancy and replaceability between them. Moreover, irrelevant features can be eliminated through the measurement of relevance between features and categories. The stronger the relevance between features and categories, the stronger the distinguishability of features from categories. Irrelevant and redundant features can be eliminated from a raw feature set according to relevance. Therefore, consideration of relevance plays an essential role in reducing data dimensions in feature selection.
On the other hand, some work [
8,
9,
10,
11,
12,
13] selected features based on wrapper methods and increased the computational complexity. To avoid the cost of searching, the idea of intersection or union operation was put forward to merge feature subsets [
23,
24].
When it comes to the problem of coping with redundant information, principal component analysis (PCA) has been extensively studied. PCA is an algorithm that can effectively extract subsets from data by reducing the dimensions of the data set [
25]. Since the principal component includes most information of the raw features which are irrelevant and do not contain redundant information, the principal component can be used to replace raw features. Based on this, PCA can realize data reduction and reduce the complexity of data processing, preventing dimensional disaster [
26]. Typical PCA algorithms like those in [
27,
28,
29,
30] are used to extract features and to reduce data dimensions.
Based on the problems mentioned above, a novel feature selection method called FF-FC-MIC based on the Feature-to-Category-Maximum Information Coefficient is proposed. The main contributions of this paper are as follows:
- (1)
A new frame of feature selection is proposed for bearing fault diagnosis, which aims at considering the relevance among features and the relevance between features and fault categories. In the new feature selection frame, strong relevance features are eliminated by an FF-MIC matrix based on the relevance between features and features. On the contrary, strong relevance features are selected by the FC-MIC matrix based on the relevance between features and categories. The proposed frame can eliminate not only redundant features but also irrelevant features from the feature set.
- (2)
In order to avoid computational complexity brought by wrapper methods, an intersection operation is applied to merge the obtained feature subsets. The intersection operation has advantages of forming a final subset with a lower dimension and saving time, instead of subset searching.
- (3)
This paper applied two datasets to validate the effectiveness and adaptability of proposed method. It turned out the proposed method has a good applicability and stability.
The remainder of this paper is organized as follows.
Section 2 introduces the basic theory and algorithm applied in this paper.
Section 3 gives the details of the proposed method.
Section 4 shows the experimental results.
Section 5 concludes the findings shown in this paper.
2. Related Basic Theory and Algorithm
Based on the two main problems mentioned before, relevance and computational complexity, the related theory for solving the problems are listed in this section. First, the maximum information coefficient (MIC) is used to measure the relevance between features and features, and the relevance between features and categories. Second, an intersection operation is employed so that it can avoid high computational complexity. Third, in order to reduce data dimensions for further and to shorten the training time of classification model, the PCA algorithm is utilized.
2.1. Maximum Information Coefficient
The MIC cannot only measure linear relationships and nonlinear relationships, but can extensively excavate non-functional dependencies between variables. MIC mainly works with MI and meshing methods. MI is an indicator of the degree of correlation between variables. Given a variable
and
where
is the number of samples, the MI is defined as follow:
where
is the joint probability density of
A and
B, and
are the boundary probability densities of
A and
B, respectively. Suppose
is a set of finite ordered pairs. It defines a division
, dividing the value range of variable
into
segments and also dividing the value range of variable
into
segments. Therefore, the
is a grid with a size of
. Meanwhile,
in each grid is calculated. Since the same grid with a size of
has several ways of dividing, the maximum value of
in different ways of dividing is chosen as the MI value of a division
. Additionally, a definition of maximum MI under a division
is as follow:
where
denotes data
are divided by
. Although it utilizes MI to indicate the quality of the grid, MIC is not just simply estimating the MI. A characteristic matrix is formed by maximum normalized MI values under different divisions. The characteristic matrix is defined as follow:
Moreover, the MIC is defined as:
where
is the upper limit of the
grid. Generally,
, where
.
2.2. Merging Feature Subsets
Merging feature subsets usually has two ways. One is the intersection approach and the other is the union approach.
Let S be the set of samples and be the feature set after preprocessing. is a subset of features selected with filter (), where denotes the number of features which are selected by and . is a subset of features selected with filter (), where denotes the number of features which are selected by and .
The union approach is to create a feature subset
, which has the number of features
, by merging all features in
and in
:
The intersection approach is to create a feature subset , which has the number of features , including these features that are present in both feature subsets .
Usually, the two approaches mentioned above are utilized to merge feature subsets selected by different filter-based feature selection methods. The union approach selects all features in both subsets. At the same time, it increases the number of features and does not achieve the goal of reducing data dimensions. On the contrast, the intersection approach selects only common features. It reduces the total number of features. However, it is possible to lose some features which are proficient [
31].
3. Proposed Method
A new feature selection method was proposed to address two issues in feature selection: relevance and computational complexity.
The MIC cannot only measure the relevance between features and features, but also measure the relevance between features and categories. The method is divided into two parallel steps to select features from both aspects mentioned above. First, strong irrelevance features can be selected based on the MIC between features and features. Second, strong relevance features can be selected based on the MIC between features and fault categories. This frame has the advantage of a comprehensive consideration of relevance to eliminate redundant and irrelevant features from a feature set.
In term of computational complexity, an intersection operation is employed to merge feature subsets which are selected by the relevance between features and features, and by the relevance between features and fault categories. The intersection operation has the advantage of obtaining a lower-dimension final subset with a lower computational complexity, containing as much as information.
Based on the above consideration, MIC is applied to measure the relevance among features and the relevance between features and fault categories. In addition, to avoid computational complexity caused by wrapper methods, an intersection operation is applied, instead of wrapper methods, to merge subsets.
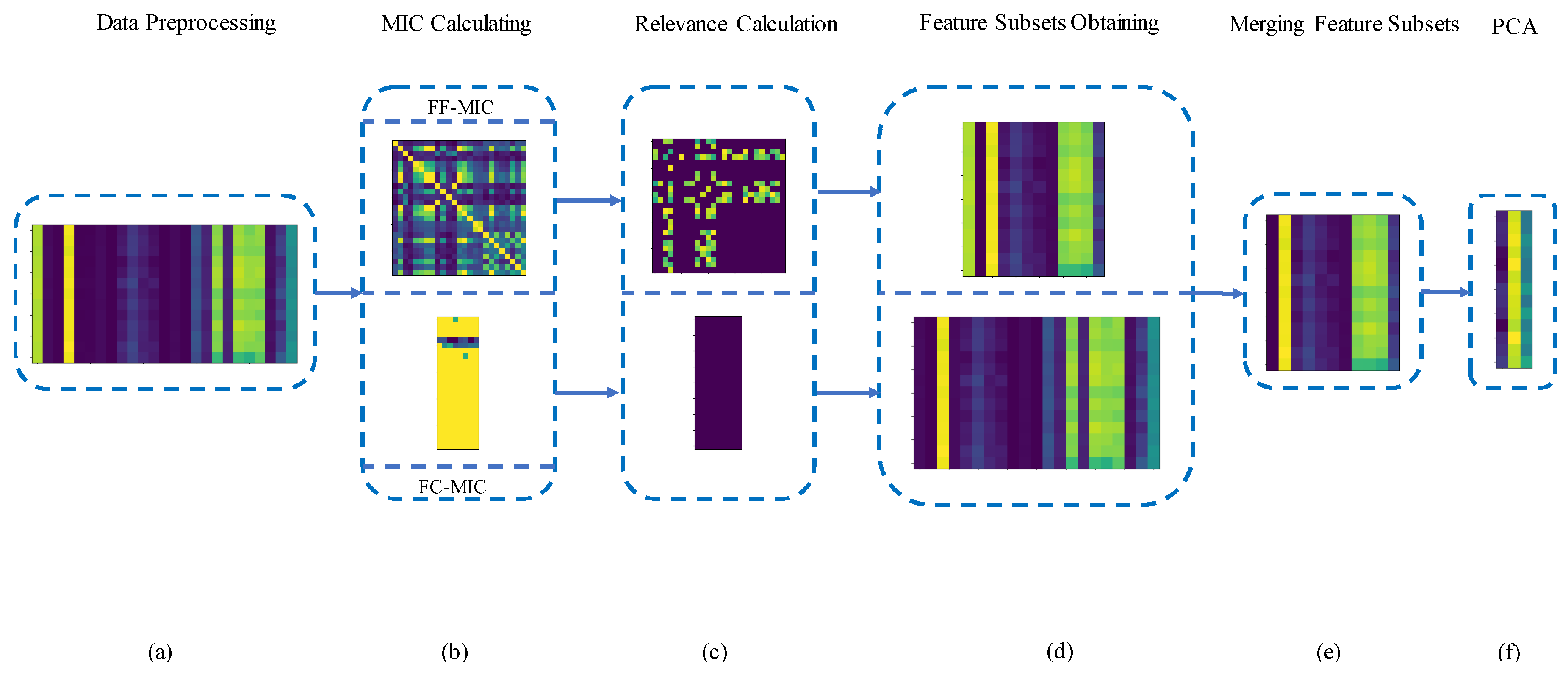
The detailed implementation steps are as follows. First, MIC among features and MIC between features and fault categories are calculated to obtain two MIC matrixes. MIC among features is called FF-MIC and MIC between features and categories is named FC-MIC. Second, strong relevance values in FF-MIC and in FC-MIC are calculated to distinguish strong and weak relevance features. Third, strong irrelevance features selected by FF-MIC and strong relevance features selected by FC-MIC are merged through an intersection operation to form a final feature subset. Finally, PCA is applied to further reduce dimensions of the final feature set. The whole process of feature selection is shown in
Figure 1.
3.1. Data Preprocessing
Since the vibration signal measured by sensors carries vital information, it should be transformed by the appropriate action and sensitive features, which can efficiently reflect the bearing working condition will be obtained. To avoid missing sensitive features, almost all features in the time and frequency domains are acquired. In order to improve the convergence speed of the model and the accuracy of the model, all features will be performed by feature scaling after the features are obtained. The details are given in Algorithm 1.
| Algorithm 1. Data preprocessing. |
Input: samples: , where is the number of samples.
Output: the preprocessed feature set .
for each in calculate each feature value from both the time domain and frequency domain and scale each feature value to [0,1], forming a feature set: , where is the number of features end for
|
3.2. MIC Calculation
MIC is used to define the relevance between features and features, and the relevance between features and categories. A matrix called FF-MIC is formed by the MIC between features and features, and a matrix called FC-MIC is formed by the MIC between features and fault categories. The construction details of FF-MIC and FC-MIC are described in Algorithm 2.
| Algorithm 2. MIC calculation. |
Input: where are fault categories, and is the number of fault categories.
Output: FF-MIC and FC-MIC.for each in calculate MIC between and , obtaining the FF-MIC matrix with a size of ; the row and column denote the serial number of features. for each in for each in calculate MIC between and , obtaining the FC-MIC matrix with a size of ; the row denotes the serial number of features and the column denotes the serial number of fault categories. end for
|
3.3. Relevance Calculation
As mentioned before, the value of MIC ranges from 0 to 1. FF-MIC denotes a matrix which can measure the relevance between features and features. The closer to 0 each element in the FF-MIC matrix approaches, the stronger the irrelevance between the features corresponding to the row and column of the element is. On the contrary, the closer to 1 each element in the FC-MIC matrix approaches, the stronger the relevance between the feature and category is. On this basis, a feature can be judged whether it is a weak relevance or strong relevance through the value in the FF-MIC matrix.
In each column of the FF-MIC matrix, each minimum value is found to form a set , and then the maximum value is found in the set . Therefore, the features, of which corresponding FF-MIC values are smaller than are, are called strong irrelevance features. The reason of setting up is that the condition of the strong irrelevance between a certain feature and each one in the rest can be observed. Through the set , the maximum of is utilized to judge whether a feature is strong irrelevant with other features.
At the same time, in each row of FC-MIC, each maximum value is found to form a set , and then the minimum value is found in the set . The features, of which corresponding FC-MIC values are bigger than the , are called strong relevance features, which are being selected soon. The reason of setting up is that the condition of the strongest relevance between a certain feature and each category can be observed. Through the set , the minimum of is utilized to judge whether a feature is strong relevant with categories.
The details of relevance calculation are shown in Algorithm 3.
| Algorithm 3. Relevance calculation |
Input: , FF-MIC, and FC-MIC.
Output: , and
for each column in the FF-MIC matrix for elements in each column find each minimum value to form a set end for for each in find the maximum in end for for each row in FC-MIC for elements in each row find each maximum value to form a set end for for each in find the minimum in end for
|
3.4. Obtaining Feature Subsets
After relevance calculation, two feature sets are formed called and , respectively, according to the and. The features, of which corresponding FF-MIC values are smaller than the , will be the elements of , because the closer to 0 the FF-MIC value, the stronger the irrelevance between features. Additionally, the features, of which corresponding FC-MIC values are bigger than the , will become the members of , because the closer to 1 the FC-MIC value, the stronger the relevance between features and categories. The details of obtaining feature subsets are shown in Algorithm 4.
| Algorithm 4. Obtaining feature subsets |
Input: , , and
Output: and . for each in select the features corresponding FF-MIC values smaller than the to form a end for for each in select the features corresponding FC-MIC values bigger than the to form a end for
|
3.5. Merging Feature Subsets and Reducing Dimensions with PCA
In above steps, two feature subsets are obtained. is a strong-irrelevance subset which contains features with strong irrelevance among them. is a strong-relevance subset which consists of features which have strong correlation with fault categories. First, an intersection operation is carried between and to obtain a final subset . contains the common elements of and Next, the variance of each feature is calculated and then the five features with the largest variance are selected. The reason of selecting the features with the five largest variances is that the smaller a variance of the feature, the less information this feature contains. Therefore, the five features with the largest variance means that almost all information is retained. Finally, PCA is employed to reduce dimensions of the . The details are given in Algorithm 5.
| Algorithm 5. Merging feature subsets. |
Input: and .
Output: .Merge and with an intersection operation to obtain . for each in employ PCA to select five features with the largest variance end for
|
5. Conclusions
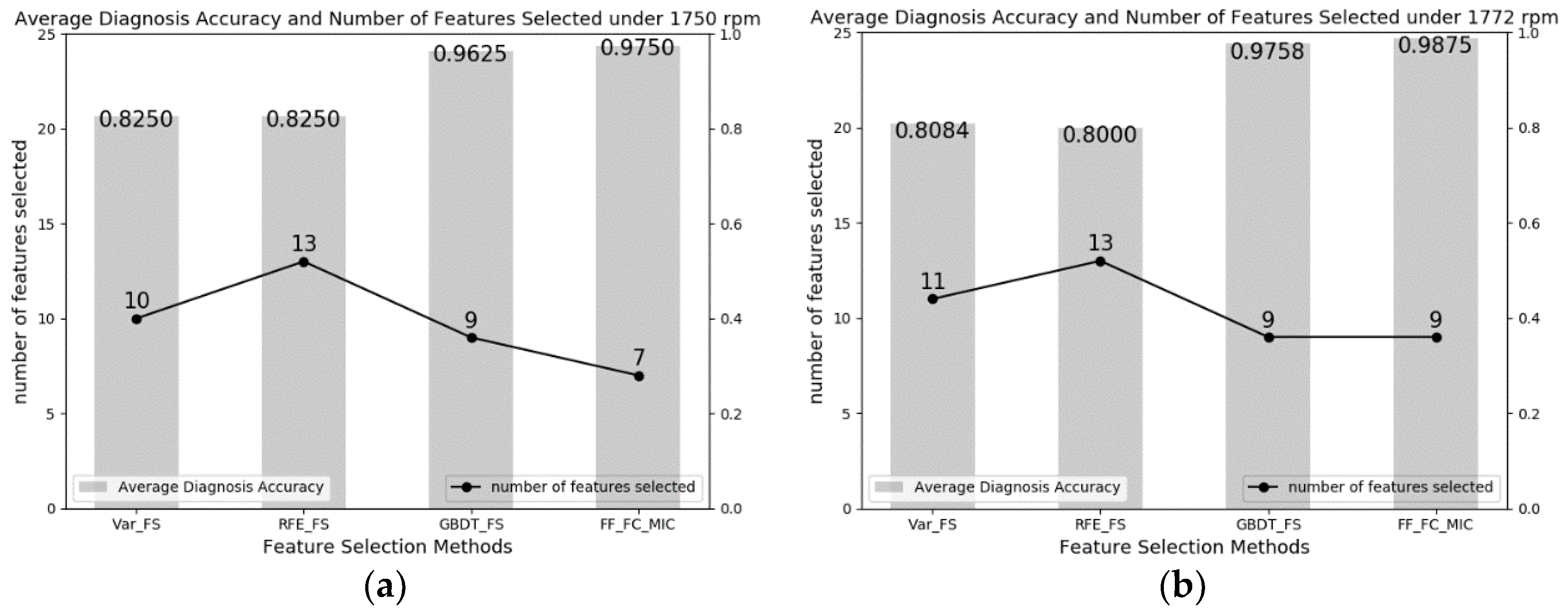
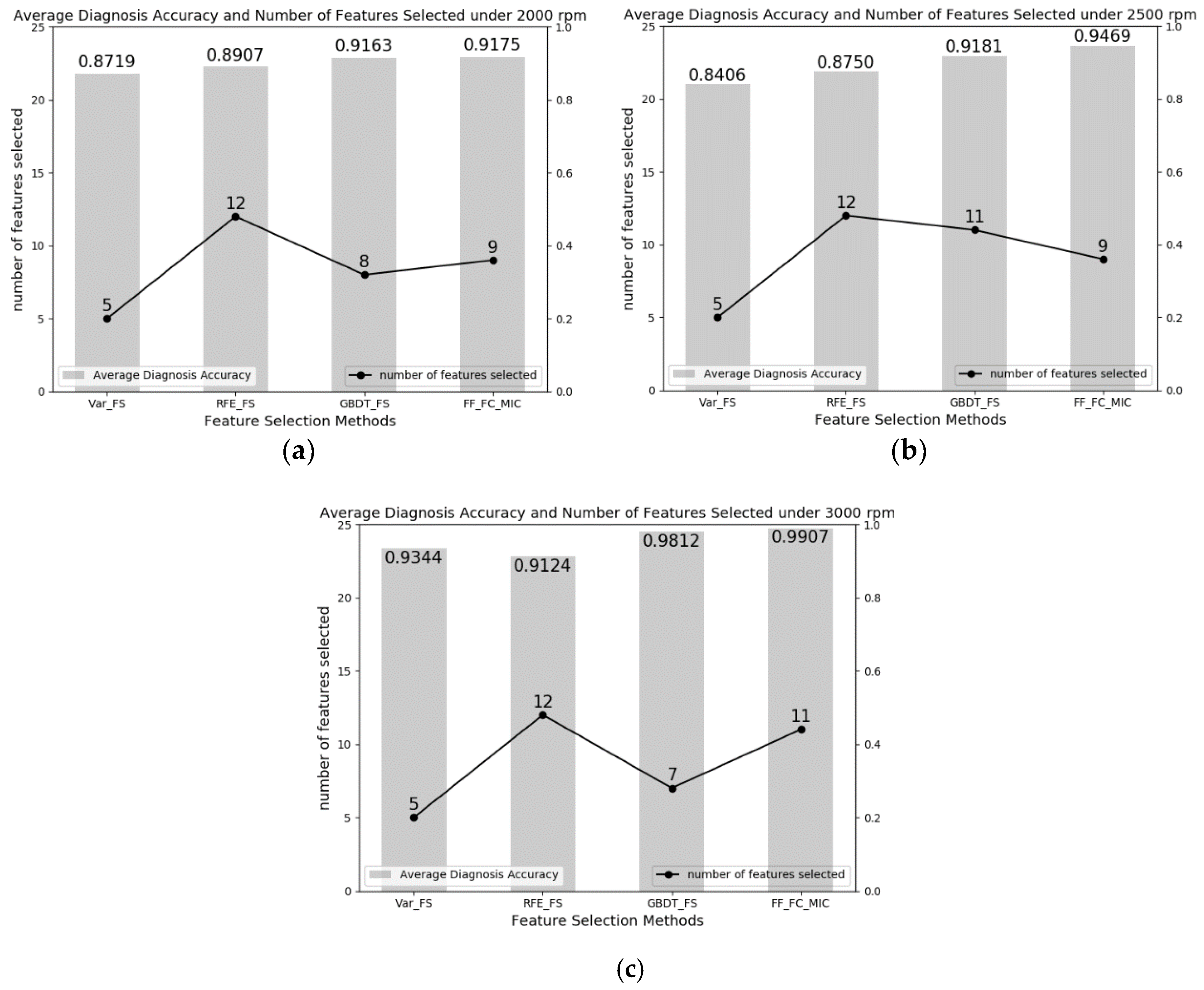
This paper presents a bearing fault diagnosis method based on the feature selection method called FF-FC-MIC by exploiting the capability of MIC to capture nonlinear relevance. The results can be summarized as follows: First, the most intuitive indicator, diagnosis accuracy, shows that the proposed method can reach 97.50%, and 98.75% in terms of average diagnosis accuracy in the CWRU dataset, and reach 91.75%, 94.69%, and 99.07% in terms of average diagnosis accuracy in the CUT-2 dataset. All the accuracies are the highest compared with those in the other feature selection methods. Second, on the basis of relevance among features and relevance between features and categories, the proposed method can select relatively low-dimension feature subsets to approach a higher diagnosis accuracy, compared with the other feature selection methods. Third, by calculating p-values under the t-test, the proposed method has a significant performance improvement, compared with traditional feature selection methods. The reasons can be summarized as follows: First, since the proposed method utilizes the MIC to measure the nonlinear and non-functional relationships between features and features, and between features and categories, it can eliminate redundant and irrelevant features. Second, the proposed method employs the intersection operation to merge two subsets, avoiding subset searching. Third, extensive experiments on the CWRU dataset and CUT-2 dataset were conducted to validate the effectiveness and adaptability of the proposed method. It turns out that the proposed method performs better in both reducing feature dimensions and achieving higher diagnosis accuracy, compared with the other 3 feature selection methods.
The relationship between the weight of features and feature subset is as essential as the work of feature selection. Besides, feature fusion technology should also be taken into consideration for feature selection. Our next work would investigate the relationship between the weight of features and feature subset and feature fusion technology to present more effective feature selection methods to reach the higher diagnosis accuracy.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









