Analysis of Lightweight Feature Vectors for Attack Detection in Network Traffic



Abstract
:Featured Application
Abstract
1. Introduction
2. Feature Sets
2.1. UNSW-NB15 Argus/Bro Feature Vector
2.2. CAIA Feature Vector
2.3. Consensus Feature Vector
2.4. Time–Activity Feature Vector
2.5. AGM Feature Vector
3. The UNSW-NB15 Dataset
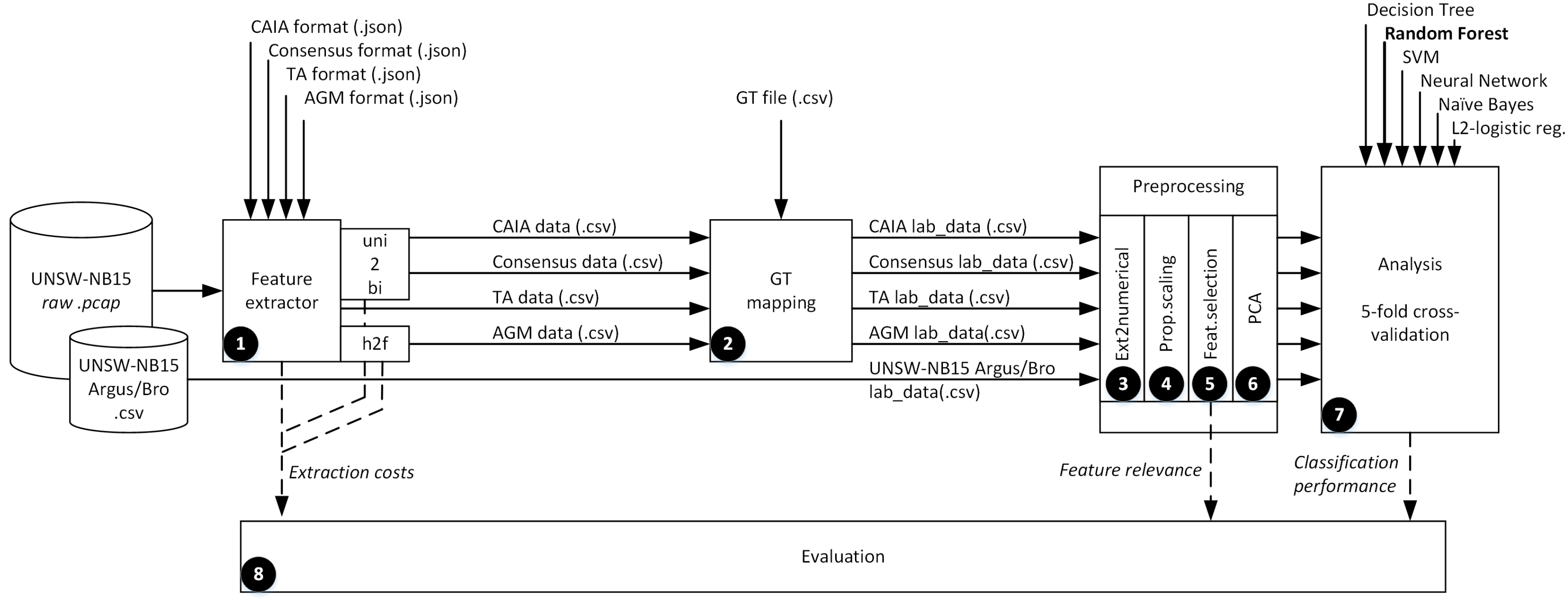
4. Experiments
4.1. Experimental Prerequisites
- A TCP/IP dataset containing normal traffic and attacks (Section 3). This dataset is available as raw captures (pcaps) and already preprocessed in a CSV file according to the UNSW-NB15 Argus/Bro format (Section 2.1).
- A Ground Truth (GT) file with information linking attacks and flows in the dataset, provided together with the UNSW-NB15 dataset (Section 3).
- Five sets of feature vectors to represent traffic (introduced in Section 2).
4.2. Experimental Design and Setup
- Basic Feature ExtractionFeatures were obtained from pcaps with a feature extractor developed in Golang. The process was the same for the CAIA, Consensus, Time–Activity (TA), and AGM vectors. As for the UNSW-NB15 Argus/Bro case, we directly used the published preprocessed data. The UNSW-NB15 Argus/Bro requires the use of Argus and Bro tools, in addition to 12 models that have not been published in the consulted sources. Due to the fact that the UNSW-NB15 format consists of a higher number of features (also more costly to extract) than the other vectors, we assumed that the UNSW-NB15 Argus/Bro vector is one of the most resource-demanding vectors for the extraction-cost comparison. Another special case is the AGM format, which requires a specific aggregation-step to transform the 8 basic features into the defined AGM vector with 22 features.In order to allow a fair comparison, CAIA and Consensus vectors, which are bidirectional defined, underwent an additional phase to convert unidirectional vectors into bidirectional vectors (uni2bi). Finally, the AGM format, which addresses source-behavior instead of flow-behavior (in the context of this work, a “flow” is defined by the classic 5-tuple format: srcIP, dstIP, srcPort, dstPort and protocol), required a conversion to unfold its samples and match the flow-key used by the other four vectors (h2f).
- GT MappingExtracted data in the different formats were cross-checked with the GT file to assign the corresponding labels to training and test datasets. There are two types of labels: Binary (0-legitimate, 1-attack) and multiclass (identifying the nine attack families contained in the used dataset). In this step, all flows were initially labeled as "legitimate" (i.e., 0-label), and later labels were overwritten whenever processed flows appeared in the GT file. The mapping script used flow-keys and timestamps to find the correct matching between flows and threats. The corresponding statistics are in Table 2.
- Extension to Numerical VectorsIn order to analyze data with purely numerical classification schemes, nominal variables were transformed into dummy variables [19]. To avoid the generation of high-dimensional sparse spaces, we used the method proposed in Reference [16], which explores the distribution of training data with frequency tables and creates variables accordingly. We also intentionally removed srcPort and dstPort from analyzed vectors to dissociate our experiments from port-based analysis. In any case, srcPort and dstPort showed low relevance or were directly negligible during preliminary experiments for all vectors. This fact does not necessarily mean that these features are not useful for discriminating traffic attacks; instead, they must be considered of low importance in the context of every vector, which might contain more revealing features highly correlated with port information (srcPort is usually irrelevant also from a general perspective). Removing srcPort and dstPort is also a good initiative from a perspective of analyzing encrypted traffic (see discussions in Section 6 and Section 6.1). Table 3 shows the new binary variables created based on frequency tables.
- Proportional ScalingWe normalized features in training and test datasets according to training max and min values. We preferred proportional scaling before standardization to avoid the manipulation of original feature variances.
- Feature SelectionWe carried out feature selection with decision trees for every feature vector. Afterwards, we removed irrelevant features (importance = 0, labeled as “negligible” in Table 6). Additionally, we analyzed the most relevant features for each case. The scheme used for feature selection is a linear decision tree implemented in Python with the scikit-learn library tools (scikit-learn v0.19.1, [20], http://scikit-learn.org/.../sklearn.tree.DecisionTreeClassifier.html). Decision tree maximum depth and minimum leaf size were adjusted by means of a randomized parameter search in order to optimize the performance and avoid overfitting (http://scikit-learn.org/stable/modules/generated/sklearn.modelselection.RandomizedSearchCV.html).
- PCA-Based Transformation and ReductionTo facilitate algorithm operations and work with a further reduced feature set, we applied PCA (Principal Component Analysis) as a last step of the preprocessing. PCA is a way to minimize feature dependencies, simplify learning models, and optimize classification performance [21]. First, training means were removed from training and test data to eliminate the intercept. This step is required when applying PCA to guarantee accurate approximations and reduce the mean square error [22]. Second, training and test data were projected based on training data PCA coefficients. Last, feature selection was applied again to remove final irrelevant features (if any) from the new problem space and reduce the dimensions of the resulting vector from PCA. This second feature selection step was also driven by the GT-labels (external criteria) to avoid losing information about classes that show low representativity in the training data.
- Cross-Validated Supervised ClassificationApplied algorithms were all based on models and operated on training and test datasets following a 5-fold cross-validated evaluation. All algorithms were also implemented in Python with the scikit-learn library (scikit-learn v0.19.1, [20]). Since some parameters showed a considerable sensitivity and broad ranges, the parameterization of learners was adjusted by means of evolutionary search (https://github.com/rsteca/sklearn-deap). The used algorithms were:
- Naive Bayes classifiers (http://scikit-learn.org/.../sklearn.naivebayes.BernoulliNB.html);
- decision trees (http://scikit-learn.org/.../sklearn.tree.DecisionTreeClassifier.html);
- random forests (http://scikit-learn.org/.../sklearn.ensemble.RandomForestClassifier.html);
- neural networks (multi-layer perceptron) (http://scikit-learn.org/.../sklearn.neuralnetwork.MLPClassifier.html);
- support vector machines (RBF kernel) (http://scikit-learn.org/.../sklearn.svm.SVC.html);
- and l2-logistic regression (http://scikit-learn.org/.../sklearn.linearmodel.LogisticRegression.html).
Preliminary experiments with all feature vectors showed the best performances (in all cases) for random forests, followed by decision trees. Naive Bayes classifiers and logistic regression obtained the worst performances, which was expected for the case of the Bayes classifier due to the high correlation commonly shown by network traffic features [23]. Random forests and decision trees not only outperformed other learners, but they were also the most robust ones. Neural networks and support vector machines obtained lower performances than random forests as well as nondeterministic issues, meaning that they suffered noticeable performance drifts in different runs with the same parameters. As a general rule, all learners in their best performances show the same preferences among the studied vectors. Due to these reasons and for the sake of simplicity, in Section 5, we only show classification results obtained with random forests. We address the interested readers to examine the complete experiments available in Reference [18]. - EvaluationThe evaluation considered three different perspectives:
- (a)
- Comparison of classification performances using common metrics in supervised classification: Accuracy, precision, recall, f1-scores, and AUC/ROC (http://scikit-learn.org/.../classes.html#module-sklearn.metrics);
- (b)
- Comparison of feature extraction costs for every different feature vector;
- (c)
- Scoring feature importances in every feature vector based on decision tree feature selection.
5. Results and Discussion
5.1. Preprocessing Performance
5.2. Classification Performance
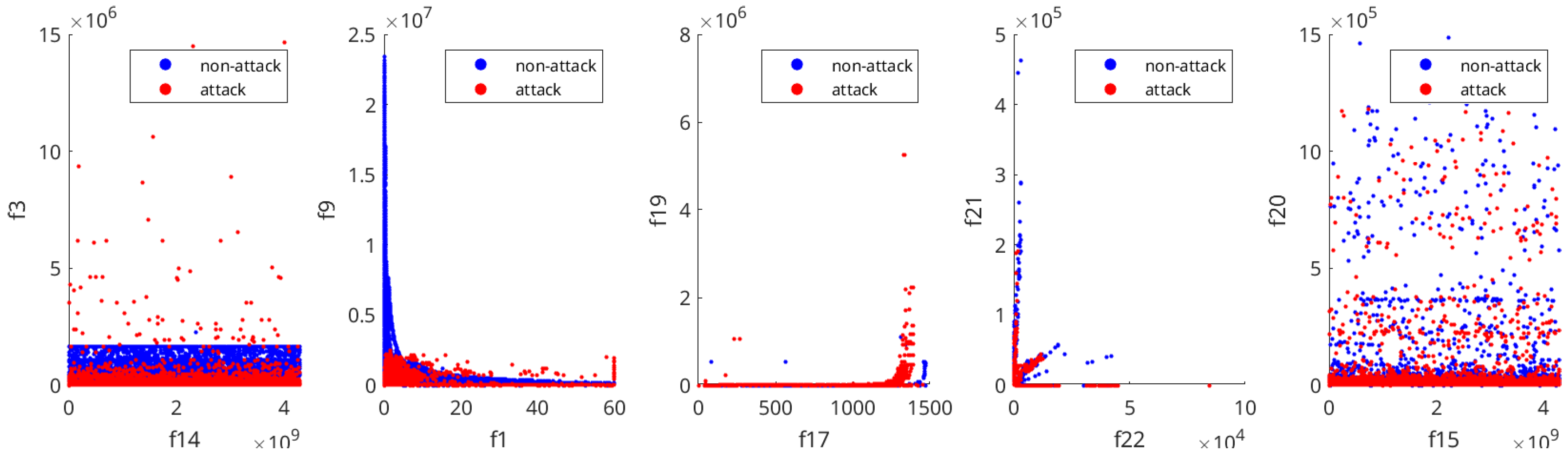
5.3. Most Relevant Features
6. Extracting Features from Encrypted Traffic
6.1. How Encryption Affects the Discovered Relevant Features
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dainotti, A.; Pescape, A.; Claffy, K.C. Issues and future directions in traffic classification. IEEE Netw. 2012, 26, 35–40. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Sperotto, A.; Schaffrath, G.; Sadre, R.; Morariu, C.; Pras, A.; Stiller, B. An Overview of IP Flow-Based Intrusion Detection. IEEE Commun. Surv. Tutor. 2010, 12, 343–356. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, D.C.; Vázquez, F.I.; Vormayr, G.; Bachl, M.; Zseby, T. A Meta-Analysis Approach for Feature Selection in Network Traffic Research. In Proceedings of the Reproducibility Workshop (Reproducibility ’17), Los Angeles, CA, USA, 25 August 2017; ACM: New York, NY, USA, 2017; pp. 17–20. [Google Scholar]
- Moustafa, N.; Slay, J. The Evaluation of Network Anomaly Detection Systems: Statistical Analysis of the UNSW-NB15 Data Set and the Comparison with the KDD99 Data Set. Inf. Sec. J. A Glob. Perspect. 2016, 25, 18–31. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Sanders, C.; Smith, J. Applied Network Security Monitoring: Collection, Detection, and Analysis, 1st ed.; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Paxson, V. Bro: a system for detecting network intruders in real-time. Comput. Netw. 1999, 31, 2435–2463. [Google Scholar] [CrossRef] [Green Version]
- Baig, M.M.; Awais, M.M.; El-Alfy, E.S.M. A multiclass cascade of artificial neural network for network intrusion detection. J. Intell. Fuzzy Syst. 2017, 32, 2875–2883. [Google Scholar] [CrossRef]
- Williams, N.; Zander, S.; Armitage, G. A Preliminary Performance Comparison of Five Machine Learning Algorithms for Practical IP Traffic Flow Classification. SIGCOMM Comput. Commun. Rev. 2006, 36, 5–16. [Google Scholar] [CrossRef]
- Lim, Y.s.; Kim, H.c.; Jeong, J.; Kim, C.k.; Kwon, T.T.; Choi, Y. Internet Traffic Classification Demystified: On the Sources of the Discriminative Power. In Proceedings of the 6th International Conference (Co-NEXT ’10), Huhhot, China, 30–31 July 2016; ACM: New York, NY, USA, 2010. [Google Scholar]
- Vlădut̨u, A.; Comăneci, D.; Dobre, C. Internet traffic classification based on flows’ statistical properties with machine learning. Int. J. Netw. Manag. 2017, 27, e1929. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, X.; Xiang, Y.; Zhou, W.; Wu, J. Robust Network Traffic Classification. IEEE/ACM Trans. Netw. 2015, 23, 1257–1270. [Google Scholar] [CrossRef]
- Anderson, B.; McGrew, D. Machine Learning for Encrypted Malware Traffic Classification: Accounting for Noisy Labels and Non-Stationarity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’17), Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 1723–1732. [Google Scholar]
- Iglesias, F.; Zseby, T. Time-activity Footprints in IP Traffic. Comput. Netw. 2016, 107, 64–75. [Google Scholar] [CrossRef]
- Iglesias, F.; Zseby, T. Pattern Discovery in Internet Background Radiation. IEEE Trans. Big Data 2017. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- CN Group, TU Wien. Feature Vectors for Network Traffic Analysis. 2018. Available online: https://cn.tuwien.ac.at/network-traffic/networkfeats/ (accessed on 7 November 2018).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Chapter Unsupervised Learning; Springer: New York, NY, USA, 2009; pp. 485–585. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hu, J.; Deng, J.; Sui, M. A New Approach for Decision Tree Based on Principal Component Analysis. In Proceedings of the International Conference on Computational Intelligence and Software Engineering, Wuhan, China, 1–13 December 2009; pp. 1–4. [Google Scholar]
- Miranda, A.A.; Borgne, Y.A.; Bontempi, G. New Routes from Minimal Approximation Error to Principal Components. Neural Process. Lett. 2008, 27, 197–207. [Google Scholar] [CrossRef] [Green Version]
- Iglesias, F.; Zseby, T. Analysis of network traffic features for anomaly detection. Mach. Learn. 2015, 101, 59–84. [Google Scholar] [CrossRef]
- Este, A.; Gringoli, F.; Salgarelli, L. On the Stability of the Information Carried by Traffic Flow Features at the Packet Level. SIGCOMM Comput. Commun. Rev. 2009, 39, 13–18. [Google Scholar] [CrossRef]
- Vormayr, G.; Zseby, T.; Fabini, J. Botnet Communication Patterns. IEEE Commun. Surv. Tutor. 2017, 19, 2768–2796. [Google Scholar] [CrossRef]
- Davis, C.R. Ipsec: Securing Vpns; McGraw-Hill Professional: New York, NY, USA, 2001. [Google Scholar]
- Turner, S. Transport Layer Security. IEEE Internet Comput. 2014, 18, 60–63. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| UNSW Argus/Bro Vector | CAIA Vector | Consensus Vector | TA Vector | AGM Vector |
|---|---|---|---|---|
| object: | object: | object: | object: | object: |
| flows (bidirectional) | flows (bidirectional) | flows (bidirectional) | flows (unidirectional) | source hosts (unidirectional) |
| number of features: | number of features: | number of features: | number of features: | number of features: |
| 45 (basic) | 30 (basic) | 19 (basic) | 13 (basic) | 8 (basic)/22 (aggregated inc.) |
| key: | key: | key: | key: | key: |
| srcIP, dstIP, srcPort, dstPort, protocol | srcIP, dstIP, srcPort, dstPort, protocol | srcIP, dstIP, srcPort, dstPort, protocol | srcIP, dstIP, srcPort, dstPort, protocol | srcIP |
| features: | features: | features: | features: | features: |
| srcPort, dstPort, protocol, state, duration, srcBytes, dstBytes, srcTTL, dstTTL, srcLoss, dstLoss, service, srcLoad, dstLoad, srcPkts, dstPkts, srcWin, dstWin, srcTcpb, dstTcpb, srcMeansz, dstMeansz, trans_depth, res_bdy_len, srcJit, dstJit, Stime, Ltime, srcIntpkt, dstIntpkt, tcprtt, synack, ackdat, is_sm_ips_ports, ct_state_TTL, ct_flw_http_mthd, is_ftp_login, ct_ftp_cmd, ct_srv_src, ct_srv_dst, ct_dst_ltm, ct_src_ltm, ct_src_dport_ltm, ct_dst_sport_ltm, ct_dst_src_ltm | protocol, duration, srcPkts, srcBytes, dstPkts, dstBytes, min_srcPktLength, mean_srcPktLength, max_srcPktLength, stdev_srcPktLength, min_dstPktLength, mean_dstPktLength, max_dstPktLength, stdev_dstPktLength, min_srcPktIAT, mean_srcPktIAT, max_srcPktIAT, stdev_srcPktIAT, min_dstPktIAT, mean_dstPktIAT, max_dstPktIAT, stdev_dstPktIAT, #srcTCPflag:syn, #srcTCPflag:ack, #srcTCPflag:fin, #srcTCPflag:cwr, #dstTCPflag:syn, #dstTCPflag:ack, #dstTCPflag:fin, #dstTCPflag:cwr | srcBytes, srcPkts, dstBytes, dstPkts, srcPort, dstPort, protocol, duration, max_srcPktLength, mode_srcPktLength, median_srcPktLength, min_srcPktLength, median_srcPktIAT, variance_srcPktIAT max_dstPktLength, mode_dstPktLength, median_dstPktLength, min_dstPktLength, median_dstPktIAT, variance_dstPktIAT | srcPort, dstPort, protocol, bytes, pkts, seconds-active, bytes_per_seconds- active, pkts_per_seconds- active, maxton, minton, maxtoff, mintoff, interval | #dstIP, mode_dstIP, pkts_mode_dstIP, #srcPort, mode_srcPort, pkts_mode_srcPort, #dstPort, mode_dstPort, pkts_mode_dstPort, #protocol, mode_protocol, pkts_mode_protocol, #TTL, mode_TTL, pkts_mode_TTL, #TCPflag, mode_TCPflag, pkts_mode_TCPflag, #pktLength, mode_pktLength, pkts_mode_pktLength, pkts |
| Global | |
|---|---|
| Total flows | 2,540,038 |
| 0-legitimate | 2,218,755 |
| 1-attacks | 321,283 |
| Attacks | |
| 1-fuzzers | 24,246 |
| 2-reconnaissance | 13,987 |
| 3-shellcode | 1511 |
| 4-analysis | 2677 |
| 5-backdoor | 2329 |
| 6-DoS | 16,353 |
| 7-exploits | 44,525 |
| 8-generic | 215,481 |
| 9-worms | 174 |
| Original | Set of Binary Features |
|---|---|
| dstIP | highly spread distribution removed from analysis |
| srcPort, mode_srcPort | highly spread distribution removed from analysis |
| dstPort, mode_dstPort | spread distribution: 53 (17.5%), 80 (11.2%), 5190 (5.7%), 6881 (5.5%), 111 (4.9%), 25 (4.3%), 143 (2.5%), 22 (2.4%), 21 (2.4%), 179 (1.6%), other (42.0%) removed from analysis |
| state | FIN (71.7%), CON (27.9%), INT (0.4%), REQ (0.1%), CLO (0.0%), RST (0.0%), ACC (0.0%), other (0.0%) |
| service | — (59.2%), dns (17.2%), http (9.3%), ftp-data (6.1%), smtp (3.8%), ssh (2.3%), ftp (2.2%), pop3 (0.0%), ssl (0.0%), snmp (0.0%), dhcp (0.0%), radius (0.0%), irc (0.0%), other (0.00%) |
| protocol, mode_protocol | tcp (90.1%), ospf (6.5%), udp (2.4%), icmp (1.1%), other (0.0%) |
| mode_TCPflag | ACK (82.5%), PUSH-ACK (34.5%), — (13.9%), SYN (0.1%) |
| Top | Vector | Extraction | One2bi | Aggreg. | GT-map. |
|---|---|---|---|---|---|
| 4th/5th | UNSW | ? | ? | ? | ? |
| 3rd | CAIA | 46 m 34 s | 04 m 21 s | — | 02 m 21 s |
| 2nd | Consensus | 41 m 49 s | 03 m 26 s | — | 02 m 07 s |
| 1st | TA | 41 m 32 s | — | — | 02 m 01 s |
| 4th/5th | AGM | 58 m 37 s | — | 57 m 16 s | 29 m 17 s |
| Top | Feat. Vector | Train./Test | Accuracy | Precision | Recall | F1_score | Roc_auc | Param. * |
|---|---|---|---|---|---|---|---|---|
| 4th | UNSW | training | 0.990 ± 0.005 | 0.859 ± 0.194 | 0.851 ± 0.100 | 0.849 ± 0.056 | 0.998 ± 0.002 | msl = 4, mdp = 14 |
| test | 0.989 ± 0.006 | 0.849 ± 0.200 | 0.851 ± 0.098 | 0.849 ± 0.059 | 0.998 ± 0.002 | |||
| 2nd/3rd | CAIA | training | 0.990 ± 0.007 | 0.861 ± 0.221 | 0.860 ± 0.081 | 0.854 ± 0.077 | 0.998 ± 0.002 | msl = 4, mdp = 14 |
| test | 0.989 ±0.007 | 0.851 ±0.229 | 0.843 ±0.097 | 0.839 ±0.075 | 0.998 ±0.003 | |||
| 2nd/3rd | Consensus | training | 0.990 ± 0.007 | 0.863 ± 0.216 | 0.856 ± 0.078 | 0.853 ± 0.074 | 0.998 ± 0.002 | msl = 4, mdp=15 |
| test | 0.989 ± 0.008 | 0.853 ± 0.225 | 0.847 ± 0.067 | 0.843 ± 0.082 | 0.998 ± 0.003 | |||
| 5th | TA | training | 0.986 ± 0.010 | 0.767 ± 0.236 | 0.839 ± 0.064 | 0.794 ± 0.106 | 0.995 ± 0.004 | msl = 6, mdp = 13 |
| test | 0.986 ± 0.009 | 0.763 ± 0.224 | 0.812 ± 0.054 | 0.780 ± 0.082 | 0.993 ± 0.003 | |||
| 1st | AGM | training | 0.995 ± 0.008 | 1.000 ± 0.000 | 0.940 ± 0.098 | 0.968 ± 0.052 | 0.990 ± 0.040 | msl = 1, mdp = 9 |
| test | 0.987 ± 0.008 | 0.946 ± 0.130 | 0.876 ± 0.057 | 0.908 ± 0.046 | 0.984 ± 0.015 |
| UNSW Arg/Br vec. | CAIA Vector | Consensus Vector | TA Vector | AGM Vector |
|---|---|---|---|---|
| highly relevant: | highly relevant: | highly relevant: | highly relevant: | highly relevant: |
| ct_state_TTL (81.6), ct_srv_dst (11.1) | min_dstPktLength (75.0) | min_dstPktLength (76.2) | bytes (14.3), pkts (16.7), bytes_per_seconds- active (50.3), interval (10.2) | #pktLength (85.2) |
| relevant: | relevant: | relevant: | relevant: | relevant: |
| dstBytes (1.5), dstMeansz (1.7), srcWin (0.7), ct_srv_src (0.8) | dstBytes (6.1), mean_srcPktLength (2.0), mean_dstPktLength (1.1), max_srcPktLength (7.1), stdev_srcPktLength (1.5), max_dstPktLength (2.0), duration (1.1), protocol:tcp (1.5), min_srcPktLength (0.7) | srcBytes (0.6), dstBytes (7.0), duration (0.9), max_srcPktLength (6.3), median_srcPktLength (5.1), min_srcPktLength (0.8), max_dstPktLength (2.2) | pkts_per_seconds- active (5.8), maxtoff (1.1), protocol:TCP (0.9) | pkts_mode_dstPort (6.1), #protocol (2.7), pkts_mode_TTL (2.1), pkts_mode_TCPflag (3.7) |
| low relevant: | low relevant: | low relevant: | low relevant: | low relevant: |
| srcBytes (0.2), service:http (0.4), service:ftp (0.0), service:other (0.2), duration (0.1), srcTTL (0.1), dstTTL (0.1), srcLoss (0.0), dstLoss (0.0), srcLoad (0.0), dstLoad (0.0), srcPkts (0.0), dstPkts (0.3), srcTcpb (0.0), dstTcpb (0.0), srcMeansz (0.4), ct_dst_src_ltm (0.0), srcJit (0.0), dstJit (0.0), srcIntpkt (0.0), dstIntpkt (0.2), tcprtt (0.1), synack (0.1), ackdat (0.0), ct_flw_http_mthd (0.0), ct_dst_ltm (0.0) | srcBytes (0.5), srcPkts (0.0), mean_srcPktIAT (0.1), max_srcPktIAT (0.0), stdev_srcPktIAT (0.1), stdev_dstPktLength (0.1), mean_dstPktIAT (0.3), stdev_dstPktIAT (0.1), #srcTCPflag:syn (0.2), #srcTCPflag:ack (0.0), #dstTCPflag:ack (0.0), #dstTCPflag:fin (0.0), max_dstPktIAT (0.0) | srcPkts (0.2), protocol:UDP (0.2), mode_srcPktLength (0.1), median_dstPktLength (0.0), median_srcPktIAT (0.1), variance_srcPktIAT (0.0) median_dstPktIAT (0.1), variance_dstPktIAT (0.1) | seconds-active (0.1), maxton (0.3), minton (0.1), protocol:UDP (0.4) | mode_pktLength (0.1) |
| negligible: | negligible: | negligible: | negligible: | negligible: |
| res_bdy_len (0), dstWin (0), trans_depth (0), is_sm_ips_ports (0), is_ftp_login (0), ct_ftp_cmd (0), ct_dst_sport_ltm (0), ct_src_dport_ltm (0), ct_src_ltm (0), state:CON (0), state:FIN (0), state:INT (0), service:dns (0), service:ftp-data (0), service:smtp(0), service:ssh (0) | dstPkts (0), min_srcPktIAT (0), min_dstPktIAT (0), #srcTCPflag:cwr (0), #srcTCPflag:fin (0), #dstTCPflag:syn (0), #dstTCPflag:cwr (0), protocol:UDP (0) | dstPkts (0), mode_dstPktLength (0), protocol:TCP (0) | mintoff (0) | pkts_mode_srcPort (0), pkts_mode_pktLength (0), #dstIP (0), mode_dstIP (0), pkts_mode_dstIP (0), #srcPort (0), mode_srcPort (0), #dstPort (0), mode_dstPort (0), mode_protocol (0), pkts_mode_protocol (0), #TTL (0), mode_TTL (0), #TCPflag (0), mode_TCPflag (0), pkts (0) |
| Vector | Flow Identif. | Feat. Extraction & Classif. (Original) | Feat. Extraction & Classif. (Reduced) |
|---|---|---|---|
| UNSW | TLS/— | —/— | —/— |
| CAIA | TLS/— | TLS/— | TLS/— |
| Con. | TLS/— | TLS/IPsec | TLS/IPsec |
| TA | TLS/— | TLS/IPsec | TLS/IPsec |
| AGM | TLS/IPsec | TLS/— | TLS/— |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meghdouri, F.; Zseby, T.; Iglesias, F. Analysis of Lightweight Feature Vectors for Attack Detection in Network Traffic. Appl. Sci. 2018, 8, 2196. https://doi.org/10.3390/app8112196
Meghdouri F, Zseby T, Iglesias F. Analysis of Lightweight Feature Vectors for Attack Detection in Network Traffic. Applied Sciences. 2018; 8(11):2196. https://doi.org/10.3390/app8112196
Chicago/Turabian StyleMeghdouri, Fares, Tanja Zseby, and Félix Iglesias. 2018. "Analysis of Lightweight Feature Vectors for Attack Detection in Network Traffic" Applied Sciences 8, no. 11: 2196. https://doi.org/10.3390/app8112196