1. Introduction
Magnetic resonance imaging (MRI) is a technique that uses powerful magnetic fields, radio waves, and computers to produce detailed medical images of the inside of a patient’s body. It is used for disease detection, diagnosis, and treatment monitoring [
1]. During the scanning process, the part of the body being imaged lies at the center of a bore. Being surrounded by a narrow tube-like device makes many patients feel uncomfortable. Additionally, due to strong fast pulsing currents that generate the magnetic fields, MRI scanners generate loud acoustic noise within the examination room and in the patient bore, which further increases the patient’s discomfort. Using hearing protection such as headphones or earplugs only helps to some extent, since the loud knocking sounds can be transmitted not only via the auditory canal but also via the cranial bone into the inner ear. Dampening methods to reduce the noise level emitted by the MRI scanner incur high cost, are difficult to implement, increase the scan time, and may impair the signal quality. Until now, there are no methods that protect the patient’s hearing without additional patient discomfort or penalties in costs, image quality or scan time [
2,
3,
4].
It is a generally accepted fact that ambient music may have a positive effect by inducing positive emotions, while reducing stress during certain situations [
5,
6]. In this paper, we consider the problem of adapting suitable music recordings to reduce the negative effects that MRI noise signals impose on patients—a process that may loosely be referred to as
noise beautification [
7]. In general, the acoustic aspects that may be considered in noise beautification are manifold including frequency, timbre, loudness, and time. The music may then be chosen accordingly and adapted with regard to pitch, harmony, instrumentation, volume, tempo, and beat. In the following, motivated by the characteristics of specific MRI devices, we concentrate on the aspects of time and beat. Many MRI scanners produce loud knocking sounds, which are typically spaced in a locally periodic fashion. These regular beat-like noise patterns may be interrupted by longer periods of silence. The sudden restart of the knocking sounds after these periods may introduce another source of the patient’s discomfort. Our approach for noise beautification relies on the assumption that, in contrast to loud hammering acoustic noise, rhythmically played musical sounds may act in a relaxing manner to a human listeners. By adapting the tempo of a music recording, the goal is to temporally synchronize the beat positions of the music with the regular hammering noise. In the ideal case, the noise signal becomes part of the played music, thus creating a more pleasant and less stressful acoustic environment. Furthermore, filling in the periods of silence between knocking pulse trains with music may have an additional protective effect on the listener (see also
Section 2).
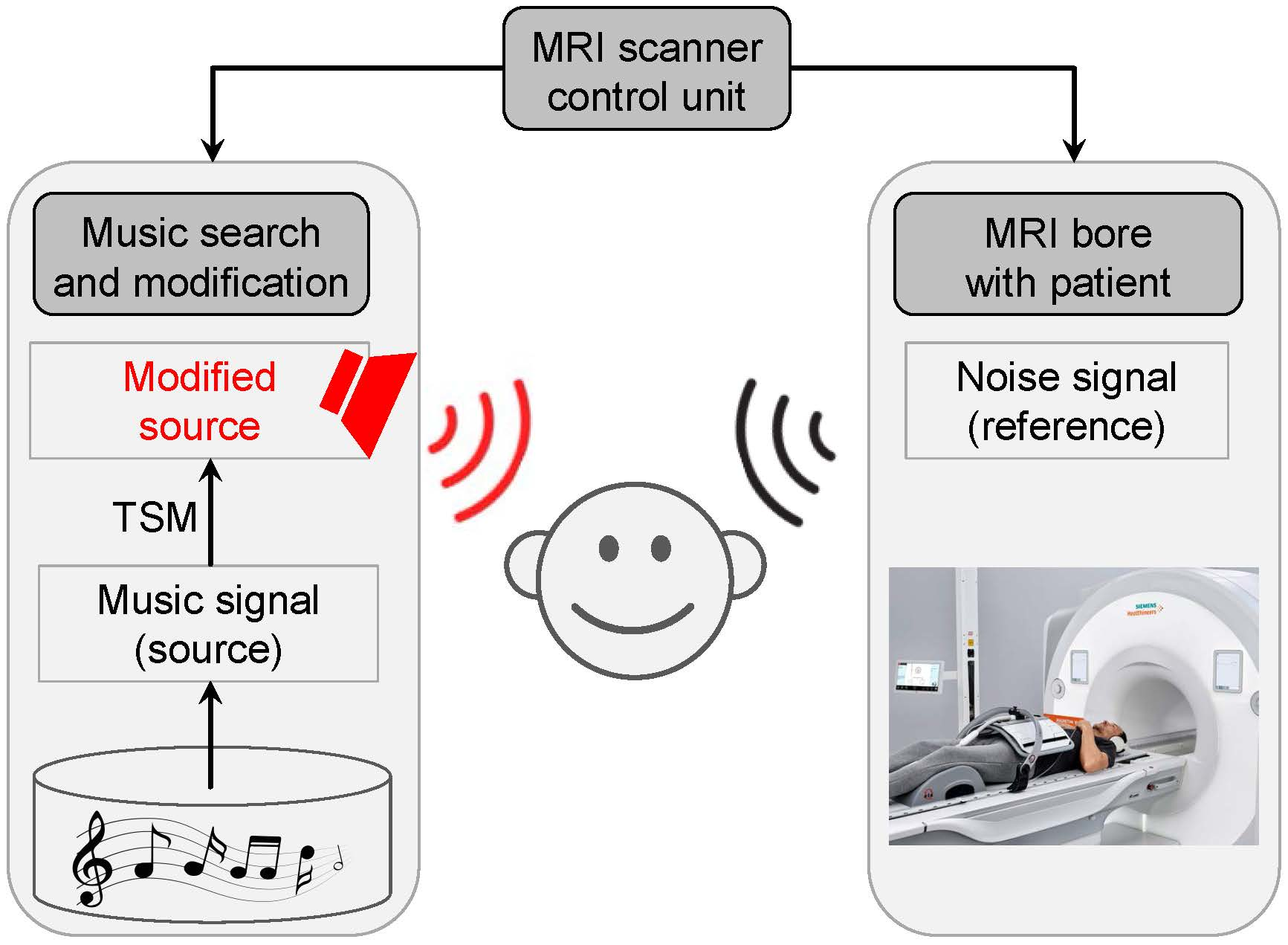
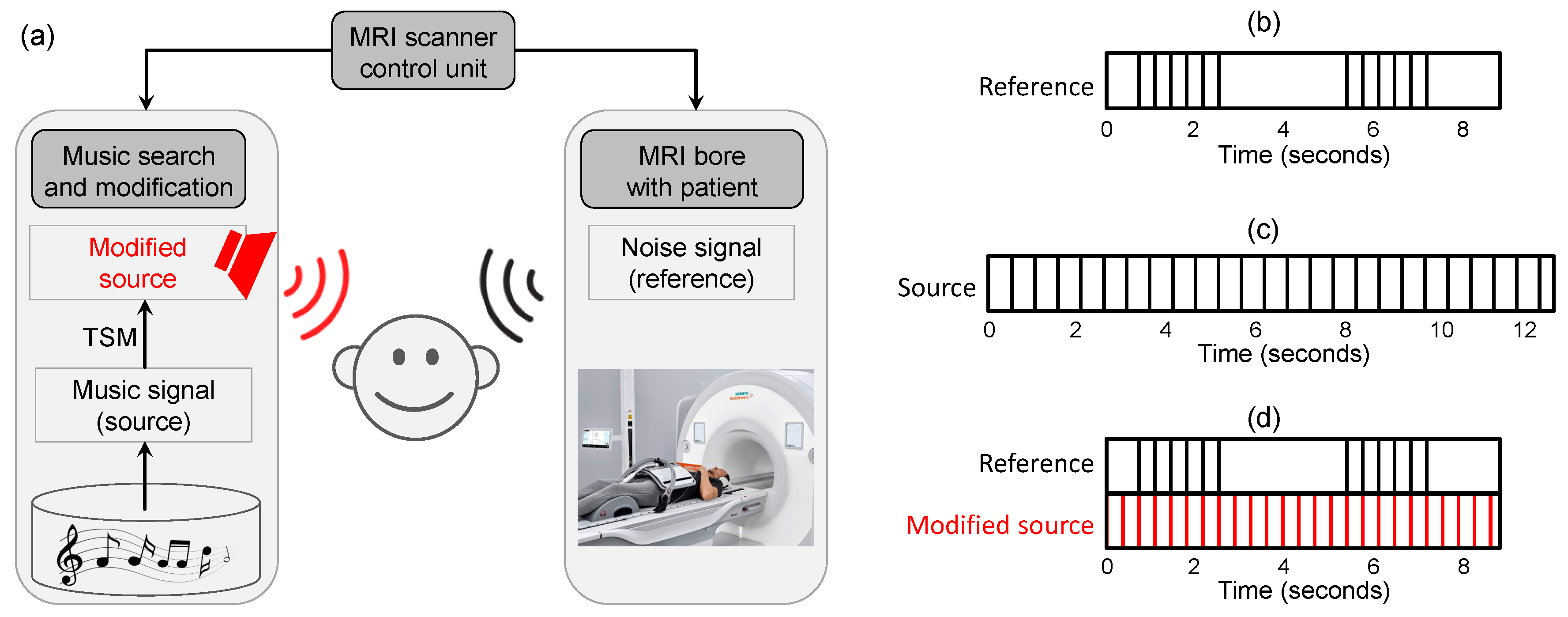
The main technical contributions of this papers are as follows. First, we formalize the problem of temporally aligning two sound signals with respect to certain constraints. The constraints are given by a reference time axis with specified time points, e.g., given by the time positions of the MRI scanner’s knocking sounds (see
Figure 1b). Furthermore, a music recording yields a source time axis with specified time points that correspond to the musical beat positions. Then the goal is to temporally modify the music signal such that all reference points are superimposed by musical beats. We model this alignment task as an optimization problem, where the objective is to compute a mapping that fulfills the constraints while minimizing strong local distortions in the adapted music signals (
Section 3). The latter condition, which can be expressed in terms of suitably defined second-order differences, tries to avoid strong local, unrhythmical tempo changes in the music. As a further contribution, we introduce a novel algorithm based on dynamic programming for finding an optimal solution as well as a greedy algorithm for finding an approximate solution of this optimization problem (
Section 4). Based on such a mapping between reference and source time points, we then describe how to apply time-scale modification (TSM) to temporally adapt the music signal in a local fashion (
Section 5). As a result, the beats of the modified music signal are in sync within the MRI scanner’s knocking sounds (see
Figure 1d). Finally, we discuss the benefits and limitations of our approach to noise beautification within the MRI application scenario by presenting a number of representative real-world and synthetic examples (
Section 6). Further background information and a discussion of relevant work can be found in
Section 2.
2. Background
In this section, we give an overview on existing approaches that are related to our MRI-based noise beautification scenario and give pointers to relevant literature. Further related work is also discussed in the subsequent sections.
Methods to reduce the acoustic noise reaching the patient ears in an MRI environment are largely divided into passive methods and active methods. Passive methods reduce the noise by acoustic noise barriers to prevent vibration of the MRI equipment itself or by protecting the patient using ear muffs or ear plugs. However, the noise reduction performance achieved by passive methods is rather poor; it is good enough for reducing the sound pressure below a safety level that guarantees a required protection of the auditory system, but it is insufficient to avoid the patient’s discomfort during MRI. Active methods usually complement passive methods by further attenuating the acoustic noise through counteracting acoustic pressure waves. Most of these methods use an external speaker (positioned far away from the MRI magnet) and a plastic tube, which transmits the counteracting sound waves from the speaker to the patient’s ears. However, due to long acoustic paths, this solution is subject to sound field disturbances and signal delays. As a result, particularly high-frequency noise components (above 1 kHz) cannot be canceled effectively, thereby not providing satisfactory noise reduction.
In the past, various alternative methods have been suggested that neither eliminate nor attenuate the MRI acoustic noise. Instead, these methods try to circumvent the problem by trying to better “accommodate” the patient by inducing a subjectively pleasant noise perception. For example, as suggested in [
2], it is possible to make use of the sound generation proprieties of the MRI gradient coils to generate additional harmonic, music-like passages at the end of each iteration of an MRI sequence during the scanning process. This idea is to break the monotony of the MRI acoustic noise by adding a succession of harmonic chords that combine into a melody, thus providing a more relaxing and calming acoustic ambient for the patients. However, this method increases the scan time as well as interferes with the evolution of nuclear spins, which may impair the image quality. Furthermore, it also does not guarantee an effective protection of the hearing organs against loud MRI noise peaks. Recognizing this problem, Schreiber [
3] suggests using a power audio amplifier and loudspeakers to generate so-called protective sounds, which rise slowly in amplitude, thus increasing the impedance in the middle ear directly before the onsets of the loud MRI sounds. This invention makes use of the
middle ear reflex—a mechanism the hearing of vertebrates possesses, where at high sound pressure the impedance of the auditory is adjusted to attenuate the vibration amplitudes of the small bones and tympanic membrane in the middle ear. Even though the patent [
3] mentions that music may be used as a protective sound, it does not disclose a method to avoid an erratic and thereby unpleasant mixing of music and the regular noise emerging out of an MRI scanner.
In [
4], Schmale and Koehler propose a method to select a suitable music piece that rhythmically matches the periodic MRI noise. The goal is to rhythmically and harmonically synchronize the complementary music piece to a specific MRI gradient sequence. Thereby, this invention coined the term of
noise beautification. However, this patent does not show how an appropriate music piece for each of the many possible clinical MRI sequences (having different repetition periods) can be found—not to speak of different musical tastes of the patients. To deal with this problem, Popescu [
7] suggests to use a virtual music composer, which uses audio processing techniques to determine a song’s melody, beat, tempo, rhythm, pitches, chords, sonic brilliance, timbre, and several other descriptors. Based on a multidimensional model of the song and of the expected MRI noise, the software synthesizes a new version of the song to match the noise. The goal is to rhythmically and harmonically mask the MRI acoustic noise, thus protecting the hearing organs by leveraging the middle ear reflex. Additionally, a patient’s specific musical preferences (such as genre, style, or language) as well as other data relevant to the patient’s age, ethnicity, and nationality can be taken into consideration.
Similar to the synthesis approach described in [
7], our approach modifies a music recording to satisfies constraints that are imposed by the MRI scanner’s acoustic noise. In our MRI application scenario, we assume that the MRI scanner’s knocking sound patterns are known beforehand. This is a realistic assumption since there is typically a limited number of different MRI scanner settings, which are left fixed during a recording session (see [
4]). In many recording situations, each such setting yields a well-defined and predictable sequence of knocking sounds (including the knowledge about the periods of silence). Therefore, one can perform the music adaptation of each of the possible settings in an offline fashion. In the actual noise beautification application, one then only needs to derive a global offset to sync the noise signal with the (precomputed) modified music signal chosen according to the respective MRI setting.
The general task of aligning and synchronizing two sound signals is not novel and plays an important role in a wide range of scenarios. For example, music producers or DJs adapt the time-scale of different music recordings in a beat-synchronous fashion for music remixing purposes for creating smooth transitions from one song to another song [
8,
9,
10]. Another conceptually related application is proposed in [
11,
12], where the goal is to adapt the tempo of the music signal according to an external reference signal such as the steps of a walker or runner. Also in the production of sound tracks for movies, video games, commercials, or audio books, automated tools for adapting existing music recordings to fulfill certain temporal constraints have been studied (see, e.g., [
13,
14,
15,
16,
17]). The pointers to the literature are not meant to be comprehensive and only yield some example scenarios. In all these applications, the common goal is to align specific time positions of two different time series under certain constraints. We hope that the specific alignment problem considered in this paper, the mathematical modeling, and the algorithms proposed are applicable and inspirational for other scenarios beyond our motivating MRI scenario.
3. Constraint-Based Alignment Task as Optimization Problem
In this section, we formalize our constraint-based alignment task. Recall that we are given two signals: the MRI noise signal to be superimposed and the music signal to be adapted. In this context, the noise signal serves as reference that defines the constraints, whereas the music signal serves as source that is to be modified according to the constraints. In the following, the time axis of the noise signal is referred to as
reference time axis, while the time axis of the music signal is called the
source time axis. In both cases, we are given a finite set of specified time points, which we also call
alignment points (APs). In the case of the reference time axis, let
be the number of APs and
be the set of APs with
. Each
is given in seconds,
. Similarly, in the case of the source time axis, let
be the number of APs and
be the set of APs with
.
Based on these notions, our overall goal is to temporally modify the source signal such that the reference APs are superimposed by suitable source APs. To model an alignment between reference and source APs, we introduce a
mapping function
which assigns a source AP
to each of the reference APs
,
. Furthermore, when modifying the source signal, we only want to apply local time-scale modifications where the temporal order of time events is preserved. Therefore, we require a
monotonicity condition expressed by
for
. In the following we say that a mapping function is
valid if it fulfills the monotonicity condition of Equation (
4). As indicated by
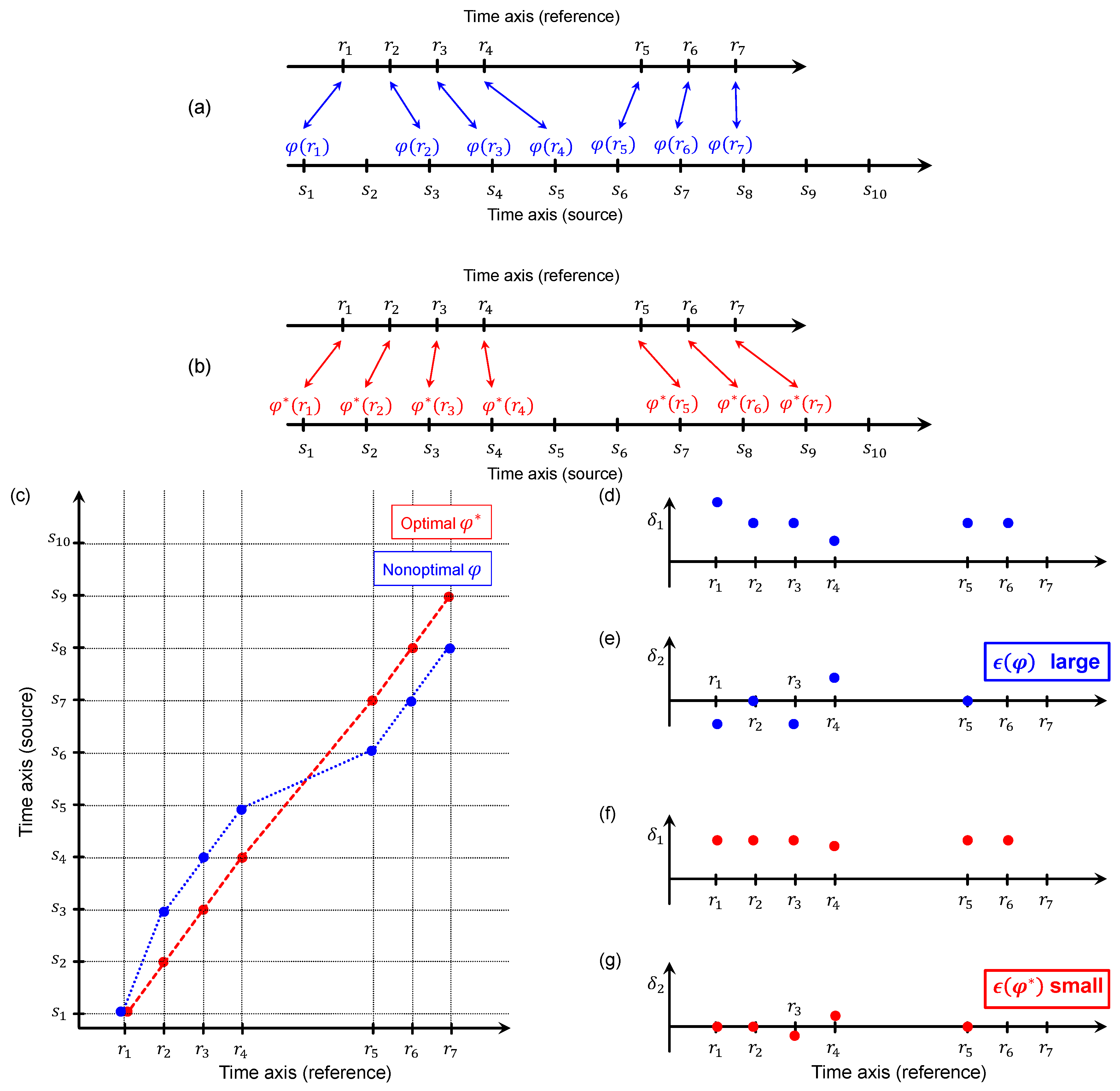
Figure 2, there are many possible valid mapping functions. More precisely, the number of valid mapping functions is
. This leads to the questions which of these mapping functions are “suitable” and how to find them.
In our application scenario, we want to temporally modify the source signal by applying non-linear TSM. In the case of a music signal with a more or less steady beat, a global change in tempo may be acceptable. However, strong local changes in the tempo may result in an unrhythmical, thus unpleasant version. Motivated by this observation, we are looking for mapping functions with as little as possible local fluctuations. Intuitively, we model this requirement by introducing an error measure that depends on second-order derivatives. Based on the discrete nature of our mapping problem, we define an error function
for a given valid mapping function
as follows:
Obviously, there are many more ways to define suitable error measures, e.g., using the sum over squared
-values or the maximum over all
-values. The definition in Equation (7) should be regarded as one possible choice; the subsequent considerations can be applied to other error measures as well.
Figure 2 illustrates the definition of our error measure by means of two examples. Based on the error measure, an
optimal mapping function is defined to be
Note that, in general, there may be more than one optimal valid mapping function.
4. Algorithms
As said before, the number of valid mapping functions
is
. This number explodes for increasing
N and
M. For example, for
and
, one obtains
possible functions. Therefore, a brute force algorithm to derive
by simply trying out all valid mapping functions is generally computationally infeasible. In this section, we introduce a more efficient algorithm based on dynamic programming that computes
in polynomial time requiring
operations (
Section 4.1). Since this algorithm is still too slow for large
N, we describe an efficient greedy algorithm that only requires
operations (
Section 4.2). However, this algorithm does generally not output an optimal mapping function, but only a coarse approximate solution. This approximation, as also shown in our experiments, may still be useful under specific assumptions that are motivated by our application scenario.
4.1. DP-Based Algorithm
In our first approach, we introduce an algorithm for computing an optimal mapping function using dynamic programming (DP)—an algorithmic paradigm that breaks down a problem into simpler subproblems in a recursive manner [
18]. Let
be a valid mapping function. Recall from Equation (7) that, for computing the error measure
, we need second-order differences
based on the triples
and
,
. In our optimization procedure, we consider all possible source triples that may occur in combination with a reference triple. In the following, we specify a source triple by a 3-element ordered subset of
with strictly increasing elements:
Let
be the number and
the list of all such source triples, where the triples are sorted in lexicographically increasing order, i.e., starting with
and ending with
. We say that a family consisting of
source triples specified by a list
is
valid if two subsequent source triples overlap in two points:
Such a valid family obviously defines a valid mapping function
by setting:
Vice versa, each valid mapping function yields a valid family of source triples given by for . In other words, there is a one-to-one correspondence between valid mapping functions and valid families of source triples having size .
Given a reference triple
for
and a source triple
for
, we define, similar to Equation (6), the second-order difference
Furthermore, we define
for any valid family, specified by
, of size
. Obviously, for a family of size
, this definition leads to the same error measure as defined in Equation (7).
With these definitions at hand, we now describe our DP-based algorithm for computing an optimal valid mapping function or, equivalently, an optimal family of source triples of size
. To this end, we consider the following subproblem for each
and
:
In other words,
yields the minimal error for mapping the first
m reference APs
to source APs using a valid mapping function with the additional constraint that the last triple is given by
. In the case that such a mapping function does not exist (i.e., that the set in Equation (
15) is empty), we set
. The matrix
can be computed recursively in a columnwise fashion. For
, one has
Furthermore, for
one can compute
as follows:
where the minimum over an empty set is again defined to be infinite.
From the matrix
one can obtain the minimal error of a valid source triple family of size
or, equivalently, the minimal error of an optimal valid mapping function
, by looking at the minimal value of the last column (specified by
) of
:
Starting with the triple
defined by
one can iteratively obtain
by backtracking the minimizing indices in Equation (
15) for
. Since this backtracking step is a standard approach in DP, we do not discuss here in this paper, but refer to the literature (e.g., [
18]) for details.
Using suitable data structures in the minimization of Equation (
17), the overall algorithmic complexity of our algorithm is determined by the size of the matrix
, which is
. For
and
, for example, the number of operations is in the order of
, compared to
using a brute force algorithm. Still, for large
N and
M, this algorithm may be too slow for real-world applications. One possible strategy is to apply a multi-stage approach, where, in the first stage, a coarse mapping is computed efficiently, e.g., using a greedy strategy based on suitable heuristics. This coarse mapping can then be further “refined” by applying the DP-based approach only locally. Similar approaches have been successfully used for time alignment approaches based on dynamic time warping (see, e.g., [
19], Chapter 4).
4.2. Greedy Algorithm
We now introduce an efficient greedy algorithm for finding an approximate solution for our mapping problem. This algorithm makes strong assumptions (motivated by our MRI noise beautification scenario) on how the reference and source APs are distributed over time. In our application, the reference APs
(corresponding to the MRI scanner’s knocking sounds) are typically spaced in a locally periodic fashion for most of the time. Similarly, the same holds for the source APs
(corresponding to the beats of the music). In other words, there are positive numbers
such that
for most of the
and
, respectively. Based on this assumption, we define a global scaling factor
Furthermore, we assume that the mapping for the first reference AP
is known and equals
for some
. The scaling factor
and source AP
are used to globally normalize and rescale the source APs:
for
. Defining
, we step through the reference APs and iteratively define
for
. Assuming that
for some
, we define
with
Note that the condition ensures the monotonicity condition of . Furthermore, note that the greedy algorithm only yields a mapping function if for all . This is typically the case when the number N of source APs is much larger then the number M of reference APs.
Intuitively speaking, using the globally scaled version of source APs (as defined in Equation (
21)) compensates for “tempo differences” between the reference MRI signal and the source music signal. Furthermore, the minimization in Equation (
23) compensates for small local deviations between reference and source APs. In regions of periodically spaced reference APs (with period
) and source APs (with period
), the second-order differences in the resulting mapping is close to zero for most of the time, thus resulting in a low error. Also, this holds if differences between subsequent APs are integer multiples of
and
, respectively. Only if there are many local irregularities in the reference or the source, the resulting mapping may yield a poor approximation of the optimal solution. Finally, note that the proposed greedy strategy may be locally refined by the DP-based approach as discussed at the end of
Section 4.1.
5. Adaption Using Time-Scale Modification (TSM)
We now describe how we apply time-scale modification (TSM) to adapt the source signal to run synchronously along the reference signal. As described in the introduction, TSM is a procedure for modifying the duration of a given audio signal while preserving other properties such as pitch and timbre. In a typical TSM approach, the input signal is decomposed into short
frames of a fixed length, typically in the range of 50 to 100 milliseconds. The frames are then relocated on the time axis to achieve the actual time-scale modification, while, at the same time, preserving the signal’s pitch (see [
20] for an overview).
Many TSM algorithms allow for stretching or compressing the signal by a constant factor. In our scenario, however, the time axis needs to be modified in a non-linear fashion. Such a non-linear modification can be formally described by a
time-stretch function, which is a strictly monotonously increasing function
yielding a continuous mapping between input time points (given in seconds) and output time points. Based on such a continuous time-stretch function
, as described in [
20], one can convert basically all frame-based global TSM procedures into non-linear versions. The main idea of the conversion is to fix an equidistant time grid for synthesis frame positions that will be used to generate the output signal. Then, for every grid point, the inverse of
is used to identify an analysis frame position of the input signal. Finally, these non-linearly spaced analysis frames are used as linearly spaced synthesis frames to construct a modified signal that has the desired local tempo changes. For details, we refer to [
20].
In our scenario, the source signal serves as input signal that needs to be modified. Recall that a valid mapping function
defines a mapping between reference APs
and source APs
,
. We use this mapping to define the pairs
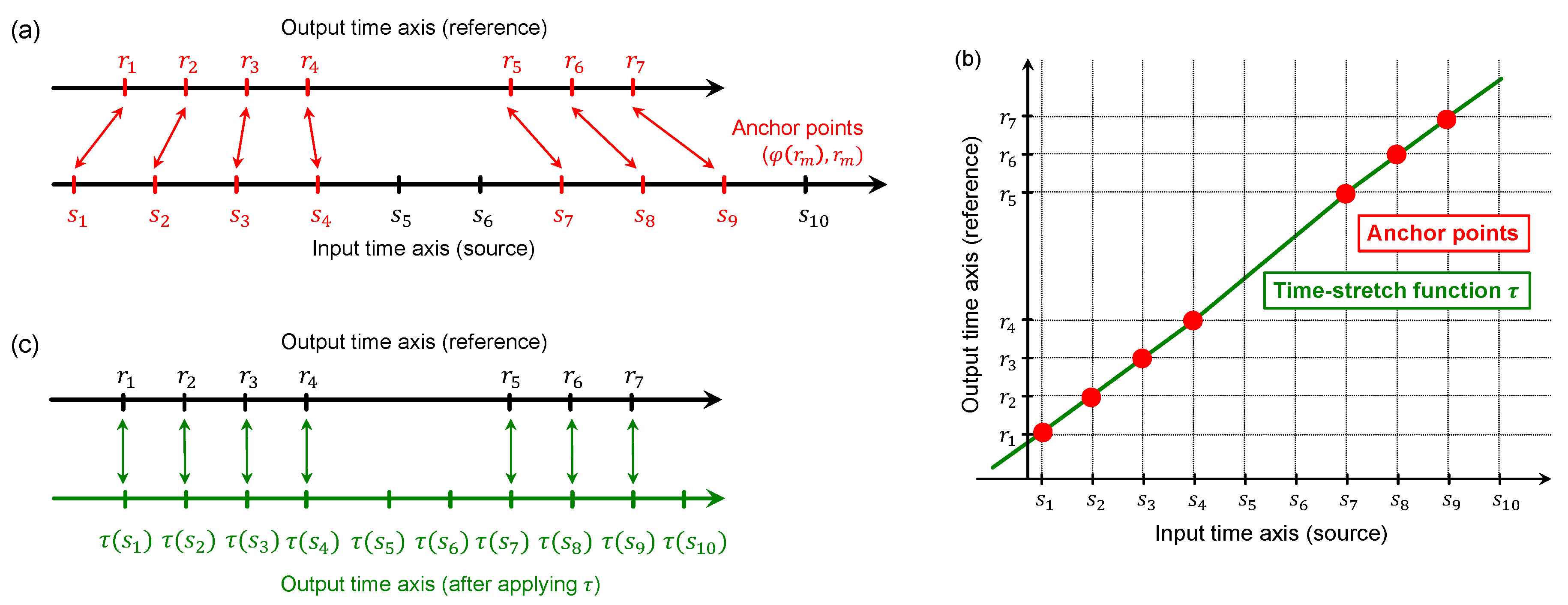
, which we call
anchor points (see
Figure 3a). Based on these anchor points, we define a time-stretch function
within the intervall
by applying linear interpolation between these anchor points (see
Figure 3b). Finally, one can extend
to the left of
and to the right of
in a linear fashion with a slop as defined for the subsequent and previous interval, respectively. Based on this time-stretch function
, one can then apply a non-linear TSM procedure as described in the previous paragraph to modify the source signal. In the resulting time axis of the output signal, the mapped source APs are now in sync with the reference APs (see
Figure 3c).
As summarized in [
20], there are different types of frame-based TSM procedures including the waveform similarity overlap-add (WSOLA) approach [
21] or the phase vocoder (PV) approach [
22,
23,
24]. Some of the procedures are designed to preserve the perceptual quality of harmonic signal components, while introducing undesired artifacts in the presence of sudden transient-like signal components. Other TSM procedures can better preserve the sharpness of percussive elements, while having problems in preserving the characteristics of harmonic passages. To reduce unwanted artifacts on both sides, we use the combined TSM procedure introduced in [
25]. The idea is to first separate the input signal into a harmonic and a percussive component, then to process each component with a different TSM procedure that preserves its respective characteristics, and finally to generate the output signal by superimposing the processed harmonic and percussive component. For our experiments, we used a publicly available MATLAB implementation of this combined TSM procedure contained in the TSM toolbox [
26] (
https://www.audiolabs-erlangen.de/resources/MIR/TSMtoolbox).
6. Experiments
To illustrate the outcome of our noise beautification approach, we now report on experiments based on reference and source signals of various types and complexity. To make the results audible and comprehensible for the reader, the original signals as well as the experimental results have been made publicly available on the website:
https://www.audiolabs-erlangen.de/resources/MIR/2018-MRI-NoiseBeauty, under a suitable Creative Commons license. The reference signals include recordings of four representative MRI noise signals, everyday noise, as well as synthetically generated pulse click tracks. An overview of these reference signals along with a short description and identifiers can be found in
Table 1. For example, the signal
is an MRI signal that consists of periodically spaced knocking sounds interleaved with periods of silence (see Figure 6a). As for the source signals, we used four music signals of different genre.
Table 2 yields a description of these music recordings.
In a preprocessing step, we determined suitable APs for all reference and source signals. To this end, we applied automated onset and pulse tracking procedures as described in [
27] (Chapter 6). As for the reference signals, a simple onset detector (see, e.g., [
28]) was sufficient to determine the positions of the transient-like knocking or clicking noise sounds. These positions define the reference APs. As for the source signals, we first specified the rough tempo that corresponds to the metrical level (e.g., sixteenth, eighth, quarter, or half note level) to be considered.
Figure 4 illustrates this by means of the source signal
. Then, we applied the predominant pulse tracking procedure from [
29] to determine the positions of the pulses on that level. These positions define the source APs. In our experiments, we used implementations provided by the publicly available tempogram toolbox (
https://www.audiolabs-erlangen.de/resources/MIR/tempogramtoolbox) (see [
30]) as well as a beat tracker by Dan Ellis (
https://labrosa.ee.columbia.edu/projects/coversongs) (see [
31]).
Based on the reference APs of a noise signal and the source APs of a music signal, we then applied the DP-based algorithm (see
Section 4.1) as well as the greedy algorithm (see
Section 4.2) to determine a mapping function. Subsequently, we utilized the procedure from
Section 5 to temporally adapt the source signal to run synchronously to the reference signal. Finally, we generated an audio file, where we superimposed the original reference signal with the modified source signal. This audio file represents our final output. To evaluate the result, we also visualized the positions of the reference APs and of the modified source APs as in
Figure 1d. The visualization along with the audio file was then integrated into an interactive website using the
trackswitch.js framework [
32] (
https://audiolabs.github.io/trackswitch.js). Providing switching and playback functionalities for the audio files while synchronously indicating the playback position within the visualizations, this website allows for understanding, navigating, and evaluating the results of our noise beautification approach (see
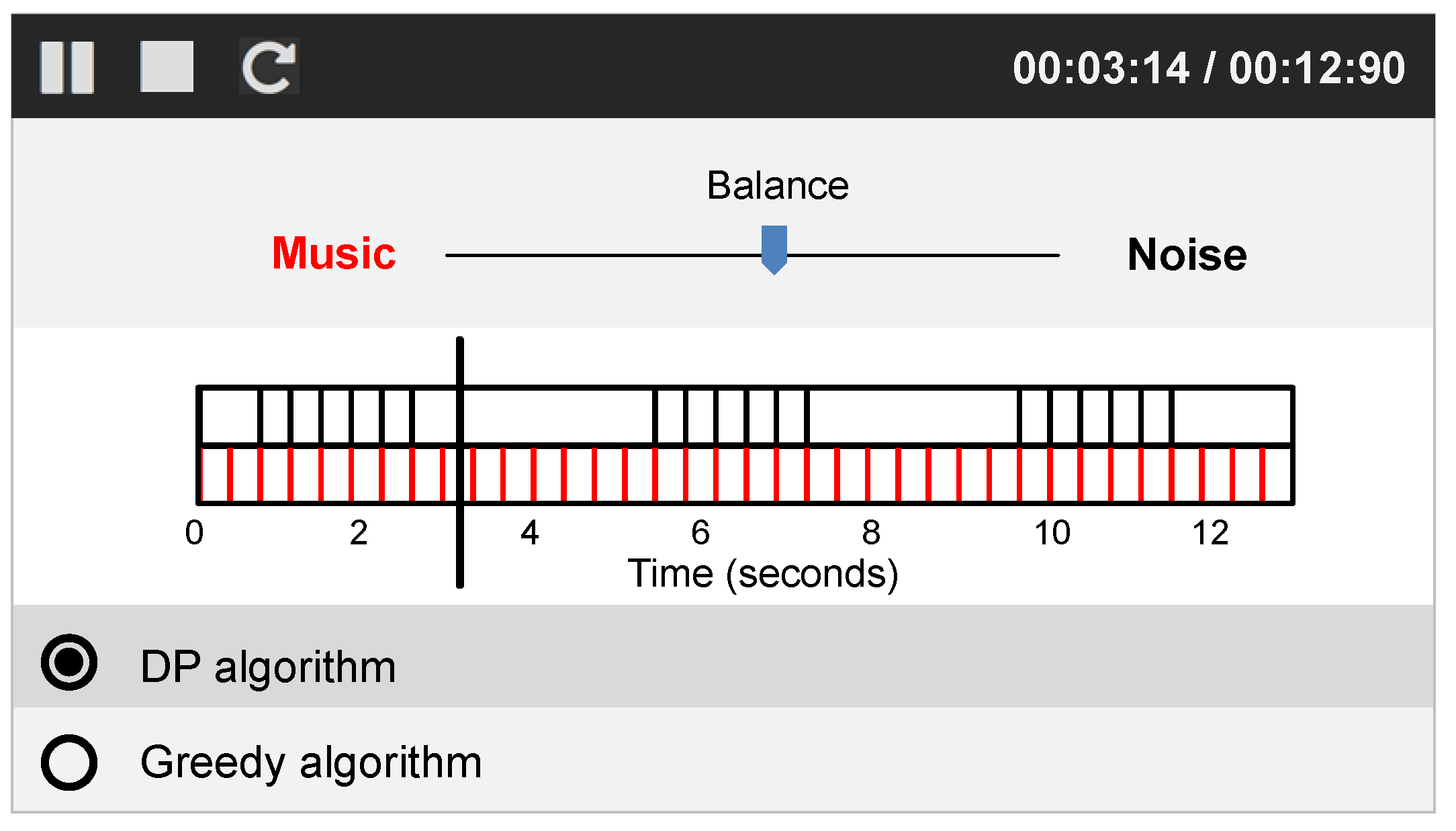
Figure 5). In particular, the balance between the reference signal and the modified source signal can be adjusted by a scroll bar. Furthermore, the output of the DP-based and greedy approach can be easily compared by the switching functionality.
On the website (
https://www.audiolabs-erlangen.de/resources/MIR/2018-MRI-NoiseBeauty) mentioned above, one can find the output for all combinations consisting of a reference signal (
Table 1) and a source signal (
Table 2). Rather than presenting a full-fledged working system for the MRI noise beautification application, these examples indicate the behavior of our approach for different types of noise and music signals. The proof for the actual usability in a real MRI scanning session and the patients’ acceptance of such a system under the various constraints of a real medical examination is beyond the scope of this paper. However, we hope that the techniques proposed are useful for the design of such systems.
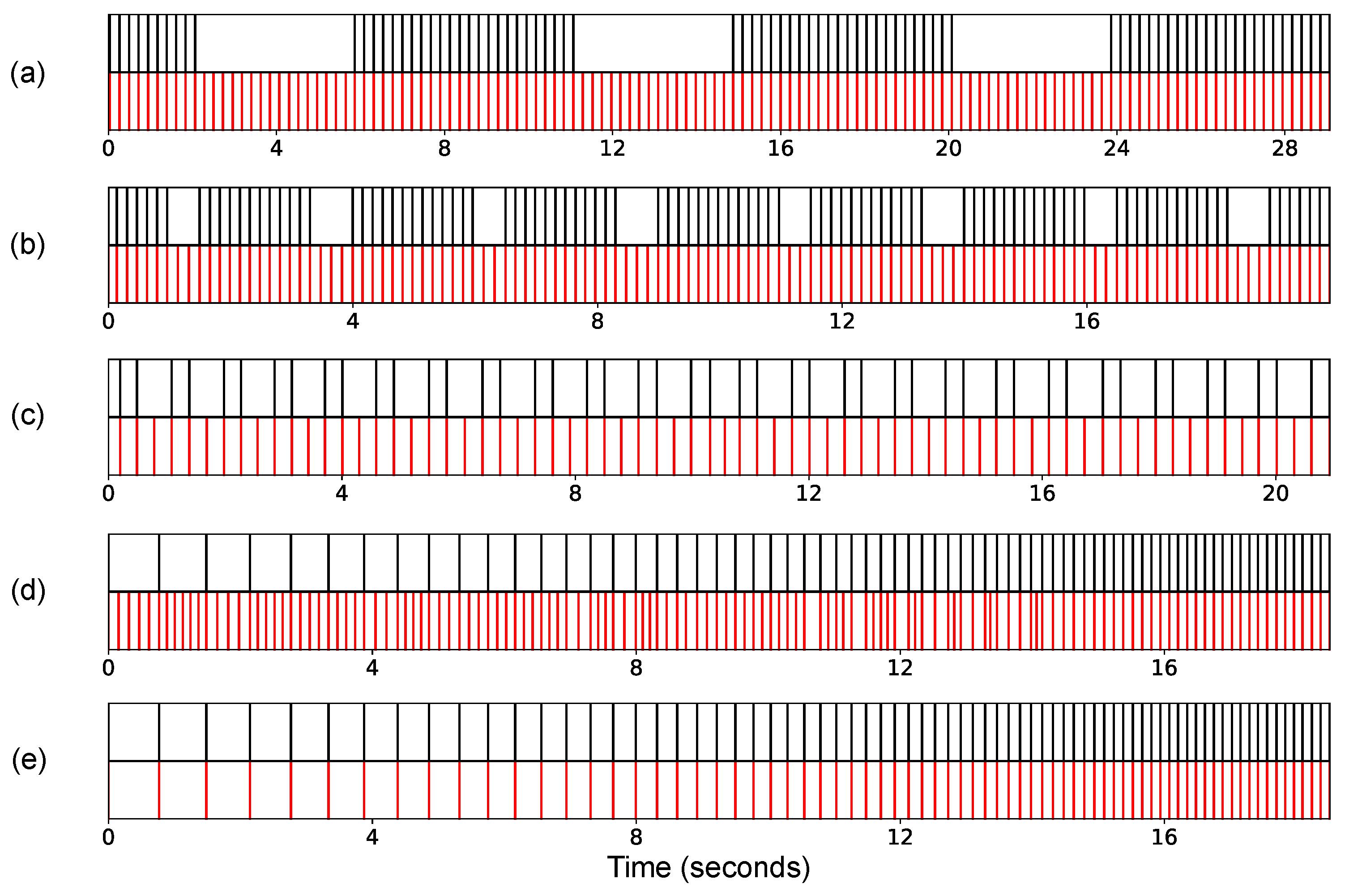
We conclude this section by having a closer look at some representative examples and report on some of our observations when conducting informal listening tests (see
Figure 6). We start with the MRI noise signal
R-MRI-06, which also served as a motivating example throughout the paper. This signal consists of periodically spaced knocking sounds at a rate of 4–5 beats per second (corresponding to a tempo of about 267 BPM), which are interleaved with periods of silence (see
Figure 6a). In the figure, the recording
(Prelude in C Major by J. S. Bach, see
Figure 4) was used as source signal using the sixteenth-note pulse level (having a tempo of about 200 BPM at that level) to define the source APs. As shown by
Figure 6a, the reference APs were matched to source APs, while the periods of silence in the reference signal
R-MRI-06 were filled without introducing local temporal distortions in the modified source signal. When listening to the superposition of the noise signal and the adaptive music signal, no major artifacts can be noticed in the music.
A similar example is shown in
Figure 6b. While the pulse trains of the noise signal
R-MRI-24 are spaced again in a locally periodic fashion, the periods of silence between these pulse trains occur in a more irregular fashion. Still our approach is capable of mapping the eighth-note pulse grid of the music signal
to superimpose the knocking sounds of the MRI signal without introducing too much local distortions in the music. Besides the temporal adjustment, the selection of suitable music pieces serving as source signals is also crucial in a noise beautification scenario. In particular, the selection may be based on a patient’s personal taste or on perceptual criteria. For example, the Balkan rock music piece
may be more suitable to blend with the knocking sounds produced by the MRI scanner than the piano piece by Bach. When selecting a piece of music, aspects such as harmony or timbre are important cues to blend the noise and music signal [
4,
7]. Also, higher-level temporal structures (e.g., the meter or regularly recurring patterns such as a riff) and boundaries between musical parts may be considered as additional constraints in the mapping process. Incorporating such cues into the music selection, mapping, and adaption processes constitutes interesting research directions.
As a third illustrative example,
Figure 6c shows a heartbeat signal with the typical “lub-dub, lub-dub” patterns used that define the references APs. When using our DP-based mapping approach, the sixteenth-note pulse grid of the source signal
is nicely mapped onto these patterns, where every third pulse of the music falls into a period of silence (between a “dub” and the subsequent “lub”). This way, all the “lub-dub, lub-dub” reference APs are superimposed, while the music signal has a nearly constant tempo. Even though generally leading to similar results, local outliers occur more often for the greedy approach compared to the DP-based one. This is also illustrated when listening to the superimposed signals provided on our websites.
As a final example, we consider the synthetic noise signal
as reference signal, which consists of a click-track of increasing speed (starting with 78 BPM and ending with 450 BPM). Note that even though our mapping algorithms were designed to cope with locally periodic pulse tracks (as occurring in our MRI application), this non-periodic reference signal nicely illustrates the behavior of our approaches. The greedy strategy maps the source APs to the reference APs while trying to keep the overall musical pulse at a constant tempo. As a result, as illustrated by
Figure 6d, the gaps (of decreasing size) between subsequent references APs are filled with a decreasing number of source APs. Using our DP-based strategy yields the solution as shown in
Figure 6e. Here, the source APs are mapped to the reference APs also with increasing tempo, which minimizes the accumulated second order differences.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}