1. Introduction
With the emerging era of Big Data, data stream classification technology has become a main topic in data mining research. Data streams are massive, extremely long, and noisy, which make traditional data mining algorithms unable to satisfy the demands of practical applications such as network analysis or target identification. In addition, concept drift, caused by the hidden concept changing in data streams, poses great challenges to classifying data streams.
Recent studies mainly employ two types of methods to realize the classification of data streams, which are single classifier learning and ensemble classifier learning [
1,
2]. An ensemble classifier usually performs better than a single classifier [
2,
3]. The streaming ensemble algorithm was first introduced in Reference [
4] to deal with concept drift in data stream classification by updating the base classifiers. The accuracy weighted ensemble (AWE) algorithm was further proposed [
3] to weight base classifiers according to the classification error rate. The accuracy update ensemble algorithm [
5] is based on nonlinear weights of the base classifiers and achieves higher precision and lower memory use than AWE. In Reference [
2], one linear function and one nonlinear function are used to weight base classifiers when input data are added under different conditions.
In order to detect concept drift and improve the classification precision further, variable sliding windows are used in Reference [
6] to capture the occurrence of concept drift including dealing with sudden concept drift using smaller windows and speeding up data processing of stable streams using larger windows. Concept drift is perceived by detecting the change in classification precision. However, false concept drift, which is caused by noise, can cause unnecessary updating of the base classifiers and can waste resources. In References [
7,
8,
9], the concept drift detection method based on double thresholds can effectively decrease the influence of noise. In Reference [
8], the method of comparing the data classification error rate of adjacent windows can detect sudden concept drift. In Reference [
9], the method of comparing the minimum values of the classification error rate for each window further improves the detection efficiency of gradual concept drift.
In addition, using attribute reduction or other dimension reduction methods to improve execution speed has become a key topic in the research of data stream processing. In Reference [
2], the number of base classifiers is set to maximum and increased or decreased under different conditions, which saves memory demand. In Reference [
10], the classification error rate of each attribute is compared to select important attributes. In Reference [
11], the attribute reduction algorithm based on rough sets reduces the computation complexity sufficiently by relaxing the measurement criteria of attribute importance and ensures the distinctiveness of the reduced data using a specific strategy. However, this algorithm uses an attribute importance measure based on the positive region, which is defined as the union of lower approximations. Compared with an attribute reduction algorithm based on information entropy, it deals with system uncertainty poorly [
12]. Meanwhile, the difference between base classifiers is the key factor that affects the overall performance of an ensemble system [
11] and perturbing the sample attribute space by attribute reduction has become the main approach to increase this difference [
13,
14].
In this paper, we propose an ensemble classification algorithm of data streams based on attribute reduction and a sliding window. In the algorithm, we use double thresholds to detect concept drift and update the sliding window size. We use the data attributes after reduction and nonlinear weights of base classifiers to improve the data classification precision of noisy data streams. Our work in this paper consists of three main parts. Using mutual information, we propose a rough set-based approximate attribute reduction algorithm to decrease the computation complexity of the ensemble classification algorithm and increase the difference between base classifiers. By introducing the sliding window idea of congestion control in the transport layer of a computer network, we propose a size control strategy of sliding windows. A double-threshold concept drift detection method is proposed based on the size control strategy. Based on attribute reduction and the sliding window, we propose an ensemble classification algorithm of noisy data streams to improve the classification precision with low complexity.
The remainder of this paper is organized as follows.
Section 2 describes the problem that we aim to solve by our proposed algorithm in the paper.
Section 3 describes the rough set-based approximate attribute reduction algorithm.
Section 4 describes the detection method of concept drift.
Section 5 describes the ensemble classification algorithm of data streams in detail.
Section 6 verifies and analyzes the algorithm performance and
Section 7 presents a summary of the study.
2. Problem Definition
For time stamp , a data stream consists of a continuous sequence of instances: . Each instance is a feature vector of -dimensional attributes, which consists of and a class label . The data stream also can be seen as a sequence of sets where each element is a set of instances in a sliding window at time .
In a data stream, the data distributions and definitions of target classes change over time. These changes are categorized into gradual or sudden concept drift depending on the appearance of novel classes in a stream and the rate of changing definitions of classes [
15].
The aim of this paper is to present a high-performance ensemble classification algorithm of noisy data streams to improve the classification precision and sensitivity to concept drift with low computation complexity. At each time stamp , the classification algorithm outputs a class prediction for each incoming instance.
3. Reduction of Data Streams
To reduce memory use and the processing time of the ensemble classification algorithm, we propose an approximate attribute reduction algorithm in this paper. The approximate attribute reduction algorithm uses mutual information gain as the attribute importance metric and two parameters known as the correction coefficient and approximation as the reduction thresholds. We implement a forward heuristic search to determine the core attributes of a decision table and reduce the attributes in an approximate manner in the proposed attribute reduction algorithm. The algorithm improves the performance when dealing with uncertainty using rough sets and mutual information. Relaxation of the attribute reduction measure is used to reduce the computation complexity and increase the difference between base classifiers in the algorithm.
The data in a sliding window can be seen as a decision system
where
is a set of samples,
is a set of condition attributes, and
is a set of decision attributes and where
and
. Moreover,
,
,
, where
is the
th condition attribute value for the
th sample.
is a subset of condition attributes. If
, for any attribute
, the importance
based on mutual information is outlined in Reference [
12].
where
is the variable-precision rough entropy and
is the approximation precision factor where
. Moreover, if
,
and
are treated as equal where
is the correction coefficient [
12]. If mutual information
,
is called an approximate reduction of
relative to
and
is the approximation [
11]. The pseudocode of the proposed approximate attribute reduction algorithm is given in Algorithm 1.
| Algorithm 1: Approximate Attribute Reduction |
| Input: Decision system , correction coefficient , approximation precision factor , approximation |
| Output: Approximate reduction of |
| 1: Discrete input data and calculate ; |
| 2: , , ; |
| 3: Calculate ; |
| 4: , calculate ; |
| 5: If , ; |
| 6: ; |
| 7: , if , go to line 8, otherwise, go to line 4; |
| 8: ; |
| 9: , , calculate ; |
| 10: If , ; |
| 11: If , go to line 12, otherwise, go to line 9; |
| 12: Output approximate reduction . |
In Algorithm 1, the core attributes of are searched in line 4–7 and the reduced attributes are calculated in line 9–11. The attribute importance is calculated in line 10. Parameters in line 5 and in line 11 relax the measurement criteria of attribute reduction to increase the diversity of the reduction results and reduce the computation complexity while ensuring the data’s classification ability.
4. Concept Drift Detection
In the paper, by introducing the definition of double thresholds in Reference [
9], we propose a variable sliding window detection method of concept drift. In this method, the minimum values of the classification error probability
and standard deviation
of base classifiers for data in a sliding window are set as the double thresholds to shorten the response time to gradual concept drift. At the same time, a size control strategy of the sliding window is proposed to improve the sensitivity to sudden concept drift.
In Reference [
9], three possible states of drift detection for the classification system are below.
- (1)
No-drift: while .
- (2)
In-drift: while .
- (3)
Warning: while and .
Here, for instances in , the error rate of a base classifier is the probability of misclassifying with the standard deviation given by . Parameters and are two constants.
Inspired by the ideas in References [
6,
8], we propose a size control strategy for the sliding window by introducing the sliding window idea of congestion control in the transport layer of computer networks. In computer networks, this sliding window method adaptively changes the amount of data flowing into the network by detecting the congestion threshold. It is a proven method and widely used in computer networks to effectively control network congestion and reduce data storage space [
16]. Its three stages of slow start, congestion avoidance, and fast recovery coincide with the three possible states of concept drift detection. Both methods are applied to detecting data streams and identifying identical purposes and aims. In this paper, we change the sliding window size based on the data classification error probability and standard deviation. Using method migration, we aim to inherit the method’s advantages in detection performance and resource use.
is the basic size of the sliding window,
is the current window size, and
is the next window size. Furthermore,
is the ensemble size and
is the current number of base classifiers. The size control strategy for the sliding window is below.
- (1)
If and , then and .
- (2)
If and , then
- (i)
while , trigger the slow start stage and set ;
- (ii)
while , trigger the drift monitoring stage and set ;
- (iii)
while , trigger the fast recovery stage and set .
In Step 2-i, the window size is increased quickly to improve the detection efficiency of stable streams in the slow start stage. In Step 2-ii, by slowly increasing the window size, we carefully probe whether a concept drift occurs or not in the drift monitoring stage. The influence of noise can be further decreased by updating the weight of the base classifiers. In Step 2-iii, by rapidly reducing the window size, we update the ensemble classifier using the minimal number of instances and improve the sensitivity of the detection method to sudden concept drift in the fast recovery stage. If the maximum size of the sliding window is restricted to the buffer limit, the next window size should be .
5. Ensemble Classification Algorithm of Data Streams
In this paper, we use the proposed approximate attribute reduction algorithm to reduce the computation complexity of the ensemble classification algorithm. The variable sliding window method is used to improve the sensitivity of the ensemble classification algorithm to become a sudden concept drift and the concept drift detection method based on double thresholds is used to improve the sensitivity of the ensemble classification algorithm with regard to noise and gradual conceptual drift. The pseudocode of the ensemble classification algorithm is given in Algorithm 2.
| Algorithm 2: Ensemble Classification of Data Streams |
| Input: Data stream , current data chunk , correction coefficient , approximation precision factor , approximation , ensemble size , current number of base classifiers , basic window size |
| Output: Classification results for instances in |
| 1: ; |
| 2: If and , . Obtain the training sets to generate the base classifiers using Algorithm 1. Update the weights of the base classifiers using their classification error rate. Use the voting method to integrate the classification results of the base classifiers.; |
| 3: If and , perform the same operations as shown in line 2 and save the values of and . |
| 4: If and , then: |
| 5: While , . Update the values of and and use the voting method to integrate the classification results of the base classifiers. |
| 6: While , . Update the weights of the base classifiers and the values of and . Use the voting method to integrate the classification results of the base classifiers. |
| 7: While , . Using Algorithm 1, obtain new training sets to generate new base classifiers. Use the new base classifier to replace the old base classifier of the maximum error rate where the maximum replacement number is . Update the weights of the base classifiers and the values of and . Use the voting method to integrate the classification results of the base classifiers. |
| 8: Output the final results. |
In Algorithm 2,
base classifiers are generated in line 2–3 and the window size is
. In line 5–7, the concept drift is detected. The base classifiers and the window size change when the detection result changes. The weights
of the
th base classifier are calculated by estimating the error rate in data chunk
, which is shown in Equation (2) [
5,
10].
where
is the mean square error of a randomly predicting classifier and is used as a reference point for the current class distribution with
being the probability of selecting class
. Function
denotes the probability given by the
th classifier that
is an instance of class
. Additionally, a very small positive value
is added to the equation to avoid division by zero problems.
In Algorithm 2, lines 2, 3, and 7 ensure the difference between base classifiers through reduced data generating base classifiers. The weight updating of base classifiers in line 6 ensures the classification precision of the ensemble classifier while filtering the influence of noise. Moreover, line 7 improves the sensitivity of the ensemble classification algorithm toward concept drift by updating the reduced attributes, base classifiers, and weights of base classifiers.
6. Experiments
Bagging is a representative algorithm that disturbs the sample instance space by randomly sampling specimens. It has a structure that can be processed in parallel, which effectively improves execution efficiency [
17]. Based on the random disturbance of bagging in the sample instance space, we use Algorithm 1 to perturb the sample attribute space to realize the multi-modal perturbation of training samples, which can increase the diversity of the reduced results and the difference between base classifiers. In this paper, the naive Bayes classifier is used. The experiments were conducted on a 3.6 GHz Intel Core CPU with 8 GB RAM. All of the tested algorithms were implemented in MATLAB R2012b.
For the experiments, we selected two synthetic datasets and two real datasets. The two synthetic datasets known as Hyperplane and WaveForm can be available from their data stream generators on MOA [
18]. The two real datasets, Covertype and Wine, can be downloaded from the UCI Machine Learning Repository [
19]. Hyperplane, WaveForm, and Covertype include concept drift. A hyperplane in
-dimensional space is the set of points
that satisfy
where
is the
ith coordinate of
. Instances for which
are labeled positive. Otherwise, they are labeled negative. This process is mainly used to generate streams with gradual concept drift by changing the orientation and position of the hyperplane in a smooth manner and by changing the relative size of the weights. Hyperplane generates a stream with 21 attributes. We used Hyperplane to generate a data stream of 100,000 instances with 5% noise and gradual concept drift. WaveForm generates a stream with three decision classes where the instances are described by 40 attributes including 19 that are irrelevant. We used Waveform to generate a data stream of 100,000 instances with 5% of noise and sudden concept drift. Covertype contains the forest cover type for 30 m × 30 m cells obtained from the US Forest Service Region 2 Resource Information System data. It contains 581,012 instances with 53 cartographic variables that describe one of seven possible forest cover types. Wine contains 178 instances with 13 condition attributes and three decision classes.
6.1. Performance Evaluation of the Approximate Attribute Reduction Algorithm
To test the proposed approximate attribute reduction algorithm, we selected the Wine dataset. In Reference [
11], the diversity of the reduction results obtained by an attribute reduction algorithm was evaluated. Compared with the algorithm in Reference [
11], the proposed attribute reduction algorithm further relaxes the measurement criteria by introducing a correction coefficient. Therefore, the diversity obtained by the proposed algorithm is not evaluated in this paper.
The experiments in this section consist of two main parts, which involve the impacts of the correction coefficient
and approximation
on the proposed attribute reduction algorithm and a performance evaluation of the proposed attribute reduction algorithm. In the first experiment, different values of
and
were used and the number of reduced attributes as well as the classification precision of a bagging ensemble classifier were determined. Since
and
have a similar value range and the same function of relaxing the attribute importance criteria, the experiment set
and tested them at the same time. In this experiment, the ensemble size was eight. Since
, the initial parameter values were set to
. The test results are shown in
Table 1.
From
Table 1, it can be seen that as
and
increase, the number of attributes selected by the attribute reduction algorithm increases and the classification precision continues to improve, but the runtime also increases. This result corresponds to the definitions of
and
. When
, the number of reduced attributes and classification precision remain unchanged and the runtime is stable with slight fluctuations, which indicate that, in the Wine dataset, the selected data attributes are stable under the definition of mutual information. Moreover,
Table 1 shows that when classification precision is satisfied, the number of selected data attributes can be reduced by decreasing the values of
and
, which reveals a method to balance the runtime and classification precision of the algorithm. Since the increase in values of the classification precision is more obvious than that of the runtime, we set
in the subsequent experiments.
When
and
, the test results of the approximate attribute reduction algorithm based on the positive region in Reference [
11] (test algorithm 1), the attribute reduction algorithm based on a variable precision rough set in Reference [
12] (test algorithm 2), and the algorithm proposed in this paper (test algorithm 3) are shown in
Table 2.
The data in
Table 2 show that test algorithm 3 performs well with respect to both classification precision and runtime. The experiment results indicate that test algorithm 3 selects important attributes and reduces the effect of noise on the classification results and the computation complexity of the classification system. In particular, the classification precision is higher than of the precision in test algorithm 1, which indicates the performance of the attribute importance measurement method while the runtime is lower than that of test algorithm 2. This indicates the performance of the approximate attribute reduction method.
6.2. Performance Evaluation of the Ensemble Classification Algorithm
To test the performance of the ensemble classification algorithm, the parameters of the experiments were set as follows:
,
,
,
[
10],
[
9],
[
9] and
[
10]. We compared the test results of five algorithms in the experiments including the ensemble classification algorithm based on weighting and updating of base classifiers in Reference [
2] (test algorithm 4), the AUE algorithm based on nonlinear weighting and updating of base classifiers in Reference [
5] (test algorithm 5), the ensemble classification algorithm based on a sliding window, double thresholds, and base classifier updating in Reference [
8] (test algorithm 6), the ensemble classification algorithm based on attribute reduction and weight updating in Reference [
10], the classification error rate used to detect concept drift (test algorithm 7), and the ensemble classification algorithm proposed in this paper (test algorithm 8).
6.2.1. Classification Precision Evaluation
To determine the algorithms’ performance with respect to gradual concept drift, sudden concept drift, and real data, we verified the classification precision of each of the five algorithms on three datasets. The classification results of the five algorithms on the HyperPlane dataset are shown in
Figure 1.
In
Figure 1, three gradual concept drifts occurred at 25,000 instances, 50,000 instances and 75,000 instances (shown as vertical lines). As shown in
Figure 1, the classification precision and sensitivity to gradual concept drift of test algorithm 8 are higher than those of the other four test algorithms. Test algorithms 4, 5, and 7 are less sensitive to concept drift than test algorithm 6 because of their fixed data window. However, since test algorithm 6 does not promptly update the weights of the base classifiers according to the classification error rate, its classification precision is lower than that of the other four test algorithms. Experimental results verify the effectiveness of the weight updating method of base classifiers and the variable sliding window method based on double thresholds. It also indicates that the proposed attribute reduction algorithm effectively selects important attributes and reduces the effect of noise on the classification results. Since the classification precision of test algorithm 6 is the lowest one, subsequent experiments were performed using test algorithms 4, 5, 7, and 8. The classification results of these four test algorithms on the WaveForm dataset are shown in
Figure 2.
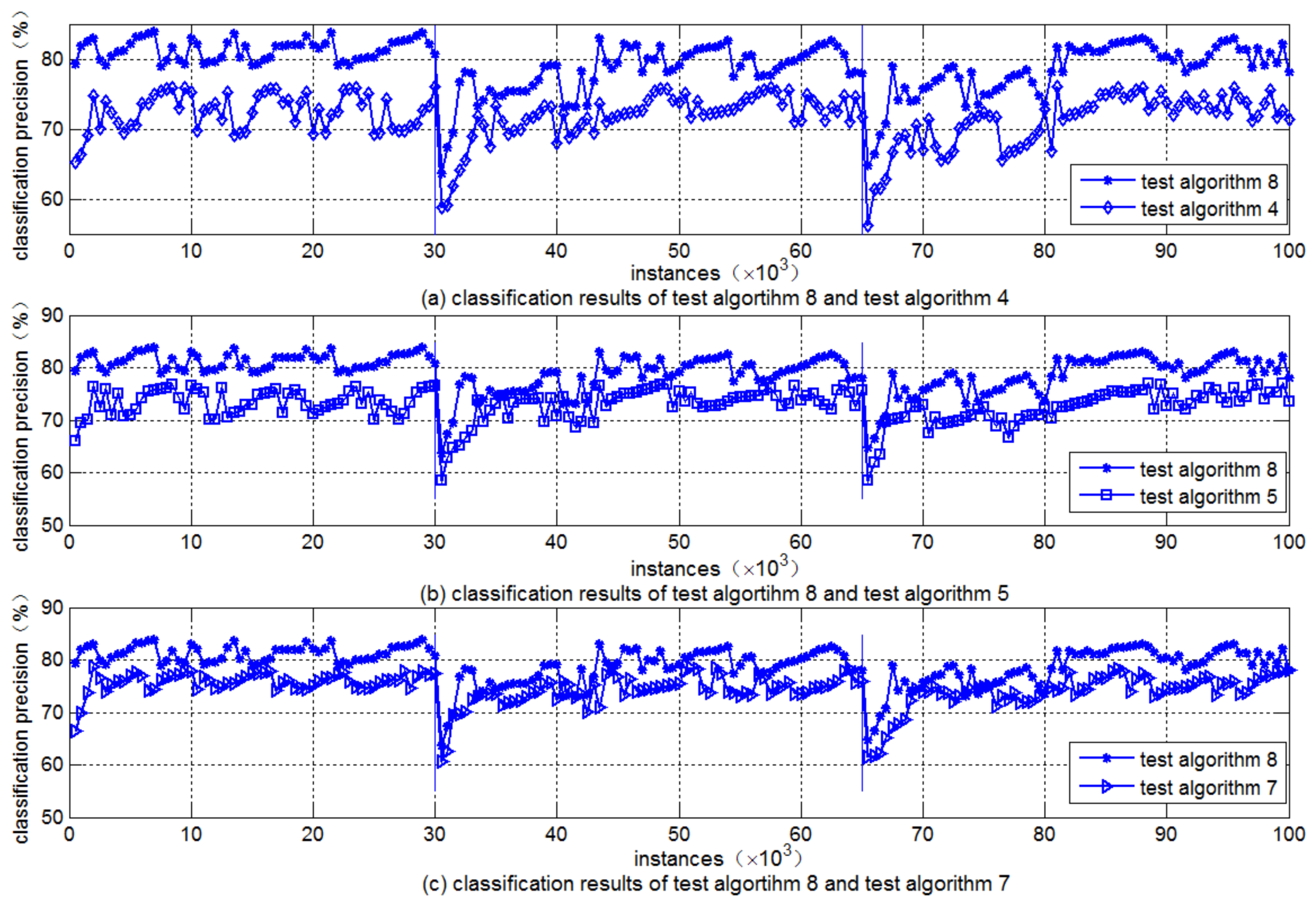
In
Figure 2, two sudden concept drifts occurred at 30,000 instances and 65,000 instances (shown as vertical lines). As shown in
Figure 2, the classification precision and sensitivity to sudden concept drift of test algorithm 4 are lower than those of test algorithm 5. Test algorithm 8 has a quicker response time to sudden concept drift than the other two test algorithms because it adopts the attribute reduction method and the variable sliding window method based on double thresholds. The higher classification precision also indicates the effectiveness of test algorithm 8. Since the classification precision of test algorithm 4 is the lowest one, subsequent experiments were performed using test algorithms 5, 7, and 8. The average classification precisions of the three test algorithms on the Covertype dataset are shown in
Table 3 and these experimental results also demonstrate the effectiveness of test algorithm 8.
6.2.2. Memory Use Evaluation
The average memory use of test algorithms 5, 7, and 8 on the three datasets is shown in
Table 4.
As
Table 4 shows, in terms of average memory use, test algorithm 8 performs better than the other two test algorithms. In test algorithm 5, the memory use is increased because each new data chunk is used to update the base classifiers. Test algorithm 7 reduces the attributes by comparing the classification error rate of each attribute, which makes its average memory use greater than that of test algorithm 8. The advantage of test algorithm 8 with respect to average memory use shows the effectiveness of the attribute reduction algorithm and the variable sliding window control strategy. For the WaveForm dataset, the attribute reduction results of test algorithm 8 are shown in
Table 5.
In
Table 5, the data points indicate the number of reduced attributes of every base classifier. Every
data points generate a base classifier and there are
base classifiers in all. Attribute reduction was performed for every base classifier to maximize the difference between them. The data values in the first row indicate the initial number of reduced attributes of every base classifier when data have just arrived and the data in the other two rows indicate the updating of reduced attributes when the new base classifiers are regenerated because of concept drift. As shown in
Table 5, the number of reduced attributes may be slightly larger than the relevant 21 attributes, but the error is less than 3 attributes. The core data attributes are saved and the amount of data is reduced in test algorithm 8.
6.2.3. Time Efficiency Evaluation
The runtimes of test algorithms 5, 7, and 8 on the three datasets are shown in
Table 6.
The data in
Table 6 shows that the runtime of test algorithm 8 is much less than that of the other two test algorithms. The runtime of test algorithm 5 is highest because of its updating strategy among the base classifiers and lack of attribute reduction. Although test algorithm 7 uses the attribute reduction method by comparing the classification error rate of each attribute, its runtime is still less than that of test algorithm 5, which fully demonstrates the effectiveness of the attribute reduction method in improving the time efficiency of large data processing.
7. Conclusions
To deal with the problem of noise and concept drift in data streams, the base classifier weight updating method and the double-threshold concept drift detection method were introduced in this paper to improve the classification precision of noisy data streams. By controlling the sliding window size in three stages (slow start, drift monitoring, and fast recovery), the detection efficiency of both gradual and sudden concept drift is improved. The approximate attribute reduction algorithm further reduces the resource use and the influence of noise and redundant data in the ensemble classification algorithm. The experimental results on synthetic and real data verify three aspects of the effectiveness among the ensemble classification algorithm including classification precision, memory use, and large gains in runtime. Our ongoing work is to decrease the result error of the attribute reduction algorithm and improve the ensemble classification performance by evaluating the performance of each of the base classifiers further.




{kind=link}
{kind=link}