1. Introduction
Presently, for social development, the power grid plays a crucial role which shoulders the important responsibilities of optimizing the allocation of energy resources and promoting social development, and it is the major implementation body of energy strategy. In recent years, the construction of China’s power grid has experienced rapid development, and its scale has leaped into the first place in the world. From 2016–2020, the investment scale of the power industry in China is planned to reach 7170 billion yuan, of which 3830 billion yuan will be invested in power generation and 3340 billion yuan in power grid investment. Accurate and effective prediction of power grid investment can not only help pool funds and rationally arrange investment in power grid construction, but also reduce capital costs and economic risks, which plays a crucial role in promoting power grid investment planning and construction process.
Recently, scholars have applied a variety of forecasting models—such as error correction model, autoregressive integrated moving average model, and grey model—to predict the investment in various fields, and have obtained some achievements. The error correction model is a specific econometric model, which was put forward by Davidson et al. in 1978 [
1]. Through cointegration analysis of variables, the long-term equilibrium relationship among variables is found out to form an error correction term. The error correction term is taken as an explanatory variable, then the short-term model is established, namely the error correction model [
2,
3]. The autoregressive integrated moving average model is a well-known time series prediction method first proposed by Box and Jenkins in the early 1970s [
4]. It transforms a nonstationary time series into a stationary time series, and then uses the lag value of the dependent variable and the present value and the lag value of the random error term as the independent variables to construct the regression model [
5]. The grey model can make fuzzy long-term description of the law of things development through establishing the grey differential prediction model with a small amount of incomplete information [
6]. The model of GM(1,1) is the most commonly applied grey model, which consists of a first order differential equation containing only one variable. The model is simple to calculate and has obvious advantages for the forecasting of small sample data with irregular distribution [
7,
8]. Lunsford [
9] proposed an error correction model based on the stock–flow relationship of housing unit start, construction, and completion to predict housing investment in the United States. Singh et al. [
10] collected the air traffic data, gross domestic product, and industrial production index of the India civil aviation department to study the corresponding elasticity coefficient, and predicted the capacity demand and investment demand of India airport infrastructure for the next 20 years. Chang and Linneman [
11] used the time series model to forecast the growth rate of real estate investment in other countries on the basis of studying the substitution model of real estate investment growth rates in Japan, Korea, Taiwan, and the United States. Gupta [
12] proposed a Bayesian vector error correction model to predict South Africa’s inventory investment based on the quarterly data of actual sales, output, undelivered orders, price level, and interest rate. Jere et al. [
13] used the simple exponential smoothing method, the three exponential smoothing method, and the autoregressive moving average method to predict the annual foreign direct investment in Zambia. By error comparison, the autoregressive moving average method was proved to be the most suitable model. However, so far, less research results have been achieved by scholars in the study of power grid investment forecasting. Zhao et al. [
14] proposed a forecasting model for power grid investment using cointegration theory and error correction model. Through screening variables by augmented dickey-fuller (ADF) unit root test and Johansen cointegration test, a long-term equilibrium model between grid investment and maximum electricity load was established, and a short-term regulation relation model was constructed by error correction model for improving prediction accuracy. Hu et al. [
15] studied a calculation model of power grid infrastructure investment by grey theory. On the basis of establishing the forecasting index system for power grid infrastructure investment and predicting the indicators by grey theory, the power grid infrastructure investment forecasting model was established by determining the impact of the changes of measurement indexes on power grid infrastructure investment through analytic hierarchy process (AHP). Fang et al. [
16] used the grey prediction method and hierarchical analysis method to construct the power grid investment forecasting model by analysis of the main influencing factors. To sum up, there are relatively few research results on power grid investment prediction, and the prediction models used by the researchers are relatively traditional, such as time series model, grey model, error correction model, and so on.
Artificial intelligence, also known as machine intelligence, is a novel technology for researching the theory, method, and application systems for simulating human intelligence [
17,
18]. Artificial intelligence is a major achievement in computer science development in the 20th century [
19,
20]. It has seen widespread use in many fields, such as prediction. Compared with classic prediction technologies, artificial intelligence prediction technology has shown strong superiority in prediction accuracy. Neural network [
21,
22,
23] and support vector machine (SVM) [
24,
25,
26] are two typical and widely used artificial intelligence prediction techniques. However, compared with neural networks, support vector machine developed in the statistical learning theory has a more solid foundation of mathematical theory, which can effectively solve the high-dimensional data model construction problems under the condition of limited samples. It has become one of the most popular research directions in the machine learning field with a stronger generalization ability. For further improving the prediction performance of SVM, researchers have used various algorithms to optimize SVM parameters, such as fruit fly optimization [
27,
28,
29], particle swarm optimization [
30,
31], genetic algorithm [
32,
33,
34], whale optimization algorithm [
35,
36], and so on. In this article, grey wolf optimization improved by differential evolution is adopted to optimize SVM parameters. The differential evolution (DE) [
37,
38] was first proposed by Storn and Price in 1995, which is mainly used to solve real number optimization problems. The algorithm is a group based adaptive global optimization algorithm, which belongs to one of the evolutionary algorithms. It has the characteristics of simple structure, easy implementation, fast convergence, and strong robustness [
39]. The differential evolution algorithm was proved to be the fastest evolutionary algorithm in the first international evolutionary computation competition in Nagoya, Japan, 1996. Grey wolf optimization (GWO) algorithm [
40,
41] is a novel algorithm for guiding the group to search the optimal value, which is inspired by wolves’ hunting behavior and social hierarchy. It has obvious advantages in global search and convergence [
42]. Jin et al. [
43] proposed a hybrid optimization method using differential evolution and grey wolf optimization. Through three simulation experiments, it was proven that the hybrid optimization algorithm had improved the solving precision, convergence speed, and search ability compared with a single algorithm. Xu and Ding [
44] proposed a short-term cloud computing resource load forecasting model using grey wolf optimization and support vector machine, which could accurately describe the complex trend of the short-term cloud computing resource loads and effectively improve the prediction accuracy of the short-term cloud computing resource loads. In this article, the three algorithms of differential evolution algorithm, grey wolf optimization algorithm, and support vector machine are combined for power grid investment forecasting. The improved combination prediction model will greatly improve the global search capability for avoiding falling into the local optimum.
In this article, for forecasting the power grid investment of China accurately, based on the construction of influencing factors system for power grid investment forecasting, a novel power grid investment prediction model based on DE-GWO-SVM algorithm is proposed in this article. The innovations of this article are as follows:
- (1)
Power grid investment forecasting in China is affected by many factors. In order to realize the accurate forecasting of China’s power grid investment, relevant factors of power grid investment forecasting are preliminarily selected based on studying a large number of literatures in this article. Through the Delphi method, multiple rounds of anonymous consultations and feedbacks are carried out on experts’ opinions, and the influencing factors system for China’s power grid investment forecasting is finally determined. From the four dimensions of economic development, electricity demand, power grid scale, and power grid benefit, the influencing factors system for power grid investment forecasting is constructed. Then, the method of grey relational analysis is used for screening the main influencing factors of power grid investment as the prediction model input.
- (2)
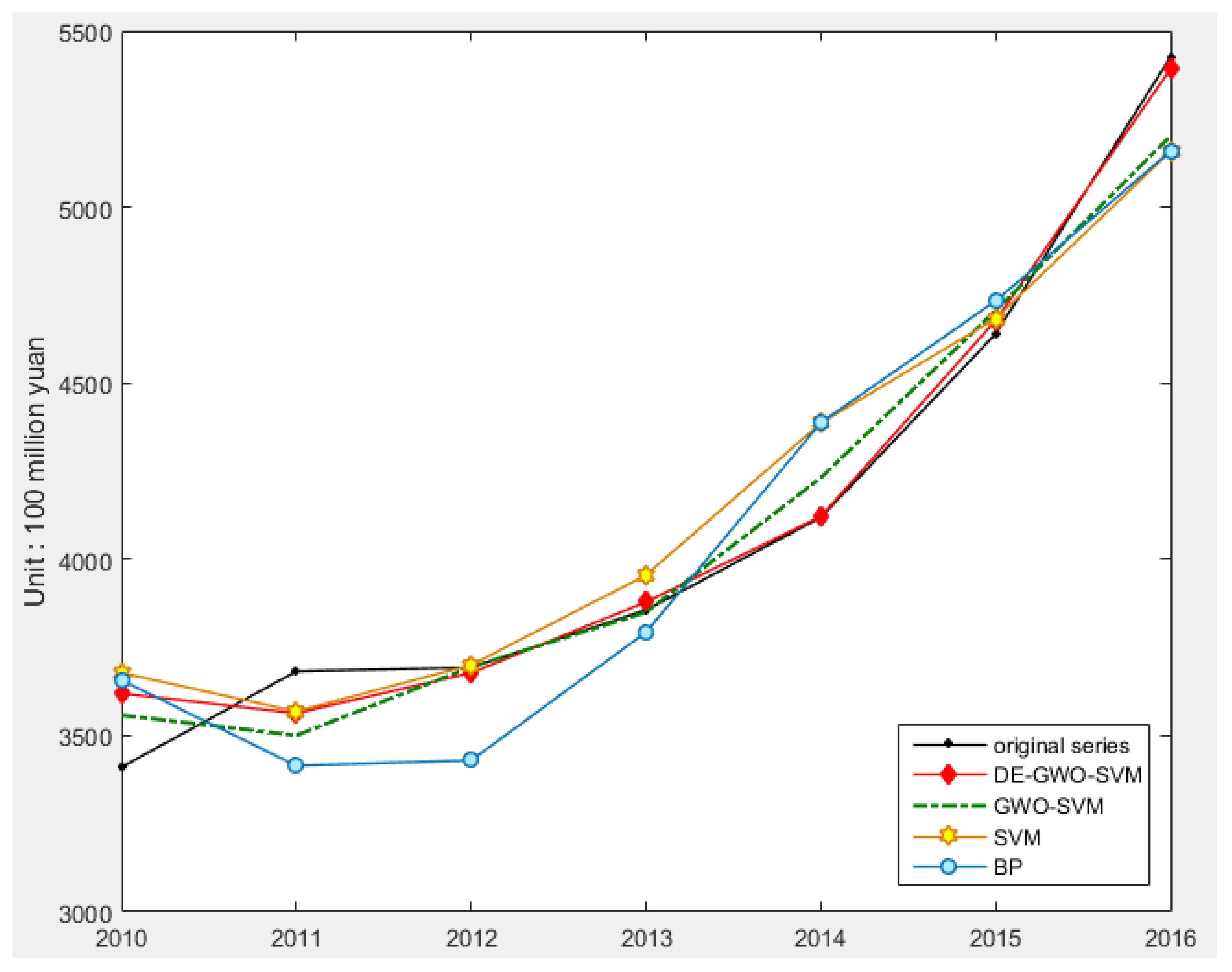
In this article, the model of DE-GWO-SVM is proposed to predict power grid investment in China. Three algorithms—differential evolution algorithm, grey wolf optimization algorithm, and support vector machine—are combined for power grid investment forecasting. The improved combination prediction model will greatly improve the global search capability for avoiding being lost into the local optimum, which can predict the power grid investment accurately. Through empirical analysis, it is proven that the DE-GWO-SVM model has strong generalization ability and robustness in power grid investment prediction, whose prediction accuracy is better than that of GWO-SVM, SVM, and back propagation (BP) neural network.
The main structure of this article is arranged as follows:
Section 2 introduces the methodology, including establishing the influencing factors system for power grid investment forecasting, introducing grey relational analysis which is used for the main influencing factors screening, and proposing the DE-GWO-SVM forecasting model.
Section 3 carries out empirical analysis to verify the validity of the proposed model for the power grid investment prediction in China, and forecasts the power grid investment in China from 2018 to 2022.
Section 4 summarizes the whole article.
2. Methodology
2.1. Construction of the Influencing Factors System for Power Grid Investment Forecasting
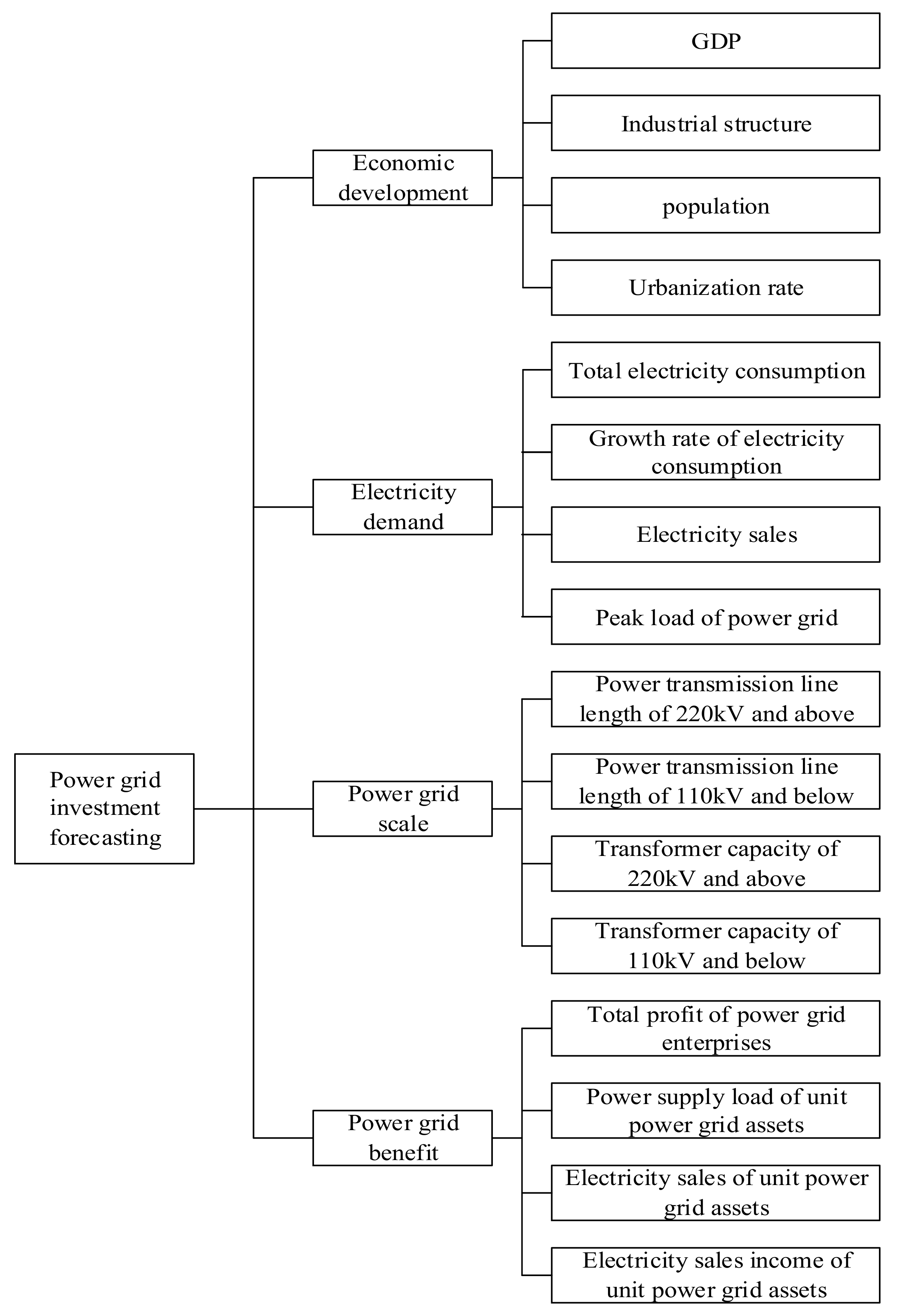
Power grid investment forecasting in China is affected by many factors. In order to realize the accurate forecasting of China’s power grid investment, relevant factors of power grid investment forecasting are preliminarily selected based on studying a large number of literatures in this article. Through the Delphi method, multiple rounds of anonymous consultations and feedbacks are carried out on experts’ opinions, and the influencing factors system for China’s power grid investment forecasting is finally determined. The influencing factors system for power grid investment forecasting is constructed from the four dimensions of economic development, electricity demand, power grid scale, and power grid benefit and each dimension contains four factors. So, there are 16 influencing factors in the influencing factors system. They are gross domestic product (GDP), industrial structure (the proportion of the third industry added value), population, urbanization rate, total electricity consumption, growth rate of electricity consumption, electricity sales, peak load of power grid, power transmission line length of 220 kV and above, power transmission line length of 110 kV and below, transformer capacity of 220 kV and above, transformer capacity of 110 kV and below, total profit of power grid enterprises, power supply load of unit power grid assets, electricity sales of unit power grid assets, and electricity sales income of unit power grid assets. The influencing factors system for power grid investment forecasting is shown in
Figure 1.
2.2. Screening of the Main Influencing Factors Based on Grey Relational Analysis
The relational degree is the degree of relevance between two things. In mathematics, it is a term for grey system analysis and refers to the degree of similarity between two functions. The calculation of grey relational degree is the core of grey relational analysis [
45,
46,
47]. In the process of system development, if the trend of two factors is consistent—that is, the degree of synchronous change is relatively high—it can be said that the relational degree between the two factors is relatively high. Otherwise, it is relatively low. Therefore, grey relational analysis is a method to measure the relational degree among factors according to the similarity or dissimilarity degree of development trends of them. In this paper, grey relational analysis is used to screen influencing factors for power grid investment forecasting. By calculating grey relational degrees between the above 16 influencing factors and power grid investment, the main influencing factors are sorted and screened out, and the selected factors are used as the input of the forecasting model.
The specific steps for calculating the grey relational degree are as follows:
(1) Determine the analysis sequences.
The time sequences of power grid investment is set as
The time sequences of various influencing factors are set as
(2) Do non-dimensional processing on each sequence.
(3) Calculate the relational coefficient.
The relational coefficient between
and
is shown as
(4) Calculate the relational degree.
The grey relational degree between
and
is shown as
(5) Conduct relational degrees sorting.
The influencing factors sequences are sorted according to the grey relational degrees. The greater the grey relational degree is, the more consistent the influencing factor sequence is with the power grid investment sequence, and the closer the link between the influencing factor and the power grid investment is.
2.3. Support Vector Machine
Support vector machine is proposed by Vapnik et al. It is a small sample machine learning method on the basis of VC dimension theory [
24,
25]. The basic idea of using the SVM algorithm to estimate the regression function is to nonlinearly map data to a high-dimensional feature space, and then carry out linear regression in this high-dimensional space [
26].
Set
training sample sets:
. Among them,
are training sample inputs of
dimension,
are training sample outputs. The nonlinear mapping
is used to map input samples from the original space
to the high-dimensional feature space
. The optimal linear regression function is constructed in the high-dimensional feature space
In the equation: is the weight vector in the high-dimensional feature space, . is the bias constant, .
Determine
and
in the light of the principle of structural risk minimization
In the equation, controls the model complexity, is the regularization parameter and is the error control function. If selects different loss functions, different forms of SVM can be constructed. The loss function of standard SVM in the optimization objective is the linear term of the error.
In the light of the principle of structural risk minimization, Equation (7) can be transformed into
In the equation, is the insensitivity coefficient, and are relaxation factors.
Solve optimization problem with Lagrange function,
In the equation, are all Lagrange multipliers and .
According to Karush–Kuhn–Tucker optimization condition,
Define
as the symmetric kernel function of the Mercer condition. Then the optimization problem can be expressed as:
The nonlinear forecasting model can be obtained:
In this article, the radial basis kernel function is selected as the kernel function of SVM, which is defined as:
In the equation, is the width parameter of radial basis kernel function.
2.4. Grey Wolf Optimization
Grey wolf optimization (GWO) algorithm is a novel heuristic swarm intelligence optimization algorithm proposed by Mirjalili et al. in 2014, which has good performance in global search and convergence [
40]. GWO simulates the social hierarchy and hunting behavior of the grey wolf population [
41,
42]. The grey wolf population in nature is divided into four grades:
,
,
, and
, in order of social status from high to low. Define the current optimum solution in the wolf population as
wolf, the second-best solution as
wolf, the third-best solution as
wolf, and other solutions as
wolf to construct the hierarchy model of the grey wolf. In the GWO algorithm, the hunting task is performed by
,
, and
wolf.
wolf follows the three wolves to carry on the prey tracking, encirclement, and suppression. Finally, the predation task is completed.
The main hunting processes of wolves are tracking the prey, encircling the prey and attacking the prey. The grey wolf behavior of encircling the prey gradually can be expressed as
In the equation, is the distance between the grey wolf and the prey is the number of current iterations. is the prey position vector. is position vector of the grey wolf. and are parameter vectors. , , and among them, and are both random vectors between [0, 1]. During the iteration, decreases linearly from 2 to 0.
To simulate the hunting behavior of grey wolves, it is assumed that wolf, wolf, and wolf have a better understanding of the location of the prey. The grey wolf population can use these three positions to determine the prey location. The process of grey wolves updating their positions according to the location information of wolf, wolf, and wolf is shown as Equations (16)–(22)
The optimization of GWO algorithm is to evaluate the location of the prey by
wolf,
wolf and
wolf. Then the rest of wolves use the location as a reference and update their locations around the prey randomly. The process of grey wolves updating their positions based on the location information of
wolf,
wolf, and
wolf is shown as
Figure 2.
2.5. Differential Evolution
Differential evolution (DE) algorithm is a heuristic random search algorithm on the basis of populational differences [
37]. It is put forward by Rainer Storn and Kenneth Price to solve Chebyshev polynomials. Differential evolution algorithm mainly includes three kinds of operations: mutation, crossover, and selection [
38,
39].
In the
dimensional search space, the size of population is
.
is the
individual of the
generation:
In the equation, is the lower bound of population individual, is the upper bound of population individual, is the maximum number of iterations.
(1) Initialization Population
initial populations are randomly generated in the entire search space:
In the equation, is a random number that obeys a uniform distribution in . and are the upper and lower bounds of the dimension respectively.
(2) Mutation Operation
The variant individual is generated by Equation (25):
In the equation, is the zoom factor with a range of . are random integers in that are not equal to each other and are not equal to .
(3) Crossover Operation
Crossover operation can increase the population diversity. For the dimension of the individual, the method of crossover operation is shown as Equation (26).
In the equation, is the crossover probability and is a random dimension.
(4) Selection Operation
In differential evolution algorithm, greedy algorithm is used to select individuals entering the next generation, that is to choose the better individuals as the new individuals, so as to ensure the direction of population evolution, which is shown as Equation (27).
2.6. Support Vector Machine Optimized by Differential Evolution Algorithm and Grey Wolf Optimization Algorithm
When SVM algorithm is used for forecasting on the basis of radial basis kernel function, the values of regularization parameter c and radial basis kernel function parameter g need to be determined. The values of these two parameters directly affect the accuracy of forecasting. Grey wolf optimization algorithm is selected to optimize the SVM parameters in this article. In fact, although the grey wolf optimization algorithm has advantages in global search and convergence, with the increase of iteration times, it is also unavoidable to fall into the local optimum. So, in this paper, the DE algorithm is introduced to improve GWO algorithm to enhance the global search ability, and then improve the SVM algorithm. The specific steps of DE-GWO-SVM are as follows:
Step 1: Set model parameters: population size N, maximum iteration number tmax, crossover probability CR, the scope of the zoom factor F.
Step 2: Initialize the parameters A, C, and a, and perform the mutation operation of the differential evolution algorithm for the population individual according to Equation (20) to produce the intermediate. Then perform the selection operation according to Equation (22) for initializing the population individual, and set the iteration number: t = 1.
Step 3: The fitness values of grey wolf individuals are calculated and ordered to determine the positions of the grey wolf individuals with the first three fitness value, which are labeled as , , and respectively.
Step 4: The distances between other grey wolf individuals in the population and , , are calculated according to Equations (11)–(13). The position of each grey wolf individual is updated according to Equations (14)–(17).
Step 5: Update the value of A, C, and a in the algorithm. Perform the crossover operation on the positions of the population individuals according to Equation (21), and preserve the better population individuals. Then perform the selection operation to produce new individuals according to Equation (22), and calculate the fitness values of all grey wolf individuals.
Step 6: Update the positions of the grey wolf individuals , , and with the first three fitness values.
Step 7: Judge whether the maximum number of iterations is reached. If so, output the current optimal solution (c, g). Otherwise, turn to Step 3 to continue parameters optimization.
Step 8: The optimized parameter values are assigned to SVM, and the forecasting model is established.
2.7. Forecasting Process
According to the previous analysis, the accuracy of power grid investment forecasting will be affected by many factors, such as economic development, electricity demand, power grid scale, and power grid benefit. In order to achieve accurate forecasting of power grid investment, on the basis of the analysis of influencing factors for power grid investment forecasting, the DE-GWO-SVM forecasting model is proposed in this article. The steps are as follows:
(1) Data Collection
Collect sample data of 16 factors, including power grid investments over the years, GDP, industrial structure, population, urbanization rate, total electricity consumption, growth rate of electricity consumption, electricity sales, peak load of power grid, power transmission line length of 220 kV and above, power transmission line length of 110 kV and below, transformer capacity of 220 kV and above, transformer capacity of 110 kV and below, total profit of power grid enterprises, power supply load of unit power grid assets, electricity sales of unit power grid assets and electricity sales income of unit power grid assets. Deal the data with non-dimensional processing.
(2) Influencing Factors Screening
The grey relational degrees between the above 16 factors and the power grid investment are calculated, the main influencing factors for power grid investment forecasting are screened out according to the ranking of grey relational degrees, and the selected factors are used as the input of the forecasting model.
(3) Power Grid Investment Forecasting Based on DE-GWO-SVM Model
The selected influencing factors for power grid investment forecasting are used as the input of the model, and the DE-GWO-SVM model is used to predict the power grid investment. First, initialize the parameters and perform the mutation operation of the differential evolution algorithm for the population individual to produce the intermediate. Then perform the selection operation for initializing the population individual. The fitness values of grey wolf individuals are calculated and ordered to determine the positions of the grey wolf individuals with the first three fitness values. The distances between other grey wolf individuals and the first three grey wolves are calculated and the position of each grey wolf individual is updated. Update the value of the parameters and perform the crossover operation on the positions of the population individuals and preserve the better population individuals. Next perform the selection operation to produce new individuals and calculate the fitness values of all grey wolf individuals and update the positions of the grey wolf individuals with the first three fitness value. Repeat the above process until the number of iterations is reached. Finally, the optimized parameter values are assigned to SVM, and the forecasting model is established to predict the power grid investment.
The specific forecasting process is shown in
Figure 3.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}