An Intelligent Condition Monitoring Approach for Spent Nuclear Fuel Shearing Machines Based on Noise Signals


Abstract
:1. Introduction
2. Theoretical Background
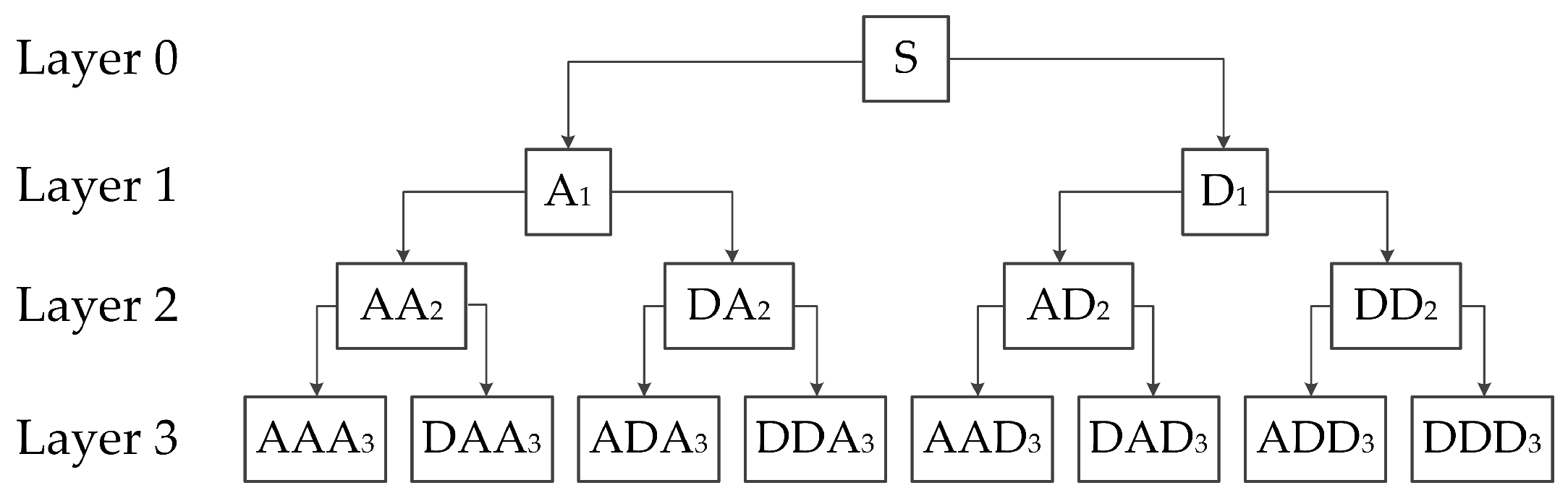
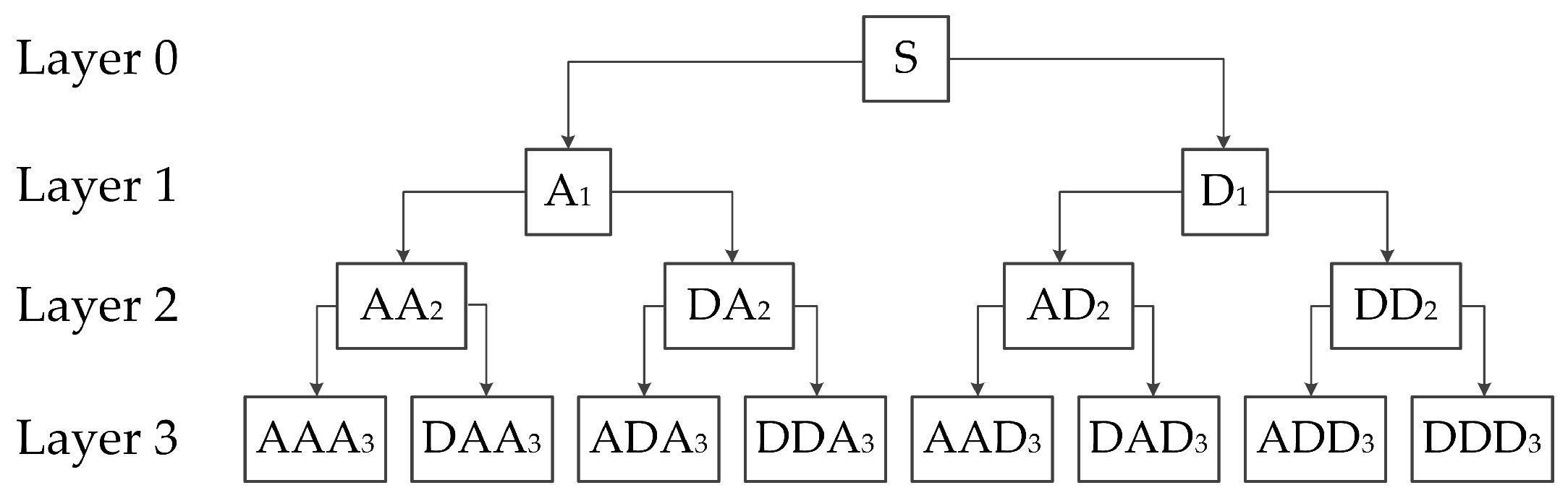
2.1. Wavelet Packet Transform
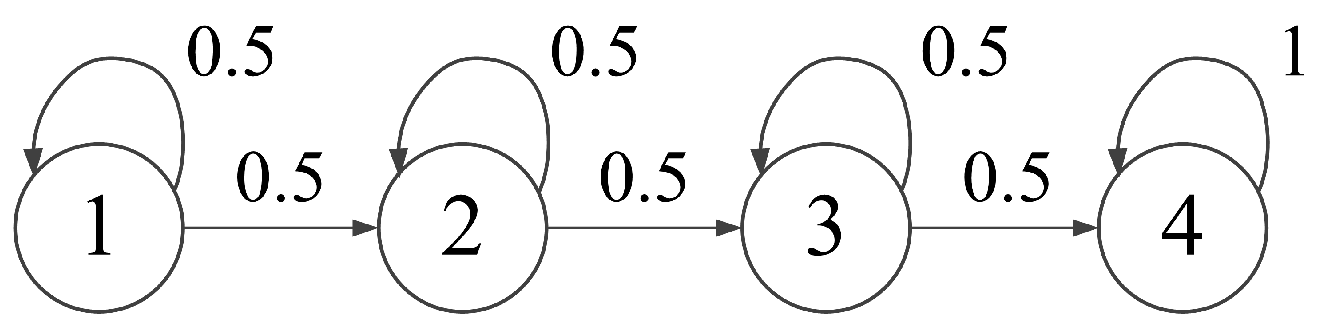
2.2. Hidden Markov Model
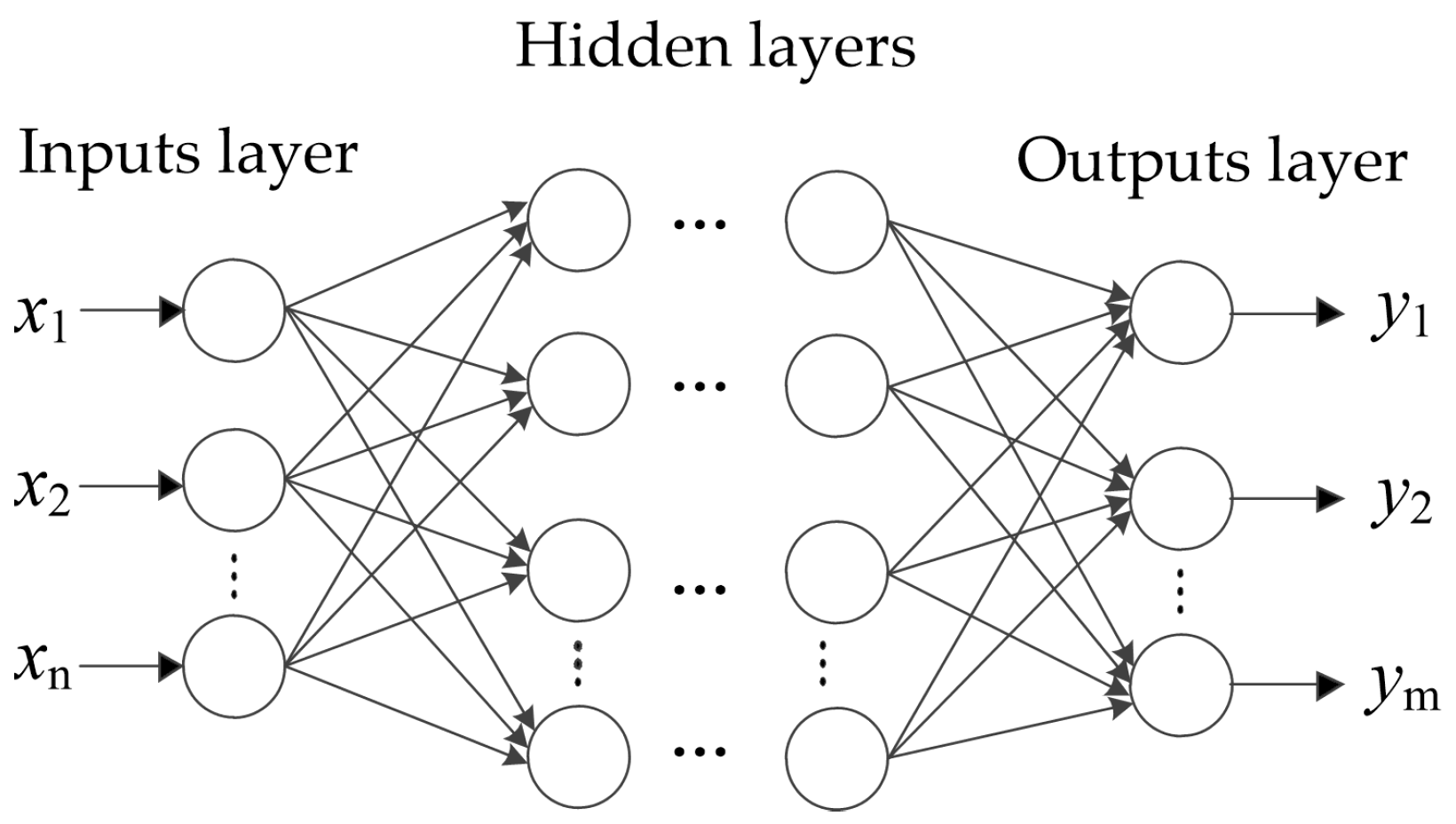
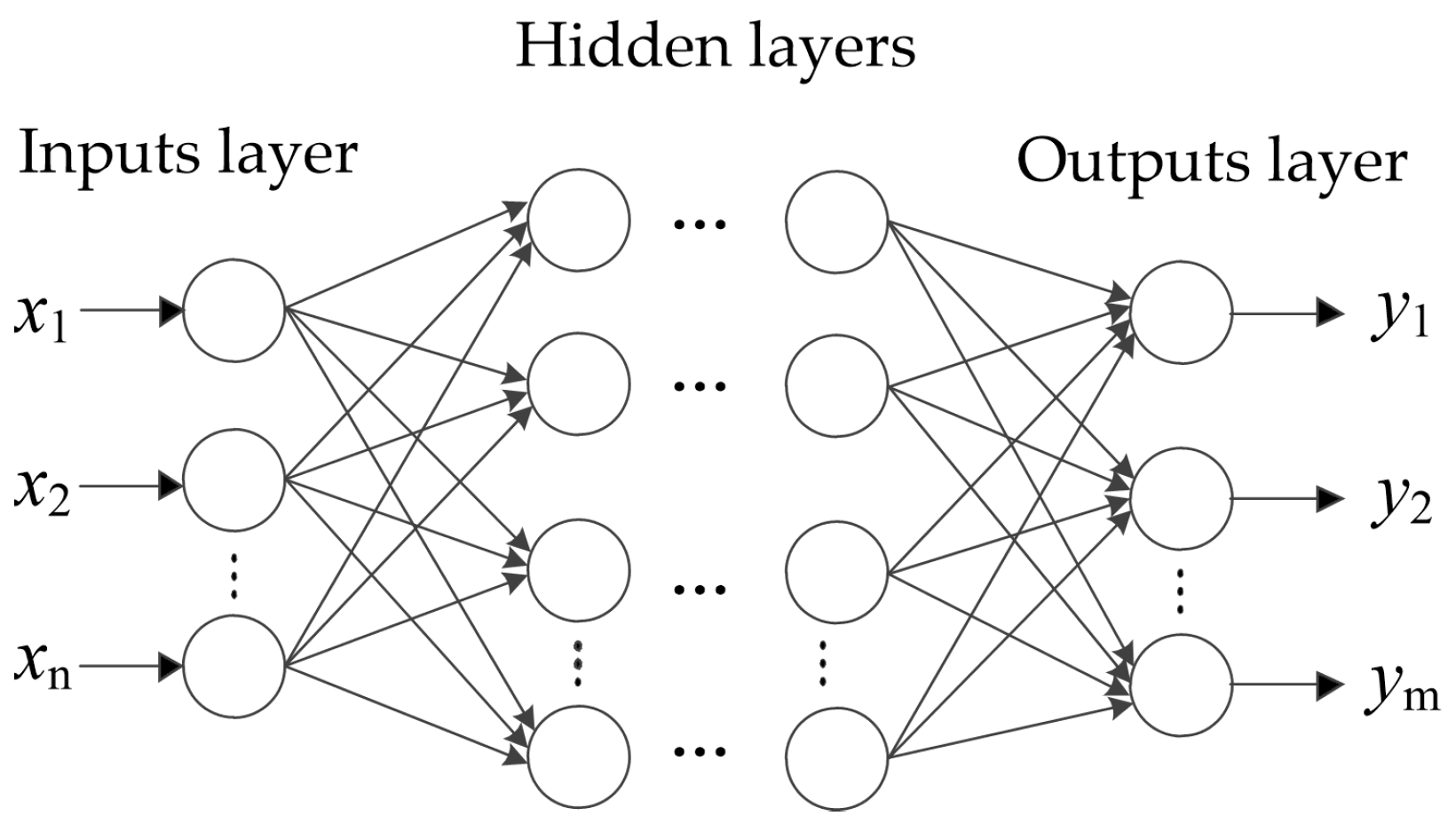
2.3. Artificial Neural Network
3. Condition Monitoring Approach for Shearing Machines
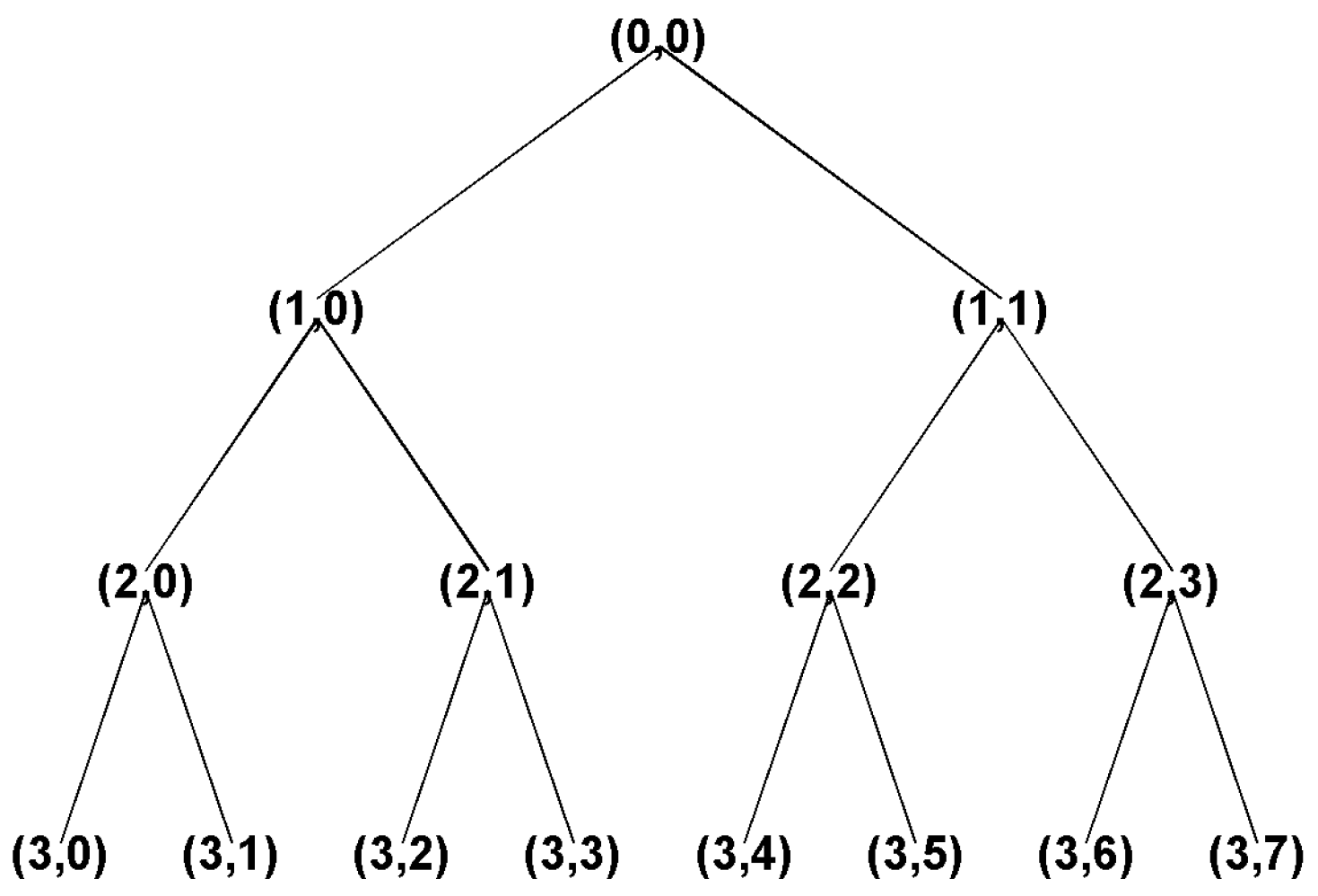
3.1. Feature Extraction Method Based on WPT
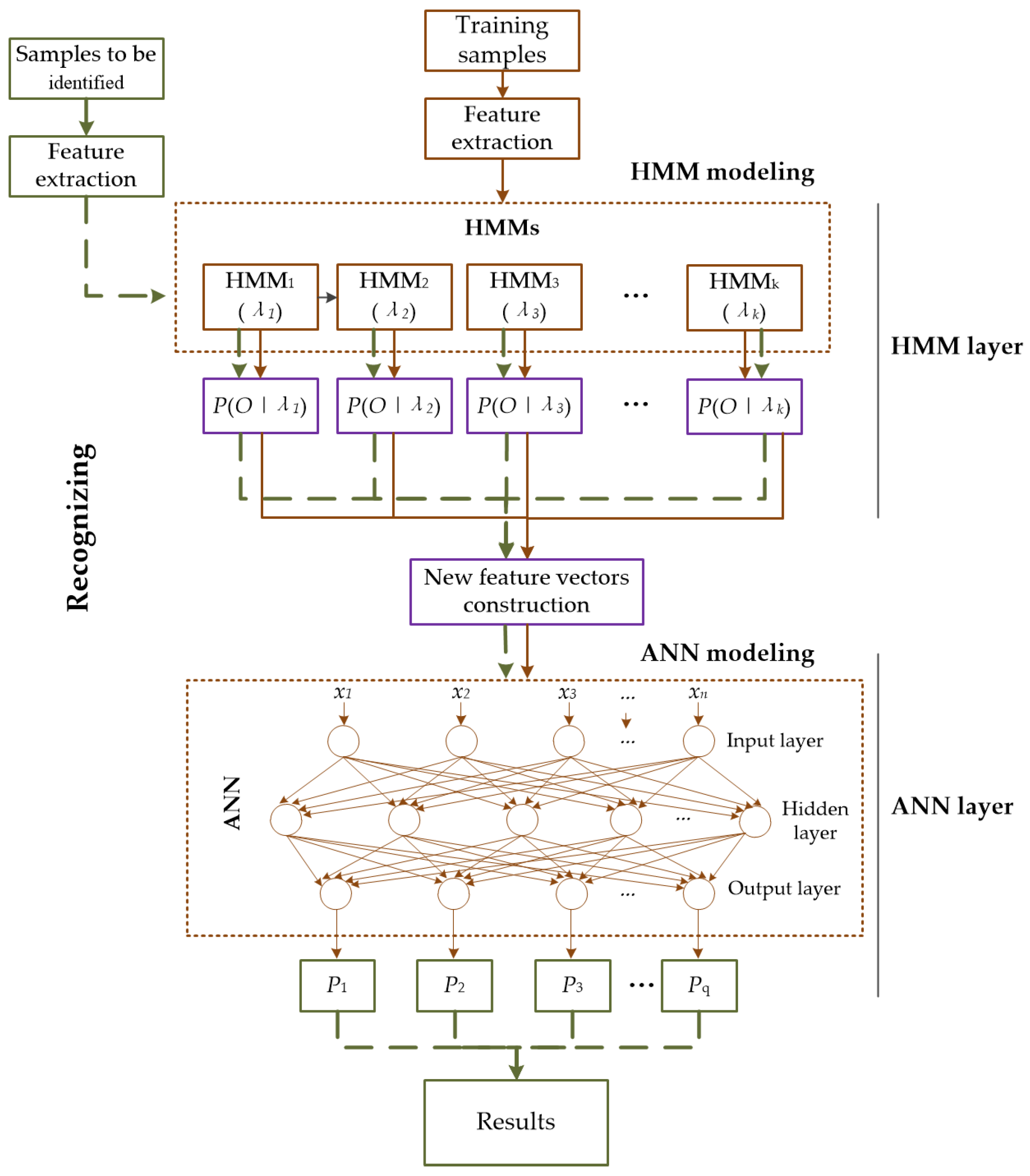
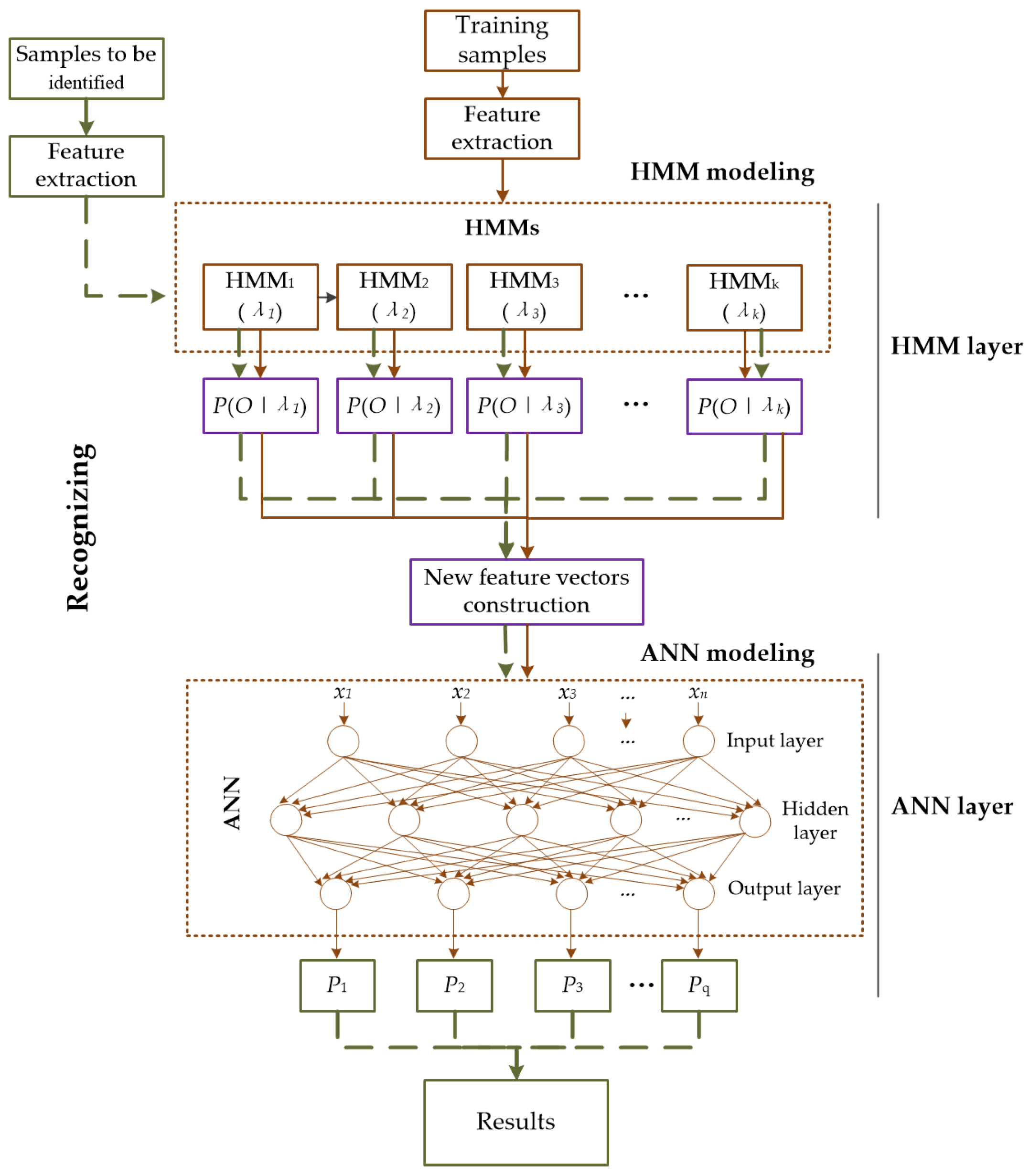
3.2. Hybrid HMM–ANN Model for Fault Diagnosis
3.3. Training and Recognizing Process of the Hybrid HMM–ANN Model
3.3.1. Training Process of the Hybrid Model
- (a)
- Initial guess of parameters. It is generally considered that the initial values of parameters and A have little effect while the initial value of parameters , and have a large influence on the training result of HMMs. The initial values and A can be set randomly or evenly. It will be detailed in the empirical part. The initial parameters , and are estimated by using the segmental k–means algorithm (see literature [40]).
- (b)
- Model revaluation. In this study, the Baum–Welch algorithm was used to reevaluate the HMM parameters. For each state of HMM, the constructed model is updated based on the following revaluation equations:where is the probability of being in state at time t given the observed sequence O and model , the probability of being in state and at times t and respectively given the observed sequence O and model .
- (c)
- Model determination. The output probabilities of the samples under the new model are calculated by using the forward–backward algorithm. If the condition is met, the model obtained in the last revaluation is considered the final model. Otherwise, return to step (b) and continue reevaluating.
- (a)
- Establishment of network. An ANN with three layers (input layer, output layer, and hidden layer) is constructed. The number of neurons in the input layer is equal to the dimension of the feature vector, and that of the output layer equals the number of health states. The number of neurons in the hidden layer is mainly determined by tests, while the following empirical equation gives a preliminary range:where m is the number of neurons in the input layer, n the number of neurons in the output layer, and a an integer constant between 1 and 10. Besides the network structures, the activation functions are critical points for the performance of ANNs.
- (b)
- Setting training parameters, e.g., selections of initial weight, threshold, goal, learning rate, momentum factor, maximum epochs, as well as selections of learning function, training function, and performance function. They are also selected according to their applicabilities, requirements of tasks and through tests.
- (c)
- Training of ANN. Use the samples to train ANN iteratively until the accuracy meets the goal value or the accuracy does no longer improve. Thus, the trained ANN model is obtained.
3.3.2. Recognizing Process of the Hybrid Model
- (a)
- Construction of input vectors for ANN. The samples to be identified are preprocessed and feature extracted with the same method as used for training samples. Consequently, observed vectors can be obtained. Next, use the feature vectors as input to calculate the output probabilities of the samples to be identified for all trained HMMs. The input vectors of ANN are constructed with these probability values.
- (b)
- Probability prediction of samples to be identified for each health state. Using the input vectors to produce the outputs of the trained ANN model. As a result, the predicted probabilities of the samples to be identified for each health state are obtained.
- (c)
- Classification decision. Finally, considering the highest likehood, the health states of the samples to be identified are determined.
4. Application and Results
4.1. Experimental Rig Setup and Data Collection
4.1.1. Experimental Setup
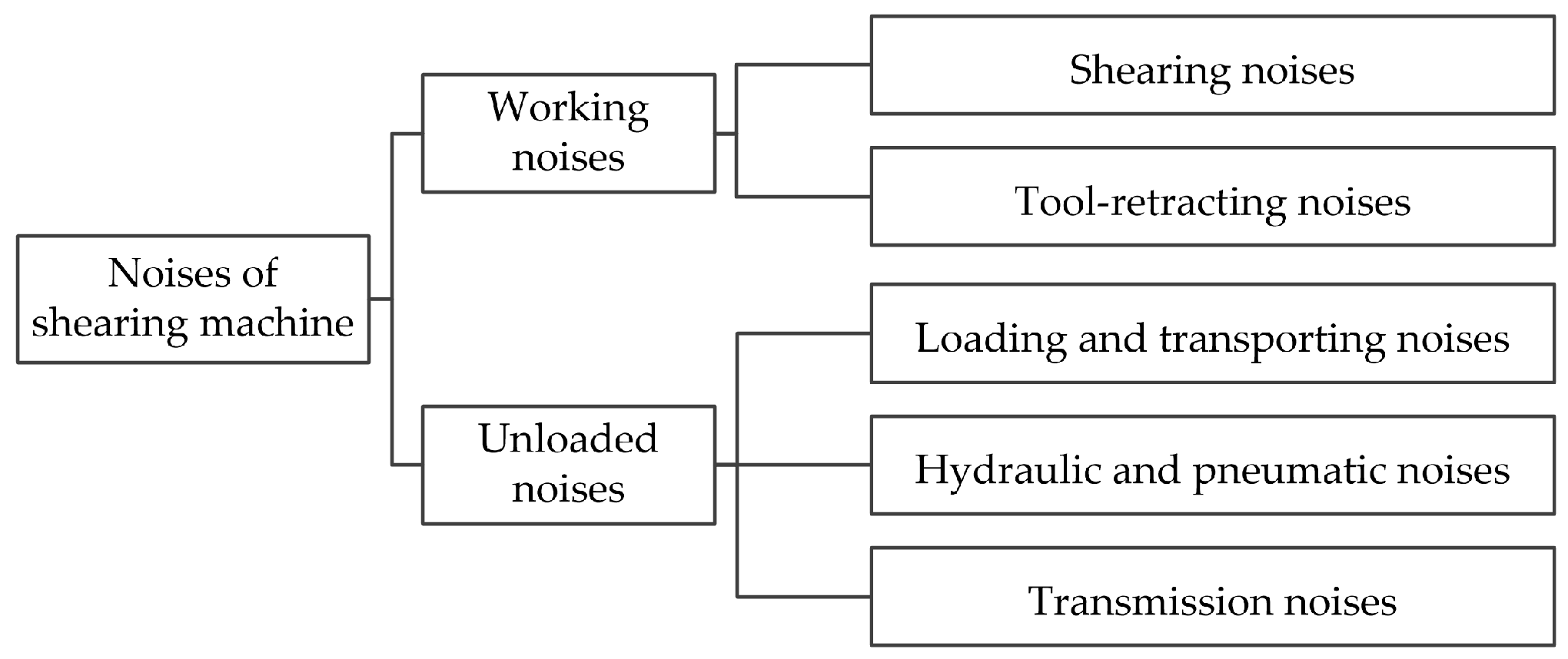
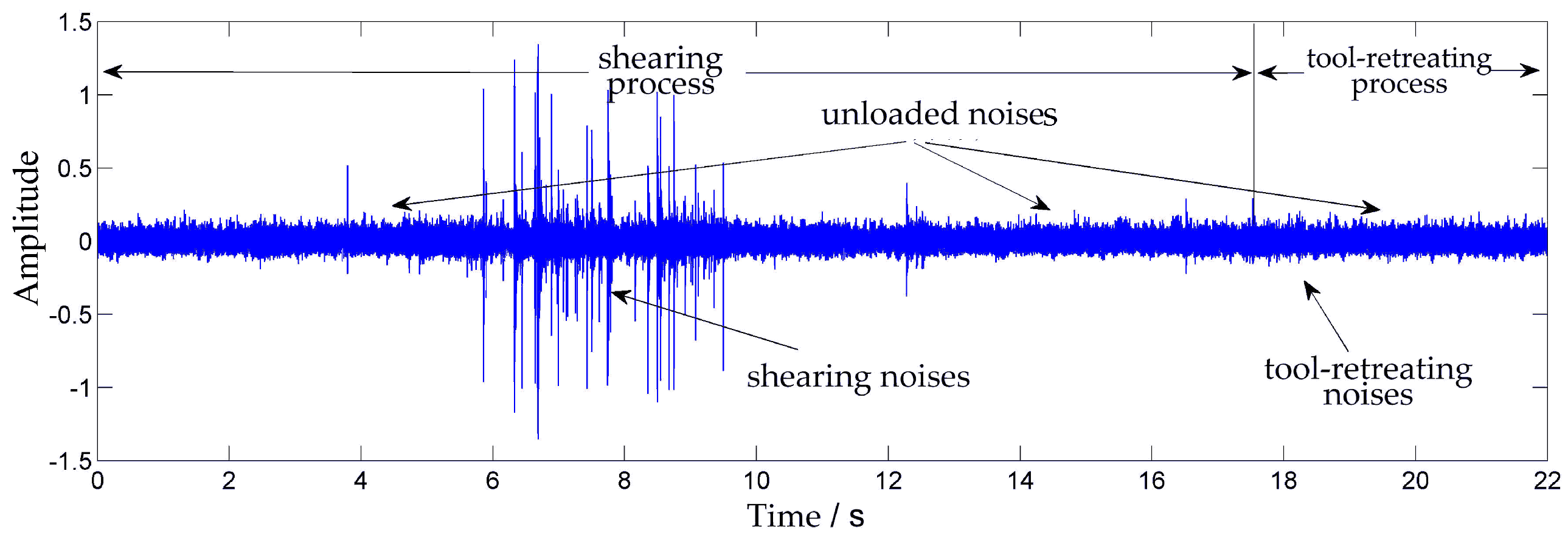
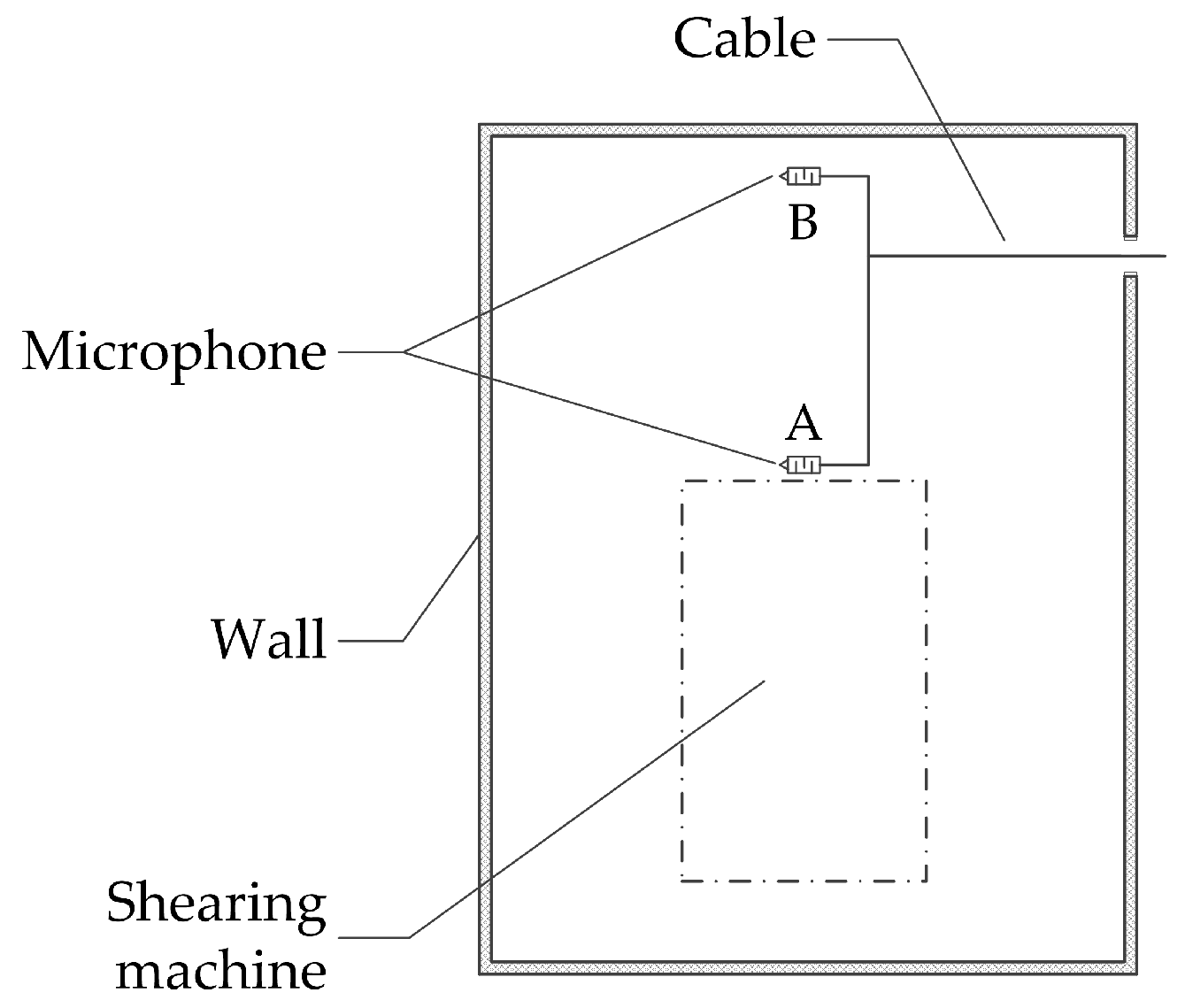
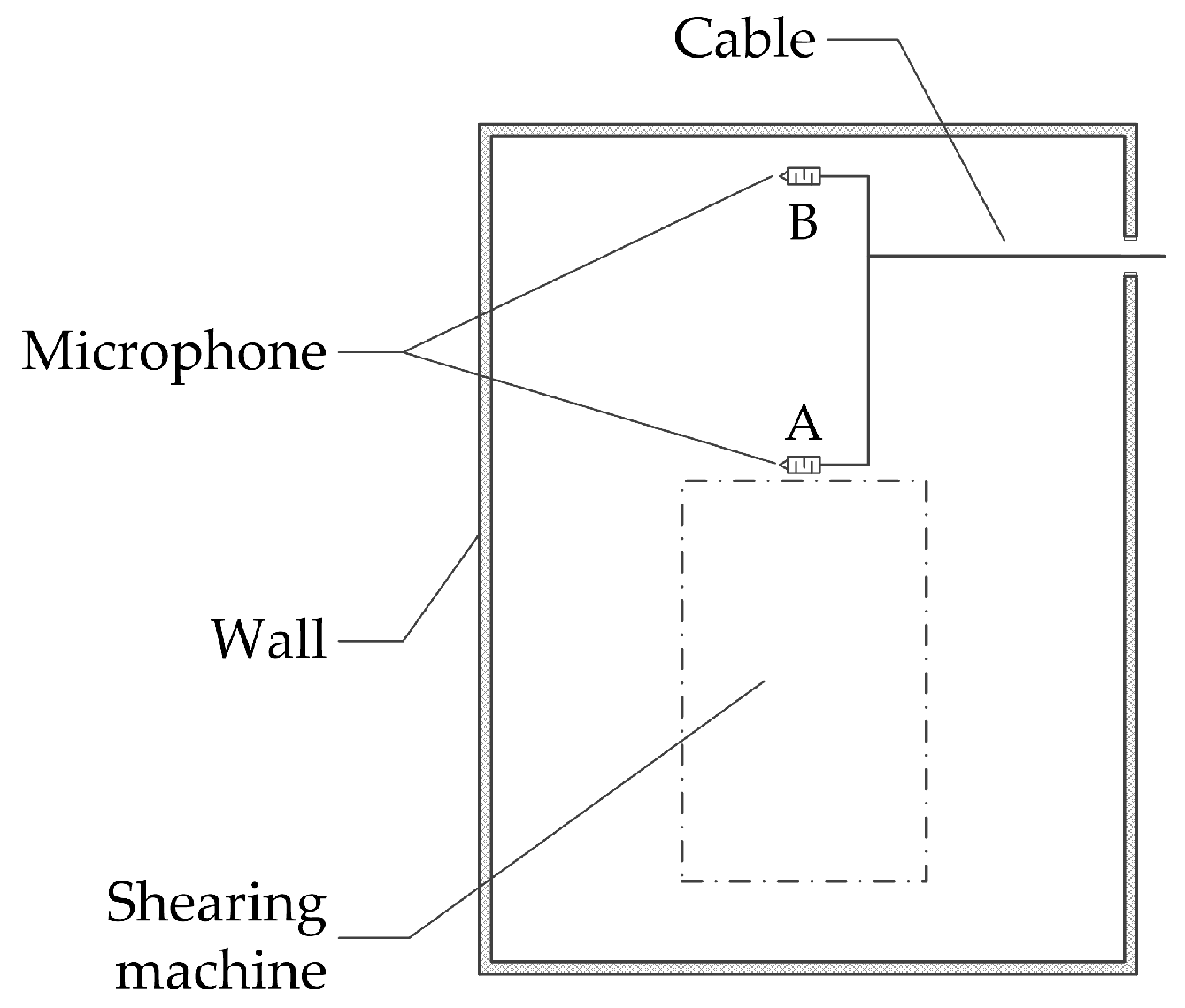
4.1.2. Noise Acquisition Method for Shearing Machines
4.1.3. Collected Data
4.2. Results and Discussions
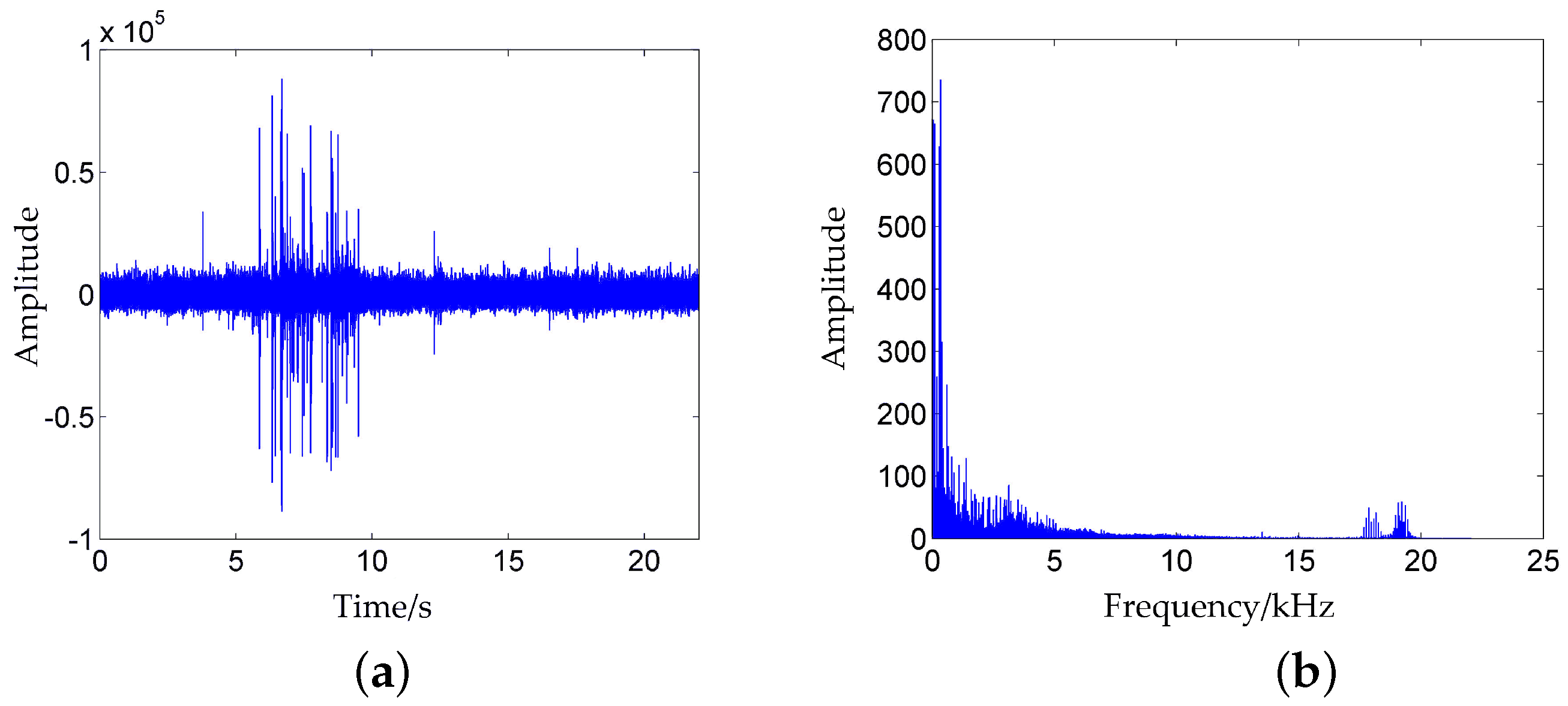
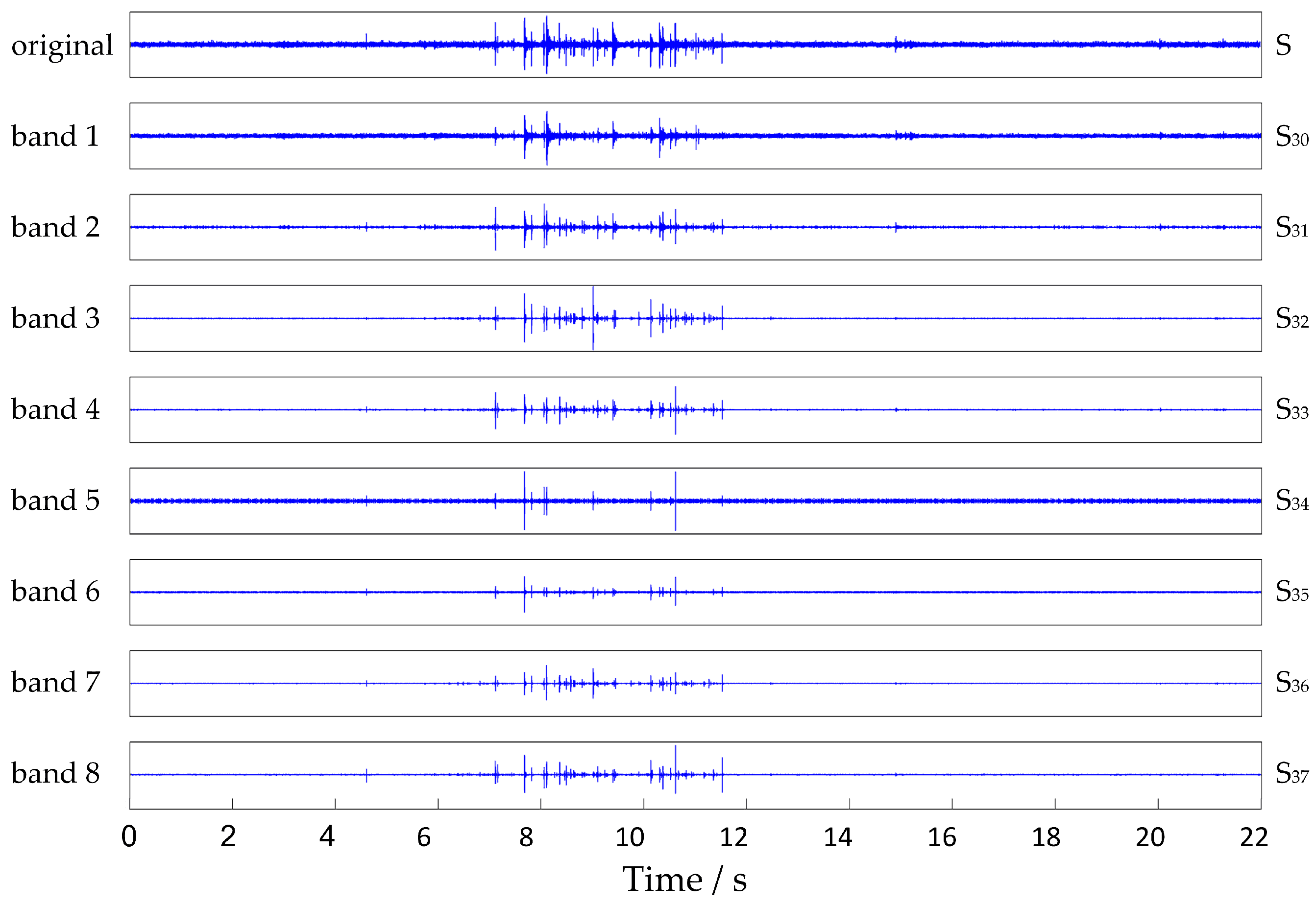
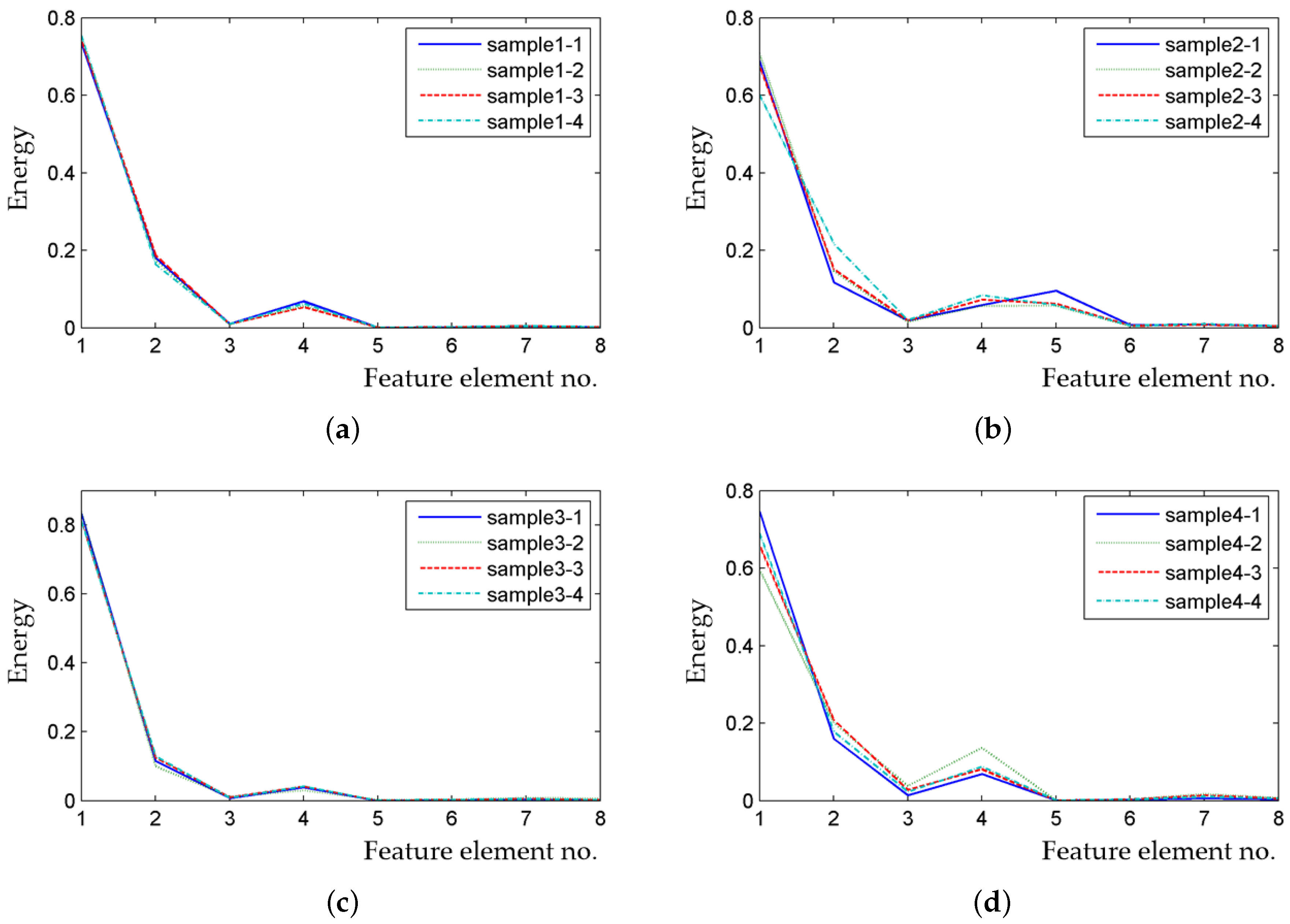
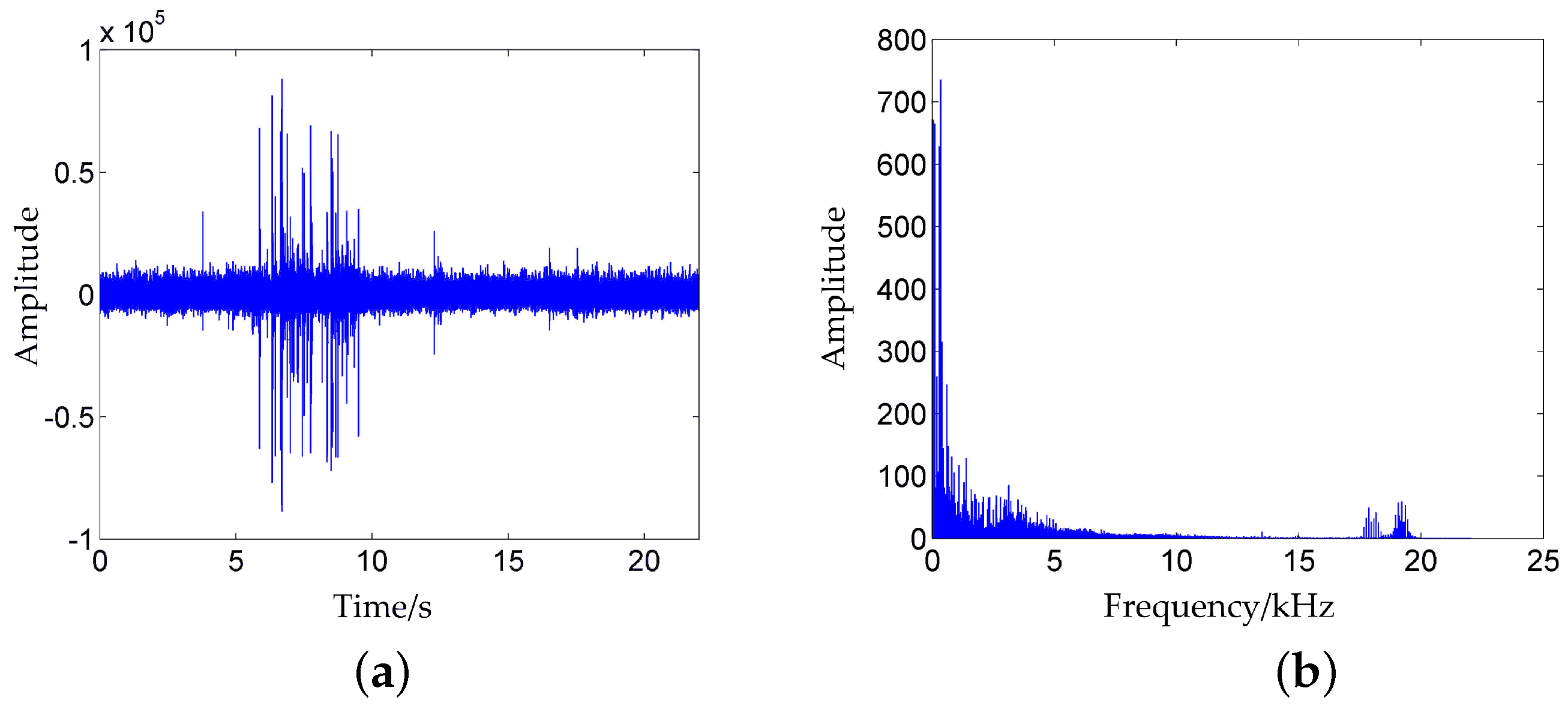
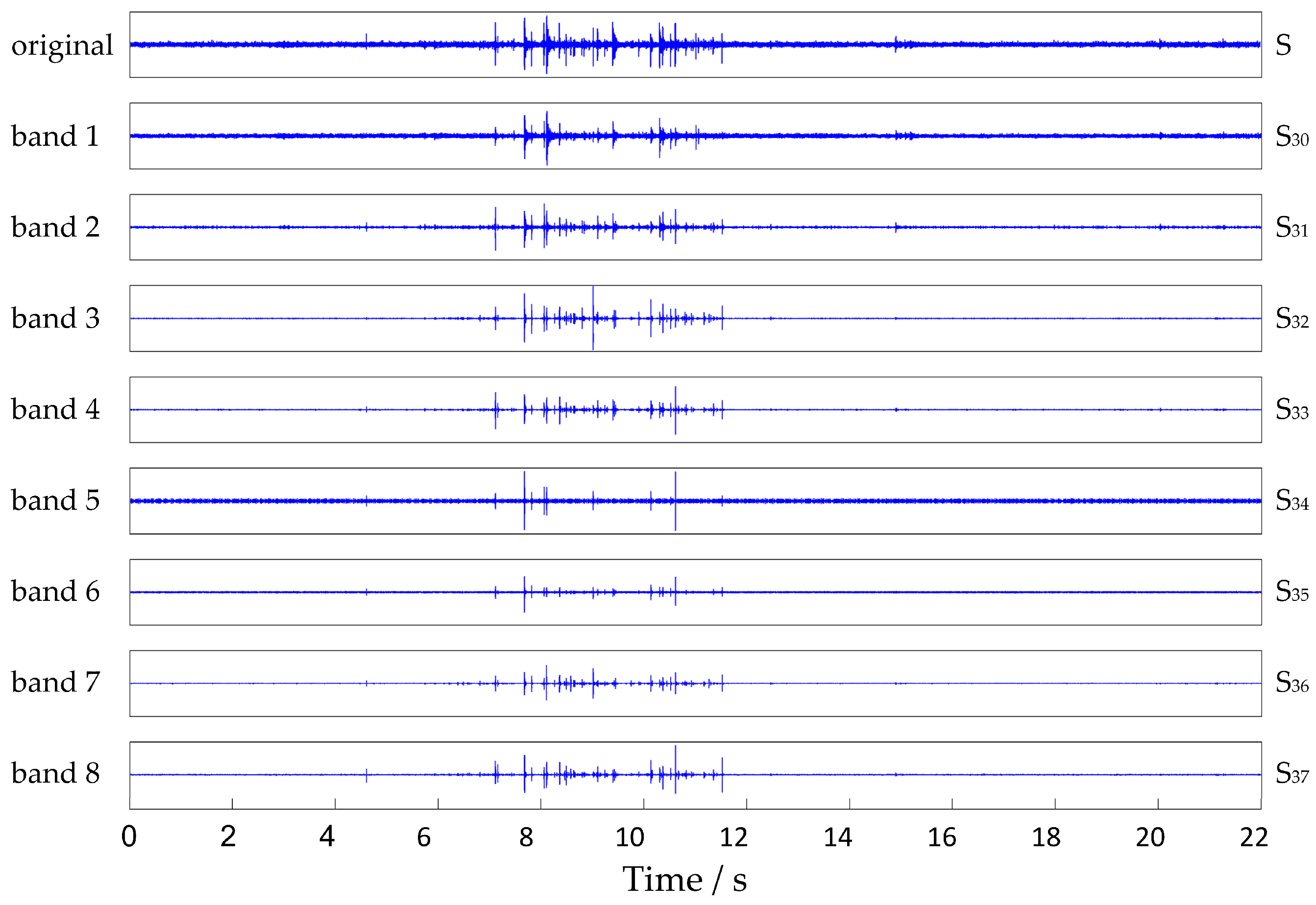
4.2.1. Feature Extraction from Noise Samples
4.2.2. HMM–ANN Modeling and Fault Detection Results
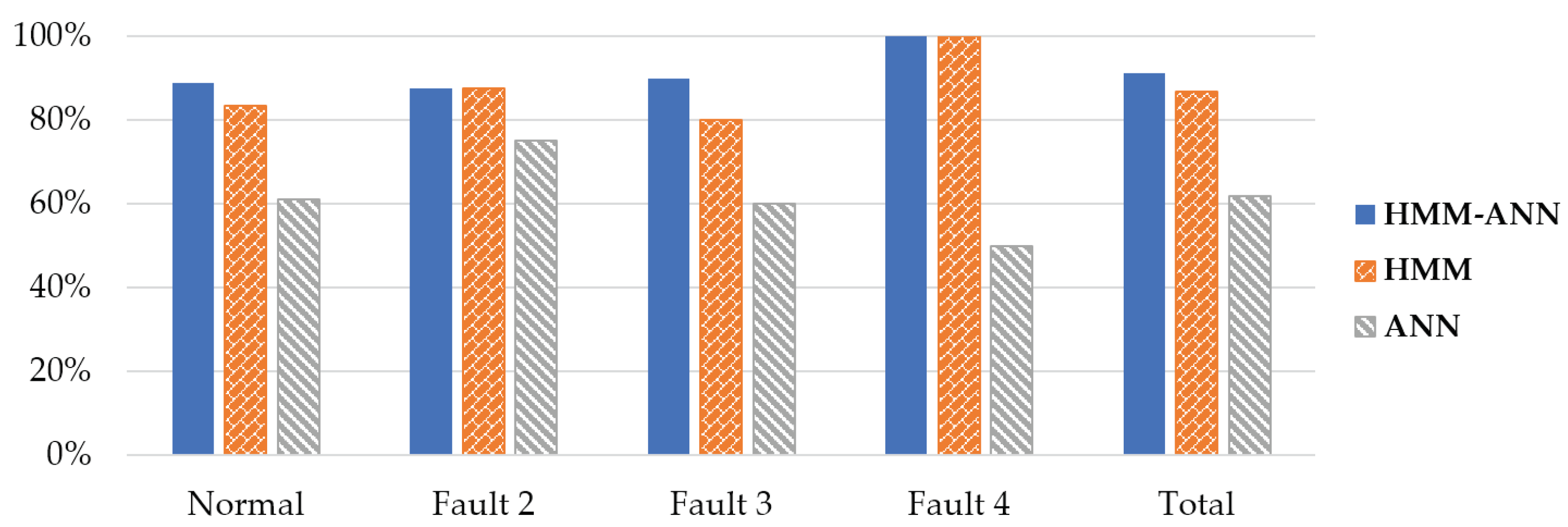
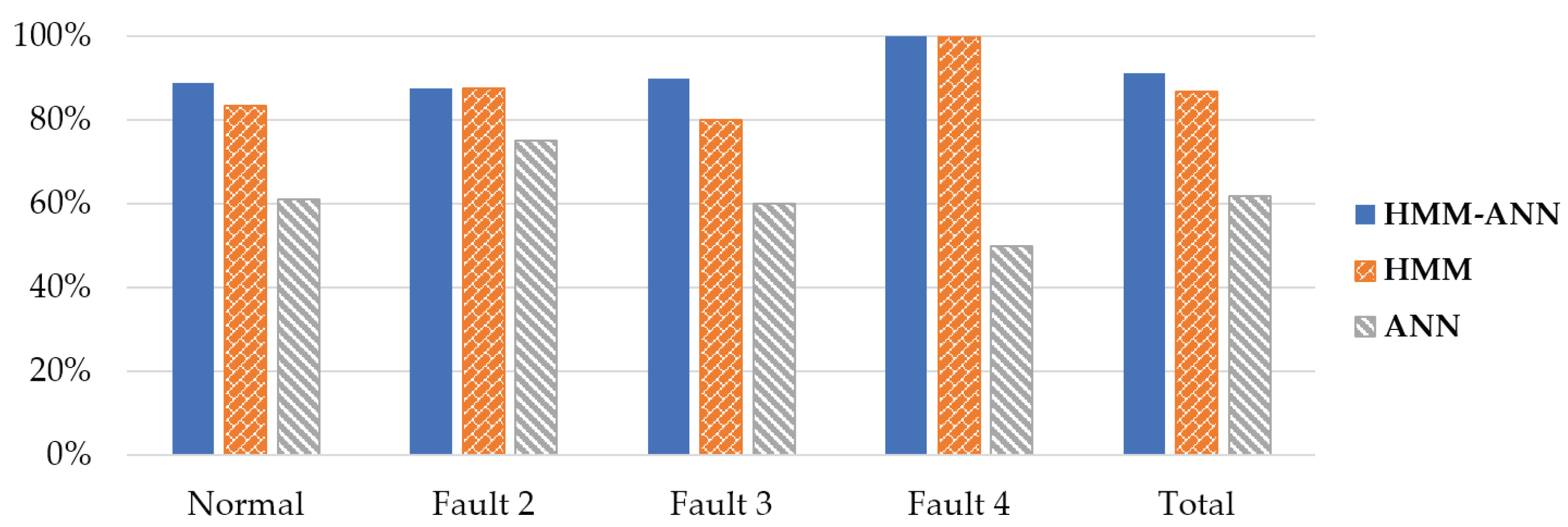
4.2.3. Comparative Analysis Results
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Poinssot, C.; Bourg, S.; Ouvrier, N.; Combernoux, N.; Rostaing, C.; Vargas-Gonzalez, M.; Bruno, J. Assessment of the environmental footprint of nuclear energy systems. Comparison between closed and open fuel cycles. Energy 2014, 69, 199–211. [Google Scholar] [CrossRef]
- Nash, K.L.; Nilsson, M. 1—Introduction to the reprocessing and recycling of spent nuclear fuels. In Reprocessing and Recycling of Spent Nuclear Fuel; Taylor, R., Ed.; Woodhead Publishing: Oxford, UK, 2015. [Google Scholar]
- Silverio, L.B.; de Queiroz Lamas, W. An analysis of development and research on spent nuclear fuel reprocessing. Energy Policy 2011, 39, 281–289. [Google Scholar] [CrossRef]
- Hanson, B. 6—Process engineering and design for spent nuclear fuel reprocessing and recycling plants. In Reprocessing and Recycling of Spent Nuclear Fuel; Taylor, R., Ed.; Woodhead Publishing: Oxford, UK, 2015. [Google Scholar]
- Zou, S.L.; Xie, Y.P.; Wang, K.; Tang, D.W. Reliability analysis and experimental research on cutting tool of vertical shearing machine. Adv. Mater. Res. 2014, 889–890, 441–449. [Google Scholar] [CrossRef]
- Zhang, X.Z.; Zhao, L.H.; Deng, Q.; Song, C. Application of wavelet packet analysis in fault diagnosis of spent nuclear fuel shears. J. Univ. South China (Sci. Technol.) 2014, 28, 69–73. [Google Scholar]
- Wang, Y.S.; Ma, Q.H.; Zhu, Q.; Liu, X.T.; Zhao, L.H. An intelligent approach for engine fault diagnosis based on hilbert–huang transform and support vector machine. Appl. Acoust. 2014, 75, 1–9. [Google Scholar] [CrossRef]
- Tafreshi, R. Feature Extraction Using Wavelet Analysis with Application to Machine Fault Diagnosis. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, 2005. [Google Scholar]
- Lenka, B. Time–frequency analysis of non–stationary electrocardiogram signals using Hilbert-Huang Transform. In Proceedings of the IEEE International Conference on Communications and Signal Processing, Melmaruvathur, India, 2–4 April 2015; pp. 1156–1159. [Google Scholar]
- Yang, Y.; Zhang, W.; Peng, Z.; Meng, G. Time–frequency fusion based on polynomial chirplet transform for non–stationary signals. IEEE Trans. Ind. Electron. 2012, 60, 3948–3956. [Google Scholar] [CrossRef]
- Sun, M.; Cui, S.; Xu, Y. Design and implementation of a time–frequency analysis system for non-stationary vibration signals using mixed programming. Int. J. Hybrid Inf. Technol. 2014, 7, 283–294. [Google Scholar] [CrossRef]
- Burriel-Valencia, J.; Puche-Panadero, R.; Martinez-Roman, J.; Sapena-Bano, A.; Pineda-Sanchez, M. Short-frequency fourier transform for fault diagnosis of induction machines working in transient regime. IEEE Trans. Instrum. Meas. 2017, 66, 432–440. [Google Scholar] [CrossRef]
- Climente-Alarcon, V.; Antonino-Daviu, J.A.; Riera-Guasp, M.; Vlcek, M. Induction motor diagnosis by advanced notch fir filters and the wigner–ville distribution. IEEE Trans. Ind. Electron. 2014, 61, 4217–4227. [Google Scholar] [CrossRef]
- Torrence, C.; Compo, G.P. A practical guide to wavelet analysis. Bull. Am. Meteorol. Soc. 1998, 79, 61–78. [Google Scholar] [CrossRef]
- Ren, H.; Ren, A.; Li, Z. A new strategy for the suppression of cross-terms in pseudo wigner–ville distribution. Signal Image Video Process. 2016, 10, 139–144. [Google Scholar] [CrossRef]
- Daubechies, I. The wavelet transform, time-frequency localisation and signal analysis. J. Renew. Sustain. Energy 2015, 36, 961–1005. [Google Scholar]
- Fei, S.W. Fault diagnosis of bearing based on wavelet packet transform–phase space reconstruction–singular value decomposition and svm classifier. Arab. J. Sci. Eng. 2017, 42, 1967–1975. [Google Scholar] [CrossRef]
- Su, J.; Chen, W.H. Model–based fault diagnosis system verification using reachability analysis. IEEE Trans. Syst. Man Cybern. Syst. 2017, 1–10. [Google Scholar] [CrossRef]
- Li, Y.H.; Wang, J.Q.; Wang, X.J.; Zhao, Y.L.; Lu, X.H.; Liu, D.L. Community detection based on differential evolution using social spider optimization. Symmetry 2017, 9, 183. [Google Scholar] [CrossRef]
- Ding, S.X. Model–Based Fault Diagnosis Techniques: Design Schemes, Algorithms, and Tools; Springer: London, UK, 2013. [Google Scholar]
- Atamuradov, V.; Medjaher, K.; Dersin, P.; Lamoureux, B.; Zerhouni, N. Prognostics and health management for maintenance practitioners-Review, implementation and tools evaluation. Int. J. Progn. Health Manag. 2017, 8, 1–31. [Google Scholar]
- Lang, L.I.; Liu, H.; Zhao, H. Review of vibration monitoring and fault diagnosis methods of wind turbines. Power Syst. Clean Energy 2017, 33, 94–100, 108. [Google Scholar]
- Ramos, A.R.; Lázaro, J.M.B.D.; Prieto-Moreno, A.; Neto, A.J.D.S.; Llanes-Santiago, O. An approach to robust fault diagnosis in mechanical systems using computational intelligence. J. Intell. Manuf. 2017, 1–15. [Google Scholar] [CrossRef]
- Witczak, M.; Pazera, M. Integrated fault diagnosis and fault–tolerant for constrained dynamic systems. In Proceedings of the International Conference on Diagnostics of Processes and Systems, Sandomierz, Poland, 11–13 September 2017; pp. 17–32. [Google Scholar]
- Yang, B.; Yin, L.; Li, G.; Deng, W.; Zhao, H. Research on a new fault diagnosis method based on WT, improved PSO and SVM for motor. Recent Patents Mech. Eng. 2017, 9, 289–298. [Google Scholar]
- Nose, T.; Kobayashi, T. A Study on Phone Duration Modeling Using Dynamic Features for Hmm–Based Speech Synthesis; Ieice Technical Report Natural Language Understanding and Models of Communication; IEICE: Tokyo, Japan, 2011; Volume 111, pp. 197–202. [Google Scholar]
- Liao, Z.; Gao, D.; Lu, Y.; Lv, Z. Multi–scale hybrid HMM for tool wear condition monitoring. Int. J. Adv. Manuf. Technol. 2016, 84, 2437–2448. [Google Scholar] [CrossRef]
- Tao, X.M.; Du, B.X.; Xu, Y. Bearings fault diagnosis based on HMM and fractal dimensions spectrum. In Proceedings of the IEEE International Conference on Mechatronics and Automation, Harbin, China, 5–8 August 2007; pp. 1671–1676. [Google Scholar]
- Ntalampiras, S. Fault Identification in Distributed Sensor Networks Based on Universal Probabilistic Modeling. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1939–1949. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Liu, G.; Qiu, J. Hybrid HMM and SVM approach for fault diagnosis. Chin. J. Sci. Instrum. 2006, 27, 45–48, 53. [Google Scholar]
- Mrugalski, M.; Luzar, M.; Pazera, M.; Witczak, M.; Aubrun, C. Neural network–based robust actuator fault diagnosis for a non-linear multi-tank system. ISA Trans. 2016, 61, 318–328. [Google Scholar] [CrossRef] [PubMed]
- Venkat, V.; Chan, K. A neural network methodology for process fault diagnosis. AIChE J. 2010, 35, 1993–2002. [Google Scholar]
- Patil, A.B.; Gaikwad, J.A.; Kulkarni, J.V. Bearing fault diagnosis using discrete wavelet transform and artificial neural network. In Proceedings of the IEEE International Conference on Applied and Theoretical Computing and Communication Technology, Bengaluru, Karnataka, India, 21–23 July 2016; pp. 399–405. [Google Scholar]
- Tian, D.; Fan, L. A brain MR images segmentation method based on SOM neural network. In Proceedings of the IEEE International Conference on Bioinformatics and Bioengineering, Wuhan, China, 6–8 July 2007; pp. 686–689. [Google Scholar]
- Bashir, Z.A.; El-Hawary, M.E. Applying wavelets to short–term load forecasting using PSO-based neural networks. IEEE Trans. Power Syst. 2009, 24, 20–27. [Google Scholar] [CrossRef]
- Mao, X.; Chen, L.; Fu, L. Multi–level speech emotion recognition based on HMM and ANN. In Proceedings of the IEEE WRI World Congress on Computer Science and Information Engineering, Los Angeles, CA, USA, 31 March–2 April 2009; pp. 225–229. [Google Scholar]
- Fan, X.; Zuo, M.J. Gearbox fault detection using hilbert and wavelet packet transform. Mech. Syst. Signal Process. 2006, 20, 966–982. [Google Scholar] [CrossRef]
- Li, Z.; Liu, B.; Hou, J. Research on rotating machinery fault diagnosis method based on infinite hidden markov model. Chin. J. Sci. Instrum. 2016, 37, 2185–2192. [Google Scholar]
- Ghobadian, B.; Rahimi, H.; Nikbakht, A.M.; Najafi, G.; Yusaf, T.F. Diesel engine performance and exhaust emission analysis using waste cooking biodiesel fuel with an artificial neural network. Renew. Energy 2009, 34, 976–982. [Google Scholar] [CrossRef] [Green Version]
- Bhowmik, T.K.; Parui, S.K.; Kar, M. Segmental k-means algorithm based hidden Markov model for shape recognition and its applications. In Proceedings of the Sixth International Conference on Advances in Pattern Recognition, Kolkata, India, 2–4 January 2007; pp. 361–365. [Google Scholar]
- Deng, Q. Irradiation experiments research of sound sensors. J. Univ. South China 2014, 28, 61–66. [Google Scholar]
- Witczak, M. Toward the training of feed–forward neural networks with the D-optimum input sequence. IEEE Trans. Neural Netw. 2006, 17, 357–373. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maximum Pressing Force | Maximum Shearing Force | Tool Feeding Speed | Feeding Step Distance | Section Size |
|---|---|---|---|---|
| 165 kN | 785 kN | 0.03 m/s | 15 mm | 65 × 65 mm |
| State No. | States | Sample Indices |
|---|---|---|
| 1 | Normal (Normal state without faults) | 1–1 to 1–45 |
| 2 | Fault 2 (Slight tool wear) | 2–1 to 2–40 |
| 3 | Fault 3 (Severe tool wear) | 3–1 to 3–50 |
| 4 | Fault 4 (Damaged tool) | 4–1 to 4–35 |
| Working State No. | Mean of Feature Element Values of All Samples in Every Frequency Band | |||||||
|---|---|---|---|---|---|---|---|---|
| band 1 | band 2 | band 3 | band 4 | band 5 | band 6 | band 7 | band 8 | |
| 1 | 0.7358 | 0.1819 | 0.0107 | 0.0622 | 0.0007 | 0.0021 | 0.0043 | 0.0023 |
| 2 | 0.6748 | 0.1537 | 0.0196 | 0.0779 | 0.0544 | 0.0054 | 0.0095 | 0.0046 |
| 3 | 0.7828 | 0.1283 | 0.0161 | 0.0506 | 0.0034 | 0.0041 | 0.0088 | 0.0060 |
| 4 | 0.6697 | 0.2064 | 0.0199 | 0.086 | 0.001 | 0.0027 | 0.0094 | 0.0049 |
| Sample Sets | Normal | Fault 2 | Fault 3 | Fault 4 | Total |
|---|---|---|---|---|---|
| Training | 27 | 24 | 30 | 21 | 102 |
| Testing | 18 | 16 | 20 | 14 | 68 |
| Training Rule | Neurons in Hidden Layer | Training Error (mse) | R |
|---|---|---|---|
| trainlm | 10 | 3.10 | 1 |
| traingdx | 10 | 5.00 | 0.85633 |
| trainrp | 10 | 4.62 | 0.86827 |
| trainscg | 10 | 1.44 | 0.96095 |
| trainlm | 5 | 2.26 | 0.99397 |
| trainlm | 8 | 3.40 | 0.99991 |
| trainlm | 12 | 7.12 | 1 |
| trainlm | 14 | 2.22 | 1 |
| States | State No. | Predicted Values | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Normal | 1 | 1 | 3 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | – | – |
| Fault 2 | 2 | 2 | 3 | 2 | 2 | 2 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | – | – | – | – |
| Fault 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 4 | 3 | 3 | 3 | 4 | 3 | 3 |
| Fault 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | – | – | – | – | – | – |
| States | State No. | Predicted Values | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Normal | 1 | 1 | 1 | 3 | 2 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | – | – |
| Fault 2 | 2 | 2 | 4 | 2 | 2 | 2 | 4 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | – | – | – | – |
| Fault 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 3 | 3 | 2 | 3 | 2 | 3 | 3 | 3 | 3 | 2 | 3 | 3 |
| Fault 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | – | – | – | – | – | – |
| States | State No. | Predicted Values | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Normal | 1 | 4 | 3 | 3 | 4 | 4 | 4 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | – | – |
| Fault 2 | 2 | 4 | 2 | 2 | 2 | 2 | 2 | 4 | 4 | 2 | 2 | 2 | 2 | 2 | 2 | 4 | 2 | – | – | – | – |
| Fault 3 | 3 | 3 | 3 | 3 | 4 | 3 | 3 | 4 | 4 | 4 | 3 | 2 | 3 | 4 | 4 | 3 | 3 | 3 | 3 | 4 | 3 |
| Fault 4 | 4 | 2 | 4 | 4 | 2 | 1 | 4 | 2 | 4 | 2 | 4 | 4 | 2 | 2 | 4 | – | – | – | – | – | – |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.-H.; Zou, S.-L. An Intelligent Condition Monitoring Approach for Spent Nuclear Fuel Shearing Machines Based on Noise Signals. Appl. Sci. 2018, 8, 838. https://doi.org/10.3390/app8050838
Chen J-H, Zou S-L. An Intelligent Condition Monitoring Approach for Spent Nuclear Fuel Shearing Machines Based on Noise Signals. Applied Sciences. 2018; 8(5):838. https://doi.org/10.3390/app8050838
Chicago/Turabian StyleChen, Jia-Hua, and Shu-Liang Zou. 2018. "An Intelligent Condition Monitoring Approach for Spent Nuclear Fuel Shearing Machines Based on Noise Signals" Applied Sciences 8, no. 5: 838. https://doi.org/10.3390/app8050838
APA StyleChen, J.-H., & Zou, S.-L. (2018). An Intelligent Condition Monitoring Approach for Spent Nuclear Fuel Shearing Machines Based on Noise Signals. Applied Sciences, 8(5), 838. https://doi.org/10.3390/app8050838