1. Introduction
According to the Smart Tourism Report 2015, as based on the tourism statistics of the Taiwanese Government and released by the United Daily News, tourism has become one of the fastest-growing economic sources in the world, accounting for 10% of the global GDP and generating 277 million jobs. In the face of the fast-growing number of international tourists, which is expected to exceed 10 million, Taiwan must consider a complete solution for smart tourism according to its advantages in the ICT industries, which feature high added value and global exemplary effects. This is the greatest motivation for this paper, to explore smart tourism.
Big data refers to information that is so massive it is impossible to manually obtain, manage, process, or summarize it into information interpreted by human beings within an appropriate period. Therefore, it is almost impossible to process big data with most traditional database management systems; instead, it must be processed by “software that can simultaneously operate on more than tens of, hundreds of, and even thousands of servers [
1,
2].” Huang [
3] argued that data periods are not necessarily as massive as TB, PB, or EB (exabytes, EB = 10
18 = 1000 PB, petabytes = 1000 TB, terabytes = 1000 GB, gigabytes), but must be in a “complete,” “relative” database, or must be processed and analyzed into useful information to show the relationship among the information segments. This is the main reason why this study adopts time-series analysis [
4,
5] for relevant analysis. Thus, the greatest challenge for this paper is to support the Dr. What-Info III system, which is based on big data technology, and to determine the feasibility of further research on Dr. What-Info and its expansion.
As mentioned by Eric E. Schmidt, Google CEO at the Asian-Pacific event “The Mobile First World” in November 2014, “The mobile revolution has driven industries from the Web First to Mobile First and then Mobile Only.” According to Bin-hsian Liang, the Director-General of Taiwan’s Internet of Things Alliance and Chairman of Flowring Technology, 2015 marked the transition from the Electronic Era to the Intelligence Era; from the perspective of intelligence, the Internet of Things, cloud technology, big data, mobile devices, and community media should be the five indispensable factors of the Intelligence Era. Based on the creation principle of Mobile Only, Dr. What-Info [
6] aims to improve the development of mobile device-related practical technologies. With the assistance of cloud technology, Dr. What-Info II [
7] introduces the latest, accurate, and complete “open data by governments”, and combines them with the ontological index architecture, thus, it provides the corresponding value-added services of cloud information with “mobile” device positioning technology. With the strong information agent system CEOntoIAS (Cloud Extension of Ontological Information Agent Shell) [
8], a suitable LBS (location-based service) is selected to achieve the optimal information solution similar to community-like inquiring and sharing. Finally, Dr. What-Info III, as based on big data technology [
9], explores the Internet, which is similar to the Internet of Things (information providers are like information sensors on the Internet), and offers the corresponding useful and latest information. The MapReduce paralleled decrement mechanism [
10,
11] of the cloud information agent CEOntoIAS, as established on the Hadoop-like architecture, and the combination of Software R [
12] and time series analysis enhance the precision, reliability, and integrity of cloud information, and effectively improves the aforesaid five indispensable factors of the Intelligence Era, and then, contributes to research on the feasibility of Dr. What-Info expansion.
4. Domestic and Foreign Literature Analysis and Development Technology
As abovementioned, 2014 was the year of the “information economy,” and since then, there has been an increasing number of domestic and foreign discussions regarding big data; moreover, they are combined with ontology and linked data [
15]. For instance, Lin [
9] adopted Pearson Correlation Analysis to confirm the homogeneity among variables, and used big data regarding external environment factors, such as temperature, humidity, wind speed, and population density to establish an alarm system for the dengue fever epidemic. Bodislav [
16] elaborated on corporate governance technology, which integrated business wisdom with hybrid leading indicators of big data. Wang et al. [
17] presented a systematic approach, which adopted a set of ontologies and methods as a first step in the direction of a formalization of partially automatic extraction and integration of sketch map content, in order to sketch map the interpretation, and work through an example that demonstrates the sketch map interpretation at different levels using the underlying method. Huang et al. [
18] proposed, developed, implemented, and evaluated a relative positioning approach that adopted a linked data-based technical framework where the data are organized according to ontologies, which are designed based on the GeoSPARQL vocabulary, in order to synchronize geometric representations for map mashups through several scales. Li et al. [
19] proposed a new development stage of geomatics entitled “Connected Geomatics,” which is defined as a multi-disciplinary science and technology that uses systematic approaches and integrates methods pertaining to any physical objects and human activities on earth, including spatio-temporal data acquisition, information extraction, network management, knowledge discovery, spatial sensing and recognition, and intelligent location-based services. As abovementioned, this system also introduces the currently-popular big data analysis, the Hadoop-like architecture, the MapReduce paralleled decrement mechanism (
http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html), Software R analysis (
http://www.r-software.org/), and time series analysis (short for the time series analysis supported by big data analysis), in order to establish OntoDMA and OntoCBRA of the multi-agent system CEOntoIAS, which supports cloud smart information processing and decision-making, in order to strengthen the system’s prediction ability, as well as the location-based operational robustness of the system. This is the greatest contribution in the research objective of Dr. What-Info III in this program.
The time series analysis has been applied in many domestic and foreign academic papers, and even combined with big data. Lin [
4] used the semi-conductor industrial stock-like factor analysis in the stock market with relevant coefficients to analyze and select factors; moreover, the time series model was combined with regression analysis to provide a fast and effective demonstration model DFSS_IDOV (Design for Six Sigma—Identify, Design, Optimize, and Verify). Schuster et al. [
20] proposed adopting intra-annual time series analysis in the comparative application of pasture habitats to explore technologies for comparison of the satellite data of RapidEye and TerraSAR-X. Pravilovic et al. [
21] presented a cluster-centric forecasting methodology that allows users to yield a characterization of correlation in geophysical time series through a spatio-temporal clustering step, and the experimental results highlight the importance of dealing with both temporal and spatial correlation, and validate the proposed cluster-centric strategy in the computation of a multivariate time series forecasting model. Shrestha and Bhatta [
22] discussed the properties of time series data, compared common data analysis methods, and presented a methodological framework with an example: Nepal’s money–price relationship for time series data analysis, and the test results obtained following this methodological framework were found to be more robust and reliable. As abovementioned, this study uses Jaccard similarity and dissimilarity distance of relevant inquiry keywords and relevant ontological keywords to analyze and select a set of corresponding keyword factors. Then, the time series model is combined with appropriate regression analysis to extract the keyword factors with the same development trend similar to that obtained with the Fourier-Gaussian decomposition method. In this way, the optimal information development trend will be obtained to support the analysis and operation of the entire system and, thus, fulfill the research objective of integrating time series with big data analysis to support Dr. What-Info III.
The MapReduce paralleled decrement mechanism has been used in many domestic and foreign academic literatures, especially those based on Hadoop. Chang [
10] adopted the Hadoop cloud operation platform to integrate TF-IDF weights with representative keywords in documents, hierarchical agglomerative clustering and K-nearest neighbor’s algorithm, and concept analysis, to determine the technologies for improving the precision of unclassified documents in the HDFS distributed archive system. Triguero et al. [
11] proposed distributing the functions of operation algorithms with an operation element cluster, and put forward many operational strategies, such as integrating some operational solutions into one to establish a new MRPR (MapReduce for Prototype Reduction) architecture. Glushkova et al. [
23] considered architectural changes and captured the execution flow of a MapReduce job by using queuing a network model, as based on an existing performance model for Hadoop 1.x. Gouasmi et al. [
24] proposed an exact MapReduce scheduling model to serve as a baseline for benchmarking and to compare and discuss heuristic algorithm results, and performance evaluation proved that the proposed algorithm FDMR (Federated Distributed MapReduce) could improve resource utilization of the cloud federation, and consequently, reduce the cost and job response time while satisfying the deadline constraint. According to the above studies, the environment for the research, development, and simulation of nearly all systems was the combination of Hadoop and MapReduce. This is the greatest motivation for this program to adopt big data analysis and the MapReduce paralleled decrement mechanism under the Hadoop-like framework.
There have been many domestic and foreign studies using R software, especially those combining with other languages. Weng [
25] used the Cox proportion risk model and random intercept to evaluate the influence of time-dependent explanatory variables on the time of existence in R statistical software. Azam [
12] studied the historical, present, and future role of R statistical software in data analysis. Bolduc et al. [
26] presented R2MCDS, which is an R package that provides tools to call the multiple-covariate distance sampling (MCDS) engine from the Distance 6.2 software in the R environment, and demonstrated the applicability of the package for multi-species surveys using data from the Eastern Canada Seabirds of the Sea (ECSAS) database. Frías et al. [
27] proposed an R package that is part of the
climate4R bundle, thus, providing transparent access to the ECOMS-UDG climate data service, which allowed a flexible application of visualizeR to a wide variety of specific seasonal forecasting problems and datasets. Manubens et al. [
28] proposed an open-source R package: s2dverification v2.8.0 for the quality assessment of climate forecasts using state-of-the-art verification scores, in order to provide tools for each step of the forecast verification process: data retrieval, processing, calculation of verification measures, and visualization of the results. As abovementioned, statistical Software R can improve statistics, drawing, programming interface, and data input/output through the packages of users, and can provide various language interfaces, such as R, LaTeX, Java, C or C++, and Fortran. Moreover, the CRAN (Comprehensive R Archive Network, URL:
https://cran.r-project.org/web/packages/) includes different software packages for economic measurement, financial analysis, humanities, and artificial intelligence. Hence, the motivation for combining R statistical software with the time series analysis in this program is obvious.
To sum up, this study focuses on presenting the development trend from the perspective of data-oriented evidence, especially open data and technologies; as those numbers can verify and prove current technology trends and user information requirements. In addition, based on the practical progress of Dr. What-Info I and II, this paper continues to develop Dr. What-Info III. Moreover, the big data technology, the MapReduce paralleled decrement mechanism of the cloud information agent CEOntoIAS, as supported by the Hadoop-like framework, R software, and time series analysis are adopted to enhance the precision, reliability, and integrity of cloud information, which will effectively improve the inquiring and sharing of mobile information.
5. Proposed System Architecture and Involved Technologies
5.1. MapReduce Paralleled Decrement Mechanism with Dr. What-Info III
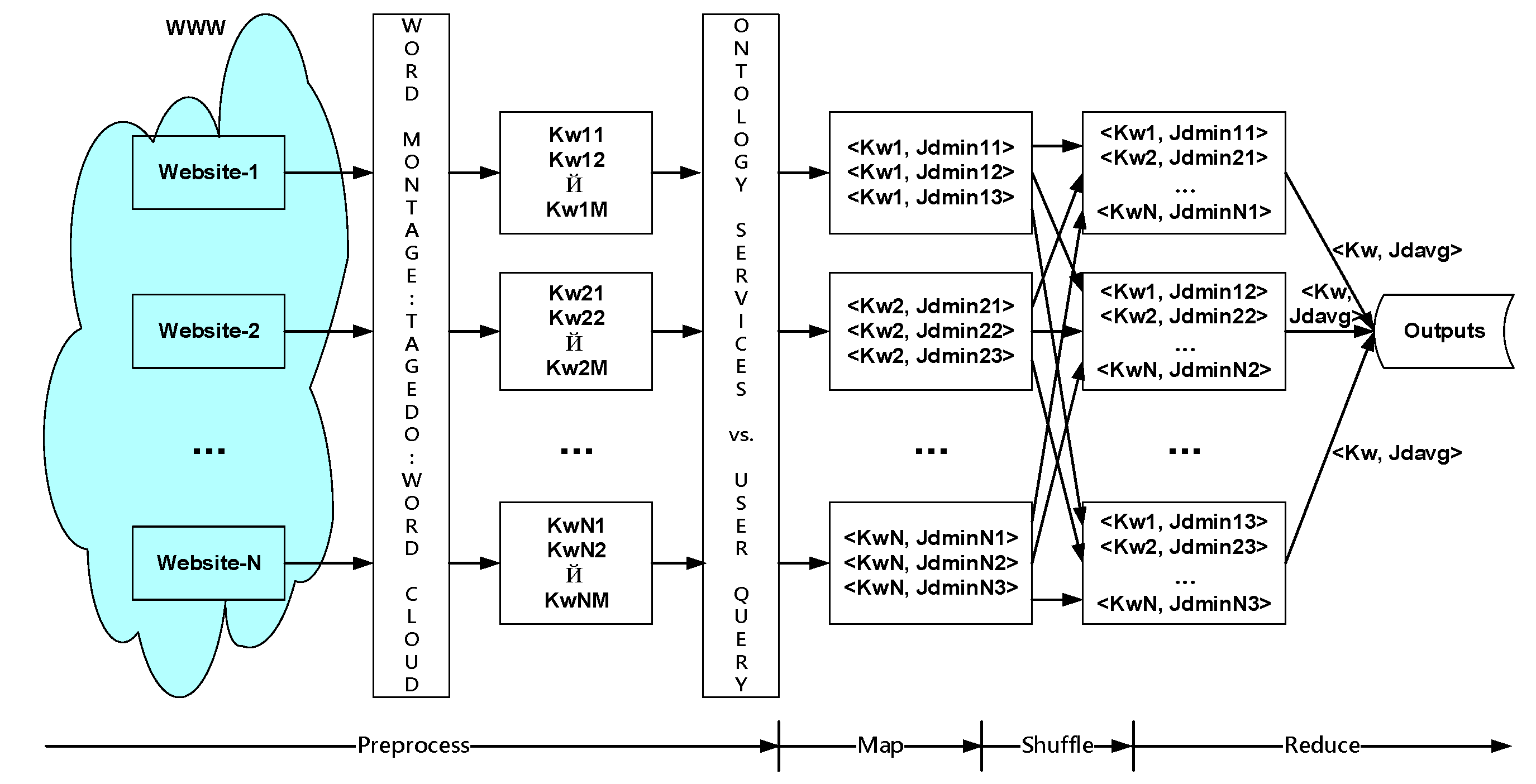
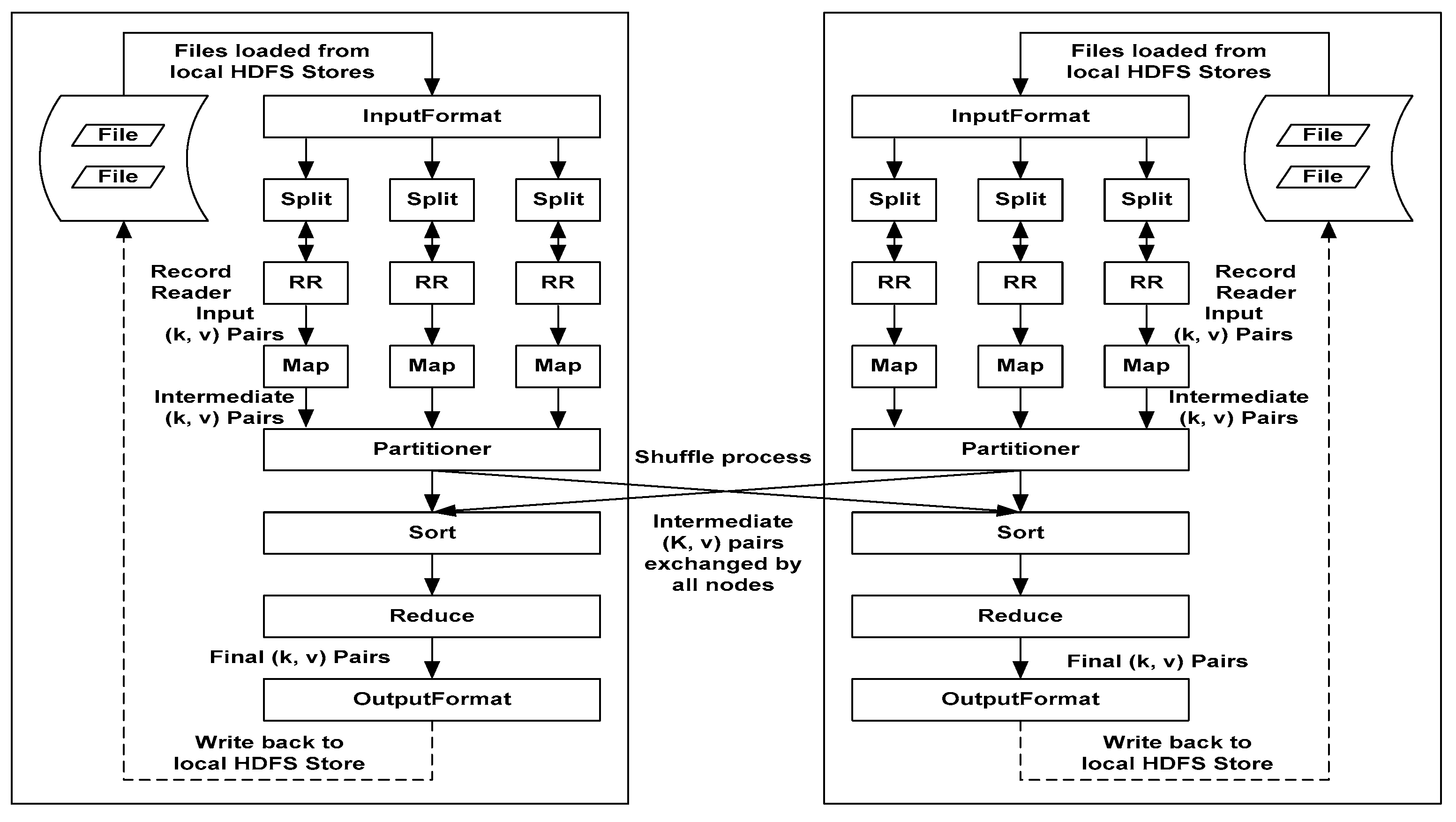
The paralleled decrement mechanism of this study consists of four steps: (1) the preprocess operation to generate the corresponding keywords of a website; (2) the Map operation using the coordinated Jaccard dissimilarity of domain ontology to obtain the three corresponding keyword sets of a website; (3) the Shuffle operation of summarizing the three optimal keyword sets of a website; and (4) the Reduce operation of using the average output of Jaccard dissimilarity [
13] and user to inquire the three closest corresponding keywords, as shown in
Figure 8.
- (1)
The preprocess operation of generating the corresponding keywords of a website;
First, Tagxedo is used, which is a word montage (Tagxedo:
http://www.tagxedo.com supporting Chinese-English word tag cloud) automatic graphic archive generator. Then, word frequency is calculated through a simple software operation (such as R) to create a colorful word cloud, which displays the important and meaningful information of the website. However, if the keyword set is too large, its information will not be representative enough to serve as the standard for the information selection and recommendation of the system. Hence, it is necessary to reduce the quantity of keywords and render the keywords more representative.
- (2)
The Map operation of using the coordinated Jaccard dissimilarity of domain ontology to obtain the three corresponding keyword sets of a website;
As abovementioned, Jaccard dissimilarity in the ontological service represents the relationship between keywords, and a closer relationship indicates a lower value of Jaccard dissimilarity. In other words, the domain ontology service is used to compare users’ relevant inquired keywords to calculate the corresponding Jaccard dissimilarity (a lower value would be closer to user’s demand for information, thus, the sequence is based on Jdmin). Then, the quantity of the keywords of the abovementioned websites is reduced to three, in order to complete this Map operation.
- (3)
The Shuffle operation of summarizing the three optimal keyword sets of a website;
First, there is correlation regarding the preference for some information among information seekers. Therefore, this shuffle operation reorganizes the optimal keywords of some websites to form an optimal keyword set to indicate that these keywords are the closest to the information demand of users. Then, second and third keyword sets are created to lay a foundation for the system to calculate the most recommended information.
- (4)
The Reduce operation of using the average output of Jaccard dissimilarity and user to inquire the three closest corresponding keywords;
If the system generates corresponding recommended information according to abovementioned steps 2–3, the recommended information will not be representative, and its quantity will be too large. This will appear to be redundant, as the information will be similar to that obtained through the search engine-based inquiry. Hence, this system aims to shorten the gap between recommended information and users’ information demand. This operation will calculate the optimal keyword set from some websites, as well as the averages of some Jaccard dissimilarities (Jdavg1, Jdavg2, and Jdavg3) of the second and third keyword sets, in order to generate three corresponding keywords closest to the user’s inquiry and, thus, fulfill the objective of achieving the narrowest gap between the most recommended information and users’ information demand.
According to the above and relevant literature analysis, this study explores the concept of “R + Hadoop = Big Data Analytics” under the open-source framework of Hadoop. In other words, the open-source framework of Hadoop will be combined with R, as well as a piece of similar open-source analysis software, in order to establish the abovementioned MapReduce paralleled decrement mechanism. Moreover, the keyword-corresponding Jaccard dissimilarities, as supported by the domain ontology service, are integrated to establish the MapReduce paralleled decrement mechanism, in order to facilitate the information services of WIAS, as based on the big data analysis in Dr. What-Info III. The actual operation map is shown in
Figure 9 [
29]. In particular, OutputFormat establishes the ontological database (OD) according to the domain ontology service index and the relationship between Jaccard dissimilarity establishment and real information. The OD will be the operational basis of the follow-up time series analysis supported by the big data analysis of the abovementioned domain ontology index.
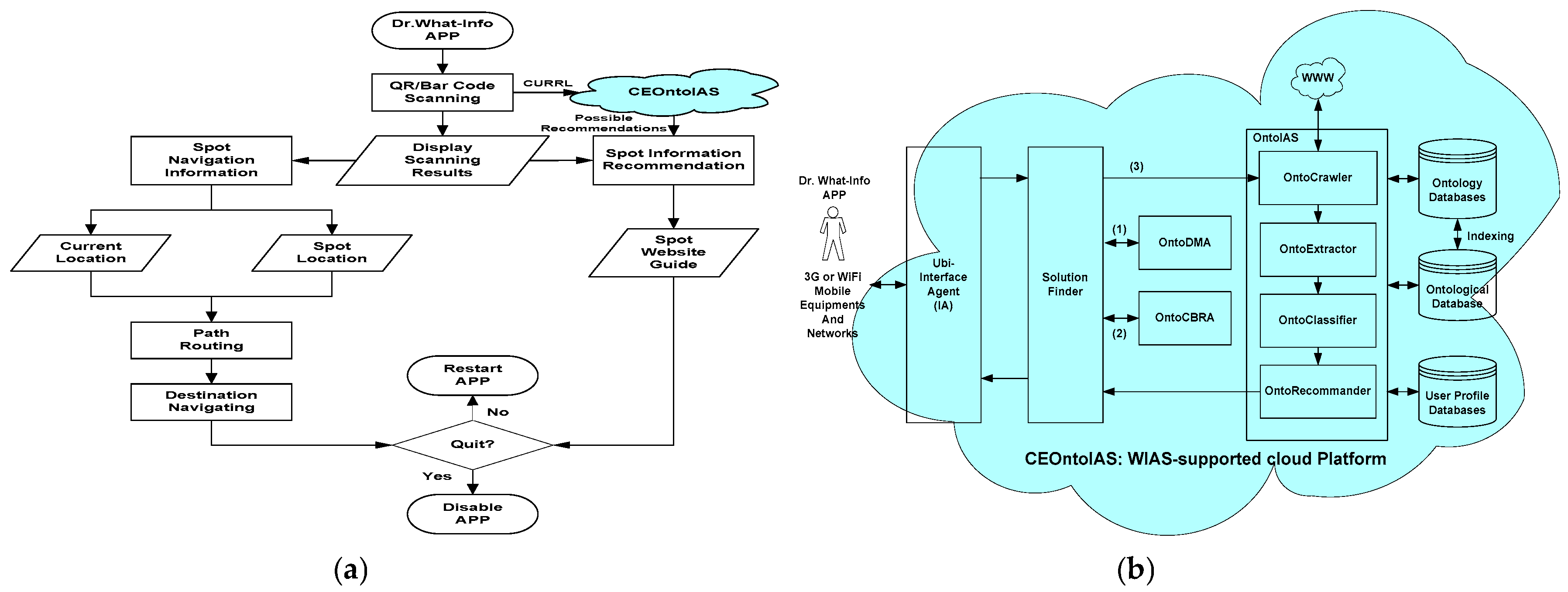
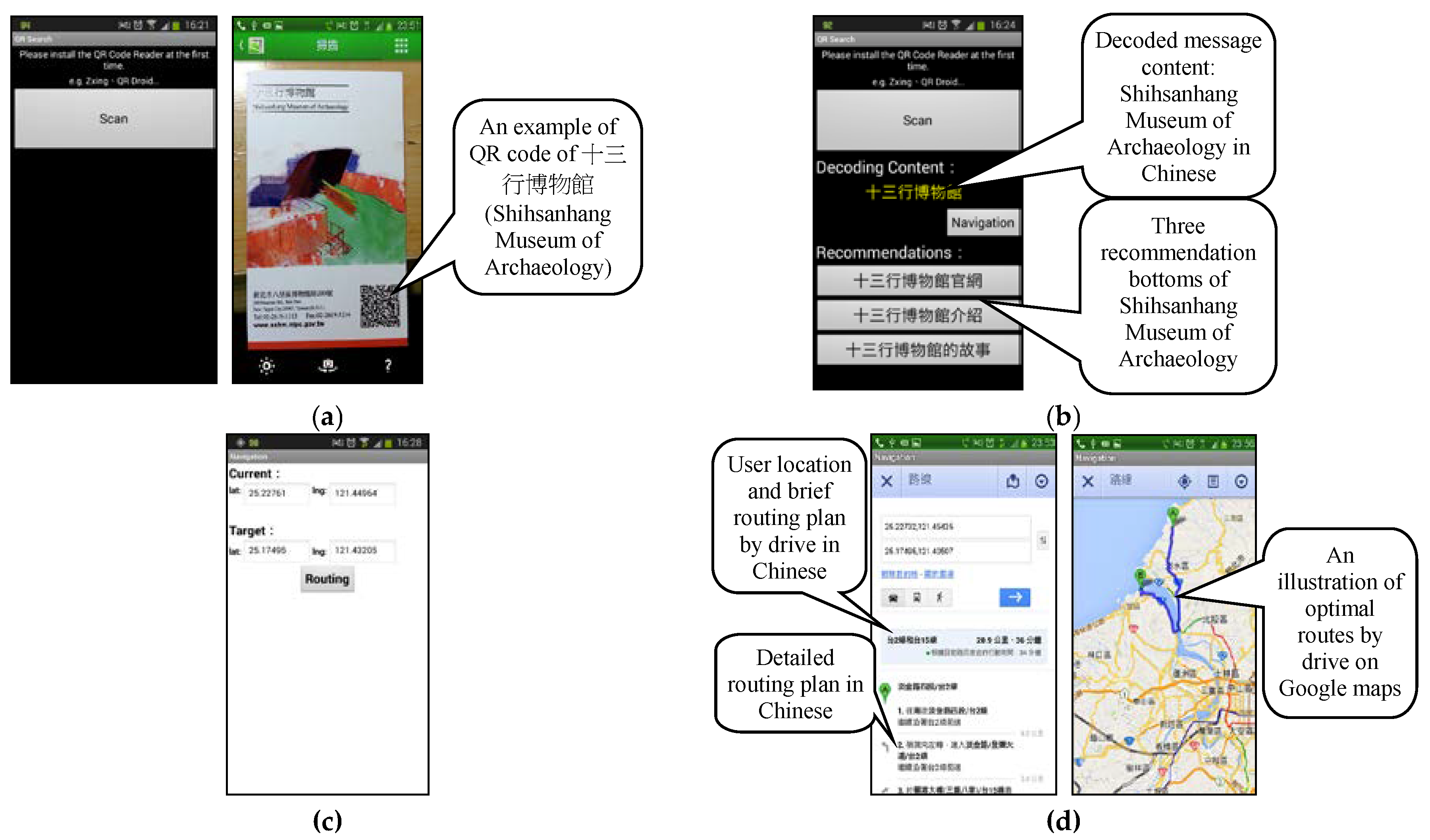
To sum up, mobile device users adopt the cameras or recorders of mobile information devices to recognize and converse corresponding inquired semantic content through the Dr. What-Info III APP and the multi-media semantic analysis sub-system, and describes it with XML. The corresponding query data are returned to the cloud server system CEOntoIAS to facilitate the processing of cloud information and the decisions regarding the inquiry. In the initial stage of the operation of Dr. What-Info III, the cloud information ontology, as established by domain experts, is combined with the corresponding preset rules to retrieve useful information about word frequency in the information inquiry, as well as the support and confidence of the corresponding prediction rules of the initialized information inquiry. Meanwhile, the inter-case similarity operation, as supported by the WIAS network service of the cloud information ontology, is conducted to initialize information agent CEOntoIAS. After the operation of Dr. What-Info III, the system will periodically respond to the frequency of information inquiry, and count the most and least frequent inquired information through time series analysis. OntoCBRA will generate the information regarding relevant cases, and use the two-stage time series prediction algorithm (to be detailed later) to trigger prediction rules consistent with the OntoDMA modification. With the technical assistance of UAI, the selection of local GPS, OpenData@Taiwan/Taipei, and the domain ontology, it will select appropriate corresponding information through comparison to effectively improve the inquiring and sharing of mobile information. Moreover, if the above two fail to provide appropriate cloud information solutions, Dr. What-Info III will trigger OntoIAS to use other technologies, such as information-like search, information selection, information classification, and information presentation (or sequence) of the Preprocess, Map, Shuffle, and Reduce of the abovementioned paralleled decrement mechanism to seek appropriate cloud information solutions outside the Internet. Then, the preset rules, as formulated by domain experts, will be followed to fully establish a learning recycle in response to information inquiry. In this manner, the time of processing inquired information is shortened through the exploration of the knowledge and rules of cloud information operations; moreover, the cases and operation models of processing cloud information are acquired to enhance the system’s robustness in processing inquired information, which will facilitate achieving the research objective of obtaining optimal cloud information solution suitable for users and domains.
5.2. Two-Stage Time Series Prediction Algorithm with OntoDMA
The OntoDAM [
5] obtains the relevant object-action pairs, or uses the Jaccard index, to convert inquiry keywords into corresponding values according to the relevant semantic location and distance of ontology. The two-stage procedure of prediction rule generation, as based on the changes to cases generated by OntoCBRA, are as follows.
- (1)
Analysis for specific period and regular location: This study adopts time series analysis to select the cases of specific semantic periods and locations as the alternative information, which is also the greatest difference between this study and traditional information systems: the system operation interface automatically has the function of self-explanation with the assistance of semantic technologies.
- (2)
Specific inquiry type analysis driven by the above events: according to the above definition of the combination of alternative information in Step (1), it is necessary to select alternative case information (
C1~
Cn), which has a period longer than that of case generation; then, the
VUP and
VDOWN of the corresponding values of the same inquiry type are made into corresponding prediction rules
P(
C1) = {
C1(
VDOWN),
C1(
VUP)},
P(
C2) = {
C2(
VDOWN),
C2(
VUP)}, …,
P(
Cn) = {
Cn(
VDOWN),
Cn(
VUP)}; the corresponding
VUP and
VDOWN are sequenced, and the set after sequencing is called
SVi (sorted values); finally, the maximum and minimum in
SVi will be the prediction rule
P(
SVi) = {
SVi(
VMAX),
SVi(
VMIN)} for specific events and inquiry type in the period. The rule analysis and generation procedures are shown in Equation (4). All prediction rule sets are integrated into a prediction rule base, and the corresponding Web services are used to obtain prediction solutions.
During the online operation of OntoDMA, the inquired information is transmitted from the Solution Finder in Ubi-IA; then, the information inquiry is conducted in relevant sub-agent systems one by one according to the abovementioned smart inquiry and decision-making processing. First, the time series is adopted to analyze the information value (
Vpro); then, the corresponding prediction rules (
PAns1(
SV1) –
PAnsN(
SVN)) of specific inquiry types (
SV1 –
SVN) driven by suitable periods and events are obtained from the prediction rule database; after that, the corresponding
VMAX and
VMIN are sequenced, and the set after sequencing is called
SSVi; finally, the maximum and minimum in
SSVi are obtained to meet the prediction solution rules
P(
SSVi) of this information data. After the generation of prediction solution rules,
Vpro is compared with corresponding
SSVi(
VMAX) and
SSVi(
VMIN). If
Vpro >
SSVi(
VMAX) or
Vpro <
SSVi(
VMIN), and the value that declines to
SSVi(
VMAX) or increases to
SSVi(
VMIN) will be taken as the prediction value of the information data (
Vpro). Finally, this system reversely converses the prediction value into corresponding cloud information solution words according to the ontological service of “semantic distance conversion of index word”. The prediction solution analysis and the generation procedure are shown in Equation (5). In case of impossible processing, none will be returned as the controlled response, which indicates the seldom appearance or non-existence of corresponding inquired information. All these actions are returned to Ubi-IA through the web-service-based interface in WIAS.
7. Conclusions and Discussion
With the creation principle of “Mobile Only,” This system develops relevant practical technologies of mobile devices, coordinates the back-end system CEOntoIAS, and adopts three-stage smart inquiry decisions, as dominated by the domain ontology, to establish the smart mobile information inquiring and sharing multi-agent system Dr. What-Info, which can precisely, quickly, and effectively inquire and share information, and is based on camera recognition technology. Dr. What-Info II is equipped with the “cloud” technology to combine the latest, accurate, and complete “open data by government” with the domain ontology index framework. Then, the positioning technology of “mobile” devices offers corresponding cloud information value-added services. By integrating the UAI with the strong back-end information agent system CEOntoIAS, it selects an appropriate LBS through comparison to give play to the “community”-like solution of inquiring and sharing optimal information. This not only effectively improves the “value-added” mobile information, it also enhances the prevision, reliability, and integrity of location-based information. Finally, the proposed system adopts big data analysis to explore the MapReduce paralleled decrement mechanism of the cloud information agent CEOntoIAS, as established on, and supported by, the Hadoop-like framework, and the combination of R software and time series analysis on the Internet, which is similar to the Internet of Things (information providers are like the information sensors on the Internet that offer corresponding useful and latest information). The development includes: (1) the time series analysis is supported by the big data analysis of the domain ontology index; (2) OntoDMA supported by CEOntoIAS is established with the network service technology; (3) OntoCBRA supported by CEOntoIAS is established with the network service technology; and 4) the smart mobile information inquiring and sharing multi-agent system equipped with big data analysis is supported by CEOntoIAS, as established with the network service technology. It is also hoped that the development of Dr. What-Info will reveal some academic achievements from the practical perspective of technical and vocational schools, in order to establish a smart mobile information inquiring and sharing multi-agent system featuring precision, fastness, robustness, universality, and initiative. The achievements and conclusions of this study are listed, as follows:
- (1)
Actively develop the agent, UAI, and big data analysis; help users quickly, precisely, and effectively obtain useful and open data in an appropriate and timely manner; apply the extended ontological information agent EOntoIAS to appropriate information fields in a more practical manner; establish CEOntoIAS with the WIAS network service technology. Therefore, this study effectively extends the research achievements of the early stage.
- (2)
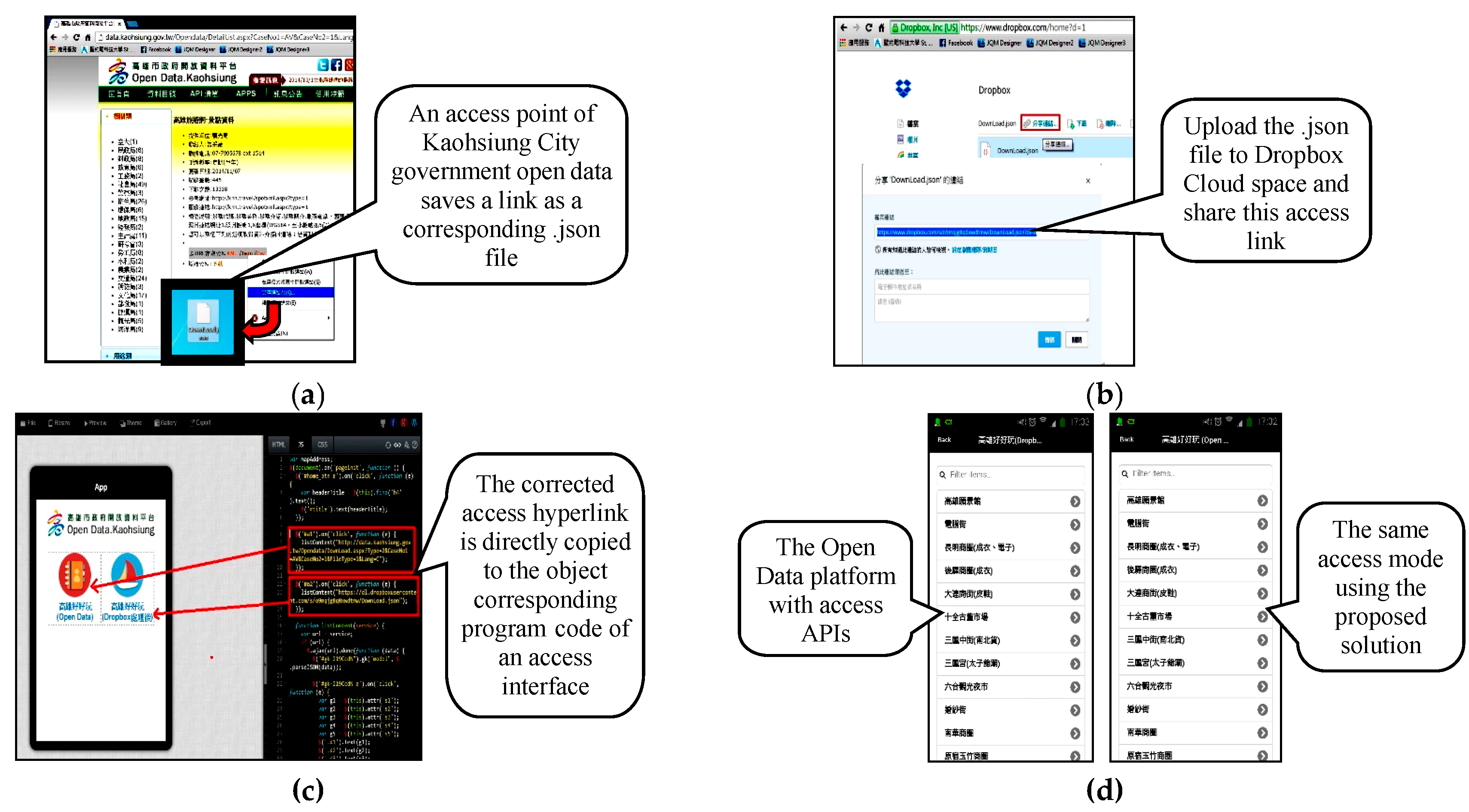
Integrate UAI and the MapReduce paralleled decrement mechanism, and combine R software with the time series analysis with the WIAS-supporting network service; establish the cloud operation interaction model for the multi-agent system of smart mobile information inquiring and sharing; achieve universal storage and retrieval of cloud information; fulfill the ultimate objective of Mobile Only and from Open Data to Open API, and extend this to research regarding the feasibility of Dr. What-Info. Therefore, this technology has some economic benefits and a bright application future.
- (3)
Establish the cloud interaction example supported by network service with the operation of CEOntoIAS; the camera and recorder of mobile devices and the sub-system of multi-media semantic analysis, as supported by ontology, are adopted for recognition and conversion; XML is used to describe the semantic contents of corresponding inquiry. With three-stage (OntoDMA, OntoCBRA, and OntoIAS) smart decision-making, the proposed system leads to the optimal cloud (mobile) information solutions for both users and domains. Moreover, it selects appropriate corresponding information with the MapReduce paralleled decrement mechanism of the cloud operation environment WIAS, as established on and supported by the Hadoop-like framework, R software, times series analysis, the UAI technology, the local GPS capture, the OpenData@Taiwan/Taipei, and the domain ontology. In this way, it effectively improves the inquiring and sharing of mobile information, and enhances the precision, reliability, and integrity of location-based information. Hence, this study is different from the information agent systems reported in the literature.
- (4)
The operation of the proposed system is conducted through the integration of open data by the Taiwanese Government, the universal application interface, the time series analysis supported by the big data analysis of the domain ontology index, and the multi-agent system CEOntoIAS for decisions on the processing, exchange, communication, operation, integration, analysis, and inquiry of smart cloud information in the above three-stage smart cloud decision. In addition to obtaining the operational truth of seeking optimal cloud information solutions in a precise, fast, robust, universal, and active manner, it effectively improves the inquiring and sharing of mobile information, and then, enhances the precision, reliability, and integrity, and improves the five indispensable elements of the abovementioned Intelligent Era, and then explores the feasibility of the extension of Dr. What-Info. Therefore, this study is innovative, as compared with the information agent systems reported in the literature.
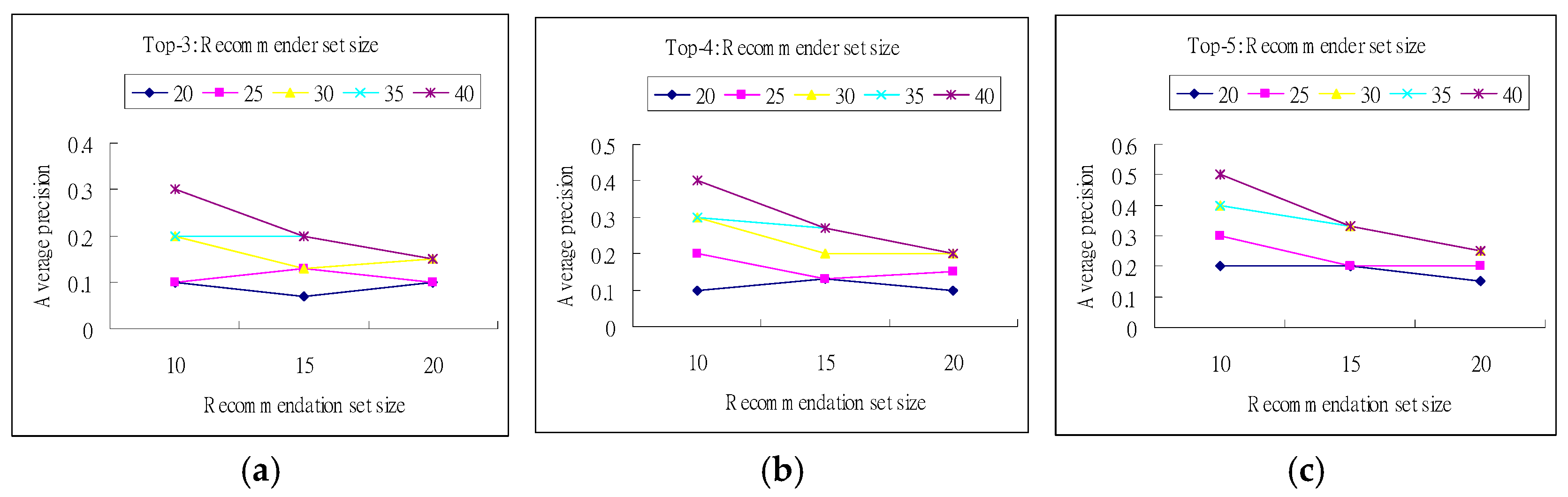
Furthermore, the overall satisfaction of the usability of the proposed system and the ease of using the interface design is 80% in terms of Quesenbery’s 5Es and Nielsen ratings, which indicates that this system must be improved in two aspects: error tolerance and help documentations. In addition, the verification results of the interface design show that the human-machine interface of our proposed system can meet important design preferences and provide approximately optimal balance. Then, the top-n experiment shows that the top-5 recommendations would be better for solving the traditional tradeoff between output quality and processing time. Finally, from system effectiveness experiments, the proposed system receives an overall function’s up-to-standard rate of 87.5%, and those recommendations provide users with high information correctness and user satisfaction. In other words, while the interface appearance is more convenient, the operation and fluency are somewhat insufficient, and should be enhanced; the information correctness is graded as being high, and the graphical menu design of the system is easy for the users, which are obvious outcomes. Although there is plenty of room for improvement in experience, the feasibility of the proposed service architecture has been proven.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}