Head Pose Detection for a Wearable Parrot-Inspired Robot Based on Deep Learning

 ,
,  , and
, and
Abstract
1. Introduction
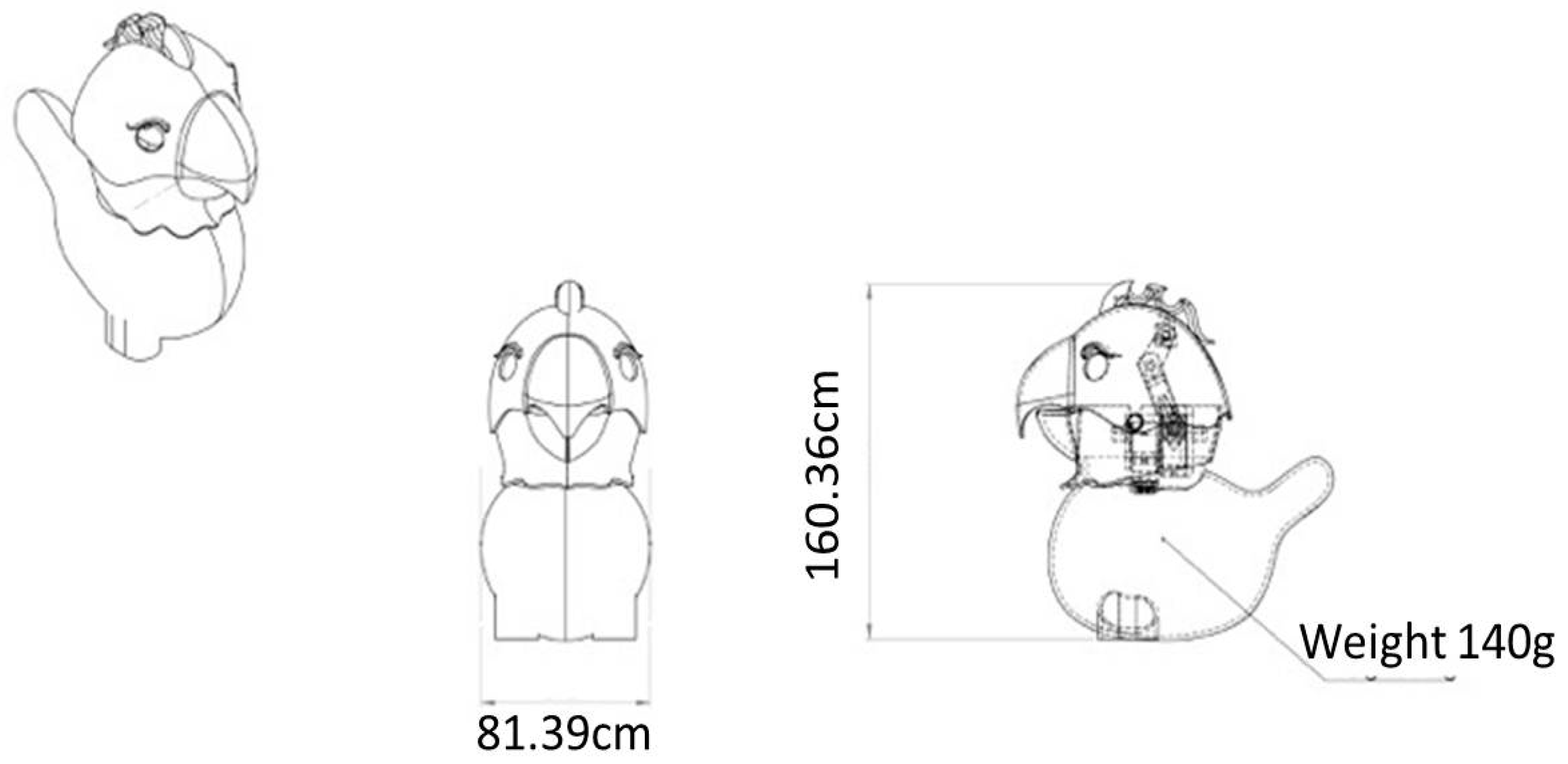
2. Robot Architecture
- Height <250 mm;
- Weight <250 g;
- Head rotation 180 degrees;
- Operate between 10 °C and 45 °C
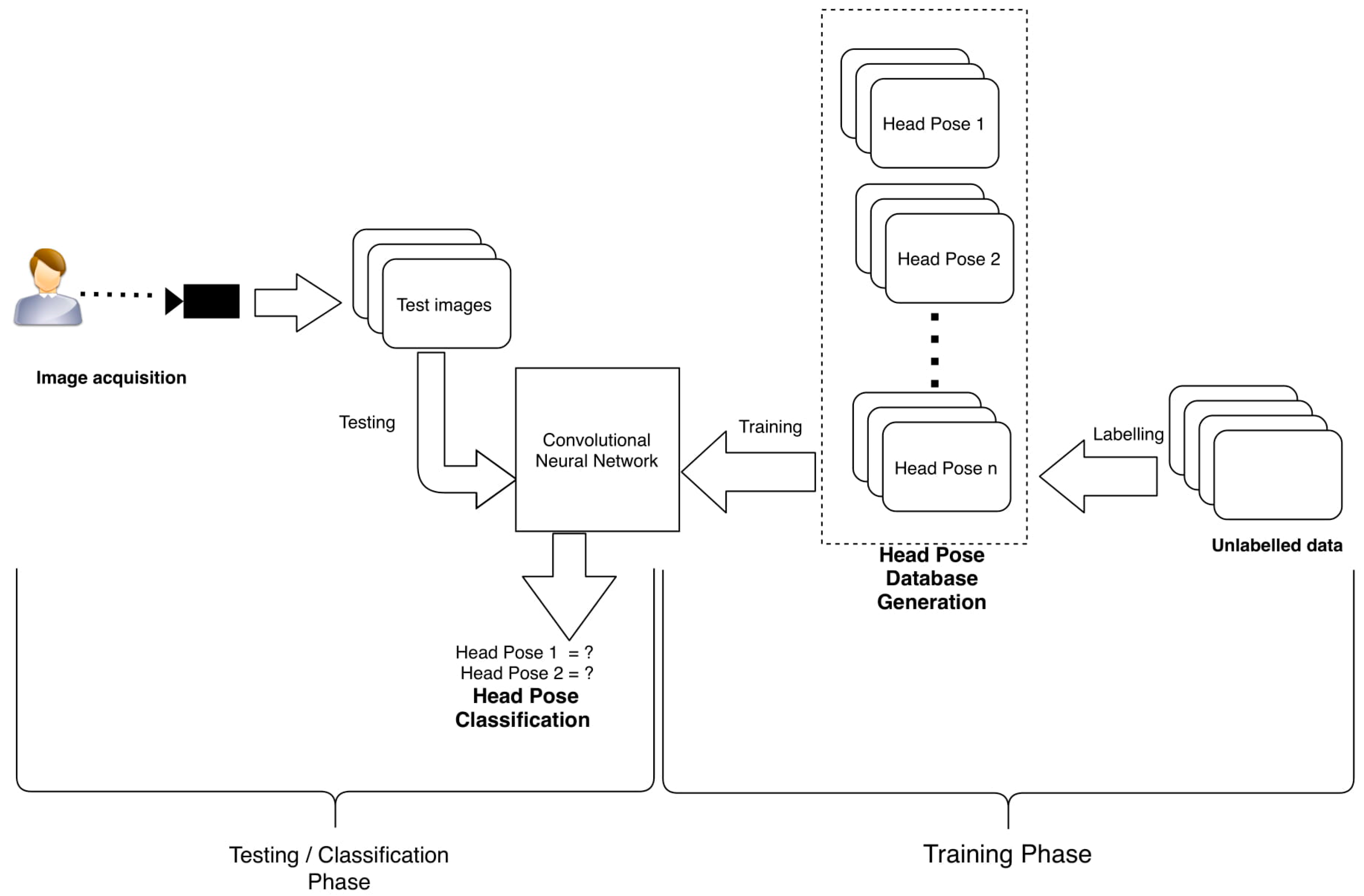
3. Learning Model
3.1. System Overview
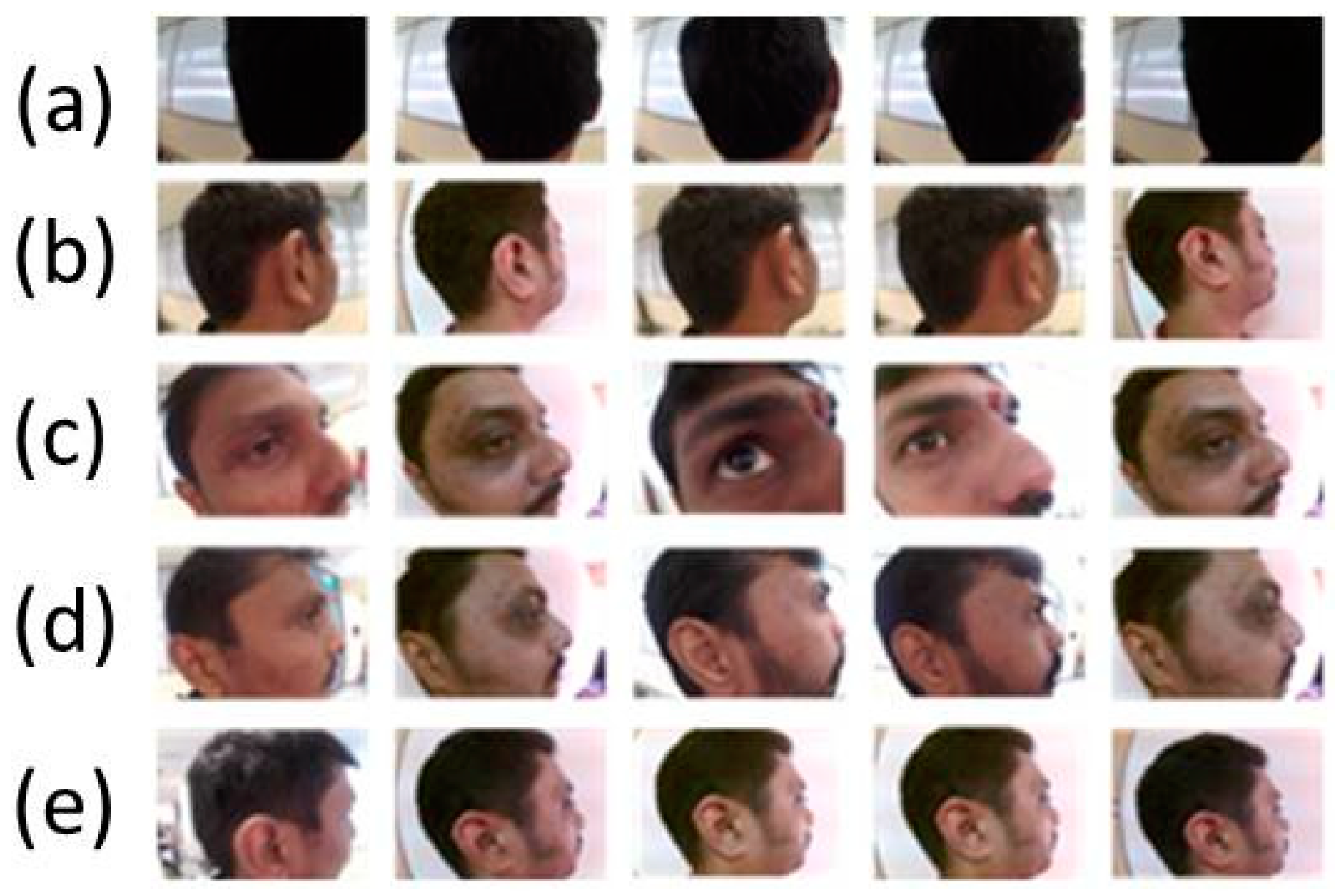
3.2. Database Generation
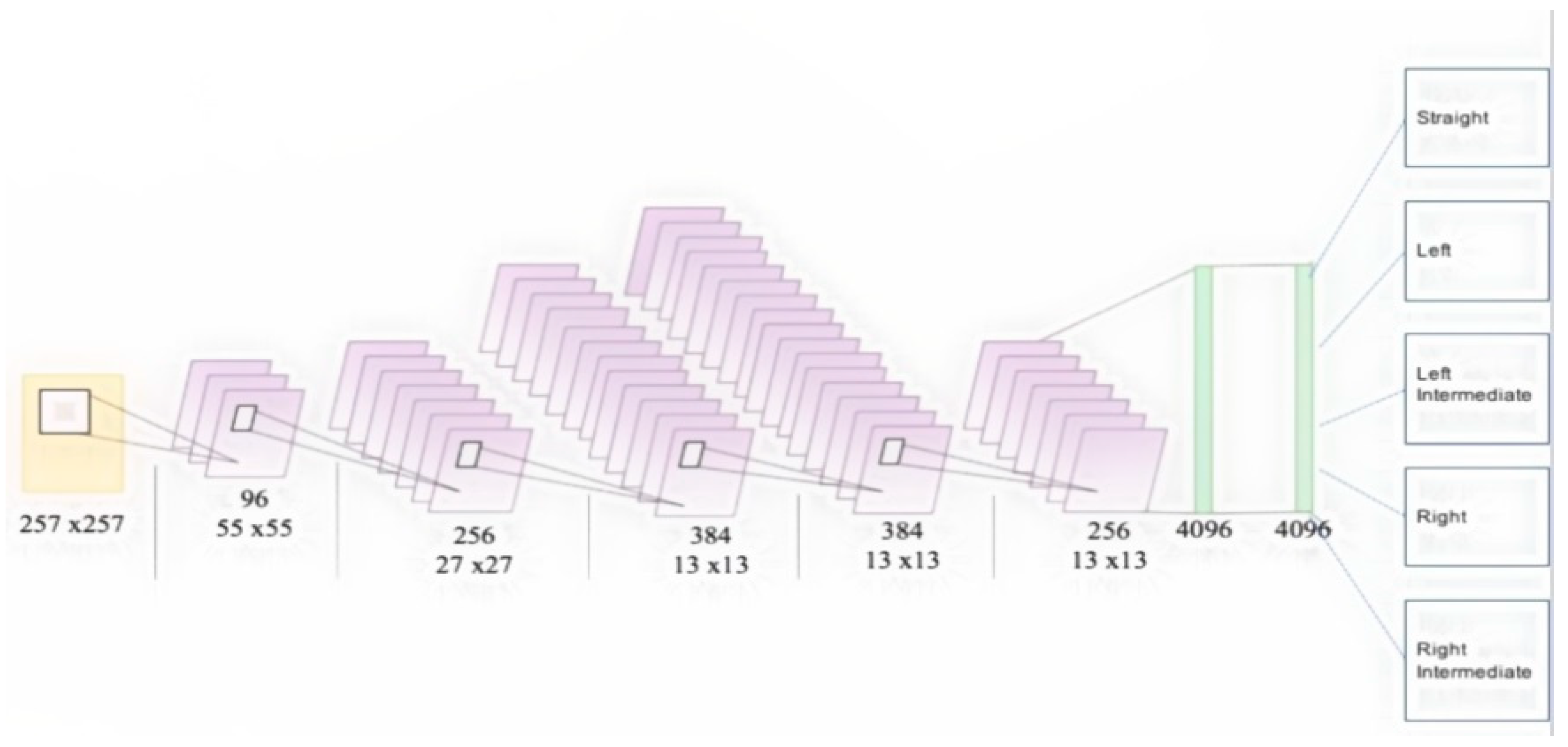
3.3. Training and Classification
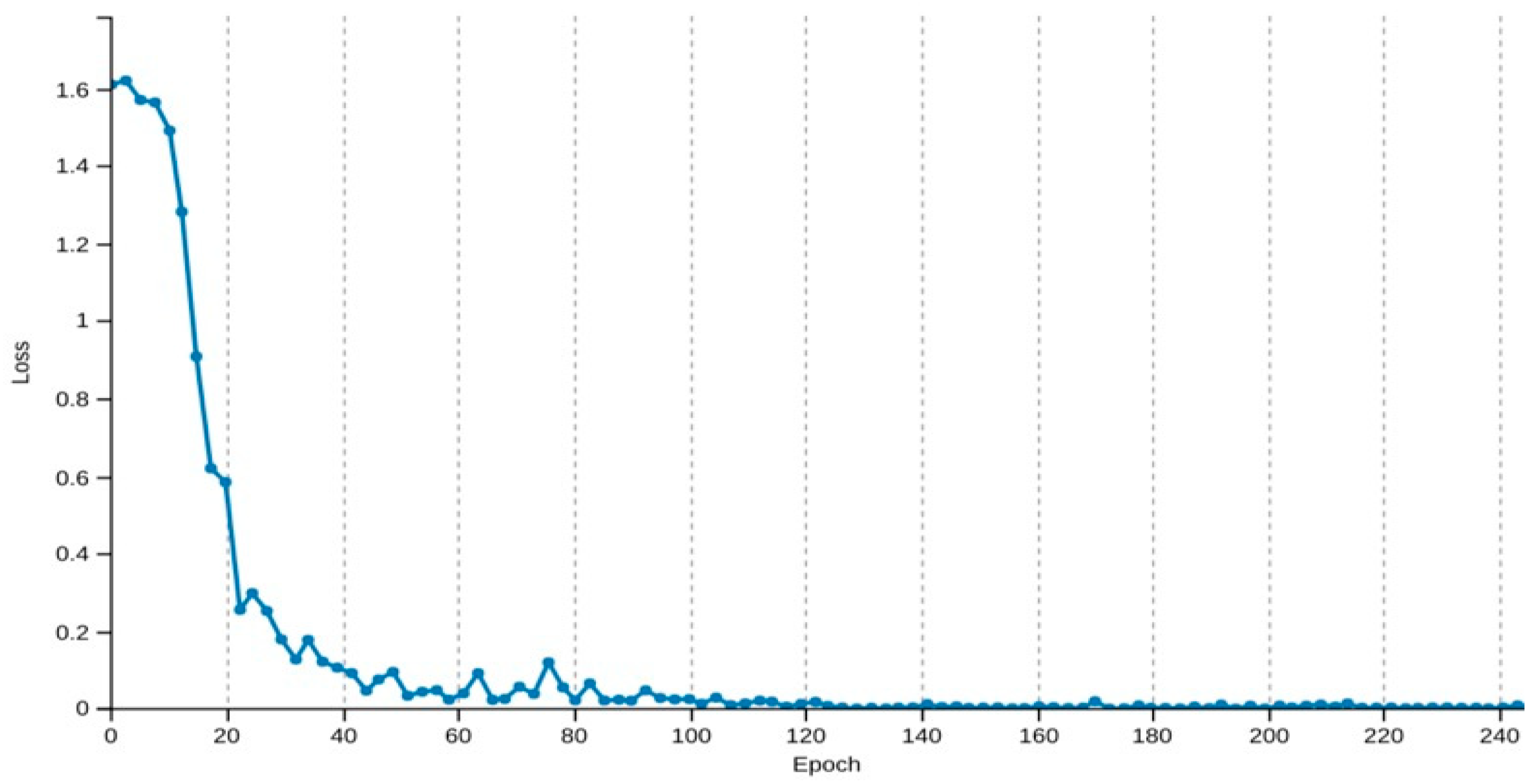
4. Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Graetzel, C.; Fong, T.; Grange, S.; Baur, C. A non-contact mouse for surgeon-computer interaction. Technol. Health Care 2004, 12, 245–257. [Google Scholar]
- Kuno, Y.; Murashina, T.; Shimada, N.; Shirai, Y. Intelligent wheelchair remotely controlled by interactive gestures. In Proceedings of the 15th International Conference on Pattern Recognition (ICPR-2000), Barcelona, Spain, 3–7 September 2000; Volume 4, pp. 672–675. [Google Scholar]
- Droeschel, D.; Stückler, J.; Holz, D.; Behnke, S. Towards joint attention for a domestic service robot-person awareness and gesture recognition using time-of-flight cameras. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1205–1210. [Google Scholar]
- Yin, X.; Xie, M. Hand gesture segmentation, recognition and application. In Proceedings of the 2001 IEEE International Symposium on Computational Intelligence in Robotics and Automation (Cat. No.01EX515), Banff, AB, Canada, 29 July–1 August 2001; pp. 438–443. [Google Scholar]
- Lee, S.W. Automatic gesture recognition for intelligent human-robot interaction. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 645–650. [Google Scholar]
- Hasanuzzaman, M.; Ampornaramveth, V.; Zhang, T.; Bhuiyan, M.A.; Shirai, Y.; Ueno, H. Real-time vision-based gesture recognition for human robot interaction. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, Shenyang, China, 22–26 August 2004; pp. 413–418. [Google Scholar]
- Hasanuzzaman, M.; Zhang, T.; Ampornaramveth, V.; Gotoda, H.; Shirai, Y.; Ueno, H. Adaptive visual gesture recognition for human–robot interaction using a knowledge-based software platform. Robot. Auton. Syst. 2007, 55, 643–657. [Google Scholar] [CrossRef]
- Breazeal, C.; Takanishi, A.; Kobayashi, T. Social robots that interact with people. In Springer Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1349–1369. [Google Scholar]
- Uddin, M.T.; Uddiny, M.A. Human activity recognition from wearable sensors using extremely randomized trees. In Proceedings of the International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), Dhaka, Bangladesh, 21–23 May 2015; pp. 1–6. [Google Scholar]
- Asri, H.; Mousannif, H.; Al Moatassime, H.; Noel, T. Big data in healthcare: Challenges and opportunities. In Proceedings of the International Conference on Cloud Technologies and Applications (CloudTech), Marrakech, Morocco, 2–4 June 2015; pp. 1–7. [Google Scholar]
- Jalal, A.; Kamal, S.; Kim, D.S. Detecting Complex 3D Human Motions with Body Model Low-Rank Representation for Real-Time Smart Activity Monitoring System. KSII Trans. Int. Inf. Syst. 2018, 12. [Google Scholar] [CrossRef]
- Zhan, Y.; Kuroda, T. Wearable sensor-based human activity recognition from environmental background sounds. J. Ambient Intell. Humaniz. Comput. 2014, 5, 77–89. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. A Depth Video-based Human Detection and Activity Recognition using Multi-features and Embedded Hidden Markov Models for Health Care Monitoring Systems. Int. J. Int. Multimed. Artif. Intell. 2017, 4. [Google Scholar] [CrossRef]
- Ren, Y.; Chen, Y.; Chuah, M.C.; Yang, J. User verification leveraging gait recognition for smartphone enabled mobile healthcare systems. IEEE Trans. Mob. Comput. 2015, 14, 1961–1974. [Google Scholar] [CrossRef]
- Jalal, A.; Sarif, N.; Kim, J.T.; Kim, T.S. Human activity recognition via recognized body parts of human depth silhouettes for residents monitoring services at smart home. Indoor Built Environ. 2013, 22, 271–279. [Google Scholar] [CrossRef]
- Shier, W.A.; Yanushkevich, S.N. Biometrics in human-machine interaction. In Proceedings of the International Conference on Information and Digital Technologies, Zilina, Slovakia, 7–9 July 2015; pp. 305–313. [Google Scholar]
- Ba, S.O.; Odobez, J.M. Recognizing visual focus of attention from head pose in natural meetings. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 39, 16–33. [Google Scholar] [CrossRef] [PubMed]
- Murphy-Chutorian, E.; Trivedi, M.M. Head pose estimation and augmented reality tracking: An integrated system and evaluation for monitoring driver awareness. IEEE Trans. Intell. Trans. Syst. 2010, 11, 300–311. [Google Scholar] [CrossRef]
- Ruiz-Del-Solar, J.; Loncomilla, P. Robot head pose detection and gaze direction determination using local invariant features. Adv. Robot. 2009, 23, 305–328. [Google Scholar] [CrossRef]
- Mudjirahardjo, P.; Tan, J.K.; Kim, H.; Ishikawa, S. Comparison of feature extraction methods for head recognition. In Proceedings of the International Electronics Symposium (IES), Surabaya, Indonesia, 29–30 September 2015; pp. 118–122. [Google Scholar]
- Farooq, A.; Jalal, A.; Kamal, S. Dense RGB-D Map-Based Human Tracking and Activity Recognition using Skin Joints Features and Self-Organizing Map. KSII Trans. Int. Inf. Syst. 2015, 9. [Google Scholar] [CrossRef]
- Almudhahka, N.Y.; Nixon, M.S.; Hare, J.S. Automatic semantic face recognition. In Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 180–185. [Google Scholar]
- Yoshimoto, H.; Date, N.; Yonemoto, S. Vision-based real-time motion capture system using multiple cameras. In Proceedings of the IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI2003), Tokyo, Japan, 1 August 2003; pp. 247–251. [Google Scholar]
- Koller, D.; Klinker, G.; Rose, E.; Breen, D.; Whitaker, R.; Tuceryan, M. Real-time vision-based camera tracking for augmented reality applications. In Proceedings of the ACM Symposium on Virtual Reality Software and Technology, Lausanne, Switzerland, 15–17 September 1997; pp. 87–94. [Google Scholar]
- Cheng, W.C. Pedestrian detection using an RGB-depth camera. In Proceedings of the International Conference on Fuzzy Theory and Its Applications (iFuzzy), Taichung, Taiwan, 9–11 November 2016; pp. 1–3. [Google Scholar]
- Kamal, S.; Jalal, A.; Kim, D. Depth images-based human detection, tracking and activity recognition using spatiotemporal features and modified HMM. J. Electr. Eng. Technol. 2016, 11, 1921–1926. [Google Scholar] [CrossRef]
- Yamazoe, H.; Habe, H.; Mitsugami, I.; Yagi, Y. Easy depth sensor calibration. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 465–468. [Google Scholar]
- Jalal, A.; Lee, S.; Kim, J.T.; Kim, T.S. Human activity recognition via the features of labeled depth body parts. In Proceedings of the International Conference on Smart Homes and Health Telematics, Artiminio, Italy, 12–15 June 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 246–249. [Google Scholar]
- Jalal, A.; Kim, J.T.; Kim, T.S. Development of a life logging system via depth imaging-based human activity recognition for smart homes. In Proceedings of the International Symposium on Sustainable Healthy Buildings, Seoul, Korea, 19 September 2012; Volume 19. [Google Scholar]
- Ye, M.; Yang, C.; Stankovic, V.; Stankovic, L.; Kerr, A. Gait analysis using a single depth camera. In Proceedings of the IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 285–289. [Google Scholar]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the Science and Information Conference (SAI), London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Jalal, A.; Kim, Y.; Kim, D. Ridge body parts features for human pose estimation and recognition from RGB-D video data. In Proceedings of the Fifth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Hefei, China, 11–13 July 2014; pp. 1–6. [Google Scholar]
- Fu, Y.; Yan, S.; Huang, T.S. Classification and feature extraction by simplexization. IEEE Trans. Inf. Forensics Secur. 2008, 3, 91–100. [Google Scholar] [CrossRef]
- Bharatharaj, J.; Huang, L.; Al-Jumaily, A.; Mohan, R.E.; Krägeloh, C. Sociopsychological and physiological effects of a robot-assisted therapy for children with autism. Int. J. Adv. Robot. Syst. 2017, 14, 1729881417736895. [Google Scholar] [CrossRef]
- Bharatharaj, J.; Huang, L.; Al-Jumaily, A.M.; Krageloh, C.; Elara, M.R. Effects of Adapted Model-Rival Method and parrot-inspired robot in improving learning and social interaction among children with autism. In Proceedings of the International Conference on Robotics and Automation for Humanitarian Applications (RAHA), Kollam, India, 18–20 December 2016; pp. 1–5. [Google Scholar]
- Bharatharaj, J.; Huang, L.; Mohan, R.E.; Al-Jumaily, A.; Krägeloh, C. Robot-assisted therapy for learning and social interaction of children with autism spectrum disorder. Robotics 2017, 6, 4. [Google Scholar] [CrossRef]
- Rossignol, E.A.; Kominsky, M.A. Wearable Pet Enclosure. U.S. Patent 5,277,148, 11 January 1994. [Google Scholar]
- Skloot, R. Creature comforts. New York Times, 31 December 2008; 31. [Google Scholar]
- Stiefelhagen, R. Estimating head pose with neural networks-results on the pointing04 icpr workshop evaluation data. In Proceedings of the Pointing 2004 Workshop: Visual Observation of Deictic Gestures, Cambridge, UK, 22 August 2004; Volume 1. [Google Scholar]
- Voit, M.; Nickel, K.; Stiefelhagen, R. Neural network-based head pose estimation and multi-view fusion. In Proceedings of the International Evaluation Workshop on Classification of Events, Activities and Relationships, Southampton, UK, 6–7 April 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 291–298. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Robot Full Body Material | PLA (Poly Lactic Acid) |
|---|---|
| Dimensions W × H (mm) | 160.36 × 81.39 |
| Weight (g) | 140 |
| Head rotation (degrees) | 180 |
| Head tilting (degrees) | 45 |
| Hardware | Specification |
|---|---|
| Controller | Raspberry pi |
| Servo motor | TowerPro SG90 |
| Servo controller | Pololu micro Meastro 18-Channer |
| Camera refresh rate | 30 Hz |
| Camera resolution | 640 × 480 |
| Focal length of lens | 20 cm |
| View angle | 30 degree |
| Camera | WiFi Ai-Ball Camera |
| Battery | Li-Po 1200 mah 7.4 v |
| No. | Layer | Maps and Neurons | Kernel |
|---|---|---|---|
| 0 | Input | 3 Maps of 227 × 227 | - |
| 1 | Convolution | 96 Maps of 55 × 55 neurons | 11 × 11 |
| 2 | Max Pooling | 96 Maps of 27 × 27 neurons | 3 × 3 |
| 3 | Convolution | 256 Maps of 13 × 13 neurons | 5 × 5 |
| 4 | Max Pooling | 256 Maps of 13 × 13 neurons | 3 × 3 |
| 5 | Convolution | 384 Maps of 13 × 13 neurons | 3 × 3 |
| 6 | Convolution | 384 Maps of 13 × 13 neurons | 3 × 3 |
| 7 | Convolution | 256 Maps of 13 × 13 neurons | 3 × 3 |
| 8 | Max Pooling | 256 Maps of 6 × 6 neurons | 3 × 3 |
| 9 | Fully Connected | 4096 neurons | 1 × 1 |
| 10 | Fully Connected | 4096 neurons | 1 × 1 |
| 0 | 1 | 2 | 3 | 4 | Accuracy (%) | |
|---|---|---|---|---|---|---|
| 0 | 50 | 0 | 0 | 0 | 0 | 100 |
| 1 | 0 | 48 | 0 | 2 | 0 | 96 |
| 2 | 0 | 0 | 50 | 0 | 0 | 100 |
| 3 | 0 | 0 | 0 | 50 | 0 | 100 |
| 4 | 0 | 11 | 1 | 0 | 38 | 76 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bharatharaj, J.; Huang, L.; Mohan, R.E.; Pathmakumar, T.; Krägeloh, C.; Al-Jumaily, A. Head Pose Detection for a Wearable Parrot-Inspired Robot Based on Deep Learning. Appl. Sci. 2018, 8, 1081. https://doi.org/10.3390/app8071081
Bharatharaj J, Huang L, Mohan RE, Pathmakumar T, Krägeloh C, Al-Jumaily A. Head Pose Detection for a Wearable Parrot-Inspired Robot Based on Deep Learning. Applied Sciences. 2018; 8(7):1081. https://doi.org/10.3390/app8071081
Chicago/Turabian StyleBharatharaj, Jaishankar, Loulin Huang, Rajesh Elara Mohan, Thejus Pathmakumar, Chris Krägeloh, and Ahmed Al-Jumaily. 2018. "Head Pose Detection for a Wearable Parrot-Inspired Robot Based on Deep Learning" Applied Sciences 8, no. 7: 1081. https://doi.org/10.3390/app8071081
APA StyleBharatharaj, J., Huang, L., Mohan, R. E., Pathmakumar, T., Krägeloh, C., & Al-Jumaily, A. (2018). Head Pose Detection for a Wearable Parrot-Inspired Robot Based on Deep Learning. Applied Sciences, 8(7), 1081. https://doi.org/10.3390/app8071081