Variational Autoencoder-Based Multiple Image Captioning Using a Caption Attention Map


Abstract
:1. Introduction
- A method for extracting caption attention maps (CAMs) from an image–sentence pair is proposed.
- A captioning model is proposed that generates multiple captions per image by adding randomness to the image region-related information using VAE.
- A methodology is introduced for evaluation of multiple image captioning tasks, which has not been done in previous studies, and it is used to evaluate our base and proposed model.
2. Related Works
3. Multiple Image Captioning
3.1. Background on VAE
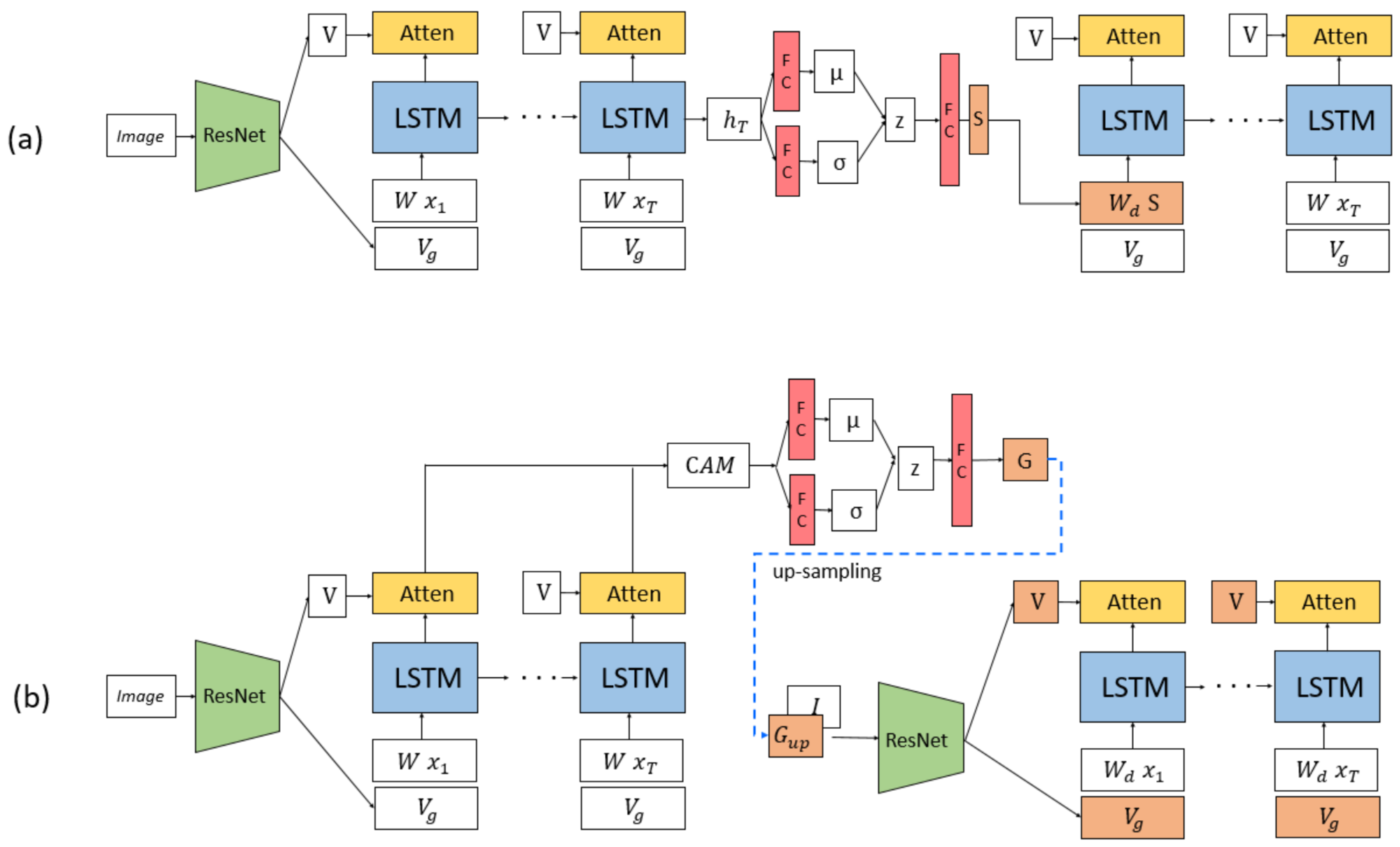
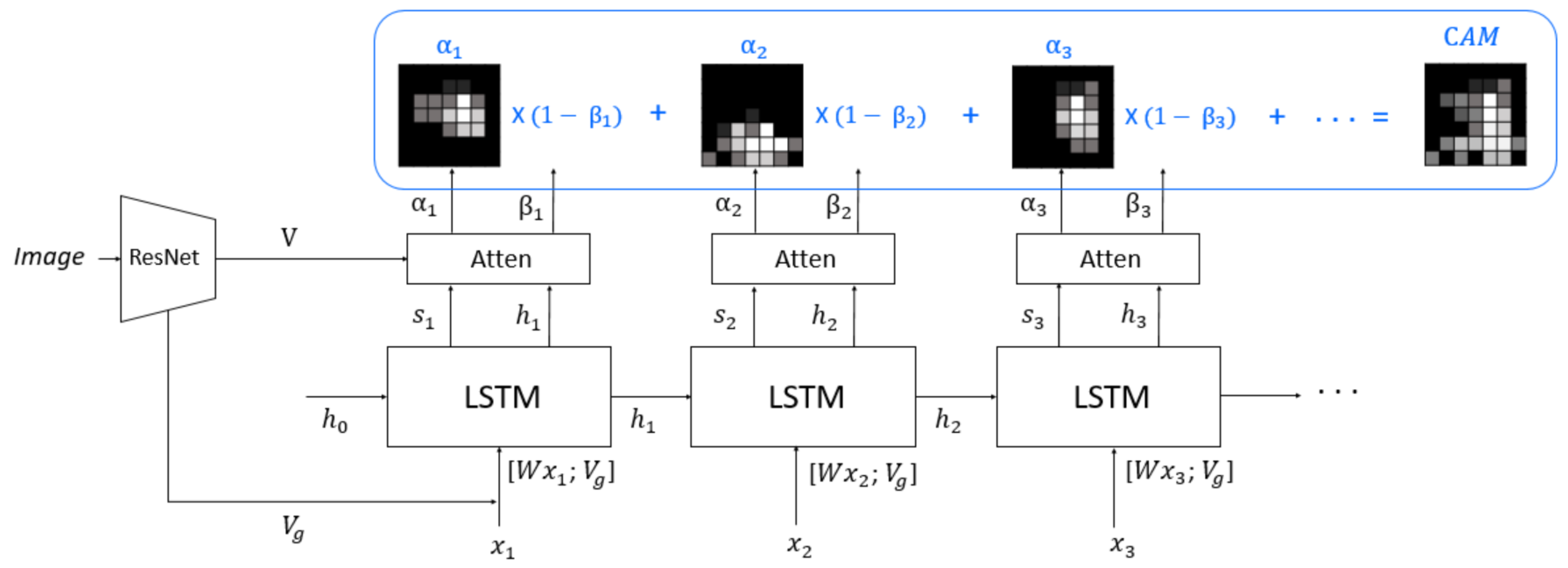
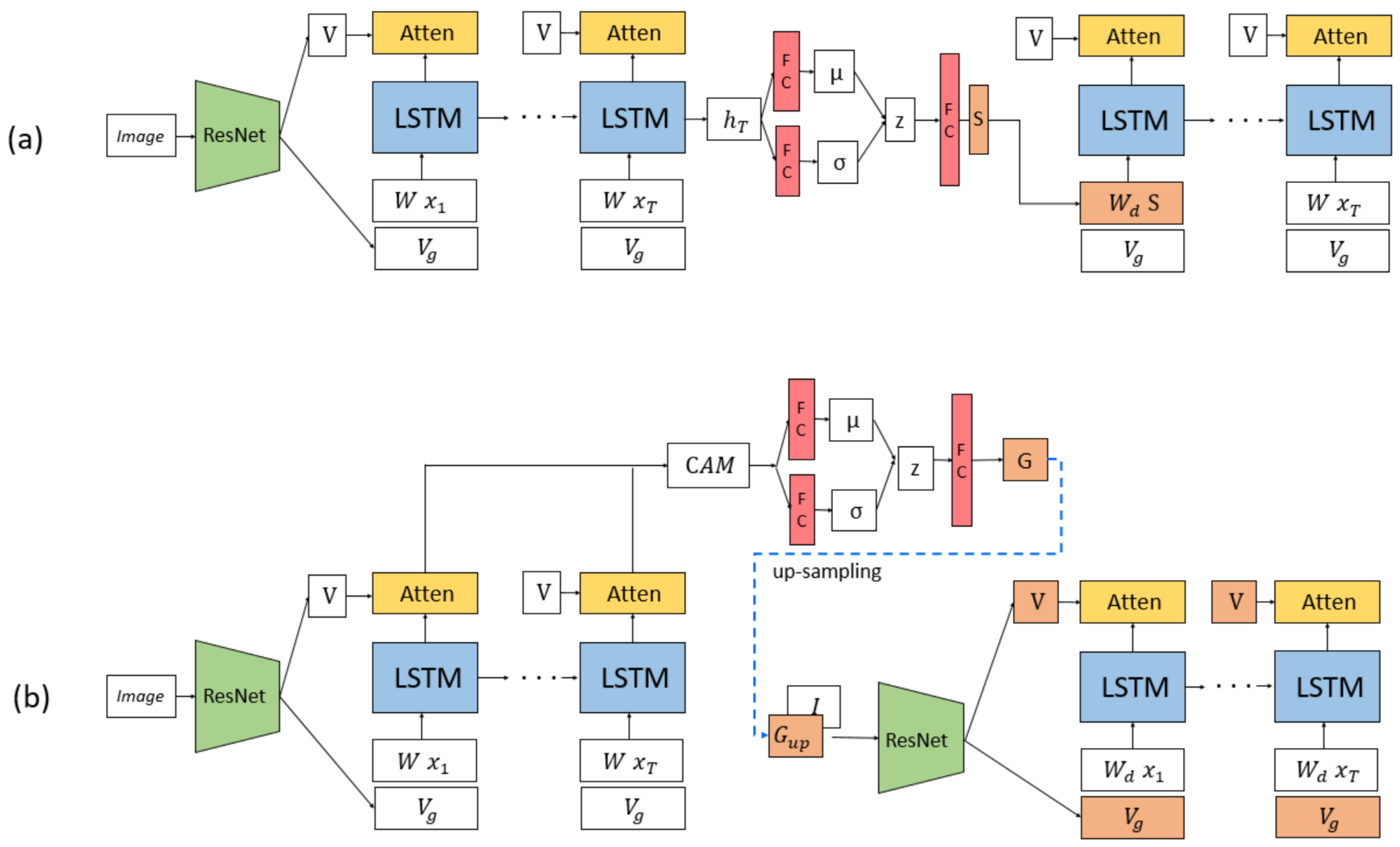
3.2. Caption Attention Map
3.3. VAE-Based Captioning Model Using CAM
4. Experiments
4.1. Experimental Setups
4.2. Multiple Image Captioning Evaluation Metrics
- -
- -
- Div-s: ratio of a number of unique sentences in to the number of sentences in . A higher ratio is more diverse.
- -
- Div-1: ratio of a number of unique unigrams in to the number of words in . A higher ratio is more diverse.
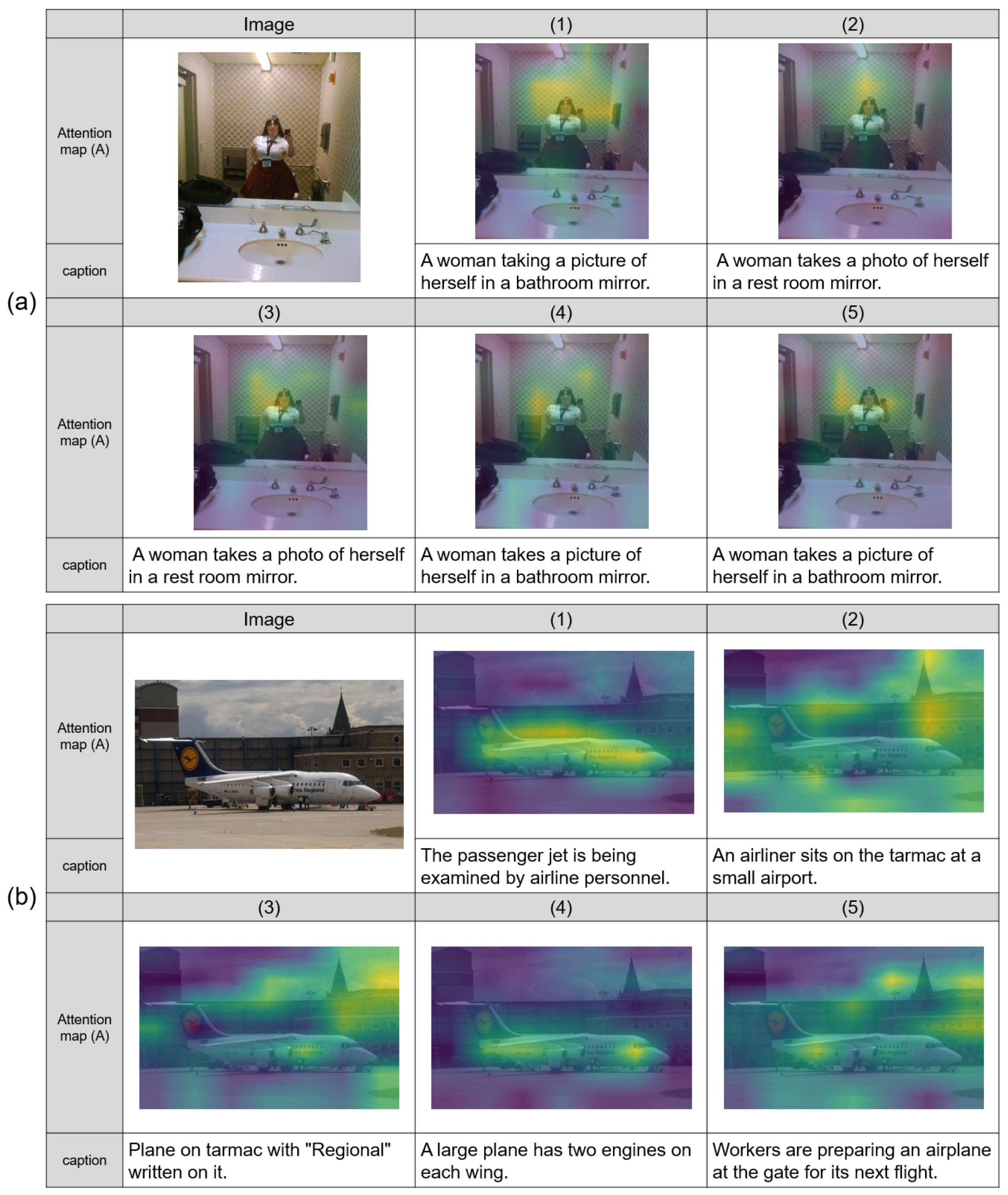
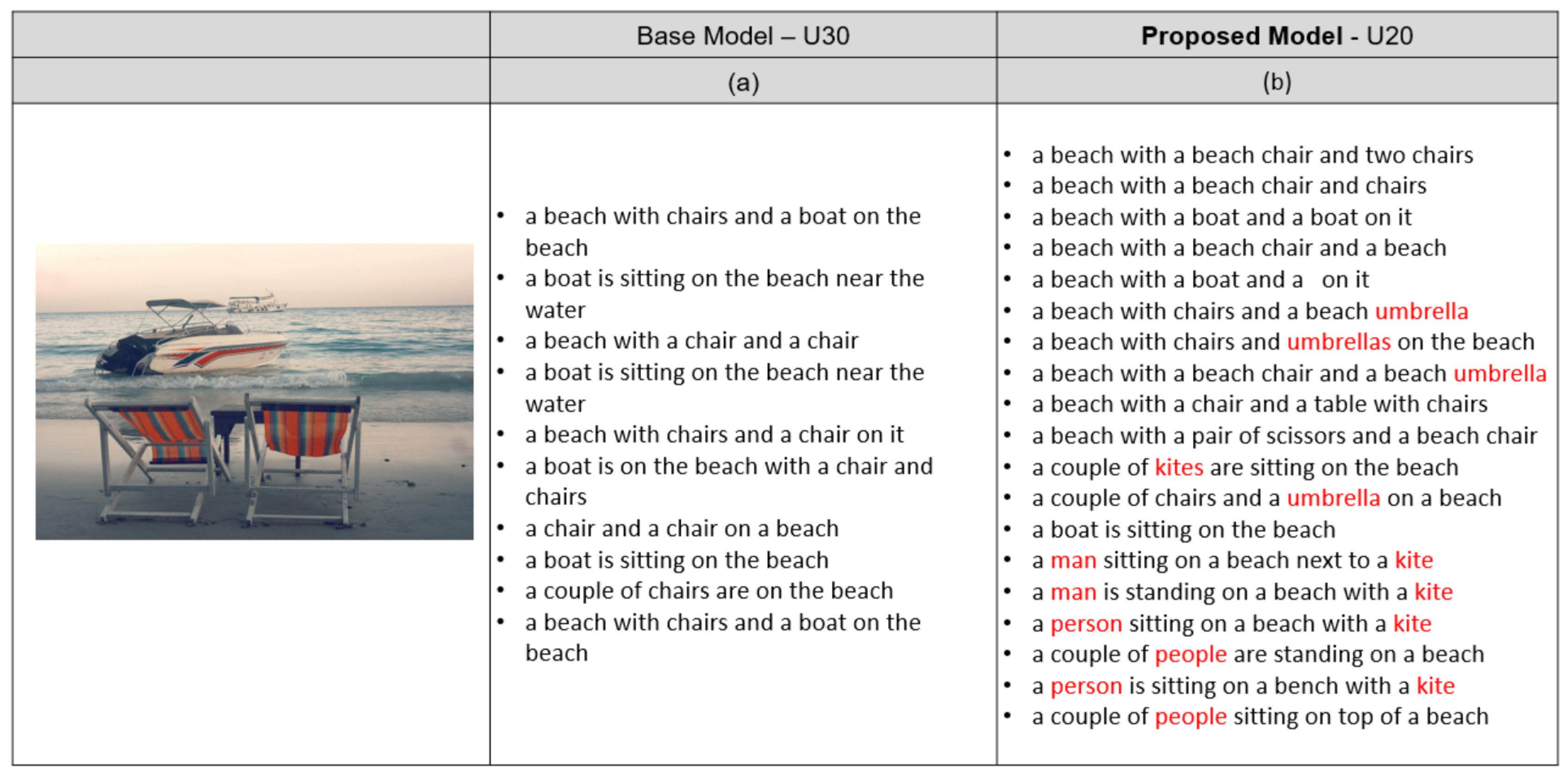
4.3. Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Wu, Q.; Shen, C.; Liu, L.; Dick, A.; Van Den Hengel, A. What value do explicit high level concepts have in vision to language problems? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 203–212. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. arXiv 2015, arXiv:1502.03044. [Google Scholar]
- Fang, H.; Gupta, S.; Iandola, F.; Srivastava, R.K.; Deng, L.; Dollár, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C.; et al. From captions to visual concepts and back. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Gan, Z.; Gan, C.; He, X.; Pu, Y.; Tran, K.; Gao, J.; Carin, L.; Deng, L. Semantic compositional networks for visual captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5630–5639. [Google Scholar]
- Liu, C.; Mao, J.; Sha, F.; Yuille, A. Attention correctness in neural image captioning. In Proceedings of the Thirty-First, AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Wang, L.; Schwing, A.; Lazebnik, S. Diverse and accurate image description using a variational auto-encoder with an additive gaussian encoding space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5756–5766. [Google Scholar]
- Jain, U.; Zhang, Z.; Schwing, A.G. Creativity: Generating diverse questions using variational autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6485–6494. [Google Scholar]
- Chatterjee, M.; Schwing, A.G. Diverse and Coherent Paragraph Generation from Images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 729–744. [Google Scholar]
- Shetty, R.; Rohrbach, M.; Anne Hendricks, L.; Fritz, M.; Schiele, B. Speaking the same language: Matching machine to human captions by adversarial training. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4135–4144. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Dai, B.; Fidler, S.; Urtasun, R.; Lin, D. Towards diverse and natural image descriptions via a conditional gan. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2970–2979. [Google Scholar]
- Bowman, S.R.; Vilnis, L.; Vinyals, O.; Dai, A.M.; Jozefowicz, R.; Bengio, S. Generating sentences from a continuous space. arXiv 2015, arXiv:1511.06349. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, X.; Fang, H.; Lin, T.Y.; Vedantam, R.; Gupta, S.; Dollár, P.; Zitnick, C.L. Microsoft COCO captions: Data collection and evaluation server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Karpathy, A.; Li, F. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 11 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. Rouge: A Package for Automatic Evaluation of Summaries. Text Summ. Branches Out. 2004, pp. 74–81. Available online: https://www.aclweb.org/anthology/W04-1013 (accessed on 18 June 2019).
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 382–398. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sampling | Base Model | Proposed Model | ||||||
|---|---|---|---|---|---|---|---|---|
| METEOR | ROUGE | SPICE | CIDEr | METEOR | ROUGE | SPICE | CIDEr | |
| N1 | 0.249 | 0.532 | 0.183 | 0.976 | 0.248 | 0.533 | 0.182 | 0.980 |
| U20 | 0.246 | 0.527 | 0.180 | 0.959 | 0.240 | 0.523 | 0.174 | 0.929 |
| U30 | 0.244 | 0.526 | 0.179 | 0.952 | 0.230 | 0.510 | 0.163 | 0.864 |
| U40 | 0.244 | 0.524 | 0.178 | 0.948 | 0.218 | 0.493 | 0.149 | 0.780 |
| Sampling | Base Model | Proposed Model | ||||||
|---|---|---|---|---|---|---|---|---|
| Div-s | k | Max Div-1 | Average Div-1 | Div-s | k | Max Div-1 | Average Div-1 | |
| N1 | 0.015 | 38.8 | 0.192 | 0.191 | 0.017 | 133.0 | 0.197 | 0.196 |
| U20 | 0.090 | 3859.6 | 0.359 | 0.307 | 0.128 | 3825.75 | 0.387 | 0.317 |
| U30 | 0.116 | 4355.8 | 0.391 | 0.319 | 0.201 | 4431.75 | 0.457 | 0.347 |
| U40 | 0.133 | 4550.2 | 0.410 | 0.326 | 0.274 | 4721.75 | 0.516 | 0.373 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.; Shin, S.; Jung, H. Variational Autoencoder-Based Multiple Image Captioning Using a Caption Attention Map. Appl. Sci. 2019, 9, 2699. https://doi.org/10.3390/app9132699
Kim B, Shin S, Jung H. Variational Autoencoder-Based Multiple Image Captioning Using a Caption Attention Map. Applied Sciences. 2019; 9(13):2699. https://doi.org/10.3390/app9132699
Chicago/Turabian StyleKim, Boeun, Saim Shin, and Hyedong Jung. 2019. "Variational Autoencoder-Based Multiple Image Captioning Using a Caption Attention Map" Applied Sciences 9, no. 13: 2699. https://doi.org/10.3390/app9132699
APA StyleKim, B., Shin, S., & Jung, H. (2019). Variational Autoencoder-Based Multiple Image Captioning Using a Caption Attention Map. Applied Sciences, 9(13), 2699. https://doi.org/10.3390/app9132699