1. Introduction
With the advent of the fourth industrial revolution in the context of industrial 4.0, intelligent manufacturing has become a symbol of the new information age. The semiconductor industry, as the cornerstone of the information age, belongs to the high-tech industry and faces many opportunities and challenges. While it brings high profits, fierce industry competition also forces semiconductor manufacturers to continuously improve production efficiency and resource utilization [
1]. In a semiconductor manufacturing process, wafer manufacturing is called the front-end process while wafer testing and packaging is called the back-end process. Because the equipment used in wafer manufacturing are expensive and the processing process is complex, it has attracted wide attention of scholars at home and abroad. Re-entrant is a remarkable feature of semiconductor wafer fabrication [
2,
3,
4], which means that the jobs may repeatedly access certain devices at different stages of the processing process. More than one machine with at least one stage is used for processing. In addition, during the processing of the wafer, various physical and chemical processing steps are needed to form a required circuit layer on the surface of the wafer, and the processing steps involved mainly include oxidation, deposition, implantation, sputtering, photolithography, etching, and cleaning, etc. There are strict order constraints between operations. The manufacturing process can be reduced to the reentrant hybrid flow shop (RHFS) problem, which has been proven to be an NP-hard (Non-deterministic polynomial hard) problem [
5]. Because of its large scale and high complexity, the RHFS problem is difficult to solve effectively in an acceptable time using traditional mathematical modeling methods. In addition, according to the “no free lunch” theorem [
6], no algorithm can achieve better results for all application problems, so it is of great significance and value to design and develop new intelligent optimization algorithms. Bertel et al. [
7] proposed an integer linear programming formulation of the hybrid flow shop with recirculation, and minimizing the weighted number of tardy jobs was regarded as the optimization goal. Then a lower bound, a greedy algorithm, and a genetic algorithm were described as approximate methods. Cho et al. [
8] proposed a Pareto genetic algorithm based on the Minkowski crossover operator to solve the RHFS problem, and is also designed as corresponding benchmark data sets for simulation experiments. Li et al. [
9] proposed an adaptive hybrid incremental learning algorithm to solve the reentrant permutation flow shop scheduling problem with make span as the optimization objective. The degree of population evolution was evaluated by using the information entropy of the probability matrix. The mutation mechanism of the probability model and the local search method of the critical path were designed to expand the search area of the population. Huang et al. [
10] designed an improved particle swarm optimization (PSO) algorithm to solve the two-stage reentrant multi-machine flow shop scheduling problem with a due window. Taking the wafer testing process as an example, aiming at minimizing the lead time or delay time, effectiveness, and robustness of the proposed algorithm were verified by large-scale test experiments. Cho et al. [
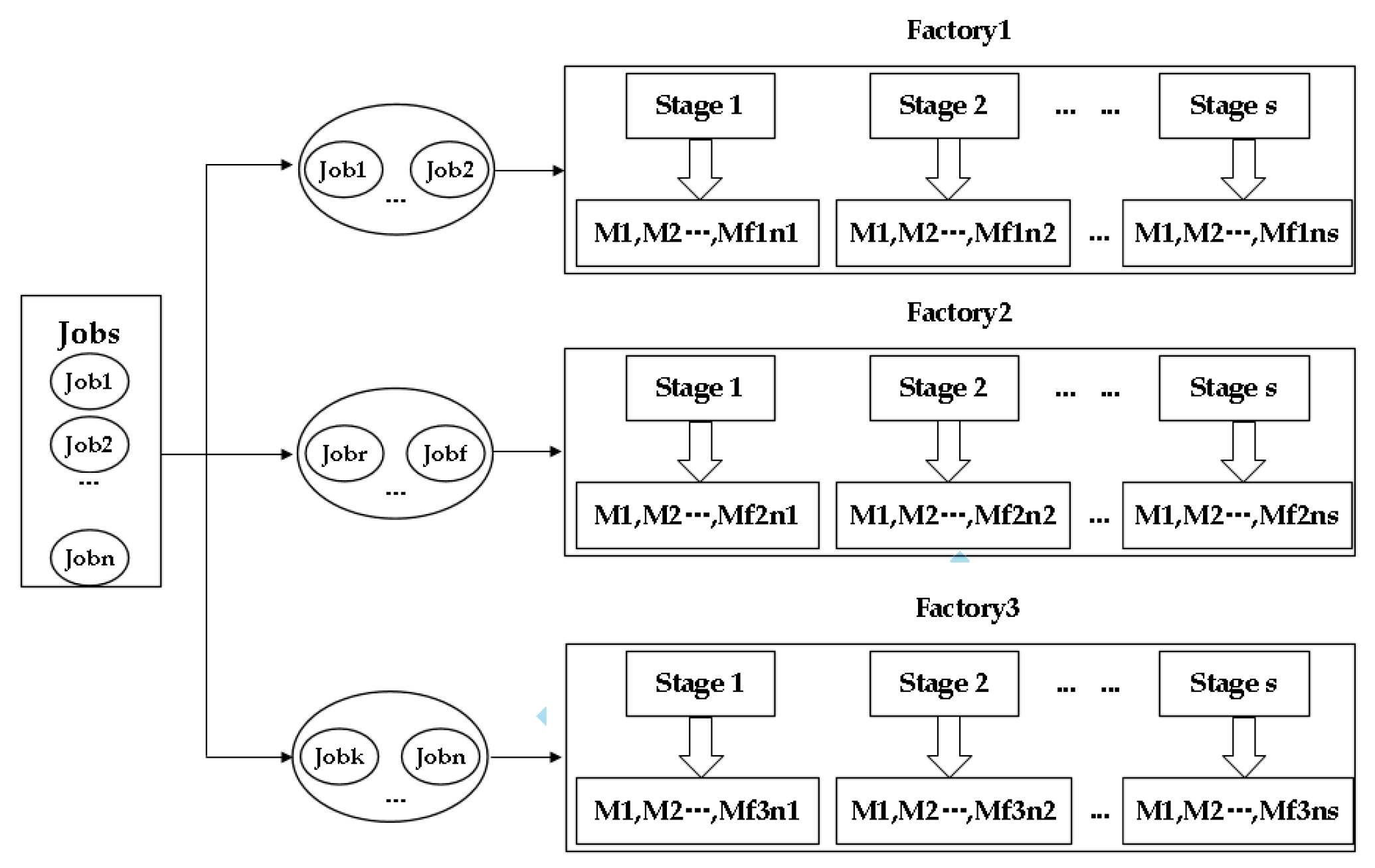
11] proposed a two-level optimization algorithm to solve the reentrant flow shop problem, which satisfied the maximization of total product quantity and minimization of the customer demand delay, and applied it to real TFT-LCD (Thin Film Transistor-Liquid Crystal Display) production. To sum up, up to now, the research on the reentrant scheduling problem in domestic and foreign literature is basically based on a single production line. However, in actual production, multi-factory manufacturing and collaborative production play a key role.
Multi-factory manufacturing, including distributed manufacturing, through the cooperation of different factories distributed in different geographical locations to complete the production of products, which can rationally allocate the resources of each factory, realize the optimal combination and sharing of resources, reduce the production cost of products, and improve the satisfaction of customers, meet the diversification of customer needs. Modoni et al. [
12] proposed an event-driven framework, which could realize the interaction of heterogeneous distributed resources. In particular, this research provided new mechanisms combining many technologies such as IIOT and Semantic Web, to notify significant information produced within the factory toward enabled and interested production resources. Renna et al. [
13] developed a distributed approach and also used the Nash bargaining solution based on game theory, for a network of independent enterprises, which could facilitate the capacity process by using a multiagent architecture and a cooperative protocol. The simulation results demonstrated that the proposed method had a better performance when the dynamicity of the environment grows. Argoneto et al. [
14] designed a framework based on a cooperative game algorithm and a fuzzy engine for capacity sharing in cloud manufacturing. The utility functions of the involved firms were taken into account in the capacity allocation policy. Xu et al. [
15] proposed an effective hybrid immune algorithm to solve the distributed permutation flow shop scheduling problem by designing a new cross mutation inoculation and local search operator. Experiments showed that the algorithm was particularly effective for large-scale test problems. Zhang et al. [
16] designed a distributed optimization method to solve distributed flow shop scheduling problems by reducing the power cost of manufacturing factories. Zhang et al. [
17] proposed a two-stage heuristic search algorithm to solve the distributed flow shop scheduling problem with flexible assembly and installation time, with the objective of minimizing make span. Lu et al. [
18] designed an improved genetic algorithm based on 3D-1D encoding and 1D-3D decoding to solve the distributed flexible job shop scheduling problem. It also introduced the allocation strategy of jobs to factories in detail. Fu et al. [
19] established a stochastic multi-objective distributed permutation flow shop scheduling model considering total tardiness, make span, and total energy consumption, which also designed a new multi-objective brainstorming optimization algorithm to solve the problem. Rifai et al. [
20] used the improved adaptive large neighborhood search algorithm to solve the distributed re-entrant permutation flow shop scheduling problem. It was the first time that the distributed re-entrant flow shop (DRFS) scheduling problem was studied, and it pointed out that DRFS problem was NP-Hard. To sum up, up to now, the studies on distributed scheduling problem in domestic and foreign literature is mostly confined to homogeneous factory, and most of them are research on flow shop, permutation flow shop, and flexible job shop. To the best of my knowledge, there is little research on a distributed reentrant hybrid flow shop. Distributed manufacturing of semiconductor wafers can be attributed to the distributed reentrant hybrid flow shop (DRHFS) problem, which has similar properties to the RHFS problem, but extends to multi-factory issues. Therefore, it is clear that it also belongs to the NP-Hard problem.
Environmental issues are the focus of global attention, and sustainable green manufacturing is a serious challenge for today’s manufacturing industry. Noises and CO
2 emissions from the manufacturing industry are the main sources of pollution. For semiconductor wafer factories, because they are usually equipped with hundreds of precision equipment, and the wafer manufacturing process is very complex, there may be hundreds of products flowing simultaneously on the production line. Once one factory is established, it will run continuously for 365 days a year and 24 hours per day. In addition, the strict control of environmental parameters in the wafer production process makes it necessary for manufacturing factories and processing equipment to meet their production continuity requirements with uninterrupted high energy consumption. For example, precise temperature control of the etching process—the temperature fluctuation of 0.1 °C up and down will cause deviation of the wafers’ excellent rate, which results in wafer scrapping. Therefore, for semiconductor wafer manufacturing, we should not only care about the process, but also put energy saving and environmental protection on the agenda. In this paper, carbon emissions from semiconductor wafer fabrication are taken as an energy-saving indicator for research. Regarding the study of carbon emissions indicator, Zhang et al. [
21] created a flexible job shop low-carbon scheduling model that considers make span, machine load, and carbon emissions indicators, and proposed a hybrid non-dominated sorting genetic algorithm II to solve the model. In order to help enterprises to quantify the carbon footprint indicator, Liu et al. [
22] proposed a method for calculating the carbon footprint of workshop products and an improved fruit fly optimization algorithm to minimize the carbon footprint and production cycle of all products. Nilakantan et al. [
23] developed a study on the robot assembly line system, using a multi-objective co-evolution algorithm to solve the carbon footprint minimization problem. Piroozfar et al. [
24] proposed an improved multi-objective genetic algorithm to solve the multi-objective flexible job shop scheduling problem while minimizing the total carbon footprint and total number of delayed jobs. So far, there is no literature on the research of carbon emissions indicator in the semiconductor wafer manufacturing.
Grey Wolf Optimizer (GWO) is a new swarm intelligence optimization algorithm designed in 2014 by Professor Mirjalili and his team. The algorithm is inspired by the strict social hierarchy and predatory behavior of the grey wolf population in nature [
25]. It is used to solve single-objective optimization problems. In 2016, Mirjalili et al. proposed a Multi-Objective Grey Wolf Optimizer (MOGWO) [
26] based on the GWO algorithm to solve multi-objective optimization problems. Due to its simple algorithm structure, parameter setting, and better optimization effect, the Grey Wolf algorithm has been widely used in the research of scheduling, image processing, medical treatment, and designing photonic crystal waveguides [
27,
28,
29,
30,
31]. However, there is no relevant literature about its application in green collaborative scheduling of the semiconductor wafer distributed heterogeneous factory. In summary, this paper constructs a green manufacturing collaborative optimal scheduling model for a semiconductor wafer distributed heterogeneous factory for the first time, and designs an improved multi-objective Grey Wolf Optimizer (IMOGWO) to solve this problem.
The remainder of this paper is organized as follows. The green manufacturing collaborative optimal scheduling model of the semiconductor wafer distributed heterogeneous factory is formulated in
Section 2. The green collaborative scheduling problem of the semiconductor wafer distributed heterogeneous factory is described in detail in
Section 3.
Section 4 presents experimental results and analysis of the results.
Section 5 provides the conclusions and future work.
5. Conclusions
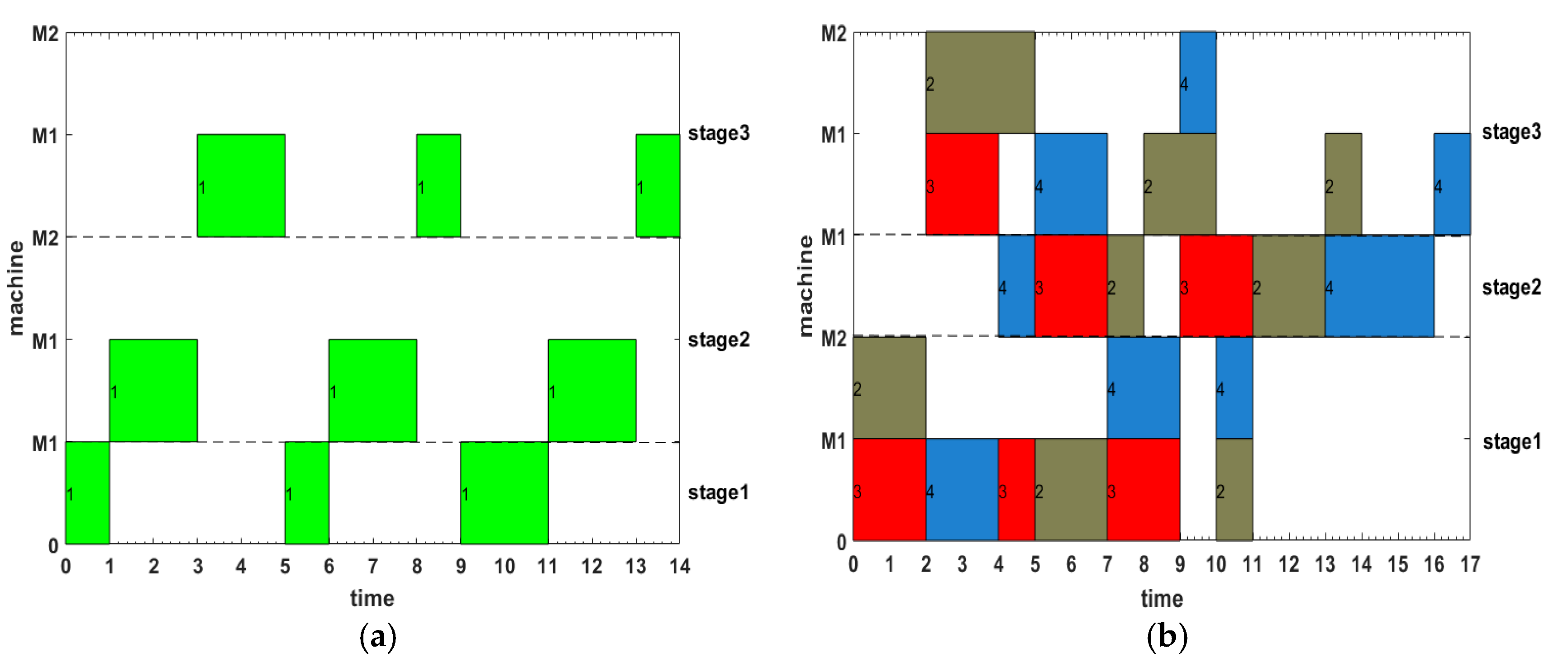
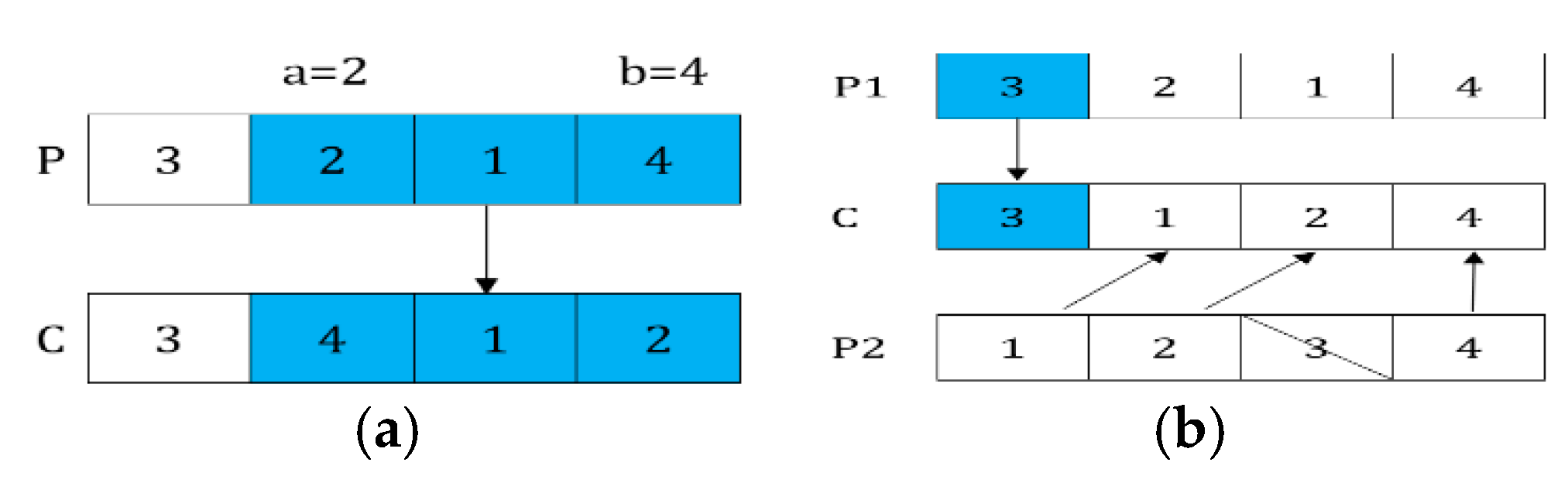
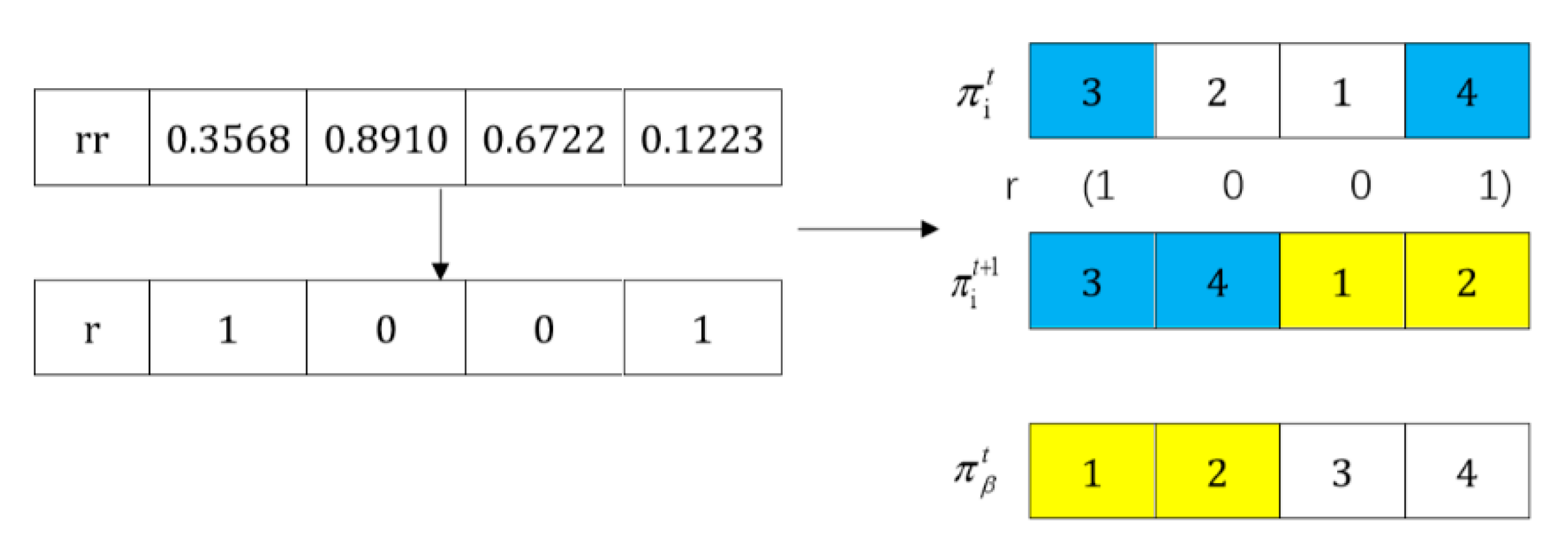
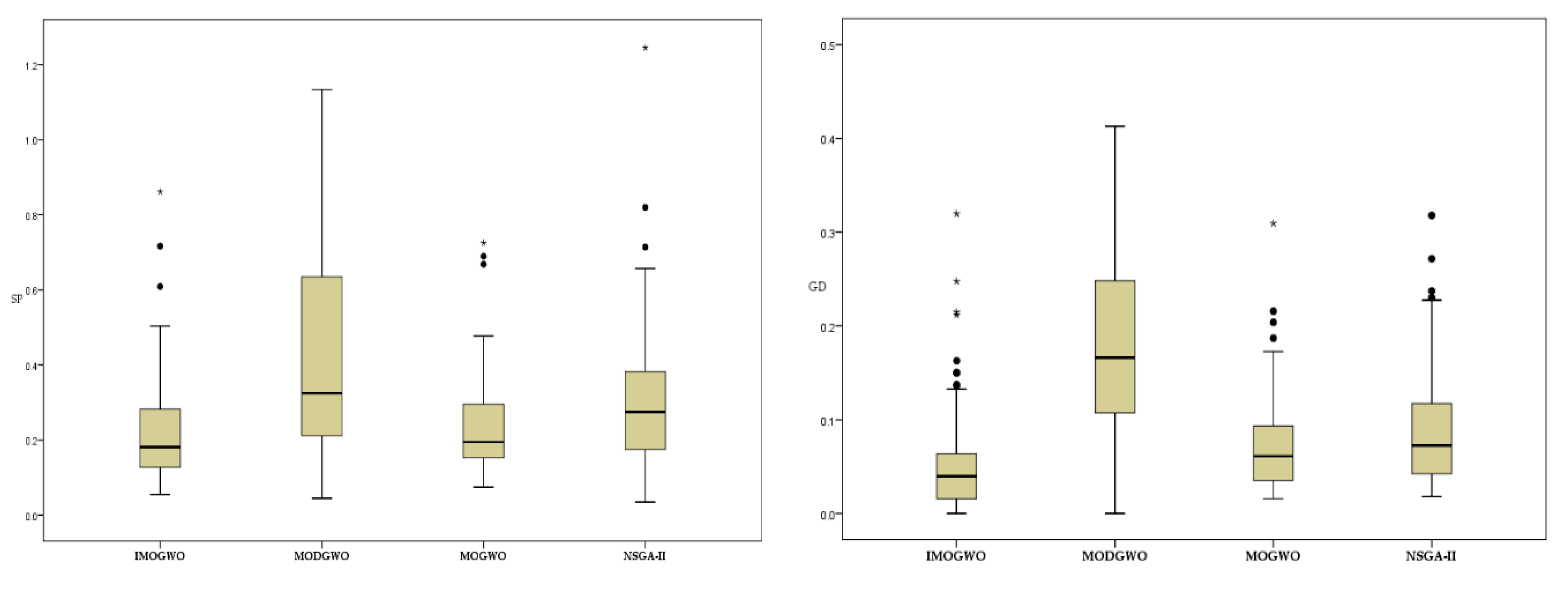
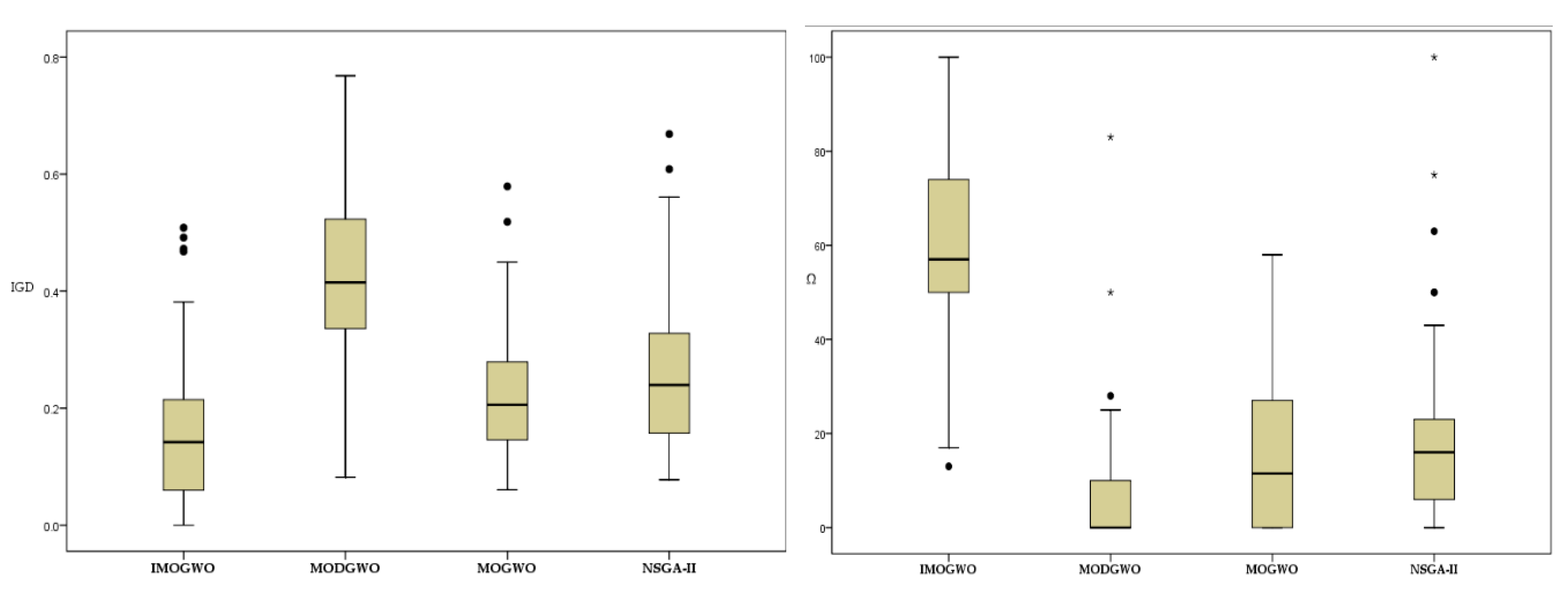
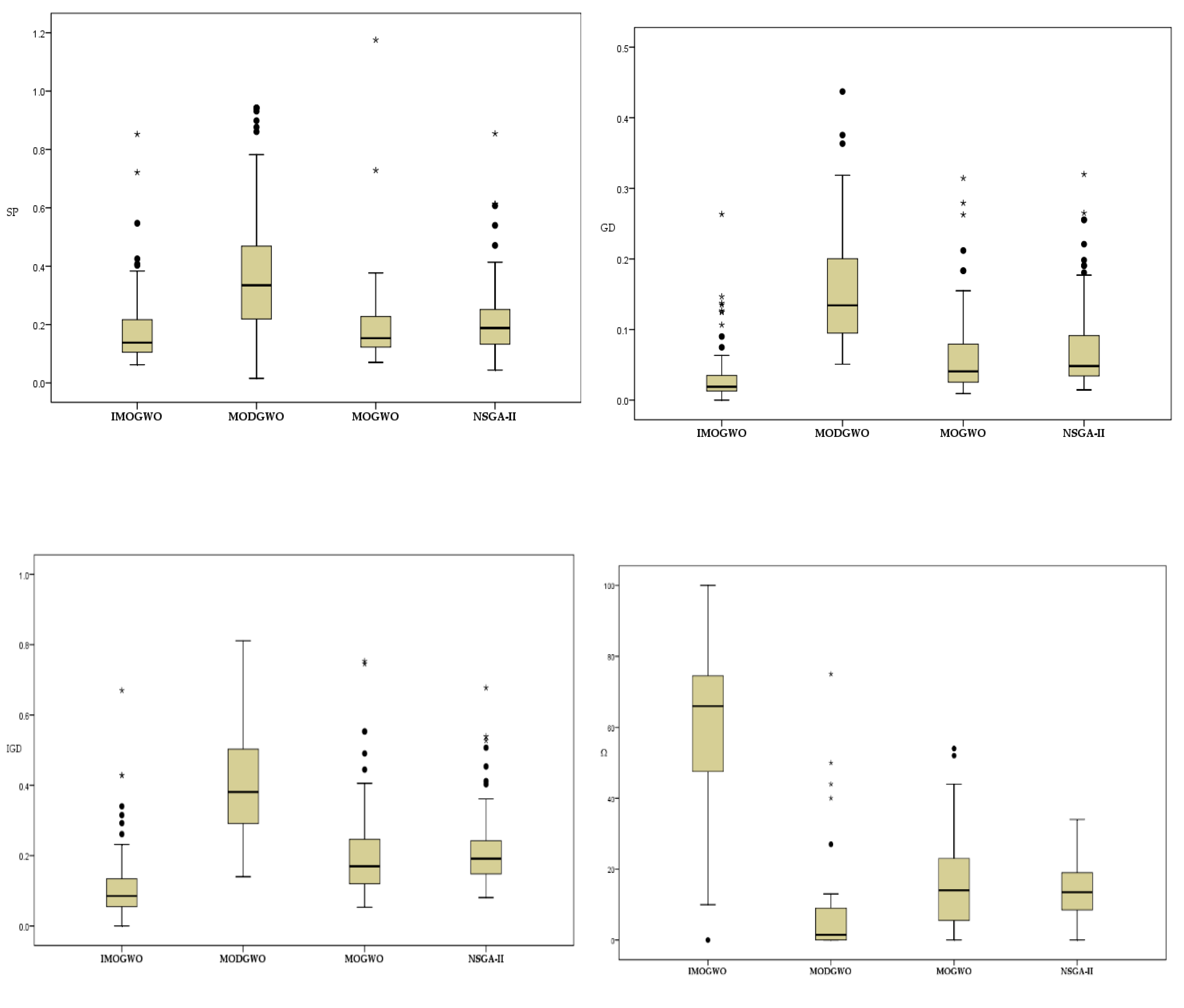
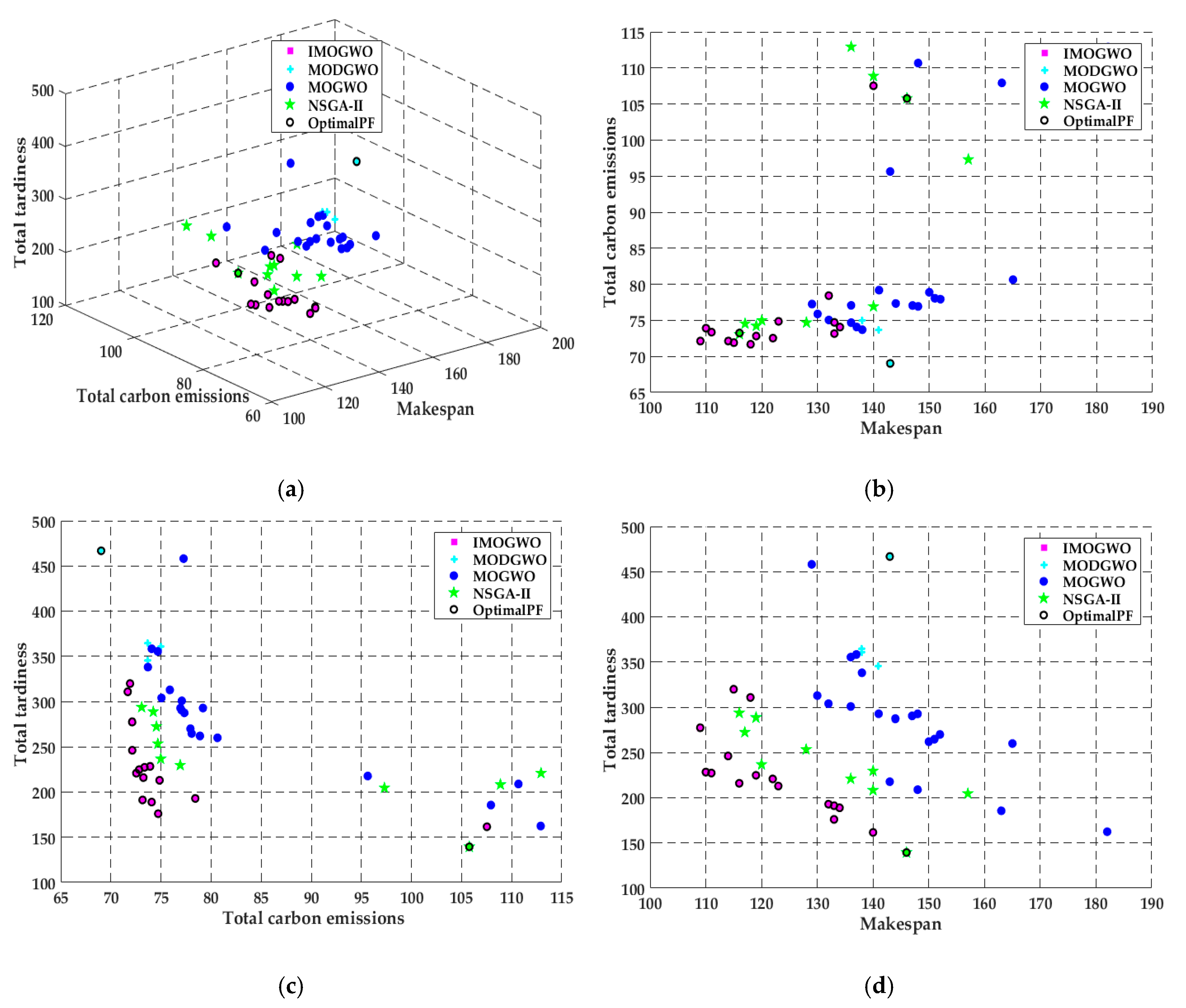
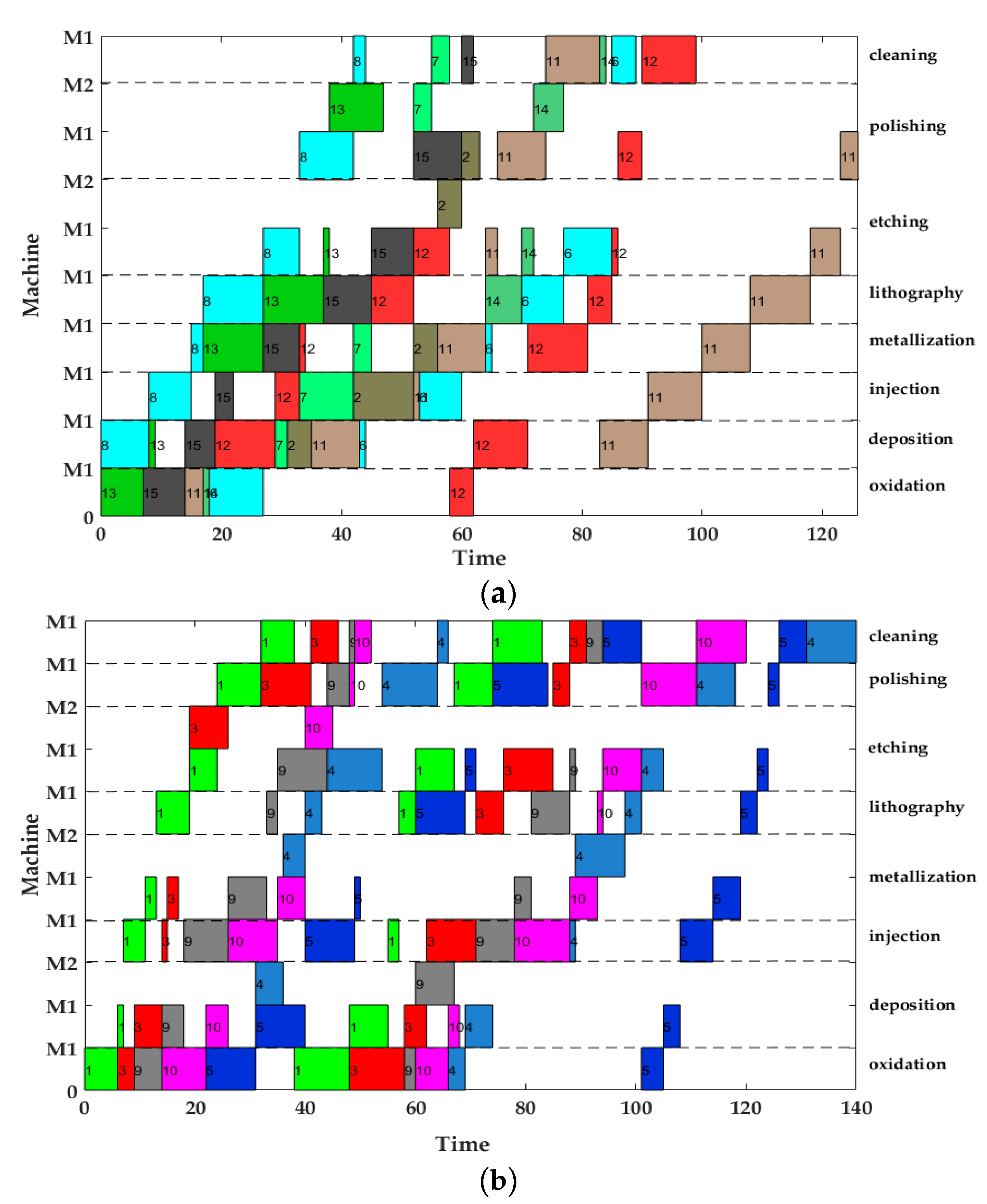
In this paper, the IMOGWO algorithm is designed to solve the green manufacturing collaborative optimization problem of the semiconductor wafer distributed heterogeneous factory. The IMOGWO realizes the rational allocation of jobs to factories and the production scheduling of assigned jobs in factories by adopting heuristic rules DR and the PS decoding method. By designing a reverse learning strategy for the initial population, the fliplr mutation and LOX cross-mutation learning strategies for the leadership level, and the LMOX cross search strategy for the grey wolf individual and randomly selected wolf, wolf, wolf, and the wolf, which enlarges the diversity of the population and improves the quality of the solution. Simulation results demonstrate that the proposed IMOGWO has certain advantages and competitiveness compared with the other three algorithms. The algorithm designed in this paper can find the optimal solution of the scheduling scheme by enlarging the diversity of the population so that the results can jump out of the local optimum. The green scheduling model designed in this paper focuses on the carbon emission indicator. All of these are also applicable to other production scheduling problems, such as distributed flexible job shop green scheduling, distributed uncertain job shop green scheduling, and so on. In the actual semiconductor production, new wafers are continuously put into processing every day, and some operations such as trial processing lead to uncertain processing time of wafers. Therefore, uncertain scheduling in semiconductor wafer manufacturing is our future research direction. In addition, a semiconductor production line may be composed of hundreds of devices, and there may be hundreds of different flowing product types. This is on a very large scale. Therefore, it is imperative to study the scheduling problem of large-scale jobs in semiconductor production.
Lastly, the discussion of more novel technical methods, such as the game theory model, the fuzzy theory, machine learning, and Internet of Things technology to solve the scheduling problem of distributed job shop manufacturing in an effective time is also the focus of our future research.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}