Hierarchical Semantic Loss and Confidence Estimator for Visual-Semantic Embedding-Based Zero-Shot Learning


Abstract
:1. Introduction
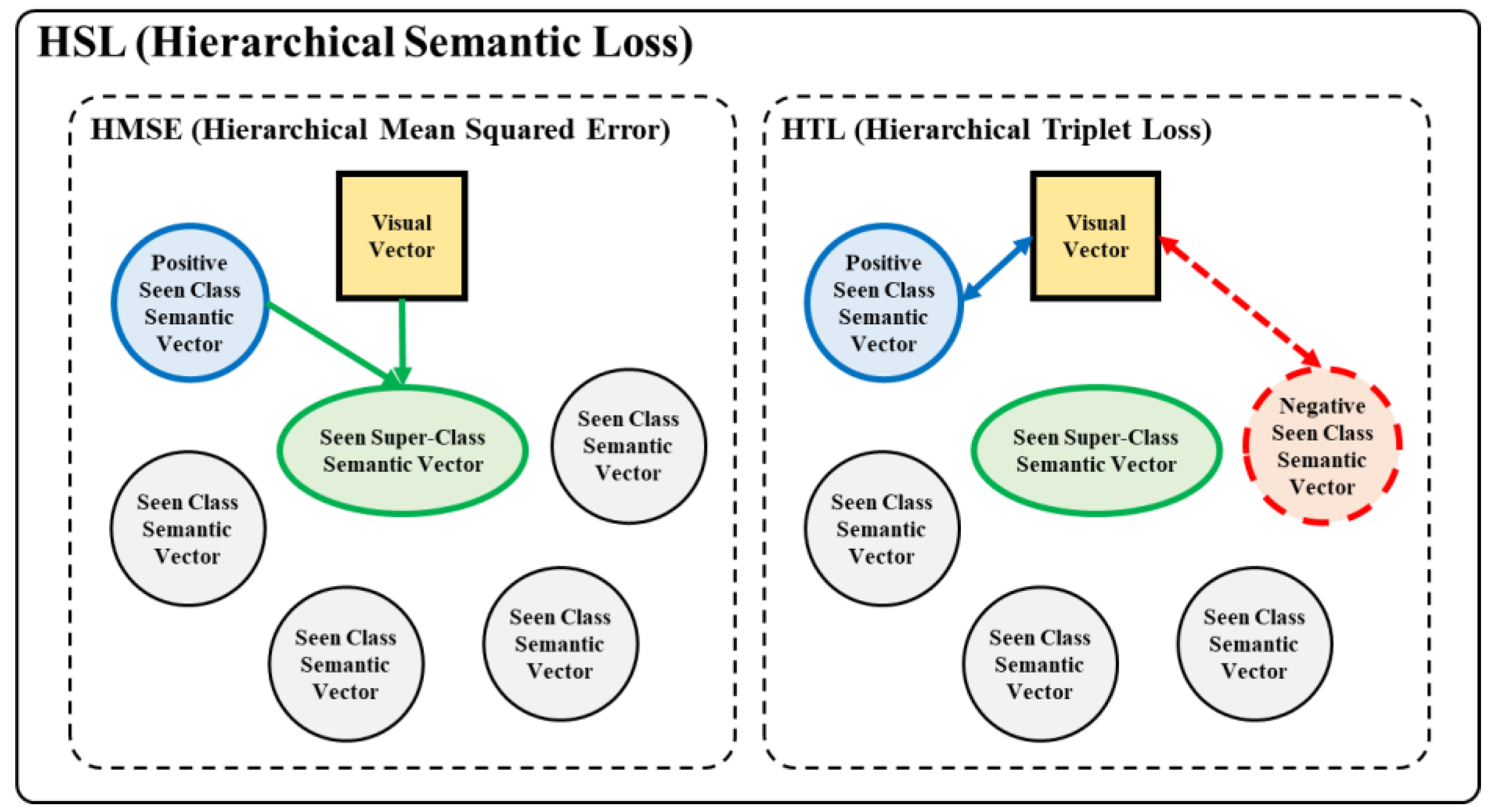
- We propose a hierarchical semantic loss in the training phase. It uses hierarchical knowledge in semantic data to calculate loss function. It shows the more meaningful embedding results in performing zero-shot cross-modal retrieval.
- We propose an unseen confidence estimator in the inference phase. It estimates the confidence score for input query image and adjusts the distances between a query image vector and unseen class semantic vectors to improve the performance of generalized zero-shot learning.
2. Related Work
2.1. Embedding-Based Zero-Shot Learning
2.2. Triplet Margin Loss
2.3. Confidence Score
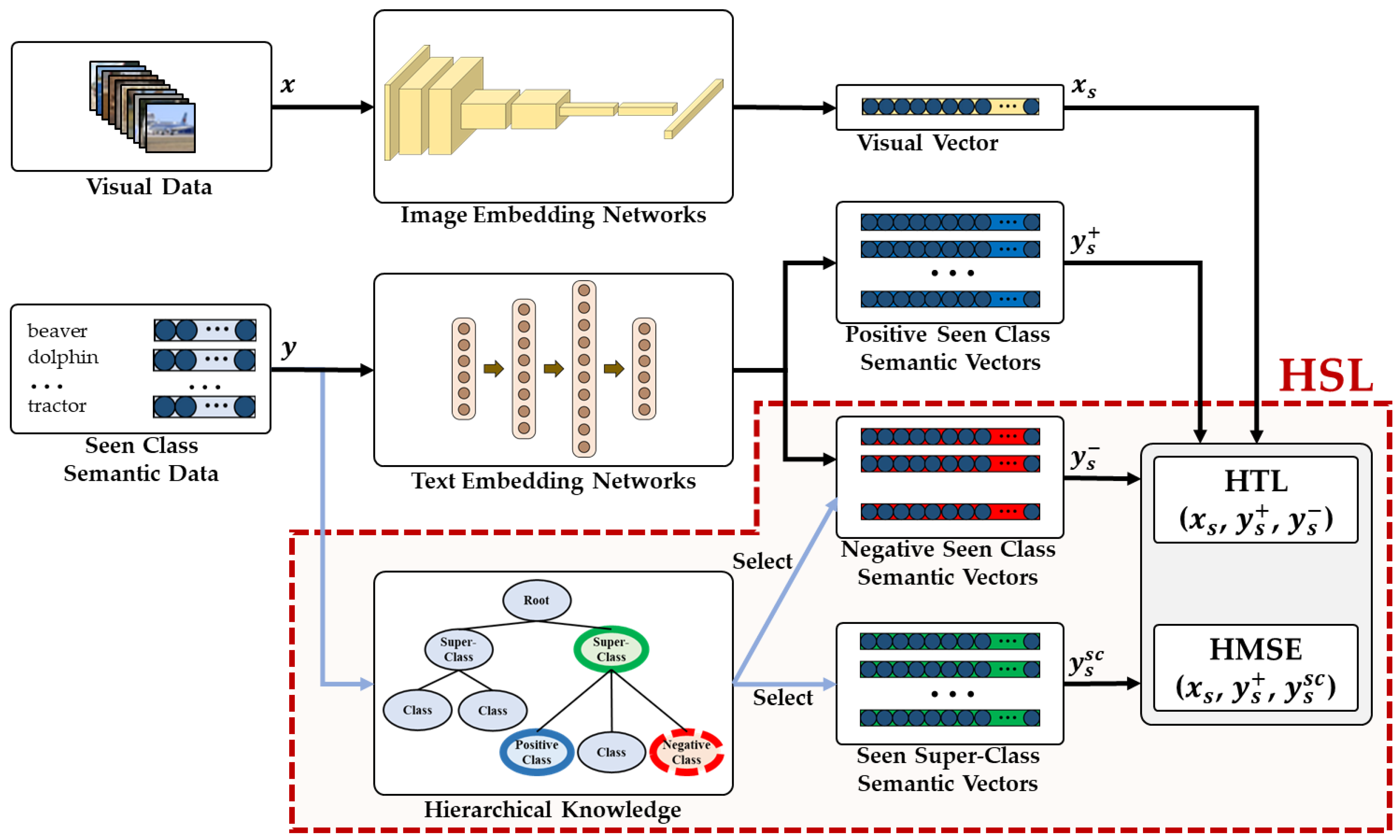
3. Hierarchical Semantic Loss and Confidence Estimator for Generalized Zero-Shot Learning
3.1. Zero-Shot Learning with Hierarchical Knowledge
- : seen-class visual data such as an image in training dataset.
- : seen-class semantic data such as a text label of in training dataset.
- : seen-class visual vector embedded from image embedding networks.
- : positive seen-class semantic vector embedded from text embedding networks.
- : negative seen-class semantic vector embedded from text embedding networks. It is selected by using hierarchical knowledge such that it has same super-class with .
- : seen super-class semantic vector obtained from pre-trained word vector and selected by using hierarchical knowledge. It is the super-class of and .
3.2. Zero-Shot Inference with Unseen Confidence Estimator
- : visual data comprise unseen-classes not used in training phase.
- : semantic data comprise both seen-classes used in training phase and unseen-classes.
- : visual vector embedded from image embedding networks as query of cross-modal retrieval task.
- : seen-class semantic vector embedded from text embedding networks as targets of cross-modal retrieval task.
- : unseen-class semantic vector embedded from text embedding networks as targets of cross-modal retrieval task.
- : distances between visual vector query and seen-class semantic vectors.
- : distances between visual vector query and unseen-class semantic vectors.
- : unseen confidence score from unseen confidence estimator adjusting visual-unseen distance .
4. Experimental Setup
4.1. Dataset and Evaluation Metric
4.2. Network Structures and Training Details
5. Experimental Results and Discussion
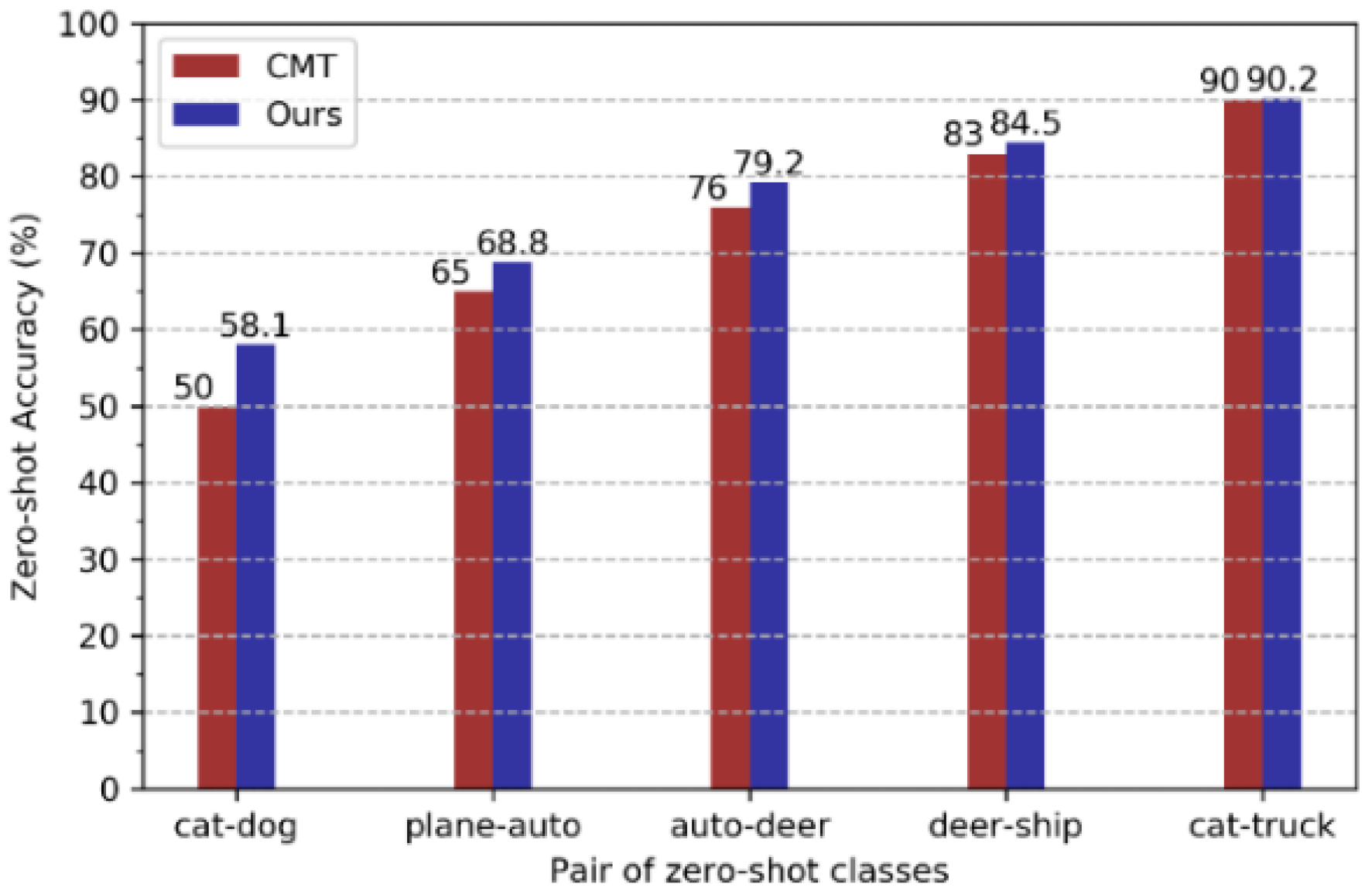
5.1. Zero-Shot Cross-Modal Retrieval Results
5.2. Generalized Zero-Shot Cross-Modal Retrieval Results
5.3. Degradation of Cross-Modal Retrieval for Seen Class Visual Data
5.4. Visualization of Embedded Visual Vectors
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A Large-scale Hierarchical Image Database. In Proceedings of the Computer Vision and Pattern Recognition 2009, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In Proceedings of the European Conference on Computer Vision 2014, Zurich, Switherland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a Model for Few-Shot Learning. In Proceedings of the 5th the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–11. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the Advances in Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 3630–3638. [Google Scholar]
- Socher, R.; Ganjoo, M.; Manning, C.D.; Ng, A. Zero-shot Learning through Cross-Modal Transfer. In Proceedings of the Advances in Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 935–943. [Google Scholar]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Mikolov, T. Devise: A Deep Visual-Semantic Embedding Model. In Proceedings of the Advances in Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2121–2129. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Special issue on learning from imbalanced data sets. ACM Sigkdd Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Ampert, C.H.; Nickisch, H.; Harmeling, S. Attribute-based classification for zero-shot visual object categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 453–465. [Google Scholar] [CrossRef] [PubMed]
- Norouzi, M.; Mikolov, T.; Bengio, S.; Singer, Y.; Shlens, J.; Frome, A.; Corrado, G.S.; Dean, J. Zero-shot learning by convex combination of semantic embeddings. arXiv 2013, arXiv:1312.5650. [Google Scholar]
- Zhang, Z.; Saligrama, V. Zero-shot Learning via Semantic Similarity Embedding. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 4166–4174. [Google Scholar]
- Akata, Z.; Reed, S.; Walter, D.; Lee, H.; Schiele, B. Evaluation of Output Embeddings for Fine-Grained Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 2927–2936. [Google Scholar]
- Xian, Y.; Akata, Z.; Sharma, G.; Nguyen, Q.; Hein, M.; Schiele, B. Latent Embeddings for Zero-Shot Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 69–77. [Google Scholar]
- Romera-Paredes, B.; Torr, P. An Embarrassingly Simple Approach to Zero-Shot Learning. In Proceedings of the International Conference on Machine Learning 2015, Lille, France, 6–11 July 2015; pp. 2152–2161. [Google Scholar]
- Akata, Z.; Perronnin, F.; Harchaoui, Z.; Schmid, C. Label-embedding for image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1425–1438. [Google Scholar] [CrossRef] [PubMed]
- Changpinyo, S.; Chao, W.L.; Gong, B.; Sha, F. Synthesized Classifiers for Zero-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 5327–5336. [Google Scholar]
- Kodirov, E.; Xiang, T.; Gong, S. Semantic autoencoder for zero-shot learning. arXiv 2017, arXiv:1704.08345. [Google Scholar]
- Zhang, L.; Xiang, T.; Gong, S. Learning a Deep Embedding Model for Zero-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 3010–3019. [Google Scholar]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-shot learning-a comprehensive evaluation of the good, the bad and the ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Chao, W.L.; Changpinyo, S.; Gong, B.; Sha, F. An Empirical Study and Analysis of Generalized Zero-Shot Learning for Object Recognition in the Wild. In Proceedings of the European Conference on Computer Vision 2016, Amsterdam, The Netherland, 11–14 October 2016; pp. 52–68. [Google Scholar]
- Aytar, Y.; Vondrick, C.; Torralba, A. See, hear, and read: Deep aligned representations. arXiv 2017, arXiv:1706.00932. [Google Scholar]
- Ge, W.; Huang, W.; Dong, D.; Scott, M.R. Deep Metric Learning with Hierarchical Triplet Loss. In Proceedings of the European Conference on Computer Vision 2018, Munich, Germany, 8–14 September 2018; pp. 272–288. [Google Scholar]
- Annadani, Y.; Biswas, S. Preserving Semantic Relations for Zero-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7603–7612. [Google Scholar]
- Lei Ba, J.; Swersky, K.; Fidler, S. Predicting Deep Zero-Shot Convolutional Neural Networks using Textual Descriptions. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 4247–4255. [Google Scholar]
- Zhang, Z.; Saligrama, V. Zero-shot Learning via Joint Latent Similarity Embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 6034–6042. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Chang, S.; Han, W.; Tang, J.; Qi, G.J.; Aggarwal, C.C.; Huang, T.S. Heterogeneous Network Embedding via Deep Architectures. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2015, Sydney, Australia, 10–13 August 2015; pp. 119–128. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv 2016, arXiv:1610.02136. [Google Scholar]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On calibration of modern neural networks. arXiv 2017, arXiv:1706.04599. [Google Scholar]
- Lee, K.; Lee, H.; Lee, K.; Shin, J. Training confidence-calibrated classifiers for detecting out-of-distribution samples. arXiv 2017, arXiv:1711.09325. [Google Scholar]
- Lee, K.; Lee, K.; Min, K.; Zhang, Y.; Shin, J.; Lee, H. Hierarchical Novelty Detection for Visual Object Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1034–1042. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, X.; Liao, S.; Lan, W.; Du, X.; Yang, G. Zero-shot image tagging by Hierarchical Semantic Embedding. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval 2018, Santiago, Chile, 9–13 August 2015; pp. 879–882. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009; Volume 1, pp. 32–35. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Zhu, X.; Bain, M. B-CNN: Branch convolutional neural network for hierarchical classification. arXiv 2017, arXiv:1709.09890. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unseen Confidence Estimator | Image Embedding Networks | Text Embedding Networks | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Layer | Weights Shape [W, H, IC, OC] | Feature Map [W, H, C] | Activation | Layer | Weights Shape [W, H, IC, OC] | Feature Map [W, H, C] | Activation | Layer | Weights Shape [IN, OH] | Activation |
| Input | - | [32, 32, 3] | - | Input | - | [32, 32, 3] | - | Input | [200] | - |
| Conv1 | [3, 3, 3, 64] | [30, 30, 64] | ReLU | Conv1 | [3, 3, 3, 64] | [30, 30, 64] | ReLU | FC1 | [200, 256] | ReLU |
| Conv2 | [3, 3, 64, 128] | [28, 28, 128] | ReLU | Conv2 | [3, 3, 64, 128] | [28, 28, 128] | ReLU | FC2 | [256, 512] | ReLU |
| Max pool | - | [14, 14, 128] | - | Max pool | - | [14, 14, 128] | - | FC3 (output) | [512, 200] | Identity |
| Conv3 | [3, 3, 128, 256] | [12, 12, 256] | ReLU | Conv3 | [3, 3, 128, 256] | [12, 12, 256] | ReLU | |||
| Conv4 | [3, 3, 256, 512] | [10, 10, 512] | ReLU | Conv4 | [3, 3, 256, 512] | [10, 10, 512] | ReLU | |||
| Conv5 | [3, 3, 512, 1024] | [8, 8, 1024] | ReLU | Conv5 | [3, 3, 512, 1024] | [8, 8, 1024] | ReLU | |||
| GAP | - | [1, 1, 1024] | - | GAP | - | [1, 1, 1024] | - | |||
| FC (output) | [1024, 100] | [100] | Identity | FC | [1024, 200] | [200] | Identity | |||
| Model (Semantic Candidates) | hit@1 | hit@2 | hit@3 | hit@4 | hit@5 | hit@6 | hit@7 | hit@8 | hit@9 | hit@10 |
|---|---|---|---|---|---|---|---|---|---|---|
| HSL (100 Seen Classes & 10 Unseen Classes) | 0.03 | 0.09 | 0.15 | 0.15 | 0.20 | 0.25 | 0.33 | 0.37 | 0.41 | 0.45 |
| HSL+UCE (100 Seen Classes & 10 Unseen Classes) | 0.14 | 0.28 | 0.40 | 0.50 | 0.58 | 0.64 | 0.69 | 0.73 | 0.76 | 0.78 |
| Image Query | HSL | HSL+UCE |
|---|---|---|
 (a) truck |
|
|
 (b) horse |
|
|
 (c) ship |
|
|
| Model (Semantic Candidates) | hit@1 | hit@2 | hit@3 | hit@4 | hit@5 | hit@6 | hit@7 | hit@8 | hit@9 | hit@10 |
|---|---|---|---|---|---|---|---|---|---|---|
| HSL (100 Seen Classes & 10 Unseen Classes) | 0.53 | 0.65 | 0.70 | 0.75 | 0.77 | 0.79 | 0.81 | 0.82 | 0.84 | 0.85 |
| HSL+UCE (100 Seen Classes & 10 Unseen Classes) | 0.44 | 0.53 | 0.59 | 0.63 | 0.66 | 0.69 | 0.72 | 0.74 | 0.76 | 0.78 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, S.; Kim, J. Hierarchical Semantic Loss and Confidence Estimator for Visual-Semantic Embedding-Based Zero-Shot Learning. Appl. Sci. 2019, 9, 3133. https://doi.org/10.3390/app9153133
Seo S, Kim J. Hierarchical Semantic Loss and Confidence Estimator for Visual-Semantic Embedding-Based Zero-Shot Learning. Applied Sciences. 2019; 9(15):3133. https://doi.org/10.3390/app9153133
Chicago/Turabian StyleSeo, Sanghyun, and Juntae Kim. 2019. "Hierarchical Semantic Loss and Confidence Estimator for Visual-Semantic Embedding-Based Zero-Shot Learning" Applied Sciences 9, no. 15: 3133. https://doi.org/10.3390/app9153133