The proposed scheme was evaluated using ndnSIM, which is an NS-3 based Named Data Networking simulator [
5]. We used four real topologies acquired from Rocketfuel [
28]. Detailed information about the topologies is shown in
Table 1.
Total nodes represents the total number of nodes in each topology. A node in a network can be classified as backbone, gateway, or leaf, and the number of each type is also shown.
Links represents the total number of links which connect the nodes and all links have the same delay. One thousand producers and consumers were randomly placed among backbone routers and leaf routers, respectively. Thus, the topologies used for the evaluation were equivalent to a network with more than 2000 nodes in total, including the producers and the consumers, which is the largest scale based on our knowledge. While producers were evenly connected to ten backbone nodes, the number of consumers in a single node was randomly chosen. We assumed that each name prefix was responsible for ten contents and each consumer generates
Interest packets for a single name prefix. Real URL data acquired from the ALEXA [
29] were used as name prefixes. The performance evaluation was conducted under various Zipf parameters [
30], which indicate the popularity of contents. The run time for each experiment was 60 seconds, and each consumer generates ten
Interest packets per second according to Poisson distribution. Thus, 600 thousand Interest packets in total were issued.
4.1. Performance Metrics
In evaluating the performance of routing schemes, we used a set of metrics: the average hop count, the total number of
Interest packets, and the memory consumption. The average hop count is the average number of nodes passed until the corresponding
Data packet arrives after an
Interest packet is sent out from a customer. Hence, the average hop count is defined as Equation (
2), where
C is the number of consumers, and
is the number of
Interests created by customer
i.
The total number of
Interest packets is defined as Equation (
3), where
is the number of routers in the network. If an
Interest is forwarded by three routers, the total number of
Interest packets is increased by three. This metric measures how many
Interest packets are forwarded towards multiple faces.
Since the lengths of name prefixes are not fixed, the memory consumption is calculated in two ways, as shown in Equations (
4) and (
5). The
in Equation (
4) assumes that each variable-length name prefix is stored in the FIB and the
in Equation (
5) assumes that a name prefix is stored as a 128-bit signature, where
is the total number of FIB entries in node
,
is the size of the
jth entry to store a name prefix into
,
is the memory requirement for storing output faces, and
is the memory requirement for storing the signature of a name prefix. Note that output faces are represented by a fixed-length vector, of which the number of bits is equal to the number of output faces. Although an FIB table also keeps the ranks of possible faces, the memory requirement for ranking is ignored for simplicity.
4.2. Performance of Proposed Work
We evaluated the performance of our proposed work using the various sizes of Bloom filters: 1024, 2048, 4096, and 8192 bits. The average hop count, the total number of Interest packets and the memory consumption were evaluated according to the Bloom filter sizes. During the experiments, it was confirmed that the consumers received the requested Data packet for every Interest packet.
Figure 6 shows the average number of hops according to the various sizes of the Bloom filter, and the performance of the proposed scheme is compared to the
shortest path scheme, which ensures the shortest path. In
Figure 6, the black dotted line is the result of the
shortest path scheme. Across all topologies, it is shown that as the size of the Bloom filter gets larger, the average hop count converges to the
shortest path.
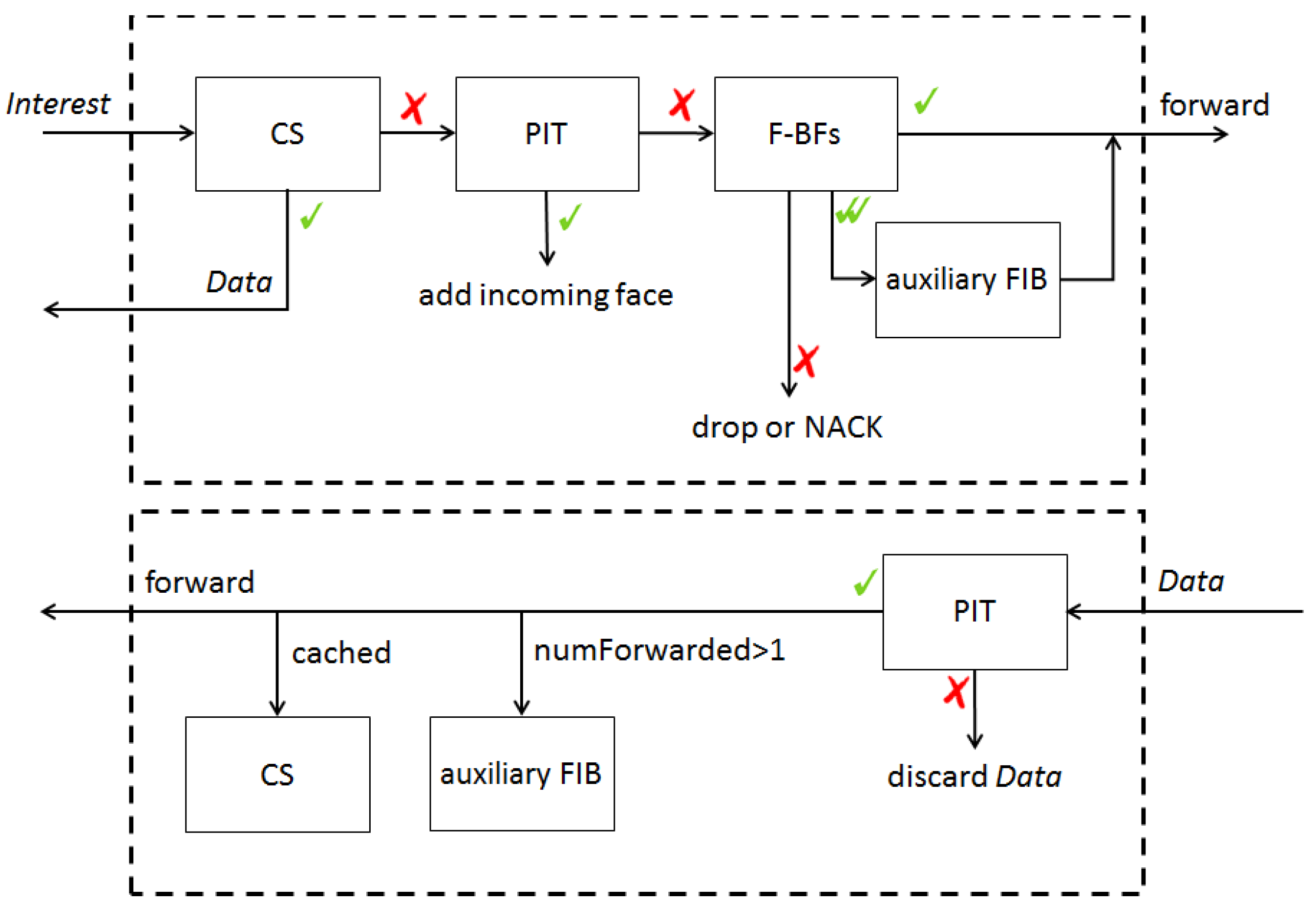
Figure 7 shows the total number of
Interest packets according to the various sizes of the Bloom filter. The
shortest path scheme forwards an
Interest packet only to the face with the minimum cost, while our proposed scheme forwards an
Interest packet to all matching faces in order to avoid the delay caused by the false positives of Bloom filters. The black dotted line shows the result of the
shortest path scheme. In all topologies, as the size of Bloom filter grows, the total number of
Interest packets converges to the
shortest path.
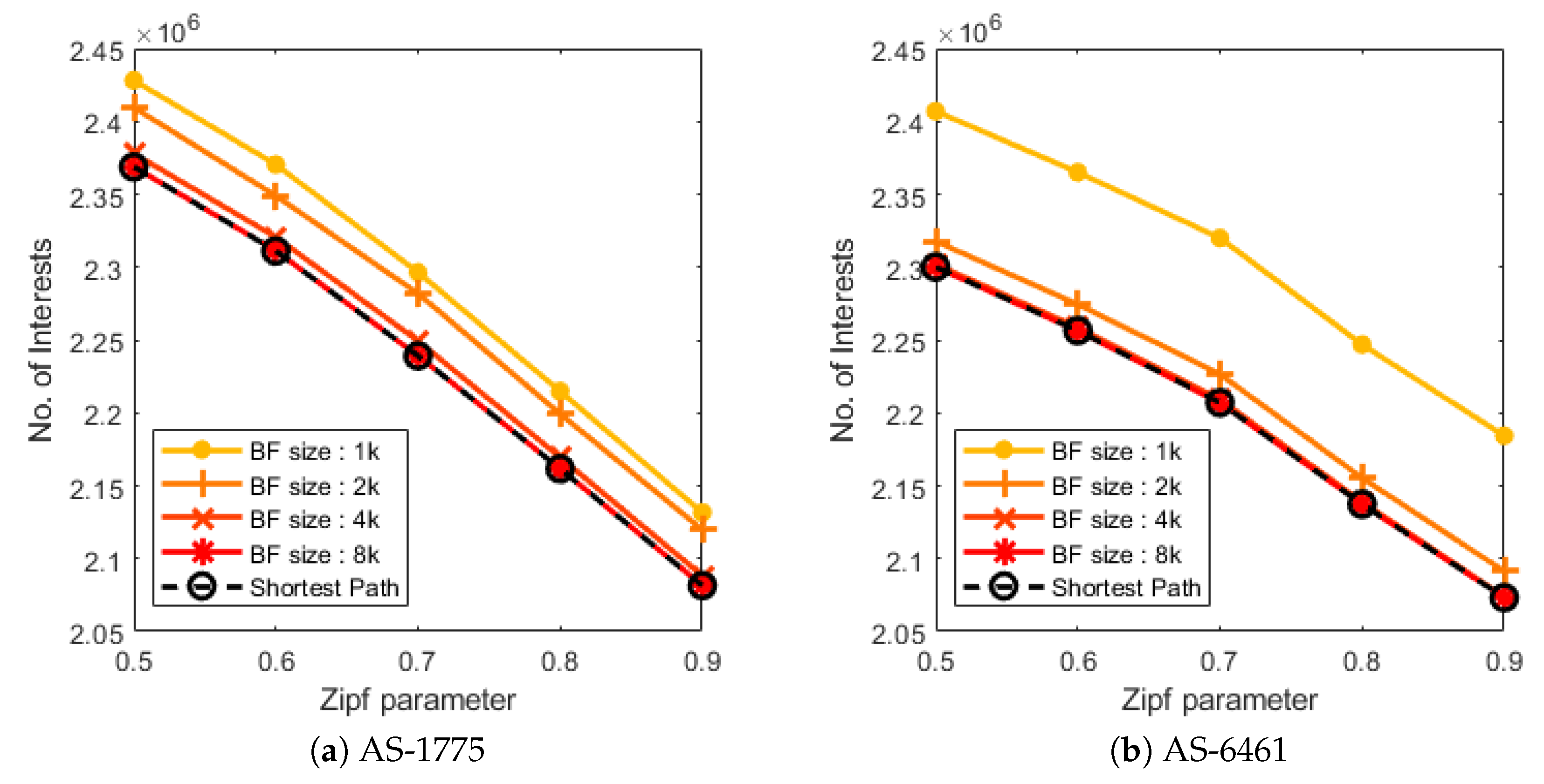
Figure 8 shows the memory consumption based on Equations (
4) and (
5). The memory consumption for the proposed scheme consists of the memory consumptions for Bloom filters and auxiliary FIB tables. As the size of the Bloom filter grows, the memory requirement for the Bloom filter naturally increases, but the number of auxiliary FIB entries decreases. As shown in the figure, the memory usages for all topologies are minimal when the size of the Bloom filter is 2048 bits.
4.3. Performance Comparison with Other Schemes
The performance of the proposed algorithm was compared to those of shortest path and flooding. The size of a Bloom filter of the proposed work in this comparison was fixed as 2048 bits, which has the minimum memory consumption for all topologies. The shortest path in ndnSIM uses Dijkstra’s algorithm, which guarantees the packet delivery along the optimal path using the minimum amount of Interest packets. The performance of the three schemes was compared based on the shortest path. The flooding scheme forwards an Interest packet to all faces other than the incoming face of the Interest if no matching entry is found in an FIB table. When a Data packet arrives as a response, the FIB table is updated using the incoming face of the Data packet as the output face of the longest matching name prefix for the Interest.
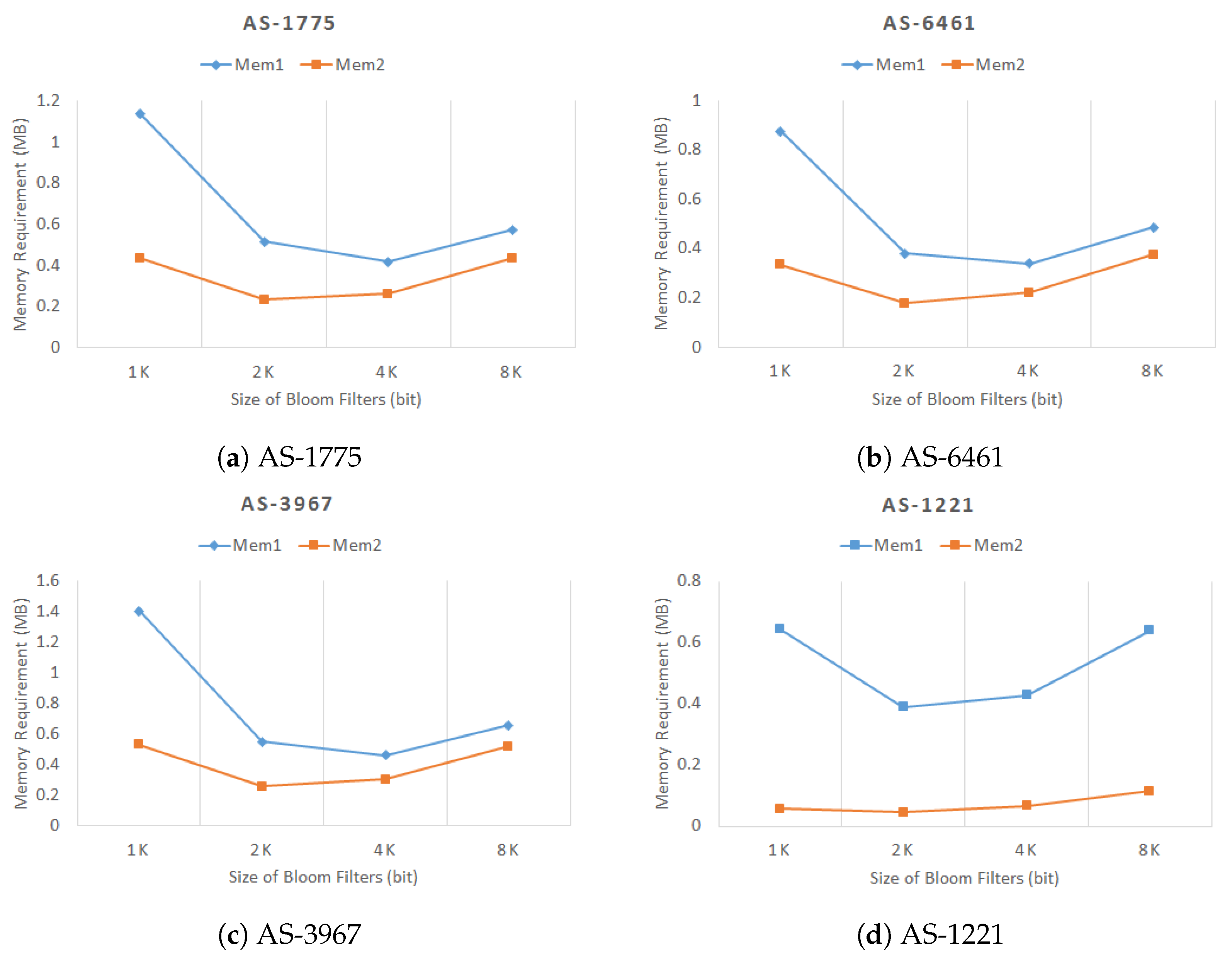
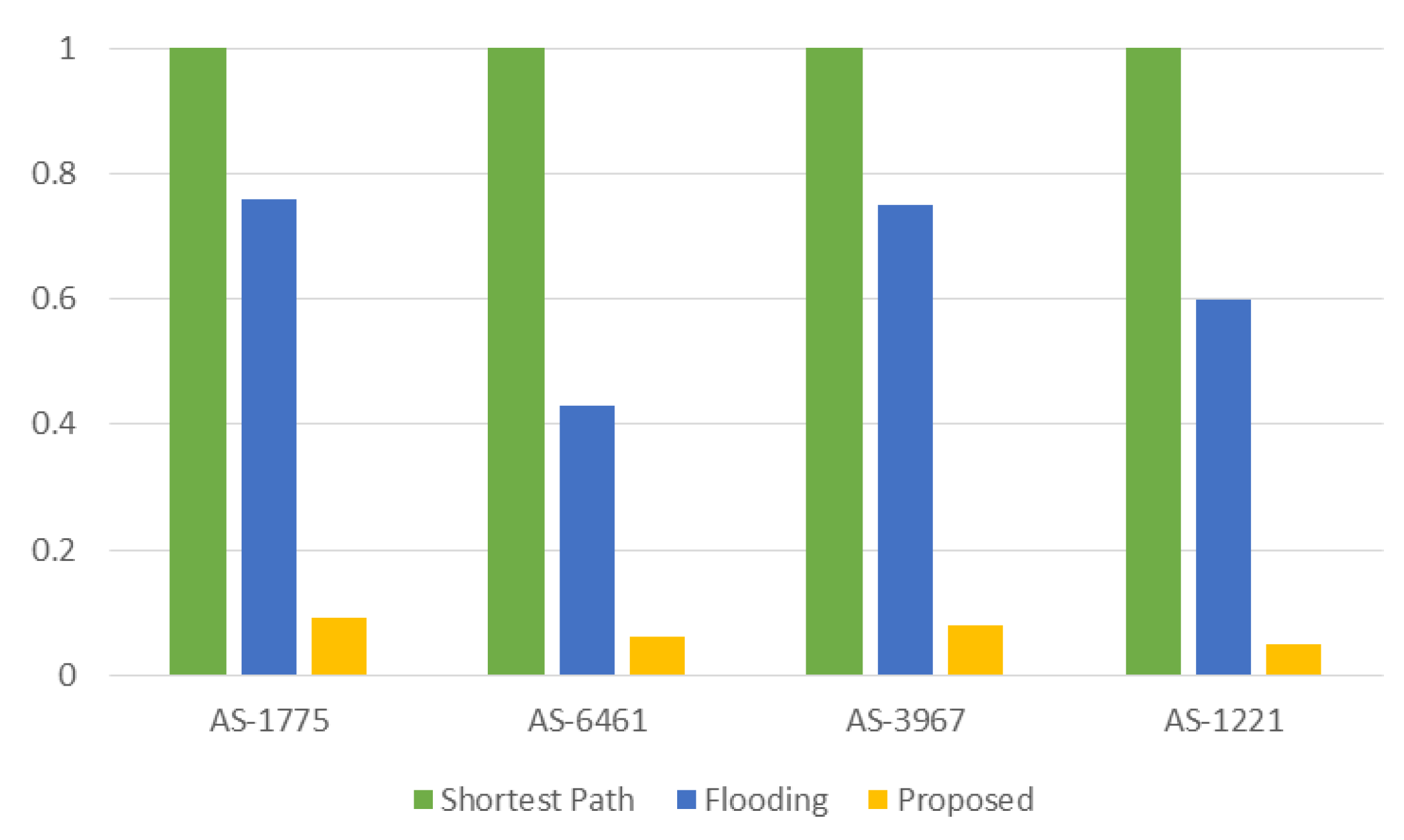
Figure 9 compares the average hop count when the Zipf parameter is 0.7. As shown in the figure, the average hop count of our proposed scheme is very close to the
shortest path algorithm in all four topologies, which means that the proposed scheme can achieve the near optimal packet delivery. We also conducted the simulation under various Zipf parameters, from 0.5 to 0.9, but those results are omitted for simplicity since they show a similar tendency. Both the proposed scheme and
flooding ensure that the
Interest packets are delivered to content sources at all times and can deliver packets along the shortest path with the same hop counts as the
shortest path in an ideal case. However, since in-network caching is a default function, duplicated
Interest packets in these schemes may cause in-network caches to store unnecessary contents, thus degrading the cache performance. The degraded in-network cache performance can generate more cache misses and lead to longer packet delivery paths.
Figure 10 compares the normalized number of
Interest packets, which is the total number of
Interests divided by the number of
Interests in the
shortest path scheme, when the Zipf parameter is 0.7. The
shortest path scheme generates the smallest number of
Interest packets by forwarding an
Interest packet only to the best matching face. The proposed scheme uses only about 1% more
Interest packets than the
shortest path scheme, regardless of the topologies. Since the number of
Interest packets of the proposed work is influenced by the size of a Bloom filter, it can be further reduced by increasing the size of Bloom filters. Since the
flooding scheme forwards packets toward multiple faces, it consumes many more
Interests. Particularly, in a large topology such as AS-1221, the
flooding consumes almost twice the number of
Interest packets compared to the
shortest path scheme. Therefore, the simple
flooding is not scalable and inappropriate for the large topology.
Table 2,
Table 3,
Table 4 and
Table 5 compare the memory consumption. For all four topologies, the
shortest path scheme has the largest number of FIB entries, because every router in the network has the complete knowledge of all name prefixes. Meanwhile, the
flooding scheme has fewer entries than the
shortest path, because routers only have the name prefix entries for requested contents. Therefore, in the
flooding scheme, if a router has never been requested for any contents, it has no entries in its FIB table. The proposed scheme has the smallest number of FIB entries in all topologies, since it updates the auxiliary FIB entries only when the
Interest packet is forwarded to multiple faces. Overall, these results indicate that the proposed algorithm is highly scalable.
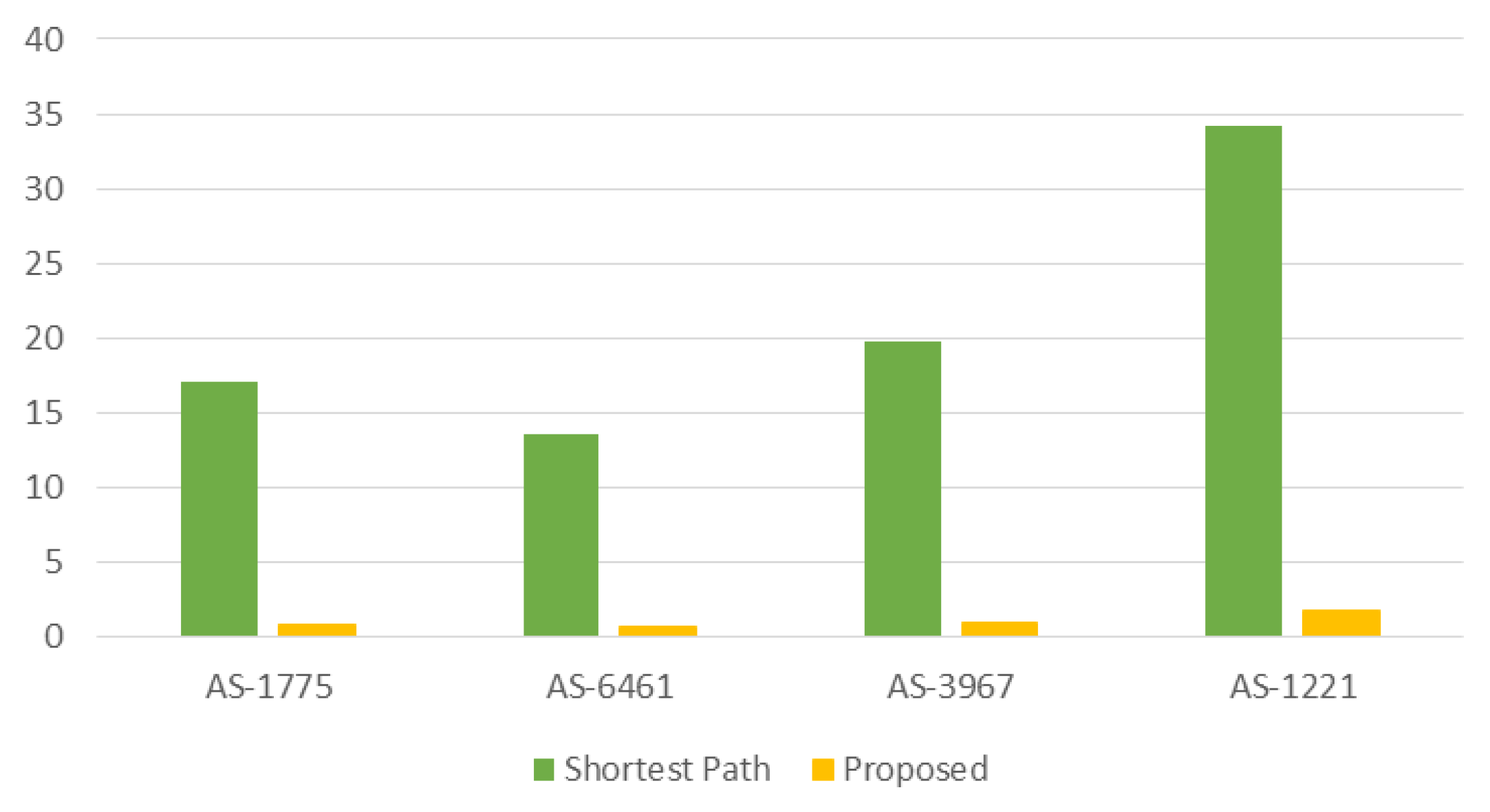
Figure 11 graphically compares the memory consumption, which is normalized by the memory consumption of the
shortest path for the
case shown in Equation (
5). It is shown that the proposed work consumes only 5–9% of the memory consumed by the
shortest path.
In our proposed work, every producer and every node which receives name prefix broadcasting from other networks needs to propagate an S-BF which contains the connectivity information. The traffic caused in propagating the connectivity information is shown in Equation (
6), where
is the number of producers,
is the size of the S-BF, and
is the number of the entire links in a network.
For link state algorithms, the pair of name prefix and its cost should be propagated in order to create an FIB table. Equation (
7) shows the traffic, where
is the number of name prefixes and
is the size of each name prefix.
Figure 12 compares the traffic amounts for routing. Because the traffic amounts for routing are related to the number of links in the network, more traffic is required for the networks with more complicated connections. Hence, the amount of consumed traffic is minimum for AS-6461. While the
shortest path scheme propagates the individual connectivity information, the proposed scheme spreads the summary of the connectivity information in the form of a Bloom filter. Therefore, the traffic used for the proposed work is much smaller than
shortest path, which is about 6–8% of the traffic of the
shortest path.
On the other hand, the flooding scheme does not cause any overhead traffic for routing, since it updates the connectivity information when a corresponding Data packet arrives after an Interest packet is flooded. However, since a Data packet has to be sent back as a response for every Interest packet, a lot of bandwidth is wasted to deliver Data packets for the flooded Interest packets. Moreover, the size of a Data packet, which carries an actual content, is usually much larger than the size of the packet carrying the connectivity information. Even though the flooding scheme does not lead to any traffic for routing, a huge amount of network bandwidth is wasted to retrieve Data packets for flooded Interest packets.
In the BFR [
13], a Bloom filter is only used for propagating the connectivity information and the FIB is populated whenever a new
Interest is issued. As a result, the full FIB is built for all requested contents similar to
flooding. However, our proposed work utilizes the Bloom filter for both sharing the connectivity information and building the forwarding engine. The proposed scheme builds the lookup architecture simply by combining the receiving S-BFs, and hence it is not necessary to store the full FIB table. While there is no protection for the extra traffic and the delivery towards the wrong origin due to false positives in the BFR, the proposed scheme adapts the auxiliary FIB in order to reduce the impact of the false positives. The BFR may have to search both a FIB and Bloom filters in the case of no matching prefix in the FIB.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}