Neural Machine Reading Comprehension: Methods and Trends


Abstract
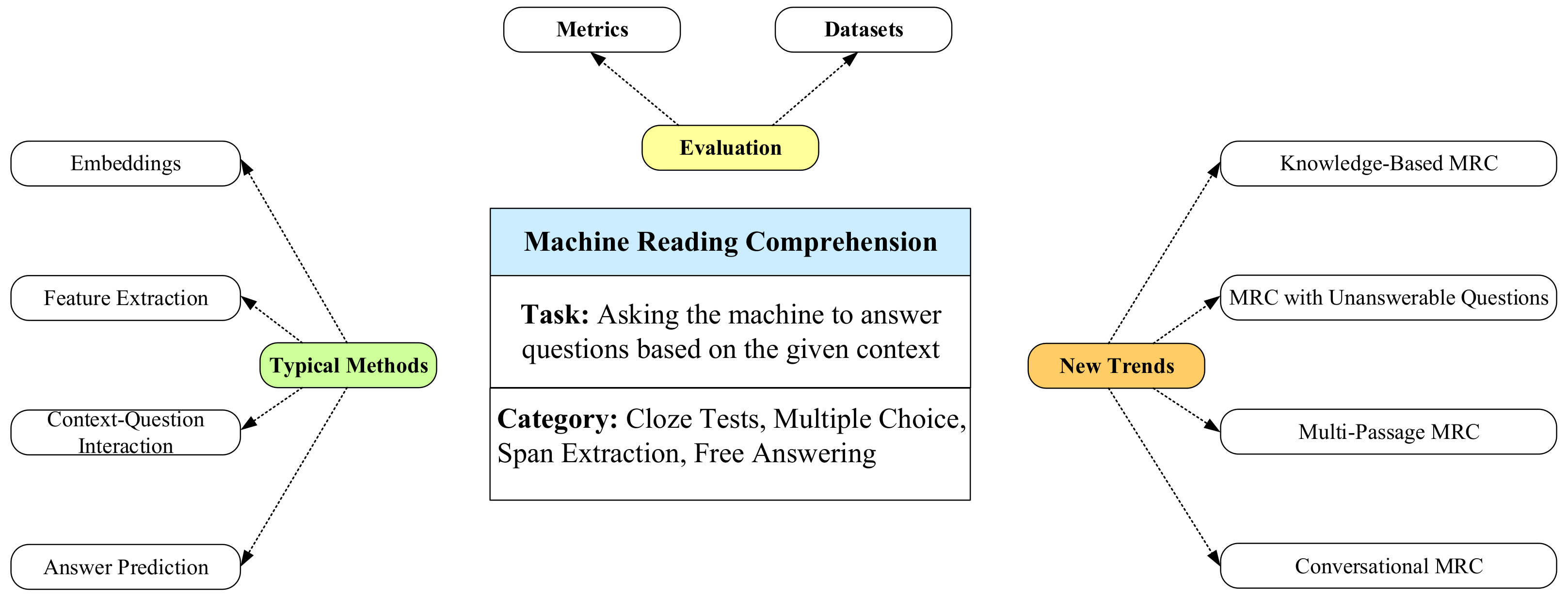
:1. Introduction
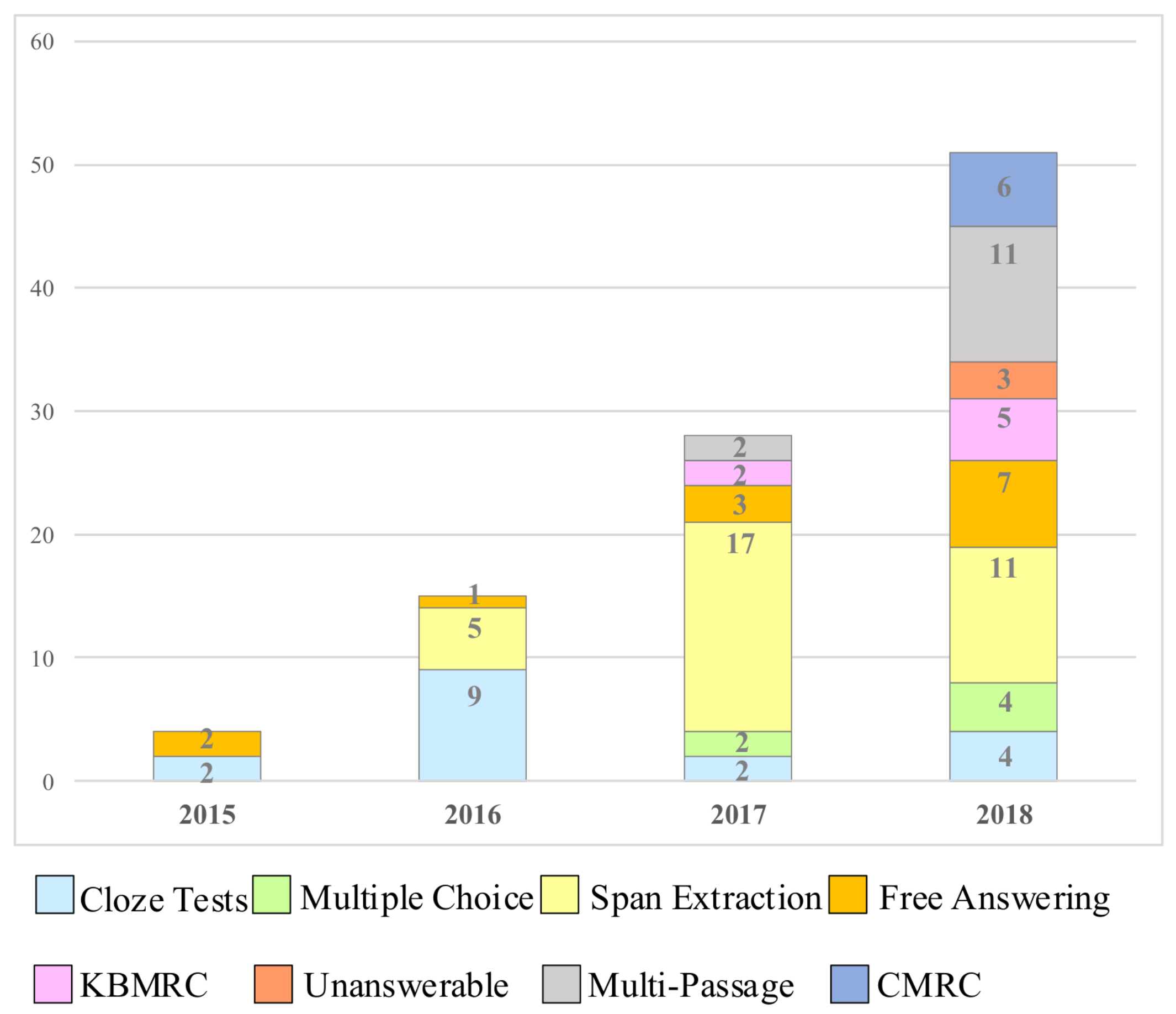
2. Tasks
2.1. Cloze Tests
2.2. Multiple Choice
2.3. Span Extraction
2.4. Free Answering
2.5. Comparison of Different Tasks
- -
- Construction: This dimension measures whether it is easy to construct datasets for the task or not. The easier it is, the higher the score.
- -
- Understanding: This dimension evaluates how well the task can test the machine’s ability to understand. If a task needs more understanding and reasoning, the score is higher.
- -
- Flexibility: The flexibility of the answer form can measure the quality of the tasks. When answers are more flexible, the flexibility score is higher.
- -
- Evaluation: Evaluation is a necessary part of MRC tasks. Whether a task can be easily evaluated also determines its quality. Tasks that are easy to evaluate get high scores in this dimension.
- -
- Application: A good task is supposed to be close to real-world application. Therefore, scores in this dimension are high, if a task can easily be applied to the real world.
3. Deep-Learning-Based Methods
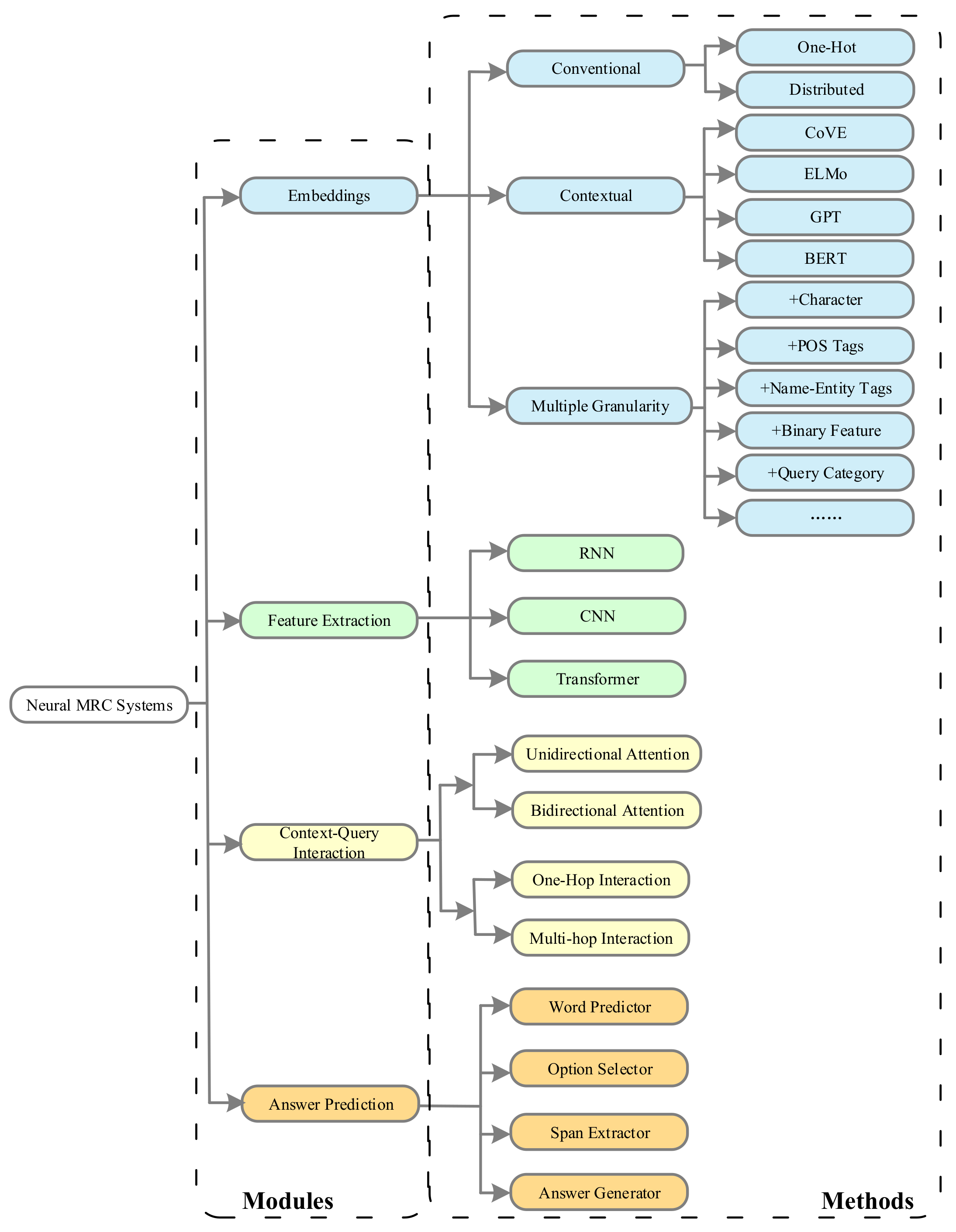
3.1. General Architecture
- -
- Embeddings: As the machine is unable to understand natural language directly, the embedding module is indispensable to change input words into fixed-length vectors at the beginning of the MRC systems. Taking the context and question as inputs, this module outputs context and question embeddings by various approaches. Classical word representation methods such as one-hot and Word2Vec, sometimes combined with other linguistic features, i.e., part-of-speech, name entity, and question category, are usually used to represent semantic and syntactic information in the words. Moreover, contextualized word representations pre-trained by a large corpus also show promising performance in encoding contextual information.
- -
- Feature Extraction: After the embedding module, context and question embeddings are fed to the feature extraction module. To better understand the context and question, this module is aimed at extracting more contextual information. Some typical deep neural networks, such as recurrent neural networks (RNNs) and convolution neural networks (CNNs) are applied to further mine contextual features from context and question embeddings.
- -
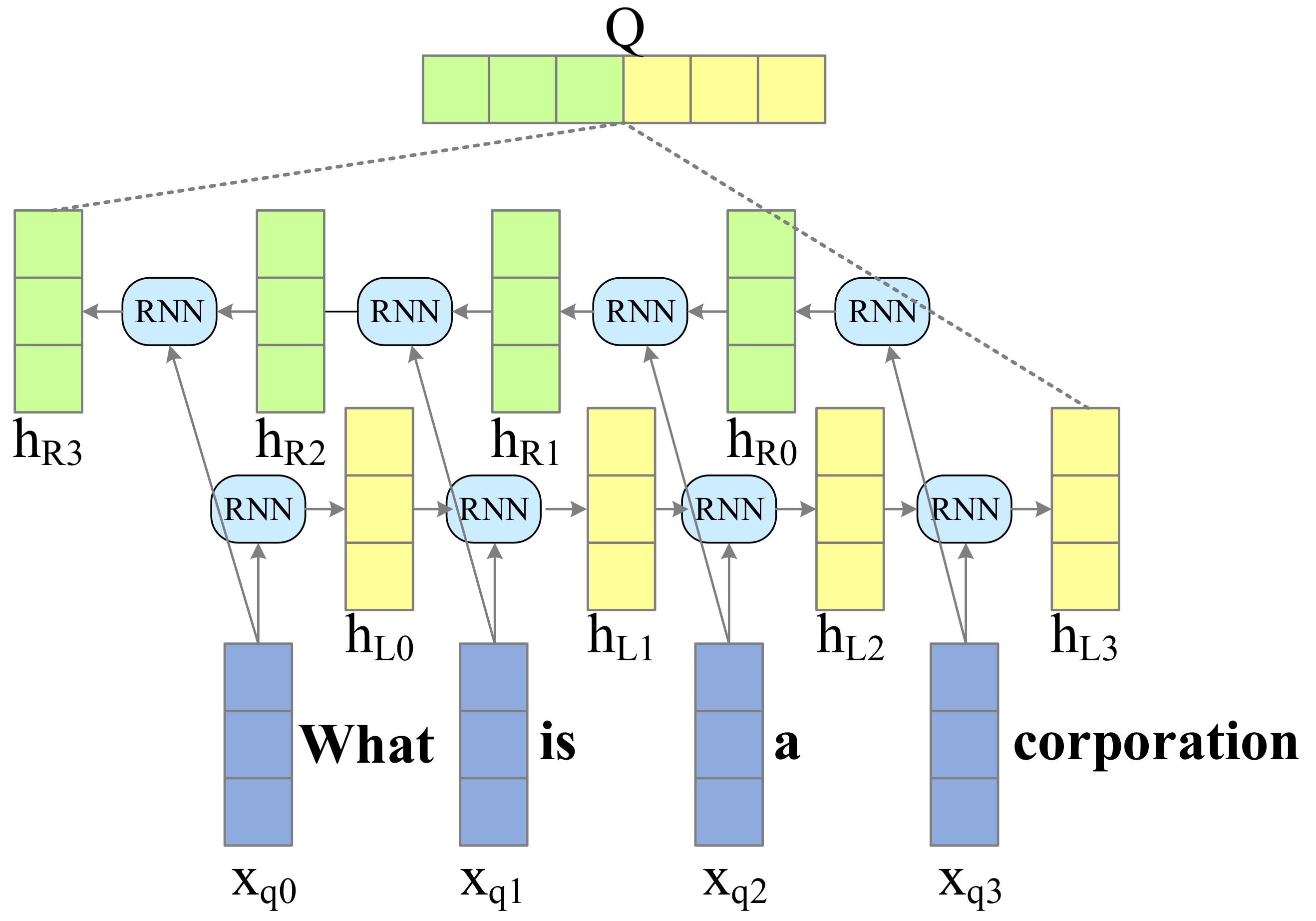
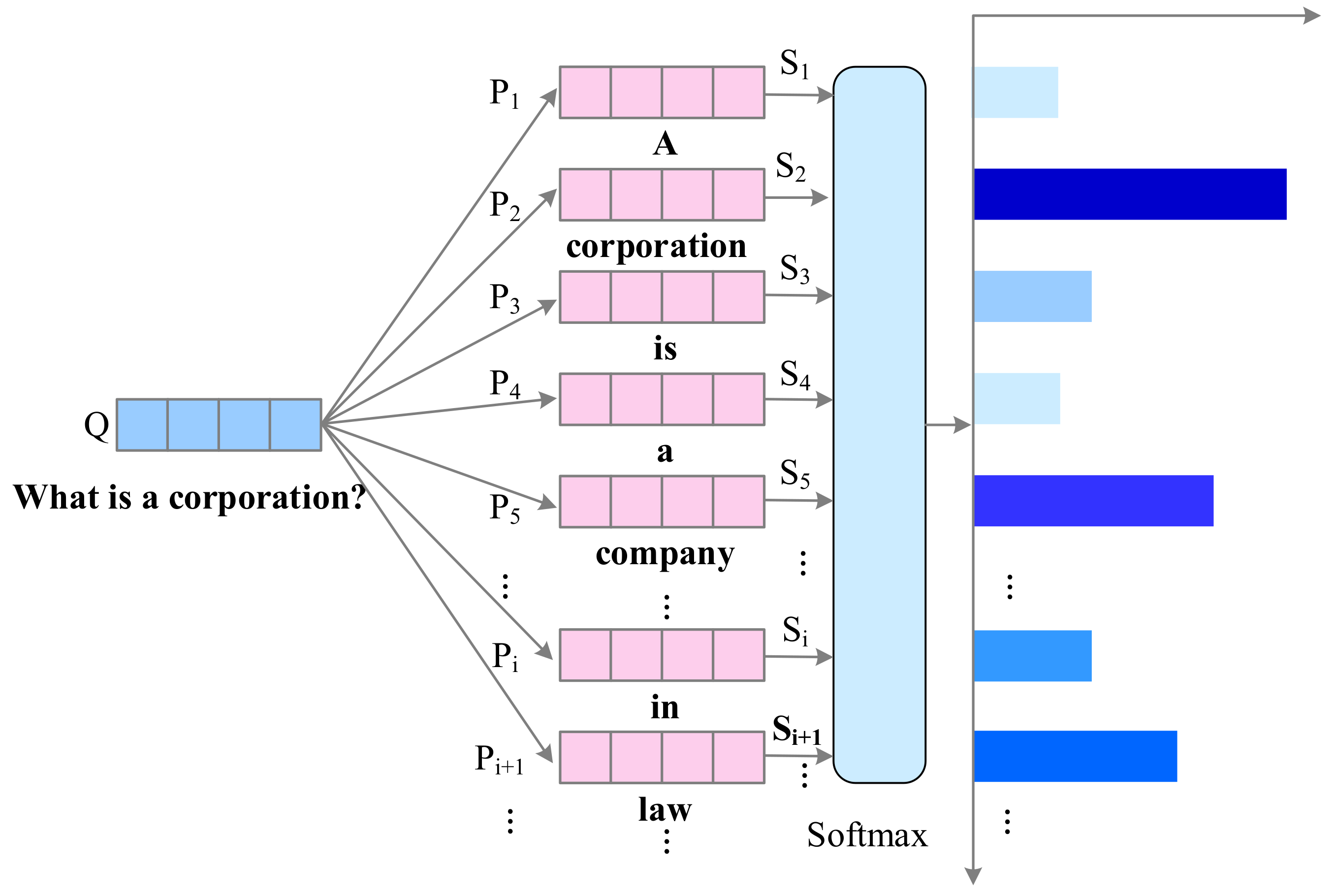
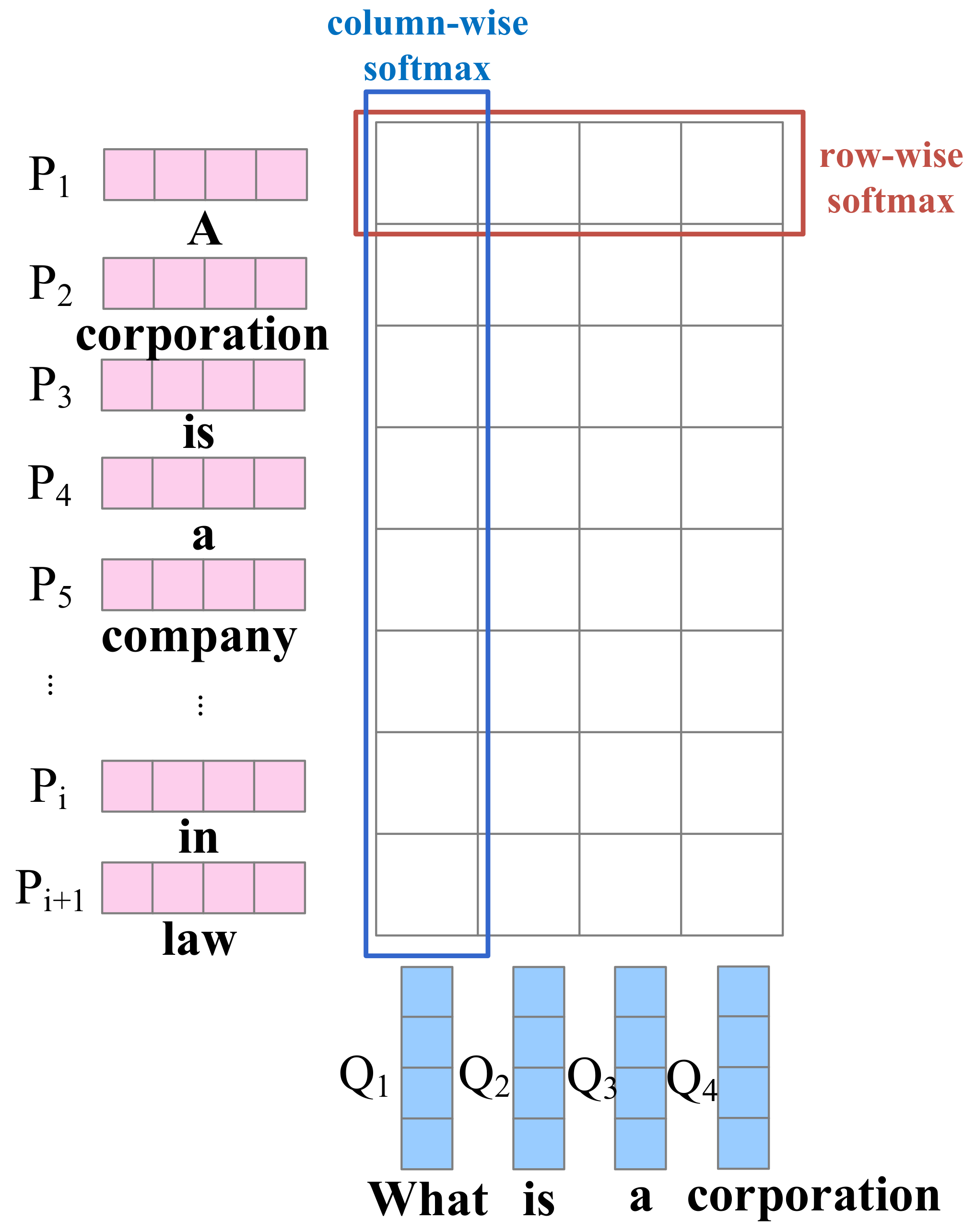
- Context-Question Interaction: The correlation between the context and the question plays a significant role in predicting the answer. With such information, the machine can find out which parts in the context are more important to answering the question. To achieve that goal, the attention mechanism, unidirectional or bidirectional, is widely used in this module to emphasize parts of the context relevant to the query. To sufficiently extract their correlation, the interaction between the context and the question sometimes involves multiple hops, which simulates the rereading process of human comprehension.
- -
- Answer Prediction: Answer prediction module, the last component of an MRC system, outputs the final answer based on all the information accumulated from previous modules. As MRC tasks can be categorized according to answer forms, this module is highly related to different tasks. For cloze tests, the output of this module is a word or entity in the original context, while the multiple-choice task requires selecting the correct answer from candidate answers. In terms of span extraction, this module extracts a subsequence of the given context as the answer. Some generation techniques are used in this module for the free answering task, as it has nearly no constraint on answer forms.
3.2. Typical Deep-Learning Methods
3.2.1. Embeddings
- -
- One-Hot
- -
- Distributed Word Representation
- -
- CoVE
- -
- ELMo
- -
- GPT
- -
- BERT
- -
- Character Embeddings
- -
- Part-of-Speech Tags
- -
- Name-Entity Tags
- -
- Binary Feature of Exact Match (EM)
- -
- Query-Category
3.2.2. Feature Extraction
3.2.3. Context-Question Interaction
3.2.4. Answer Prediction
| Context: | A UFO was observed above our city in January and again in March. |
| Question: | An observer has spotted a UFO in _____. |
3.3. Additional Tricks
3.3.1. Reinforcement Learning
3.3.2. Answer Ranker
3.3.3. Sentence Selector
4. Datasets and Evaluation Metrics
4.1. Datasets
4.1.1. Cloze Tests Datasets
- -
- CNN & Daily Mail
- -
- CBT
- -
- LAMBADA
- -
- Who-did-What
- -
- CLOTH
- -
- CliCR
4.1.2. Multiple-Choice Datasets
- -
- MCTest
- -
- RACE
4.1.3. Span Extraction Datasets
- -
- SQuAD
- -
- NewsQA
- -
- TriviaQA
- -
- DuoRC
4.1.4. Free Answering Datasets
- -
- bAbI
- -
- MS MARCO
- -
- SearchQA
- -
- NarrativeQA
- -
- DuReader
4.2. Evaluation Metrics
- -
- Accuracy
- -
- F1 Score
- -
- ROUGE-L
- -
- BLEU
5. New Trends
5.1. Knowledge-Based Machine Reading Comprehension
- -
- Relevant External Knowledge Retrieval
- -
- External Knowledge Integration
5.2. Machine Reading Comprehension with Unanswerable Questions
- -
- Unanswerable Question Detection
- -
- Plausible Answer Discrimination
5.3. Multi-Passage Machine Reading Comprehension
- -
- Massive Document Corpus
- -
- Noisy Document Retrieval
- -
- No Answer
- -
- Multiple Answers
- -
- Evidence Aggregation
5.4. Conversational Machine Reading Comprehension
- -
- Conversational History
- -
- Coreference Resolution
6. Open Issues
- -
- Limitation of Given Context
- -
- Robustness of MRC Systems
- -
- Incorporation of External Knowledge
- -
- Lack of Inference Ability
- -
- Difficulty in Interpretation
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Glossary of Items Mentioned
| Term | Definition |
| Curse of Dimensionality | A phenomenon that appears with high-dimensional data, where the computational complexity grows exponentially with the number of dimensions increasing. |
| Transfer Learning | A method of using knowledge from a related task that has already been learned to learn new tasks. |
| Coattention | A kind of bidirectional attention mechanism designed by Xiong et al. [17] which can attend to the context and question simultaneously. |
| Dynamic Decoder | A mechanism proposed by Xiong et al. [17] that is based on LSTMs, dynamically predicting the start and end positions of the answer. |
| Zero-Shot Setting | A setting where labeled examples for training are not enough. |
| Masked Language Model | A model designed by Devlin et al. [32], which randomly mask some tokens from the input, and requires predicting the masked word based on its context. |
| Next-Sentence Prediction | A task designed by Devlin et al. [32], judging whether sentence B follows sentence A. |
| Out-of-Vocabulary | Unknown words that appear in the training examples but not in the pre-defined vocabulary. |
| Fine-Grained Gating | A mechanism proposed by Yang et al. [44] which uses linguistic features, such as POS tags and name-entity tags, as a gate to control the amount of information flowing to word-level and character-level representations. |
| Gradient Explosion | A problem where a considerable gradient accumulate as it moves backward through the layers while training a deep neural network. |
| Gradient Vanishing | A problem where the gradient tends to get smaller as it moves backward through the layers while training a deep neural network. |
| Multi-Head Attention | A mechanism proposed by Vaswani et al. [41] using different linear projections to project queries, keys and values more than once when performing attention function. |
| Self-Attention | Also Intra-Attention, an attention mechanism computing attention weights in a single sequence to highlight importance of different positions in the sequence. |
| Residual Connections | A mechanism that skip some layer connections to facilitate single propagation and mitigate gradient degradation. |
| Back-Propagation | A shortened form of backward propagation of errors, a method of training neural networks with errors propagating backwards. |
| Textual Entailment | A task to judge the relationship between text fragments whether a truth of one text fragment follows from another. |
| Pointer Networks | A neural architecture proposed by Vinyals et al. [56] which uses attention mechanism as a pointer to select several discrete tokens in input sequence as the output. |
| Maxout Networks | A model proposed by Goodfellow et al. [57] whose output is the maximum of a set of inputs, to improve optimization and model averaging with dropout. |
| Highway Networks | An architecture proposed by Srivastava et al. [58] which contains information highways to accelerate the training process of gradient -based deep neural networks. |
| Multi-Task Learning | A kind of transfer learning which solves multiple tasks at the same time. |
| Key-Value Memory Networks | A neural network proposed by Miller et al. [85] which stores memory as key-value pairs for easy access. |
| Data Enrichment | The process of enriching the amount of raw data. |
References
- Lehnert, W.G. The Process of Question Answering. Ph.D. Thesis, Yale University, New Haven, CT, USA, 1977. [Google Scholar]
- Hirschman, L.; Light, M.; Breck, E.; Burger, J.D. Deep Read: A Reading Comprehension System. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics, College Park, MD, USA, 20–26 June 1999; Association for Computational Linguistics: Stroudsburg, PA, USA, 1999; pp. 325–332. [Google Scholar]
- Riloff, E.; Thelen, M. A Rule-Based Question Answering System for Reading Comprehension Tests. In Proceedings of the 2000 ANLP/NAACL Workshop on Reading Comprehension Tests as Evaluation for Computer-based Language Understanding Sytems—Volume 6, Seattle, WA, USA, 4 May 2000; Association for Computational Linguistics: Stroudsburg, PA, USA, 2000; pp. 13–19. [Google Scholar]
- Poon, H.; Christensen, J.; Domingos, P.; Etzioni, O.; Hoffmann, R.; Kiddon, C.; Lin, T.; Ling, X.; Ritter, A.; Schoenmackers, S.; et al. Machine Reading at the University of Washington. In Proceedings of the NAACL HLT 2010 First International Workshop on Formalisms and Methodology for Learning by Reading, Los Angeles, CA, USA, 6 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 87–95. [Google Scholar]
- Hermann, K.M.; Kočiskỳ, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching Machines to Read and Comprehend. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2015; pp. 1693–1701. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2383–2392. [Google Scholar]
- Nguyen, T.; Rosenberg, M.; Song, X.; Gao, J.; Tiwary, S.; Majumder, R.; Deng, L. MS MARCO: A Human Generated Machine Reading Comprehension Dataset. arXiv 2016, arXiv:1611.09268. [Google Scholar]
- Qiu, B.; Chen, X.; Xu, J.; Sun, Y. A Survey on Neural Machine Reading Comprehension. arXiv 2019, arXiv:1906.03824. [Google Scholar]
- Chen, D. Neural Reading Comprehension and Beyond. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2018. [Google Scholar]
- Lai, G.; Xie, Q.; Liu, H.; Yang, Y.; Hovy, E. RACE: Large-Scale ReAding Comprehension Dataset from Examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 785–794. [Google Scholar]
- Sukhbaatar, S.; Weston, J.; Fergus, R.; Szlam, A. End-to-End Memory Networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2015; pp. 2440–2448. [Google Scholar]
- Chen, D.; Bolton, J.; Manning, C.D. A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2358–2367. [Google Scholar]
- Kadlec, R.; Schmid, M.; Bajgar, O.; Kleindienst, J. Text Understanding with the Attention Sum Reader Network. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 908–918. [Google Scholar]
- Sordoni, A.; Bachman, P.; Trischler, A.; Bengio, Y. Iterative Alternating Neural Attention for Machine Reading. arXiv 2016, arXiv:1606.02245. [Google Scholar]
- Wang, S.; Jiang, J. Machine Comprehension Using Match-LSTM and Answer Pointer. arXiv 2016, arXiv:1608.07905. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional Attention Flow for Machine Comprehension. arXiv 2016, arXiv:1611.01603. [Google Scholar]
- Xiong, C.; Zhong, V.; Socher, R. Dynamic Coattention Networks for Question Answering. arXiv 2016, arXiv:1611.01604. [Google Scholar]
- Cui, Y.; Chen, Z.; Wei, S.; Wang, S.; Liu, T.; Hu, G. Attention-over-Attention Neural Networks for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 593–602. [Google Scholar]
- Dhingra, B.; Liu, H.; Yang, Z.; Cohen, W.; Salakhutdinov, R. Gated-Attention Readers for Text Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1832–1846. [Google Scholar]
- Pan, B.; Li, H.; Zhao, Z.; Cao, B.; Cai, D.; He, X. MEMEN: Multi-Layer Embedding with Memory Networks for Machine Comprehension. arXiv 2017, arXiv:1707.09098. [Google Scholar]
- Wang, W.; Yang, N.; Wei, F.; Chang, B.; Zhou, M. Gated Self-Matching Networks for Reading Comprehension and Question Answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 189–198. [Google Scholar]
- Xiong, C.; Zhong, V.; Socher, R. DCN+: Mixed Objective and Deep Residual Coattention for Question Answering. arXiv 2017, arXiv:1711.00106. [Google Scholar]
- Tan, C.; Wei, F.; Yang, N.; Du, B.; Lv, W.; Zhou, M. S-Net: From Answer Extraction to Answer Synthesis for Machine Reading Comprehension. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- McCann, B.; Bradbury, J.; Xiong, C.; Socher, R. Learned in Translation: Contextualized Word Vectors. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 6294–6305. [Google Scholar]
- Yu, A.W.; Dohan, D.; Luong, M.T.; Zhao, R.; Chen, K.; Norouzi, M.; Le, Q.V. QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension. arXiv 2018, arXiv:1804.09541. [Google Scholar]
- Hu, M.; Peng, Y.; Huang, Z.; Qiu, X.; Wei, F.; Zhou, M. Reinforced Mnemonic Reader for Machine Reading Comprehension. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, CA, USA, 13–19 July 2018; AAAI Press: Palo Alto, CA, USA, 2018; pp. 4099–4106. [Google Scholar] [Green Version]
- Chen, Z.; Cui, Y.; Ma, W.; Wang, S.; Hu, G. Convolutional Spatial Attention Model for Reading Comprehension with Multiple-Choice Questions. arXiv 2018, arXiv:1811.08610. [Google Scholar] [CrossRef]
- Chaturvedi, A.; Pandit, O.; Garain, U. CNN for Text-Based Multiple Choice Question Answering. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 272–277. [Google Scholar]
- Zhu, H.; Wei, F.; Qin, B.; Liu, T. Hierarchical Attention Flow for Multiple-Choice Reading Comprehension. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. arXiv 2018, arXiv:1802.05365. [Google Scholar] [Green Version]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; Technical Report; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 3–5 June 2019; pp. 4171–4186. [Google Scholar]
- Dhingra, B.; Liu, H.; Salakhutdinov, R.; Cohen, W.W. A Comparative Study of Word Embeddings for Reading Comprehension. arXiv 2017, arXiv:1703.00993. [Google Scholar]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press: New York, NY, USA; Addison-Wesley: Harlow, UK, 2011. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Nakov, P.; Ritter, A.; Rosenthal, S.; Sebastiani, F.; Stoyanov, V. SemEval-2016 Task 4: Sentiment Analysis in Twitter. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 1–18. [Google Scholar]
- Clark, C.; Gardner, M. Simple and Effective Multi-Paragraph Reading Comprehension. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 845–855. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multi-Task Learners. OpenAI Blog 2019, 1, 8. [Google Scholar]
- Wang, Z.; Mi, H.; Hamza, W.; Florian, R. Multi-Perspective Context Matching for Machine Comprehension. arXiv 2016, arXiv:1612.04211. [Google Scholar]
- Yang, Z.; Dhingra, B.; Yuan, Y.; Hu, J.; Cohen, W.W.; Salakhutdinov, R. Words or Characters? Fine-Grained Gating for Reading Comprehension. arXiv 2016, arXiv:1611.01724. [Google Scholar]
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1870–1879. [Google Scholar]
- Zhang, J.; Zhu, X.; Chen, Q.; Dai, L.; Wei, S.; Jiang, H. Exploring Question Understanding and Adaptation in Neural-Network-Based Question Answering. arXiv 2017, arXiv:1703.04617. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Sort-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-Based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. arXiv 2015, arXiv:1509.00685. [Google Scholar] [Green Version]
- Wang, Y.; Huang, M.; Zhao, L. Attention-Based LSTM for Aspect-Level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Cheng, H.; Fang, H.; He, X.; Gao, J.; Deng, L. Bi-Directional Attention with Agreement for Dependency Parsing. arXiv 2016, arXiv:1608.02076. [Google Scholar]
- Cui, Y.; Liu, T.; Chen, Z.; Wang, S.; Hu, G. Consensus Attention-Based Neural Networks for Chinese Reading Comprehension. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 1777–1786. [Google Scholar]
- Weston, J.; Chopra, S.; Bordes, A. Memory Networks. arXiv 2014, arXiv:1410.3916. [Google Scholar]
- Yu, S.; Indurthi, S.R.; Back, S.; Lee, H. A Multi-Stage Memory Augmented Neural Network for Machine Reading Comprehension. In Proceedings of the Workshop on Machine Reading for Question Answering, Melbourne, Australia, 19 July 2018; pp. 21–30. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2692–2700. [Google Scholar]
- Goodfellow, I.J.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout Networks. arXiv 2013, arXiv:1302.4389. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway Networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- Shen, Y.; Huang, P.S.; Gao, J.; Chen, W. Reasonet: Learning to Stop Reading in Machine Comprehension. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 1047–1055. [Google Scholar]
- Trischler, A.; Ye, Z.; Yuan, X.; Bachman, P.; Sordoni, A.; Suleman, K. Natural Language Comprehension with the EpiReader. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 128–137. [Google Scholar]
- Yu, Y.; Zhang, W.; Hasan, K.; Yu, M.; Xiang, B.; Zhou, B. End-to-End Answer Chunk Extraction and Ranking for Reading Comprehension. arXiv 2016, arXiv:1610.09996. [Google Scholar]
- Min, S.; Zhong, V.; Socher, R.; Xiong, C. Efficient and Robust Question Answering from Minimal Context over Documents. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1725–1735. [Google Scholar]
- Suster, S.; Daelemans, W. CliCR: A Dataset of Clinical Case Reports for Machine Reading Comprehension. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 1551–1563. [Google Scholar]
- Onishi, T.; Wang, H.; Bansal, M.; Gimpel, K.; McAllester, D. Who did What: A Large-Scale Person-Centered Cloze Dataset. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2230–2235. [Google Scholar]
- Saha, A.; Aralikatte, R.; Khapra, M.M.; Sankaranarayanan, K. DuoRC: Towards Complex Language Understanding with Paraphrased Reading Comprehension. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1683–1693. [Google Scholar]
- Hill, F.; Bordes, A.; Chopra, S.; Weston, J. The Goldilocks Principle: Reading Children’s Books with Explicit Memory Representations. arXiv 2015, arXiv:1511.02301. [Google Scholar]
- Bajgar, O.; Kadlec, R.; Kleindienst, J. Embracing Data Abundance: Booktest Dataset for Reading Comprehension. arXiv 2016, arXiv:1610.00956. [Google Scholar]
- Paperno, D.; Kruszewski, G.; Lazaridou, A.; Pham, N.Q.; Bernardi, R.; Pezzelle, S.; Baroni, M.; Boleda, G.; Fernandez, R. The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1525–1534. [Google Scholar]
- Xie, Q.; Lai, G.; Dai, Z.; Hovy, E. Large-Scale Cloze Test Dataset Created by Teachers. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2344–2356. [Google Scholar]
- Richardson, M.; Burges, C.J.; Renshaw, E. MCTest: A Challenge Dataset for the Open-Domain Machine Comprehension of Text. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 193–203. [Google Scholar]
- Trischler, A.; Wang, T.; Yuan, X.; Harris, J.; Sordoni, A.; Bachman, P.; Suleman, K. NewsQA: A Machine Comprehension Dataset. In Proceedings of the 2nd Workshop on Representation Learning for NLP, Vancouver, BC, Canada, 3 August 2017; pp. 191–200. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 784–789. [Google Scholar]
- Joshi, M.; Choi, E.; Weld, D.; Zettlemoyer, L. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1601–1611. [Google Scholar]
- Weston, J.; Bordes, A.; Chopra, S.; Rush, A.M.; van Merriënboer, B.; Joulin, A.; Mikolov, T. Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks. arXiv 2015, arXiv:1502.05698. [Google Scholar]
- Dunn, M.; Sagun, L.; Higgins, M.; Guney, V.U.; Cirik, V.; Cho, K. SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine. arXiv 2017, arXiv:1704.05179. [Google Scholar]
- Kočiskỳ, T.; Schwarz, J.; Blunsom, P.; Dyer, C.; Hermann, K.M.; Melis, G.; Grefenstette, E. The NarrativeQA Reading Comprehension Challenge. Trans. Assoc. Comput. Linguist. 2018, 6, 317–328. [Google Scholar] [CrossRef] [Green Version]
- He, W.; Liu, K.; Liu, J.; Lyu, Y.; Zhao, S.; Xiao, X.; Liu, Y.; Wang, Y.; Wu, H.; She, Q.; et al. DuReader: A Chinese Machine Reading Comprehension Dataset from Real-world Applications. In Proceedings of the Workshop on Machine Reading for Question Answering, Melbourne, Australia, 19 July 2018; pp. 37–46. [Google Scholar]
- Lin, C.Y. Rouge: A Package for Automatic Evaluation of Summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 311–318. [Google Scholar]
- Ostermann, S.; Modi, A.; Roth, M.; Thater, S.; Pinkal, M. MCScript: A Novel Dataset for Assessing Machine Comprehension Using Script Knowledge. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC-2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Long, T.; Bengio, E.; Lowe, R.; Cheung, J.C.K.; Precup, D. World Knowledge for Reading Comprehension: Rare Entity Prediction with Hierarchical LSTMs Using External Descriptions. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 825–834. [Google Scholar]
- Yang, B.; Mitchell, T. Leveraging Knowledge Bases in LSTMs for Improving Machine Reading. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1436–1446. [Google Scholar]
- Mihaylov, T.; Frank, A. Knowledgeable Reader: Enhancing Cloze-Style Reading Comprehension with External Commonsense Knowledge. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 821–832. [Google Scholar]
- Sun, Y.; Guo, D.; Tang, D.; Duan, N.; Yan, Z.; Feng, X.; Qin, B. Knowledge Based Machine Reading Comprehension. arXiv 2018, arXiv:1809.04267. [Google Scholar]
- Miller, A.; Fisch, A.; Dodge, J.; Karimi, A.H.; Bordes, A.; Weston, J. Key-Value Memory Networks for Directly Reading Documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1400–1409. [Google Scholar]
- Wang, C.; Jiang, H. Explicit Utilization of General Knowledge in Machine Reading Comprehension. In Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2263–2272. [Google Scholar]
- Levy, O.; Seo, M.; Choi, E.; Zettlemoyer, L. Zero-Shot Relation Extraction via Reading Comprehension. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 333–342. [Google Scholar]
- Tan, C.; Wei, F.; Zhou, Q.; Yang, N.; Lv, W.; Zhou, M. I Know There Is No Answer: Modeling Answer Validation for Machine Reading Comprehension. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Hohhot, China, 26–30 August 2018; Springer: Cham, Switzerland, 2018; pp. 85–97. [Google Scholar]
- Hu, M.; Wei, F.; Peng, Y.; Huang, Z.; Yang, N.; Li, D. Read+ Verify: Machine Reading Comprehension with Unanswerable Questions. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6529–6537. [Google Scholar]
- Sun, F.; Li, L.; Qiu, X.; Liu, Y. U-Net: Machine Reading Comprehension with Unanswerable Questions. arXiv 2018, arXiv:1810.06638. [Google Scholar]
- Dhingra, B.; Mazaitis, K.; Cohen, W.W. Quasar: Datasets for Question Answering by Search and Reading. arXiv 2017, arXiv:1707.03904. [Google Scholar]
- Htut, P.M.; Bowman, S.R.; Cho, K. Training a Ranking Function for Open-Domain Question Answering. In Proceedings of the NAACL HLT 2018, New Orleans, LA, USA, 2–4 June 2018; p. 120. [Google Scholar]
- Lee, J.; Yun, S.; Kim, H.; Ko, M.; Kang, J. Ranking Paragraphs for Improving Answer Recall in Open-Domain Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 565–569. [Google Scholar]
- Wang, S.; Yu, M.; Guo, X.; Wang, Z.; Klinger, T.; Zhang, W.; Chang, S.; Tesauro, G.; Zhou, B.; Jiang, J. R 3: Reinforced Ranker-Reader for Open-Domain Question Answering. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Das, R.; Dhuliawala, S.; Zaheer, M.; McCallum, A. Multi-Step Retriever-Reader Interaction for Scalable Open-domain Question Answering. arXiv 2019, arXiv:1905.05733. [Google Scholar]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Su, L.; Cheng, X. HAS-QA: Hierarchical Answer Spans Model for Open-domain Question Answering. arXiv 2019, arXiv:1901.03866. [Google Scholar] [CrossRef]
- Lin, Y.; Ji, H.; Liu, Z.; Sun, M. Denoising Distantly Supervised Open-Domain Question Answering. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1736–1745. [Google Scholar]
- Wang, S.; Yu, M.; Jiang, J.; Zhang, W.; Guo, X.; Chang, S.; Wang, Z.; Klinger, T.; Tesauro, G.; Cambell, M. Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering. arXiv 2017, arXiv:1711.05116. [Google Scholar]
- Reddy, S.; Chen, D.; Manning, C.D. CoQA: A Conversational Question Answering Challenge. Trans. Assoc. Comput. Linguist. 2019, 7, 249–266. [Google Scholar] [CrossRef]
- Choi, E.; He, H.; Iyyer, M.; Yatskar, M.; Yih, W.t.; Choi, Y.; Liang, P.; Zettlemoyer, L. QuAC: Question Answering in Context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2174–2184. [Google Scholar]
- Ma, K.; Jurczyk, T.; Choi, J.D. Challenging Reading Comprehension on Daily Conversation: Passage Completion on Multiparty Dialog. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 2039–2048. [Google Scholar]
- Yatskar, M. A Qualitative Comparison of CoQA, SQuAD 2.0 and QuAC. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 3–5 June 2019; pp. 2318–2323. [Google Scholar]
- Huang, H.Y.; Choi, E.; Yih, W.t. FlowQA: Grasping Flow in History for Conversational Machine Comprehension. arXiv 2018, arXiv:1810.06683. [Google Scholar]
- Zhu, C.; Zeng, M.; Huang, X. SDNet: Contextualized Attention-Based Deep Network for Conversational Question Answering. arXiv 2018, arXiv:1812.03593. [Google Scholar]
- Kaushik, D.; Lipton, Z.C. How Much Reading Does Reading Comprehension Require? A Critical Investigation of Popular Benchmarks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 5010–5015. [Google Scholar]
- Jia, R.; Liang, P. Adversarial Examples for Evaluating Reading Comprehension Systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2021–2031. [Google Scholar]
- Liu, S.; Zhang, S.; Zhanga, X.; Wang, H. R-Trans: RNN Transformer Network for Chinese Machine Reading Comprehension. IEEE Access 2019, 7, 27736–27745. [Google Scholar] [CrossRef]
- Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.; Salakhutdinov, R.; Manning, C.D. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2369–2380. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Shcherbina, A.; Kundaje, A. Not Just a Black Box: Learning Important Features through Propagating Activation Differences. arXiv 2016, arXiv:1605.01713. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability. arXiv 2016, arXiv:1606.03490. [Google Scholar] [CrossRef]
- Montavon, G.; Lapuschkin, S.; Binder, A.; Samek, W.; Müller, K.R. Explaining Nonlinear Classification Decisions with Deep Taylor Decomposition. Pattern Recognit. 2017, 65, 211–222. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Reading Comprehension |
|---|
| Given the context C and question Q, machine reading comprehension tasks ask the model to give the correct answer A to the question Q by learning the function such that . |
| Cloze Tests | ||
|---|---|---|
| CNN & Daily Mail [5] | Context: | the ent381 producer allegedly struck by ent212 will not press charges against the “ent153” host, his lawyer said Friday. ent212, who hosted one of the most-watched television shows in the world, was dropped by the ent381 Wednesday after an internal investigation by the ent180 broadcaster found he had subjected producer ent193 “to an unprovoked physical and verbal attack.” |
| Question: | producer X will not press charges against ent212, his lawyer says. | |
| Answer: | ent193 | |
| Multiple Choice | ||
| RACE [10] | Context: | If you have a cold or flu, you must always deal with used tissues carefully. Do not leave dirty tissues on your desk or on the floor. Someone else must pick these up and viruses could be passed on. |
| Question: | Dealing with used tissues properly is important because _____. | |
| Options: | A. it helps keep your classroom tidy B. people hate picking up dirty tissues C. it prevents the spread of colds and flu D. picking up lots of tissues is hard work | |
| Answer: | C | |
| Span Extraction | ||
| SQuAD [6] | Context: | Computational complexity theory is a branch of the theory of computa- tion in theoretical computer science that focuses on classifying compu- tational problems according to their inherent difficulty, and relating those classes to each other. A computational problem is understood to be a task that is in principle amenable to being solved by a computer, which is equivalent to stating that the problem may be solved by mechanical application of mathematical steps, such as an algorithm. |
| Question: | By what main attribute are computational problems classified using computational complexity theory? | |
| Answer: | inherent difficulty | |
| Free Answering | ||
| MS MARCO [7] | Context 1: | Rachel Carson’s essay on The Obligation to Endure, is a very convincing argument about the harmful uses of chemical, pesticides, herbicides and fertilizers on the environment. |
| Context 5: | Carson believes that as man tries to eliminate unwanted insects and weeds; however he is actually causing more problems by polluting the environment with, for example, DDT and harming living things. | |
| Context 10: | Carson subtly defers her writing in just the right writing for it to not be subject to an induction run rampant style which grabs the readers interest without biasing the whole article. | |
| Question: | Why did Rachel Carson write an obligation to endure? | |
| Answer: | Rachel Carson writes The Obligation to Endure because believes that as man tries to eliminate unwanted insects and weeds; however he is actu -ally causing more problems by polluting the environment. | |
| Cloze Tests |
|---|
| Given the context C, from which a word or an entity is removed, the cloze tests ask the model to fill in the blank with the right word or entity A by learning the function such that . |
| Multiple Choice |
|---|
| Given the context C, the question Q and a list of candidate answers , the multiple-choice task is to select the correct answer from A by learning the function such that |
| Span Extraction |
|---|
| Given the context C, which consists of n tokens, that is , and the question Q, the span extraction task requires extracting the continuous subsequence from context C as the correct answer to question Q by learning the function such that . |
| Free Answering |
|---|
| Given the context C and the question Q, the correct answer A in free answering task may not be subsequence in the original context C, namely either or . The task requires predicting the correct answer A by learning the function such that . |
| Models | Methods | |||
|---|---|---|---|---|
| Embeddings | Feature Extraction | Context-Question Interaction | Answer Prediction | |
| Attentive Reader (Hermann et al. 2015) [5] | Conventional | RNN | Unidirectional One-Hop | Word Predictor |
| Impatient Reader (Hermann et al. 2015) [5] | Conventional | RNN | Unidirectional Multi-hop | Word Predictor |
| End-to-End Memory Networks (Sukhbaatar et al. 2015) [11] | Conventional | / | Multi-Hop | Word Predictor |
| Standford Reader (Chen et al. 2016) [12] | Conventional | RNN | Unidirectional One-Hop | Word Predictor |
| AS Reader (Kadlec et al. 2016) [13] | Conventional | RNN | Unidirectional One-Hop | Word Predictor |
| IA Reader (Sordoni et al. 2016) [14] | Conventional | RNN | Unidirectional Multi-Hop | Word Predictor |
| Match-LSTM (Wang & Jiang 2016) [15] | Conventional | RNN | Unidirectional Multi-Hop | Span Extractor |
| Bi-DAF (Seo et al. 2016) [16] | Multiple Granularity | RNN | Bidirectional One-Hop | Span Extractor |
| DCN (Xiong et al. 2016) [17] | Conventional | RNN | Bidirectional One-Hop | Span Extractor |
| AoA Reader (Cui et al. 2017) [18] | Conventional | RNN | Bidirectional One-hop | Word Predictor |
| GA Reader (Dhingta et al. 2017) [19] | Conventional | RNN | Unidirectional Multi-Hop | Word Predictor |
| MEMEN (Pan et al. 2017) [20] | Multiple Granularity | RNN | Multi-Hop | Span Extractor |
| R-NET (Wang et al. 2017) [21] | Multiple Granularity | RNN | Unidirectional Multi-Hop | Span Extractor |
| DCN+ (Xiong et al. 2017) [22] | Conventional | RNN | Bidirectional Multi-Hop | Span Extractor |
| S-NET (Tan et al. 2017) [23] | Multiple Granularity | RNN | Unidirectional Multi-Hop | Answer Generator |
| CoVe + DCN (Mccann et al. 2017) [24] | Contextual | RNN | Bidirectional One-Hop | Span Extractor |
| QANet (Yu et al. 2018) [25] | Multiple Granularity | Transformer | Bidirectional One-Hop | Span Extractor |
| Reinforced Mnemonic Reader (Hu et al. 2018) [26] | Multiple Granularity | RNN | Bidirectional Multi-Hop | Span Extractor |
| CSA (Chen et al. 2018) [27] | Multiple Granularity | RNN&CNN | Bidirectional One-Hop | Option Selector |
| CNN Model (Chaturvedi et al. 2018) [28] | Conventional | CNN | Unidirectional One-Hop | Option Selector |
| Hierarchical Attention Flow (Zhu et al. 2018) [29] | Conventional | RNN | Bidirectional One-Hop | Option Selector |
| ELMo + improved Bi-DAF (Peters et al. 2018) [30] | Contextual | RNN | Bidirectional One-Hop | Span Extractor |
| GPT (Radford et al. 2018) [31] | Contextual | / | / | Option Selector |
| BERT (Devlin et al. 2018) [32] | Contextual | / | / | Span Extractor |
| Tokens in Reference | Tokens Not in Reference | |
|---|---|---|
| tokens in candidate | TP | FP |
| tokens not in candidate | FN | TN |
| Knowledge-Based Machine Reading Comprehension |
|---|
| Given the context C, question Q and external knowledge K, the task requires predicting the correct answer A by learning the function such that . |
| MCScripts | |
|---|---|
| Context: | Before you plant a tree, you must contact the utility company. They will come to your property and mark out utility lines. Without doing this, you may dig down and hit a line, which can be lethal! Once you know where to dig, select what type of tree you want. Take things into consideration such as how much sun it gets, what zone you are in, and how quickly you want it to grow. Dig a hole large enough for the tree and roots. Place the tree in the hole and then fill the hole back up with dirt⋯ |
| Question: | Why are trees important? |
| Candidate Answers: | A. create B. because they are green |
| Machine Reading Comprehension with Unanswerable Questions |
|---|
| Given the context C and question Q, the machine first determines whether Q can be answered or not based on the given context C. If the question is impossible to be answered, the model marks it as unanswerable and abstain from answering, otherwise predicts the correct answer A by learning the function such that . |
| SQuAD 2.0 | |
|---|---|
| Context: | … Other legislation followed, including the Migratory Bird Conservation Act of 1929, |
| a 1937 treaty prohibiting the hunting of right and gray whales, and the Bald Eagle Protec | |
| -tion Act of 1940. These later laws had a low cost to society—the species were relatively | |
| rare—and little opposition was raised. | |
| Question: | What was the name of the 1937 treaty |
| Plausible Answer: | Bald Eagle Protection Act |
| Multi-Passage Machine Reading Comprehension |
|---|
| Given a collection of m documents and the question Q, the multi-passage MRC task requires giving the correct answer A to question Q according to documents by learning the function such that . |
| Conversational Machine Reading Comprehension |
|---|
| Given the context C, the conversation history with previous questions and answers and the current question , the CMRC task is to predict the correct answer by learning the function such that . |
| CMRC | |
|---|---|
| Passage: | Jessica went to sit in her rocking chair. Today was her birthday and she was turning 80. Her |
| granddaughter Annie was coming over in the afternoon and Jessica was very excited to see | |
| her. Her daughter Melanie and Melanie’s husband Josh were coming as well. | |
| Question 1: | Who had a birthday? |
| Answer 1: | Jessica |
| Question 2: | How old would she be? |
| Answer 2: | 80 |
| Question 3: | Did she plan to have any visitors? |
| Answer 3: | Yes |
| Question 4: | How many? |
| Answer 4: | Three |
| Question 5: | Who? |
| Answer 5: | Annie, Melanie and Josh |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Zhang, X.; Zhang, S.; Wang, H.; Zhang, W. Neural Machine Reading Comprehension: Methods and Trends. Appl. Sci. 2019, 9, 3698. https://doi.org/10.3390/app9183698
Liu S, Zhang X, Zhang S, Wang H, Zhang W. Neural Machine Reading Comprehension: Methods and Trends. Applied Sciences. 2019; 9(18):3698. https://doi.org/10.3390/app9183698
Chicago/Turabian StyleLiu, Shanshan, Xin Zhang, Sheng Zhang, Hui Wang, and Weiming Zhang. 2019. "Neural Machine Reading Comprehension: Methods and Trends" Applied Sciences 9, no. 18: 3698. https://doi.org/10.3390/app9183698
APA StyleLiu, S., Zhang, X., Zhang, S., Wang, H., & Zhang, W. (2019). Neural Machine Reading Comprehension: Methods and Trends. Applied Sciences, 9(18), 3698. https://doi.org/10.3390/app9183698