Utility-Centric Service Provisioning in Multi-Access Edge Computing




Abstract
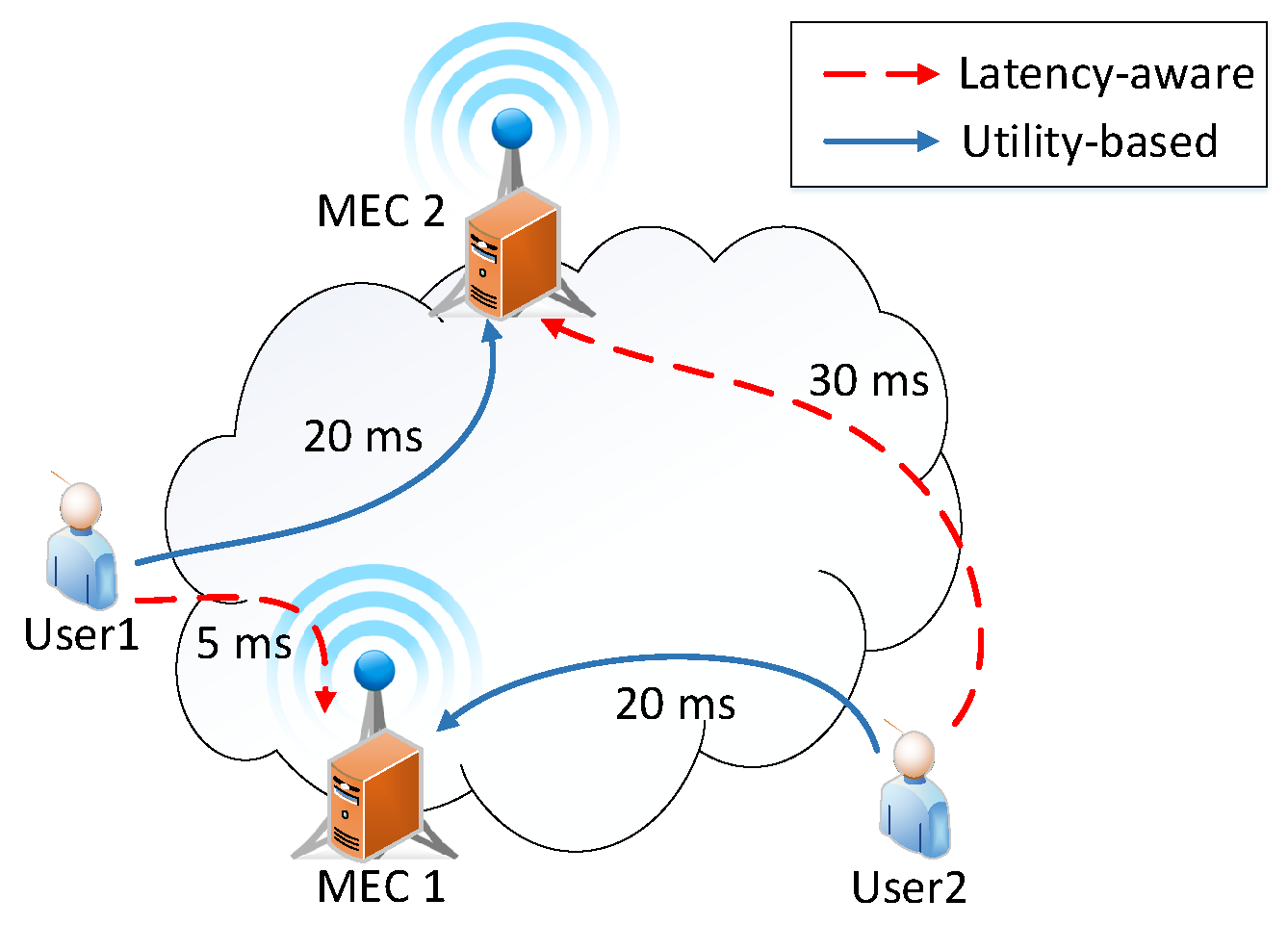
:1. Introduction
- We formulate the problem of service provisioning as an Integer Nonlinear Programming (INLP) problem that jointly optimizes the service placement decisions and request scheduling decisions so as to maximize the total utility (or satisfaction) of all users within both the storage and computation resource constraints in MEC systems.
- We then propose a Nested-Genetic algorithm (Nested-GA) that consists of two genetic algorithms (outer and inner), each of whom solves a sub-problem (i.e., service placement or request scheduling).
- We justify the efficiency of our proposed algorithm by extensive simulations. The experimental results show that our proposal consistently outperforms baselines in terms of the total utility and can provide close-to-optimal solutions.
2. Related Work
3. System Model and Problem Formulation
3.1. Scenario Description
3.2. Notation and Variable
3.3. Service Latency Estimation
3.3.1. Communication Latency
3.3.2. Processing Latency
3.3.3. Service Latency
3.4. Utility Model
- : Depending on the service type, the quality perception of users is the best at a pre-defined threshold , and no further improvement in quality can be perceived by users of that service even if the latency t reduces below this value. In this case, the utility remains unchanged ()
- : The service latency t is within an acceptable range. User experience reduces as t increases, and the utility get a value between 0 and 1 (). In this case, it is possible to define an optional point () from which the users begin to feel the quality drops clearly to a poor experience.
- : The service quality is really bad and beyond the acceptable range. In this case, the utility has a negative value ().
3.5. Problem Formulation
4. Proposed Nested-Genetic Algorithm
| Algorithm 1: Nested-Genetic Algorithm (Nested-GA) |
| Input: Input parameters of Equation (7); the parameters of the outer-GA , |
| , , , ; and the parameters of the Inner-GA. |
| Output: Optimal service placement and request scheduling solution (x*, y*). |
| 1. Generate initial population of individuals for the JSPRS problem. |
| 1.a. Initialize a population of number of service placement individuals |
| under the constraint Equation (7b), denoted as . |
| 1.b. For each x in , conduct the Inner-GA (Algorithm 2) to find the optimal |
| request scheduling y*, thus producing a complete solution (x, y*) for the problem |
| Equation (7). |
| 2. REPEAT /Search for optimal service placement x*/ |
| 2.a. Find the best individuals to be preserved (elitism mechanism). Add |
| them to the parent set. |
| 2.b. Select some other parents according to the principles of tournament selection with |
| tournament size of . |
| 2.c. Choose two service placement x1 and x2 of the parent set randomly. Then apply |
| the crossover operation to create two new offspring. Repeat this step until the number |
| of offspring is equal to (). |
| 2.d. For each offspring x (service placement), do the mutation operation with the |
| mutation probability . Then if the mutated x does not exist in the population, |
| conduct the Inner-GA (Algorithm 2) to find the best request scheduling y* for the new x. |
| 2.e. Replace the current generation with the new one filled by both the elite and |
| offspring. |
| UNTIL the population converges or reaching the maximum number of iterations |
| . |
| Algorithm 2: Inner Genetic Algorithm (Inner-GA) |
| Input: Input parameters of Equation (7); a service placement x; and the parameters of the |
| Inner-GA , , , , . |
| Output: Optimal request schedule y* for a service placement x. |
| 1. Initialize a population of number of request scheduling individuals according to |
| the service placement x (i.e., all request must be scheduled to nodes at which the required |
| service is stored). |
| 2. REPEAT |
| 2.a. Compute the fitness of each individual according to the objective function in |
| Equation (7). |
| 2.b. Find the best individuals to be preserved (elitism mechanism). Add |
| them to the parent set. |
| 2.c. Select some other parents according to the principles of tournament selection with |
| tournament size of . |
| 2.d. Choose two individuals y1 and y2 of the parent set randomly. Then apply the |
| crossover operation to create two new offspring. Repeat this step until the number of |
| offspring is equal to (). |
| 2.e. For each offspring y (request scheduling), do the mutation operation with the |
| mutation probability . |
| 2.f. Replace the current generation with the new generation filled by both the elite and |
| offspring. |
| UNTIL the population converges or reaching the maximum number of iterations |
| . |
4.1. Chromosome and Initialization
4.2. Selection
4.3. Crossover and Mutation
5. Performance Evaluation and Discussion
5.1. Simulation Settings
- The optimal solution of Equation (7) using BONMIN solver in the COIN-OR toolbox, which is a well-known open-source optimization tool for solving non-linear programming. BONMIN solver uses IPOPT package, which implements an interior point line search filter method to find relaxed solutions for the NLP problems.
- Top-R service placement with Nearest-based request scheduling (abbr., Top-R Nearest) algorithm, which first places services at each MEC in descending order of service popularity until reaching the storage capacity (i.e., the Top-R most popular services are placed), and then schedules each user request to the nearest (i.e., smallest network latency) hosting node of the requested service.
- Top-R service placement with Genetic-based request scheduling (abbr., Top-R Genetic) algorithm, in which the service placement strategy is similar to the Top-R Nearest, and the request scheduling strategy follows the Inner-GA (Algorithm 2). In other words, the service placement and request scheduling decisions are addressed separately, and only the request scheduling is optimized.
5.2. Simulation Results
5.3. Discussion
- (i)
- The policy can handle user demand changes over time more effectively by considering migration cost. Typically, a small change in the user demand may make the current solution no longer optimal; and hence, the policy must be adapted accordingly. The adaptation of service placement requires service migration between MEC nodes or from the core cloud to a MEC node. In the worst case, major migrations may cause a tremendous amount of data to move back and forth between computing nodes, thereby overloading the backhaul links. To avoid it, we can impose a budget constraint on the migration cost, allowing only incremental adjustments.
- (ii)
- The energy consumption of both the centralized cloud and MEC nodes may be soaring while processing a large volume of service requests. Hence, an energy-efficient service provisioning policy is needed while guaranteeing QoE is still a challenge.
- (iii)
- In some cases, the service provisioning may have to consider the monetary cost of using resources. For example, the centralized cloud and the MEC nodes are managed on different administration domains. A cloud service provider (CSP) does not have MEC infrastructure, and thus rents the MEC resources of network operators (e.g., computing, storage, network) to deploy services closer to the IoT devices or end-users. Due to the wide geographical distribution of IoT devices, the MEC resources may be offered from different parties with diverse prices. In this case, the objective of service provisioning policy is to maximize the total utility of all users under the budget constraint of the CSP in using MEC resources.
- (iv)
- It is also necessary to design provision policy for composite services consisting of multiple interdependent components. In this case, it becomes the problem of mapping task graphs onto a processor graph. In particular, the task graph represents service components and communication among these components while the processor graph represents the computing nodes and communication links in the physical system.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| VR/AR | Virtual/Augmented reality |
| MCC | Mobile cloud computing |
| MEC | Multi-access edge computing |
| BS | Base station |
| QoS | Quality of service |
| QoE | Quality of experience |
| MOS | Mean opinion score |
| SDN | Software Defined Networking |
| CSP | Cloud Service Provider |
References
- Dinh, H.T.; Lee, C.; Niyato, D.; Wang, P. A survey of mobile cloud computing: Architecture, applications, and approaches. Wirel. Commun. Mob. Comput. 2013, 13, 1587–1611. [Google Scholar] [CrossRef]
- Celesti, A.; Fazio, M.; Galán, M.F.; Glikson, A.; Mauwa, H.; Bagula, A.; Celesti, F.; Villari, M. How to Develop IoT Cloud e-Health Systems Based on FIWARE: A Lesson Learnt. J. Sens. Actuator Networks 2019, 8, 7. [Google Scholar] [CrossRef]
- Wang, X.; Jin, Z. An Overview of Mobile Cloud Computing for Pervasive Healthcare. IEEE Access 2019, 7, 66774–66791. [Google Scholar] [CrossRef]
- Dang, L.M.; Piran, M.J.; Han, D.; Min, K.; Moon, H. A Survey on Internet of Things and Cloud Computing for Healthcare. Electronics 2019, 8, 768. [Google Scholar] [CrossRef]
- Cubo, J.; Nieto, A.; Pimentel, E. A Cloud-Based Internet of Things Platform for Ambient Assisted Living. Sensors 2014, 14, 14070–14105. [Google Scholar] [CrossRef] [PubMed]
- Xia, Q.; Sifah, E.B.; Smahi, A.; Amofa, S.; Zhang, X. BBDS: Blockchain-Based Data Sharing for Electronic Medical Records in Cloud Environments. Information 2017, 8, 44. [Google Scholar] [CrossRef]
- Poyyeri, S.R.; Sivadasan, V.; Ramamurthy, B.; Nieveen, J. MHealthInt: Healthcare intervention using mobile app and Google Cloud Messaging. In Proceedings of the 2016 IEEE International Conference on Electro Information Technology (EIT), Grand Forks, ND, USA, 19–21 May 2016; pp. 0145–0150. [Google Scholar]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A Survey on the Edge Computing for the Internet of Things. IEEE Access. 2018, 6, 6900–6919. [Google Scholar] [CrossRef]
- Porambage, P.; Okwuibe, J.; Liyanage, M.; Ylianttila, M.; Taleb, T. Survey on Multi-Access Edge Computing for Internet of Things Realization. IEEE Commun. Surv. Tutor. 2018, 20, 2961–2991. [Google Scholar] [CrossRef] [Green Version]
- Balasubramanian, V.; Kouvelas, N.; Chandra, K.; Prasad, R.V.; Voyiatzis, A.G.; Liu, W. A Unified Architecture for Integrating Energy Harvesting IoT Devices with the Mobile Edge Cloud. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; pp. 13–18. [Google Scholar]
- Hu, Y.-C.; Patel, M.; Sabella, D.; Sprecher, N.; Young, V. Mobile Edge Computing: A Key Technology towards 5G. ETSI White Paper. 2015. Available online: https://www.etsi.org/images/files/ETSIWhitePapers/etsi_wp11_mec_a_key_technology_towards_5g.pdf (accessed on 20 August 2019).
- Ndikumana, A.; Tran, N.H.; Ho, T.M.; Han, Z.; Saad, W.; Niyato, D.; Hong, C.S. Joint Communication, Computation, Caching, and Control in Big Data Multi-access Edge Computing. IEEE Trans. Mob. Comput. 2019. [Google Scholar] [CrossRef]
- Xiao, Y.; Krunz, M. QoE and Power Efficiency Tradeoff for Fog Computing Networks with Fog Node Cooperation. In Proceedings of the IEEE INFOCOM 2017—IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Tong, L.; Li, Y.; Gao, W. A Hierarchical Edge Cloud Architecture for Mobile Computing. In Proceedings of the IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–15 April 2016; pp. 1–9. [Google Scholar]
- Ren, J.; Yu, G.; He, Y.; Li, G.Y. Collaborative Cloud and Edge Computing for Latency Minimization. IEEE Trans. Veh. Technol. 2019, 68, 5031–5044. [Google Scholar] [CrossRef]
- Liu, F.; Huang, Z.; Wang, L. Energy-Efficient Collaborative Task Computation Offloading in Cloud-Assisted Edge Computing for IoT Sensors. Sensors 2019, 19, 1105. [Google Scholar] [CrossRef] [PubMed]
- Nan, Y.; Li, W.; Bao, W.; Delicato, F.C.; Pires, P.F.; Zomaya, A.Y. Cost-Effective Processing for Delay-Sensitive Applications in Cloud of Things Systems. In Proceedings of the 2016 IEEE 15th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 30 October–2 November 2016; pp. 162–169. [Google Scholar]
- Pham, X.Q.; Nguyen, T.D.; Nguyen, V.D.; Huh, E.N. Joint Node Selection and Resource Allocation for Task Offloading in Scalable Vehicle-Assisted Multi-Access Edge Computing. Symmetry 2019, 11, 58. [Google Scholar] [CrossRef]
- Wang, S.; Zafer, M.; Leung, K.K. Online placement of multicomponent applications in edge computing environments. IEEE Access 2017, 5, 2514–2533. [Google Scholar] [CrossRef]
- Schmoll, R.; Pandi, S.; Braun, P.J.; Fitzek, F.H.P. Demonstration of VR/AR Offloading to Mobile Edge Cloud for Low Latency 5G Gaming Application. In Proceedings of the 2018 15th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 12–15 January 2018; pp. 1–3. [Google Scholar]
- Maia, A.M.; Ghamri-Doudane, Y.; Vieira, D.; Castro, M.F. Optimized Placement of Scalable IoT Services in Edge Computing. In Proceedings of the 2019 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Arlington, VA, USA, 8–12 April 2019; pp. 189–197. [Google Scholar]
- Yousefpour, A.; Patil, A.; Ishigaki, G.; Kim, I.; Wang, X.; Cankaya, H.C.; Zhang, Q.; Xie, W.; Jue, J.P. FogPlan: A Lightweight QoS-aware Dynamic Fog Service Provisioning Framework. IEEE Internet Things J. 2019. [Google Scholar] [CrossRef]
- ITU-T FG IPTV. Definition of Quality of Experience (QoE). 2007. Available online: https://www.itu.int/md/T05-FG.IPTV-IL-0050/en (accessed on 20 May 2019).
- Mahmud, R.; Srirama, S.N.; Ramamohanarao, K.; Buyya, R. Quality of Experience (QoE)-aware placement of applications in Fog computing environments. J. Parallel Distrib. Comput. 2018. [Google Scholar] [CrossRef]
- Khan, M.A.; Toseef, U. User utility function as Quality of Experience(QoE). In Proceedings of the 10th ICN, Cambridge, UK, 17–20 May 2011; pp. 99–104. [Google Scholar]
- Phan, T.K.; Griffin, D.; Maini, E.; Rio, M. Utility-Centric Networking: Balancing Transit Costs With Quality of Experience. IEEE/ACM Trans. Netw. 2018, 26, 245–258. [Google Scholar] [CrossRef]
- Phan, T.K.; Griffin, D.; Maini, E.; Rio, M. Utilitarian Placement of Composite Services. IEEE Trans. Netw. Serv. Manag. 2018, 15, 638–649. [Google Scholar] [CrossRef]
- Kjetil, R.; Ivar, K. Measuring Latency in Virtual Reality Systems. In Proceedings of the 14th International Conference on Entertainment Computing (ICEC), Trondheim, Norway, 29 September–2 Ocotober 2015; pp. 457–462. [Google Scholar]
- Shea, R.; Liu, J.; Ngai, E.C.; Cui, Y. Cloud gaming: Architecture and performance. IEEE Netw. 2013, 27, 16–21. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Zhang, Y.; Wang, L.; Yang, J.; Wang, W. A Survey on Mobile Edge Networks: Convergence of Computing, Caching and Communications. IEEE Access 2017, 5, 6757–6779. [Google Scholar] [CrossRef]
- Ahlehagh, H.; Dey, S. Video-Aware Scheduling and Caching in the Radio Access Network. IEEE/ACM Trans. Netw. 2014, 22, 1444–1462. [Google Scholar] [CrossRef]
- Müller, S.; Atan, O.; van der Schaar, M.; Klein, A. Context-Aware Proactive Content Caching With Service Differentiation in Wireless Networks. IEEE Trans. Wirel. Commun. 2017, 16, 1024–1036. [Google Scholar] [CrossRef]
- Jiang, W.; Feng, G.; Qin, S. Optimal Cooperative Content Caching and Delivery Policy for Heterogeneous Cellular Networks. IEEE Trans. Mob. Comput. 2017, 16, 1382–1393. [Google Scholar] [CrossRef]
- Dehghan, M.; Jiang, B.; Seetharam, A.; He, T.; Salonidis, T.; Kurose, J.; Towsley, D.; Sitaraman, R. On the Complexity of Optimal Request Routing and Content Caching in Heterogeneous Cache Networks. IEEE/ACM Trans. Netw. 2017, 25, 1635–1648. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, J. Optimal Placement of Virtual Machines for Supporting Multiple Applications in Mobile Edge Networks. IEEE Trans. Veh. Technol. 2018, 67, 6533–6545. [Google Scholar] [CrossRef]
- Urgaonkar, R.; Wang, S.; He, T.; Zafer, M.; Chan, K.; Leung, K.K. Dynamic service migration and workload scheduling in edge-clouds. Perform. Eval. 2015, 91, 205–228. [Google Scholar] [CrossRef]
- He, T.; Khamfroush, H.; Wang, S.; Porta, T.L.; Stein, S. It’s Hard to Share: Joint Service Placement and Request Scheduling in Edge Clouds with Sharable and Non-Sharable Resources. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 365–375. [Google Scholar]
- Konstantinos, P.; Jaime, L.; Antonia, M.T.; Ian, T.; Leandros, T. Joint Service Placement and Request Routing in Multi-cell Mobile Edge Computing Networks. arXiv 2019, arXiv:1901.08946. [Google Scholar]
- Luong, D.-H.; Outtagarts, A.; Hebbar, A. Traffic Monitoring in Software Defined Networks Using Opendaylight Controller. In Proceedings of the International Conference on Mobile, Secure and Programmable Networking, Paris, France, 1–3 June 2016; pp. 38–48. [Google Scholar]
- Guo, H.; Liu, J. Collaborative Computation Offloading for Multiaccess Edge Computing Over Fiber–Wireless Networks. IEEE Trans. Veh. Technol. 2018, 67, 4514–4526. [Google Scholar] [CrossRef]
- Ye, D.; Wu, M.; Tang, S.; Yu, R. Scalable Fog Computing with Service Offloading in Bus Networks. In Proceedings of the 2016 IEEE 3rd International Conference on Cyber Security and Cloud Computing (CSCloud), Beijing, China, 25–27 June 2016; pp. 247–251. [Google Scholar]
- Nguyen, T.; Vojnovic, M. Weighted Proportional Allocation. In Proceedings of the ACM SIGMETRICS Joint International Conference on Measurement and Modeling of Computer Systems, San Jose, CA, USA, 7–11 June 2011; pp. 173–184. [Google Scholar]
- Xu, H.; Li, B. Joint Request Mapping and Response Routing for Geo-Distributed Cloud Services. In Proceedings of the 2013 IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 854–862. [Google Scholar]
- Hemmecke, R.; Köppe, M.; Lee, J.; Weismantel, R. Nonlinear Integer Programming. In 50 Years of Integer Programming 1958-2008: From the Early Years to the State-of-the-Art; Jünger, M., Liebling, T.M., Naddef, D., Nemhauser, G.L., Pulleyblank, W.R., Reinelt, G., Rinaldi, G., Wolsey, L.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 561–618. [Google Scholar]
- David, E.; Kalyanmoy, D. A comparative analysis of selection schemes used in genetic algorithms. In Foundations of Genetic Algorithms; Morgan Kaufmann: San Francisco, CA, USA, 1991; pp. 69–93. [Google Scholar]
- The OpenCellid Database. Available online: https://www.opencellid.org/ (accessed on 20 May 2019).
- Nguyen, T.; Huh, E.; Jo, M. Decentralized and Revised Content-Centric Networking-Based Service Deployment and Discovery Platform in Mobile Edge Computing for IoT Devices. IEEE Internet Things J. 2019, 6, 4162–4175. [Google Scholar] [CrossRef]
- WonderNetwork. Available online: https://wondernetwork.com/ (accessed on 20 May 2019).
- Nielsen, J. Usability Engineering; Morgan Kauffman: San Fransisco, CA, USA, 1993. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Population size of service placement individuals (Outer-GA), | 60 |
| Population size of request scheduling individuals (Inner-GA), | 100 |
| Number of the elite for the Outer-GA, | |
| Number of the elite for the Inner-GA, | |
| Tournament size of the Outer-GA, | 3 |
| Tournament size of the Inner-GA, | 5 |
| Mutation probability of the Outer-GA, | 0.1 |
| Mutation probability of the Inner-GA, | 0.2 |
| Maximum number of iterations for Outer-GA, | 100 |
| Maximum number of iterations for Inner-GA, | 100 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, X.-Q.; Nguyen, T.-D.; Nguyen, V.; Huh, E.-N. Utility-Centric Service Provisioning in Multi-Access Edge Computing. Appl. Sci. 2019, 9, 3776. https://doi.org/10.3390/app9183776
Pham X-Q, Nguyen T-D, Nguyen V, Huh E-N. Utility-Centric Service Provisioning in Multi-Access Edge Computing. Applied Sciences. 2019; 9(18):3776. https://doi.org/10.3390/app9183776
Chicago/Turabian StylePham, Xuan-Qui, Tien-Dung Nguyen, VanDung Nguyen, and Eui-Nam Huh. 2019. "Utility-Centric Service Provisioning in Multi-Access Edge Computing" Applied Sciences 9, no. 18: 3776. https://doi.org/10.3390/app9183776
APA StylePham, X.-Q., Nguyen, T.-D., Nguyen, V., & Huh, E.-N. (2019). Utility-Centric Service Provisioning in Multi-Access Edge Computing. Applied Sciences, 9(18), 3776. https://doi.org/10.3390/app9183776