Instruction2vec: Efficient Preprocessor of Assembly Code to Detect Software Weakness with CNN †

 ,
, 
Abstract
:1. Introduction
2. Background
2.1. Limitations of Static Binary Analysis
2.2. Advantages of Machine Learning
2.2.1. Word2vec
2.2.2. Convolutional Neural Networks (CNNs) and Text-CNN
2.3. Software Weakness Dataset
3. Related Work
3.1. Vulnerability Detection Using Machine Learning
3.2. Malware Classification via Binary Data Visualization
4. Proposed Scheme
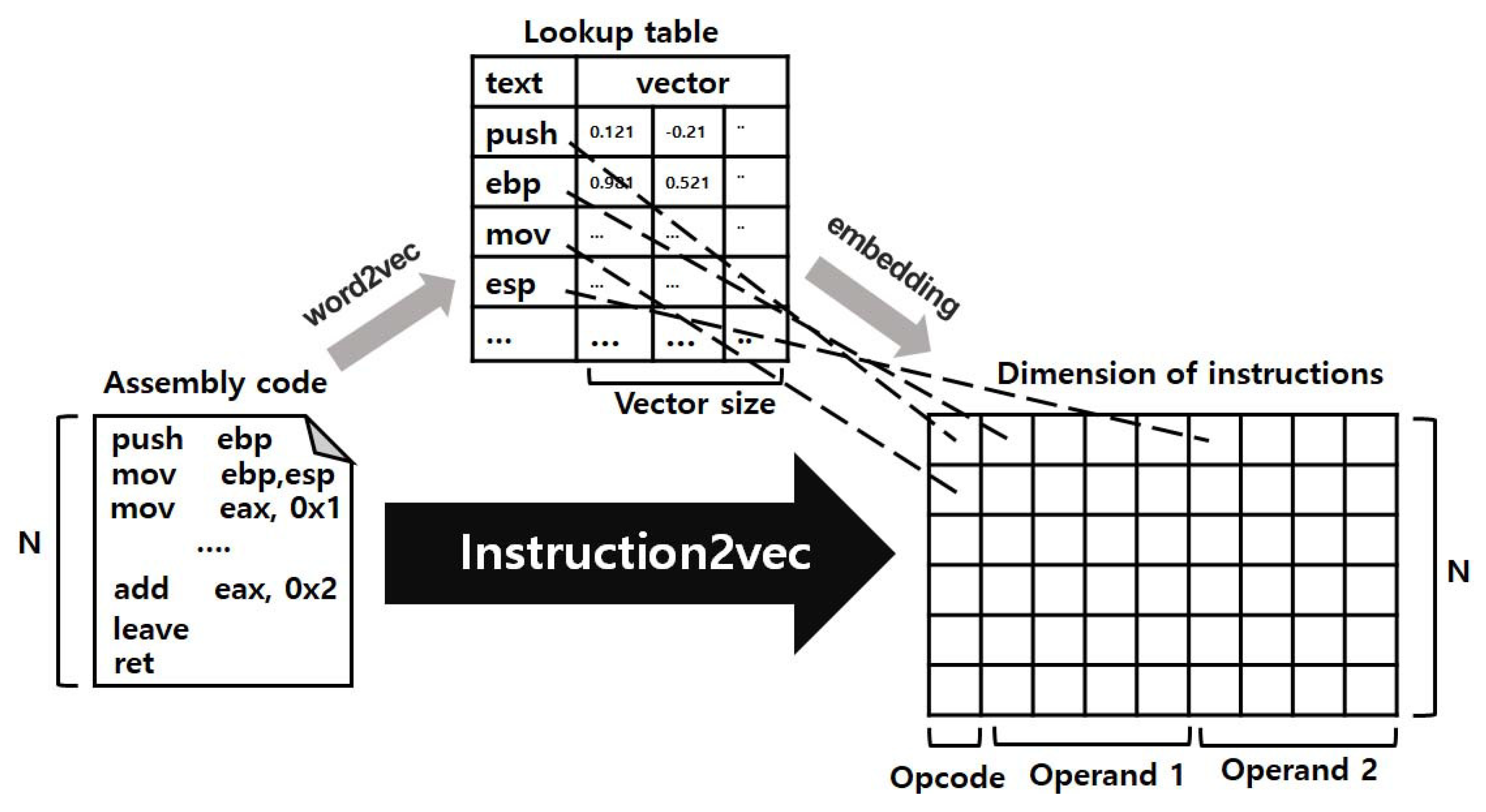
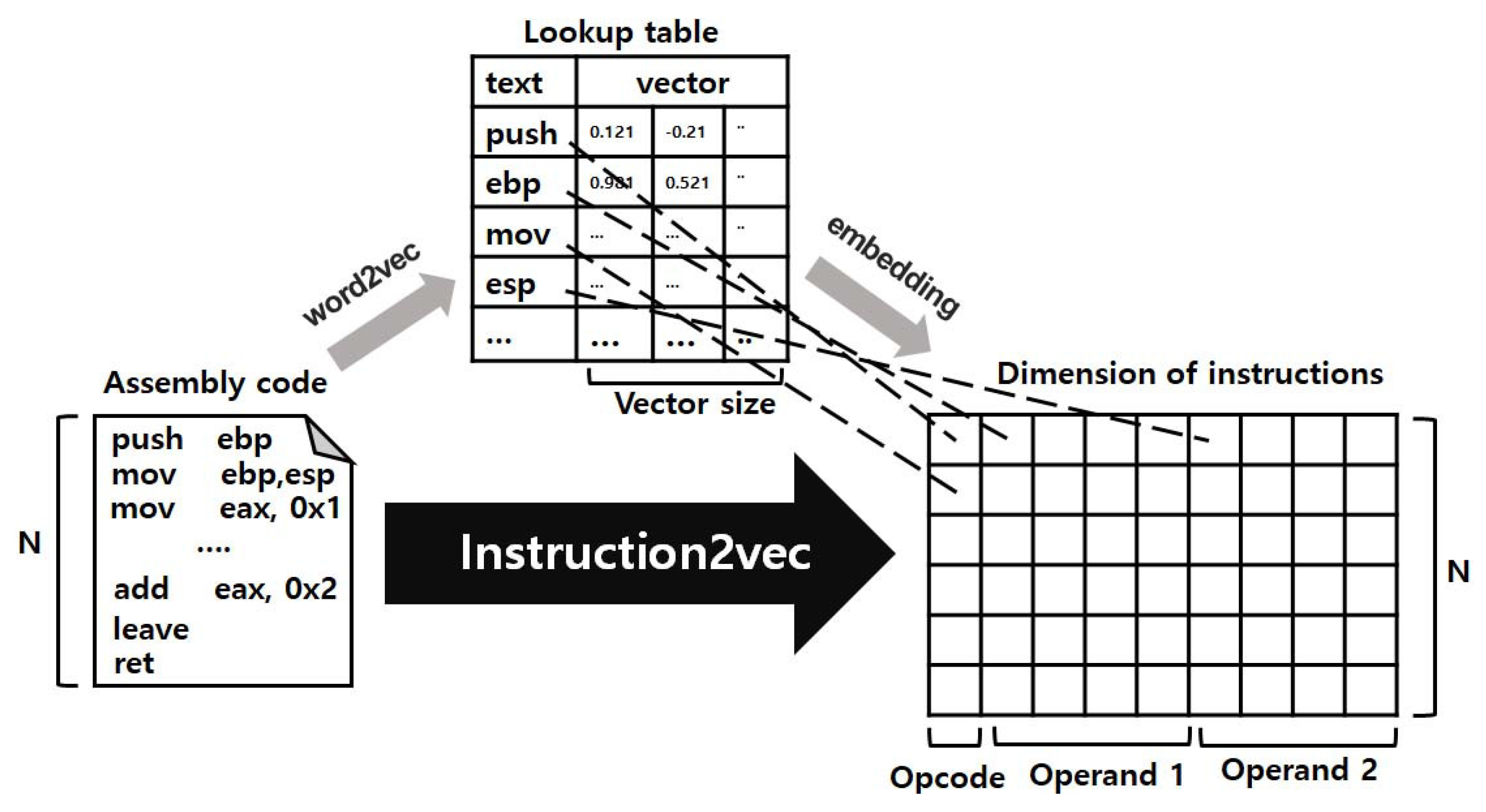
4.1. Design of Instruction2vec
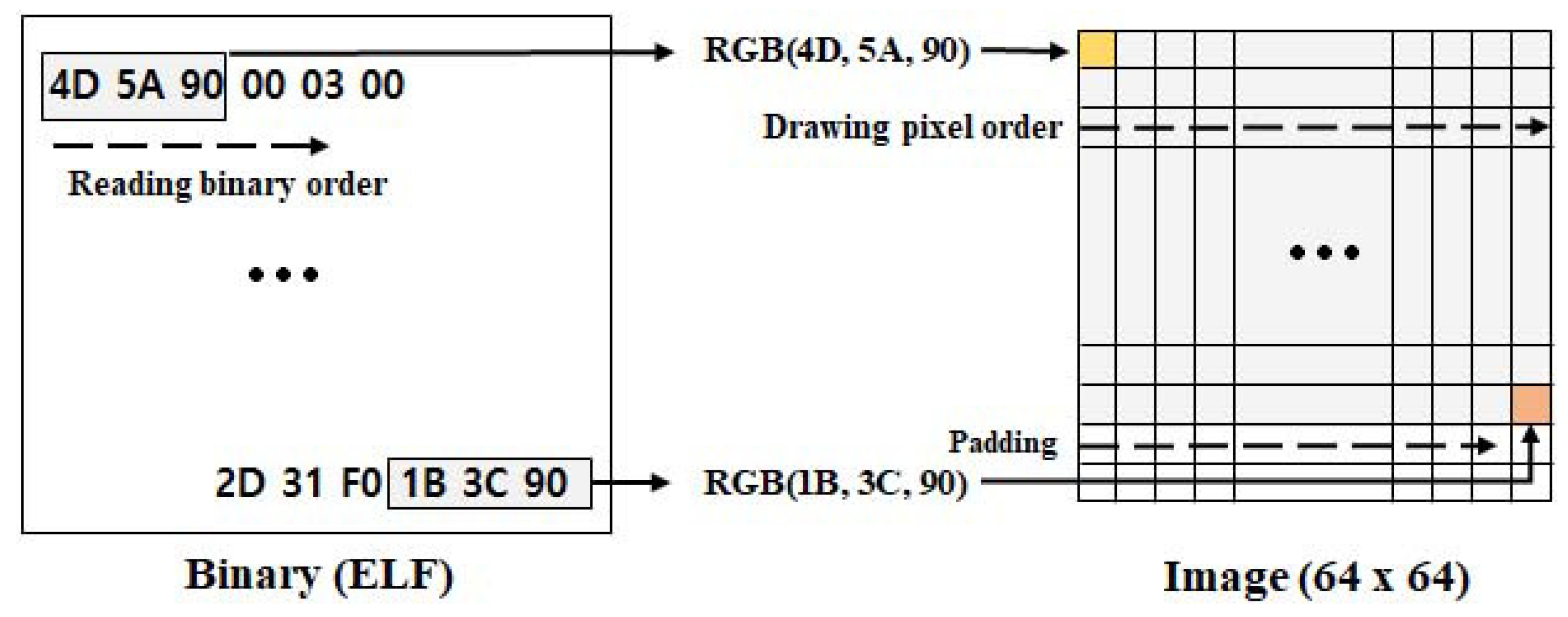
4.2. Design of Binary2img
4.3. Design of Word2vec
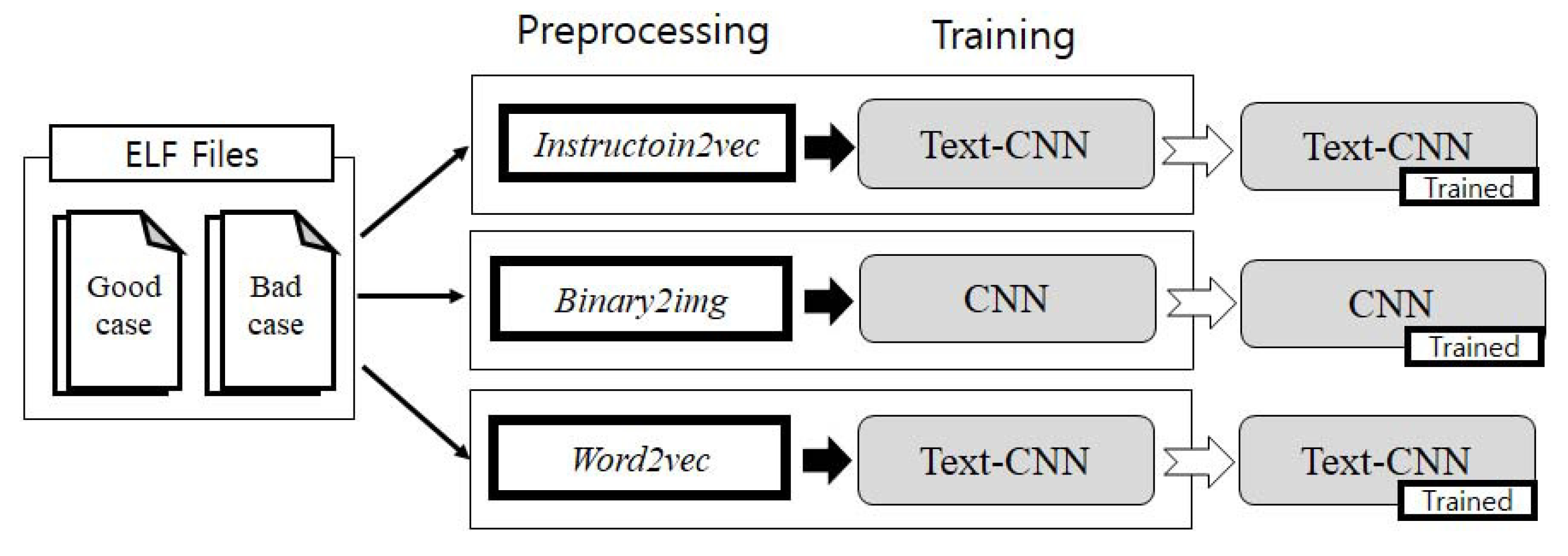
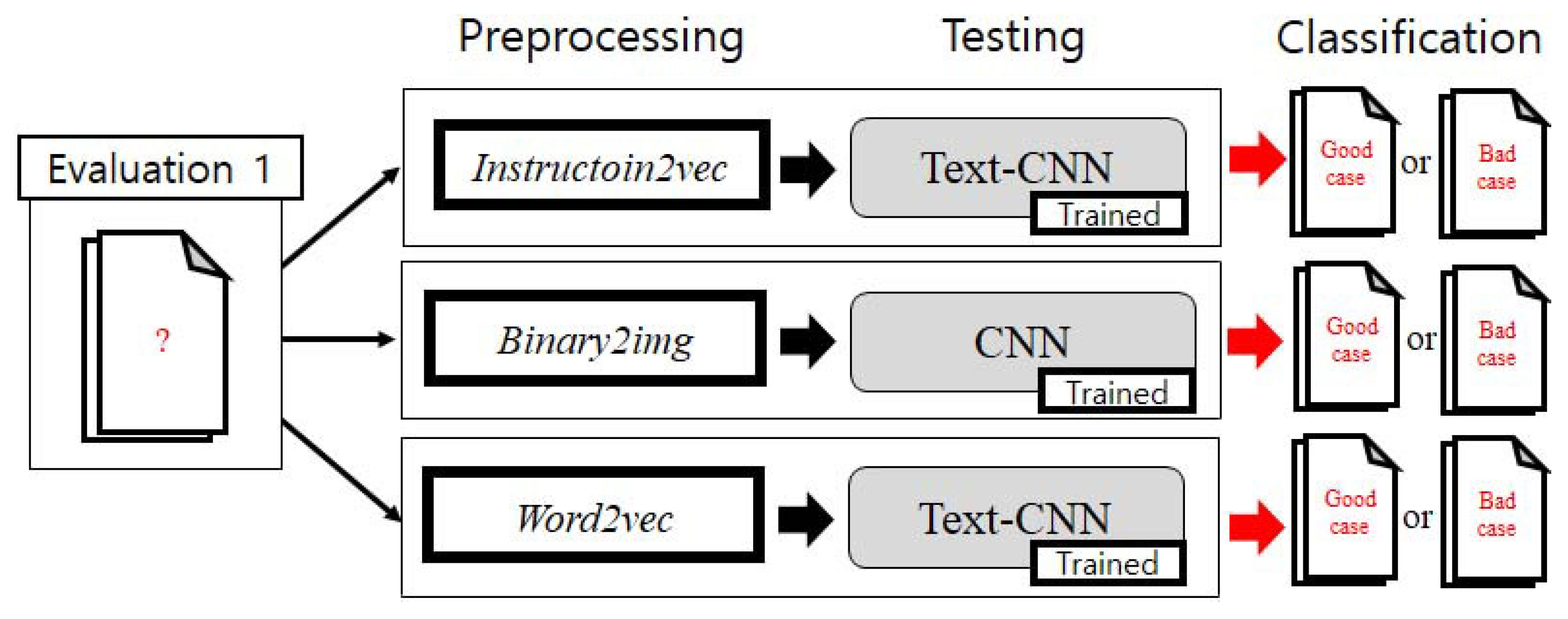
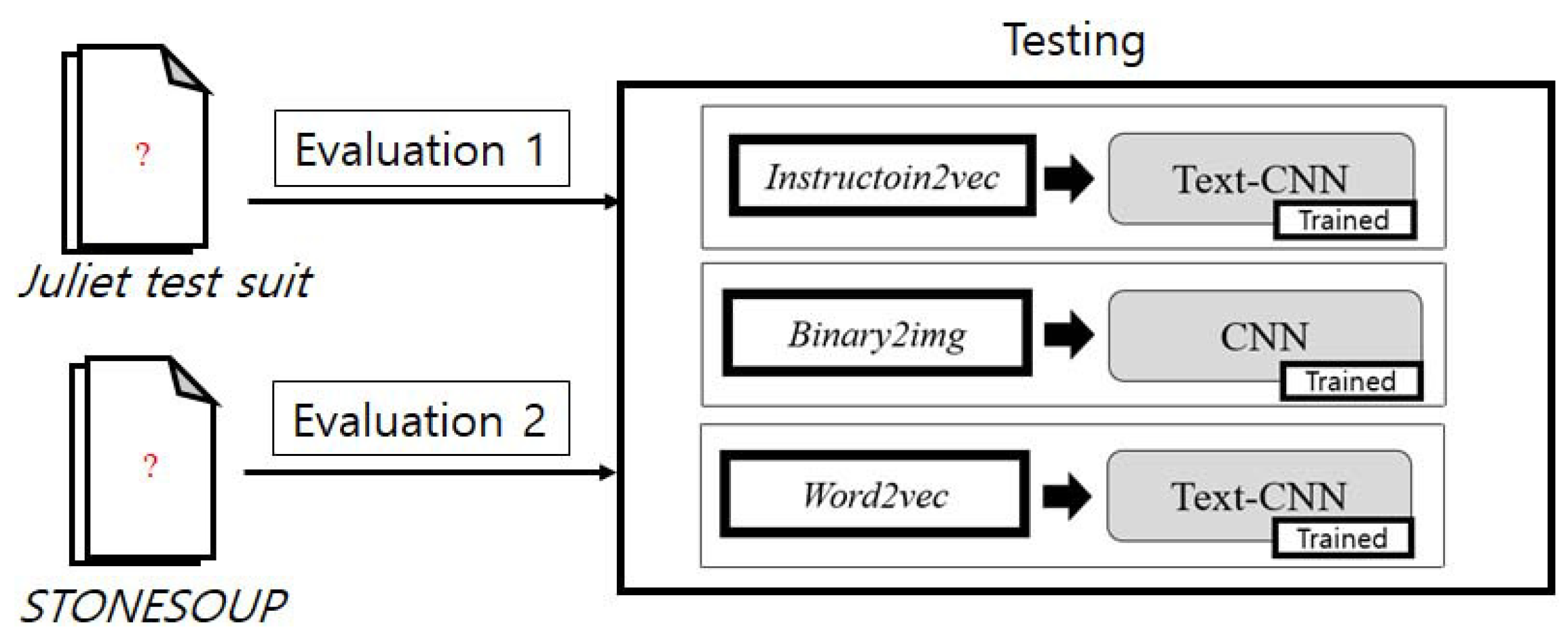
5. Experiment and Evaluation
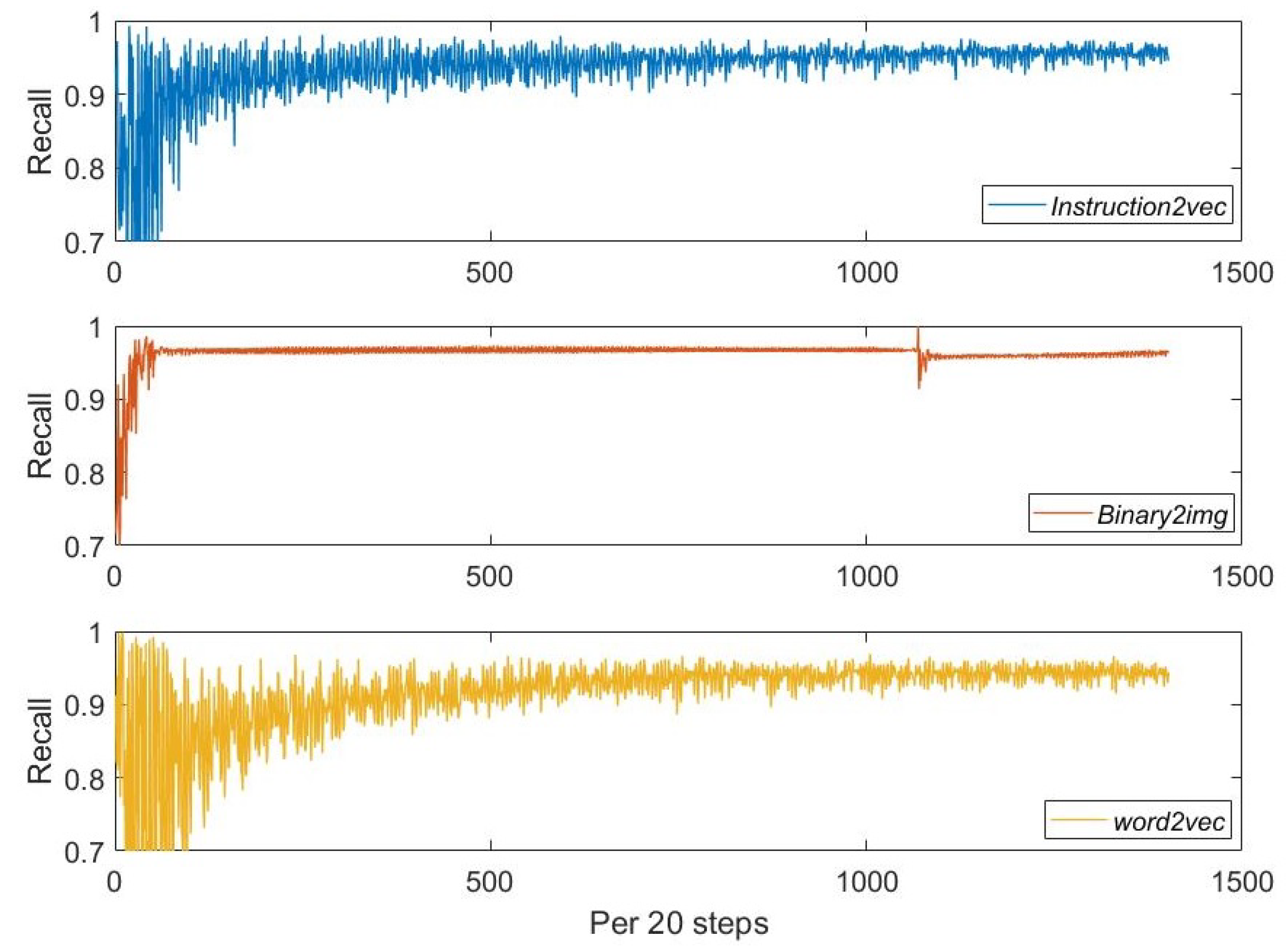
5.1. Evaluation 1–Juliet Test Suite
5.1.1. Dataset Generation
5.1.2. Environment
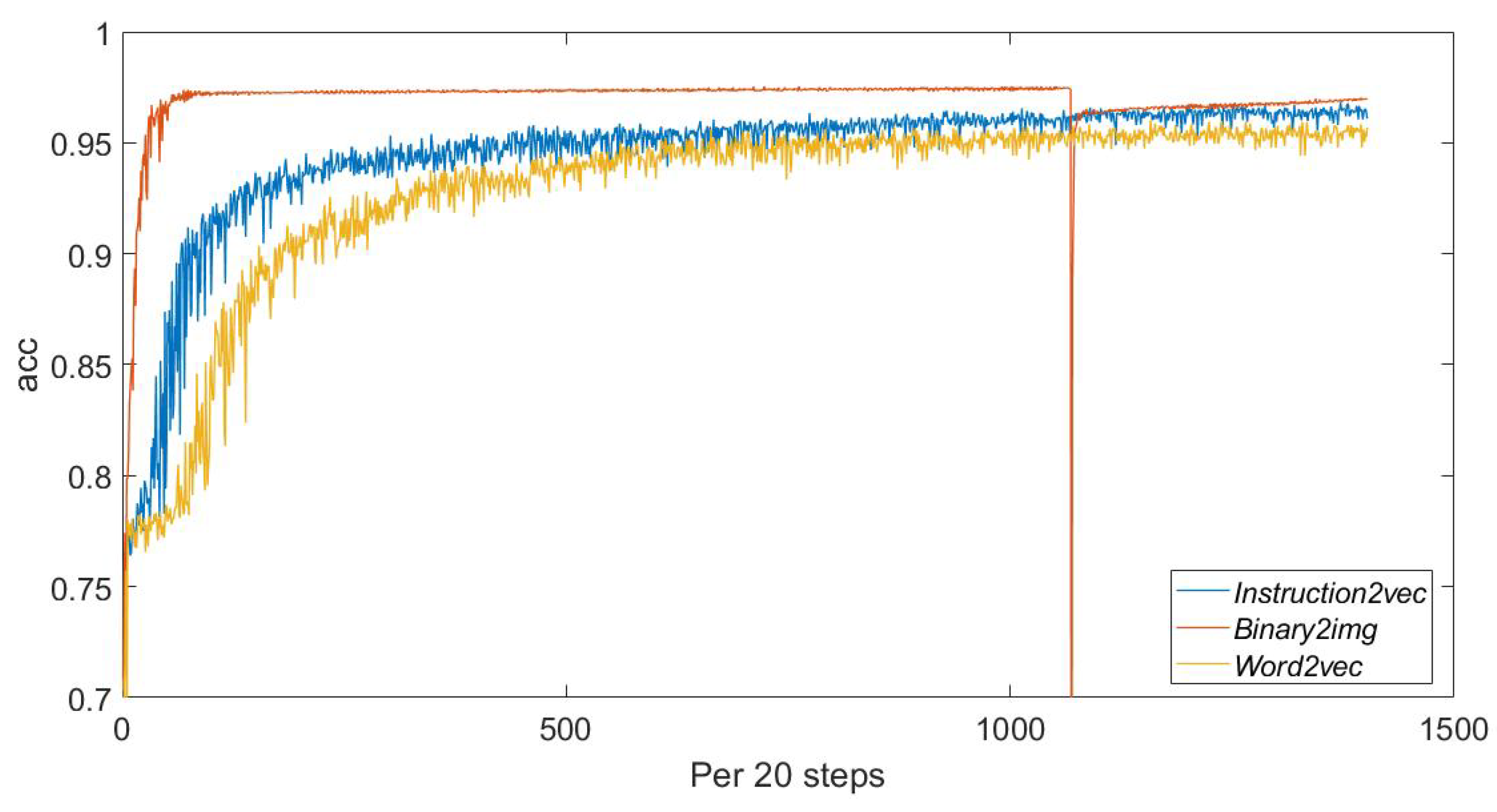
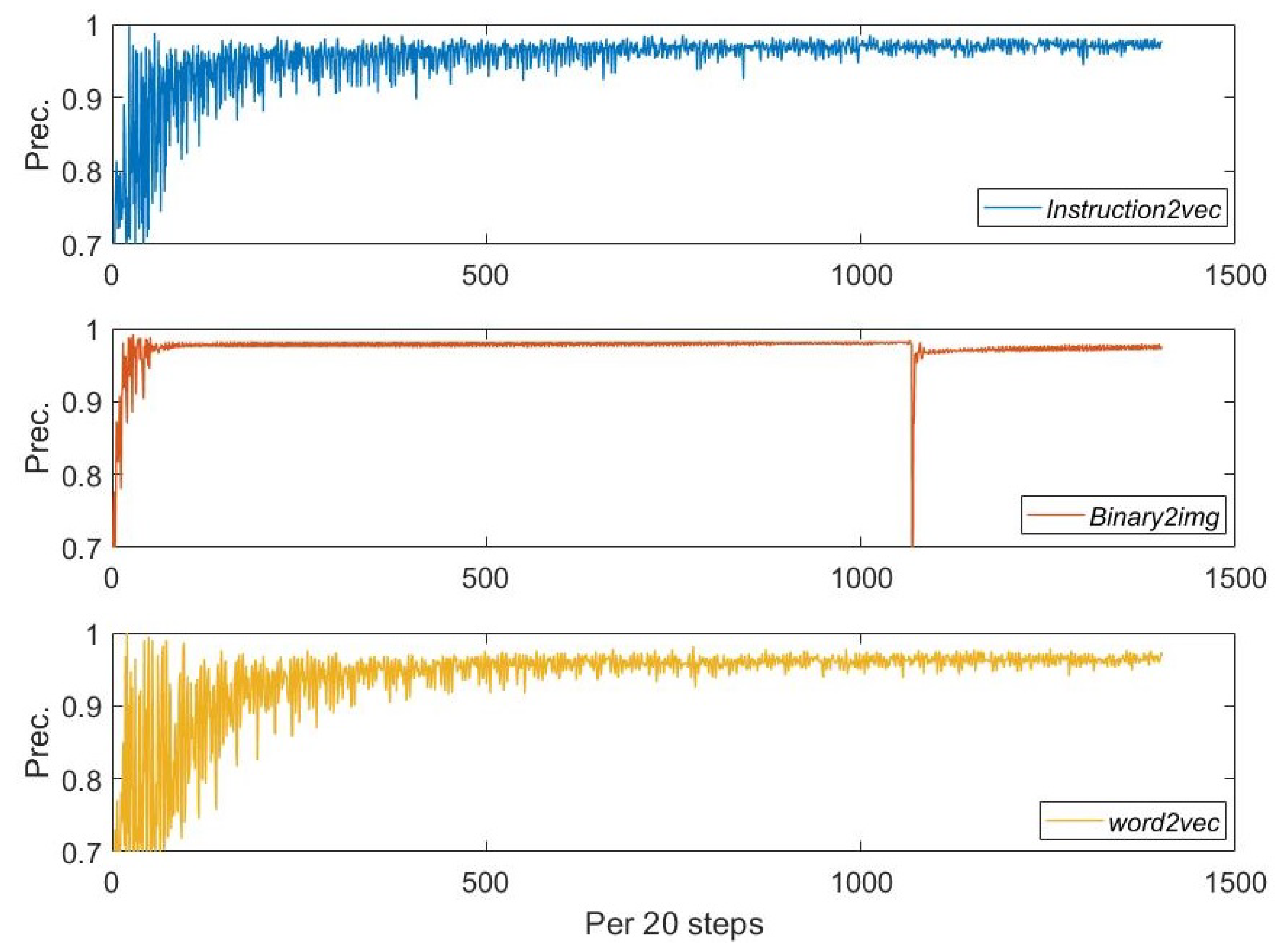
5.1.3. Results
5.2. Evaluation 2–STONESOUP
5.2.1. Dataset Generation
5.2.2. Result
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Common Vulnerabilities and Exposures. Available online: https://cve.mitre.org/ (accessed on 20 September 2019).
- Shoshitaishvili, Y.; Wang, R.; Salls, C.; Stephens, N.; Polino, M.; Dutcher, A.; Grosen, J.; Feng, S.; Hauser, C.; Kruegel, C.; et al. Sok: (State of) the art of war: Offensive techniques in binary analysis. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 138–157. [Google Scholar]
- Brooks, T.N. Survey of Automated Vulnerability Detection and Exploit Generation Techniques in Cyber Reasoning Systems. 2017; Volume abs/1702.06162. Available online: http://xxx.lanl.gov/abs/1702.06162 (accessed on 20 September 2019).
- Pewny, J.; Garmany, B.; Gawlik, R.; Rossow, C.; Holz, T. Cross-architecture bug search in binary executables. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 17–21 May 2015; pp. 709–724. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Lee, Y.J.; Choi, S.H.; Kim, C.; Lim, S.H.; Park, K.W. Learning binary code with deep learning to detect software weakness. In Proceedings of the KSII The 9th International Conference on Internet (ICONI) 2017 Symposium, Vientien, Laos, 17–20 December 2017. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B. Malware images: Visualization and automatic classification. In Proceedings of the 8th International Symposium on Visualization for Cyber Security, Pittsburgh, PA, USA, 20 July 2011; p. 4. [Google Scholar]
- Boland, T.; Black, P.E. Juliet 1. 1 C/C++ and java test suite. Computer 2012, 45, 88–90. [Google Scholar] [CrossRef]
- Vanderlinde, W. Securely Taking on New Executable Software of Uncertain Provenance (STONESOUP). Available online: http://www. iarpa. gov/index. php/research-programs/stonesoup (accessed on 20 September 2019).
- Mitchell, T.M. Machine learning and data mining. Commun. ACM 1999, 42, 30. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 1, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105, NIPS’12. [Google Scholar]
- Martin, R.A. Common Weakness Enumeration; Mitre Corporation: McLean, VA, USA, 2007. [Google Scholar]
- Black, P.E. SARD: Thousands of reference programs for software assurance. J. Cyber Secur. Inf. Syst. Tools Test. Tech. Assur. Softw. Dod Softw. Assur. Community Pract. 2017, 2, 5. [Google Scholar]
- Yamaguchi, F.; Lindner, F.; Rieck, K. Vulnerability extrapolation: Assisted discovery of vulnerabilities using machine learning. In Proceedings of the 5th USENIX Conference on Offensive Technologies, San Francisco, CA, USA, 8 August 2011; USENIX Association: Berkeley, CA, USA, 2011. WOOT’11. p. 13. [Google Scholar]
- Grieco, G.; Grinblat, G.L.; Uzal, L.; Rawat, S.; Feist, J.; Mounier, L. Toward large-scale vulnerability discovery using machine learning. In Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 9–11 March 2016; pp. 85–96. [Google Scholar] [CrossRef]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. VulDeePecker: A Deep Learning-Based System for Vulnerability Detection. CoRR 2018. Available online: http://xxx.lanl.gov/abs/1801.01681 (accessed on 20 September 2019).
- Russell, R.L.; Kim, L.; Hamilton, L.H.; Lazovich, T.; Harer, J.A.; Ozdemir, O.; Ellingwood, P.M.; McConley, M.W. Automated Vulnerability Detection in Source Code Using Deep Representation Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018. [Google Scholar]
- Ronen, R.; Radu, M.; Feuerstein, C.; Yom-Tov, E.; Ahmadi, M. Microsoft malware classification challenge. arXiv 2018, arXiv:1802.10135. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Type | Instruction2vec | Binary2img | Word2vec |
|---|---|---|---|
| Text-CNN | Vanilla CNN | Text-CNN | |
| Input | 117 × 320 | 64 × 64 | 13 × 1100 |
| Filters | Conv [117, 2, 128] Conv [117, 4, 128] Conv [117, 6, 128] Conv [117, 8, 128] Conv [117, 10, 128] Conv [117, 12, 128] Conv [117, 14, 128] Conv [117, 16, 128] | Conv [3, 3, 32] Max pooling [2, 2] Conv [3, 3, 64] Max pooling [2, 2] | Conv [13, 4, 128] Conv [13, 10, 128] Conv [13, 20, 128] Conv [13, 60, 128] |
| Dropout | 0.4 | 0.5 | 0.4 |
| Learning rate | 0.001 | 0.001 | 0.001 |
| Initializer | xavier initializer | - | xavier initializer |
| Optimizer | AdamOptimizer | ||
| Batch size | 128 | ||
| Epochs | 550 | ||
| Description | Accuracy | Recall | Precision |
|---|---|---|---|
| Instruction2vec | 96.81% | 97.07% | 96.65% |
| Binary2img | 97.53% | 97.05% | 97.91% |
| Word2vec | 96.01% | 96.07% | 95.92% |
| Description | Accuracy | Loss | Recall | Precision |
|---|---|---|---|---|
| Instruction2vec | 91.11% | 0.3058 | 93.33% | 70.00% |
| Binary2img | 53.33% | 0.6894 | 46.39% | 49.67% |
| Word2vec | 18.98% | 4.6809 | 100% | 18.98% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.; Kwon, H.; Choi, S.-H.; Lim, S.-H.; Baek, S.H.; Park, K.-W. Instruction2vec: Efficient Preprocessor of Assembly Code to Detect Software Weakness with CNN. Appl. Sci. 2019, 9, 4086. https://doi.org/10.3390/app9194086
Lee Y, Kwon H, Choi S-H, Lim S-H, Baek SH, Park K-W. Instruction2vec: Efficient Preprocessor of Assembly Code to Detect Software Weakness with CNN. Applied Sciences. 2019; 9(19):4086. https://doi.org/10.3390/app9194086
Chicago/Turabian StyleLee, Yongjun, Hyun Kwon, Sang-Hoon Choi, Seung-Ho Lim, Sung Hoon Baek, and Ki-Woong Park. 2019. "Instruction2vec: Efficient Preprocessor of Assembly Code to Detect Software Weakness with CNN" Applied Sciences 9, no. 19: 4086. https://doi.org/10.3390/app9194086