Table Recognition for Sensitive Data Perception in an IoT Vision Environment

Abstract
:1. Introduction
2. Related Works
2.1. Table-Recognition Methods
2.2. Table-Recognition Evaluation Metric
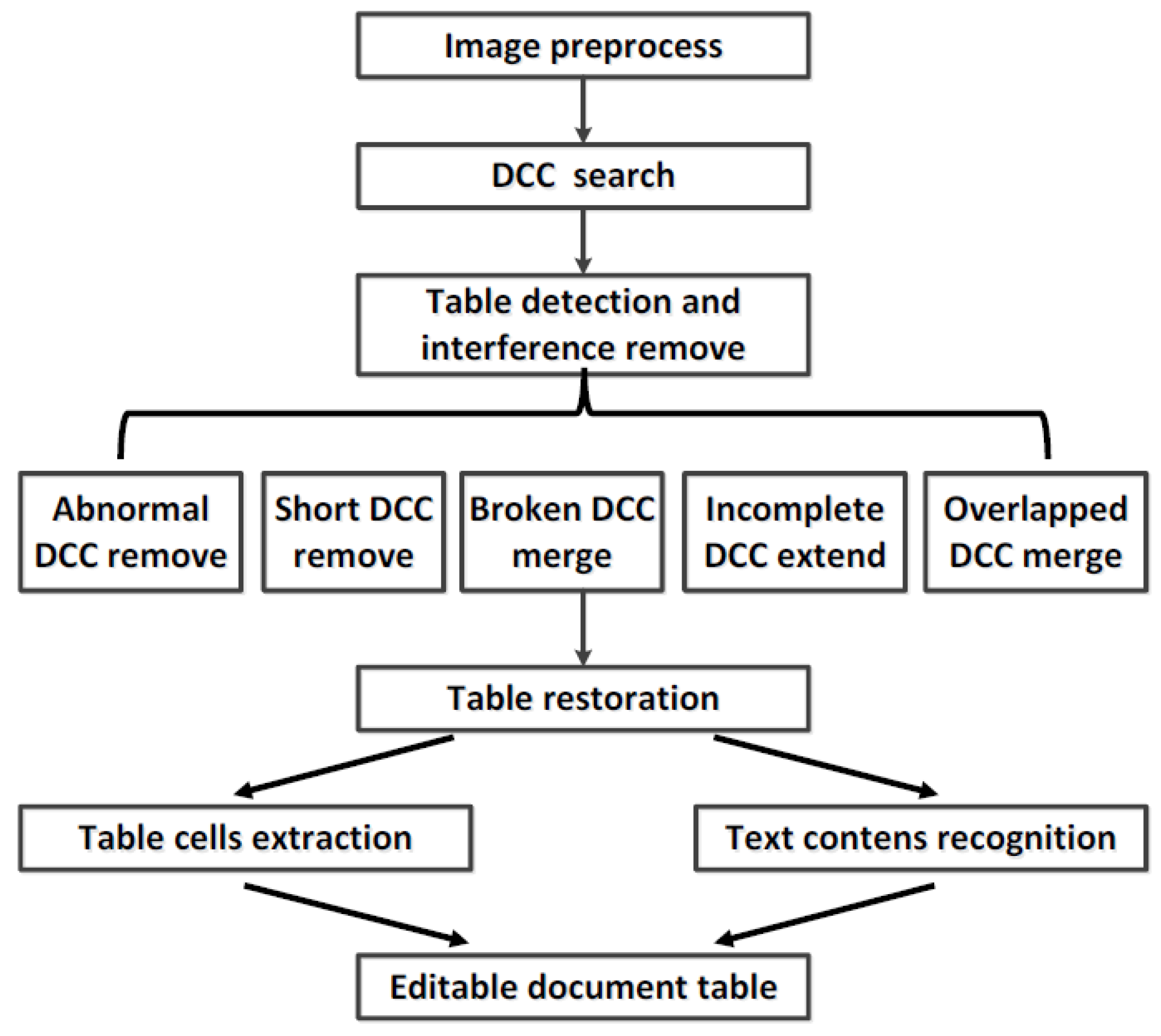
3. Recognition Method Design
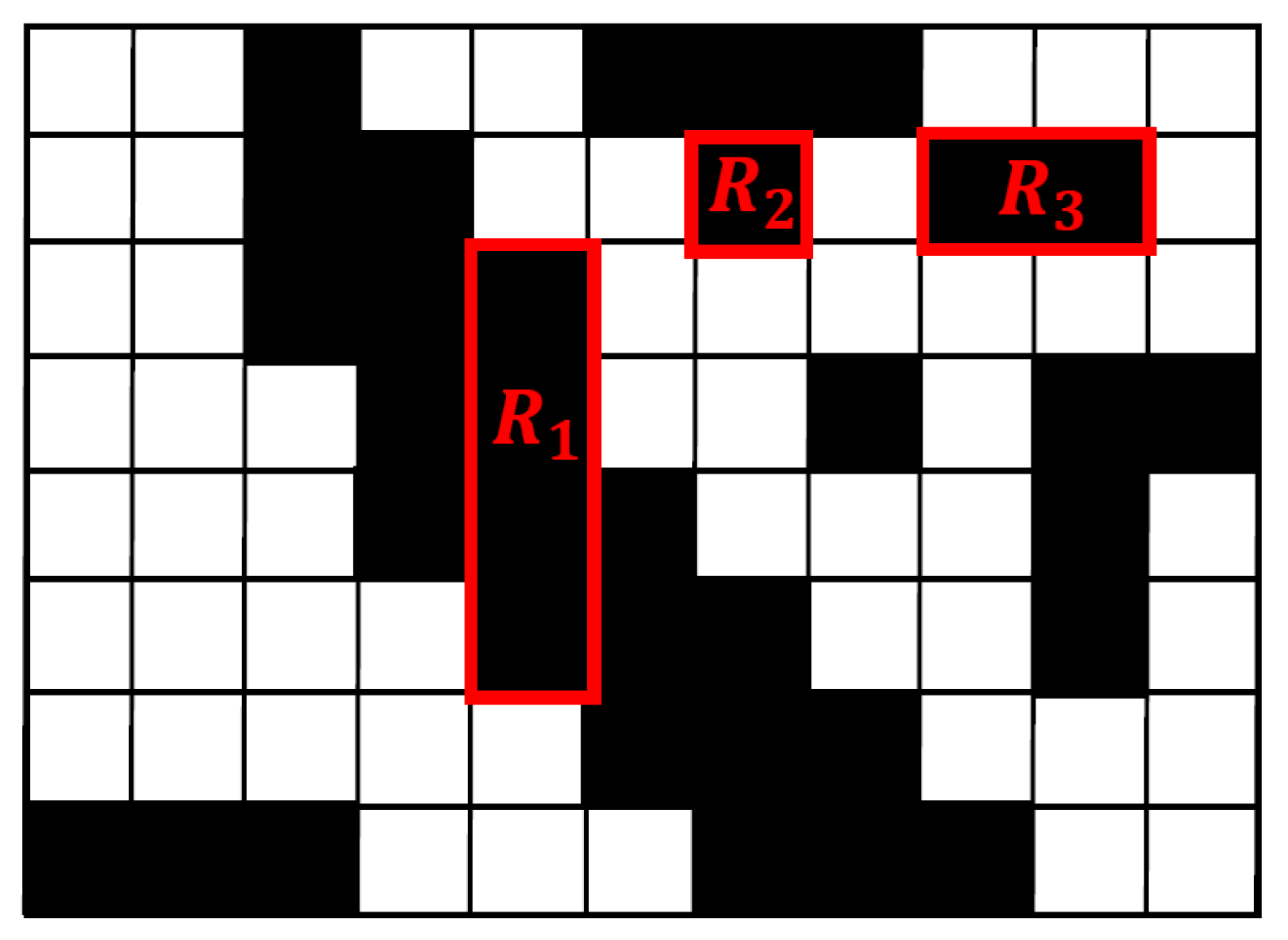
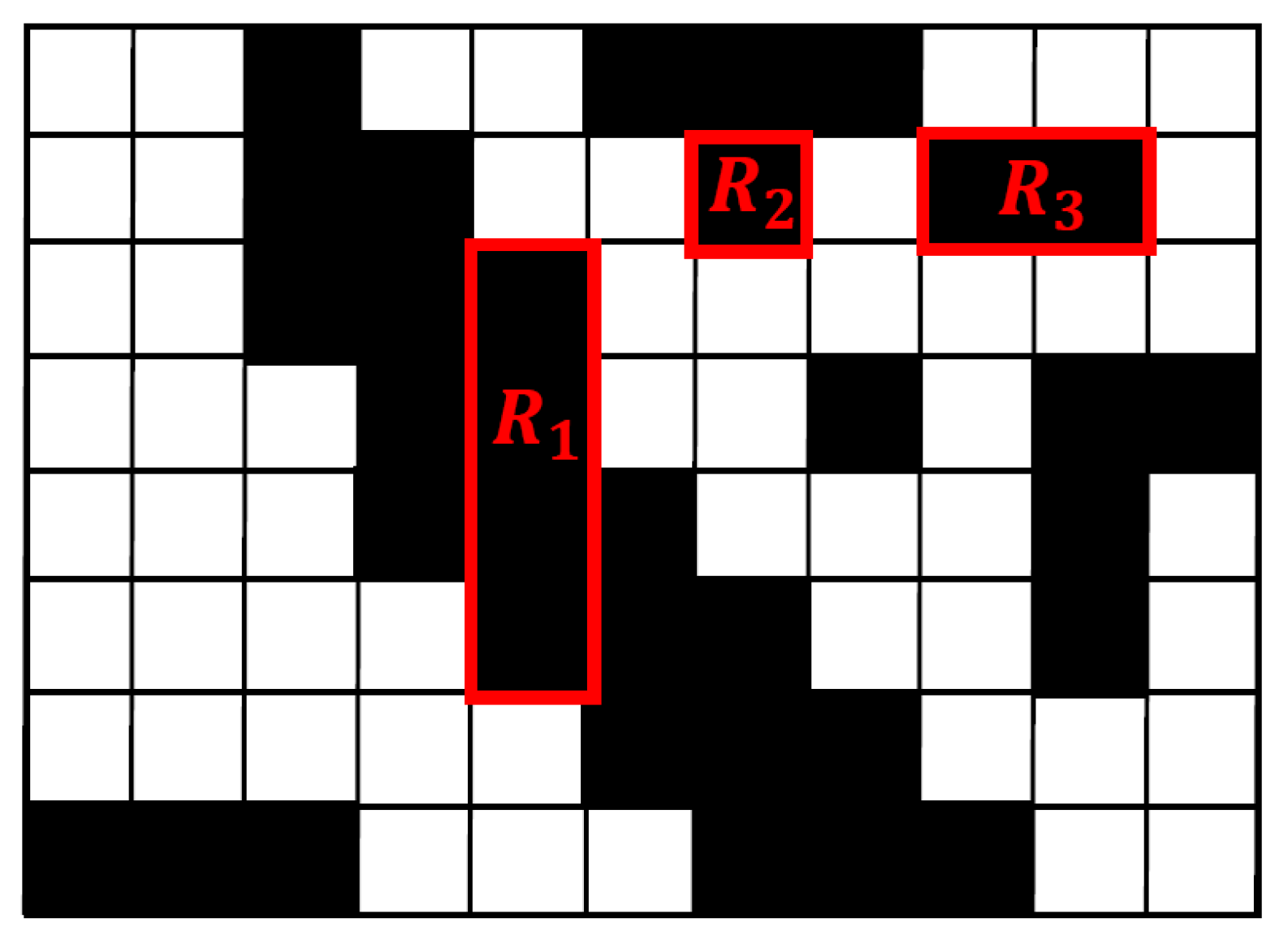
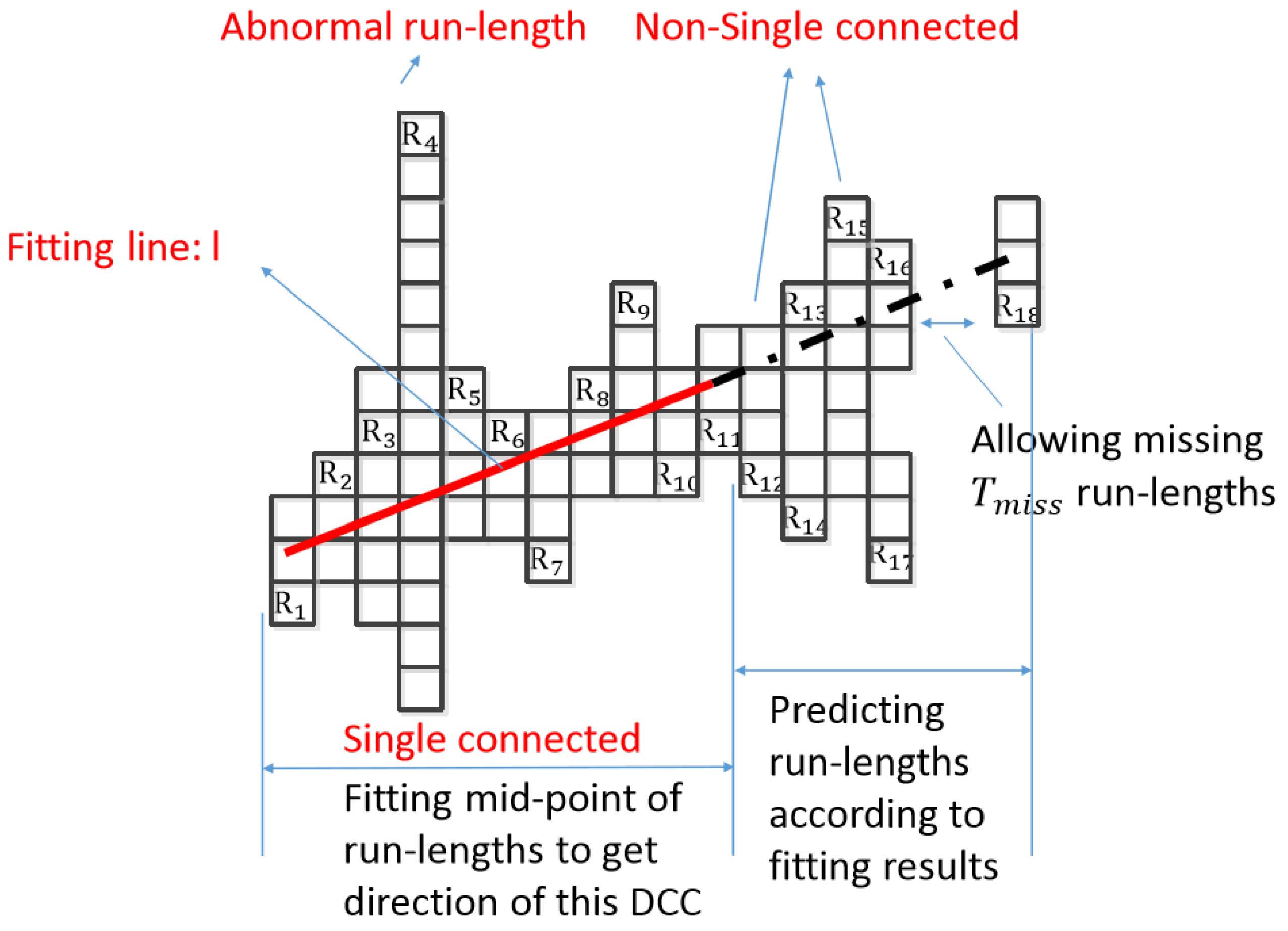
3.1. Directional Connected Chain (DCC)
3.2. Table-Frame Detection
3.2.1. Abnormal DCC Removal
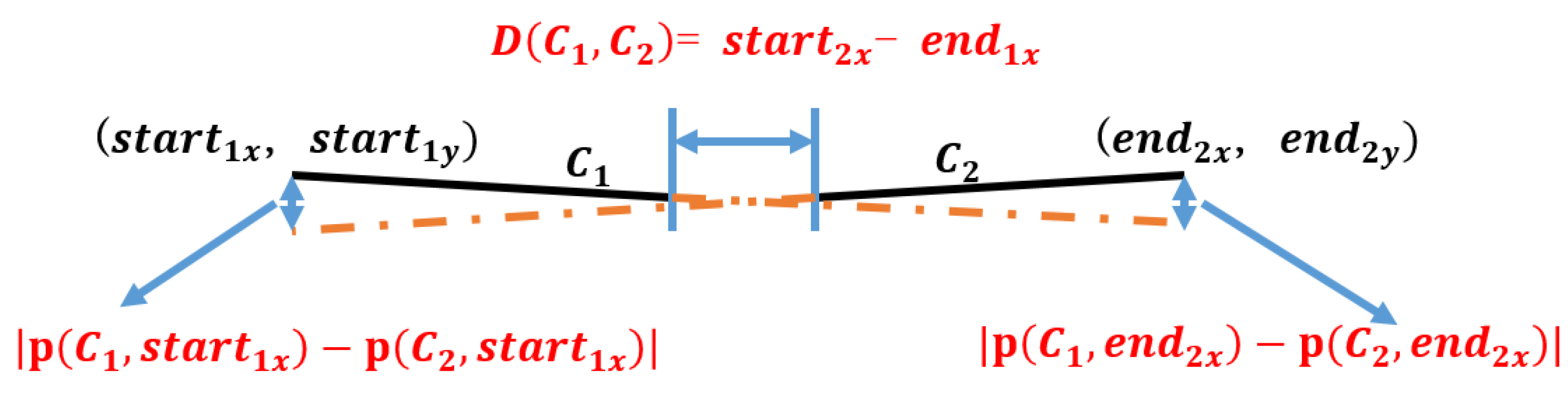
3.2.2. Broken DCC Mergence
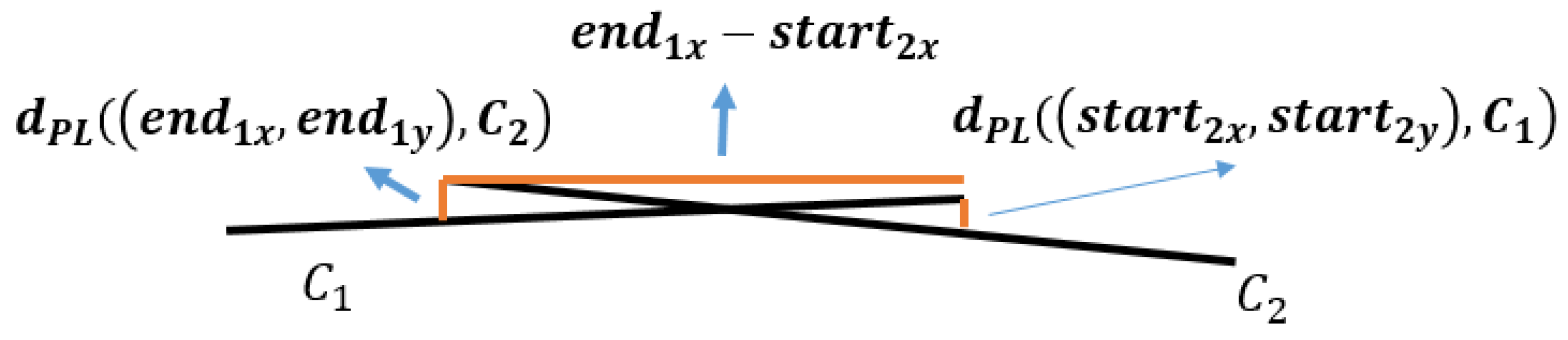
3.2.3. Overlapped DCC Mergence
3.2.4. Stamp and Handwritten Signature Interference Processing
3.3. Table Restoration and Table-Cell Extraction
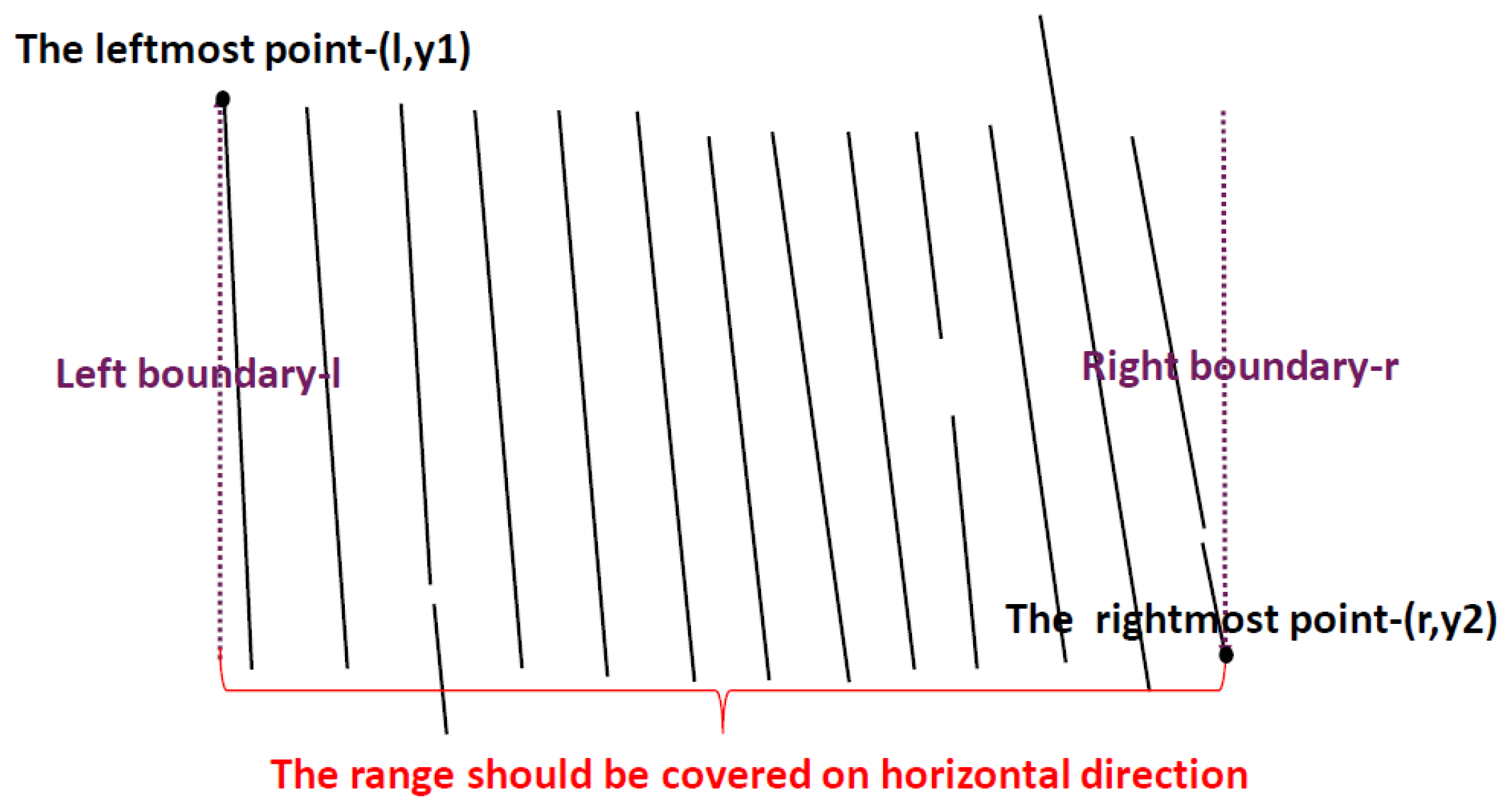
3.3.1. Table Restoration by Inverse Perspective Transformation
| Algorithm 1 Table outermost border detection. |
| Input: Output: The four point of the table outermost border:
|
3.3.2. Table-Cell Extraction
4. Experiments and Analysis
4.1. Evaluation Metric and Dataset
- The general rotation made by rotating the intelligent IoT vision device around the z-axis only;
- The table becomes trapezoid by rotating the intelligent IoT vision device around x-axis or y-axis;
- The table becomes an arbitrary quadrilateral by rotating the intelligent IoT vision device around both x-axis and z-axis, or y-axis and z-axis;
4.2. Experiment Setup
4.3. Perspective Transformation Analysis
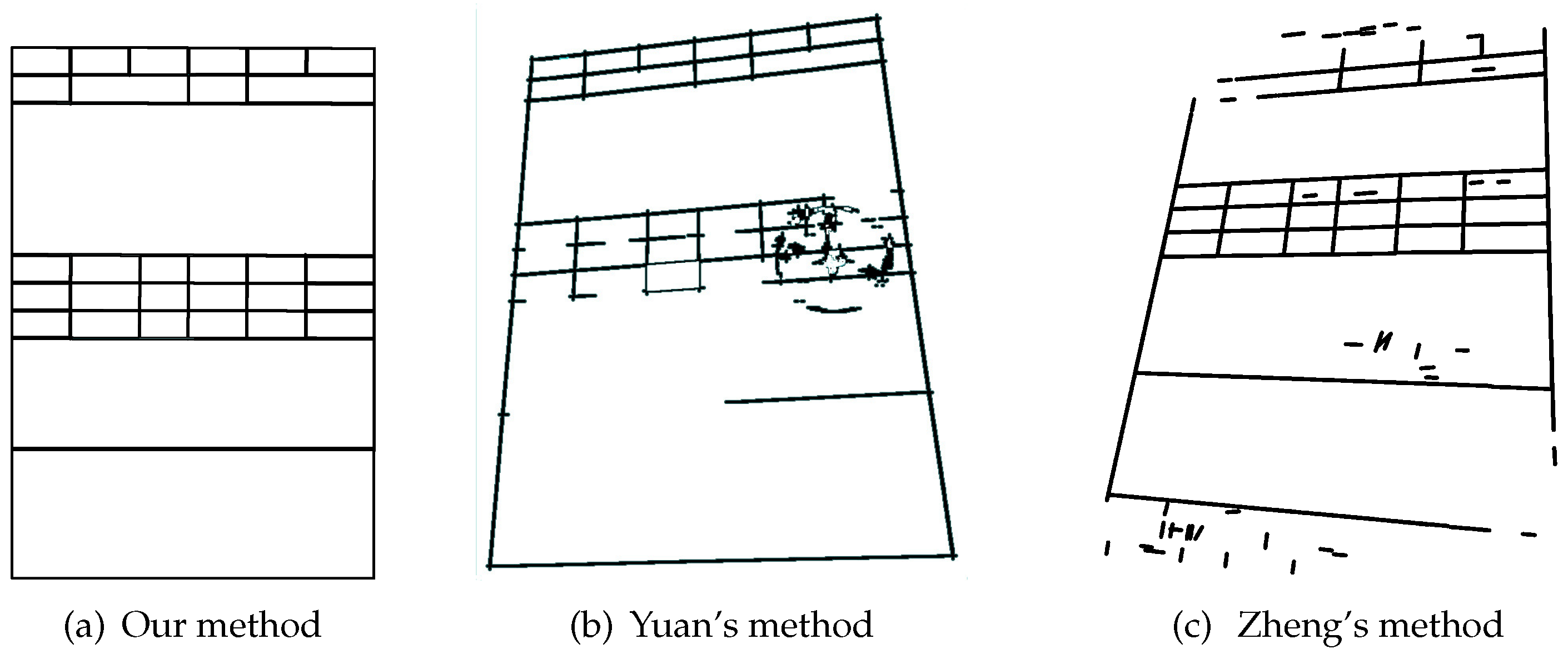
4.4. Error Type Analysis
4.5. Stamp Interference Analysis
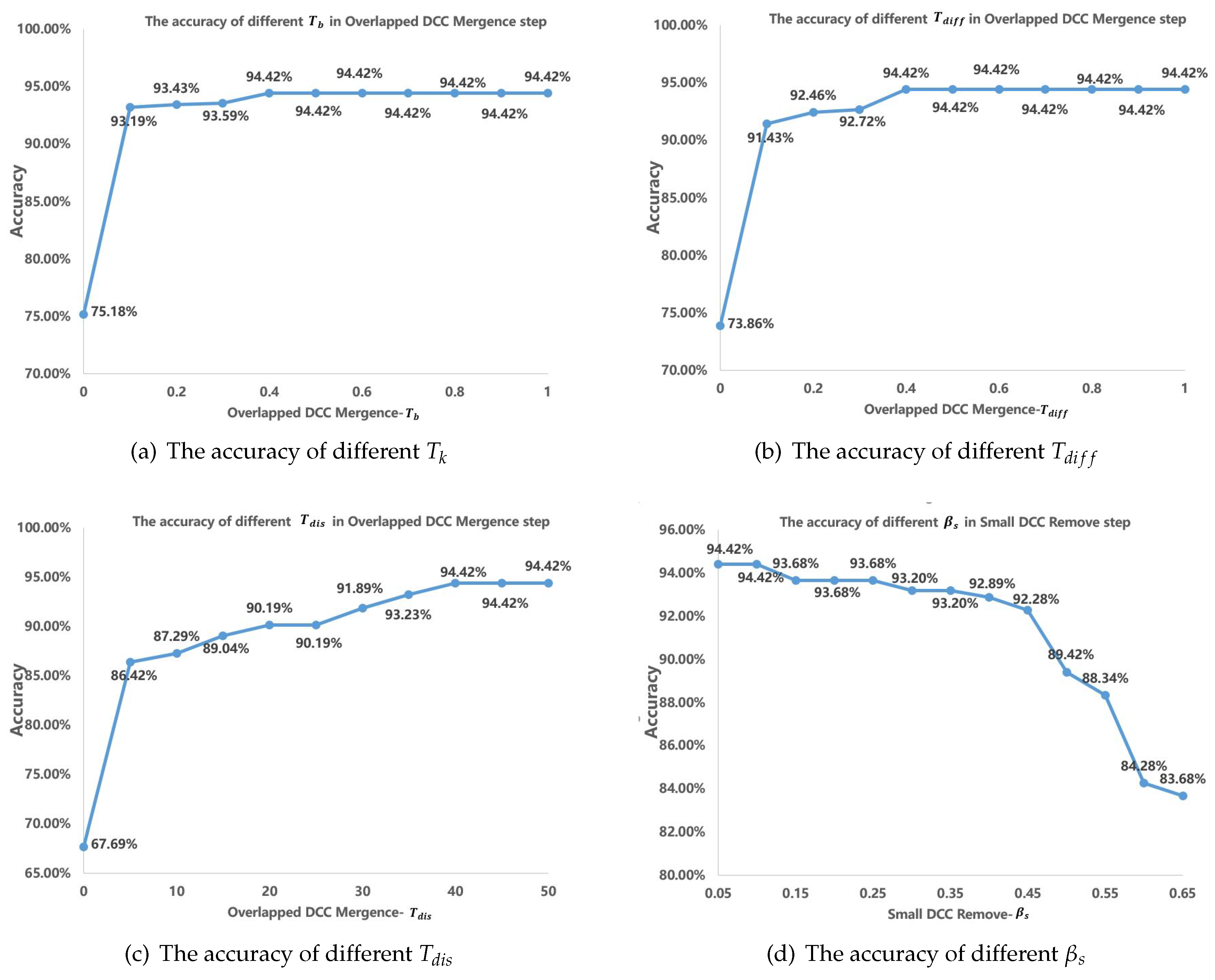
4.6. Threshold Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Floris, A.; Atzori, L. Managing the Quality of Experience in the Multimedia Internet of Things: A Layered-Based Approach. Sensors 2016, 16, 2057. [Google Scholar] [CrossRef] [PubMed]
- Anjomshoa, F.; Aloqaily, M.; Kantarci, B.; Erol-Kantarci, M.; Schuckers, S. Social Behaviometrics for Personalized Devices in the Internet of Things Era. IEEE Access 2017, 5, 12199–12213. [Google Scholar] [CrossRef]
- Karaadi, A.; Sun, L.; Mkwawa, I. Multimedia Communications in Internet of Things QoT or QoE. In Proceedings of the 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Exeter, UK, 21–23 June 2017; pp. 23–29. [Google Scholar]
- Otoum, S.; Kantarci, B.; Mouftah, H.T. On the Feasibility of Deep Learning in Sensor Network Intrusion Detection. IEEE Netw. Lett. 2019, 1, 68–71. [Google Scholar] [CrossRef]
- Otoum, S.; Kantarci, B.; Mouftah, H.T. Detection of Known and Unknown Intrusive Sensor Behavior in Critical Applications. IEEE Sens. Lett. 2017, 1, 7500804. [Google Scholar] [CrossRef]
- Thirumalai, C.; Kar, H. Memory efficient multi key (MEMK) generation scheme for secure transportation of sensitive data over cloud and IoT devices. In Proceedings of the 2017 Innovations in Power and Advanced Computing Technologies (i-PACT), Vellore, India, 21–22 April 2017. [Google Scholar]
- Zhang, Z.; Cho, M.C.Y.; Wang, C.; Hsu, C.; Chen, C.; Shieh, S. IoT Security: Ongoing Challenges and Research Opportunities. In Proceedings of the 2014 IEEE 7th International Conference on Service-Oriented Computing and Applications, Matsue, Japan, 17–19 November 2014; pp. 230–234. [Google Scholar]
- Koo, H.I.; Kim, J.; Cho, N.I. Composition of a dewarped and enhanced document image from two view images. IEEE Trans. Image Process. 2009, 18, 1551–1562. [Google Scholar] [PubMed]
- Faisal, S.; Ray, S. Table detection in heterogeneous documents. In Proceedings of the 9th IAPR International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010; pp. 65–72. [Google Scholar]
- Zhang, J.; Xie, Y.; Liu, W.; Gong, X. Dataaset of Table Recognition for Sensitive Data Perception in an IoT Vision Environment. Available online: http://www.mobisys.cc/pages/resource.html (accessed on 8 May 2012).
- Kieninger, T.G. Table structure recognition based on robust block segmentation. Proc. SPIE 1998. [Google Scholar] [CrossRef]
- Tran, D.N.; Aly, T.; Oh, A. Table detection from document image using vertical arrangement of text blocks. Int. J. Contents 2015, 11. [Google Scholar] [CrossRef]
- Armon, R.M.; Fan, Z.; Raineror, E.V. Tabular document recognition. Proc. SPIE 1994. [Google Scholar] [CrossRef]
- Wang, Y.; Phillips, I.T. Automatic table ground truth generation and a background-analysis-based table structure extraction method. In Proceedings of the Sixth International Conference on Document Analysis and Recognition(ICDAR), Seattle, WA, USA, 13 September 2001. [Google Scholar]
- Mandal, S.; Chowdhury, S.P.; Das, A.K. A simple and effective table detection system from document images. Int. J. Doc. Anal. Recog. (IJDAR) 2006, 8, 172–182. [Google Scholar] [CrossRef]
- Neves, L.A.P.; Facon, J. Methodology of automatic extraction of table-form cells. In Proceedings of the 13th Brazilian Symposium on Computer Graphics and Image Processing, Gramado, Brazil, 17–20 October 2000; pp. 15–21. [Google Scholar]
- Zanibbi, R.; Blostein, D.; Cordy, J.R. A survey of table recognition. Doc. Anal. Recog. 2004, 7, 1–16. [Google Scholar] [CrossRef]
- Liang, J.; Doermann, D.; Li, H. Camera-based analysis of text and documents: A survey. Int. J. Doc. Anal. Recognit. (IJDAR) 2005, 7, 84–104. [Google Scholar] [CrossRef]
- Mirmehdi, M. Special issue on camera-based text and document recognition. Int. J. Doc. Anal. Recognit. (IJDAR) 2005, 7, 83. [Google Scholar] [CrossRef]
- Seo, W.; Koo, H.I.; Cho, N.I. Junction-based table detection in camera-captured document images. Int. J. Doc. Anal. Recognit. 2015, 18, 47–57. [Google Scholar] [CrossRef]
- Yuan, J.; Chen, H.; Cao, H. An efficient junction detection approach for mobile-Captured golf scorecard images. In Proceedings of the 3rd International Conference on Information Technology and Quantitative Management, Rio De Janeiro, Brazil, 21–24 July 2015; pp. 792–801. [Google Scholar]
- Yuan, J.; Chen, H.; Cao, H. Junction based table detection in mobile captured golf scorecard images. Ind. IoT Technol. Appl. 2016, 173, 179–188. [Google Scholar]
- Zheng, Y.; Liu, C.; Ding, X.; Pan, S. Form frame line detection with directional single-connected chain. In Proceedings of the Sixth International Conference on Document Analysis and Recognition, Seattle, WA, USA, 10–13 September 2001; pp. 699–703. [Google Scholar]
- Li, F.; Shi, G.; Zhao, H. A method of automatic performance evaluation of table processing. In Proceedings of the 2009 Chinese Control and Decision Conference, Guilin, China, 17–19 June 2009; pp. 3985–3989. [Google Scholar]
- Wang, Y.; Phillips, I.T.; Haralick, R.M. Table structure understanding and its performance evaluation. Pattern Recog. 2004, 37, 1479–1497. [Google Scholar] [CrossRef]
- Kasar, T.; Barlas, P.; Adam, S. Learning to detect tables in scanned document images using line information. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1185–1189. [Google Scholar]
- Silva, A.C. New metrics for evaluating performance in document analysis tasks application to the table case. Q. Appl. Math. 2007, 1, 164–168. [Google Scholar]
- Hu, J.; Kashi, R.S.; Lopresti, D.P.; Wilfong, G. Table structure recognition and its evaluation. Proc. SPIE 2000, 4307. [Google Scholar] [CrossRef]
- Jean, S. Image Analysis and Mathematical Morphology; Academic Press, Inc.: Orlando, FL, USA, 1983. [Google Scholar]
- Ole, S. Morphology-based black and white filters for topology optimization. Struct. Multidiscip. Opt. 2007, 33, 401–424. [Google Scholar] [Green Version]
- Kenneth, L. A method for the solution of certain non-linear problems in least squares. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; pp. 481–485. [Google Scholar]
- Smith, R. An Overview of the Tesseract OCR Engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; pp. 629–633. [Google Scholar]
- Liu, H.; Ding, X. Handwritten character recognition using gradient feature and quadratic classifier with multiple discrimination schemes. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, Korea, 29 August–1 September 2005; pp. 1520–5363. [Google Scholar]
- Hu, J.; Kashi, R.; Lopresti, D.; Nagy, G.; Wilfong, G. Why table ground-truthing is hard. In Proceedings of the Sixth International Conference on Document Analysis and Recognition, Seattle, WA, USA, 10–13 September 2001; pp. 129–133. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: New York, NY, USA, 2000. [Google Scholar]
- Mezirow, J. Perspective transformation. Adult Educ. 1978, 28, 100–110. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Notation | Symbol | Notation |
|---|---|---|---|
| R | run length | the threshold of overlapped distance | |
| k | the x-coordinate of the end point of l | ||
| l | the fitting line | x-coordinate of the starting point of l | |
| the weight of k | the threshold of the length of run length | ||
| b | the intercept of l | the distance from the point (x, y) to C | |
| len(C) | the length of C | overlapped deviation between and | |
| C | directional connected chain | threshold of interval distance between and | |
| A | perspective transformation matrix | y-coordinate predicted by when x-coordinate is x | |
| overlapped distance | distance between and on horizontal direction | ||
| the threshold of overlapped mistake |
| Method | Rotation | Trapezoid | Quadrangle | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Slight | Obvious | Serious | Slight | Obvious | Serious | Slight | Obvious | Serious | |
| Our method | 94.84% | 96.51% | 92.46% | 94.42% | 93.66% | 79.62% | 94.41% | 93.66% | 84.11% |
| Yuan’s method | 89.22% | 28.38% | 5.60% | 81.12% | 84.91% | 70.74% | 92.73% | 78.50% | 69.34% |
| Zheng’s method | 84.94% | 82.65% | 68.90% | 81.86% | 77.93% | 62.98% | 83.39% | 78.21% | 70.00% |
| Method | Entry Fields | Fixed Fields | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Miss | Fault | Merge | Split | Total | Miss | Fault | Merge | Split | Total | |
| Our method | 15 | 0 | 23 | 14 | 52 | 14 | 0 | 4 | 1 | 19 |
| Yuan’s method | 60 | 0 | 10 | 0 | 70 | 30 | 0 | 5 | 0 | 35 |
| Zheng’s method | 110 | 0 | 29 | 50 | 189 | 37 | 0 | 3 | 19 | 59 |
| Method | Entry Fields | Fixed Fields | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Miss | Fault | Merge | Split | Total | Miss | Fault | Merge | Split | Total | |
| Our method | 41 | 0 | 36 | 8 | 85 | 5 | 0 | 14 | 7 | 26 |
| Yuan’s method | 257 | 0 | 5 | 0 | 262 | 58 | 0 | 7 | 0 | 65 |
| Zheng’s method | 126 | 0 | 31 | 41 | 198 | 37 | 0 | 3 | 19 | 59 |
| Method | Rotation | Trapezoid | Quadrangle | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Slight | Obvious | Serious | Slight | Obvious | Serious | Slight | Obvious | Serious | |
| with stamp | 95.17% | 95.79% | 92.83% | 95.63% | 94.41% | 85.01% | 94.56% | 94.92% | 88.60% |
| without stamp | 95.53% | 95.72% | 92.45% | 95.17% | 94.48% | 82.91% | 93.84% | 94.80% | 87.30% |
| Threshold | Notation | Optimal Value |
|---|---|---|
| the threshold of slope difference in Equation (6) | 2 | |
| the threshold of intercept difference in Equation (6) | 0 | |
| the threshold of fitting deviation in Equation (6) | 2 | |
| the threshold of slope difference in Equation (9) | 1 | |
| the threshold of intercept difference in Equation (9) | 0.4 | |
| the threshold of overlapped distance in Equation (9) | 40 | |
| the threshold of mistake in Equation (9) | 0.4 | |
| the coefficient in in Equation (2) | 0.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Xie, Y.; Liu, W.; Gong, X. Table Recognition for Sensitive Data Perception in an IoT Vision Environment. Appl. Sci. 2019, 9, 4162. https://doi.org/10.3390/app9194162
Zhang J, Xie Y, Liu W, Gong X. Table Recognition for Sensitive Data Perception in an IoT Vision Environment. Applied Sciences. 2019; 9(19):4162. https://doi.org/10.3390/app9194162
Chicago/Turabian StyleZhang, Jin, Yanmiao Xie, Weilai Liu, and Xiaoli Gong. 2019. "Table Recognition for Sensitive Data Perception in an IoT Vision Environment" Applied Sciences 9, no. 19: 4162. https://doi.org/10.3390/app9194162
APA StyleZhang, J., Xie, Y., Liu, W., & Gong, X. (2019). Table Recognition for Sensitive Data Perception in an IoT Vision Environment. Applied Sciences, 9(19), 4162. https://doi.org/10.3390/app9194162