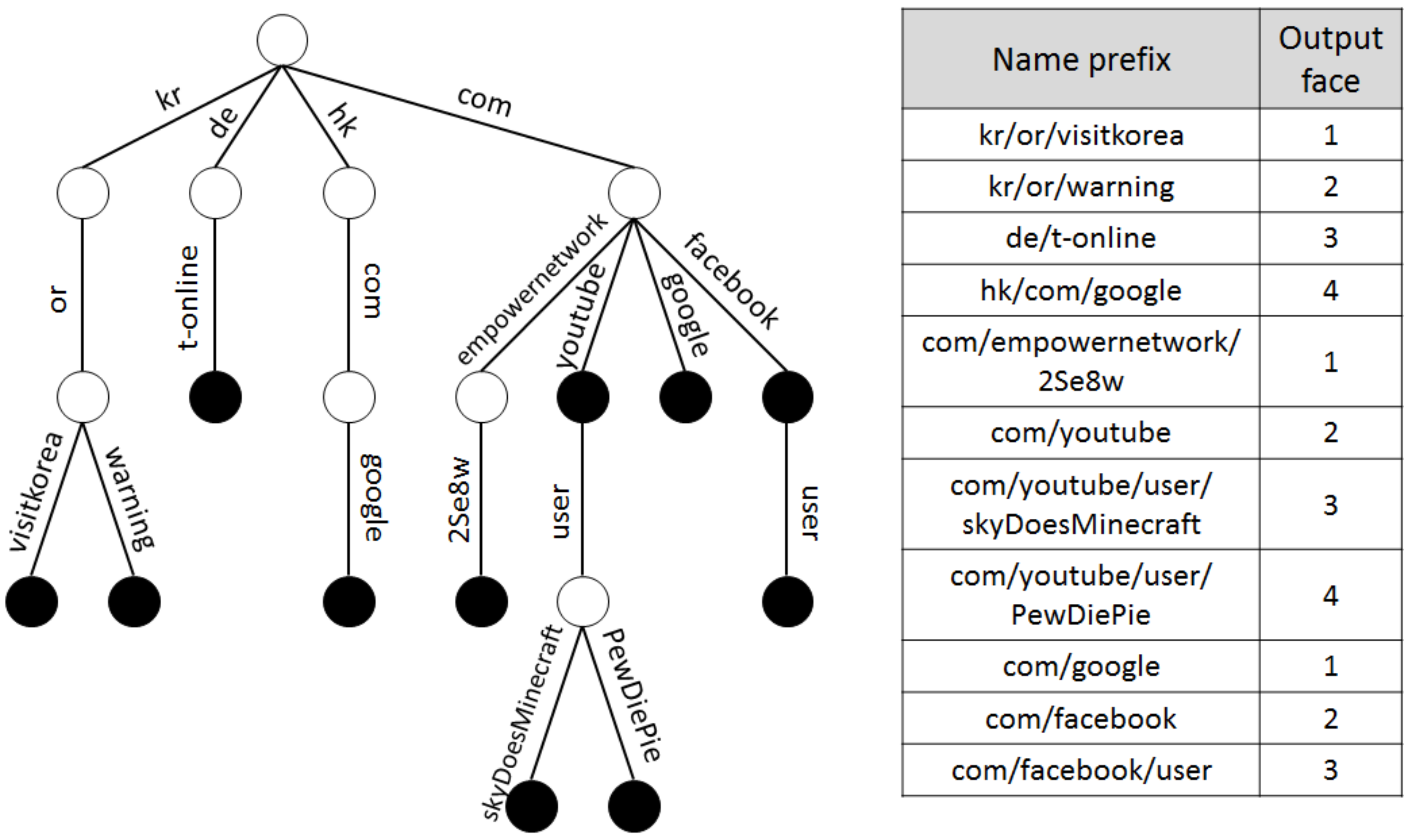
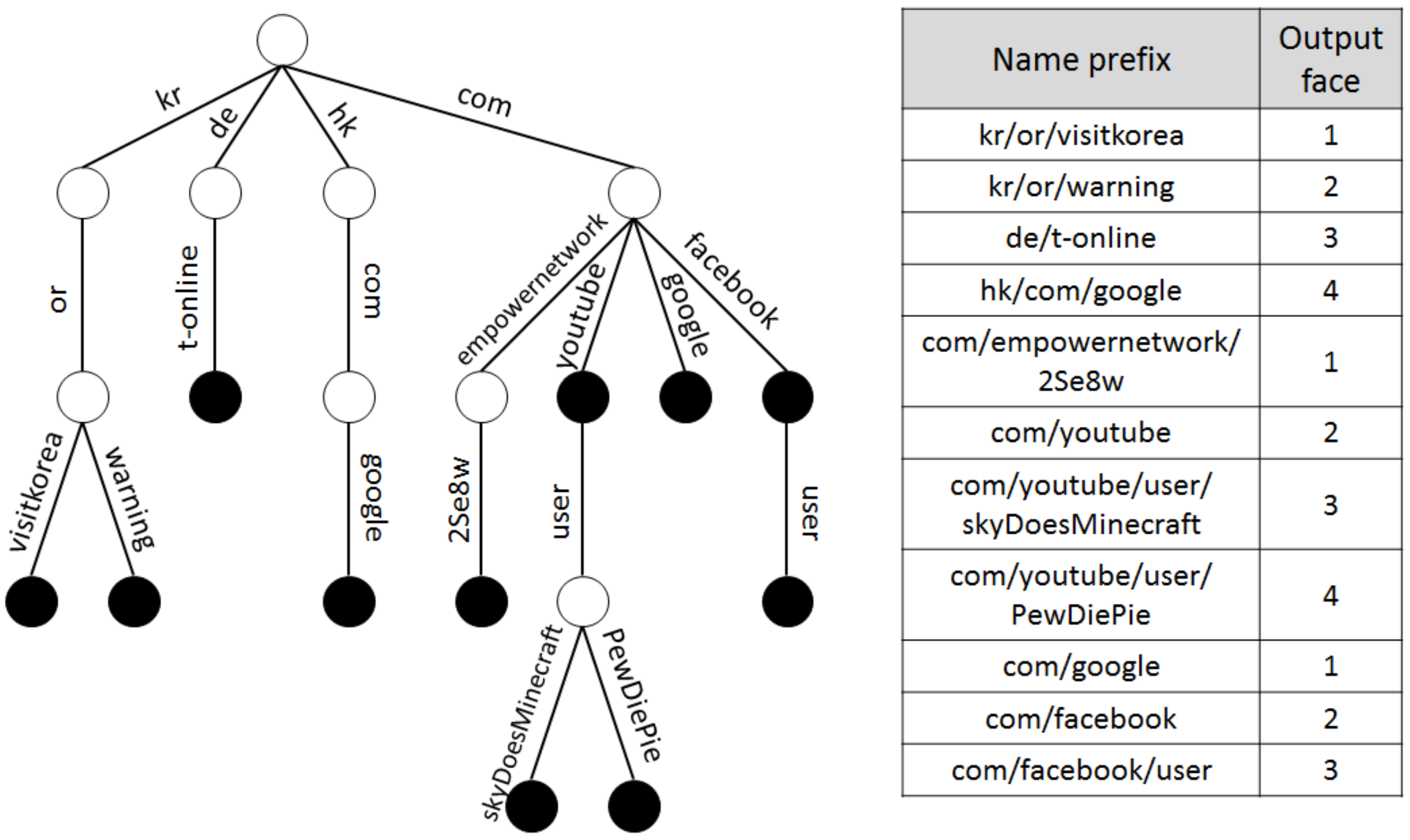
For the implementation of the LPT and the hash table shown in
Figure 2, we propose using two functional Bloom filters: a level Bloom filter (
l-BF) and a port Bloom filter (
p-BF). In the proposed architecture, the level information stored in the LPT is programmed to
l-BF, while the output face information stored in the hash table is programmed to
p-BF.
3.2.1. Construction
Figure 3 shows the proposed 2-phase Bloom filter architecture. The
l-BF is programmed for every node (except for the root node) of the LPT and stores the level for each node. For example, since node
shown in
Figure 2 has level 4,
k cells corresponding to the hash indexes generated by key
are set to value 4. The
p-BF is then programmed for every name prefix in an FIB table and stores the output face information corresponding to each prefix. For example,
k cells corresponding to the hash indexes generated by name prefix
, shown in
Figure 1, are set to value 3, since the output face of the name prefix is 3. In programming the
l-BF or the
p-BF, it is important to note that a cell is set to the maximum value (denoted by
in this paper) in order to represent the
conflict, if two or more values are programmed to a cell. In querying the
l-BF or the
p-BF, a value will be returned if the accessed cells (except conflict cells) have the same value. If every returned cell value of the
p-BF is considered to be a
conflict cell for a given input, the output face cannot be determined. The hash table shown in
Figure 3, the details of which will be described in the next section, is provided for this case.
3.2.2. Search
Figure 3 also shows a brief overview of the search procedure of the proposed architecture. The search procedure proceeds by interactively querying the
l-BF and the
p-BF. By querying the
l-BF, the level is returned. The returned level is used in querying the
p-BF, and the output face is obtained. This process is repeated until a negative result is returned in
l-BF.
For example, assume an input . The l-BF is first queried using as the hash key. If at least one non-conflict cell exists, the l-BF returns level value 4. Since the returned value is larger than the number of components used in querying, it can be noticed that node is an LP-node. The p-BF is queried with the key . In this case, the p-BF returns a negative result. Hence, the l-BF is queried again using and returns 2. Since the level information returned by string is the same as the number of components, node is considered to be an ordinary node. Hence, the search procedure queries the l-BF again using . The l-BF returns a negative result, meaning that neither node nor its children exist. Hence, level 2 is the last level and the p-BF is queried using . The search procedure is completed by returning output face 2. In this case, the total number of Bloom filter queries is 5, and no accesses to the off-chip hash table occur.
As another example, assume input name . First, the l-BF is queried using and returns level 4. However, since the number of input components is fewer than 4, the l-BF is queried again using . The l-BF then returns level 2. Since an ordinary node is accessed, the l-BF query should be continued, but there are no more input components. Hence, the p-BF is queried using . Subsequently, the p-BF returns the output face and the search is complete. In this case, the total number of Bloom filter accesses is 3, without any off-chip memory accesses.
Algorithm 1 describes the search procedure in detail, which consists of the
l-BF query and the
p-BF query. Algorithms 2 and 3 show the detailed querying procedure of the
l-BF and the
p-BF, respectively.
| Algorithm 1: Search Procedure |
![Applsci 09 00329 i001]() |
For a given input name, querying the l-BF produces one of four types of results: ORD, PRI, NEG, and INDET, as shown in Algorithm 2. The ORD result occurs when an ordinary node is accessed. In this case, the current level is remembered as the , and the l-BF querying continues as shown in Algorithm 1. The PRI result occurs when an LP-node is accessed. In this case, the p-BF is queried using the returned level. If the p-BF returns the output face by producing a positive result, the search immediately ends. Otherwise, if the p-BF produces a negative result (meaning that the longest name prefix does not match the input), the search procedure returns to the l-BF query for the next level. For the NEG (negative) result in the l-BF querying, the p-BF is queried from the while the level of access is decreased until a matching output face is found in the p-BF.
The INDET result occurs when every accessed cell of the
l-BF has a
conflict value. Even though the INDET is likely a
positive, since the type (ORD and PRI) of the node causing the INDET is unknown, the search cannot proceed to the next level. Hence, for the INDET result, we perform
p-BF querying beginning from the longest level of the input name until a matching output face is found in the
p-BF.
| Algorithm 2: Querying Procedure of the l-BF |
![Applsci 09 00329 i002]() |
For the INDET result of the
p-BF shown in Algorithm 3, a matching output face cannot be determined with only 2-phase Bloom filter queries. In order to address this issue, an off-chip hash table is also required. Backtracking should then occur from the indeterminable level in the hash table.
| Algorithm 3: Querying Procedure of the p-BF |
![Applsci 09 00329 i003]() |
3.2.3. Update
The functional Bloom filters used in our proposed architecture can provide incremental insertions and deletions by ensuring that each cell is programmed by a single key. When programming the return value for a given key, if a cell indicated by the hash index generated for the given key already has a value (meaning that the cell has already been programmed by another element), the cell is set to conflict . Since each cell with a value other than is programmed by a single key, the functional Bloom filter can provide delete operations. In deleting an element from a functional Bloom filter, each cell among the k cells with a value other than is changed to 0; conflict cells are not changed in this process.
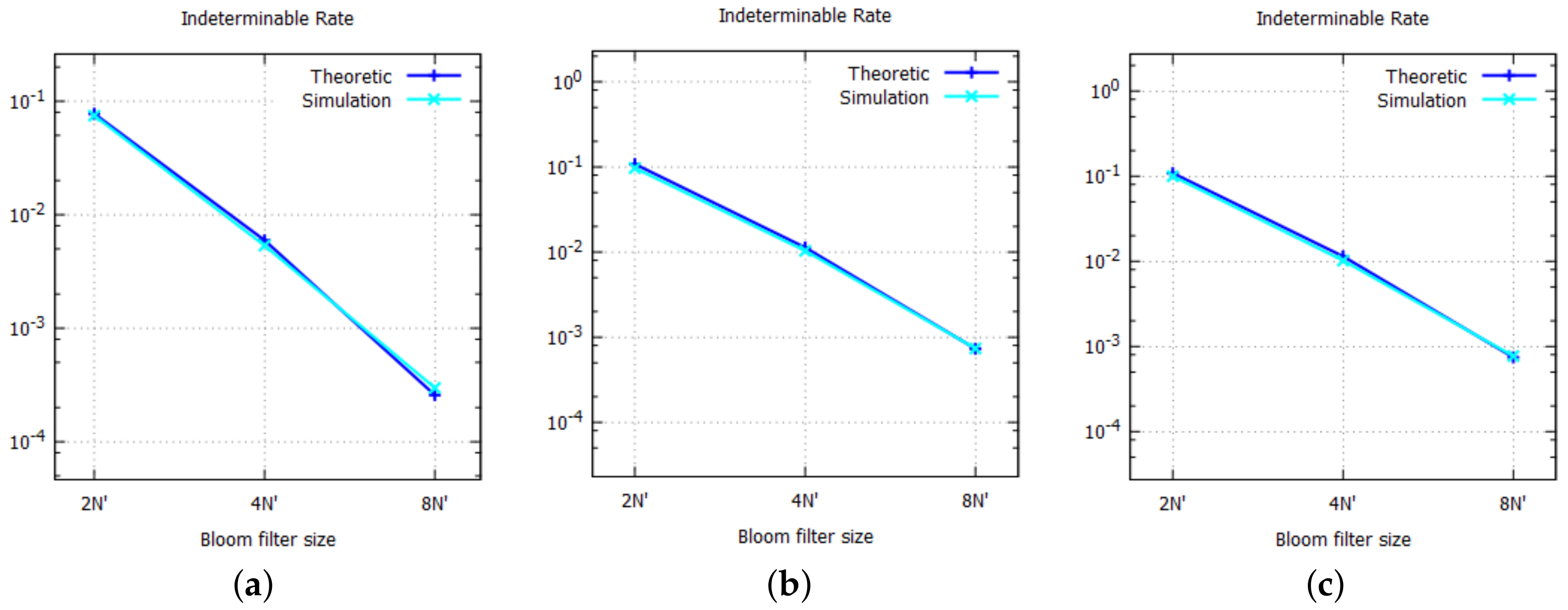
Repeated insertions and deletions will increase the number of conflict cells, and, accordingly, degrade the performance of the functional Bloom filter. Hence, the proposed architecture should be reconstructed if the number of conflict cells is larger than a pre-defined threshold value. Determining the threshold value for the desired performance in terms of false positive rate and indeterminable rate is beyond the scope of this paper.
3.2.4. Discussion
The LPT proposed in this paper provides benefits in terms of both the search performance and the memory requirement. If we assume a naive Bloom filter structure implementing an NPT, many empty nodes should be programmed and queried, starting from a root node. In order to avoid queries to empty nodes, if the search begins with the longest level, Bloom filter querying should continue until a matching name prefix is found while decreasing the level of access. Hence, if the NPT is more unbalanced, more memory accesses occur.
The proposed LPT takes advantage of both cases. The search procedure in an LPT initially begins with the root, and the level increases when ordinary nodes are encountered. However, when a level-priority node is encountered at a certain level, the input is compared with the longest prefix. Based on the comparison result, the search can either be completed or continue to the next level.
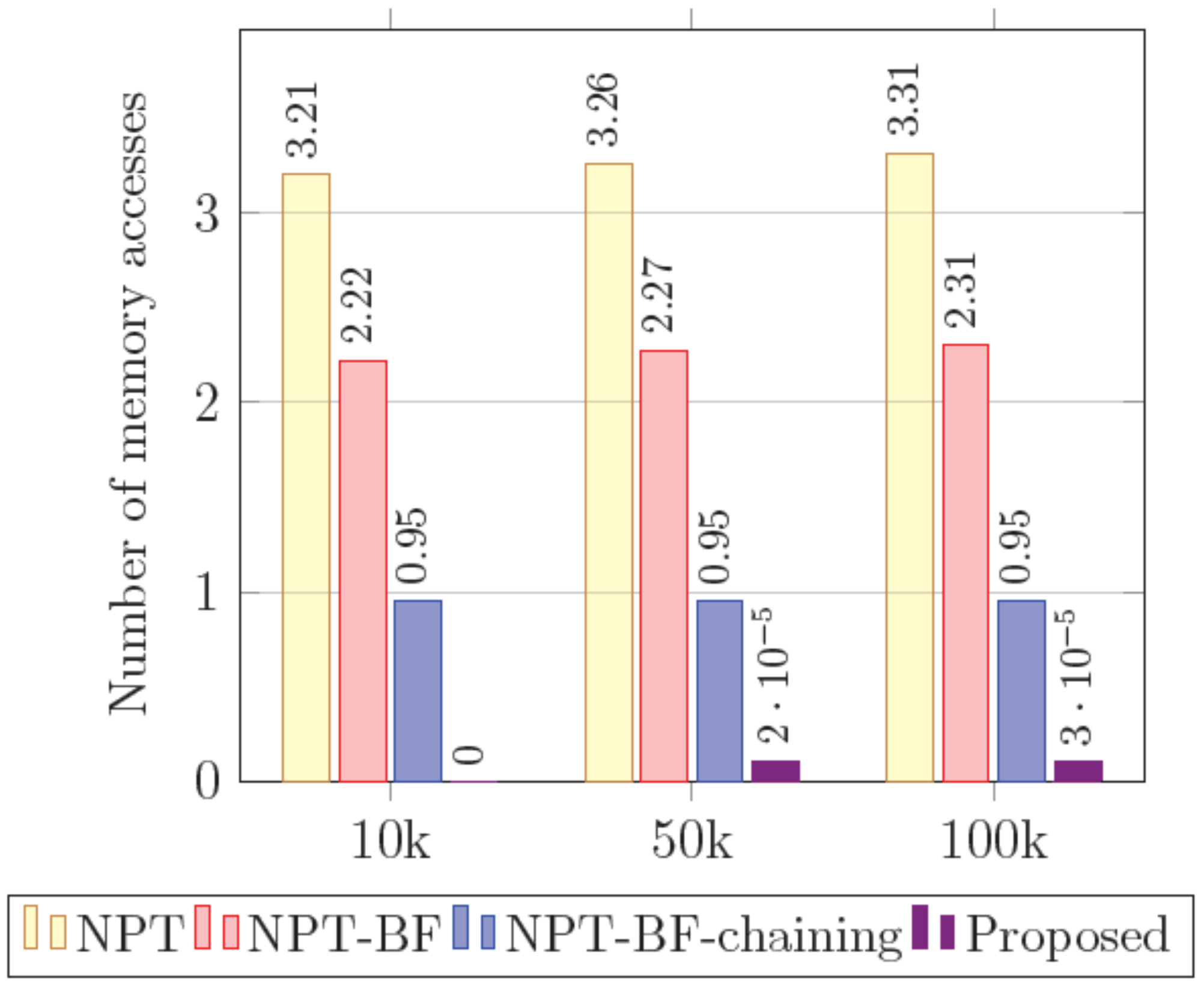
In addition, the LPT-based search can easily be implemented with the functional Bloom filters as described. A functional Bloom filter is a space-efficient data structure that only stores return values without the signature of each programmed element, since different combinations of cell indexes can work as the signature of each different key. Hence, the proposed structure can be implemented with on-chip memories, and the FIB lookup can be completed with a small number of on-chip accesses, as will be shown through simulation in a later section.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}