1. Introduction
Recently, a large amount of spatiotemporal data has been generated, and the applications of spatiotemporal data has been increasing. Consequently, the importance of spatiotemporal data processing also has been increasing. There are many moving objects that generate spatiotemporal data. They are everywhere, such as vehicles on the road, pedestrians on the street, trains on the railroad, ships on the sea, airplanes in the sky, objects in CCTVs, climbers in the mountains, and so on. These moving objects produce very large spatiotemporal data every day. Major areas of spatiotemporal data generation and application are as follows. New York City TLC (Taxi and Limousine Commission) archives more than 1.1 billion trajectories [
1]. Twitter has more than 5 million tweets per day, and 80% of mobile users are mobile [
1].
Most moving objects transmit their locations periodically to their servers. Recently, various methods have been proposed to deal with the increased importance of very large spatiotemporal data processing. In some studies, parallel and distributed indexing methods to process the location data of moving objects have been proposed [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. According to reference [
11], these methods can be divided into two groups depending on what big data processing frameworks, such as Apache Hadoop [
12] and Apache Spark [
13], are using.
Apache Hadoop is a successful big data processing framework, but it has limited performance improvements due to disk-based data storage and data sharing among MapReduce phases. The significant drop in main-memory cost has initiated a wave of main-memory distributed processing systems. Apache Spark is an open source and general-purpose engine for large-scale data processing systems. It provides primitives for in-memory cluster computing to avoid the IO (Input and Output) bottleneck that occurs when Hadoop MapReduce repeatedly performs computations for jobs.
The big spatiotemporal data processing methods proposed in References [
1,
2,
3,
4] are based on Apache Hadoop. They were designed and implemented by using HDFS [
12], MapReduce [
12], or HBase [
14] for data storage, indexing, and query processing. References [
7,
8,
9] proposed Apache Spark-based big spatiotemporal data processing methods. They proposed indexing and query processing methods based on Apache Spark to overcome the limit of performance improvements caused by the disk-based architecture of Apache Hadoop. Besides References [
5,
6], most of them are aimed at batch loading, querying, and analysis for spatiotemporal data rather than at real-time data ingestion and querying.
Reference [
5] proposes an indexing method for moving objects based on Apache Spark to manage the index and to store location data on distributed in-memory. However, it does not consider the case that the memory is full of index structures and location data. It uses grid-based indexing techniques. When memory is full, index structures and location data are processed according to the configuration of Spark. Reference [
6] also proposes a distributed in-memory moving objects management system based on Spark that solves the memory full problem of reference [
5]. References [
5,
6] achieved a high data ingestion throughput based on a distributed in-memory framework. However, if the amount of processing is larger than the memory size, disk I/O occurs and there is a limit to performance improvement. In addition, there is a problem in that data ingestion cannot provide parallelism.
GeoMesa [
15] is a commercial spatiotemporal data management system to process queries and analytics of big spatiotemporal data based on distributed computing systems. It supports spatiotemporal indexing on top of the various NoSQL (non SQL or non-relational) systems such as Accumulo [
16], HBase [
14], and so on. Also, GeoMesa provides near real-time stream processing of spatiotemporal data by using Apache Kafka [
17].
Since References [
1,
2,
3,
4] are based on Apache Hadoop, which is a disk-based and IO optimized system, they inherit the performance limitations of Apache Hadoop. Although the methods in References [
5,
6,
7,
8,
9] are based on Apache Spark, they do not perform well due to its overhead such as scheduling, distributed coordination, and lack of memory for large amount of data. As described above, Geomesa is designed to use various NoSQL systems as its storage engine. Specifically, it uses Apache Accumulo, which uses memory table, cache, and write ahead logs to alleviate IO overhead. It exploits the data distribution feature of Apache Accumulo for indexing spatiotemporal data with space-filling curve techniques. However, to our knowledge, Geomesa may suffer performance degradation since its indexing method is not pipelined and the resolution of space-filling curve is static [
18].
In this paper, we propose a real-time parallel ingestion method for big spatiotemporal data by using Apache Accumulo like Geomesa. In addition, a spatiotemporal query processing method that maximizes parallelism of query processing is proposed. The proposed parallel query processing and ingestion methods are based on the table split feature of Apache Accumulo and use in-memory storage. The spatiotemporal data is classified into cells in a dynamic grid index by clients, and the data is parallelly ingested into the partitioned tables (tablets) distributed to the nodes using the threads corresponding to each cell. Our dynamic grid index can be adapted to the data distribution. Query processing is also performed in a similar manner. We identify the cells that need to be accessed during query processing and perform query processing on the tablets corresponding to each cell in parallel.
This paper is organized as follows.
Section 2 describes the existing distributed spatiotemporal data processing methods, and
Section 3 presents the architecture of the proposed spatiotemporal data processing system and its application for location tracking for mountain hikers. In
Section 4, the performance evaluation results of the proposed system are given, and finally, we conclude this paper in
Section 5.
3. Parallel Insertion and Indexing Method for Proposed Spatiotemporal Data
Figure 3 shows the overall architecture of the proposed parallel ingestion and indexing method of big spatiotemporal data stream based on Apache Accumulo [
16]. As shown in the figure, the spatiotemporal data generated by moving objects are transmitted periodically to the ingest manager in the form of a data stream through Apache Kafka. Ingest manager stores the transmitted spatiotemporal data in a data buffer of fixed size. The spatiotemporal data in the data buffer is distributed to tablet servers of Apache Accumulo to be stored in a data table. Before storing the data to the data table, indexing process is performed.
The index data created from the spatiotemporal data in the data buffer is stored in an index buffer of fixed size, which may be greater than the size of the data buffer. The index buffer is flushed whenever the buffer is full. This process is performed by an index manager. We use Hilbert Curve technique for mapping the spatiotemporal properties of data to one-dimensional data and the Grid technique to distribute spatiotemporal data to tablet servers. Spatiotemporal data and index data are inserted in parallel into the tablet servers in charge of the mapped value to which the respective data belong. The indexing and insertion of the data are implemented as Kafka’s consumer, and the number of Consumers is equal to that of table servers. Each consumer can simultaneously insert the data into each table server to maximize parallelism.
Figure 4 shows the schema of data table and index table and the overall data ingestion process of the proposed method in this paper. As shown in the figure, the key of the data table is a combination of the ID (the moving object ID) and the timestamp of a spatiotemporal record. The key of the index table is a combination of cellID (Hilbert Curve value) and the timestamp of the record. Our indexing procedure begins with moving objects. All the moving objects have indexing information such as grid size and time interval for Hilvert Curve mapping. As shown in the figure, a moving object maps timestamp and location of a record to a Hilbert Curve value (cellID) and then transmits the record with the cellID to the ingest manager.
Ingest manager stores the input spatiotemporal data stream from moving objects in the data buffer of fixed size. Concurrently, the index manager creates index records with the records in a data buffer. The data buffer consists of a hash table. An index record consists of a key (cellID and timestamp) and a value (its key of the data table). The index records are stored in an index buffer which has a KD-tree [
21] structure. Spatiotemporal data and index data in both buffers are flushed into Apache Accumulo. Apache Accumulo has multiple tablet servers, and cellIDs (Hilbert Curve values) are assigned to tablet servers. Thus, the flush operations for both buffers are performed in parallel by the tablet servers.
As described earlier, Apache Accumulo enables to split data in advance and to assign key ranges to tablet servers. We use this feature to assign cellIDs (Hilbert Curve values) to tablet servers.
Figure 5 shows an example of the proposed method. Index manager creates a grid for a given area on a time interval. In this figure, time interval is 10, i.e., the first TI (time interval) is T0–T9 and the second TI is T10–T19. The Hilbert Curve value of the grid for TI
i where
i (0–
k) means the order of TI starts at
, where
i means TI and
rowsize and
columnsize mean the row size and the column size of the grid, respectively. In this figure, TI
0 starts at 0 and TI
1 starts at 16 when the grid size is
. Then, a mapped Hilbert Curve value (cellID) is assigned to a tablet server, for example, cellIDs 0–3 and 16–19 are assigned to tablet server
1. The assignment depends on the number of servers and the size of the grid.
Generally, locations of moving objects can be skewed to a specific area and the area may be changed with time. The indexing method described above cannot process efficiently the skewed location data. Therefore, we propose a dynamic grid technique that can be adapted to the skewed location data.
Figure 6 shows the proposed dynamic grid indexing method. In our method, multilevel grid technique is used. Initially, multilevel grid starts with only level 1. Then, when the number of records contained in a grid cell exceeds a given threshold value, we create lower level grids for the cell. As shown in
Figure 6, grid cell 7 in level 1 exceeds a threshold and then level 2 is created for the cell. CellID is calculated by Equation (1). In the figure,
HCVi means the Hilbert Curve value of
ith level.
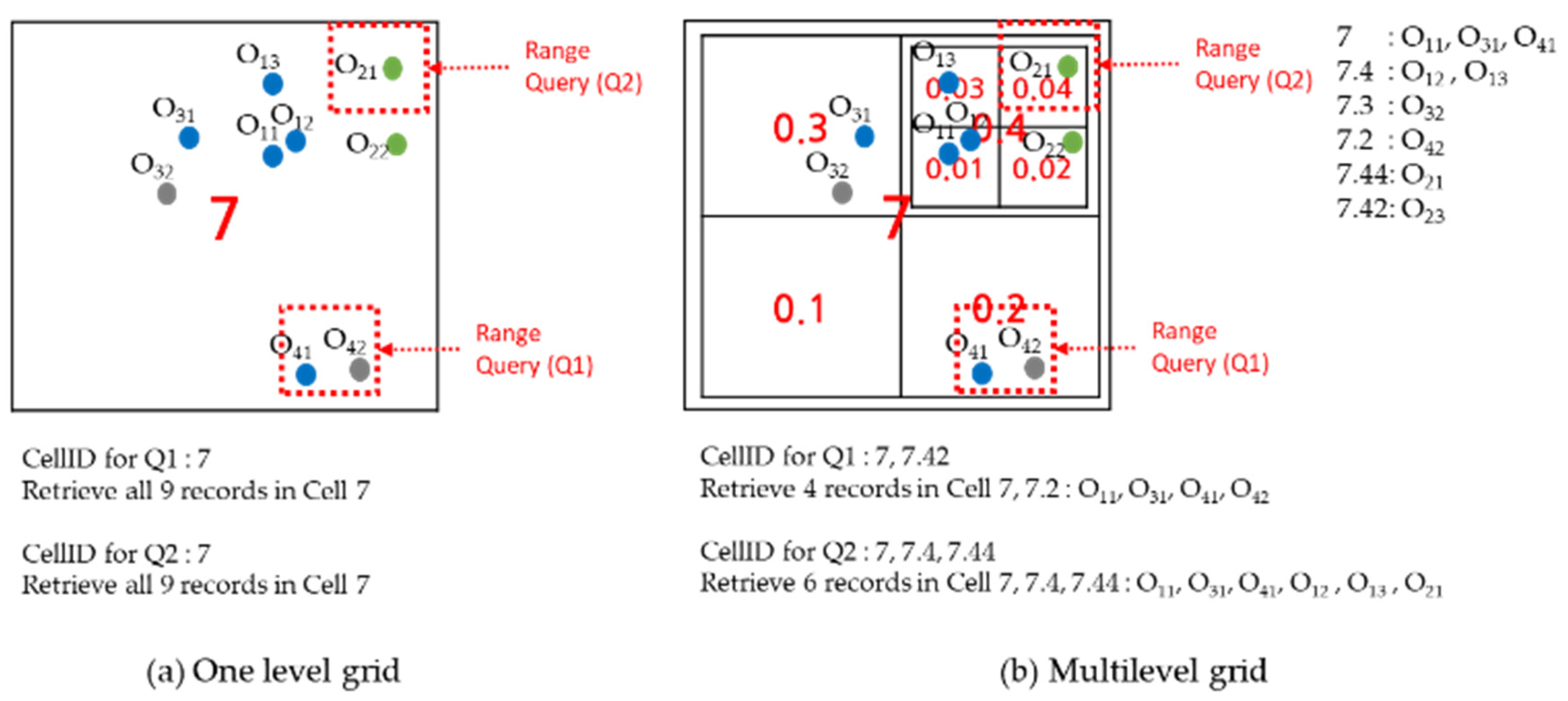
In
Figure 7, there is an example of the proposed indexing method. The threshold value for the number of data records for a cell is 3 in that example. O11, O31, and O41 are inserted sequentially into the area for the grid cell 7. According to the Equation (1), cellIDs of the newly created grid are 7.1, 7.2, 7.3, and 7.4. Then, level 2 grid for the grid cell is created, and after that, O12, O13, O42, and O32 are inserted. In this example, the grid cell 7.4 exceeds the threshold, so the level 3 grid is created for the cell.
In the above example, cellIDs are assigned to the data records like
Table 1. As shown in the table, data records inserted before a new level of grid is created have cellIDs assigned to it. Consequently, all levels of cellIDs must be considered to process a range query. In
Figure 8, we show an example to process range queries.
Figure 8a shows an example of range query processing on one level grid. Range queries Q1 and Q2 overlap the grid cell 7 so to process the queries we need to compare all data records in the cell. In
Figure 8b, range queries are processed on dynamic multilevel grid indexing method. In this example, to process Q1 and Q2, retrieve 4 records and 6 records only, respectively.
4. Performance Evaluation
In this paper, we compare the proposed method with Geomesa in terms of ingestion and range query throughput through experiments. Geomesa is one of the well-known big spatiotemporal data management systems. It is currently maintained and professionally supported by CCRi. The most recent version of Geomesa is 2.3.1 released in July. 2019. We use the Geomesa 2.3.1 version in our experiments for the comparison.
Table 2 shows the experimental environment of this paper. Nine nodes are used for Geomesa and the proposed method, and 8 nodes are used for clients that request queries and data insertion. Client HW(Hardware) specifications are higher than server HW specifications. The reason is to run multiple client processes on each client node to provide enough workload for Geomesa and the proposed method.
We generate a couple of synthetic spatiotemporal data sets from the GPS coordinate area (37.2125, 128.1361111–36.79444444, 127.6611111), as shown in
Figure 9. The first dataset is 100,000,000 spatiotemporal data with a uniform distribution. The second dataset is a 100,000,000 spatiotemporal dataset with a hot spot where 80% of the total data places 20% of the area. We also generate two query sets. Like the data set, the first query set has a uniform distribution of query ranges and the second query set has the same hot spot as that of the second data set. The average number of returned objects of the range queries is about 120. To compare the performance of the proposed method and Geomesa, we measure ingestion and query throughputs with varying the number of nodes.
4.1. Experiments with Uniform Distribution Data Set (Data Set 1)
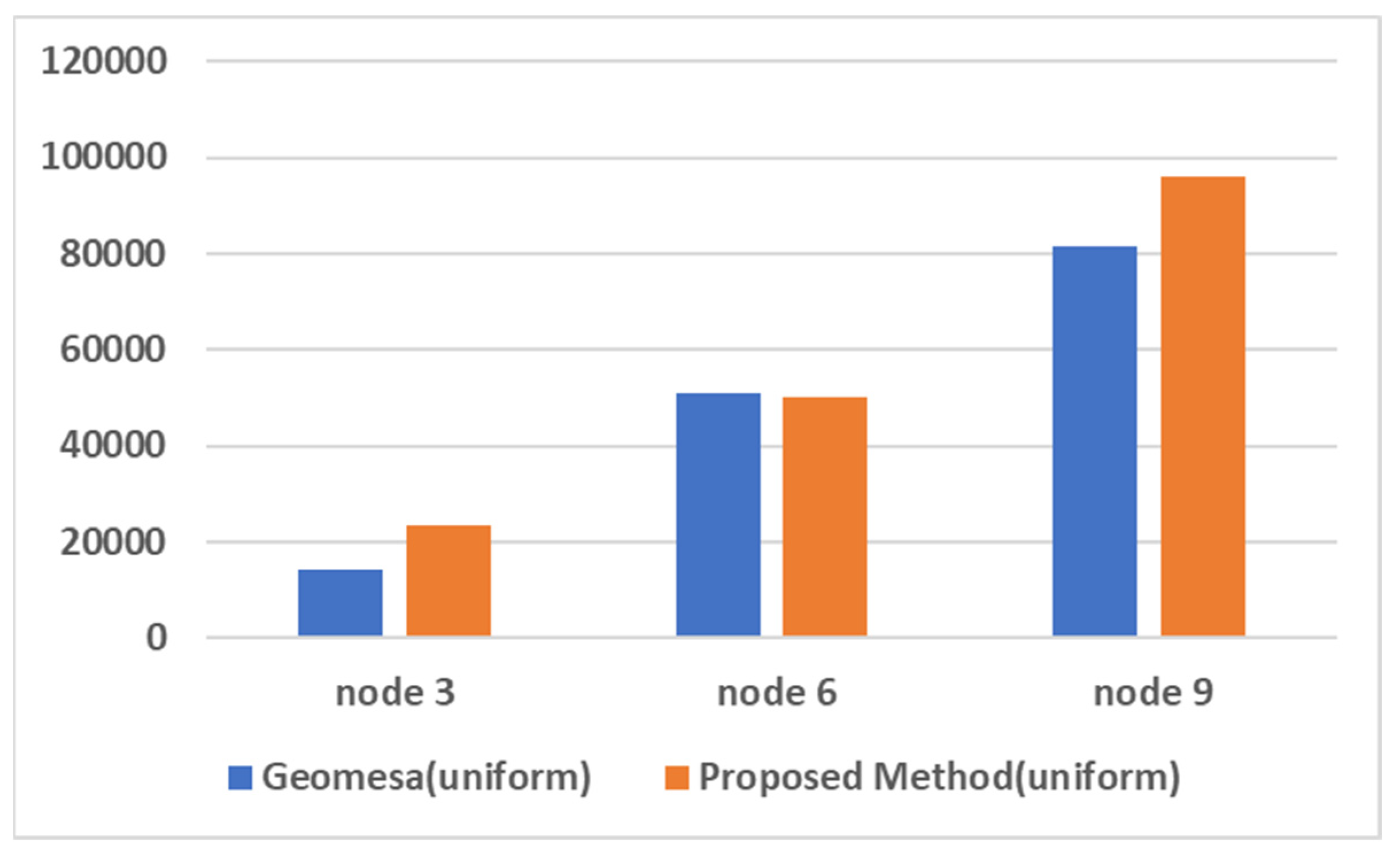
In our first experiments, we execute 40 client processes in 8 client nodes that send 100,000,000 (uniform distribution) insertion workloads to Geomesa and our proposed spatiotemporal data management system with varying the number of server nodes from 3 to 9. While performing experiments, we measure the number of completed insertion operations in each server node and the total execution time.
Figure 10 shows the experimental results, i.e., ingestion throughput of Geomesa and the proposed method as nodes increase. As shown in the figure, the ingestion throughput of our proposed method scales up well as nodes increase while that of Geomesa does not increase well when the number of nodes is greater than 6. Also, the throughput of the proposed method is about 4.5 times higher than that of Geomesa.
In our second experiments, we also execute 40 client processes in 8 client nodes that send 5,000,000 range query (uniform distribution) workloads to both systems with varying number of server nodes from 3 to 9. While performing experiments, we measure the number of completed range queries and their results in each server node and the total execution time. The results of range queries of both systems are used to compare the accuracy of range queries. In
Figure 11, the experimental results are shown. As shown in the figure, the throughput difference between the proposed method and Geomesa is small. When the number of nodes is 6, the range query throughput of both methods are almost the same, and when the number of nodes is 3 and 9, the throughput of the proposed method is about 1.3 times higher. In terms of scalability, the range query throughput of both systems scale up well as node increases.
4.2. Experiments with Hot Spot Data Set (Data Set 2)
We also perform experiments with the hot spot data set (Data Set 2 in
Table 1) and the hot spot query set (Query Set 2 in
Table 1). As described earlier, the second data set has hot spots. The experimental process is the same to that of the experiments using Data Set 1.
Figure 12 shows the experimental results, i.e., ingestion throughput of Geomesa and the proposed method as nodes increase. As shown in the figure, the ingestion throughput of our proposed method scales up well as nodes increase while that of Geomesa does not increase well when the number of nodes is greater than 6. Also, the throughput of the proposed method is about 4.8 times higher than that of Geomesa.
In
Figure 13, the experimental results are shown. As shown in the figure, the range query throughput of the proposed method scales well while that of Geomesa does not. The throughput of the proposed method is about 1.7 times higher than that of Geomesa. Specifically, when the number of nodes is 9, the throughput of the proposed method is about 2.2 times higher.
4.3. Analysis of Experimental Results
GeoMesa may suffers a performance degradation during data ingestion because its indexing method is not pipelined. However, our proposed method inserts asynchronously data records and index records. Our proposed method uses lazy insertion policy for index records and always ensures the data records are inserted ahead their index records. If index records are lost due to some failures, since data records are stored, the lost index records can be recovered.
Also, the proposed dynamic grid indexing method can partition spatiotemporal data evenly across each node to increase the parallelism. Consequently, it can increase the ingestion throughput and range query throughput.
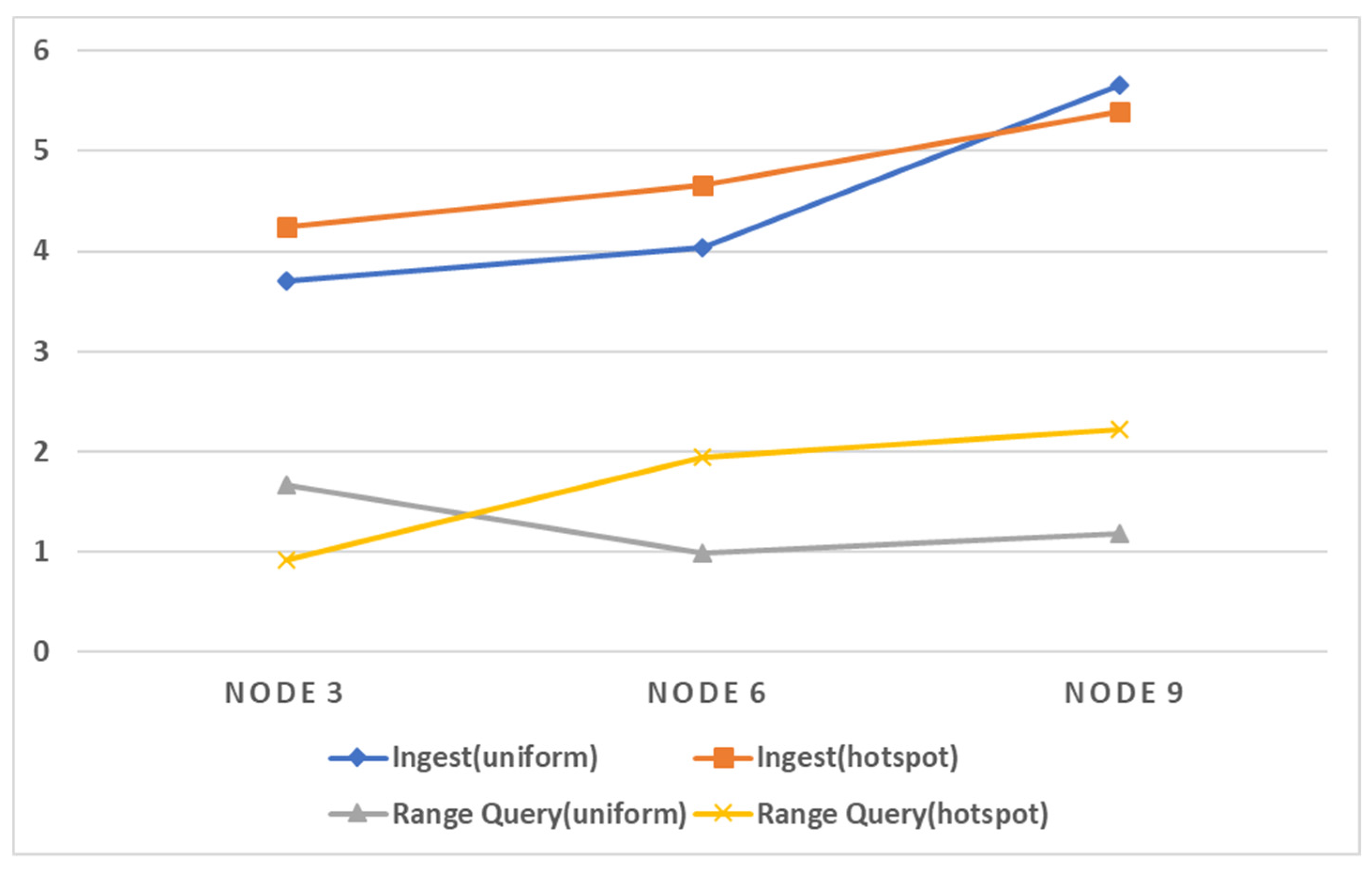
Figure 14 shows the performance improvement rates of the range queries and insert operations of the proposed method compared to Geomesa. As shown in figure, the performance improvement rates are higher in the experiments with hot spot data and queries.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}