Smart System for the Retrieval of Digital Educational Content





Abstract
:1. Introduction
2. Related Work
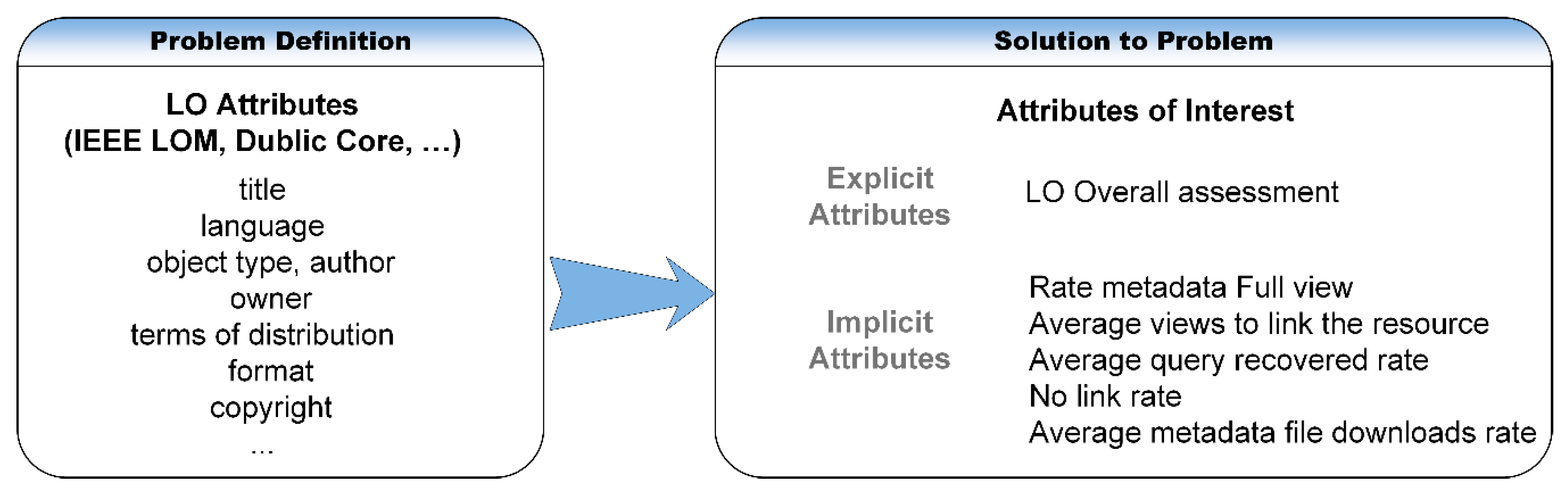
2.1. Standards for the Learning Object Paradigm
- The biggest problem is the LOR’s tight structure, which prevents external management from becoming flexible and powerful. These features are essential if we are to ensure interoperable systems and easy access to dispersed and heterogeneous sources. This tight structure also impedes external users from managing resources. This tight structure also impedes comprehensive user management according to user interests in line with other users in the same context. Furthermore, the LOR’s search interface does not display accurate and reliable LO information because it cannot retrieve data from the Deep Web.
- Another problem is that the internal logic of the majority of LORs is not understandable to the applications that access them. Most of them need some intermediate abstraction layer, such as web services or related technologies. The extraction of LOs is, therefore, a complicated and slow process that sometimes requires the user to intervene manually. The systems that include a middleware layer also encounter problems, such as high response times, unavailable LORs, erroneous results, etc.
- The following group of problems is directly related to the absence of automatic mechanisms that would control the quality of the labels and of the contents, according to technical, semantic and syntactic aspects of the LOs, ensuring the correct specification of these LOs in any of the metadata schemes that describe them. This improvement would provide simple channels for the user to access all possible resources. On many occasions, the same contents may have different metadata, depending on the repository in which the search is performed.
2.2. State of the Art
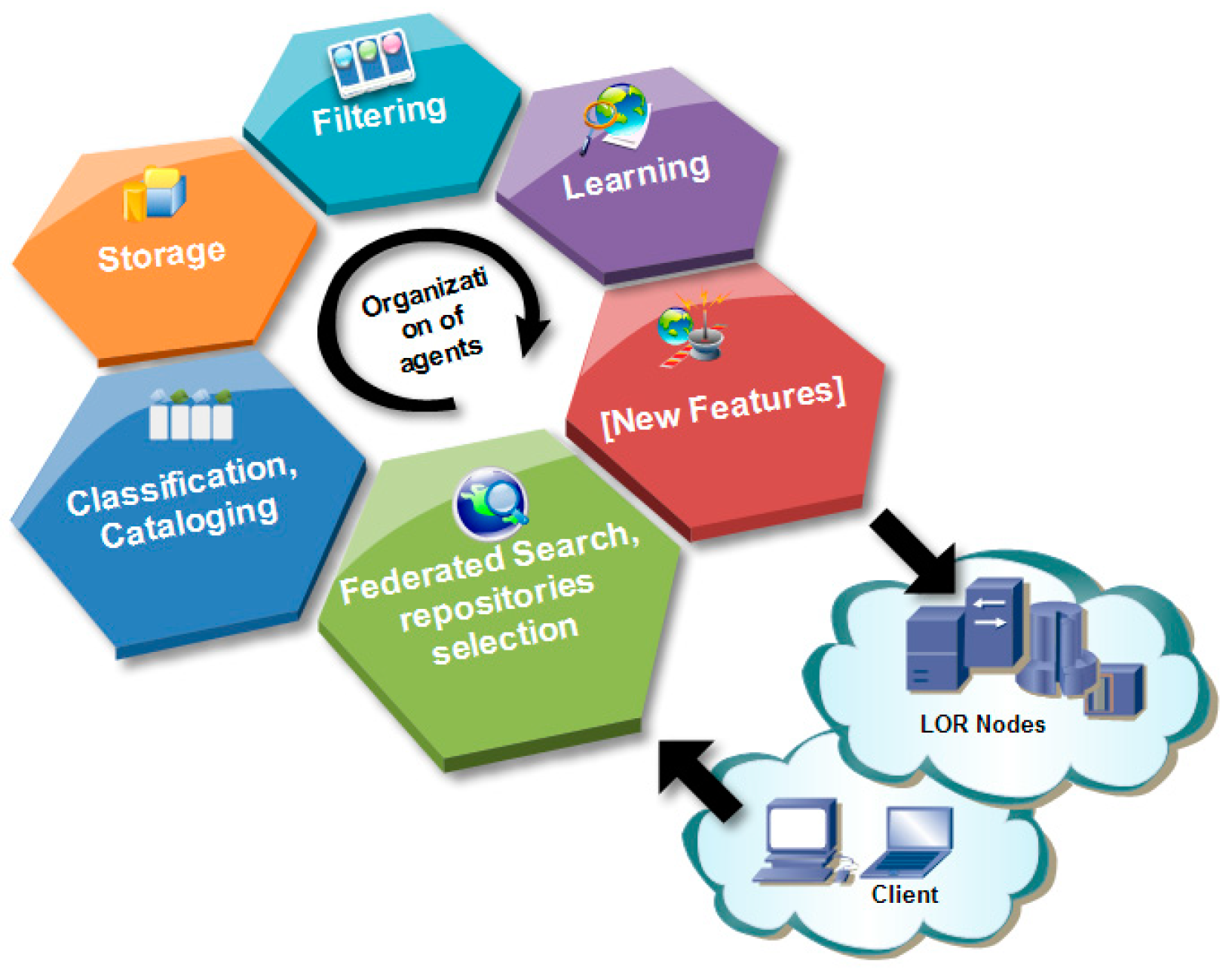
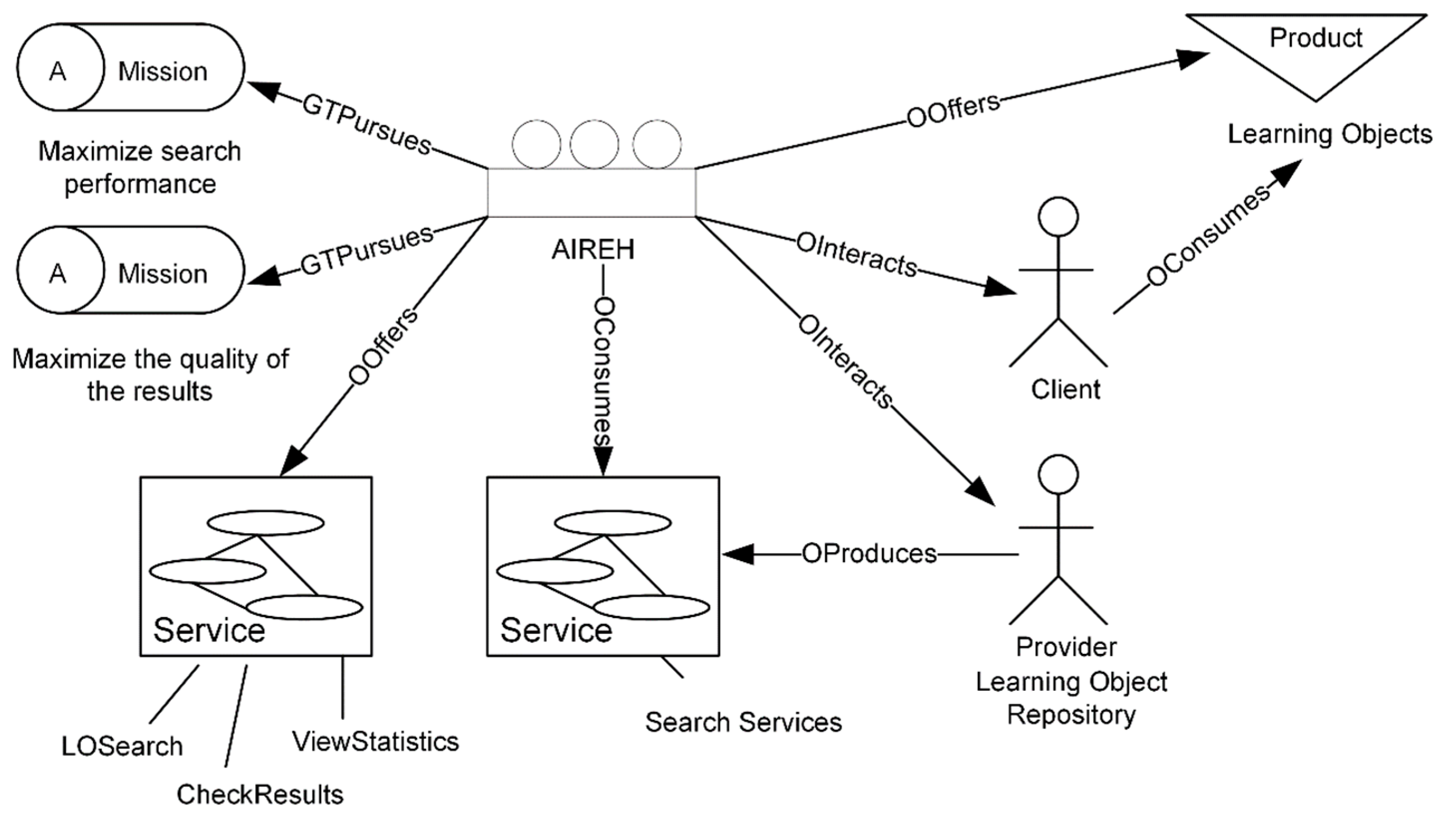
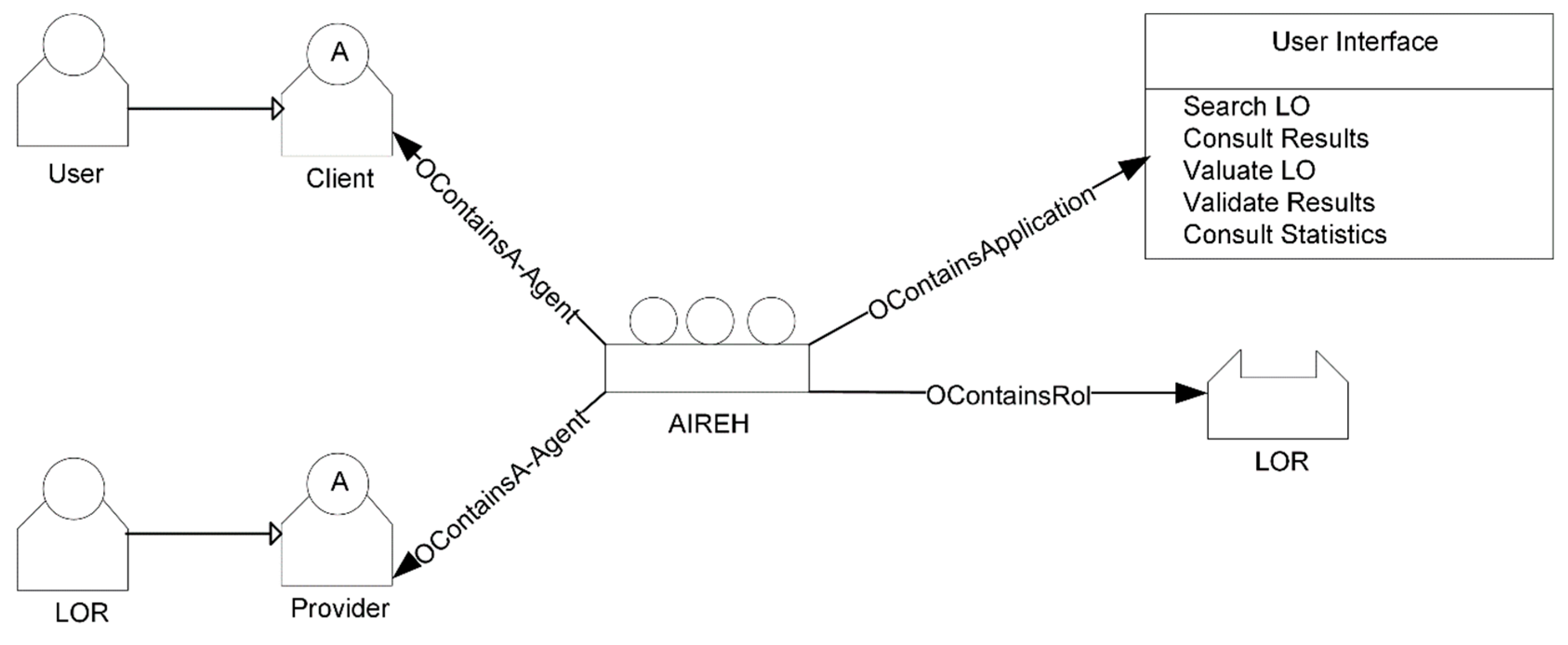
3. Model of the AIREH Architecture
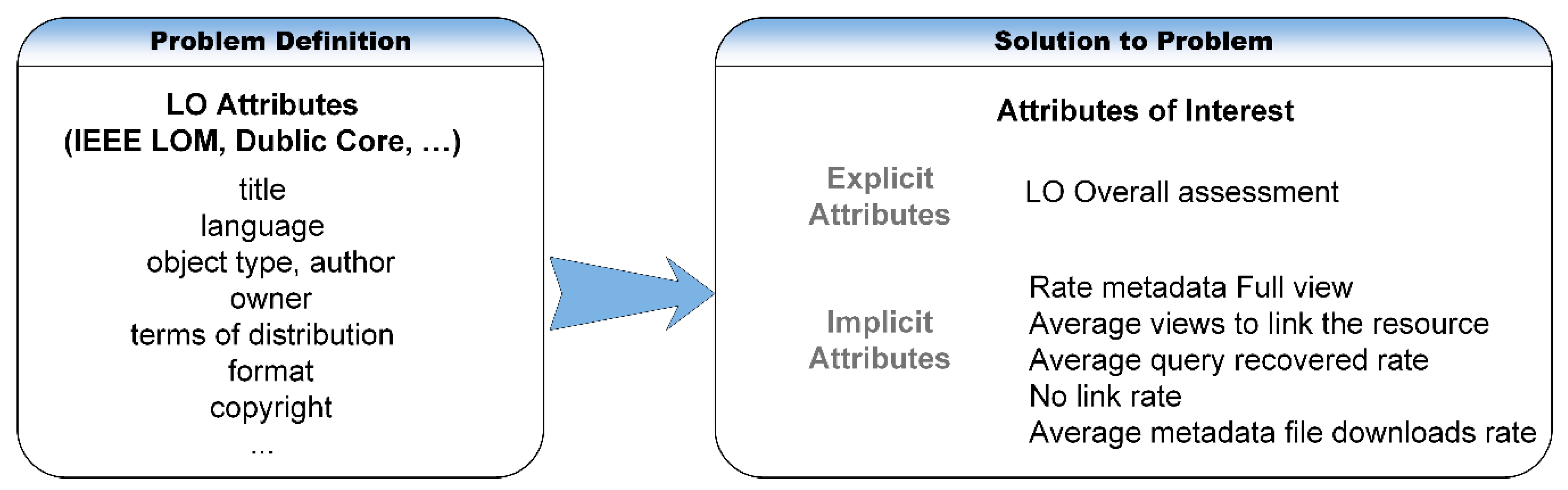
3.1. On the Proposed Solution
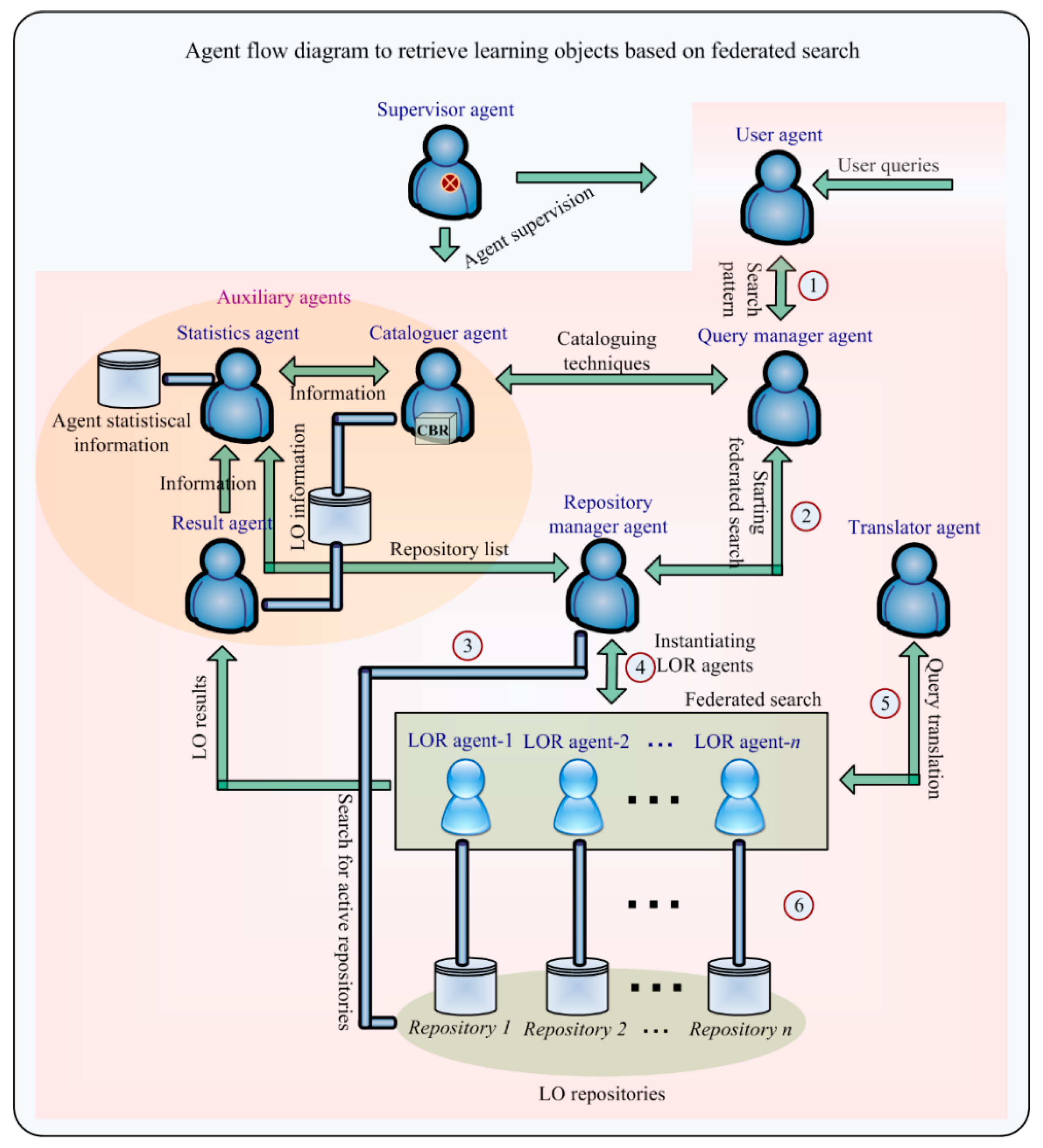
3.2. Description of the Model
- User agent. Defines the user or client in the system. This agent is responsible for launching the federated search process by sending a search request to the Query Manager agent. This agent evaluates the results of the query, in terms of the relevance of the content of the LOs and the order in which they are given. Also, the user agent has access to statistical information about both LORs and LOs.
- Query Manager agent (QMA). This agent is in charge of supervising the entire federated search process. As mentioned previously, a federated search is a simultaneous search for LOs in multiple repositories. The agent receives a natural language query from the user agent and is responsible for completing the query by using propositional logic. It initiates the federated search by querying the Repository Manager agent with respect to the received query. When the Repository Manager agent indicates the end of the federated search, the QMA requests the Cataloguer agent to apply cataloguing techniques and collaborative filtering to the results. Then, the QMA sends the results about the federated query, ordering the items according to the preferences to the user agent for evaluation.
- Repository Manager agent (RMA). The role of this agent involves the control of the queries sent to different LORs, e.g., it has control over the federated search process, quality aspects. This agent receives formalized queries from the QMA. It checks the repositories that are active and requests all statistic data from the Statistics agent, these data are included in a list of high-performing repositories. It instantiates the LOR agents needed to perform the federated search, one for each of the repositories. Once the LOR agents have been instantiated, the RMA sends a query in formalized language to each LOR agent. The QMA notifies the RMA when the federated search is completed. It is responsible for monitoring the proper functioning of LOR agents and prevents yield loss if the repository stops working properly during the query.
- Learning Object Repository agent. Depending on the assigned LOR, there are different types of agents that take on this role. Each single LOR agent is in charge of conducting the query to a single repository. Each agent type implements a different middleware layer; however, this is not a problem as the overall system includes different agents for all possible middleware layers. In a case where a query is sent to a single repository with multiple interfaces, the interface with best performance is chosen. In a federated search there will be many LOR agents. This agent is responsible for requesting individual LOR agents, different instances of this agent will work simultaneously. The agent performs the LOR query, carrying out all the processes defined in the specification of the middleware layer of a given repository. The LOR agent is responsible for sending the LO results received in response to the query, it also sends the Statistics agent the statistical data related to the query.
- Translator agent. This agent is responsible for transforming the user query into the formalized language of the repository to which the query is sent. The agent receives the query in propositional logic from its LOR agent and converts it for the LOR, acting as an intermediary between the LOR and the architecture.
- Results agent. This agent receives all the LOs retrieved from each of the LOR agents during a federated search. It automatically extracts the information from the metadata schema, eliminating the items whose data are not valid. Although in the theoretical proposal there seems to be a single results agent, in the deployed model the same role is taken on by different agents. Each implements a different standardized metadata scheme. They are responsible for the correct reception of the federated search results by extracting useful information from their assigned LOR. This agent, therefore, extracts metadata and data structures from the LORs. Before storing the extracted LOs, it performs filtering that eliminates the defects that would otherwise impede the use of the LO by the users. It executes an algorithm that evaluates the degree of overlap between retrieved LOs, avoiding duplicate LO. It collects relevant statistical data such as memory and response accuracy from the LOR agent and sends them to the statistical agent.
- Cataloguer agent. In coordination with the RMA, this agent is responsible for preparing the ranking of the LOs obtained as a result of the federated searches in the different LORs. After carrying out a pre-filtration, where it eliminates the incomplete LOs, it stores the rest. This agent implements CBR which uses information from previous searches in order to classify the elements that best suit the user’s needs. This CBR incorporates each user’s profile information as well as the type of educational content they are looking for (content-based filtering). Subsequently, it makes use of the user’s votes as well as the suitability of the previous results classification (collaborative filtering). In this way, this agent orders the retrieved LOs according to the user’s preferences, considering their profile and level of education. In order to carry out this process, the Cataloguer agent requests the LO voting histories, previous LO rankings and user feedback from the Statistics agent. With all this information it generates the ranking of the LOs that best adapt to the user who made the query. Like other agents in the organization, it also sends the ranking information to the Statistics agent, who stores it for future recommendations.
- Statistics agent. This agent is responsible for collecting and providing statistical data to other agents in the organization. It provides statistical data to the RMA which creates a list of high-performing repositories, making it possible to optimize the efficiency of the system. It helps the Results agent improve the quality of the results and it sends statistical data to the cataloguer agent which ranks LOs in each federated search. The Statistics agent receives query statistics from the LOR agents. Moreover, it receives the LO evaluation and results in relevance feedback from the User agent.
- Supervisor. This agent maintains overall control of AIREH. It analyzes the structure and syntax of all the messages that enter and leave the system, supervising the correct functioning of the agents within the architecture.
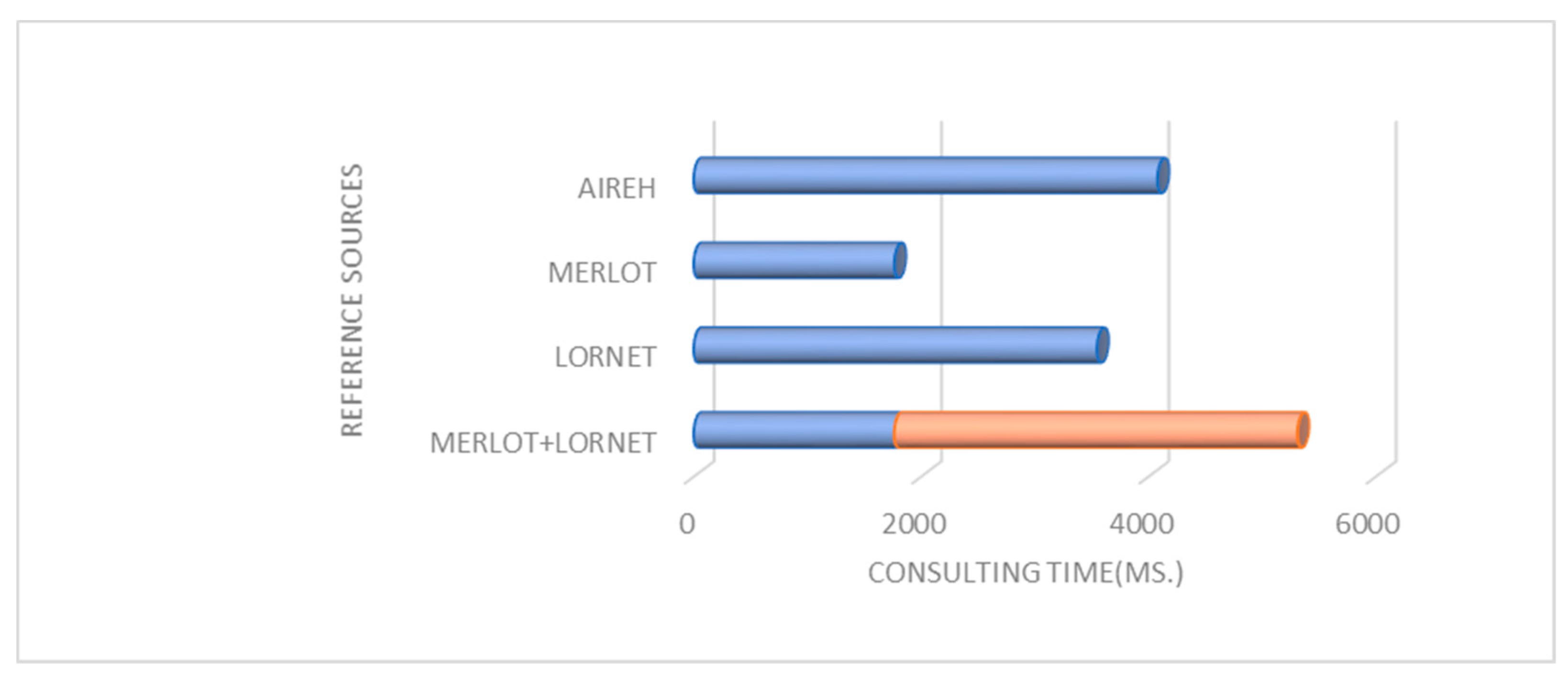
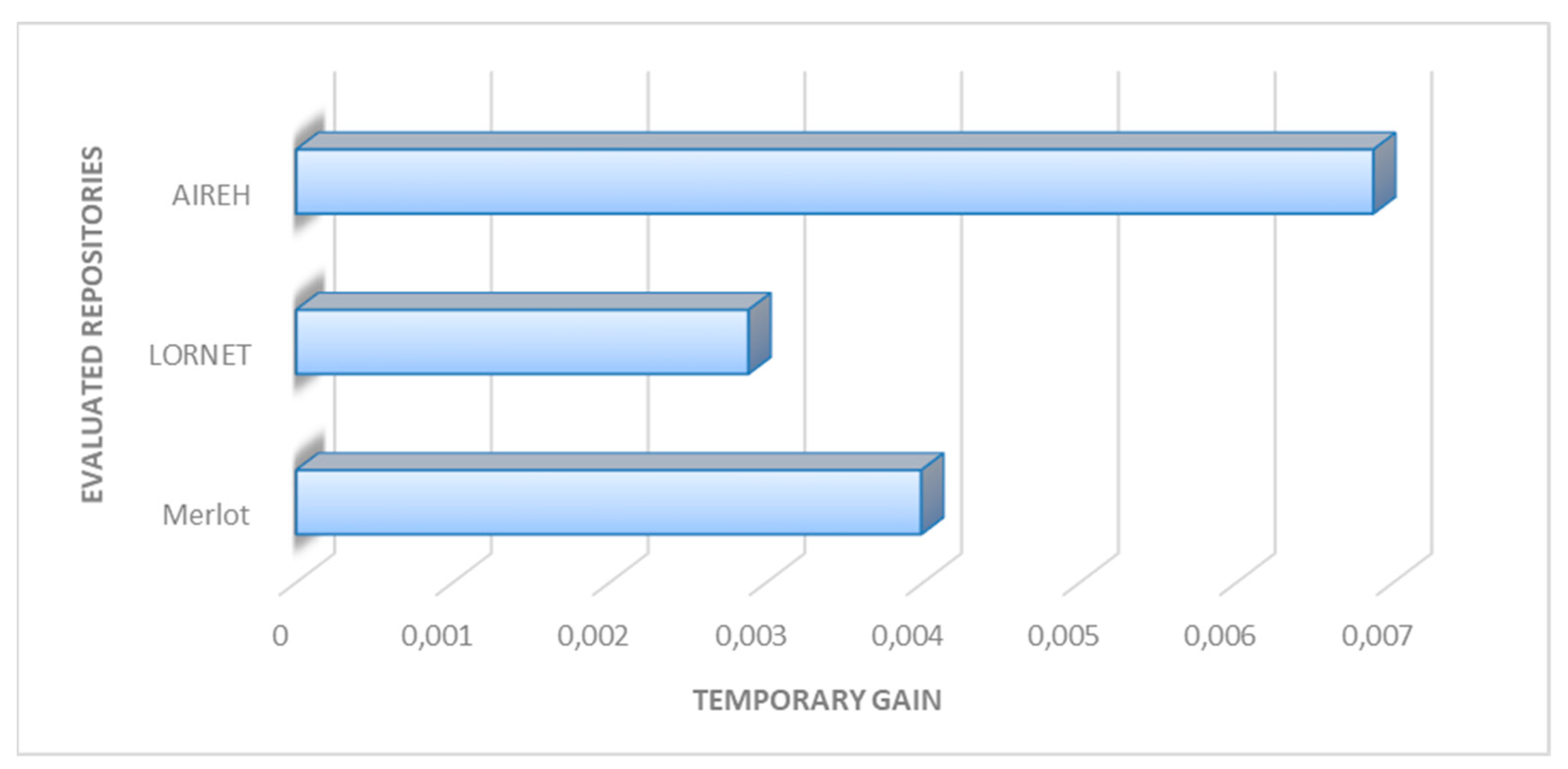
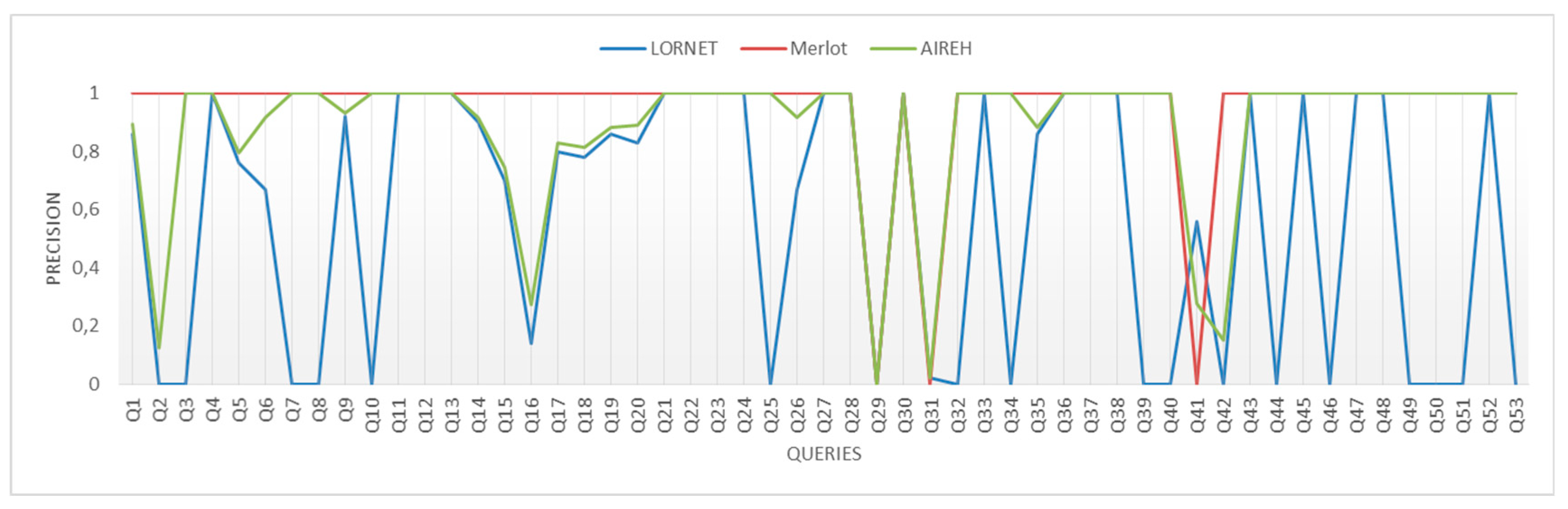
4. Results
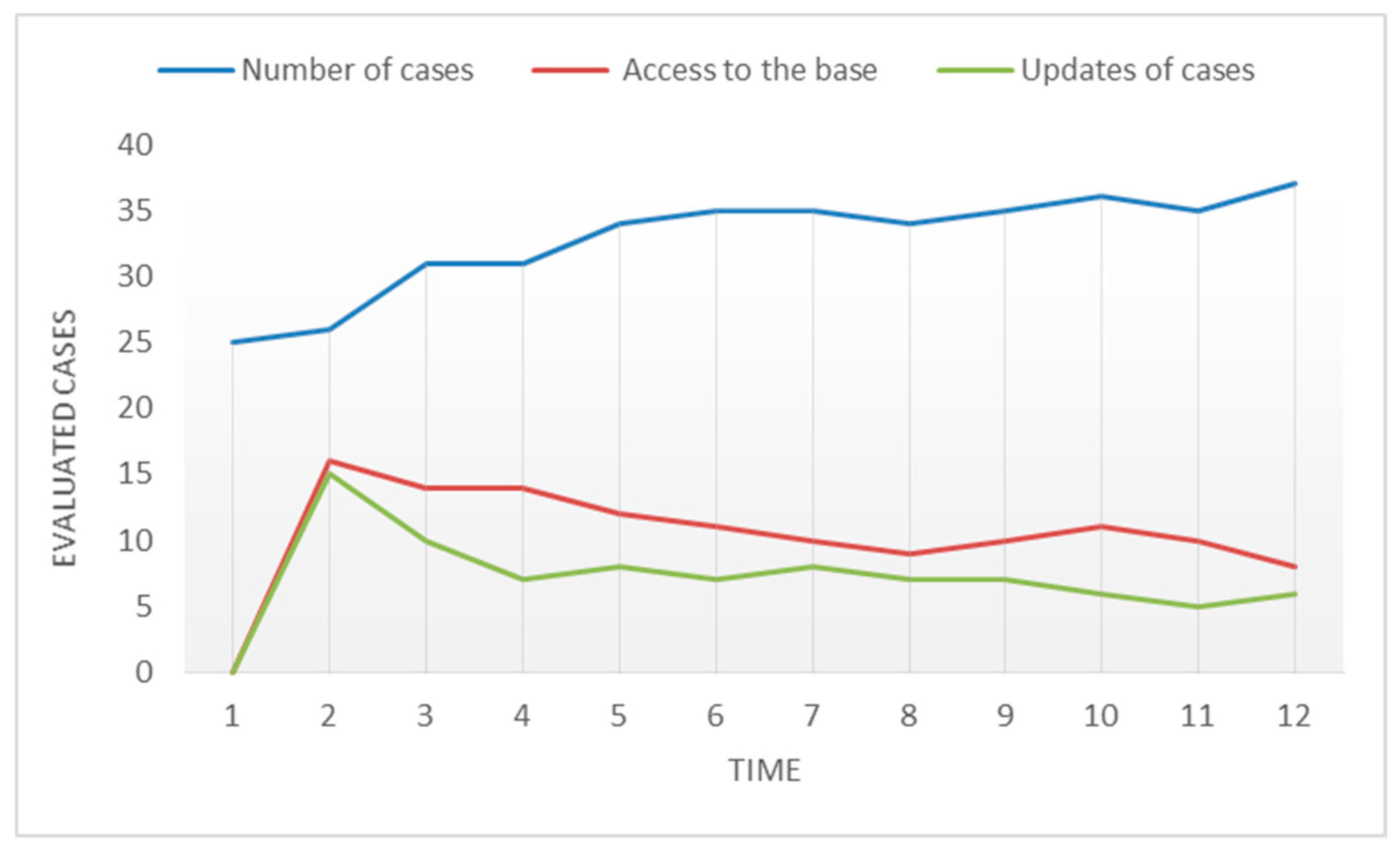
4.1. Experimental Results
- Completeness. The metadata of the LO must give a detailed description of its contents. Compliance with this condition will lead to a more rigorous search process, better reasoning mechanisms and a more accurate recommendation system.
- Reliability. Good quality metadata labelling is essential for the optimized retrieval of content items. The metadata contains LO access information (file, metadata, and educational content) and gives the LOR that stores them a higher degree of trust in the system.
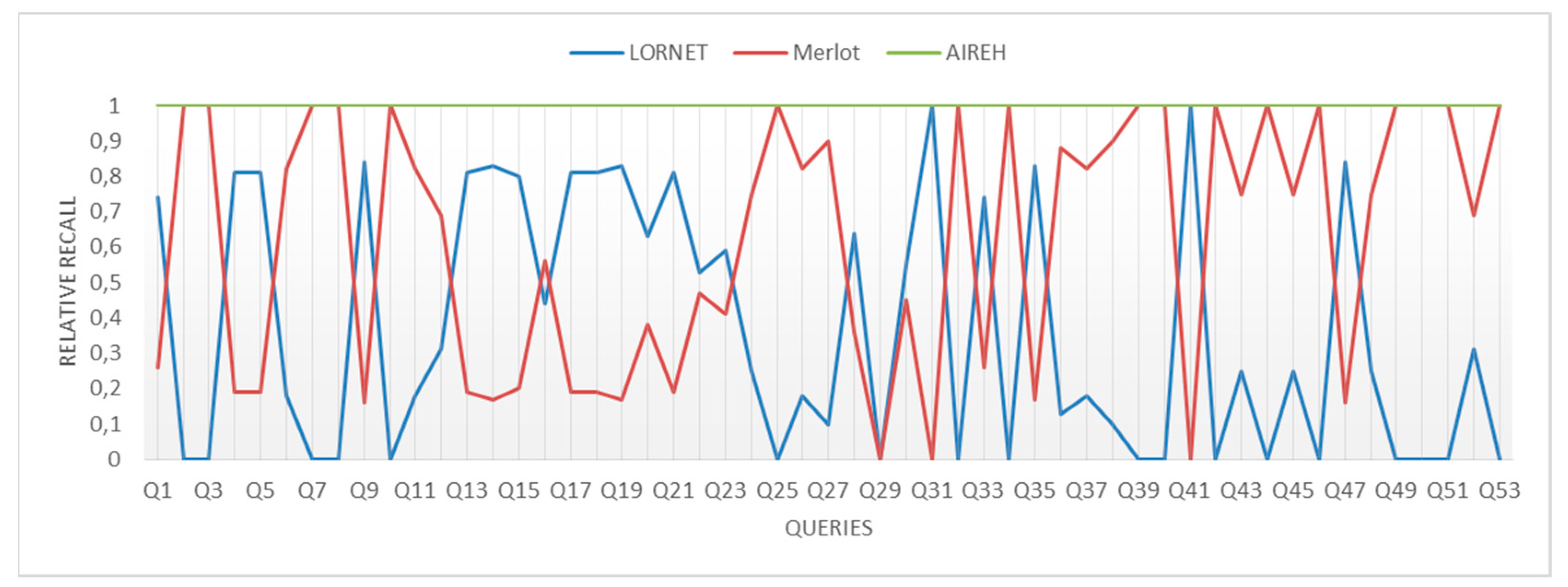
- Accuracy of Results. An answer to a user request may include a large set of LOs. The classification algorithm filters the LOs in this set and sorts them according to their relevance to the user’s request and the educational context of the query. Ordering the LOs according to their relevance is important because it facilitates the user’s choice. Attributes associated with the user domain are important because they enable the CBR recommender system to make personalized content-based recommendations.
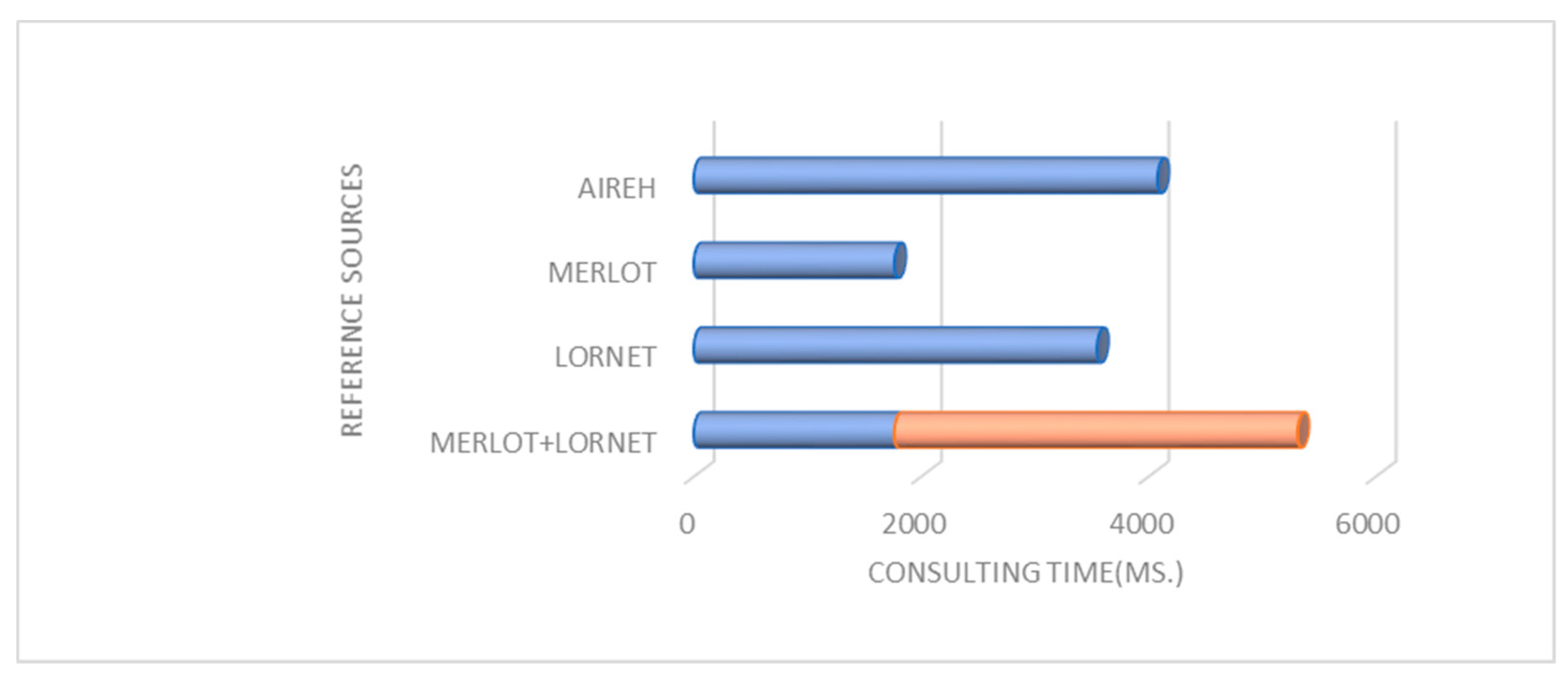
Evaluating the Performance of the Content Retrieval Architecture
- If the LO cannot be recovered because it lacks a label that would indicate the source of the resource (mainly the <location> attribute of the <technical> category of LOM), it is qualified as irrelevant and is attributed a 0.
- In any other case, it is qualified as relevant with value 1.
4.2. Recommendation Strategy
5. Discussion
- Testing and Validation. Much more extensive testing is needed in order to assess the proposed architecture in terms of application and design, calculation of response time, quality of LOs, etc. The results could lead to the development of more refined models and robust systems.
- Resolution of new practical problems. To more thoroughly check the validity of the proposed model, it must be applied to new, practical problems. In this way, it would be possible to check if it can properly resolve different types of problems, or if the model is limited to the specific problems that have been studied in this work.
- Integration of semantic aspects in retrieving and cataloguing content. Even when educational resources are labeled according to a metadata standard, they are mainly descriptive and do not provide semantic information. The search results would benefit greatly from the inclusion of semantic search processes and from LO processing based on knowledge models such as domain ontologies. This would increase the functionality of the proposal because not only would quantitative aspects be taken into account but also the semantic features of the query. The search results would be filtered according to the semantic meaning of the content in the learning objects.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Begosso, L.C.; Begosso, L.R.; Ribeiro, A.; dos Santos, R.M.; Begosso, R.H. The Use of Learning Objects for Teaching Computer Programming. In Proceedings of the 2015 IEEE Frontiers in Education Conference (FIE), El Paso, TX, USA, 21–24 October 2015; pp. 1–6. [Google Scholar]
- Wiley, D.A. Connecting Learning Objects to Instructional Design Theory: A Definition, a Metaphor, and a taxonomy. Instr. Use Learn. Objects 2000, 2830, 1–35. [Google Scholar]
- Silveira, I.F.; Omar, N.; Mustaro, P. Architecture of Learning objects Repositories; Learning Objects: Standards, Metadata, Repositories and LCMS; Informing Science Institute: Santa Rosa, CA, USA, 2007; Volume 1, pp. 131–156. [Google Scholar]
- Lagoze, C. The Making of the Open Archives Initiative Protocol for Metadata Harvesting. Library Hi Tech. 2003, 21, 118–128. [Google Scholar] [CrossRef]
- IEEE. IEEE Recommended Practice for Learning Technology—Open Archives Initiative Object Reuse and Exchange Abstract Model (OAI-ORE)—Mapping to the Conceptual Model for Resource Aggregation; IEEE Std 1484.13.6-2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–32. [Google Scholar] [CrossRef]
- Weibel, S.L.; Koch, T. The Dublin Core Metadata Initiative. D Lib Mag. 2000, 6, 1082–9873. [Google Scholar] [CrossRef]
- IEEE. IEEE Standard for Learning Object Metadata; IEEE Std 1484.12.1-2002; IEEE: Piscataway, NJ, USA, 2002; pp. 1–40. [Google Scholar] [CrossRef]
- Open Education Consortium. 2019. Available online: http://www.oeconsortium.org/ (accessed on 14 October 2019).
- Spanish Ministry of Education. Application Profile of the LOM Metadata Scheme for the Spanish Educational Community (LOM-ES). 2010. Available online: http://educalab.es/documents/10180/40863/1LOM-ES.pdf/67a11fe2-edc0-487f-b6d5-6a87dc258668 (accessed on 14 October 2019).
- Vicari, R.M.; Ribeiro, A.; da Silva, J.M.C.; Santos, E.R.; Primo, T.; Bez, M. Brazilian Proposal for Agent-Based Learning Objects Metadata Standard—OBAA; Springer: Berlin/Heidelberg, Germany, 2010; pp. 300–311. [Google Scholar]
- Cechinel, C. Scientific Collaboration between Countries in Laclo from a Social Network Analysis Perspective; Conferencias LACLO: Valdivia, Chile, 2013; Volume 4. [Google Scholar]
- Dublin Core Metadata Initiative. LRMI Metadata. 2015. Available online: https://www.dublincore.org/specifications/lrmi/lrmi_terms/ (accessed on 14 October 2019).
- Kolodner, J. Case-Based Reasoning; Morgan Kaufmann: Burlington, MA, USA, 2014. [Google Scholar]
- Ramchurn, S.D.; Huynh, D.; Jennings, N.R. Trust in Multi-Agent Systems. Knowl. Eng. Rev. 2004, 19, 1–25. [Google Scholar] [CrossRef]
- Knapp, M.; Risha, Z.; Gatewood, R.; Van Der Volgen, J.; Brown, R.; Kizilboga, R. Learning to Love the LOR: Implementing an Internal Learning Object Repository at a Large National Organization; Medical Reference Services Quarterly: Philadelphia, PA, USA, 2019; Volume 38, pp. 143–155. [Google Scholar] [CrossRef]
- Franzoni, V.; Tasso, S.; Pallottelli, S.; Perri, D. Sharing Linkable Learning Objects with the Use of Metadata and a Taxonomy Assistant for Categorization; Springer: Cham, UK, 2019; pp. 336–348. [Google Scholar]
- Sucunuta, M.; Riofrio, G.; Tovar, E. Information Retrieval Model for Open Educational Resources. In Proceedings of the 2019 IEEE Global Engineering Education Conference (EDUCON), Porto, Portugal, 8–11 April 2019; pp. 1255–1261. [Google Scholar]
- Callan, J. Distributed Information Retrieval. In Advances in Information Retrieval: Recent Research from the Center for Intelligent Information Retrieval; Croft, W.B., Ed.; Springer US: Boston, MA, USA, 2000; pp. 127–150. [Google Scholar]
- Verbert, K.; Hoebelheinrich, N.J.; Blinco, K.; Lewis, S.; Kraan, W. RAMLET: A conceptual model for resource aggregation for learning, education, and training. D Lib Mag. 2016, 22, 1–11. [Google Scholar] [CrossRef]
- Verbert, K.; Duval, E. Towards a global architecture for learning objects: A comparative analysis of learning object content models. In Proceedings of the 2004 EdMedia+ Innovate Learning; LearnTechLib: Waynesville, NC, USA, 2004; pp. 202–208. [Google Scholar]
- Frantiska, J., Jr. Creating Reusable Learning Objects; Springer International Publishing: New York, NY, USA, 2016; Available online: https://www.springer.com/gp/book/9783319328881 (accessed on 14 October 2019).
- Guevara, C.; Aguilar, J.; González-Eras, A. The model of adaptive learning objects for virtual environments instanced by the competences. Adv. Sci. Technol. Eng. Syst. J. 2017, 2, 345–355. [Google Scholar] [CrossRef]
- Gil, A.; de la Prieta, F.; Rodríguez, S.; Martín, B. Educational content retrieval based on semantic Web services. In Proceedings of the 2011 7th International Conference on Next Generation Web Services Practices, Salamanca, Spain, 19–21 October 2011; pp. 135–140. [Google Scholar]
- Melara Abarca, R.; Perez-Martinez, C.; Gelbukh, A.; López Morteo, G.; Martinez Reyes, M.; Pérez López, M. Wikification of Learning Objects Using Metadata as an Alternative Context for Disambiguation. Computación y Sistemas 2014, 18, 755–765. [Google Scholar]
- Simon, B. A Simple Query Interface Specification for Learning Repositories; CEN Workshop Agreement: Chiba, Japan, 2005. [Google Scholar]
- Simon, B.; Massart, D.; Van Assche, F.; Ternier, S.; Duval, E.; Brantner, S.; Miklós, Z. A Simple Query Interface for Interoperable Learning Repositories. In Proceedings of the WWW* 05 Workshop on Interoperability of Web-Based Educational Systems, Chiba, Japan, 10–14 May 2015; pp. 11–18. [Google Scholar]
- De Santiago, R.; Raabe, A. Architecture for Learning Objects Sharing among Learning Institutions—LOP2P. IEEE Trans. Learn. Technol. 2010, 3, 91–95. [Google Scholar] [CrossRef]
- Deora, B.S.; Sarangdevot, S.S. E-Learning Standards and their Necessity. Int. J. Adv. Res. Comput. Sci. 2011, 2, 500–504. [Google Scholar]
- IEEE Standards Association. ECMAScript Application Programming Interface for Content to Runtime Services Communication; IEEE Standards Association: Piscataway, NJ, USA, 2019; Available online: https://standards.ieee.org/project/1484_11_2.html (accessed on 14 October 2019).
- Bates, T. Questioning the value of re-usable learning objects in education: The need for a business case. In Proceedings of the II Simposio Pluridisciplinar sobre Diseño, Evaluación y Descripción de Contenidos Educativos Reutilizables, Barcelona, Spain, 19–21 Otober 2005. [Google Scholar]
- Casquero, O.; Portillo, J.; Benito, M.; Romo, J. BILDU: Compile, unify, wrap, and share digital learning resources. Interdiscip. J. E Learn. Learn. Objects 2008, 4, 97–111. [Google Scholar] [CrossRef]
- Qu, C.; Nejdl, W. Interacting the Edutella/JXTA peer-to-peer network with web services. In Proceedings of the 2004 International Symposium on Applications and the Internet, Tokyo, Japan, 26–30 January 2004; pp. 67–73. [Google Scholar]
- Kärger, P.; Ullrich, C.; Melis, E. Integrating Learning Object Repositories Using a Mediator Architecture; Springer: Berlin/Heidelberg, Germany, 2006; pp. 185–197. [Google Scholar]
- Yen, N.Y.; Shih, T.K.; Jin, Q. A new paradigm of ranking & searching in learning object repository. In Proceedings of the Second ACM International Workshop on Multimedia Technologies for Distance Leaning, Firenze, Italy, 25–29 October 2010; pp. 1–6. [Google Scholar]
- Lee, M.C.; Tsai, K.H.; Wang, T.I. A practical ontology query expansion algorithm for semantic-aware learning objects retrieval. Comput. Educ. 2008, 50, 1240–1257. [Google Scholar] [CrossRef]
- Alejandra Segura, N.; Salvador, S.; García-Barriocanal, E.; Prieto, M. An empirical analysis of ontology-based query expansion for learning resource searches using MERLOT and the Gene ontology. Knowl. Based Syst. 2011, 24, 119–133. [Google Scholar] [CrossRef]
- Shih, T.K.; Chang, C.C.; Lin, H.W. Reusability on Learning Object Repository; Springer: Berlin/Heidelberg, Germany, 2006; pp. 203–214. [Google Scholar]
- Barak, M.; Ziv, S. Wandering: A Web-based platform for the creation of location-based interactive learning objects. Comput. Educ. 2013, 62, 159–170. [Google Scholar] [CrossRef]
- Fernández Diego, M.; Gordo Monzó, M.L.; Boza García, A.; Cuenca, L.; Ruiz Font, L.; Alemany Díaz, M.D.M.; Alarcón Valero, F. Metadata, repository and methodology in learning objects. In Proceedings of the EDULEARN15: 7th International Conference on Education and New Learning Technologies, Barcelona, Spain, 6–8 July 2015; pp. 4755–4761. [Google Scholar]
- González Ruiz, L.M.; Hermida Carbonell, J.M.; Montoyo, A. Towards a New Proposal to Evaluate the Learning Objects Quality in Learning Strategies for Education (QEES). June 2012. Available online: http://hdl.handle.net/10045/35627 (accessed on 14 October 2019).
- Fuentes, M.D.L.M.; Arteaga, J.M.; Rodríguez, F.Á.; Vanderdonkt, J.; Orey, M. MIRROS: Intermediary model to recovery learning objects. Computación y Sistemas 2010, 13, 373–384. [Google Scholar]
- Carrion, J.S.; Gordo, E.G.; Sanchez-Alonso, S. Semantic learning object repositories. Int. J. Contin. Eng. Educ. Life Long Learn. 2007, 17, 432. [Google Scholar] [CrossRef]
- Manouselis, N.; Vuorikari, R.; Van Assche, F. Collaborative recommendation of e-learning resources: An experimental investigation. J. Comput. Assist. Learn. 2010, 26, 227–242. [Google Scholar] [CrossRef]
- Martins, E. Learning objects and training complex machines. Work 2012, 41, 184–187. [Google Scholar] [Green Version]
- Bobadilla, J.; Serradilla, F.; Hernando, A. Collaborative filtering adapted to recommender systems of e-learning. Knowl. Based Syst. 2009, 22, 261–265. [Google Scholar] [CrossRef]
- Khribi, M.K.; Jemni, M.; Nasraoui, O. Automatic personalization in e-learning based on recommendation systems: An overview. In Intelligent and Adaptive Learning Systems: Technology Enhanced Support for Learners and Teachers; IGI Global: Hershey, PA, USA, 2012; pp. 19–33. [Google Scholar]
- Recker, M.M.; Walker, A.; Lawless, K. What do you recommend? Implementation and analyses of collaborative information filtering of web resources for education. Instr. Sci. 2003, 31, 299–316. [Google Scholar] [CrossRef]
- Lemire, D. Collaborative filtering and inference rules for context-aware learning object recommendation. Interact. Technol. Smart Educ. 2005, 2, 179–188. [Google Scholar] [CrossRef]
- McCalla, G. The ecological approach to the design of e-learning environments: Purpose-based capture and use of information about learners. J. Interact. Media Educ. 2004, Art. 3. [Google Scholar] [CrossRef]
- Dong, A.; Wang, B. Domain-Based Recommendation and Retrieval of Relevant Materials in E-learning. In Proceedings of the 2008 IEEE International Workshop on Semantic Computing and Applications, Santa Clara, CA, USA, 10–11 July 2008; pp. 103–108. [Google Scholar]
- Ghauth, K.I.; Abdullah, N.A. Learning materials recommendation using good learners’ ratings and content-based filtering. Educ. Technol. Res. Dev. 2010, 58, 711–727. [Google Scholar] [CrossRef]
- Yang, Y.J.; Wu, C. An attribute-based ant colony system for adaptive learning object recommendation. Expert Syst. Appl. 2009, 36, 3034–3047. [Google Scholar] [CrossRef]
- Wan, S.; Niu, Z. An e-learning recommendation approach based on the self-organization of learning resource. Knowl. Based Syst. 2018, 160, 71–87. [Google Scholar] [CrossRef]
- Imran, H.; Belghis-Zadeh, M.; Chang, T.W.; Graf, S. PLORS: A personalized learning object recommender system. Vietnam J. Comput. Sci. 2016, 3, 3–13. [Google Scholar] [CrossRef]
- Kerkiri, T.; Manitsaris, A.; Mavridou, A. Reputation Metadata for Recommending Personalized e-Learning Resources. In Proceedings of the Second International Workshop on Semantic Media Adaptation and Personalization (SMAP 2007), London, UK, 17–18 December 2007; pp. 110–115. [Google Scholar]
- Wolpers, M.; Najjar, J.; Verbert, K.; Duval, E. Tracking actual usage: The attention metadata approach. Educ. Technol. Soc. 2007, 10, 106–121. [Google Scholar]
- Klašnja-Milićević, A.; Ivanović, M.; Nanopoulos, A. Recommender systems in e-learning environments: A survey of the state-of-the-art and possible extensions. Artif. Intell. Rev. 2015, 44, 571–604. [Google Scholar] [CrossRef]
- Wooldridge, M. Intelligent agents. Multiagent Syst. 1999, 35, 51. [Google Scholar]
- Zambonelli, F.; Jennings, N.R.; Wooldridge, M. Developing multiagent systems: The Gaia methodology. ACM Trans. Softw. Eng. Methodol. 2003, 12, 317–370. [Google Scholar] [CrossRef]
- Dignum, M.V. A Model for Organizational Interaction: Based on Agents, Founded in Logic; SIKS: Amsterdam, The Nederlands, 2004. [Google Scholar]
- Dignum, V. The role of organization in agent systems. In Handbook of Research on Multi-Agent Systems: Semantics and Dynamics of Organizational Models; IGI Global: Hershey, PA, USA, 2009; pp. 1–16. [Google Scholar]
- Argente, E.; Botti, V.; Julian, V. Organizational-Oriented Methodological Guidelines for Designing Virtual Organizations; Springer: Berlin/Heidelberg, Germany, 2009; pp. 154–162. [Google Scholar]
- Giret, A.; Julián, V.; Rebollo, M.; Argente, E.; Carrascosa, C.; Botti, V. An Open Architecture for Service-Oriented Virtual Organizations; Springer: Berlin/Heidelberg, Germany, 2009; pp. 118–132. [Google Scholar]
- Argente, E.; Botti, V.; Carrascosa, C.; Giret, A.; Julian, V.; Rebollo, M. An abstract architecture for virtual organizations: The THOMAS approach. Knowl. Inf. Syst. 2011, 29, 379–403. [Google Scholar] [CrossRef]
- Schell, G.P.; Burns, M. Merlot: A repository of e-learning objects for higher education. E Serv. 2002, 1, 53–64. [Google Scholar]
- Saliah-Hassane, H.; Kourri, A.; la Teja, I.D. Building a Repository for Online Laboratory Learning Scenarios. In Proceedings of the 36th Annual Conference Frontiers in Education, San Jose, CA, USA, 27–31 October 2006; pp. 19–22. [Google Scholar]
- Hawking, D.; Craswell, N.; Bailey, P.; Griffihs, K. Measuring Search Engine Quality. Inf. Retr. 2001, 4, 33–59. [Google Scholar] [CrossRef]
- Norris, M.; Oppenheim, C.; Rowland, F. Finding open access articles using Google, Google Scholar, OAIster and OpenDOAR. Online Inf. Rev. 2008, 32, 709–715. [Google Scholar] [CrossRef] [Green Version]
- Gil, A.; Rodríguez, S.; de la Prieta, F.; Martín, B.; Moreno, M. Intelligent Recovery Architecture for Personalized Educational Content; Springer: Berlin/Heidelberg, Germany, 2012; pp. 85–93. [Google Scholar]
- Gil, A.; Rodríguez, S.; De la Prieta, F.; De Paz, J.F.; Martín, B. CBR Proposal for Personalizing Educational Content; Springer: Berlin/Heidelberg, Germany, 2012; pp. 115–123. [Google Scholar]
- Duval, E.; Forte, E.; Cardinaels, K.; Verhoeven, B.; Van Durm, R.; Hendrikx, K.; Haenni, F. The Ariadne knowledge pool system. Commun. ACM 2001, 44, 72–78. [Google Scholar] [CrossRef]
- Lundgren-Cayrol, K.; Ruelland, D.; Habel, G.; Magnan, F. Modeling for Tools and Environments Specification. In Visual Knowledge Modeling for Semantic Web Technologies: Models and Ontologies; IGI Global: Hershey, PA, USA, 2010; pp. 414–438. [Google Scholar]
- Paquette, G.; Léonard, M.; Lundgren-Cayrol, K.; Mihaila, S.; Gareau, D. Learning design based on graphical knowledge-modelling. J. Educ. Technol. Soc. 2006, 9, 97–112. [Google Scholar]
- Gil, A.B.; Rodríguez, S.; De la Prieta, F.; Corchado, J.M. Learning object retrieval in heterogeneous environments. Int. J. Web Eng. Technol. 2013, 8, 197–213. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case Field | Element Type |
|---|---|
| USER | User Profile |
| QUERY | Initial User Query |
| PREF | User Preferences |
| STIME | Time Stamp |
| Features/Tools | Paloma | Globe | AIREH |
|---|---|---|---|
| Access to distributed repositories | Yes | Yes (just what makes up the Alliance) Currently only ARIADNE (in beta) | Yes |
| Inclusion of different query languages | NO | NO | Yes |
| Personalization | NO | NO | Yes |
| Incorporation of social aspects | NO | NO | Yes |
| Metadata access by the user | Yes | NO | Yes |
| Tracing historical storage | NO | NO | Yes |
| Search with Language criteria | NO | Not Implemented | Yes |
| Different standards of tagged languages | No, only LOM | Yes | Yes |
| Web Client | Yes | Yes | Yes |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gil, A.B.; de la Prieta, F.; Rodríguez, S.; Corchado, J.M. Smart System for the Retrieval of Digital Educational Content. Appl. Sci. 2019, 9, 4400. https://doi.org/10.3390/app9204400
Gil AB, de la Prieta F, Rodríguez S, Corchado JM. Smart System for the Retrieval of Digital Educational Content. Applied Sciences. 2019; 9(20):4400. https://doi.org/10.3390/app9204400
Chicago/Turabian StyleGil, Ana B., Fernando de la Prieta, Sara Rodríguez, and Juan M. Corchado. 2019. "Smart System for the Retrieval of Digital Educational Content" Applied Sciences 9, no. 20: 4400. https://doi.org/10.3390/app9204400
APA StyleGil, A. B., de la Prieta, F., Rodríguez, S., & Corchado, J. M. (2019). Smart System for the Retrieval of Digital Educational Content. Applied Sciences, 9(20), 4400. https://doi.org/10.3390/app9204400