Improving Hybrid CTC/Attention Architecture with Time-Restricted Self-Attention CTC for End-to-End Speech Recognition


Abstract
:1. Introduction
2. End-to-End Speech Recognition
2.1. Connectionist Temporal Classification (CTC)
2.2. Attention-Based Encoder–Decoder
2.3. Hybrid CTC/Attention Encoder–Decoder
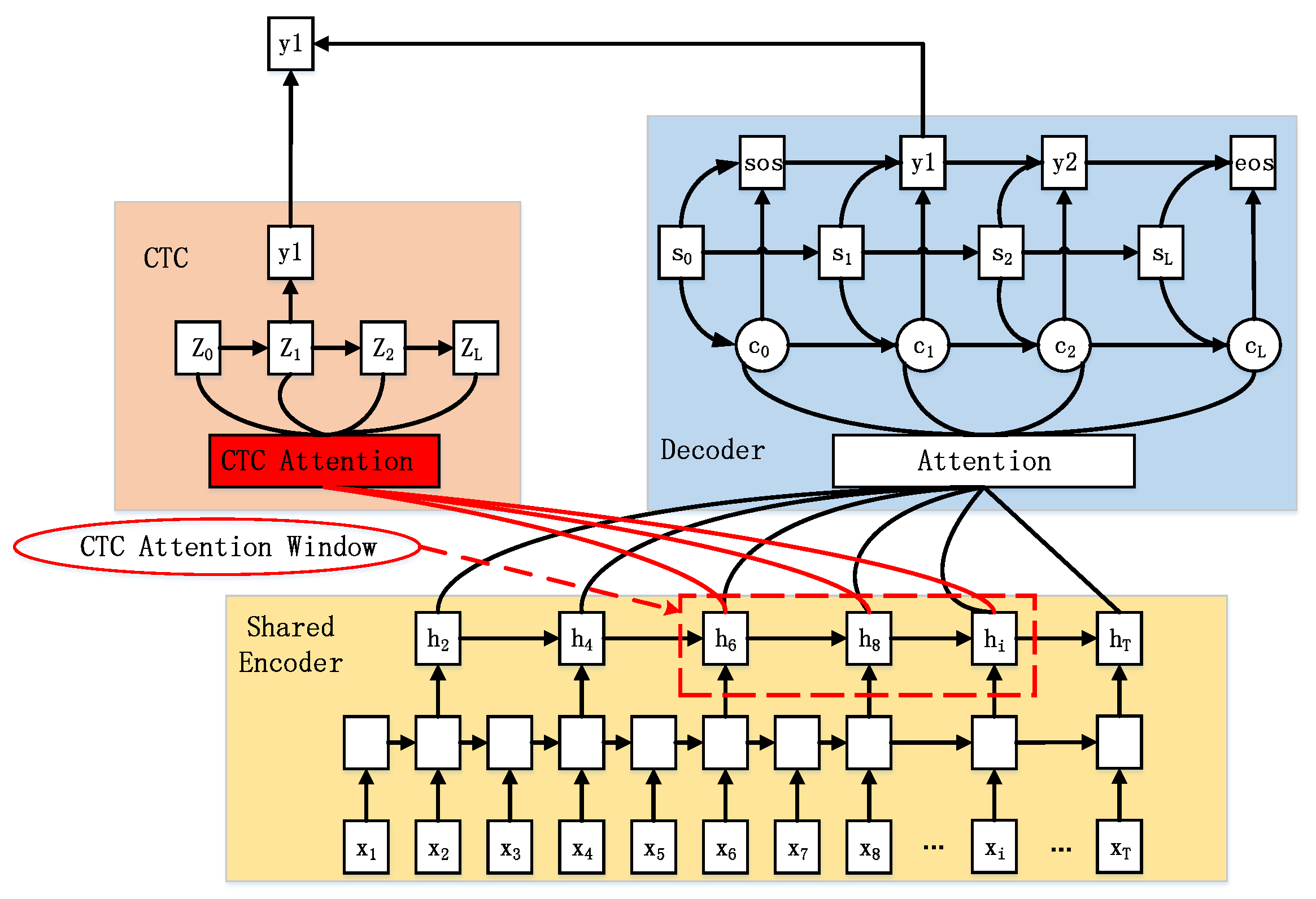
3. Time-Restricted Attention CTC/Attention Encoder–Decoder
3.1. LA CTC/Attention
3.2. SA CTC/Attention
4. Experiments
4.1. Experimental Setup
4.2. WSJ, AMI, and SWBD
4.2.1. Baseline Results
4.2.2. LA CTC/Attention
4.2.3. SA CTC/Attention
4.3. CHIME-4
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yu, D.; Li, J. Recent Progresses in Deep Learning Based Acoustic Models. IEEE/CAA J. Autom. Sin. 2017, 4, 396–409. [Google Scholar] [CrossRef]
- Miao, Y.; Gowayyed, M.; Metze, F. EESEN: End-to-End Speech Recognition Using Deep RNN Models and WFST-Based Decoding. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AR, USA, 13–17 December 2015; pp. 167–174. [Google Scholar] [CrossRef]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, Attend and Spell: A Neural Network for Large Vocabulary Conversational Speech Recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar] [CrossRef]
- Prabhavalkar, R.; Rao, K.; Sainath, T.N.; Li, B.; Johnson, L.; Jaitly, N. A Comparison of Sequence-to-Sequence Models for Speech Recognition. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 939–943. [Google Scholar] [CrossRef]
- Battenberg, E.; Chen, J.; Child, R.; Coates, A.; Li, Y.G.Y.; Liu, H.; Satheesh, S.; Sriram, A.; Zhu, Z. Exploring Neural Transducers for End-to-End Speech Recognition. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 206–213. [Google Scholar] [CrossRef]
- Sak, H.; Shannon, M.; Rao, K.; Beaufays, F. Recurrent Neural Aligner: An Encoder-Decoder Neural Network Model for Sequence to Sequence Mapping. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar] [CrossRef]
- Chiu, C.C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-Art Speech Recognition with Sequence-to-Sequence Models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar] [CrossRef]
- Sainath, T.N.; Chiu, C.C.; Prabhavalkar, R.; Kannan, A.; Wu, Y.; Nguyen, P.; Chen, Z. Improving the Performance of Online Neural Transducer Models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5864–5868. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd International Conference on Machine Learning—ICML ’06, Pittsburgh, PA, USA, 25–26 June 2006; pp. 369–376. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N. Towards End-To-End Speech Recognition with Recurrent Neural Networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1764–1772. [Google Scholar]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-End Attention-Based Large Vocabulary Speech Recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar] [CrossRef]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Graves, A. Sequence Transduction with Recurrent Neural Networks. Comput. Sci. 2012, 58, 235–242. [Google Scholar]
- Rao, K.; Sak, H.; Prabhavalkar, R. Exploring Architectures, Data and Units for Streaming End-to-End Speech Recognition with RNN-Transducer. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 193–199. [Google Scholar] [CrossRef]
- Das, A.; Li, J.; Zhao, R.; Gong, Y. Advancing Connectionist Temporal Classification with Attention Modeling. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4769–4773. [Google Scholar] [CrossRef]
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/Attention Architecture for End-to-End Speech Recognition. IEEE J. Sel. Top. Signal Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Yalta, N.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-to-End Speech Processing Toolkit. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 2207–2211. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762 [cs]. [Google Scholar]
- Povey, D.; Hadian, H.; Ghahremani, P.; Li, K.; Khudanpur, S. A Time-Restricted Self-Attention Layer for ASR. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5874–5878. [Google Scholar] [CrossRef]
- Paul, D.B.; Baker, J.M. The Design for the Wall Street Journal-Based CSR Corpus. In Proceedings of the Workshop on Speech and Natural Language—HLT ’91, Harriman, NY, USA, 23–26 February 1992; p. 357. [Google Scholar] [CrossRef]
- Carletta, J.; Ashby, S.; Bourban, S.; Flynn, M.; Guillemot, M.; Hain, T.; Kadlec, J.; Karaiskos, V.; Kraaij, W.; Kronenthal, M.; et al. The AMI Meeting Corpus: A Pre-Announcement. In Machine Learning for Multimodal Interaction; Renals, S., Bengio, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3869, pp. 28–39. [Google Scholar] [CrossRef]
- Glenn, M.L.; Strassel, S.; Lee, H.; Maeda, K.; Zakhary, R.; Li, X. Transcription Methods for Consistency, Volume and Efficiency. In Proceedings of the LREC, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Vincent, E.; Watanabe, S.; Nugraha, A.A.; Barker, J.; Marxer, R. An Analysis of Environment, Microphone and Data Simulation Mismatches in Robust Speech Recognition. Comput. Speech Language 2017, 46, 535–557. [Google Scholar] [CrossRef]
- Ochiai, T.; Watanabe, S.; Hori, T.; Hershey, J.R.; Xiao, X. Unified Architecture for Multichannel End-to-End Speech Recognition With Neural Beamforming. IEEE J. Sel. Top. Signal Process. 2017, 11, 1274–1288. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.K.; Hannemann, M.; Motlícek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi Speech Recognition Toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Big Island, HI, USA, 11–15 December 2011. [Google Scholar]
- Povey, D.; Peddinti, V.; Galvez, D.; Ghahremani, P.; Manohar, V.; Na, X.; Wang, Y.; Khudanpur, S. Purely Sequence-Trained Neural Networks for ASR Based on Lattice-Free MMI. In Proceedings of the INTERSPEECH, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar] [CrossRef]
- Xiong, W.; Droppo, J.; Huang, X.; Seide, F.; Seltzer, M.; Stolcke, A.; Yu, D.; Zweig, G. Achieving Human Parity in Conversational Speech Recognition. arXiv 2016, arXiv:1610.05256. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar] [Green Version]
- Heymann, J.; Drude, L.; Böddeker, C.; Hanebrink, P.; Häb-Umbach, R. Beamnet: End-to-End Training of a Beamformer-Supported Multi-Channel ASR System. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5325–5329. [Google Scholar] [CrossRef]
- Braun, S.; Neil, D.; Anumula, J.; Ceolini, E.; Liu, S.C. Multi-Channel Attention for End-to-End Speech Recognition. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | WSJ | AMI | SWBD |
|---|---|---|---|
| Encoder type | Vggblstmp | blstmp | blstmp |
| Encoder layers | 6 | 8 | 6 |
| Subsampling | 4 | 4 | 4 |
| Attention | Location-aware | Location-aware | Location-aware |
| CTCWeight train | 0.5 | 0.5 | 0.5 |
| CTCWeight decode | 0.3 | 0.3 | 0.3 |
| RNNLM-unit | Word | Word | Word |
| WSJ | LM Weight = 1 | LM Weight = 0 | |||||||
| CER | WER | CER | WER | ||||||
| Model | dev | test | dev | test | dev | test | dev | test | |
| Baseline | 3.9 | 2.4 | 8.6 | 5.4 | 7.5 | 5.7 | 22.2 | 17.7 | |
| 3.8 | 2.4 | 8.4 | 5.3 | 7.8 | 5.9 | 22.8 | 17.9 | ||
| 3.9 | 2.4 | 8.6 | 5.1 | 7.5 | 5.5 | 22 | 16.7 | ||
| 3.9 | 2.6 | 8.6 | 5.6 | 7.3 | 5.4 | 21.5 | 16.7 | ||
| 3.9 | 2.5 | 8.6 | 5.5 | 7.7 | 6.0 | 22.6 | 18.2 | ||
| AMI | LM Weight = 1 | LM Weight = 0 | |||||||
| CER | WER | CER | WER | ||||||
| Model | dev | test | dev | test | dev | test | dev | test | |
| Baseline | 22.3 | 23.2 | 35.1 | 37.4 | 23.4 | 24.7 | 39.6 | 42.2 | |
| 22.3 | 23.6 | 35.3 | 38.1 | 23.5 | 25.1 | 40.1 | 43.1 | ||
| 24.3 | 23.0 | 39.2 | 36.3 | 24.2 | 25.8 | 41.5 | 44.5 | ||
| 26.1 | 24.3 | 41.6 | 38.8 | 25.4 | 27.5 | 43.7 | 47.1 | ||
| 24.9 | 26.2 | 39.3 | 42.0 | 27.6 | 25.9 | 47.2 | 44.3 | ||
| SWBD | LM Weight = 1 | LM Weight = 0 | |||||||
| CER | WER | CER | WER | ||||||
| Model | eval | rt03 | eval | rt03 | eval | rt03 | eval | rt03 | |
| Baseline | 30.2 | 31.9 | 47.8 | 50.6 | 30.8 | 32.5 | 51.0 | 54.0 | |
| 29.4 | 31.5 | 47.3 | 50.3 | 30.1 | 32.4 | 50.5 | 53.8 | ||
| WSJ | LM Weight = 1 | LM Weight = 0 | |||||||
| CER | WER | CER | WER | ||||||
| Model | dev | test | dev | test | dev | test | dev | test | |
| Baseline | 3.9 | 2.4 | 8.6 | 5.4 | 7.5 | 5.7 | 22.2 | 17.7 | |
| LA CTC/Attention | 3.9 | 2.4 | 8.6 | 5.1 | 7.5 | 5.5 | 22.0 | 16.7 | |
| SA CTC/Attention | 3.7 | 2.2 | 8.1 | 4.9 | 7.4 | 5.5 | 21.5 | 16.8 | |
| AMI | LM Weight = 1 | LM Weight = 0 | |||||||
| CER | WER | CER | WER | ||||||
| Model | dev | test | dev | test | dev | test | dev | test | |
| Baseline | 22.3 | 23.2 | 35.1 | 37.4 | 23.4 | 24.7 | 39.6 | 42.2 | |
| LA CTC/Attention | 22.3 | 23.6 | 35.3 | 38.1 | 23.5 | 25.1 | 40.1 | 43.1 | |
| SA CTC/Attention | 21.0 | 22.1 | 33.4 | 35.8 | 22.1 | 23.7 | 37.7 | 40.8 | |
| SWBD | LM Weight = 1 | LM Weight = 0 | |||||||
| CER | WER | CER | WER | ||||||
| Model | eval | rt03 | eval | rt03 | eval | rt03 | eval | rt03 | |
| Baseline | 30.2 | 31.9 | 47.8 | 50.6 | 30.8 | 32.5 | 51.0 | 54.0 | |
| LA CTC/Attention | 29.4 | 31.5 | 47.3 | 50.3 | 30.1 | 32.4 | 50.5 | 53.8 | |
| SA CTC/Attention | 26.9 | 29.0 | 43.7 | 47.0 | 27.8 | 30.0 | 46.7 | 50.2 | |
| CHIME-4 | LM Weight = 0 | ||||||||
| CER | WER | ||||||||
| Model | et05simu | et05real | dt05simu | dt05real | et05simu | et05real | dt05simu | dt05real | |
| Baseline | 12.2 | 14.5 | 8.7 | 8.6 | 29.5 | 33.1 | 21.5 | 21.7 | |
| LA CTC/Attention | 12.7 | 15.1 | 9.5 | 9.2 | 30.4 | 34.2 | 23.4 | 22.9 | |
| SA CTC/Attention | 11.9 | 14.0 | 8.8 | 8.5 | 28.4 | 32.2 | 21.7 | 21.7 | |
| CHIME-4 | LM Weight = 1 | ||||||||
| CER | WER | ||||||||
| Model | et05simu | et05real | dt05simu | dt05real | et05simu | et05real | dt05simu | dt05real | |
| Baseline | 6.9 | 9.2 | 4.1 | 4.5 | 13.4 | 16.9 | 8.0 | 9.2 | |
| LA CTC/Attention | 6.9 | 8.9 | 4.5 | 4.6 | 13.0 | 16.2 | 8.8 | 9.1 | |
| SA CTC/Attention | 6.2 | 8.3 | 4.1 | 4.1 | 11.9 | 15.6 | 8.0 | 8.2 | |
| CHIME-4 | et05simu | dt05simu | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | PED | CAF | STR | BUS | MEAN | PED | CAF | STR | BUS | MEAN | |
| Baseline | 2.667 | 2.598 | 2.681 | 2.864 | 2.702 | 2.736 | 2.504 | 2.667 | 2.827 | 2.683 | |
| LA CTC/Attention | 2.653 | 2.598 | 2.682 | 2.860 | 2.698 | 2.740 | 2.518 | 2.667 | 2.826 | 2.687 | |
| SA CTC/Attention | 2.667 | 2.603 | 2.679 | 2.865 | 2.703 | 2.743 | 2.524 | 2.672 | 2.831 | 2.692 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, L.; Li, T.; Wang, L.; Yan, Y. Improving Hybrid CTC/Attention Architecture with Time-Restricted Self-Attention CTC for End-to-End Speech Recognition. Appl. Sci. 2019, 9, 4639. https://doi.org/10.3390/app9214639
Wu L, Li T, Wang L, Yan Y. Improving Hybrid CTC/Attention Architecture with Time-Restricted Self-Attention CTC for End-to-End Speech Recognition. Applied Sciences. 2019; 9(21):4639. https://doi.org/10.3390/app9214639
Chicago/Turabian StyleWu, Long, Ta Li, Li Wang, and Yonghong Yan. 2019. "Improving Hybrid CTC/Attention Architecture with Time-Restricted Self-Attention CTC for End-to-End Speech Recognition" Applied Sciences 9, no. 21: 4639. https://doi.org/10.3390/app9214639
APA StyleWu, L., Li, T., Wang, L., & Yan, Y. (2019). Improving Hybrid CTC/Attention Architecture with Time-Restricted Self-Attention CTC for End-to-End Speech Recognition. Applied Sciences, 9(21), 4639. https://doi.org/10.3390/app9214639