Automated Method of Road Extraction from Aerial Images Using a Deep Convolutional Neural Network



Abstract
:1. Introduction
2. Methodology
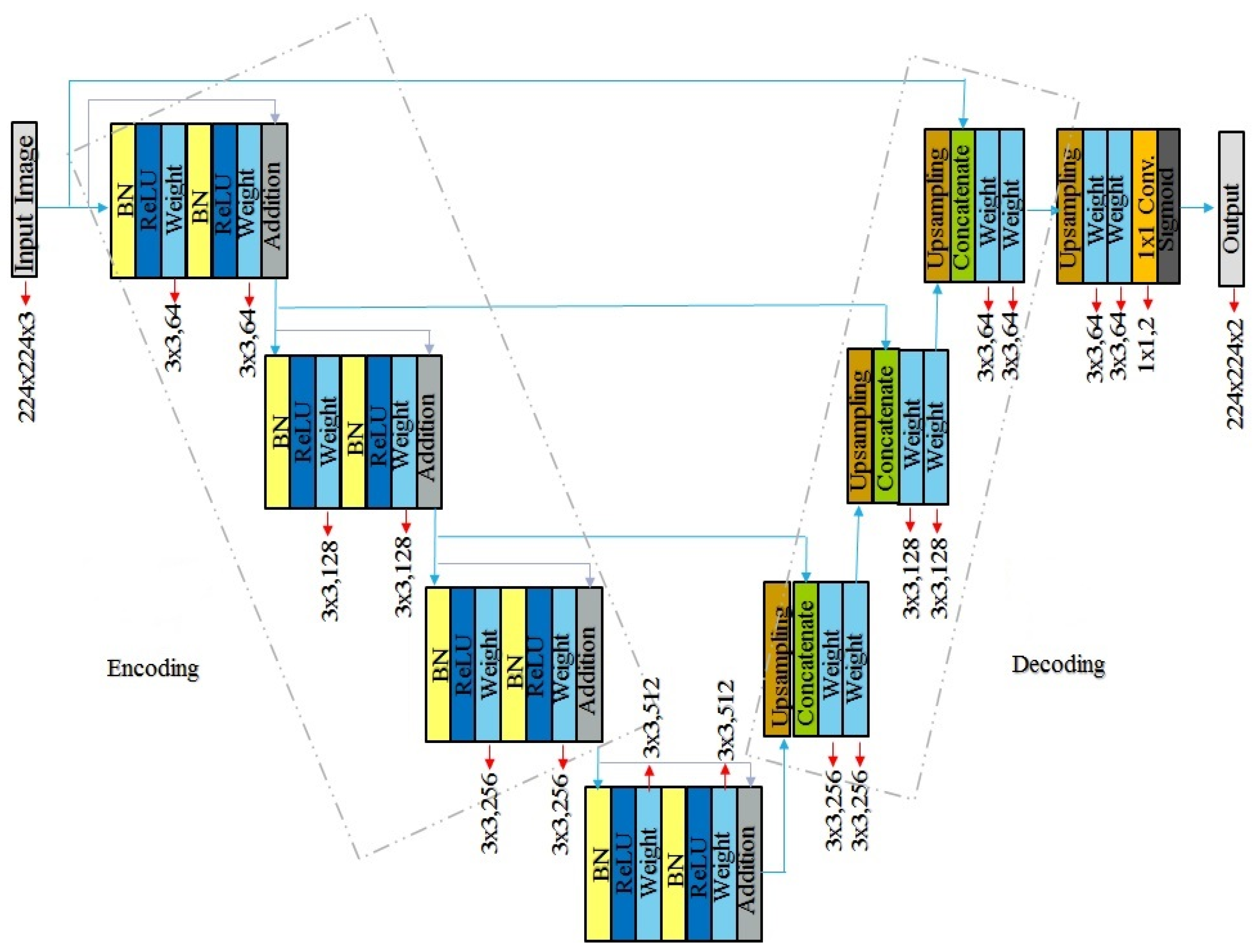
2.1. The Proposed Model
2.2. Dataset
3. Results
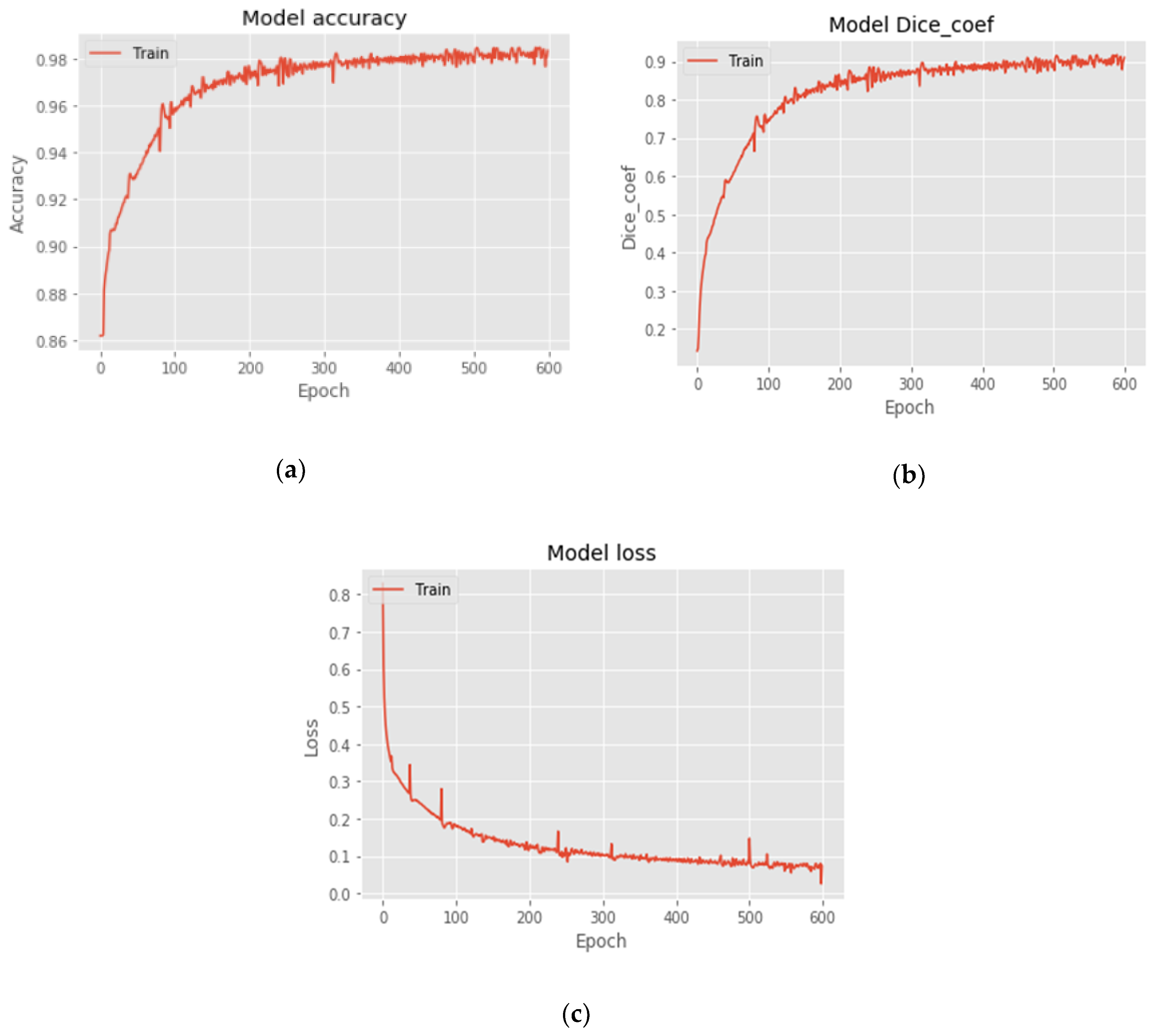
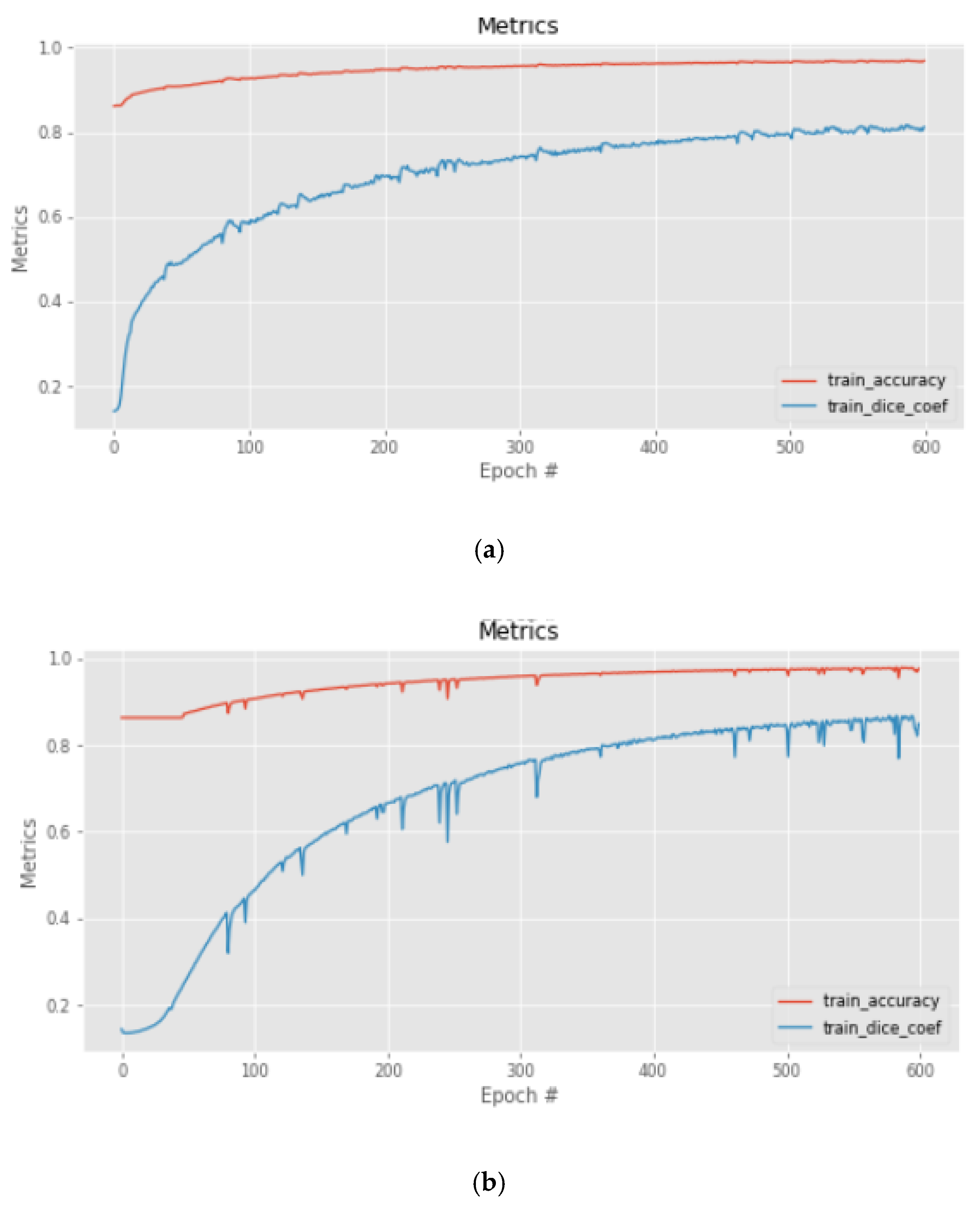
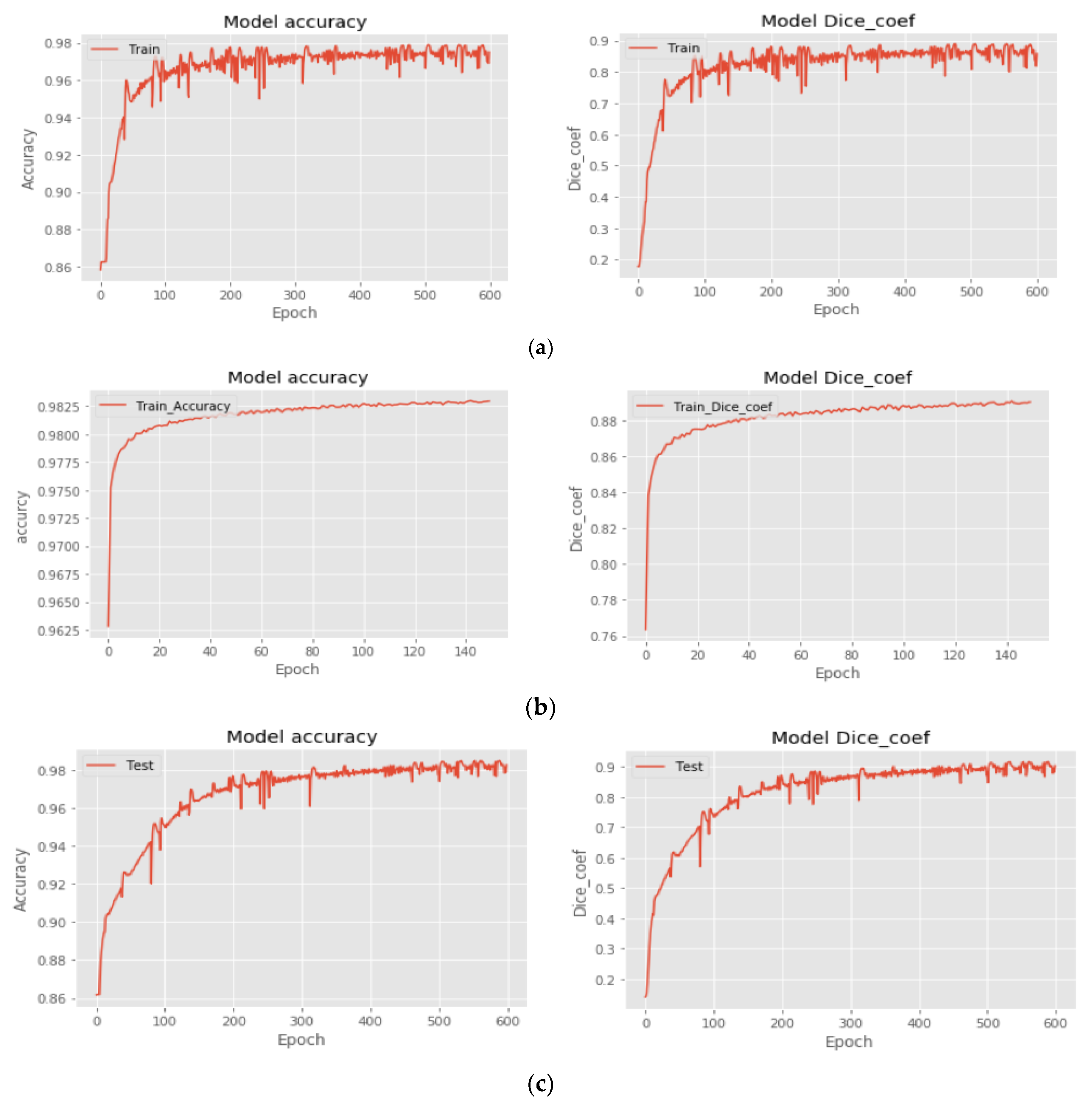
3.1. Training and Implementation Details
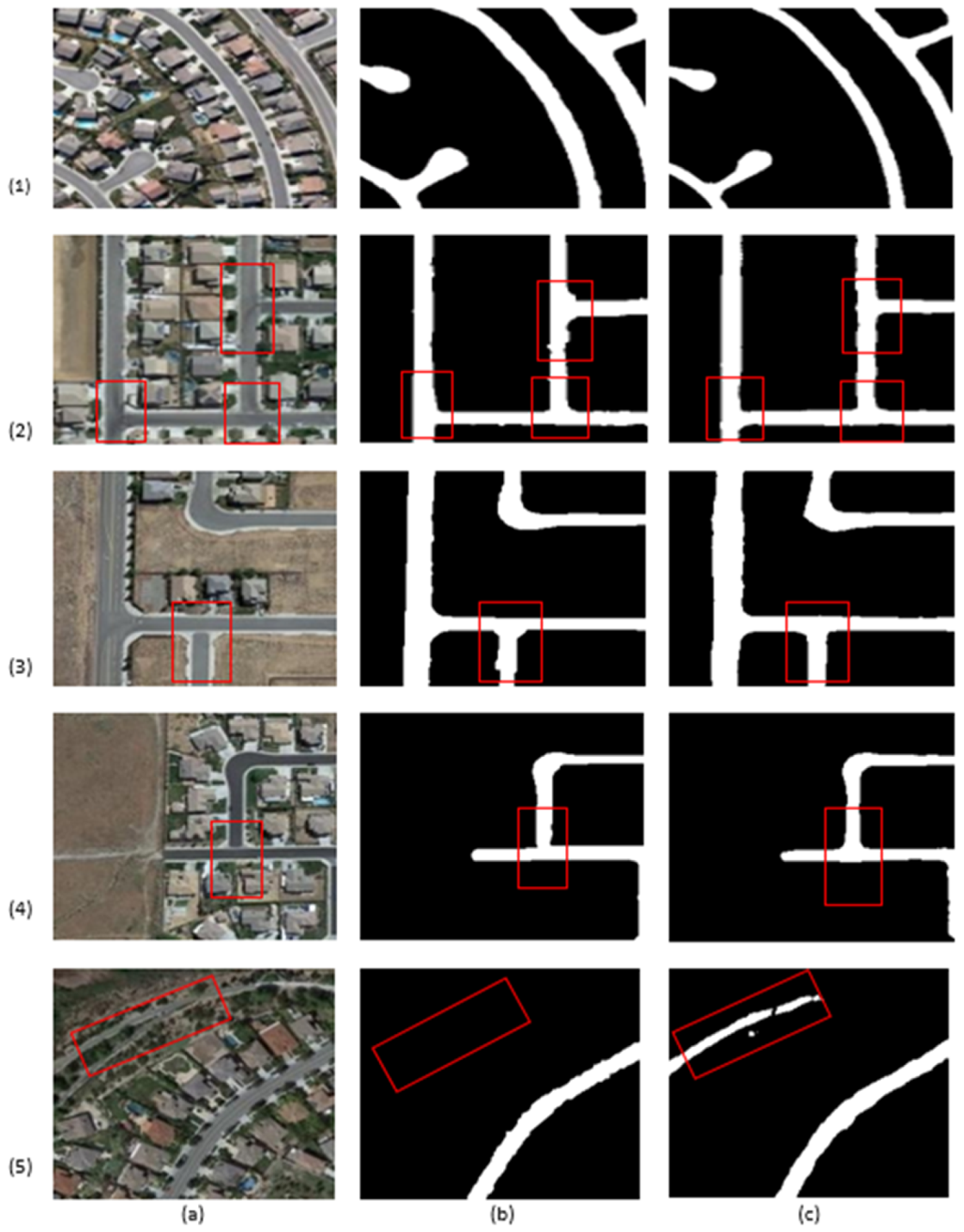
3.2. Comparisons with Other models
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. (Engl. Ed.) 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Bacher, U.; Mayer, H. Automatic road extraction from multispectral high resolution satellite images. In Proceedings of the ISPRS Workshop CMRT 2005: Object Extraction for 3D City Models, Road Databases and Traffic Monitoring - Concepts, Algorithms and Evaluation Vienna, Austria, 29–30 August 2005; ISPRS Archives: Vienna, Austria, 2005; Volume XXXVI-3/W24, p. 6. [Google Scholar]
- Bicego, M.; Dalfini, S.; Vernazza, G.; Murino, V. Automatic Road Extraction from Aerial Images by Probabilistic Contour Tracking. In Proceedings of the 2003 International Conference on Image Processing (Cat. No. 03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 3, p. 585. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Amo, M.; Martinez, F.; Torre, M. Road extraction from aerial images using region competition algorithm. IEEE Trans. Image Process. 2006, 15, 1192–1201. [Google Scholar] [CrossRef] [PubMed]
- Heipke, C.; Mayer, H.; Wiedemann, C. Evaluation of automatic road extraction. Int. Arch. ISPRS J. Photogramm. Remote Sens. 1997, 32, 47–56. [Google Scholar]
- Gamba, P.; DellAcqua, F.; Lisini, G. Improving urban road extraction in high-resolution images exploiting directional filtering, perceptual grouping, and simple topological concepts. IEEE Geosci. Remote Sens. Lett. 2006, 3, 387–391. [Google Scholar] [CrossRef]
- Gruen, A.; Li, H. Road extraction from aerial and satellite images by dynamic programming. ISPRS J. Photogramm. Remote Sens. 1995, 50, 11–20. [Google Scholar] [CrossRef]
- Heipke, C.; Steger, T.; Multhammer, R. Hierarchical approach to automatic road extraction from aerial imagery. In Proceedings of the SPIE 2486, Integrating Photogrammetric Techniques with Scene Analysis and Machine Vision II, Orlando, FL, USA, 5 July 1995; p. 2486. [Google Scholar] [CrossRef]
- Long, H.; Zhao, Z. Urban road extraction from high-resolution optical satellite images. Int. J. Remote Sens. 2005, 26, 4907–4921. [Google Scholar] [CrossRef]
- Hormese, J.; Saravanan, C. Automated road extraction from high resolution satellite images. Procedia Technol. 2016, 24, 1460–1467. [Google Scholar] [CrossRef]
- Li, Y.; Briggs, R. Automatic extraction of roads from high resolution aerial and satellite images with heavy noise. Int. J. Comp. Inf. Eng. 2009, 3, 1571–1577. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Z.; Zhang, J. An approach of semiautomated road extraction from aerial image based on template matching and neural network. Int. Arch. ISPRS J. Photogramm. Remote Sens. 2000, 33, 994–999. [Google Scholar]
- Xia, W.; Zhang, Y.; Liu, J.; Luo, L.; Yang, K. Road extraction from high resolution image with deep convolution network—A case study of GF-2 image. In Proceedings of the 2nd International Electronic Conference on Remote Sensing (ECRS 2018), 22 March–5 April 2018; Volume 2, p. 325. Available online: www.sciforum.net/conference/ecrs-2 (accessed on 20 May 2019). [CrossRef]
- Kahraman, I.; karas, I.R.; Akay, A.E. Road extraction techniques from remote sensing images: A review. In The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Proceedings of the International Conference on Geomatics and Geospatial Technology (GGT 2018), Kuala Lumpur, Malaysia, 3–5 September 2018; XLII-4/W9; pp. 339–342. [CrossRef]
- Shackelford, A.; Davis, C. Fully automated road network extraction from high-resolution satellite multispectral imagery. In Proceedings of the IGARSS 2003, 2003 IEEE International Geoscience and Remote Sensing Symposium (IEEE Cat. No.03CH37477), Toulouse, France, 21–25 July 2003; Volume 1, pp. 461–463. [Google Scholar] [CrossRef]
- Hu, X.; Vincent Tao, C.; Hu, Y. Automatic road extraction from dense urban area by integrated processing of high imagery and LIDAR data, processing of high resolution imagery and LIDAR data. In Proceedings of the International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences IAPRSIS, Istanbul, Turkey, –23 July 2004; Volume 35, pp. 288–292. [Google Scholar]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. J. Imaging Sci. Tech. 2016, 60, 10402-1–10402-9. [Google Scholar] [CrossRef]
- Vosselman, G.; De Knecht, J. Road Tracing by Profile Matching and Kalman filtering, Workshop on Automatic Extraction of Manmade Objects from Aerial and Space Images; Birkhauser: Berlin, Germany, 1995; pp. 265–274. [Google Scholar] [CrossRef]
- Mokhtarzade, M.; Valadan Zoej, M. Road detection from high- resolution satellite images using artificial neural networks, inter. J. Appl. Earth Obs. Geoinf. 2007, 9, 32–40. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Image net classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Mnih, V.; Hinton, G. Learning to detect roads in high-resolution aerial images. In Proceedings of the 11th European Conference on Computer Vision ECCV’10, Crete, Greece, 5–11 Spetember 2010; Part VI. pp. 210–223. [Google Scholar] [CrossRef]
- Vicini, D.; Hamas, M.; Taivo, P. Road Extraction from Aerial Images. Available online: https://github.com/mato93/road-extraction-from-aerial-images (accessed on 15 June 2019).
- Wang, S.; Sun, J.; Phillips, P.; Zhao, G.; Zhang, Y. Polarimetric synthetic aperture radar image segmentation by convolutional neural network using graphical processing units. J. Real Time Image Process. 2017, 15, 631–642. [Google Scholar] [CrossRef]
- Li, Z.; Wang, S.; Fan, R.; Cao, G.; Zhang, Y.; Guo, T. Teeth category classification via seven-layer deep convolutional neural network with max pooling and global average pooling. Int. J. Image Syst. Technol. IMA 2019. [Google Scholar] [CrossRef]
- Kaiming, H.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2015; pp. 770–778. [Google Scholar] [CrossRef]
- Kaiming, H.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Part IV. pp. 630–645. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. Proceeding of International Conference on Learning Representations ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P. Going deeper with convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T.; U-Net. Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceeding of 18th International Conference, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Swizerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual U-Net. IEEE Geosci. Remote Sensing Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Buslaev, A.; Seferbekov, S.S.; Iglovikov, V.I.; Shvets, A.A. Fully convolutional network for automatic road extraction from satellite imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 197–1973. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road extraction from high-resolution remote sensing imagery using deep learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Google. Google Earth. Available online: http://www.google.cn/intl/zh-CN/earth/ (accessed on 20 May 2019).
- Wang, H.; Wnag, Y.; Zhang, Q.; Xinag, S.; Pan, C. Gated convolutional neural network for semantic segmentation in high-resolution images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef]
- Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 8 November 2019).
- Kingma, D.P.; Ba, J. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Binarycrossentropy. Available online: https://peltarion.com/knowledgecenter/documentation/modeling-view/build-an-ai-model/loss-functions/binary-crossentropy (accessed on 9 April 2019).
- Understanding Binary Cross-Entropy/Log Loss: A Visual Explanation. Available online: https://towardsdatascience.com/understanding-binary-cross-entropy-log-loss-a-visual-explanation-a3ac6025181a (accessed on 9 April 2019).
- Powers, D. What the F-measure doesn’t measure: Features, flaws, fallacies and fixes. arXiv 2015, arXiv:1503.06410. [Google Scholar]
- Taylor, J.R. An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements, 2nd ed.; University Sciences Books: Sausalito, CA, USA, 1999; pp. 128–129. [Google Scholar]
- Zou, K.H.; Warfield, S.K. Statistical validation of image segmentation quality based on a spatial overlap index: Scientific Reports. Acad. Radiol. 2004, 11, 178–189. [Google Scholar] [CrossRef] [Green Version]
- Al-Faris, A.Q.; Ngah, U.K.; Isa, N.; Shuaib, I.L. MRI breast skin-line segmentation and removal using integration method of level set active contour and morphological thinning algorithms. J. Med. Sci. 2012, 12, 286–291. [Google Scholar] [CrossRef] [Green Version]
- Cardenes, R.; Luis-Garcia, R.; Bach-Cuadra, M. A multidimensional segmentation evaluation for medical image data. Comput. Methods Prog. Biomed. 2009, 96, 108–124. [Google Scholar] [CrossRef] [PubMed]
- Derczynski, L. Complementarity F-score and NLP Evaluation. In Proceedings of the 10th Edition of the Language Resources and Evaluation Conference, Portoroz, Slovenia, 23–28 May 2016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted | |||
| Road (1) | Background (0) | ||
| Actual | Road (1) | True positive (TP) | False positive (FP) |
| Background (0) | False negative (FN) | True negative (TN) | |
| OAA | DSC | |
|---|---|---|
| Proposed Model | 98.35% | 90.97% |
| Model | OAA | DSC |
|---|---|---|
| Res-Unet | 96.96% | 81.73% |
| U-Net | 97.52% | 84.84% |
| Our Model | 98.35% | 90.97% |
| Model | Overall Accuracy | DSC |
|---|---|---|
| Auto-encoder.ResNet (first trial) | 97.51% | 85.84% |
| 1Full Res-Unet (second model) | 98.30% | 89.02% |
| Res-Unet (2Orig. Rse.) (third model) | 98.33% | 89.23% |
| Our Model | 98.35% | 90.97% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshaikhli, T.; Liu, W.; Maruyama, Y. Automated Method of Road Extraction from Aerial Images Using a Deep Convolutional Neural Network. Appl. Sci. 2019, 9, 4825. https://doi.org/10.3390/app9224825
Alshaikhli T, Liu W, Maruyama Y. Automated Method of Road Extraction from Aerial Images Using a Deep Convolutional Neural Network. Applied Sciences. 2019; 9(22):4825. https://doi.org/10.3390/app9224825
Chicago/Turabian StyleAlshaikhli, Tamara, Wen Liu, and Yoshihisa Maruyama. 2019. "Automated Method of Road Extraction from Aerial Images Using a Deep Convolutional Neural Network" Applied Sciences 9, no. 22: 4825. https://doi.org/10.3390/app9224825
APA StyleAlshaikhli, T., Liu, W., & Maruyama, Y. (2019). Automated Method of Road Extraction from Aerial Images Using a Deep Convolutional Neural Network. Applied Sciences, 9(22), 4825. https://doi.org/10.3390/app9224825