Improving Agent Quality in Dynamic Smart Cities by Implementing an Agent Quality Management Framework



Abstract
:1. Introduction
2. Related Research
2.1. Quality Management in Agent Systems
2.2. Quality Requirements in Smart Cities
2.3. Data Quality Management
2.4. Agent Tools
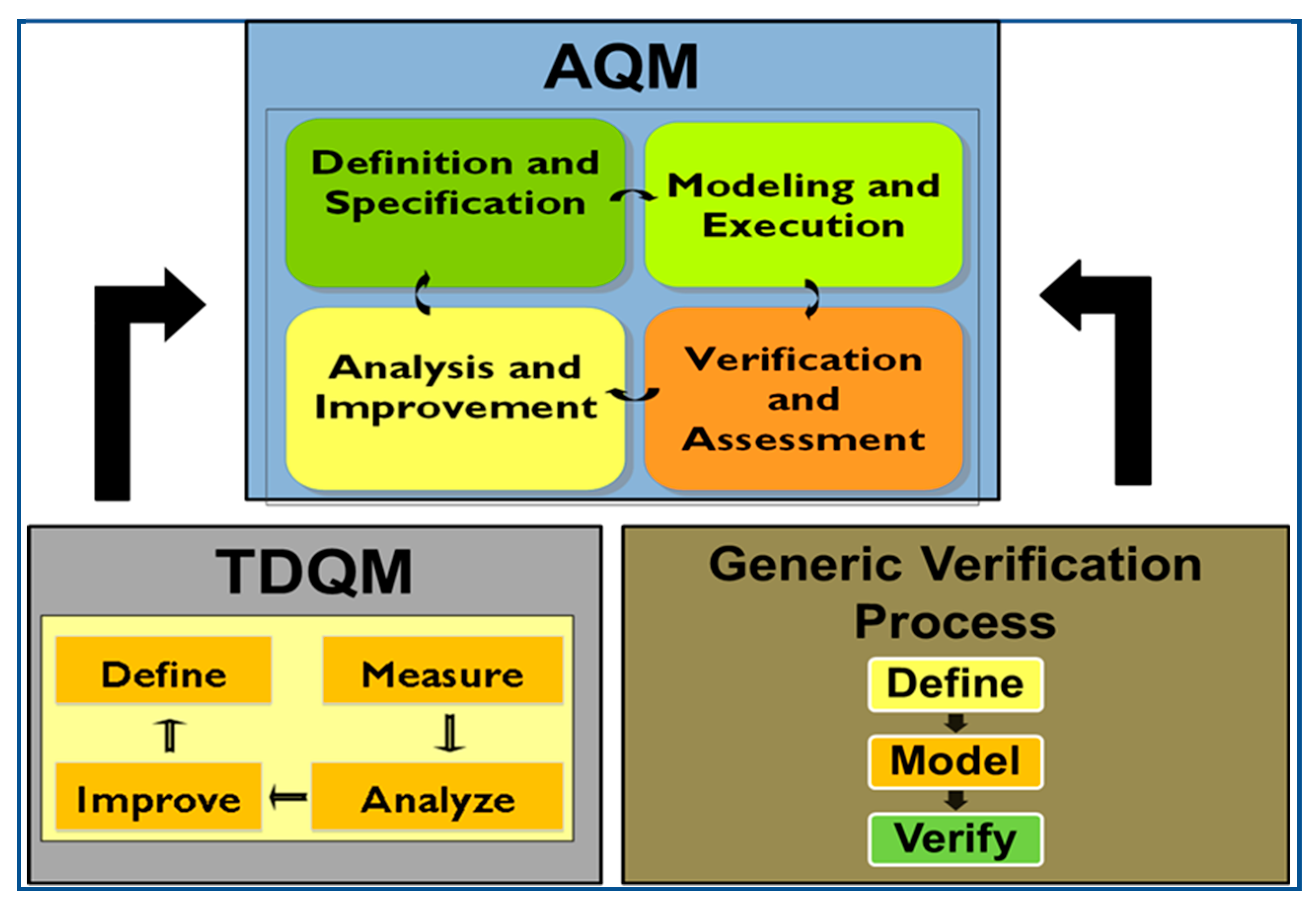
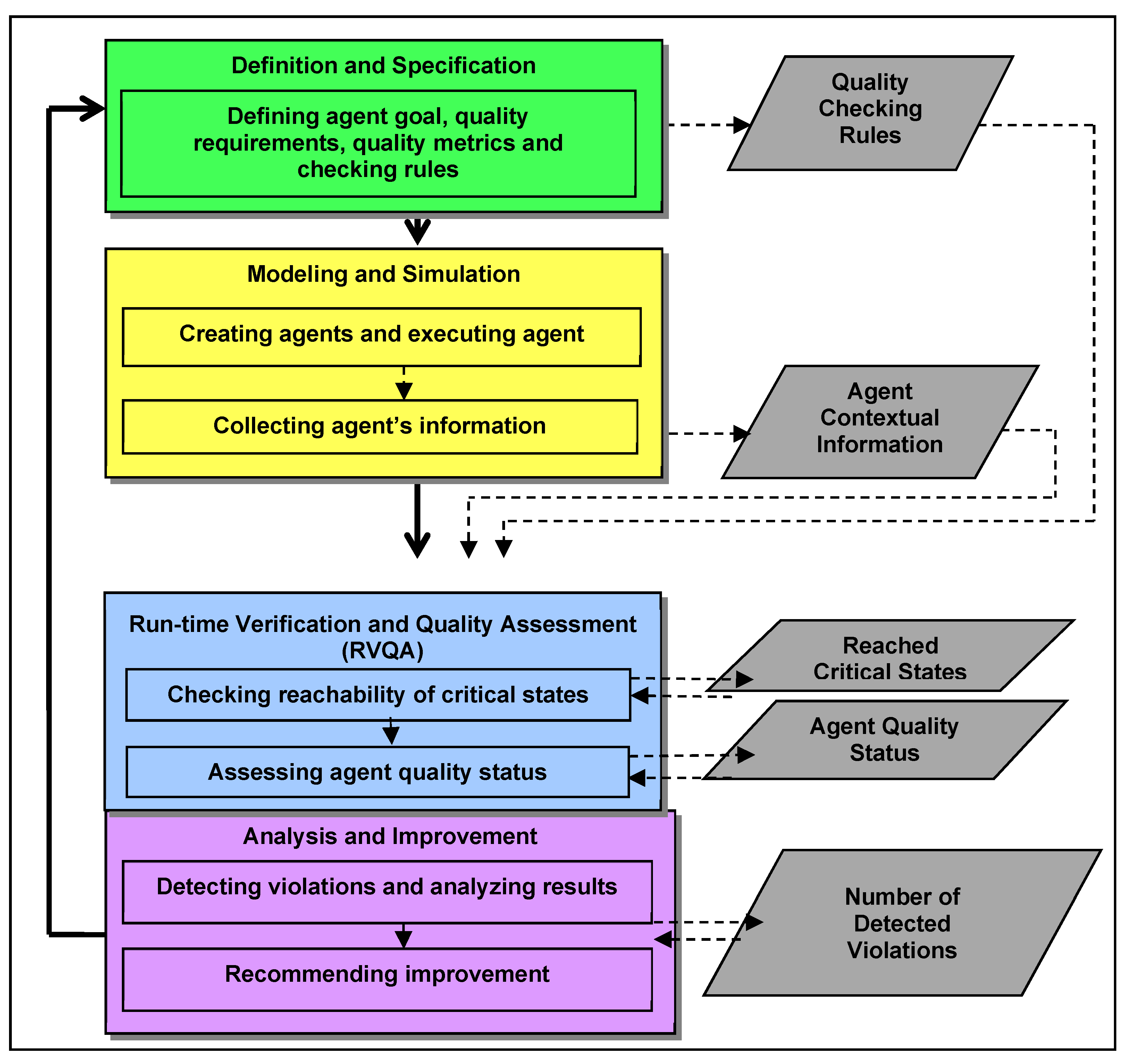
3. AQM Framework for Smart City Applications
- definition and specification,
- modeling and simulation,
- verification and assessment,
- analysis and improvement.
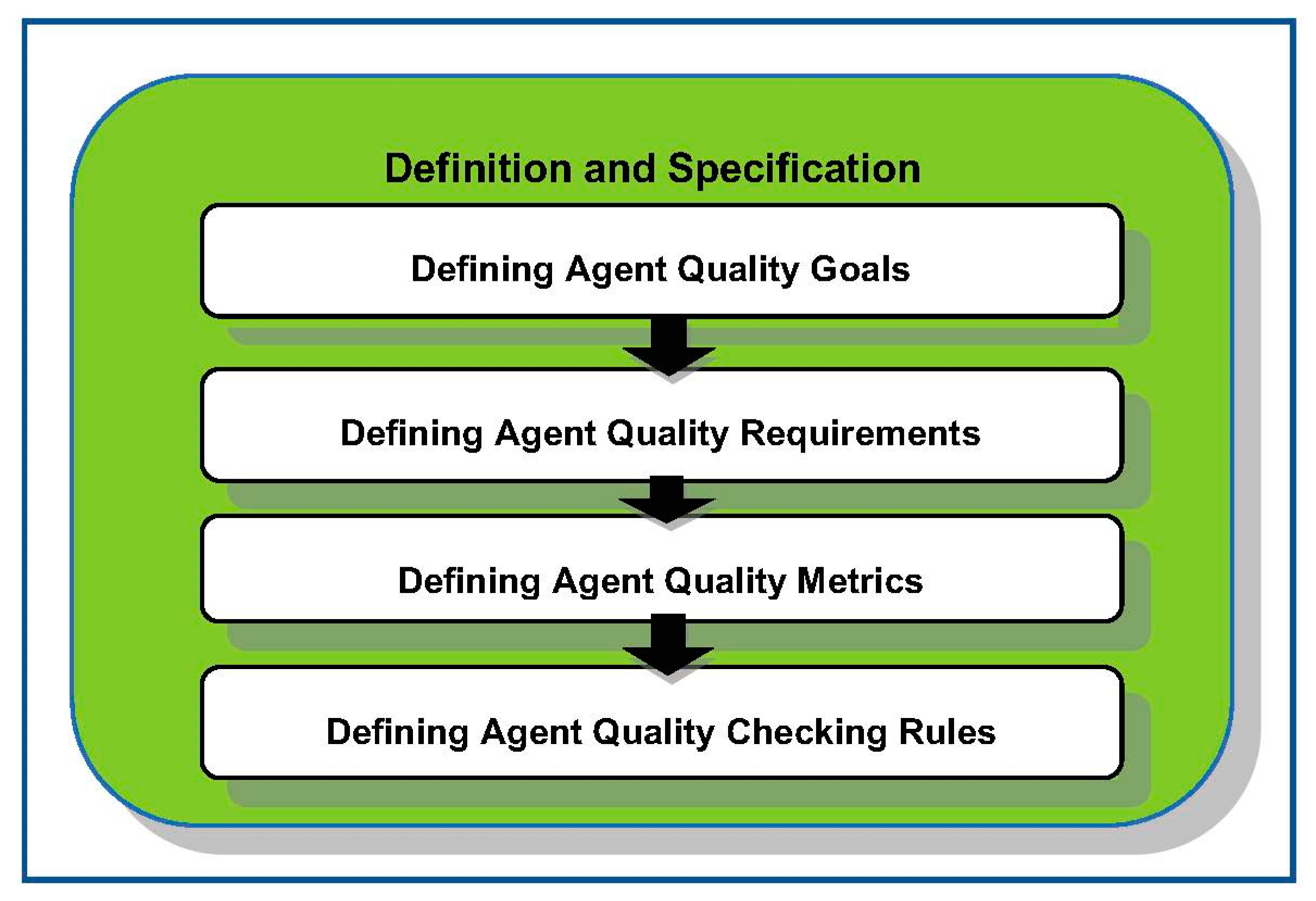
3.1. Definition and Specification
- Defining the agent quality goal for an agent system: The agent quality goals during run-time are used to ensure that agents are high in quality such that the non-functional agent requirements are fulfilled. The examples of agent non-functional requirements are trust, reputation, privacy, confidentiality, and integrity.
- Defining agent quality requirements: To define the agent quality requirements, the selected criteria should represent the quality of agents in various conditions and activities during execution. The selected criteria are preferably measurable in order for the introduced metrics so that these criteria can be used to continuously quantify agent quality statuses during run-time. For each quality criterion, the contributing factors (contextual conditions) that can cause satisfaction and possible violations of requirements are identified. The requirements that are defined are the most important non-functional requirements or constraints of the agents as an individual or group. The list is not exhaustive and it should rather be considered as the minimal agent quality requirements to be verified and assessed. The list can be extended further during the definition process in the next AQM process cycle.
- Defining agent quality metrics: The abstraction of agent quality requirements and violations that are defined is translated into a more concrete form of representation known as agent quality metrics. The agent parameters and critical states are defined so they can be included in the agent quality metric definition. An agent quality metric is a measure of agent quality properties.
- Defining agent quality checking rules: Rules and indicators (in the form of quality statuses) are associated with each metric based on the contextual conditions. The agent quality requirements, parameters, and critical states identified are transformed into the checking rules for each metric, which reflect the specifications and real condition of the agent quality status. The main aim of the checking rules is to tie together the agent parameters that contribute to the checking and assessment of the agent quality statuses. The rules defined in this phase will be used in the verification and assessment phase as the checking rules to perform run-time verification and quality assessment within the agent models. The rules for agent quality metrics range from simple if–else statements to more complex formal specifications (e.g., written in temporal logic) for verification purposes. For each metric, the rules require the execution of run-time verification to detect the reachability of critical states where quality assessment will be performed.
- The agent quality metrics and checking rules for each agent quality requirements are formally specified. The specification in AQM refers to the specification of the reachability of certain states that are defined as critical. Critical states occur when the agent states that determine either agent quality requirements are violated. When these critical states are reached, the quality assessment is performed by determining the quality statuses based on the conditions that are defined as violations and non-violations for the agent. Finally, the checking rules containing the preconditions and the assigned quality statuses are specified using temporal logic and are presented as the output for this definition phase.
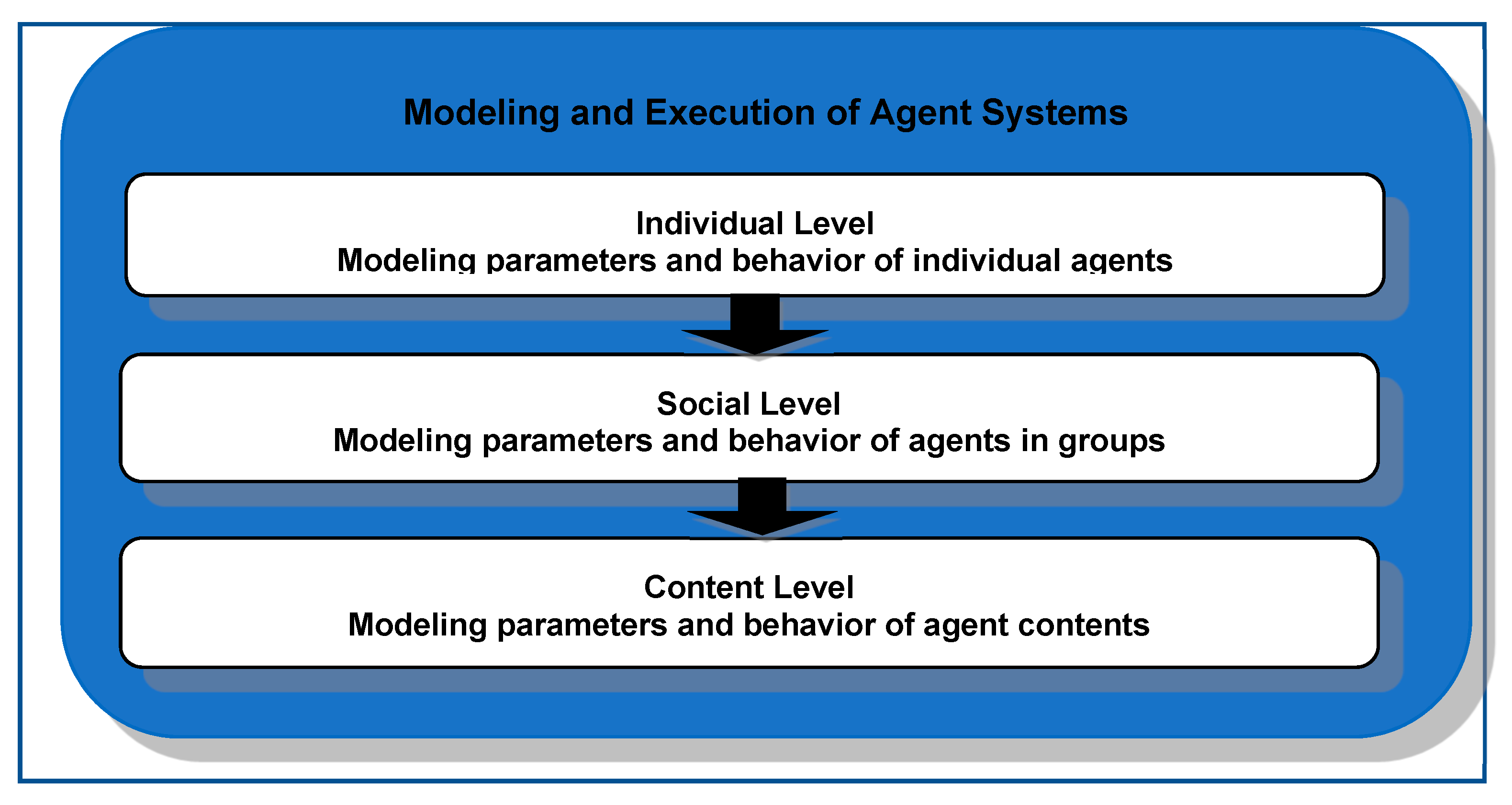
3.2. Modeling and Execution
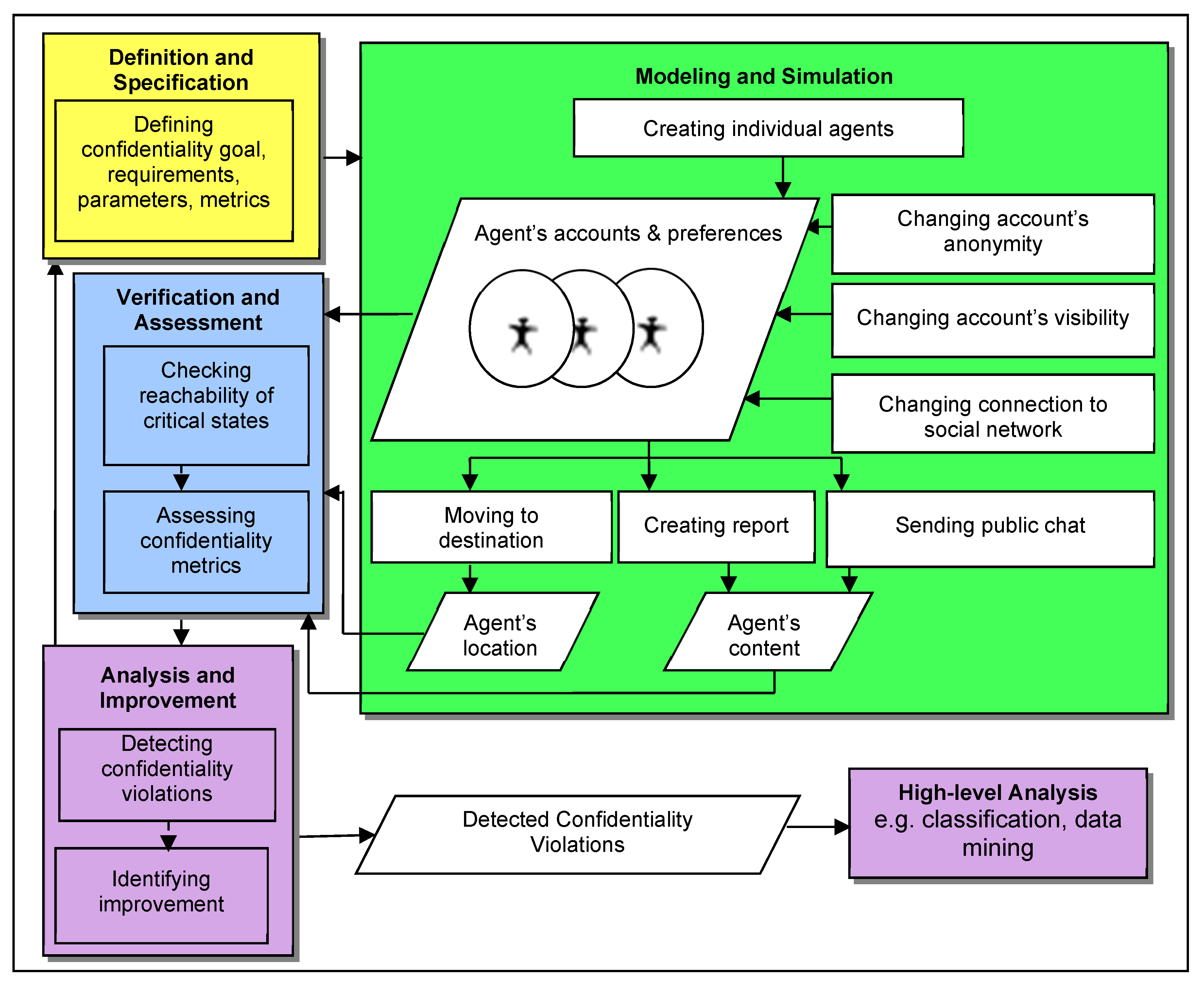
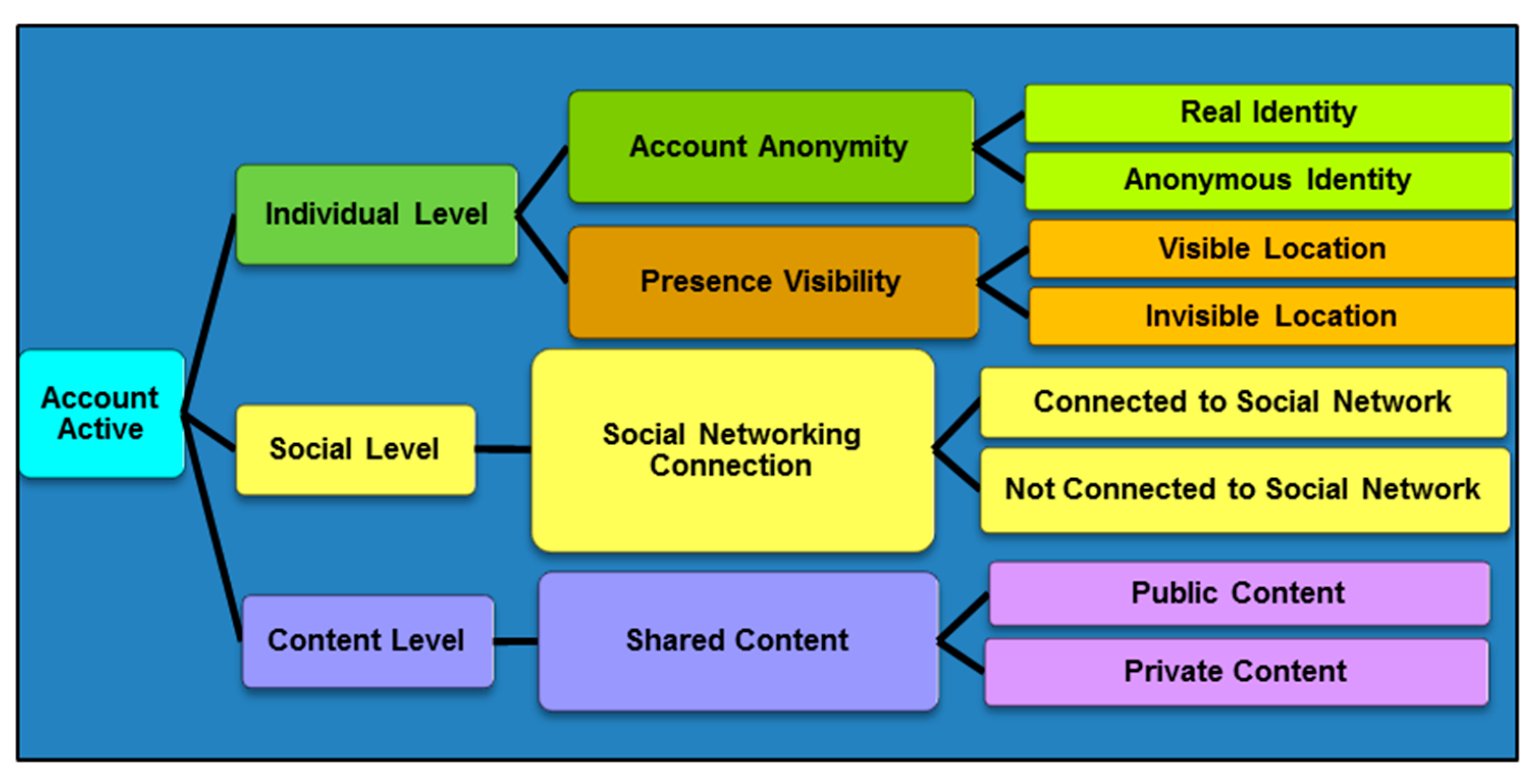
- Individual level: The verification and assessment of an individual agent’s quality parameter includes the monitoring of agent activities by tracking the active states and verifying the reachability of critical states. Next, the assessment of the exposure level for each parameter is performed. The continuous assessment produces real-time exposure statuses that consider real time and dynamic agent contextual information that are the privacy preference settings for each agent parameter, such as the profile, the presence (online) status and the chatting availability, and the confidentiality settings for each agent content.
- Social level: The second layer verifies the agent relationship quality parameter in which the privacy preference settings and social activities of other agents directly and indirectly affect the agent’s privacy.
- Content level. The third layer is to check the agent quality parameter as a content owner and content sharing partner. As a content owner, the agent quality depends directly on the agent preference settings, and as a content sharing partner, the agent quality depends indirectly on other agent relationship privacy preference and sharing activities.
3.3. Verification and Assessment
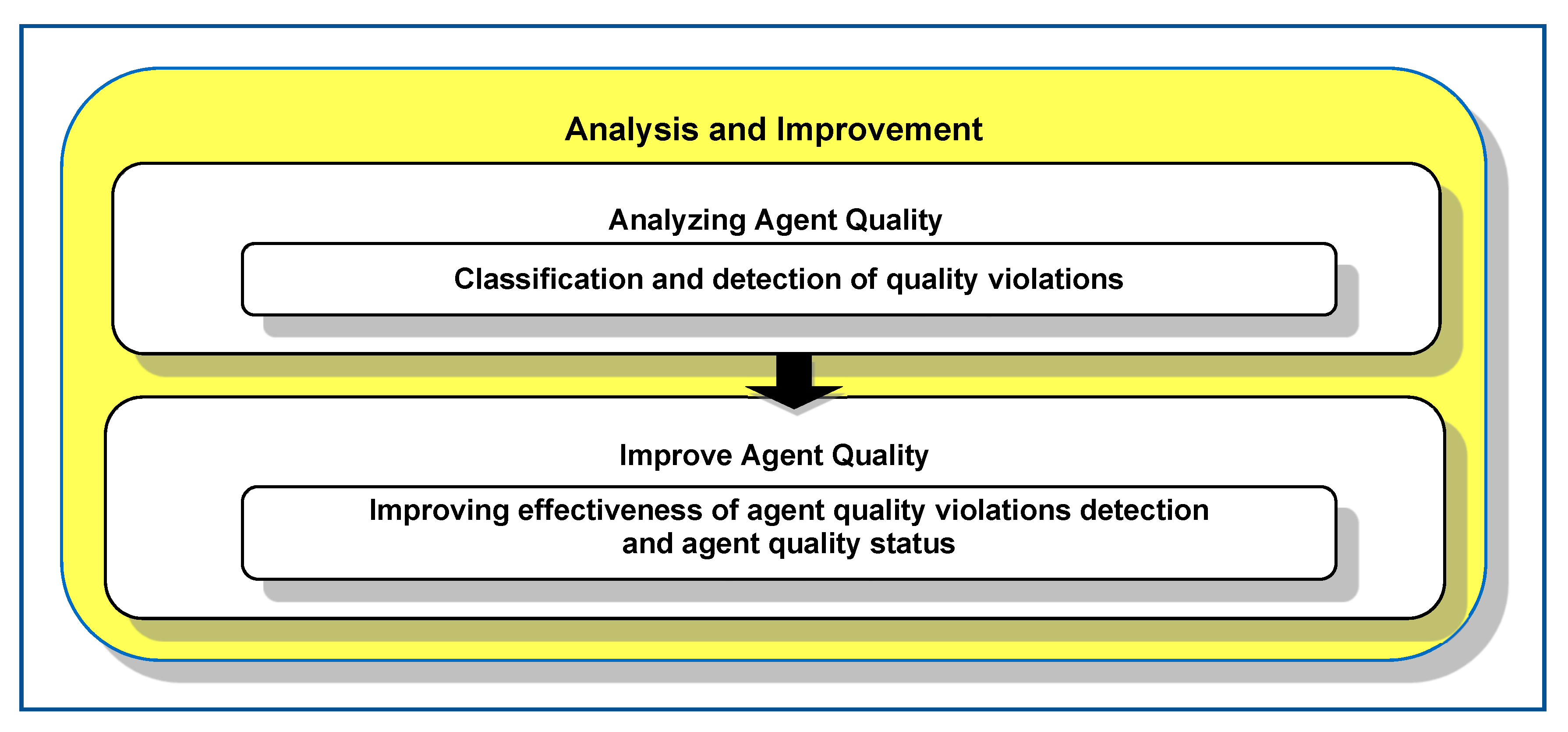
3.4. Analysis and Improvement
3.5. Incorporating AQM within the Agent System Model
4. Case Study: AQM Implementation
4.1. Definition and Specification for the CNS
4.2. Modeling and Execution of the CNS
4.3. Verification and Assessment for the CNS
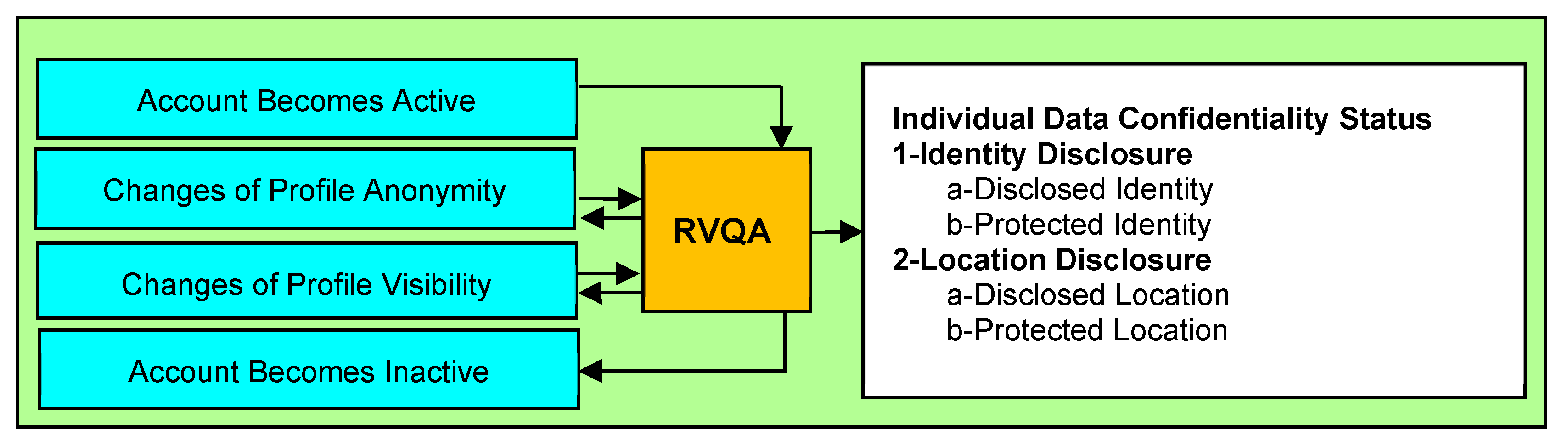
4.3.1. The RVQA Process at the Agent Individual Level of the CNS
| Algorithm 1. Identity and location confidentiality disclosures detection. | |
| Input: | Agent Index: x, Current Time: t |
| Output: | noDisclosedIdentity, noNotDisclosedIdentity, noDisclosedLocation, noNotDisclosedLocation, noDisclosures |
| 1 | begin |
| 2 | if AccountActive(x,t) then |
| 3 | Critical(x,t) → true |
| 4 | if ProfileReal(x,t) then |
| 5 | IdentityDisclosed(x,t) |
| 6 | increase(x,noDisclosedIdentity) |
| 7 | increase(x,noDisclosures) |
| 8 | end |
| 9 | if ProfileAnonymous(x,t) then |
| 10 | IdentityNotDisclosed(x,t) |
| 11 | increase(x,noNotDisclosedIdentity) |
| 12 | end |
| 13 | if PresenceVisible(x,t) then |
| 14 | LocationDisclosed(x,t) |
| 15 | increase(x,noDisclosedLocation) |
| 16 | increase(x,noDisclosures) |
| 17 | end |
| 18 | if PresenceInvisible(x,t) then |
| 19 | LocationNotDisclosed(x,t) |
| 20 | increase(x,noNotDisclosedLocation) |
| 21 | end |
| 22 | end |
| 23 | end |
| 24 | return noDisclosedIdentity, noNotDisclosedIdentity, noDisclosedLocation, noNotDisclosedLocation, noDisclosures |
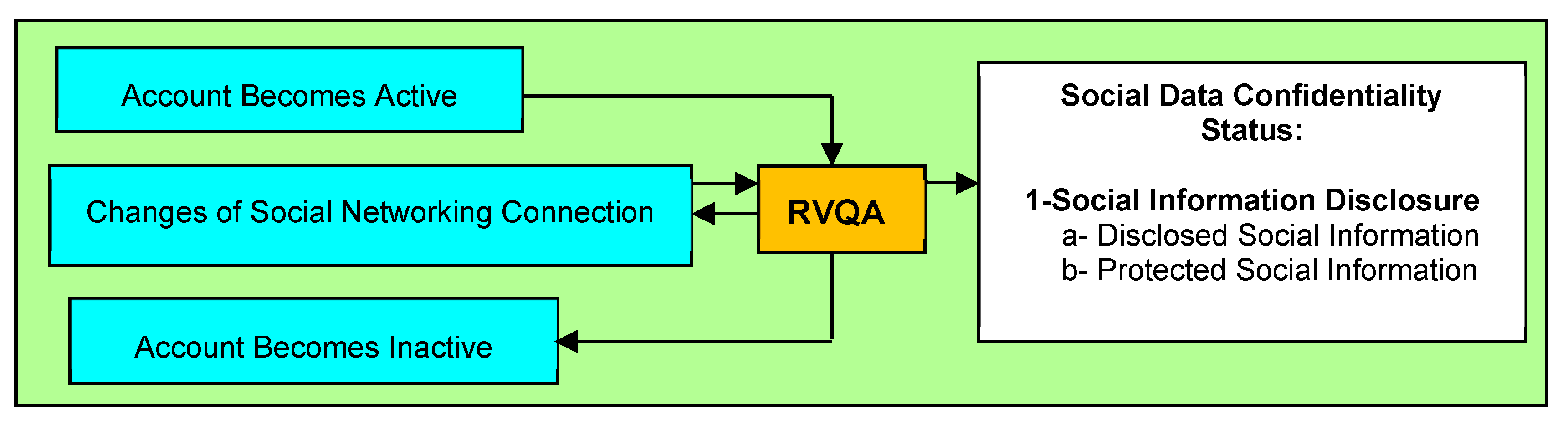
4.3.2. The RVQA Process at the Agent Social Level of the CNS
| Algorithm 2. Identity and location confidentiality disclosures detection. | |
| Input: | Agent Index: x, Current Time: t |
| Output: | noDisclosedSocialInformation, noNotDisclosedSocialInformation, noDisclosures |
| 1 | begin |
| 2 | if AccountActive(x,t) then |
| 3 | Critical(x,t) → true |
| 4 | if SocialNetworkingConnected(x,t) then |
| 5 | SocialInformationDisclosed(x,t) |
| 6 | increase(noDisclosedSocialInformation) |
| 7 | increase(x,noDisclosures) |
| 8 | end |
| 9 | if SocialNetworkingNotConnected(x,t) then |
| 10 | SocialInformationNotDisclosed(x,t) |
| 11 | increase(noNotDisclosedSocialInformation) |
| 12 | end |
| 13 | end |
| 14 | end |
| 15 | return noDisclosedSocialInformation, noNotDisclosedSocialInformation, noDisclosures |
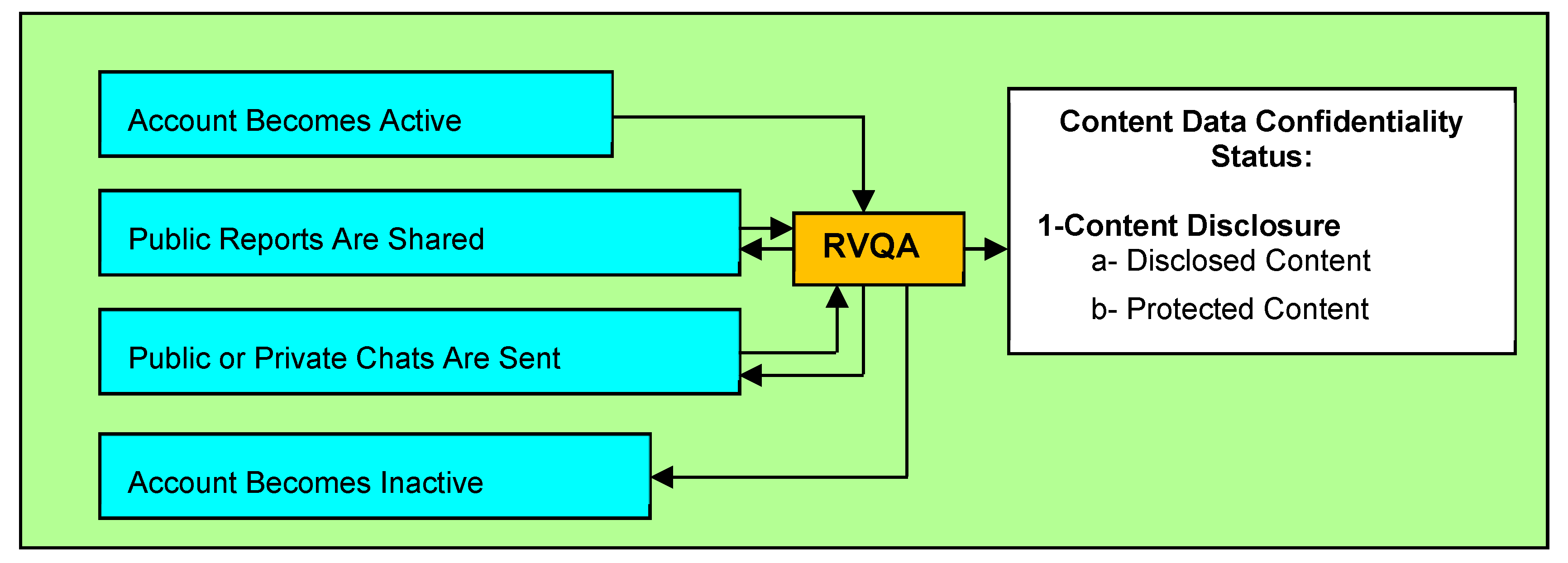
4.3.3. The RVQA Process at the Agent Content Level of the CNS
| Algorithm 3. Content confidentiality disclosures detection. | |
| Input: | Agent Index: x, Current Time: t |
| Output: | noDisclosedContent, noProtectedContent, noDisclosures |
| 1 | begin |
| 2 | if ContentShared(x,t) then |
| 3 | Critical(x,t) → true |
| 4 | if ContentPublic(x,t) then |
| 5 | ContentDisclosed(x,t) |
| 6 | increase(noDisclosedContent) |
| 7 | increase(noDisclosures) |
| 8 | end |
| 9 | if ContentPrivate(x,t) then |
| 10 | ContentProtected(x,t) |
| 11 | increase(noProtectedContent) |
| 12 | end |
| 13 | end |
| 14 | end |
| 15 | return noDisclosedContent, noProtectedContent, noDisclosures |
5. Experiment Procedure
5.1. RVQA Procedures for Detecting Data Confidentiality Violations
- For a single agent at the individual level, the RVQA obtained the number of individual data confidentiality violations, RVQASingleAgentIndividualDCV, by keeping track of the number of the agent accounts that disclosed its identity and location to the public, as shown in Equation (1):RVQASingleAgentIndividualDCV = noDisclosedIdentity + noDisclosedLocation
- For a single agent at the social level, the RVQA calculated the number of social data confidentiality violations, RVQASingleAgentSocialDCV, by including the number of established connections to the online social network. Equation (2) was used for the calculation:RVQASingleAgentSocialDCV = noDisclosedSocialInformation
- For a single agent at the content level, the RVQA calculated the number of content data confidentiality violations, RVQASingleAgentContentDCV, by including the amount of contents disclosed to the public. Equation (3) was used for the calculation:RVQASingleAgentContentDCV = noDisclosedContent
- The total number of data confidentiality violations detected by the RVQA from individual, social, and content levels for all agents in the executed CNS model, RVQATotalDetectedDCV, was calculated using Equation (4). In this experiment, x is the agent identification and n is the number of agents executed in CNS.
5.2. CNS Searching Procedures
- For a single agent at the individual level, CNS Searching obtained the number of individual data confidentiality violations by keeping track of the agent identity and locations that are exposed to the public, as shown in Equation (5):SearchingSingleAgentIndividualDCV = noDisclosedIdentity + noDisclosedLocation
- For a single agent at the social level, CNS Searching did not obtain any social data confidentiality violation as it did not consider the connection to a social network as a condition for data confidentiality violations.
- For a single agent at the content level, CNS Searching did not detect any social data confidentiality violation as it did not consider publicly published contents as a condition for data confidentiality violations.
- The total number of data confidentiality violations detected by CNS Searching for all agents in the executed CNS model, SearchingTotalDetectedDCV, was calculated using Equation (6). In this experiment, x is the agent identification and n is the number of agents executed in CNS.
6. Results and Discussion
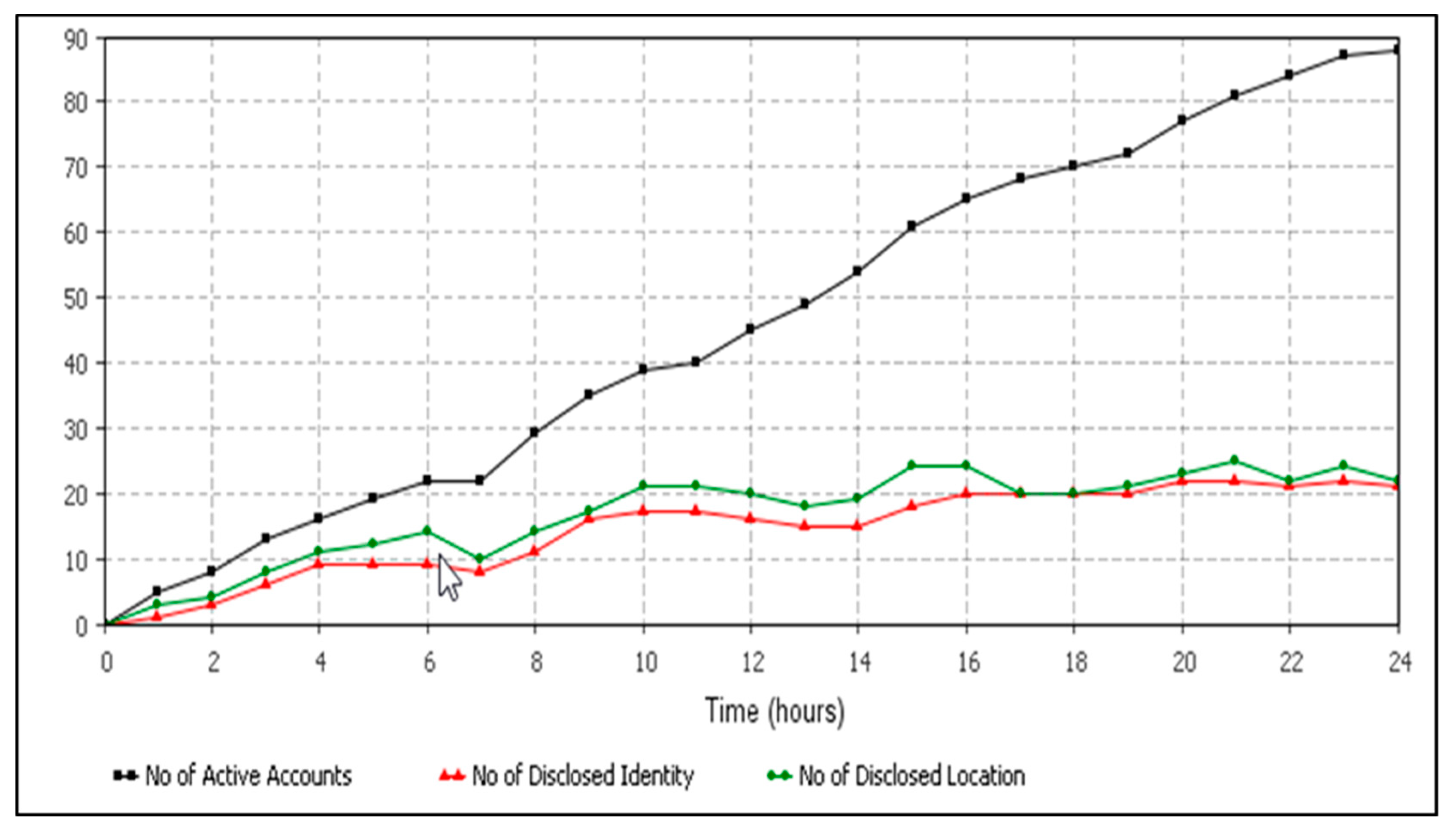
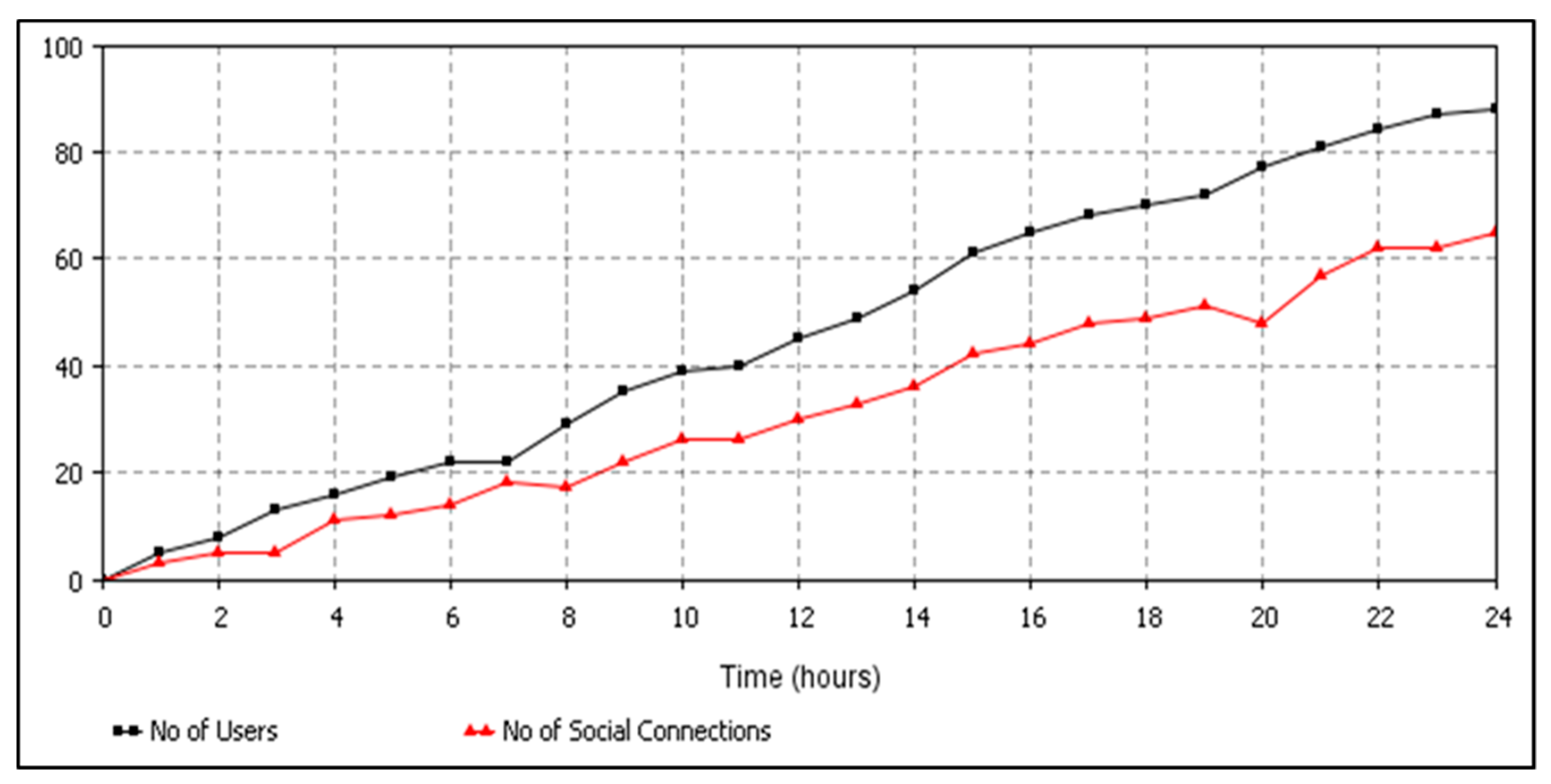
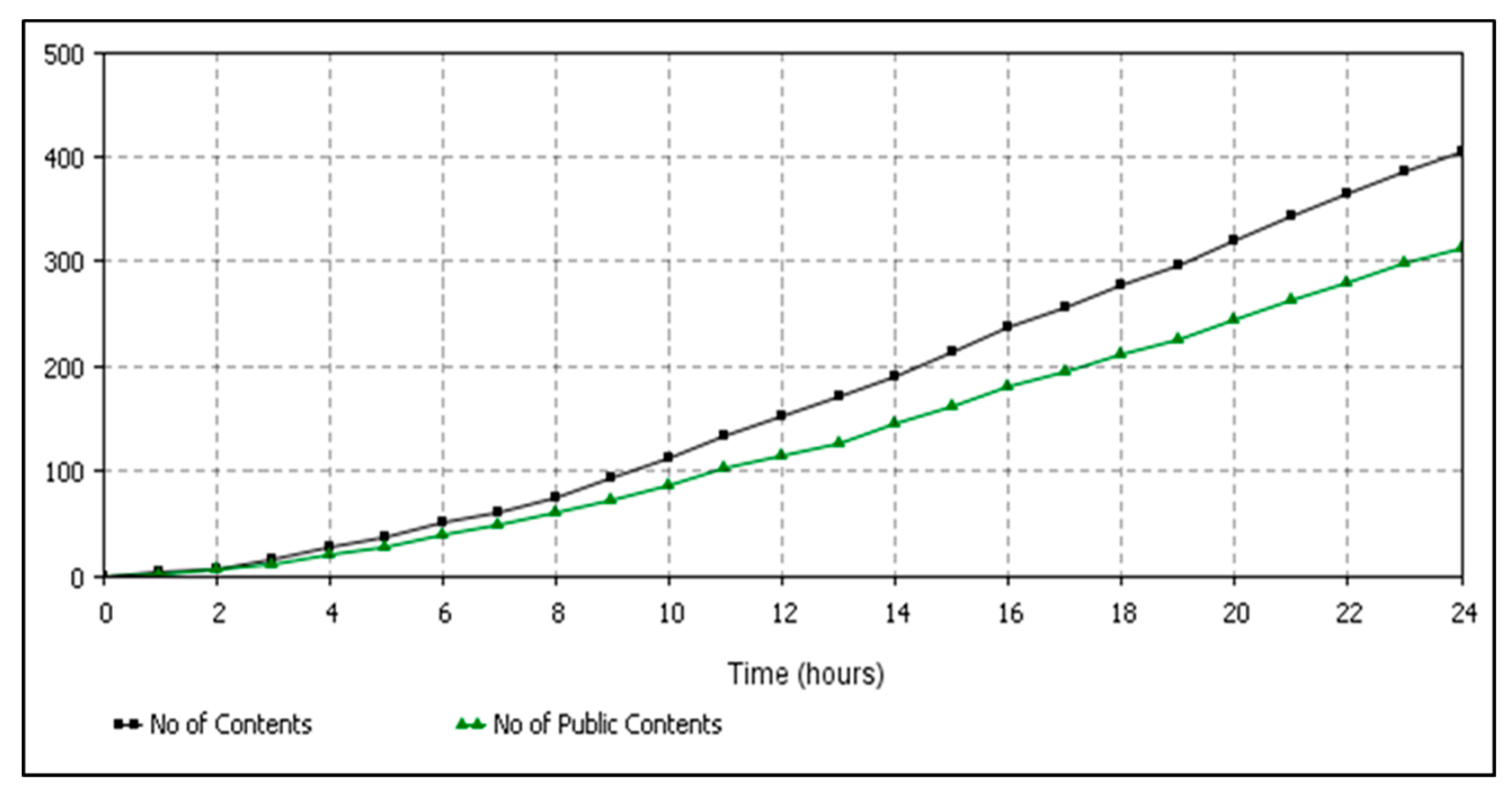
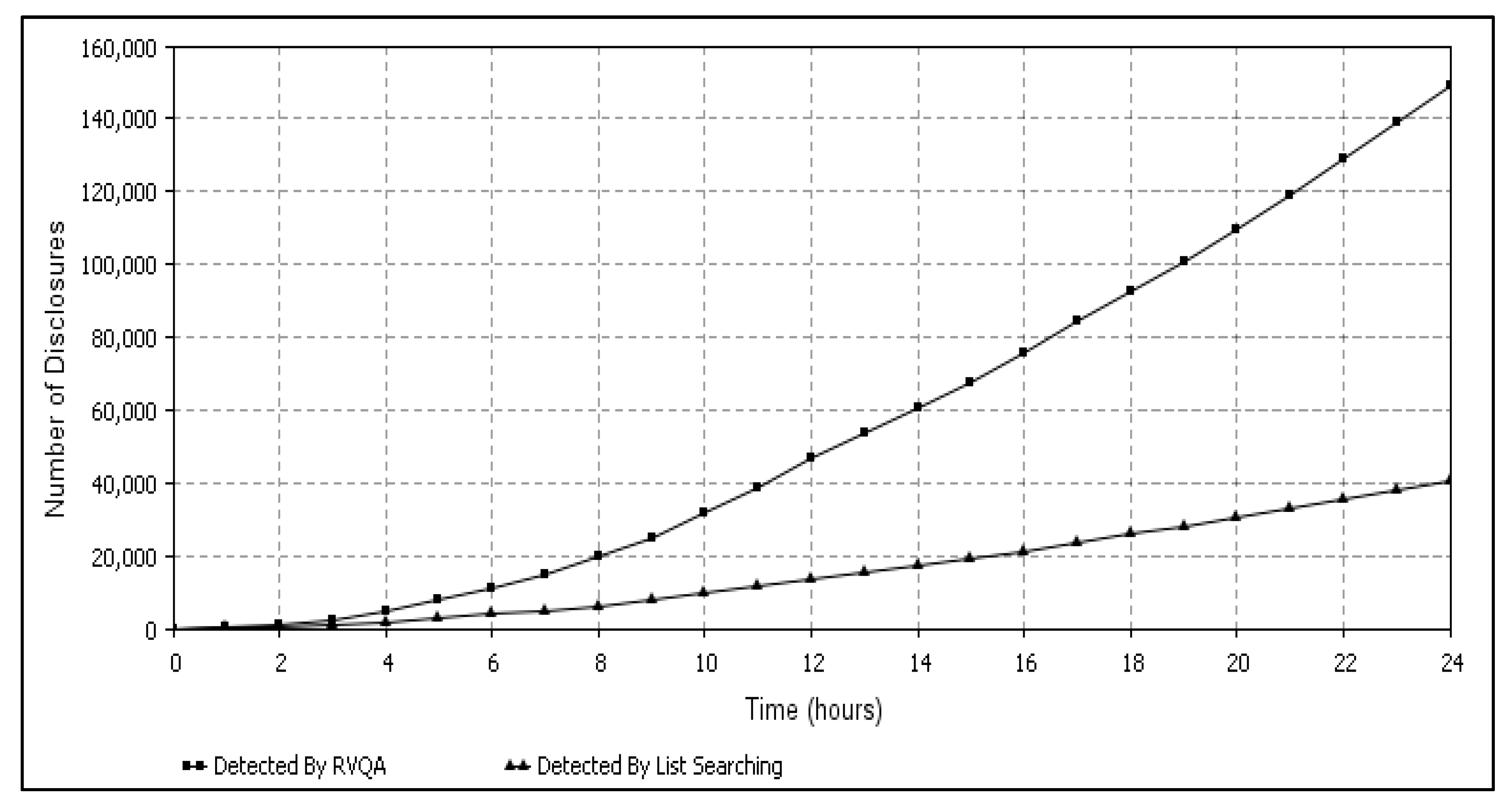
6.1. Data Confidentiality Violations Detection Results
6.2. Comparison of Data Confidentiality Violation Detection Results
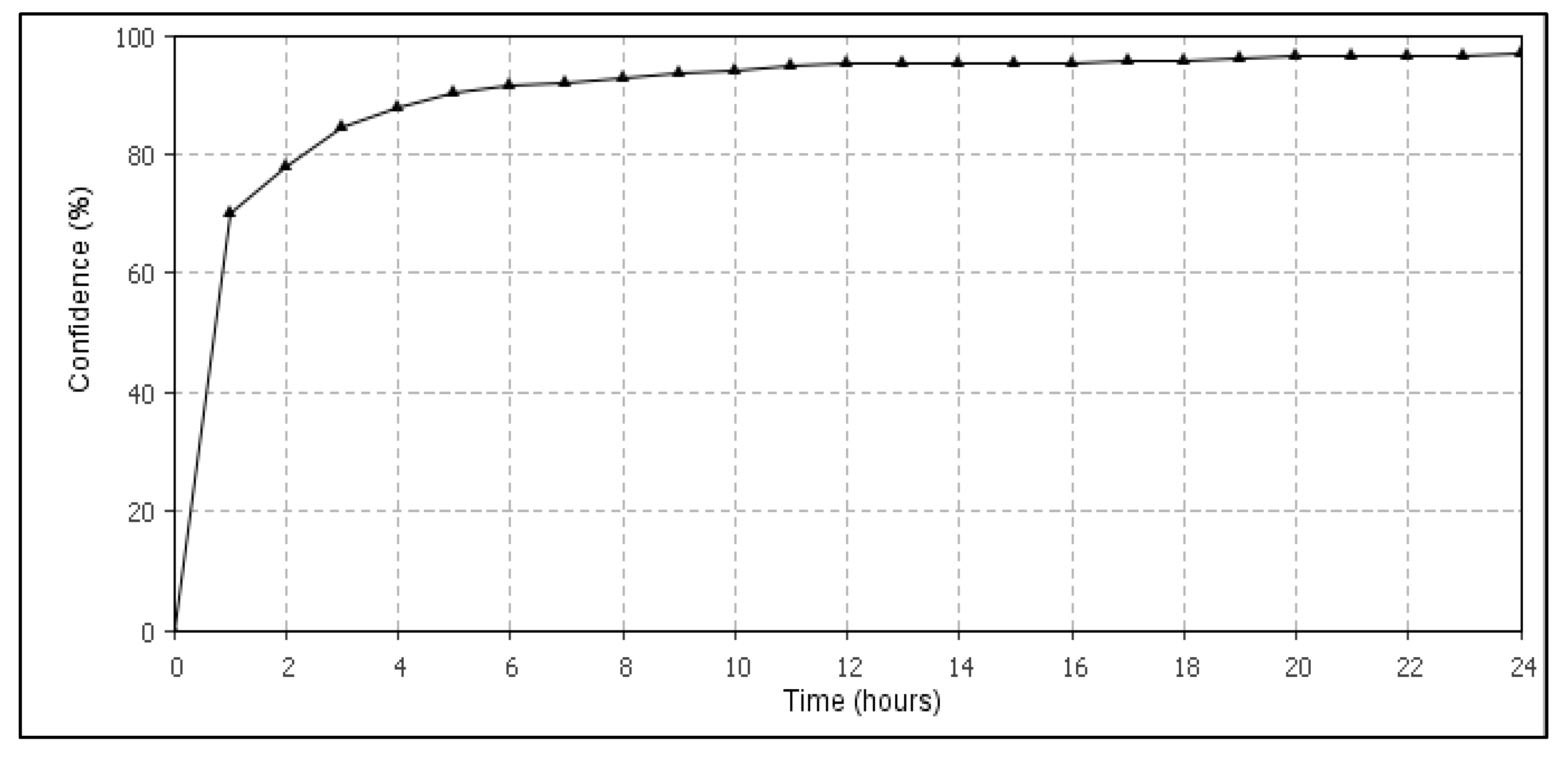
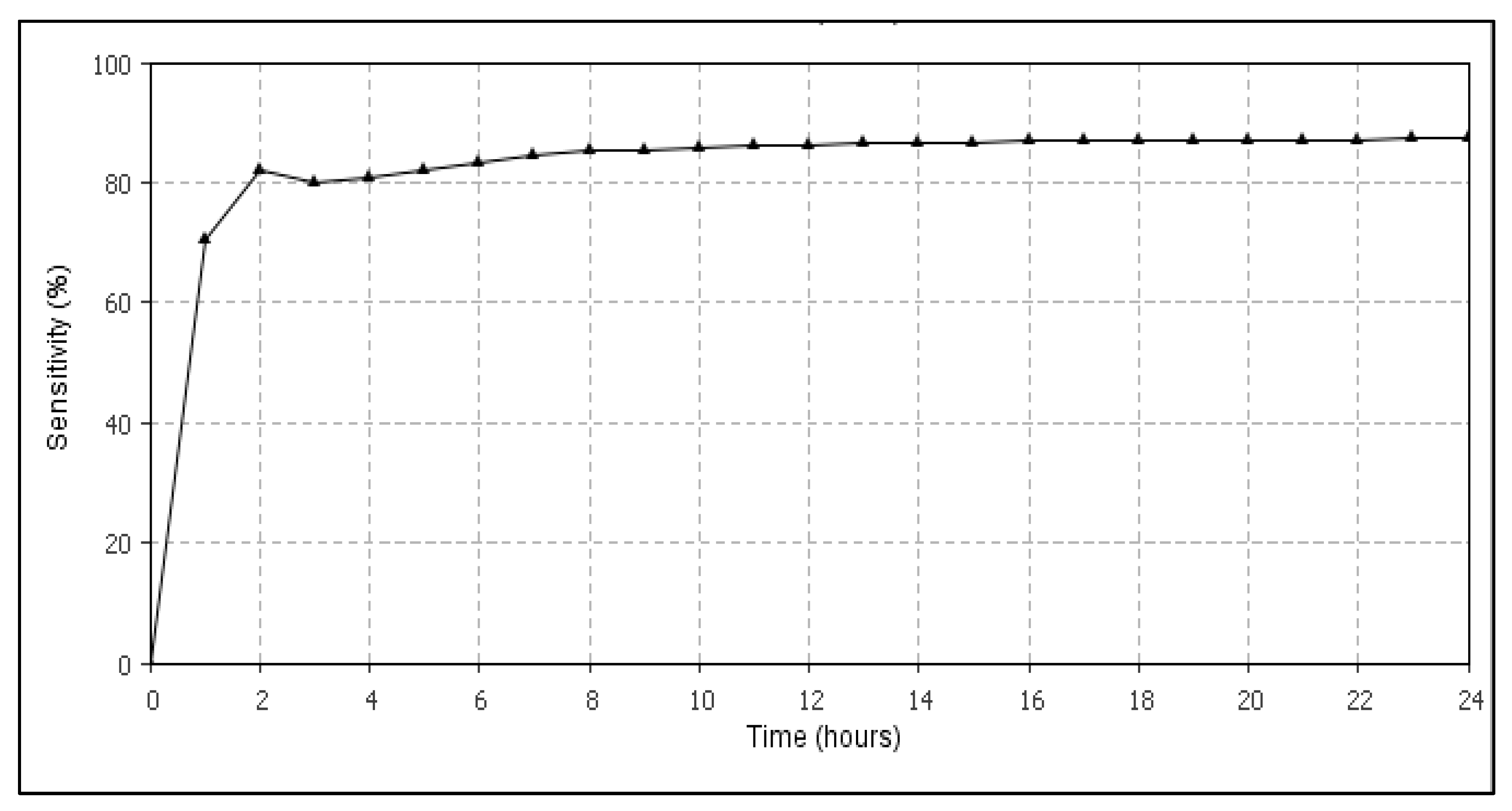
6.3. Results Validation Using Evaluation Metrics
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Eckhoff, D.; Wagner, I. Privacy in the Smart City—Applications, Technologies, Challenges, and Solutions. IEEE Commun. Surv. Tutor. 2017, 20, 489–516. [Google Scholar] [CrossRef]
- Feng, W.; Yan, Z.; Zhang, H.; Zeng, K.; Xiao, Y.; Hou, Y.T. A Survey on Security, Privacy and Trust in Mobile Crowdsourcing. IEEE Int. Things J. 2018, 5, 2971–2992. [Google Scholar] [CrossRef]
- Touq, A.B.; Ijeh, A. Information Security and Ecosystems in Smart Cities: The Case of Dubai. IJISSC 2018, 9, 16. [Google Scholar] [CrossRef]
- Loper, M.L. Situational Awareness in Megacities. In Technology and the Intelligence Community: Challenges and Advances for the 21st Century; Kosal, M.E., Ed.; Springer International Publishing: Cham, Switzerland, 2018; pp. 205–235. ISBN 978-3-319-75232-7. [Google Scholar] [CrossRef]
- Leitão, P.; Karnouskos, S. Industrial Agents: Emerging Applications of Software Agents in Industry; Industrial Agents, Morgan Kaufmann, Elsevier Inc.: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Bakar, N.A.; Selamat, A. Runtime Verification and Quality Assessment for Privacy Violations Detection in Social Networking System. In Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Netherlands, 2016; Volume 286, pp. 346–357. [Google Scholar]
- García-Magariño, I.; Lacuesta, R. ABS-SmartPriority: An Agent-Based Simulator of Strategies for Managing Self-Reported Priorities in Smart Cities. Wirel. Commun. Mob. Comput. 2017, 9, 7254181. [Google Scholar] [CrossRef]
- Hu, J.; Lin, H.; Guo, X.; Yang, J. DTCS: An Integrated Strategy for Enhancing Data Trustworthiness in Mobile Crowdsourcing. IEEE Internet Things J. 2018, 5, 4663–4671. [Google Scholar] [CrossRef]
- Zhang, K.; Ni, J.; Yang, K.; Liang, X.; Ren, J.; Shen, X.S. Security and Privacy in Smart City Applications: Challenges and Solutions. IEEE Commun. Mag. 2017, 55, 122–129. [Google Scholar] [CrossRef]
- Bakar, N.A.; Selamat, A. Agent systems verification: Systematic literature review and mapping. Appl. Intell. 2018, 48, 1251–1274. [Google Scholar] [CrossRef]
- Sabater, J.; Sierra, C. REGRET: A reputation model for gregarious societies. In Proceedings of the 4th Int. Workshop on Deception, Fraud and Trust in Agent Societies, Catalonia, Spain, 28 May–1 June 2001; Volume 73, pp. 194–195. [Google Scholar] [CrossRef]
- Carbo, J.; Molina, J.M.; Davila, J. Trust Management Through Fuzzy Reputation. Int. J. Coop. Inf. Syst. 2003, 12, 135–155. [Google Scholar] [CrossRef]
- Qureshi, B.; Min, G.; Kouvatsos, D. Collusion detection and prevention with FIRE+ trust and reputation model. In Proceedings of the 10th IEEE International Conference on Computer and Information Technology, Bradford, UK, 29 June–1 July 2010; pp. 2548–2555. [Google Scholar] [CrossRef]
- Nusrat, S.; Vassileva, J. Recommending services in a trust-based decentralized user modeling system. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2012; Volume 7138 LNCS, pp. 230–242. ISBN 9783642285080. [Google Scholar]
- Sadra, A.; Samira, S. A trust-based service suggestion system using human plausible reasoning. Appl. Intell. 2014, 41, 55–75. [Google Scholar]
- Yu, E.; Cysneiros, L.M. Designing for privacy in a multi-agent world. In Lecture Notes in Artificial Intelligence (Subseries of Lecture Notes in Computer Science); Springer: Berlin/Heidelberg, Germany, 2003; Volume 2631, pp. 209–223. ISSN 0302-9743. [Google Scholar]
- Piolle, G.; Demazeau, Y.; Caelen, J. Privacy Management in User-Centred Multi-agent Systems. In Proceedings of the 7th International Workshop on Engineering Societies in the Agents World VII (ESAW’07), Dublin, Ireland, 6–8 September 2006; Volume 4457, pp. 354–367, ISBN 9783540755241. [Google Scholar]
- Krupa, Y. Privacy as Contextual Integrity in Decentralized Multi-Agent Systems. Ph.D. Thesis, Ecole Nationale Supérieure des Mines de Saint-Etienne, Saint-Etienne, France, 2012. Available online: http://www.theses.fr/2012EMSE0657 (accessed on 29 October 2019).
- Husseini, Z.M.; Zarandi, M.F.; Husseini, S.M. Trust evaluation for buyer-supplier relationship concerning fuzzy approach. In Proceedings of the 2015 Annual Conference of the North American Fuzzy Information Processings of the Society (NAFIPS) Held Jointly with 2015 5th World Conference on Soft Computing (WConSC), Redmond, WA, USA, 17–19 August 2015; pp. 1–6. [Google Scholar]
- Aref, A.; Tran, T. FTE: A Fuzzy Logic Based Trust Establishment Model for Intelligent Agents. In Proceedings of the 2015 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Singapore, 6–9 December 2015; Volume 2, pp. 133–138. [Google Scholar]
- Aref, A.; Tran, T. Modeling Trust Evaluating Agents: Towards a Comprehensive Trust Management for Multi-agent Systems. In Proceedings of the Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Rishwaraj, G.; Ponnambalam, S.G.; Kiong, L.C. An efficient trust estimation model for multi-agent systems using temporal difference learning. Neural Comput. Appl. 2016, 28, 461–474. [Google Scholar] [CrossRef]
- Singh, M.M.; Chin, T.Y. Hybrid Multi-faceted Computational Trust Model for Online Social Network (OSN). Int. J. Adv. Comput. Sci. Appl. 2016, 7, 1–11. [Google Scholar] [CrossRef]
- Gharib, M.; Giorgini, P.; Mylopoulos, J. Towards an Ontology for Privacy Requirements via a Systematic Literature Review. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2017; Volume 10650 LNCS, pp. 193–208. ISBN 9783319699035. [Google Scholar] [CrossRef]
- Maglaras, L.A.; Al-Bayatti, A.H.; He, Y.; Wagner, I.; Janicke, H. Social Internet of Vehicles for Smart Cities. J. Sens. Actuator Netw. 2016, 5, 3. [Google Scholar] [CrossRef]
- Hassan, N.H.; Rahim, F.A. The Rise of Crowdsourcing Using Social Media Platforms: Security and Privacy Issues. Pertanika J. Sci. Technol. 2017, 25, 79–88. [Google Scholar]
- Khan, Z.; Pervez, Z.; Ghafoor, A. Towards Cloud Based Smart Cities Data Security and Privacy Management. In Proceedings of the 2014 IEEE/ACM 7th International Conference on Utility and Cloud Computing, London, UK, 8–11 December 2014; pp. 806–811. [Google Scholar] [CrossRef]
- Moffat, S.; Hammoudeh, M.; Hegarty, R. A Survey on Ciphertext-Policy Attribute-based Encryption (CP-ABE) Approaches to Data Security on Mobile Devices and Its Application to IoT. In Proceedings of the International Conference on Future Networks and Distributed Systems, ICFNDS ’17, Cambridge, UK, 19–20 July 2017; ISBN 978-1-4503-4844-7. [Google Scholar] [CrossRef]
- Hernández-Ramos, J.; Bernabe, J.; Moreno, M.; Skarmeta, A. Preserving Smart Objects Privacy through Anonymous and Accountable Access Control for a M2M-Enabled Internet of Things. Sensors 2015, 15, 15611–15639. [Google Scholar] [CrossRef] [PubMed]
- Shehada, D.; Yeun, C.Y.; Zemerly, M.J.; Al-Qutayri, M.; Al Hammadi, Y. Secure Mobile Agent Protocol for Vehicular Communication Systems in Smart Cities. In Information Innovation Technology in Smart Cities; Springer: Singapore, 2017. [Google Scholar]
- Zhang, F.; Lee, V.E.; Jin, R.; Garg, S.; Choo, K.K.R.; Maasberg, M.; Dong, L.; Cheng, C. Privacy-aware smart city: A case study in collaborative filtering recommender systems. J. Parallel Distrib. Comput. 2018, 127, 145–159. [Google Scholar] [CrossRef]
- Joy, J.; McGoldrick, C.; Gerla, M. Mobile Privacy-Preserving Crowdsourced Data Collection in the Smart City; Scientific Challenges in Data and Event-driven Smart City Service and Applications (SDESS 2016); Cornell University: Irvine, CA, USA, 2016; pp. 1–6. [Google Scholar]
- Barata, J.; Cunha, P.R. Synergies between quality management and information systems: A literature review and map for further research. Total Qual. Manag. Bus. Excell. 2017, 28, 282–295. [Google Scholar] [CrossRef]
- Srima, S.; Wannapiroon, P.; Nilsook, P. Design of Total Quality Management Information System (TQMIS) for Model School on Best Practice. Procedia Soc. Behav. Sci. 2015, 174, 2160–2165. [Google Scholar] [CrossRef]
- Wang, R.Y. A product perspective on total data quality management. Commun. ACM 1998, 41, 58–65. [Google Scholar] [CrossRef]
- Agarwal, N.; Yiliyasi, Y. Information quality challenges in social media. In Proceedings of the 15th International Conference on Information Quality (ICIQ-2010), Little Rock, AR, USA, 12–14 November 2010; pp. 234–248. [Google Scholar]
- Idris, N.; Ahmad, K. Managing Data Source quality for data warehouse in manufacturing services. In Proceedings of the 2011 International Conference on Electrical Engineering and Informatics, Bandung, Indonesia, 17–19 July 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Moges, H.T.; Dejaeger, K.; Lemahieu, W.; Baesens, B. A multidimensional analysis of data quality for credit risk management: New insights and challenges. Inf. Manag. 2013, 50, 43–58. [Google Scholar] [CrossRef]
- Endler, G.; Schwab, P.K.; Wahl, A.M.; Tenschert, J.; Lenz, R. An Architecture for Continuous Data Quality Monitoring in Medical Centers. In Studies in Health Technology and Informatics; US National Library of Medicine National Institutes of Health: Bethesda, MD, USA, 2015; pp. 852–856. [Google Scholar] [CrossRef]
- AnyLogic. AnyLogic: Multimethod Simulation Software. 2017. Available online: http://www.anylogic.com/ (accessed on 29 October 2019).
- Bellifemine, F.L.; Caire, G.; Greenwood, D. Developing Multi-Agent Systems with JADE; John Wiley & Sons, Ltd.: West Sussex, UK, 2007. [Google Scholar]
- Cougaar Software Inc. Cougaar Agent Architecture. 2019. Available online: http://www.cougaarsoftware.com/ (accessed on 29 October 2019).
- Bordini, R.H.; Hübner, J.F.; Wooldridge, M. Programming Multi-Agent Systems in Agent Speak Using Jason; John Wiley & Sons, Ltd.: West Sussex, UK, 2017. [Google Scholar]
- Botía, J.A.; Gómez-Sanz, J.J.; Pavón, J. Intelligent Data Analysis for the Verification of Multi-Agent Systems Interactions. In International Conference on Intelligent Data Engineering and Automated Learning (Lecture Notes in Computer Science); Corchado, E., Yin, H., Botti, V., Fyfe, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1207–1214. [Google Scholar]
- Bakar, N.A.; Selamat, A. Analyzing model checking approach for multi agent system verification. In Proceedings of the 2011 5th Malaysian Conference in Software Engineering, MySEC 2011, Johor Bahru, Malaysia, 3–14 December 2011; pp. 95–100, ISBN 9781457715310. [Google Scholar] [CrossRef]
- Naumann, F. Quality-Driven Query Answering for Integrated Information Systems; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Naumann, F. Data Profiling Revisited; ACM SIGMOD Record: New York, NY, USA, 2014; Volume 42, pp. 40–49. [Google Scholar]
- Borshchev, A. Simulation Modeling with AnyLogic: Agent Based. Discrete Event Syst. Dynam. Methods 2013, 225–269. [Google Scholar]
- Lindamood, J.; Heatherly, R.; Kantarcioglu, M.; Thuraisingham, B. Inferring private information using social network data. In Proceedings of the 18th International Conference on World wide web WWW 09, Madrid, Spain, 20–24 April 2009; pp. 1145–1146. [Google Scholar] [CrossRef]
- Zheleva, E.; Getoor, L. To Join or Not to Join: The Illusion of Privacy in Social Networks with Mixed Public and Private User Profiles. Security. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; Volume 7, pp. 531–540. [Google Scholar] [CrossRef]
- Bakar, N.A.; Selamat, A. Detection of data confidentiality violations using Runtime Verification and Quality Assessment. In Proceedings of the 2016 2nd International Symposium on Agent, Multi-Agent Systems and Robotics (ISAMSR), Bangi, Malaysia, 23–24 August 2016; pp. 22–26. [Google Scholar]
- ISO/IEC 10181-5:1996. Information Technology—Open Systems Interconnection—Security Frameworks for open Systems: Confidentiality Framework. Last reviewed and conformed in 2006. Available online: https://www.iso.org/standard/24329.html (accessed on 29 October 2019).
- Waze. Waze: Privacy Issues. Available online: https://wiki.waze.com/wiki/Privacy_issues (accessed on 29 October 2019).
- Ricardo, B.Y.; Berthier, R.N. Modern Information Retrieval: The Concepts and Technology behind Search; ACM Press Books; IEEE: New York, NY, USA, 2011. [Google Scholar]
- Jacques, J.; Taillard, J.; Delerue, D.; Jourdan, L.; Dhaenens, C. MOCA-I: Discovering rules and guiding decision maker in the context of partial classification in large and imbalanced datasets. In Learning and Intelligent Optimization; Nicosia, G., Pardalos, P., Eds.; Springer Nature: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Pehcevski, J.; Piwowarski, B. Evaluation Metrics; Encyclopedia of Database Systems; Liu, L., Tamer Özsu, M., Eds.; Springer Nature: Berlin/Heidelberg, Germany, 2007. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Agent Quality Management Literature | Quality Properties | ||||
|---|---|---|---|---|---|---|
| Trust | Reputation | Privacy | Confidentiality | Integrity | ||
| 1 | REGRET [11] | - | ✓ | - | - | - |
| 2 | AFRAS [12] | ✓ | ✓ | - | - | - |
| 3 | i*framework [16] | - | - | ✓ | - | - |
| 4 | FIRE+ [13] | ✓ | ✓ | - | - | - |
| 5 | Privacy Management [17] | - | - | ✓ | - | - |
| 6 | [14] | ✓ | ✓ | - | - | - |
| 7 | PrivaCIAS [18] | - | - | ✓ | - | ✓ |
| 8 | ScubAA [15] | ✓ | ✓ | - | - | - |
| 9 | [19] | ✓ | - | - | - | - |
| 10 | FTE [20] | ✓ | ✓ | - | - | - |
| 11 | TEIF [21] | ✓ | ✓ | - | - | - |
| 12 | [22] | ✓ | - | - | - | - |
| 13 | [23] | - | - | ✓ | - | - |
| No. | Proposed Solutions | Quality Properties | |||
|---|---|---|---|---|---|
| Trust | Privacy | Confidentiality | Integrity | ||
| 1 | Security and privacy framework [27] | ✓ | ✓ | - | - |
| 2 | Anonymous and Accountable Access Control Design [29] | - | ✓ | - | - |
| 3 | Authorized Analytics Architecture [32] | - | ✓ | ✓ | - |
| 4 | Secure Mobile Agent Protocol (SMAP) [30] | - | - | ✓ | ✓ |
| 5 | Ciphertext-Policy Attribute-based Encryption (CP-ABE) [28] | - | - | ✓ | - |
| 6 | Privacy-preserving collaborative filtering model [31] | - | ✓ | - | - |
| 7 | Data trustworthiness enhanced crowdsourcing strategy (DTCS) [8] | ✓ | - | - | - |
| No. | Agent Tools | Features | ||||
|---|---|---|---|---|---|---|
| Design | Modelling | Simulation | Development | Analysis | ||
| 1 | AnyLogic [40] | √ | √ | √ | √ | √ |
| 2 | Java Agent Development Framework (JADE) [41] | √ | ||||
| 3 | Cougaar [42] | √ | ||||
| 4 | Jason [43] | √ | ||||
| 5 | ACLAnalyzer [44] | √ | ||||
| Experiment | # Expected Data Confidentiality Violations | # Detected Using RVQA | Average Confidence of RVQA | Average Sensitivity of RVQA |
|---|---|---|---|---|
| 1 | 152,628 | 137,373 | 89.72% | 80.74% |
| 2 | 180,896 | 161,985 | 88.14% | 79.30% |
| 3 | 135,692 | 122,489 | 84.57% | 82.78% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abu Bakar, N.; Selamat, A.; Krejcar, O. Improving Agent Quality in Dynamic Smart Cities by Implementing an Agent Quality Management Framework. Appl. Sci. 2019, 9, 5111. https://doi.org/10.3390/app9235111
Abu Bakar N, Selamat A, Krejcar O. Improving Agent Quality in Dynamic Smart Cities by Implementing an Agent Quality Management Framework. Applied Sciences. 2019; 9(23):5111. https://doi.org/10.3390/app9235111
Chicago/Turabian StyleAbu Bakar, Najwa, Ali Selamat, and Ondrej Krejcar. 2019. "Improving Agent Quality in Dynamic Smart Cities by Implementing an Agent Quality Management Framework" Applied Sciences 9, no. 23: 5111. https://doi.org/10.3390/app9235111