Prediction Interval Adjustment for Load-Forecasting using Machine Learning


 ,
,  and
and 
Abstract
Featured Application
Abstract
1. Introduction
2. Literature Review
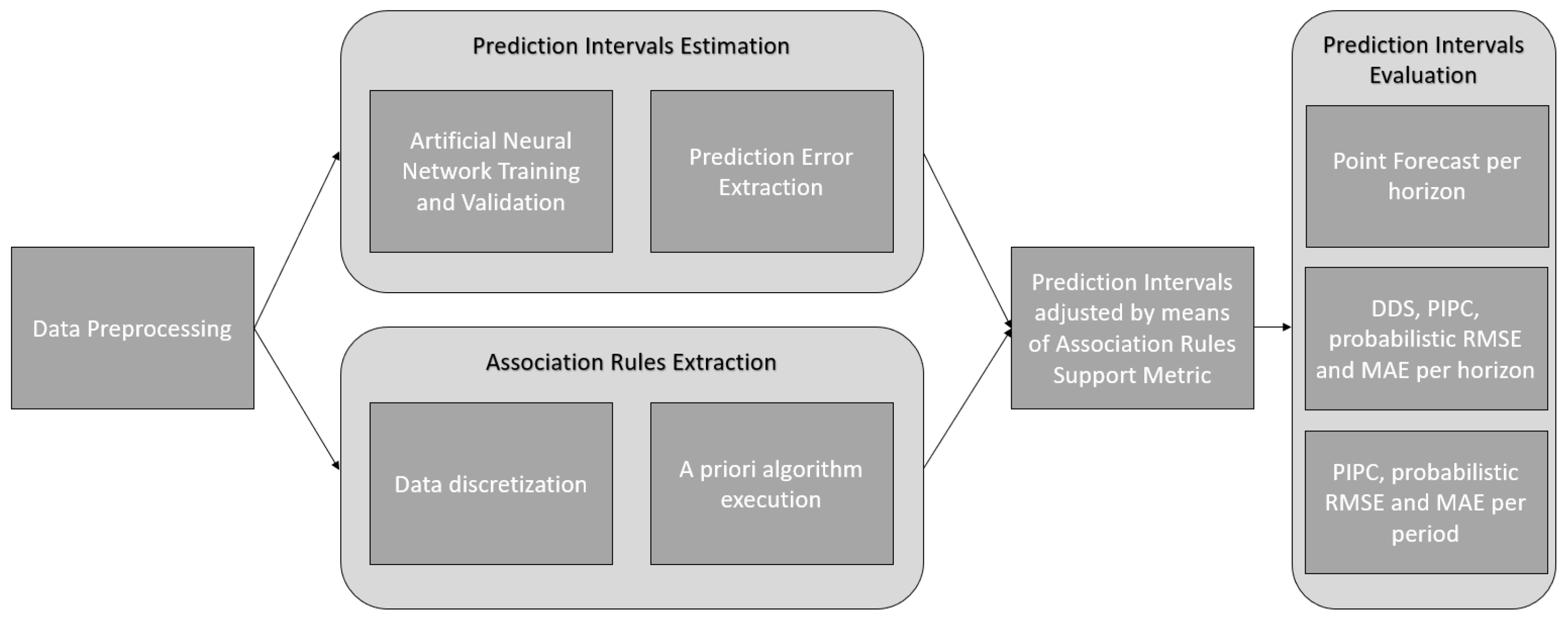
3. Materials and Methods
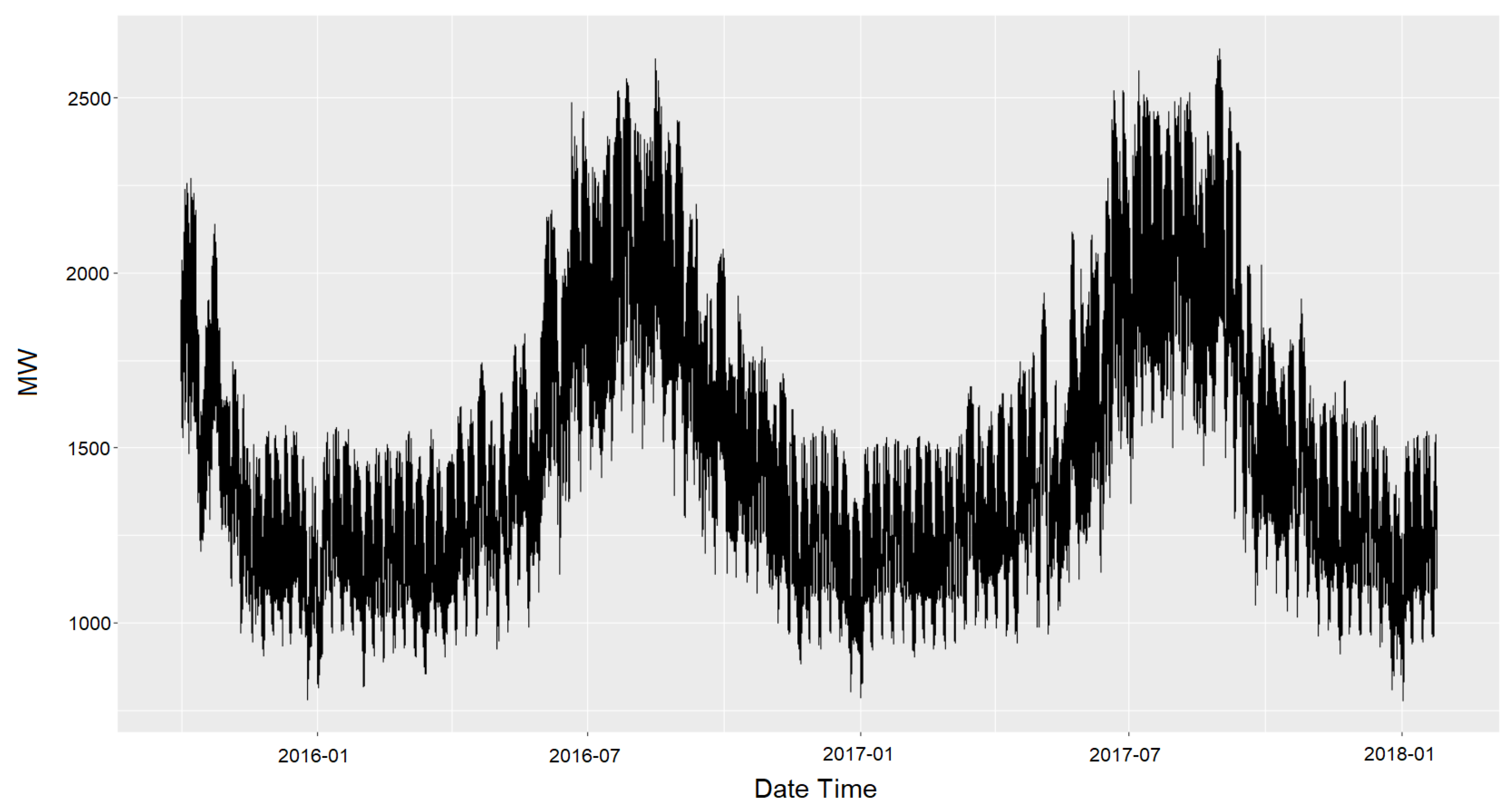
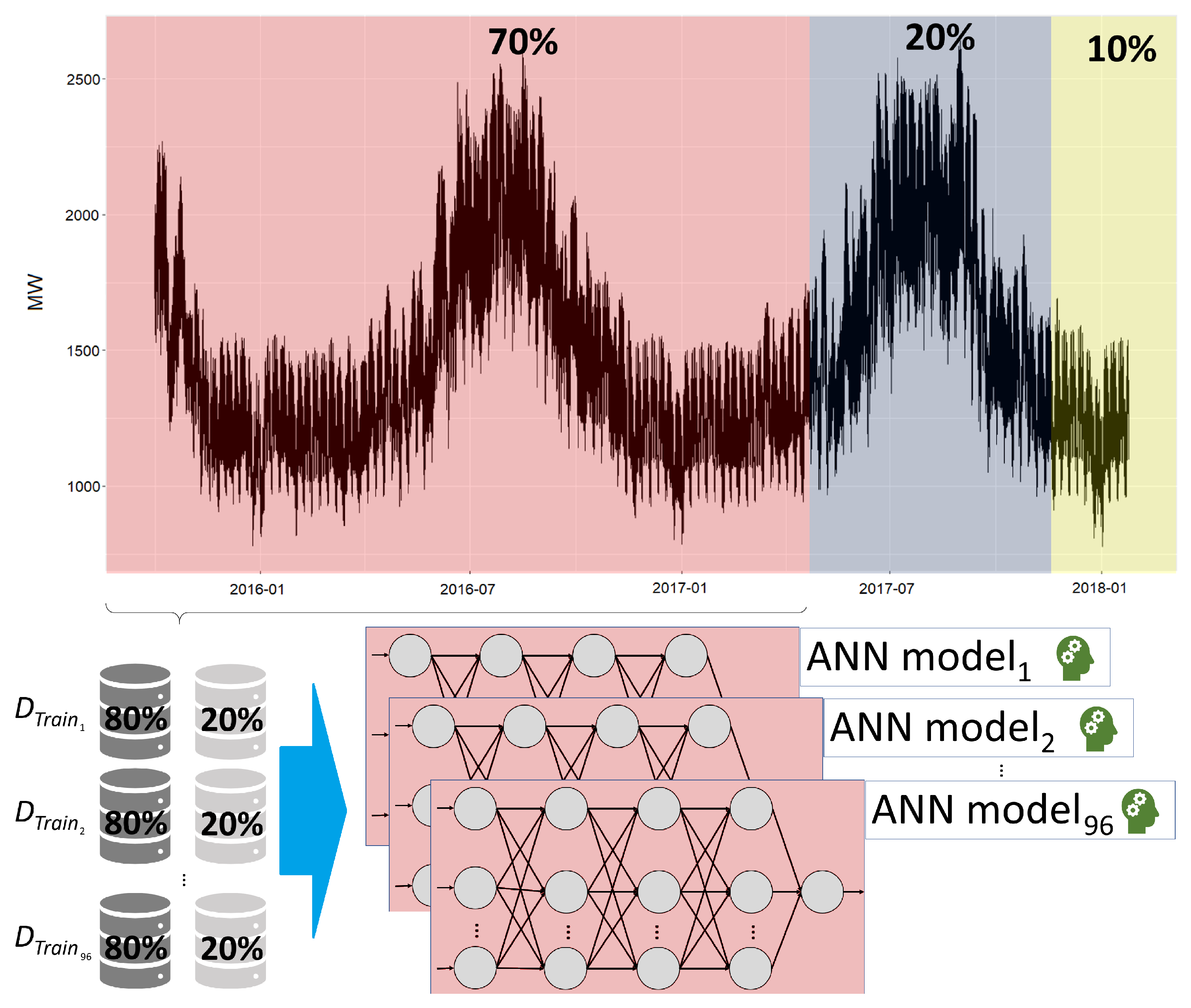
3.1. Data Preprocessing
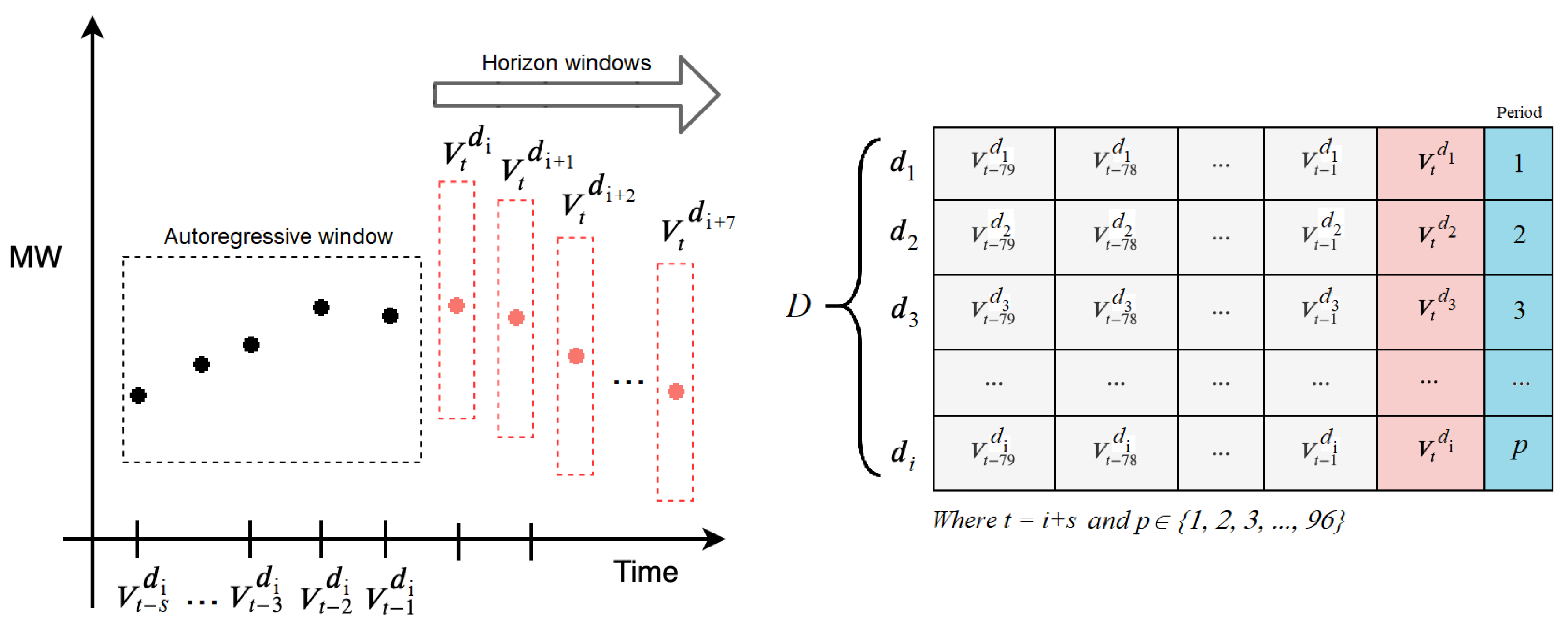
3.1.1. Load Data Embedding
3.2. Prediction Interval Estimation
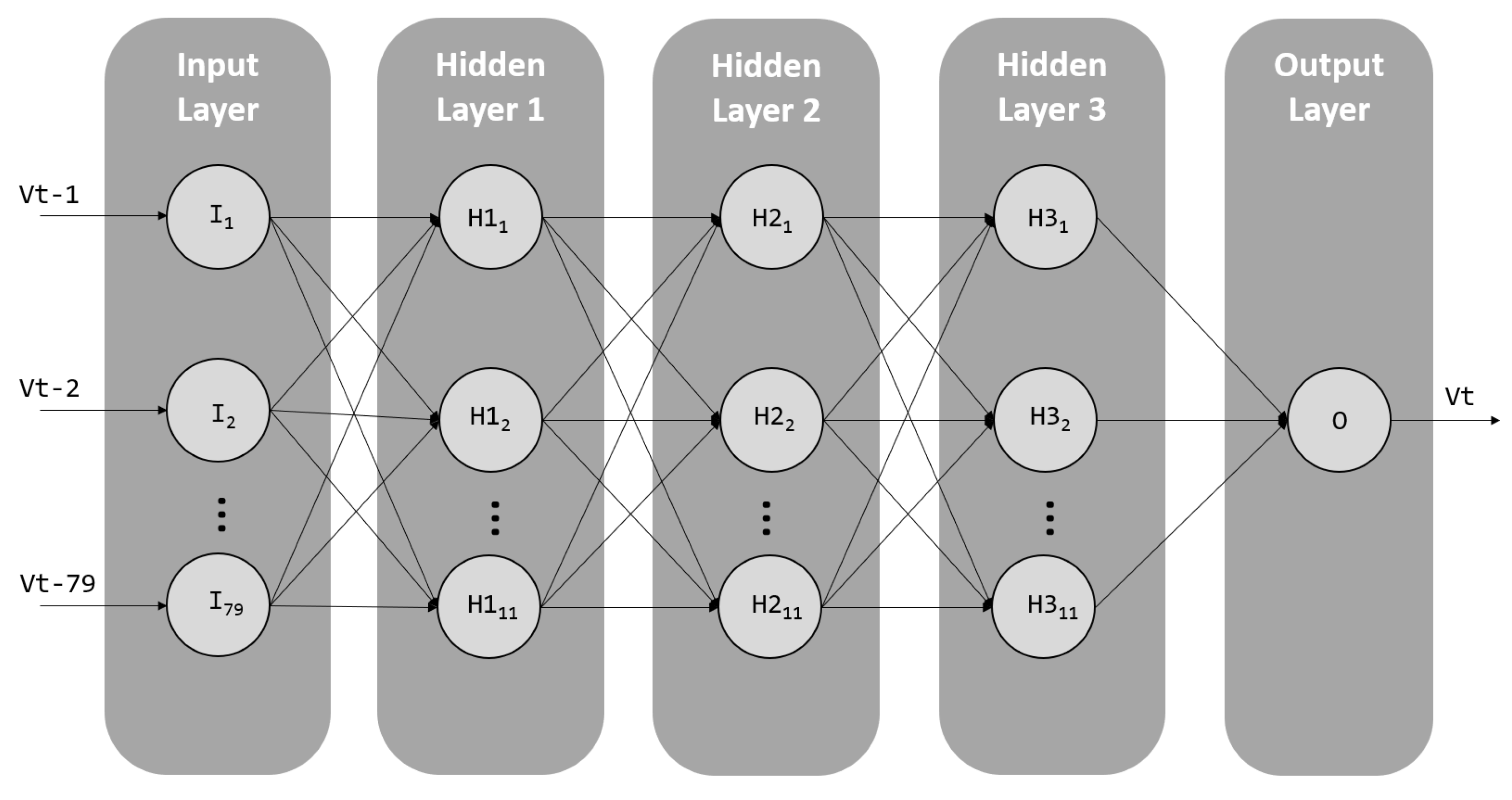
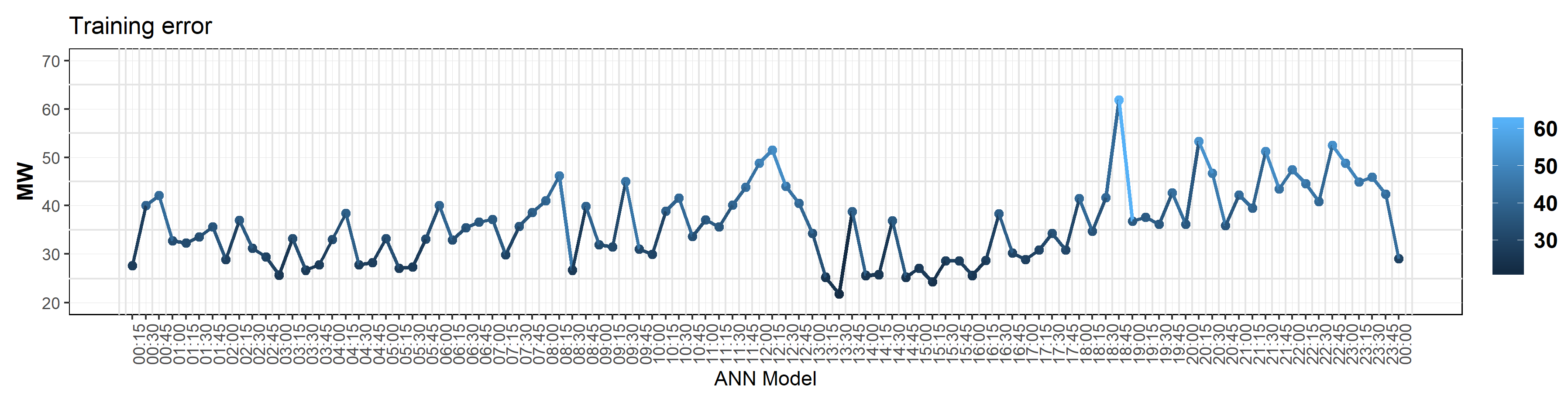
3.2.1. Artificial Neural Network Training and Validation
3.2.2. Prediction Error Extraction
3.3. Association Rules Extraction
3.3.1. Data Discretization
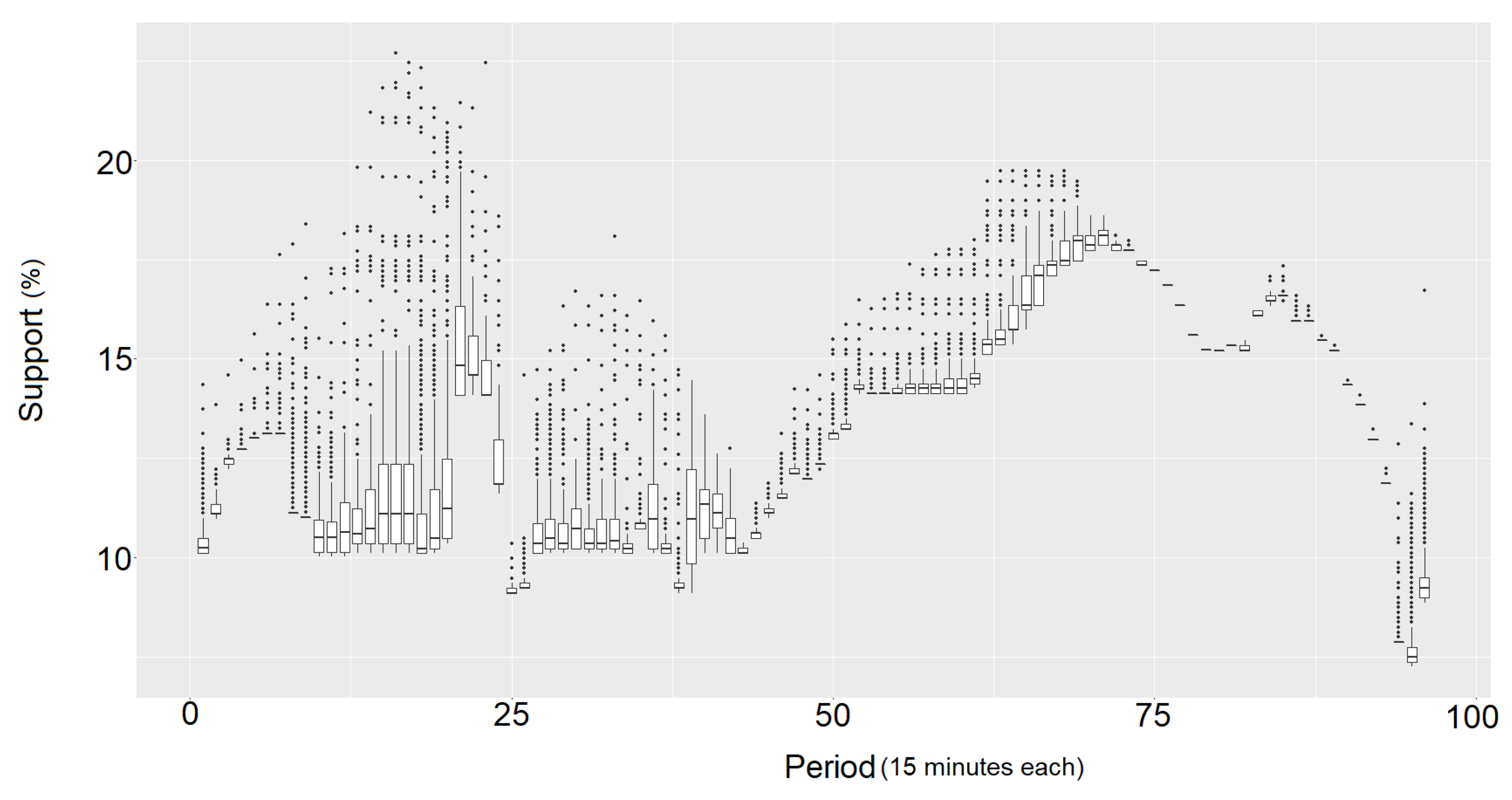
3.4. Prediction Intervals Adjusted by Means of Association Rules Support Metric
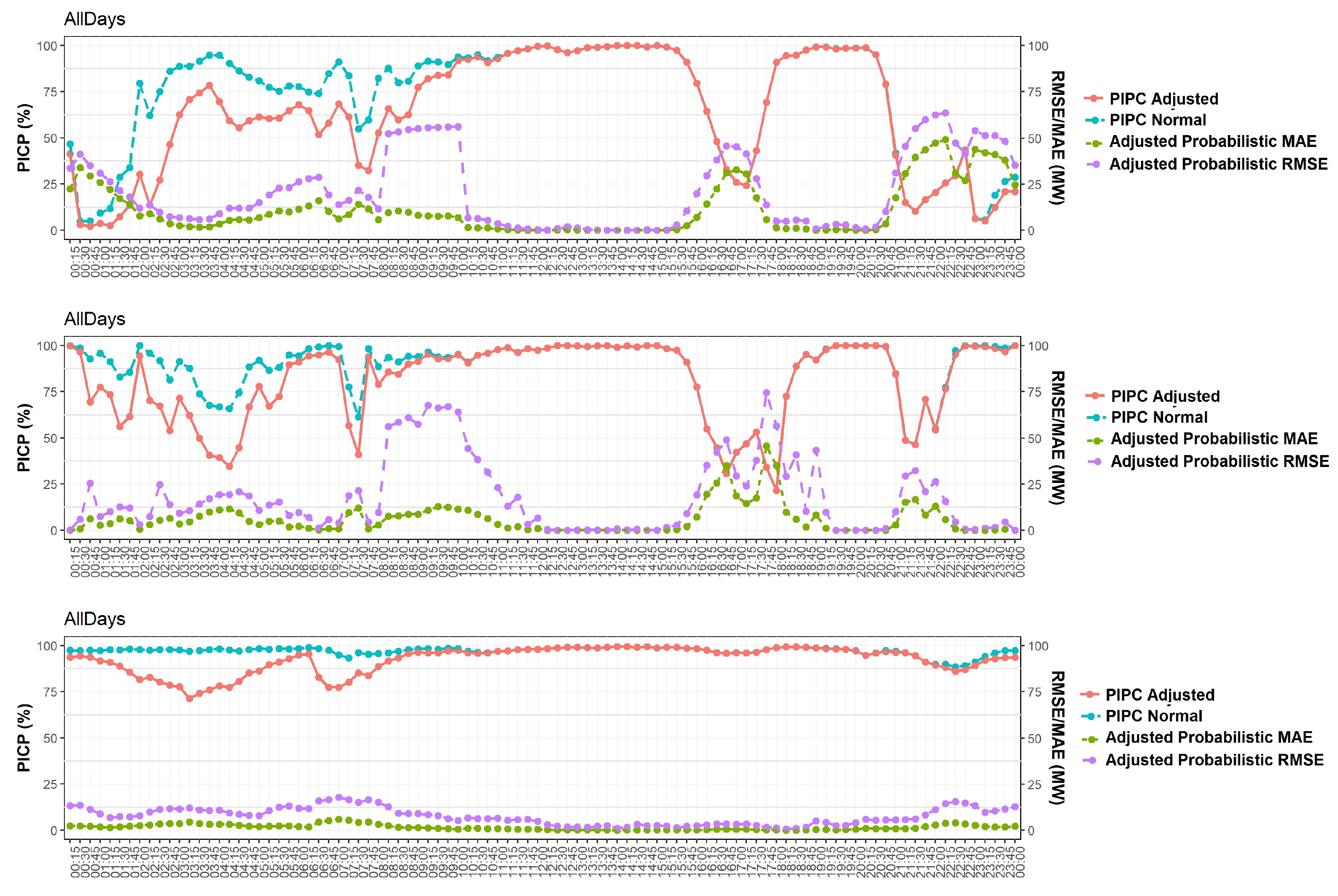
4. Experiments and Results
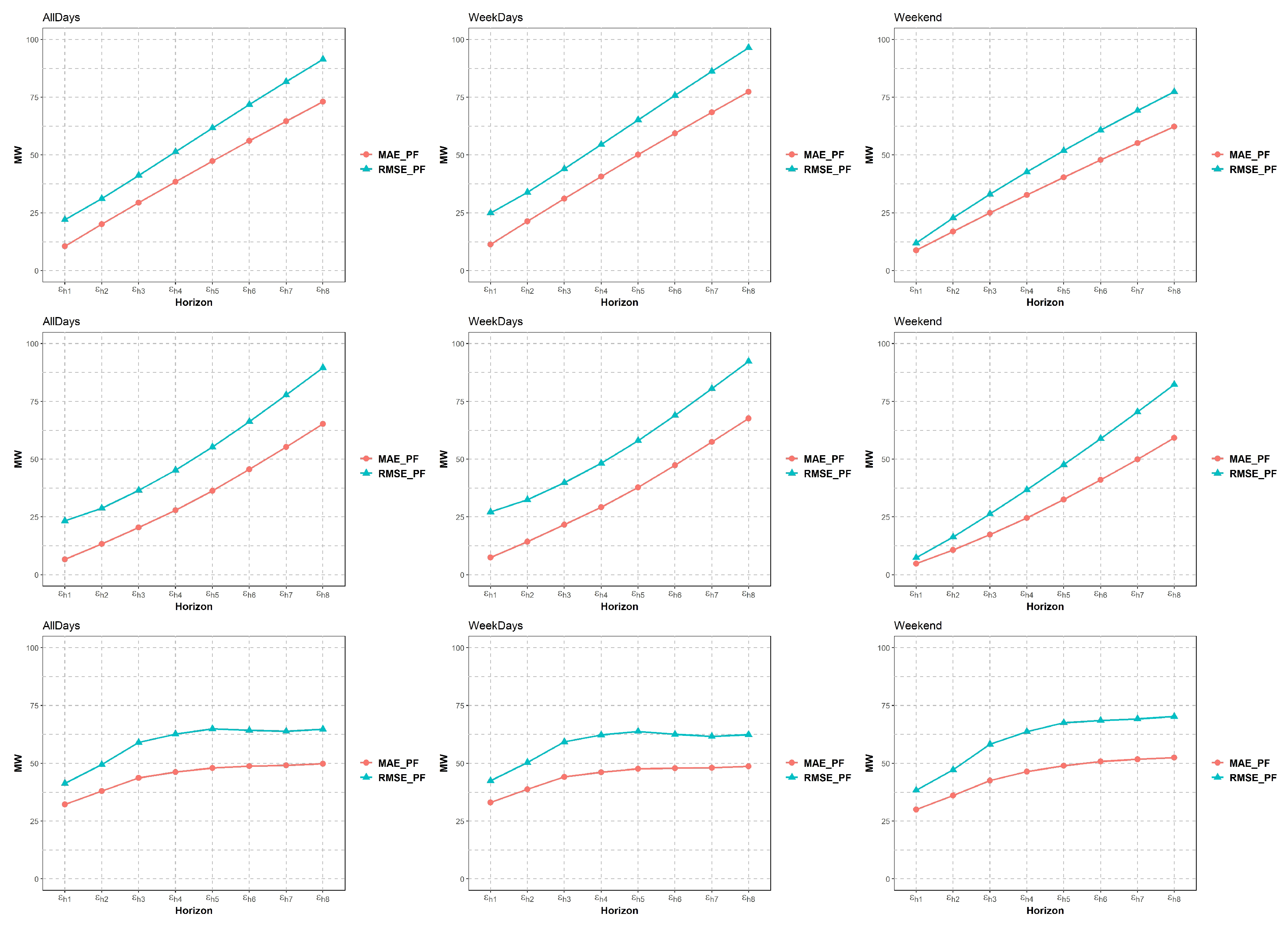
- Calculate Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) for the point forecasts for each horizon.
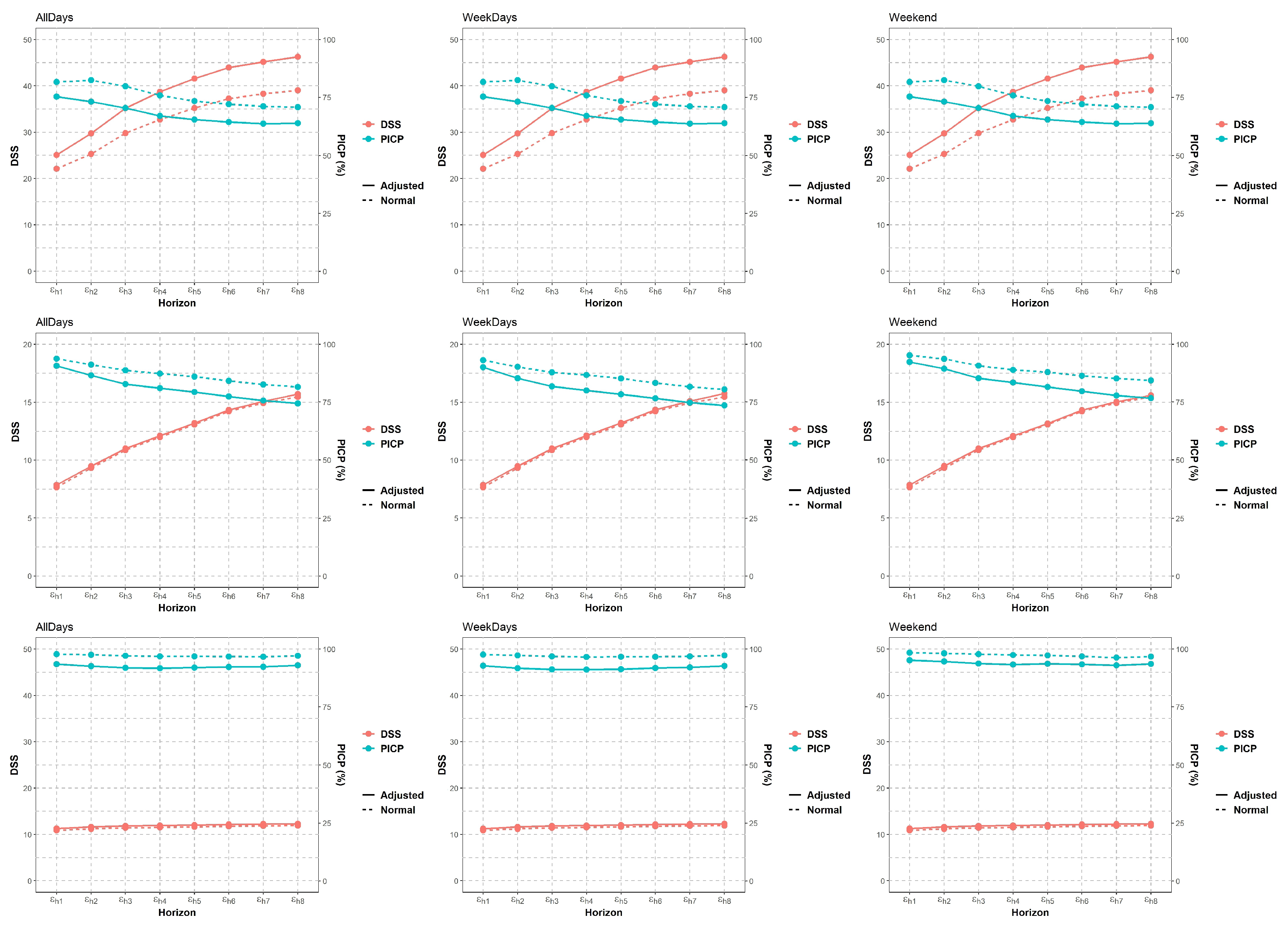
- Calculate the Dawid–Sebastiani score (DSS) and Prediction Interval Coverage Probability (PIPC) along with Probabilistic RMSE and MAE per horizon.
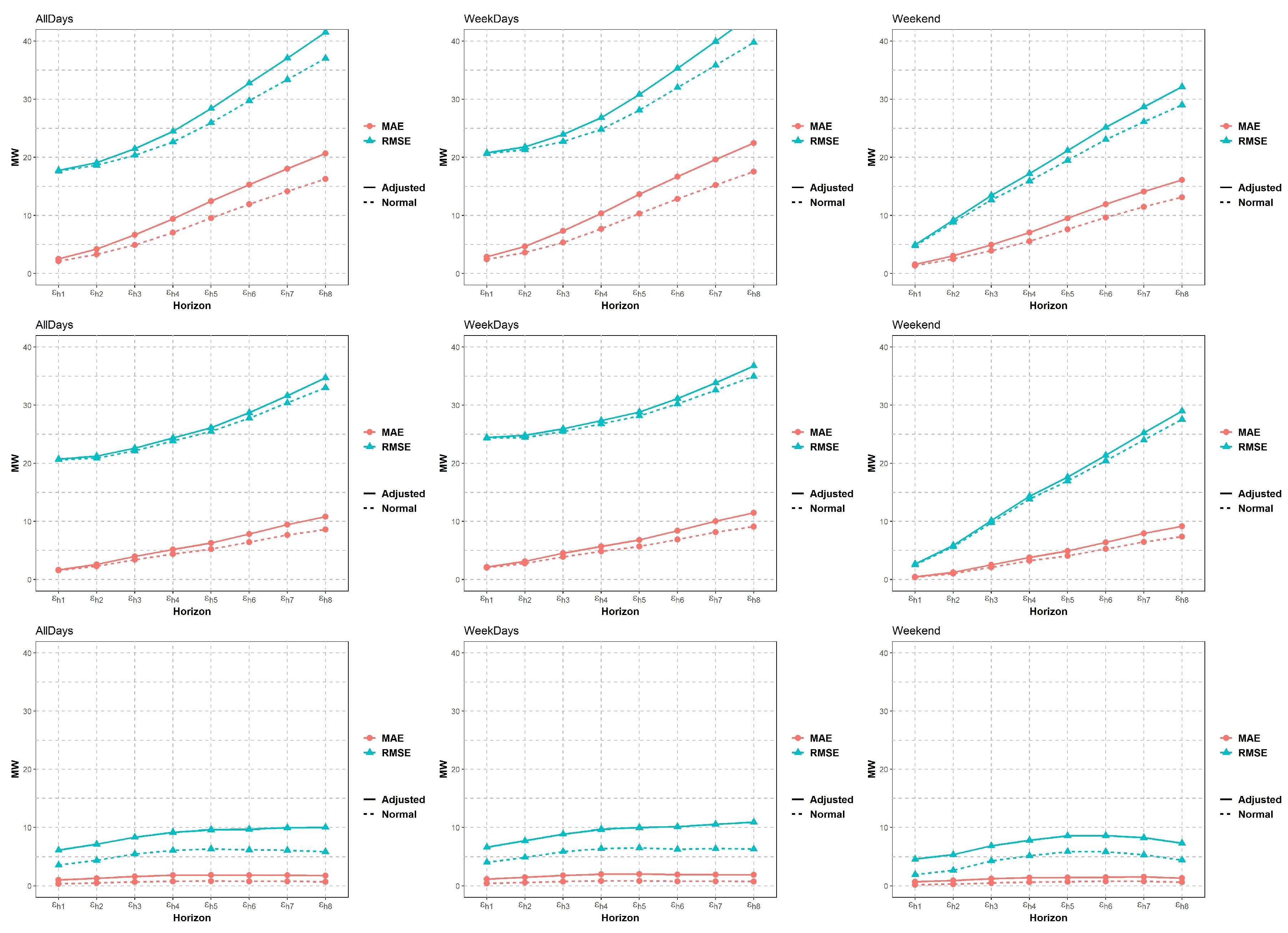
- Estimate PIPC and probabilistic RMSE and MAE of the Adjusted prediction interval per period.
4.1. Prediction Intervals Evaluation Metrics
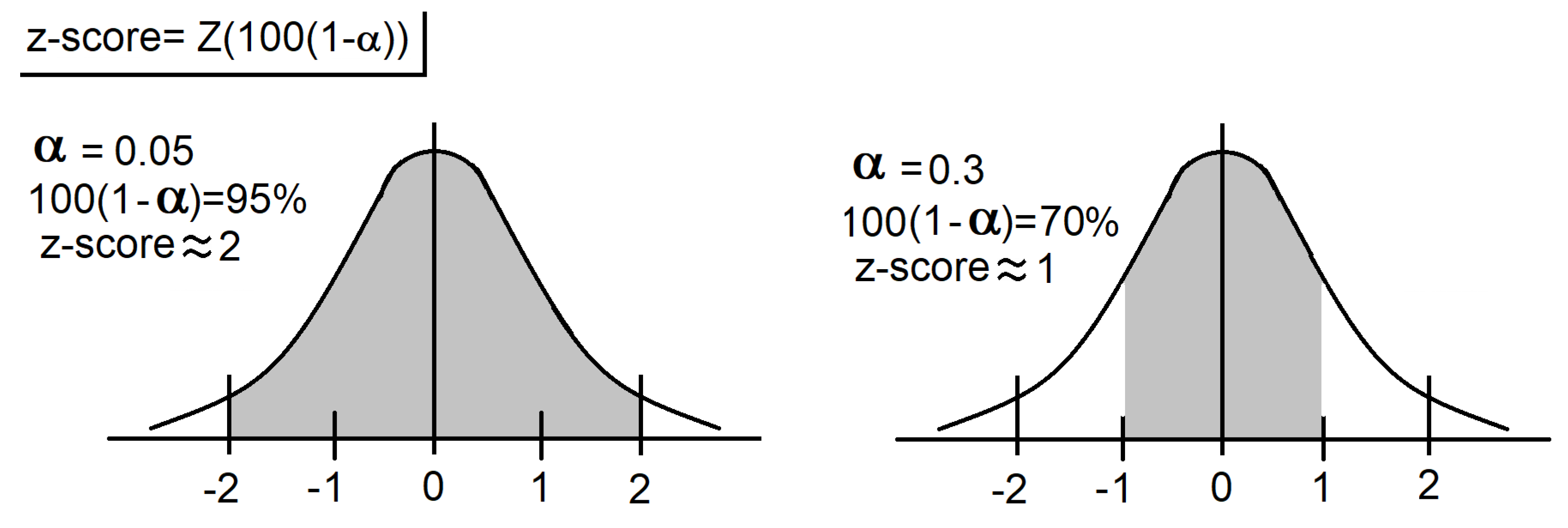
4.1.1. PICP (Prediction Interval Coverage Probability)
4.1.2. Probabilistic and Point-Forecast RMSE (Root Mean Squared Error) and MAE (Mean Absolute error)
4.1.3. DSS (Dawid–Sebastiani Score)
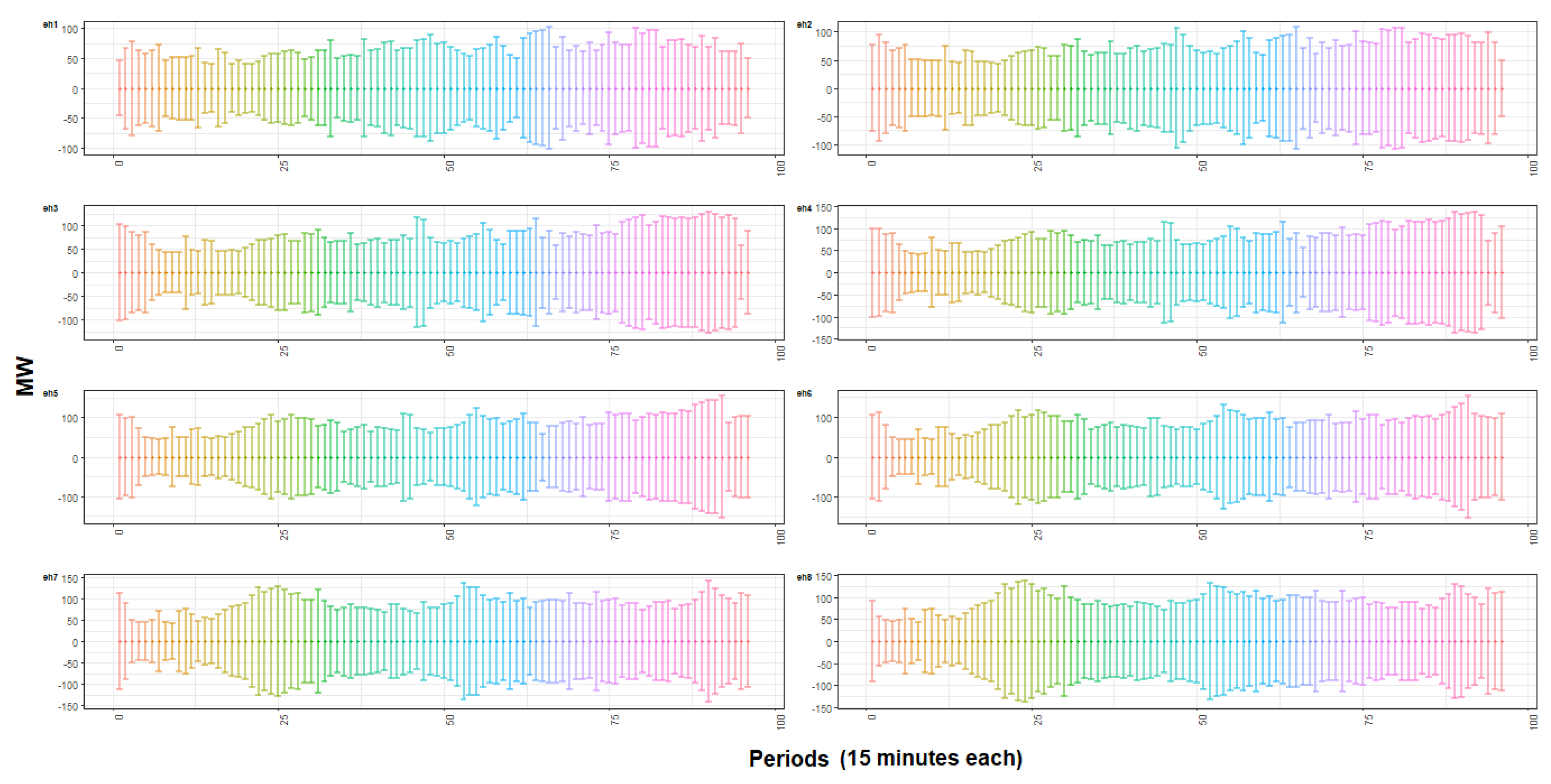
4.2. Results and Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Association Rules
Appendix A.1. Measures of Interest
Appendix B. The a priori Algorithm
| Algorithm A1 a priori algorithm Pseudocode. |
|
References
- Oconnell, N.; Pinson, P.; Madsen, H.; Omalley, M. Benefits and challenges of electrical demand response: A critical review. Renew. Sustain. Energy Rev. 2014, 39, 686–699. [Google Scholar] [CrossRef]
- Alfares, H.K.; Nazeeruddin, M. Electric load forecasting: Literature survey and classification of methods. Int. J. Syst. Sci. 2002, 33, 23–34. [Google Scholar] [CrossRef]
- Fan, S.; Hyndman, R.J. Short-term load forecasting based on a semi-parametric additive model. IEEE Trans. Power Syst. 2012, 27, 134–141. [Google Scholar] [CrossRef]
- SENER; Secretaría de Energía (MX). Acuerdo por el que se emite el Manual de Mercado de Energía de Corto Plazo; Published Reform in 2016-06-17 Second Section; Diario Oficial de la Federación (DOF): Ciudad de México, México, 2016; pp. 10–76. [Google Scholar]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Almeshaiei, E.; Soltan, H. A methodology for Electric Power Load Forecasting. Alex. Eng. J. 2011, 50, 137–144. [Google Scholar] [CrossRef]
- Lee, D.; Park, Y.G.; Park, J.B.; Roh, J.H. Very short-Term wind power ensemble forecasting without numerical weather prediction through the predictor design. J. Electr. Eng. Technol. 2017, 12, 2177–2186. [Google Scholar]
- Martínez-Álvarez, F.; Troncoso, A.; Asencio-Cortés, G.; Riquelme, J. A Survey on Data Mining Techniques Applied to Electricity-Related Time Series Forecasting. Energies 2015, 8, 13162–13193. [Google Scholar] [CrossRef]
- Burda, M.; Štěpnička, M.; Štěpničková, L. Fuzzy Rule-Based Ensemble for Time Series Prediction: Progresses with Associations Mining. In Strengthening Links Between Data Analysis and Soft Computing; Springer International Publishing: Cham, Switzerland, 2015; Volume 315, pp. 261–271. [Google Scholar] [CrossRef]
- Yadav, M.; Jain, S.; Seeja, K.R. Prediction of Air Quality Using Time Series Data Mining. In Opinion Mining of Saubhagya Yojna for Digital India; Springer: Singapore, 2019; Volume 55, pp. 13–20. [Google Scholar] [CrossRef]
- Wang, C.; Zheng, X. Application of improved time series Apriori algorithm by frequent itemsets in association rule data mining based on temporal constraint. Evol. Intell. 2019. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Zabkowski, T. Data mining techniques for detecting household characteristics based on smart meter data. Energies 2015, 8, 7407–7427. [Google Scholar] [CrossRef]
- Singh, S.; Yassine, A. Big Data Mining of Energy Time Series for Behavioral Analytics and Energy Consumption Forecasting. Energies 2018, 11, 452. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D. Construction of optimal prediction intervals for load forecasting problems. IEEE Trans. Power Syst. 2010, 25, 1496–1503. [Google Scholar] [CrossRef]
- Quan, H.; Srinivasan, D.; Khosravi, A.; Nahavandi, S.; Creighton, D. Construction of neural network-based prediction intervals for short-term electrical load forecasting. In Proceedings of the IEEE Symposium on Computational Intelligence Applications in Smart Grid (CIASG), Singapore, 16–19 April 2013; pp. 66–72. [Google Scholar]
- Rana, M.; Koprinska, I.; Khosravi, A.; Agelidis, V.G. Prediction intervals for electricity load forecasting using neural networks. In Proceedings of the International Joint Conference on Neural Networks, Dallas, TX, USA, 4–9 August 2013. [Google Scholar]
- Moulin, L.S.; da Silva, A.P.A. Neural Network Based Short-Term Electric Load Forecasting with Confidence Intervals. IEEE Trans. Power Syst. 2000, 15, 1191–1196. [Google Scholar]
- Liu, H.; Han, Y.H. An electricity load forecasting method based on association rule analysis attribute reduction in smart grid. Front. Artif. Intell. Appl. 2016, 293, 429–437. [Google Scholar]
- Chiu, C.C.; Kao, L.J.; Cook, D.F. Combining a neural network with a rule-based expert system approach for short-term power load forecasting in Taiwan. Expert Syst. Appl. 1997, 13, 299–305. [Google Scholar] [CrossRef]
- Box, G.E.P.; Tiao, G.C. Intervention Analysis with Applications to Economic and Environmental Problems. J. Am. Stat. Assoc. 1975, 70, 70–79. [Google Scholar] [CrossRef]
- Chatfield, C. Time-Series Forecasting, 1st ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2000. [Google Scholar]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice, 2nd ed.; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer New York Inc.: New York, NY, USA, 2001. [Google Scholar]
- Heaton, J. Introduction to Neural Networks for Java, 2nd ed.; Heaton Research, Inc.: Washington, DC, USA, 2008. [Google Scholar]
- Jeff, H. The Number of Hidden Layers. Available online: https://www.heatonresearch.com/2017/06/01/hidden-layers.html (accessed on 21 August 2017).
- Riedmiller, M. Rprop-Description and Implementation Details. Available online: http://www.inf.fu-berlin.de/lehre/WS06/Musterererkennung/Paper/rprop.pdf (accessed on 1 September 2017).
- Chang, H.; Nakaoka, S.; Ando, H. Effect of shapes of activation functions on predictability in the echo state network. arXiv 2019, arXiv:1905.09419. [Google Scholar]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining Association Rules Between Sets of Items in Large Databases. SIGMOD Rec. 1993, 22, 207–216. [Google Scholar] [CrossRef]
- Frawley, W.J.; Piatetsky-Shapiro, G.; Matheus, C.J. Knowledge Discovery in Databases—An Overview. Knowl. Discov. Databases 1992, 1–30. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Fan, Y. Sample Quantiles in Statistical Packages. Am. Stat. 1996, 50, 361–365. [Google Scholar]
- Quan, H.; Srinivasan, D.; Khosravi, A. Uncertainty handling using neural network-based prediction intervals for electrical load forecasting. Energy 2014, 73, 916–925. [Google Scholar] [CrossRef]
- Czado, C.; Gneiting, T.; Held, L. Predictive Model Assessment for Count Data. Biometrics 2009, 65, 1254–1261. [Google Scholar] [CrossRef] [PubMed]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series Forecasting: The forecast Package for R. J. Stat. Softw. 2008, 27. [Google Scholar] [CrossRef]
- Coimbra, C.F.; Pedro, H.T. Chapter 15—Stochastic-Learning Methods. In Solar Energy Forecasting and Resource Assessment; Kleissl, J., Ed.; Academic Press: Boston, MA, USA, 2013; pp. 383–406. [Google Scholar]
- CENACE. Servicios Conexos. Available online: https://www.cenace.gob.mx/SIM/VISTA/REPORTES/ServConexosSisMEM.aspx (accessed on 30 November 2019).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Value |
|---|---|
| Minimum | 779.2 MW |
| Median | 1418.6 MW |
| Mean | 1501.8 MW |
| Maximum | 2641.0 MW |
| 0% | 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% |
|---|---|---|---|---|---|---|---|---|---|---|
| 779 | 1079 | 1178 | 1273 | 1353 | 1418 | 1508 | 1631 | 1810 | 2088 | 2641 |
 | ||||||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuniga-Garcia, M.A.; Santamaría-Bonfil, G.; Arroyo-Figueroa, G.; Batres, R. Prediction Interval Adjustment for Load-Forecasting using Machine Learning. Appl. Sci. 2019, 9, 5269. https://doi.org/10.3390/app9245269
Zuniga-Garcia MA, Santamaría-Bonfil G, Arroyo-Figueroa G, Batres R. Prediction Interval Adjustment for Load-Forecasting using Machine Learning. Applied Sciences. 2019; 9(24):5269. https://doi.org/10.3390/app9245269
Chicago/Turabian StyleZuniga-Garcia, Miguel A., G. Santamaría-Bonfil, G. Arroyo-Figueroa, and Rafael Batres. 2019. "Prediction Interval Adjustment for Load-Forecasting using Machine Learning" Applied Sciences 9, no. 24: 5269. https://doi.org/10.3390/app9245269
APA StyleZuniga-Garcia, M. A., Santamaría-Bonfil, G., Arroyo-Figueroa, G., & Batres, R. (2019). Prediction Interval Adjustment for Load-Forecasting using Machine Learning. Applied Sciences, 9(24), 5269. https://doi.org/10.3390/app9245269