1. Introduction
With the radical evolution in information technology and the growing number of internet users (approximately 4 billion internet users across the globe in 2018) [
1]), internet usage has turned out to be a significant communication bridge between customers and organizations. Different social networking sites or discussion portals enable this communication by providing a facility to share customers’ opinions and reviews. These reviews are wealthy of information such as sentiments, critics, and customers’ concerns [
2]. The in-depth analysis of these reviews is helpful in different applications, such as predicting trends, discussion topics, and popular keywords.
Though the easy accessibility of the internet is a blessing, it brings many challenges too. The increasing number of internet misuse cases in the form of fraud, harassment, and information leakage has become a prevalent concern for the users and administrative parties.
According to the Internet Crime Report 2018 [
3], there are billions of dollars recorded as fraud on the internet, as shown in
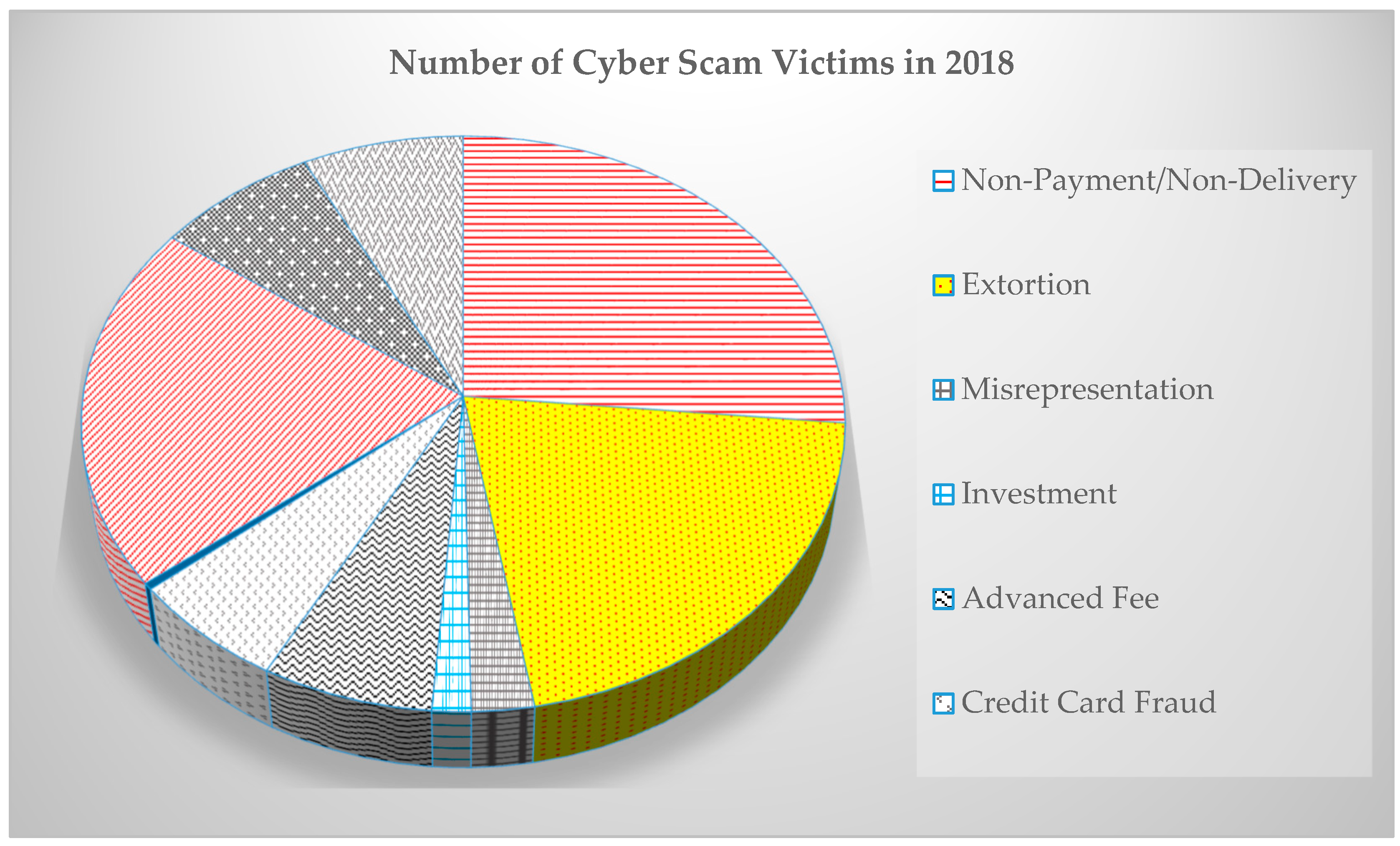
Figure 1. Crowd-thieving is enabling fraudsters to illegally raise money in terms of misrepresenting their ideas, taking an advance fee, investments, non-payments, or non-delivery or personal data breach, as shown in
Figure 2.
Crowdfunding has emerged to be a modern and provocative process to attract a substantial number of investors towards innovative startups. It also withstands the challenges of ensuring accountability, regulating laws, administrating ethics, and handling funds [
4]. The idea that anyone with an innovative concept can start to collect funds for a product, and the arduous process to access a campaign’s legitimacy [
5], raise a growing sense of alarm for the crowdfunding platforms. There is a dire need to build a recommendation system to suggest reliable projects to investors according to their preferences. It is essential to have a reasonable amount of data for these recommendation systems to perform well. To address this challenge, utilizing comments or reviews is the right approach as these reviews represents the user preferences and product characteristics. Therefore, latent feature vectors can be obtained comparatively in a more natural way. In previous studies, user reviews are analyzed primarily through topic modeling-based approaches such as Latent Dirichlet Allocation (LDA), which aims to discover hidden themes in textual documents [
6]. However, topic modeling approaches fail to capture contextual information [
7].
In comparison with topic modeling, deep learning approaches, such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNNs), can capture the contextual and temporal dependencies. Regardless of the strength and power of these deep learning methods, there are still some limitations in terms of the sliding window size. For example, if the window size is too small, it can cause CNN to fail in connecting words to sentences. Similarly, RNN finds it challenging when it comes to sentence size; in other words, if a review is too long, RNN’s ability to extract contextual information will be limited.
To alleviate the problem, we suggest the integration of deep learning approaches with language modeling techniques. Therefore, we propose a hybrid method that takes advantage of both the solution domains, to provide a deeper understanding of the comments. The deep learning methods can help reserve the context information, whereas topic modeling focuses on word relationships, which mollifies the chances of information loss. For the language modeling part, we use the most common topic modeling approach, i.e., LDA. For deep learning, we opted for a particular RNN type known as Long-Short-Term Memory (LSTM) network because of its strengths of reserving time-dependent information and improved performance over other neural systems. Finally, these two modules are integrated into a hybrid framework resulting in a better model towards topic clustering and predictions. The results of this module can be utilized in other applications such as recommendations based on user preferences, or sentiment classification.
To make some project recommendations for the investors, we have built a recommendation system on top of the prediction module, which is based on the best predictions and user preferences. In order to make an ideal recommendation system for investors and to save them from the risks of potential frauds, extensive contextual learning is required. In summary, the proposed system based on a hybrid approach primarily consists of two major modules: (1) Prediction module (2) Optimized recommendation module. In the prediction module, the latent topics are learned through LDA and are fed to LSTM. LSTM then predicts the topic class for the next word in the corpus. The optimal recommendation module takes the user’s preferences into account in combination with the projects having the highest level of authenticity. The authenticity level (a measure of a project’s credibility) is measured on the bases of the topic clusters. If topic clusters fall into topics depicting suspicions, then authenticity level will be lower. The user preferences include project category, project location, level of rewards, and delivery date. We have also formulated an objective function based on Particle Swarm Optimization (PSO), which aims to find optimal recommendations for the user for ongoing crowdfunding projects. The objective function maximizes the user preferences and minimizes the impact of topic classes, which have low authenticity levels.
The rest of the paper is divided as follows.
Section 2 presents the literature review related to our proposed mechanism,
Section 3 presents the algorithmic approaches such as basics of language modeling, LSTMs, and PSO.
Section 4 presents the propose model in detail.
Section 5 sheds light on the implementation and experimental environment.
Section 6 presents the preliminary results and a comparative analysis of the proposed approach with baseline algorithms. In last section, we discuss the challenges, limitation, and contributions of our study.
3. Algorithmic Approaches used in the Methodology
In this section, we present the algorithmic approaches used in the proposed mechanism.
Section 3.1 presents the related works on language modeling and LDA.
Section 3.2 presents the related works on LSTM, and
Section 3.3 presents related works on optimization algorithms.
3.1. Language Modeling
Language modeling depends on a function learning that calculates the log probability of an activity as (ω|model), or a sentence as ω = (ω1, ω2, …, ωn). This function is then used for the prediction of the next word or activity. It can also be used in different other ways, e.g., LDA uses a bag-of-words approach. Alternatively, it can be used in RNN modeling to prevent temporal information loss, to model (ωn| ω1, ω2, …, ωn-1, model).
Latent Dirichlet Allocation (LDA)
In our proposed system, LDA is used for topic modeling,
Figure 3 presents the basic block diagram of LDA, where a user comment is treated as a document and fed to the LDA model, after some preprocessing. LDA results into clusters of similar words indicating a topic or theme. This process is repeated for all the comments in the dataset.
3.2. Long Short-Term Memory (LSTM)
The traditional topic modeling approaches have some limitations when it comes to context learning. For any language model, temporal aspects are also fundamental. Therefore, a well suitable method is required to perform this task. An RNN type, LSTM, can effectively learn the context and temporal features and can better classify or predict, primarily when we have large data sets with time-series information.
RNNs are the type of networks that generate recurrent connections to memorize. Language models based on recurrent neural networks have lately established state-of-the-art performance in different applications. The dynamic temporal behavior of RNN makes them favorable for sequential classification-based problems.
For training, it takes the first-word w from the sequence of input; the output h0 along with the next word w1 is taken as input in the next step, and so on. This way, it keeps remembering the context while training, as shown in
Figure 4.
Simply defining an RNN, we can elaborate it in terms of (∑, S, δ) where ∑ represents the inputs, S represents the states, and δ is the transition function of the neural network. For example, a traditional language model based on RNN considers a document as a sequence. To predict the next word, an LSTM is trained which also takes into account the previous words. Hence, it maximizes p (wt|wt−1|, wt−2, …, w0; model). The input words are transformed to vectors in Σ which eventually is used for the LSTM state update. For the output, a projection of st is required into a vector of the size of the dictionary and is followed by an activation function, e.g., Softmax. However, challenges occur with more extensive size dictionaries.
3.3. Particle Swarm Optimization (PSO)
The PSO was first proposed by J. Kennedy and R. Eberhart in 1995 [
48]. It is a population-based optimization algorithm, which became very famous because of its continuous optimization process towards the best solution.
It is derived from the concepts of swarming habits of animals, e.g., fish or birds and also from genetic algorithms. At a given time
t, PSO upholds multiple possible solutions, each represented by a particle. The fitness of these solutions is calculated during each iteration by using an optimization function. There is a certain velocity which each particle has to move with, in order to reach the maximum value, returned by the objective function. At each iteration, the particle’s position and velocity are updated according to the following Equations (1) and (2):
where V is the particle’s velocity, X(
t) is particle’s current position at time
t. Y(
t) is the individually best solution of the particle at time
t, and G(
t) is the global best solution of the swarm at time
t. W is the coefficient of inertia, usually ranges between 0.8 to 1.2. r1 and r2 are the random numbers generated in the range [0,1], and c1 and c2 are the cognitive and social coefficients, respectively. These coefficients are also known as learning factors, and their value is usually kept as 2.
7. Discussions and Concluding Remarks
This section emphasizes the challenges, implications, and limitations in the development of the proposed recommendation system in crowdfunding field. In this study, an optimized recommendation system is developed to help investors in the selection process of authentic and reliable projects by accommodating their interests. We have presented a hybrid model of RNN-LSTLM and topic modeling that combine the benefits of both LSTMs, which can capture time dependencies for the topic and class prediction, and topic modeling, which can extract topics that can help predict scams. Our proposed model has improved the accuracy of scam prediction significantly from the baseline LDA-based models. We have also embedded an optimized recommendation strategy based on a project’s credibility.
There were several challenges in the development of the proposed system. One of the key challenges was collection of ground truth data, and its verification, was a tedious task. As there is no public data available for scam cases in crowdfunding, so we hand-collected data from the most substantial reward-based and leading crowdfunding platform—Kickstarter. Additionally, all the relevant data and clues were cross-checked manually several times, which was quite a time taking task.
The primary goal of our recommendation systems is to determine the credibility of a project before recommending it to the investors by incorporating their preferences. Online markets, e-commerce, and all form of online business exchanges involve risks and uncertainty. Similarly, for crowdfunding platforms, it is very crucial to establish or build investors’ trust to curtail the chances of uncertainty and risky investments. Previous studies show that many elements are vital for trust-building in any domain, such as content quality and readability [
49] and presence of profile picture [
50]. Therefore, to determine the credibility of a project, we evaluate essential elements such as the profile of the creator, his or her communication patterns and sentiments of investors. The projects with highest credibility level are safe to recommend. However, in case of crowdfunding projects, the amount of risk an investor can tolerate becomes subjective. If an investor is not concerned about the money and only interested in the idea, he or she can invest money to bring that idea to life. Therefore, we present the authenticity scores of projects and evaluate their credibility accordingly. The rest is in the investor’s hand to make a decision accordingly. Some theoretical and practical contributions of the study can be summarized as follows.
First, our results complement the previous studies [
42,
43] and show that the hybrid approaches perform better in topic identification. With LSTM-LDA, we were able to achieve 96% accuracy in topic predictions. We also evaluated these topic classes to help identify suspicious campaigns.
Second, we investigated to discover how configuring comments along with project timelines can help improve the prediction quality. For this experiment, we divided the comments into five different batches described in
Table 7. Each batch represents a specific timeline, such as batch 1 represents the period between the campaign launched until fundraising. Similarly, other batches are created based on different development phases of a project. There are 50–70 comments in each batch. Projects with less than 50 comments were dropped out for this experiment. From
Table 7, we can observe that the most recent comments in a project are significant towards an accurate classification of scam or non-scams. Additionally, the comments discovered in the latest batch, i.e., batch 5, are pure towards one topic class. In other words, they are less likely to have a mixture of discussions as people are generally sharing the same thoughts in recent comments.
Third, there is plenty of data on the internet, which is beneficial for almost every organization, beating informational uncertainty and economic risks remains a hefty challenge for people. There is an ample amount of work done on user-generated content, such as comments and reviews, for different domain-specific applications. However, in crowdfunding, these comments and reviews are often ignored. Due to an increasing threat of fraudulent and suspicious actions on such forums, accurate and timely analysis of the content generated by the stakeholders can help us mitigate these risks. Therefore, we are finding a project’s credibility based on both the content and behavioral patterns of the creator.
Fourth, the optimized recommendations based on the project’s credibility is also a significant addition in the crowdfunding domain. Moreover, this module gives weight to the user preferences and helps them invest in the most credible project.
In
Table 8, a comparison of recent works in crowdfunding with our proposed approach is presented. Here, we have compared our approach and interests with few past recent papers (since 2015) in crowdfunding. In [
51] and [
52], different crowdfunding domains are targeted, such as tourism and medical crowdfunding, respectively. Though both of these studies have attempted risk assessments and fraud identification, none of these studies focus on the project content or linguistic features. In [
53,
54,
55,
56,
57], Kickstarter is used as a crowdfunding platform primarily for project success predictions. The work in [
58,
59] and [
26], targets to acquire knowledge of fraudulent behaviors in crowdfunding by analyzing linguistic patterns. In [
60], comments and updates of successful projects are used to estimate the delivery duration of rewards. In comparison with all the recent works, and to the best of our knowledge, the proposed approach is first of its kind in considering investors’ comments and utilizing them for optimized and reliable recommendations.
The idea of using user reviews and comments for prediction and recommendation is not novel. Many studies have been conducted, which make use of reviews to tackle different problems in diverse fields. Some studies have focused on the reviews content to find the satisfaction of hotel guests [
61], tourist satisfaction [
62], and sentiments related to a product [
63]. Therefore, we compared our approach with other recent approaches in
Table 9. All of the studies [
61,
62,
63,
64,
65,
66,
67,
68] are very recent and are targeting different problem domains by using online reviews. All the studies either detect sentiments or the credibility of a review. Our proposed approach is based on a deep contextual understanding of the comments for discovering discussion patterns and making recommendations accordingly.
However, there are some limitations to our work that can be overcome in future research.
First, we have not taken all the profile related features of project creators into consideration. For example, the history of their work on Kickstarter in terms of the number of projects they have been part of (either as a creator or an investor) can tell a lot about their credibility.
Second, it is very challenging to evaluate the risk for each user. There might be some investors who have a great interest in a specific project, and they are ready to take any monetary risk to try that project regardless of the credibility of a project. In that case, a project with an adverse credibility level will less likely be suggested.
Third, we have used data only from one crowdfunding site Kickstarer.com, which is a leading reward-based platform. Hence, it requires to be verified on other platforms to check if the results can be generalized or not. Additionally, considering other platforms can increase dataset size, which can improve the efficiency of our recommendation system.
Fourth, we considered a limited number of features or variables. For example, for credibility assessment, we considered readability score. However, in the future, we can use other linguistic features such as use of pronouns, adjectives, and expressiveness. We aim to address these limitations and challenges in the future.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}