Extraction of Creation-Time for Recovered Files on Windows FAT32 File System



Abstract
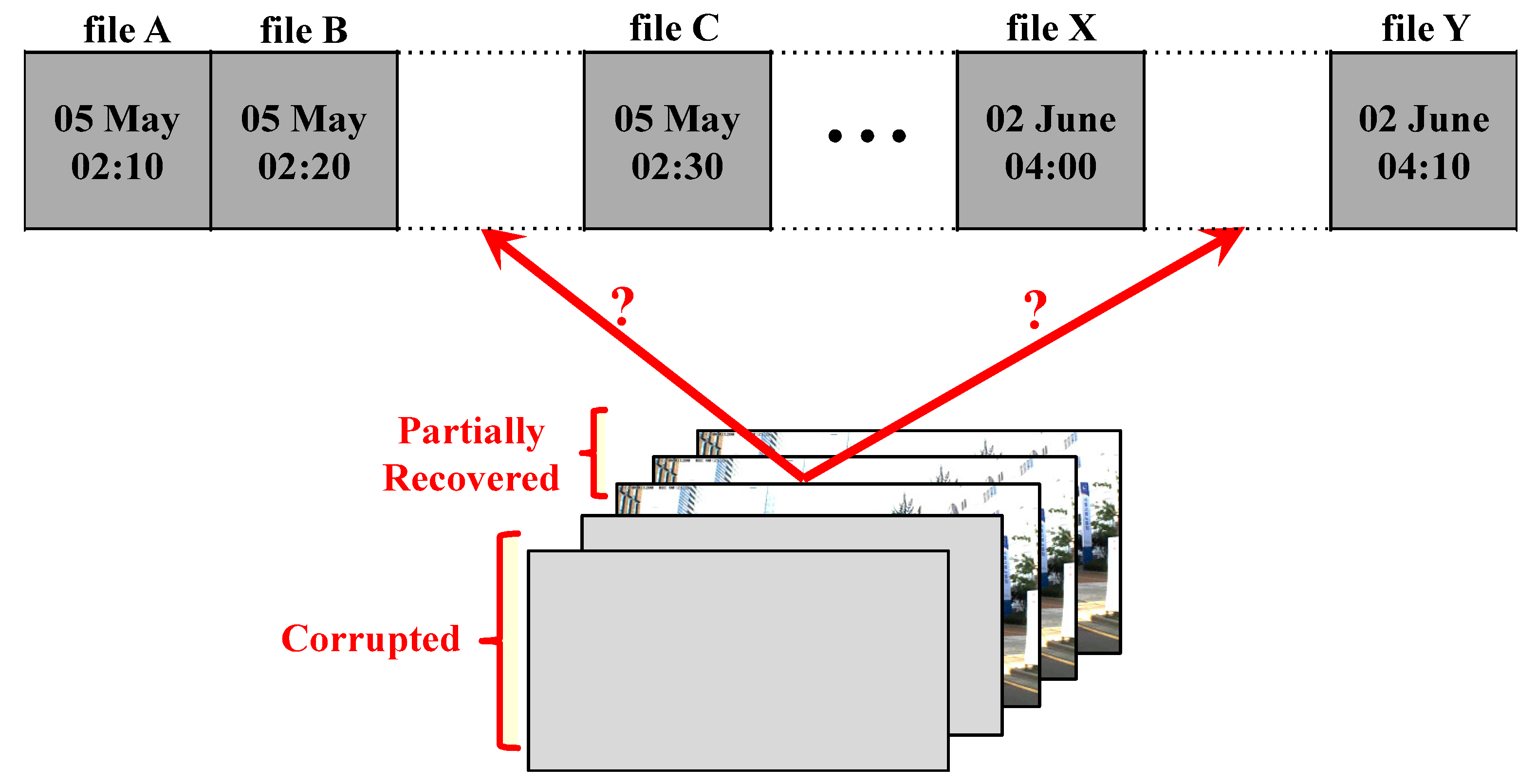
:1. Introduction
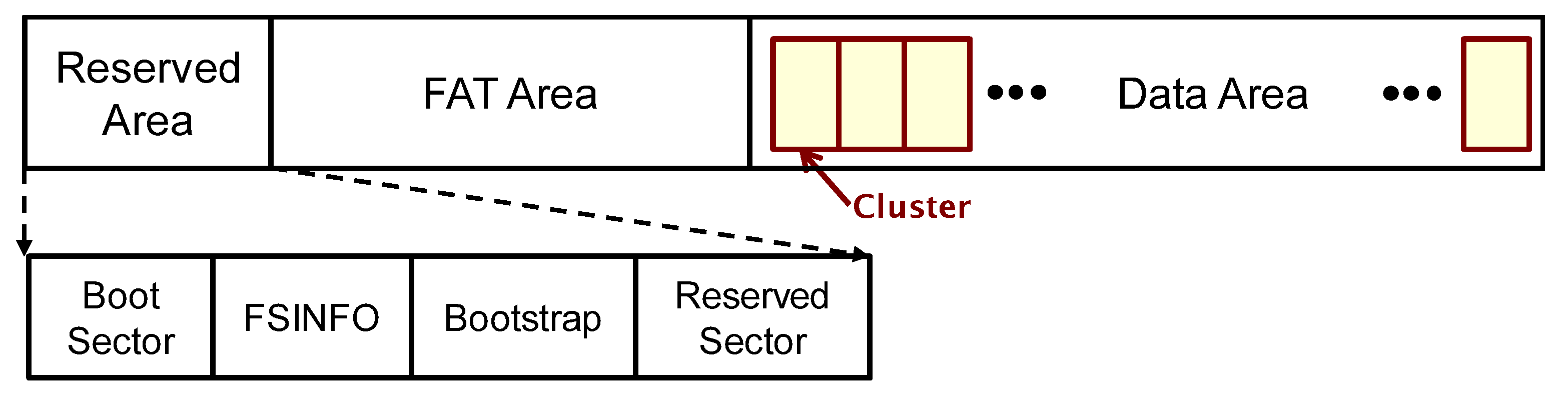
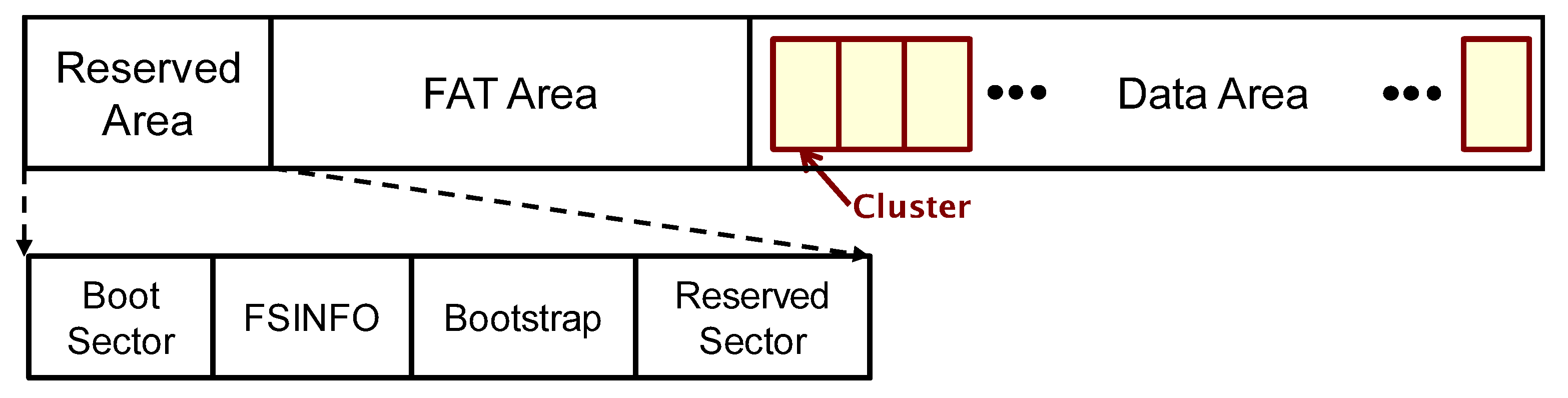
2. File Allocation Behavior of Windows FAT32 File System
2.1. Allocation of Content Clusters to Store File Contents
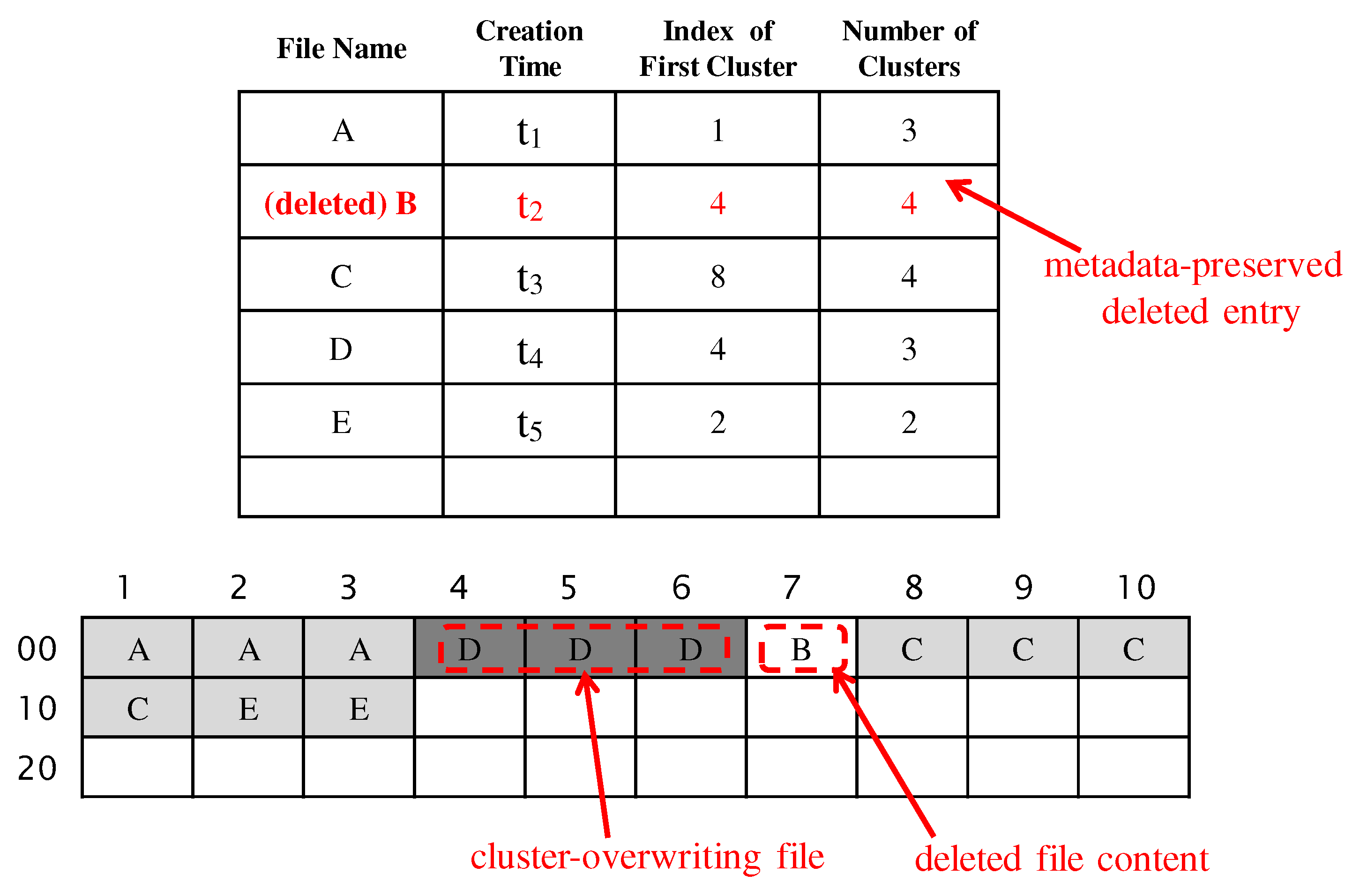
2.2. Allocation of Directory Entries to Record Meta Information of Files
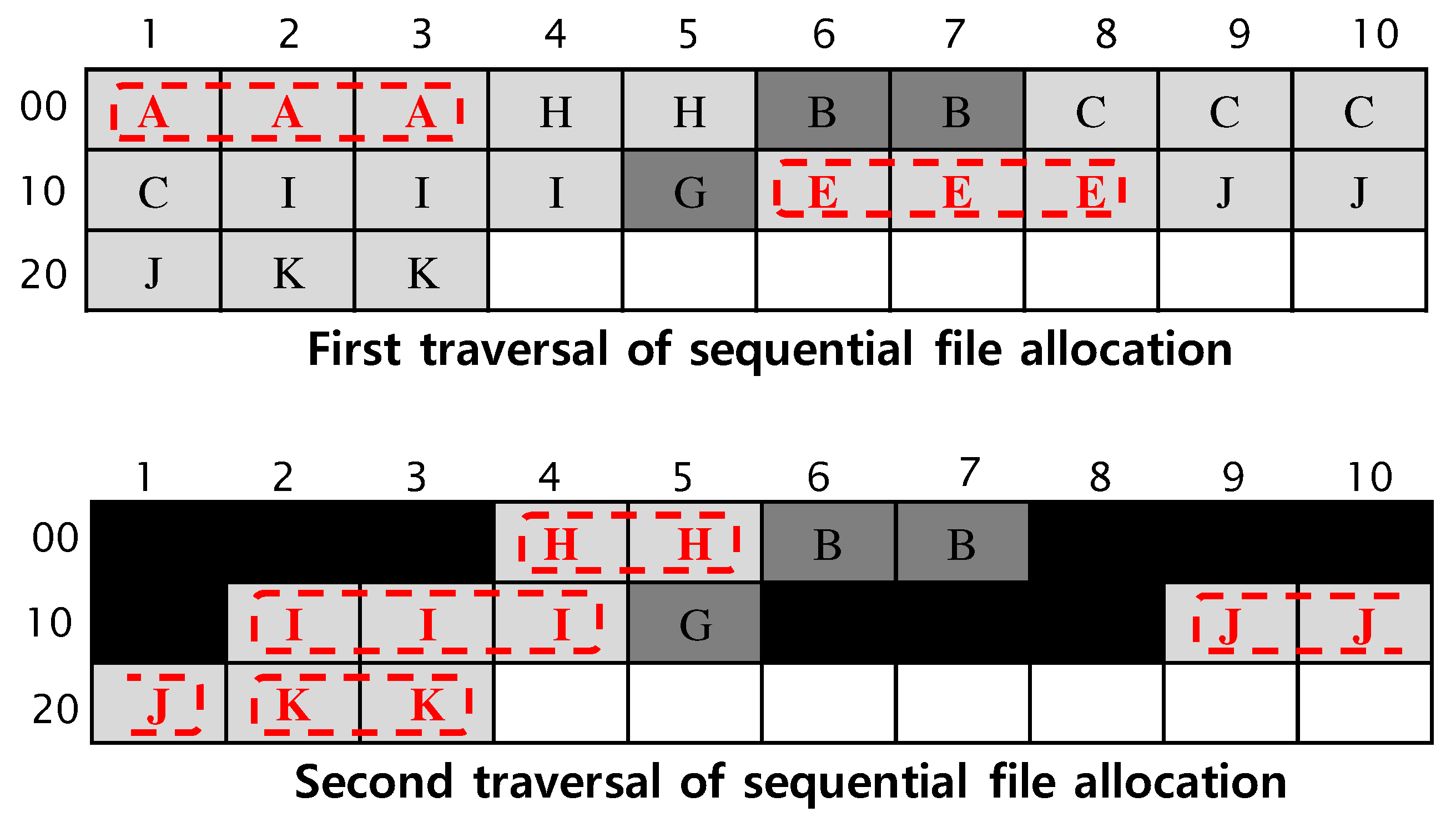
3. Proposed Method to Extract Creation-Time Bound
3.1. Working Mechanism of Proposed Method
3.2. Developed Software Tool
4. Evaluation
4.1. Experiment Results
4.2. Performance Comparison
5. Conclusions and Discussions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Lanh, T.V.; Chong, K.S.; Emmanuel, S.; Kankanhalli, M.S. A Survey on Digital Camera Image Forensic Methods. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Beijing, China, 2–5 July 2007; pp. 16–19. [Google Scholar]
- Singh, R.D.; Aggarwal, N. Video Content Authentication Techniques: A Comprehensive Survey. Multimedia Syst. 2018, 24, 211–240. [Google Scholar] [CrossRef]
- Pahade, R.; Singh, B.; Singh, U. A Survey on Multimedia File Carving. Int. J. Comput. Sci. Eng. Surv. 2015, 6, 27–46. [Google Scholar] [CrossRef]
- Husain, F. A Survey of Digital Watermarking Techniques for Multimedia Data. Int. J. Electron. Commun. Eng. 2011, 2, 37–43. [Google Scholar]
- Kk, S.; Mehtre, B. Digital video tampering detection: An overview of passive techniques. Dig. Invest. 2016, 18, 8–22. [Google Scholar]
- Lee, S.; Song, J.E.; Lee, W.Y.; Ko, Y.W.; Lee, H. Integrity Verification Scheme of Video Contents in Surveillance Cameras for Digital Forensic Investigations. IEICE Trans. Inf. Syst. 2015, E98-D, 95–97. [Google Scholar] [CrossRef] [Green Version]
- Song, J.; Lee, K.; Lee, W.Y.; Lee, H. Integrity Verification of the Ordered Data Structures in Manipulated Video Content. Dig. Invest. 2016, 18, 1–7. [Google Scholar] [CrossRef]
- Sim, S.G.; Kim, E.S.; Kim, D.S.; Lee, S.W.; Lee, W.Y. Apparatus and Method for Verifying the Integrity of Video File. U.S. Patent 10,382,835, 13 August 2019. [Google Scholar]
- Poisel, R.; Tjoa, S. A Comprehensive Literature Review of File Carving. In Proceedings of the International Conference on Availability, Reliability and Security (ARES), Regensburg, Germany, 2–6 September 2013; Volume 11, pp. 475–484. [Google Scholar]
- Pal, A.; Memon, N. The evaluation of file carving. IEEE Sig. Process. Mag. 2009, 26, 59–71. [Google Scholar] [CrossRef]
- Aronson, L.; van den Bos, J. Towards an Engineering Approach to File Carver Construction. In Proceedings of the Annual Computer Software and Applications Conference (COMPSAC), Munich, Germany, 18–22 July 2011; Volume 35, pp. 368–373. [Google Scholar]
- Poisel, R.; Rybnicek, M.; Schildendorfer, B.; Tjoa, S. Classification and Recovery of Fragmented Multimedia Files Using the File Carving Approach. Int. J. Mob. Comput. Multimedia Commun. 2013, 5, 50–67. [Google Scholar] [CrossRef] [Green Version]
- Richard, G.G.; Roussev, V. Scalpel: A Frugal, High Performance File Carver. In Proceedings of the Digital Forensic Research Workshop(DFRWS), New Orleans, LA, USA, 17–19 August 2005; Volume 5, pp. 1–10. [Google Scholar]
- Garfinkel, S.L. Carving contiguous and fragmented files with fast object validation. Dig. Invest. 2007, 4, 2–12. [Google Scholar] [CrossRef]
- Yoo, B.; Park, J.; Lim, S.; Bang, J.; Lee, S. A study on multimedia file carving method. Multimedia Tools Appl. 2012, 61, 243–261. [Google Scholar] [CrossRef]
- Na, G.H.; Shin, K.S.; Moon, K.W.; Kong, S.G.; Kim, E.S.; Lee, J. Frame-based recovery of corrupted video files using video codec specifications. IEEE Trans. Image Process. 2013, 23, 317–326. [Google Scholar]
- Alghafli, K.; Martin, T. Identification and Recovery of Video Fragments for Forensic File Carving. In Proceedings of the International Conference for Internet Technology and Secured Transactions (ICITST), Barcelona, Spain, 5–7 December 2016; Volume 11, pp. 267–272. [Google Scholar]
- Yang, Y.; Xu, Z.; Liu, L.; Sun, G. A security carving approach for AVI video based on frame size and index. Multimedia Tools Appl. 2017, 76, 3293–3312. [Google Scholar] [CrossRef]
- Dabir, A.; Abdou, A.; Matrawy, A. A Survey on Forensic Event Reconstruction Systems. Int. J. Inf. Comput. Secur. 2017, 9, 337–360. [Google Scholar] [CrossRef]
- Khan, M.N.; Chatwin, C.R.; Young, R. A Framework for Post-Event Timeline Reconstruction Using Neural Networks. Dig. Invest. 2007, 4, 146–157. [Google Scholar] [CrossRef]
- Hargreaves, C.; Patterson, J. An Automated timeline reconstruction apporach for digital forensic investigations. Dig. Invest. 2012, 9, S69–S79. [Google Scholar] [CrossRef] [Green Version]
- Kang, J.; Lee, S.; Lee, H. A Digital Forensic Framework for Automated User Activity Reconstruction. In Proceedings of the International Conference on Information Security Practice and Experience (ISPEC), Lanzhou, China, 12–14 May 2013; Volume 9, pp. 263–277. [Google Scholar]
- Chabot, Y.; Bertaux, A.; Nicolle, C.; Kechadi, T. A Complete Formalized Knowledge Representation Model for Advanced Digital Forensic Timeline Analysis. In Digital Forensic Research Workshop (DFRWS); Elsevier: Amsterdam, The Netherlands, 2014; Volume 14, pp. 95–105. [Google Scholar]
- Tse, W.H.K. Forensic Analysis Using FAT32 Cluster Allocation Patterns. Master’s Thesis, The University of Hong Kong, Hong Kong, China, 2011. [Google Scholar]
- Minnaard, W. The Linux FAT32 allocator and file creation order reconstruction. Dig. Invest. 2014, 11, 224–233. [Google Scholar] [CrossRef]
- Lee, W.Y.; Kwon, H.; Lee, H. Comments on The Linux FAT32 Allocator and File Creation Order Reconstruction. Dig. Invest. 2015, 15, 119–123. [Google Scholar] [CrossRef]
- Willassen, S.Y. Finding Evidence of Antedating in Digital Investigation. In Proceedings of the International Conference on Availability, Reliability and Security (ARES), Barcelona, Spain, 4–7 March 2008; Volume 3, pp. 926–932. [Google Scholar]
- Carrier, B. File System Forensic Analysis; Addison-Wesley: Boston, MA, USA, 2005. [Google Scholar]
- Microsoft Corporation. Microsoft Extensible Firmware Initiative FAT32 File System Specification. Available online: http://msdn.microsoft.com/en-us/library/windows/hardware/gg463080.aspx (accessed on 6 December 2000).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| ? | a single hidden event of a deleted file |
| * | uncertain number of continuous hidden events of deleted files |
| file X stored in the directory entry position of | |
| sequential file creation event flow from the beginning of direction entries to their end | |
| sequential file allocation flow from the beginning of content clusters to their end |
| No. of Created | No. of Recovered | No. of Recovered | Avg. No. of Found | No. of Possible |
|---|---|---|---|---|
| (Deleted) Files | Files | Files w/o Time | Orders | Orders |
| 50 (12) | 6 | 5 | 43 | |
| 100 (25) | 12 | 9 | 86 | |
| 150 (37) | 17 | 13 | 127 |
| No. of Created (Deleted) Files | Proposed Scheme | Previous Method |
|---|---|---|
| 50 (12) | 100% | 60% |
| 100 (25) | 100% | 33.3% |
| 150 (37) | 100% | 15.4% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, W.Y.; Kim, K.H.; Lee, H. Extraction of Creation-Time for Recovered Files on Windows FAT32 File System. Appl. Sci. 2019, 9, 5522. https://doi.org/10.3390/app9245522
Lee WY, Kim KH, Lee H. Extraction of Creation-Time for Recovered Files on Windows FAT32 File System. Applied Sciences. 2019; 9(24):5522. https://doi.org/10.3390/app9245522
Chicago/Turabian StyleLee, Wan Yeon, Kyong Hoon Kim, and Heejo Lee. 2019. "Extraction of Creation-Time for Recovered Files on Windows FAT32 File System" Applied Sciences 9, no. 24: 5522. https://doi.org/10.3390/app9245522
APA StyleLee, W. Y., Kim, K. H., & Lee, H. (2019). Extraction of Creation-Time for Recovered Files on Windows FAT32 File System. Applied Sciences, 9(24), 5522. https://doi.org/10.3390/app9245522