1. Introduction
In recent years, wind energy has become the focus of managers and researchers in the energy field, due to the advantages of wind power, such as renewability and cleanliness.
In 2016, the global installed capacity of wind power exceeded 54 GW. This installed capacity is distributed between 90 countries, which have an installed capacity of more than 10 GW, with 29 countries having an installed capacity of 1 GW [
1]. Cumulative installed capacity increased by 12.6%, and accumulated capacity reached 486.8 GW. In the United States, more than 53,000 wind turbines operate, generating more than 84.1 GW of electricity in 41 states [
2]. On the other side of the globe, wind power may become China's second largest power source by 2050 [
3].
Accurate forecasting of wind speed is an important prerequisite for using wind power due to the following reasons: 1) it reduces rotating and operating costs of wind-farm equipment; 2) it helps dispatching departments to adjust their plans in time; 3) it reduces the impact on the entire power grid; 4) it effectively reduces or avoids the negative impact of wind farms on the power system, and 5) it improves the ability of wind power in power market competition.
However, because of the chaotic and random fluctuations of wind speed, it is a challenging and difficult task to obtain satisfactory wind-speed forecasting results [
4,
5,
6]. To have satisfying results and reduce errors, and improve the accuracy and stability of the forecasting results, various wind-speed forecasting methods have been proposed and developed by former researchers. The methods can be classified in four categories: 1) physical models; 2) statistical models; 3) artificial-intelligence models; and 4) spatial-correlation models [
7].
The common physical models include weather research and forecast, the consortium for small-scale modeling, and mesoscale model 5 (MM5) [
8]. These methods are based on physics and the atmosphere, and forecast wind speed with additional background information [
8]. Statistical models include the fuzzy methods [
9], Autoregressive Moving Average (ARMA) model [
10], the Autoregressive Integrate Moving Average (ARIMA) model [
11,
12], and the grey model [
13], combined with neurofuzzy techniques [
14] and Markov chains [
15]. Statistical methods aim to mine the relationship between historical data and establish prediction models, including traditional statistical and machine-learning models, to describe the potential sampling of wind-speed forecasting [
16]. In recent years, because of their powerful nonlinear character, many artificial-intelligence forecasting methods, such as artificial neural networks (ANN) [
17,
18,
19,
20,
21,
22,
23,
24,
25] and support vector machines (SVM) [
26,
27], have been widely applied to wind-speed forecasting. The wind speed of the spatial relationship between different sites is considered in spatial-correlation models [
28] to forecast wind speed.
However, these four categories of methods have disadvantages because of their character: 1) physical models need accurate numerical weather-prediction data and detailed information of wind-farm locality, input parameters, and data acquisition. Processing and calculation are complex [
29,
30]; 2) traditional statistical models can address forecasting with linear trends well, but times-series wind speed is always random, chaotic, and nonlinear, and the performance of these models does not satisfy researchers and managers; 3) although artificial-intelligence forecasting methods have some advantages, due to their nonlinear mapping capability compared with traditional statistical models, their main disadvantages and shortcomings are that they are easy to reach local optimal values, and they suffer from overfitting and slow convergence [
31]; 4) spatial-correlation methods should consider many influential factors, such as the relationship of the time-series wind-speed data between different sites, original data from several stations, and if the time-series wind speed of the forecasting point and its neighbors is used for forecasting [
28].
To overcome the problem of forecasting accuracy and stability and take advantage of single models, a combined model based on multi-objective optimization and combined theory is proposed by us to overcome their defects, including low accuracy and weak stability. Because wind-speed forecasting is a complex study, single-objective optimization is not enough to solve the wind-speed forecasting problem. Solving the single-objective optimization problem (SOP) is a direct task, but multiple-objective problems (like the wind-speed forecasting problem) are often complex, and objective functions are competing (or conflicting) with each other. Due to this reason, there is no single optimal solution, commonly known as a series of Pareto-optimal solutions, which simultaneously optimize all objective functions. A set of optimal solutions, called a Pareto-optimal Set (PS), of which mapping in the target space is named the Pareto front (PF), and not a single optimal solution, is the goal of solving the multiple-objective optimization problem (MOP). In MOPs, the favored solution from the PS is chosen by researchers, but not the optimal solution. Obviously, it is difficult to select one objective function from a number of objective functions and ensure that the selected objective function can achieve a lower mean absolute percentage error (MAPE) and stronger stability. Due to these reasons, multiple-objective optimization can solve the low accuracy and weak stability of the wind-speed forecasting problem through simultaneously searching the goal of multiple functions.
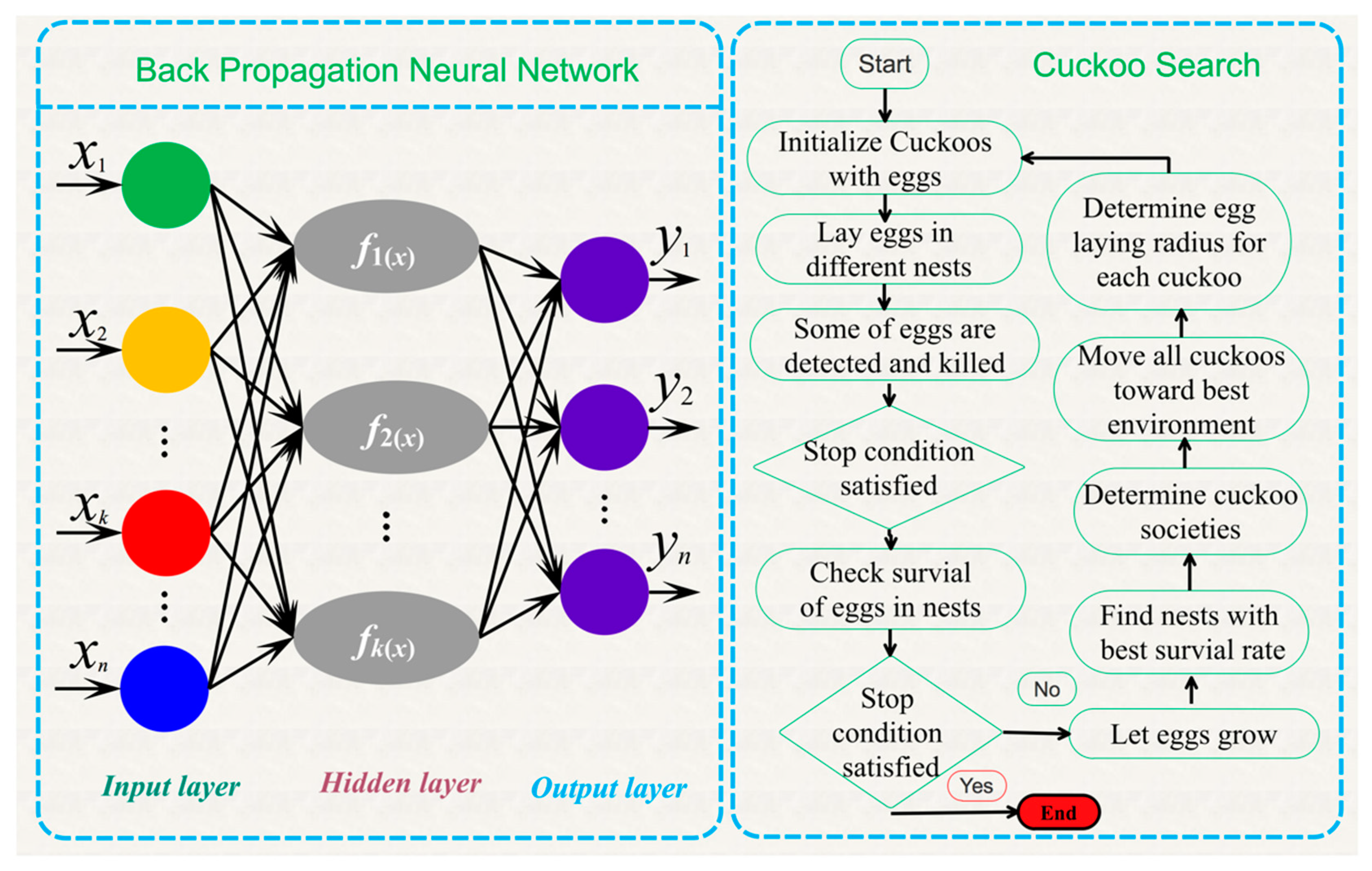
In this paper, a new combined model [
32] that integrates nonpositive constraint theory [
33], four branch models, including two nonlinear hybrid neural networks (Cuckoo Search-Back-Propagation Neural Network (CS-BPNN) and DE-Online Extreme Learning Machine (DE-OSELM)), two linear models (ARIMA and HW), and a nondominated sorting genetic algorithm (NSGA-III) [
34], which optimizes the weights of the branch models, is proposed in this paper. Ten-minute time-series wind-speed data from three wind-farm sites were applied to examine our proposed model. We also chose three combined models with two objective functions to test its performance.
The major contributions and innovations of this paper are as follows:
1. According to the observed time-series wind-speed data, the trajectory matrix was constructed, decomposed, and reconstructed to extract signals representing different components of the original time series, such as long-term trend signals, periodic signals, and noise signals, so that the structure of the time series could be analyzed and used for further forecasting.
2. Our proposed combined model is based on MOP theory, which can obtain both accuracy and stability. The wind-speed forecasting problem is a MOP, so the theory overcomes the difficulty of selecting one objective function from multiple functions to obtain higher precision and stronger stability.
3. Due to the wind-speed data having both linear and nonlinear characteristics, linear models (ARIMA and HW) and nonlinear models (BPNN) and OSELM) were chosen to be the branch models of our proposed combined model. The combination of these two kinds of models can solve the wind-speed forecast problem with both linear and nonlinear characteristics.
4. Our novel developed combined model with three objective functions, which can be applied to forecast wind speed, is proposed in this paper. As compared with other models, the proposed model not only guarantees accuracy, but also has strong stability. The results of the experiments mean that the proposed integrated combined model is a more effective model for wind-speed forecasting and wind-farm management.
5. The forecasting performance of the combined model was evaluated scientifically and comprehensively. The evaluation system used five experiments and four performance metrics to effectively evaluate the forecasting accuracy and stability of the proposed combined model.
The remainder of the paper is arranged as follows. The strategy of the proposed combined model is shown in
Section 2. Singular-spectrum analysis is presented in
Section 3. Nonlinear back propagation, an extreme learning machine neural network, two linear models, autoregressive integrated moving average and Holt–Winters, heuristic algorithms, and the optimization procedure are introduced in
Section 4. In
Section 5, we show our proposed combined model. In
Section 6, forecasting performance metrics, the forecasting results of individual models and of the proposed combined model, and comparisons are discussed, and the views and results of the entire paper are summarized. Finally,
Section 7 concludes the study.
3. Results
The denoising process consists of four steps, embedding, singular-value decomposition, grouping, and diagonal averaging [
35]. According to the observed time-series wind-speed data and these four steps, the trajectory matrix was constructed. The trajectory matrix was decomposed and reconstructed to extract signals representing different components of the original time series, such as long-term trend signals, periodic signals, and noise signals. In order to obtain satisfying results, the noise signals were abandoned. The detailed process is as follows:
(1) Embedding:
Form the trajectory matrix of the series
X, which is the
matrix:
where
are lagged vectors of size
L. Matrix
X is a Hankel matrix that means that
X has equal elements
on the anti-diagonals
i +j=const.
(2) Singular-Value Decomposition:
Perform the singular value decomposition (SVD) of trajectory matrix X. Set and denote by the eigenvalues of S taken in the decreasing order of magnitude , and by the orthonormal system of the eigenvectors of matrix S corresponding to these eigenvalues.
Set (note that d = L for a typical real-life series) and . In this notation, the SVD of trajectory matrix X can be written as .
Where are matrices having rank 1; these are called elementary matrices. Collection is the ith eigentriple (ET) of the SVD. Vectors are the left singular vectors of matrix X, and numbers are the singular values and provide the singular spectrum of X; this gives the name to SSA. Vectors are the vectors of principal components (PCs).
(3) Eigentriple grouping:
Partition set of indices into m disjoint subsets .
Let . Then, resultant matrix corresponding to group I is defined as . The resultant matrices are computed for the groups, and the grouped SVD expansion of X can now be written as .
(4) Diagonal averaging:
Each matrix
of the grouped decomposition is hankelized, and then the obtained Hankel matrix is transformed into a new series of length
N using the one-to-one correspondence between Hankel matrices and the time series. Diagonal averaging applied to a resultant matrix
produces a reconstructed series
. In this way, the initial series
is decomposed into a sum of
m reconstructed subseries:
This decomposition is the main result of the SSA algorithm. The decomposition is meaningful if each reconstructed subseries could be forecast as a part of either a trend, some periodic component, or noise.
The pseudocode for denoising is provided in
Appendix A, Algorithm 1.
6. Experiments
Some performance metrics must be described to comprehensively understand the model characteristics. Diebold-Mariano and forecasting effectiveness were used in this study. Four experiments are given in this section to text the data and our proposed combined system.
6.1. The Performance Metric
Some performance metrics must be described to comprehensively understand the model characteristics. Four metrics, that is, AE, MAE, MSE, and MAPE, are shown in
Table 1.
6.1.1. Diebold Mariano test
A comparison test, the Diebold Mariano (DM) test, was proposed by Diebold, F.X., and Mariano [
46], which focused on the predictive accuracy and evaluating the forecasting performance between two or more-time series models.
The forecast errors from the two models are:
A suitable loss function, i = 1,2., was applied to measure the accuracy of each forecast. Square error loss and absolute-deviation error loss are the most popular loss functions.
The DM test statistics estimate the forecasts according to arbitrary loss function
L(
g):
where
is an estimator of the variance of
.
The null hypothesis is:
versus the alternative hypothesis, which is:
The null hypothesis means that the two forecasts have the same accuracy. The alternative hypothesis means that the two forecasts have different levels of accuracy. Under the null hypothesis, test statistic
DM is asymptotically
N (0, 1) distributed. The null hypothesis of no difference is rejected if the computed
DM statistic falls outside the range from -
zα/2 to
zα/2, that is, if
where
zα/2 is the upper (or positive) z-value from the standard normal table, corresponding to half of the desired
α level of the test.
6.1.2. Forecasting Effectiveness
Both the square sum of forecasting error and the mean and mean squared deviation were applied to measure the forecasting accuracy by forecasting effectiveness. In some practical cases, it is necessary to further consider the kurtosis and skewness of the forecasting-accuracy distribution. On this basis, the general discrete from of forecasting effectiveness is given in this section [
47].
Definition 5. is called the forecasting accuracy at time n.
Definition 6. is the forecasting-accuracy effectiveness unit, k is a positive integer, is the discrete-probability distribution at time n, and. Especially if the a priori information of the discrete-probability distribution is unknown, we define, n = 1, 2,…, N.
Definition 7. mkis thek-order forecasting-effectiveness unit, andHis a continuous function of a certainkunit. H (m1, m2, …, mk) is the k-order forecasting effectiveness.
Definition 8. WhenH(x) = xis a continuous function of one variable, H (m1) = m1 is the first-order forecasting effectiveness. When , it is a continuous function of two variables.
6.2. Experiment I: Use the Linear and Nonlinear Functions to Test the Feature of a Wind-Speed Series.
Only by better understanding the characteristics of the research data can we better select the model for future work. To achieve better results, we must consider the characteristics of the data.
In general, the linear model fits the linear data better, just as the non-linear model fits the non-linear data better. Only by understanding the characteristics of the data can we achieve good results in future forecasting work. For data, it is not only linear or non-linear, but also may both. Therefore, it is necessary to judge the linear nonlinearity of the data used in this paper. Therefore, we carried out the following experiment. In order to verify the linear or nonlinear character of wind speed, three functions were structured: (1) linear function ; (2) nonlinear function ; and (3) nonlinear function .
From the results of
Table 2 and
Table 3, the wind speed data are both linear and nonlinear by hypothesis test. Therefore, the linear models and nonlinear models considered in our proposed forecasting model are correct and necessary.
6.3. Experiment II: Models Tested with Wind-Speed Data From Site 1
In order to evaluate the accuracy and stability of the forecasting system, we selected the average results of 100 trials, which were divided into two parts: accuracy and stability. In the accuracy section, we compare the AE, MAE, MSE, and MAPE values for a single model and combined model (as shown in
Table 4).
(a) The results of
Table 4 show the following:
(1) CS-BPNN reached the best results in Tuesday, Wednesday, and Thursday compared to other branch models, with MAPE values being 3.726%, 4.081%, and 5.173%, respectively.
(2) On Monday and Sunday, DE-OSELM obtained the lowest MAPE compared with other branch models.
(3) HW achieved the most accurate forecasting value of all branch models on Friday and Saturday.
(4) Although ARIMA could achieve higher forecasting precision, their forecasting performance was worse than nonlinear models and HW
(5) Our combined model had a significant improvement in forecasting accuracy with a lower MAPE compared with all branch models. The MAPE values from Monday to Sunday are 5.691%, 3.698%, 4.078%, 5.166%, 5.692%, 6.443%, and 5.082%, respectively.
(b) The results of
Figure 4 show the following:
(1) Part A shows the MAE, MSE, and MAPE of five models, although our combined model did not achieve the lowest MAE every day; the lowest MSE and MAPE were obtained by our proposed model.
(2) Part B shows the forecasting results of CS-BPNN, DE-OSELM, ARIMA, HW, and the combined model.
(3) Part C also shows the 95% confidence intervals (CIs) obtained by each model; the figure indicates that both the upper and lower CIs were close between four branch models but, for linear models, there were more points in the confidence interval. As Part C shows, the errors of the combined model were very small, and our combined model also achieved a small CI.
Remark 1. From Table 4 and Figure 4, the results indicate that our proposed model showed better performance than the other branch models. In brief, it can be explained that SSA, which could denoise the time-series wind-speed data as a preprocessing method, and the combined model, which took advantage of the branch models, could improve forecasting accuracy. 6.4. Experiment III: The Performance of Branch Models at Each Time Point.
In this experiment, four models, two nonlinear hybrid models (CS-BPNN and DE-OSELM) and two linear models (ARIMA and HW), were tested for performance at each time points. In this part the, wind-speed data of Tuesday from Site 2 were used in our experiments.
(a) All Tuesday results in
Figure 5 show the following:
(1) Part A shows the MAPE values of four branch models. From the figure, we can see that ARIMA performed the worst, but the MAPE of these four models were approximately.
(2) From
Figure 5, Part B, we can see that the MSE and MAE of the four models were not high. The values are very close between these four models.
(3)
Figure 5, Part C also shows the 95% CIs obtained by the four branch models, and it indicates that both the upper and lower CI were close between the two nonlinear models. For the linear models, however, the CI of ARIMA was smaller.
(b) Every-hours’ Tuesday results in
Table 5 show the following:
(1) CS-BPNN obtained the lowest MAPE values of all branch models at 1:00, 7:00, 14:00, and 22:00, and the values are 1.87%, 3.90%, 0.07%, and 5.93%, respectively.
(2) At 1:00, 5:00, 8:00, 18:00, and 22:00, DE-OSELM reached the most accurate forecasting value.
(3) With the MAPE values 0.57%, 0.71%, 0.81%, 0.62%, 2.78%, 8.52%, 4.17%, and 1.25% at eight time points, ARIMA obtained the maximum time-point accuracy results on Tuesday from Site 2.
(4) HW achieved the lowest MAPE values of all branch models at 4:00, 6:00, 9:00, 13:00, 17:00, 19:00, and 20:00, and HW is also the model that had the best performance than the other branch models at all hours.
(5) The results reveal that there is no model that can reach the best results at every time point.
Remark 2. There is no one model that can reach the best results at every time point; each model has advantages and disadvantages. The combined models can add up the forecasting models to overcome these dilemmas. This experiment provides a reason to apply combined-model theory to forecast wind speed.
6.5. Experiment IV: Stability Comparison with Branch Models
In Experiments II and III, we tested the time-point performance and accuracy of the branch models. In this experiment, we evaluated the stability of the proposed combined model by comparing the standard deviation of the MAPE (STD-MAPE) values (as shown in
Table 6). Because there is no randomness in the mathematical models, we just tested CS-BPNN and DE-OSELMNN of branch models in terms of stability. Here, we show the wind-speed data from Sites 1 and 2, and the results of MAPE and STD-MAPE from 100 time experiments.
The results in
Table 6 show the following:
(1) CS-BPNN performs better than DE-OSELM in accuracy on most test days.
(2) In terms of stability, CS-BPNN obtained lower STD-MAPE than DE-OSELM in Site 1, but in Site 2, DE-OSELM was better than CS-BPNN.
(3) Our proposed combined model reached the best accuracy and stability values compared to the two other models.
(4) The lowest STD-MAPE value of CS-BPNN was achieved on Wednesday on Site 2; at the same time, the STD-MAPE of DE-OSELM and our combined model were 0.2430 and 1846, respectively.
Remark 3. From the results shown in Table 6, our combined model obtained the lowest MAPE and STD-MAPE, which means that our combined-model functions could achieve high accuracy and strong stability compared with the single models. 6.6. Experiment V: Comparison with Three Combined Models (Two Objective Functions)
We proposed three other combined models with two objective functions in
Section 5.2. In this experiment, we tested the accuracy and stability between our proposed system and the other three combined models. Here, wind-speed data from Site 3 were used in our experiments, and all of the models in this part were run 100 times.
(1)
Table 7 shows the average AE, MAE, and MSE. It can be seen that the forecast performance and the results of our proposed combined model were better in accuracy.
(2) The average results of the three two-objective-function models were close to the combined system (three objective functions). Especially on Friday, the difference between the combined model (three objective functions) and the combined models (two objective functions) was only 0.65%.
(3) As shown in
Table 8, after running the models for 100 times, the standard-deviation MAPE and the MAPE range of the two-objective-function models was much higher and larger than the combined model. This shows that the stability of our combined model’s performance was much better than the combined models with the two objective functions.
(1) Part A shows that, with regard to the minimum, maximum, and average results of MAPE from 100 experiments, our proposed combined model with three objective functions reached the lowest values compared with the other combined models on each day.
(2) Part C presents that the MAE and MSE of our proposed combined model with three objective functions were also lower than the other models.
Remark 4. The results show that the performance of the combined model with two objective functions was close to the combined model with three objective functions when we chose the result average. However, the single results of the combined model with three objective functions could be given a high degree of trust, as accuracy and stability were successfully enhanced by our combined model based on NSGA-III in the forecasting problems.
6.7. Experiment VI: Forecasting Results Test
To evaluate the forecasting results of these models, two important evaluation metrics, the DM test and forecasting availability, were applied in this part. We discuss the results from Site 3.
(1) The results of the DM test are shown in
Table 9, which indicate that the combined system was different from the other models at a significant difference level in different datasets.
(2) As shown in
Table 10, the first-order and second-order forecasting availabilities of the proposed combined system performed better than the other models for seven datasets from three regions in electricity-load forecasting. For example, in the Monday dataset, the first-order forecasting availabilities offered by each forecasting models were 0.9110, 0.9143, 0.8432, 0.8851, 0.9284, 0.9291, 0.9249, and 0.9456, respectively.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}