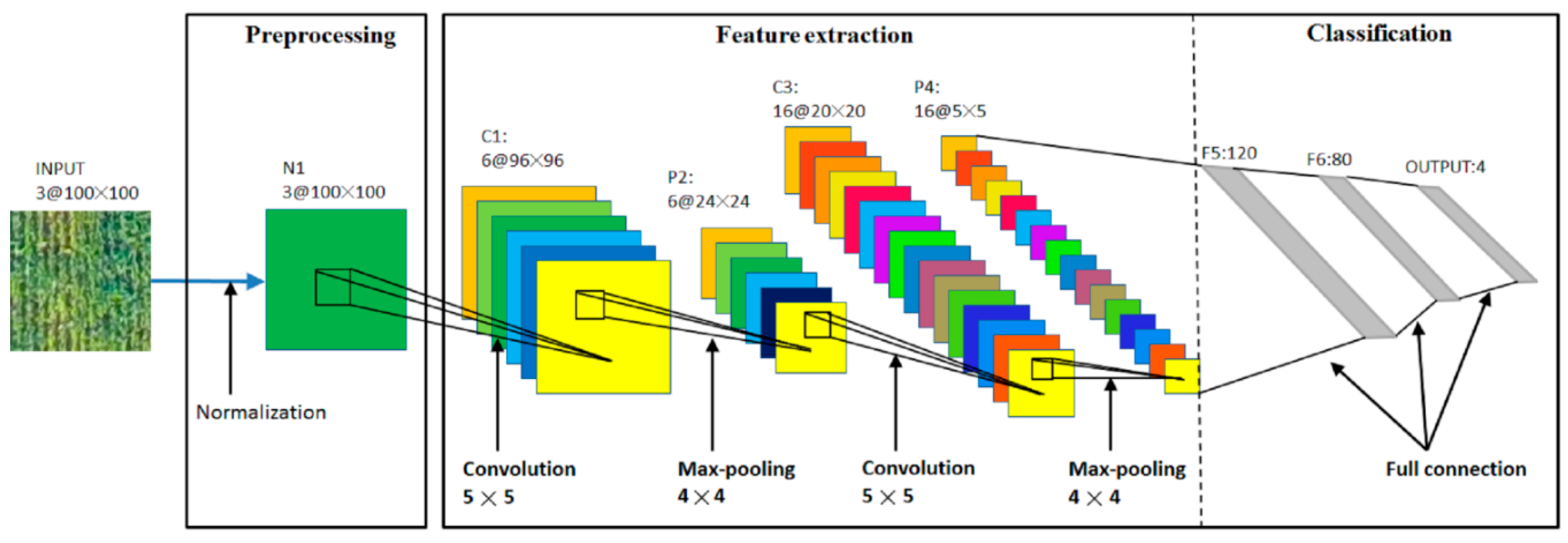
3.1. Dataset Preparation
The resolution of UAV imagery is 4000 × 3000. According to the result of the ground investigation, the symptomatic sites were mainly distributed in 3 × 3 m areas in different locations of the field. As shown in
Table 1, the imagery was captured at a height of 80 m, with a resolution of 3.4 cm. To reflect the areas (3 m × 3 m) of the symptomatic sites, smaller samples were divided from the original UAV imagery in the size of 100 × 100 pixels. Two thousand and four hundred samples were generated from the collected imagery. Each sample represented a small area in the wheat field and was assigned a certain label (normal, light, medium, and heavy) according to the ground investigation results.
At this point, the dataset was composed of a collection of samples divided from the original UAV imagery. Each sample consisted of 100 × 100 pixels and a label (normal, light, medium, and heavy) according to the ground investigation. Since the experiment was conducted when HLB disease was in its initial stage, no heavy category was found in the field, as shown in
Figure 6.
Next, the dataset was divided into two parts: (a) training samples; (b) validation samples. At this stage of the work, 60% of samples in each category were randomly selected as the training samples, while the remaining 40% as the validation samples. In our dataset, the number of normal samples was larger than other categories. To avoid the problem of data imbalance, similar numbers of each category were selected, as shown in
Table 3.
Training samples from the dataset were used for CNN training and parameter updating, while the validation samples were used for performance evaluation.
3.3. Experiments on Hyper-Parameters Tuning
Deep neural networks show great potential in many vision classification applications, but their final performance is strongly affected by the selection of hyper-parameters [
35]. To obtain approximately optimal hyper-parameters, several experiments on hyper-parameters selection were conducted. Their impact was demonstrated via MCA curves on training samples and validation samples, as shown in
Figure 8,
Figure 9,
Figure 10 and
Figure 11. In each figure, one hyper-parameter was changed while the others were kept constant.
The performance of different learning rates is shown in
Figure 8. From
Figure 8, it can be observed that a too-small learning rate slows down the convergence of the cost function, as shown in
Figure 8a, while a too-large learning rate leads to the neural network divergence. A better classification performance can be obtained by choosing an appropriate learning rate, as shown in
Figure 8b.
The classifier performance of different momentums is shown in
Figure 9. It can be observed that appropriately increasing the momentum coefficient can well accelerate the convergence of the cost function. However, using a too-large momentum coefficient (0.97) destabilizes the training process at the initial stages. A better selection of the momentum coefficient is shown in
Figure 9b,c.
The performance of different batch sizes is shown in
Figure 10. It can be observed that a too-small batch size can cause oscillation at initial stages, as shown in
Figure 10a. However, a too-large batch size slows down the learning process and degrades the classification accuracy, as shown in
Figure 10d. A better classifier performance can be obtained by using an appropriate batch size, as shown in
Figure 10b,c.
The performance of different weight decays are shown in
Figure 11. From
Figure 11, it can be observed that using weight decay has no impact on improving the classifier performance. In this case, we decided not to use weight decay in this study. After hyper-parameter tuning, the selected hyper-parameter values are shown in
Table 4.
3.4. Comparison with Other Methods
In comparison with the CNN methods, four more algorithms for HLB disease category classification were explored. For the first comparison algorithm, only the color histogram was used for feature extraction, and SVM was applied for multi-class classification. For the second comparison algorithm, only the LBPH method was used for feature extraction and the SVM for multi-class classification. The radius and sampling points were set to 1 and 8, respectively. For the third comparison algorithm, only eight vegetation indices were computed as feature vector and SVM was used as the classifier. For the fourth comparison algorithm, the color histogram, LBPH, and vegetation indices were concatenated as the feature vector, which was used for SVM classification. For all the SVM models, the radial basis function (RBF) was chosen as the kernel function. The penalty parameter was set to 1.0, and the “one against one” strategy was used for multi-class classification.
To evaluate the performance of different methods, overall accuracy (OA) and standard error (SE) were calculated, which were used to measure the classification accuracy and the standard deviation of the experimental results [
36]. In our experiments, the training and validation samples were randomly selected from our dataset (
Table 3). To minimize the effects of randomness, the sample selection and classification were iterated for 10 times. The quantified measurement of OA, SE, and confusion matrix for 10 consecutive experiments were recorded and averaged. The final OA and SE are shown in
Table 5, and its corresponding confusion matrix is demonstrated in
Table 6.
From
Table 5, it can be observed that the
LBPH + SVM approach results in low accuracy. The reason for this result is that the texture features of different categories shared little difference. However, the
Color Histogram + SVM approach achieved higher accuracy, since the color difference of different categories was more obvious, as can be observed from
Figure 6. The
VI + SVM approach obtained an approximate performance with the
Color Histogram method since the mathematic computation on different color channels (vegetation index) can be regarded as another kind of color information. The
Color Histogram + LBPH + VI + SVM approach further increased the accuracy, since extra effective features help to improve the classification. Experimental results showed that the
CNN method achieved the highest OA and lowest SE, which outperformed other methods in terms of accuracy and stabilization. On the other hand, for the recognition of the diseased samples, the
CNN method significantly outperformed others, as shown in
Table 6. One possible reason for this result was that the
CNN emphasis automatic feature learning, which may combine the color and texture features and extract better features for the classification stage.




 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}